Embed Size (px)
Citation preview

LIN 3098 Corpus LinguisticsLecture 6
Albert Gatt

In this lecture…
More on corpora for lexicography collocations as a window on lexical
semantics uses of collocations:
distinguishing near-synonyms cross-register variation
case study: synonymy and the “contextual” view of meaning

Part 1
What is a collocation?

The empiricist tradition in lexical semantics
Main exponent: Firth (1957) Fundamental position:
the meaning of words is best discovered through an analysis of the context in which they occur
Contrast to more traditional, rationalist approaches: meaning is usually defined in terms of concepts
or features words can be distinguished based on distinctions
among their features

Collocations and collocational strength
Example 1: Adjective-noun combinations large number big number large distinction big distinction Why are large and big not equally acceptable
with different nouns?
Example 2: Noun compounds computer scientist computer terminal computer desk Are these compounds equally well-established?

Uses of collocations Collocations can tell us something about:
distinctions in word meaning between apparently synonymous words
whether certain expressions should be considered as “frozen” or nearly so
We should view such phrases as falling on a continuum: one extreme: simple, syntactic combination (kick
the door) other extreme: fully frozen idiomatic expressions
(kick the bucket) plenty of intermediate cases

Properties of collocations
1. Frequency and regularity2. Textual proximity3. Limited compositionality4. Non-substitutability5. Non-modifiability6. Category restrictions

Frequency and regularity
We know that language is regular (non-random) and rule-based. this aspect is emphasised by rationalist
approaches to grammar
We also need to acknowledge that frequency of usage is an important factor in language development. why do big and large collocate differently
with different nouns?

Regularity/frequency
f(strong tea) > f(powerful tea)
f(credit card) > f(credit bankruptcy)
f(white wine) > f(yellow wine) (even though white wine is actually
yellowish)

Narrow window (textual proximity) Usually, we specify an n-gram window within which to
analyse collocations: bigram: credit card, credit crunch trigram: credit card fraud, credit card expiry …
The idea is to look at co-occurrence of words within a specific n-gram window
We can also count n-grams with intervening words: federal (.*) subsidy matches: federal farm subsidy, federal manufacturing
subsidy…

Textual proximity (continued)
Usually collocates of a word occur close to that word. may still occur across a span
Examples: bigram: white wine, powerful tea >bigram: knock on the door; knock on
X’s door

Non-compositionality white wine
not really “white”, meaning not fully predictable from component words + syntax
signal interpretation a term used in Intelligent Signal Processing:
connotations go beyond compositional meaning Similarly:
regression coefficient good practice guidelines
Extreme cases: idioms such as kick the bucket meaning is completely frozen

Non-substitutability
If a phrase is a collocation, we can’t substitute a word in the phrase for a near-synonym, and still have the same overall meaning.
E.g.: white wine vs. yellow wine powerful tea vs. strong tea …

Non-modifiability Often, there are restrictions on inserting
additional lexical items into the collocation, especially in the case of idioms.
Example: kick the bucket vs. ?kick the large bucket
NB: this is a matter of degree! non-idiomatic collocations are more flexible

Category restrictions Frequency alone doesn’t indicate
collocational strength: by the is a very frequent phrase in English not a collocation
Collocations tend to be formed from content words: A+N: powerful tea N+N: regression coefficient, mass
demonstration N+PREP+N: degrees of freedom

Part 2
Distinguishing near-synonyms: a case study (from Biber et al 1993)

Near-synonyms What’s the difference between:
big, large, great
A traditional dictionary (OED online): large adj. of considerable or relatively great
size, extent, or capacity big adj. of considerable size, physical power, or
extent great adj. of an extent, amount, or intensity
considerably above average
Is this informative enough?
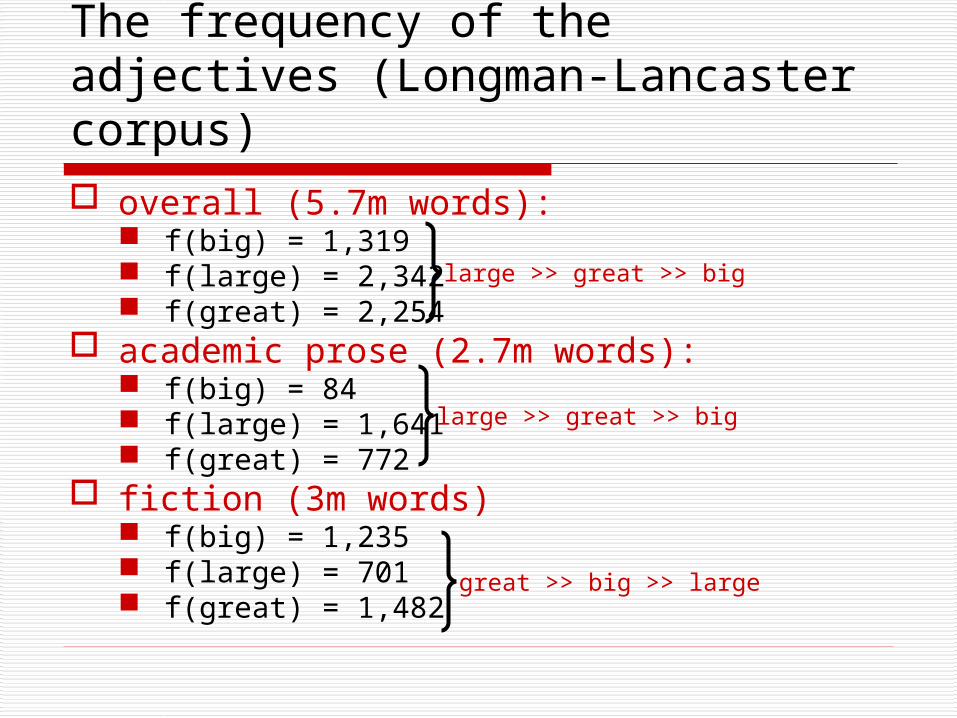
The frequency of the adjectives (Longman-Lancaster corpus) overall (5.7m words):
f(big) = 1,319 f(large) = 2,342 f(great) = 2,254
academic prose (2.7m words): f(big) = 84 f(large) = 1,641 f(great) = 772
fiction (3m words) f(big) = 1,235 f(large) = 701 f(great) = 1,482
large >> great >> big
large >> great >> big
great >> big >> large

Immediate right collocate: big academic prose:
big enough (2.2 / m) big traders (1.1 / m)
fiction: big man (9.6 / m) big enough (8.9 / m) big house (7.6 / m)
Seems to be used for physical size or object, person, or organisation big enough is usually used for size as well the house is big enough
Also occurs often with descriptive adjectives: big black X etc.

Immediate right collocates: large Academic prose:
large number (48.3/m) large numbers (31.3/m) large scale (29.4/m)
Fiction large black (4.3 / m) large enough (3.6 / m) large room (2.7 / m) large number (2.3 / m)
Used more often than big for quantities or proportions. large enough is usually used for such quantities too the ratio is large enough
Lemmatisation wouldallow us to combine these

Immediate right collocates: great academic prose:
great deal (44.6 / m) great importance (12.6 / m) great variety (7.0 / m) great detail (2.6 / m)
fiction: great deal (40.4 / m) great man (6.6 /m)
In academic prose, mostly used for amount or quantity. Rather like large, but also occurs with deal. Great also used for intensity:great importance, great care…
In fiction, mostly used for amounts: a great deal of apple juice

Salient differences This is a very brief overview of uses and
senses of the three adjectives.
It helps explain the different frequency distribution across registers: fiction often contains physical descriptions (thus,
big is more frequent than in academic prose) academic prose more often concerned with
proportions, amounts, quantities (thus, great is more frequent here)

Widening the window Two words can co-occur regularly
even with a few words between them:
academic prose: large X of large X in large X open large X that
fiction: large X of large X and large X in large X eyes

Widening the window - II The most frequent collocate of large in a
three-word window is of. What nouns intervene between large and
of? large amounts of, large numbers of… again, typically quantities or proportions
Large X eyes is very frequent in fiction (not academic prose) his large hazel eyes… confirms earlier conclusion that fiction has more
physical descriptions

Interim summary
This brief overview shows that:
collocations help to distinguish between near-synonyms
can also help to discover patterns of variation across registers

Part 3
The contextual theory of synonymy and similarity:Corpus-based and psycholinguistic evidence

Synonymy Different phonological words with highly
related meanings: sofa / couch boy / lad żgħir (small) / ċkejken (little)
Traditional definition: w1 is synonymous with w2 if w1 can replace w2
in a sentence, salva veritate Is this ever the case? Can we replace one word
for another and keep our sentence identical?

Imperfect synonymy
Synonyms often exhibit slight differences, espcially in connotations żgħir (“small”) is fairly neutral with
respect to the thing spoken of ċkejken (“small”/”little”) might be used
for a little child, but not a teenager may carry connotations of dependence,
cuteness, etc...

The importance of register
With near-synonyms, there are often register-governed conditions of use.
E.g. naive vs gullible vs ingenuous gullible / naive seem critical, or even
offensive ingenuous more likely in a formal context

Synonymy vs. Similarity The contextual theory of synonymy:
based on the work of Wittgenstein (1953), and Firth (1957)
You shall know a word by the company it keeps (Firth 1957)
Under this view, perfect synonyms might not exist.
But words can be judged as highly similar if people put them into the same linguistic contexts, and judge the change to be slight.

Synonymy vs. similarity: example Miller & Charles 1991:
Weak contextual hypothesis: The similarity of the context in which 2 words appear contributes to the semantic similarity of those words.
E.g. snake is similar to [resp. synonym of] serpent to the extent that we find snake and serpent in the same linguistic contexts.
It is much more likely that snake/serpent will occur in similar contexts than snake/toad
NB: this is not a discrete notion of synonymy, but a continuous definition of similarity

The Miller/Charles experiment Subjects were given sentences with missing words; asked to
place words they felt were OK in each context.
Method to compare words A and B: find sentences containing A find sentences containing B delete A and B from sentences and shuffle them ask people to choose which sentences to place A and B in.
Showed that people will put similar words in the same context, and this is highly correlated with occurrence in similar contexts in corpora.

Issues with similarity “Similar” is a much broader concept than
“synonymous”: “Contextually related, though differing in
meaning”: man / woman boy / girl master / pupil
“Contextually related, but with opposite meanings”: big / small clever / stupid

Part 4
Bonus Topic: Mutual Information for ranking collocations

General idea
Suppose we identify several multiword units in a corpus (e.g. several N-N compounds).
We would like to know to what extent the words making them up are “strongly collocated”.
Could be that these words occur together purely by chance.

An analogy Suppose Tom and Viv are an item turn up
everywhere unless they’re together. From your point of view:
Seeing Tom increases your certainty (your information) that Viv is around.
Seeing Viv does the same with respect to Tom.
Your assumptions would be very different if you knew that Tom and Viv had never been able
to stand eachother… Or you only knew them separately, and had no
idea they had a relationship

The reasoning (I) Example: collocations involving post A search through a corpus throws up lots of
co-occurring words, e.g.: the post post in post office post mortem
We don’t want to call all these collocations. E.g.: the is extremely frequent, and this is
probably why it occurs very frequently with post. (remember Zipf’s law)

The reasoning (II) Suppose we suspect a strong relationship between
post and mortem. There are two possibilities:
1. post + mortem just co-occur randomly, so they’re as likely to occur together as separately.
2. post + mortem is indeed a collocation, so finding mortem should increase our certainty that we’ll also find post in its immediate environment. thus, the two words have high mutual information
Given the word w, the mutual information score tells us how much our certainty increases that post is in the vicinity.

Mutual information: post mortem
1. compute the frequency of post, mortem and post mortem. Denoted f(post), f(mortem), f(post
mortem)
2. compute the probability of these this is just the frequency divided by the
corpus size: f(post)/N etc a better estimate, because proportional we denote these p(post), p(mortem) etc

Mutual information: post mortem
3. Compare the probability of finding post + mortem to the probability of finding either word on its own:
p(mortem)p(post)
mortem) post (
p
Probability of finding the two words together
within a certain window.
Probability of the two words independently.

Mutual information: post mortem
4. Finally, we turn this probability ratio into a measure of information.
5. Information is measured in bits. 6. A probability estimate is turned into an
information value by taking its log (usually to base 2).
ortem)p(post)p(m
mortem) postp(log
The amount of information about post
increases by this amount if we know that there is an accompanying word
mortem.

Interpreting MI If MI is positive, and reasonably high
(usually 2 or higher), then the two words are strongly collocated.
If MI is negative, then the two words are actually unlikely to occur together.
If MI is approximately zero, then the two words tend to occur independently.

Summary
This lecture has focused on another use of corpora for lexicography dominant paradigm is the empiricist view
of meaning and language takes a very different approach to issues
of synonymy than rationalist approaches
We have also introduced the concept of Mutual Information, as a way of measuring collocational strength.