Embed Size (px)
Citation preview

Lisa Torrey and Jude Shavlik
University of Wisconsin
Madison WI, USA
Policy Transfer viaMarkov Logic Networks

Background
Approaches for transfer in reinforcement learning
Relational transfer with Markov Logic Networks
Two new algorithms for MLN transfer
Outline

Background
Approaches for transfer in reinforcement learning
Relational transfer with Markov Logic Networks
Two new algorithms for MLN transfer
Outline

Transfer Learning
Given
Learn
Task T
Task S

Reinforcement Learning
Environment
s1
AgentQ(s1, a) = 0
policy π(s1) = a1 a
1
s2
r2
δ(s1, a1) = s2
r(s1, a1) = r2
Q(s1, a1) Q(s1, a1) + Δ
π(s2) = a2a2
δ(s2, a2) = s3
r(s2, a2) = r3
s3
r3
Exploration Exploitation
Maximize reward
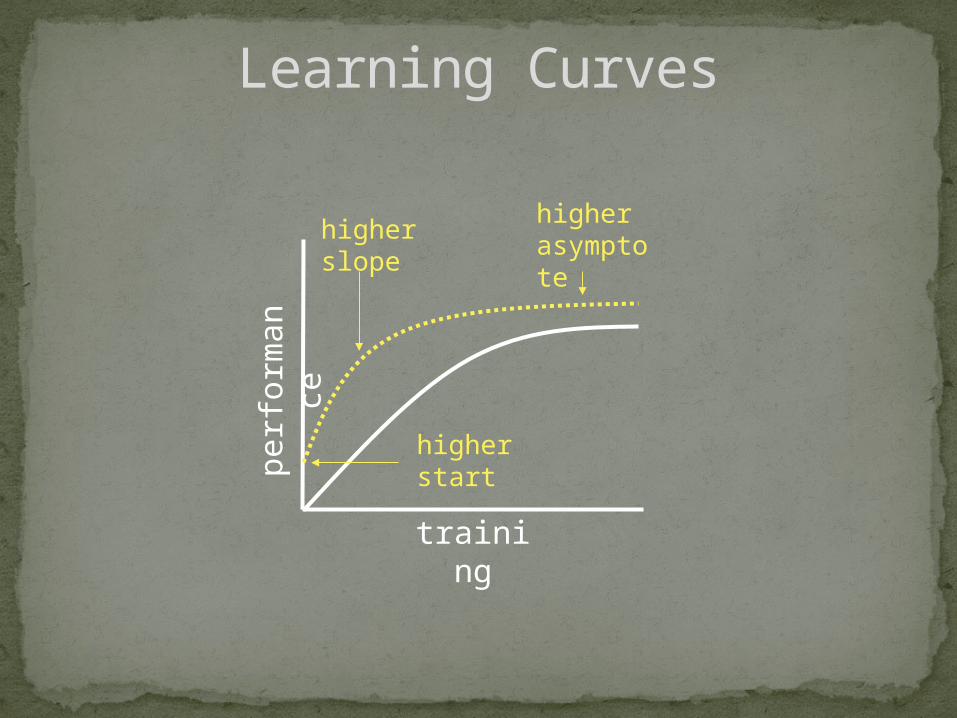
Learning Curves
perf
orm
an
ce
training
higher start
higher slope
higher asymptote

RoboCup Domain
3-on-2 BreakAway
2-on-1 BreakAway
Hand-coded defendersSingle learning agent

Background
Approaches for transfer in reinforcement learning
Relational transfer with Markov Logic Networks
Two new algorithms for MLN transfer
Outline

Madden & Howley 2004Learn a set of rulesUse during exploration steps
Croonenborghs et al. 2007Learn a relational decision treeUse as an additional action
Our prior work, 2007Learn a relational macroUse as a demonstration
Related Work

Background
Approaches for transfer in reinforcement learning
Relational transfer with Markov Logic Networks
Two new algorithms for MLN transfer
Outline

IF distance(GoalPart) > 10AND angle(ball, Teammate, Opponent) > 30THEN
Relational Transfer
pass(t
1)
pass(t
2)
pass(Teammate)
goalLeft
goalRight

Markov Logic Networks
Formulas (F)
evidence1(X) AND query(X)evidence2(X) AND query(X)
Weights (W)
w0 = 1.1w1 = 0.9
Fi
ii worldnwZ
worldP )(exp1
)(
ni(world) = # true groundings of ith formula in world
query(x1)
e1 e2 …
query(x2)
e1 e2 …
Richardson and Domingos, Machine Learning 2006

Transfer with MLNs
Algorithm 1: Transfer source-task Q-function as an MLN
Algorithm 2: Transfer source-task policy as an MLN
Task T
Task S
MLN Q-function
Task T
Task S
MLN Policy

Demonstration Method
Use MLN
Use regular
target-task training

Background
Approaches for transfer in reinforcement learning
Relational transfer with Markov Logic Networks
Two new algorithms for MLN transfer
Outline

MLN Q-function Transfer Algorithm
Source
Target
Aleph, Alchemy
Demonstration
MLN foraction 1
State Q-value
MLN Q-function
MLN foraction 2
State Q-value
…

MLN Q-function
0 ≤ Qa < 0.2 0.2 ≤ Qa < 0.4 0.4 ≤ Qa < 0.6
… … …
…
Bin Number
Pro
bab
ilit
y
Bin Number
Pro
bab
ilit
y
Bin Number
Pro
bab
ilit
y
bins
bina binQEprobsQ ]|[)(

IF … THEN 0 < Q < 0.2
IF … THEN 0 < Q < 0.2
Learning an MLN Q-function
Bins: Hierarchical clustering
Formulas for each bin: Aleph (Srinivasan)
w0 = 1.1w1 = 0.9…
Weights: Alchemy (U. Washington)
IF … THEN 0 < Q < 0.2

Selecting Rules to be MLN Formulas
Rule 1Precision=1.0Rule 2Precision=0.99Rule3Precision=0.96… …
Does rule increase F-score of ruleset?
yes Add toruleset
Aleph rules
F = 2 x Precision x Recall Precision + Recall

MLN Q-function RulesExamples for transfer from 2-on-1 BreakAway to 3-on-2
BreakAwayIF distance(me, GoalPart) ≥ 42
distance(me, Teammate) ≥ 39
THEN pass(Teammate) falls into [0, 0.11]
IF angle(topRight, goalCenter, me) ≤ 42
angle(topRight, goalCenter, me) ≥ 55
angle(goalLeft, me, goalie) ≥ 20angle(goalCenter, me, goalie) ≤
30
THEN pass(Teammate) falls into [0.11, 0.27]
IF distance(Teammate, goalCenter) ≤ 9
angle(topRight, goalCenter, me) ≤ 85
THEN pass(Teammate) falls into [0.27, 0.43]

MLN Q-function ResultsTransfer from 2-on-1 BreakAway to 3-on-2 BreakAway

Background
Approaches for transfer in reinforcement learning
Relational transfer with Markov Logic Networks
Two new algorithms for MLN transfer
Outline

MLN Policy-Transfer Algorithm
Source
Target
Aleph, Alchemy
Demonstration
MLN(F,W)
StateAction
Probability
MLN Policy

MLN Policy
move(ahead) pass(Teammate) shoot(goalLeft)
… … …
…
Policy: choose highest-probability action

IF … THEN pass(Teammate)
IF … THEN pass(Teammate)
Learning an MLN Policy
Formulas for each action: Aleph (Srinivasan)
w0 = 1.1w1 = 0.9…
Weights: Alchemy (U. Washington)
IF … THEN pass(Teammate)

MLN Policy RulesExamples for transfer from 2-on-1 BreakAway to 3-on-2
BreakAwayIF angle(topRight, goalCenter, me) ≤ 70
timeLeft ≥ 98distance(me, Teammate) ≥ 3
THEN pass(Teammate)
IF distance(me, GoalPart) ≥ 36distance(me, Teammate) ≥ 12timeLeft ≥ 91angle(topRight, goalCenter, me)
≤ 80THEN pass(Teammate)
IF distance(me, GoalPart) ≥ 27angle(topRight, goalCenter, me)
≤ 75distance(me, Teammate) ≥ 9angle(Teammate, me, goalie) ≥
25THEN pass(Teammate)

MLN Policy ResultsMLN policy transfer from 2-on-1 BreakAway to 3-on-2
BreakAway

ILP rulesets can represent a policy by themselvesDoes the MLN provide extra benefit?Yes, MLN policies perform as well or better
MLN policies can include action-sequence knowledgeDoes this improve transfer?No, the Markov assumption appears to hold in
RoboCup
Additional Experimental Findings

MLN transfer can improve reinforcement learningHigher initial performance
Policies transfer better than Q-functionsSimpler and more general
Policies can transfer better than macros, but not alwaysMore detailed knowledge, risk of overspecialization
MLNs transfer better than rulesetsStatistical-relational over pure relational
Action-sequence information is redundantMarkov assumption holds in our domain
Conclusions
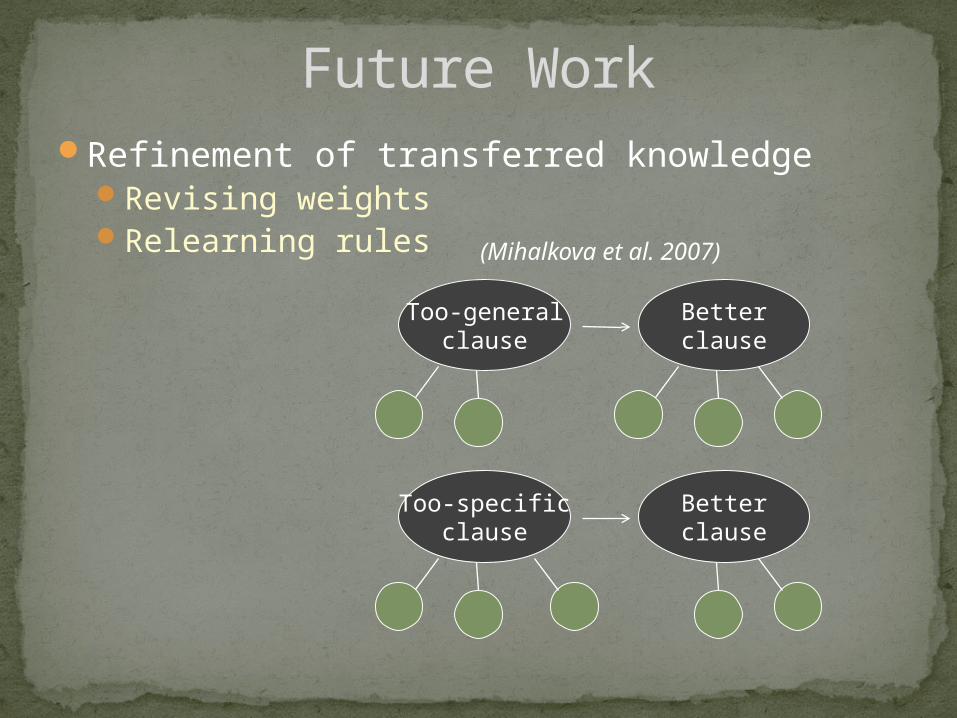
Future WorkRefinement of transferred knowledge
Revising weightsRelearning rules
Too-specificclause
Betterclause
Too-generalclause
Betterclause
(Mihalkova et al. 2007)

Relational reinforcement learningQ-learning with MLN Q-functionPolicy search with MLN policies or macro
Future Work
Bin Number
Pro
bab
ilit
y
bins
binaction binQEpstateQ ]|[)(
MLN Q-functions lose too much information:

Co-author: Jude Shavlik
GrantsDARPA HR0011-04-1-0007DARPA FA8650-06-C-7606
Thank You





























