Embed Size (px)
Citation preview
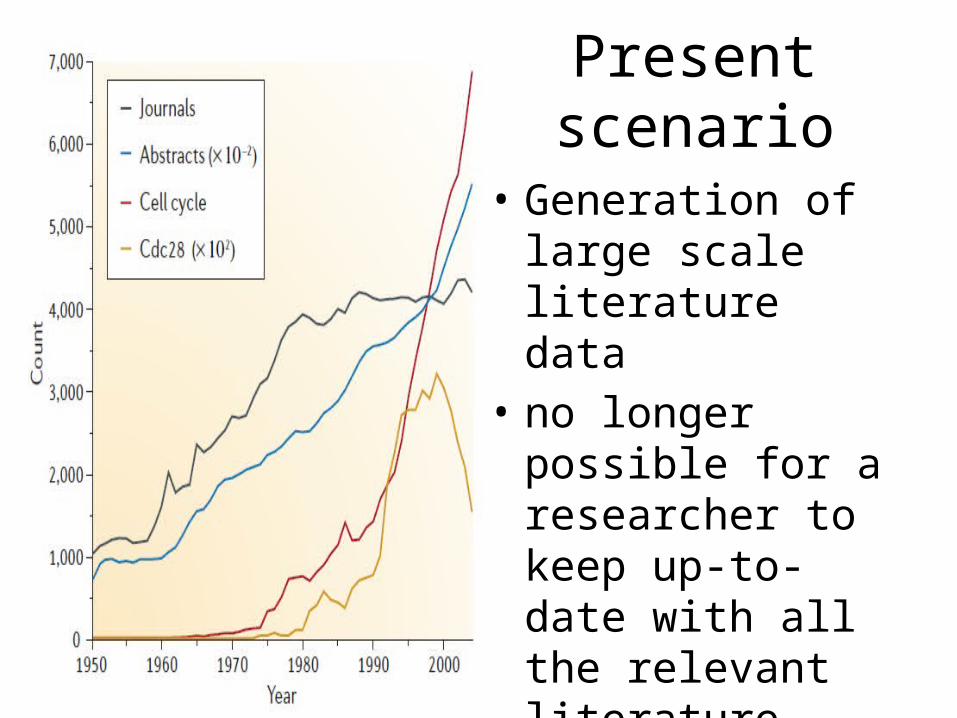
Present scenario
• Generation of large scale literature data
• no longer possible for a researcher to keep up-to-date with all the relevant literature manually

What is Literature Mining?
• For an average biologist– Keyword search in PubMed/CeRa/CAB Abstracts– ‘maps of science’ that cluster papers together on
the basis of how often they cite one another, or by similarities in the frequencies of certain keywords
Machine learningThe ability of a machine to learn from experience or extract knowledge fromexamples in a database. Artificial neural networks and support-vector machines are two commonly used types of machine-learning method.

Literature Mining
• To identify relevant articles (Information Retrieval - IR)
• For recognizing biological entities mentioned in these articles (Entity recognition - ER)
• To enable specific facts to be pulled out from papers (Information Extraction - IE)

Text mining or Data mining
• Integrate the literature with other large data sets such as genome sequences, microarray expression studies, or protein–protein interaction screens
• Dig out the deeper meaning that leads to biological discoveries
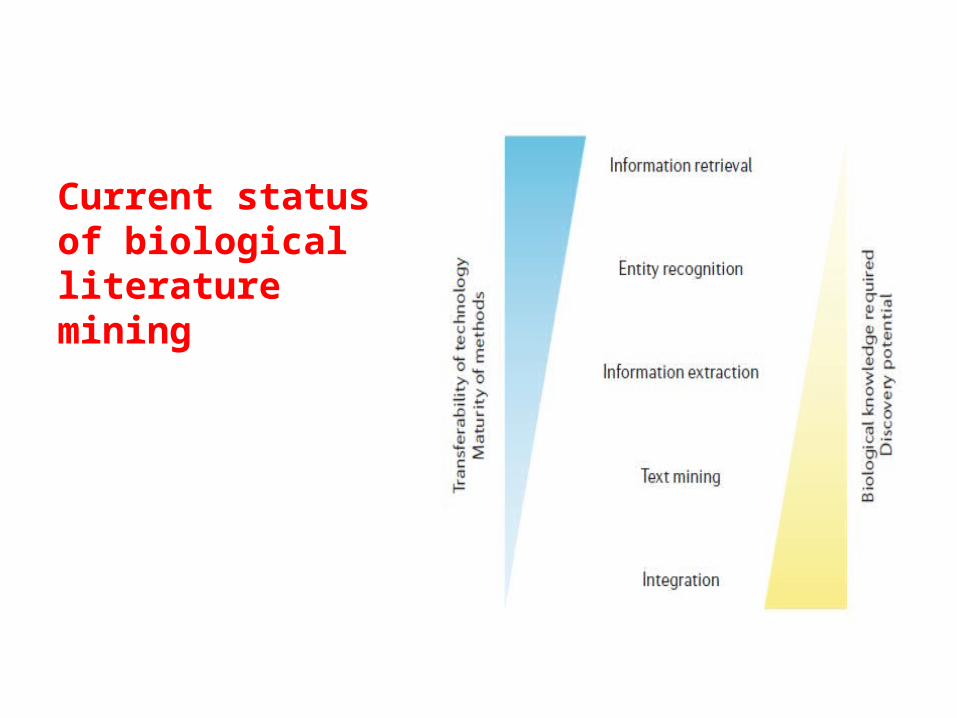
Current status of biological literature mining

IR – Information Retrieval
• to identify the text segments (be it full articles, abstracts, paragraphs or sentences) that pertain to a certain topic

Tools for IR
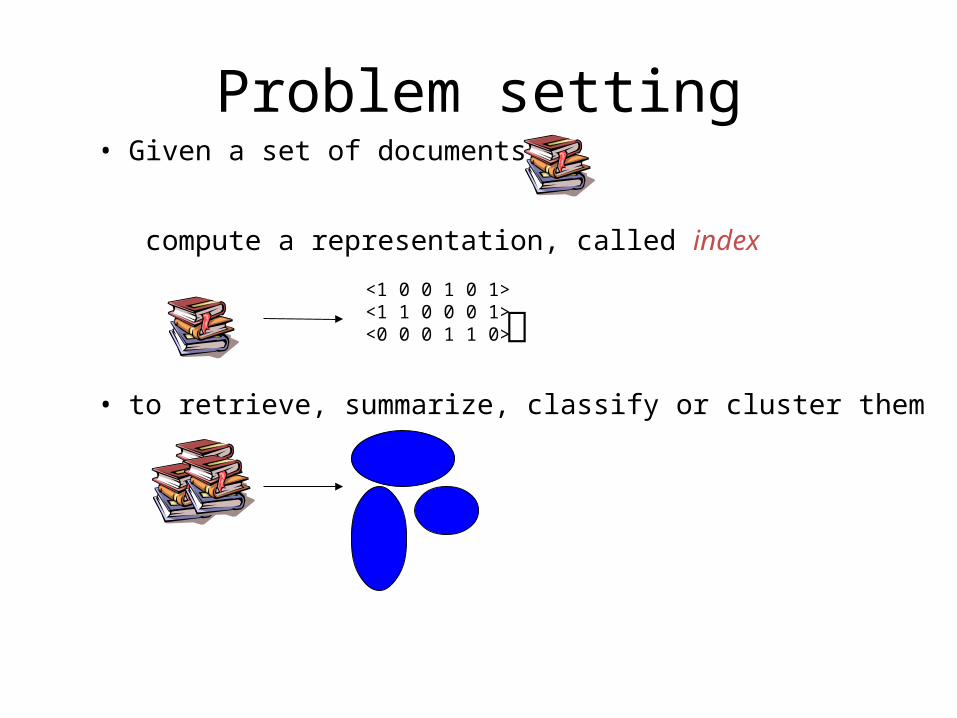
Problem setting• Given a set of documents,
compute a representation, called index
• to retrieve, summarize, classify or cluster them
<1 0 0 1 0 1> <1 1 0 0 0 1> <0 0 0 1 1 0>

Problem setting• Given a set of genes (and their literature),
• compute a representation, called gene index
• to retrieve, summarize, classify or cluster them
<1 0 0 1 0 1> <1 1 0 0 0 1> <0 0 0 1 1 0>

Vector space model Document processing
Remove punctuation & grammatical structure (`Bag of words’)Define a vocabulary
• Identify Multi-word terms (e.g., tumor suppressor) (phrases)• Eliminate words low content (e.g., and, thus, gene, ...) (stopwords)• Map words with same meaning (synonyms)• Strip plurals, conjugations, ... (stemming)
Define weighing scheme and/or transformations (tf-idf,svd,..)
Compute index of textual resources:
T 1
T 3
T 2
vocabulary
gene

Biomedical Text Mining: Methods
• Databases• Natural Language Processing• Information Retrieval• Information Extraction• Ontologies• Clustering• Classification• Visualization
Gene OntologyA set of controlled vocabularies that are used to describe the molecular functions of a gene product, the biological processes in which it participates and the cellular components in which it can be found.
MeSH termsA controlled vocabulary that is used for annotating Medline abstracts. Several classes of MeSH term exist, the most relevant for literature mining being ‘Chemicals and Drugs’ (MeSH-D) and ‘Diseases’ (MeSH-C).

Example
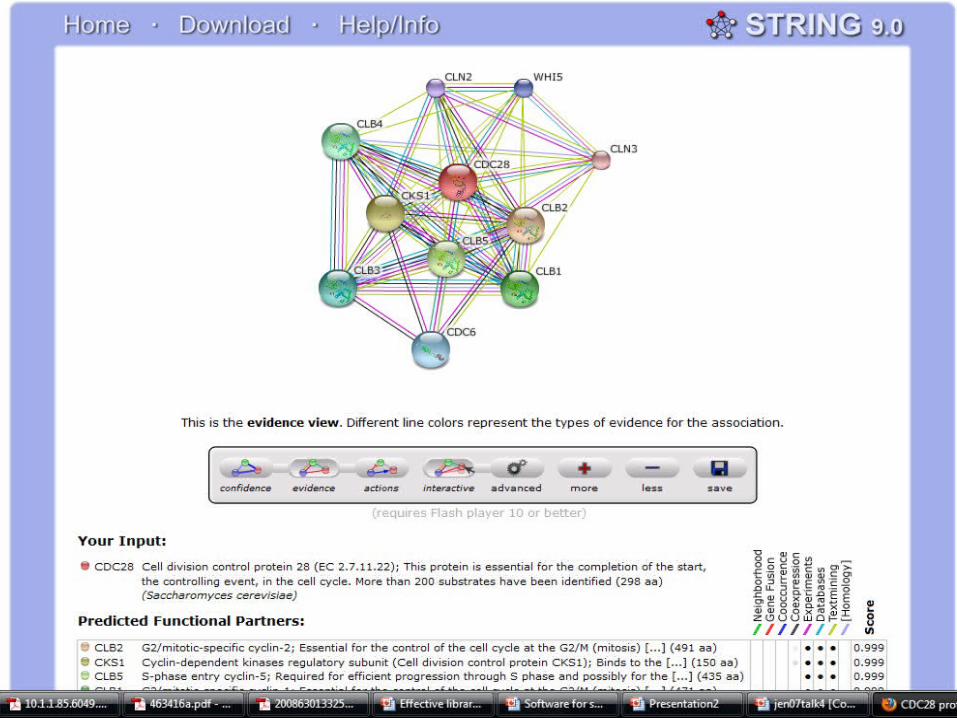
Mitotic cyclin (Clb2)-bound Cdc28 (Cdk1 homolog) directly phosphorylated Swe1 and this modification served as a priming step to promote subsequent Cdc5-dependent Swe1 hyperphosphorylation and degradation

Ad hoc IR
• These systems are very useful since the user can provide any query– The query is typically Boolean (yeast AND cell cycle)– A few systems instead allow the relative weight of each
search term to be specified by the user
• The art is to find the relevant papers even if they do not actually match the query– Ideally our example sentence should be extracted by the
query yeast cell cycle although none of these words are mentioned

Automatic query expansion
• In a typical query, the user will not have provided all relevant words and variants thereof
• By automatically expanding queries with additional search terms, recall can be improved– Stemming removes common endings (yeast / yeasts)– Thesauri can be used to expand queries with synonyms
and/or abbreviations (yeast / S. cerevisiae)– The next logical step is to use ontologies to make
complex inferences (yeast cell cycle / Cdc28 )

Document similarity
• The similarity of two documents can be defined based on their word content– Each document can be represented by a word vector– Words should be weighted based on their frequency
and background frequency– The most commonly used scheme is tf*idf weighting
• Document similarity can be used in ad hoc IR– Rather than matching the query against each document
only, the N most similar documents are also considered

Document clustering
• Unsupervised clustering algorithms can be applied to a document similarity matrix– All pairwise document similarities are calculated– Clusters of “similar documents” can be constructed
using one of numerous standard clustering methods
• Practical uses of document clustering– The “related documents” function in PubMed– Logical organization of the documents found by IR

Entity recognition
• An important but boring problem– The genes/proteins/drugs mentioned within a given
text must be identified
• Recognition vs. identification– Recognition: find the words that are names of
entities– Identification: figure out which entities they refer to– Recognition without identification is of limited use

Example
Mitotic cyclin (Clb2)-bound Cdc28 (Cdk1 homolog) directly phosphorylated Swe1 and this modification served as a priming step to promote subsequent Cdc5-dependent Swe1 hyperphosphorylation and degradation
Entities identified– S. cerevisiae proteins: Clb2 (YPR119W), Cdc28
(YBR160W), Swe1 (YJL187C), and Cdc5 (YMR001C)



Co-occurrence extraction
• Relations are extracted for co-occurring entities– Relations are always symmetric– The type of relation is not given
• Scoring the relations– More co-occurrences more significant– Ubiquitous entities less significant– Same sentence vs. same paragraph
• Simple, good recall, poor precision

Example
Mitotic cyclin (Clb2)-bound Cdc28 (Cdk1 homolog) directly phosphorylated Swe1 and this modification served as a priming step to promote subsequent Cdc5-dependent Swe1 hyperphosphorylation and degradation
Relations– Correct: Clb2–Cdc28, Clb2–Swe1, Cdc28–Swe1, and
Cdc5–Swe1– Wrong: Clb2–Cdc5 and Cdc28–Cdc5


Mining text for nuggets• New relations can be
inferred from published ones– This can lead to actual
discoveries if no person knows all the facts required for making the inference
– Combining facts from disconnected literatures
• Swanson’s pioneering work– Fish oil and Reynaud's disease– Magnesium and migraine
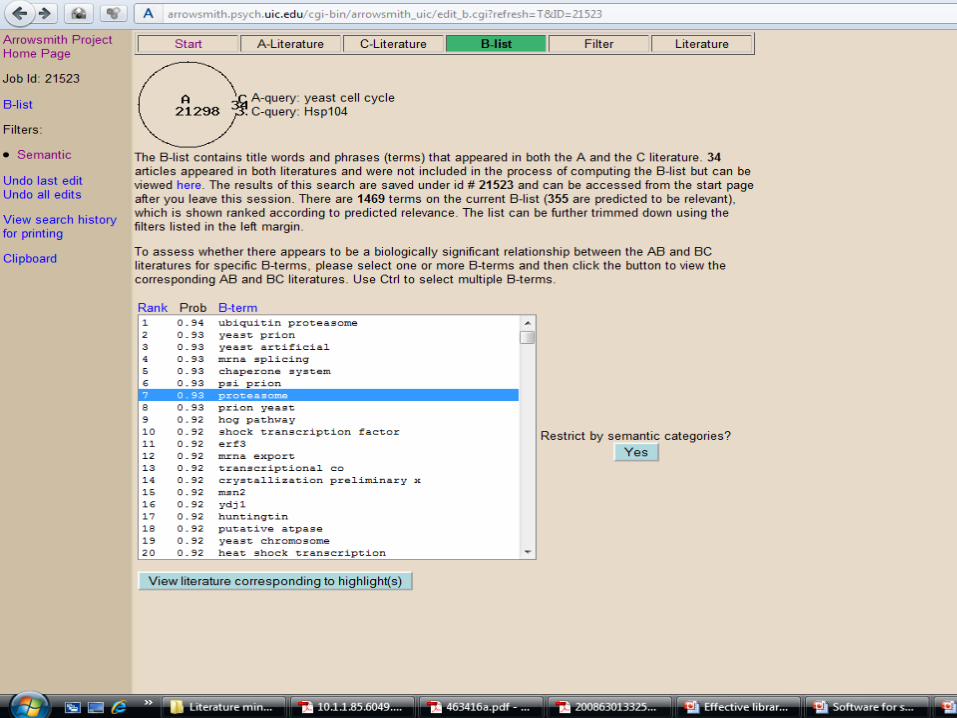
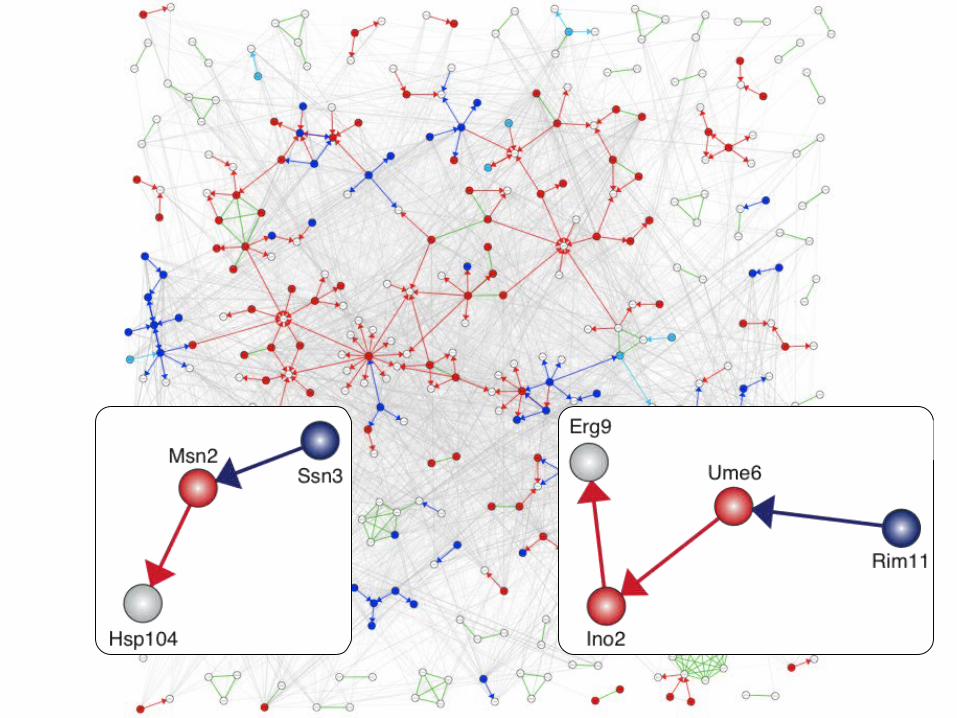

Integration
• Automatic annotation of high-throughput data– Loads of fairly trivial methods
• Protein interaction networks– Can unify many types of interactions– Powerful as exploratory visualization tools
• More creative strategies– Identification of candidate genes for genetic diseases– Linking genes to traits based on species distributions

Tools for information retrievalE-BioSciEBIMedGoogle ScholarGoPubMedMedMinerPubMedPubFinderTextpressoXplorMed
http://www.e-biosci.orghttp://www.ebi.ac.uk/Rebholz-srv/ebimedhttp://scholar.google.com http://www.gopubmed.orghttp://discover.nci.nih.gov/textmininghttp://www.pubmed.orghttp://www.glycosciences.de/tools/PubFinderhttp://www.textpresso.orghttp://www.ogic.ca/projects/xplormed

ER & IE Tools
Entity recognition
iHOP http://www.pdg.cnb.uam.es/UniPub/iHOP
Information extraction
iProLINK JournalMine.PreBIND PubGene
http://pir.georgetown.edu/iprolinkhttp://textmine.cu-genome.orghttp://prebind.bind.cahttp://www.pubgene.org

Text mining & integration tools
Text miningArrowsmithLitInspectorCoPubGeneiBeeSpace Navigator
http://arrowsmith.psych.uic.eduhttp://www.litinspector.org/http://services.nbic.nl/cgi-bin/copub/CoPub.plhttp://cbdm.mdc-berlin.de/tools/genie/www.beespace.illinois.edu
IntegrationBITOLA G2D ProLinksSTRING
http://www.mf.uni-lj.si/bitolahttp://www.ogic.ca/projects/g2d_2http://dip.doe-mbi.ucla.edu/pronavhttp://string.embl.de

Permission denied
• Open access– Literature mining methods cannot retrieve, extract, or
correlate information from text unless it is accessible– Restricted access is already now the primary problem
• Standard formats– Getting the text out of a PDF file is not trivial– Many journals now store papers in XML format
• Where do I get all the patent text?!
Thank You





















![FICO Material Santhosh[1].Kaparthi](https://img.pdfslide.us/doc/110x75/5476ff40b4af9f76108b456e/fico-material-santhosh1kaparthi.jpg)








