Embed Size (px)
Citation preview

Link AnalysisLink Analysis
1
Wu-Jun LiDepartment of Computer Science and Engineering
Shanghai Jiao Tong UniversityLecture 7: Link Analysis
Mining Massive Datasets

Link AnalysisLink Analysis
2
Link Analysis Algorithms PageRank Hubs and Authorities Topic-Sensitive PageRank Spam Detection Algorithms Other interesting topics we won’t cover
Detecting duplicates and mirrors Mining for communities (community detection)
(Refer to Chapter 10 of the textbook)

Link AnalysisLink Analysis
3
Outline
PageRank
Topic-Sensitive PageRank
Hubs and Authorities
Spam Detection
Link AnalysisLink Analysis
4
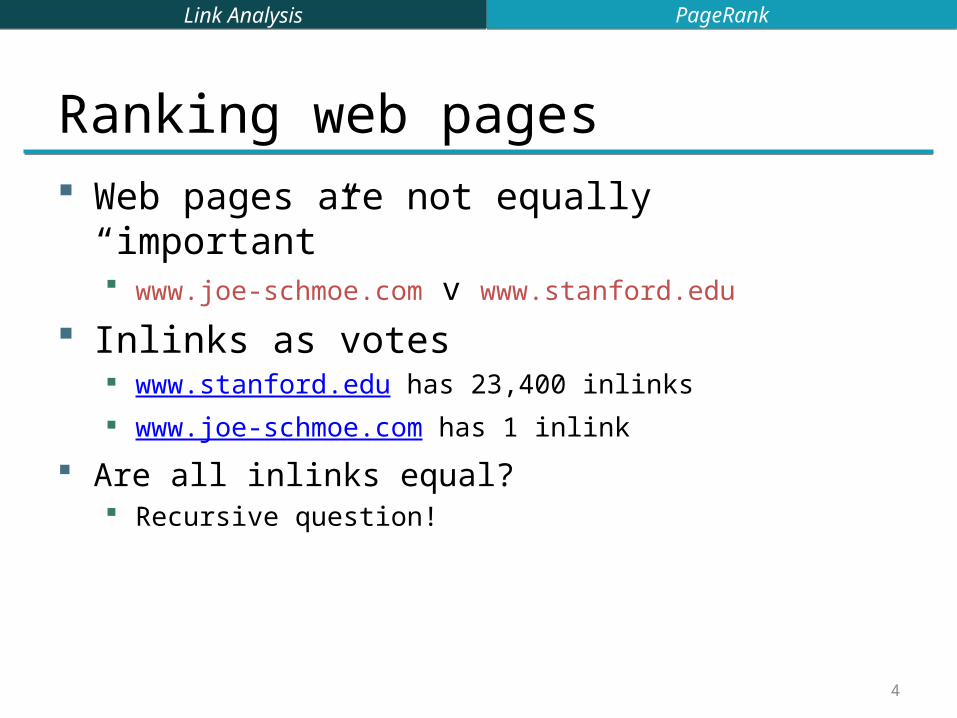
Ranking web pages Web pages are not equally “important”
www.joe-schmoe.com v www.stanford.edu
Inlinks as votes www.stanford.edu has 23,400 inlinks www.joe-schmoe.com has 1 inlink
Are all inlinks equal? Recursive question!
PageRank

Link AnalysisLink Analysis
5
Simple recursive formulation Each link’s vote is proportional to the importance of
its source page If page P with importance x has n outlinks, each link
gets x/n votes Page P’s own importance is the sum of the votes on
its inlinks
PageRank

Link AnalysisLink Analysis
6
Simple “flow” modelThe web in 1839
Yahoo
M’softAmazon
y
a m
y/2
y/2
a/2
a/2
m
y = y /2 + a /2a = y /2 + mm = a /2
PageRank

Link AnalysisLink Analysis
7
Solving the flow equations 3 equations, 3 unknowns, no constants
No unique solution All solutions equivalent modulo scale factor
Additional constraint forces uniqueness y+a+m = 1 y = 2/5, a = 2/5, m = 1/5
Gaussian elimination method works for small examples, but we need a better method for large graphs
PageRank
Link AnalysisLink Analysis
8
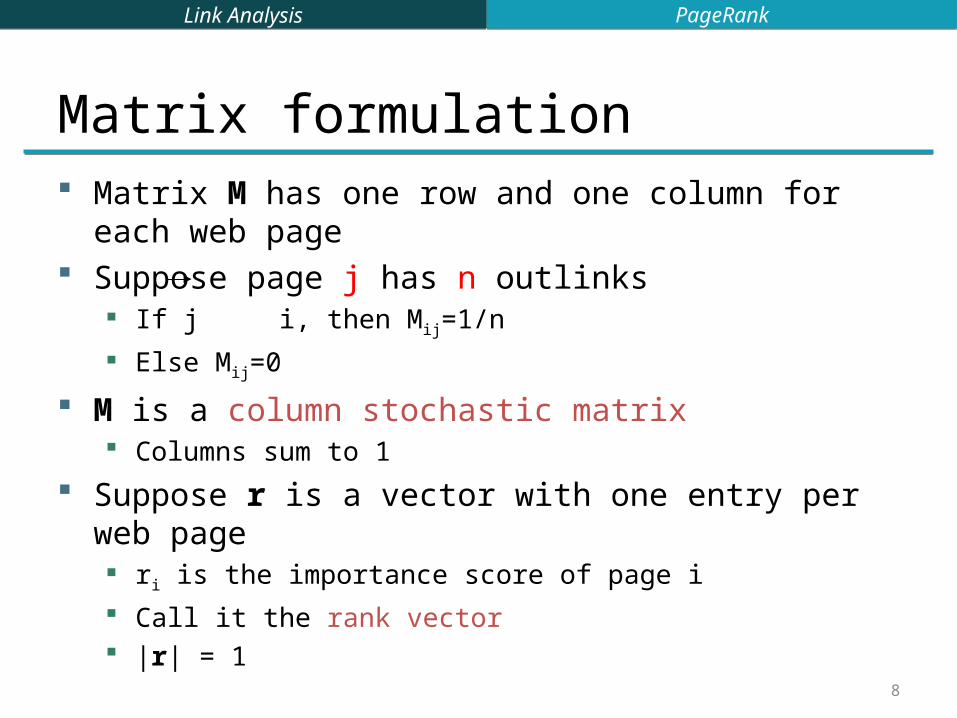
Matrix formulation Matrix M has one row and one column for each web page Suppose page j has n outlinks
If j i, then Mij=1/n
Else Mij=0
M is a column stochastic matrix Columns sum to 1
Suppose r is a vector with one entry per web page ri is the importance score of page i Call it the rank vector |r| = 1
PageRank

Link AnalysisLink Analysis
9
Example
Suppose page j links to 3 pages, including i
i
j
M r r
=i
1/3
PageRank

Link AnalysisLink Analysis
10
Eigenvector formulation The flow equations can be written
r = Mr So the rank vector is an eigenvector of the stochastic
web matrix In fact, its first or principal eigenvector, with corresponding
eigenvalue 1
PageRank

Link AnalysisLink Analysis
11
Example
Yahoo
M’softAmazon
y 1/2 1/2 0a 1/2 0 1m 0 1/2 0
y a m
y = y /2 + a /2a = y /2 + mm = a /2
r = Mr
y 1/2 1/2 0 y a = 1/2 0 1 a m 0 1/2 0 m
PageRank

Link AnalysisLink Analysis
12
Power Iteration method Simple iterative scheme (aka relaxation) Suppose there are N web pages Initialize: r0 = [1/N,….,1/N]T
Iterate: rk+1 = Mrk
Stop when |rk+1 - rk|1 < |x|1 = 1≤i≤N|xi| is the L1 norm Can use any other vector norm e.g., Euclidean
PageRank

Link AnalysisLink Analysis
13
Power Iteration Example
Yahoo
M’softAmazon
y 1/2 1/2 0a 1/2 0 1m 0 1/2 0
y a m
ya =m
1/31/31/3
1/31/21/6
5/12 1/3 1/4
3/811/241/6
2/52/51/5
. . .
PageRank

Link AnalysisLink Analysis
14
Random Walk Interpretation Imagine a random web surfer
At any time t, surfer is on some page P At time t+1, the surfer follows an outlink from P uniformly
at random Ends up on some page Q linked from P Process repeats indefinitely
Let p(t) be a vector whose ith component is the probability that the surfer is at page i at time t p(t) is a probability distribution on pages
PageRank

Link AnalysisLink Analysis
15
The stationary distribution Where is the surfer at time t+1?
Follows a link uniformly at random p(t+1) = Mp(t)
Suppose the random walk reaches a state such that p(t+1) = Mp(t) = p(t) Then p(t) is called a stationary distribution for the random
walk Our rank vector r satisfies r = Mr
So it is a stationary distribution for the random surfer
PageRank

Link AnalysisLink Analysis
16
Existence and UniquenessA central result from the theory of random walks (aka Markov processes):
For graphs that satisfy certain conditions, the stationary distribution is unique and eventually will be reached no matter what the initial probability distribution at time t = 0.
PageRank

Link AnalysisLink Analysis
17
Spider traps A group of pages is a spider trap if there are no links
from within the group to outside the group Random surfer gets trapped
Spider traps violate the conditions needed for the random walk theorem
PageRank

Link AnalysisLink Analysis
18
Microsoft becomes a spider trap
Yahoo
M’softAmazon
y 1/2 1/2 0a 1/2 0 0m 0 1/2 1
y a m
ya =m
111
11/23/2
3/41/27/4
5/83/82
003
. . .
PageRank

Link AnalysisLink Analysis
19
Random teleports The Google solution for spider traps At each time step, the random surfer has two
options: With probability , follow a link at random With probability 1-, jump to some page uniformly at
random Common values for are in the range 0.8 to 0.9
Surfer will teleport out of spider trap within a few time steps
PageRank

Link AnalysisLink Analysis
20
Random teleports ()
Yahoo
M’softAmazon
1/2
1/2
0.8*1/2
0.8*1/2
0.2*1/3
0.2*1/3
0.2*1/3
y 1/2a 1/2m 0
y
1/2 1/2 0
y
0.8* 1/3 1/3 1/3
y
+ 0.2*
1/2 1/2 0 1/2 0 0 0 1/2 1
1/3 1/3 1/3 1/3 1/3 1/3 1/3 1/3 1/3
y 7/15 7/15 1/15a 7/15 1/15 1/15m 1/15 7/15 13/15
0.8 + 0.2
PageRank

Link AnalysisLink Analysis
21
Random teleports ()
Yahoo
M’softAmazon
1/2 1/2 0 1/2 0 0 0 1/2 1
1/3 1/3 1/3 1/3 1/3 1/3 1/3 1/3 1/3
y 7/15 7/15 1/15a 7/15 1/15 1/15m 1/15 7/15 13/15
0.8 + 0.2
ya =m
111
1.000.601.40
0.840.601.56
0.7760.5361.688
7/11 5/1121/11
. . .
PageRank

Link AnalysisLink Analysis
22
Matrix formulation Suppose there are N pages
Consider a page j, with set of outlinks O(j) We have Mij = 1/|O(j)| when j i and Mij = 0 otherwise The random teleport is equivalent to
adding a teleport link from j to every other page with probability (1-)/N
reducing the probability of following each outlink from 1/|O(j)| to /|O(j)|
Equivalent: tax each page a fraction (1-) of its score and redistribute evenly
PageRank

Link AnalysisLink Analysis
23
PageRank Construct the N*N matrix A as follows
Aij = Mij + (1-)/N
Verify that A is a stochastic matrix The PageRank vector r is the principal eigenvector of
this matrix satisfying r = Ar
Equivalently, r is the stationary distribution of the random walk with teleports
PageRank

Link AnalysisLink Analysis
24
Dead ends Pages with no outlinks are “dead ends” for the
random surfer Nowhere to go on next step
PageRank

Link AnalysisLink Analysis
25
Microsoft becomes a dead end
Yahoo
M’softAmazon
ya =m
111
10.60.6
0.7870.5470.387
0.6480.4300.333
000
. . .
1/2 1/2 0 1/2 0 0 0 1/2 0
1/3 1/3 1/3 1/3 1/3 1/3 1/3 1/3 1/3
y 7/15 7/15 1/15a 7/15 1/15 1/15m 1/15 7/15 1/15
0.8 + 0.2
Non-stochastic!
PageRank

Link AnalysisLink Analysis
26
Dealing with dead ends Teleport
Follow random teleport links with probability 1.0 from dead ends
Adjust matrix accordingly Prune and propagate
Preprocess the graph to eliminate dead ends Might require multiple passes Compute PageRank on reduced graph Approximate values for dead ends by propagating values
from reduced graph
PageRank

Link AnalysisLink Analysis
27
Computing PageRank Key step is matrix-vector multiplication
rnew = Arold
Easy if we have enough main memory to hold A, rold, rnew
Say N = 1 billion pages We need 4 bytes for each entry (say) 2 billion entries for vectors, approx 8GB Matrix A has N2 entries
1018 is a large number!
PageRank

Link AnalysisLink Analysis
28
Rearranging the equationr = Ar, whereAij = Mij + (1-)/N
ri =1≤j≤N Aij rj
ri =1≤j≤N [Mij + (1-)/N] rj
= 1≤j≤N Mij rj + (1-)/N 1≤j≤N rj
= 1≤j≤N Mij rj + (1-)/N, since |r| = 1
r = Mr + [(1-)/N]N
where [x]N is an N-vector with all entries x
PageRank

Link AnalysisLink Analysis
29
Sparse matrix formulation We can rearrange the PageRank equation:
r = Mr + [(1-)/N]N
[(1-)/N]N is an N-vector with all entries (1-)/N
M is a sparse matrix! 10 links per node, approx 10N entries
So in each iteration, we need to: Compute rnew = Mrold
Add a constant value (1-)/N to each entry in rnew
PageRank

Link AnalysisLink Analysis
30
Sparse matrix encoding Encode sparse matrix using only nonzero entries
Space proportional roughly to number of links say 10N, or 4*10*1 billion = 40GB still won’t fit in memory, but will fit on disk
0 3 1, 5, 7
1 5 17, 64, 113, 117, 245
2 2 13, 23
sourcenode
degree destination nodes
PageRank

Link AnalysisLink Analysis
31
Basic Algorithm Assume we have enough RAM to fit rnew, plus some
working memory Store rold and matrix M on disk
Basic Algorithm: Initialize: rold = [1/N]N
Iterate: Update: Perform a sequential scan of M and rold to update rnew
Write out rnew to disk as rold for next iteration Every few iterations, compute |rnew-rold| and stop if it is below
threshold Need to read in both vectors into memory
PageRank
Link AnalysisLink Analysis
32
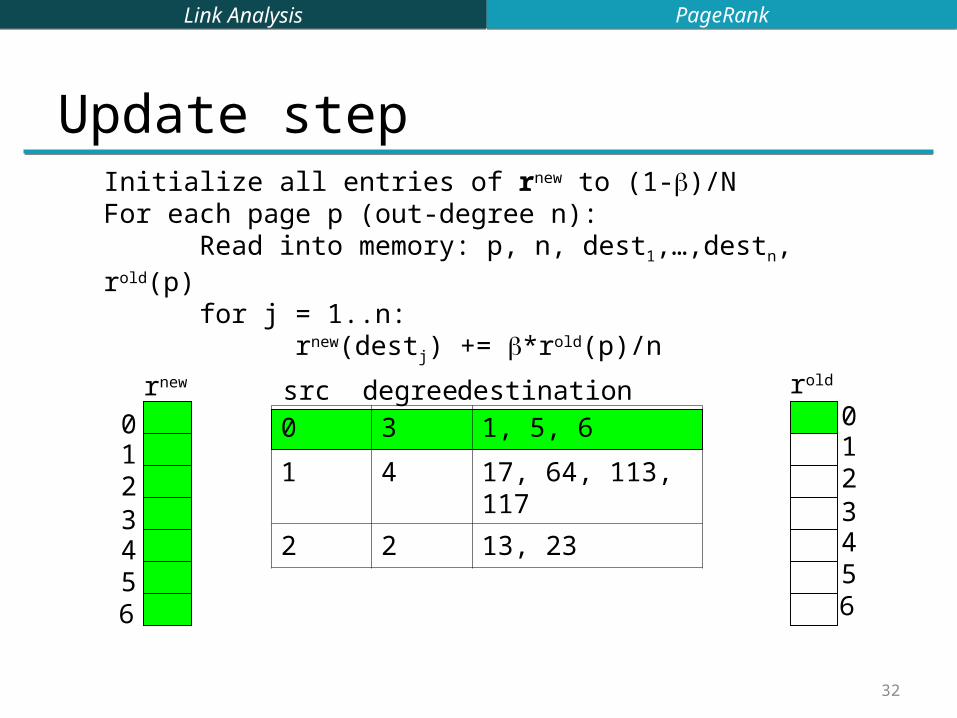
Update step
0 3 1, 5, 6
1 4 17, 64, 113, 117
2 2 13, 23
src degree destination0123456
0123456
rnew rold
Initialize all entries of rnew to (1-)/NFor each page p (out-degree n):
Read into memory: p, n, dest1,…,destn, rold(p)for j = 1..n:
rnew(destj) += *rold(p)/n
PageRank

Link AnalysisLink Analysis
33
Analysis In each iteration, we have to:
Read rold and M Write rnew back to disk IO Cost = 2|r| + |M|
What if we had enough memory to fit both rnew and rold?
What if we could not even fit rnew in memory? 10 billion pages
PageRank

Link AnalysisLink Analysis
34
Strip-based update
Problem: thrashing
PageRank

Link AnalysisLink Analysis
35
Block Update algorithm
PageRank

Link AnalysisLink Analysis
36
Block Update algorithm
0 3 0, 1
1 2 0
src degree destination
01
23
0123
rnew
rold
3 2 2
0 3 3
1 2 2
PageRank
2 1 0
3 2 1

Link AnalysisLink Analysis
37
Block Update algorithm Some additional overhead
But usually worth it
Cost per iteration |M|(1+) + (k+1)|r|
PageRank

Link AnalysisLink Analysis
38
Outline
PageRank
Topic-Sensitive PageRank
Hubs and Authorities
Spam Detection

Link AnalysisLink Analysis
39
Some problems with PageRank Measures generic popularity of a page
Biased against topic-specific authorities Ambiguous queries e.g., jaguar
Uses a single measure of importance Other models e.g., hubs-and-authorities
Susceptible to link spam Artificial link topographies created in order to boost page
rank
Topic-Sensitive PageRank

Link AnalysisLink Analysis
40
Topic-Sensitive PageRank Instead of generic popularity, can we measure popularity
within a topic? E.g., computer science, health
Bias the random walk When the random walker teleports, he picks a page from a set S of
web pages S contains only pages that are relevant to the topic E.g., Open Directory (DMOZ) pages for a given topic (www.dmoz.org)
For each teleport set S, we get a different rank vector rS
Topic-Sensitive PageRank

Link AnalysisLink Analysis
41
Matrix formulation Aij = Mij + (1-)/|S| if i is in S
Aij = Mij otherwise Show that A is stochastic We have weighted all pages in the teleport set S
equally Could also assign different weights to them
Topic-Sensitive PageRank

Link AnalysisLink Analysis
42
Example
1
2 3
4
Suppose S = {1}, = 0.8
Node Iteration0 1 2… stable
1 1.0 0.2 0.52 0.2942 0 0.4 0.08 0.1183 0 0.4 0.08 0.3274 0 0 0.32 0.261
Note how we initialize the PageRank vector differently from theunbiased PageRank case.
0.2
0.50.5
1
1 1
0.40.4
0.8
0.8 0.8
Topic-Sensitive PageRank

Link AnalysisLink Analysis
43
How well does TSPR work? Experimental results [Haveliwala 2000] Picked 16 topics
Teleport sets determined using DMOZ E.g., arts, business, sports,…
“Blind study” using volunteers 35 test queries Results ranked using PageRank and TSPR of most closely
related topic E.g., bicycling using Sports ranking In most cases volunteers preferred TSPR ranking
Topic-Sensitive PageRank

Link AnalysisLink Analysis
44
Which topic ranking to use? User can pick from a menu Use Bayesian classification schemes to classify query
into a topic Can use the context of the query
E.g., query is launched from a web page talking about a known topic
History of queries e.g., “basketball” followed by “jordan”
User context e.g., user’s My Yahoo settings, bookmarks, …
Topic-Sensitive PageRank

Link AnalysisLink Analysis
45
Outline
PageRank
Topic-Sensitive PageRank
Hubs and Authorities
Spam Detection

Link AnalysisLink Analysis
46
Hubs and Authorities Suppose we are given a collection of documents on
some broad topic e.g., stanford, evolution, iraq perhaps obtained through a text search
Can we organize these documents in some manner? PageRank offers one solution HITS (Hypertext-Induced Topic Selection) is another
proposed at approx the same time (1998)
Hubs and Authorities

Link AnalysisLink Analysis
47
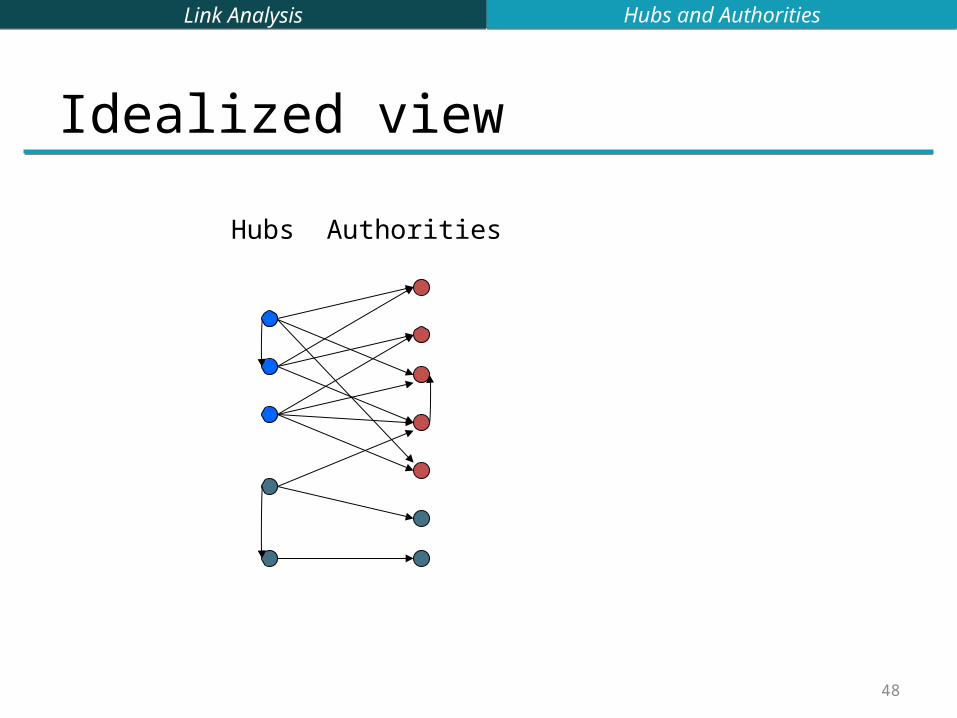
HITS Model Interesting documents fall into two classes Authorities are pages containing useful information
course home pages home pages of auto manufacturers
Hubs are pages that link to authorities course bulletin list of US auto manufacturers
Hubs and Authorities
Link AnalysisLink Analysis
48
Idealized view
Hubs Authorities
Hubs and Authorities

Link AnalysisLink Analysis
49
Mutually recursive definition A good hub links to many good authorities A good authority is linked from many good hubs Model using two scores for each node
Hub score and Authority score Represented as vectors h and a
Hubs and Authorities

Link AnalysisLink Analysis
50
Transition Matrix A HITS uses a matrix A[i, j] = 1 if page i links to page j, 0
if not AT, the transpose of A, is similar to the PageRank
matrix M, but AT has 1’s where M has fractions
Hubs and Authorities

Link AnalysisLink Analysis
51
Example
Yahoo
M’softAmazon
y 1 1 1a 1 0 1m 0 1 0
y a m
A =
Hubs and Authorities

Link AnalysisLink Analysis
52
Hub and Authority Equations The hub score of page P is proportional to the sum of
the authority scores of the pages it links to h = λAa Constant λ is a scale factor
The authority score of page P is proportional to the sum of the hub scores of the pages it is linked from a = μAT h Constant μ is scale factor
Hubs and Authorities

Link AnalysisLink Analysis
53
Iterative algorithm Initialize h, a to all 1’s h = Aa Scale h so that its max entry is 1.0 a = ATh Scale a so that its max entry is 1.0 Continue until h, a converge
Hubs and Authorities

Link AnalysisLink Analysis
54
Example
1 1 1A = 1 0 1 0 1 0
1 1 0AT = 1 0 1 1 1 0
a(yahoo)a(amazon)a(m’soft)
===
111
111
14/51
1 0.75 1
. . .
. . .
. . .
10.7321
h(yahoo) = 1h(amazon) = 1h(m’soft) = 1
12/31/3
1 0.73 0.27
. . .
. . .
. . .
1.0000.7320.268
10.710.29
Hubs and Authorities

Link AnalysisLink Analysis
55
Existence and Uniquenessh = λAaa = μAT hh = λμAAT ha = λμATA a
Under reasonable assumptions about A, the dual iterative algorithm converges to vectors h* and a* such that:• h* is the principal eigenvector of the matrix AAT
• a* is the principal eigenvector of the matrix ATA
Hubs and Authorities

Link AnalysisLink Analysis
56
Bipartite cores
Hubs Authorities
Most densely-connected core(primary core)
Less densely-connected core(secondary core)
Hubs and Authorities

Link AnalysisLink Analysis
57
Secondary cores A single topic can have many bipartite cores
corresponding to different meanings, or points of view abortion: pro-choice, pro-life evolution: darwinian, intelligent design jaguar: auto, Mac, NFL team, panthera onca
How to find such secondary cores?
Hubs and Authorities

Link AnalysisLink Analysis
58
Non-primary eigenvectors AAT and ATA have the same set of eigenvalues
An eigenpair is the pair of eigenvectors with the same eigenvalue
The primary eigenpair (largest eigenvalue) is what we get from the iterative algorithm
Non-primary eigenpairs correspond to other bipartite cores The eigenvalue is a measure of the density of links in the
core
Hubs and Authorities

Link AnalysisLink Analysis
59
Finding secondary cores Once we find the primary core, we can remove its
links from the graph Repeat HITS algorithm on residual graph to find the
next bipartite core Technically, not exactly equivalent to non-primary
eigenpair model
Hubs and Authorities

Link AnalysisLink Analysis
60
Creating the graph for HITS
We need a well-connected graph of pages for HITS to work well
Hubs and Authorities

Link AnalysisLink Analysis
61
PageRank and HITS PageRank and HITS are two solutions to the same
problem What is the value of an inlink from S to D? In the PageRank model, the value of the link depends on
the links into S In the HITS model, it depends on the value of the other
links out of S The destinies of PageRank and HITS post-1998 were
very different Why?
Hubs and Authorities

Link AnalysisLink Analysis
62
Outline
PageRank
Topic-Sensitive PageRank
Hubs and Authorities
Spam Detection

Link AnalysisLink Analysis
63
Web Spam Search has become the default gateway to the web Very high premium to appear on the first page of
search results e.g., e-commerce sites advertising-driven sites
Spam Detection

Link AnalysisLink Analysis
64
What is web spam? Spamming = any deliberate action solely in order to
boost a web page’s position in search engine results, incommensurate with page’s real value
Spam = web pages that are the result of spamming This is a very broad defintion
SEO industry might disagree! SEO = search engine optimization
Approximately 10-15% of web pages are spam
Spam Detection

Link AnalysisLink Analysis
65
Web Spam Taxonomy We follow the treatment by Gyongyi and Garcia-
Molina [2004] Boosting techniques
Techniques for achieving high relevance/importance for a web page
Hiding techniques Techniques to hide the use of boosting
From humans and web crawlers
Spam Detection

Link AnalysisLink Analysis
66
Boosting techniques Term spamming
Manipulating the text of web pages in order to appear relevant to queries
Link spamming Creating link structures that boost page rank or hubs and
authorities scores
Spam Detection

Link AnalysisLink Analysis
67
Term Spamming Repetition
of one or a few specific terms e.g., free, cheap, viagra Goal is to subvert TF.IDF ranking schemes
Dumping of a large number of unrelated terms e.g., copy entire dictionaries
Weaving Copy legitimate pages and insert spam terms at random positions
Phrase Stitching Glue together sentences and phrases from different sources
Spam Detection

Link AnalysisLink Analysis
68
Link spam Three kinds of web pages from a spammer’s point of
view Inaccessible pages Accessible pages
e.g., web log comments pages spammer can post links to his pages
Own pages Completely controlled by spammer May span multiple domain names
Spam Detection

Link AnalysisLink Analysis
69
Link Farms Spammer’s goal
Maximize the page rank of target page t Technique
Get as many links from accessible pages as possible to target page t
Construct “link farm” to get page rank multiplier effect
Spam Detection

Link AnalysisLink Analysis
70
Link Farms
InaccessibleInaccessible
t
Accessible Own
1
2
M
One of the most common and effective organizations for a link farm
Spam Detection

Link AnalysisLink Analysis
71
Analysis
Suppose rank contributed by accessible pages = xLet page rank of target page = yRank of each “farm” page = y/M + (1-)/Ny = x + M[y/M + (1-)/N] + (1-)/N = x + 2y + (1-)M/N + (1-)/Ny = x/(1-2) + cM/N where c = /(1+)
Inaccessible
Inaccessible
t
Accessible Own
12
M
Very small; ignore
Spam Detection

Link AnalysisLink Analysis
72
Analysis
y = x/(1-2) + cM/N where c = /(1+) For = 0.85, 1/(1-2)= 3.6
Multiplier effect for “acquired” page rank By making M large, we can make y as large as we want
Inaccessible
Inaccessible t
Accessible Own
12
M
Spam Detection

Link AnalysisLink Analysis
73
Detecting Spam Term spamming
Analyze text using statistical methods e.g., Naïve Bayes classifiers
Similar to email spam filtering Also useful: detecting approximate duplicate pages
Link spamming Open research area One approach: TrustRank
Spam Detection

Link AnalysisLink Analysis
74
TrustRank idea Basic principle: approximate isolation
It is rare for a “good” page to point to a “bad” (spam) page
Sample a set of “seed pages” from the web Have an oracle (human) identify the good pages and
the spam pages in the seed set Expensive task, so must make seed set as small as possible
Spam Detection

Link AnalysisLink Analysis
75
Trust Propagation Call the subset of seed pages that are identified as
“good” the “trusted pages” Set trust of each trusted page to 1 Propagate trust through links
Each page gets a trust value between 0 and 1 Use a threshold value and mark all pages below the trust
threshold as spam
Spam Detection

Link AnalysisLink Analysis
77
Rules for trust propagation Trust attenuation
The degree of trust conferred by a trusted page decreases with distance
Trust splitting The larger the number of outlinks from a page, the less
scrutiny the page author gives each outlink Trust is “split” across outlinks
Spam Detection

Link AnalysisLink Analysis
78
Simple model Suppose trust of page p is t(p)
Set of outlinks O(p) For each q in O(p), p confers the trust
t(p)/|O(p)| for 0<<1 Trust is additive
Trust of p is the sum of the trust conferred on p by all its inlinked pages
Note similarity to Topic-Specific PageRank Within a scaling factor, trust rank = biased page rank with
trusted pages as teleport set
Spam Detection

Link AnalysisLink Analysis
79
Picking the seed set Two conflicting considerations
Human has to inspect each seed page, so seed set must be as small as possible
Must ensure every “good page” gets adequate trust rank, so need make all good pages reachable from seed set by short paths
Spam Detection

Link AnalysisLink Analysis
80
Approaches to picking seed set Suppose we want to pick a seed set of k pages PageRank
Pick the top k pages by page rank Assume high page rank pages are close to other highly
ranked pages We care more about high page rank “good” pages
Spam Detection

Link AnalysisLink Analysis
81
Inverse page rank Pick the pages with the maximum number of outlinks Can make it recursive
Pick pages that link to pages with many outlinks Formalize as “inverse page rank”
Construct graph G’ by reversing each edge in web graph G Page rank in G’ is inverse page rank in G
Pick top k pages by inverse page rank
Spam Detection

Link AnalysisLink Analysis
82
Spam Mass In the TrustRank model, we start with good pages
and propagate trust Complementary view: what fraction of a page’s page
rank comes from “spam” pages? In practice, we don’t know all the spam pages, so we
need to estimate
Spam Detection

Link AnalysisLink Analysis
83
Spam mass estimationr(p) = page rank of page pr+(p) = page rank of p with teleport into “good” pages
onlyr-(p) = r(p) – r+(p)Spam mass of p = r-(p)/r(p)
Spam Detection

Link AnalysisLink Analysis
84
Good pages For spam mass, we need a large set of “good” pages
Need not be as careful about quality of individual pages as with TrustRank
One reasonable approach .edu sites .gov sites .mil sites
Spam Detection

Link AnalysisLink Analysis
85
Acknowledgement Slides are from
Prof. Jeffrey D. Ullman Dr. Anand Rajaraman





























