Embed Size (px)
Citation preview

188 Int. J. Knowledge and Learning, Vol. 8, Nos. 3/4, 2012
Copyright © 2012 Inderscience Enterprises Ltd.
Linked open data for learning object discovery in adaptive e-learning systems
Burasakorn Yoosooka* Department of Computer Science, Faculty of Science and Technology, Rajamangala University of Technology Thanyaburi, Pathumthani, 12110, Thailand E-mail: [email protected] *Corresponding author
Vilas Wuwongse Department of Electrical and Computer Engineering, Faculty of Engineering, Thammasat University, Rangsit Campus, KlongLuang, Pathumthani, 12120, Thailand E-mail: [email protected]
Abstract: This paper proposes a new approach to automatic retrieval of learning objects (LOs) from local or external LO repositories via linked open data (LOD) principles. The approach dynamically selects the most appropriate LOs for an individual learning package in an adaptive e-learning system based on the use of LO metadata, learner profiles, ontology, and LOD principles. The approach has been designed to interlink the domain ontology with external open knowledge in the LOD cloud. SPARQL endpoints for datasets in the LOD cloud are also provided for instructors and learners to discover their desired LOs. Moreover, commonly known vocabularies such as Dublin core (DC), IEEE learning object metadata (IEEE LOM), web ontology language (OWL), and resource description framework (RDF) are employed to represent metadata and to link it with external LO repositories as well as DBpedia, the central hub of the LOD cloud. By using these techniques, the LOs and external knowledge can be exchangeable, shareable, and interoperable, resulting in an enhanced access to better learning resources. Based on the proposed approach, a prototype system has been developed and evaluated. It has been discovered that the system has yielded positive effects in terms of the learners’ satisfaction.
Keywords: linked open data; LOD; learning object discovery; personalised e-learning; automatic composition SCORM.
Reference to this paper should be made as follows: Yoosooka, B. and Wuwongse, V. (2012) ‘Linked open data for learning object discovery in adaptive e-learning systems’, Int. J. Knowledge and Learning, Vol. 8, Nos. 3/4, pp.188–218.
Biographical notes: BurasakornYoosooka is an Assistant Professor in the Computer Science Programme, Faculty of Science and Technology, Rajamangala University of Technology Thanyaburi, Thailand. In 1997, she received her BSc from the Department of Computer Science, Rajamangala

Linked open data for learning object discovery in adaptive e-learning systems 189
University of Technology, Thailand. In 1999, she also received her MSc degree from the Department of Information Management, Mahidol University, Thailand. In 2012, she received her PhD from Computer Science and Information Management Programme, School of Engineering and Technology Asian Institute of Technology, Thailand. Her research interests include information representation: semantic web, and e-learning.
Vilas Wuwongse is a Professor in the Department of Electrical and Computer Engineering, Faculty of Engineering, Thammasat University, Thailand. He obtained his BEng, MEng, and DEng from Tokyo Institutes of Technology, Japan, 1977, 1979 and 1982, respectively. His research interests include information modelling, semantic web and digital libraries.
This paper is a revised and expanded version of a paper entitled ‘Linked open data for learning object discovery in adaptive e-learning systems’ presented at the Third IEEE International Conference on Intelligent Networking and Collaborative Systems (IEEE INCoS 2011), Fukuoka, Japan, 30 November to 2 December 2011.
1 Introduction
One of the vital elements of e-learning is the provision of relevant and worthwhile learning materials. A unit of learning materials in e-learning is often called a learning object (LO). A good LO normally demands considerable time, effort, budget as well as human resources from many areas of expertise for its development. A single instructor alone would hardly be able to produce an adequate LO, if the LO requires multidisciplinary knowledge and the latest techniques in information technology. It would be more efficient if a new LO could be developed by the reuse, modification or enhancement of some existing LOs provided all the legal terms and conditions can be satisfied (Yu et al., 2011). Therefore, the sharing of LOs on e-learning has become major practice in recent years and a number of research studies have been devoted to the development of mechanisms for the sharing and reuse of LOs for instructors and learners. Sharable and reusable LOs can help instructors to save time and costs on their development; and they help learners to obtain LOs that satisfy their learning needs. Instructors and learners share and exchange LOs between school or university repositories via their LO discovery systems. The discovery of appropriate LOs is particularly important for adaptive e-learning systems which need flexible selection and the composition of various relevant LOs. However, the current LO discovery systems cannot efficiently support the retrieval of LOs, particularly when the retrieval is to be carried out automatically and adaptively based on a learner’s characteristics (Yu et al., 2011).
In learning and investigation tasks, learners and instructors are required to thoroughly explore the tedious and laborious tasks of discovering LOs, identifying and analysing different LOs, extracting the LO concepts, and linking the concepts across LOs in order to create their own conceptual schemas for their topics of interest. LOs are usually dispersed and duplicated among different LO repositories, and the key concepts within these LOs on top of their connections or relationships are not openly displayed to the users. The semantic web has recently redefined itself as the web of ‘linked open data

190 B. Yoosooka and V. Wuwongse
(LOD)’ by establishing principles which support the sharing of large datasets on the social web. However, we consider that the application of LOD principles within and across LOs can clearly create the essential structure and links among LOs, providing better convenience to learners and instructors in the tasks of learning and investigation. Moreover, the ability to share large datasets which could include descriptive metadata of LOs could lead to their more effective discovery, i.e., the discovery of LOs that satisfy the needs of individual learners. Therefore, the adoption of LOD within an adaptive learning environment has become a dominant paradigm in the development of adaptive e-Learning (Krieger and Rosner, 2011).
In this paper, an approach to automatic retrieval of LOs from local or external LO repositories for individual learners are proposed. The approach adopts LOD principles (Berners-Lee, 2009) to facilitate LO sharing by creating rich interlinking among LO repositories and knowledge sharing by linking to the LOD cloud (Cyganiak and Jentzsch, 2011). As a result, users can discover other LOs from external LO repositories such as the Open University of UK (Zablith et al., 2011) or additional information from the LOD cloud (Cyganiak and Jentzsch, 2011). The discovery has to work via the same standards; so IEEE LOM standard which is a part of the sharable content object reference model (SCORM) (ADL, 2009) is employed to represent LO metadata via resource description framework (RDF) (W3C, 2004b) in order to support LO sharing. The approach also supports multidimensional learners’ characteristics which are used as criteria in the selection of LOs. We adopt the IMS learner information package (IMS LIP) standard (IMS LIP, 2001) which is based on a data model that describes those characteristics of a learner needed for general purposes. The IMS LIP represents and models learners’ characteristics in extensible markup language (XML). In addition, the approach interlinks the domain ontology which is represented by web ontology language (OWL) (W3C, 2004a) to external open knowledge in the LOD cloud. Based on the proposed approach, a prototype system has been developed with the following capabilities:
• adaptive selection of appropriate learning courses based on the prior and background knowledge of learners
• automatic adaptive selection of LOs from both local and external LO repositories in a chosen course based on learning styles
• provision of a means to link selected LOs to the LOD cloud for additional related knowledge
• automatic composition of LOs into a personalised SCORM (ADL, 2004) package in real-time.
Section 2 presents the background of related studies from the literature. Section 3 describes the system architecture of the approach. The implementation of a prototype system is detailed in Section 4 and its evaluation in Section 5. Finally, Section 6 draws conclusions and presents recommendations for future work.
2 Literature review
Dicheva (2008) has classified the generations of web-based educational systems into three categories. The first generation systems provide the centre of entry-points for

Linked open data for learning object discovery in adaptive e-learning systems 191
accessing learning resources. The second generation systems support learning personalisation and learning adaptation. The third generation systems utilise and enable semantic web technologies in order to obtain scalability, reusability and interoperability of LOs distributed over the web. The e-learning with the semantic annotations is proactive to deliver learning content by an agent to an individual learner according to the learner specific context, problem, and requirements. The learners varying in their knowledge, backgrounds, requirements, learning styles, and preferences can specify their interests and provide their specific characteristics to the agents. The active delivery based on personalised agents can locate suitable content or construct new content gathering from different sources to the learner. With these behaviours, the new learning process can be characterised as proactive, dynamic, personalised and adaptive to an individual learner. A number of published special issues of international journals (Dicheva and Aroyo, 2006) have demonstrated the focus of interest and the state-of-the-art in the semantic web-based adaptive e-learning area. Most of them, however, have attempted to exploit the semantic web technologies to facilitate learning adaptation and the sharing of learning resources.
In the learning resource sharing and recommendation context, the conventional information retrieval technologies, such as the keyword-based vector space model, is not suitable for the retrieval of LOs due to two major drawbacks. First, it is necessary for a keyword-based approach to analyse the content of the learning documents. Second, the documents in which semantically unrelated to the learning domain maybe retrieved and displayed because of the lacking of semantics of learning resources. Moreover, many e-learning systems recommend LOs to learners by data mining approach. It is used to mine learner profiles and discovery LOs from repositories. But the approach is not reusable. The lack of reusability of LOs in e-learning systems is a problem (Shishehchi et al., 2010). To address these problems, the benefit of ontology with its capabilities of explicitly defining concepts and their attributes and relationships to retrieve learning LOs will be applied. The ontological representation of the domain concept is a way of dealing with the exchangeability and reusability of LOs. This can be achieved through the providing of a semantic infrastructure that will explicitly announce the semantics and keywords used in labelling LOs.
Currently, many adaptive e-learning systems are not capable of automatically recommending and importing information from external LO repositories. They can only utilise information from their own local repositories, which behave as independent data silos. Hence, the sharing and discovery of LOs are not effectively achieved. For LO sharing among different learning institutions, a peer-to-peer architecture (LOP2P) is proposed in many systems which promote the development of course material by using shared LOs repositories among different educational institutions. The major advantage of the peer-to-peer approach is the simplicity in integrating LO repositories after adding the LOP2P plug-in and mediation layer to each different repository. Another similar peer-to peer architecture has also been introduced in the EduLearn project (Prakash et al., 2009). For LO query, simple query interface (SQI) has been introduced and designed to query different LO repositories using a comment query language (FOAF, 2011). However, the query format and result format need to be mutually agreed among different repository providers before the query functionalities can be used. This means a wrapper service is required to ensure compliancy of all involved repositories with an agreed format. These approaches share a major disadvantage which is the sharing functionalities are limited by

192 B. Yoosooka and V. Wuwongse
using a defined mediation layer. The mediation is based on syntactic matching, which is not an efficient mechanism to deal with an open and distributed environment. For these reasons, our work is innovative in the sense that it demonstrates how semantic web technologies, particularly the LOD techniques, can benefit LO discovery and LO sharing in adaptive e-learning contexts.
LOD breaks the old data silos and explores the linking of endless information. Hence, data and services can be potentially smarter. LOD concentrates on publishing and interlinking web data to seek other related information. When we compare the existing web of documents with the new web of data, several changes are noticeable. In the traditional web, a document is accessed via typical web browsers, which is different from the web of data in which accessibility is achieved via LOD browsers. As in the document web, instead of using hyperlinks to navigate between documents, LOD browsers enable users to navigate between different data sources via RDFlinks. Therefore, a user can begin with one data source and then connect through a potentially endless web of data represented in an RDF triple data format (W3C, 2004b). RDF annotated resources are usually named by uniform resource identifier references (URIs). The major aim of LOD is to reveal the power of ‘web of data’ by identifying existing datasets that are available under open licenses, converting them to RDF based on the LOD principles, and publishing them on the web. Berners-Lee (2009) proposed four main principles in designing and publishing LOD. Therefore, when designing LOD for any datasets in any domain, it is advisable to use these principles as standard guidelines. They are:
1 name the things that you want to publish using URIs
2 use HTTP URIs to name things
3 display useful information when somebody looks up those URIs
4 link other data sources using RDF links.
The LOD is not merely a novel way of exposing data on the web, but its principles promote the integration of related data, connecting many related domain topics, and improving several workflows. The great successes of widely adopted LOD approaches have led to the diversified availability of vast amounts of public data, such as DBpedia (Morsey, 2011) and WordNet (W3C, 2007) RDF. DBpedia, a large linked dataset, essentially enables Wikipedia’s content to become available in RDF. Moreover, the significant essence of DBpedia is not only the inclusion of Wikipedia data, but also the links incorporated to other datasets on the web.
A number of educational institutions have now begun to employ or exploit LOD techniques (Zablith et al., 2011). For example, the University of Sheffield’s, Department of Computer Science provides a linked data service describing research groups, staff and publications, which are semantically linked together. Similarly, the University of Southampton has recently announced the release of their LOD portal (http://data.southampton.ac.uk), in which more data will become available in the near future. Furthermore, the University of Manchester’s library catalogue records can now be accessed and retrieved in RDF format. In addition, the other universities are currently working on transforming and linking their data: the University of Bristol, the University of Edinburgh (e.g., the university’s buildings information is now generated in LOD), and Oxford University. Furthermore, the University of Muenster announced a funded project, LODUM, which is aimed to release the university’s research information as linked data.

Linked open data for learning object discovery in adaptive e-learning systems 193
This includes information related to people, projects, publications, prizes and patents. LOD deployment in the DBLP Bibliography Server Berlin (Bizer and Cyganiak, 2006) is the source of bibliographical information about scientific papers. Another example is the web services, which offer educational linked data from The Open University (Zablith et al., 2011), and provide a SPARQL endpoint (Semantic Web, 2009) where respond messages are in RDF-based on top of LO repositories. SPARQL is a query language and a protocol for accessing RDF. It provides the description of what the application wants, in the form of a query, and returns that information, in the form of a set of bindings or an RDF graph (W3C, 2008). Open University is the first UK University to expose and publish its own organisational information in LOD. With the increase of the adoption of LOD publishing standards, the exchange of data will be much easier, not only within one university, but also across the LOD ready ones. This enables, for example, the comparison of specific qualifications offered by different universities in terms of courses required, pricing and availability.
Our approach has been built on a fundamental belief in the potential of the LOD-based approach. This is to fulfil the adaptive e-learning vision of web-scale interoperability of highly personalised LOs. The LOD principles are employed as a light-weight mechanism for data integration, promoting new opportunities for the organisation, integration, discovery and archival of LOs and social knowledge retrieval. The application of LOD technologies, within and across educational institutions, can explicitly generate the necessary structure and connections among LO repositories, providing abetter support to learners in their learning and investigation tasks.
3 System architecture
This approach adopts the LOD principles based on RDF platform to review more knowledge from the LOD cloud and discover LOs from external LO repositories for more effective adaptations and much better learning experiences.
Figure 1 Framework of the system (see online version for colours)

194 B. Yoosooka and V. Wuwongse
Figure 1 shows the architecture of the framework which consists of four complementary models in the system:
1 the learner model
2 the domain model
3 the adaptation model
4 the learning resource model.
Moreover, there are the LOD cloud and the remote site SPARQL endpoints of learning resources which are linked to the system, and other SPARQL endpoints in the LOD cloud. The dashed line represents a logical connection among LOs while the arrow line shows the direction of information.
3.1 Learner model
The learner model is designed to store learner profiles which consist of identification, learning histories, goals, preferences, and learning styles of learners. All information in this model are based on the IMS LIP standard (2008) and be obtained and represented by identification, goal, activity, interest, and affiliation XML elements.
We construct the learner model according to the learner’s knowledge and characteristics acquired directly or indirectly at the time of learning. The direct information extraction is used to acquire identification, learning histories, goals, and learners’ preferences for certain types of information. Indirect information extraction is used in recommending learning styles of learners. There are two different methods to obtain learning style, one is through data on the learning logs, and the other is through psychological tests. For the first method, the behaviour tracker monitors and stores the learning resource type and the format of LOs frequently selected by learners while they are learning to the learning logs, in order to update a learning style that enables LO sequencing to be flexible. For the second method, a psychological questionnaire namely the ‘index of learning styles (ILS)’ is used for the learning style extraction tool. It is an instrument designed to assess preferences on the four dimensions of the Felder-Silverman learning style model (FSLSM). The web-based version of the ILS is taken hundreds of thousands of times per year and has been used in a number of published studies, some of which include data reflecting on the reliability and validity of the instrument. They concluded that their reliability and validity data justified a claim that the ILS is a suitable instrument for assessing learning styles (Felder, 1993). The questionnaire can classify learners according to 16 learning styles: active (A)/reflective (R), sensing (S)/intuitive (I), visual (Vi)/verbal (Ve), and sequential (Se)/global (G) based on FSLSM from Felder’s theory which is the most appropriate learning styles model for adaptive systems (Canavan, 2004). We focus on active/reflective, sensing/intuitive, visual/verbal, and sequential/global:
• Active/reflective: active learner (learns by trying things out, working with others) and the reflection learner (learns by thinking things through, working alone).
• Sensing/intuitive: sensing (concrete information such descriptions of physical phenomena, practical, oriented toward facts and procedures) and intuitive (conceptual, innovative, oriented toward theories and meanings).

Linked open data for learning object discovery in adaptive e-learning systems 195
• Visual/verbal: visual learner (prefers visual representations, pictures, diagrams, and flowchart) and verbal learner (prefers written and spoken explanations).
• Sequential/global: sequential learners tend to gain understanding in linear steps and the global learners tend to learn in large jumps, absorbing material almost randomly without seeing content’s connections and relationships.
Felder pointed out that learners with a strong preference for a specific learning style may have difficulties if the teaching style does not match their preferred learning styles (Graf et al., 2007). And based on the human dynamics or personality dynamics, the learning styles of each learner can consequently be changed. The behaviour tracker will support this case. In addition, the knowledge progress tracker will update the learning history, which will affect the next courses/units and the difficulty of exercises or exams recommendations.
3.2 Adaptation model
The adaptation model is designed to store the adaptation rules which are: the concept selection rule, the LO selection rule, and the LO sequencing rule. The adaptation model needs learner profiles from the learner model, knowledge from the domain model and LO metadata from the learning resource model to be the input of its process. For the output, the concept selection rule will recommend suitable learning paths/courses and learning content for each learner.
Figure 2 Adaptation layer (see online version for colours)
profile, requirements preferences,
requirementsrequirements
Career list Domain concept Unit Learning object SCORM package layer layer layer layer layer
Figure 2 shows the adaptation layers of the model beginning from the career list layer (optional), through the domain concept ontology layer, and finally to the individual SCORM package (personalised learning path) layer. The career list layer can assist some learners who do not really know which course to take, by starting with the learners’ career goal. This layer provides two methods: direct and indirect career extraction. The

196 B. Yoosooka and V. Wuwongse
learners who know their career goals can identify their career goals directly, but if they do not know their career goals, they can use the career questionnaire as an option to obtain potential careers. The next layer, namely the domain concept layer, will recommend a course list which relates to the learners’ career goals. A course can be selected from the list based upon the learners’ requirements. Next, the system will verify the learners’ background knowledge and recommend suitable learning paths (order of courses) by the application of concept selection rules. The selected courses in the path will be expanded into their component units in the next layer. After that, the system will look for relevant LOs by means of the LO selection rules. Finally, the relevant LOs selected will be sequenced based according to the learners’ profiles and by the execution of LO sequencing rules. After that, the system will look for relevant LOs by means of the LO selection rules. Finally, the relevant LOs selected will be sequenced based according to the learners’ styles and LO sequencing rules and by the execution of LO sequencing rules.
The following parameters for adaptation can come from learner profiles in multidimensional, domain model, and learning objects metadata (LOM): • concept selection rule’s parameters: learners’ knowledge, learners’ query (goal), and
domain concept ontology • LO selection rule’s parameters: selected concept, learning styles (FSLSM) of
learners, learners’ preferences, and LOM attributes • LO sequencing rule’s parameters: learning styles (FSLSM) of learners, and LOM
attributes. All identified parameters will be used for creating rules. We have designed the model to enable the adaptation rules to become general. You do not need to change any part of the rules when using them in different learning courses (their examples will be shown in implementation section). These rules are not specific to any course or learner profiles. Hence, application to all domains (all e-learning programmes) is possible such as biology, commerce, music, engineering, etc. Moreover, the rules are independent of each other. A rule can be modified and deleted with no effect on the other rules. The way for designing adaptation rules is similar to that of the following examples: • The concept selection rule consists of sub rules which are the prerequisite rule, the
course pass rule, and the course recommendation rule. These rules use the learners’ background knowledge, learners’ goals, and the domain concept ontology as their inputs. The output of the concept selection rule is the learning paths of the learners’ course goals. Different background knowledge will provide different learning paths. The learning paths show the order of courses following the domain concept ontology. If any learners have passed some courses which are prerequisite courses of the course goals, those courses will disappear from their learning paths. For example, a learner’s goal is ‘database administrator’ but he/she does not have any background in ‘database’, so the system will provide an ‘introduction to database’ concept in his/her learning path.
• The LO selection rule uses the learners’ preferences (such as language, age, status, available time), ability, learning styles (16 styles), and LO metadata (such as keywords, language, learning resource type, format, typical age range, difficulty, and duration) as its inputs. The output of the rule is the set of LOs which have metadata matching the preferences and learning styles of the learners. Moreover, the difficulty

Linked open data for learning object discovery in adaptive e-learning systems 197
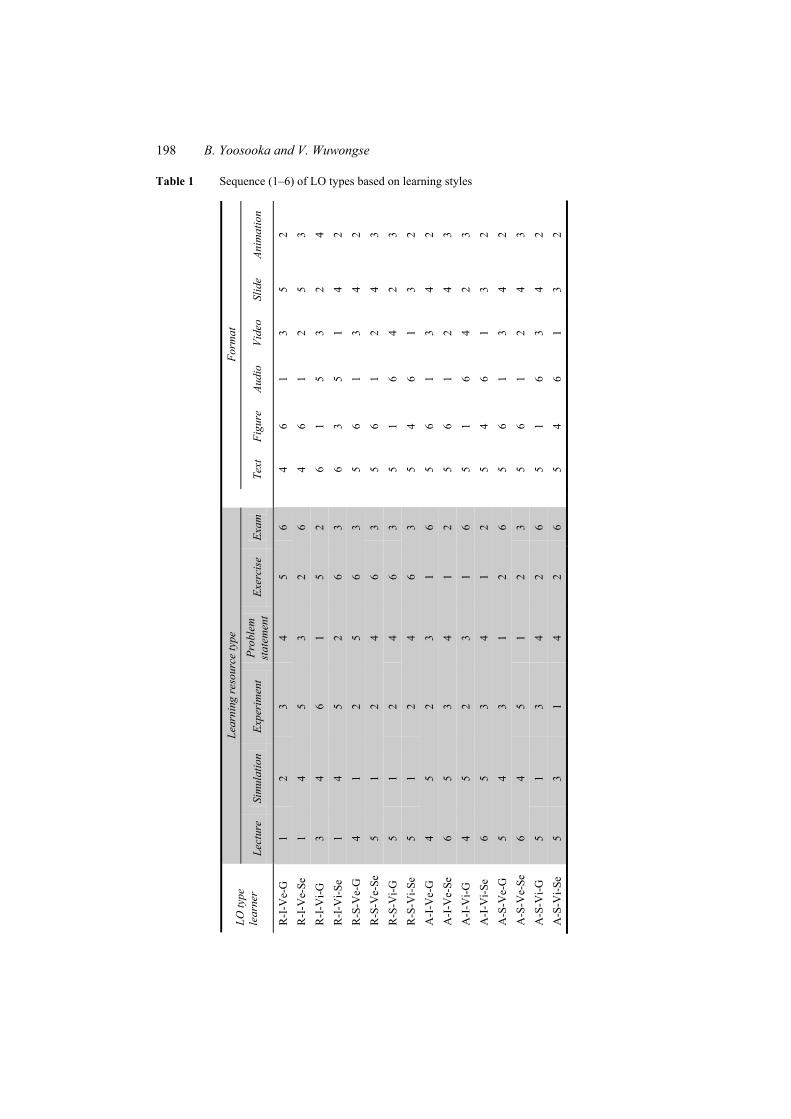
of LOs (exercises and exams) will be matched with learner’s ability which is considered from exercises and exams’ scores. The selected or preferred LOs (LOs which suit to my age range, learning duration, gender, language, learning style, and ability) will be sequenced based on the LO sequencing rule by matching LO metadata: learning resource types (lecture, simulation, experiment, problem statement, exercise, examination) and formats (text, figure, audio, video, slide, animation) with the learning styles of the learners; active (A)/reflective (R), sensing (S)/intuitive (I), visual (Vi)/verbal (Ve), and sequential (Se)/global (G). Table 1 shows the sequences of learning resource types (Lecture,…, Examination) and formats (Text,…, Animation) of LOs for each learning style.
In Table 1, learning styles can be reported by R = reflective, A = active, S = sensing, I = intuitive, Vi = visual, Ve = verbal, Se = sequential, and G = global. Each style can be the combination of those characteristics to 16 learning styles such as R-I-Ve-G representing reflect-intuitive-verbal-global. The table also shows the sequence of learning resource type and format for each learning style. The learners who have different learning styles will get different LO sequences
For example, for R-I-Ve-G learning styles, the learning resource type is sequenced as lecture, simulation, experiment, problem statement, exercise, and exam. Each learning resource type has sequence of format as audio, animation, video, text, slide, and figure.
In the other ways, examples can be explained in sequential symbolic as the follow: • The LO sequence of the ‘active-sensing-verbal-global’ learning style is:
Learning resource type order: Problem statement-> Exercise-> Experiment-> Simulation-> Lecture-> Exam and Format order in each learning resource type: Audio-> Animation-> Video-> Slide-> Text-> Figure.
• The LO sequence of the ‘reflective-inductive-visual-sequential’ learning style is: Learning resource type order: Lecture-> Problem statement-> Exam-> Simulation-> Experiment-> Exercise, and Format order in each learning resource type: Video-> Animation-> Figure-> Slide-> Audio->Text.
We represent these rules by XML declarative description (XDD) which is an expressive knowledge representation (Anutariya et al., 2005; Wuwongse et al., 2001). Because our rules are general rules and XDD is interesting and comfortable for the rules and their parameters which are XML. XDD employs XML’s nested tree structure and declarative description theory as a framework to enhance its expressive power. Can enables direct representation of XML items and extends their expressiveness by facilitation of simple means for succinct and uniform expression of implicit information, integrity constraints, conditional relationships and axioms, so it allows other developers who are familiar with XML to understand it easily. Semantic web applications, offering certain web services and comprising the three basic modelling components: 1 application data 2 application rules and logic 3 learners queries and service requests, are represented in XDD language as XDD
descriptions.
By means of XDD language, a new declarative approach to the development and the execution of Semantic Web applications is constructed (Wuwongse et al., 2001).
198 B. Yoosooka and V. Wuwongse
Table 1 Sequence (1–6) of LO types based on learning styles
Lear
ning
reso
urce
type
Form
at
LO ty
pe
lear
ner
Lect
ure
Sim
ulat
ion
Expe
rim
ent
Prob
lem
st
atem
ent
Exer
cise
Ex
am
Te
xt
Figu
re
Audi
o Vi
deo
Slid
e An
imat
ion
R-I
-Ve-
G
1 2
3 4
5 6
4
6 1
3 5
2 R
-I-V
e-Se
1
4 5
3 2
6
4 6
1 2
5 3
R-I
-Vi-G
3
4 6
1 5
2
6 1
5 3
2 4
R-I
-Vi-S
e 1
4 5
2 6
3
6 3
5 1
4 2
R-S
-Ve-
G
4 1
2 5
6 3
5
6 1
3 4
2 R
-S-V
e-Se
5
1 2
4 6
3
5 6
1 2
4 3
R-S
-Vi-G
5
1 2
4 6
3
5 1
6 4
2 3
R-S
-Vi-S
e 5
1 2
4 6
3
5 4
6 1
3 2
A-I
-Ve-
G
4 5
2 3
1 6
5
6 1
3 4
2 A
-I-V
e-Se
6
5 3
4 1
2
5 6
1 2
4 3
A-I
-Vi-G
4
5 2
3 1
6
5 1
6 4
2 3
A-I
-Vi-S
e 6
5 3
4 1
2
5 4
6 1
3 2
A-S
-Ve-
G
5 4
3 1
2 6
5
6 1
3 4
2 A
-S-V
e-Se
6
4 5
1 2
3
5 6
1 2
4 3
A-S
-Vi-G
5
1 3
4 2
6
5 1
6 3
4 2
A-S
-Vi-S
e 5
3 1
4 2
6
5 4
6 1
3 2

Linked open data for learning object discovery in adaptive e-learning systems 199
3.3 Domain model
The domain model contains ontologies describing the structures of the domain knowledge. The ontologies are particularly useful in defining complex structures based on the concept of the courses and their relationships in learning environments. The ontologies represent the concepts of the domain as the connection (graph) between each concept linked together by OWL. We created an ontology based on ACM Computing Curriculum 2008 for Computer Science (CS) (ACM, 2008) which is a comprehensive work that defines CS curriculum for undergraduate studies which are our case study. Being endorsed by both ACM and IEEE, the broad acceptance of the CS is acknowledged (McGettrick, 2009). Information of 14 areas, 16 units, 132 topics, the learning objectives, and the prerequisite courses were recommended.
We used the ontology for acquiring information about course sequences, number of units in a course and the learning objectives, etc. This information will provide the guidelines and conditions for the planning of the learning paths for each learner. The benefit of ontology, a major tool in the semantic web technologies that is its capabilities of explicitly defining concepts and their attributes and relationships to retrieve LOs will be applied. The ontological representation of domain concept is a way to deal with the interoperability and reusability of LOs through providing a semantic infrastructure that will explicitly declare the semantics and forms of keywords used in labelling LOs. The names of courses or units in the ontology will be the keywords to tag LOs.
Because we may meet several vocabularies for class and property element names in different ontologies for the same domain, our system is designed to support a general ontology. The system provides a way of selecting suitable ontologies for any domain (such as computers, business, biology, and language), and identifies property vocabularies. Moreover, we integrated the ontology with DBpedia in the LOD cloud for further information and within the LO repositories to facilitate the discovery of LOs. The link with DBpedia is created via property ‘owl:sameAs’ of the ontology.
3.4 Learning resource model
The learning resource model is designed to store the LOs complying with the SCORM standard and their metadata which are linked to the local SPARQL endpoint. The learning resource model is associated with ontologies in the domain model. The ontology and SCORM based LOs can increase share ability and reusability and hence reduce the need for reinventing the wheel. The ontologies enable development of LOs that can be mixed and matched in different learning contexts and for different topics. The LOs have to be labelled in a consistent way in order to support various search engines. Therefore, there is a need for the standardising and labelling of LOs by using metadata and packaging standards such as Dublin core (DC) and IEEE Learning Object Metadata (IEEE LOM) (IEEE, 2002) in SCORM. The SCORM provides standardised data structures and communication protocols which promote easy exchange of LOs or data between different learning management systems based on different technologies. The SCORM LOs are represented in the form of shareable content objects (SCOs) and assets. The SCOs and assets and their metadata are encapsulated in content packaging (SCORM) to allow interoperation and reusing of the LOs. The SCORM content package consists of LOs and a manifest about how these LOs can be put together to form learning modules.

200 B. Yoosooka and V. Wuwongse
The manifest, an essential part of all SCORM content packages, is defined as an XML-based file named ‘imsmanifest.xml’.
IEEE LOM is the LO metadata standard which is used in the imsmanifest.xml file of the SCORM content package. The IEEE LOMv1.0 base schema for imsmanifest.xml file consists of nine categories: general, rights, life cycle, relation, meta-metadata, annotation, technical, classification, and education. From the nine categories of IEEE LOM, we select some elements of the categories as inputs in our adaptation model such as keywords, language, format, duration, learning resource type, typical age range, and difficulty. We use these LOM elements for matching LOs with learners’ preferences and requirements. If they are suitable for the learner profile, their related LOs will be selected.
The LO repositories in our approach will be linked to the LOD cloud via the LO metadata. But the LO metadata are represented by XML which cannot provide the linking based on Berners-Lee (2009) four principles. So we have to transform LOM XML to LOM RDF. We employed PHP to transform each LOM XML to LOM RDF elements. Then we store them in the database using RDF Triple format. An RDF Triple statement is of the form: [subject property object]. RDF is usually named resources by uniform resource identifier (URI) references. URIs are short strings that identify web resources and are used for linking data. Teachers can exchange and share their LOs via SPARQL endpoints which are the endpoints of LOM RDF. Moreover, learners can discover other LOs or browse for further information from the LOD cloud, whenever they want or whenever the system recommended LOs cannot meet their requirements.
3.5 The LOD cloud
The web of ‘LOD’ establishes principles in the sharing of all large datasets on the web, with a technology stack (the use of URIs, RDF, and SPARQL) aimed at their realisation. So far it has resulted in an openly available web of data comprising several billion RDF triples. LOD captures knowledge from diverse domains and is constantly growing. Some of the domains include: information from Wikipedia, governmental and geospatial data, entertainment, bio-informatics and publications. The largest dataset is the DBpedia. It essentially enables Wikipedia’s content to become available in RDF. Moreover, the significant essence of DBpedia is not only the inclusion of Wikipedia data, but also the links incorporated to other datasets on the web. It serves both RDF and HTML documents.
LOD allows applications to exploit the extra (and possibly more precise) knowledge from other datasets. Thus, by exploiting the links within and between the datasets, applications can find new information that would be very difficult to extract in any other way and may provide a much better user experience. Instructors can make links from their data to existing datasets, thus connecting LOs. In the LOD, all information is encoded using RDF that allows the linking of different LOs together using predicates, and also defining literal values, such as names, for the resources. All resources in the LOD are identified by URIs. This allows for requesting more information using the URIs in a machine-processable manner. In practice, this means that if a software agent requests a URI, then for example all the triples where this URI is used as a subject could be returned, or alternatively even all triples where this URI is used as a subject, predicate or object. In the LOD for our framework this means everything is identified via URIs: courses, topics, and learning objectives datasets. We link our LOs of SCORM packages

Linked open data for learning object discovery in adaptive e-learning systems 201
to the LOD cloud via ‘title’ element of their metadata files (imsmanifest.xml) which have to be transformed to RDF format first. The RDF files show all metadata elements in URIs format and have to include the URIs to reference to LOs of their SCORM package for LO accessing. The detail of publish LOD is in the implementation section.
3.6 SPARQL endpoints
Currently, there are a lot of SPARQL endpoints, which store a lot of useful data including LOD, and they are available for free use on the internet, for example, the SPARQL endpoint for DBpedia (http://dbpedia.org/sparql). In a personal learning environment (PLE), for instance, it is currently possible to access more LOs by merely crawling the RDF triple store exposed using the SPARQL endpoint, even for users from external platforms, and thus there is no longer a need to implement special web services. The SPARQL endpoint can be used within the LO repository to discover the LOs based on search criteria. As the learners search for an LO, the system uses SPARQL to query the LO via LO SPARQL endpoints. The query needs some of the prefixes which are predefined in the SPARQL endpoint. Thus, it increases the discoverability of the LOs and enhances their reusability.
Because it is always easier to build upon and modify existing things you can have a look at the following queries that have been shown to work. Preceding the query is a short description what it actually does. Depending on the query you will also need some of the following prefixes. They are predefined in the web interface, but you have to provide them yourself if you send the SPARQL query using a different client. An example of SPARQL is shown in Figure 3.
Figure 3 SPARQL for query Los
After SPARQL endpoint, we have to open our datasets by publishing LOD. There are easy steps for publishing LOD that can be considered as standard guidelines (Bizer et al., 2007). Chronologically put, they are:
• select suitable vocabularies
• partition RDF graph into data pages
• assign unique URI for each data page
• create variation for each data pages and assign URIs to each entity
• add page metadata
• add semantic sitemap.

202 B. Yoosooka and V. Wuwongse
4 Implementation
We have developed and implemented the system on ‘Moodle’ (Dougiamas, 2008), a learning management system, using PHP language. The information from learners’ profiles, learners’ requirements, domain ontology, SCORM (LOs and their metadata), and the results from the XDD general rules are inputted into the system. Moreover, we adopt the LOD principles based on RDF platform to the approach. We decided to link our system to DBpedia dataset which is a hub of the LOD cloud and to implement SPARQL endpoints in order to discover LOs.
4.1 System workflow
First, the system extracts general information, background knowledge, preferences, learning styles, and requirements of learners by direct or indirect ways and stores this information in the learner model. Learners who are not confident about their learning requirements (courses) can verify them by reviewing more open information about any courses from the LOD cloud by click the word ‘link’ behind any courses in the right part as shown in Figure 4.
Figure 4 Verify learners’ requirements by reviewing more information from DBpedia (see online version for colours)
After learners can select a course, the system will recommend suitable learning paths, a list of units and prerequisites of the course based on learners’ requirements, background knowledge in the learner model and domain ontology which keeps the course sequences in the domain model. After that, the system will retrieve suitable LOs from LO repositories. The LO retrieval method starts with the search for and selection of LOs which have the same title as the unit title required by the learner. Those selected LOs will then be compared with learner preferences via their LOM elements (language, typical age range, duration, and difficulty). For exam LOs, the system will select from three level of difficulty: easy, medium, difficult based on previous exam score. Finally, the most

Linked open data for learning object discovery in adaptive e-learning systems 203
suitable LOs will be retrieved. After the retrieval, the system will compose the retrieved LOs by first ordering them one by one based on individual learning styles, learning resource types, and learning resource formats as shown in Figure 5.
Figure 5 Learning path, unit list, and prerequisite courses of course goal (see online version for colours)
The learning path of course goal (start from the first prerequisite course to the course goal) Course goal
For learning style: active‐intuitive‐visual‐sequential
For learning style: active‐sensing‐verbal‐global

204 B. Yoosooka and V. Wuwongse
In this case, a learner selected ‘databases’ from the available courses in the right part to be his/her course goal then the learning path of databases which based on his/her background knowledge will be shown in the left part. The learning path started from ‘Introduction to the computer’ to ‘databases’. After the learner selected ‘databases’ from the learning path, the list of related units will be shown in the next screen. After that the learner selected ‘foundations of human-computer interaction’ from unit list in the left part. Then the system will discover LOs which related to the unit then selected LOs based on his/her requirement. Finally, the sequence of LOs based on his/her learning style will be shown. If suitable LOs cannot be found in the local LO repository, the system will use SPARQL endpoints to discover LOs from linked external LO repositories (remote) which we link to the sites via owl:sameAs for the same courses as shown in Figure 6.
Figure 6 Recommend external LO repositories or ways for discover Los (see online version for colours)
Figure 7 SPARQL endpoint (see online version for colours)

Linked open data for learning object discovery in adaptive e-learning systems 205
In the case of no preferred LOs in the linked external LO repositories for the same courses, the system will provide a link to the LOD cloud where learners can review more information or discover preferred LOs for themselves via other SPARQL endpoints as shown in Figure 7.
Finally, the system will automatically create an imsmanifest.xml and imsmanifest.rdf files which are SCORM package metadata files holding IEEE LOM and LO sequences data. And finally, all retrieved LOs and the metadata files will be composed into a SCORM package. Learners can download their own SCORM packages in the form of zip files. Different learners can get different SCORM packages. Moreover, the SCORM packages can share LOs for the same unit of any courses. For example, the ‘databases’ and ‘human-computer interaction’ courses can share the same LO for the unit ‘foundation of human-computer interaction’ which is the same unit for both courses.
4.2 Learner model development
Table 2 shows all the elements of the learner profiles that we use in our system and the methods we use to extract them. Table 2 Learner profile elements
Learner profile Element Kind of information Extraction
Learner ID Direct Registration Name Direct Registration
Date of Birth Direct Registration Gender Direct Registration
Identification
Nationality Direct Registration Course ID Direct Learner input, learning, test
Course name Direct Learner input, learning, test Unit ID Direct Learner input, learning, test
Unit Name Direct Learner input, learning, test Score Indirect (calculation) Test score calculation
Learning history
Status Direct Score analysis Career direct or indirect
(questionnaire) Learner query, career
questionnaire Goal
Course goal direct or indirect (questionnaire)
Learner query, career recommend
Language Direct Learner requirement Preferences Duration Direct Learner requirement
Learning style Learning style direct or indirect (questionnaire)
Felder Silverman learning style questionnaire, behaviour
tracker
All elements in this model are based on IMS LIP standards which can be represented by XML as shown in Figure 8. It shows how to develop the learner model based on the IMS LIP standard and represented in XML. The following code example in the figure shows two parts:

206 B. Yoosooka and V. Wuwongse
1 learners’ general information is kept in <identification>, <name>, <gender>, <date>, <email>, <goal>, <language>, <duration>, <preference> (learning styles), <status> (full or normal or fail) XML elements
2 learners’ knowledge progression information is kept in <units> (unit name and score), <learningactivityref> (course id), <definition> (course name), <testimonial> (complete or incomplete) XML elements.
The learner information will be used as criteria for selecting and sequencing suitable LOs.
Figure 8 A learner profile based on the IMS LIP
4.3 Adaptation model development
All rules in the adaptation model are expressed by means of XDD, which is based on XML. As the information in the other parts of the system is also expressed in XML, the linkage between the adaptation model and other models is straightforward. An example of a rule in the adaptation model that is represented in XDD is shown in Figure 9. The rule will recommend a course for a learner.

Linked open data for learning object discovery in adaptive e-learning systems 207
However, for the sake of efficiency, SWI-Prolog (Prolog, 2008) has been employed to implement the rules. Examples of concept selection rules for finding the most suitable concepts are:
• prerequisiteOf(course(A),course(B)): prerequisiteOf(course(X), course(B)), prerequisiteOf(course(A),course(X)).
• passCourse(learner(A),course(C)): bagof(unit(U), unitOf(unit(U), course(C)), Result), passAllUnit(learner(A), Result).
• passCourse(learner(A),course(C)): prerequisiteOf(course(C), course(X)), passCourse(learner(A), course(X)).
• passAllUnit(learner(_),[]):-!.
• passAllUnit(learner(A),[H|T]): passUnit(learner(A), H), passAllUnit(learner(A), T).
• passUnitWithCoursePass(learner(A),unit(U)): passCourse(learner(A), course(C)), unitOf(unit(U), course(C)).
• passCourseWithUnitPassByCourse(learner(A),course(C)): (unitOf(unit(U), course(C)), not(passUnitWithCoursePass(learner(A), unit(U)))) ->fail; course(C).
Figure 9 Course recommendation rule
The rule for LO selection and sequencing which selects the LOs related to the selected concept:

208 B. Yoosooka and V. Wuwongse
• physicalFileRecommend(learner(A),Key,Status,PhysicalFile):
profiles(learner(A), age(Age), lang(Lang), formatStyle(FStyle), duration(Duration)), ((ageRangeOf(LowLimitAge, HightLimitAge, physicalFile(PhysicalFile)), Age>=LowLimitAge,Age=<HightLimitAge), (langOf(Lang, physicalFile(PhysicalFile))), (durationOf(DurationOfFile, physicalFile(PhysicalFile)), DurationOfFile=<Duration)), keyOf(Key, physicalFile(PhysicalFile)), level(Level, Status, PhysicalFile), difficultyOf(Level, physicalFile(PhysicalFile)).
We have designed the model to enable the adaptation rules to be generalised. These rules are not specific to any course or learner profiles. Hence, application to all domains is possible. Moreover, the rules are independent of each other. A rule can be modified and deleted with no effect on the other rules. They will still work although other rules have been deleted or have failed as shown in the following examples. The rules are used for checking courses that have been passed. If one of them fails, the system still works.
• passCourse(student(A),course(C)): bagof(unit(U), unitOf(unit(U), course(C)), Result), pasAllUnit(student(A), Result).
• passCourse(student(A),course(C)): prerequisiteOf(course(C), course(X)), passCourse(student(A), course(X)).
Figure 10 Snippet of OWL representing the ontology code
4.4 Domain model development
The computer science domain model is selected in our case study. It is developed by using Protégé, a free open source visual ontology editor (Protégé, 2008). Figure 10 depicts a part of the ontology. The ontology is used to define classes and their properties. The classes are <COURSE> (has subclasses: <Introduction_courses>, <Intermediate_courses>, <Advanced_courses>), <FIELD> (has subclass: <AREA> (has subclass: <UNIT>)), <LEARNING_OBJECTset>, and <TOPICset>. We created new properties which are needed for classes in our ontology. The properties are separated into two types:

Linked open data for learning object discovery in adaptive e-learning systems 209
1 object properties (<AREASlot>, <LEARNING_OBJECTIVESSlot>, <PREREQUISITE>, <TOPICSSlot>, <UNITSlot>, <UNITset>) relationship between objects
2 data type properties (<AREA_NAME>, <DESCRIPTION>, <OBJECTIVE>, <SUBJECT_NAME>, <TOPIC>, <UNIT_NAME>, <_ID>, <type>) link objects and their strings.
Figure 11 An example of transform LOM XML toLOM RDF by PHP (see online version for colours)
PHP
LOM XML
LOM RDF

210 B. Yoosooka and V. Wuwongse
Moreover, we employed a web service, http://sameas.org/, for browsing datasets which relate to our domain (CS) from the LOD cloud. From the browsing results, we decide to link our domain ontology to DBpedia dataset which can give more meaningful information about CS courses to learners by using owl:sameAs property. The learners can verify their requirements with this information.
4.5 Learning resource model development
The learning resource model which consists of LOs, LO metadata and its SPARQL endpoint is developed. We have created LOs in many formats, such as documents, audios, videos, slides, animations, and simulations that means the LOs for particular learning styles will be available. These LOs are stored in our local repository. Their metadata is created according to the IEEE LOM by Reload editor, a LOM editor which collects the required information and turns it into a properly-structured XML document, and then subsequently stores it in the database. However, we are responsible for providing accurate, appropriate, and complete information for at least the fields that are required by the LO discovery and adaptation. The LO metadata is expressed in XML. The XML elements which are kept the LO metadata such as <identifier>, <language>, <keyword>, <format>, <location>, <learningResourceType>, <typicalAgeRange>, <difficulty>, and <typicalLearningTime>. In using this approach, we also need LOM in the RDF based on the LOD principles. LOM XML will be transformed to LOM RDF by PHP as shown in Figure 11.
Figure 12 Triple store and linking to LOs in local repository (see online version for colours)
http://dublincore.org/2010/10/11/dcelements.rdf#source
“c://xampp/htdocs/moodle/scorm/database1/database1.son”

Linked open data for learning object discovery in adaptive e-learning systems 211
In RDF, the semantics of each LOM element decides its binding. In contrast to XML schemas, which are applied for XML records validation, RDF schemas are used to describe the semantics of RDF classes and properties. Because some of the LOM elements are semantically similar to DC elements which have their own RDF schema (Nilsson et al., 2003), our RDF representation of LOM relies closely on the DC metadata element set and its representation in RDF. However, It is not always possible to map a clean DC construct with a LOM element without adding information, as LOM requires a more specific structure in many elements, such as lom:learningResourceType, lom:typicalAgeRange, and lom:typicalLearningTime, lom:difficulty. We also included some well-known properties, such as owl:sameAs, rdfs:seeAlso in LO metadata for links to other external information or LOs and we used dc:source property to access LOs.
We kept the LO metadata in the RDF triple store which represents an RDF statement as subject, predicate, object by ARC2 as shown in Figure 12. So the LOM RDF can be queried by SPARQL easily.
Figure 13 An example of ARC2
The system queries LOs which have the same language as the preferred language of the learners. After the system obtains the LOs, they will be launched to the learners for learning in run time. If the LOs come from the external LO repositories, they will not be stored in the local LO repository because the external LOs can be modified by their

212 B. Yoosooka and V. Wuwongse
owners at any time. Moreover, we employed ARC2 which is a semantic web library for the RDF Triple store and SPARQL endpoint development that provides the way for discovering LOs and then publish LOD. ARC is a flexible RDF system for semantic web and PHP practitioners. It is free, open-source, easy to use, and runs in most web server environments (ARC2, 2012). Figure 13 is a quick example that hopefully illustrates how ARC2 works.
After the publishing, other learners can query LOs via our SPARQL endpoint. Based on standard guideline for publishing LOD (Heath and Bizer, 2007), our robot.txt and sitemap.xml file which points to database1.rdf (LOM RDF) have to create as shown in Figure 14.
Figure 14 Publish LOD
5 Evaluation
In order to evaluate the satisfaction of learners to the proposed approach, an experiment with sixty undergraduate learners from Rajamangala University of Technology, Thanyaburi, Thailand, was conducted. All learners are the representative of all kinds of

Linked open data for learning object discovery in adaptive e-learning systems 213
learners which were categorised by questionnaire namely the ‘ILS’ of Felder (1993). They are the subjects of evaluation. The approach is evaluated according to four different dimensions (treatments): ‘system usefulness’, ‘system ease of use’, ‘system adaptability’, and ‘intention to use the system’ that are the main factors for the evaluation of adaptive e-learning system based on reliability analysis of Tobing et al. (2008). For satisfaction comparison between two systems, the subjects were requested to learn computer science topics via adaptive e-learning system with LOD for LO discovery which is our proposed system (for 1 month) and adaptive e-learning system without LOD for LO discovery (for 1 month) as supplementary teaching materials. After two months of learning, they were asked to evaluate the systems by answering well-designed, four-dimensional questionnaires with a ten-point ranging scale or Likert scale (Tobing et al., 2008). Few examples of the questions are as follows:
• System usefulness dimension (Treatment 1): 1 A link to external information has assisted me in verifying my requirement. 2 The content package (SCORM) which is automatic composed makes me
comfortable to download and use it outside the system or other SCORM compliant learning management systems.
• System ease of use dimension (Treatment 2): 1 The user interface of the system is understandable. 2 I found the system is easy to use and adventurous to my learning.
• System adaptability dimension (Treatment 3): 1 The provided learning path suits to my current knowledge-level. 2 The learning content, presented according to my current knowledge-level,
improves my comprehensiveness on the learning topic. 3 The contents provided in the system are related to my needs. 4 The system was able to list all recommended learning path based on my current
knowledge level. 5 The system was able to select all relevant LOs in lesson suitable to my age
range, learning duration and preferred language. 6 My preferred approach to learning was calculated correctly through the learning
style questionnaire. 7 The system was able to discover relevant LOs from external repositories if they
are more suitable to me. 8 The system was able to select and order relevant LOs in lesson based on my
learning style. 9 When a new course was built following learning style adjustments, the new
course reflected these changes.
• Intention to use the system dimension (Treatment 4): 1 The LOs and learning path, provided in the system, made a good impression on
me. 2 I intend to use the system in the future as an alternative learning method instead
of class-based lecture.
214 B. Yoosooka and V. Wuwongse
3 Overall, I am satisfied with this system and will recommend to my friends.
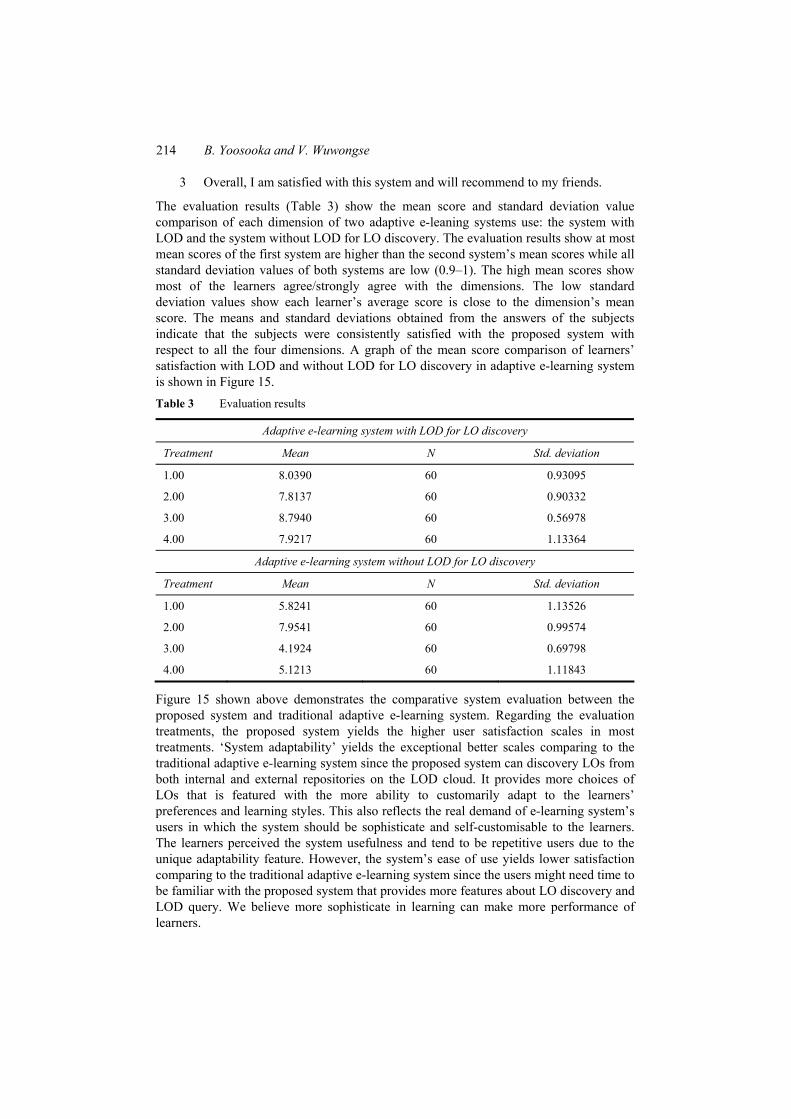
The evaluation results (Table 3) show the mean score and standard deviation value comparison of each dimension of two adaptive e-leaning systems use: the system with LOD and the system without LOD for LO discovery. The evaluation results show at most mean scores of the first system are higher than the second system’s mean scores while all standard deviation values of both systems are low (0.9–1). The high mean scores show most of the learners agree/strongly agree with the dimensions. The low standard deviation values show each learner’s average score is close to the dimension’s mean score. The means and standard deviations obtained from the answers of the subjects indicate that the subjects were consistently satisfied with the proposed system with respect to all the four dimensions. A graph of the mean score comparison of learners’ satisfaction with LOD and without LOD for LO discovery in adaptive e-learning system is shown in Figure 15. Table 3 Evaluation results
Adaptive e-learning system with LOD for LO discovery
Treatment Mean N Std. deviation
1.00 8.0390 60 0.93095
2.00 7.8137 60 0.90332
3.00 8.7940 60 0.56978
4.00 7.9217 60 1.13364
Adaptive e-learning system without LOD for LO discovery
Treatment Mean N Std. deviation
1.00 5.8241 60 1.13526
2.00 7.9541 60 0.99574
3.00 4.1924 60 0.69798
4.00 5.1213 60 1.11843
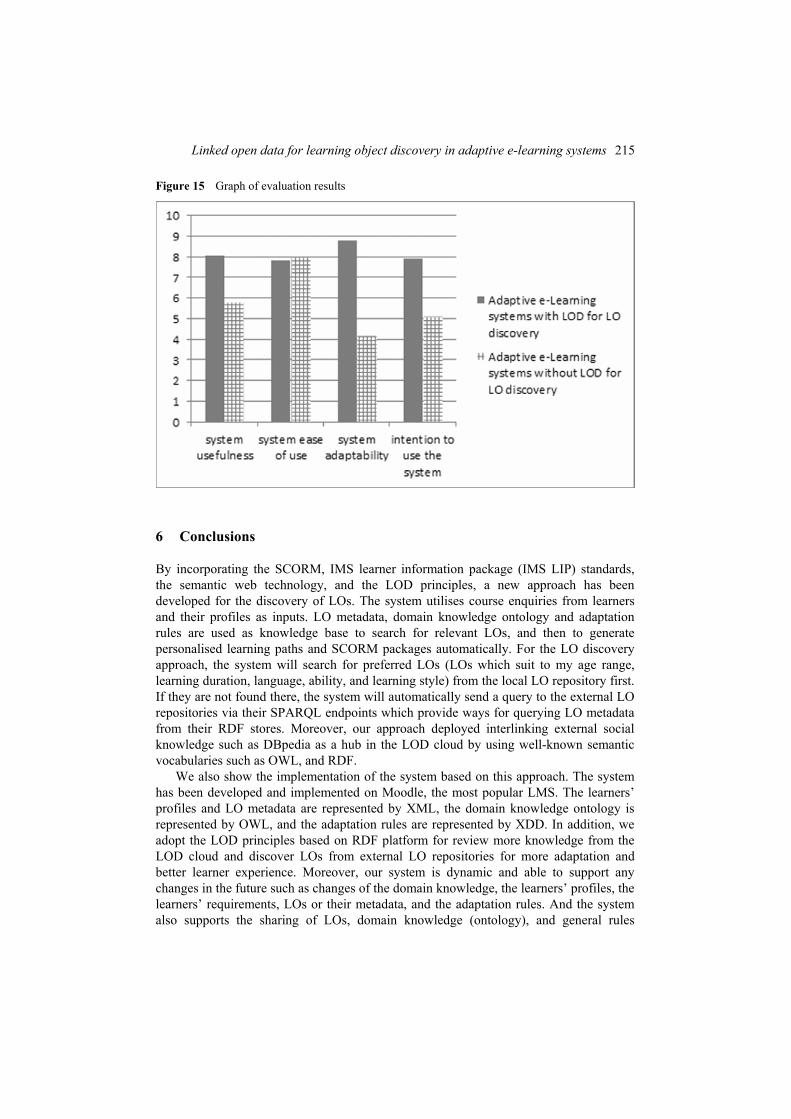
Figure 15 shown above demonstrates the comparative system evaluation between the proposed system and traditional adaptive e-learning system. Regarding the evaluation treatments, the proposed system yields the higher user satisfaction scales in most treatments. ‘System adaptability’ yields the exceptional better scales comparing to the traditional adaptive e-learning system since the proposed system can discovery LOs from both internal and external repositories on the LOD cloud. It provides more choices of LOs that is featured with the more ability to customarily adapt to the learners’ preferences and learning styles. This also reflects the real demand of e-learning system’s users in which the system should be sophisticate and self-customisable to the learners. The learners perceived the system usefulness and tend to be repetitive users due to the unique adaptability feature. However, the system’s ease of use yields lower satisfaction comparing to the traditional adaptive e-learning system since the users might need time to be familiar with the proposed system that provides more features about LO discovery and LOD query. We believe more sophisticate in learning can make more performance of learners.
Linked open data for learning object discovery in adaptive e-learning systems 215
Figure 15 Graph of evaluation results
6 Conclusions
By incorporating the SCORM, IMS learner information package (IMS LIP) standards, the semantic web technology, and the LOD principles, a new approach has been developed for the discovery of LOs. The system utilises course enquiries from learners and their profiles as inputs. LO metadata, domain knowledge ontology and adaptation rules are used as knowledge base to search for relevant LOs, and then to generate personalised learning paths and SCORM packages automatically. For the LO discovery approach, the system will search for preferred LOs (LOs which suit to my age range, learning duration, language, ability, and learning style) from the local LO repository first. If they are not found there, the system will automatically send a query to the external LO repositories via their SPARQL endpoints which provide ways for querying LO metadata from their RDF stores. Moreover, our approach deployed interlinking external social knowledge such as DBpedia as a hub in the LOD cloud by using well-known semantic vocabularies such as OWL, and RDF.
We also show the implementation of the system based on this approach. The system has been developed and implemented on Moodle, the most popular LMS. The learners’ profiles and LO metadata are represented by XML, the domain knowledge ontology is represented by OWL, and the adaptation rules are represented by XDD. In addition, we adopt the LOD principles based on RDF platform for review more knowledge from the LOD cloud and discover LOs from external LO repositories for more adaptation and better learner experience. Moreover, our system is dynamic and able to support any changes in the future such as changes of the domain knowledge, the learners’ profiles, the learners’ requirements, LOs or their metadata, and the adaptation rules. And the system also supports the sharing of LOs, domain knowledge (ontology), and general rules

216 B. Yoosooka and V. Wuwongse
between SCORM compliant systems. A preliminary evaluation of the system has shown that the system is effective in terms of ‘usefulness’, ‘ease of use’, ‘adaptability’, ‘better LO discoverability’, and ‘intention to use’.
A major difficulty in the implementation we have experienced is the response time of the system. The computation of suitable learning paths and LO sequences for a learner takes some time. This is due to the fact that the general rules compare a learner profile with all domain ontologies and LOs’ metadata. These general rules are a distinctive feature of the proposed approach, making it flexible and widely applicable; and hence should be maintained. The slow response time has been solved by creating individual rules, which are derived from the general rules, for each learner after his or her first session. As a result, the response time has been reduced in the following sessions. Other limitation of the system is that the LOs, which will automatically be composed into individual SCORM packages, must be equipped with their IEEE LOM metadata on title, language, typical age range, duration, difficulty, learning resource type, and format. The creation of such metadata demands some efforts and resources.
Regarding our experiences in LOD employment, we found four advantages of application of the LOD platform within the education context. Firstly, the links which are generated across the different LO repositories have provided a new way that learners can browse, access and share the open linked LOs together. This method allows learners to find their preferred LOs easily in a single site via SPARQL endpoints with all the information they are looking for. Hence, learners can have more opportunity and flexibility in their learning. Secondly, the linked data can give more knowledge and reliability for any topics of interest via the LOD cloud. We should also aim at stronger and more reliable interlinking with additional open LO repositories and other linked datasets. Thirdly, the publicity of all data resources as open Web resources provides or offers better opportunities for the growth of interesting and novel applications, such as open m-Learning, open library, open government, and any open knowledge. The opened information can be shared and accessed by any anybody via the LOD cloud, so it is a very good way of expanding knowledge or interesting information throughout the whole world. Finally, the interconnection of information and a social network can enhance global productivity and satisfaction of the academic community, and also facilitate the collaborative learning process of learners. The learners in the community can share and exchange their ideas. They can recommend interesting courses or good study materials to their friends that can guide others to learn effectively in a similar fashion and the learners can also easily collaborate with others in their learning. They can compare their keywords or ideas with others terms which are available on the social network, counting the frequency of overlapping terms from the LOD cloud in order to rank the keywords or ideas to find better answers. By extracting concepts from the collection of terms, recommendations can be generated that are more accurate and better suited to answer the learners’ questions. Without LOD, this would not be possible.
As an undeniable of the interdependent of the society, researchers have realised the significant role of LOD that could be blended within the educational society. We believe that universities should expose knowledge and share educational material. Moreover, the linkage among many parties such as educator, instructor, learner, content developer and so on has become closer than ever. With the help of open data and its ubiquitous the educational pedagogy could be shifted to the better accessible between institutes. We as a part of the society are looking forward to seeing the more researchers who are willing to donate themselves to the LOD approach. The more widespread and newly created

Linked open data for learning object discovery in adaptive e-learning systems 217
applications that expose more educational contents that serves the attribute of reusable and linkable. Moreover, we are going to experience with a different type and a larger number of learners during a long period to test the system’s satisfaction and in order to consider more motivation and variables regarding learners’ behaviours, attitudes, perceptions, and values in the affective dimension of learning. The teachers can also increase their effectiveness by considering the affective domain in planning courses, delivering lectures and activities, and assessing student learning.
References ACM (2008) ‘Computer science curricular 2008’, ACM Journal of Educational Resources in
Computing, June, Vol. 8, No. 2, pp.35–36 [online] http://www.acm.org/education/curricula/ ComputerScience2008.pdf (accessed 15 January 2009).
ADL (2004) ‘Sharable content object reference model (SCORM) 2004’ [online] http://www.adlnet.gov/Technologies/scorm/default.aspx (accessed 14 July 2008).
Anutariya, C., Wuwongse, V. and Akama, K. (2005) ‘XML declarative description with first-order logical constraints’, Computational Intelligence, Vol. 21, No. 2, pp.130–156.
ARC2 (2012) ‘Getting started with ARC2’ [online] https://github.com/semsol/arc2/wiki/Getting-started-with-ARC2 (accessed 20 January 2012).
Berners-Lee, T. (2009) ‘Linked data’ [online] http://www.w3.org/DesignIssues/LinkedData.html (accessed 18 June 2009).
Bizer, C. and Cyganiak, R. (2006) ‘D2R server publishing the DBLP bibliography database’ [online] http://www4.wiwiss.fu-berlin.de/dblp(accessed 2 November 2010).
Bizer, C., Cyganiak, R. and Heath, T. (2007) How to Publish Linked Data on the Web [onlie] http://www4.wiwiss.fu-berlin.de/bizer/pub/LinkedDataTutorial/ (accessed 5 January 2011).
Canavan, J. (2004) Personalized E-Learning through Learning Style Aware Adaptive Systems, Published dissertation, University of Dublin, Ireland.
Cyganiak, R. and Jentzsch, A. (2011) ‘The linking open data cloud diagram’ [online] http://richard.cyganiak.de/2007/10/lod/lod-datasets_2011-09-19.pdf (accessed 5 January 2011).
Dicheva, D. (2008) ‘Ontologies and semantic web for e-learning’, Handbook on Information Technologies for Education and Training, International Handbooks on Information Systems, pp.47–65.
Dicheva, D. and Aroyo, L. (2006) ‘Special issue on application of semantic web technologies in e-learning’, International Journal of Continuing Engineering Education and Life-Long Learning, Vol. 16, Nos. 1/2, pp.1–149.
Dougiamas, M. (2008) ‘Moodle’ [online] http://docs.moodle.org/en/About_Moodle (accessed 15 January 2008).
Felder, R.M. (1993) ‘Reaching the second tier: learning and teaching styles in college science education’, J. College Science Teaching, Vol. 23, No. 5, pp.286–290.
FOAF (2011) ‘FOAF vocabulary specification 0.9’ [online] http://xmlns.com/foaf/0.1/ (accessed 27 February 2011).
Graf, S., Viola, S.R., Leo, T. and Kinshuk (2007) ‘In-depth analysis of the Felder-Silverman learning style dimensions’, Journal of Research on Technology in Education, Vol. 40, No. 1, pp.79–93.
Heath, T. and Bizer, C. (2007) ‘Linked data: evolving the web into a global data space’ [online] http://www4.wiwiss.fu-berlin.de/bizer/pub/LinkedDataTutorial/ (accessed 5 January 2011).
IEEE (2002) ‘IEEE draft standard for learning object metadata’, IEEE P1484.12.1/d6.4 http://ltsc.ieee.org/wg12/files/LOM_1484_12_1_v1 _ Final_Draft.pdf (accessed 2 October 2008).

218 B. Yoosooka and V. Wuwongse
IMS LIP (2001) ‘IMS learner information package specification’, Final Specification v1.0 [online] http://www.imsglobal.org/profiles/index.html(accessed 4 July 2008).
Krieger, K. and Rosner, D. (2011) ‘Linked data in e-learning: a survey’, Semantic Web 0, IOS Press Journal, Vol. 2011, No. 1, pp.1–9.
McGettrick, A., McCauley, R., LeBlanc, R. and Topi, H. (2009) ‘Report on the ACM/IEEE-CS undergraduate curricula recommendations’, in Proceeding of the 40th ACM Technical Symposium on Computer Science Education, Chattanooga, Tennessee, USA, pp.267–268.
Morsey, M. (2011) ‘DBpedia’ [online] http://dbpedia.org/About (accessed 14 June 2011). Nilsson, M., Palmer, M., and Brase, J. (2003) ‘The LOM RDF binding – principles and
implementation’, in Proceeding of the 3rd annual ARIADNE Conference, Katholieke Universiteit Leuven, Belgium, pp.1–7.
Prakash, L.S., Saini, D.K. and Kutti, N.S. (2009) ‘Integrating EduLearn learning content management system (LCMS) with cooperating learning object repositories (LORs) in a peer to peer (P2P) architectural framework’, SIGSOFT Software Engineering Notes, Vol. 34, No. 3, pp.1–7.
Prolog (2008) ‘SWI-Prolog’s home’ [online] http://www.swi-prolog.org/ (accessed 1 August 2009). Protégé (2008) ‘Welcome to Protégé’ [online] http://protege.stanford.edu/
(accessed 1 August 2009). Semantic Web (2009) ‘SPARQL endpoint’ [online]
http://semanticweb.org/wiki/SPARQL_endpoint (accessed 10 January 2010). Shishehchi, S., Banihashem, S. and Zin, N. (2010) ‘A proposed semantic recommendation system
for e-learning: a rule and ontology based e-learning recommendation system’, in Information Technology (ITSim), 2010 International Symposium, Vol. 1, pp.1–5.
Tobing, V., Hamzah, M., Sura, S. and Amin, H. (2008) ‘Assessing the acceptability of adaptive e-learning system’, in Proceeding of 5th International Conference on eLearning for Knowledge-Based Society, Bangkok, Thailand, pp.13.1–13.10.
W3C (2004a) ‘OWL web ontology language’ [online] http://www.w3.org/TR/owl-features/ (accessed 5 May 2009).
W3C (2004b) ‘Resource description framework (RDF)’ [online] http://www.w3.org/RDF/ (accessed 27 November 2010).
W3C (2007) ‘WordNet RDF/OWL files’ [online] http://www.w3.org/2006/03/wn/wn20/ (accessed 27 November 2010).
W3C (2008) ‘SPARQL query language for RDF’ [online] http://www.w3.org/TR/rdf-sparql-query/ (accessed 27 November 2010).
Wuwongse, V., Anutariya, C., Akama, K. and Nantajeewarawat, E. (2001) ‘XML declarative description (XDD): a language for semantic web’, IEEE Intelligent Systems, Vol. 16, No. 3, pp.54–65.
Yu, H.Q., Dietze, S., Li, N., Pedrinaci, C., Taibi, D., Dovrolis, N., Stefanut, T., Kaldoudi, E. and Domingue, J. (2011) ‘A linked data-driven & service-oriented architecture for sharing educational resources’, in 1st International Workshop on eLearning Approaches for Linked Data Age (Linked Learning 2011), 8th Extended Semantic Web Conference (ESWC2011), 29 May, Heraklion, Greece.
Zablith, F., Fernandaz, M. and Rowe, M. (2011) ‘The OU linked open data: production and consumption’, in Linked Learning 2011: 1st International Workshop on eLearning Approaches for the Linked Data Age, 8th Extended Semantic Web Conference (ESWC2011), 29 May, Heraklion, Greece.