Embed Size (px)
Citation preview

LIN3022 Natural Language Processing
Lecture 3Albert Gatt
1LIN3022 Natural Language
Processing

LIN3022 Natural Language Processing
2
Reminder: Non-deterministic FSA
• An FSA where there can be multiple paths for a single input (tape).
• Two basic approaches for recognition:1. Either take a ND machine and convert it to a D
machine and then do recognition with that.2. Or explicitly manage the process of recognition
as a state-space search (leaving the machine as is).
LIN3022 Natural Language Processing
3
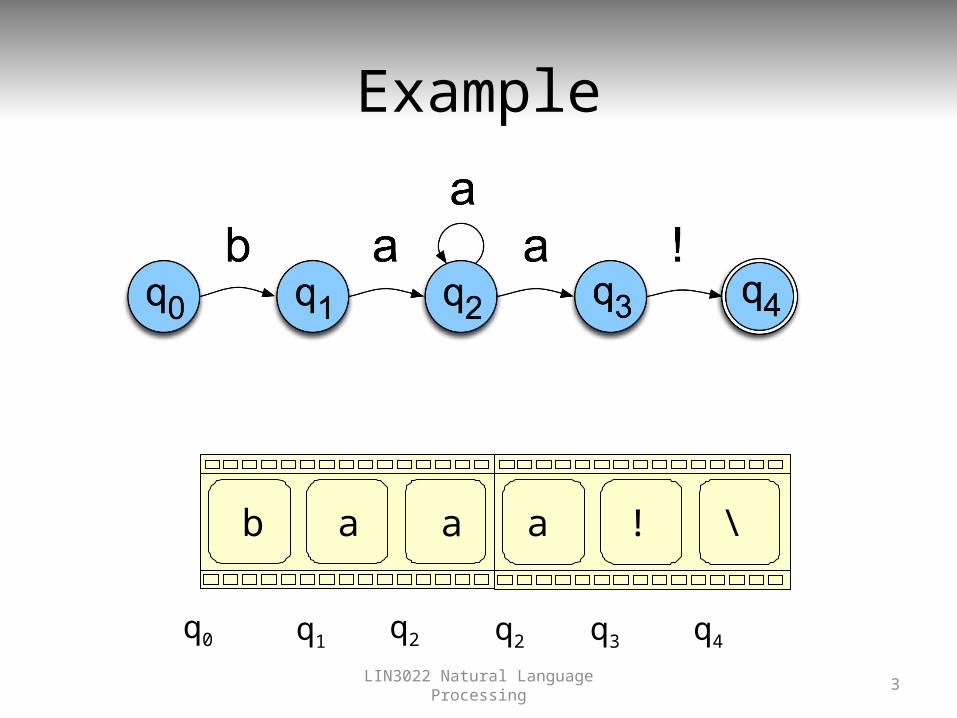
Example
b a a a ! \
q0 q1 q2 q2 q3 q4

LIN3022 Natural Language Processing
4
Non-Deterministic Recognition: Search
• Given an ND FSA representing some language and given an input string :– If the input string belongs to the language, the ND FSA will contain at
least one path for that string;– If the input string does not belong to the language, there will be no
path;– Not all paths directed through the machine for an accept string lead
to an accept state.
• A recognition algorithm succeeds if a path is found for the input string; fails otherwise.

LIN3022 Natural Language Processing
5
Words
• Finite-state methods are particularly useful in dealing with a lexicon
• Many devices need access to large lists of words– Spell checkers– Syntactic parsers– Language Generators– Machine translation systems
• What sort of knowledge should a computational lexicon contain?– What we’re mainly concerned with today is morphology (inflection
and derivation)

LIN3022 Natural Language Processing
6
Computational tasks involving morphology
• Morphological analysis (parsing):– ommijiet omm+PL
• Morphological (lexical) generation– omm+PL ommijiet
• Stemming– Ommijiet omm– Ommijiethom omm– Ommna omm– (map from a word to its stem)

LIN3022 Natural Language Processing
7
Computational tasks involving morphology
• Lemmatisation– Convert words to their “basic” form• Ommijiet omm• Ommijiethom omm• ...
• Tokenisation– Split running text into individual tokens– Qtilt il-kelb qtilt, il-, kelb– Xrobt l-ilma xrobt, l-, ilma

LIN3022 Natural Language Processing
8
Regular, irregular and messy
• The problem is to cover everything, of course:– Mouse/mice, goose/geese, ox/oxen (PLURAL)– Go/went, fly/flew (PAST)– Solid/solidify, mechanical/mechanise
(NOMINALISATION)

LIN3022 Natural Language Processing
9
Inflection vs Derivation
• Inflection is typically fairly straightforward– Relatively easy to identify regular and irregular
cases
• Derivational morphology is much messier.– Quasi-systematicity– Irregular meaning change– Changes of word class
LIN3022 Natural Language Processing 10
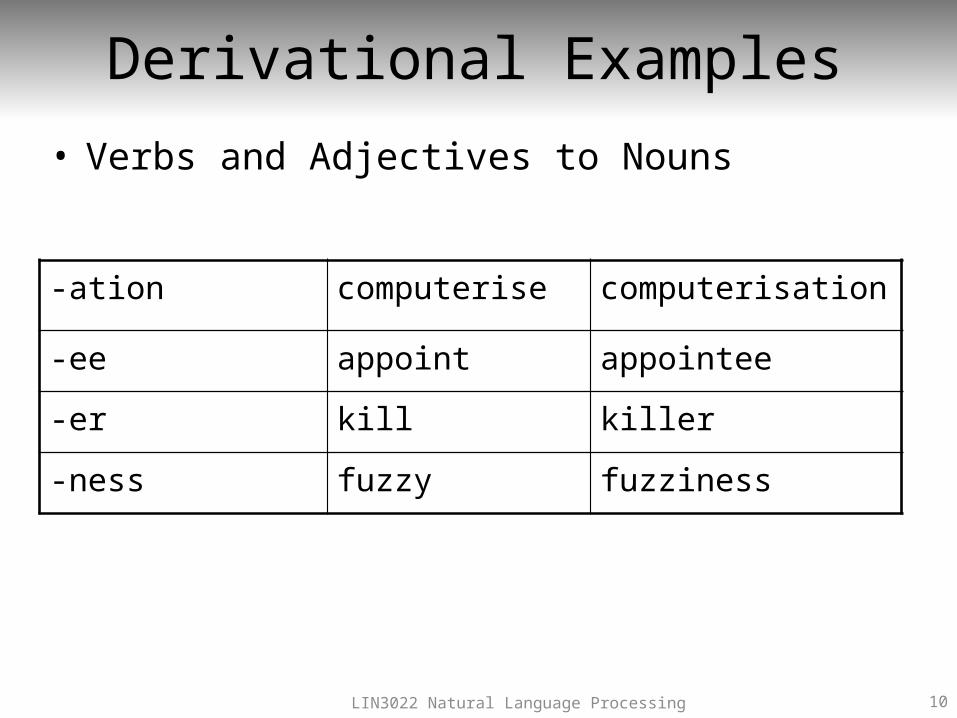
Derivational Examples• Verbs and Adjectives to Nouns
-ation computerise computerisation
-ee appoint appointee
-er kill killer
-ness fuzzy fuzziness

LIN3022 Natural Language Processing 11
Derivational Examples• Nouns and Verbs to Adjectives
-al computation computational
-able embrace embraceable
-less clue clueless

LIN3022 Natural Language Processing
12
Example: Compute
• Many paths are possible…
• Start with compute– Computer -> computerise -> computerisation– Computer -> computerise -> computerisable
• But not all paths/operations are equally good– Clue
• Clue -> *clueable

LIN3022 Natural Language Processing
13
Morphology, recognition and FSAs
• We’d like to use the machinery provided by FSAs to capture these facts about morphology– Accept strings that are in the language– Reject strings that are not– ... in an efficient way:• Without listing every word in the language• Capturing some generalisations• Enabling fast search

LIN3022 Natural Language Processing
14
What does a morphological parser or recogniser need?
• Lexicon– Often not feasible to just list all the words.
• Maltese has literally thousands of forms for some verbs...• Some morphological processes are productive; we’re likely to meet
completely new formations.
• Morphotactics (order of morphemes)– E.g. English plural morpheme after the noun stem
• E.g. Maltese “accusative” -l before dative pronominal suffixes (e.g Qatilulna)
• E.g. English –ise before –ation (formalisation)
• Orthographic rules– Needed to handle variations of the spelling of the stem– E.g. English nouns ending in –y change to –i (city cities)

LIN3022 Natural Language Processing
15
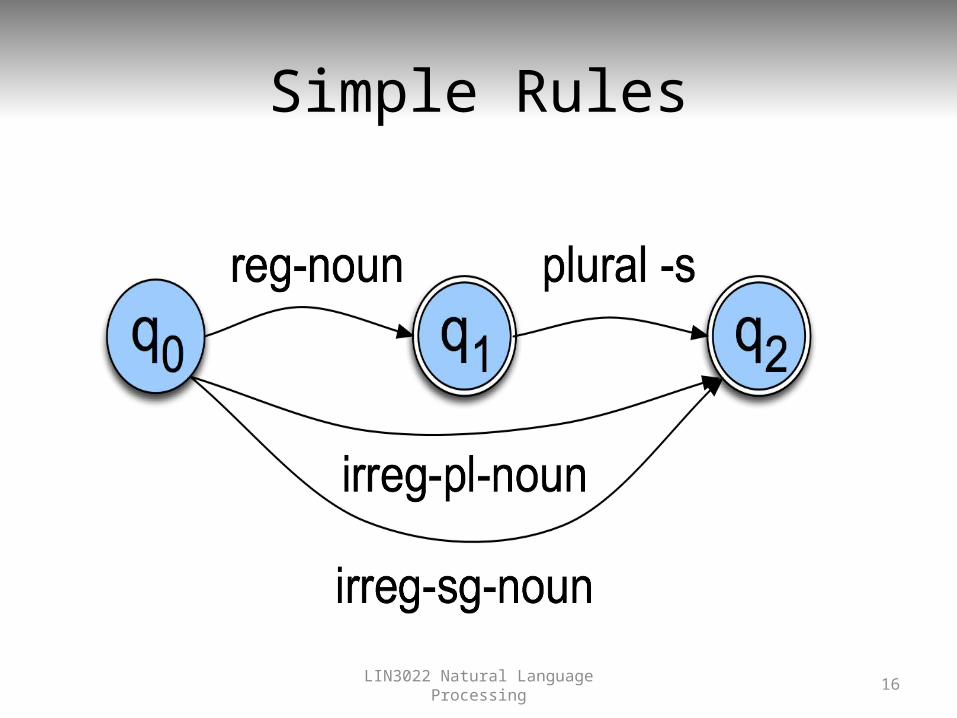
Start Simple
• Regular singular nouns are ok• Regular plural nouns have an -s on the end• Irregulars are ok as is (i.e. treat as atomic for
now)
LIN3022 Natural Language Processing
16
Simple Rules

LIN3022 Natural Language Processing
17
Substitute words for word classes• Idea is to be able to use this kind of FSA for
recognition.• We’ve replaced classes like “reg-noun” with
the actual words.

LIN3022 Natural Language Processing
18
Derivational Rules
If everything is an accept state how do things ever get rejected?

LIN3022 Natural Language Processing
19
Lexicons
• Lexicon can be stored as an FSA.
• A base lexicon (with baseforms) can be plugged into a larger FSA to capture morphological rules and morphotactics.

LIN3022 Natural Language Processing
20
Part 2
• Finite state transducers
• Morphological parsing
• Morphological generation

LIN3022 Natural Language Processing
21
Parsing/Generation vs. Recognition
• We can now run strings through these machines to recognize strings in the language
• But recognition is usually not quite what we need – Often if we find some string in the language we might like to
assign a structure to it (parsing)– Or we might have some structure and we want to produce a
surface form for it (production/generation)

LIN3022 Natural Language Processing
22
Finite State Transducers
• The simple story– Add another tape– Add extra symbols to the transitions
– On one tape we read “cats”, on the other we write “cat +N +PL”

LIN3022 Natural Language Processing
23
What is a finite-state transducer
• A transducer is a machine that takes input of a certain form and outputs something of a different form.– We can think of morphological analysis as
transduction (from a word to stem+features)• Ommijietna omm + PL + POSS.1PL
– So is morphological generation (from a stem+feature combination to a word)• Omm + PL + POSS.1PL ommijietna

LIN3022 Natural Language Processing
24
Structure of an FST
• The easiest way to think of an FST is as a variation on the classic FSA
• A simple FSA has states and transitions, and recognises something on an input tape.
• An FST has states and transitions, but works with two tapes.– One corresponds to the input.– The other to the output.

LIN3022 Natural Language Processing
25
The uses of an FST
• Recognition:– Take a pair of strings (on two tapes) as input, output accept
or reject• Generation:– Output a pair of strings from the language
• Translation:– Read one string and output another
• Relation between two sets– A machine that computes the relation between the set of
possible input strings and the set of possible output strings.

LIN3022 Natural Language Processing
26
FSTs

LIN3022 Natural Language Processing
27
Morphological parsing
• Morphological analysis or parsing can either be • An important stand-alone component of many
applications (spelling correction, information retrieval)
• Or simply a link in a chain of further linguistic analysis
• Interestingly, FSTs are bidirectional, i.e. can be used for parsing and generation
LIN3022 Natural Language Processing 28
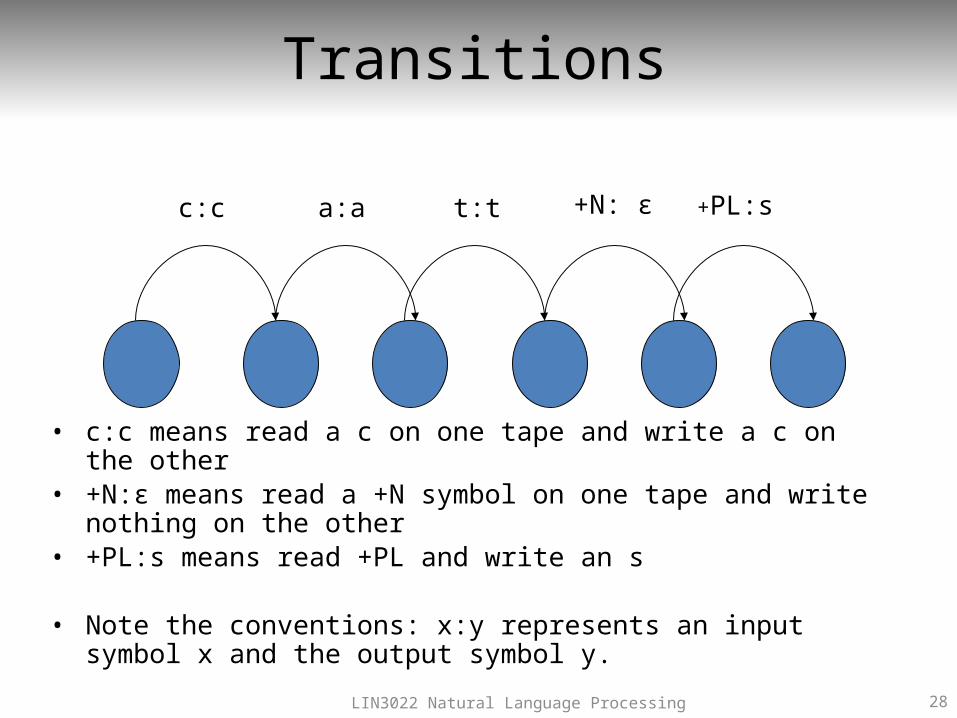
Transitions
• c:c means read a c on one tape and write a c on the other• +N:ε means read a +N symbol on one tape and write nothing on the other• +PL:s means read +PL and write an s
• Note the conventions: x:y represents an input symbol x and the output symbol y.
c:c a:a t:t +N: ε +PL:s

LIN3022 Natural Language Processing
29
Typical Uses
• Typically, we’ll read from one tape using the first symbol on the machine transitions (just as in a simple FSA).
• And we’ll write to the second tape using the other symbols on the transitions.

LIN3022 Natural Language Processing
30
Ambiguity
• Recall that in non-deterministic recognition multiple paths through a machine may lead to an accept state.• Didn’t matter which path was actually traversed
• In FSTs the path to an accept state does matter since different paths represent different parses and different outputs will result

LIN3022 Natural Language Processing
31
Ambiguity
• What’s the right parse (segmentation) for• Unionisable• Union-ise-able• Un-ion-ise-able
• Each represents a valid path through the derivational morphology machine.
• Unlike in an FST, the differences matter! (Some are not legal parses in English)

LIN3022 Natural Language Processing
32
Ambiguity
• There are a number of ways to deal with this problem• Simply take the first output found• Find all the possible outputs (all paths) and return
them all (without choosing)• Bias the search so that only one or a few likely
paths are explored

LIN3022 Natural Language Processing
33
The Gory Details
• Of course, its not as easy as • “cat +N +PL” <-> “cats”
• As we saw earlier there are geese, mice and oxen
• But there are also a whole host of spelling/pronunciation changes that go along with inflectional changes• Cats vs Dogs• Fox and Foxes

LIN3022 Natural Language Processing
34
Multi-Tape Machines
• To deal with these complications, we will add more tapes and use the output of one tape machine as the input to the next– This gives us a cascade of FSTs
• So to handle irregular spelling changes we’ll add intermediate tapes with intermediate symbols
LIN3022 Natural Language Processing 35
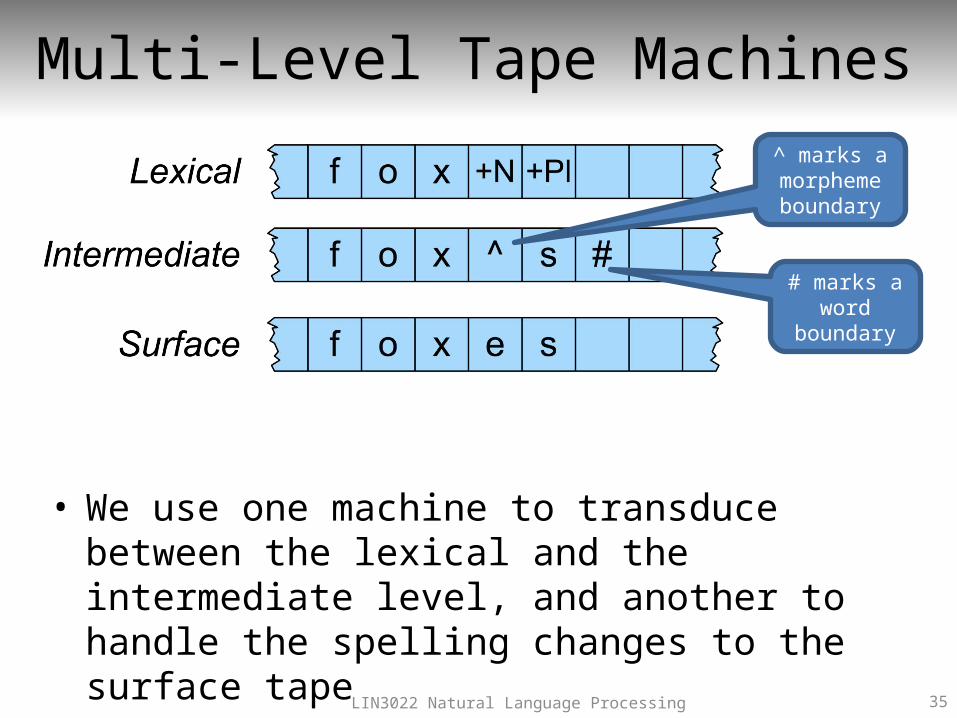
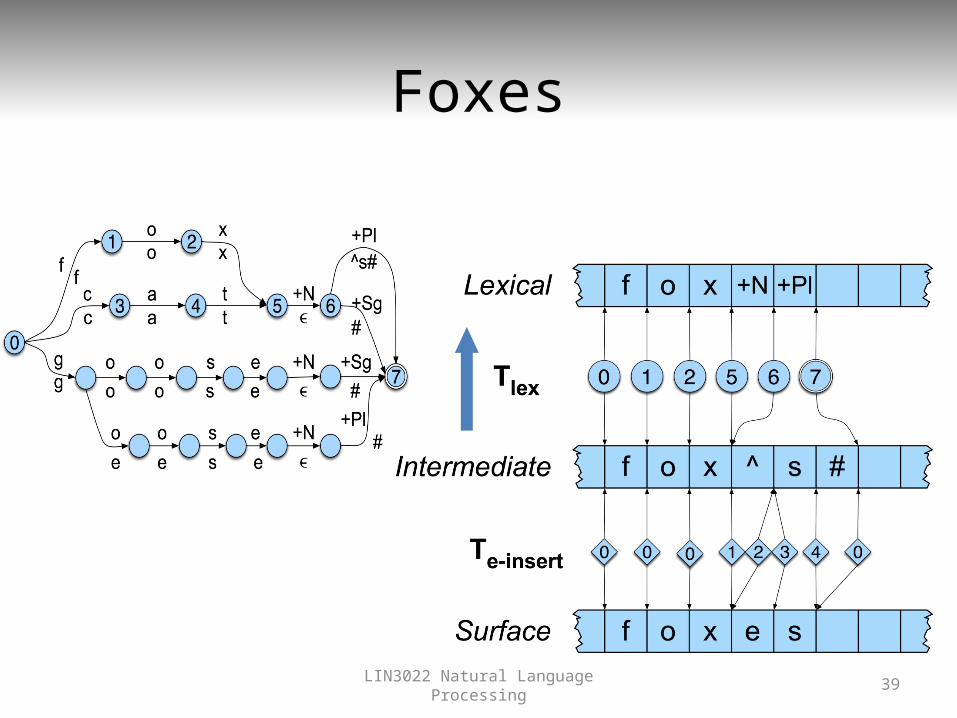
Multi-Level Tape Machines
• We use one machine to transduce between the lexical and the intermediate level, and another to handle the spelling changes to the surface tape
^ marks a morpheme boundary
# marks a word
boundary
LIN3022 Natural Language Processing
36
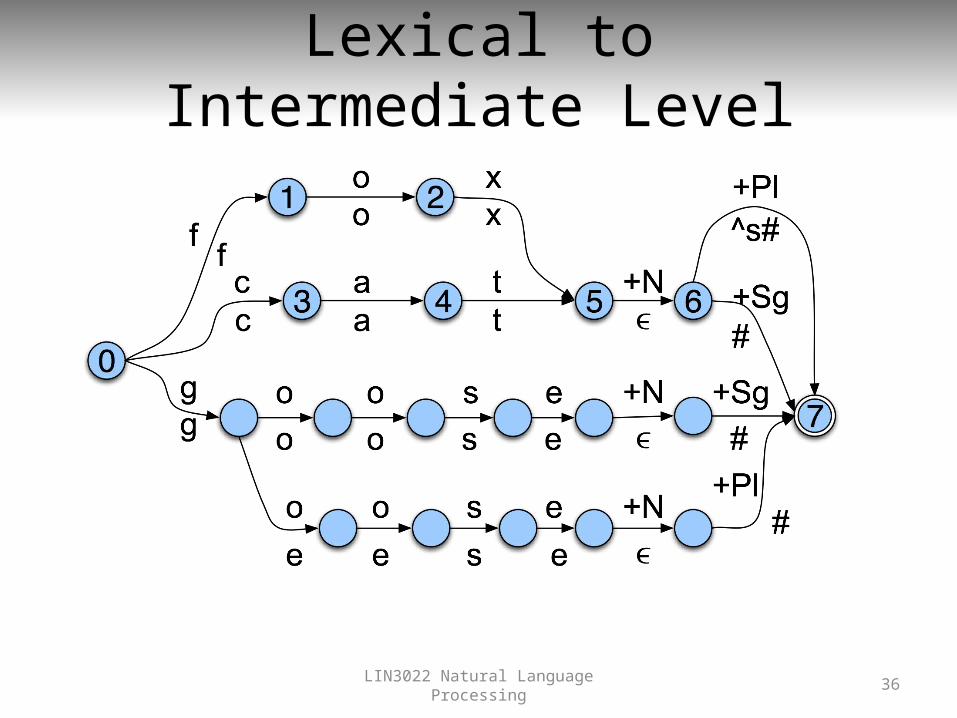
Lexical to Intermediate Level
LIN3022 Natural Language Processing 37
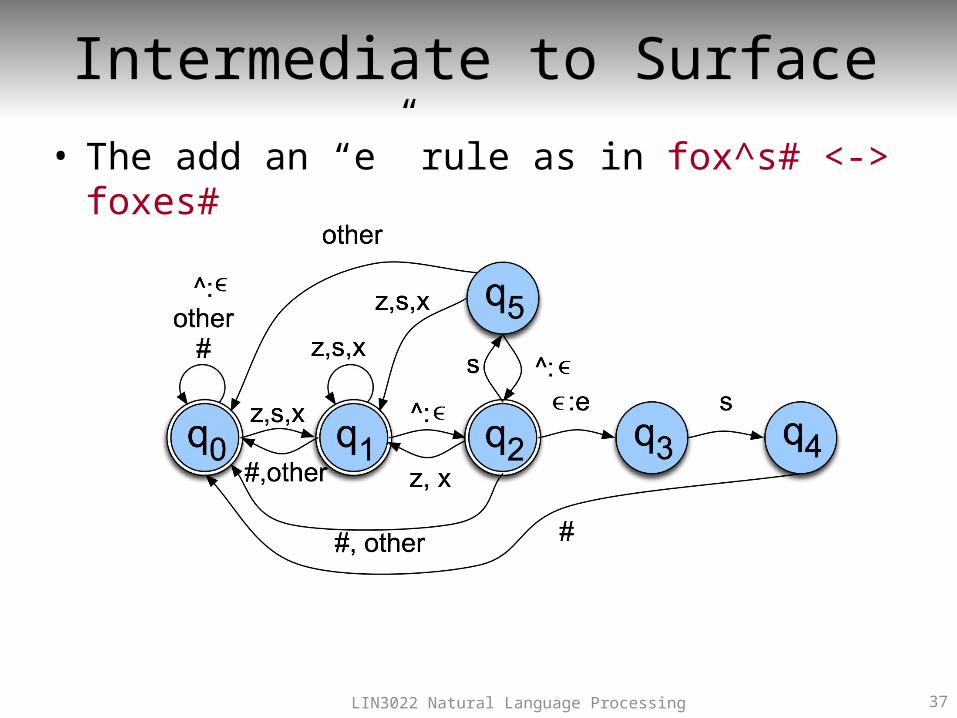
Intermediate to Surface• The add an “e” rule as in fox^s# <-> foxes#
LIN3022 Natural Language Processing
38
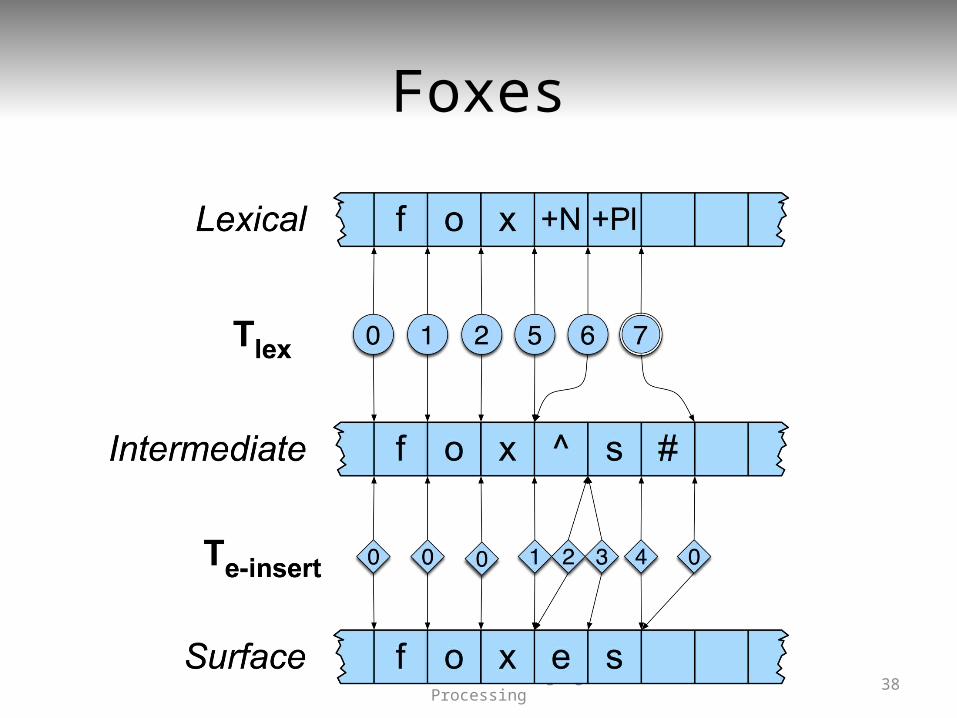
Foxes
LIN3022 Natural Language Processing
39
Foxes
LIN3022 Natural Language Processing
40
Foxes

LIN3022 Natural Language Processing
41
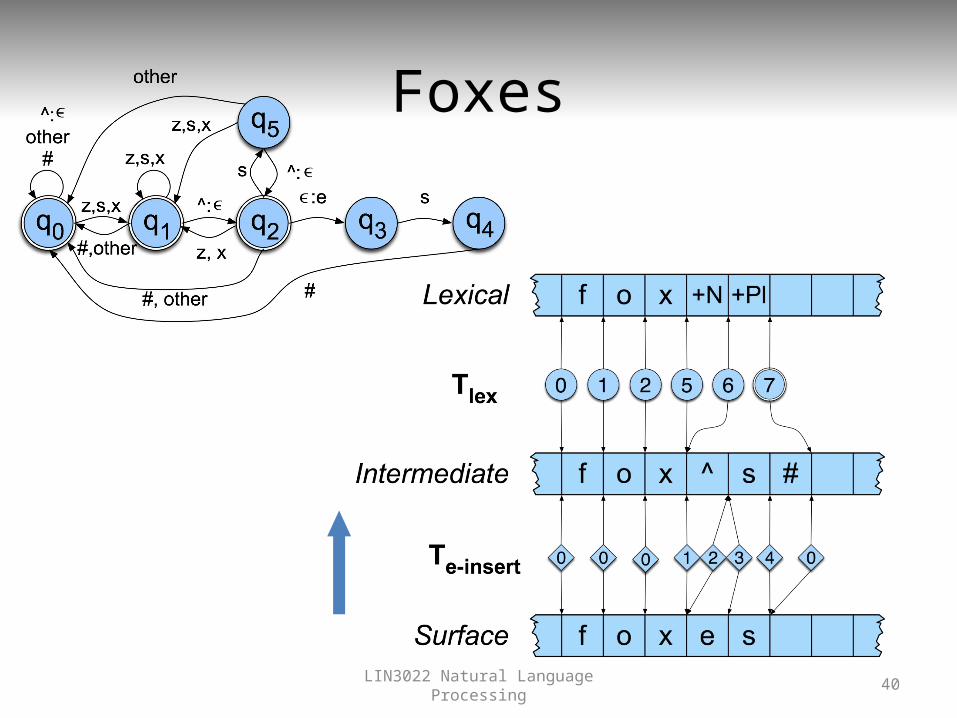
Note
• A key feature of this lower machine is that it has to do the right thing for inputs to which it doesn’t really apply. So...– Fox -> foxes but bird -> birds

LIN3022 Natural Language Processing
42
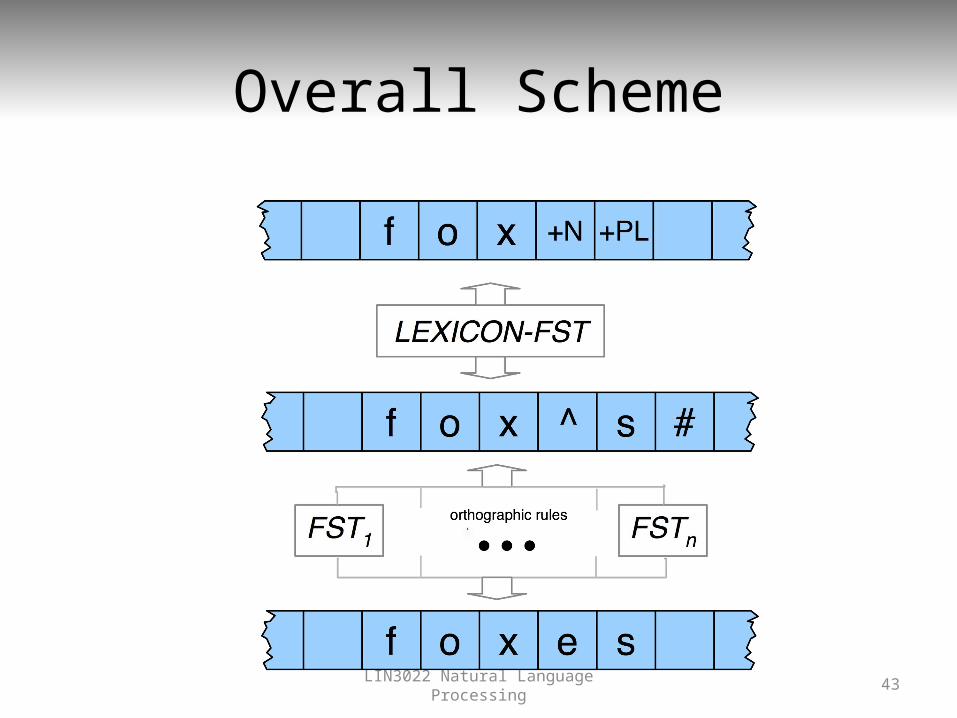
Overall Scheme
• We now have one FST that has explicit information about the lexicon (actual words, their spelling, facts about word classes and regularity).– Lexical level to intermediate forms
• We have a larger set of machines that capture orthographic/spelling rules.– Intermediate forms to surface forms
LIN3022 Natural Language Processing
43
Overall Scheme

LIN3022 Natural Language Processing
44
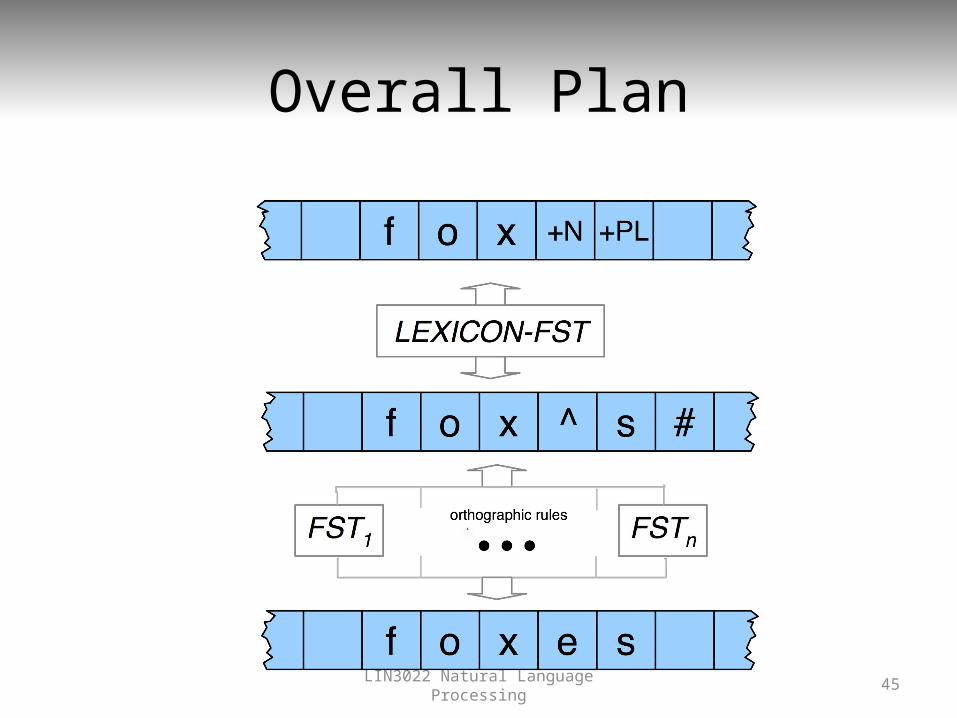
Cascades
• This is a common architecture• Overall processing is divided up into distinct
rewrite steps• The output of one layer serves as the input to the
next• The intermediate tapes may or may not wind up
being useful in their own right
LIN3022 Natural Language Processing
45
Overall Plan

LIN3022 Natural Language Processing
46
Part 3
• A brief look at stemming...
• A brief look at tokenisation

LIN3022 Natural Language Processing
47
Stemming
• Stemming is the process of stripping affixes from words to reduce them to their stems– NB The stem is not necessarily the baseform– Examples:• Strip “ing” from all word endings
– Going go– Stripping stripp– ...

LIN3022 Natural Language Processing
48
Uses of stemming
• Often used in Information Retrieval– The basic technology underlying search engines– Task: given a query (e.g. Keywords), retrieve
documents which match it– Stemming is useful because it increases the
likelihood of matches– E.g. Search for kangaroos returns documents
containing kangaroo or kangaroos

LIN3022 Natural Language Processing
49
The Porter stemmer
• Built by Martin Porter in 1980• Still widely used• Very simple FST-based stemmer• No lexicon, just rules
• View a demo online here: http://qaa.ath.cx/porter_js_demo.html

LIN3022 Natural Language Processing
50
Rules in the Porter Stemmer
• ATIONAL ATE– E.g. relational relate– But what about rational?
• ING Є– E.g. Shivering shiver
• These can be viewed as an FST, but without a lexical layer.

LIN3022 Natural Language Processing
51
Errors in the Porter stemmer
• Simple rules like the ones used by the Porter stemmer are error-prone (miss exceptions)
• Errors of commission:– Rational ration
• Errors of omission:– European Europe

LIN3022 Natural Language Processing
52
Tokenisation
• Defined as the task of splitting running text into component tokens.
• Related task: sentence segmentation (split running text into sentences)
• Simplest technique:– Just split on whitespace
• But what about:– Punctuation – Clitics – ...

LIN3022 Natural Language Processing
53
Tokenisation & Sentence segmentation
• Often go hand in hand!• Example:– Full stop can be a sentence boundary or an intra-
word boundary– “Punctuation” marks in numbers:
• 30,000• 20.2
• Can get a long way using simple regular expressions, at least in Indo-European languages.

LIN3022 Natural Language Processing
54
Example from Maltese• Treat numbers as tokens, with or without decimals:
– \d+(\.\d+)?
• Honorifics shouldn’t be broken up at full-stops or apostrophes:– sant['’]|(onor|sra|nru|dott|kap|mons|dr|prof)\.
• Definite articles shouldn’t be broken up at hyphens:– i?[dtlrnsxzżċ]-
• ...[other exceptions]
• General rule: – A word is just a sequence of characters: \w+\s

LIN3022 Natural Language Processing
55
Chinese
• Words in Chinese are composed of hanzi characters.
• Each character usually represents one morpheme.
• Words tend to be quite short (ca. 2.4 characters long on average)
• There is no whitespace between words!

LIN3022 Natural Language Processing
56
A simple algorithm for segmenting Chinese
• Maximum Matching (maxmatch)– Requires a lexicon.– Start by pointing at the beginning of the input
string– Choose the longest item in the lexicon that
matches the input up to now.– If no word matches, move the pointer one symbol
forward.

LIN3022 Natural Language Processing
57
MaxMatch example
• Imagine an English string with no whitespace:– The table down there– thetabledownthere
• The first item found by MaxMatch is theta– Because the algorithm tries to match the longest portion
of the input– Then: bled, own, there
• Result: theta bled own there• Luckily, it works better for Chinese, because words
there tend to be shorter than in English!























