Embed Size (px)
Citation preview

LNS Subtraction Using Novel Cotransformation and/or Interpolation
Panagiotis VouzisComputer Engineering
Lehigh UniversityBethlehem, PA, 18015
Sylvain CollangeEcole Normale Superieure de Lyon
46 Allee d’Italie69364 Lyon Cedex 07, [email protected]
Mark ArnoldComputer Engineering
Lehigh UniversityBethlehem, PA, 18015
Abstract
The Logarithmic Number System (LNS) makes multipli-cation, division and powering easy, but subtraction is ex-pensive. Cotransformation converts the difficult operationof logarithmic subtraction into the easier operation of loga-rithmic addition. In this paper, a new variant of cotransfor-mation is proposed, which is simpler to design and moreeconomical in hardware than previous cotransformationmethods. The novel method commutes operands differentlyfor addition than for subtraction. Simulation results showhow many guard bits are required by the new cotransforma-tion to guarantee faithful rounding and that, even withoutguard bits, cotransformation produces an LNS unit more ac-curate than a previously published Hardware-Description-Language (HDL) library for LNS arithmetic that uses onlymultipartite tables or 2nd-order interpolation.
Keywords: Logarithmic Number System, MultipartiteTables, Interpolation, Cotransformation, Hardware De-scription Languages.
1. Introduction
The Floating Point (FP) number system [1] and the Log-arithmic Number System (LNS) [21] are two alternativesfor applications that require an increased dynamic range fortheir arithmetic operations, i.e., a fixed-point number sys-tem is not adequate. Both the dynamic range and the ac-curacy of the two alternatives can be adjusted by choos-ing the wordlength of their representations appropriately.For a particular application, the choice of the most suitablearithmetic system depends largely on the implementationrequirements of area, delay, and accuracy.
The difference between LNS and FP is that in LNS anumber is a fixed-point representation of the logarithm ofits real value, which, unlike FP, does not require the steps ofshifting, normalization, postnormalization, etc., to carry out
any arithmetic operation. LNS is more efficient for multi-plication, division and powering, since they are reduced toaddition, subtraction, and multiplication. The difficulty liesin the operations of addition and subtraction where the func-tions sb(z) = logb(1 + bz) and db(z) = logb(1 − bz) areneeded. The memory requirements for these two functionsgrow exponentially with respect to the fractional bits of therepresentation, rendering an LNS implementation less effi-cient than a FP one as the wordlength increases.
Although the penetration of LNS in industrial appli-cations is low, mainly due to the absence of a standard(like the IEEE-754 for FP), there are several implementa-tions that use LNS, and it has been proven a viable alter-native for special-purpose-hardware designs. For the FastFourier Transform (FFT) in [22] it is shown that an LNSimplementation uses a smaller word size than a compara-ble fixed-point system, while achieving the same error per-formance. LNS has also been used for matrix [7] and fil-ter [17] applications. Bleris et al. [6] show that a 16-bit LNSApplication-Specific Integrated Processor (ASIP) is capableof implementing Model Predictive Control (MPC) in em-bedded applications, a possibility hindered previously bythe high computational requirements of MPC using double-precision FP arithmetic. LNS is useful for multimedia ap-plications, such as Wrigley’s ray-tracing engine [25]. Themost notable and widespread uses of LNS are the GRAPEsupercomputers designed by Makino et al. [20], which wonthe Gordon Bell Prize in 1995, 1996, and 1999 for thecomputation of N -body gravitational forces among stars,and Hidden Markov Modeling (HMM) for computing log-probabilities in applications like speech recognition andDNA sequencing [16, 24, 26]. It is noteworthy that GRAPEand HMMs use only LNS addition; it appears the difficultyof LNS subtractions has precluded a wider range of practi-cal LNS applications.
There are numerous studies that compare FP againstLNS. Among others in [14] it is shown how the ratio ofthe number of additions over the number of multiplica-tions of an algorithm affects the area and the latency of

both LNS and FP for a Field-Programmable-Gate-Array(FPGA) implementation. In [9] Collange et al. compareLNS against FP in terms of area, latency and accuracy forsimple arithmetic manipulations. They show that the LNS-FP library used to solve two arithmetic case studies rendersLNS smaller and faster for precisions smaller than 15 bits,and faster for precisions up to 23 bits, while FP producesslightly better visual quality than LNS for a toy-graphicsbenchmark application. However, as the authors in [9] state,these results should not be considered conclusive, and eachapplication should be studied separately by using, for ex-ample, the publicly-available library in [9, 12].
This work enhances certain characteristics of the LNSsubtraction implementation. We present a novel cotransfor-mation technique that reduces the complexity of the mostrecent cotransformation [3], which results in a reduced areaand delay of the hardware implementation. Moreover, westudy, by simulation, how many guard bits are required bythis new cotransformation to guarantee faithful rounding,and we show that, even without using any guard bits, theerror behavior of the LNS subtraction is improved consid-erably compared to the library in [9, 12]. Additionally,cotransformation reduces the area of the LNS subtraction,with the drawback of an increase in the latency of the cir-cuit due to the multiple tables required [23]. However, adesigner interested in reduced area and, more importantly,interested in increased accuracy of an LNS unit should con-sider the alternative of cotransformation. The scope of thiswork is to broaden the design space of an LNS implemen-tation by presenting a new cotransformation technique thatleads to a more economical implementation without sacri-ficing accuracy or performance.
2. Basic Addition and Subtraction
Given x = logb |X| and y = logb |Y |, logarithmic addi-tion can be performed as
logb(|X| + |Y |) = max(x, y) + sb(−|x − y|), (1)
or as
logb(|X| + |Y |) = min(x, y) + sb(|x − y|), (2)
where sb(z) = logb(1 + bz). Both (1) and (2) are validbecause of commutativity, which in the logarithmic domainis reflected by the relationship
sb(z) = sb(−z) + z. (3)
If we note that |x − y| = max(x, y) − min(x, y), substi-tuting (3) into (1) yields (2), and vice versa. In practice, animplementation uses either (1) or (2), and only needs to tab-ulate sb(z) for negative z or for positive z, thereby cutting
the number of words required in half. Since 0 < sb(z) ≤ 1for z ≤ 0, most hardware implementations have used (1)because no bits are required for storing the integer part ofsb(z) for z < 0. In contrast, (2) requires typically 3 to 5extra bits per word tabulated, which usually amounts to a10 to 20 percent increase.
In an algebraically analogous way, logarithmic subtrac-tion can be performed as
logb ||X| − |Y || = max(x, y) + db(−|x − y|), (4)
or as
logb ||X| − |Y || = min(x, y) + db(|x − y|), (5)
where db(z) = logb(1 − bz). There is only a single bit (thesign bit) of memory savings by choosing (4) over (5) be-cause db(z) < 0 for z < 0, which is not true for z > 0.Prior implementations have chosen to use consistent ad-dition and subtraction techniques. In other words, priorLNS implementations have used either (1) together with (4),which is the most common choice, or, more rarely some im-plementations [5] have used (2) together with (5). This pa-per will deviate from this assumption of consistent additionand subtraction techniques in order to explore a novel tech-nique that combines (1) with (5). We can generalize (1)–(5)as
t = logb ||X| ± |Y || = w + f(z, zs), (6)
where w is either max(x, y) or min(x, y), and z is either|x − y| or −|x − y| depending on which of the (1), (2), (4)or (5) is used. The appropriate values for w and z are calcu-lated by a preprocessing circuit and they are fed either to thesb or the db function depending on whether the differenceor the sum is sought. In parallel with w and z, the prepro-cessing circuit calculates ts which is the value sign of theresult t.
The signed LNS involves a comparison of the value-signbits, sign(X) and sign(Y ) (which are distinct from the log-arithm sign bits, sign(x) and sign(y)). Assuming the LNSfunctions are tabulated for z ≤ 0, the LNS “+” operationuses (1) when the value-sign bits are the same, thereby eval-uating sb. The identical LNS “+” operation uses (4) whenthe value-sign bits are different, thereby evaluating db. Ofcourse, if the LNS functions are tabulated for z ≥ 0, (2)and (5) are used instead, but the selection of sb for samesigns and db for different signs is similar. In a typical LNSimplementation, zs = sign(X) XOR sign(Y ).
3. Techniques for LNS Addition and Subtrac-tion
The bottleneck of an LNS addition/subtraction circuit isthe calculation of the sb and the db functions which are tab-ulated in Look-Up Tables (LUTs), and in order to reduce

the size of these tables the techniques of interpolation [19],multipartite tables [10] and cotransformation [3] have beenproposed. Linear interpolation, which uses two tables (onefor the values of the function and one for the slopes) anda multiplier, can be applied adequately for the sb functionsince 0 < s′b(z) < 1. However, db(0) = d′b(0) = d′′(0) =−∞, which means interpolation becomes very expensiveclose to zero if the accuracy in this region must be kept con-sistent with the rest of the domain. For example, Lewis [19]uses over ten times as much storage to interpolate db than tointerpolate sb.
The multipartite technique [11, 15] is an implementa-tion of interpolation which uses multiple tables addressedby overlapping subsets of bits to evaluate the function with-out a multiplier. The benefit of this approach is the reducedlatency, which is counterbalanced by an increase in the areaof the circuit. Nonetheless, multipartite tables suffer fromthe same storage problem with interpolation when consis-tent accuracy is sought close to zero.
The accuracy problem of interpolation and multipartitetables can be mitigated by the technique of cotransforma-tion proposed initially in [8], which is dubbed “Coleman’sCotransformation.” This method transforms the subtrac-tion to db(z) = db(z1) + db(z1 + db(z2) − db(z1)), wherez = z1 + z2 with sign(z1) = sign(z2). Although db is morecomplicated (requires db(z1), db(z2) and db(z1 + db(z2) −db(z1)), it avoids the singularity by transferring the evalu-ation of db away from zero (for an algebraic proof of thisproperty the interested reader is referred to [8]).
Another cotransformation is presented in [5], which isdubbed “Arnold’s Cotransformation.” It is proven that
db(z) = db(z1) + sb(z1 + db(z2) − db(z1)) (7)
for sign(z1) = sign(z2). In a practical system, the termsdb(z1) and db(z2) can come from small lookup tables, butthe sb evaluation is performed by an approximation methodlike interpolation or multipartite tables. In other words, themore difficult evaluation of the db function can always beturned into an evaluation of the sb function of a transformedargument plus an extra term obtained from a small table.The name “cotransformation” was proposed for this tech-nique in [5] because the hardware (6) uses the unmodifiedw = min(x, y), z = |x − y| and zs = 0 for LNS ad-dition, but w, z and zs are cotransformed together to bew = db(z1) + min(x, y), z = z1 + db(z2) − db(z1) andzs = 0 from the original w = min(x, y), z = |x − y| andzs = 1 for LNS subtraction. The notation z denotes thecotransformed value of the variable z. In theory, there arespecial cases for z1 = 0 and z2 = 0, but in practice, thesecan be implemented by storing sufficiently negative but fi-nite values to approximate −∞. An advantage of this formof cotransformation is that all subtractions can be turnedinto additions (that avoid the singularity), although, if de-
sired, the cotransformation may be limited only to valuesof z close to the singularity. Also, an advantage is that theoriginal argument and the transformed argument are bothpositive (i.e., z > 0 means z > 0). The disadvantage, asmentioned above, is that this case moderately increases thebit width of the sb table.
The “Improved Cotransformation” in [3] combines theadvantages of [5] and [8] by using z < 0 and by calculatingthe db function through the sb as follows:
db(z) = z + F1(zh) + sb(F2(zl) − z − F1(zh)),zh = −δh ∧ z = −2δh (8)
db(z) = F2(zl), zh = −δh (9)
db(z) = db(−2δh), z = −2δh, (10)
where zl consists of the last j bits of z, zh consists ofthe rest k + (f − j) bits of z (z is a two’s-complementnumber with k integer and f fractional bits), δh = 2j−f ,F1(zh) = db(−zh − δh) and F2(zl) = db(zl − δh). Thespecial case (9) guarantees that the argument of sb is notinfinity, and if (10) were not a special case the argumentsof sb would become positive which would increase the im-plementation cost. Although the accuracy of this cotrans-formation is studied in [3] and it is shown to be better than“Coleman’s Cotransformation” at no extra cost, the specialcase (9) is not accurately stated. In [23] it is proven that theargument of sb becomes positive not only for z = −2δh,but also for more values of z, which depend on the choiceof j. Nonetheless, if the value of j is chosen appropriatelythe hardware required to deal with this new special case isminimal and the error characteristics of the cotransforma-tion in [3] do not change.
Recently the technique of High-Order Table-BasedMethod (HOTBM) [13] has been proposed for hardwareevaluation of elementary functions, which are approximatedby an arbitrary-order interpolation in combination withmultipartite-like tables at a given precision that guaranteesfaithful rounding. Although the HOTBM can be used forthe direct evaluation of the sb and the db functions, the sin-gularity of the db would again cause increased hardware re-quirements for a faithful evaluation. There is no prior tech-nique to directly evaluate the db function that avoids theincreased hardware requirements posed by the singularity,but rather there are techniques that mitigate the negative ef-fects of this problem. Cotransformation bypasses this issueby transferring the evaluation of the db function away fromzero, while keeping the accuracy constant in the whole do-main of z. The scope of this work, apart from proposingthe “Novel Cotransformation Combination,” is to highlightthe benefits of using cotransformation, which would benefitthe HOTBM-based LNS Arithmetic Logic Units (ALUs) aswell as interpolation-based LNS ALUs.
In all of the previous techniques for addition and sub-traction a considerable memory reduction can be achieved

by exploiting the convergence of both sb and db to zero asz → −∞. The two functions become essentially zero aftera particular value of z, denoted as esb
and edb; i.e., the func-
tions need to be tabulated only up to their essential zero. Forsb, esb
= logb(b2−f − 1) ≈ −f , thus only f · 2n words areactually used.
4. Novel Cotransformation Combination
Unlike all the previous works that have used the samesign of z for both LNS addition and subtraction, a new im-plementation alternative that has not been considered beforeis to use z < 0 for LNS addition, which minimizes the bit-width in the sb table, but use z > 0 for LNS subtraction,which allows the use of “Arnold’s Cotransformation” with-out any special cases.
Using the identity sb(z) = sb(−z) + z in (7), we have
db(z)=db(z1) + sb(z1 + db(z2) − db(z1))=db(z1) + z1 + db(z2) − db(z1) +
sb(−(z1 + db(z2) − db(z1)))=z1 + db(z2) + sb((db(z1) − z1) − db(z2)).(11)
Assuming z1 > 0 and z2 > 0, (db(z1) − z1) − db(z2) < 0because db(z1) − z1 = db(−z1) < db(z2) for z2 > z1,which can be satisfied by making z2 = zh and z1 = zl. Inthis alternative, the hardware (6) uses the unmodified w =max(x, y), z = −|x − y| and zs = 0 for LNS addition, butuses w = z1 + db(z2) + min(x, y), z = (db(z1) − z1) −db(z2) and zs = 0 from different original arguments forLNS subtraction (w = min(x, y), z = |x − y| and zs = 1)than is used for addition. In other words, the preprocessingblock provides the negative absolute difference for addition,and the positive absolute difference for subtraction. Thepartitioning of z1 and z2 is based on the positive absolutedifference. In practice, the preprocessing block described inthe literature consists of two subtractors and two muxes inparallel. Changing whether a positive or negative absolutevalue is provided is simply a matter of exclusive-ORing theselect lines of the muxes with the original zs. A similartrivial change selects max(x, y) for addition and min(x, y)for subtraction.
A slight improvement in the critical path for this cir-cuit can be obtained by storing F3(zl) = db(−zl) in oneLUT and F4(zh) = db(zh) in the other. In this case,the cotransformed arguments for LNS subtraction are w =zl + F4(zh) + min(x, y) and z = F3(zl) − F4(zh).
4.1. Eliminating Special Cases
Two minor modifications to the hardware eliminate thespecial cases for z1 = 0 and z2 = 0. First, let the unparti-
tioned linear interpolator produce
sb(z)=
0, z ≤ esb
sb(zH) + s′b(zH + ε) · zL, esb< z < 0
logb(2), z = 0z, z > 0
(12)
where zH consists of the high (k + n) bits and zL of thelow (f − n) bits of the two’s-complement fixed-point z.The slope, s′b(zH + ε), can either be stored in a separateROM, or computed from function values [18]. “Unparti-tioned” means zH is a multiple of a constant (∆ = 2−n)and 0 ≤ zL < ∆. The variable ε can take any value in theinterval [0,∆], but the best accuracy occurs with ε ≈ ∆/2.The behavior for z > 0 is inexpensive but would be in-accurate in the normal context. Second, let Ω be a highlynegative finite value, like −2f , which is used as the resultfor db(0), such that Ω < −esb
+ db(2−f ).Case A: z1 = 0, z2 > 0.
t = min(x, y) + z1 + db(z2) +sb((db(z1) − z1) − db(z2))
= min(x, y) + db(z2) + s(Ω − db(z2)). (13)
Since z2 > 0, it follows that the quantized 2−f < z2.From this we derive that db(2−f ) ≤ db(z2) since db ismonotone increasing for positive arguments. Adding esb
to both sides and rearranging, we have −esb+ db(2−f ) −
db(z2) < −esb. Combining this with the definition of Ω
we prove Ω − db(z2) < −esb+ db(2−f ) − db(z2). Since
db(2−f ) < db(z2), we know Ω−d(z2) < −esb. This means
sb(Ω − db(z2)) = 0. Therefore, t = min(x, y) + d(z2),which is the correct result in this case.
Case B: z1 ≥ 0, z2 = 0.
t = min(x, y) + z1 + db(z2) +sb((db(z1) − z1) − db(z2))
= min(x, y) + z1 + Ω + sb((db(z1) − z1) − Ω).(14)
By similar reasoning to case A, (db(z1)− z1)−Ω > +esb.
Since the interpolator is designed to treat all positive ar-guments as essential identities, sb(d(z1) − z1) − d(z2) =(d(z1) − z1) − d(z2) which means
t = min(x, y) + z1 + db(z2) + db(z1) − z1 − db(z2)= min(x, y) + db(z1), (15)
which is the correct result in this case.
4.2. Synthesis
The “Novel Cotransformation Combination” describedin this paper eliminates the special cases requiredby [3, 5, 23] resulting in a reduction of the total area
0
50000
100000
150000
200000
250000
300000
350000
400000
450000
8 9 10 11 12 13 14 15 16
f
Gat
esNovel Cotr. CombinationImproved Cotranformation
(a) Area.
0
5
10
15
20
25
30
8 9 10 11 12 13 14 15 16
f
Lat
ency
(ns
)
Novel Cotr. Combination
Improved Cotranformation
(b) Latency.
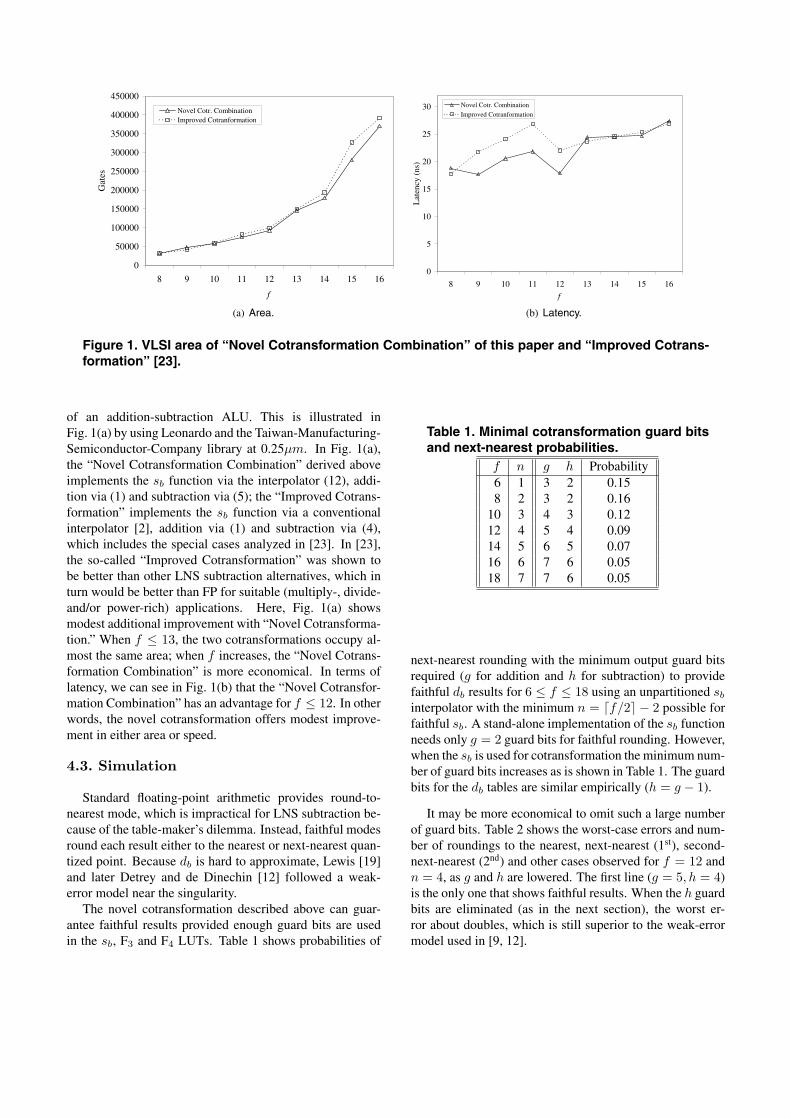
Figure 1. VLSI area of “Novel Cotransformation Combination” of this paper and “Improved Cotrans-formation” [23].
of an addition-subtraction ALU. This is illustrated inFig. 1(a) by using Leonardo and the Taiwan-Manufacturing-Semiconductor-Company library at 0.25µm. In Fig. 1(a),the “Novel Cotransformation Combination” derived aboveimplements the sb function via the interpolator (12), addi-tion via (1) and subtraction via (5); the “Improved Cotrans-formation” implements the sb function via a conventionalinterpolator [2], addition via (1) and subtraction via (4),which includes the special cases analyzed in [23]. In [23],the so-called “Improved Cotransformation” was shown tobe better than other LNS subtraction alternatives, which inturn would be better than FP for suitable (multiply-, divide-and/or power-rich) applications. Here, Fig. 1(a) showsmodest additional improvement with “Novel Cotransforma-tion.” When f ≤ 13, the two cotransformations occupy al-most the same area; when f increases, the “Novel Cotrans-formation Combination” is more economical. In terms oflatency, we can see in Fig. 1(b) that the “Novel Cotransfor-mation Combination” has an advantage for f ≤ 12. In otherwords, the novel cotransformation offers modest improve-ment in either area or speed.
4.3. Simulation
Standard floating-point arithmetic provides round-to-nearest mode, which is impractical for LNS subtraction be-cause of the table-maker’s dilemma. Instead, faithful modesround each result either to the nearest or next-nearest quan-tized point. Because db is hard to approximate, Lewis [19]and later Detrey and de Dinechin [12] followed a weak-error model near the singularity.
The novel cotransformation described above can guar-antee faithful results provided enough guard bits are usedin the sb, F3 and F4 LUTs. Table 1 shows probabilities of
Table 1. Minimal cotransformation guard bitsand next-nearest probabilities.
f n g h Probability6 1 3 2 0.158 2 3 2 0.16
10 3 4 3 0.1212 4 5 4 0.0914 5 6 5 0.0716 6 7 6 0.0518 7 7 6 0.05
next-nearest rounding with the minimum output guard bitsrequired (g for addition and h for subtraction) to providefaithful db results for 6 ≤ f ≤ 18 using an unpartitioned sb
interpolator with the minimum n = f/2 − 2 possible forfaithful sb. A stand-alone implementation of the sb functionneeds only g = 2 guard bits for faithful rounding. However,when the sb is used for cotransformation the minimum num-ber of guard bits increases as is shown in Table 1. The guardbits for the db tables are similar empirically (h = g − 1).
It may be more economical to omit such a large numberof guard bits. Table 2 shows the worst-case errors and num-ber of roundings to the nearest, next-nearest (1st), second-next-nearest (2nd) and other cases observed for f = 12 andn = 4, as g and h are lowered. The first line (g = 5, h = 4)is the only one that shows faithful results. When the h guardbits are eliminated (as in the next section), the worst er-ror about doubles, which is still superior to the weak-errormodel used in [9, 12].

Table 2. Effect of (g) interpolator- and (h) cotransformation-guard bits on error and rounding withf = 12 and n = 4. The “nearest”, “1st”, “2nd”, and “other” represent the cases that the roundings aredone to the nearest, next-nearest, second-next-nearest, and to all other cases, respectively.
g h pos. error neg. error nearest 1st 2nd other5 4 1.93e-4 -2.40e-4 44855 4297 0 05 3 1.93e-4 -2.52e-4 43525 5625 2 05 2 1.72e-4 -2.69e-4 41109 8006 37 05 1 1.72e-4 -3.46e-4 36257 12484 411 05 0 1.31e-4 -4.49e-4 20555 20668 7705 2244 3 1.93e-4 -2.52e-4 43424 5724 4 04 2 1.72e-4 -2.69e-4 40984 8120 48 04 1 1.72e-4 -3.32e-4 36111 12595 446 04 0 1.31e-4 -4.80e-4 20418 20704 7789 2413 2 1.72e-4 -2.81e-4 40957 8158 37 03 1 1.72e-4 -3.32e-4 36034 12665 453 03 0 1.31e-4 -4.80e-4 20375 20727 7807 2432 1 1.31e-4 -3.35e-4 37638 11104 410 02 0 1.31e-4 -4.80e-4 20329 21355 7239 229
4.4. Optimized Interpolation/Cotransforma-tion Hybrid
Coleman’s method requires, and the other cotransforma-tions allow, db(z) for z not near zero to be implemented byinterpolation. The interpolation multiplier, etc. would beshared by sb and db. The only extra cost is the additionalwords for the portion of db approximated by interpolation.Although it has been suggested to combine these two tech-niques before, an analysis of the optimum combination hasnot been published previously.
Assuming power-of-two partitioning for interpolation,and an m-bit address-bus size for the two cotransforma-tion ROMs, the total number of words for db is (k + f −2m)2n + 2 · 2m. Taking the derivative with respect to mand solving to find m gives the minimum number of words:2 · 2n = 2 ln 2 · 2m or m = n − log2(ln 2) ≈ n. Thusthe total cost of the optimal interpolation/cotransformationcombination is about (k + f − 2n)2n + 2 · 2n. If interpola-tion alone were used, the total cost would be (k+f −n)2n,and the ratio would be (k + f − 2n + 2)/(k + f − n). Forlinear interpolation with single precision (f = 23, k = 5and n = 10), the size for the cotransformation/interpolationcombination is 5/9 that of pure interpolation.
5. Error Analysis
The singularity of db near zero requires excessive mem-ory in order to attain a particular accuracy. Some imple-mentations relax accuracy in this region to achieve reason-able memory size; as in [12], the multipartite tables give
lower db(z) accuracy for z close to zero. Fig. 2(a) showsthe multipartite-db error of [12] for f = 10. The errorsgrow almost to 0.01, which is about ten times larger thandesired.
Fig. 2(b), which shows “Improved Cotransformation”described in [23] (f = 10 using the multipartite method forsb and special cases for db with no guard bits) has a moreuniform error distribution closer to the target accuracy of2−10 than the multipartite method alone. Finally, Fig. 2(c)presents the error performance of the “Novel Cotransfor-mation Combination” derived here (f = 10 using 1st-orderinterpolation for sb and “Novel Cotransformation Combi-nation” for db). Although this last implementation is thecheapest in terms of area, its error performance is similarto Fig. 2(b), which was previously shown [23] to be bet-ter than other LNS subtraction options, which in turn havebeen shown previously can be better than FP for certain ap-plications. In other words, the cotransformations presentedhere produce much more accurate results than [12], eventhough, for economy, cotransformation was implementedwithout guard bits.
6. Conclusions
Interpolation and multipartite tables are two differenttechniques for the implementation of addition and subtrac-tion circuits in an LNS unit. Both of them have been ana-lyzed in previous works, but in this paper their combinationwith cotransformation has been studied. The novel varia-tion of cotransformation presented here, eliminates the spe-cial cases in [23] and uses less memory than [5], and con-

−16 −12 −8 −4 00
0.002
0.004
0.006
0.008
0.01
z
Rel
ativ
e er
ror
(a) db implemented by the multipartitemethod [12].
−16 −12 −8 −4 00
0.002
0.004
0.006
0.008
0.01
z
Rel
ativ
e er
ror
(b) db implemented by “Improved Cotrans-formation” [23] and sb by the multipartitemethod [12].
−16 −12 −8 −4 00
0.002
0.004
0.006
0.008
0.01
z
Rel
ativ
e er
ror
(c) db implemented by “Novel Cotransforma-tion Combination” and sb by 1st-order inter-polation (Section 4).
Figure 2. Error performance of the db function for different implementation choices for f = 10.
sequently is more economical at higher precisions. Simu-lations determine the required guard bits for addition andsubtraction when faithful rounding is desired. Nonethe-less, even without the guard bits, cotransformation is muchmore accurate for subtraction of nearly equal values (z closeto zero), as has been illustrated by exhaustive simulation.When put in the context of earlier LNS methods, the pro-posed cotransformation offers a reasonable tradeoff of area,speed and accuracy, which can be better than floating pointfor limited classes of suitable application-specific systems(multimedia [4, 25], embedded control [6], scientific sim-ulation [20]) having a majority of easy (multiply, divide orpower) operations but a minority of subtractions that needto be performed with faithful or near-faithful accuracy forsuccessful application performance.
Acknowledgements
The authors would like to thank Nicolas Frantzen and Je-sus Garcia for their contributions in the early stages of thiswork.
References
[1] ANSI/IEEE. Standard 754-1985 for Binary Floating-PointArithmetic. 1985.
[2] M. G. Arnold. A Pipelined LNS ALU. In Proceedings of theIEEE Workshop on VLSI, pages 155–161, Orlando, Florida,19–20 April 2001.
[3] M. G. Arnold. An Improved Cotransformation for Logarith-mic Subtraction. In Proceedings of the International Sym-posium on Circuits and Systems, pages 752–755, Scottsdale,Arizona, 26–29 May 2002.
[4] M. G. Arnold. Redundant Logarithmic Arithmetic forMPEG Decoding. In Proceedings of the International Sym-posium on Optical Science SPIE Annual Meeting, volume5559, pages 112–122, Denver, CO, 2–6 Aug. 2004.
[5] M. G. Arnold, T. A. Bailey, J. R. Cowles, and M. D. Winkel.Arithmetic Co-transformations in the Real and ComplexLogarithmic Number Systems. IEEE Transactions on Com-puters, 47(7):777–786, July 1998.
[6] L. G. Bleris, J. G. Garcia, M. V. Kothare, and M. G.Arnold. Towards Embedded Model Predictive Control forSystem-on-a-Chip Applications. Journal of Process Con-trol, 16(4):255–264, March 2006.
[7] E. I. Chester and J. N. Coleman. Matrix Engine for Sig-nal Processing Applications Using the Logarithmic Num-ber System. In Proceedings of the IEEE International Con-ference on Application-Specific Systems, Architectures andProcessors, pages 315–324, San Jose, CA, 17–19 July 2002.
[8] J. N. Coleman. Simplification of Table Structure in Log-arithmic Arithmetic. IEE Electronic Letters, 31(22):1905–1906, 26 Oct. 1995.
[9] S. Collange, F. de Dinechin, and J. Detrey. Floating Point orLNS: Choosing the Right Arithmetic on an Application Ba-sis. In Proceedings of the 9th EuroMicro Digital System De-sign , pages 197–203, Dubrovnik, Croatia, 30 Aug.–1 Sept.2006.
[10] F. de Dinechin and A. Tisserand. Some Improvements onMultipartite Table Methods. In Proceedings of the 15th Sym-posium on Computer Arithmetic, pages 128–135, Vail, Col-orado, 11–13 June 2001.
[11] F. de Dinechin and A. Tisserand. Multipartite Table Meth-ods. IEEE Transactions on Computers, 54(3):319–330,March 2005.
[12] J. Detrey and F. de Dinechin. A VHDL Library of LNS Op-erations. In 37th Asilomar Conference on Signals, Systems,and Computers, volume 2, pages 2227–2231, Pacific Grove,CA, 9–12 Nov. 2003.
[13] J. Detrey and F. de Dinechin. Table-based Polynomials forForward Function Evaluation. In Proceedings of the 16th In-ternational Conference on Application-Specific Systems, Ar-chitectures and Processors, pages 328–333, Samos, Greece,23–25 July 2005.
[14] M. Haselman, M. Beauchamp, A. Wood, S. Hauck, K. Un-derwood, and K. S. Hemmert. A Comparison of FloatingPoint and Logarithmic Number Systems for FPGAs. InProceedings of the 13th Annual IEEE Symposium on Field-Programmable Custom Computing Machines, pages 181–190, Washington, DC, 17–20 April 2005.
[15] H. Hassler and N. Takagi. Function Evaluation by TableLook-up and Addition. In Proceedings of the 12th Sympo-sium on Computer Arithmetics, pages 10–16, Bath, England,19–21 July 1995.

[16] R. Hughey and A. D. Blas. The UCSC Kestrel Application-Unspecific Processor. In Proceedings of the IEEE Inter-national Conference on Application-Specific Systems, Ar-chitectures, and Processors, pages 163–168, SteamboatSprings, CO, 11–13 Sept. 2006.
[17] G. A. Jullien. Array Processing Using Alternate Arithmetic -A 20 Year Legacy. In Proceedings of the IEEE InternationalConference on Application-Specific Systems, Architectures,and Processors, pages 199–204, Steamboat Springs, CO,11–13 Sept. 2006.
[18] D. M. Lewis. An Architecture for Addition and Subtractionof Long Word Length Numbers in the Logarithmic NumberSystem. IEEE Transactions on Computers, 39(11):1325–1336, Nov. 1990.
[19] D. M. Lewis. 114 MFLOPS Logarithmic Number SystemArithmetic Unit for DSP Applications. IEEE Journal ofSolid-State Circuits, 30(12):1547–1553, Dec. 1995.
[20] J. Makino and M. Taiji. Scientific Simulations with Special-Purpose Computers: The GRAPE Systems. John Wiley &Son Ltd., Feb. 1998.
[21] E. E. Swartzlander and A. G. Alexopoulos. TheSign/Logarithm Number System. IEEE Transactions onComputers, 24(12):1238–1242, Dec. 1975.
[22] E. E. Swartzlander, D. Chandra, T. Nagle, and S. A. Starks.Sign/Logarithm Arithmetic for FFT Implementation. IEEETransactions on Computers, C-32:526–534, 1983.
[23] P. Vouzis, S. Collange, and M. Arnold. CotransformationProvides Area and Accuracy Improvement in an HDL Li-brary for LNS Subtraction. Accepted for The 10th EuroMi-cro Conference on Digital Systems and Design, Lubeck,Germany, 27–31 Aug. 2007.
[24] M. Wazlowski, A. Smith, R. Citro, and H. Silverman.Performing Log-Scale Addition on a Distributed MemoryMIMD Multicomputer with Reconfigurable Computing Ca-pabilities. In Proceedings of the International Conferenceon Parallel Processing, volume 3, pages III-211–III-214,Urbana-Champaign, IL, 14–18 Aug. 1995.
[25] A. Wrigley. Real-Time Ray Tracing on a Novel HDTVFramestore. PhD thesis, University of Cambridge, England,1993.
[26] S. Young, D. Kershaw, J. Odell, D. Ollason, V. Valtchev,and P. Woodland. The HTK Book (Version 3.4). CambridgeUniversity Engineering Department, Dec. 2006.





























