Embed Size (px)
Citation preview

Freescale SemiconductorReference Manual
Document Number: LSPAPURMRev. 3, 12/2012
Lightweight Signal Processing APU (LSP APU) Reference Manual
© Freescale Semiconductor, Inc., 2011–2012. All rights reserved.

Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor2
Table of Contents1.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.2 Nomenclature and conventions . . . . . . . . . . . . . . . . . . . 81.3 LSP programming model . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3.1 GPR registers. . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.3.2 GPR register pairings. . . . . . . . . . . . . . . . . . . . . . 91.3.3 LSP Status and Control Register (SPEFSCR). . 101.3.4 SPV exception bit in ESR. . . . . . . . . . . . . . . . . . 111.3.5 Data formats. . . . . . . . . . . . . . . . . . . . . . . . . . . . 121.3.6 Computational operations . . . . . . . . . . . . . . . . . 131.3.7 Load and store instructions . . . . . . . . . . . . . . . . 20
1.4 LSP load/store APU addressing modes . . . . . . . . . . . . 201.4.1 Addressing modes – non-update forms . . . . . . . 211.4.2 Addressing mode – update form . . . . . . . . . . . . 211.4.3 Addressing mode – modify forms. . . . . . . . . . . . 22
1.5 Vector load and store instruction summary. . . . . . . . . . 231.5.1 LSP exceptions and interrupts . . . . . . . . . . . . . . 25
1.6 Instruction definitions. . . . . . . . . . . . . . . . . . . . . . . . . . . 251.6.1 Absolute value, negate, rotate left, saturation,
check overflow, shift left, bit reverse, round, extend, and mask models. . . . . . . . . . . . . . . . . . 25
1.6.2 Effective address calculation models . . . . . . . . . 281.6.3 Simple arithmetic, shift, compare, vector data
arrangement, and misc. instructions. . . . . . . . . . 291.6.4 Load and store instructions. . . . . . . . . . . . . . . . 1081.6.5 Multiply, multiply/accumulate, and dot product
instructions . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1541.6.6 Instruction forms and opcodes . . . . . . . . . . . . . 2261.6.7 Load/store instruction forms and opcodes . . . . 259
1.7 Document revision history . . . . . . . . . . . . . . . . . . . . . . 263

Chapter 1 Lightweight Signal Processing APU (LSP APU)
1.1 OverviewThis document provides a description of the Lightweight Signal Processing APU, version 1 (LSP APU). The LSP APU is designed to accelerate signal processing applications normally suited to DSP operation. This is accomplished using the 32-bit GPRs, and supporting vector multiply/multiply accumulate/ dot product operations using either a single or a pair of GPR registers as a source/destination accumulator or as a destination.
1.2 Nomenclature and conventionsSeveral conventions regarding nomenclature are used in this document:
• The Lightweight Signal Processing APU is abbreviated as LSP.
• All register bit numbering is 32-bit with bit 32 being the most significant bit. Bit 63 is the least significant bit.
• Bits 32:47 of a 32-bit register are referenced as halfword 0. Bits 48:63 are referred to as halfword 1. Each halfword is an element of a 32-bit GPR.
• Bits 32:47 are also referenced as even halfwords. Bits 48:63 are referenced as odd halfwords.
• Mnemonics for LSP instructions generally begin with the letter(s) ‘z’ or ‘zv’.
• The use of italics generally provides information that is not part of the architecture. It is used to annotate, provide engineering, software, or architecture notes. In some cases it is used to describe some parts of other APUs that may share registers or state with these APUs. It is also used to give names to specified items.
• The following additional RTL conventions are used in this document:
Table 1. RTL notation
Notation Meaning
sf Signed fractional multiplication.
Result of multiplying two quantities having bit lengths x and y taking the least significant x+y-1 bits of the product and concatenating a zero to the least significant bit forming a signed fractional result of x+y bits.
si Signed integer multiplication
su, sui Signed by unsigned multiplication (same for integer and fraction)
÷sf Signed fractional division. The quotient satisfies the equation dividend = (quotient x divisor) + remainder, where the sign of the remainder (if non-zero) is the same as the sign of the dividend. The magnitude of the remainder is less than the magnitude of the divisor.
<sf, <=sf, >sf, >=sf Signed fractional comparison operators
<si, <=si, >si, >=si Signed integer comparison operators
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 3

1.3 LSP programming modelThe LSP APU utilizes a general purpose register file with thirty-two 32-bit registers. LSP instructions generally take elements from a first source register and operate on them with the corresponding elements of a second source register (and/or a third source register or register pair acting as an accumulator) to produce results. Results are placed in the destination register (32-bit results) or register pair (64-bit results). Instructions that are vector in nature (that is, produce results of more than one element) provide results for each element that are independent of the computation of the other elements.
LSP compare instructions and set instructions with record store the comparison result into the Condition Register (CR). LSP compare instructions specify a CR field, two source registers, and the type of compare: greater than, less than, or, equal. Two bits of the CR field are written with the result of the vector compare, one for each of the high and low 32 bits of the result. The remaining two bits reflect the ANDing and ORing of the vector compare results.
1.3.1 GPR registers
The LSP APU requires a GPR register file with thirty-two 32-bit registers. Certain LSP APU instructions view the 32-bit register as being composed of a vector of elements, each of which is 16 bits wide. The most significant 16-bits are called halfword 0 (H0), the upper halfword, high halfword or even halfword. The least significant 16-bits are called halfword 1 (H1), the lower halfword, low halfword or odd halfword. LSP instructions write all 32 bits of the destination register.
Figure 1. GPR registers
1.3.2 GPR register pairings
Certain LSP instructions require a 64-bit source or destination. For these operands, a pair of general purpose registers (register pair) are used. Pairs are always defined as an adjacent even/odd pair, such as r10/r11, r12/r13, etc. Instruction encodings indicate the even register of the pair in the rD field.
<ui, <=ui, >ui, >=ui Unsigned integer comparison operators
<< Logical shift left. x << y shifts value x left by y bits, leaving zeros in the vacated bits.
TY TY-type multiplication.TY=00 is unsigned integer (xui); TY= 01 is signed integer (xsi);TY=10 is signed by unsigned integer (xsui); TY=11 is signed fractional (xsf);
>> Logical shift right. x >> y shifts value x right by y bits, leaving zeros in the vacated bits.
3
2
3
9
4
0
4
7
4
8
5
5
5
6
63
GPR halfword 0 halfword 1
GPR byte 0 byte 1 byte 2 byte 3
Table 1. RTL notation (continued)
Notation Meaning
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor4
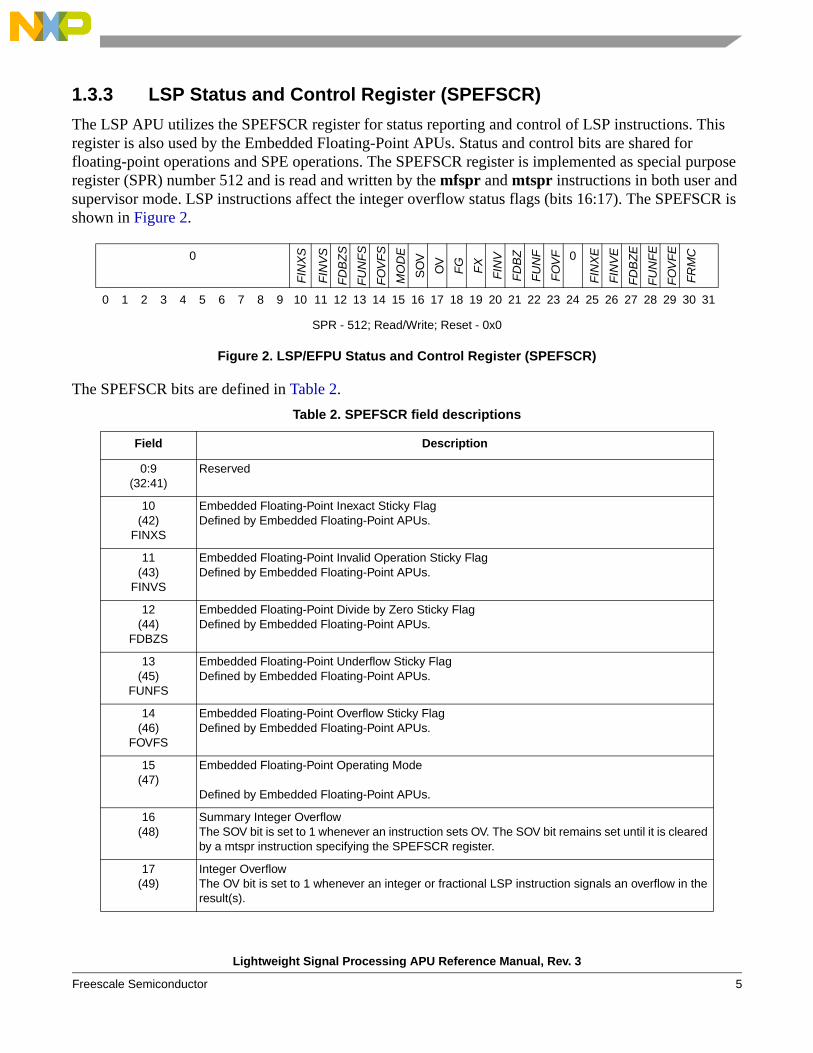
1.3.3 LSP Status and Control Register (SPEFSCR)
The LSP APU utilizes the SPEFSCR register for status reporting and control of LSP instructions. This register is also used by the Embedded Floating-Point APUs. Status and control bits are shared for floating-point operations and SPE operations. The SPEFSCR register is implemented as special purpose register (SPR) number 512 and is read and written by the mfspr and mtspr instructions in both user and supervisor mode. LSP instructions affect the integer overflow status flags (bits 16:17). The SPEFSCR is shown in Figure 2.
The SPEFSCR bits are defined in Table 2.
0
FIN
XS
FIN
VS
FD
BZ
S
FU
NF
S
FO
VF
S
MO
DE
SO
V
OV
FG FX
FIN
V
FD
BZ
FU
NF
FO
VF 0
FIN
XE
FIN
VE
FD
BZ
E
FU
NF
E
FO
VF
E
FR
MC
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
SPR - 512; Read/Write; Reset - 0x0
Figure 2. LSP/EFPU Status and Control Register (SPEFSCR)
Table 2. SPEFSCR field descriptions
Field Description
0:9(32:41)
Reserved
10(42)
FINXS
Embedded Floating-Point Inexact Sticky FlagDefined by Embedded Floating-Point APUs.
11(43)
FINVS
Embedded Floating-Point Invalid Operation Sticky FlagDefined by Embedded Floating-Point APUs.
12(44)
FDBZS
Embedded Floating-Point Divide by Zero Sticky FlagDefined by Embedded Floating-Point APUs.
13(45)
FUNFS
Embedded Floating-Point Underflow Sticky FlagDefined by Embedded Floating-Point APUs.
14(46)
FOVFS
Embedded Floating-Point Overflow Sticky FlagDefined by Embedded Floating-Point APUs.
15(47)
Embedded Floating-Point Operating Mode
Defined by Embedded Floating-Point APUs.
16(48)
Summary Integer OverflowThe SOV bit is set to 1 whenever an instruction sets OV. The SOV bit remains set until it is cleared by a mtspr instruction specifying the SPEFSCR register.
17(49)
Integer OverflowThe OV bit is set to 1 whenever an integer or fractional LSP instruction signals an overflow in the result(s).
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 5

1.3.4 SPV exception bit in ESR
ESRSPV is defined as the signal processing/vector exception bit. This bit is set whenever the processor takes an exception related to the execution of an LSP APU instruction.
18(50)
Embedded Floating-Point Guard bit (low/scalar)
Defined by Embedded Floating-Point APUs.
19(51)
Embedded Floating-Point Inexact bit (low/scalar)
Defined by Embedded Floating-Point APUs.
20(52)
Embedded Floating-Point Invalid Operation / Input error (low/scalar)
Defined by Embedded Floating-Point APUs.
21(53)
Embedded Floating-Point Divide by Zero (low/scalar)
Defined by Embedded Floating-Point APUs.
22(54)
Embedded Floating-Point Underflow (low/scalar)
Defined by Embedded Floating-Point APUs.
23(55)
Embedded Floating-Point Overflow (low/scalar)
Defined by Embedded Floating-Point APUs.
24(56)
Reserved
25(57)
Embedded Floating-Point Round (Inexact) Exception Enable
Defined by Embedded Floating-Point APUs.
26(58)
Embedded Floating-Point Invalid Operation / Input Error Exception Enable
Defined by Embedded Floating-Point APUs.
27(59)
Embedded Floating-Point Divide by Zero Exception Enable
Defined by Embedded Floating-Point APUs.
28(60)
Embedded Floating-Point Underflow Exception Enable
Defined by Embedded Floating-Point APUs.
29(61)
Embedded Floating-Point Overflow Exception Enable
Defined by Embedded Floating-Point APUs.
30:31(62:63)
Embedded Floating-Point Rounding Mode Control
Defined by Embedded Floating-Point APUs.
Table 2. SPEFSCR field descriptions (continued)
Field Description
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor6

1.3.5 Data formats
The LSP APU provides two different data formats, integer and fractional. Integer data formats can be treated as signed or unsigned quantities. Fractional data formats are treated as signed quantities
1.3.5.1 Integer format
Integer data format is the same as what is conventionally used in computing.
Unsigned integers consist of 16-, 32-, or 64-bit binary integer values. The largest representable value is 2n – 1 where n represents the number of bits in the value. The smallest representable value is 0. Certain computations that produce values larger than 2n-1 or smaller than 0 set OV in the SPEFSCR.
Signed integers consist of 16-, 32-, or 64-bit binary values in twos-complement form. The largest representable value is 2n – 1 – 1 where n represents the number of bits in the value. The smallest representable value is –2n – 1. Certain computations that produce values larger than 2n – 1 – 1 or smaller than –2n – 1 set OV in the SPEFSCR.
1.3.5.2 Fractional format
Fractional data format is the same that is conventionally used for DSP fractional arithmetic. Fractional data is useful for representing data converted from analog devices.
Unsigned fractions consist of 16-, 32-, or 64-bit binary fractional values that range from 0 to less than 1. Unsigned fractions place the decimal point immediately to the left of the most significant bit. The most significant bit of the value represents the value 2–1, the next most significant bit represents the value 2–2 and so on. The largest representable value is 1 – 2-n where n represents the number of bits in the value. The smallest representable value is 0. Certain computations that produce values larger than 1 – 2–n or smaller than 0 set OV in the SPEFSCR. LSP does not contain explicit instructions that manipulate unsigned fractional data. Unsigned integer forms produce the same bit exact results as unsigned fractional values would, therefore unsigned fractional instruction forms are not defined for LSP.
Signed fractions consist of 16- or 32-bit binary fractional values in twos complement form that range from –1 to less than 1. Signed fractions in 1.15, or 1.31 format place the decimal point immediately to the right of the most significant bit. The largest representable value is 1 – 2–(n – 1) where n represents the number of bits in the value. The smallest representable value is -1. Certain computations that produce values larger than 1 – 2–(n – 1)or smaller than –1 set OV in the SPEFSCR. Multiplication of two signed fractional values causes the result to be shifted left one bit to remove the resultant redundant sign bit in the product. In this case, a 0 bit is concatenated as the least significant bit of the shifted result.
Guarded fractional representations are available in 9.23, 33.31, and in 17.47 format for a small subset of operations, providing for significant guarding capabilities.Signed fractions in 9.23, 33.31 or 17.47 format place the decimal point immediately to the right of the least significant guard bit. The largest representable positive value is 2(9,33,17) – 2-(n) where n represents the number of fractional bits in the value. The most negative representable value is –2(9,33,17).
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 7

1.3.6 Computational operations
LSP supports several different computational capabilities. Both modulo and saturation results can be performed. Modulo results produce truncation of the overflow bits in a calculation. Saturation provides a maximum or minimum representable value (for the data type) for positive or negative overflow respectively. Instructions are provided for a wide range of computational capability. The operation types can be divided into several basic categories:
• Simple instructions. These instructions use the corresponding elements of the operands to produce a result that is placed in the destination register.
• Simple vector instructions. These instructions use the corresponding elements of the operands to produce a vector result that is placed in the destination register.
Figure 3. Simple vector instructions
— Arithmetic, shift of vector elements
— Rounding and saturation, operations
— Vector packing and unpacking operations
— Vector merge and extraction operations
• Complex instructions. The divide fractional instruction uses the operands to perform a fractional divide result that is placed in the destination register.
• Multiply and accumulate instructions. These instructions perform multiply operations, optionally add the result to the accumulator value in the destination register, and place the result into the destination register. These instructions are composed of different multiply forms, data formats and data accumulate options.
• Dot product instructions. These instructions perform multiple multiply operations, optionally add the result to the accumulator value in the destination register, and place the result into the destination register. These instructions are composed of different forms, data formats and data accumulate options.
• Load and store instructions. These instructions provide load and store capabilities for moving data to and from memory. A variety of forms are provided that position data for efficient computation.
• Compare instructions.
• Miscellaneous instructions. These instructions perform miscellaneous functions such as field manipulation, bit-reversed and circular incrementing, count leading sign/zero bits, etc.
0 15 16 31
rA
rB
operation operation
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor8
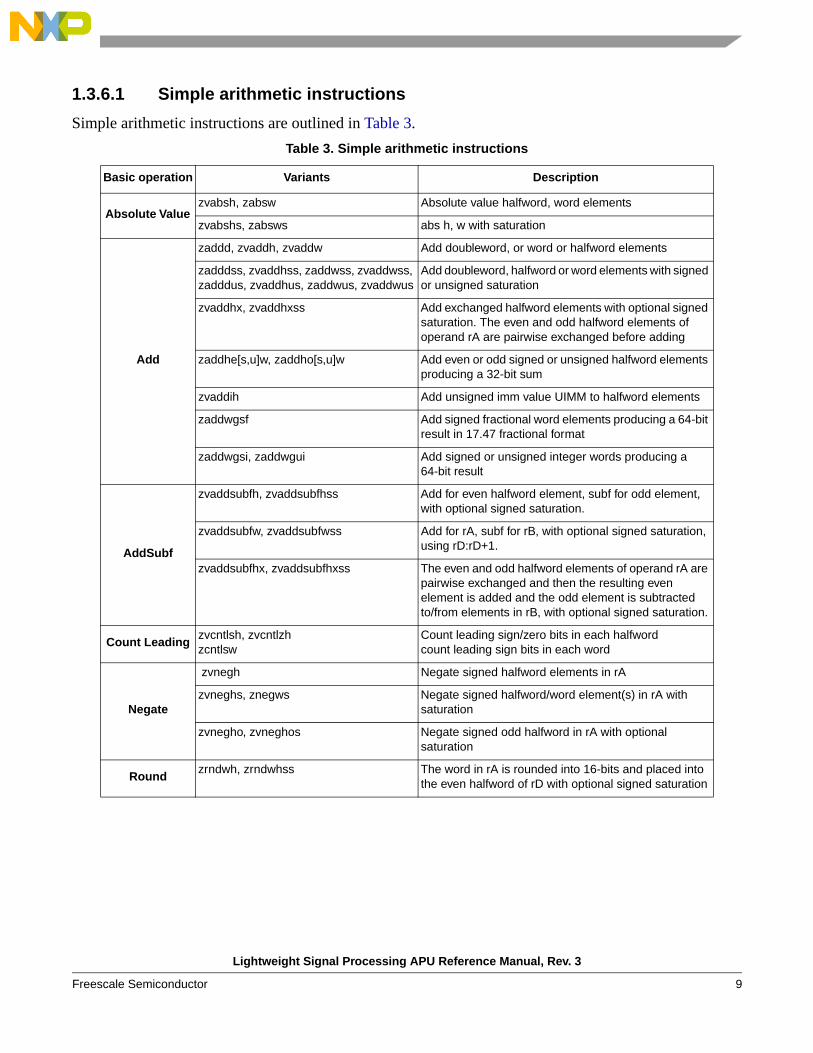
1.3.6.1 Simple arithmetic instructions
Simple arithmetic instructions are outlined in Table 3.
Table 3. Simple arithmetic instructions
Basic operation Variants Description
Absolute Value zvabsh, zabsw Absolute value halfword, word elements
zvabshs, zabsws abs h, w with saturation
Add
zaddd, zvaddh, zvaddw Add doubleword, or word or halfword elements
zadddss, zvaddhss, zaddwss, zvaddwss, zadddus, zvaddhus, zaddwus, zvaddwus
Add doubleword, halfword or word elements with signed or unsigned saturation
zvaddhx, zvaddhxss Add exchanged halfword elements with optional signed saturation. The even and odd halfword elements of operand rA are pairwise exchanged before adding
zaddhe[s,u]w, zaddho[s,u]w Add even or odd signed or unsigned halfword elements producing a 32-bit sum
zvaddih Add unsigned imm value UIMM to halfword elements
zaddwgsf Add signed fractional word elements producing a 64-bit result in 17.47 fractional format
zaddwgsi, zaddwgui Add signed or unsigned integer words producing a 64-bit result
AddSubf
zvaddsubfh, zvaddsubfhss Add for even halfword element, subf for odd element, with optional signed saturation.
zvaddsubfw, zvaddsubfwss Add for rA, subf for rB, with optional signed saturation, using rD:rD+1.
zvaddsubfhx, zvaddsubfhxss The even and odd halfword elements of operand rA are pairwise exchanged and then the resulting even element is added and the odd element is subtracted to/from elements in rB, with optional signed saturation.
Count Leadingzvcntlsh, zvcntlzhzcntlsw
Count leading sign/zero bits in each halfwordcount leading sign bits in each word
Negate
zvnegh Negate signed halfword elements in rA
zvneghs, znegws Negate signed halfword/word element(s) in rA with saturation
zvnegho, zvneghos Negate signed odd halfword in rA with optional saturation
Roundzrndwh, zrndwhss The word in rA is rounded into 16-bits and placed into
the even halfword of rD with optional signed saturation
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 9
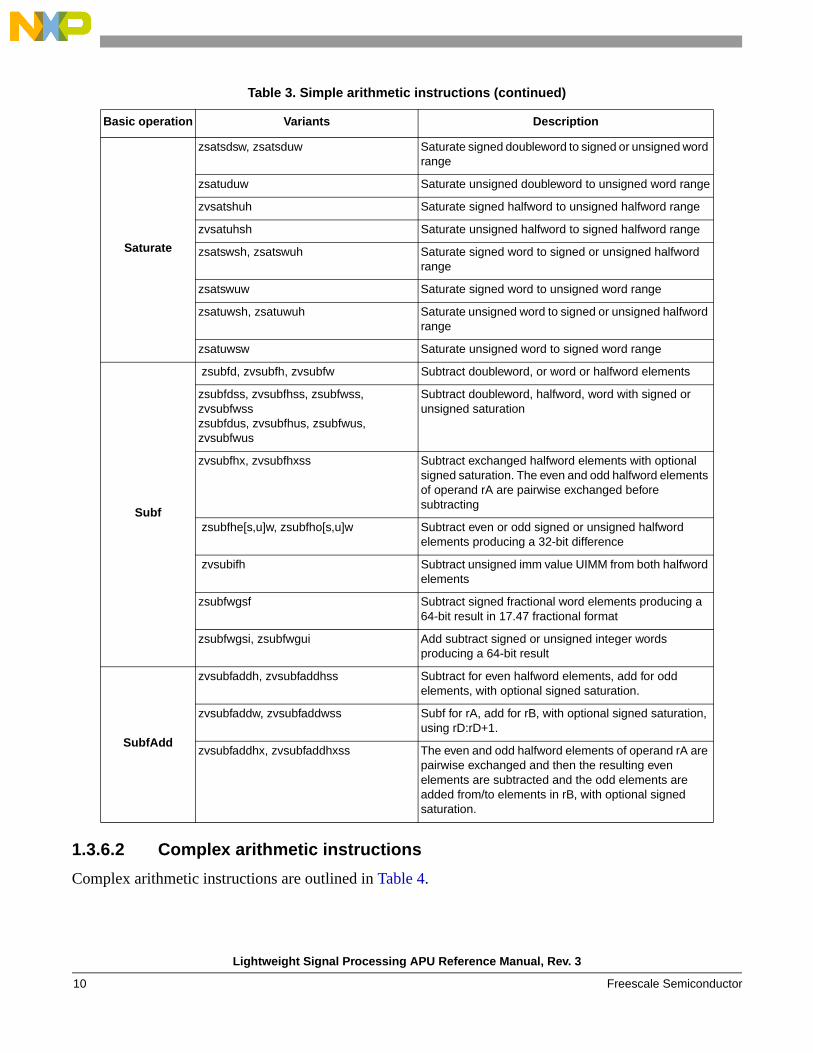
1.3.6.2 Complex arithmetic instructions
Complex arithmetic instructions are outlined in Table 4.
Saturate
zsatsdsw, zsatsduw Saturate signed doubleword to signed or unsigned word range
zsatuduw Saturate unsigned doubleword to unsigned word range
zvsatshuh Saturate signed halfword to unsigned halfword range
zvsatuhsh Saturate unsigned halfword to signed halfword range
zsatswsh, zsatswuh Saturate signed word to signed or unsigned halfword range
zsatswuw Saturate signed word to unsigned word range
zsatuwsh, zsatuwuh Saturate unsigned word to signed or unsigned halfword range
zsatuwsw Saturate unsigned word to signed word range
Subf
zsubfd, zvsubfh, zvsubfw Subtract doubleword, or word or halfword elements
zsubfdss, zvsubfhss, zsubfwss, zvsubfwsszsubfdus, zvsubfhus, zsubfwus, zvsubfwus
Subtract doubleword, halfword, word with signed or unsigned saturation
zvsubfhx, zvsubfhxss Subtract exchanged halfword elements with optional signed saturation. The even and odd halfword elements of operand rA are pairwise exchanged before subtracting
zsubfhe[s,u]w, zsubfho[s,u]w Subtract even or odd signed or unsigned halfword elements producing a 32-bit difference
zvsubifh Subtract unsigned imm value UIMM from both halfword elements
zsubfwgsf Subtract signed fractional word elements producing a 64-bit result in 17.47 fractional format
zsubfwgsi, zsubfwgui Add subtract signed or unsigned integer words producing a 64-bit result
SubfAdd
zvsubfaddh, zvsubfaddhss Subtract for even halfword elements, add for odd elements, with optional signed saturation.
zvsubfaddw, zvsubfaddwss Subf for rA, add for rB, with optional signed saturation, using rD:rD+1.
zvsubfaddhx, zvsubfaddhxss The even and odd halfword elements of operand rA are pairwise exchanged and then the resulting even elements are subtracted and the odd elements are added from/to elements in rB, with optional signed saturation.
Table 3. Simple arithmetic instructions (continued)
Basic operation Variants Description
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor10
1.3.6.3 Shift/rotate instructions
Shift and rotate instructions are outlined in Table 5.
1.3.6.4 Vector compare instructions
Vector compare instructions are outlined in Table 6. The compare operations update the condition register with the results of the comparison.
1.3.6.5 Vector select instructions
Vector select instructions are outlined in Table 7.
Table 4. Simple arithmetic instructions
Basic operation Variants Description
Divide zdivwsf 32 / 32 32 signed fractional divide
Table 5. Simple vector shift/rotate instructions
Basic operation Variants Description
Logical shift leftzvslh, zvslhi Logical shift left of the halfword elements in rA by the
amounts in rB or by the immediate value UIMM
Logical shift right zvsrhuzvsrhiu
Logical shift right of halfword elements in rA by the amounts in rB or by the immediate value UIMM
Rotate leftzvrlh, zvrlhi Rotate left of the halfword elements in rA by the amounts
in rB or by the immediate value UIMM
Signed shift left and saturate
zslwss, zslwiss,zvslhss, zvslhiss
Signed shift left of the word or halfword element(s) in rA by the amount(s) in rB or by the immediate value UIMM, with saturate
Unsigned shift left and saturate
zslwus, zslwius,zvslhus, zvslhius
Unsigned shift left of the word or halfword element(s) in rA by the amount(s) in rB or by the immediate value UIMM, with saturate
Arithmetic shift right
zvsrhs, zvsrhis Arithmetic shift right of the halfword elements in rA by the amounts in rB or by the immediate value UIMM
Table 6. Vector compare instructions
Basic comparison operation
Variants Description
= zvcmpeqh Compare halfword elements for equal
>zvcmpgths, zvcmpgthu Compare halfword elements for greater than
signed/unsigned
< zvcmplths, zvcmplthu Compare halfword elements for less than signed/unsigned
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 11
1.3.6.6 Vector data arrangement instructions
Vector data arrangement instructions are outlined in Table 8. These instructions are used to rearrange fields of elements from one or more source vector registers.
Table 7. Vector select instructions
Operation Variants Description
Selectzvselh Select halfword elements from rA or rB based on cr0 condition
register field
Table 8. Vector data arrangement instructions
Basic operation
Variants Description
Extract zxtrw Extract a word from rA:rB and place into rD
Merge
zvmergehih Merge high halfwords; the high halfword from rA is placed into the high halfword of rD and the high halfword of rB is placed into the low halfword of rD
zvmergehiloh Merge high/low halfwords; the high halfword from rA is placed into the high halfword of rD and the low halfword of rB is placed into the low halfword of rD
zvmergeloh Merge low halfwords; the low halfword from rA is placed into the high halfword of rD and the low halfword of rB is placed into the low halfword of rD
zvmergelohih Merge low/high halfwords; the low halfword from rA is placed into the high halfword of rD and the halfword word of rB is placed into the low halfword of rD
Pack
zvpkswshfrs, zpkswgshfrs Pack the signed fractional word or word guarded elements from rA and rB into signed fractional halfword elements in rD with rounding, saturating if necessary
zvpkswshs, zvpkswuhs, zvpkuwuhs Pack the signed or unsigned word elements from rA and rB into signed or unsigned halfword elements in rD, saturating if necessary
zpkswgswfrs Pack the signed 17.47 guarded fractional element from rA:rB into a signed word element in rD with rounding, saturating if necessary
zvpkshgwshfrs Pack the signed 9.23 guarded fractional elements from rA:rB into a pair of signed halfword elements in rD with rounding, saturating if necessary
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor12
1.3.6.7 Multiply and accumulate instructions
These instructions perform multiply operations, optionally add the result to rD or rD:rD+1 and place the result into rD or rD:rD + 1. These instructions are composed of different multiply forms, data formats and data accumulate options. The mnemonics for these instructions indicate their various characteristics. These are shown in Table 9.
Splat
zvsplatfih Splat the 5-bit SIMM field as a signed fraction into both halfword elements of rD
zvsplatih Splat the 5-bit SIMM field as a signed integer into both halfword elements of rD
Unpack
zunpkwgsf Unpack the word of rA into guarded signed fractional (17.47) format in rD:rD+1
zvunpkhgwsf Unpack the halfwords of rA into guarded signed fractional (9.23) format in rD:rD+1
zvunpkhsf, zvunpkhsi, zvunpkhui Unpack the halfwords of rA into signed fractional, signed integer, or unsigned integer words to rD:rD + 1
Table 9. Mnemonic extensions for multiply accumulate Instructions
Extension Meaning Comments
Multiply form
he Halfword even 16 X 16 32
heg Halfword even guarded 16 X 16 32, 64-bit final accumulate result
heo Halfword even/odd 16 X 16 32
heog Halfword even/odd guarded 16 X 16 32, 64-bit final accumulate result
ho Halfword odd 16 X 16 32
hog Halfword odd guarded 16 X 16 32, 64-bit final accumulate result
hxxgw Halfword to guarded-word 16 X 16 32, 9.23 format result
w Word 32 X 32 32
wl Word low 32 X 32 32 (low order 32 bits of product)
wg Word guarded 32 X 32 64
Data format
smf[r] Signed modulo fractional [round] Modulo, no saturation or overflow, [rounding]
si Signed (modulo) integer Modulo, no saturation or overflow
Table 8. Vector data arrangement instructions (continued)
Basic operation
Variants Description
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 13
1.3.6.8 Dot product instructions
These instructions perform multiple multiply operations, optionally add the results to rD or rD:rD+1, and place the result into the destination register. These instructions are composed of different forms, data formats and data accumulate options. The mnemonics for these instructions indicate their various characteristics. These are shown in Table 10.
sis Signed integer saturate Saturation on product
sf Signed (saturate) fractional Saturation on product and accumulate
sfr Signed (saturate) fractional round Saturation on product and accumulate, rounding
ui Unsigned (modulo) integer Modulo, no saturation or overflow
uis Unsigned saturate integer Saturation on product
Accumulate Option
aa Add to Accumulate rD + result rD
an Add negated to Accumulate rD – result rD
anp Add negated/positive to Accumulate rD – result | rD + result rD
aas Add to Accumulate with Saturate rD + sat result rD
ansAdd negated to Accumulate with Saturate
rD – sat result rD
Table 10. Mnemonic extensions for dot product instructions
Extension Meaning Comments
Multiply Form
h Halfwords 16 x 16 + 16 x 16 32
hg Halfwords guarded 16 x 16 + 16 x 16 64
hxgaHalfword exchanged guarded add (16 x 16 + 16 x 16) 64, even and odd rA halfwords
exchanged
hxgsHalfword exchanged guarded subtract (16 x 16 - 16 x 16) 64, even and odd rA halfwords
exchanged
w Word 32 x 32 op 32 x 32 64
wg Word guarded 32 x 32 op 32 x 32 64 in 17.47 fractional format
Operation
a Add Addition of intermediate products
Table 9. Mnemonic extensions for multiply accumulate Instructions (continued)
Extension Meaning Comments
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor14

1.3.6.9 Misc. vector instructions
Miscellaneous vector instructions are outlined in Table 11.
1.3.7 Load and store instructions
The LSP APU provides a number of load and store instructions. These instructions provide load and store capabilities for moving data elements between the GPRs and memory. Data elements of 16, 32, and 64 bits are supported. A variety of forms are provided that position data for efficient computation. The memory accesses are endian-aware for implementations supporting big- and little-endian accesses, and allow for writing endian-neutral software. A summary is given below.
1.4 LSP load/store APU addressing modesSeveral addressing modes are supported by the LSP LDST APU for efficient access to data operands. These modes are described in the following subsections.
s Subtract Subtraction of intermediate products
Data format
si Signed integer Modulo, no saturation or overflow
sf Signed saturate fractional Saturation on product and accumulate
sfr Signed saturate fractional round Saturation on product and accumulate, rounding based on
current rounding mode
sis Signed saturate integer saturate Saturation on product and accumulate
ui Unsigned modulo integer Modulo, no saturation or overflow
uis Unsigned integer saturate Saturation on product and accumulate
Accumulate option
aa Add to Accumulate rD + result rD
an Add negated to Accumulate rD – result rD
Table 11. Misc. vector instructions
Operation Variants Description
Bit reversed masked increment
zbrminc Compute a bit-reversed increment for a memory offset for bit-reversed addressing
Circular Incrementzcircinc Computes a modulo increment for supporting
circular buffer index pointer modification
Table 10. Mnemonic extensions for dot product instructions (continued)
Extension Meaning Comments
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 15

1.4.1 Addressing modes – non-update forms
Base + Index and Base + Scaled Immediate addressing modes are provided. Base registers hold 64-bit pointer values (32-bit pointers in a 32-bit implementation of the architecture), while registers used as index values provide 64-bit index values (32-bit index values in 32-bit mode, or in a 32-bit implementation of the architecture). Scaled immediate values are unsigned and are scaled by the size of the access.
1.4.1.1 Base + scaled immediate addressing – non-update form
In the Base + Scaled Immediate addressing mode, register rA holds a 64-bit pointer value (32-bit pointer in 32-bit mode, or in a 32-bit implementation of the architecture), or a value of zero (if rA=0), and an immediate field in the instruction word provides a 5-bit unsigned immediate value which is zero-extended and scaled (shifted left) by 1, 2, or 3 depending on the size (halfword, word, or doubleword) of the access. The sum of the value in rA and the zero-extended scaled immediate form the effective address.
For a 64-bit implementation of the architecture, the calculation is:if rA=0 then b 640else b (rA0:63)SCL {2,4,8} // halfword, word, or doublewordEA b + EXTZ(UIMM*SCL)
For a 32-bit implementation of the architecture, the calculation is:if rA=0 then b 320else b (rA32:63)SCL {2,4,8} // halfword, word, or doublewordEA b + EXTZ(UIMM*SCL)
1.4.1.2 Base + Index addressing
In the Base + Index addressing mode, register rA holds a 64-bit pointer value (32-bit pointer in 32-bit mode, or in a 32-bit implementation of the architecture) or a value of zero (if rA=0), while register rB provides a 64-bit index (32-bit index in 32-bit mode, or in a 32-bit implementation of the architecture). The sum forms the effective address.
For a 64-bit implementation of the architecture, the calculation is:if rA=0 then b 640else b (rA0:63)EA b + (rB)
For a 32-bit implementation of the architecture, the calculation is:if rA=0 then b 320else b (rA32:63)EA b + (rB)
1.4.2 Addressing mode – update form
The Base + Scaled Immediate addressing mode is also provided with an update form. As in the non-update form, base register rA holds 64-bit pointer values (32-bit pointers in a 32-bit implementation of the architecture). For the update form of the Base+Scaled Immediate addressing mode, the same effective
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor16

address calculation is used as defined in Section 1.4.1.1, Base + scaled immediate addressing – non-update form, and the calculated effective address is placed into rA by the instruction.
For the Base + Scaled Immediate with update addressing mode, scaled immediate values of 0 are reserved for future definition and are treated as illegal. Instruction encodings with rA=0 are also reserved for future definition and are treated as illegal instructions.
1.4.3 Addressing mode – modify forms
In the Modify forms, register rB holds 64-bit pointer values (32-bit pointers in a 32-bit implementation of the architecture), while register rA is used to provide specialized control information for performing a post-modification to the lower bits of rA.
Modify forms are provided to allow for parallel address computations to occur, which are useful for sequential accessing of circular buffers and other complex data structures. Modify forms of load and store instructions cause a calculated update value to be placed in register rA.
For the Modify forms, the modify calculation mode selection is based on a mode field in register rA (rA32:34). Modify forms modify the original value in rA based on an addressing calculation performed in parallel with the load or store instruction, which is not the value of the effective address of the load or store instruction. This is in contrast to normal “update forms” of the PowerISA load and store instructions, since the new value placed into rA need not correspond to the effective address of the load or store.
One modify calculation mode is currently defined, and is selected by the value in rA32:34:
• Circular addressing: mode = 100
All other mode encodings are reserved, and result in an illegal instruction exception.
Instruction encodings with rA = 0 are reserved for future definition and are treated as illegal instructions.
1.4.3.1 Circular addressing modify mode
Circular addressing modify mode is provided to support addressing of circular buffers. Circular buffers must be aligned on a doubleword boundary and must be multiples of 8 bytes in length. Buffers may range in size from 8 bytes to 8Kbytes. Circular addressing mode causes a circular increment to be performed on the circular buffer index portion of rA (rA51:63) after the EA calculation, using the biased Offset and the Length specifiers in rA. rA32:50 is left unchanged. The encoded Offset value in rA35:40 is a biased value if positive, and the actual offset will be one greater than the encoded value, while rA35:40 specifies an unbiased offset value if negative. Actual offsets thus range from -32..-1,+1..+32. rA51:63 (Index) must be <ui buffer length in bytes, and the magnitude of the actual offset values must be <=ui buffer length in bytes, or the result is boundedly undefined. rB must point to a doubleword boundary in memory or an alignment error will be generated.
The following shows how rA is used in forming the update value for mode 100 (circinc).
32 34 35 40 41 50 51 63
Mode(100)
Offset(signed)
Length(unsigned)
Index(unsigned)
rA
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 17

Offset0:12 EXTS13(rA35:40); // biased signed byte offset, absval must be <= BuffLen// if rA35 = 0 (positive), then actual offset added to Index
// is rA35:40 + 1, otherwise actual offset = rA35:40 (negative)Length0:9 rA41:50;// unsigned buffer length-1 in doublewords. Length0:9 is doubleword
// index of last doubleword in buffer.// Buffer indices are 0:(Length0:9 ||
31)// buffer must be aligned on a doubleword boundary, and is a
// multiple of 8 bytesLastBufferIndex0:12 = (Length0:9 ||
31)Index0:12 rA51:63; // index into buffer, must be <=ui LastBufferIndexif ((Offset0 = 0) & ((Offset0:12 + Index0:12) >ui LastBufferIndex0:12)) then // biasedrA51:63 Index0:12 + Offset0:12 - LastBufferIndex0:12; // wrap at end
elseif ((Offset0 = 1) & ((EXTS14(Offset0:12) + EXTZ14(Index0:12)) <si 0)) then rA51:63 Index0:12 + Offset0:12 + (LastBufferIndex0:12 + 1); // wrap at start
else rA51:63 Index0:12 + Offset0:12 + ~Offset0;
Note that misalignment may cause the operand fetched to span the “virtual boundary” between the last byte of the buffer at byte Buffer[Length] and the first byte of the Buffer at byte Buffer[0].
1.5 Vector load and store instruction summaryVector load and store instructions are provided to load and store various size vectors of halfword, word or double word size. These instructions allow for endian-neutral code to be written. In addition, update forms of the non-indexed instructions are provided to allow for base register updates. Variations of certain load instructions provide splat (replication) capability for placing a halfword vector element into multiple element positions in a vector register, or replicating load data into a register pair.
Vector Load and Store instructions are outlined in Table 12.
Table 12. Vector load and store instructions
Operation Variants Description
Load Doubleword into Register Pair
zldd, zlddu, zlddx, zlddmx Load doubleword as doubleword into register pair rD:rD+1
zldh, zldhu, zldhx, zldhmx Load doubleword as halfword elements into register pair rD:rD+1
zldw, zldwu, zldwx, zldwmx Load doubleword as word elements into register pair rD:rD+1
Load Halfword
zlhhe, zlhheu, zlhhex, zlhhemx Load halfword into even halfword element, zeroing the odd halfword element
zlhhos, zlhhosu, zlhhosx, zlhhosmx Load halfword into odd halfword element, sign-extended into the even halfword element
zlhhou, zlhhouu, zlhhoux, zlhhoumx Load halfword into odd halfword element, zero extended into the even halfword element
zlhgwsf, zlhgwsfu, zlhgwsfx, zlhgwsfmx Load halfword into word with 9.23 guarded signed fractional format
zlhhsplat, zlhhsplatu, zlhhsplatx, zlhhsplatmx
Load halfword into both halfword elements
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor18
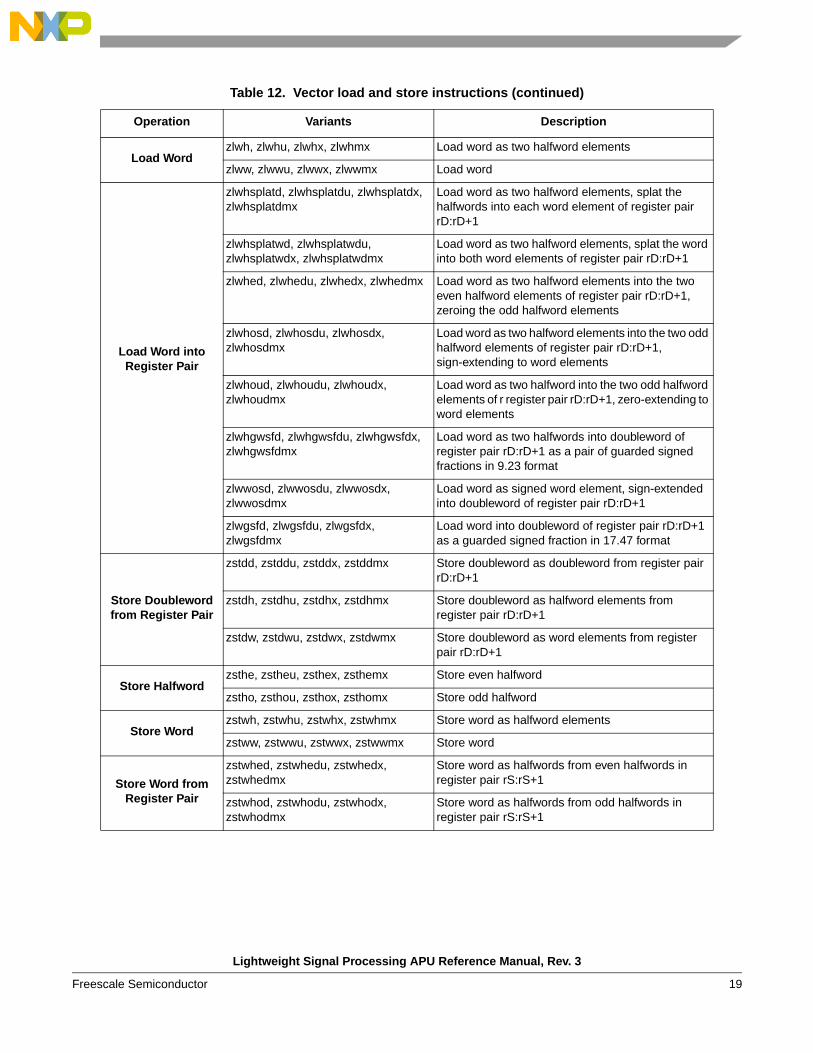
Load Wordzlwh, zlwhu, zlwhx, zlwhmx Load word as two halfword elements
zlww, zlwwu, zlwwx, zlwwmx Load word
Load Word into Register Pair
zlwhsplatd, zlwhsplatdu, zlwhsplatdx, zlwhsplatdmx
Load word as two halfword elements, splat the halfwords into each word element of register pair rD:rD+1
zlwhsplatwd, zlwhsplatwdu, zlwhsplatwdx, zlwhsplatwdmx
Load word as two halfword elements, splat the word into both word elements of register pair rD:rD+1
zlwhed, zlwhedu, zlwhedx, zlwhedmx Load word as two halfword elements into the two even halfword elements of register pair rD:rD+1, zeroing the odd halfword elements
zlwhosd, zlwhosdu, zlwhosdx, zlwhosdmx
Load word as two halfword elements into the two odd halfword elements of register pair rD:rD+1, sign-extending to word elements
zlwhoud, zlwhoudu, zlwhoudx, zlwhoudmx
Load word as two halfword into the two odd halfword elements of r register pair rD:rD+1, zero-extending to word elements
zlwhgwsfd, zlwhgwsfdu, zlwhgwsfdx, zlwhgwsfdmx
Load word as two halfwords into doubleword of register pair rD:rD+1 as a pair of guarded signed fractions in 9.23 format
zlwwosd, zlwwosdu, zlwwosdx, zlwwosdmx
Load word as signed word element, sign-extended into doubleword of register pair rD:rD+1
zlwgsfd, zlwgsfdu, zlwgsfdx, zlwgsfdmx
Load word into doubleword of register pair rD:rD+1 as a guarded signed fraction in 17.47 format
Store Doubleword from Register Pair
zstdd, zstddu, zstddx, zstddmx Store doubleword as doubleword from register pair rD:rD+1
zstdh, zstdhu, zstdhx, zstdhmx Store doubleword as halfword elements from register pair rD:rD+1
zstdw, zstdwu, zstdwx, zstdwmx Store doubleword as word elements from register pair rD:rD+1
Store Halfwordzsthe, zstheu, zsthex, zsthemx Store even halfword
zstho, zsthou, zsthox, zsthomx Store odd halfword
Store Wordzstwh, zstwhu, zstwhx, zstwhmx Store word as halfword elements
zstww, zstwwu, zstwwx, zstwwmx Store word
Store Word from Register Pair
zstwhed, zstwhedu, zstwhedx, zstwhedmx
Store word as halfwords from even halfwords in register pair rS:rS+1
zstwhod, zstwhodu, zstwhodx, zstwhodmx
Store word as halfwords from odd halfwords in register pair rS:rS+1
Table 12. Vector load and store instructions (continued)
Operation Variants Description
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 19

1.5.1 LSP exceptions and interrupts
1.5.1.1 Exceptions
The architecture defines the following LSP APU exceptions:
• LSP APU Vector Alignment exception
1.5.1.2 LSP vector alignment exception
The LSP vector alignment exception may occur if the effective address of any of the LSP load/store instructions in not aligned to a natural boundary, or if another alignment constraint for an LSP load/store instruction is violated. Depending on the data element size being accessed, and details of the hardware implementation, certain load/store instructions can cause LSP Vector Alignment Exceptions.
In addition, an LSP alignment exception can occur if certain parameters are violated for one of the specialized “with modify” addressing modes.
When a LSP vector alignment exception occurs, an Alignment Interrupt is taken and the processor suppresses execution of the instruction causing the exception. The SRR0, SRR1, MSR, ESR and DEAR registers are modified as follows:
• SRR0 is set to the effective address of the instruction causing the interrupt.
• SRR1 is set to the contents of the MSR at the time of the interrupt.
• MSR bits CE, ME and DE are unchanged. All other bits are cleared.
• ESRSPV bit is set. ESRST is set if the instruction causing the interrupt is a store. All other ESR bits are cleared.
• DEAR is updated with the effective address used in the load or the store.
Implementations are encouraged, but not required to support arbitrary alignment of all vector types in hardware. Refer to the hardware implementation documentation for exact details of supported alignments.
1.6 Instruction definitions
1.6.1 Absolute value, negate, rotate left, saturation, check overflow, shift left, bit reverse, round, extend, and mask models
Pseudo-RTL is provided here to more accurately describe certain functions that are referenced in the instruction pseudo-RTL.
1.6.1.1 Absolute valueABS(value)if value <si 0 thenreturn(0-value)else
return value
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor20

1.6.1.2 NegateNEG(value)return(0-value)
1.6.1.3 Rotate leftROTLxx(value, count)a = xx - 1c = countwhile (count > a) doc -= xxend
if count = 0 thenreturn(value)elsereturn(valuec:a || value0:c-1)SaturationSATURATE(overflow, carry, saturated_underflow, saturated_overflow, value)if overflow thenif carry then
return saturated_underflowelse
return saturated_overflowelsereturn value
1.6.1.4 Check overflowchk_ovf(value)vsize sizeof(value)if (value = vsize0) | (value = vsize1) thenreturn 0elsereturn 1
1.6.1.5 Check unsigned overflowchk_ovfu(value)vsize sizeof(value)if (value = vsize0) thenreturn 0elsereturn 1
1.6.1.6 Shift leftSL(value, cnt)if cnt > 31 thenreturn 0elsereturn (value << cnt)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 21

1.6.1.7 Bit reverseBITREVERSE(value)result 0mask shift 31cnt 32while cnt > 0 dot value & maskif shift >= 0 then
result t << shift) | resultelse
result t >> -shift) | resultcnt cnt - 1shift shift - 2mask mask << 1return result
1.6.1.8 Round ROUND(value, bits)vsize sizeof(value)mask (vsize-bits1 || bits0)result 1 << (bits-1)) + value) & maskreturn result
1.6.1.9 EXTxx EXTxx(value, TY)vsize sizeof(value)xsize xxS value0if (TY = 00) then // unsignedresult xsize - vsize)0 || valueelse // signedresult xsize - vsize)S || valuereturn result
1.6.1.10 EXTSxx EXTSxx(value)vsize sizeof(value)xsize xxS value0result xsize - vsize)S || valuereturn result
1.6.1.11 EXTZxx EXTZxx(value)vsize sizeof(value)xsize xxresult xsize - vsize)0 || valuereturn result
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor22

1.6.1.12 MASKSSxx - Mask for signed shiftMASKSSxx(value)result value+11 || xx - value-1)0 return result
1.6.1.13 MASKUSxx - Mask for unsigned shiftMASKUSxx(value)result value1 || xx - value)0 return result
1.6.2 Effective address calculation models
For certain effective address calculations and register updates, the pseudo RTL is provided here to describe those functions that are referenced in the instruction pseudo RTL.
1.6.2.1 Load and store indexed [with-modify] <EA> calculationCalc_EA(rA,rB,M) {if (M = 0) then // Normal Index mode
if rA=0 then b 0;else b (rA);EA b + (rB)
else if rA32:34 !=3‘b100 then take_illegal_exception // M=1, mode != 100else // M=1, mode = 100, circular addressing mode
EA EXTZ(rA51:63) + (rB)}
1.6.2.2 Load and store indexed with modify rA update calculationCalc_rA_update(rA,rB) {Offset0:12 EXTS13(rA35:40); // biased signed byte offset, absval must be <= BuffLen
// if rA35 = 0 (positive), then actual offset added to Index // is rA35:40 + 1, otherwise actual offset = rA35:40 (negative)
Length0:9 rA41:50;// unsigned buffer length-1 in doublewords. Length0:9 is doubleword// index of last doubleword in buffer.
// Buffer indices are 0:(Length0:9 || 31)
// buffer must be aligned on a doubleword boundary, and is a // multiple of 8 bytes
LastBufferIndex0:12 = (Length0:9 || 31)
Index0:12 rA51:63; // index into buffer, must be <=ui LastBufferIndexif ((Offset0 = 0) & ((Offset0:12 + Index0:12) >ui LastBufferIndex0:12)) then // biasedrA51:63 Index0:12 + Offset0:12 - LastBufferIndex0:12; // wrap at end
elseif ((Offset0 = 1) & ((EXTS14(Offset0:12) + EXTZ14(Index0:12)) <si 0)) then rA51:63 Index0:12 + Offset0:12 + (LastBufferIndex0:12 + 1); // wrap at start
else rA51:63 Index0:12 + Offset0:12 + ~Offset0;}
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 23

1.6.3 Simple arithmetic, shift, compare, vector data arrangement, and misc. instructions
1.6.3.1 Bit-reversed masked increment (zbrminc)
zbrminc rD,rA,rB
n MASKBITS // Imp dependent # of mask bitsMask rb64-n:63 // mask value is log2(#points)1, zero extended, then left
// shifted log2(element size in bytes). e.g., a 16 point FFT // on halfwords has a mask of 16‘b0000000000011110
a rA48:63 // up to 64Kbytes in a single FFTd bitreverse(1 + bitreverse(a | ~Mask)))rD32:63 rA32:47 || ((rA48:63 & ~Mask) |(d & Mask)) // different than brinc.
zbrminc provides a way for software to access FFT data in a bit-reversed manner. rA contains the index into a buffer that contains data on which FFT is to be performed. rB contains a mask that allows the index to be updated with bit-reversed addressing. Typically this instruction precedes a load with index instruction; for example,
zbrminc r2, r3, r4lhax r8, r5, r2
rB contains a bit-mask that is based on the number of points in an FFT. To access a buffer containing n byte sized data that is to be accessed with bit-reversed addressing, the mask has log2n 1s in the least significant bit positions and 0s in the remaining most significant bit positions. If, however, the data size is a multiple of a halfword or a word, the mask is constructed so that the 1s are shifted left by log2 (size of the data) and 0s are placed in the least significant bit positions. Table 13 shows example values of masks for different data sizes and number of data.
NOTEAn implementation can restrict the number of bits specified in a mask. The number of bits in a mask may not exceed 32.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 0 1 0 0 0
Table 13. Data samples and sizes
Number of data samplesData size
Byte Halfword Word Double word
8 000...00000111 000...00001110 000...000011100 000...0000111000
16 000...00001111 000...00011110 000...000111100 000...0001111000
32 000...00011111 000...00111110 000...001111100 000...0011111000
64 000...00111111 000...01111110 000...011111100 000...0111111000
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor24

NOTEThis instruction only modifies the lower 32 bits of the destination register in 32-bit implementations. For 64-bit implementations in 32-bit mode, the contents of the upper 32 bits of the destination register are undefined.
1.6.3.2 Circular increment (zcircinc)
zcircinc rD,rA,rB
temp0:31 rA32:63;Offset0:13 rB50:63; // biased signed byte offset, absval must be <= BuffLen
// if rB50 = 0 (positive), then actual offset added to Index // is rB50:63 + 1, otherwise actual offset = rB50:63 (negative)
Length0:9 rA41:50;// unsigned buffer length-1 in doublewords. Length0:9 is doubleword// index of last doubleword in buffer.
// Buffer indices are 0:(Length0:9 || 31)
// buffer must be aligned on a doubleword boundary, and is a // multiple of 8 bytes
LastBufferIndex0:13 = EXTZ14(Length0:9 || 31);
Index0:13 EXTZ14(rA51:63); // index into buffer, must be <=ui LastBufferIndexif ((Offset0 = 0) & ((Offset0:13 + Index0:13) >ui LastBufferIndex0:13)) then // biasedtemp19:31 Index1:13 + Offset1:13 - LastBufferIndex1:13; // wrap at end
elseif ((Offset0 = 1) & ((Offset0:13 + Index0:13) <si 0)) then temp19:31 Index1:13 + Offset1:13 + (LastBufferIndex1:13 + 1); // wrap at start
else temp19:31 Index1:13 + Offset1:13 + ~Offset0;rD32:63 temp0:31;
zcircinc provides a way for software to modify a circular buffer index value. rA contains the index value into a circular buffer that contains data accessed by a load or store instruction using circular addressing, and control information that allows the index to be updated with circular addition. rB contains a signed biased offset value. zcircinc causes a circular increment to be performed on the circular buffer index portion of rA (rA51:63) using the biased Offset specified in rB, and the Length specifier in rA, and the result is placed into rD51:63. The value of rA32:50 is copied into rD32:50 unchanged.
The encoded Offset value in rB50:63 is a biased value if positive, and the actual offset will be one greater than the encoded value, while rB50:63 specifies an unbiased offset value if negative. Actual offsets thus range from –8192..-1,+1..+8192. rA51:63 (Index) must be <ui buffer length in bytes, and the magnitude of the actual offset values must be <=ui buffer length in bytes, or the result is boundedly undefined.
Typically this instruction is used to update a new buffer pointer value following a sequence of buffer accesses, to allow the pointer into the buffer to be moved to the next starting element for a future calculation.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 0 1 0 0 1
32 40 41 50 51 63
Length(unsigned)
Index(unsigned)
rA
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 25

NOTEAn implementation can restrict the allowable values of the Length and Offset. Unallowed values may generate a boundedly undefined result. Implementations must support a set of values that allow for calculations supporting circular buffers that are a multiple of 8 bytes, where the index points to an element of the buffer, and the buffer length is 2N bytes, where N ranges from 0 to 13. Implementations are highly encouraged to support arbitrary buffer lengths of 1 to 1024 doublewords however.
1.6.3.3 Vector Absolute Value Halfword (zvabsh)
zvabsh rD,rA
rD32:47ABS(rA32:47)rD48:63ABS(rA48:63)
The absolute value of each halfword in rA is placed in the corresponding elements of rD. An absolute value of 0x8000 (most negative number) returns 0x8000. No overflow is detected.
Figure 4. Vector absolute value halfword (zvabsh)
1.6.3.4 Vector absolute value halfword and saturate (zvabshs)
zvabshs rD,rA
if (rA32:47 = 0x8000) then rD32:470x7FFFovelserD32:47ABS(rA32:47) ovendifif (rA48:63 = 0x8000) then
32 40 41 50 63
Offset(signed)
rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 0 1 0 0 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 0 1 0 1 0 1 0 0 0 1 1 1 1 1 1
32 47 48 63
rA
rD
ABS ABS
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor26

rD48:630x7FFFovelse rD48:63ABS(rA48:63)
SPEFSCROV SPEFSCROVSPEFSCRSOV SPEFSCRSOV | ov
The absolute value of each halfword in rA is placed into rD. The absolute value of 0x8000 (most negative number) returns 0x7FFF. Any overflow is reported in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 5. Vector absolute value halfword and saturate (zvabshs)
1.6.3.5 Absolute value word (zabsw)
zabsw rD,rA
rD32:63ABS(rA32:63)
The absolute value of rA is placed into rD. An absolute value of 0x8000_0000 (most negative number) returns 0x8000_0000. No overflow is detected.
Figure 6. Absolute value word (zabsw)
1.6.3.6 Absolute value word and saturate (zabsws)
zabsws rD,rA
if (rA32:63 = 0x8000_0000) then rD32:63 0x7FFF_FFFF
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 0 1 1 0 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 0 1 1 1 0 1 0 0 0 1 1 1 1 1 1
32 47 48 63
rA
rD
ABS&SAT ABS&SAT
32 63
rA
ABS
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 27

ov else rD32:63ABS(rA32:63)ov endifSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The absolute value of the word in rA is placed into rD. The absolute value of 0x8000_0000 (most negative number) returns 0x7FFF_FFFF. Any overflow is reported in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 7. Absolute value word and saturate (zabsws)
1.6.3.7 Add doubleword (zaddd)
zaddd rD,rA,rB
rD32:63:rD+132:63 rD32:63:rD+132:63 + rA32:63:rB32:63
The 64-bit value in rA:rB is added to the 64-bit value in rD:rD+1 and the result is placed into rD:rD+1.
Figure 8. Add doubleword (zaddd)
1.6.3.8 Add doubleword signed saturate (zadddss)
zadddss rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 0 0 1 0
32 63
rA
ABS&SAT
rD
0 63
rD:rD+1
rA:rB
+
rD:rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor28

temp0:64 EXTS65(rA32:63:rB32:63) + EXTS65(rD32:63:rD+132:63)ov temp0 temp1rD32:63:rD+132:63 SATURATE(ov, temp0, 0x8000_0000_0000_0000, 0x7fff_ffff_ffff_ffff, temp1:64)SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov.
The 64-bit value in rA:rB is added to the 64-bit value in rD:rD+1, saturating if positive or negative overflow occurs, and the result is placed into rD:rD+1. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 9. Add doubleword signed saturate (zadddss)
1.6.3.9 Add doubleword unsigned saturate (zadddus)
zadddus rD,rA,rB
temp0:64 EXTZ65(rA32:63:rB32:63) + EXTZ65(rD32:63:rD+132:63)ov temp0rD32:63:rD+132:63 SATURATE(ov, 1, 0xffff_ffff_ffff_ffff, -----------------, temp1:64)SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov.
The 64-bit value in rA:rB is added to the 64-bit value in rD:rD+1, saturating if overflow occurs, and the result is placed into rD:rD+1. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 1 0 1 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 1 0 0 1 0
0 63
rD:rD+1
rA:rB
+sat
rD:rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 29

Figure 10. Add doubleword unsigned saturate (zadddus)
1.6.3.10 Vector add halfwords (zvaddh)
zvaddh rD,rA,rB
rD32:47rA32:47 + rB32:47// Modulo sumrD48:63rA48:63+ rB48:63// Modulo sum
The two halfword elements of rA are added to the two halfword elements of rB and the results are placed into rD. The sum is a modulo sum.
Figure 11. Vector add halfwords (zvaddh)
1.6.3.11 Vector add halfwords signed and saturate (zvaddhss)
zvaddhss rD,rA,rB
temp0:31 EXTS32(rA32:47) + EXTS32(rB32:47)ovh0 temp15 temp16rD32:47 SATURATE(ovh0, temp15, 0x8000, 0x7fff, temp16:31)
// h3temp0:31 EXTS32(rA48:63) + EXTS32(rB48:63)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 0 0 1 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 0 1 1 0
0 63
rD:rD+1
rA:rB
+sat
rD:rD+1
32 47 48 63
rA
rB
+ +
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor30

ovh1 temp15 temp16rD48:63 SATURATE(ovh1, temp15, 0x8000, 0x7fff, temp16:31)ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The two signed halfword elements of rA are added to the corresponding signed halfword elements of rB, saturating if positive or negative overflow occurs, and the results are placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 12. Vector add halfwords signed and saturate (zvaddhss)
1.6.3.12 Vector add halfwords unsigned and saturate (zvaddhus)
zvaddhus rD,rA,rB
// h0temp0:31 EXTZ32(rA32:47) + EXTZ32(rB32:47)ovh0 temp15rD32:47 SATURATE(ovh0, 1, 0xffff, ------, temp16:31)
// h1temp0:31 EXTZ32(rA48:63) + EXTZ32(rB48:63)ovh1 temp15rD48:63 SATURATE(ovh1, 1, 0xffff, ------, temp16:31)ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The unsigned halfword elements of rA are added to the unsigned halfword elements of rB, saturating if overflow occurs, and the results are placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 0 1 0 0
32 47 48 63
rA
rB
+ +
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 31

Figure 13. Vector add halfwords unsigned and saturate (zvaddhus)
1.6.3.13 Vector add halfwords exchanged (zvaddhx)
zvaddhx rD,rA,rB
// h0rD32:47 rB32:47 + rA48:63 // modulo sum// h1rD48:63 rB48:63 + rA32:47 // modulo sum
The two exchanged halfword elements of rA are added to the two halfword elements of rB. The sum is a modulo sum.
Figure 14. Vector add halfwords exchanged (zvaddhx)
1.6.3.14 Vector add halfwords exchanged, signed and saturate (zvaddhxss)
zvaddhxss rD,rA,rB
// h0temp0:31 EXTS32(rB32:47) + EXTS32(rA48:63)ovh0 temp15 temp16
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 0 1 1 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 1 1 0 0
32 47 48 63
rA
rB
+ +
rD
32 47 48 63
rB
rA
+ +
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor32

rD32:47 SATURATE(ovh0, temp15, 0x8000, 0x7fff, temp16:31)
// h1temp0:31 EXTS32(rB48:63) + EXTS32(rA32:47)ovh1 temp15 temp16rD48:63 SATURATE(ovh1, temp15, 0x8000, 0x7fff, temp16:31)ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The two exchanged signed halfword elements of rA are added to two signed halfword elements of rB, saturating if positive or negative overflow occurs, and the results are placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 15. Vector add halfwords exchanged signed and saturate (zvaddhxss)
1.6.3.15 Vector add immediate halfword (zvaddih)
zvaddih rD,rA,UIMM
rD32:47rA32:47 + EXTZ16(UIMM)// Modulo sumrD48:63rA48:63+ EXTZ16(UIMM)// Modulo sum
UIMM is zero-extended and added to the halfword elements of rA and the results are placed into rD. Note that the same value is added to both elements of the register. UIMM is 5 bits.
Figure 16. Vector add immediate halfword (zvaddih)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA UIMM 0 1 0 0 0 0 0 0 0 0 0
32 47 48 63
rB
rA
+ +
rD
32 47 48 63
rA
UIMM
+ +
rD
UIMM
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 33

1.6.3.16 Vector add / subtract from halfword (zvaddsubfh)
zvaddsubfh rD,rA,rB
rD32:47rB32:47 + rA32:47// Modulo sumrD48:63rB48:63- rA48:63// Modulo difference, rB – rA
The even halfword of rA is added to the even halfword of rB, the odd halfword of rA is subtracted from the odd halfword of rB, and the results are placed into rD. The sum and difference are modulo.
Figure 17. Vector add / subtract from halfword (zvaddsubfh)
1.6.3.17 Vector add / subtract from halfword signed and saturate (zvaddsubfhss)
zvaddsubfhss rD,rA,rB
// h0temp0:31 EXTS32(rB32:47) + EXTS32(rA32:47)ovh0 temp15 temp16rD32:47 SATURATE(ovh0, temp15, 0x8000, 0x7fff, temp16:31)// h3temp0:31 EXTS32(rB48:63) – EXTS32(rA48:63)ovh1 temp15 temp16rD48:63 SATURATE(ovh1, temp15, 0x8000, 0x7fff, temp16:31)ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The signed even halfword of rA is added to the even signed halfword of rB, the odd signed halfword of rA is subtracted from the odd signed halfword of rB, saturating if positive or negative overflow occurs, and the results are placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 0 0 1 1 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 1 0 1 0
32 47 48 63
rB
rA
+ –
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor34

Other registers altered: SPEFSCR
Figure 18. Vector add an/d subtract from halfword signed and saturate (zvaddsubfhss)
1.6.3.18 Vector add / subtract from halfword exchanged (zvaddsubfhx)
vaddsubfhx rD,rA,rB
// h0rd32:47 rb32:47 + ra48:63 // modulo// h1rd48:63 rb48:63 – ra32:47 // modulo
The odd halfword of rA is added to the even halfword of rB, the even halfword of rA is subtracted from the odd halfword of rB, and the results are placed into rD. The sum and difference are modulo.
Figure 19. Vector add / subtract from halfword exchanged (zvaddsubfhx)
1.6.3.19 Vector add / subtract from halfword exchanged, signed and saturate (zvaddsubfhxss)
zvaddsubfhxss rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 0 1 1 1 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 1 1 1 0
32 47 48 63
rB
rA
+ –
rD
32 47 48 63
rB
rA
+ –
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 35

// h0temp0:31 exts32(rb32:47) + exts32(ra48:63)ovh0 temp15 temp16rd32:47 saturate(ovh0, temp15, 0x8000, 0x7fff, temp16:31)// h3temp0:31 exts32(rb48:63) - exts32(ra32:47)ovh1 temp15 temp16rd48:63 saturate(ovh1, temp15, 0x8000, 0x7fff, temp16:31)ov ovh0 | ovh1
spefscrov ovspefscrsov spefscrsov | ov
The odd signed halfword of rA is added to the even signed halfword of rB, the even signed halfword of rA is subtracted from the odd signed halfword of rB, saturating if positive or negative overflow occurs, and the results are placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 20. Vector add / subtract from halfword exchanged, signed and saturate (zvaddsubfhxss)
1.6.3.20 Add halfword even signed to word (zaddhesw)
zaddhesw rD,rA,rB
rD32:63 EXTS32(rB32:47) + EXTS32(rA32:47) // modulo
The even halfword elements of rA and rB are sign-extended to 32 bits and added together to produce a 32-bit sum, and the result is placed into rD.
NOTEzaddhesw can also be used to add 1.15 fractions to produce a 17.15 fractional sum.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 0 0 1 0
32 47 48 63
rB
rA
+ –
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor36

Figure 21. Add halfword even signed to word (zaddhesw)
1.6.3.21 Add halfword even unsigned to word (zaddheuw)
zaddheuw rD,rA,rB
rD32:63 EXTZ32(rB32:47) + EXTZ32(rA32:47) // modulo
The even halfword elements of rA and rB are zero-extended to 32 bits and added together to produce a 32-bit sum, and the result is placed into rD.
Figure 22. Add halfword even unsigned to word (zaddheuw)
1.6.3.22 Add halfword odd signed to word (zaddhosw)
zaddhosw rD,rA,rB
rD32:63 EXTS32(rB48:63) + EXTS32(rA48:63)
The odd halfword elements of rA and rB are sign-extended to 32 bits and added together to produce a 32-bit sum, and the result is placed into rD.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 0 0 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 0 1 1 0
32 47 48 63
rB
rA
+
rD
32 47 48 63
rB
rA
+
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 37

NOTEzaddhosw can also be used to add 1.15 fractions to produce a 17.15 fractional sum.
Figure 23. Add halfword odd signed to word (zaddhosw)
1.6.3.23 Add halfword odd unsigned to word (zaddhouw)
zaddhouw rD,rA,rB
rD32:63 EXTZ32(rB48:63) + EXTZ32(rA48:63)
The odd halfword elements of rA and rB are zero-extended to 32 bits and added together to produce a 32-bit sum, and the result is placed into rD.
Figure 24. Add halfword odd unsigned to word (zaddhouw)
1.6.3.24 Vector add word (zvaddw)
zvaddw rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 0 1 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 0 1 1 0
32 47 48 63
rB
rA
+
rD
32 47 48 63
rB
rA
+
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor38

rD32:63rD32:63 + rA32:63 // Modulo sumrD+132:63rD+132:63 + rB32:63 // Modulo sum
The word elements of rA:rB are added to the corresponding word elements of rD:rD+1 and the results are placed into rD:rD+1. The sum is a modulo sum.
Figure 25. Vector add word (zvaddw)
1.6.3.25 Vector add / subtract from word (zvaddsubfw)
zvaddsubfw rD,rA,rB
rD32:63rD32:63 + rA32:63 // Modulo sumrD+132:63rD+132:63 - rB32:63 // Modulo difference
The word in rA is added to the word in rD, the word in rB is subtracted from the word in rD+1, and the results are placed into rD:rD+1. The sum and difference are modulo.
Figure 26. Vector add / subtract from word (zvaddsubfw)
1.6.3.26 Vector add / subtract from word signed and saturate (zvaddsubfwss)
zvaddsubfwss rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 0 1 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1 rA rB 1 0 0 0 1 1 0 1 1 0 0
32 63
rA
rD
+
rD
32 63
rB
rD+1
+
rD+1
32 63
rA
rD
+
rD
32 63
rB
rD+1
–
rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 39

temph0:32 EXTS33(rD32:63) + EXTS33(rA32:63)ovh temph0 temph1rD32:63 SATURATE(ovh, temph0, 0x8000_0000, 0x7fff_ffff, temph1:32)
templ0:32 EXTS33(rD+132:63) - EXTS33(rB32:63)ovl templ0 templ1rD+132:63 SATURATE(ovl, templ0, 0x8000_0000, 0x7fff_ffff, templ1:32)
SPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
The signed word in rA is added to the signed word in rD and the signed word in rB is subtracted from the signed word in rD+1, saturating if positive or negative overflow occurs, and the results are placed into rD:rD+1. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 27. Vector add / subtract from word signed and saturate (zvaddsubfwss)
1.6.3.27 Add word guarded signed fraction (zaddwgsf)
zaddwgsf rD,rA,rB
rD32:63:rD+132:63 EXTS48(rB32:63) || 160) + (EXTS48(rA32:63) ||
160)
The word elements of rA and rB are sign-extended with 16 guard bits and padded with 16 0’s, and then added together to produce a 64-bit sum, and the result is placed into rD, rD+1.
NOTEzaddwgsf is used to add 1.31 fractions to produce a 17.47 fractional sum.
1 rD odd is illegal
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 1 0 0 0 0
32 63
rA
rD
+SSAT
rD
32 63
rB
rD+1
–SSAT
rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor40

Figure 28. Add Word Guarded Signed Fraction (zaddwgsf)
1.6.3.28 Add word guarded signed integer (zaddwgsi)
zaddwgsi rD,rA,rB
rD32:63:rD+132:63 EXTS64(rB32:63) + EXTS64(rA32:63)
The word elements of rA and rB are sign-extended to 64 bits and added together to produce a 64-bit sum, and the result is placed into rD.
NOTEzaddwgsi can also be used to add 1.31 fractions to produce a 33.31 fractional sum.
Figure 29. Add word guarded signed integer (zaddwgsi)
1.6.3.29 Add word guarded unsigned integer (zaddwgui)
zaddwgui rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 1 0 0 0
32 63
rB
rA
0 63
rD:rD+1
15 16 17
.
+
32 63
rB
rA
0 63
rD:rD+1
+ EXTS64
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 41

rD32:63:rD+132:63 EXTZ64(rB32:63) + EXTZ64(rA32:63)
The word elements of rA and rB are zero-extended to 64 bits and added together to produce a 64-bit sum, and the result is placed into rD.
Figure 30. Add word guarded unsigned integer (zaddwgui)
1.6.3.30 Add word signed and saturate (zaddwss)
zaddwss rD,rA,rB
temp0:32 EXTS33(rB32:63) + EXTS33(rA32:63)ov temp0 temp1rD32:63 SATURATE(ov, temp0, 0x8000_0000, 0x7fff_ffff, temp1:32)
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The word in rA is added to the word in rB, saturating if positive or negative overflow occurs, and the result is placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 0 0 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 0 0 1 0
32 63
rB
rA
0 63
rD:rD+1
+ EXTZ64
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor42
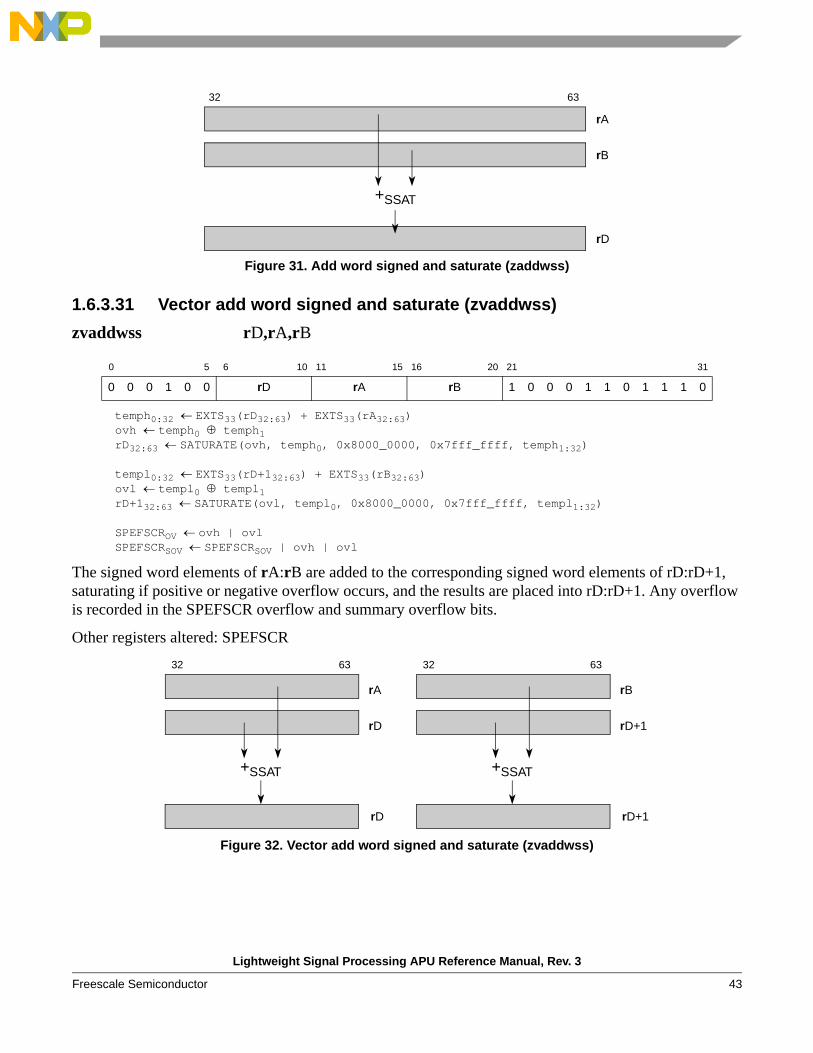
Figure 31. Add word signed and saturate (zaddwss)
1.6.3.31 Vector add word signed and saturate (zvaddwss)
zvaddwss rD,rA,rB
temph0:32 EXTS33(rD32:63) + EXTS33(rA32:63)ovh temph0 temph1rD32:63 SATURATE(ovh, temph0, 0x8000_0000, 0x7fff_ffff, temph1:32)
templ0:32 EXTS33(rD+132:63) + EXTS33(rB32:63)ovl templ0 templ1rD+132:63 SATURATE(ovl, templ0, 0x8000_0000, 0x7fff_ffff, templ1:32)
SPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
The signed word elements of rA:rB are added to the corresponding signed word elements of rD:rD+1, saturating if positive or negative overflow occurs, and the results are placed into rD:rD+1. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 32. Vector add word signed and saturate (zvaddwss)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 0 0 0 1 1 0 1 1 1 0
32 63
rA
rB
+SSAT
rD
32 63
rA
rD
+SSAT
rD
32 63
rB
rD+1
+SSAT
rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 43

1.6.3.32 Add Word Unsigned And Saturate (zaddwus)
zaddwus rD,rA,rB
temp0:31 EXTZ33(rB32:63) + EXTZ33(rA32:63)ov temp0rD32:63 SATURATE(ov, 1, 0xffff_ffff, -------------, temp1:32)
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The unsigned word in rA is added to the unsigned word in rB, saturating if overflow occurs, and the result is placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 33. Add word unsigned and saturate (zaddwus)
1.6.3.33 Vector add word unsigned and saturate (zvaddwus)
zvaddwus rD,rA,rB
temph0:31 EXTZ33(rD32:63) + EXTZ33(rA32:63)ovh temph0rD32:63 SATURATE(ovh, 1, 0xffff_ffff, -------------, temph1:32)
templ0:31 EXTZ33(rD+132:63) + EXTZ33(rB32:63)ovl templ0rD+132:63 SATURATE(ovl, 1, 0xffff_ffff, -------------, templ1:32)
SPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
The unsigned word elements of rA:rB are added to the corresponding unsigned word elements of rD:rD+1, saturating if overflow occurs, and the results are placed into rD:rD+1. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 0 0 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 1 0 1 1 0
32 63
rA
rB
+USAT
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor44

Other registers altered: SPEFSCR
Figure 34. Vector add word unsigned and saturate (zvaddwus)
1.6.3.34 Vector compare equal halfword (zvcmpeqh)
zvcmpeqh crD,rA,rB
ahrA32:47alrA48:63bhrB32:47blrB48:63if (ah = bh) then ch1else ch0if (al = bl) then cl1else cl0CR4*crD:4*crD+3ch || cl || (ch | cl) || (ch & cl)
The most significant bit in crD is set if the high-order halfword in rA is equal to the high-order halfword in rB; it is cleared otherwise. The next bit in crD is set if the low-order halfword in rA is equal to the low-order halfword in rB and cleared otherwise. The last two bits of crD are set to the OR and AND of the result of the compare of the high and low elements.
Figure 35. Vector compare equal halfword (zvcmpeqh)
0 5 6 8 9 10 11 15 16 20 21 31
0 0 0 1 0 0 crD 0 0 rA rB 0 1 0 0 0 1 1 0 0 1 0
32 63
rA
rD
+USAT
rD
32 63
rB
rD+1
+USAT
rD+1
32 47 48 63
rA
rB
= =
crD
OR
AND
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 45

1.6.3.35 Vector compare greater than halfword signed (zvcmpgths)
zvcmpgths crD,rA,rB
ahrA32:47alrA48:63bhrB32:47blrB48:63if (ah > bh) then ch1else ch0if (al > bl) then cl1else cl0CR4*crD:4*crD+3ch || cl || (ch | cl) || (ch & cl)
The most significant bit in crD is set if the high-order halfword in rA is greater than the high-order halfword in rB; it is cleared otherwise. The next bit in crD is set if the low-order halfword in rA is greater than the low-order halfword in rB and cleared otherwise. The last two bits of crD are set to the OR and AND of the result of the compare of the high and low elements.
Figure 36. Vector compare greater than halfword signed (zvcmpgths)
1.6.3.36 Vector compare greater than halfword unsigned (zvcmpgthu)
zvcmpgthu crD,rA,rB
ahrA32:47alrA48:63bhrB32:47blrB48:63if (ah >ui bh) then ch1else ch0if (al >ui bl) then cl1else cl0CR4*crD:4*crD+3ch || cl || (ch | cl) || (ch & cl)
0 5 6 8 9 10 11 15 16 20 21 31
0 0 0 1 0 0 crD 0 1 rA rB 0 1 0 0 0 1 1 0 0 0 0
0 5 6 8 9 10 11 15 16 20 21 31
0 0 0 1 0 0 crD 0 0 rA rB 0 1 0 0 0 1 1 0 0 0 0
32 47 48 63
rA
rB
> >
crD
OR
AND
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor46

The most significant bit in crD is set if the high-order halfword in rA is greater than the high-order halfword in rB; it is cleared otherwise. The next bit in crD is set if the low-order halfword in rA is greater than the low-order halfword in rB and cleared otherwise. The last two bits of crD are set to the OR and AND of the result of the compare of the high and low elements.
Figure 37. Vector compare greater than halfword unsigned (zvcmpgthu)
1.6.3.37 Vector compare less than halfword signed (zvcmplts)
zvcmplts crD,rA,rB
ahrA32:47alrA48:63bhrB32:47blrB48:63if (ah < bh) then ch1else ch0if (al < bl) then cl1else cl0CR4*crD:4*crD+3ch || cl || (ch | cl) || (ch & cl)
The most significant bit in crD is set if the high-order element of rA is less than the high-order element of rB; it is cleared otherwise. The next bit in crD is set if the low-order element of rA is less than the low-order element of rB and cleared otherwise. The last two bits of crD are set to the OR and AND of the result of the compare of the high and low elements.
0 5 6 8 9 10 11 15 16 20 21 31
0 0 0 1 0 0 crD 0 1 rA rB 0 1 0 0 0 1 1 0 0 0 1
32 47 48 63
rA
rB
> >
crD
OR
AND
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 47

Figure 38. Vector compare less than halfword signed (zvcmplths)
1.6.3.38 Vector compare less than halfword unsigned (zvcmplthu)
zvcmplthu crD,rA,rB
ahrA32:47alrA48:63bhrB32:47blrB48:63if (ah <ui bh) then ch1else ch0if (al <ui bl) then cl1else cl0CR4*crD:4*crD+3ch || cl || (ch | cl) || (ch & cl)
The most significant bit in crD is set if the high-order halfword in rA is less than the high-order halfword in rB; it is cleared otherwise. The next bit in crD is set if the low-order halfword in rA is less than the low-order halfword in rB and cleared otherwise. The last two bits of crD are set to the OR and AND of the result of the compare of the high and low elements.
Figure 39. Vector compare less than halfword unsigned (zvcmplthu)
0 5 6 8 9 10 11 15 16 20 21 31
0 0 0 1 0 0 crD 0 0 rA rB 0 1 0 0 0 1 1 0 0 0 1
32 47 48 63
rA
rB
< <
crD
OR
AND
32 47 48 63
rA
rB
< <
crD
OR
AND
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor48

1.6.3.39 Vector count leading signed bits halfword (zvcntlsh)
zvcntlsh rD,rA
The leading sign bits in each halfword in rA are counted, and the respective count is placed into each halfword in rD. The result is in the range [0,16] inclusive.
Figure 40. Vector count leading signed bits halfword (zvcntlsh)
1.6.3.40 Count leading signed bits word (zcntlsw)
zcntlsw rD,rA
The leading sign bits in rA are counted, and the respective count is placed into of rD. The result is in the range [0,32] inclusive.
cntlzw is used for unsigned operands; zcntlsw is used for signed operands.
Figure 41. Count leading signed bits word (zcntlsw)
1.6.3.41 Vector count leading zeros halfword (zvcntlzh)
zvcntlzh rD,rA
The leading zero bits in each halfword in rA are counted, and the respective count is placed into each halfword in rD. The result is in the range [0,16] inclusive.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 0 0 1 1 1 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 0 0 1 0 1 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 0 0 1 1 0 0 1 0 0 0 1 1 1 1 1 1
32 47 48 63
rA
rD
ssss_sss... ssss_sss...
count of leading signed bits count of leading signed bits
32 63
rA
rD
ssss_sss...
count of leading sign bits
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 49

Figure 42. Vector count leading zeros halfword (zvcntlzh)
1.6.3.42 Divide word signed fractional and saturate (zdivwsf)
zdivwsf rD,rA,rB
dividendrA32:63divisorrB32:63rD32:63dividend sf divisorov0
if (((dividend0 ^ divisor0) = 1) & ((|dividend| > |divisor|) | (divisor = 0))) thenrD32:630x8000_0000ov1
else if (((dividend0 ̂ divisor0) = 0) & & ((|dividend| >= |divisor|) | (divisor = 0))) thenrD32:630x7fff_ffffov1
SPEFSCROVovSPEFSCRSOVSPEFSCRSOV | ov
The dividend in rA is divided by the divisor in rB. The resulting 32-bit quotient is placed into rD. The remainder is not supplied. The operands and quotient are interpreted as signed fractions. The quotient satisfies the equation dividend = (quotient xsf divisor) + remainder, where the sign of the remainder (if non-zero) is the same as the sign of the dividend. The magnitude of the remainder is less than the magnitude of the divisor. If overflow, underflow, or divide by zero occurs, the overflow and summary overflow SPEFSCR bits are set. Note that any overflow indication is always set as a side effect of this instruction. No form is defined that disables the setting of the overflow bits. In case of overflow, a saturated value is delivered into the destination register.
Figure 43. Divide word signed fraction (zdivwsf)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 0 1 0 1 1
32 47 48 63
rA
rD
00000... 00000...
count of leading zeros count of leading zeros
32 63rA (dividend)
rB (divisor)
rA/rB
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor50

1.6.3.43 Vector merge high halfwords (zvmergehih)
zvmergehih rD,rA,rB
rD32:47 rA32:47rD48:63 rB32:47
The high-order halfword elements of rA and rB are merged and placed into rD, as shown in Figure 44.
Figure 44. High order element merging (zvmergehih)
NOTEA vector splat high can be performed by specifying the same register in rA and rB.
1.6.3.44 Vector merge high/low halfwords (zvmergehiloh)
zvmergehiloh rD,rA,rB
rD32:47 rA32:47rD48:63 rB48:63
The high-order halfword in rA and the low-order halfword in rB are merged and placed into rD, as shown in Figure 45.
Figure 45. High order element merging (zvmergehiloh)
NOTEApplication note: With appropriate specification of rA and rB, zvmergehih, zvmergeloh, zvmergehiloh, and zvmergelohih provide a full 32-bit permute of two source operands.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 1 1 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 1 1 1 0
32 47 48 63
rA
rB
rD
32 47 48 63
rA
rB
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 51

1.6.3.45 Vector merge low halfwords (zvmergeloh)
zvmergeloh rD,rA,rB
rD32:47 rA48:63rD48:63 rB48:63
The low-order halfword elements of rA and rB are merged and placed into rD, as shown in Figure 46.
Figure 46. Low order element merging (zvmergeloh)
NOTEA vector splat low can be performed by specifying the same register in rA and rB.
1.6.3.46 Vector merge low/high halfwords (zvmergelohih)
zvmergelohih rD,rA,rB
rD32:47 rA48:63rD48:63 rB32:47
The low-order halfword in rA and the high-order halfword in rB are merged and placed into rD, as shown in Figure 47.
Figure 47. Low order element merging (zvmergelohih)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 1 1 0 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 1 1 1 1
32 47 48 63
rA
rB
rD
32 47 48 63
rA
rB
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor52
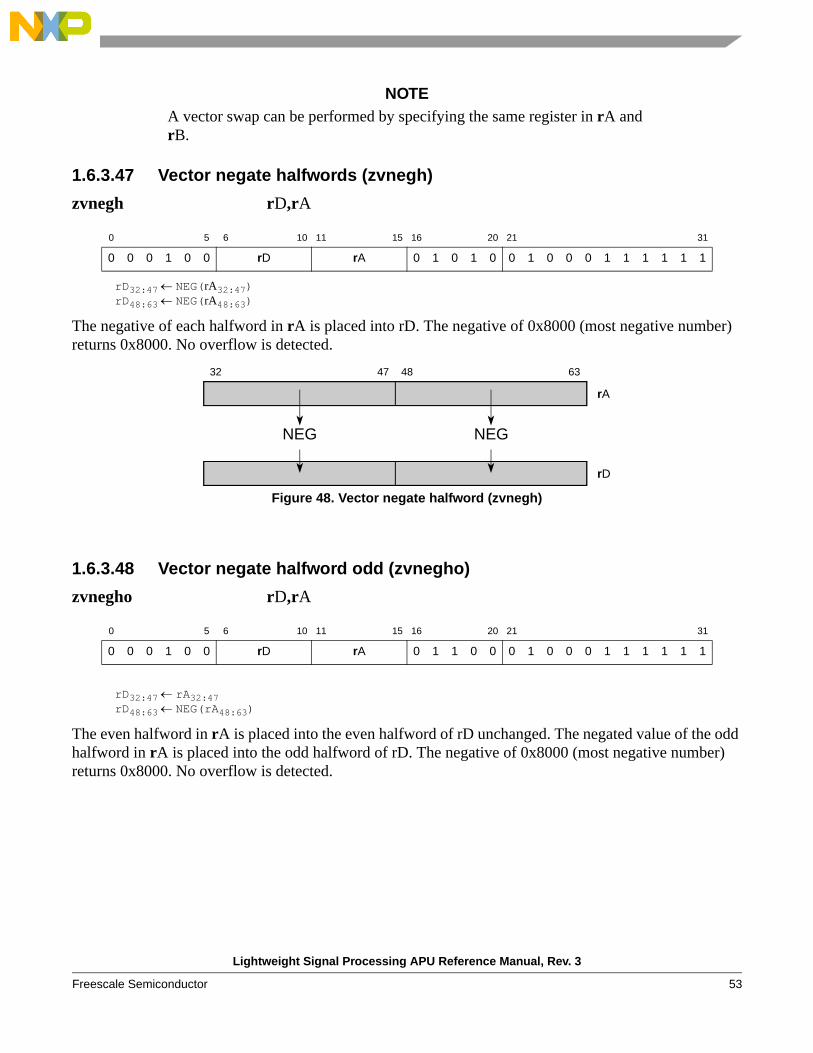
NOTEA vector swap can be performed by specifying the same register in rA and rB.
1.6.3.47 Vector negate halfwords (zvnegh)
zvnegh rD,rA
rD32:47NEG(rA32:47)rD48:63NEG(rA48:63)
The negative of each halfword in rA is placed into rD. The negative of 0x8000 (most negative number) returns 0x8000. No overflow is detected.
Figure 48. Vector negate halfword (zvnegh)
1.6.3.48 Vector negate halfword odd (zvnegho)
zvnegho rD,rA
rD32:47rA32:47rD48:63NEG(rA48:63)
The even halfword in rA is placed into the even halfword of rD unchanged. The negated value of the odd halfword in rA is placed into the odd halfword of rD. The negative of 0x8000 (most negative number) returns 0x8000. No overflow is detected.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 0 1 0 1 0 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 0 1 1 0 0 0 1 0 0 0 1 1 1 1 1 1
32 47 48 63
rA
NEG NEG
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 53

Figure 49. Vector negate halfwords odd (zvnegho)
1.6.3.49 Vector negate halfwords odd and saturate (zvneghos)
zvneghos rD,rA
rD32:47rA32:47
if (rA48:63 = 0x8000) then rD48:630x7FFFov else rD48:63NEG(rA48:63)ov endif
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The even halfword of rA is placed into the even halfword of rD unchanged. The negated value of the odd halfword of rA is placed into the odd halfword of rD. The negative of 0x8000 (most negative number) returns 0x7FFF. Any overflow is reported in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 50. Vector negate halfwords odd and saturate (zvneghos)
1.6.3.50 Vector negate halfword and saturate (zvneghs)
zvneghs rD,rA
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 0 1 1 0 1 0 1 0 0 0 1 1 1 1 1 1
32 47 48 63
rA
NEG
rD
32 47 48 63
rA
NEG&SAT
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor54

if (rA32:47 = 0x8000) thenrD32:470x7FFFovelserD32:47NEG(rA32:47) ovendifif (rA48:63 = 0x8000) then rD48:630x7FFFovelse rD48:63NEG(rA48:63)
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The negative of each halfword in rA is placed into rD. The negative of 0x8000 (most negative number) returns 0x7FFF. Any overflow is reported in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 51. Vector negate halfword and saturate (zvneghs)
1.6.3.51 Negate word and saturate (znegws)
znegws rD,rA
if (rA32:63 = 0x8000_0000) then rD32:630x7FFF_FFFFov else rD32:63 NEG(rA32:63)ov endif
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 0 1 0 1 1 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 0 1 0 0 1 0 1 0 0 0 1 1 1 1 1 1
32 47 48 63
rA
NEG&SAT NEG&SAT
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 55

The negative of the word in rA is placed into rD. The negative of 0x8000_0000 (most negative number) returns 0x7FFF_FFFF. Any overflow is reported in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 52. Negate word and saturate (znegws)
1.6.3.52 Vector pack signed halfwords guarded to word to signed halfwords fractional round and saturate (zvpkshgwshfrs)
zvpkshgwshfrs rD,rA,rB
// h0if (rA32:63 >=si 0x007F_FF80) | (rA32:63 <si 0xFF7F_FF80) then ovh0 temph00:31 SATURATE(ovh0, rA32, 0x0080_0000, 0x007f_ffff, --------)else ovh0 temph00:31 ROUND(rA32:63,8)rD32:47 temph08:23
// h1if (rB32:63 >=si 0x007F_FF80) | (rB32:63 <si 0xFF7F_FF80) then ovh1 temph10:31 SATURATE(ovh1, rB32, 0x0080_0000, 0x007f_ffff, --------)else ovh1 temph10:31 ROUND(rB32:63,8)rD48:63 temph18:23
SPEFSCROV ovh0 | ovh1SPEFSCRSOV SPEFSCRSOV | ovh0 | ovh1
The signed fractional 9.23 format elements in rA and rB are rounded and saturated to 1.15 fractional format. The 16-bit results in 1.15 fractional format are packed into the halfwords of rD. The original values are assumed to be in 9.23 fractional format as a result of one or more guarded to-word halfword fractional operations. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 1 1 0 1 0
32 63
rA
NEG&SAT
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor56

Figure 53. Vector pack signed halfwords guarded to word to signed halfwords fractional round and saturate (zvpkshgwshfrs)
1.6.3.53 Pack signed word guarded to signed halfword fractional round and saturate (zpkswgshfrs)
zpkswgshfrs rD,rA,rB
if ((rA32:63:rB32:63 <si 0xFFFF_7FFF_8000_0000) | (rA32:63:rB32:63 >=si 0x0000_7FFF_8000_0000)) then ov=1templ0:15 SATURATE(ov, rA32, 0x8000, 0x7fff, -----)else ov=0tempr0:63 ROUND(rA32:63:rB32:63, 32)templ0:15 tempr16:31
rD32:63 templ0:15 || 160
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The signed 17.47 format fractional element in rA:rB is saturated to a 1.15 format fractional element, then padded on the right with 16 zeros. The 32-bit result is placed into rD. The original values are assumed to be in 17.47 fractional format as a result of one or more guarded word fractional operations. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 1 1 0 0 0
32 63
rA
32 63
rB
40 41
.
40 41
.
ROUND&SAT
rD
32 48 63
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 57

Figure 54. Pack signed word guarded to signed halfword fractional round and saturate (zpkswgshfrs)
1.6.3.54 Pack signed word guarded to signed word fractional round and saturate (zpkswgswfrs)
zpkswgswfrs rD,rA,rB
if ((rA32:63:rB32:63 <si 0xFFFF_7FFF_FFFF_8000) | (rA32:63:rB32:63 >=si 0x0000_7FFF_FFFF_8000)) then ov=1templ0:31 SATURATE(ov, rA32, 0x8000_0000, 0x7fff_ffff, -----)else ov=0tempr0:63 ROUND(rA32:63:rB32:63, 16)templ0:31 tempr16:47rD32:63 templ0:31
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The signed 17.47 format fractional element in rA:rB is saturated to a 1.31 format fractional element. The 32-bit result is placed into rD. The original values are assumed to be in 17.47 fractional format as a result of one or more guarded word fractional operations. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 1 1 0 0 1
32 63
rA
rD
32 63
32 63
rB
47 48 49
.
ROUND&SAT
0000_0000_0000_0000
47 48
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor58

Figure 55. Pack signed word guarded to signed word fractional round and saturate (zpkswgswfrs)
1.6.3.55 Vector pack signed words to signed halfwords fractional, round and saturate (zvpkswshfrs)
zvpkswshfrs rD,rA,rB
if (rA32:63 >=si 0x7FFF_8000) then ovh0 1; temph00:15 0x7FFF else ovh0 0; tempr0:63 ROUND(EXTS64(rA32:63),16); temph00:15 tempr32:47rD32:47 temph00:15
if (rB32:63 >=si 0x7FFF_8000) then ovh1 1; temph10:15 0x7FFF else ovh1 0; tempr0:63 ROUND(EXTS64(rB32:63),16); temph10:15 tempr32:47rD48:63 temph30:15
ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The signed 32-bit fractional elements in rA and rB are rounded and saturated to 16 bits. The 16-bit results are packed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 1 1 0 1 1
32 63
rA
rD
32 63
32 63
rB
47 48 49
.
ROUND&SAT
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 59

Figure 56. Vector pack signed words to signed halfwords fractional, round and saturate (zvpkswshfrs)
1.6.3.56 Vector pack signed words to signed halfwords and saturate (zvpkswshs)
zvpkswshs rD,rA,rB
// h0if ((rA32:63 <si 0xFFFF8000) | (rA32:63 >si 0x00007FFF)) then ovh0=1 else ovh1=0;rD32:47 SATURATE(ovh0, rA32, 0x8000, 0x7fff, rA48:63)
// h1if ((rB32:63 <si 0xFFFF8000) | (rB32:63 >si 0x00007FFF)) then ovh1=1 else ovh1=0;rD48:63 SATURATE(ovh3, rB32, 0x8000, 0x7fff, rB48:63)
ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The signed 32-bit integer elements in rA and rB are saturated to 16 bits. The 16-bit results are packed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 1 1 1 0 1
32 63
rA
rD
32 47 48 63
32 63
rB
RND & SATRND & SAT
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor60

Figure 57. Vector pack signed words to signed halfwords and saturate (zvpkswshs)
1.6.3.57 Vector pack signed words to unsigned halfwords and saturate (zvpkswuhs)
zvpkswuhs rD,rA,rB
// h0if ((rA32:63 <si 0x00000000) | (rA32:63 >si 0x0000FFFF)) then ovh0=1 else ovh0=0;rD32:47 SATURATE(ovh0, rA32, 0x0000, 0xFFFF, rA48:63)
// h1if ((rB32:63 <si 0x00000000) | (rB32:63 >si 0x0000FFFF)) then ovh1=1 else ovh1=0;rD48:63 SATURATE(ovh1, rB32, 0x0000, 0xFFFF, rB48:63)
ov ovh0 | ovh1
SPEFSCROV ovlSPEFSCRSOV SPEFSCRSOV | ov
The signed 32-bit integers in rA and rB are saturated to 16-bit unsigned halfword elements. Negative values saturate to 0. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 1 1 1 0 0
32 63
rA
rD
32 47 48 63
32 63
rB
SATSAT
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 61

Figure 58. Vector pack signed words to unsigned halfwords and saturate (zvpkswuhs)
1.6.3.58 Vector pack unsigned words to unsigned halfwords and saturate (zvpkuwuhs)
zvpkuwuhs rD,rA,rB
// h0if ((rA32:63 >ui 0x0000FFFF) then ovh0=1 else ovh0=0;rD32:47 SATURATE(ovh0, 0, ------, 0xFFFF, rA48:63)
// h1if ((rB32:63 >ui 0x0000FFFF) then ovh1=1 else ovh1=0;rD48:63 SATURATE(ovh1, 0, ------, 0xFFFF, rB48:63)
ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The unsigned 32-bit integers in rA and rB are saturated to 16 bits. The 16-bit unsigned results are packed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 1 1 1 1 0
32 63
rA
rD
32 47 48 63
32 63
rB
SATSAT
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor62
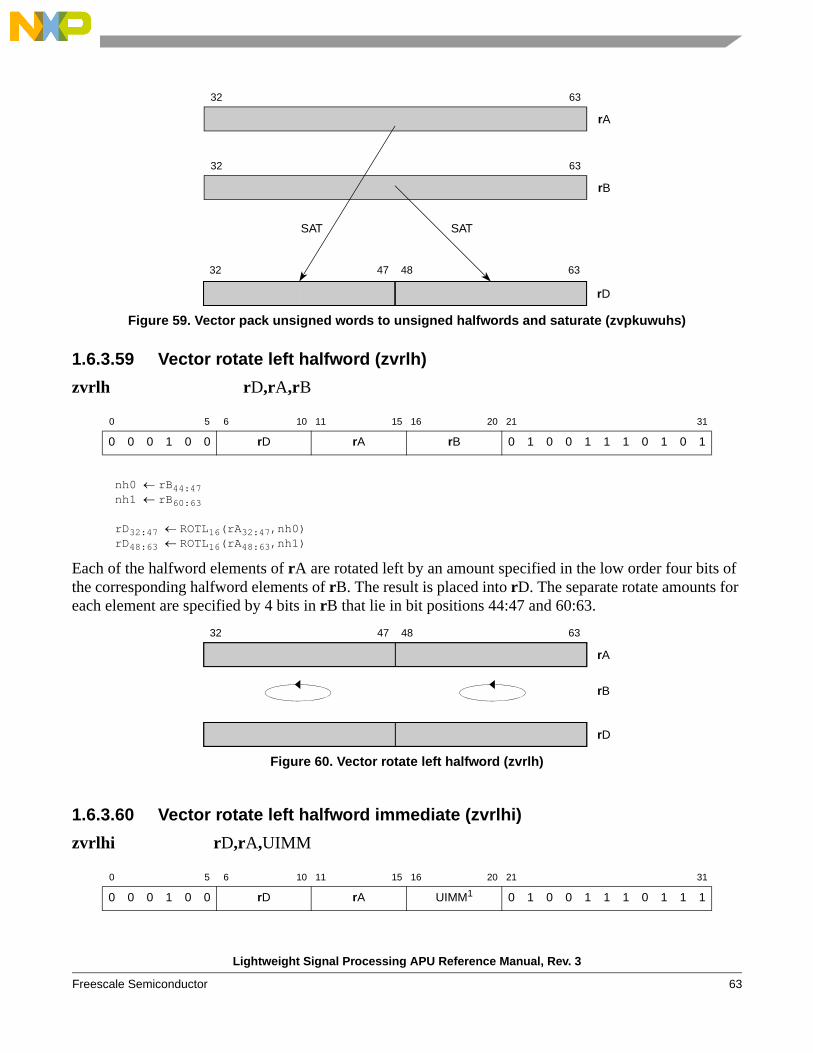
Figure 59. Vector pack unsigned words to unsigned halfwords and saturate (zvpkuwuhs)
1.6.3.59 Vector rotate left halfword (zvrlh)
zvrlh rD,rA,rB
nh0 rB44:47nh1 rB60:63
rD32:47 ROTL16(rA32:47,nh0)rD48:63 ROTL16(rA48:63,nh1)
Each of the halfword elements of rA are rotated left by an amount specified in the low order four bits of the corresponding halfword elements of rB. The result is placed into rD. The separate rotate amounts for each element are specified by 4 bits in rB that lie in bit positions 44:47 and 60:63.
Figure 60. Vector rotate left halfword (zvrlh)
1.6.3.60 Vector rotate left halfword immediate (zvrlhi)
zvrlhi rD,rA,UIMM
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 1 0 1 0 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA UIMM1 0 1 0 0 1 1 1 0 1 1 1
32 63
rA
rD
32 47 48 63
32 63
rB
SATSAT
32 47 48 63
rA
rB
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 63

n UIMM
rD32:47 ROTL16(rA32:47,n)rD48:63 ROTL16(rA48:63,n)
Each of the halfword elements of rA are rotated left by the 5-bit immediate value specified in UIMM. The result is placed into rD.
Figure 61. Vector rotate left halfword immediate (zvrlhi)
1.6.3.61 Round word to halfword (zrndwh)
zrndwh rD,rA
rD32:63 (rA32:63 + 0x0000_8000) & 0xFFFF_0000 // Modulo sum
The 32-bit word in rA is rounded into 16 bits. The resulting 16 bits are placed in the most significant 16 bits of rD, zeroing out the low order 16 bits.
Figure 62. Round word to halfword (zrndwh)
1.6.3.62 Round word to halfword signed and saturate (zrndwhss)
zrndwhss rD,rA
if (rA32:63 >=si 0x7FFF_8000) then templ0:31 = 0x7FFF_0000; ov 1else templ0:31 = (rA32:63 + 0x0000_8000); ov 0
1 UIMM values >15 are illegal
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 0 0 0 0 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 0 0 0 1 0 1 0 0 0 1 1 1 1 1 1
32 47 48 63
rA
UIMM
rD
32 63
rA
rD
32 47 48 63
ROUND
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor64

rD32:63 templ0:31 & 0xFFFF_0000
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The signed 32-bit word in rA is rounded with saturation into 16 bits. The 16-bit result is placed in the most significant 16 bits of rD, zeroing out the low order 16 bits of rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 63. Round word to halfword signed and saturate (zrndwhss)
1.6.3.63 Saturate signed doubleword to signed word range (zsatsdsw)
zsatsdsw rD,rA,rB
temp0:63 rA32:63rB32:63if ((temp0:63 <si 0xFFFF_FFFF_8000_0000) | (temp0:63 >si 0x0000_0000_7FFF_FFFF)) then ov=1 else ov=0;rD32:63 SATURATE(ov, rA32, 0x8000_0000, 0x7fff_ffff, rB32:63)
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov.
The signed 64-bit value in rA:rB is saturated to a 32-bit signed value and placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 64. Saturate signed doubleword to signed word range (zsatsdsw)
1.6.3.64 Saturate signed doubleword to unsigned word range (zsatsduw)
zsatsduw rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 0 0 0 0 1
32 63
rA
rD
32 47 48 63
ROUND & SAT
0 63
rA : rB
rD
32 63
Saturate value to signed-word range
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 65

temp0:63 rA32:63rB32:63if ((temp0:63 <si 0x0000_0000_0000_0000) | (temp0:63 >si 0x0000_0000_FFFF_FFFF)) then ov=1 else ov=0;rD32:63 SATURATE(ov, rA32, 0x0000_0000, 0xFFFF_FFFF, rB32:63)
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov.
The signed 64-bit value in rA:rB is saturated to a 32-bit unsigned value and placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 65. Saturate signed doubleword to unsigned word range (zsatsduw)
1.6.3.65 Vector saturate signed halfwords to unsigned halfword range (zvsatshuh)
zvsatshuh rD,rA
// h0if (rA32:47 <si 0x0000) then ovh0=1 else ovh0=0;rD32:47 SATURATE(ovh0, 0, ------, 0x0000, rA32:47)
// h1if (rA48:63 <si 0x0000) then ovh1=1 else ovh1=0;rD48:63 SATURATE(ovh1, 0, ------, 0x0000, rA48:63)
ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The signed 16-bit elements of rA are saturated to 16-bit unsigned values. Negative elements saturate to 0. The 16-bit results are placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 0 0 0 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 1 1 0 0 0 1 0 0 0 1 1 1 1 1 1
0 63
rA : rB
rD
32 63
Saturate value to unsigned-word range
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor66
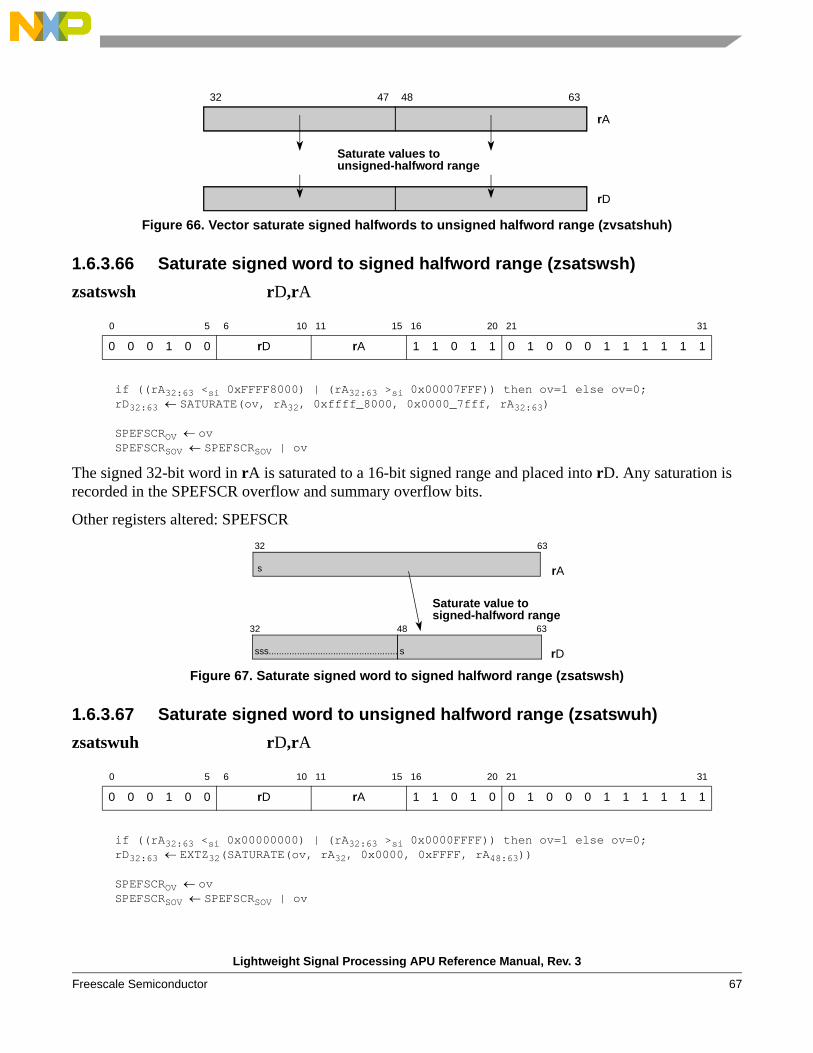
Figure 66. Vector saturate signed halfwords to unsigned halfword range (zvsatshuh)
1.6.3.66 Saturate signed word to signed halfword range (zsatswsh)
zsatswsh rD,rA
if ((rA32:63 <si 0xFFFF8000) | (rA32:63 >si 0x00007FFF)) then ov=1 else ov=0;rD32:63 SATURATE(ov, rA32, 0xffff_8000, 0x0000_7fff, rA32:63)
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The signed 32-bit word in rA is saturated to a 16-bit signed range and placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 67. Saturate signed word to signed halfword range (zsatswsh)
1.6.3.67 Saturate signed word to unsigned halfword range (zsatswuh)
zsatswuh rD,rA
if ((rA32:63 <si 0x00000000) | (rA32:63 >si 0x0000FFFF)) then ov=1 else ov=0;rD32:63 EXTZ32(SATURATE(ov, rA32, 0x0000, 0xFFFF, rA48:63))
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 1 0 1 1 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 1 0 1 0 0 1 0 0 0 1 1 1 1 1 1
32 47 48 63
rA
rD
Saturate values to unsigned-halfword range
32 48 63
rD
63
rA
sss.................................................. s
Saturate value to signed-halfword range
32
s
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 67

The signed 32-bit word in rA is saturated to a 16-bit unsigned value. Negative values in rA saturate to 0. The 16-bit unsigned value is zero-extended to 32 bits and placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 68. Saturate signed word to unsigned halfword range (zsatswuh)
1.6.3.68 Saturate signed word to unsigned word range (zsatswuw)
zsatswuw rD,rA
if (rA32:63 <si 0x00000000) then ov=1 else ov=0;rD32:63 SATURATE(ov, 0, ----------, 0x0000_0000, rA32:63)
SPEFSCROV ov
SPEFSCRSOV SPEFSCRSOV | ov
The signed 32-bit word in rA is saturated to a 32-bit unsigned value. Negative values in rA saturate to 0. The result is placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 69. Saturate signed word to unsigned word range (zsatswuw)
1.6.3.69 Saturate unsigned doubleword to unsigned word range (zsatuduw)
zsatuduw rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 1 0 0 0 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 0 0 0 1 0
32 48 63
rD
63
rA
Saturate value to unsigned-halfword range
32
32 63
rD
32 63
rA
z
Saturate value to unsigned-word range
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor68

if (rA32:63 != 0x0000_0000) then ov=1 else ov=0;rD32:63 SATURATE(ov, 0, ----------, 0xffff_ffff, rB32:63)
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The unsigned 64-bit element in rA || rB is saturated to 32 bits. The 32-bit result is placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 70. Saturate unsigned doubleword to unsigned word range (zsatuduw)
1.6.3.70 Vector saturate unsigned halfword to signed halfword range (zvsatuhsh)
zvsatuhsh rD,rA
// h0if ((rA32:47 >ui 0x00007FFF) then ovh0=1 else ovh0=0;rD32:47 SATURATE(ovh0, 0, ------, 0x7FFF, rA32:47)
// h1if (rA48:63 >ui 0x00007FFF) then ovh1=1 else ovh1=0;rD48:63 SATURATE(ovh1, 0, ------, 0x7FFF, rA48:63)
ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The unsigned 16-bit elements of rA are saturated to 16-bit signed values. The 16-bit results are placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 1 1 0 1 0 1 0 0 0 1 1 1 1 1 1
0 63
rA || rB
rD
32 63
Saturate value to unsigned-word range
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 69
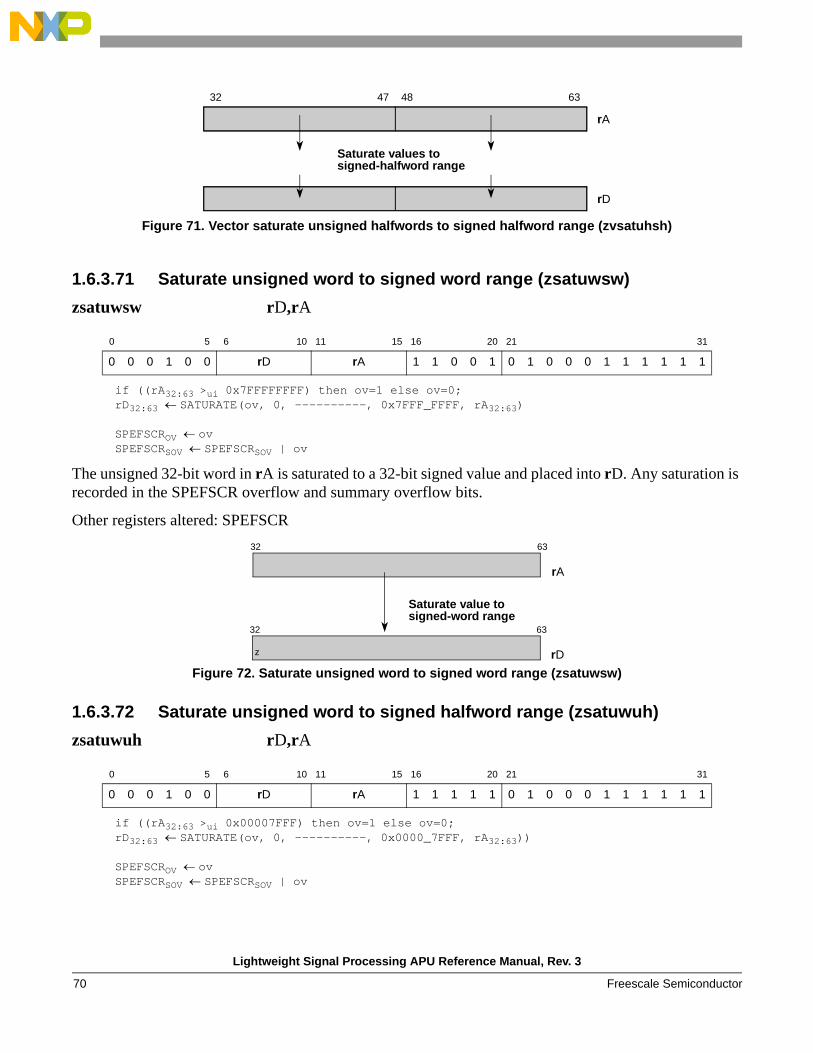
Figure 71. Vector saturate unsigned halfwords to signed halfword range (zvsatuhsh)
1.6.3.71 Saturate unsigned word to signed word range (zsatuwsw)
zsatuwsw rD,rA
if ((rA32:63 >ui 0x7FFFFFFFF) then ov=1 else ov=0;rD32:63 SATURATE(ov, 0, ----------, 0x7FFF_FFFF, rA32:63)
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The unsigned 32-bit word in rA is saturated to a 32-bit signed value and placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 72. Saturate unsigned word to signed word range (zsatuwsw)
1.6.3.72 Saturate unsigned word to signed halfword range (zsatuwuh)
zsatuwuh rD,rA
if ((rA32:63 >ui 0x00007FFF) then ov=1 else ov=0;rD32:63 SATURATE(ov, 0, ----------, 0x0000_7FFF, rA32:63))
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 1 0 0 1 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 1 1 1 1 0 1 0 0 0 1 1 1 1 1 1
32 47 48 63
rA
rD
Saturate values to signed-halfword range
32 63
rD
32 63
rA
z
Saturate value to signed-word range
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor70
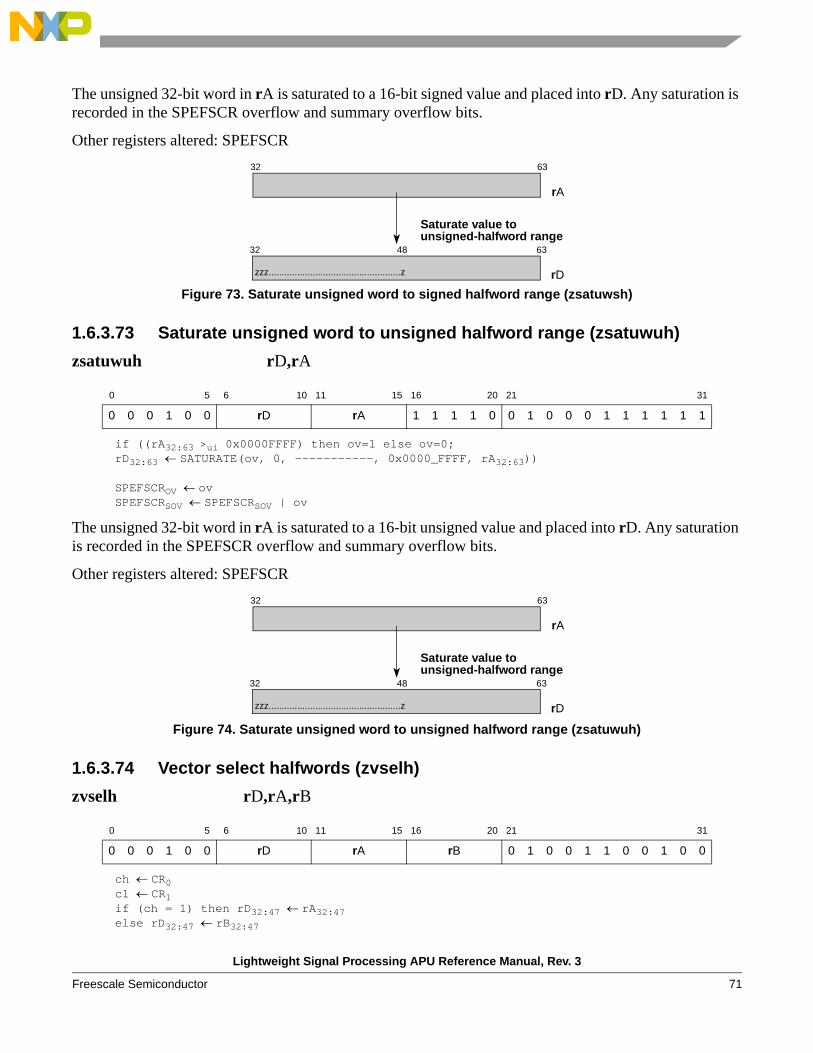
The unsigned 32-bit word in rA is saturated to a 16-bit signed value and placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 73. Saturate unsigned word to signed halfword range (zsatuwsh)
1.6.3.73 Saturate unsigned word to unsigned halfword range (zsatuwuh)
zsatuwuh rD,rA
if ((rA32:63 >ui 0x0000FFFF) then ov=1 else ov=0;rD32:63 SATURATE(ov, 0, -----------, 0x0000_FFFF, rA32:63))
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The unsigned 32-bit word in rA is saturated to a 16-bit unsigned value and placed into rD. Any saturation is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 74. Saturate unsigned word to unsigned halfword range (zsatuwuh)
1.6.3.74 Vector select halfwords (zvselh)
zvselh rD,rA,rB
ch CR0cl CR1if (ch = 1) then rD32:47 rA32:47else rD32:47 rB32:47
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA 1 1 1 1 0 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 0 0 1 0 0
32 48 63
rD
32 63
rA
zzz...................................................z
Saturate value to unsigned-halfword range
32 48 63
rD
32 63
rA
zzz...................................................z
Saturate value to unsigned-halfword range
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 71
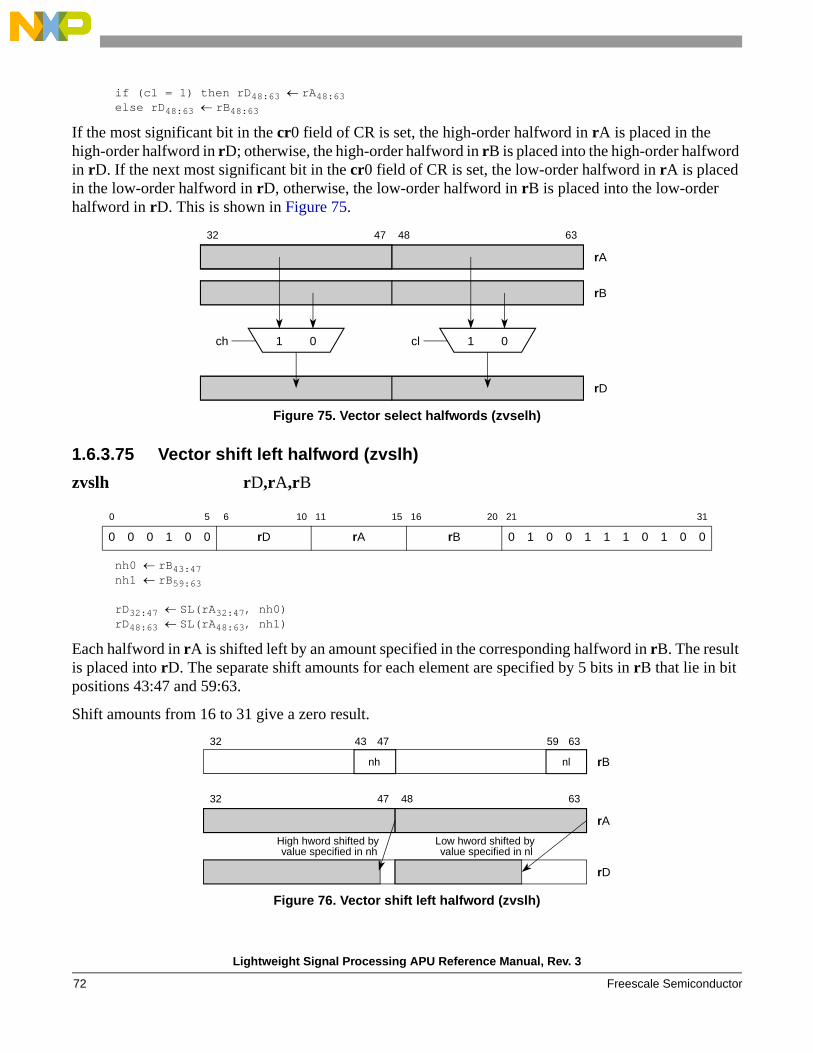
if (cl = 1) then rD48:63 rA48:63else rD48:63 rB48:63
If the most significant bit in the cr0 field of CR is set, the high-order halfword in rA is placed in the high-order halfword in rD; otherwise, the high-order halfword in rB is placed into the high-order halfword in rD. If the next most significant bit in the cr0 field of CR is set, the low-order halfword in rA is placed in the low-order halfword in rD, otherwise, the low-order halfword in rB is placed into the low-order halfword in rD. This is shown in Figure 75.
Figure 75. Vector select halfwords (zvselh)
1.6.3.75 Vector shift left halfword (zvslh)
zvslh rD,rA,rB
nh0 rB43:47nh1 rB59:63
rD32:47 SL(rA32:47, nh0)rD48:63 SL(rA48:63, nh1)
Each halfword in rA is shifted left by an amount specified in the corresponding halfword in rB. The result is placed into rD. The separate shift amounts for each element are specified by 5 bits in rB that lie in bit positions 43:47 and 59:63.
Shift amounts from 16 to 31 give a zero result.
Figure 76. Vector shift left halfword (zvslh)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 1 0 1 0 0
32 47 48 63
rA
rB
rD
clch 1 0 01
32 47 48 63
rA
rB
rD
nh nl
32 47 6343 59
High hword shifted by value specified in nh
Low hword shifted by value specified in nl
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor72

1.6.3.76 Vector shift left halfword immediate (zvslhi)
zvslhi rD,rA,UIMM
n UIMM
rD32:47 SL(rA32:47, n)rD48:63 SL(rA48:63, n)
Each halfword in rA is shifted left by the UIMM (range of 0–15) value and the results are placed into rD.
Figure 77. Vector shift left halfword (zvslhi)
1.6.3.77 Vector shift left halfword signed and saturate (zvslhss)
zvslhss rD,rA,rB
nh0 rB43:47nh1 rB59:63if rB43=0 then mask0 MASKSS16(nh0) else mask0 161if rB59=0 then mask1 MASKSS16(nh1) else mask1 161
// h0if (rA32:47 & mask0) != (
16rA32 & mask0) then ovh1 else ovh0if (rB43=1 & (rA32:47 != 0x0000)) then ovh1
temp32:47 SATURATE(ovh, rA32, 0x8000, 0x7fff, SL(rA32:47, nh0))// h1if (rA48:63 & mask1) != (
16rA48 & mask1) then ovl1 else ovl0if (rB59=1 & (rA48:63 != 0x0000)) then ovl1
temp48:63 SATURATE(ovl, rA48, 0x8000, 0x7fff, SL(rA48:63, nh1))
rD32:63 temp32:63ov ovh | ovl
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
Each halfword in rA is shifted left by an amount specified in the corresponding halfword in rB. Overflow occurs if any bits are shifted out which differ from the sign bit of the original halfword or if the sign of the
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA UIMM1
1 UIMM values >15 are illegal
0 1 0 0 1 1 1 0 1 1 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 1 1 0 0 1
32 47 48 63
rA
rD
High and low halfwords shifted by UIMM value
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 73

intermediate result value differs from the sign bit of the original halfword, and the result is then saturated to the most positive or negative signed halfword value. The results are placed into rD. The separate shift amounts for each element are specified by 5 bits in rB that lie in bit positions 43:47 and 59:63. Shift amounts from 16 to 31 result in overflow unless the original operand is 0x0000.
Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 78. Vector shift left halfword signed and saturate (zvslhss)
1.6.3.78 Vector shift left halfword immediate signed and saturate (zvslhiss)
zvslhiss rD,rA,UIMM
n UIMM
mask MASKSS16(n)
// h0if (rA32:47 & mask) != (
16rA32 & mask) then ovh1 else ovh0temp32:47 SATURATE(ovh, rA32, 0x8000, 0x7fff, SL(rA32:47, n))// h1if (rA48:63 & mask) != (
16rA48 & mask) then ovl1 else ovl0temp48:63 SATURATE(ovl, rA48, 0x8000, 0x7fff, SL(rA48:63, n))
rD32:63 temp32:63ov ovh | ovl
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
Each halfword in rA is shifted left by the UIMM (range of 0–15) value. Overflow occurs if any bits are shifted out which differ from the sign bit of the original halfword or if the sign of the intermediate result value differs from the sign bit of the original halfword, and the result is saturated. The results are placed into rD.
Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA UIMM1
1 UIMM values >15 are illegal
0 1 0 0 1 1 1 1 0 1 1
32 47 48 63
rA
rB
rD
nh nl
32 47 6343 59
High hword shifted by value specified in nh, with saturate
Low hword shifted by value specified in nl, with saturate
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor74

Figure 79. Vector shift left halfword immediate signed and saturate (zvslhiss)
1.6.3.79 Vector shift left halfword unsigned and saturate (zvslhus)
zvslhus rD,rA,rB
nh0 rB43:47nh1 rB59:63if rB43=0 then mask0 MASKUS16(nh0) else mask0 161if rB59=0 then mask1 MASKUS16(nh1) else mask1 161
// h0if (rA32:47 & mask0) !=
160 then ovh1 else ovh0temp48:63 SATURATE(ovh, 0, ------, 0xffff, SL(rA32:47, nh0))
// h1if (rA48:63 & mask1) !=
160 then ovl1 else ovl0temp48:63 SATURATE(ovl, 0, ------, 0xffff, SL(rA48:63, nh1))
rD32:63 temp32:63ov ovh | ovl
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
Each halfword in rA is shifted left by an amount specified in the corresponding halfword in rB. Overflow occurs if any 1 bits are shifted out, and the result is saturated to the most positive unsigned halfword value (0xffff). The results are placed into rD. The separate shift amounts for each element are specified by 5 bits in rB that lie in bit positions 43:47 and 59:63. Shift amounts from 16 to 31 give a zero result.
Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 80. Vector shift left halfword unsigned and saturate (zvslhus)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 1 1 0 0 0
32 47 48 63
rA
rD
High and low halfwords shifted by UIMM value with saturate
32 47 48 63
rA
rB
rD
nh nl
32 47 6343 59
High hword shifted by value specified in nh, with saturate
Low hword shifted by value specified in nl, with saturate
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 75

1.6.3.80 Vector shift left halfword immediate unsigned and saturate (zvslhius)
zvslhius rD,rA,UIMM
n UIMM
mask MASKUS16(n)
// h0if (rA32:47 & mask) !=
160 then ovh1 else ovh0temp48:63 SATURATE(ovh, 0, ------, 0xffff, SL(rA32:47, n))
// h1if (rA48:63 & mask) !=
160 then ovl1 else ovl0temp48:63 SATURATE(ovl, 0, ------, 0xffff, SL(rA48:63, n))
rD32:63 temp32:63ov ovh | ovl
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
Each halfword in rA is shifted left by the UIMM (range of 0-15) value. Overflow occurs if any 1 bits are shifted out, and the result is saturated to the most positive unsigned halfword value (0xffff). The results are placed into rD.
Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 81. Vector shift left halfword immediate unsigned and saturate (zvslhius)
1.6.3.81 Shift left word signed and saturate (zslwss)
zslwss rD,rA,rB
n rB58:63if rB58=0 then mask MASKSS32(n) else mask 321
if (rA32:63 & mask) != (32rA32 & mask) then ov1 else ov0
if rB58=1 & rA32:63 != 0x0000_0000 then ov1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA UIMM1
1 UIMM values >15 are illegal
0 1 0 0 1 1 1 1 0 1 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 1 1 1 0 1
32 47 48 63
rA
rD
High and low halfwords shifted by UIMM value with saturate
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor76

temp32:63 SATURATE(ov, rA32, 0x8000_0000, 0x7fff_ffff, SL(rA32:63, n))
rD32:63 temp32:63SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The value in rA is shifted left by ‘n’ bit positions specified in rB58:63, filling vacated bit positions with zeros. Overflow occurs if any bits are shifted out which differ from the sign bit of the original value or if the sign of the intermediate result value differs from the sign bit of the original value, and the result is saturated. The result is placed into rD. Shift amounts from 32 to 63 result in overflow unless the original operand is 0x0000_0000.
Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 82. Shift left word signed and saturate (zslwss)
1.6.3.82 Shift left word immediate signed and saturate (zslwiss)
zslwiss rD,rA,UIMM
n UIMMmask MASKSS32(n)
if (rA32:63 & mask) != (32rA32 & mask) then ov1 else ov0
temp32:63 SATURATE(ov, rA32, 0x8000_0000, 0x7fff_ffff, SL(rA32:63,n))
rD32:63 temp32:63
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The value in rA is shifted left by the UIMM (range of 0–15) value, filling vacated bit positions with zeros. Overflow occurs if any bits are shifted out which differ from the sign bit of the original value or if the sign
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA UIMM 0 1 0 0 1 1 1 1 1 1 1
Bits shifted by value specified in rB58:63
32 63rD
32 63rA
00..0
32 63rB
58
n//
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 77

of the intermediate result value differs from the sign bit of the original value, and the result is saturated. The result is placed into rD.
Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 83. Shift left word immediate signed and saturate (zslwiss)
1.6.3.83 Shift left word unsigned and saturate (zslwus)
zslwus rD,rA,rB
n rB58:63if rB58=0 then mask MASKUS32(n) else mask 321
if (rA32:63 & mask) != 320 then ov1 else ov0
temp32:63 SATURATE(ov, 0, ----------, 0xffff_ffff, SL(rA32:63,n))
rD32:63 temp32:63SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The value in rA is shifted left by an amount specified in bits 58:63 of rB. Overflow occurs if any 1 bits are shifted out, and the result is saturated. The results are placed into rD. Shift amounts from 32 to 63 result in overflow unless the original operand is 0x0000_0000.
Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 1 1 1 0 0
Bits shifted by UIMM value
32 63rD
32 63rA
00..0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor78
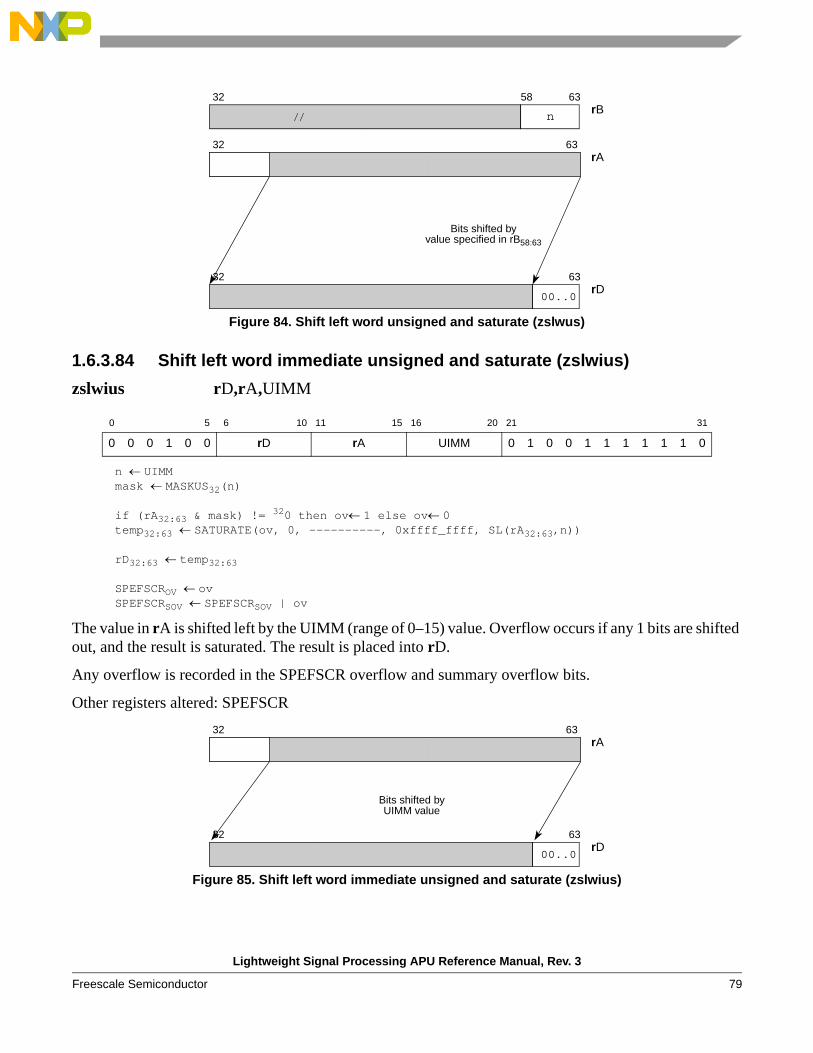
Figure 84. Shift left word unsigned and saturate (zslwus)
1.6.3.84 Shift left word immediate unsigned and saturate (zslwius)
zslwius rD,rA,UIMM
n UIMMmask MASKUS32(n)
if (rA32:63 & mask) != 320 then ov1 else ov0
temp32:63 SATURATE(ov, 0, ----------, 0xffff_ffff, SL(rA32:63,n))
rD32:63 temp32:63
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The value in rA is shifted left by the UIMM (range of 0–15) value. Overflow occurs if any 1 bits are shifted out, and the result is saturated. The result is placed into rD.
Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 85. Shift left word immediate unsigned and saturate (zslwius)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA UIMM 0 1 0 0 1 1 1 1 1 1 0
Bits shifted by value specified in rB58:63
32 63rD
32 63rA
00..0
32 63rB
58
n//
Bits shifted by UIMM value
32 63rD
32 63rA
00..0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 79
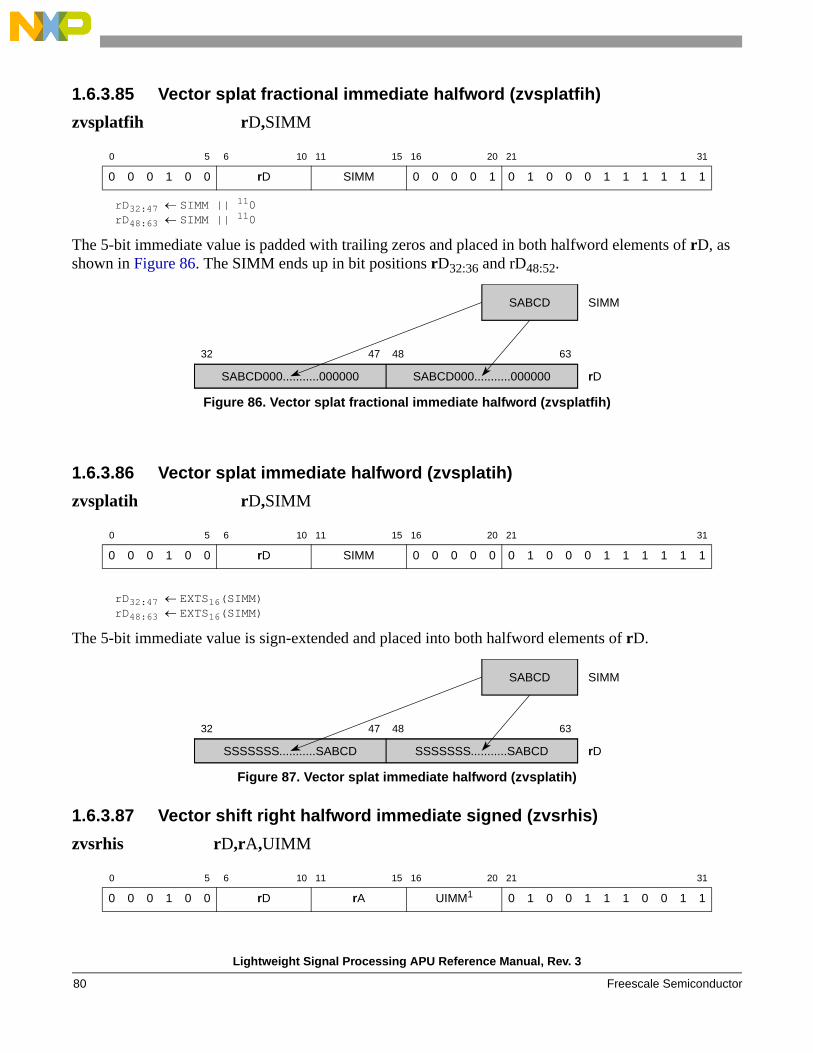
1.6.3.85 Vector splat fractional immediate halfword (zvsplatfih)
zvsplatfih rD,SIMM
rD32:47 SIMM || 110rD48:63 SIMM || 110
The 5-bit immediate value is padded with trailing zeros and placed in both halfword elements of rD, as shown in Figure 86. The SIMM ends up in bit positions rD32:36 and rD48:52.
Figure 86. Vector splat fractional immediate halfword (zvsplatfih)
1.6.3.86 Vector splat immediate halfword (zvsplatih)
zvsplatih rD,SIMM
rD32:47 EXTS16(SIMM)rD48:63 EXTS16(SIMM)
The 5-bit immediate value is sign-extended and placed into both halfword elements of rD.
Figure 87. Vector splat immediate halfword (zvsplatih)
1.6.3.87 Vector shift right halfword immediate signed (zvsrhis)
zvsrhis rD,rA,UIMM
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD SIMM 0 0 0 0 1 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD SIMM 0 0 0 0 0 0 1 0 0 0 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA UIMM1 0 1 0 0 1 1 1 0 0 1 1
SIMM
rD
32 47 48 63
SABCD
SABCD000...........000000 SABCD000...........000000
SIMM
rD
32 47 48 63
SABCD
SSSSSSS...........SABCD SSSSSSS...........SABCD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor80

n UIMMrD32:47 EXTS16(rA32:47-n)rD48:63 EXTS16(rA48:63-n)
Each of the halfword elements of rA are shifted right by the UIMM (range of 0–15) value. Bits in the most significant positions vacated by the shift are filled with a copy of the sign bit.
Figure 88. Vector shift right halfword immediate signed (zvsrhis)
1.6.3.88 Vector shift right halfword immediate unsigned (zvsrhiu)
zvsrhiu rD,rA,UIMM
n UIMM
rD32:47 EXTZ16(rA32:47-n)rD48:63 EXTZ16(rA48:63-n)
Each of the halfword elements of rA are shifted right by the UIMM (range of 0–15) value. Bits in the most significant positions vacated by the shift are filled with zeros.
Figure 89. Vector shift right halfword immediate unsigned (zvsrhiu)
1.6.3.89 Vector shift right halfword signed (zvsrhs)
zvsrhs rD,rA,rB
nh0 rB43:47nh1 rB59:63
rD32:47 EXTS16(rA32:47-nh0)rD48:63 EXTS16(rA48:63-nh1)
1 UIMM values >15 are illegal
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA UIMM1
1 UIMM values >15 are illegal
0 1 0 0 1 1 1 0 0 1 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 1 0 0 0 1
32 47 48 63
rA
rD
High and low halfwords shifted by UIMM value
s
sss
s
sss
32 47 48 63
rA
rD
High and low halfwords shifted by UIMM value
0000
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 81

Each of the halfword elements of rA are shifted right by an amount specified in the corresponding halfword elements of rB. The result is placed into rD. The separate shift amounts for each element are specified by 5 bits in rB that lie in bit positions 43:47 and 59:63. Bits in the most significant positions vacated by the shift are filled with a copy of the sign bit
Shift amounts from 16 to 31 give a result of 16 sign bits.
Figure 90. Vector shift right halfword signed (zvsrhs)
1.6.3.90 Vector shift right halfword unsigned (zvsrhu)
zvsrhu rD,rA,rB
nh0 rB43:47nh1 rB59:63
rD32:47 EXTZ16(rA32:47-nh0)rD48:63 EXTZ16(rA48:63-nh1)
Each of the halfword elements of rA are shifted right by an amount specified in the corresponding halfword elements of rB. The result is placed into rD. The separate shift amounts for each element are specified by 5 bits in rB that lie in bit positions 43:47 and 59:63. Bits in the most significant positions vacated by the shift are filled with zeros.
Shift amounts from 16 to 31 give a zero result.
Figure 91. Vector shift right halfword unsigned (zvsrhu)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 1 0 0 0 0
32 47 48 63
rA
rB
rD
nh nl
32 47 48 6343 59
Low hword shifted by value specified in nl
High hword shifted by value specified in nh
s
sss............ss
s
sss
32 47 48 63
rA
rB
rD
nh nl
32 47 48 6343 59
low hword shifted by value specified in nl
high hword shifted by value specified in nh
00............0 00
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor82

1.6.3.91 Vector subtract from / add halfwords (zvsubfaddh)
zvsubfaddh rD,rA,rB
rD32:47rB32:47 - rA32:47// Modulo difference, rB - rArD48:63rB48:63+ rA48:63// Modulo sum
The even halfword in rA is subtracted from the even halfword in rB, the odd halfword in rA is added to the odd halfword elements of rB, and the results are placed into rD. The sum and difference are modulo.
T
Figure 92. Vector subtract from / add halfwords (zvsubfaddh)
1.6.3.92 Vector subtract from / add halfwords signed and saturate (zvsubfaddhss)
zvsubfaddhss rD,rA,rB
// h0temp0:31 EXTS32(rB32:47) - EXTS32(rA32:47)ovh0 temp15 temp16rD32:47 SATURATE(ovh0, temp15, 0x8000, 0x7fff, temp16:31)// h1temp0:31 EXTS32(rB48:63) + EXTS32(rA48:63)ovh1 temp15 temp16rD48:63 SATURATE(ovh1, temp15, 0x8000, 0x7fff, temp16:31)ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The even signed halfword of rA is subtracted from the even signed halfword of rB, the odd signed halfword of rA is added to the odd signed halfword of rB, saturating if positive or negative overflow occurs, and the results are placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 0 0 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 1 0 1 1
32 47 48 63
rB
rA
– +
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 83
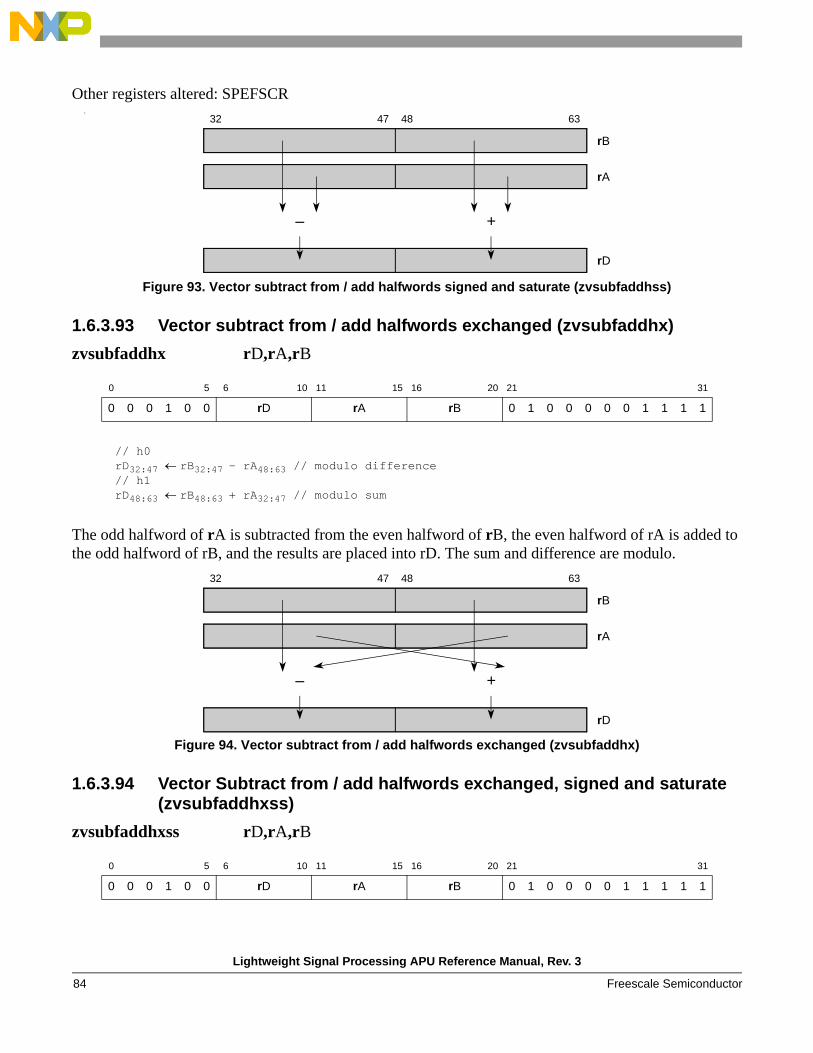
Other registers altered: SPEFSCR T
Figure 93. Vector subtract from / add halfwords signed and saturate (zvsubfaddhss)
1.6.3.93 Vector subtract from / add halfwords exchanged (zvsubfaddhx)
zvsubfaddhx rD,rA,rB
// h0rD32:47 rB32:47 - rA48:63 // modulo difference// h1rD48:63 rB48:63 + rA32:47 // modulo sum
The odd halfword of rA is subtracted from the even halfword of rB, the even halfword of rA is added to the odd halfword of rB, and the results are placed into rD. The sum and difference are modulo.
Figure 94. Vector subtract from / add halfwords exchanged (zvsubfaddhx)
1.6.3.94 Vector Subtract from / add halfwords exchanged, signed and saturate (zvsubfaddhxss)
zvsubfaddhxss rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 0 1 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 1 1 1 1
32 47 48 63
rB
rA
– +
rD
32 47 48 63
rB
rA
– +
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor84

// h0temp0:31 EXTS32(rB32:47) - EXTS32(rA48:63)ovh0 temp15 temp16rD32:47 SATURATE(ovh0, temp15, 0x8000, 0x7fff, temp16:31)// h1temp0:31 EXTS32(rB48:63) + EXTS32(rA32:47)ovh1 temp15 temp16rD48:63 SATURATE(ovh1, temp15, 0x8000, 0x7fff, temp16:31)ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The odd signed halfword of rA is subtracted from the even signed halfword of rB, the even signed halfword of rA is added to the odd signed halfword of rB, saturating if positive or negative overflow occurs, and the results are placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 95. Vector subtract from / add halfwords exchanged, signed and saturate (zvsubfaddhxss)
1.6.3.95 Subtract from doubleword (zsubfd)
zsubfd rD,rA,rB
rD32:63:rD+132:63 rD32:63:rD+132:63 - rA32:63:rB32:63
The 64-bit value in rA:rB is subtracted from the 64-bit value in rD:rD+1 and the result is placed into rD:rD+1.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 0 0 1 1
32 47 48 63
rB
rA
– +
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 85
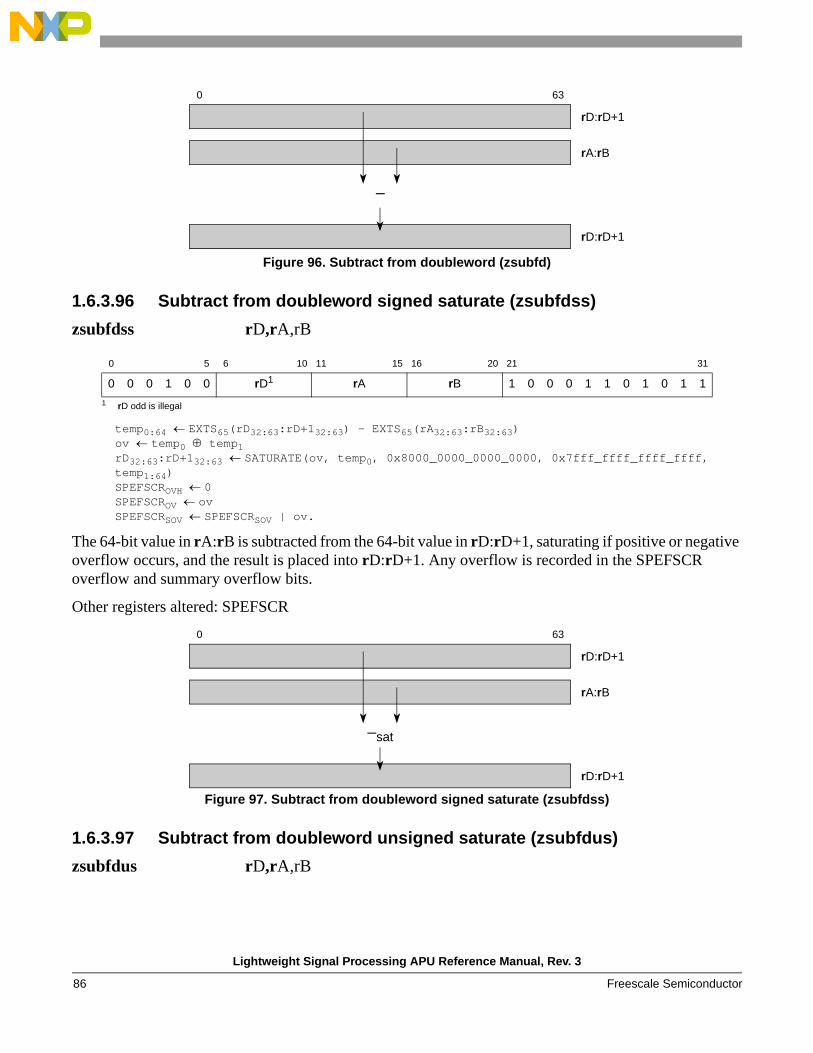
Figure 96. Subtract from doubleword (zsubfd)
1.6.3.96 Subtract from doubleword signed saturate (zsubfdss)
zsubfdss rD,rA,rB
temp0:64 EXTS65(rD32:63:rD+132:63) - EXTS65(rA32:63:rB32:63)ov temp0 temp1rD32:63:rD+132:63 SATURATE(ov, temp0, 0x8000_0000_0000_0000, 0x7fff_ffff_ffff_ffff, temp1:64)SPEFSCROVH 0SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov.
The 64-bit value in rA:rB is subtracted from the 64-bit value in rD:rD+1, saturating if positive or negative overflow occurs, and the result is placed into rD:rD+1. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 97. Subtract from doubleword signed saturate (zsubfdss)
1.6.3.97 Subtract from doubleword unsigned saturate (zsubfdus)
zsubfdus rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 1 0 1 1
0 63
rD:rD+1
rA:rB
–
rD:rD+1
0 63
rD:rD+1
rA:rB
–sat
rD:rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor86

temp0:64 EXTZ65(rD32:63:rD+132:63) - EXTZ65(rA32:63:rB32:63)ov temp0rD32:63:rD+132:63 SATURATE(ov, 1, 0x0000_0000_0000_0000, -----------------, temp1:64)SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov.
The 64-bit value in rA:rB is subtracted from the 64-bit value in rD:rD+1, saturating if underflow occurs, and the result is placed into rD:rD+1. Any underflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 98. Subtract from doubleword unsigned saturate (zsubfdus)
1.6.3.98 Vector subtract from halfword (zvsubfh)
zvsubfh rD,rA,rB
rD32:47rB32:47 - rA32:47// Modulo differencerD48:63rB48:63- rA48:63// Modulo difference
The halfword elements of rA are subtracted from the corresponding halfword elements of rB and the results are placed into rD. The difference is a modulo difference.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 1 0 0 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 0 0 1 0 1
0 63
rD:rD+1
rA:rB
–sat
rD:rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 87

Figure 99. Vector subtract from halfword (zvsubfh)
1.6.3.99 Subtract from halfword even signed to word (zsubfhesw)
zsubfhesw rD,rA,rB
rD32:63EXTS32(rB32:47) - EXTS32(rA32:47) // Modulo
The even halfword element of rA is sign-extended to 32 bits and subtracted from the sign-extended even halfword element of rB, and the 32-bit result is placed into rD. The difference is a modulo difference.
Figure 100. Subtract from halfword even signed to word (zsubfhesw)
1.6.3.100 Subtract from halfword even unsigned to word (zsubfheuw)
zsubfheuw rD,rA,rB
rD32:63EXTZ32(rB32:47) - EXTZ32(rA32:47) // Modulo
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 0 0 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 0 0 0 1
32 47 48 63
rB
rA
– –
rD
32 47 48 63
rA
rB
–
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor88

The even halfword element of rA is zero-extended to 32 bits and subtracted from the zero-extended even halfword element of rB, and the 32-bit result is placed into rD. The difference is a modulo difference.
Figure 101. Subtract from halfword even unsigned to word (zsubfheuw)
1.6.3.101 Subtract from halfword odd signed to word (zsubfhosw)
zsubfhosw rD,rA,rB
rD32:63EXTS32(rB48:63) - EXTS32(rA48:63) // Modulo
The odd halfword element of rA is sign-extended to 32 bits and subtracted from the sign-extended odd halfword element of rB, and the 32-bit result is placed into rD. The difference is a modulo difference.
Figure 102. Subtract from halfword odd signed to word (zsubfhosw)
1.6.3.102 Vector subtract from halfword odd unsigned to word (zsubfhouw)
zsubfhouw rD,rA,rB
rD32:63EXTZ32(rB48:63) - EXTZ32(rA48:63) // Modulo
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 0 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 1 0 0 1 0 1
32 47 48 63
rA
rB
–
rD
32 47 48 63
rB
rA
–
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 89

The odd halfword element of rA is zero-extended to 32 bits and subtracted from the zero-extended odd halfword element of rB, and the 32-bit result is placed into rD. The difference is a modulo difference.
Figure 103. Subtract from halfword odd unsigned to word (zsubfhouw)
1.6.3.103 Vector subtract from halfword signed and saturate (zvsubfhss)
zvsubfhss rD,rA,rB
// h0temp0:31 EXTS32(rB32:47) - EXTS32(rA32:47)ovh0 temp15 temp16rD32:47 SATURATE(ovh0, temp15, 0x8000, 0x7fff, temp16:31)// h1temp0:31 EXTS32(rB48:63) - EXTS32(rA48:63)ovh1 temp15 temp16rD48:63 SATURATE(ovh1, temp15, 0x8000, 0x7fff, temp16:31)ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The signed halfword elements of rA are subtracted from the corresponding signed halfword elements of rB, saturating if positive or negative overflow occurs, and the results are placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 104. Vector subtract from halfword signed and saturate (zvsubfhss)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 0 1 1 1
32 47 48 63
rB
rA
–
rD
32 47 48 63
rB
rA
– –
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor90

1.6.3.104 Vector subtract from halfword unsigned and saturate (zvsubfhus)
zvsubfhus rD,rA,rB
// h0temp0:31 EXTZ32(rB32:47) - EXTZ32(rA32:47)ovh0 temp15rD32:47 SATURATE(ovh0, 1, 0x0000, ------, temp16:31)
// h1temp0:31 EXTZ32(rB48:63) - EXTZ32(rA48:63)ovh1 temp15rD48:63 SATURATE(ovh1, 1, 0x0000, ------, temp16:31)ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The unsigned halfword elements of rA are subtracted from the unsigned halfword elements of rB, saturating if underflow occurs, and the results are placed into rD. Any underflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 105. Vector subtract from halfword unsigned and saturate (zvsubfhus)
1.6.3.105 Vector subtract from halfwords exchanged (zvsubfhx)
zvsubfhx rD,rA,rB
// h0rD32:47 rB32:47 - rA48:63 // modulo difference// h1rD48:63 rB48:63 - rA32:47 // modulo difference
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 0 1 0 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 0 1 1 0 1
32 47 48 63
rB
rA
– –
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 91

The exchanged halfword elements of rA are subtracted from the halfword elements of rB. The difference is a modulo difference.
Figure 106. Vector subtract from halfwords exchanged (zvsubfhx)
1.6.3.106 Vector subtract from halfwords exchanged, signed and saturate (zvsubfhxss)
zvsubfhxss rD,rA,rB
// h0temp0:31 EXTS32(rB32:47) - EXTS32(rA48:63)ovh0 temp15 temp16rD32:47 SATURATE(ovh0, temp15, 0x8000, 0x7fff, temp16:31)
// h3temp0:31 EXTS32(rB48:63) - EXTS32(rA32:47)ovh1 temp15 temp16rD48:63 SATURATE(ovh1, temp15, 0x8000, 0x7fff, temp16:31)ov ovh0 | ovh1
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The exchanged signed halfword elements of rA are subtracted from the signed halfword elements of rB, saturating if positive or negative overflow occurs, and the results are placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 1 1 0 1
32 47 48 63
rB
rA
– –
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor92

Figure 107. Vector subtract from halfwords exchanged signed and saturate (zvsubfhxss)
1.6.3.107 Vector subtract from word (zvsubfw)
zvsubfw rD,rA,rB
rD32:63rD32:63 - rA32:63 // Modulo rD+132:63rD+132:63 - rB32:63 // Modulo
The word elements of rA:rB are subtracted from the corresponding word elements of rD:rD+1 and the results are placed into rD:rD+1. The difference is a modulo difference.
Figure 108. Vector subtract from word (zvsubfw)
1.6.3.108 Vector subtract from / add word (zvsubfaddw)
zvsubfaddw rD,rA,rB
rD32:63rD32:63 - rA32:63 // Modulo differencerD+132:63rD+132:63 + rB32:63 // Modulo sum
The word in rA is subtracted from the word in rD, the word in rB is added to the word in rD+1, and the results are placed into rD:rD+1. The sum and difference are modulo.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 0 1 1 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 0 1 0 1
32 47 48 63
rB
rA
– –
rD
32 63
rA
rD
–
rD
32 63
rB
rD+1
–
rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 93

Figure 109. Vector subtract from / add word (zvsubfaddw)
1.6.3.109 Vector subtract from / add word signed and saturate (zvsubfaddwss)
zvsubfaddwss rD,rA,rB
temph0:32 EXTS33(rD32:63) - EXTS33(rA32:63)ovh temph0 temph1rD32:63 SATURATE(ovh, temph0, 0x8000_0000, 0x7fff_ffff, temph1:32)
templ0:32 EXTS33(rD+132:63) + EXTS33(rB32:63)ovl templ0 templ1rD+132:63 SATURATE(ovl, templ0, 0x8000_0000, 0x7fff_ffff, templ1:32)
SPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
The signed word in rA is subtracted from the signed word in rD and the signed word in rB is added to the signed word in rD+1, saturating if positive or negative overflow occurs, and the results are placed into rD:rD+1. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 110. Vector subtract from / add word signed and saturate (zvsubfaddwss)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 1 1 0 1
32 63
rA
rD
–
rD
32 63
rB
rD+1
+
rD+1
32 63
rA
rD
–SSAT
rD
32 63
rB
rD+1
+SSAT
rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor94

1.6.3.110 Subtract from word guarded signed fraction (zsubfwgsf)
zsubfwgsf rD,rA,rB
rD32:63:rD+132:63 EXTS48(rB32:63) || 160) - (EXTS48(rA32:63) ||
160)
The word elements of rA and rB are sign-extended with 16 guard bits and padded with 16 0’s, and then the rA value is subtracted from the rB value to produce a 64-bit difference, and the result is placed into rD.
NOTEzsubfwgsf is used to subtract 1.31 fractions to produce a 17.47 fractional difference.
Figure 111. Subtract from word guarded signed fraction (zsubfwgsf)
1.6.3.111 Subtract from word guarded signed integer (zsubfwgsi)
zsubfwgsi rD,rA,rB
rD32:63:rD+132:63 EXTS64(rB32:63) - EXTS64(rA32:63)
The word in rA is sign-extended to 64 bits and subtracted from the sign-extended word in rB to produce a 64-bit difference, and the result is placed into rD.
NOTEzsubfwgsi can also be used to subtract 1.31 fractions to produce a 33.31 fractional difference.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 1 0 0 0 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 1 0 0 1
32 63
rB
rA
0 63
rD:rD+1
15 16 17
.
–
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 95

Figure 112. Subtract from word guarded signed integer (zsubfwgsi)
1.6.3.112 Subtract from word guarded unsigned integer (zsubfwgui)
zsubfwgui rD,rA,rB
rD32:63:rD+132:63 EXTZ64(rB32:63) - EXTZ64(rA32:63)
The word in rA is zero-extended to 64 bits and subtracted from the zero-extended word in rB to produce a 64-bit difference, and the result is placed into rD.
Figure 113. Subtract from word guarded unsigned integer (zsubfwgui)
1.6.3.113 Subtract from word signed and saturate (zsubfwss)
zsubfwss rD,rA,rB
temp0:32 EXTS33(rB32:63) - EXTS33(rA32:63)ov temp0 temp1rD32:63 SATURATE(ov, temp0, 0x8000_0000, 0x7fff_ffff, temp1:32)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 0 0 0 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 0 0 1 1
32 63
rB
rA
0 63
rD:rD+1
–
32 63
rB
rA
0 63
rD:rD+1
–
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor96

SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The word in rA is subtracted from the word in rB, saturating if positive or negative overflow occurs, and the result is placed into rD. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 114. Subtract from word signed and saturate (zsubfwss)
1.6.3.114 Vector subtract from word signed and saturate (zvsubfwss)
zvsubfwss rD,rA,rB
temph0:32 EXTS33(rD32:63) - EXTS33(rA32:63)ovh temph0 temph1rD32:63 SATURATE(ovh, temph0, 0x8000_0000, 0x7fff_ffff, temph1:32)
templ0:32 EXTS33(rD+132:63) - EXTS33(rB32:63)ovl templ0 templ1rD+132:63 SATURATE(ovl, templ0, 0x8000_0000, 0x7fff_ffff, templ1:32)
SPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
The signed word elements of rA:rB are subtracted from the corresponding signed word elements of rD:rD+1, saturating if positive or negative overflow occurs, and the results are placed into rD:rD+1. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 0 1 1 1 1
32 63
rB
rA
–sat
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 97

Figure 115. Vector subtract from word signed and saturate (zvsubfwss)
1.6.3.115 Subtract from word unsigned and saturate (zsubfwus)
zsubfwus rD,rA,rB
temp0:32 EXTZ33(rB32:63) - EXTZ33(rA32:63)ov temp0rD32:63 SATURATE(ov, 1, 0x0000_0000, ----------, temp1:32)
SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The word in rA is subtracted from the word in rB, saturating if underflow occurs, and the result is placed into rD. Any underflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 116. Subtract from word unsigned and saturate (zsubfwus)
1.6.3.116 Vector subtract from word unsigned and saturate (zvsubfwus)
zvsubfwus rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 0 0 1 0 0 0 1
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 0 1 1 1 0 1 1 1
32 63
rA
rD
–SSAT
rD
32 63
rB
rD+1
–SSAT
rD+1
32 63
rB
rA
–
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor98

temph0:32 EXTZ33(rD32:63) - EXTZ33(rA32:63)ovh temph0rD32:63 SATURATE(ovh, 1, 0x0000_0000, ----------, temph1:32)
templ0:32 EXTZ33(rD+132:63) - EXTZ33(rB32:63)ovl templ0rD+132:63 SATURATE(ovl, 1, 0x0000_0000, ----------, templ1:32)
SPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
The unsigned word elements of rA:rB are subtracted from the corresponding unsigned word elements of rD:rD+1, saturating if positive or negative overflow occurs, and the results are placed into rD:rD+1. Any overflow is recorded in the SPEFSCR overflow and summary overflow bits.
Other registers altered: SPEFSCR
Figure 117. Vector subtract from word unsigned and saturate (zvsubfwus)
1.6.3.117 Vector subtract immediate from halfword (zvsubifh)
zvsubifh rD,rA,UIMM
rD32:47rA32:47 - EXTZ16(UIMM)// Modulo differencerD48:63rA48:63- EXTZ16(UIMM)// Modulo difference
UIMM is zero-extended and subtracted from the halfword elements of rA and the results are placed into rD. Note that the same value is subtracted from both halfwords of the register. UIMM is 5 bits.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA UIMM 0 1 0 0 0 0 0 0 0 0 1
32 63
rA
rD
–USAT
rD
32 63
rB
rD+1
–USAT
rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 99
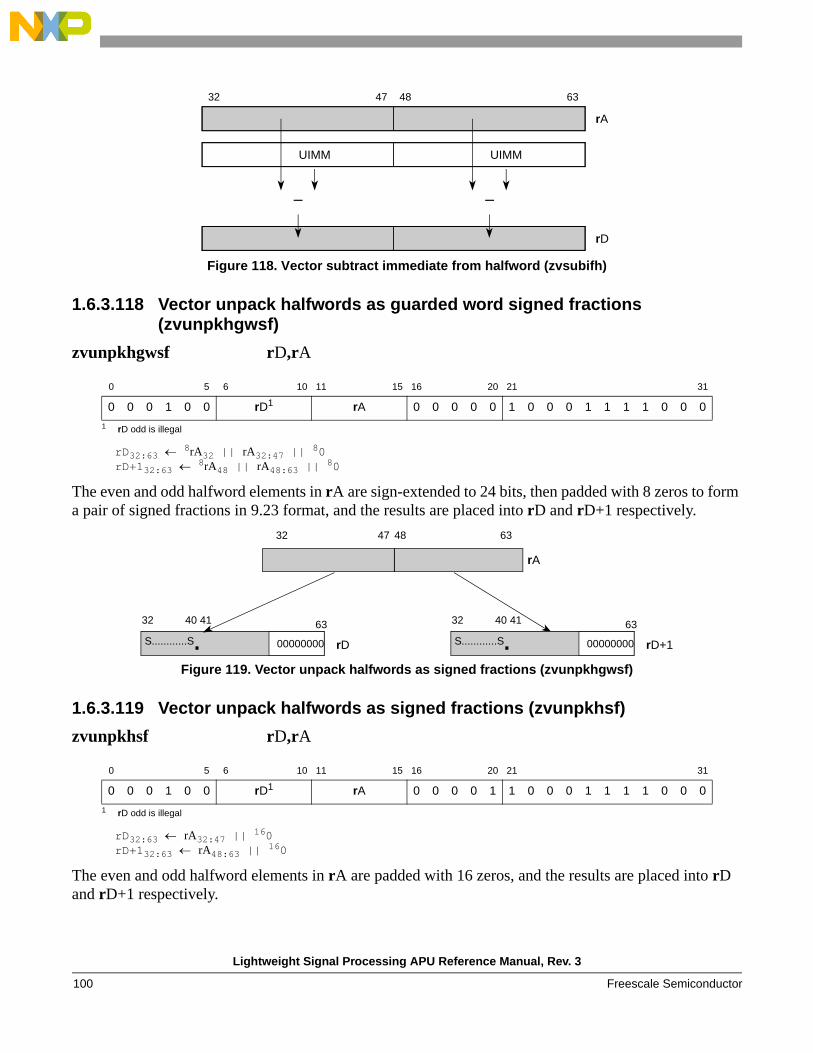
Figure 118. Vector subtract immediate from halfword (zvsubifh)
1.6.3.118 Vector unpack halfwords as guarded word signed fractions (zvunpkhgwsf)
zvunpkhgwsf rD,rA
rD32:63 8rA32 || rA32:47 || 80
rD+132:63 8rA48 || rA48:63 || 80
The even and odd halfword elements in rA are sign-extended to 24 bits, then padded with 8 zeros to form a pair of signed fractions in 9.23 format, and the results are placed into rD and rD+1 respectively.
Figure 119. Vector unpack halfwords as signed fractions (zvunpkhgwsf)
1.6.3.119 Vector unpack halfwords as signed fractions (zvunpkhsf)
zvunpkhsf rD,rA
rD32:63 rA32:47 || 160
rD+132:63 rA48:63 || 160
The even and odd halfword elements in rA are padded with 16 zeros, and the results are placed into rD and rD+1 respectively.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA 0 0 0 0 0 1 0 0 0 1 1 1 1 0 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA 0 0 0 0 1 1 0 0 0 1 1 1 1 0 0 0
32 47 48 63
rA
UIMM
– –
rD
UIMM
32 63
rA
47 48
rD
32 40 41
.S............S
63
00000000 rD+1
32 40 41
.S............S
63
00000000
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor100
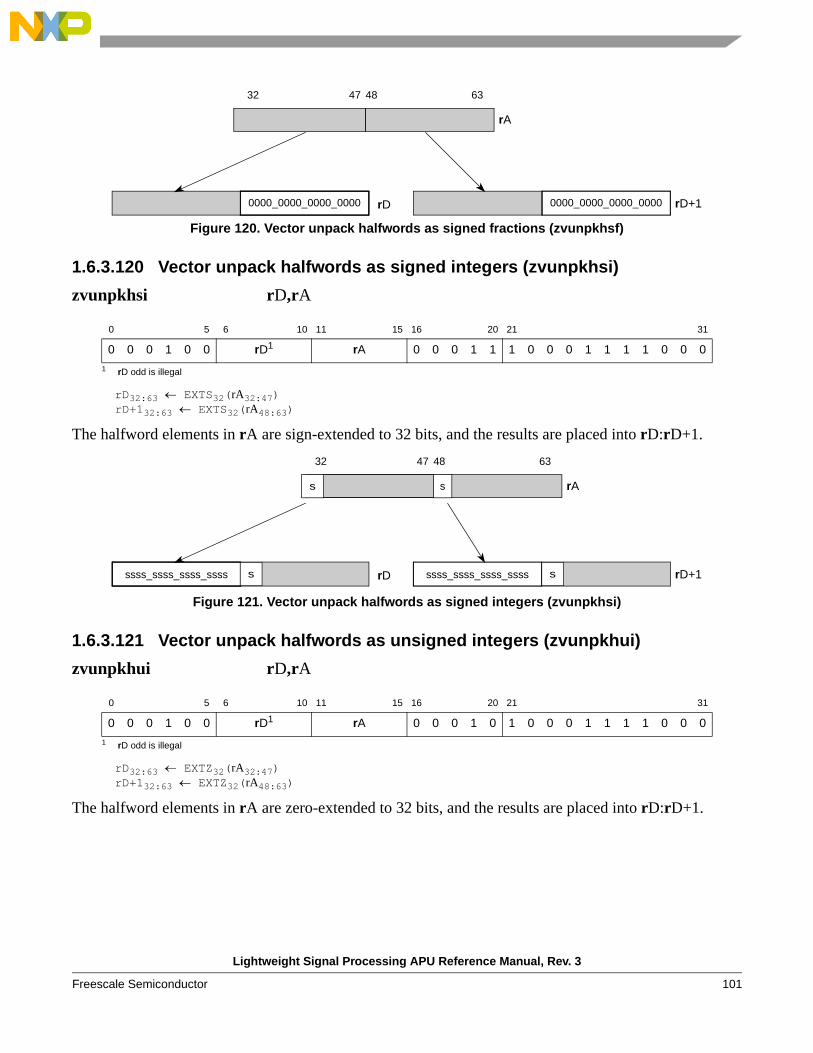
Figure 120. Vector unpack halfwords as signed fractions (zvunpkhsf)
1.6.3.120 Vector unpack halfwords as signed integers (zvunpkhsi)
zvunpkhsi rD,rA
rD32:63 EXTS32(rA32:47)rD+132:63 EXTS32(rA48:63)
The halfword elements in rA are sign-extended to 32 bits, and the results are placed into rD:rD+1.
Figure 121. Vector unpack halfwords as signed integers (zvunpkhsi)
1.6.3.121 Vector unpack halfwords as unsigned integers (zvunpkhui)
zvunpkhui rD,rA
rD32:63 EXTZ32(rA32:47)rD+132:63 EXTZ32(rA48:63)
The halfword elements in rA are zero-extended to 32 bits, and the results are placed into rD:rD+1.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA 0 0 0 1 1 1 0 0 0 1 1 1 1 0 0 0
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA 0 0 0 1 0 1 0 0 0 1 1 1 1 0 0 0
0000_0000_0000_0000 0000_0000_0000_0000
32 63
rA
rD+1
47 48
rD
ssss_ssss_ssss_ssss ssss_ssss_ssss_ssss rD+1rD
32 63
rA
47 48
s s
s s
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 101
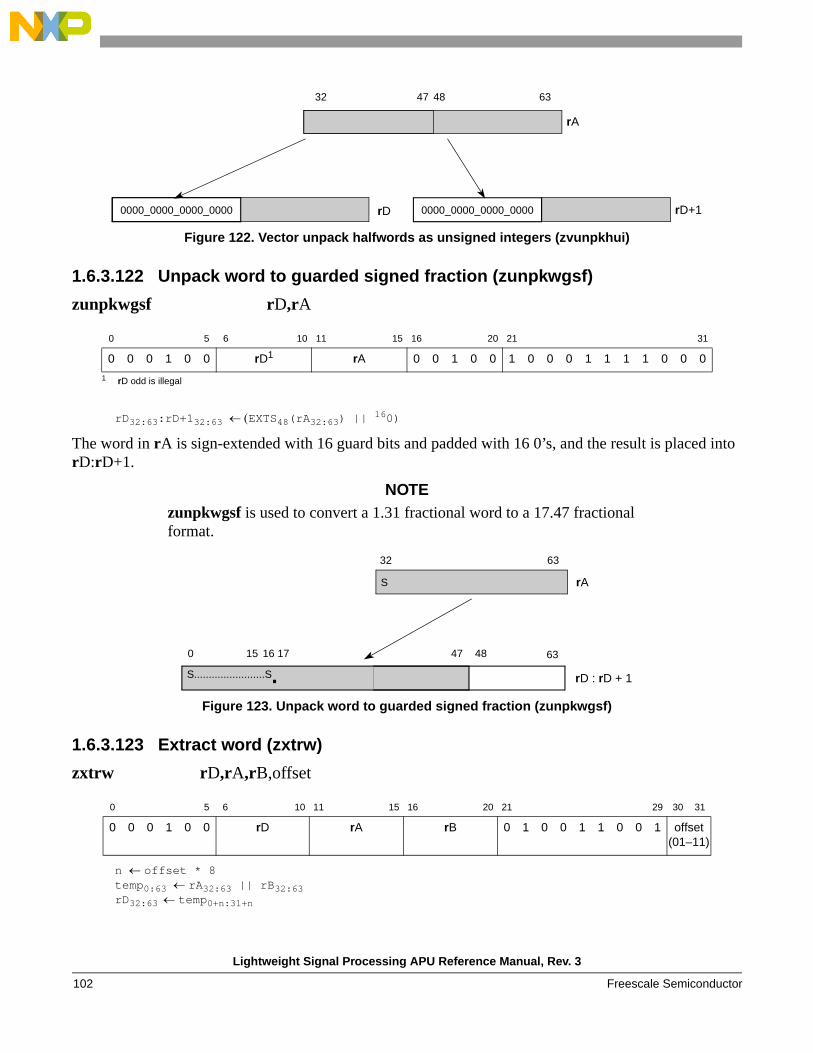
Figure 122. Vector unpack halfwords as unsigned integers (zvunpkhui)
1.6.3.122 Unpack word to guarded signed fraction (zunpkwgsf)
zunpkwgsf rD,rA
rD32:63:rD+132:63 EXTS48(rA32:63) || 160)
The word in rA is sign-extended with 16 guard bits and padded with 16 0’s, and the result is placed into rD:rD+1.
NOTEzunpkwgsf is used to convert a 1.31 fractional word to a 17.47 fractional format.
Figure 123. Unpack word to guarded signed fraction (zunpkwgsf)
1.6.3.123 Extract word (zxtrw)
zxtrw rD,rA,rB,offset
n offset * 8temp0:63 rA32:63 || rB32:63 rD32:63 temp0+n:31+n
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA 0 0 1 0 0 1 0 0 0 1 1 1 1 0 0 0
0 5 6 10 11 15 16 20 21 29 30 31
0 0 0 1 0 0 rD rA rB 0 1 0 0 1 1 0 0 1 offset(01–11)
0000_0000_0000_0000 0000_0000_0000_0000 rD+1rD
32 63
rA
47 48
32 63
rA
0
S
rD : rD + 1
47 48 6315 16 17
.S........................S
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor102

A word is extracted from the concatenation of rA and rB beginning at byte offset “offset” and placed into rD. “offset” must be in the range [1:3].
Figure 124. Extract word (zxtrw)
1.6.4 Load and store instructions
1.6.4.1 Vector load doubleword into doubleword [with update] (zldd[u])
zldd rD,d(rA) (U = 0)zlddu rD,d(rA) (U = 1)
if (rA=0 & U=1) then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*8)rD:rD+1 MEM(EA,8)if U=1 then rA EA
The doubleword addressed by EA is loaded from memory and placed into even/odd register pair rD, rD+1.
If U=1 (‘with update’), EA is placed into rA.
Figure 125 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA UIMM2
2 displacement = UIMM * 8; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 0 0 0 0 1
offset
rB
rD
rA
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 103

Figure 125. zldd[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.2 Vector load doubleword into doubleword [with modify] indexed (zldd[m]x)
zlddx rD,rA,rB (M = 0)zlddmx rD,rA,rB (M = 1)
if (rA=0 & M=1) then take_illegal_exceptionEA calc_EA(rA,rB,M)rD:rD+1 MEM(EA,8)*
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The doubleword addressed by EA is loaded from memory and placed into even/odd register pair rD:rD+1.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 126 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 0 0 0 0 0
c d e f h
0 1 2 3 4 5 6 7
a b g
c d e f ha b g
f e d c ah g b
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor104

Figure 126. zldd[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.3 Vector load doubleword into four halfwords [with update] (zldh[u])
zldh rD,d(rA) (U = 0)zldhu rD,d(rA) (U = 1)
if (rA=0 & U=1) then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*8)rD32:47 MEM(EA,2)rD48:63 MEM(EA+2,2)rD+132:47 MEM(EA+4,2)rD+148:63 MEM(EA+6,2)if U=1 then rA EA
The doubleword addressed by EA is loaded from memory and placed into even/odd register pair rD, rD+1.
If U=1 (‘with update’), EA is placed into rA.
Figure 127 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA UIMM2
2 displacement = UIMM * 8; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 0 0 1 0 1
c d e f h
0 1 2 3 4 5 6 7
a b g
c d e f ha b g
f e d c ah g b
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 105

Figure 127. zldh[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.4 Vector load doubleword into four halfwords [with modify] indexed (zldh[m]x)
zldhx rD,rA,rB (M = 0)zldhmx rD,rA,rB (M = 1)
if (rA=0 & M=1) then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:47 MEM(EA,2)*
rD48:63 MEM(EA+2,2)*
rD+132:47 MEM(EA+4,2)*
rD+148:63 MEM(EA+6,2)*
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The doubleword addressed by EA is loaded from memory and placed into even/odd register pair rD, rD+1.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 128 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 0 0 1 0 0
c d e f h
0 1 2 3 4 5 6 7
a b g
c d e f ha b g
d c f e gb a h
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor106

Figure 128. zldh[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.5 Vector load doubleword into two words [with update] (zldw[u])
zldw rD,d(rA) (U = 0)zldwu rD,d(rA) (U = 1)
if (rA=0 & U=1) then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*8)rD32:63 MEM(EA,4)rD+132:63 MEM(EA+4,4)if U=1 then rA EA
The doubleword addressed by EA is loaded from memory and placed into even/odd register pair rD, rD+1.
If U=1 (‘with update’), EA is placed into rA.
Figure 129 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
Figure 129. zldw[u] results in big- and little-endian modes
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA UIMM2
2 displacement = UIMM * 8; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 0 0 0 1 1
c d e f h
0 1 2 3 4 5 6 7
a b g
c d e f ha b g
d c f e gb a h
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
c d e f h
0 1 2 3 4 5 6 7
a b g
c d e f ha b g
b a h g ed c f
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 107

NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.6 Vector load double into two words [with modify] indexed (zldw[m]x)
zldwx rD,rA,rB (M = 0)zldwmx rD,rA,rB (M = 1)
if (rA=0 & M=1) then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:63 MEM(EA,4)*
rD+132:63 MEM(EA+4,4)*
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The doubleword addressed by EA is loaded from memory and placed into even/odd register pair rD:rD+1.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 130 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
Figure 130. zldw[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.7 Vector load halfword guarded to word signed fraction [with update] (zlhgwsf[u])
zlhgwsf rD,d(rA) (U = 0)zlhgwsfu rD,d(rA) (U = 1)
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 0 0 0 1 0
c d e f h
0 1 2 3 4 5 6 7
a b g
c d e f ha b g
b a h g ed c f
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor108

if (rA=0 & U=1) then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*2)temph0:15 MEM(EA,2)
rD32:63 8(temph0) || temph0:15 || 80
if U=1 then rA EA
The halfword addressed by EA is loaded from memory, and is sign-extended to 24 bits and padded with 8 0’s to form a guarded signed fraction in 9.23 format, and then placed into register rD.
If U=1 (‘with update’), EA is placed into rA.
Figure 131 shows how bytes are loaded into rD as determined by the endian mode.
Figure 131. zlhgwsf[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.8 Vector load halfword guarded to word signed fraction [with modify] indexed (zlhgwsf[m]x)
zlhgwsfx rD,rA,rB (M = 0)zlhgwsfmx rD,rA,rB (M = 1)
if (rA=0 & M=1) then take_illegal_exceptionEA calc_EA(rA,rB,M)temph0:15 MEM(EA,2)*
rD32:63 8(temph0) || temph0:15 || 80
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA UIMM1
1 displacement = UIMM * 2; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 1 1 1 0 1
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA rB 0 1 1 0 M 0 1 1 1 0 0
ZaS b
0 1
a b
Z
Memory
GPR in big-endian
GPR in little-endian1
Byte address
1-— Not supported in all implementations
bS a S = sign, Z = zero
S = sign, Z = zero
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 109

if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The halfword addressed by EA is loaded from memory, and is sign-extended to 24 bits and padded with 8 0’s to form a guarded signed fraction in 9.23 format, and then placed into register rD.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 132 shows how bytes are loaded into rD as determined by the endian mode.
Figure 132. zlhgwsf[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.9 Vector load halfword into halfword even [with update] (zlhhe[u])
zlhhe rD,d(rA) (U = 0)zlhheu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*2)rD32:47 MEM(EA,2)rD48:63 0x0000if U=1 then rA EA
The halfword addressed by EA is loaded from memory and placed into the even halfword of rD. The odd halfword is zeroed.
If U=1 (‘with update’), EA is placed into rA.
Figure 133 shows how bytes are loaded into rD as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA UIMM1
1 displacement = UIMM * 2; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 1 0 0 0 1
ZaS b
0 1
a b
Z
Memory
GPR in big-endian
GPR in little-endian1
Byte address
1— Not supported in all implementations
bS a S = sign, Z = zero
S = sign, Z = zero
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor110

Figure 133. zlhhe[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.10 Vector load halfword into halfword even [with modify] indexed (zlhhe[m]x)
zlhhex rD,rA,rB (M = 0)zlhhemx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:47 MEM(EA,2)*
rD48:63 0x0000if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The halfword addressed by EA is loaded from memory and placed into the even halfword of rD. The odd halfword is zeroed.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 134 shows how bytes are loaded into rD as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA rB 0 1 1 0 M 1 1 0 0 0 0
0 1
a b
Z Za b
Z Zb a
Memory
GPR in big-endian
GPR in little-endian1
Byte address
Z = zero
Z = zero
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 111

Figure 134. zlhhe[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.11 Vector load halfword into halfword odd signed (with sign extension) [with update] (zlhhos[u])
zlhhos rD,d(rA) (U = 0)zlhhosu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*2)rD32:63 EXTS32(MEM(EA,2)if U=1 then rA EA
The halfword addressed by EA is loaded from memory, sign-extended to 32 bits, and placed into rD.
If U=1 (‘with update’), EA is placed into rA.
Figure 135 shows how bytes are loaded into rD as determined by the endian mode.
Figure 135. zlhhos[u] results in big- and little-endian modes
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA UIMM1
1 displacement = UIMM * 2; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 1 0 0 1 1
0 1
a b
Z Za b
Z Zb a
Memory
GPR in big-endian
GPR in little-endian1
Byte address
Z = zero
Z = zero
1— Not supported in all implementations
0 1
a b
a bS S
b aS S
Memory
GPR in big-endian
GPR in little-endian1
Byte address
S = sign
S = sign
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor112

In big-endian memory, the most significant bit of a is sign-extended. In little-endian memory, the most significant bit of b is sign-extended.
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.12 Vector load halfword into halfword odd signed [with modify] indexed (with sign extension) (zlhhos[m]x)
zlhhosx rD,rA,rB (M = 0)zlhhosmx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:63 EXTS32(MEM(EA,2)
*
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The halfword addressed by EA is loaded from memory, sign-extended to 32 bits, and placed into rD.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 136 shows how bytes are loaded into rD as determined by the endian mode.
Figure 136. zlhhos[m]x results in big- and little-endian modes
In big-endian memory, the most significant bit of a is sign-extended. In little-endian memory, the most significant bit of b is sign-extended.
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA rB 0 1 1 0 M 1 1 0 0 1 0
0 1
a b
a bS S
b aS S
Memory
GPR in big-endian
GPR in little-endian1
Byte address
S = sign
S = sign
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 113

1.6.4.13 Vector load halfword into halfword odd unsigned (zero-extended) [with update] (zlhhou[u])
zlhhou rD,d(rA) (U = 0)zlhhouu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*2)rD32:47 0x0000rD48:63 MEM(EA+2)if U=1 then rA EA
The halfword addressed by EA is loaded from memory, zero-extended, and placed into rD.
If U=1 (‘with update’), EA is placed into rA.
Figure 137 shows how bytes are loaded into rD as determined by the endian mode.
Figure 137. zlhhou[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.14 Vector load halfword into halfword odd unsigned [with modify] indexed (zero-extended) (zlhhou[m]x)
zlhhoux rD,rA,rB (M = 0)zlhhoumx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA UIMM1
1 displacement = UIMM * 2; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 1 0 1 0 1
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA rB 0 1 1 0 M 1 1 0 1 0 0
0 1
a b
a bZ Z
b aZ Z
Memory
GPR in big-endian
GPR in little-endian1
Byte address
Z = zero
Z = zero
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor114

rD32:47 0x0000rD48:63 MEM(EA,2)*
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The halfword addressed by EA is loaded from memory, zero-extended, and placed into rD.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 138 shows how bytes are loaded into rD as determined by the endian mode.
Figure 138. zlhhou[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.15 Vector load halfword into halfwords and splat [with update] (zlhhsplat[u])
zlhhsplat rD,d(rA) (U = 0)zlhhsplatu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*2)rD32:47 MEM(EA,2)rD48:63 MEM(EA,2)if U=1 then rA EA
The halfword addressed by EA is loaded from memory and placed in the halfword elements of rD.
If U=1 (‘with update’), EA is placed into rA.
Figure 139 shows how bytes are loaded into rD as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA UIMM1
1 displacement = UIMM * 2; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 1 1 1 1 1
0 1
a b
a bZ Z
b aZ Z
Memory
GPR in big-endian
GPR in little-endian1
Byte address
Z = zero
Z = zero
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 115

Figure 139. zlhhsplat[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.16 Vector load halfword into halfwords and splat [with modify] indexed (zlhhsplat[m]x)
zlhhsplatx rD,rA,rB (M = 0)zlhhsplatmx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:47 MEM(EA,2)rD48:63 MEM(EA,2)if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The halfword addressed by EA is loaded from memory and placed in the halfword elements of rD.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 140 shows how bytes are loaded into rD as determined by the endian mode.
Figure 140. zlhhsplat[m]x results in big- and little-endian modes
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA rB 0 1 1 0 M 0 1 1 1 1 0
0 1
a b
a ba b
b ab a
Memory
GPR in big-endian
GPR in little-endian1
Byte address
1— Not supported in all implementations
0 1
a b
a ba b
b ab a
Memory
GPR in big-endian
GPR in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor116

NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.17 Vector load word as guarded signed fraction to doubleword [with update] (zlwgsfd[u])
zlwgsfd rD,d(rA) (U = 0)zlwgsfdu rD,d(rA) (U = 1)
if (rA=0 & U=1) then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)temp0:31 MEM(EA,4)rD32:63 16(temp0) || temp0:15rD+132:63 temp16:31 ||
160if U=1 then rA EA
The word addressed by EA is loaded from memory, sign-extended to 48 bits, padded with 16 0’s to form a guarded signed fraction in 17.47 format, and placed into even/odd register pair rD:rD+1.
If U=1 (‘with update’), EA is placed into rA.
Figure 141 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
Figure 141. zlwgsfd[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.18 Vector load word as guarded signed fraction to doubleword [with modify] indexed (zlwgsfd[m]x)
zlwgsfdx rD,rA,rB (M = 0)
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA UIMM2
2 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 0 1 0 0 1
b a ZZS S
c d
0 1 2 3
a b
c d ZZ
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
a b S = sign, Z = zero
S = sign, Z = zero
S S
d c
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 117

zlwgsfdmx rD,rA,rB (M = 1)
if (rA=0 & M=1) then take_illegal_exceptionEA calc_EA(rA,rB,M)temp0:31 MEM(EA,4)*
rD32:63 16(temp0) || temp0:15rD+132:63 temp16:31 ||
160if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The word addressed by EA is loaded from memory, sign-extended to 48 bits, padded with 16 0’s to form a guarded signed fraction in 17.47 format, and placed into even/odd register pair rD:rD+1.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 142 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
Figure 142. zlwgsfd[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.19 Vector load word into two halfwords [with update] (zlwh[u])
zlwh rD,d(rA) (U = 0)zlwhu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 0 1 0 0 0
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA UIMM1
1 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 1 1 0 0 1
b a ZZS S
c d
0 1 2 3
a b
c d ZZ
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
a b S = sign, Z = zero
S = sign, Z = zero
S S
d c
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor118

rD32:47 MEM(EA,2)rD48:63 MEM(EA+2,2)if U=1 then rA EA
The word addressed by EA is loaded from memory and placed in the halfword elements of rD.
If U=1 (‘with update’), EA is placed into rA.
Figure 143 shows how bytes are loaded into rD as determined by the endian mode.
Figure 143. zlwh[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.20 Vector load word into two halfwords [with modify] indexed (zlwh[m]x)
zlwhx rD,rA,rB (M = 0)zlwhmx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:47 MEM(EA,2)*
rD48:63 MEM(EA+2,2)*
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The word addressed by EA is loaded from memory and placed in the halfword elements of rD.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 144 shows how bytes are loaded into rD as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA rB 0 1 1 0 M 0 1 1 0 0 0
c da b
d cb a
GPR in big-endian
GPR in little-endian1
1— Not supported in all implementations
c d
0 1 2 3
a bMemory
Byte address
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 119

Figure 144. zlwh[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.21 Vector load word into two halfwords even to doubleword [with update] (zlwhed[u])
zlwhed rD,d(rA) (U = 0)zlwhedu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)rD32:47 MEM(EA,2)rD48:63 0x0000rD+132:47 MEM(EA+2,2)rD+148:63 0x0000if U=1 then rA EA
The word addressed by EA is loaded from memory and placed in the even halfwords in each word element of rD:rD+1. The odd halfwords are zeroed.
If U=1 (‘with update’), EA is placed into rA.
Figure 145 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA UIMM2
2 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 1 0 0 1 1
c da b
d cb a
GPR in big-endian
GPR in little-endian1
1— Not supported in all implementations
c d
0 1 2 3
a bMemory
Byte address
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor120

Figure 145. zlwhed[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.22 Vector load word into two halfwords even to doubleword [with modify] indexed (zlwhed[m]x)
zlwhedx rD,rA,rB (M = 0)zlwhedmx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:47 MEM(EA,2)*
rD32:47 0x0000rD+132:47 MEM(EA+2,2)*
rD+148:63 0x0000if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The word addressed by EA is loaded from memory and placed in the even halfwords in each word element of rD:rD+1. The odd halfwords are zeroed.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 146 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 1 0 0 1 0
c d
0 1 2 3
a b
Z Z c d Za b Z
Z Z d c Zb a Z
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
Z = zero
Z = zero
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 121

Figure 146. zlwhed[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.23 Vector load word as halfwords guarded to word signed fraction to doubleword [with update] (zlwhgwsfd[u])
zlwhgwsfd rD,d(rA) (U = 0)zlwhgwsfdu rD,d(rA) (U = 1)
if (rA=0 & U=1) then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)temph0:15 MEM(EA,2)templ0:15 MEM(EA+2,2)
rD32:63 8(temph0) || temph0:15 || 80
rD+132:63 8(templ0) || templ0:15 || 80
if U=1 then rA EA
The word addressed by EA is loaded from memory as two halfwords, each of which is sign-extended to 24 bits and padded with 8 0’s to form a pair of guarded signed fractions in 9.23 format, and then placed into even/odd register pair rD:rD+1.
If U=1 (‘with update’), EA is placed into rA.
Figure 147 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA UIMM2
2 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 1 0 0 0 1
c d
0 1 2 3
a b
Z Z c d Za b Z
Z Z d c Zb a Z
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
Z = zero
Z = zero
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor122

Figure 147. zlwhgwsfd[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.24 Vector load word as halfwords guarded to word signed fraction to doubleword [with modify] Indexed (zlwhgwsfd[m]x)
zlwhgwsfdx rD,rA,rB (M = 0)zlwhgwsfdmx rD,rA,rB (M = 1)
if (rA=0 & M=1) then take_illegal_exceptionEA calc_EA(rA,rB,M)temph0:15 MEM(EA,2)*
templ0:15 MEM(EA+2,2)*
rD32:63 8(temph0) || temph0:15 || 80
rD+132:63 8(templ0) || templ0:15 || 80
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The word addressed by EA is loaded from memory as two halfwords, each of which is sign-extended to 24 bits and padded with eight 0’s to form a pair of guarded signed fractions in 9.23 format, and then placed into even/odd register pair rD:rD+1.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 148 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 1 0 0 0 0
d ZZ caS b S
c d
0 1 2 3
a b
c ZZ d
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
bS a S = sign, Z = zero
S = sign, Z = zero
S
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 123

Figure 148. zlwhgwsfd[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.25 Vector load word into two halfwords odd signed (with sign extension) to doubleword [with update] (zlwhosd[u])
zlwhosd rD,d(rA) (U = 0)zlwhosdu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)rD32:63 EXTS32(MEM(EA,2))rD+132:63 EXTS32(MEM(EA+2,2))if U=1 then rA EA
The word addressed by EA is loaded from memory and placed in the odd halfwords, sign-extended into each word element of rD:rD+1.
If U=1 (‘with update’), EA is placed into rA.
Figure 149 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA UIMM2
2 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 1 0 1 0 1
c ZZ dbS a S
d ZZ caS b S
c d
0 1 2 3
a bMemory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
S = sign, Z = zero
S = sign, Z = zero
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor124

Figure 149. zlwhosd[u] results in big- and little-endian modes
In big-endian memory, the most significant bits of a and c are sign-extended. In little-endian memory, the most significant bits of b and d are sign-extended.
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.26 Vector load word into two halfwords odd signed to doubleword [with modify] indexed (with sign extension) (zlwhosd[m]x)
zlwhosdx rD,rA,rB (M = 0)zlwhosdmx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:63 EXTS32(MEM(EA,2)
*)rD+132:63 EXTS32(MEM(EA+2,2)
*)if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The word addressed by EA is loaded from memory and placed in the odd halfwords, sign-extended into each word element of rD:rD+1.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 150 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 1 0 1 0 0
c d
0 1 2 3
a b
a b S dS S c
b a S S cS S d
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
S = sign
S = sign
1— Not supported in all implementations
S
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 125

Figure 150. zlwhosd[m]x results in big- and little-endian modes
In big-endian memory, the most significant bits of a and c are sign-extended. In little-endian memory, the most significant bits of b and d are sign-extended.
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.27 Vector load word into two halfwords odd unsigned (zero-extended) to doubleword [with update] (zlwhoud[u])
zlwhoud rD,d(rA) (U = 0)zlwhoudu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)rD32:47 0x0000rD48:63 MEM(EA,2)rD+132:47 0x0000rD+148:63 MEM(EA+2,2)if U=1 then rA EA
The word addressed by EA is loaded from memory and placed in the odd halfwords, zero-extended into each word element of rD:rD+1.
If U=1 (‘with update’), EA is placed into rA.
Figure 151 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA UIMM2
2 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 1 0 1 1 1
c d
0 1 2 3
a b
a b S S dS S c
b a S S cS S d
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
S = sign
S = sign
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor126

Figure 151. zlwhoud[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.28 Vector load word into two halfwords odd unsigned to doubleword [with modify] indexed (zero-extended) (zlwhoud[m]x)
zlwhoudx rD,rA,rB (M = 0)zlwhoudmx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:47 0x0000rD48:63 MEM(EA,2)*
rD+132:47 0x0000rD+148:63 MEM(EA+2,2)*
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The word addressed by EA is loaded from memory and placed in the odd halfwords, zero-extended into each word element of rD:rD+1.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 152 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 1 0 1 1 0
c d
0 1 2 3
a b
a b Z Z dZ Z c
b a Z Z cZ Z d
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
Z = zero
Z = zero
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 127

Figure 152. zlwhoud[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.29 Vector load word into two halfwords and splat to doubleword [with update] (zlwhsplatd[u])
zlwhsplatd rD,d(rA) (U = 0)zlwhsplatdu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)rD32:47 MEM(EA,2)rD48:63 MEM(EA,2)rD+132:47 MEM(EA+2,2)rD+148:63 MEM(EA+2,2)if U=1 then rA EA
The word addressed by EA is loaded from memory and placed in both the even and odd halfwords in each word element of rD:rD+1.
If U=1 (‘with update’), EA is placed into rA.
Figure 153 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA UIMM2
2 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 0 1 1 1 1
c d
0 1 2 3
a b
a b Z Z dZ Z c
b a Z Z cZ Z d
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
Z = zero
Z = zero
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor128

Figure 153. zlwhsplatd[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.30 Vector load word into two halfwords and splat to doubleword [with modify] indexed (zlwhsplatd[m]x)
zlwhsplatdx rD,rA,rB (M = 0)zlwhsplatdmx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:47 MEM(EA,2)*
rD48:63 MEM(EA,2)*
rD+132:47 MEM(EA+2,2)*
rD+148:63 MEM(EA+2,2)*
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The word addressed by EA is loaded from memory and placed in both the even and odd halfwords in each word element of rD:rD+1.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 154 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 0 1 1 1 0
c d
0 1 2 3
a b
a b c d da b c
b a d c cb a d
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 129

Figure 154. zlwhsplatd[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.31 Vector load word as halfwords and splat words to doubleword [with update] (zlwhsplatwd[u])
zlwhsplatwd rD,d(rA) (U = 0)zlwhsplatwdu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)rD32:47 MEM(EA,2)rD48:63 MEM(EA+2,2)rD+132:47 MEM(EA,2)rD+148:63 MEM(EA+2,2)if U=1 then rA EA
The word addressed by EA is loaded from memory as a pair of halfwords and placed in both word elements of rD:rD+1.
If U=1 (‘with update’), EA is placed into rA.
Figure 155 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA UIMM2
2 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 0 1 1 0 1
c d
0 1 2 3
a b
a b c d da b c
b a d c cb a d
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor130

Figure 155. zlwhsplatwd[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.32 Vector load word as halfwords and splat words to doubleword [with modify] indexed (zlwhsplatwd[m]x)
zlwhsplatwdx rD,rA,rB (M = 0)zlwhsplatwdmx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:47 MEM(EA,2)*
rD48:63 MEM(EA+2,2)*
rD+132:47 MEM(EA,2)*
rD+148:63 MEM(EA+2,2)*
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The word addressed by EA is loaded from memory as a pair of halfwords and placed in both word elements of rD:rD+1.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 156 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 0 1 1 0 0
c d
0 1 2 3
a b
c d a b da b c
d c b a cb a d
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 131

Figure 156. zlwhsplatwd[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.33 Vector load word into word [with update] (zlww[u])
zlww rD,d(rA) (U = 0)zlwwu rD,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)rD32:63 MEM(EA,4)if U=1 then rA EA
The word addressed by EA is loaded from memory and placed into rD.
If U=1 (‘with update’), EA is placed into rA.
Figure 157 shows how bytes are loaded into rD as determined by the endian mode.
Figure 157. zlww[u] results in big- and little-endian modes
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA UIMM1
1 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 0 1 1 0 1 1
c d
0 1 2 3
a b
c d a b da b c
d c b a cb a d
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
c da b
b ad c
GPR in big-endian
GPR in little-endian1
1— Not supported in all implementations
c d
0 1 2 3
a bMemory
Byte address
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor132
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.34 Vector load word into word [with modify] indexed (zlww[m]x)
zlwwx rD,rA,rB (M = 0)zlwwmx rD,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)rD32:63 MEM(EA,4)*
if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The word addressed by EA is loaded from memory and placed into rD.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 158 shows how bytes are loaded into rD as determined by the endian mode.
Figure 158. zlww[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.35 Vector load word as word odd signed to doubleword [with update] (zlwwosd[u])
zlwwosd rD,d(rA) (U = 0)zlwwosdu rD,d(rA) (U = 1)
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD rA rB 0 1 1 0 M 0 1 1 0 1 0
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1 rA UIMM2 0 1 1 0 U 0 0 1 0 1 1
c da b
b ad c
GPR in big-endian
GPR in little-endian1
1— Not supported in all implementations
c d
0 1 2 3
a bMemory
Byte address
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 133

if (rA=0 & U=1) then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)rD+132:63 MEM(EA,4)rD32:63 32(rD+132)if U=1 then rA EA
The word addressed by EA is loaded from memory, sign-extended to 64 bits, and placed into even/odd register pair rD:rD+1.
If U=1 (‘with update’), EA is placed into rA.
Figure 159 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
Figure 159. zlwwosd[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.36 Vector load word as word odd signed to doubleword [with modify] indexed (zlwwosd[m]x)
zlwwosdx rD,rA,rB (M = 0)zlwwosdmx rD,rA,rB (M = 1)
if (rA=0 & M=1) then take_illegal_exceptionEA calc_EA(rA,rB,M)rD+132:63 MEM(EA,4)*
rD32:63 32(rD+132)if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
1 rD odd is illegal2 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 0 1 1 0 M 0 0 1 0 1 0
S SS S d c ab
S SS S
c d
0 1 2 3
a b
a b dc
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
S = sign
S = sign
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor134

The word addressed by EA is loaded from memory, sign-extended to 64 bits, and placed into even/odd register pair rD:rD+1.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 160 shows how bytes are loaded into rD:rD+1 as determined by the endian mode.
Figure 160. zlwwosd[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.37 Vector store double of double [with update] (zstdd[u])
zstdd rS,d(rA) (U = 0)zstddu rS,d(rA) (U = 1)
if (rA=0 & U=1) then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*8)MEM(EA,8) RS32:63 || RS+132:63 if U=1 then rA EA
The contents of even/odd register pair rS:rS+1 are stored as a doubleword in storage addressed by EA.
If U=1 (‘with update’), EA is placed into rA.
Figure 161 shows how bytes are stored in memory as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS1
1 rS odd is illegal
rA UIMM2
2 displacement = UIMM * 8; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 0 0 0 0 1
S SS S d c ab
S SS S
c d
0 1 2 3
a b
a b dc
Memory
rD:rD+1 in big-endian
rD:rD+1 in little-endian1
Byte address
1— Not supported in all implementations
S = sign
S = sign
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 135

Figure 161. zstdd[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.38 Vector store double of double [with modify] indexed
zstddx rS,rA,rB (M = 0)zstddmx rS,rA,rB (M = 1)
if (rA=0 & M=1) then take_illegal_exceptionEA calc_EA(rA,rB,M)MEM(EA,8)* RS32:63 || RS+132:633if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The contents of even/odd register pair rS:rS+1 are stored as a doubleword in storage addressed by EA.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 162 shows how bytes are stored in memory as determined by the endian mode.
Figure 162. zstdd[m]x Results in big- and little-endian modes
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS1
1 rS odd is illegal
rA rB 0 1 1 0 M 1 0 0 0 0 0
c d e f ha b g
0 1 2 3 4 5 6 7
c d e f ha b g
f e d c ah g b
rS:rS+1
Memory in big-endian
Memory in little-endian1
Byte address
1— Not supported in all implementations
c d e f ha b g
0 1 2 3 4 5 6 7
c d e f ha b g
f e d c ah g b
rS:rS+1
Memory in big-endian
Memory in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor136

NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.39 Vector store double of four halfwords [with update] (zstdh[u])
zstdh rS,d(rA) (U = 0)zstdhu rS,d(rA) (U = 1)
if (rA=0 & U=1) then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*8)MEM(EA,2) RS32:47MEM(EA+2,2) RS48:63MEM(EA+4,2) RS+132:47MEM(EA+6,2) RS+148:63if U=1 then rA EA
The contents of even/odd register pair rS:rS+1 are stored as four halfwords in storage addressed by EA.
If U=1 (‘with update’), EA is placed into rA.
Figure 163 shows how bytes are stored in memory as determined by the endian mode.
Figure 163. zstdh[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.40 Vector store double of four halfwords [with modify] indexed (zstdh[m]x)
zstdhx rS,rA,rB (M = 0)zstdhmx rS,rA,rB (M = 1)
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS1
1 rS odd is illegal
rA UIMM2
2 displacement = UIMM * 8; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 0 0 1 0 1
c d e f ha b g
0 1 2 3 4 5 6 7
c d e f ha b g
d c f e gb a h
rS:rS+1
Memory in big-endian
Memory in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 137

if (rA=0 & M=1) then take_illegal_exceptionEA calc_EA(rA,rB,M)MEM(EA,2)* RS32:47MEM(EA+2,2)* RS48:63MEM(EA+4,2)* RS+132:47MEM(EA+6,2)* RS+148:63if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The contents of even/odd register pair rS:rS+1 are stored as four halfwords in storage addressed by EA.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 164 shows how bytes are stored in memory as determined by the endian mode.
Figure 164. zstdh[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.41 Vector store double of two words [with update]
zstdw rS,d(rA) (U = 0)zstdwu rS,d(rA) (U = 1)
if (rA=0 & U=1) then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*8)MEM(EA,4) RS32:63MEM(EA+4,4) RS+132:63
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS1
1 rS odd is illegal
rA rB 0 1 1 0 M 1 0 0 1 0 0
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS1
1 rS odd is illegal
rA UIMM2
2 displacement = UIMM * 8; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 0 0 0 1 1
c d e f ha b g
0 1 2 3 4 5 6 7
c d e f ha b g
d c f e gb a h
rS:rS+1
Memory in big-endian
Memory in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor138

if U=1 then rA EA
The contents of even/odd register pair rS:rS+1 are stored as two words in storage addressed by EA.
If U=1 (‘with update’), EA is placed into rA.
Figure 165 shows how bytes are stored in memory as determined by the endian mode.
Figure 165. zstdw[u] Results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.42 Vector store double of two words [with modify] indexed (zstdw[m]x)
zstdwx rS,rA,rB (M = 0)zstdwmx rS,rA,rB (M = 1)
if (rA=0 & M=1) then take_illegal_exceptionEA calc_EA(rA,rB,M)MEM(EA,4)* RS32:63MEM(EA+4,4)* RS+132:63if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The contents of even/odd register pair rS:rS+1 are stored as two words in storage addressed by EA.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 166 shows how bytes are stored in memory as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS1
1 rS odd is illegal
rA rB 0 1 1 0 M 1 0 0 0 1 0
c d e f ha b g
0 1 2 3 4 5 6 7
c d e f ha b g
b a h g ed c f
rS:rS+1
Memory in big-endian
Memory in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 139

Figure 166. zstdw[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.43 Vector store halfword even [with update] (zsthe[u])
zsthe rS,d(rA) (U = 0)zstheu rS,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*2)MEM(EA,2) RS32:47if U=1 then rA EA
The even halfword from rS is stored as a halfword in storage addressed by EA.
If U=1 (‘with update’), EA is placed into rA.
Figure 167 shows how bytes are stored in memory as determined by the endian mode.
Figure 167. zsthe[u] results in big- and little-endian modes
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS rA UIMM1
1 displacement = UIMM * 2; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 1 1 0 0 1
c d e f ha b g
0 1 2 3 4 5 6 7
c d e f ha b g
b a h g ed c f
rS:rS+1
Memory in big-endian
Memory in little-endian1
Byte address
1— Not supported in all implementations
c da b
a b
b a
GPR
Memory in big-endian
Memory in little-endian1
0 1Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor140

NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.44 Vector store halfword even [with modify] indexed (zsthe[m]x)
zsthex rS,rA,rB (M = 0)zsthemx rS,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)MEM(EA,2)* RS32:47if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The even halfword from rS is stored as a halfword in storage addressed by EA.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 168 shows how bytes are stored in memory as determined by the endian mode.
Figure 168. zsthe[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.45 Vector store halfword odd [with update] (zstho[u])
zstho rS,d(rA) (U = 0)zsthou rS,d(rA) (U = 1)
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS rA rB 0 1 1 0 M 1 1 1 0 0 0
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS rA UIMM1
1 displacement = UIMM * 2; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 1 1 0 1 1
c da b
a b
b a
GPR
Memory in big-endian
Memory in little-endian1
0 1Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 141

if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*2)MEM(EA,2) RS48:63if U=1 then rA EA
The odd halfword from rS is stored as a halfword in storage addressed by EA.
If U=1 (‘with update’), EA is placed into rA.
Figure 169 shows how bytes are stored in memory as determined by the endian mode.
Figure 169. zstho[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.46 Vector store halfword odd [with modify] indexed (zstho[m]x)
zsthox rS,rA,rB (M = 0)zsthomx rS,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)MEM(EA,2)* RS48:63if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The odd halfword from rS is stored as a halfword in storage addressed by EA.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 170 shows how bytes are stored in memory as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS rA rB 0 1 1 0 M 1 1 1 0 1 0
c da b
c d
d c
GPR
Memory in big-endian
Memory in little-endian1
0 1Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor142

Figure 170. zstho[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.47 Vector store word of two halfwords [with update] (zstwh[u])
zstwh rS,d(rA) (U = 0)zstwhu rS,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)MEM(EA,2) RS32:47MEM(EA+2,2) RS48:63if U=1 then rA EA
The halfwords from each element of rS are stored as two halfwords in storage addressed by EA.
If U=1 (‘with update’), EA is placed into rA.
Figure 171 shows how bytes are stored in memory as determined by the endian mode.
Figure 171. zstwh[u] results in big- and little-endian modes
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS rA UIMM1
1 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 1 1 1 0 1
c da b
c d
d c
GPR
Memory in big-endian
Memory in little-endian1
0 1Byte address
1— Not supported in all implementations
c da b
d cb a
GPR
Memory in big-endian
Memory in little-endian1
0 1 2 3Byte address
c da b
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 143

NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.48 Vector store word of two halfwords [with modify] indexed (zstwh[m]x)
zstwhx rS,rA,rB (M = 0)zstwhmx rS,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)MEM(EA,2)* RS32:47MEM(EA+2,2)* RS48:63if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The halfwords from each element of rS are stored as two halfwords in storage addressed by EA.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 172 shows how bytes are stored in memory as determined by the endian mode.
Figure 172. zstwh[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.49 Vector store word of two halfwords even from double [with update] (zstwhed[u])
zstwhed rS,d(rA) (U = 0)zstwhedu rS,d(rA) (U = 1)
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS rA rB 0 1 1 0 M 1 1 1 1 0 0
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS1 rA UIMM2 0 1 1 0 U 1 0 1 0 0 1
c da b
d cb a
GPR
Memory in big-endian
Memory in little-endian1
0 1 2 3Byte address
c da b
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor144

if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)MEM(EA,2) RS32:47MEM(EA+2,2) RS+132:47if U=1 then rA EA
The even halfwords from rS:rS+1 are stored as two halfwords in storage addressed by EA.
If U=1 (‘with update’), EA is placed into rA.
Figure 173 shows how bytes are stored in memory as determined by the endian mode.
Figure 173. zstwhed[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.50 Vector store word of two halfwords even from double [with modify] indexed (zstwhed[m]x)
zstwhedx rS,rA,rB (M = 0)zstwhedmx rS,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)MEM(EA,2)* RS32:47MEM(EA+2,2)* RS+132:47if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The even halfwords from rS:rS+1 are stored as two halfwords in storage addressed by EA.
1 rS odd is illegal2 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS1
1 rS odd is illegal
rA rB 0 1 1 0 M 1 0 1 0 0 0
c d e f ha b g
e fa b
f eb a
rS:rS+1
Memory in big-endian
Memory in little-endian1
0 1 2 3Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 145

If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 174 shows how bytes are stored in memory as determined by the endian mode.
Figure 174. zstwhed[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.51 Vector store word of two halfwords odd from double [with update] (zstwhod[u])
zstwhod rS,d(rA) (U = 0)zstwhodu rS,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)MEM(EA,2) RS48:63MEM(EA+2,2) RS+148:63if U=1 then rA EA
The odd halfwords from rS:rS+1 are stored as two halfwords in storage addressed by EA.
If U=1 (‘with update’), EA is placed into rA.
Figure 175 shows how bytes are stored in memory as determined by the endian mode.
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS1
1 rS odd is illegal
rA UIMM2
2 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 0 1 0 1 1
c d e f ha b g
e fa b
f eb a
rS:rS+1
Memory in big-endian
Memory in little-endian1
0 1 2 3Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor146

Figure 175. zstwhod[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.52 Vector store word of two halfwords odd from double [with modify] indexed (zstwhod[m]x)
zstwhodx rS,rA,rB (M = 0)zstwhodmx rS,rA,rB (M = 1)
if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)MEM(EA,2)* RS48:63MEM(EA+2,2)* RS+148:63if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The odd halfwords from rS:rS+1 are stored as two halfwords in storage addressed by EA.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 176 shows how bytes are stored in memory as determined by the endian mode.
Figure 176. zstwhod[m]x results in big- and little-endian modes
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS1
1 rS odd is illegal
rA rB 0 1 1 0 M 1 0 1 0 1 0
c d e f ha b g
0 1 2 3
g hc d
h gd c
rS:rS+1
Memory in big-endian
Memory in little-endian1
Byte address
1— Not supported in all implementations
c d e f ha b g
0 1 2 3
g hc d
h gd c
rS:rS+1
Memory in big-endian
Memory in little-endian1
Byte address
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 147

NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.53 Vector store word of word [with update] (zstww[u])
zstww rS,d(rA) (U = 0)zstwwu rS,d(rA) (U = 1)
if rA=0 & U=1 then take_illegal_exceptionif rA=0 & U=0 then b 0else b (rA)EA b + EXTZ(UIMM*4)MEM(EA,4) RS32:63if U=1 then rA EA
The word in rS is stored in storage addressed by EA.
If U=1 (‘with update’), EA is placed into rA.
Figure 177 shows how bytes are stored in memory as determined by the endian mode.
Figure 177. zstww[u] results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.4.54 Vector store word of word [with modify] indexed (zstww[m]x)
zstwwx rS,rA,rB (M = 0)zstwwmx rS,rA,rB (M = 1)
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS rA UIMM1
1 displacement = UIMM * 4; UIMM = 00000 is illegal if U=1
0 1 1 0 U 1 1 1 1 1 1
0 5 6 10 11 15 16 20 21 25 31
0 0 0 1 0 0 rS rA rB 0 1 1 0 M 1 1 1 1 1 0
c da b
b ad c
GPR
Memory in big-endian
Memory in little-endian1
0 1 2 3Byte address
c da b
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor148

if rA=0 & M=1 then take_illegal_exceptionEA calc_EA(rA,rB,M)MEM(EA,4)* RS32:63if (M=1) then rA32:63 calc_rA_update(rA,rB)
* - may wrap at length boundary for M=1 and mode 100.
The word in rS is stored in storage addressed by EA.
If M=1 (‘with modify’), rA32:63 is updated with an address value determined by the mode specifier in rA. See Section 1.4.3, Addressing mode – modify forms.
Figure 178 shows how bytes are stored in memory as determined by the endian mode.
Figure 178. zstww[m]x results in big- and little-endian modes
NOTEImplementation dependent. Depending on EA alignment, an alignment exception may occur.
1.6.5 Multiply, multiply/accumulate, and dot product instructions
1.6.5.1 Multiply halfwords, {even, even/odd, odd} guarded, {signed integer, unsigned integer, signed by unsigned integer, signed modulo fractional} (zmh{e,eo,o}g{si,ui,sui,smf})
zmhegsi rD,rA,rB (HS=00,TY=01,)zmhegsmf rD,rA,rB (HS=00,TY=11,)zmhegsui rD,rA,rB (HS=00,TY=10,)zmhegui rD,rA,rB (HS=00,TY=00,)zmheogsi rD,rA,rB (HS=01,TY=01,)zmheogsmf rD,rA,rB (HS=01,TY=11,)zmheogsui rD,rA,rB (HS=01,TY=10,)zmheogui rD,rA,rB (HS=01,TY=00,)zmhogsi rD,rA,rB (HS=10,TY=01,)zmhogsmf rD,rA,rB (HS=10,TY=11,)zmhogsui rD,rA,rB (HS=10,TY=10,)zmhogui rD,rA,rB (HS=10,TY=00,)
c da b
b ad c
GPR
Memory in big-endian
Memory in little-endian1
0 1 2 3Byte address
c da b
1— Not supported in all implementations
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 149

if HS=0x then src10:15 = rA32:47 else src10:15 = rA48:63if HS=00 then src20:15 = rB32:47 else src20:15 = rB48:63
temp10:31 src10:15 TY src20:15temp20:63 EXT64(temp10:31, TY)
rD32:63:rD+132:63 temp20:63
The selected halfword elements in rA and rB are multiplied. The intermediate product is extended to 64 bits and placed into rD:rD+1.
NOTEFor signed modulo fractional types (TY=11), if the two input operands are both -1.0, the result is represented as +1.0 (0x0000_0000_8000_0000).
Figure 179. Multiply halfwords guarded
1.6.5.2 Multiply halfwords, {even, even/odd, odd} guarded, {signed integer, unsigned integer, signed by unsigned integer, signed modulo fractional} and accumulate [negative] (zmh{e,eo,o}g{si,ui,sui,smf}{aa,an})
zmhegsiaa rD,rA,rB (HS=00,TY=01,ACC=01)zmhegsmfaa rD,rA,rB (HS=00,TY=11,ACC=01)zmhegsuiaa rD,rA,rB (HS=00,TY=10,ACC=01)zmheguiaa rD,rA,rB (HS=00,TY=00,ACC=01)zmheogsiaa rD,rA,rB (HS=01,TY=01,ACC=01)zmheogsmfaa rD,rA,rB (HS=01,TY=11,ACC=01)zmheogsuiaa rD,rA,rB (HS=01,TY=10,ACC=01)zmheoguiaa rD,rA,rB (HS=01,TY=00,ACC=01)zmhogsiaa rD,rA,rB (HS=10,TY=01,ACC=01)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 HS TY 0 0 0
150
Intermediate product
src2
X
rD:rD+1
src1
EXTZ (TY=00) / EXTS (TY=01,10,11)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor150

zmhogsmfaa rD,rA,rB (HS=10,TY=11,ACC=01)zmhogsuiaa rD,rA,rB (HS=10,TY=10,ACC=01)zmhoguiaa rD,rA,rB (HS=10,TY=00,ACC=01)zmhegsian rD,rA,rB (HS=00,TY=01,ACC=10)zmhegsmfan rD,rA,rB (HS=00,TY=11,ACC=10)zmhegsuian rD,rA,rB (HS=00,TY=10,ACC=10)zmheguian rD,rA,rB (HS=00,TY=00,ACC=10)zmheogsian rD,rA,rB (HS=01,TY=01,ACC=10)zmheogsmfan rD,rA,rB (HS=01,TY=11,ACC=10)zmheogsuian rD,rA,rB (HS=01,TY=10,ACC=10)zmheoguian rD,rA,rB (HS=01,TY=00,ACC=10)zmhogsian rD,rA,rB (HS=10,TY=01,ACC=10)zmhogsmfan rD,rA,rB (HS=10,TY=11,ACC=10)zmhogsuian rD,rA,rB (HS=10,TY=10,ACC=10)zmhoguian rD,rA,rB (HS=10,TY=00,ACC=10)
if HS=0x then src10:15 = rA32:47 else src10:15 = rA48:63if HS=00 then src20:15 = rB32:47 else src20:15 = rB48:63
temp10:31 src10:15 TY src20:15temp20:63 EXT64(temp10:31,TY)
if (ACC=01) then rD32:63:rD+132:63 rD32:63:rD+132:63 + temp20:63// accumulateelserD32:63:rD+132:63 rD32:63:rD+132:63 - temp20:63// accumulate negative
The selected halfword elements in rA and rB are multiplied. The intermediate product is extended to 64 bits and added to or subtracted from the contents of rD:rD+1, and the result is placed into rD:rD+1.
NOTEFor signed modulo fractional types (TY=11), if the two input operands are both -1.0, the intermediate product is represented as +1.0 (0x0000_0000_8000_0000).
NOTEThis is a modulo accumulate. There is no overflow check and no saturation is performed. Any overflow of the accumulated value is not recorded into the SPEFSCR.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 HS TY ACC 0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 151
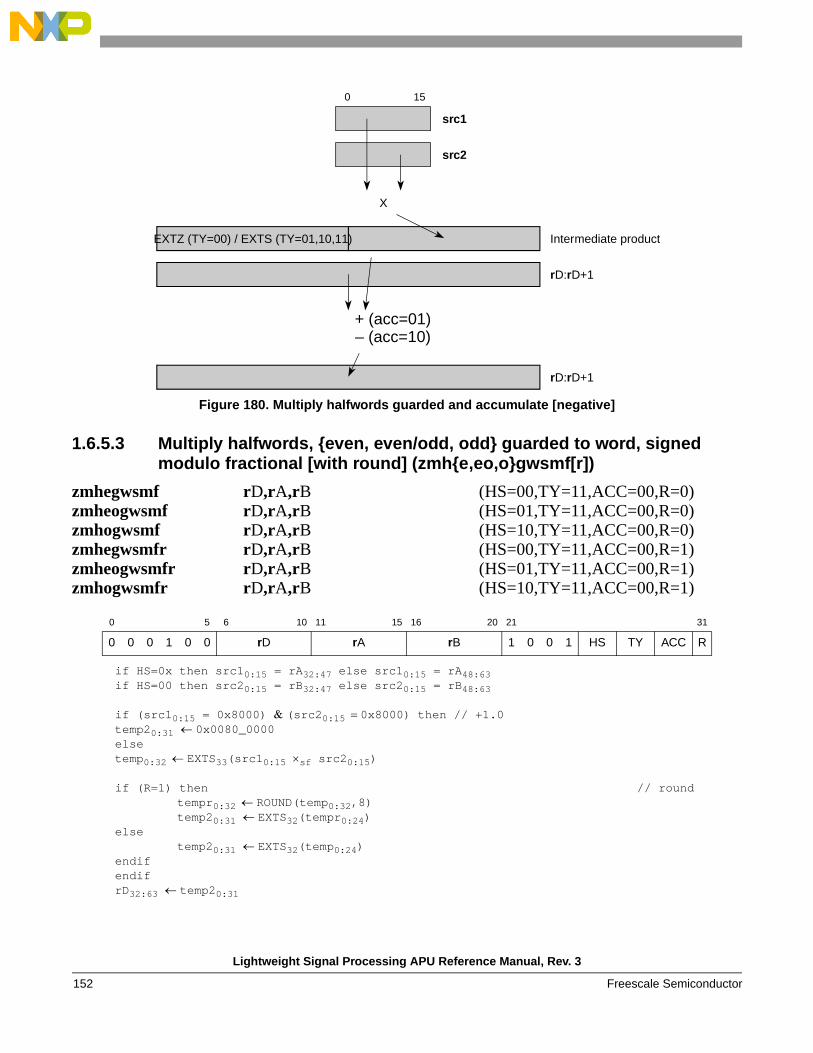
Figure 180. Multiply halfwords guarded and accumulate [negative]
1.6.5.3 Multiply halfwords, {even, even/odd, odd} guarded to word, signed modulo fractional [with round] (zmh{e,eo,o}gwsmf[r])
zmhegwsmf rD,rA,rB (HS=00,TY=11,ACC=00,R=0)zmheogwsmf rD,rA,rB (HS=01,TY=11,ACC=00,R=0)zmhogwsmf rD,rA,rB (HS=10,TY=11,ACC=00,R=0)zmhegwsmfr rD,rA,rB (HS=00,TY=11,ACC=00,R=1)zmheogwsmfr rD,rA,rB (HS=01,TY=11,ACC=00,R=1)zmhogwsmfr rD,rA,rB (HS=10,TY=11,ACC=00,R=1)
if HS=0x then src10:15 = rA32:47 else src10:15 = rA48:63if HS=00 then src20:15 = rB32:47 else src20:15 = rB48:63
if (src10:15 = 0x8000) (src20:15 0x8000) then // +1.0temp20:31 0x0080_0000elsetemp0:32 EXTS33(src10:15 sf src20:15)
if (R=1) then // roundtempr0:32 ROUND(temp0:32,8)temp20:31 EXTS32(tempr0:24)
else temp20:31 EXTS32(temp0:24)
endifendifrD32:63 temp20:31
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 0 0 1 HS TY ACC R
Intermediate product
rD:rD+1
+ (acc=01)
rD:rD+1
EXTZ (TY=00) / EXTS (TY=01,10,11)
150
src2
X
src1
– (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor152

The selected signed fractional halfword elements in rA and rB are multiplied. The 32-bit fractional product is sign-extended to 33 bits, then optionally rounded or truncated to 25 bits, and the 25-bit value is sign-extended to 32 bits to produce an intermediate product in 9.23 fractional format. The intermediate product is then placed into rD.
NOTEIf the two input operands are both –1.0, the fractional product is represented as +1.0 (0x0080_0000).
Figure 181. Fractional multiply halfwords guarded-word [with round]
1.6.5.4 Multiply halfwords, {even, even/odd, odd} guarded-word, signed modulo fractional [with round] and accumulate [negative] (zmh{e,eo,o}gwsmf[r]{aa,an})
zmhegwsmfaa rD,rA,rB (HS=00,TY=11,ACC=01,R=0)zmheogwsmfaa rD,rA,rB (HS=01,TY=11,ACC=01,R=0)zmhogwsmfaa rD,rA,rB (HS=10,TY=11,ACC=01,R=0)zmhegwsmfan rD,rA,rB (HS=00,TY=11,ACC=10,R=0)zmheogwsmfan rD,rA,rB (HS=01,TY=11,ACC=10,R=0)zmhogwsmfan rD,rA,rB (HS=10,TY=11,ACC=10,R=0)zmhegwsmfraa rD,rA,rB (HS=00,TY=11,ACC=01,R=1)zmheogwsmfraa rD,rA,rB (HS=01,TY=11,ACC=01,R=1)zmhogwsmfraa rD,rA,rB (HS=10,TY=11,ACC=01,R=1)zmhegwsmfran rD,rA,rB (HS=00,TY=11,ACC=10,R=1)zmheogwsmfran rD,rA,rB (HS=01,TY=11,ACC=10,R=1)zmhogwsmfran rD,rA,rB (HS=10,TY=11,ACC=10,R=1)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 0 0 1 HS TY ACC R
0 15
src2
X
src1
32 63
rD
40 41
.S........................S
S
230
exts
[ROUND]
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 153

if HS=0x then src10:15 = rA32:47 else src10:15 = rA48:63if HS=00 then src20:15 = rB32:47 else src20:15 = rB48:63
if (src10:15 = 0x8000) (src20:15 0x8000) thentemp20:31 0x0080_0000elsetemp0:32 EXTS33(src10:15 sf src20:15)
if (R=1) then // roundtempr0:32 ROUND(temp0:32,8)temp20:31 EXTS32(tempr0:24)
else temp20:31EXTS32(temp0:24)
endifendif
if (ACC=01) then rD32:63 rD32:63 + temp20:31// accumulateelserD32:63 rD32:63 - temp20:31// accumulate negative
The selected signed fractional halfword elements in rA and rB are multiplied. The 32-bit fractional product is sign-extended to 33 bits, then rounded or truncated to 25 bits, and the 25-bit value is sign-extended to 32 bits to produce an intermediate product in 9.23 fractional format. The intermediate product is then added to/subtracted from the contents of rD and the result is placed into rD. The accumulation is a modulo accumulation. No overflow/underflow is detected on the accumulation.
NOTEIf the two input operands are both –1.0, the fractional product is represented as +1.0 (0x0080_0000).
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor154

Figure 182. Fractional multiply halfwords guarded-word [with round] and accumulate [negative]
1.6.5.5 Multiply halfwords, {even, even/odd, odd}, signed fractional [round] (zmh{e,eo,o}sf[r])
zmhesf rD,rA,rB (HS=00,TY=11,ACC=00,R=0)zmheosf rD,rA,rB (HS=01,TY=11,ACC=00,R=0)zmhosf rD,rA,rB (HS=10,TY=11,ACC=00,R=0)zmhesfr rD,rA,rB (HS=00,TY=11,ACC=00,R=1)zmheosfr rD,rA,rB (HS=01,TY=11,ACC=00,R=1)zmhosfr rD,rA,rB (HS=10,TY=11,ACC=00,R=1)
if HS=0x then src10:15 = rA32:47 else src10:15 = rA48:63if HS=00 then src20:15 = rB32:47 else src20:15 = rB48:63
if (src10:15 = 0x8000) (src20:15 = 0x8000) thenif (R=1) then rD32:63 0x7FFF_0000else rD32:63 0x7FFF_FFFFelsetemp0:31 src10:15 sf src20:15
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 HS TY ACC R
0 15
src2
X
src1
32 63
intermediate product
40 41
.S........................S
S
230
exts
rD
rD
[ROUND]
+ (acc=01)– (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 155

if (R=1) then temp0:31 ROUND(temp0:31,16)rD32:63 temp0:31
The selected signed fractional halfword elements in rA and rB are multiplied. The 32-bit fractional product is optionally rounded to 16 bits, and then placed into rD. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF if R=0, or 0x7FFF_0000 if R=1.
Figure 183. Fractional multiply halfwords
1.6.5.6 Multiply halfwords, {even, even/odd, odd} signed fractional [round] and accumulate [negative] with saturate (zmh{e,eo,o}sf[r]{aa,an}s)
zmhesfaas rD,rA,rB (HS=00,TY=11,ACC=01,R=0)zmheosfaas rD,rA,rB (HS=01,TY=11,ACC=01,R=0)zmhosfaas rD,rA,rB (HS=10,TY=11,ACC=01,R=0)zmhesfans rD,rA,rB (HS=00,TY=11,ACC=10,R=0)zmheosfans rD,rA,rB (HS=01,TY=11,ACC=10,R=0)zmhosfans rD,rA,rB (HS=10,TY=11,ACC=10,R=0)zmhesfraas rD,rA,rB (HS=00,TY=11,ACC=01,R=1)zmheosfraas rD,rA,rB (HS=01,TY=11,ACC=01,R=1)zmhosfraas rD,rA,rB (HS=10,TY=11,ACC=01,R=1)zmhesfrans rD,rA,rB (HS=00,TY=11,ACC=10,R=1)zmheosfrans rD,rA,rB (HS=01,TY=11,ACC=10,R=1)zmhosfrans rD,rA,rB (HS=10,TY=11,ACC=10,R=1)
if HS=0x then src10:15 = rA32:47 else src10:15 = rA48:63if HS=00 then src20:15 = rB32:47 else src20:15 = rB48:63
if (src10:15 = 0x8000) (src20:15 = 0x8000) thentemp0:31 0x7FFF_FFFFelsetemp0:31 src10:15 sf src20:15 if (ACC=01) then temp0:63 EXTS64(rD32:63) + EXTS64(temp0:31)// accumulateelsetemp0:63 EXTS64(rD32:63) - EXTS64(temp0:31)// accumulate negative
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 HS TY ACC R
15
src1
src2
rD
X
0
[ROUND]
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor156

if (R=1) thentemp0:63 ROUND(temp0:63),16) //roundov chk_ovf(temp30:32)rD32:63 SATURATE(ov, temp30, 0x8000_0000, 0x7FFF_0000, temp32:63) elseov chk_ovf(temp30:32)rD32:63 SATURATE(ov, temp30, 0x8000_0000, 0x7FFF_FFFF, temp32:63)
// update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The selected signed fractional halfword elements in rA and rB are multiplied producing a 32-bit product. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF. The 32-bit product is then added to/subtracted from the word in rD, with optional rounding to 16-bit signed fractional range, saturating if positive or negative overflow occurs, and the result is placed into rD.
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 184. Fractional multiply halfwords and accumulate [negative] [with round] with saturate
1.6.5.7 Multiply halfwords, {even, even/odd, odd}, {signed, signed by unsigned, unsigned} integer (zmh{e,eo,o}{s,su,u}i)
zmhesi rD,rA,rB (HS=00,TY=01,ACC=00)zmheosi rD,rA,rB (HS=01,TY=01,ACC=00)zmhosi rD,rA,rB (HS=10,TY=01,ACC=00)zmhesui rD,rA,rB (HS=00,TY=10,ACC=00)zmheosui rD,rA,rB (HS=01,TY=10,ACC=00)zmhosui rD,rA,rB (HS=10,TY=10,ACC=00)zmheui rD,rA,rB (HS=00,TY=00,ACC=00)
0 15
Intermediate product
rD
src2
X
rD
src1
+[round], sat (acc=01)–[round], sat (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 157

zmheoui rD,rA,rB (HS=01,TY=00,ACC=00)zmhoui rD,rA,rB (HS=10,TY=00,ACC=00)
if HS=0x then src10:15 = rA32:47 else src10:15 = rA48:63if HS=00 then src20:15 = rB32:47 else src20:15 = rB48:63
rD32:63 src10:15 ty src20:15
The halfword integer elements in rA and rB are multiplied. The 32-bit product is placed into rD.
Figure 185. Multiply halfwords integer
1.6.5.8 Multiply halfwords, {even, even/odd, odd}, {signed, signed by unsigned, unsigned} integer and accumulate [negative] (zmh{e,eo,o}{s,su,u}i{aa,an})
zmhesiaa rD,rA,rB (HS=00,TY=01,ACC=01)zmheosiaa rD,rA,rB (HS=01,TY=01,ACC=01)zmhosiaa rD,rA,rB (HS=10,TY=01,ACC=01)zmhesian rD,rA,rB (HS=00,TY=01,ACC=10)zmheosian rD,rA,rB (HS=01,TY=01,ACC=10)zmhosian rD,rA,rB (HS=10,TY=01,ACC=10)zmhesuiaa rD,rA,rB (HS=00,TY=10,ACC=01)zmheosuiaa rD,rA,rB (HS=01,TY=10,ACC=01)zmhosuiaa rD,rA,rB (HS=10,TY=10,ACC=01)zmhesuian rD,rA,rB (HS=00,TY=10,ACC=10)zmheosuian rD,rA,rB (HS=01,TY=10,ACC=10)zmhosuian rD,rA,rB (HS=10,TY=10,ACC=10)zmheuiaa rD,rA,rB (HS=00,TY=00,ACC=01)zmheouiaa rD,rA,rB (HS=01,TY=00,ACC=01)zmhouiaa rD,rA,rB (HS=10,TY=00,ACC=01)zmheuian rD,rA,rB (HS=00,TY=00,ACC=10)zmheouian rD,rA,rB (HS=01,TY=00,ACC=10)zmhouian rD,rA,rB (HS=10,TY=00,ACC=10)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 HS TY ACC 0
15
src1
src2
rD
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor158

if HS=0x then src10:15 = rA32:47 else src10:15 = rA48:63if HS=00 then src20:15 = rB32:47 else src20:15 = rB48:63
temp0:31 src10:15 ty src20:15
if (ACC=01) then rD32:63 rD32:63 + temp0:31 // accumulateelserD32:63 rD32:63 - temp0:31 // accumulate negative
The halfword integer elements in rA and rB are multiplied. The intermediate 32-bit product is added to/subtracted from the contents of rD and the result is placed into rD.
Figure 186. Integer halfword multiply and accumulate
1.6.5.9 Multiply halfwords, {even, even/odd, odd}, {signed, signed by unsigned, unsigned} integer and accumulate [negative] with saturate (zmh{e,eo,o}{s,su,u}i{aa,an}s)
zmhesiaas rD,rA,rB (HS=00,TY=01,ACC=01)zmheosiaas rD,rA,rB (HS=01,TY=01,ACC=01)zmhosiaas rD,rA,rB (HS=10,TY=01,ACC=01)zmhesians rD,rA,rB (HS=00,TY=01,ACC=10)zmheosians rD,rA,rB (HS=01,TY=01,ACC=10)zmhosians rD,rA,rB (HS=10,TY=01,ACC=10)zmhesuiaas rD,rA,rB (HS=00,TY=10,ACC=01)zmheosuiaas rD,rA,rB (HS=01,TY=10,ACC=01)zmhosuiaas rD,rA,rB (HS=10,TY=10,ACC=01)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 HS TY ACC 0
0 15
Intermediate product
rD
src2
X
rD
src1
+ (acc=01)– (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 159

zmhesuians rD,rA,rB (HS=00,TY=10,ACC=10)zmheosuians rD,rA,rB (HS=01,TY=10,ACC=10)zmhosuians rD,rA,rB (HS=10,TY=10,ACC=10)zmheuiaas rD,rA,rB (HS=00,TY=00,ACC=01)zmheouiaas rD,rA,rB (HS=01,TY=00,ACC=01)zmhouiaas rD,rA,rB (HS=10,TY=00,ACC=01)zmheuians rD,rA,rB (HS=00,TY=00,ACC=10)zmheouians rD,rA,rB (HS=01,TY=00,ACC=10)zmhouians rD,rA,rB (HS=10,TY=00,ACC=10)
if HS=0x then src10:15 = rA32:47 else src10:15 = rA48:63if HS=00 then src20:15 = rB32:47 else src20:15 = rB48:63
temp0:31 src10:15 ty src20:15
if (ACC=01) then temp0:63 EXT64(rD32:63,TY) + EXT64(temp0:31,TY) // accumulateelsetemp0:63 EXT64(rD32:63,TY) - EXT64(temp0:31,TY) // accumulate negative
if (TY=00) then // unsigned overflowov temp31rD32:63 SATURATE(ov, temp0, 0x0000_0000, 0xFFFF_FFFF, temp32:63)else //signed overflowov (temp31 temp32)rD32:63 SATURATE(ov, temp0, 0x8000_0000, 0x7FFF_FFFF, temp32:63)
// update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The halfword integer elements in rA and rB are multiplied producing a 32-bit product. The 32-bit product is then added to/subtracted from the word in rD, saturating if positive or negative overflow occurs, and the result is placed into rD.
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 HS TY ACC 1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor160

Figure 187. Multiply halfword integer and accumulate [negative] with saturate
1.6.5.10 Vector multiply halfword signed, fractional, to halfword (zvmhsfh)
zvmhsfh rD,rA,rB
temp00:31 rA32:47 sf rB32:47 if (rA32:47 = 0x8000) (rB32:47 = 0x8000) thentemp00:31 0x7FFF_FFFF //saturate temp10:31 rA48:63 sf rB48:63 if (rA48:63 = 0x8000) (rB48:63 = 0x8000) thentemp10:31 0x7FFF_FFFF //saturate rD32:47 temp00:15; rD48:63 temp10:15
For each halfword element in the destination, corresponding halfword pairs of signed fractional elements in rA and rB are multiplied, and the result is placed into the corresponding rD halfword. If both inputs are –1.0, the product is represented as 0x7FFF and no overflow is reported.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 1 1 1 1 0 0 0
0 15
Intermediate product
rD
src2
X
rD
src1
+sat (acc=01)–sat (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 161

Figure 188. Vector multiply halfword, signed, fractional, to halfword (zvmhsfh)
1.6.5.11 Vector multiply halfword signed, fractional and round, to halfword (zvmhsfrh)
zvmhsfrh rD,rA,rB
temp00:31 (rA32:47 sf rB32:47) if (rA32:47 = 0x8000) (rB32:47 = 0x8000) thentemp00:31 0x7FFF_0000 //saturate elsetemp00:31 ROUND(temp00:31,16)endiftemp10:31 (rA48:63 sf rB48:63) if (rA48:63 = 0x8000) (rB48:63 = 0x8000) thentemp10:31 0x7FFF_0000 //saturate elsetemp10:31 ROUND(temp10:31,16)endifrD32:47 temp00:15; rD48:63 temp10:15
For each halfword element in the destination, corresponding halfword pairs of signed fractional elements in rA and rB are multiplied. The 32-bit product is then rounded to 16 bits, and the result is placed into the corresponding rD halfword. If both inputs are –1.0, the product is represented as 0x7FFF and no overflow is reported.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 1 1 1 1 0 0 1
47 4832 63
Intermediate
rB
x
rA
products(two 32-bit)
x
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor162

Figure 189. Vector multiply halfword, signed, fractional and round, to halfword
1.6.5.12 Vector multiply halfword, signed fractional [round] and accumulate [negative] to halfword with saturate (zvmhsf[r]{aa,an}hs)
zvmhsfaahs rD,rA,rB (ACC=01,R=0)zvmhsfanhs rD,rA,rB (ACC=10,R=0)zvmhsfraahs rD,rA,rB (ACC=01,R=1)zvmhsfranhs rD,rA,rB (ACC=10,R=1)
// upper resultif (rA32:47 = 0x8000) (rB32:47 = 0x8000) thentemph0:31 0x7FFF_FFFFelsetemph0:31 rA32:47 sf rB32:47
if (ACC=01) then temph0:33 EXTS34(rD32:47 ||
160) + EXTS34(temph0:31)// accumulateelsetemph0:33 EXTS34(rD32:47 ||
160) - EXTS34(temph0:31)// accumulate negative
if (R=1) then temph0:33 ROUND(temph0:33,16) //round
ovh chk_ovf(temph0:2)rD32:47 SATURATE(ovh, temph0, 0x8000, 0x7FFF, temph2:17)
// lower resultif (rA48:63 = 0x8000) (rB48:63 = 0x8000) thentempl0:31 0x7FFF_FFFFelsetempl0:31 rA48:63 sf rB48:63
if (ACC=01) then templ0:33 EXTS34(rD48:63 ||
160) + EXTS34(temph0:31) // accumulateelse
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 1 1 1 1 ACC R
47 4832 63
Intermediate
rB
x
rA
products(two 32-bit)
x
rD
ROUND ROUND
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 163

templ0:33 EXTS34(rD48:63 || 160) - EXTS34(temph0:31) // accumulate negative
if (R=1) then templ0:33 ROUND(templ0:33,16) //round
ovl chk_ovf(templ0:2)rD48:63 SATURATE(ovl, templ0, 0x8000, 0x7FFF, templ2:17)
// update SPEFSCRSPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
For each result, the halfword signed fractional elements in rA and rB are multiplied producing a 32-bit product. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF. Each 32-bit product is then added to/subtracted from the corresponding zero-padded halfword in rD with optional rounding, and saturated to a 16-bit fractional result. The results are placed into the corresponding halfwords of rD.
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 190. Vector fractional multiply halfwords [round] and accumulate [negative] to halfword with saturate
1.6.5.13 Vector multiply halfword {signed, signed by unsigned, unsigned} integer to halfword (zvmh{s,su,u}ih)
zvmhsih rD,rA,rBzvmhsuih rD,rA,rBzvmhuih rD,rA,rB
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 1 1 0 0 0 0 0
15
rA32:47
rB32:47
X
0
310
rD32:47
rD32:47
+ [round],sat (acc=01)
- [round],sat (acc=1x)
15
rA48:63
rB48:63
X
0
160
310
rD48:63
rD48:63
+ [round],sat (acc=01)
- [round],sat (acc=1x)
160
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor164

temph00:31 (rA32:47 ui rB32:47) temph10:31 (rA48:63 ui rB48:63)
rD32:47 temph116:31rD48:63 temph216:31
For each halfword element in the destination, corresponding halfword pairs of unsigned integer elements in rA and rB are multiplied producing a 32-bit product. The low-order 16 bits of the product are placed into the corresponding rD halfword.
NOTEThe least significant 16 bits of the products are independent of whether the halfword elements in rA and rB are treated as signed or unsigned 16-bit integers.
Figure 191. Vector multiply halfword, unsigned integer to halfword (zvmhuih)
1.6.5.14 Vector multiply halfword {signed, signed by unsigned} integer to halfword with saturate (zvmh{s,su,u}ihs)
zvmhsihs rD,rA,rB (TY=01)zvmhsuihs rD,rA,rB (TY=10)zvmhuihs rD,rA,rB (TY=00)
// upper resulttemph0:31 rA32:47 ty rB32:47if (TY=00) then // unsigned overflowovh chk_ovfu(temph0:15)rD32:47 SATURATE(ovh, 0, ----------, 0xFFFF, temph16:31)else //signed overflowovh chk_ovf(temph0:16)rD32:63 SATURATE(ovh, temph0, 0x8000, 0x7FFF, temph16:31)
// lower resulttempl0:31 rA48:63 ty rB48:63 if (TY=00) then // unsigned overflow
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 1 1 TY 0 0 1
47 4832 63
Intermediate
rB
xui
rA
products(two 32-bit)
xui
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 165

ovl chk_ovfu(templ0:15)rD48:63 SATURATE(ovl, 0, ----------, 0xFFFF, templ16:31)else //signed overflowovl chk_ovf(templ0:16)rD48:63 SATURATE(ovl, templ0, 0x8000, 0x7FFF, templ16:31)
// update SPEFSCRSPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
For each halfword element in the destination, corresponding halfword pairs of integer elements in rA and rB are multiplied, and the result is placed into the corresponding rD halfword. If the result exceeds the magnitude of a halfword, the result saturates. The overflow and summary overflow bits are recorded in the SPEFSCR based on an underflow or overflow from the multiply.
Other registers altered: SPEFSCR
Figure 192. Vector multiply halfword integer to halfword with saturate
1.6.5.15 Vector multiply halfword {signed, signed by unsigned, unsigned} integer and accumulate [negative] to halfword (zvmh{s,su,u}i{aa,an}h)
zvmhsiaah rD,rA,rB (ACC=01)zvmhsuiaah rD,rA,rB (ACC=01)zvmhuiaah rD,rA,rB (ACC=01)zvmhsianh rD,rA,rB (ACC=10)zvmhsuianh rD,rA,rB (ACC=10)zvmhuianh rD,rA,rB (ACC=10)
temph00:31 (rA32:47 ui rB32:47) temph10:31 (rA48:63 ui rB48:63)
if (ACC=01) then // accumulaterD32:47 rD32:47 + temph016:31rD48:63 rD48:63 + temph116:31else // accumulate negative
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 1 1 0 0 ACC 0
47 4832 63
Intermediate
rB
xty
rA
products(two 32-bit)
xty
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor166

rD32:47 rD32:47 - temph016:31rD48:63 rD48:63 - temph116:31
For each halfword element in the destination, corresponding halfword pairs of unsigned integer elements in rA and rB are multiplied producing a 32-bit product. The low order 16 bits of each product are added to/subtracted from the corresponding halfword element of rD and the results are placed into rD.
NOTEThe least significant 16 bits of the products are independent of whether the halfword elements in rA and rB are treated as signed or unsigned 16-bit integers.
Figure 193. Vector multiply halfword integer to halfword and accumulate [negative]
1.6.5.16 Vector multiply halfwords {signed, signed by unsigned, unsigned} integer and accumulate [negative] to halfword with saturate (zvmh{s,su,u}i{aa,an}hs)
zvmhsiaahs rD,rA,rB (TY=01,ACC=01)zvmhsuiaahs rD,rA,rB (TY=10,ACC=01)zvmhuiaahs rD,rA,rB (TY=00,ACC=01)zvmhsianhs rD,rA,rB (TY=01,ACC=10)zvmhsuianhs rD,rA,rB (TY=10,ACC=10)zvmhuianhs rD,rA,rB (TY=00,ACC=10)
// upper resulttemph0:31 rA32:47 ty rB32:47 if (ACC=01) then
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 0 1 1 TY ACC 1
47 4832 63
Intermediate
rB
xui
rA
products(two 32-bit)
xui
rD
rD
+ (acc=01)
– (acc=10)
+ (acc=01)
– (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 167

temph0:33 EXT34(rD32:47,TY) + EXT34(temph0:31,TY) // accumulateelsetemph0:33 EXT34(rD32:47,TY) - EXT34(temph0:31,TY) // accumulate negative
if (TY=00) then // unsigned overflowovh chk_ovfu(temph0:17)rD32:47 SATURATE(ovh, temph0, 0x0000, 0xFFFF, temph18:33)else //signed overflowovh chk_ovf(temph0:18)rD32:63 SATURATE(ovh, temph0, 0x8000, 0x7FFF, temph18:33)
// lower resulttempl0:31 rA48:63 ty rB48:63 if (ACC=01) then templ0:33 EXT34(rD48:63,TY) + EXT34(templ0:31,TY) // accumulateelsetempl0:33 EXT34(rD48:63,TY) - EXT34(templ0:31,TY) // accumulate negative
if (TY=00) then // unsigned overflowovl chk_ovfu(templ0:17)rD48:63 SATURATE(ovl, templ0, 0x0000, 0xFFFF, templ18:33)else //signed overflowovh chk_ovf(templ0:18)rD48:63 SATURATE(ovl, templ0, 0x8000, 0x7FFF, templ18:33)
// update SPEFSCRSPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
For each result, the halfword integer elements in rA and rB are multiplied producing a 32-bit product. The 32-bit product is then added to/subtracted from the corresponding sign or zero extended halfword in rD, saturating if overflow occurs, and the results are placed into the corresponding halfwords of rD.
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor168

Figure 194. Vector multiply halfword integer and accumulate [negative] to halfword with saturate
1.6.5.17 Multiply word guarded, {signed, unsigned, signed by unsigned} integer (zmwg{s,u,su}i)
zmwgsi rD,rA,rB (TY=01,ACC=00)zmwgsui rD,rA,rB (TY=10,ACC=00)zmwgui rD,rA,rB (TY=00,ACC=00)
rD32:63:rD+132:63 rA32:63 ty rB32:63
The integer word elements in rA and rB are multiplied producing a 64-bit product. The product is placed into rD:rD+1.
Figure 195. Integer multiply word guarded
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 1 1 TY ACC 0
47
rD32:47
32
15
rA32:47
rB32:47
X
0
310
EXT(rD32:47)
+sat (acc=01)–sat (acc=10)
63
rD48:63
48
15
rA32:47
rB32:47
X
0
310
EXT(rD48:63)
+sat (acc=01)–sat (acc=10)
32 63
rD:rD+1
rB
X
rA
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 169

1.6.5.18 Multiply word guarded, {signed, unsigned, signed by unsigned} integer and accumulate [negative] (zmwg{s,u,su}i{aa,an})
zmwgsiaa rD,rA,rB (TY=01,ACC=01)zmwgsian rD,rA,rB (TY=01,ACC=10)zmwgsuiaa rD,rA,rB (TY=10,ACC=01)zmwgsuian rD,rA,rB (TY=10,ACC=10)zmwguiaa rD,rA,rB (TY=00,ACC=01)zmwguian rD,rA,rB (TY=00,ACC=10)
temp0:63 rA32:63 ty rB32:63
if (ACC=01) then rD32:63:rD+132:63 rD32:63:rD+132:63 + temp0:63// accumulateelserD32:63:rD+132:63 rD32:63:rD+132:63 - temp0:63// accumulate negative
The integer word elements in rA and rB are multiplied producing a 64-bit intermediate product. The intermediate product is added to/subtracted from the contents of rD:rD+1, and the result is placed into rD:rD+1.
Figure 196. Multiply word guarded, integer and accumulate [negative]
1.6.5.19 Multiply word guarded, {signed, unsigned, signed by unsigned} integer and accumulate [negative] with saturate (zmwg{s,u,su}i{aa,an}s)
zmwgsiaas rD,rA,rB (TY=01,ACC=01)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 1 1 TY ACC 0
32 63
Intermediate product
rD:rD+1
rB
X
rD:rD+1
rA
+ (acc=01)– (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor170

zmwgsians rD,rA,rB (TY=01,ACC=10)zmwgsuiaas rD,rA,rB (TY=10,ACC=01)zmwgsuians rD,rA,rB (TY=10,ACC=10)zmwguiaas rD,rA,rB (TY=00,ACC=01)zmwguians rD,rA,rB (TY=00,ACC=10)
temp10:63 rA32:63 ty rB32:63
if (ACC=01) then temp0:65 EXT66(rD32:63:rD+132:63,TY) + EXT66(temp10:63,TY) // accumulateelsetemp0:65 EXT66(rD32:63:rD+132:63,TY) - EXT66(temp10:63,TY) // accumulate negative
if (TY=00) then // unsigned overflowov temp1rD32:63:rD+132:63 SATURATE(ov, temp0, 0x0000000000000000, 0xFFFFFFFFFFFFFFFF,
temp2:65)else //signed overflowov (temp1 temp2)rD32:63:rD+132:63 SATURATE(ov, temp0, 0x8000000000000000, 0x7FFFFFFFFFFFFFFF,
temp2:65) // update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The integer word elements in rA and rB are multiplied producing a 64-bit product. The 64-bit product is then added to/subtracted from rD:rD+1 to form an intermediate result. If the intermediate result has overflowed, the appropriate saturation value is placed into rD:rD+1. Otherwise, the low 64 bits of the intermediate result are placed into rD:rD+1. The overflow and summary overflow bits are recorded to indicate occurrence of saturation in the accumulation.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 1 1 TY ACC 1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 171

Figure 197. Multiply word guarded, signed integer and accumulate [negative] with saturate
1.6.5.20 Multiply word guarded signed, modulo, fractional [with round] (zmwgsmf[r])
zmwgsmf rD,rA,rB (R = 0)zmwgsmfr rD,rA,rB (R = 1)
temp0:63 rA0:31 sf rB0:31
if (rA0:31 = 0x8000_0000) (rB0:31 0x8000_0000) thenrD32:63:rD+132:63 0x0000_8000_0000_0000elsetemp0:64 EXTS65(temp0:63)if (R=1) then
tempr0:64 ROUND(temp0:64,16)rD32:63:rD+132:63 EXTS64(tempr0:48)
else rD32:63:rD+132:63 EXTS64(temp0:48)
endif
The signed fractional word elements in rA and rB are multiplied. The 64-bit fractional product is sign-extended to 65 bits, then optionally rounded to 49 bits or truncated to 49 bits, and the 49-bit value is sign-extended to 64 bits to produce a fractional product in 17.47 fractional format. If both inputs are –1.0, the intermediate product is represented as +1.0. The intermediate product is then placed into rD:rD+1.
0 5 6 10 11 15 16 20 21 25 26 27 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 1 1 1 1 0 0 R
32 63
Intermediate product
rD:rD+1
rB
X
rD:rD+1
rA
+sat (acc=01)–sat (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor172

Figure 198. Multiply word guarded, signed, modulo, fractional [with round] (zmwgsmf[r])
1.6.5.21 Multiply word guarded signed, modulo, fractional, [round] and accumulate [negative] (zmwgsmf[r]{aa,an})
zmwgsmfaa rD,rA,rB (R=0,TY=11,ACC=01)zmwgsmfan rD,rA,rB (R=0,TY=11,ACC=10)zmwgsmfraa rD,rA,rB (R=1,TY=11,ACC=01)zmwgsmfran rD,rA,rB (R=1,TY=11,ACC=10)
if (rA0:31 = 0x8000_0000) (rB0:31 0x8000_0000) thentemp20:63 0x0000_8000_0000_0000else temp10:64 EXTS65(rA0:31 sf rB0:31)if (R=1) then
tempr0:64 ROUND(temp10:64,16)temp20:63 EXTS64(tempr0:48)
else temp20:63 EXTS64(temp10:48);endifif (ACC=01) then rD32:63:rD+132:63 rD32:63:rD+132:63 + temp20:63 // accumulateelserD32:63:rD+132:63 rD32:63:rD+132:63 - temp20:63) // accumulate negative
The signed fractional word elements in rA and rB are multiplied. The 64-bit fractional product is sign-extended to 65 bits, then rounded or truncated to 49 bits, and the 49-bit value is then sign-extended
0 5 6 10 11 15 16 20 21 25 26 27 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 1 1 TY ACC R
32 63
rB
X
rA
0 63
rD:rD+1
15 16 17
.S........................S
S
470
exts
[ROUND]
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 173

to 64 bits to produce an intermediate product in 17.47 fractional format. If both inputs are –1.0, the fractional product is represented as +1.0. The intermediate product is then added to/subtracted from the contents of rD:rD+1 and the result is placed into rD:rD+1.
Figure 199. Multiply word guarded, signed, modulo, fractional, [round] and accumulate [negative]
1.6.5.22 Multiply word low signed integer with saturate (zmwl{s,su}is)
zmwlsis rD,rA,rB (TY=01,ACC=00)zmwlsuis rD,rA,rB (TY=10,ACC=00)
temp10:63 rA32:63 ty rB32:63 if (temp10:63 >si 0x0000_0000_7FFF_FFFF) (temp10:63 <si 0xFFFF_FFFF_8000_0000) thenmov 1temp132:63 SATURATE(mov, temp10, 0x8000_0000, 0x7FFF_FFFF, temp132:63)elsemov 0rD32:63 temp132:63
// update SPEFSCRSPEFSCROV movSPEFSCRSOV SPEFSCRSOV | mov
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 1 TY ACC 1
32 63
rB
X
rA
0 63
intermediate product
15 16 17
.S........................S
S
470
exts
rD:rD+1
rD:rD+1
[ROUND]
+ (acc=01)– (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor174

The signed integer word element in rA and signed or unsigned word element in rB are multiplied producing a 64-bit signed intermediate product. The intermediate product is saturated to 32 bits and placed into rD.
If there is an overflow, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 200. Multiply word signed [by unsigned] integer with saturate
1.6.5.23 Multiply word low unsigned integer with saturate (zmwluis)
zmwluis rD,rA,rB (TY=00,ACC=00)
temp10:63 rA32:63 ui rB32:63 if (temp10:63 >ui 0x0000_0000_FFFF_FFFF) thenmov 1temp132:63 SATURATE(mov, 0, ----------, 0xFFFF_FFFF, temp132:63)elsemov 0
rD0:31 temp032:63 ; rD32:63 temp132:63
// update SPEFSCRSPEFSCROVH movh; SPEFSCROV movl SPEFSCRSOVH SPEFSCRSOVH | movh; SPEFSCRSOV SPEFSCRSOV | movl
The unsigned word integer elements in rA and rB are multiplied producing a 64-bit intermediate product. The intermediate product is saturated to 32 bits and placed into rD.
If there is an overflow, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 1 TY ACC 1
32 63
Intermediate product
rB
X
sat
rA
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 175

Figure 201. Multiply word low unsigned integer with saturate (zmwluis)
1.6.5.24 Multiply word low {signed, signed by unsigned, unsigned} integer and accumulate [negative] (zmwl{s, su, u}i{aa,an})
zmwlsiaa rD,rA,rB (TY=00,ACC=01)zmwlsuiaa rD,rA,rB (TY=00,ACC=01)zmwluiaa rD,rA,rB (TY=00,ACC=01)zmwlsian rD,rA,rB (TY=00,ACC=10)zmwlsuian rD,rA,rB (TY=00,ACC=10)zmwluian rD,rA,rB (TY=00,ACC=10)
temp0:63 rA32:63 ty rB32:63
if (ACC=01) then rD32:63 rD32:63 + temp32:63// accumulateelserD32:63 rD32:63 - temp32:63// accumulate negative
The integer word elements in rA and rB are multiplied. The least significant 32 bits of the intermediate product is added to/subtracted from the contents of rD, and the result is placed into rD.
NOTEThe result is the same for both signed and unsigned integers. Thus, only a single opcode TY encoding is used.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 1 TY ACC 0
32 63
Intermediate product
rB
X
sat
rA
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor176

Figure 202. Multiply word low integer and accumulate [negative]
1.6.5.25 Multiply word low {signed, unsigned, signed by unsigned} integer and accumulate [negative] with saturate (zmwl{s,u,su}i{aa,an}s)
zmwlsiaas rD,rA,rB (TY=01,ACC=01)zmwlsians rD,rA,rB (TY=01,ACC=10)zmwlsuiaas rD,rA,rB (TY=10,ACC=01)zmwlsuians rD,rA,rB (TY=10,ACC=10)zmwluiaas rD,rA,rB (TY=00,ACC=01)zmwluians rD,rA,rB (TY=00,ACC=10)
temp0:63 rA32:63 ty rB32:63
if (ACC=01) then temp0:64 EXT65(rD32:63,TY) + EXT65(temp0:63,TY) // accumulateelsetemp0:64 EXT65(rD32:63,TY) - EXT65(temp0:63,TY)// accumulate negative
if (TY=00) then // unsigned overflowov chk_ovfu(temp0:32)rD32:63 SATURATE(ov, temp0, 0x0000_0000, 0xFFFF_FFFF, temp33:64)else //signed overflowov chk_ovf(temp0:33)rD32:63 SATURATE(ov, temp0, 0x8000_0000, 0x7FFF_FFFF, temp33:64)
// update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 1 TY ACC 1
32 63
Intermediate product
rB
X
rD
rA
rD
+ (acc=01)– (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 177

The integer word elements in rA and rB are multiplied producing a 64-bit product. The product is then added to/subtracted from the sign or zero extended word in rD, and then saturated to a 32-bit result, and the result is placed into rD.
If there is an positive or negative overflow from the saturation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 203. Multiply word low integer and accumulate [negative] with saturate
1.6.5.26 Multiply word signed, fractional [with round] (zmwsf[r])
zmwsf rD,rA,rB (R=0)zmwsfr rD,rA,rB (R=1)
if (rA32:63 = 0x8000_0000) (rB32:63 0x8000_0000) thentemp0:63 0x7FFF_FFFF_0000_0000 //saturateelsetemp0:63 rA32:63 sf rB32:63
if (R=1) then // roundtempr0:63ROUND(temp0:63,32)rD32:63 tempr0:31 elserD32:63 temp0:31
The signed fractional word elements in rA and rB are multiplied. The 64-bit product is rounded or truncated to 32 bits and the result is placed into rD. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF and no overflow is reported.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 1 1 1 0 0 R
32 63
Intermediate product
rB
X
rD
rA
rD
+sat (acc=01)–sat (acc=10)
EXTS/EXTZ
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor178

Figure 204. Multiply word signed, fractional [with round]
1.6.5.27 Multiply word signed, fractional, [round] and accumulate [negative] with saturate (zmwsf[r]{aa,an}s)
zmwsfaas rD,rA,rB (TY=11,ACC=01,R=0)zmwsfans rD,rA,rB (TY=11,ACC=10,R=0)zmwsfraas rD,rA,rB (TY=11,ACC=01,R=1)zmwsfrans rD,rA,rB (TY=11,ACC=10,R=1)
if (rA32:63 = 0x8000_0000) (rB32:63 0x8000_0000) thentemp10:63 0x7FFF_FFFF_FFFF_FFFFelse temp10:63 rA32:63 sf rB32:63
if (ACC=01) then temp20:65 ((EXTS66(rD32:63 || 320)) + EXTS66(temp10:63)) // acc
else temp20:65 ((EXTS66(rD32:63 || 320)) - EXTS66(temp10:63)) // acc negative
if (R=1) then temp20:65 ROUND(temp20:65,32) //roundov chk_ovf(temp20:2)rD32:63 SATURATE(ov, temp20, 0x8000_0000, 0x7FFF_FFFF, temp22:33)
// update SPEFSCRSPEFSCROV ov SPEFSCRSOV SPEFSCRSOV | ov
The signed fractional word elements in rA and rB are multiplied. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF_FFFF_FFFF. The 64-bit product is added to/subtracted from the zero-padded word in rD, the result is rounded or truncated to 32 bits, saturating if positive or negative overflow occurs, and the 32-bit result is placed into rD. If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 1 TY ACC R
32 63
Intermediate product
rB
rD
rA
X
[ROUND]
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 179

Figure 205. Multiply word signed, fractional, [round] and accumulate [negative] with saturate
1.6.5.28 Vector multiply halfwords, {upper/lower. lower/lower, upper/upper, exchanged/lower} guarded-word, signed modulo fractional [with round] (zvmh{ul,ll,uu,xl}gwsmf[r])
zvmhulgwsmf rD,rA,rB (HS=00,ACC=00,R=0)zvmhllgwsmf rD,rA,rB (HS=01,ACC=00,R=0)zvmhuugwsmf rD,rA,rB (HS=10,ACC=00,R=0)zvmhxlgwsmf rD,rA,rB (HS=11,ACC=00,R=0)zvmhulgwsmfr rD,rA,rB (HS=00,ACC=00,R=1)zvmhllgwsmfr rD,rA,rB (HS=01,ACC=00,R=1)zvmhuugwsmfr rD,rA,rB (HS=10,ACC=00,R=1)zvmhxlgwsmfr rD,rA,rB (HS=11,ACC=00,R=1)
if HS=00 then // ULsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=01 then // LLsrc1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=10 then //UUsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63else // HS=11XLsrc1h0:15 = rA48:63 ; src2h0:15 = rB48:63 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
// high resultif (src1h0:15 = 0x8000) (src2h0:15 0x8000) then temp2h0:31 0x0080_0000 // +1.0else temp1h0:31 src1h0:15 sf src2h0:15temph0:32 EXTS33(temp1h0:31)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 1 HS 1 0 ACC R
rD
+[round],sat or –sat, [round],sat
32 63
Intermediate product
rB
X
rA
rD 320
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor180

if (R=1) then // roundtemph0:32 ROUND(temph0:32,8)temp2h0:31 EXTS32(temph0:24)
else temp2h0:31 EXTS32(temph0:24);endifrD32:63 temp2h0:31// low resultif (src1l0:15 = 0x8000) (src2l0:15 0x8000) then temp2l0:31 0x0080_0000 // +1.0else templ0:32 EXTS33(src1l0:15 sf src2l0:15)
if (R=1) then // roundtemprl0:32 ROUND(templ0:32,8)temp2l0:31 EXTS32(temprl0:24)
else temp2l0:31 EXTS32(templ0:24);endifrD+132:63 temp2l0:31
For each result, the selected signed fractional halfword elements in rA and rB are multiplied. The 32-bit fractional product is sign-extended to 33 bits, then optionally rounded or truncated to 25 bits, and the 25-bit value is sign-extended to 32 bits to produce an intermediate product in 9.23 fractional format. The intermediate product is then placed into rD (high result element) or rD+1 (low result element).
NOTEIf the two source input operands are both –1.0, the fractional product is represented as +1.0 (0x0080_0000).
Figure 206. Vector fractional multiply halfwords guarded-word [with round]
1.6.5.29 Vector multiply halfwords, {upper/lower. lower/lower, upper/upper, exchanged/lower} guarded-word, signed modulo fractional [with round] and accumulate [negative, negative/positive] (zvmh{ul,ll,uu,xl}gwsmf[r]{aa,an,anp})
zvmhulgwsmfaa rD,rA,rB (HS=00,ACC=01,R=0)zvmhllgwsmfaa rD,rA,rB (HS=01,ACC=01,R=0)
15
src1h
src2h
X
0
S
230
[ROUND]
32 6340 41
.S.................S
exts
rD
15
src1l
src2l
X
0
S
230
[ROUND]
32 6340 41
.S.................S
exts
rD+1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 181

zvmhuugwsmfaa rD,rA,rB (HS=10,ACC=01,R=0)zvmhxlgwsmfaa rD,rA,rB (HS=11,ACC=01,R=0)zvmhulgwsmfraa rD,rA,rB (HS=00,ACC=01,R=1)zvmhllgwsmfraa rD,rA,rB (HS=01,ACC=01,R=1)zvmhuugwsmfraa rD,rA,rB (HS=10,ACC=01,R=1)zvmhxlgwsmfraa rD,rA,rB (HS=11,ACC=01,R=1)zvmhulgwsmfan rD,rA,rB (HS=00,ACC=10,R=0)zvmhllgwsmfan rD,rA,rB (HS=01,ACC=10,R=0)zvmhuugwsmfan rD,rA,rB (HS=10,ACC=10,R=0)zvmhxlgwsmfan rD,rA,rB (HS=11,ACC=10,R=0)zvmhulgwsmfran rD,rA,rB (HS=00,ACC=10,R=1)zvmhllgwsmfran rD,rA,rB (HS=01,ACC=10,R=1)zvmhuugwsmfran rD,rA,rB (HS=10,ACC=10,R=1)zvmhxlgwsmfran rD,rA,rB (HS=11,ACC=10,R=1)zvmhulgwsmfanp rD,rA,rB (HS=00,ACC=11,R=0)zvmhllgwsmfanp rD,rA,rB (HS=01,ACC=11,R=0)zvmhuugwsmfanp rD,rA,rB (HS=10,ACC=11,R=0)zvmhxlgwsmfanp rD,rA,rB (HS=11,ACC=11,R=0)zvmhulgwsmfranp rD,rA,rB (HS=00,ACC=11,R=1)zvmhllgwsmfranp rD,rA,rB (HS=01,ACC=11,R=1)zvmhuugwsmfranp rD,rA,rB (HS=10,ACC=11,R=1)zvmhxlgwsmfranp rD,rA,rB (HS=11,ACC=11,R=1)
if HS=00 then // ULsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=01 then // LLsrc1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=10 then //UUsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63else // HS=11XLsrc1h0:15 = rA48:63 ; src2h0:15 = rB48:63 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
// high resultif (src1h0:15 = 0x8000) (src2h0:15 0x8000) then temp2h0:31 0x0080_0000else temph0:32 EXTS33(src1h0:15 sf src2h0:15)if (R=1) then // round
temprh0:32 ROUND(temph0:32,8)temp2h0:31 EXTS32(temprh0:24)
else temp2h0:31EXTS32(temph0:24);endif
// low resultif (src1l0:15 = 0x8000) (src2l0:15 0x8000) then temp2l0:31 0x0080_0000else templ0:32 EXTS33(src1l0:15 sf src2l0:15)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 0 1 HS 1 0 ACC R
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor182

if (R=1) then // roundtemprl0:32 ROUND(templ0:32,8)temp2l0:31 EXTS32(temprl0:24)
else temp2l0:31EXTS32(templ0:24);endif
if (ACC=01) then rD32:63 rD32:63 + temp2h0:31; rD+132:63 rD+132:63 + temp2l0:31 // accumulateelseif (ACC=10) thenrD32:63 rD32:63 - temp2h0:31; rD+132:63 rD+132:63 - temp2l0:31 // acc negativeelse // (ACC=11) rD32:63 rD32:63 - temp2h0:31; rD+132:63 rD+132:63 + temp2l0:31 // acc neg/pos
For each result, the selected signed fractional halfword elements in rA and rB are multiplied. The 32-bit fractional product is sign-extended to 33 bits, then rounded or truncated to 25 bits, and the 25-bit value is sign-extended to 32 bits to produce an intermediate product in 9.23 fractional format. The intermediate product is then added to/subtracted from the contents of into rD (high result) or rD+1 (low result) and the result is placed into rD (high result) or rD+1 (low result). The accumulation is a modulo accumulation. No overflow/underflow is detected on the accumulation.
NOTEIf the two input operands are both –1.0, the fractional product is represented as +1.0 (0x0080_0000).
Figure 207. Vector fractional multiply halfwords guarded-word [with round] and accumulate [negative]
15
src1h
src2h
X
0
S
230
[ROUND]
32 6340 41
.S.................S
exts
rD
rD
+ (acc=01)– (acc=1x)
15
src1l
src2l
X
0
S
230
[ROUND]
32 6340 41
.S.................S
exts
rD+1
rD+1
+ (acc=x1)– (acc=10)
intermediate products
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 183

1.6.5.30 Vector multiply halfwords, {upper/lower. lower/lower, upper/upper, exchanged/lower}, signed fractional [round] (zvmh{ul,ll,uu,xl}sf[r])
zvmhulsf rD,rA,rB (HS=00,TY=11,ACC=00,R=0)zvmhllsf rD,rA,rB (HS=01,TY=11,ACC=00,R=0)zvmhuusf rD,rA,rB (HS=10,TY=11,ACC=00,R=0)zvmhxlsf rD,rA,rB (HS=11,TY=11,ACC=00,R=0)zvmhulsfr rD,rA,rB (HS=00,TY=11,ACC=00,R=1)zvmhllsfr rD,rA,rB (HS=01,TY=11,ACC=00,R=1)zvmhuusfr rD,rA,rB (HS=10,TY=11,ACC=00,R=1)zvmhxlsfr rD,rA,rB (HS=11,TY=11,ACC=00,R=1)
if HS=00 then // ULsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=01 then // LLsrc1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=10 then //UUsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63else // HS=11XLsrc1h0:15 = rA48:63 ; src2h0:15 = rB48:63 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
// upper resultif (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) thenif (R=1) then rD32:63 0x7FFF_0000else rD32:63 0x7FFF_FFFFelsetemph0:31 src1h0:15 sf src2h0:15if (R=1) then temph0:31 ROUND(temph0:31,16)rD32:63 temph0:31
// lower resultif (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) thenif (R=1) then rD+132:63 0x7FFF_0000else rD+132:63 0x7FFF_FFFFelsetempl0:31 src1l0:15 sf src2l0:15if (R=1) then templ0:31 ROUND(templ0:31,16)rD+132:63 templ0:31
For each result, the selected signed fractional halfword elements in rA and rB are multiplied. The 32-bit fractional products are optionally rounded to 16 bits, and then placed into rD (high result) and rD+1 (low result). If both inputs are –1.0, the product is represented as 0x7FFF_FFFF if R=0, or 0x7FFF_0000 if R=1.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 1 HS TY ACC R
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor184

Figure 208. Vector fractional multiply halfwords
1.6.5.31 Vector multiply halfwords, {upper/lower. lower/lower, upper/upper, exchanged/lower}, signed fractional and accumulate [negative, negative/positive] with saturate (zvmh{ul,ll,uu,xl}sf{aa,an,anp}s)
zvmhulsfaas rD,rA,rB (HS=00,TY=11,ACC=01)zvmhllsfaas rD,rA,rB (HS=01,TY=11,ACC=01)zvmhuusfaas rD,rA,rB (HS=10,TY=11,ACC=01)zvmhxlsfaas rD,rA,rB (HS=11,TY=11,ACC=01)zvmhulsfans rD,rA,rB (HS=00,TY=11,ACC=10)zvmhllsfans rD,rA,rB (HS=01,TY=11,ACC=10)zvmhuusfans rD,rA,rB (HS=10,TY=11,ACC=10)zvmhxlsfans rD,rA,rB (HS=11,TY=11,ACC=10)zvmhulsfanps rD,rA,rB (HS=00,TY=11,ACC=11)zvmhllsfanps rD,rA,rB (HS=01,TY=11,ACC=11)zvmhuusfanps rD,rA,rB (HS=10,TY=11,ACC=11)zvmhxlsfanps rD,rA,rB (HS=11,TY=11,ACC=11)
if HS=00 then // ULsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=01 then // LLsrc1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=10 then //UUsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63else // HS=11Xsrc1h0:15 = rA48:63 ; src2h0:15 = rB48:63 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
// upper resultif (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) thentemph0:31 0x7FFF_FFFFelsetemph0:31 src1h0:15 sf srch20:15if (ACC=01) then temph0:63 EXTS64(rD32:63) + EXTS64(temph0:31)// accumulateelse
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 1 HS TY ACC 0
15
src1h
src2h
rD
X
0 15
src1l
src2l
rD+1
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 185

temph0:63 EXTS64(rD32:63) - EXTS64(temph0:31)// accumulate negativeovh (temph31 temph32)rD32:63 SATURATE(ovh, temph31, 0x8000_0000, 0x7FFF_FFFF, temph32:63)
// lower resultif (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) thentempl0:31 0x7FFF_FFFFelsetempl0:31 src1l0:15 sf src2l0:15 if (ACC=x1) then templ0:63 EXTS64(rD+132:63) + EXTS64(templ0:31)// accumulateelsetempl0:63 EXTS64(rD+132:63) - EXTS64(templ0:31)// accumulate negativeovl (templ31 templ32)rD+132:63 SATURATE(ovl, templ31, 0x8000_0000, 0x7FFF_FFFF, templ32:63)
// update SPEFSCRSPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
For each result, the halfword signed fractional elements in rA and rB are multiplied producing a 32-bit product. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF. The 32-bit product is then added to/subtracted from the word in rD (high result) or rD+1 (low result), saturating if positive or negative overflow occurs, and the result is placed into rD (high result) or rD+1 (low result).
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 209. Vector fractional multiply halfwords and accumulate [negative] with saturate
15
src1h
src2h
X
0
310
rD
rD
+ sat (acc=01)
– sat (acc=1x)
15
src1l
src2l
X
0
310
rD+1
rD+1
+ sat (acc=x1)
– sat (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor186

1.6.5.32 Vector multiply halfwords, {upper/lower. lower/lower, upper/upper, exchanged/lower}, signed fractional round (to halfword) and accumulate [negative, negative/positive] with saturate (zvmh{ul,ll,uu,xl}sfr{aa,an,anp}s)
zvmhulsfraas rD,rA,rB (HS=00,TY=11,ACC=01)zvmhllsfraas rD,rA,rB (HS=01,TY=11,ACC=01)zvmhuusfraas rD,rA,rB (HS=10,TY=11,ACC=01)zvmhxlsfraas rD,rA,rB (HS=11,TY=11,ACC=01)zvmhulsfrans rD,rA,rB (HS=00,TY=11,ACC=10)zvmhllsfrans rD,rA,rB (HS=01,TY=11,ACC=10)zvmhuusfrans rD,rA,rB (HS=10,TY=11,ACC=10)zvmhxlsfrans rD,rA,rB (HS=11,TY=11,ACC=10)zvmhulsfranps rD,rA,rB (HS=00,TY=11,ACC=11)zvmhllsfranps rD,rA,rB (HS=01,TY=11,ACC=11)zvmhuusfranps rD,rA,rB (HS=10,TY=11,ACC=11)zvmhxlsfranps rD,rA,rB (HS=11,TY=11,ACC=11)
if HS=00 then // ULsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=01 then // LLsrc1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=10 then //UUsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63else // HS=11Xsrc1h0:15 = rA48:63 ; src2h0:15 = rB48:63 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
// upper resultif (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) thentemph0:31 0x7FFF_FFFFelsetemph0:31 src1h0:15 sf srch20:15if (ACC=01) then temph0:33 EXTS34(rD32:63) + EXTS34(temph0:31)// accumulateelsetemph0:33 EXTS34(rD32:63) - EXTS34(temph0:31)// accumulate negativetemprh0:33 ROUND(temph0:33,16) ovh chk_ovf(temprh0:2)rD32:63 SATURATE(ovh, temprh0, 0x8000_0000, 0x7FFF_0000, temprh2:33)
// lower resultif (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) thentempl0:31 0x7FFF_FFFFelsetempl0:31 src1l0:15 sf src2l0:15 if (ACC=x1) then templ0:33 EXTS34(rD+132:63) + EXTS34(templ0:31)// accumulateelse
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 1 HS TY ACC 1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 187

templ0:33 EXTS34(rD+132:63) - EXTS34(templ0:31)// accumulate negativetemprl0:33 ROUND(templ0:33,16) ovl chk_ovf(temprl0:2)rD+132:63 SATURATE(ovl, temprl0, 0x8000_0000, 0x7FFF_0000, temprl2:33)
// update SPEFSCRSPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
For each result, the halfword signed fractional elements in rA and rB are multiplied producing a 32-bit product. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF. The 32-bit product is added to/subtracted from the word in rD (high result) or rD+1 (low result) with rounding to 16-bits, saturating if positive or negative overflow occurs, and the result is placed into rD (high result) or rD+1 (low result).
If there is an overflow from the accumulation with round, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 210. Vector fractional multiply halfwords round with accumulate [negative] with saturate
1.6.5.33 Vector multiply halfwords, {upper/lower. lower/lower, upper/upper, exchanged/lower}, {signed, signed by unsigned, unsigned} integer (zvmh{ul,ll,uu,xl}{s,su,u}i)
zvmhulsi rD,rA,rB (HS=00,TY=01,ACC=00)zvmhllsi rD,rA,rB (HS=01,TY=01,ACC=00)zvmhuusi rD,rA,rB (HS=10,TY=01,ACC=00)zvmhxlsi rD,rA,rB (HS=11,TY=01,ACC=00)zvmhulsui rD,rA,rB (HS=00,TY=10,ACC=00)zvmhllsui rD,rA,rB (HS=01,TY=10,ACC=00)
15
src1h
src2h
X
0
310
rD
rD
+ round, sat (acc=01)– round, sat(acc=1x)
15
src1l
src2l
X
0
310
rD+1
rD+1
+ round, sat (acc=x1)– round, sat (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor188

zvmhuusui rD,rA,rB (HS=10,TY=10,ACC=00)zvmhxlsui rD,rA,rB (HS=11,TY=10,ACC=00)zvmhului rD,rA,rB (HS=00,TY=00,ACC=00)zvmhllui rD,rA,rB (HS=01,TY=00,ACC=00)zvmhuuui rD,rA,rB (HS=10,TY=00,ACC=00)zvmhxlui rD,rA,rB (HS=11,TY=00,ACC=00)
if HS=00 then // ULsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=01 then // LLsrc1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=10 then //UUsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63else // HS=11XLsrc1h0:15 = rA48:63 ; src2h0:15 = rB48:63 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
// upper resultrD32:63 src1h0:15 ty src2h0:15 // upper resultrD+132:63 src1l0:15 ty src2l0:15
For each result, the halfword integer elements in rA and rB are multiplied. The 32-bit product is placed into rD (high result) or rD+1 (low result).
Figure 211.
Figure 212. Vector multiply halfwords integer
1.6.5.34 Vector multiply halfwords, {upper/lower. lower/lower, upper/upper, exchanged/lower}, {signed, signed by unsigned, unsigned} integer and accumulate [negative, negative/positive] (zvmh{ul,ll,uu,xl}{s,su,u}i{aa,an,anp})
zvmhulsiaa rD,rA,rB (HS=00,TY=01,ACC=01)zvmhllsiaa rD,rA,rB (HS=01,TY=01,ACC=01)zvmhuusiaa rD,rA,rB (HS=10,TY=01,ACC=01)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 1 HS TY ACC 0
15
src1h
src2h
rD
X
0 15
src1l
src2l
rD+1
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 189

zvmhxlsiaa rD,rA,rB (HS=11,TY=01,ACC=01)zvmhulsian rD,rA,rB (HS=00,TY=01,ACC=10)zvmhllsian rD,rA,rB (HS=01,TY=01,ACC=10)zvmhuusian rD,rA,rB (HS=10,TY=01,ACC=10)zvmhxlsian rD,rA,rB (HS=11,TY=01,ACC=10)zvmhulsianp rD,rA,rB (HS=00,TY=01,ACC=11)zvmhllsianp rD,rA,rB (HS=01,TY=01,ACC=11)zvmhuusianp rD,rA,rB (HS=10,TY=01,ACC=11)zvmhxlsianp rD,rA,rB (HS=11,TY=01,ACC=11)zvmhulsuiaa rD,rA,rB (HS=00,TY=10,ACC=01)zvmhllsuiaa rD,rA,rB (HS=01,TY=10,ACC=01)zvmhuusuiaa rD,rA,rB (HS=10,TY=10,ACC=01)zvmhxlsuiaa rD,rA,rB (HS=11,TY=10,ACC=01)zvmhulsuian rD,rA,rB (HS=00,TY=10,ACC=10)zvmhllsuian rD,rA,rB (HS=01,TY=10,ACC=10)zvmhuusuian rD,rA,rB (HS=10,TY=10,ACC=10)zvmhxlsuian rD,rA,rB (HS=11,TY=10,ACC=10)zvmhulsuianp rD,rA,rB (HS=00,TY=10,ACC=11)zvmhllsuianp rD,rA,rB (HS=01,TY=10,ACC=11)zvmhuusuianp rD,rA,rB (HS=10,TY=10,ACC=11)zvmhxlsuianp rD,rA,rB (HS=11,TY=10,ACC=11)zvmhuluiaa rD,rA,rB (HS=00,TY=00,ACC=01)zvmhlluiaa rD,rA,rB (HS=01,TY=00,ACC=01)zvmhuuuiaa rD,rA,rB (HS=10,TY=00,ACC=01)zvmhxluiaa rD,rA,rB (HS=11,TY=00,ACC=01)zvmhuluian rD,rA,rB (HS=00,TY=00,ACC=10)zvmhlluian rD,rA,rB (HS=01,TY=00,ACC=10)zvmhuuuian rD,rA,rB (HS=10,TY=00,ACC=10)zvmhxluian rD,rA,rB (HS=11,TY=00,ACC=10)zvmhuluianp rD,rA,rB (HS=00,TY=00,ACC=11)zvmhlluianp rD,rA,rB (HS=01,TY=00,ACC=11)zvmhuuuianp rD,rA,rB (HS=10,TY=00,ACC=11)zvmhxluianp rD,rA,rB (HS=11,TY=00,ACC=11)
if HS=00 then // ULsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=01 then // LLsrc1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=10 then //UUsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63else // HS=11XLsrc1h0:15 = rA48:63 ; src2h0:15 = rB48:63 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 1 HS TY ACC 0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor190

// upper resulttemph0:31 src1h0:15 ty src2h0:15 if (ACC=01) then rD32:63 rD32:63 + temph0:31 // accumulateelse rD32:63 rD32:63 - temph0:31 // accumulate negative// lower resulttemp0:31 src1l0:15 ty src2l0:15 if (ACC=x1) then rD+132:63 rD+132:63 + templ0:31 // accumulateelse (ACC=10) rD+132:63 rD+132:63 - templ0:31 // accumulate negative
For each result, the halfword integer elements in rA and rB are multiplied. The intermediate 32-bit product is added to/subtracted from the contents of rD (high result) or rD+1 (low result) and the result is placed into rD (high result) or rD+1 (low result).
Figure 213. Vector integer halfword multiply and accumulate
1.6.5.35 Vector multiply halfwords, {upper/lower, lower/lower, upper/upper, exchanged/lower}, {signed, signed by unsigned, unsigned} integer and accumulate [negative, negative/positive] with saturate (zvmh{ul,ll,uu,xl}{s,su,u}i{aa,an,anp}s)
zvmhulsiaas rD,rA,rB (HS=00,TY=01,ACC=01)zvmhllsiaas rD,rA,rB (HS=01,TY=01,ACC=01)zvmhuusiaas rD,rA,rB (HS=10,TY=01,ACC=01)zvmhxlsiaas rD,rA,rB (HS=11,TY=01,ACC=01)zvmhulsians rD,rA,rB (HS=00,TY=01,ACC=10)zvmhllsians rD,rA,rB (HS=01,TY=01,ACC=10)zvmhuusians rD,rA,rB (HS=10,TY=01,ACC=10)zvmhxlsians rD,rA,rB (HS=11,TY=01,ACC=10)zvmhulsianps rD,rA,rB (HS=00,TY=01,ACC=11)zvmhllsianps rD,rA,rB (HS=01,TY=01,ACC=11)
15
src1h
src2h
X
0
310
rD
rD
+ (acc=01)– (acc=1x)
15
src1l
src2l
X
0
310
rD+1
rD+1
+ (acc=x1)– (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 191

zvmhuusianps rD,rA,rB (HS=10,TY=01,ACC=11)zvmhxlsianps rD,rA,rB (HS=11,TY=01,ACC=11)zvmhulsuiaas rD,rA,rB (HS=00,TY=10,ACC=01)zvmhllsuiaas rD,rA,rB (HS=01,TY=10,ACC=01)zvmhuusuiaas rD,rA,rB (HS=10,TY=10,ACC=01)zvmhxlsuiaas rD,rA,rB (HS=11,TY=10,ACC=01)zvmhulsuians rD,rA,rB (HS=00,TY=10,ACC=10)zvmhllsuians rD,rA,rB (HS=01,TY=10,ACC=10)zvmhuusuians rD,rA,rB (HS=10,TY=10,ACC=10)zvmhxlsuians rD,rA,rB (HS=11,TY=10,ACC=10)zvmhulsuianps rD,rA,rB (HS=00,TY=10,ACC=11)zvmhllsuianps rD,rA,rB (HS=01,TY=10,ACC=11)zvmhuusuianps rD,rA,rB (HS=10,TY=10,ACC=11)zvmhxlsuianps rD,rA,rB (HS=11,TY=10,ACC=11)zvmhuluiaas rD,rA,rB (HS=00,TY=00,ACC=01)zvmhlluiaas rD,rA,rB (HS=01,TY=00,ACC=01)zvmhuuuiaas rD,rA,rB (HS=10,TY=00,ACC=01)zvmhxluiaas rD,rA,rB (HS=11,TY=00,ACC=01)zvmhuluians rD,rA,rB (HS=00,TY=00,ACC=10)zvmhlluians rD,rA,rB (HS=01,TY=00,ACC=10)zvmhuuuians rD,rA,rB (HS=10,TY=00,ACC=10)zvmhxluians rD,rA,rB (HS=11,TY=00,ACC=10)zvmhuluianps rD,rA,rB (HS=00,TY=00,ACC=11)zvmhlluianps rD,rA,rB (HS=01,TY=00,ACC=11)zvmhuuuianps rD,rA,rB (HS=10,TY=00,ACC=11)zvmhxluianps rD,rA,rB (HS=11,TY=00,ACC=11)
if HS=00 then // ULsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=01 then // LLsrc1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63elseif HS=10 then //UUsrc1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63else // HS=11XLsrc1h0:15 = rA48:63 ; src2h0:15 = rB48:63 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
// upper resulttemph0:31 src1h0:15 ty src2h0:15 if (ACC=01) then temph0:63 EXT64(rD32:63,TY) + EXT64(temph0:31,TY) // accumulateelsetemph0:63 EXT64(rD32:63,TY) - EXT64(temph0:31,TY) // accumulate negative
if (TY=00) then // unsigned overflowovh temph31
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 1 HS TY ACC 1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor192

rD32:63 SATURATE(ovh, temph0, 0x0000_0000, 0xFFFF_FFFF, temph32:63)else //signed overflowovh (temph31 temph32)rD32:63 SATURATE(ovh, temph0, 0x8000_0000, 0x7FFF_FFFF, temph32:63)
// lower resulttempl0:31 src1l0:15 ty src2l0:15 if (ACC=x1) then templ0:63 EXT64(rD+132:63,TY) + EXT64(templ0:31,TY) // accumulateelsetempl0:63 EXT64(rD+132:63,TY) - EXT64(templ0:31,TY) // accumulate negative
if (TY=00) then // unsigned overflowovl templ31rD+132:63 SATURATE(ovl, templ0, 0x0000_0000, 0xFFFF_FFFF, templ32:63)else //signed overflowovl (templ31 templ32)rD+132:63 SATURATE(ovl, templ0, 0x8000_0000, 0x7FFF_FFFF, templ32:63)
// update SPEFSCRSPEFSCROV ovh | ovlSPEFSCRSOV SPEFSCRSOV | ovh | ovl
For each result, the halfword integer elements in rA and rB are multiplied producing a 32-bit product. The 32-bit product is then added to/subtracted from the word in rD (high result) or rD+1 (low result), saturating if positive or negative overflow occurs, and the result is placed into rD (high result) or rD+1 (low result).
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 214. Vector multiply halfword integer and accumulate [negative] with saturate
15
src1h
src2h
X
0
310
rD
rD
+ sat (acc=01)– sat (acc=1x)
15
src1l
src2l
X
0
310
rD+1
rD+1
+ sat (acc=x1)– sat (acc=10)
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 193

1.6.5.36 Vector dot product of halfwords [exchanged], guarded, add, {signed integer, unsigned integer, signed by unsigned integer, signed modulo fractional} (zvdotph[x]ga{si,ui,sui,smf})
zvdotphgaui rD,rA,rB (X=0,TY=00,ACC=00)zvdotphxgaui rD,rA,rB (X=1,TY=00,ACC=00)zvdotphgasi rD,rA,rB (X=0,TY=01,ACC=00)zvdotphxgasi rD,rA,rB (X=1,TY=01,ACC=00)zvdotphgasui rD,rA,rB (X=0,TY=10,ACC=00)zvdotphxgasui rD,rA,rB (X=1,TY=10,ACC=00)zvdotphgasmf rD,rA,rB (X=0,TY=11,ACC=00)zvdotphxgasmf rD,rA,rB (X=1,TY=11,ACC=00)
if X=0 then src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63else // X=1src1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
temp00:31 src1h0:15 TY src2h0:15temp10:31 src1l0:15 TY src2l0:15
//modulo sumtemp0:63 EXT64(temp00:31) + EXT64(temp10:31,TY) rD32:63:rD+132:63 temp0:63
The selected halfword elements in rA and rB are multiplied. The intermediate products are sign-extended and added together to produce a 64-bit result and the sum is placed into rD:rD+1.
NOTEIf the two input operands to a fractional multiply (TY=11) are both –1.0, the intermediate product is represented as +1.0 (10 || 0x8000_0000), prior to sign extension.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 0 X TY 0 0 1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor194

Figure 215. Dot product of halfwords [exchanged], guarded, add
1.6.5.37 Vector dot product of halfwords [exchanged], guarded, add, {signed integer, unsigned integer, signed by unsigned integer, signed modulo fractional} and accumulate [negative] (zvdotph[x]ga{si,ui,sui,smf}{aa,an})
zvdotphgauiaa rD,rA,rB (X=0,TY=00,ACC=01)zvdotphxgauiaa rD,rA,rB (X=1,TY=00,ACC=01)zvdotphgasiaa rD,rA,rB (X=0,TY=01,ACC=01)zvdotphxgasiaa rD,rA,rB (X=1,TY=01,ACC=01)zvdotphgasuiaa rD,rA,rB (X=0,TY=10,ACC=01)zvdotphxgasuiaa rD,rA,rB (X=1,TY=10,ACC=01)zvdotphgasmfaa rD,rA,rB (X=0,TY=11,ACC=01)zvdotphxgasmfaa rD,rA,rB (X=1,TY=11,ACC=01)zvdotphgauian rD,rA,rB (X=0,TY=00,ACC=10)zvdotphxgauian rD,rA,rB (X=1,TY=00,ACC=10)zvdotphgasian rD,rA,rB (X=0,TY=01,ACC=10)zvdotphxgasian rD,rA,rB (X=1,TY=01,ACC=10)zvdotphgasuian rD,rA,rB (X=0,TY=10,ACC=10)zvdotphxgasuian rD,rA,rB (X=1,TY=10,ACC=10)zvdotphgasmfan rD,rA,rB (X=0,TY=11,ACC=10)zvdotphxgasmfan rD,rA,rB (X=1,TY=11,ACC=10)
if X=0 then src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63else // X=1src1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 0 X TY ACC 1
Intermediate products(two 32-bit)
rD : rD + 1
+
EXT EXT
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 195

temp00:31 src1h0:15 TY src2h0:15temp10:31 src1l0:15 TY src2l0:15
//modulo sumtemp0:63 EXT64(temp00:31) + EXT64(temp10:31,TY)
if (ACC=01) then rD32:63:rD+132:63 rD32:63:rD+132:63 + temp0:63// accumulateelserD32:63:rD+132:63 rD32:63:rD+132:63 - temp0:63// accumulate negative
The selected halfword elements in rA and rB are multiplied. The intermediate products are sign- or zero-extended to 64 bits, then added together to produce a 64-bit result, the sum is added to or subtracted from the contents of rD:rD+1, and the result is placed into rD:rD+1.
NOTEFor signed modulo fractional types (TY=11), if the two input operands are both –1.0, the intermediate product is represented as +1.0 (0x0000_0000_8000_0000).
Figure 216. Dot product of halfwords [exchanged], guarded, add, and accumulate [negative]
Intermediate products(two 32-bit)
rD:rD + 1
+
EXT EXT
rD : rD + 1
+ (acc=01)
– (acc=10)
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor196

1.6.5.38 Vector dot product of halfwords, guarded, subtract, {signed integer, unsigned integer, signed by unsigned integer, signed modulo fractional} (zvdotphgs{si,ui,sui,smf})
zvdotphgsui rD,rA,rB (TY=00,ACC=00)zvdotphgssi rD,rA,rB (TY=01,ACC=00)zvdotphgssui rD,rA,rB (TY=10,ACC=00)zvdotphgssmf rD,rA,rB (TY=11,ACC=00)
src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63
temp00:31 src1h0:15 TY src2h0:15temp10:31 src1l0:15 TY src2l0:15
//modulo differencetemp0:63 EXT64(temp00:31) - EXT64(temp10:31,TY) rD32:63:rD+132:63 temp0:63
The selected halfword elements in rA and rB are multiplied. The intermediate products are sign-extended and the low product is subtracted from the high product to produce a 64-bit difference and the difference is placed into rD:rD+1.
NOTEIf the two input operands to a fractional multiply (TY=11) are both –1.0, the intermediate product is represented as +1.0 (10 || 0x8000_0000), prior to sign extension.
Figure 217. Dot product of halfwords, guarded, subtract
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 1 0 TY ACC 1
Intermediate products(two 32-bit)
rD : rD + 1
–
EXT EXT
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 197

1.6.5.39 Vector dot product of halfwords, guarded, subtract, {signed integer, unsigned integer, signed by unsigned integer, signed modulo fractional} and accumulate [negative] (zvdotphgs{si,ui,sui,smf}{aa,an})
zvdotphgsuiaa rD,rA,rB (TY=00,ACC=01)zvdotphgssiaa rD,rA,rB (TY=01,ACC=01)zvdotphgssuiaa rD,rA,rB (TY=10,ACC=01)zvdotphgssmfaa rD,rA,rB (TY=11,ACC=01)zvdotphgsuian rD,rA,rB (TY=00,ACC=10)zvdotphgssian rD,rA,rB (TY=01,ACC=10)zvdotphgssuian rD,rA,rB (TY=10,ACC=10)zvdotphgssmfan rD,rA,rB (TY=11,ACC=10)
src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63
temp00:31 src1h0:15 TY src2h0:15temp10:31 src1l0:15 TY src2l0:15
//modulo sumtemp0:63 EXT64(temp00:31,TY) - EXT64(temp10:31,TY)
if (ACC=01) then rD32:63:rD+132:63 rD32:63:rD+132:63 + temp0:63// accumulateelserD32:63:rD+132:63 rD32:63:rD+132:63 - temp0:63// accumulate negative
The selected halfword elements in rA and rB are multiplied. The intermediate products are sign or zero extended to 64 bits, then the low intermediate product is subtracted from the high intermediate product to produce a 64-bit difference. The difference is added to or subtracted from the contents of rD:rD+1, and the result is placed into rD:rD+1.
NOTEFor signed modulo fractional types (TY=11), if the two input operands are both –1.0, the intermediate product is represented as +1.0 (0x0000_0000_8000_0000).
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD1
1 rD odd is illegal
rA rB 1 0 1 0 1 0 TY ACC 1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor198

Figure 218. Dot product of halfwords, guarded, subtract, and accumulate [negative]
1.6.5.40 Vector dot product of halfwords [exchanged], add, signed fractional [round], with saturate (zvdotph[x]asf[r]s)
zvdotphasfs rD,rA,rB (X=0,TY=11,ACC=00,R=0)zvdotphxasfs rD,rA,rB (X=1,TY=11,ACC=00,R=0)zvdotphasfrs rD,rA,rB (X=0,TY=11,ACC=00,R=1)zvdotphxasfrs rD,rA,rB (X=1,TY=11,ACC=00,R=1)
if X=0 then src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63else // X=1src1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
if (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) thentemph0:31 0x7FFF_FFFF elsetemph0:31 src1h0:15 sf src2h0:15
if (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) thentempl0:31 0x7FFF_FFFFelsetempl0:31 src1l0:15 sf src2l0:15
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 0 X TY 0 0 R
Intermediate products
(two 32-bit)
rD:rD + 1
–
EXT EXT
rD : rD + 1
+ (acc=01)– (acc=10)
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 199

temp0:63 EXTS64(temph0:31) + EXTS64(templ0:31)// accumulate
if (R=1) then temp0:63 ROUND(temp0:63,16)
ov chk_ovf(temp30:32)
if (R=1) then rD32:63 SATURATE(ov, temp30, 0x8000_0000, 0x7FFF_0000, temp32:63) else rD32:63 SATURATE(ov, temp30, 0x8000_0000, 0x7FFF_FFFF, temp32:63)
// update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The selected signed fractional halfword elements in rA and rB are multiplied producing a pair of 32-bit products. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF. The 32-bit products are then added together, with optional rounding to 16-bit signed fractional range, saturating if positive or negative overflow occurs, and the result is placed into rD.
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 219. Dot product of halfwords [exchanged], fractional, add [with round] and saturate
1.6.5.41 Vector dot product of halfwords [exchanged], add, signed fractional, [round], and accumulate [negative] with saturate (zvdotph[x]asf[r]{aa,an}s)
zvdotphasfaas rD,rA,rB (X=0,TY=11,ACC=01,R=0)zvdotphxasfaas rD,rA,rB (X=1,TY=11,ACC=01,R=0)zvdotphasfans rD,rA,rB (X=0,TY=11,ACC=10,R=0)zvdotphxasfans rD,rA,rB (X=1,TY=11,ACC=10,R=0)zvdotphasfraas rD,rA,rB (X=0,TY=11,ACC=01,R=1)zvdotphxasfraas rD,rA,rB (X=1,TY=11,ACC=01,R=1)
Intermediate products(two 32-bit)
rD
+[round], sat
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor200

zvdotphasfrans rD,rA,rB (X=0,TY=11,ACC=10,R=1)zvdotphxasfrans rD,rA,rB (X=1,TY=11,ACC=10,R=1)
if X=0 then src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63else // X=1src1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
if (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) thentemph0:31 0x7FFF_FFFF elsetemph0:31 src1h0:15 sf src2h0:15
if (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) thentempl0:31 0x7FFF_FFFF elsetempl0:31 src1l0:15 sf src2l0:15
if (ACC=01) then temp0:63 EXTS64(rD32:63) + EXTS64(temph0:31) + EXTS64(templ0:31) // accelse temp0:63 EXTS64(rD32:63) - (EXTS64(temph0:31) + EXTS64(templ0:31)) // acc neg
if (R=1) then temp0:63 ROUND(temp0:63,16)
ov chk_ovf(temp30:32)
if (R=1) then rD32:63 SATURATE(ov, temp30, 0x8000_0000, 0x7FFF_0000, temp32:63) else rD32:63 SATURATE(ov, temp30, 0x8000_0000, 0x7FFF_FFFF, temp32:63)
// update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The selected signed fractional halfword elements in rA and rB are multiplied. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF. The intermediate products are then added together to produce a 33-bit result, the sum is added to or subtracted from the contents of rD, (with optional rounding to 16-bit signed fractional range), saturating if positive or negative overflow occurs, and the result is placed into rD.
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 0 X TY ACC R
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 201
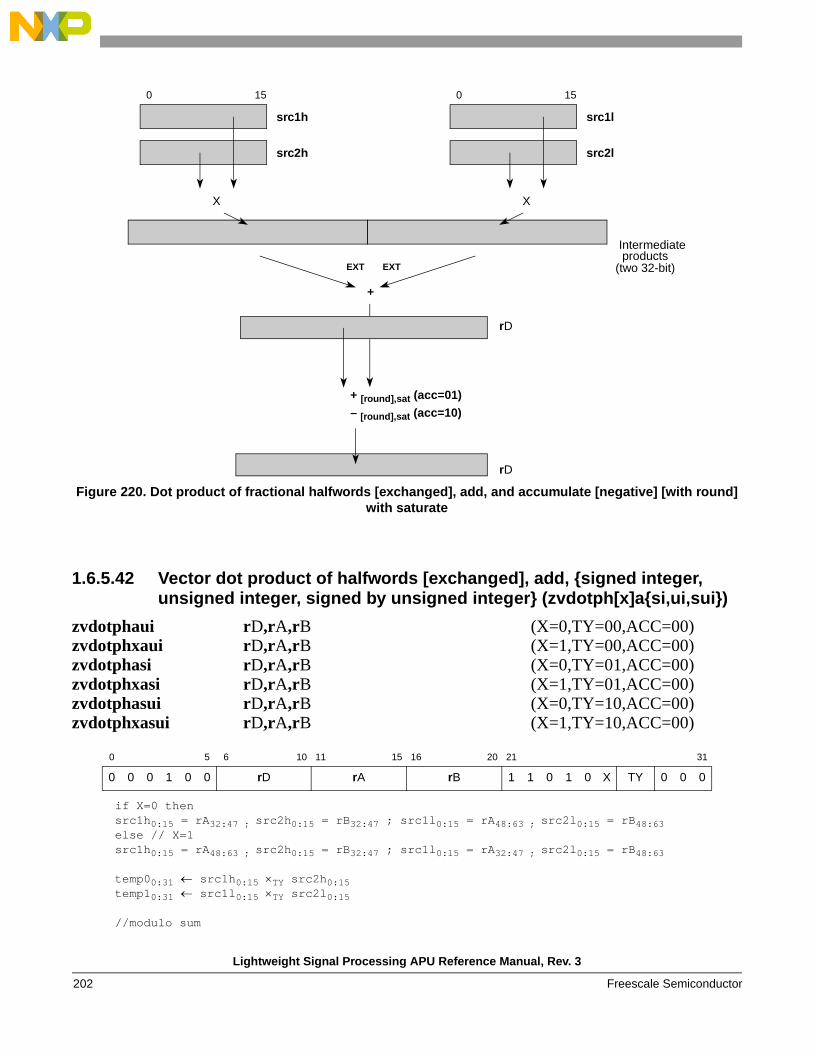
Figure 220. Dot product of fractional halfwords [exchanged], add, and accumulate [negative] [with round] with saturate
1.6.5.42 Vector dot product of halfwords [exchanged], add, {signed integer, unsigned integer, signed by unsigned integer} (zvdotph[x]a{si,ui,sui})
zvdotphaui rD,rA,rB (X=0,TY=00,ACC=00)zvdotphxaui rD,rA,rB (X=1,TY=00,ACC=00)zvdotphasi rD,rA,rB (X=0,TY=01,ACC=00)zvdotphxasi rD,rA,rB (X=1,TY=01,ACC=00)zvdotphasui rD,rA,rB (X=0,TY=10,ACC=00)zvdotphxasui rD,rA,rB (X=1,TY=10,ACC=00)
if X=0 then src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63else // X=1src1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
temp00:31 src1h0:15 TY src2h0:15temp10:31 src1l0:15 TY src2l0:15
//modulo sum
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 0 X TY 0 0 0
Intermediate products
(two 32-bit)
rD
+
EXT EXT
rD
+ [round],sat (acc=01)– [round],sat (acc=10)
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor202

temp0:31 temp00:31 + temp10:31 rD32:63 temp0:31
The selected halfword elements in rA and rB are multiplied. The intermediate products are added together to produce a 32-bit result and the sum is placed into rD.
Figure 221. Dot product of integer halfwords [exchanged], add
1.6.5.43 Vector dot product of halfwords [exchanged], add, {signed integer, unsigned integer, signed by unsigned integer} and accumulate [negative] (zvdotph[x]a{si,ui,sui}{aa,an})
zvdotphauiaa rD,rA,rB (X=0,TY=00,ACC=01)zvdotphxauiaa rD,rA,rB (X=1,TY=00,ACC=01)zvdotphasiaa rD,rA,rB (X=0,TY=01,ACC=01)zvdotphxasiaa rD,rA,rB (X=1,TY=01,ACC=01)zvdotphasuiaa rD,rA,rB (X=0,TY=10,ACC=01)zvdotphxasuiaa rD,rA,rB (X=1,TY=10,ACC=01)zvdotphauian rD,rA,rB (X=0,TY=00,ACC=10)zvdotphxauian rD,rA,rB (X=1,TY=00,ACC=10)zvdotphasian rD,rA,rB (X=0,TY=01,ACC=10)zvdotphxasian rD,rA,rB (X=1,TY=01,ACC=10)zvdotphasuian rD,rA,rB (X=0,TY=10,ACC=10)zvdotphxasuian rD,rA,rB (X=1,TY=10,ACC=10)
if X=0 then src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63else // X=1src1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
temph0:31 src1h0:15 TY src2h0:15
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 0 X TY ACC 0
rD
Intermediate products
(two 32-bit)
+
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 203

templ0:31 src1l0:15 TY src2l0:15
//modulo sumtemp0:31 temph0:31 + templ0:31
if (ACC=01) then rD32:63 rD32:63 + temp0:31// accumulateelserD32:63 rD32:63 - temp0:31// accumulate negative
The selected halfword elements in rA and rB are multiplied. The intermediate products are then added together to produce a 32-bit result, the sum is added to or subtracted from the contents of rD, and the result is placed into rD.
Figure 222. Dot product of integer halfwords [exchanged], add, and accumulate [negative]
1.6.5.44 Vector dot product of halfwords [exchanged], add, {signed integer, unsigned integer, signed by unsigned integer}, with saturate (zvdotph[x]a{si,ui,sui}s)
zvdotphauis rD,rA,rB (X=0,TY=00,ACC=00)zvdotphxauis rD,rA,rB (X=1,TY=00,ACC=00)zvdotphasis rD,rA,rB (X=0,TY=01,ACC=00)zvdotphxasis rD,rA,rB (X=1,TY=01,ACC=00)zvdotphasuis rD,rA,rB (X=0,TY=10,ACC=00)zvdotphxasuis rD,rA,rB (X=1,TY=10,ACC=00)
rD
Intermediate products(two 32-bit)
rD
+
+ (acc=01)– (acc=10)
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor204

if X=0 then src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63else // X=1src1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
temph0:31 src1h0:15 TY src2h0:15templ0:31 src1l0:15 TY src2l0:15
temp0:63 EXT64(temph0:31,TY) + EXT64(templ0:31,TY)
if (TY=00) thenov temp31rD32:63 SATURATE(ov, 0, ----------, 0xFFFF_FFFF, temp32:63) elseov chk_ovf(temp31:32)rD32:63 SATURATE(ov, temp31, 0x8000_0000, 0x7FFF_FFFF, temp32:63)
// update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The selected halfword elements in rA and rB are multiplied. The intermediate products are added together to produce a 32-bit result, saturating if positive or negative overflow occurs, and the sum is placed into rD.
Other registers altered: SPEFSCR
Figure 223. Dot product of integer halfwords [exchanged], add, saturate
1.6.5.45 Vector dot product of halfwords [exchanged], add, {signed integer, unsigned integer, signed by unsigned integer} and accumulate [negative] with saturate (zvdotph[x]a{si,ui,sui}{aa,an}s)
zvdotphauiaas rD,rA,rB (X=0,TY=00,ACC=01)zvdotphxauiaas rD,rA,rB (X=1,TY=00,ACC=01)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 0 X TY 0 0 1
rD
Intermediate products(two 32-bit)
+sat
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 205

zvdotphasiaas rD,rA,rB (X=0,TY=01,ACC=01)zvdotphxasiaas rD,rA,rB (X=1,TY=01,ACC=01)zvdotphasuiaas rD,rA,rB (X=0,TY=10,ACC=01)zvdotphxasuiaas rD,rA,rB (X=1,TY=10,ACC=01)zvdotphauians rD,rA,rB (X=0,TY=00,ACC=10)zvdotphxauians rD,rA,rB (X=1,TY=00,ACC=10)zvdotphasians rD,rA,rB (X=0,TY=01,ACC=10)zvdotphxasians rD,rA,rB (X=1,TY=01,ACC=10)zvdotphasuians rD,rA,rB (X=0,TY=10,ACC=10)zvdotphxasuians rD,rA,rB (X=1,TY=10,ACC=10)
if X=0 then src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63else // X=1src1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
temph0:31 src1h0:15 TY src2h0:15templ0:31 src1l0:15 TY src2l0:15
if (ACC=01) then temp0:63 EXT64(rD32:63,TY) + EXT64(temph0:31,TY) + EXT64(templ0:31,TY)elsetemp0:63 EXT64(rD32:63,TY) - (EXT64(temph0:31,TY) + EXT64(templ0:31,TY))
if (TY=00) thenov chk_ovfu(temp30:31)rD32:63 SATURATE(ov, temp0, 0x0000_0000, 0xFFFF_FFFF, temp32:63) elseov chk_ovf(temp30:32)rD32:63 SATURATE(ov, temp0, 0x8000_0000, 0x7FFF_FFFF, temp32:63)
// update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The selected halfword elements in rA and rB are multiplied. The intermediate products are then added together to produce a 33-bit result, the sum is added to or subtracted from the contents of rD, saturating if positive or negative overflow occurs, and the result is placed into rD.
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 0 X TY ACC 1
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor206
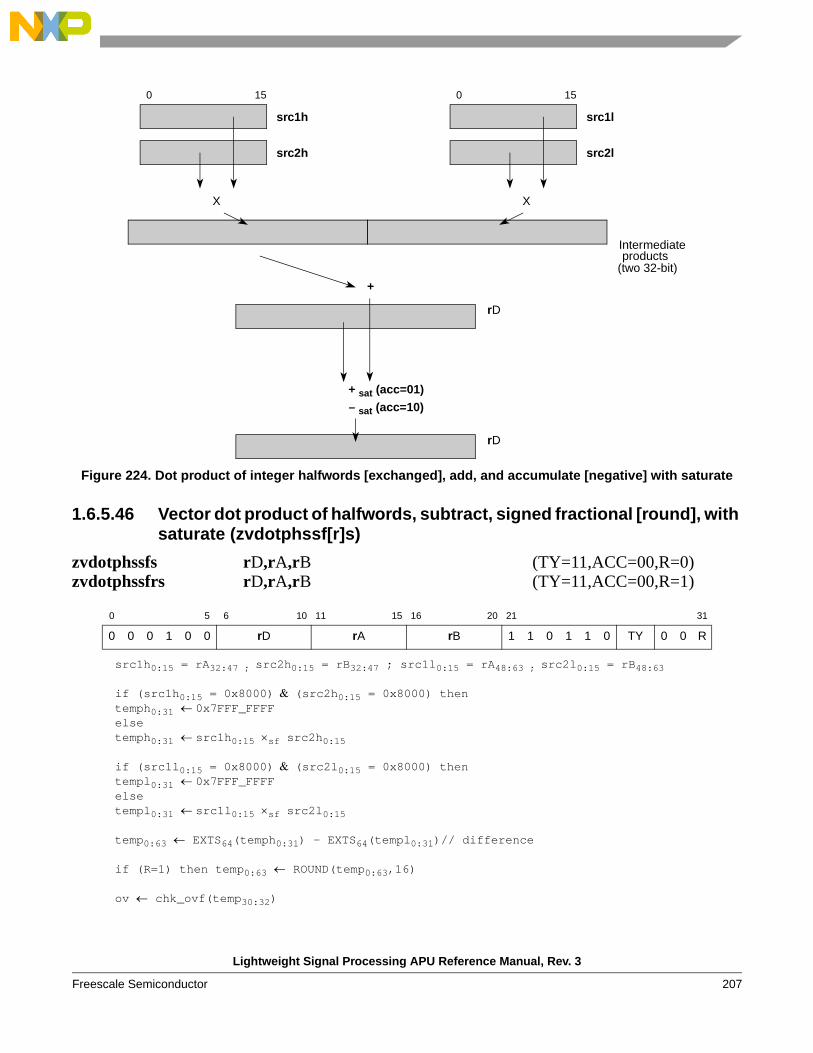
Figure 224. Dot product of integer halfwords [exchanged], add, and accumulate [negative] with saturate
1.6.5.46 Vector dot product of halfwords, subtract, signed fractional [round], with saturate (zvdotphssf[r]s)
zvdotphssfs rD,rA,rB (TY=11,ACC=00,R=0)zvdotphssfrs rD,rA,rB (TY=11,ACC=00,R=1)
src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63
if (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) thentemph0:31 0x7FFF_FFFFelsetemph0:31 src1h0:15 sf src2h0:15
if (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) thentempl0:31 0x7FFF_FFFF elsetempl0:31 src1l0:15 sf src2l0:15
temp0:63 EXTS64(temph0:31) - EXTS64(templ0:31)// difference
if (R=1) then temp0:63 ROUND(temp0:63,16)
ov chk_ovf(temp30:32)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 0 TY 0 0 R
rD
rD
Intermediate products(two 32-bit)
+
+ sat (acc=01)– sat (acc=10)
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 207

if (R=1) then rD32:63 SATURATE(ov, temp30, 0x8000_0000, 0x7FFF_0000, temp32:63) else rD32:63 SATURATE(ov, temp30, 0x8000_0000, 0x7FFF_FFFF, temp32:63)
// update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The selected signed fractional halfword elements in rA and rB are multiplied producing a pair of 32-bit products. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF. The low 32-bit product is then subtracted from the high 32-bit product, with optional rounding to 16-bit signed fractional range, saturating if positive or negative overflow occurs, and the result is placed into rD.
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 225. Dot product of halfwords, fractional, subtract [round] with saturate
1.6.5.47 Vector dot product of halfwords, subtract, signed fractional, [round], and accumulate [negative] with saturate (zvdotphssf[r]{aa,an}s)
zvdotphssfaas rD,rA,rB (TY=11,ACC=01,R=0)zvdotphssfans rD,rA,rB (TY=11,ACC=10,R=0)zvdotphssfraas rD,rA,rB (TY=11,ACC=01,R=1)zvdotphssfrans rD,rA,rB (TY=11,ACC=10,R=1)
src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63
if (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) thentemph0:31 0x7FFF_FFFFelsetemph0:31 src1h0:15 sf src2h0:15
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 0 TY ACC R
rD
Intermediate products
(two 32-bit)
– [round],sat
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor208

if (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) thentempl0:31 0x7FFF_FFFF elsetempl0:31 src1l0:15 sf src2l0:15
if (ACC=01) then temp0:63 EXTS64(rD32:63) + (EXTS64(temph0:31) - EXTS64(templ0:31)) else temp0:63 EXTS64(rD32:63) - (EXTS64(temph0:31) - EXTS64(templ0:31))
if (R=1) then temp0:63 ROUND(temp0:63,16)
ov chk_ovf(temp30:32)
if (R=1) then rD32:63 SATURATE(ov, temp30, 0x8000_0000, 0x7FFF_0000, temp32:63) else rD32:63 SATURATE(ov, temp30, 0x8000_0000, 0x7FFF_FFFF, temp32:63)
// update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The selected signed fractional halfword elements in rA and rB are multiplied. If both inputs are –1.0, the product is represented as 0x7FFF_FFFF. The low intermediate product is subtracted from the high intermediate product to produce a 33-bit result, the difference is added to or subtracted from the contents of rD (with optional rounding to 16-bit signed fractional range), saturating if positive or negative overflow occurs, and the result is placed into rD.
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 209

Figure 226. Dot product of fractional halfwords, subtract, and accumulate [negative] [round] with saturate
1.6.5.48 Vector dot product of halfwords, subtract, {signed integer, unsigned integer, signed by unsigned integer} (zvdotphs{si,ui,sui})
zvdotphsui rD,rA,rB (TY=00,ACC=00)zvdotphssi rD,rA,rB (TY=01,ACC=00)zvdotphssui rD,rA,rB (TY=10,ACC=00)
src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63
temph0:31 src1h0:15 TY src2h0:15templ0:31 src1l0:15 TY src2l0:15
//modulo sumtemp0:31 temph0:31 - templ0:31 rD32:63 temp0:31
The selected halfword elements in rA and rB are multiplied. The low intermediate product is subtracted from the high intermediate product to produce a 32-bit result and the difference is placed into rD.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 0 TY 0 0 0
rD
Intermediate products(two 32-bit)
–
+ [round], sat (acc=01)– [round], sat (acc=10)
15
src1h
src2h
X
0 15
src1l
src2l
X
0
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor210

Figure 227. Dot product of integer halfwords, subtract
1.6.5.49 Vector dot product of halfwords, subtract, {signed integer, unsigned integer, signed by unsigned integer} and accumulate [negative] (zvdotphs{si,ui,sui}{aa,an})
zvdotphsuiaa rD,rA,rB (TY=00,ACC=01)zvdotphssiaa rD,rA,rB (TY=01,ACC=01)zvdotphssuiaa rD,rA,rB (TY=10,ACC=01)zvdotphsuian rD,rA,rB (TY=00,ACC=10)zvdotphssian rD,rA,rB (TY=01,ACC=10)zvdotphssuian rD,rA,rB (TY=10,ACC=10)
src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63
temph0:31 src1h0:15 TY src2h0:15templ0:31 src1l0:15 TY src2l0:15
//modulo differencetemp0:31 temph0:31 - templ0:31
if (ACC=01) then rD32:63 rD32:63 + temp0:31// accumulateelserD32:63 rD32:63 - temp0:31// accumulate negative
The selected halfword elements in rA and rB are multiplied. The low intermediate product is subtracted from the high intermediate product to produce a 32-bit result, the difference is added to or subtracted from the contents of rD, and the result is placed into rD.
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 0 TY ACC 0
rD
Intermediate products
(two 32-bit)
–
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 211

Figure 228. Dot product of integer halfwords, subtract, and accumulate [negative]
1.6.5.50 Vector dot product of halfwords, subtract, {signed integer, unsigned integer, signed by unsigned integer}, with saturate (zvdotphs{si,ui,sui}s)
zvdotphsuis rD,rA,rB (TY=00,ACC=00)zvdotphssis rD,rA,rB (TY=01,ACC=00)zvdotphssuis rD,rA,rB (TY=10,ACC=00)
src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63
temph0:31 src1h0:15 TY src2h0:15templ0:31 src1l0:15 TY src2l0:15
temp0:63 EXT64(temph0:31,TY) - EXT64(templ0:31,TY)
if (TY=00) thenov temp31rD32:63 SATURATE(ov, temp0, 0x0000_0000, 0xFFFF_FFFF, temp32:63) elseov chk_ovf(temp31:32)rD32:63 SATURATE(ov, temp0, 0x8000_0000, 0x7FFF_FFFF, temp32:63)
// update SPEFSCR
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 0 TY 0 0 1
rD
Intermediate products
(two 32-bit)
–
+ (acc=01)– (acc=10)
15
src1h
src2h
X
0 15
src1l
src2l
X
0
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor212

SPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The selected halfword elements in rA and rB are multiplied. The low intermediate product is subtracted from the high intermediate product to produce a 32-bit result, saturating if positive or negative overflow occurs, and the difference is placed into rD.
If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 229. Dot product of integer halfwords, subtract, saturate
1.6.5.51 Vector dot product of halfwords, subtract, {signed integer, unsigned integer, signed by unsigned integer} and accumulate [negative] with saturate (zvdotphs{si,ui,sui}{aa,an}s)
zvdotphsuiaas rD,rA,rB (TY=00,ACC=01)zvdotphssiaas rD,rA,rB (TY=01,ACC=01)zvdotphssuiaas rD,rA,rB (TY=10,ACC=01)zvdotphsuians rD,rA,rB (TY=00,ACC=10)zvdotphssians rD,rA,rB (TY=01,ACC=10)zvdotphssuians rD,rA,rB (TY=10,ACC=10)
src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63
temph0:31 src1h0:15 TY src2h0:15templ0:31 src1l0:15 TY src2l0:15
if (ACC=01) then temp0:63 EXT64(rD32:63,TY) +(EXT64(temph0:31,TY) - EXT64(templ0:31,TY))else
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 1 0 1 1 0 TY ACC 1
rD
Intermediate products
(two 32-bit)
–sat
15
src1h
src2h
X
0 15
src1l
src2l
X
0
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 213

temp0:63 EXT64(rD32:63,TY) - (EXT64(temph0:31,TY) - EXT64(templ0:31,TY))
if (TY=00) thenov chk_ovfu(temp30:31)rD32:63 SATURATE(ov, temp0, 0x0000_0000, 0xFFFF_FFFF, temp32:63) elseov chk_ovf(temp30:32)rD32:63 SATURATE(ov, temp0, 0x8000_0000, 0x7FFF_FFFF, temp32:63)
// update SPEFSCRSPEFSCROV ovSPEFSCRSOV SPEFSCRSOV | ov
The selected halfword elements in rA and rB are multiplied. The low intermediate product is subtracted from the high intermediate product to produce a 33-bit result, the difference is added to or subtracted from the contents of rD, saturating if positive or negative overflow occurs, and the result is placed into rD. If there is an overflow from the accumulation, the overflow and summary overflow bits are recorded in the SPEFSCR.
Other registers altered: SPEFSCR
Figure 230. Dot product of integer halfwords, subtract, and accumulate [negative] with saturate
1.6.5.52 Vector dot product of halfwords [exchanged], guarded to word, add, signed modulo fractional [round] (zvdotph[x]gwasmf[r])
zvdotphgwasmf rD,rA,rB (X=0,R=0)zvdotphxgwasmf rD,rA,rB (X=1,R=0)zvdotphgwasmfr rD,rA,rB (X=0,R=1)
rD
Intermediate products
(two 32-bit)
–
+ sat (acc=01)– sat (acc=10)
15
src1h
src2h
X
0 15
src1l
src2l
X
0
rD
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor214

zvdotphxgwasmfr rD,rA,rB (X=1,R=1)
if X=0 then src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63else // X=1src1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
if (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) then temph0:33 0x8000_0000)else temph0:33 EXTS34(src1h0:15 sf src2h0:15)
if (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) then templ0:33 0x8000_0000)else templ0:33 EXTS34(src1l0:15 sf src2l0:15)
temp10:33 temph0:33 + templ0:33// addif (R=1) then // roundtempr0:33 ROUND(temp10:33,8)temp20:31 EXTS32(tempr0:25)else temp20:31EXTS32(temp10:25);endif
rD32:63 temp20:31
The selected signed fractional halfword elements in rA and rB are multiplied producing a pair of 32-bit products. The 32-bit fractional products are sign-extended to 34 bits, added to produce a 34-bit intermediate sum which is then rounded or truncated to 26 bits, and the 26-bit value is sign-extended to 32 bits to produce the result in 9.23 fractional format. The result is placed into rD. The accumulation is a modulo accumulation. No overflow/underflow is detected on the accumulation.
NOTEIf the two input operands are both –1.0, the sign-extended 34-bit fractional product is represented as +1.0 (20 || 0x8000_0000).
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 0 0 1 0 X 0 1 0 0 R
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 215

Figure 231. Dot product of halfwords [exchanged] guarded to word, fractional, add [with round]
1.6.5.53 Vector dot product of halfwords [exchanged], guarded to word, add, signed modulo fractional, [round], and accumulate [negative] (zvdotph[x]gwasmf[r]{aa,an})
zvdotphgwasmfaa rD,rA,rB (X=0,ACC=01,R=0)zvdotphxgwasmfaa rD,rA,rB (X=1,ACC=01,R=0)zvdotphgwasmfan rD,rA,rB (X=0,ACC=10,R=0)zvdotphxgwasmfan rD,rA,rB (X=1,ACC=10,R=0)zvdotphgwasmfraa rD,rA,rB (X=0,ACC=01,R=1)zvdotphxgwasmfraa rD,rA,rB (X=1,ACC=01,R=1)zvdotphgwasmfran rD,rA,rB (X=0,ACC=10,R=1)zvdotphxgwasmfran rD,rA,rB (X=1,ACC=10,R=1)
if X=0 then src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63else // X=1src1h0:15 = rA48:63 ; src2h0:15 = rB32:47 ; src1l0:15 = rA32:47 ; src2l0:15 = rB48:63
if (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) then temph0:33 0x8000_0000)else temph0:33 EXTS34(src1h0:15 sf src2h0:15)
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 0 0 1 0 X 0 1 ACC R
15
src1l
src2l
X
0
S
310
[ROUND]
32 6340 41
.S.................S
exts
intermediate products
15
src1h
src2h
X
0
S
310
rD
+
330
[EXTS][EXTS]
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor216

if (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) then templ0:33 0x8000_0000)else templ0:33 EXTS34(src1l0:15 sf src2l0:15)
temp10:33 temph0:33 + templ0:33// addif (R=1) then // roundtempr0:33 ROUND(temp10:33,8)temp20:31 EXTS32(tempr0:25)else temp20:31EXTS32(temp10:25);endif
if (ACC=01) then rD32:63 rD32:63 + temp20:31 // accumulateelseif (ACC=10) thenrD32:63 rD32:63 - temp20:31 // acc negative
The selected signed fractional halfword elements in rA and rB are multiplied producing a pair of 32-bit products. The 32-bit fractional products are sign-extended to 34 bits, added to produce a 34-bit intermediate sum which is then rounded or truncated to 26 bits, and the 26-bit value is sign-extended to 32 bits to produce an intermediate result in 9.23 fractional format. The intermediate 9.23 fractional format result is then added to/subtracted from the contents of rD, and the final result is placed into rD. The accumulation is a modulo accumulation. No overflow/underflow is detected on the accumulation.
NOTEIf the two input operands are both –1.0, the sign-extended 34-bit fractional product is represented as +1.0 (20 || 0x8000_0000).
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 217
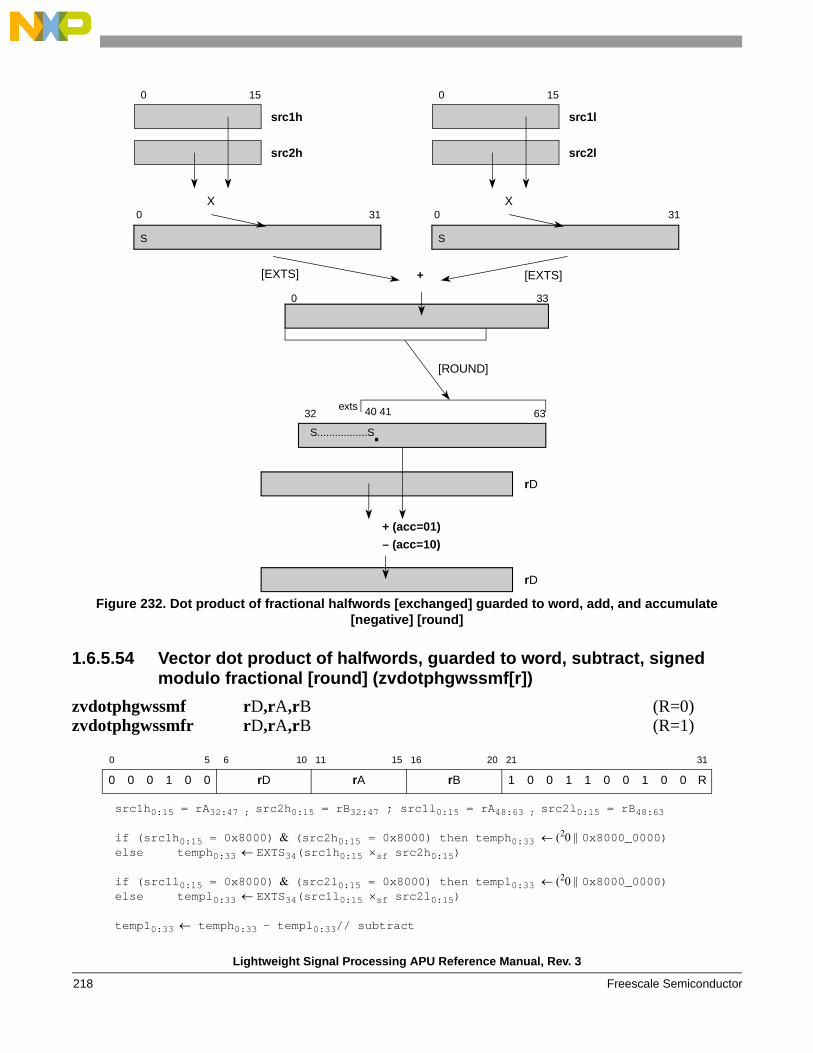
Figure 232. Dot product of fractional halfwords [exchanged] guarded to word, add, and accumulate [negative] [round]
1.6.5.54 Vector dot product of halfwords, guarded to word, subtract, signed modulo fractional [round] (zvdotphgwssmf[r])
zvdotphgwssmf rD,rA,rB (R=0)zvdotphgwssmfr rD,rA,rB (R=1)
src1h0:15 = rA32:47 ; src2h0:15 = rB32:47 ; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63
if (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) then temph0:33 0x8000_0000)else temph0:33 EXTS34(src1h0:15 sf src2h0:15)
if (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) then templ0:33 0x8000_0000)else templ0:33 EXTS34(src1l0:15 sf src2l0:15)
temp10:33 temph0:33 - templ0:33// subtract
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 0 0 1 1 0 0 1 0 0 R
15
src1l
src2l
X
0
S
310
15
src1h
src2h
X
0
S
310
rD
rD
+ (acc=01)– (acc=10)
[ROUND]
32 6340 41
.S.................S
exts
+
330
[EXTS][EXTS]
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor218

if (R=1) then // roundtempr0:33 ROUND(temp10:33,8)temp20:31 EXTS32(tempr0:25)else temp20:31EXTS32(temp10:25);endif
rD32:63 temp20:31
The selected signed fractional halfword elements in rA and rB are multiplied producing a pair of 32-bit products. The 32-bit fractional products are sign-extended to 34 bits, the low product is subtracted from the high product to produce a 34-bit intermediate difference which is then rounded or truncated to 26 bits, and the 26-bit value is sign-extended to 32 bits to produce the result in 9.23 fractional format. The result is placed into rD. The subtract is a modulo subtract. No overflow/underflow is detected on the subtraction.
NOTEIf the two input operands are both –1.0, the sign-extended 34-bit fractional product is represented as +1.0 (20 || 0x8000_0000).
Figure 233. Dot product of halfwords guarded to word, fractional, subtract [with round]
1.6.5.55 Vector dot product of halfwords, guarded to word, subtract, signed modulo fractional, [round], and accumulate [negative] (zvdotphgwssmf[r]{aa,an})
zvdotphgwssmfaa rD,rA,rB (ACC=01,R=0)zvdotphgwssmfan rD,rA,rB (ACC=10,R=0)zvdotphgwssmfraa rD,rA,rB (ACC=01,R=1)
15
src1l
src2l
X
0
S
310
[ROUND]
32 6340 41
.S.................S
exts
intermediate products
15
src1h
src2h
X
0
S
310
rD
–
330
[EXTS][EXTS]
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 219

zvdotphgwssmfran rD,rA,rB (ACC=10,R=1)
src1h0:15 = rA32:47 ; src2h0:15 = rB32:47; src1l0:15 = rA48:63 ; src2l0:15 = rB48:63
if (src1h0:15 = 0x8000) (src2h0:15 = 0x8000) then temph0:33 0x8000_0000)else temph0:33 EXTS34(src1h0:15 sf src2h0:15)
if (src1l0:15 = 0x8000) (src2l0:15 = 0x8000) then templ0:33 0x8000_0000)else templ0:33 EXTS34(src1l0:15 sf src2l0:15)
temp10:33 temph0:33 - templ0:33// subif (R=1) then // roundtempr0:33 ROUND(temp10:33,8)temp20:31 EXTS32(tempr0:25)else temp20:31EXTS32(temp10:25);endif
if (ACC=01) then rD32:63 rD32:63 + temp20:31 // accumulateelseif (ACC=10) thenrD32:63 rD32:63 - temp20:31 // acc negative
The selected signed fractional halfword elements in rA and rB are multiplied producing a pair of 32-bit products. The 32-bit fractional products are sign-extended to 34 bits, and the low product is subtracted from the high product to produce a 34-bit intermediate difference which is then rounded or truncated to 26 bits, and the 26-bit value is sign-extended to 32 bits to produce an intermediate result in 9.23 fractional format. The intermediate 9.23 fractional format result is then added to/subtracted from the contents of rD, and the final result is placed into rD. The accumulation is a modulo accumulation. No overflow/underflow is detected on the accumulation or subtraction.
NOTEIf the two input operands are both –1.0, the sign-extended 34-bit fractional product is represented as +1.0 (20 || 0x8000_0000).
0 5 6 10 11 15 16 20 21 31
0 0 0 1 0 0 rD rA rB 1 0 0 1 1 0 0 1 ACC R
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor220

Figure 234. Dot product of fractional halfwords guarded to word, subtract, and accumulate [negative] [round]
1.6.6 Instruction forms and opcodes
The opcode space for LSP is contained within the primary opcode 4 (bits 0–5). Opcodes are used that do not overlap with Embedded Floating Point APUs, but do overlap with the AltiVec and SPE APUs.
Table 14 shows the division of opcode space for LSP.
Table 14. LSP opcode space division
OpcodeInstruction class
Bits 21:24 Bits 25:28
00xx xxxx — Reserved
15
src1l
src2l
X
0
S
310
15
src1h
src2h
X
0
S
310
rD
rD
+ (acc=01)– (acc=10)
[ROUND]
32 6340 41
.S.................S
exts
+
330
[EXTS][EXTS]
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 221
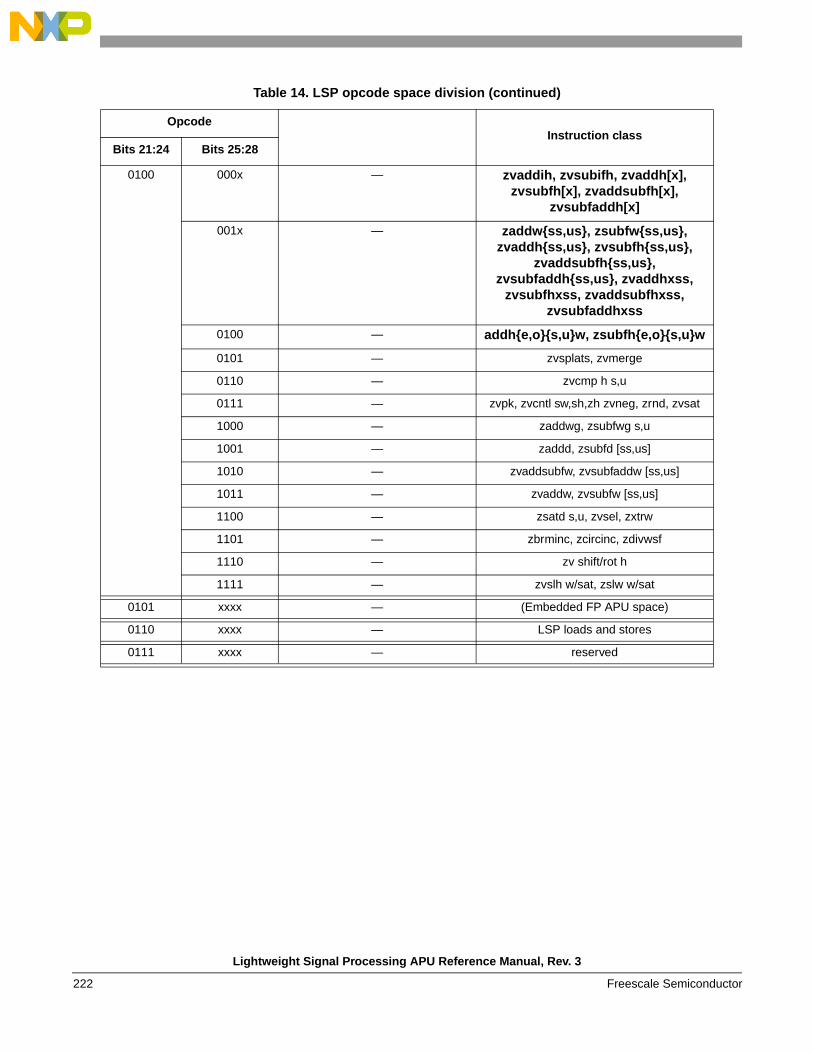
0100 000x — zvaddih, zvsubifh, zvaddh[x], zvsubfh[x], zvaddsubfh[x],
zvsubfaddh[x]
001x — zaddw{ss,us}, zsubfw{ss,us}, zvaddh{ss,us}, zvsubfh{ss,us},
zvaddsubfh{ss,us}, zvsubfaddh{ss,us}, zvaddhxss,
zvsubfhxss, zvaddsubfhxss, zvsubfaddhxss
0100 — addh{e,o}{s,u}w, zsubfh{e,o}{s,u}w
0101 — zvsplats, zvmerge
0110 — zvcmp h s,u
0111 — zvpk, zvcntl sw,sh,zh zvneg, zrnd, zvsat
1000 — zaddwg, zsubfwg s,u
1001 — zaddd, zsubfd [ss,us]
1010 — zvaddsubfw, zvsubfaddw [ss,us]
1011 — zvaddw, zvsubfw [ss,us]
1100 — zsatd s,u, zvsel, zxtrw
1101 — zbrminc, zcircinc, zdivwsf
1110 — zv shift/rot h
1111 — zvslh w/sat, zslw w/sat
0101 xxxx — (Embedded FP APU space)
0110 xxxx — LSP loads and stores
0111 xxxx — reserved
Table 14. LSP opcode space division (continued)
OpcodeInstruction class
Bits 21:24 Bits 25:28
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor222
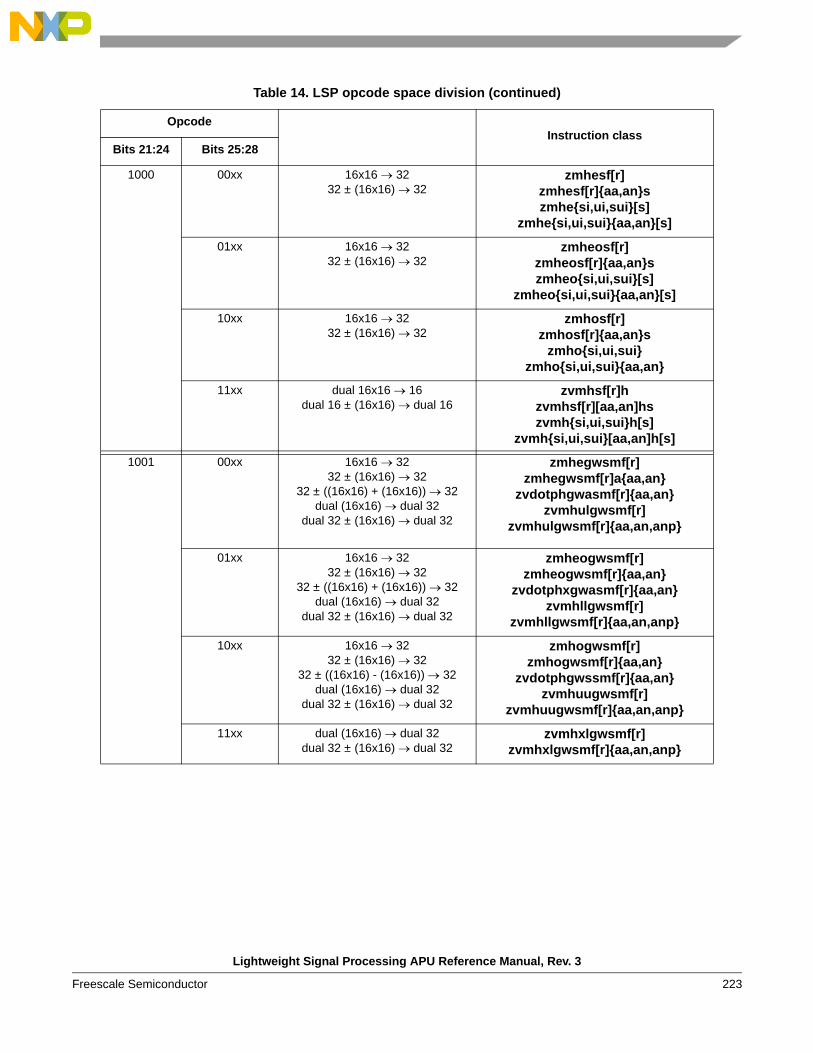
1000 00xx 16x16 3232 ± (16x16) 32
zmhesf[r]zmhesf[r]{aa,an}szmhe{si,ui,sui}[s]
zmhe{si,ui,sui}{aa,an}[s]
01xx 16x16 3232 ± (16x16) 32
zmheosf[r]zmheosf[r]{aa,an}szmheo{si,ui,sui}[s]
zmheo{si,ui,sui}{aa,an}[s]
10xx 16x16 3232 ± (16x16) 32
zmhosf[r]zmhosf[r]{aa,an}s
zmho{si,ui,sui}zmho{si,ui,sui}{aa,an}
11xx dual 16x16 16dual 16 ± (16x16) dual 16
zvmhsf[r]hzvmhsf[r][aa,an]hszvmh{si,ui,sui}h[s]
zvmh{si,ui,sui}[aa,an]h[s]
1001 00xx 16x16 3232 ± (16x16) 32
32 ± ((16x16) + (16x16)) 32dual (16x16) dual 32
dual 32 ± (16x16) dual 32
zmhegwsmf[r]zmhegwsmf[r]a{aa,an}
zvdotphgwasmf[r]{aa,an}zvmhulgwsmf[r]
zvmhulgwsmf[r]{aa,an,anp}
01xx 16x16 3232 ± (16x16) 32
32 ± ((16x16) + (16x16)) 32dual (16x16) dual 32
dual 32 ± (16x16) dual 32
zmheogwsmf[r]zmheogwsmf[r]{aa,an}
zvdotphxgwasmf[r]{aa,an}zvmhllgwsmf[r]
zvmhllgwsmf[r]{aa,an,anp}
10xx 16x16 3232 ± (16x16) 32
32 ± ((16x16) - (16x16)) 32dual (16x16) dual 32
dual 32 ± (16x16) dual 32
zmhogwsmf[r]zmhogwsmf[r]{aa,an}
zvdotphgwssmf[r]{aa,an}zvmhuugwsmf[r]
zvmhuugwsmf[r]{aa,an,anp}
11xx dual (16x16) dual 32dual 32 ± (16x16) dual 32
zvmhxlgwsmf[r]zvmhxlgwsmf[r]{aa,an,anp}
Table 14. LSP opcode space division (continued)
OpcodeInstruction class
Bits 21:24 Bits 25:28
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 223
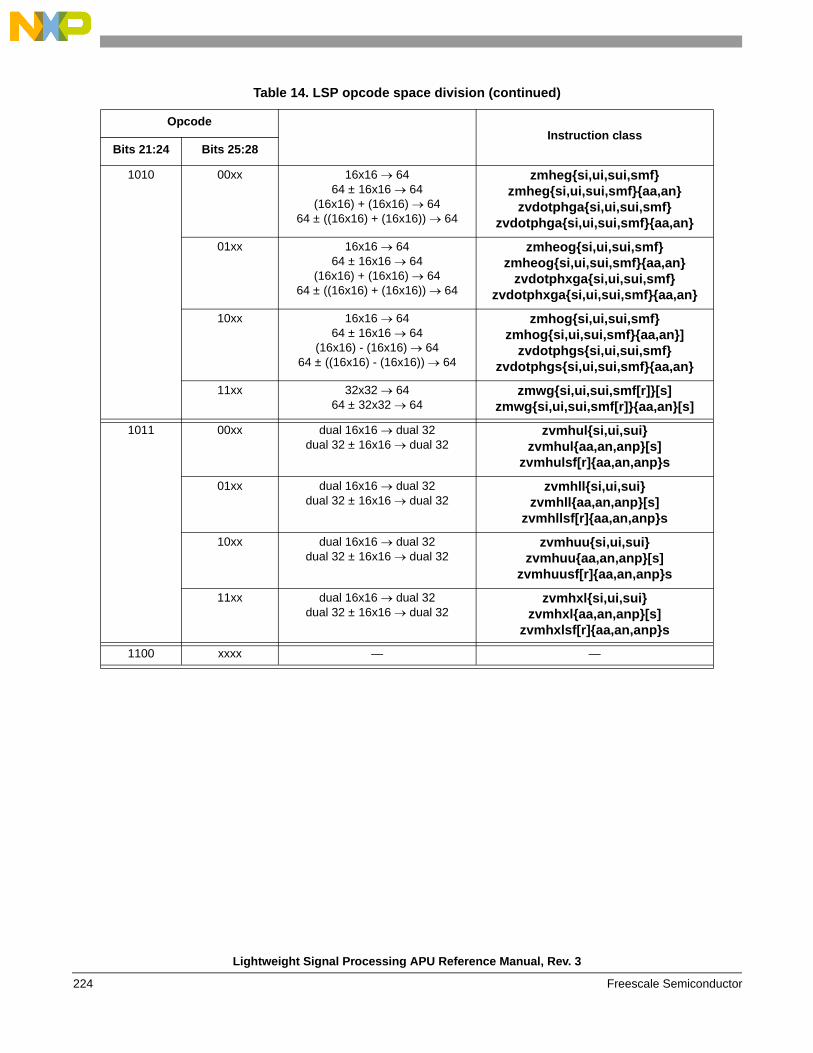
1010 00xx 16x16 64 64 ± 16x16 64
(16x16) + (16x16) 6464 ± ((16x16) + (16x16)) 64
zmheg{si,ui,sui,smf}zmheg{si,ui,sui,smf}{aa,an}
zvdotphga{si,ui,sui,smf}zvdotphga{si,ui,sui,smf}{aa,an}
01xx 16x16 64 64 ± 16x16 64
(16x16) + (16x16) 6464 ± ((16x16) + (16x16)) 64
zmheog{si,ui,sui,smf}zmheog{si,ui,sui,smf}{aa,an}
zvdotphxga{si,ui,sui,smf}zvdotphxga{si,ui,sui,smf}{aa,an}
10xx 16x16 64 64 ± 16x16 64
(16x16) - (16x16) 6464 ± ((16x16) - (16x16)) 64
zmhog{si,ui,sui,smf}zmhog{si,ui,sui,smf}{aa,an}]
zvdotphgs{si,ui,sui,smf}zvdotphgs{si,ui,sui,smf}{aa,an}
11xx 32x32 64 64 ± 32x32 64
zmwg{si,ui,sui,smf[r]}[s]zmwg{si,ui,sui,smf[r]}{aa,an}[s]
1011 00xx dual 16x16 dual 32dual 32 ± 16x16 dual 32
zvmhul{si,ui,sui}zvmhul{aa,an,anp}[s]
zvmhulsf[r]{aa,an,anp}s
01xx dual 16x16 dual 32dual 32 ± 16x16 dual 32
zvmhll{si,ui,sui}zvmhll{aa,an,anp}[s]
zvmhllsf[r]{aa,an,anp}s
10xx dual 16x16 dual 32dual 32 ± 16x16 dual 32
zvmhuu{si,ui,sui}zvmhuu{aa,an,anp}[s]
zvmhuusf[r]{aa,an,anp}s
11xx dual 16x16 dual 32dual 32 ± 16x16 dual 32
zvmhxl{si,ui,sui}zvmhxl{aa,an,anp}[s]
zvmhxlsf[r]{aa,an,anp}s
1100 xxxx — —
Table 14. LSP opcode space division (continued)
OpcodeInstruction class
Bits 21:24 Bits 25:28
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor224
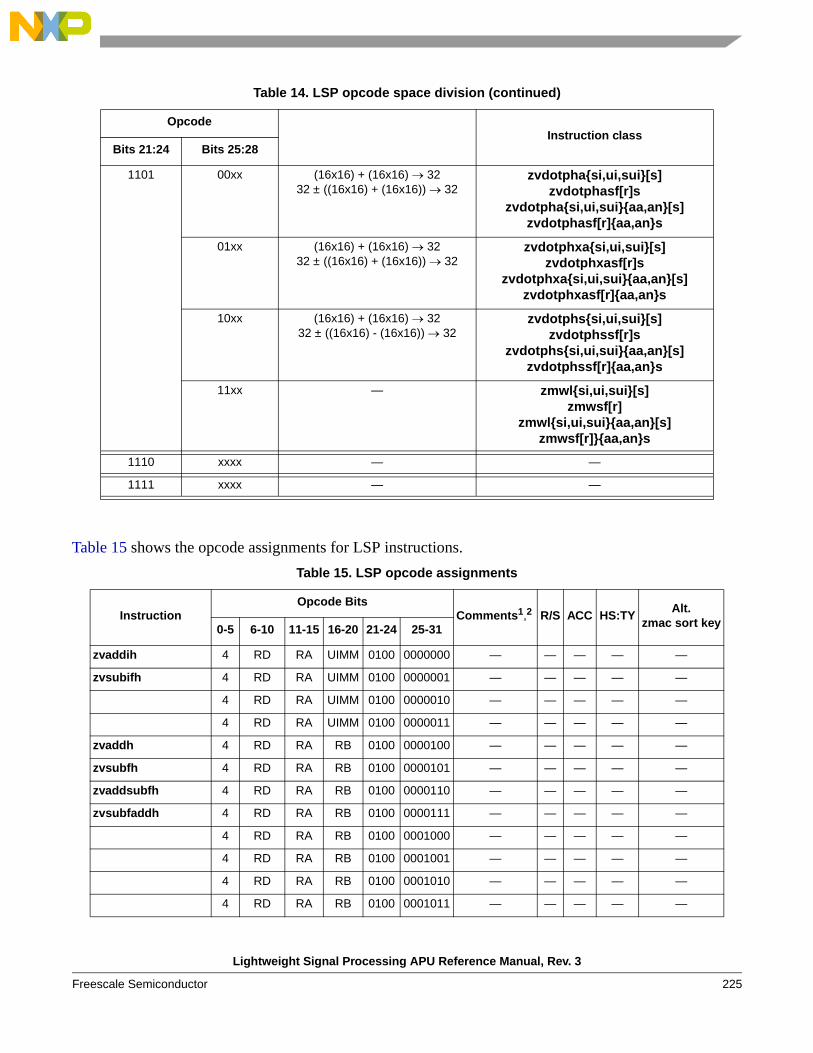
Table 15 shows the opcode assignments for LSP instructions.
1101 00xx (16x16) + (16x16) 3232 ± ((16x16) + (16x16)) 32
zvdotpha{si,ui,sui}[s]zvdotphasf[r]s
zvdotpha{si,ui,sui}{aa,an}[s]zvdotphasf[r]{aa,an}s
01xx (16x16) + (16x16) 3232 ± ((16x16) + (16x16)) 32
zvdotphxa{si,ui,sui}[s]zvdotphxasf[r]s
zvdotphxa{si,ui,sui}{aa,an}[s]zvdotphxasf[r]{aa,an}s
10xx (16x16) + (16x16) 3232 ± ((16x16) - (16x16)) 32
zvdotphs{si,ui,sui}[s]zvdotphssf[r]s
zvdotphs{si,ui,sui}{aa,an}[s]zvdotphssf[r]{aa,an}s
11xx — zmwl{si,ui,sui}[s]zmwsf[r]
zmwl{si,ui,sui}{aa,an}[s]zmwsf[r]}{aa,an}s
1110 xxxx — —
1111 xxxx — —
Table 15. LSP opcode assignments
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
zvaddih 4 RD RA UIMM 0100 0000000 — — — — —
zvsubifh 4 RD RA UIMM 0100 0000001 — — — — —
4 RD RA UIMM 0100 0000010 — — — — —
4 RD RA UIMM 0100 0000011 — — — — —
zvaddh 4 RD RA RB 0100 0000100 — — — — —
zvsubfh 4 RD RA RB 0100 0000101 — — — — —
zvaddsubfh 4 RD RA RB 0100 0000110 — — — — —
zvsubfaddh 4 RD RA RB 0100 0000111 — — — — —
4 RD RA RB 0100 0001000 — — — — —
4 RD RA RB 0100 0001001 — — — — —
4 RD RA RB 0100 0001010 — — — — —
4 RD RA RB 0100 0001011 — — — — —
Table 14. LSP opcode space division (continued)
OpcodeInstruction class
Bits 21:24 Bits 25:28
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 225
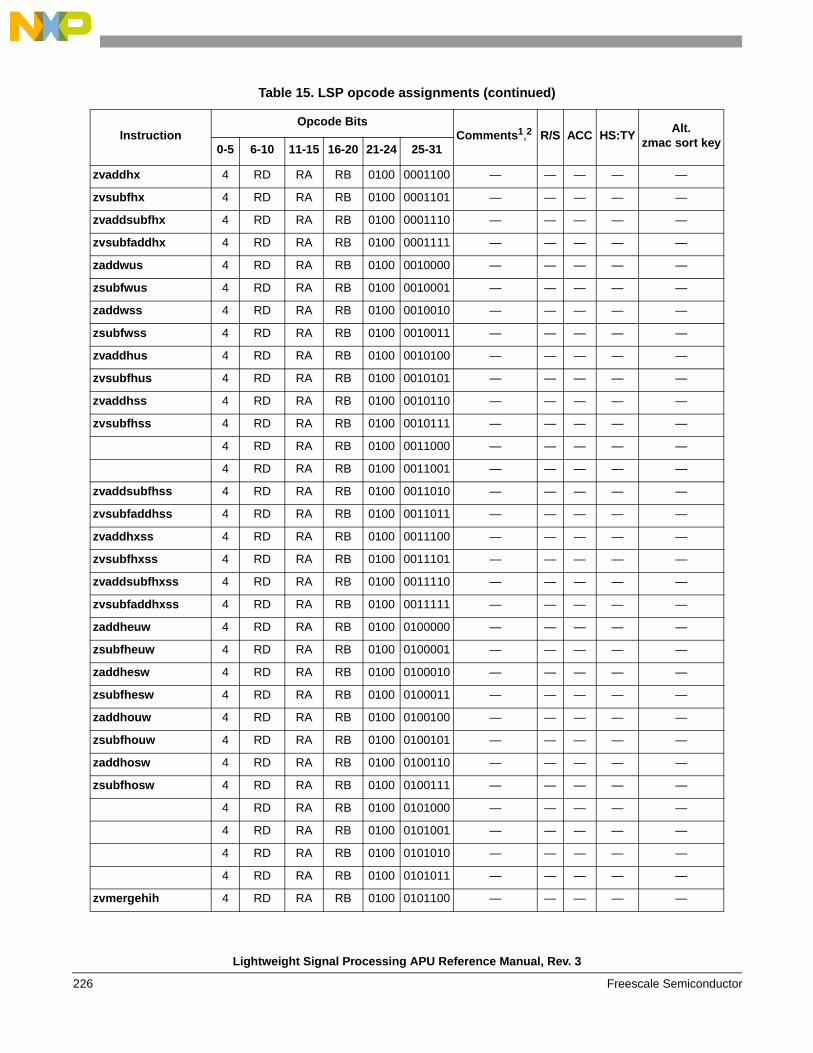
zvaddhx 4 RD RA RB 0100 0001100 — — — — —
zvsubfhx 4 RD RA RB 0100 0001101 — — — — —
zvaddsubfhx 4 RD RA RB 0100 0001110 — — — — —
zvsubfaddhx 4 RD RA RB 0100 0001111 — — — — —
zaddwus 4 RD RA RB 0100 0010000 — — — — —
zsubfwus 4 RD RA RB 0100 0010001 — — — — —
zaddwss 4 RD RA RB 0100 0010010 — — — — —
zsubfwss 4 RD RA RB 0100 0010011 — — — — —
zvaddhus 4 RD RA RB 0100 0010100 — — — — —
zvsubfhus 4 RD RA RB 0100 0010101 — — — — —
zvaddhss 4 RD RA RB 0100 0010110 — — — — —
zvsubfhss 4 RD RA RB 0100 0010111 — — — — —
4 RD RA RB 0100 0011000 — — — — —
4 RD RA RB 0100 0011001 — — — — —
zvaddsubfhss 4 RD RA RB 0100 0011010 — — — — —
zvsubfaddhss 4 RD RA RB 0100 0011011 — — — — —
zvaddhxss 4 RD RA RB 0100 0011100 — — — — —
zvsubfhxss 4 RD RA RB 0100 0011101 — — — — —
zvaddsubfhxss 4 RD RA RB 0100 0011110 — — — — —
zvsubfaddhxss 4 RD RA RB 0100 0011111 — — — — —
zaddheuw 4 RD RA RB 0100 0100000 — — — — —
zsubfheuw 4 RD RA RB 0100 0100001 — — — — —
zaddhesw 4 RD RA RB 0100 0100010 — — — — —
zsubfhesw 4 RD RA RB 0100 0100011 — — — — —
zaddhouw 4 RD RA RB 0100 0100100 — — — — —
zsubfhouw 4 RD RA RB 0100 0100101 — — — — —
zaddhosw 4 RD RA RB 0100 0100110 — — — — —
zsubfhosw 4 RD RA RB 0100 0100111 — — — — —
4 RD RA RB 0100 0101000 — — — — —
4 RD RA RB 0100 0101001 — — — — —
4 RD RA RB 0100 0101010 — — — — —
4 RD RA RB 0100 0101011 — — — — —
zvmergehih 4 RD RA RB 0100 0101100 — — — — —
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor226
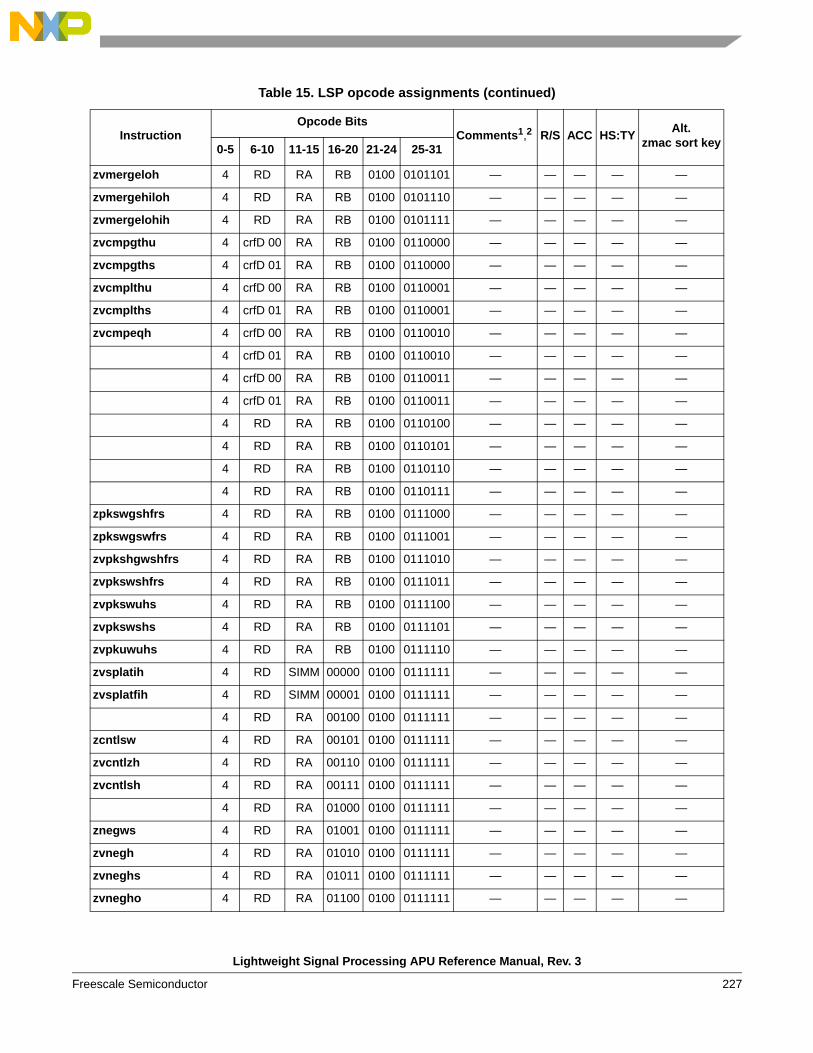
zvmergeloh 4 RD RA RB 0100 0101101 — — — — —
zvmergehiloh 4 RD RA RB 0100 0101110 — — — — —
zvmergelohih 4 RD RA RB 0100 0101111 — — — — —
zvcmpgthu 4 crfD 00 RA RB 0100 0110000 — — — — —
zvcmpgths 4 crfD 01 RA RB 0100 0110000 — — — — —
zvcmplthu 4 crfD 00 RA RB 0100 0110001 — — — — —
zvcmplths 4 crfD 01 RA RB 0100 0110001 — — — — —
zvcmpeqh 4 crfD 00 RA RB 0100 0110010 — — — — —
4 crfD 01 RA RB 0100 0110010 — — — — —
4 crfD 00 RA RB 0100 0110011 — — — — —
4 crfD 01 RA RB 0100 0110011 — — — — —
4 RD RA RB 0100 0110100 — — — — —
4 RD RA RB 0100 0110101 — — — — —
4 RD RA RB 0100 0110110 — — — — —
4 RD RA RB 0100 0110111 — — — — —
zpkswgshfrs 4 RD RA RB 0100 0111000 — — — — —
zpkswgswfrs 4 RD RA RB 0100 0111001 — — — — —
zvpkshgwshfrs 4 RD RA RB 0100 0111010 — — — — —
zvpkswshfrs 4 RD RA RB 0100 0111011 — — — — —
zvpkswuhs 4 RD RA RB 0100 0111100 — — — — —
zvpkswshs 4 RD RA RB 0100 0111101 — — — — —
zvpkuwuhs 4 RD RA RB 0100 0111110 — — — — —
zvsplatih 4 RD SIMM 00000 0100 0111111 — — — — —
zvsplatfih 4 RD SIMM 00001 0100 0111111 — — — — —
4 RD RA 00100 0100 0111111 — — — — —
zcntlsw 4 RD RA 00101 0100 0111111 — — — — —
zvcntlzh 4 RD RA 00110 0100 0111111 — — — — —
zvcntlsh 4 RD RA 00111 0100 0111111 — — — — —
4 RD RA 01000 0100 0111111 — — — — —
znegws 4 RD RA 01001 0100 0111111 — — — — —
zvnegh 4 RD RA 01010 0100 0111111 — — — — —
zvneghs 4 RD RA 01011 0100 0111111 — — — — —
zvnegho 4 RD RA 01100 0100 0111111 — — — — —
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 227
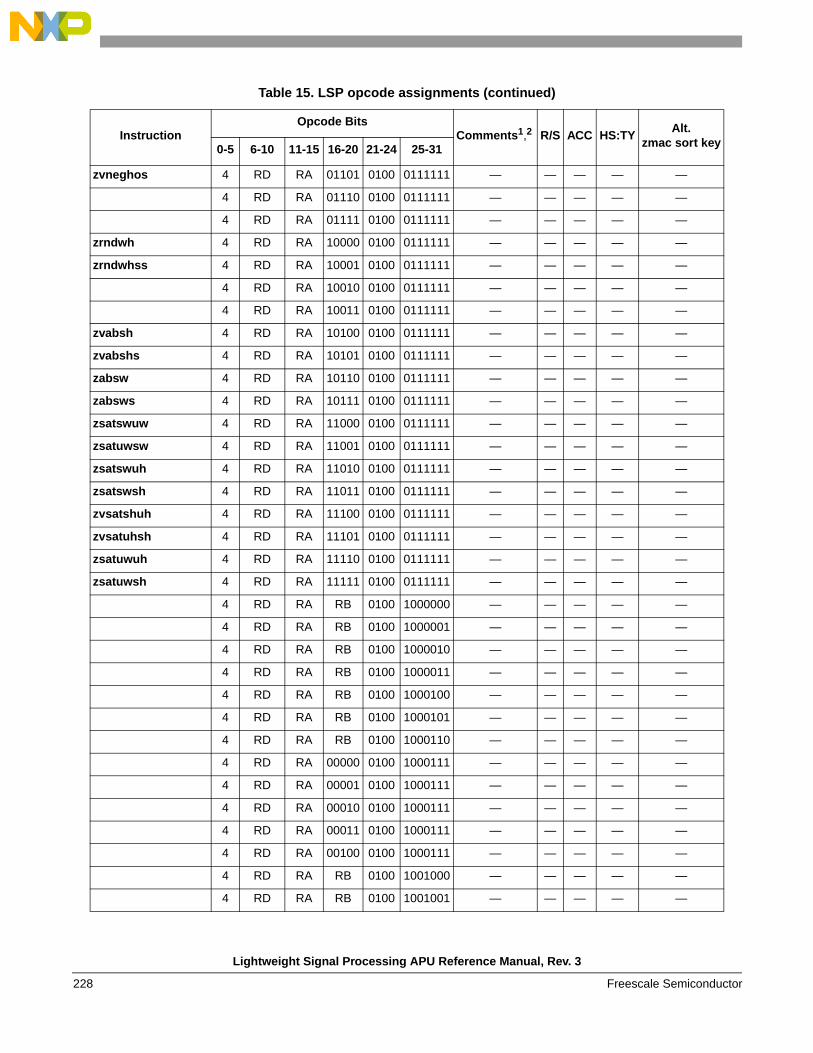
zvneghos 4 RD RA 01101 0100 0111111 — — — — —
4 RD RA 01110 0100 0111111 — — — — —
4 RD RA 01111 0100 0111111 — — — — —
zrndwh 4 RD RA 10000 0100 0111111 — — — — —
zrndwhss 4 RD RA 10001 0100 0111111 — — — — —
4 RD RA 10010 0100 0111111 — — — — —
4 RD RA 10011 0100 0111111 — — — — —
zvabsh 4 RD RA 10100 0100 0111111 — — — — —
zvabshs 4 RD RA 10101 0100 0111111 — — — — —
zabsw 4 RD RA 10110 0100 0111111 — — — — —
zabsws 4 RD RA 10111 0100 0111111 — — — — —
zsatswuw 4 RD RA 11000 0100 0111111 — — — — —
zsatuwsw 4 RD RA 11001 0100 0111111 — — — — —
zsatswuh 4 RD RA 11010 0100 0111111 — — — — —
zsatswsh 4 RD RA 11011 0100 0111111 — — — — —
zvsatshuh 4 RD RA 11100 0100 0111111 — — — — —
zvsatuhsh 4 RD RA 11101 0100 0111111 — — — — —
zsatuwuh 4 RD RA 11110 0100 0111111 — — — — —
zsatuwsh 4 RD RA 11111 0100 0111111 — — — — —
4 RD RA RB 0100 1000000 — — — — —
4 RD RA RB 0100 1000001 — — — — —
4 RD RA RB 0100 1000010 — — — — —
4 RD RA RB 0100 1000011 — — — — —
4 RD RA RB 0100 1000100 — — — — —
4 RD RA RB 0100 1000101 — — — — —
4 RD RA RB 0100 1000110 — — — — —
4 RD RA 00000 0100 1000111 — — — — —
4 RD RA 00001 0100 1000111 — — — — —
4 RD RA 00010 0100 1000111 — — — — —
4 RD RA 00011 0100 1000111 — — — — —
4 RD RA 00100 0100 1000111 — — — — —
4 RD RA RB 0100 1001000 — — — — —
4 RD RA RB 0100 1001001 — — — — —
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor228
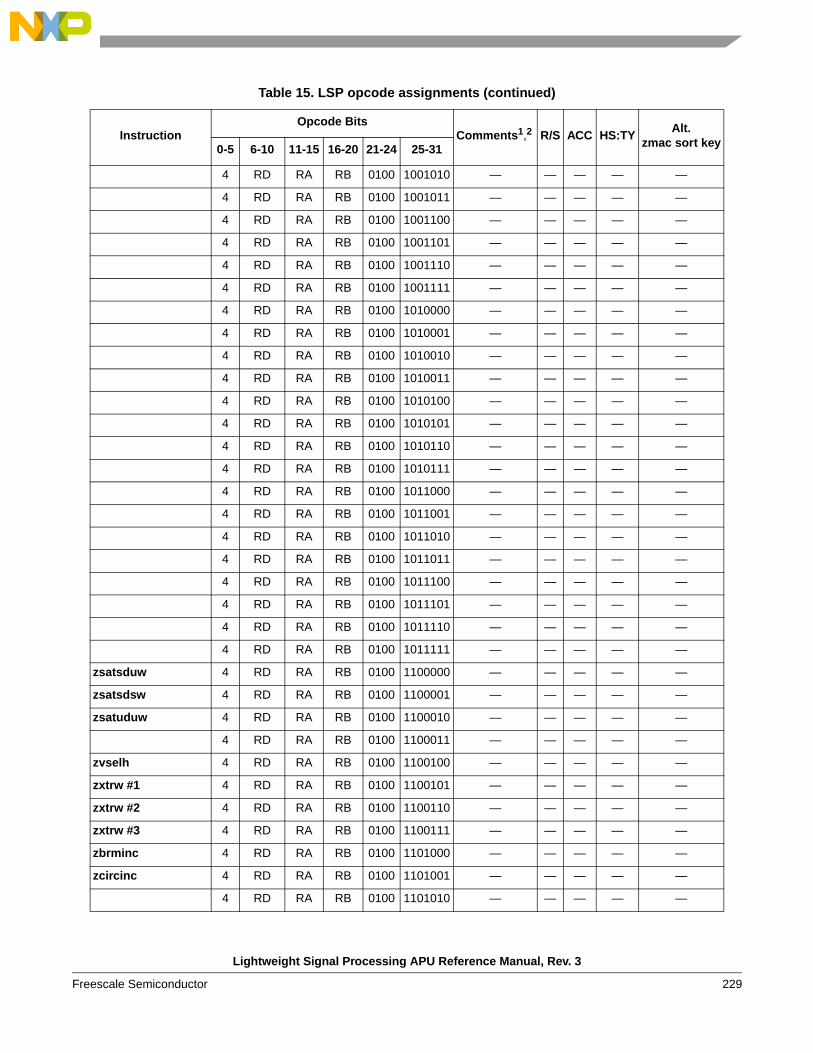
4 RD RA RB 0100 1001010 — — — — —
4 RD RA RB 0100 1001011 — — — — —
4 RD RA RB 0100 1001100 — — — — —
4 RD RA RB 0100 1001101 — — — — —
4 RD RA RB 0100 1001110 — — — — —
4 RD RA RB 0100 1001111 — — — — —
4 RD RA RB 0100 1010000 — — — — —
4 RD RA RB 0100 1010001 — — — — —
4 RD RA RB 0100 1010010 — — — — —
4 RD RA RB 0100 1010011 — — — — —
4 RD RA RB 0100 1010100 — — — — —
4 RD RA RB 0100 1010101 — — — — —
4 RD RA RB 0100 1010110 — — — — —
4 RD RA RB 0100 1010111 — — — — —
4 RD RA RB 0100 1011000 — — — — —
4 RD RA RB 0100 1011001 — — — — —
4 RD RA RB 0100 1011010 — — — — —
4 RD RA RB 0100 1011011 — — — — —
4 RD RA RB 0100 1011100 — — — — —
4 RD RA RB 0100 1011101 — — — — —
4 RD RA RB 0100 1011110 — — — — —
4 RD RA RB 0100 1011111 — — — — —
zsatsduw 4 RD RA RB 0100 1100000 — — — — —
zsatsdsw 4 RD RA RB 0100 1100001 — — — — —
zsatuduw 4 RD RA RB 0100 1100010 — — — — —
4 RD RA RB 0100 1100011 — — — — —
zvselh 4 RD RA RB 0100 1100100 — — — — —
zxtrw #1 4 RD RA RB 0100 1100101 — — — — —
zxtrw #2 4 RD RA RB 0100 1100110 — — — — —
zxtrw #3 4 RD RA RB 0100 1100111 — — — — —
zbrminc 4 RD RA RB 0100 1101000 — — — — —
zcircinc 4 RD RA RB 0100 1101001 — — — — —
4 RD RA RB 0100 1101010 — — — — —
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 229
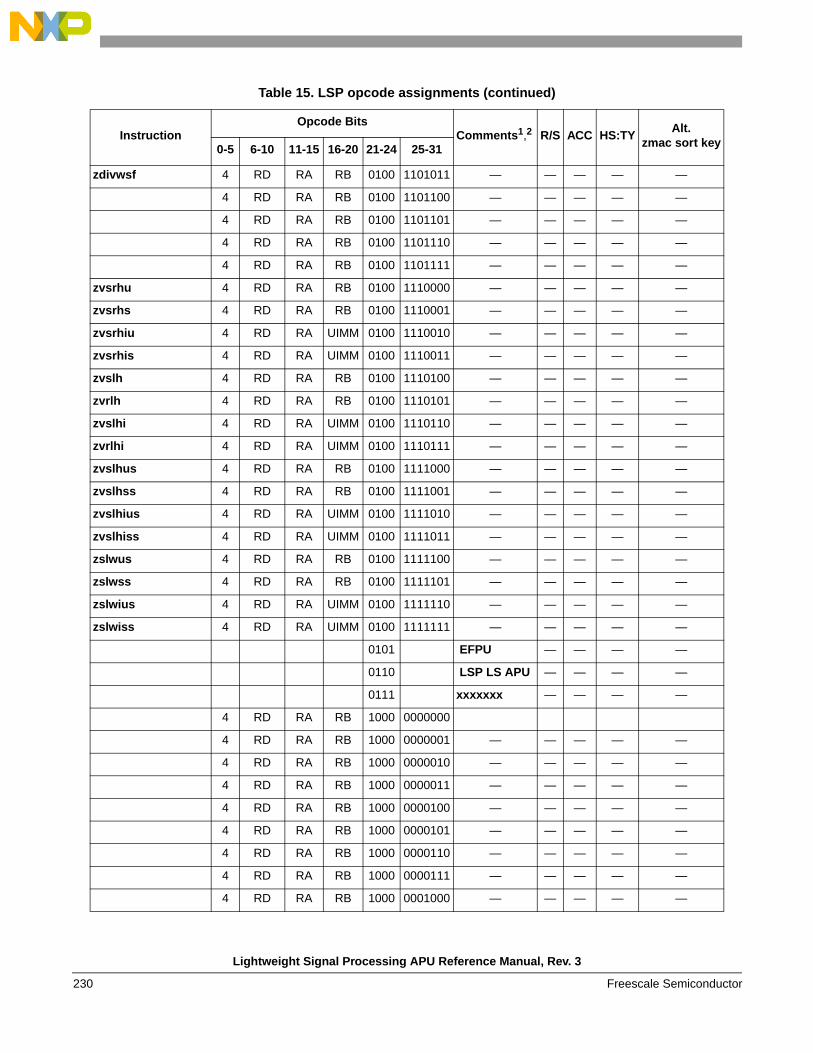
zdivwsf 4 RD RA RB 0100 1101011 — — — — —
4 RD RA RB 0100 1101100 — — — — —
4 RD RA RB 0100 1101101 — — — — —
4 RD RA RB 0100 1101110 — — — — —
4 RD RA RB 0100 1101111 — — — — —
zvsrhu 4 RD RA RB 0100 1110000 — — — — —
zvsrhs 4 RD RA RB 0100 1110001 — — — — —
zvsrhiu 4 RD RA UIMM 0100 1110010 — — — — —
zvsrhis 4 RD RA UIMM 0100 1110011 — — — — —
zvslh 4 RD RA RB 0100 1110100 — — — — —
zvrlh 4 RD RA RB 0100 1110101 — — — — —
zvslhi 4 RD RA UIMM 0100 1110110 — — — — —
zvrlhi 4 RD RA UIMM 0100 1110111 — — — — —
zvslhus 4 RD RA RB 0100 1111000 — — — — —
zvslhss 4 RD RA RB 0100 1111001 — — — — —
zvslhius 4 RD RA UIMM 0100 1111010 — — — — —
zvslhiss 4 RD RA UIMM 0100 1111011 — — — — —
zslwus 4 RD RA RB 0100 1111100 — — — — —
zslwss 4 RD RA RB 0100 1111101 — — — — —
zslwius 4 RD RA UIMM 0100 1111110 — — — — —
zslwiss 4 RD RA UIMM 0100 1111111 — — — — —
0101 EFPU — — — —
0110 LSP LS APU — — — —
0111 xxxxxxx — — — —
4 RD RA RB 1000 0000000
4 RD RA RB 1000 0000001 — — — — —
4 RD RA RB 1000 0000010 — — — — —
4 RD RA RB 1000 0000011 — — — — —
4 RD RA RB 1000 0000100 — — — — —
4 RD RA RB 1000 0000101 — — — — —
4 RD RA RB 1000 0000110 — — — — —
4 RD RA RB 1000 0000111 — — — — —
4 RD RA RB 1000 0001000 — — — — —
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor230
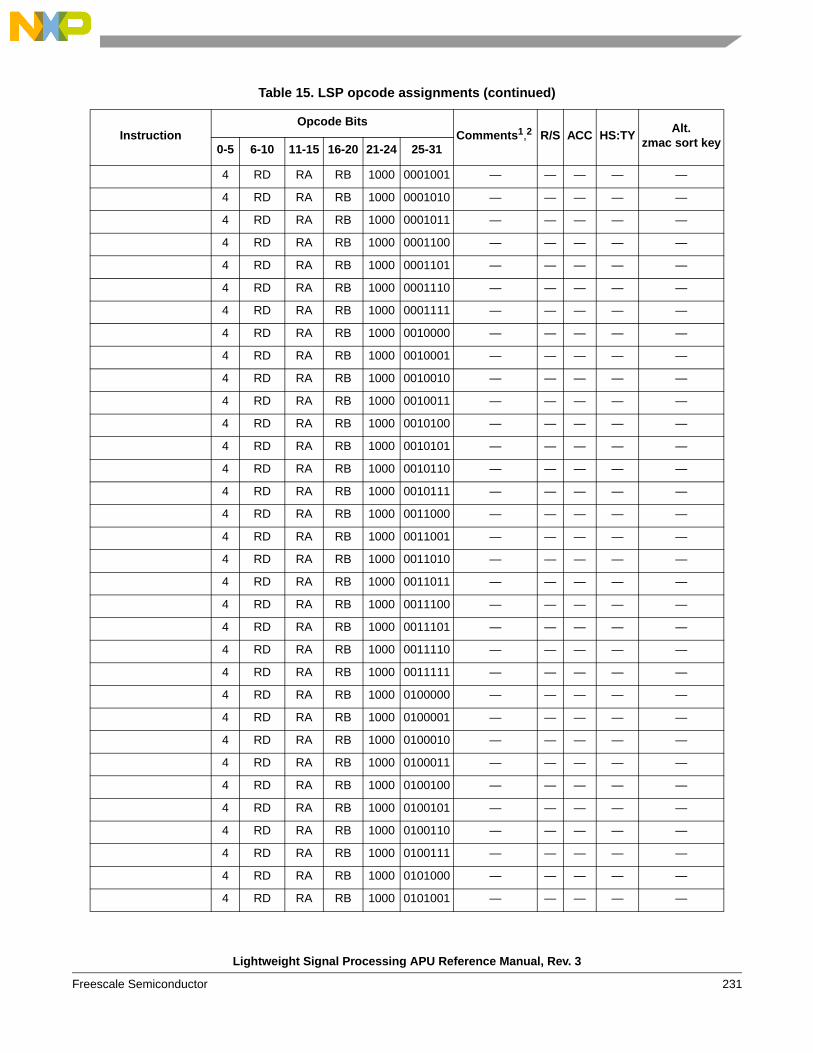
4 RD RA RB 1000 0001001 — — — — —
4 RD RA RB 1000 0001010 — — — — —
4 RD RA RB 1000 0001011 — — — — —
4 RD RA RB 1000 0001100 — — — — —
4 RD RA RB 1000 0001101 — — — — —
4 RD RA RB 1000 0001110 — — — — —
4 RD RA RB 1000 0001111 — — — — —
4 RD RA RB 1000 0010000 — — — — —
4 RD RA RB 1000 0010001 — — — — —
4 RD RA RB 1000 0010010 — — — — —
4 RD RA RB 1000 0010011 — — — — —
4 RD RA RB 1000 0010100 — — — — —
4 RD RA RB 1000 0010101 — — — — —
4 RD RA RB 1000 0010110 — — — — —
4 RD RA RB 1000 0010111 — — — — —
4 RD RA RB 1000 0011000 — — — — —
4 RD RA RB 1000 0011001 — — — — —
4 RD RA RB 1000 0011010 — — — — —
4 RD RA RB 1000 0011011 — — — — —
4 RD RA RB 1000 0011100 — — — — —
4 RD RA RB 1000 0011101 — — — — —
4 RD RA RB 1000 0011110 — — — — —
4 RD RA RB 1000 0011111 — — — — —
4 RD RA RB 1000 0100000 — — — — —
4 RD RA RB 1000 0100001 — — — — —
4 RD RA RB 1000 0100010 — — — — —
4 RD RA RB 1000 0100011 — — — — —
4 RD RA RB 1000 0100100 — — — — —
4 RD RA RB 1000 0100101 — — — — —
4 RD RA RB 1000 0100110 — — — — —
4 RD RA RB 1000 0100111 — — — — —
4 RD RA RB 1000 0101000 — — — — —
4 RD RA RB 1000 0101001 — — — — —
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 231
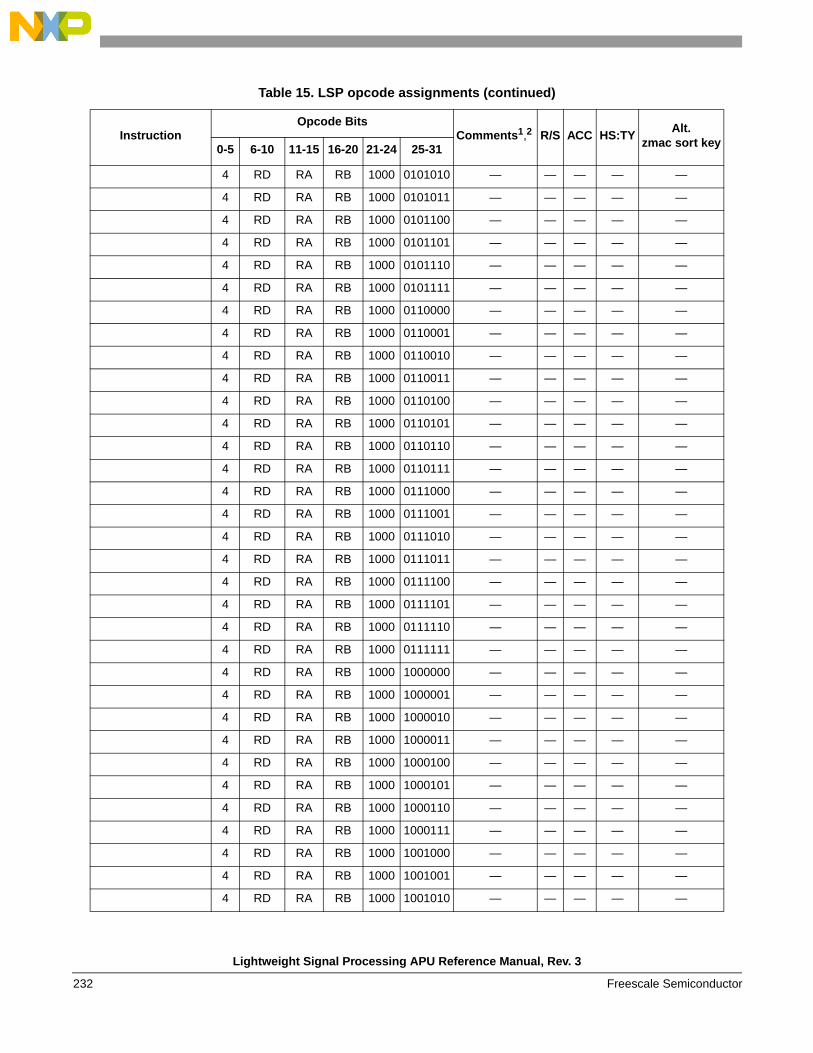
4 RD RA RB 1000 0101010 — — — — —
4 RD RA RB 1000 0101011 — — — — —
4 RD RA RB 1000 0101100 — — — — —
4 RD RA RB 1000 0101101 — — — — —
4 RD RA RB 1000 0101110 — — — — —
4 RD RA RB 1000 0101111 — — — — —
4 RD RA RB 1000 0110000 — — — — —
4 RD RA RB 1000 0110001 — — — — —
4 RD RA RB 1000 0110010 — — — — —
4 RD RA RB 1000 0110011 — — — — —
4 RD RA RB 1000 0110100 — — — — —
4 RD RA RB 1000 0110101 — — — — —
4 RD RA RB 1000 0110110 — — — — —
4 RD RA RB 1000 0110111 — — — — —
4 RD RA RB 1000 0111000 — — — — —
4 RD RA RB 1000 0111001 — — — — —
4 RD RA RB 1000 0111010 — — — — —
4 RD RA RB 1000 0111011 — — — — —
4 RD RA RB 1000 0111100 — — — — —
4 RD RA RB 1000 0111101 — — — — —
4 RD RA RB 1000 0111110 — — — — —
4 RD RA RB 1000 0111111 — — — — —
4 RD RA RB 1000 1000000 — — — — —
4 RD RA RB 1000 1000001 — — — — —
4 RD RA RB 1000 1000010 — — — — —
4 RD RA RB 1000 1000011 — — — — —
4 RD RA RB 1000 1000100 — — — — —
4 RD RA RB 1000 1000101 — — — — —
4 RD RA RB 1000 1000110 — — — — —
4 RD RA RB 1000 1000111 — — — — —
4 RD RA RB 1000 1001000 — — — — —
4 RD RA RB 1000 1001001 — — — — —
4 RD RA RB 1000 1001010 — — — — —
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor232
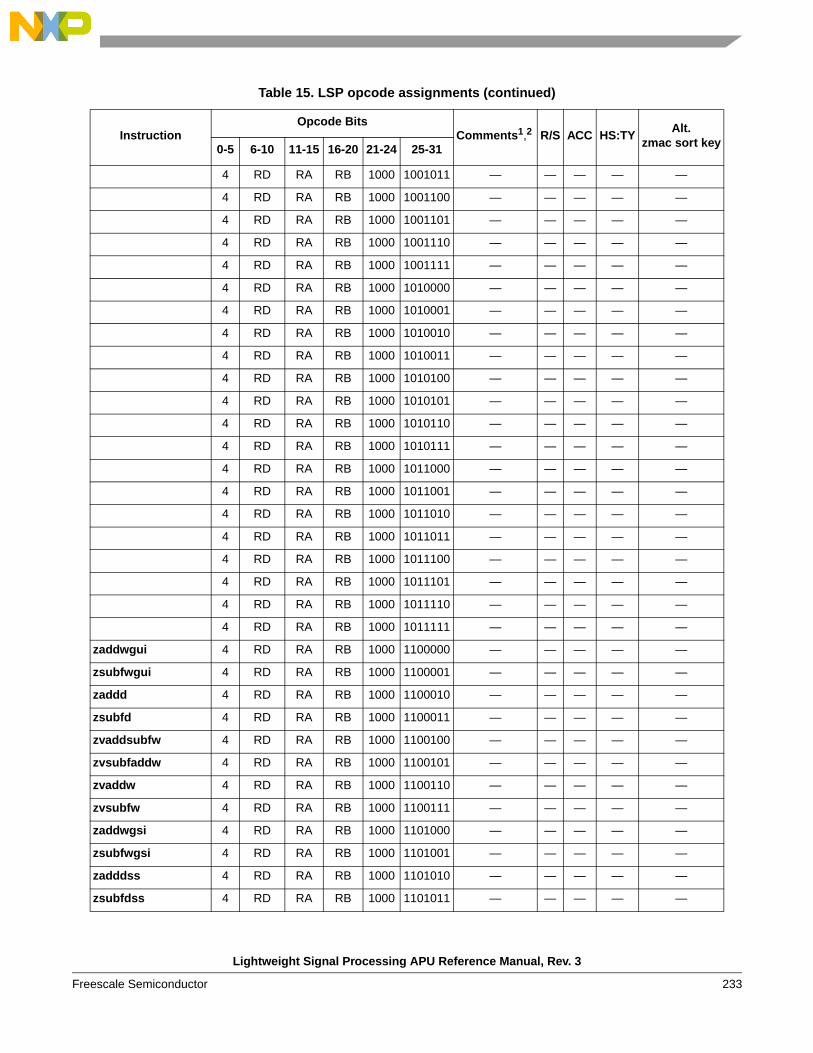
4 RD RA RB 1000 1001011 — — — — —
4 RD RA RB 1000 1001100 — — — — —
4 RD RA RB 1000 1001101 — — — — —
4 RD RA RB 1000 1001110 — — — — —
4 RD RA RB 1000 1001111 — — — — —
4 RD RA RB 1000 1010000 — — — — —
4 RD RA RB 1000 1010001 — — — — —
4 RD RA RB 1000 1010010 — — — — —
4 RD RA RB 1000 1010011 — — — — —
4 RD RA RB 1000 1010100 — — — — —
4 RD RA RB 1000 1010101 — — — — —
4 RD RA RB 1000 1010110 — — — — —
4 RD RA RB 1000 1010111 — — — — —
4 RD RA RB 1000 1011000 — — — — —
4 RD RA RB 1000 1011001 — — — — —
4 RD RA RB 1000 1011010 — — — — —
4 RD RA RB 1000 1011011 — — — — —
4 RD RA RB 1000 1011100 — — — — —
4 RD RA RB 1000 1011101 — — — — —
4 RD RA RB 1000 1011110 — — — — —
4 RD RA RB 1000 1011111 — — — — —
zaddwgui 4 RD RA RB 1000 1100000 — — — — —
zsubfwgui 4 RD RA RB 1000 1100001 — — — — —
zaddd 4 RD RA RB 1000 1100010 — — — — —
zsubfd 4 RD RA RB 1000 1100011 — — — — —
zvaddsubfw 4 RD RA RB 1000 1100100 — — — — —
zvsubfaddw 4 RD RA RB 1000 1100101 — — — — —
zvaddw 4 RD RA RB 1000 1100110 — — — — —
zvsubfw 4 RD RA RB 1000 1100111 — — — — —
zaddwgsi 4 RD RA RB 1000 1101000 — — — — —
zsubfwgsi 4 RD RA RB 1000 1101001 — — — — —
zadddss 4 RD RA RB 1000 1101010 — — — — —
zsubfdss 4 RD RA RB 1000 1101011 — — — — —
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 233
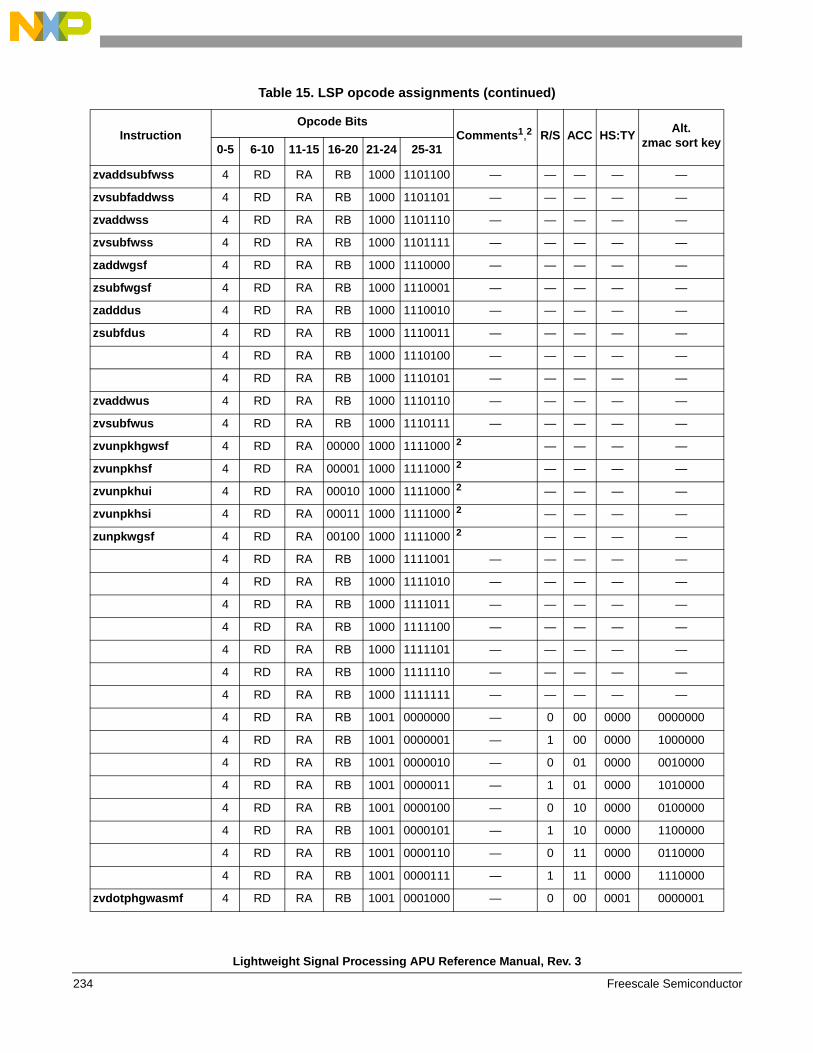
zvaddsubfwss 4 RD RA RB 1000 1101100 — — — — —
zvsubfaddwss 4 RD RA RB 1000 1101101 — — — — —
zvaddwss 4 RD RA RB 1000 1101110 — — — — —
zvsubfwss 4 RD RA RB 1000 1101111 — — — — —
zaddwgsf 4 RD RA RB 1000 1110000 — — — — —
zsubfwgsf 4 RD RA RB 1000 1110001 — — — — —
zadddus 4 RD RA RB 1000 1110010 — — — — —
zsubfdus 4 RD RA RB 1000 1110011 — — — — —
4 RD RA RB 1000 1110100 — — — — —
4 RD RA RB 1000 1110101 — — — — —
zvaddwus 4 RD RA RB 1000 1110110 — — — — —
zvsubfwus 4 RD RA RB 1000 1110111 — — — — —
zvunpkhgwsf 4 RD RA 00000 1000 1111000 2 — — — —
zvunpkhsf 4 RD RA 00001 1000 1111000 2 — — — —
zvunpkhui 4 RD RA 00010 1000 1111000 2 — — — —
zvunpkhsi 4 RD RA 00011 1000 1111000 2 — — — —
zunpkwgsf 4 RD RA 00100 1000 1111000 2 — — — —
4 RD RA RB 1000 1111001 — — — — —
4 RD RA RB 1000 1111010 — — — — —
4 RD RA RB 1000 1111011 — — — — —
4 RD RA RB 1000 1111100 — — — — —
4 RD RA RB 1000 1111101 — — — — —
4 RD RA RB 1000 1111110 — — — — —
4 RD RA RB 1000 1111111 — — — — —
4 RD RA RB 1001 0000000 — 0 00 0000 0000000
4 RD RA RB 1001 0000001 — 1 00 0000 1000000
4 RD RA RB 1001 0000010 — 0 01 0000 0010000
4 RD RA RB 1001 0000011 — 1 01 0000 1010000
4 RD RA RB 1001 0000100 — 0 10 0000 0100000
4 RD RA RB 1001 0000101 — 1 10 0000 1100000
4 RD RA RB 1001 0000110 — 0 11 0000 0110000
4 RD RA RB 1001 0000111 — 1 11 0000 1110000
zvdotphgwasmf 4 RD RA RB 1001 0001000 — 0 00 0001 0000001
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor234
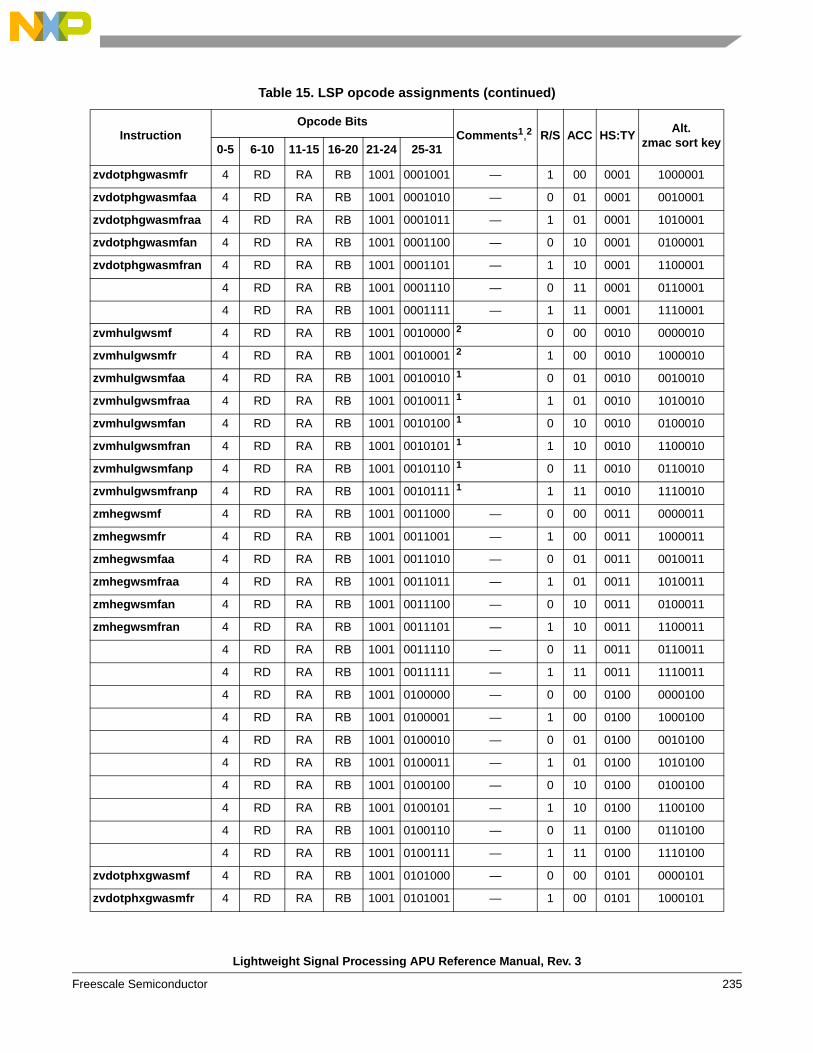
zvdotphgwasmfr 4 RD RA RB 1001 0001001 — 1 00 0001 1000001
zvdotphgwasmfaa 4 RD RA RB 1001 0001010 — 0 01 0001 0010001
zvdotphgwasmfraa 4 RD RA RB 1001 0001011 — 1 01 0001 1010001
zvdotphgwasmfan 4 RD RA RB 1001 0001100 — 0 10 0001 0100001
zvdotphgwasmfran 4 RD RA RB 1001 0001101 — 1 10 0001 1100001
4 RD RA RB 1001 0001110 — 0 11 0001 0110001
4 RD RA RB 1001 0001111 — 1 11 0001 1110001
zvmhulgwsmf 4 RD RA RB 1001 0010000 2 0 00 0010 0000010
zvmhulgwsmfr 4 RD RA RB 1001 0010001 2 1 00 0010 1000010
zvmhulgwsmfaa 4 RD RA RB 1001 0010010 1 0 01 0010 0010010
zvmhulgwsmfraa 4 RD RA RB 1001 0010011 1 1 01 0010 1010010
zvmhulgwsmfan 4 RD RA RB 1001 0010100 1 0 10 0010 0100010
zvmhulgwsmfran 4 RD RA RB 1001 0010101 1 1 10 0010 1100010
zvmhulgwsmfanp 4 RD RA RB 1001 0010110 1 0 11 0010 0110010
zvmhulgwsmfranp 4 RD RA RB 1001 0010111 1 1 11 0010 1110010
zmhegwsmf 4 RD RA RB 1001 0011000 — 0 00 0011 0000011
zmhegwsmfr 4 RD RA RB 1001 0011001 — 1 00 0011 1000011
zmhegwsmfaa 4 RD RA RB 1001 0011010 — 0 01 0011 0010011
zmhegwsmfraa 4 RD RA RB 1001 0011011 — 1 01 0011 1010011
zmhegwsmfan 4 RD RA RB 1001 0011100 — 0 10 0011 0100011
zmhegwsmfran 4 RD RA RB 1001 0011101 — 1 10 0011 1100011
4 RD RA RB 1001 0011110 — 0 11 0011 0110011
4 RD RA RB 1001 0011111 — 1 11 0011 1110011
4 RD RA RB 1001 0100000 — 0 00 0100 0000100
4 RD RA RB 1001 0100001 — 1 00 0100 1000100
4 RD RA RB 1001 0100010 — 0 01 0100 0010100
4 RD RA RB 1001 0100011 — 1 01 0100 1010100
4 RD RA RB 1001 0100100 — 0 10 0100 0100100
4 RD RA RB 1001 0100101 — 1 10 0100 1100100
4 RD RA RB 1001 0100110 — 0 11 0100 0110100
4 RD RA RB 1001 0100111 — 1 11 0100 1110100
zvdotphxgwasmf 4 RD RA RB 1001 0101000 — 0 00 0101 0000101
zvdotphxgwasmfr 4 RD RA RB 1001 0101001 — 1 00 0101 1000101
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 235
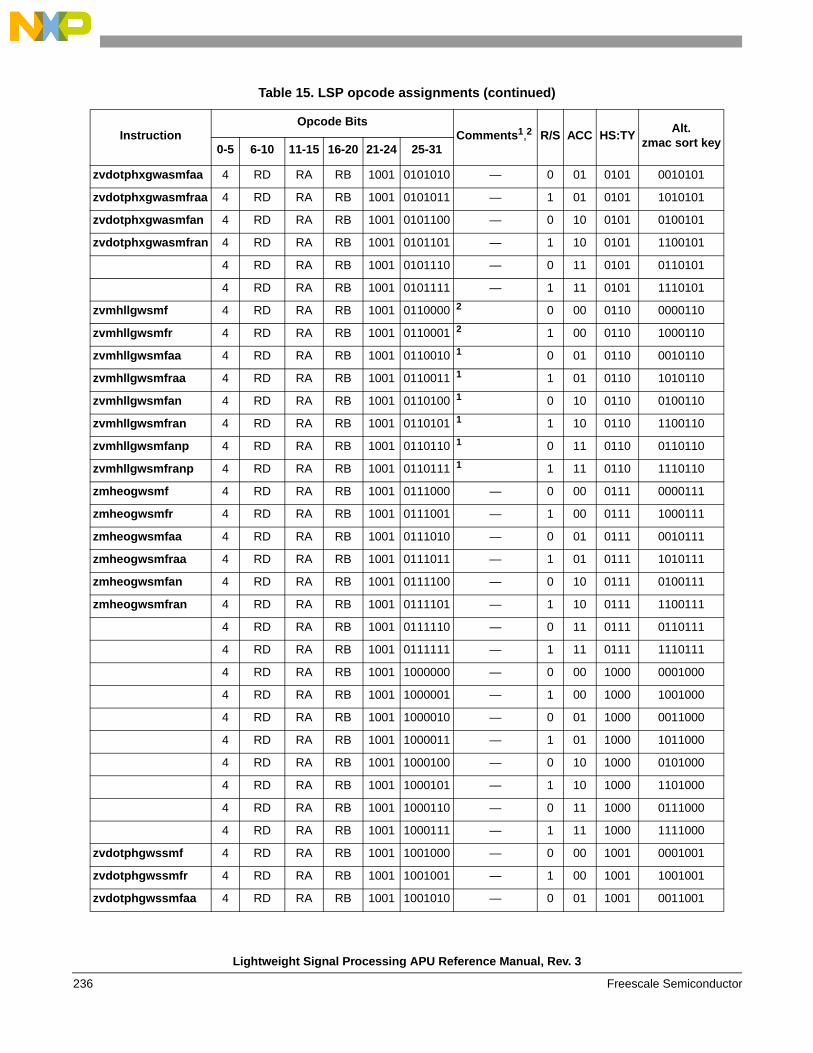
zvdotphxgwasmfaa 4 RD RA RB 1001 0101010 — 0 01 0101 0010101
zvdotphxgwasmfraa 4 RD RA RB 1001 0101011 — 1 01 0101 1010101
zvdotphxgwasmfan 4 RD RA RB 1001 0101100 — 0 10 0101 0100101
zvdotphxgwasmfran 4 RD RA RB 1001 0101101 — 1 10 0101 1100101
4 RD RA RB 1001 0101110 — 0 11 0101 0110101
4 RD RA RB 1001 0101111 — 1 11 0101 1110101
zvmhllgwsmf 4 RD RA RB 1001 0110000 2 0 00 0110 0000110
zvmhllgwsmfr 4 RD RA RB 1001 0110001 2 1 00 0110 1000110
zvmhllgwsmfaa 4 RD RA RB 1001 0110010 1 0 01 0110 0010110
zvmhllgwsmfraa 4 RD RA RB 1001 0110011 1 1 01 0110 1010110
zvmhllgwsmfan 4 RD RA RB 1001 0110100 1 0 10 0110 0100110
zvmhllgwsmfran 4 RD RA RB 1001 0110101 1 1 10 0110 1100110
zvmhllgwsmfanp 4 RD RA RB 1001 0110110 1 0 11 0110 0110110
zvmhllgwsmfranp 4 RD RA RB 1001 0110111 1 1 11 0110 1110110
zmheogwsmf 4 RD RA RB 1001 0111000 — 0 00 0111 0000111
zmheogwsmfr 4 RD RA RB 1001 0111001 — 1 00 0111 1000111
zmheogwsmfaa 4 RD RA RB 1001 0111010 — 0 01 0111 0010111
zmheogwsmfraa 4 RD RA RB 1001 0111011 — 1 01 0111 1010111
zmheogwsmfan 4 RD RA RB 1001 0111100 — 0 10 0111 0100111
zmheogwsmfran 4 RD RA RB 1001 0111101 — 1 10 0111 1100111
4 RD RA RB 1001 0111110 — 0 11 0111 0110111
4 RD RA RB 1001 0111111 — 1 11 0111 1110111
4 RD RA RB 1001 1000000 — 0 00 1000 0001000
4 RD RA RB 1001 1000001 — 1 00 1000 1001000
4 RD RA RB 1001 1000010 — 0 01 1000 0011000
4 RD RA RB 1001 1000011 — 1 01 1000 1011000
4 RD RA RB 1001 1000100 — 0 10 1000 0101000
4 RD RA RB 1001 1000101 — 1 10 1000 1101000
4 RD RA RB 1001 1000110 — 0 11 1000 0111000
4 RD RA RB 1001 1000111 — 1 11 1000 1111000
zvdotphgwssmf 4 RD RA RB 1001 1001000 — 0 00 1001 0001001
zvdotphgwssmfr 4 RD RA RB 1001 1001001 — 1 00 1001 1001001
zvdotphgwssmfaa 4 RD RA RB 1001 1001010 — 0 01 1001 0011001
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor236
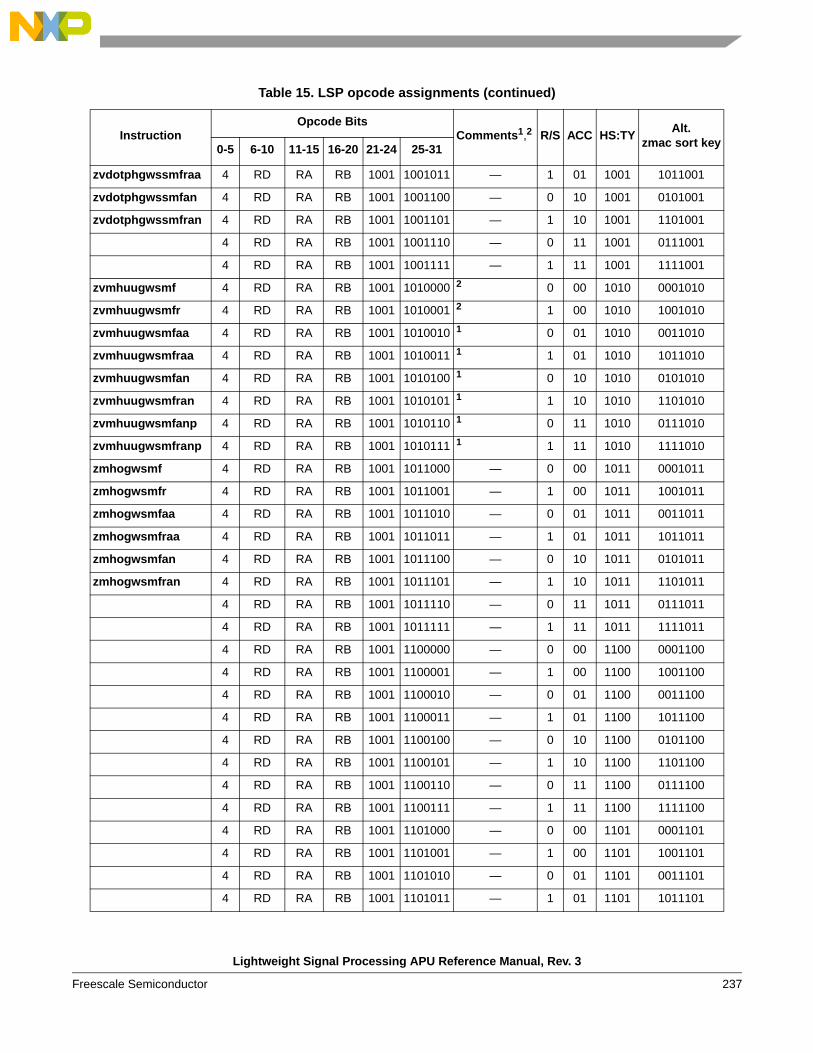
zvdotphgwssmfraa 4 RD RA RB 1001 1001011 — 1 01 1001 1011001
zvdotphgwssmfan 4 RD RA RB 1001 1001100 — 0 10 1001 0101001
zvdotphgwssmfran 4 RD RA RB 1001 1001101 — 1 10 1001 1101001
4 RD RA RB 1001 1001110 — 0 11 1001 0111001
4 RD RA RB 1001 1001111 — 1 11 1001 1111001
zvmhuugwsmf 4 RD RA RB 1001 1010000 2 0 00 1010 0001010
zvmhuugwsmfr 4 RD RA RB 1001 1010001 2 1 00 1010 1001010
zvmhuugwsmfaa 4 RD RA RB 1001 1010010 1 0 01 1010 0011010
zvmhuugwsmfraa 4 RD RA RB 1001 1010011 1 1 01 1010 1011010
zvmhuugwsmfan 4 RD RA RB 1001 1010100 1 0 10 1010 0101010
zvmhuugwsmfran 4 RD RA RB 1001 1010101 1 1 10 1010 1101010
zvmhuugwsmfanp 4 RD RA RB 1001 1010110 1 0 11 1010 0111010
zvmhuugwsmfranp 4 RD RA RB 1001 1010111 1 1 11 1010 1111010
zmhogwsmf 4 RD RA RB 1001 1011000 — 0 00 1011 0001011
zmhogwsmfr 4 RD RA RB 1001 1011001 — 1 00 1011 1001011
zmhogwsmfaa 4 RD RA RB 1001 1011010 — 0 01 1011 0011011
zmhogwsmfraa 4 RD RA RB 1001 1011011 — 1 01 1011 1011011
zmhogwsmfan 4 RD RA RB 1001 1011100 — 0 10 1011 0101011
zmhogwsmfran 4 RD RA RB 1001 1011101 — 1 10 1011 1101011
4 RD RA RB 1001 1011110 — 0 11 1011 0111011
4 RD RA RB 1001 1011111 — 1 11 1011 1111011
4 RD RA RB 1001 1100000 — 0 00 1100 0001100
4 RD RA RB 1001 1100001 — 1 00 1100 1001100
4 RD RA RB 1001 1100010 — 0 01 1100 0011100
4 RD RA RB 1001 1100011 — 1 01 1100 1011100
4 RD RA RB 1001 1100100 — 0 10 1100 0101100
4 RD RA RB 1001 1100101 — 1 10 1100 1101100
4 RD RA RB 1001 1100110 — 0 11 1100 0111100
4 RD RA RB 1001 1100111 — 1 11 1100 1111100
4 RD RA RB 1001 1101000 — 0 00 1101 0001101
4 RD RA RB 1001 1101001 — 1 00 1101 1001101
4 RD RA RB 1001 1101010 — 0 01 1101 0011101
4 RD RA RB 1001 1101011 — 1 01 1101 1011101
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 237
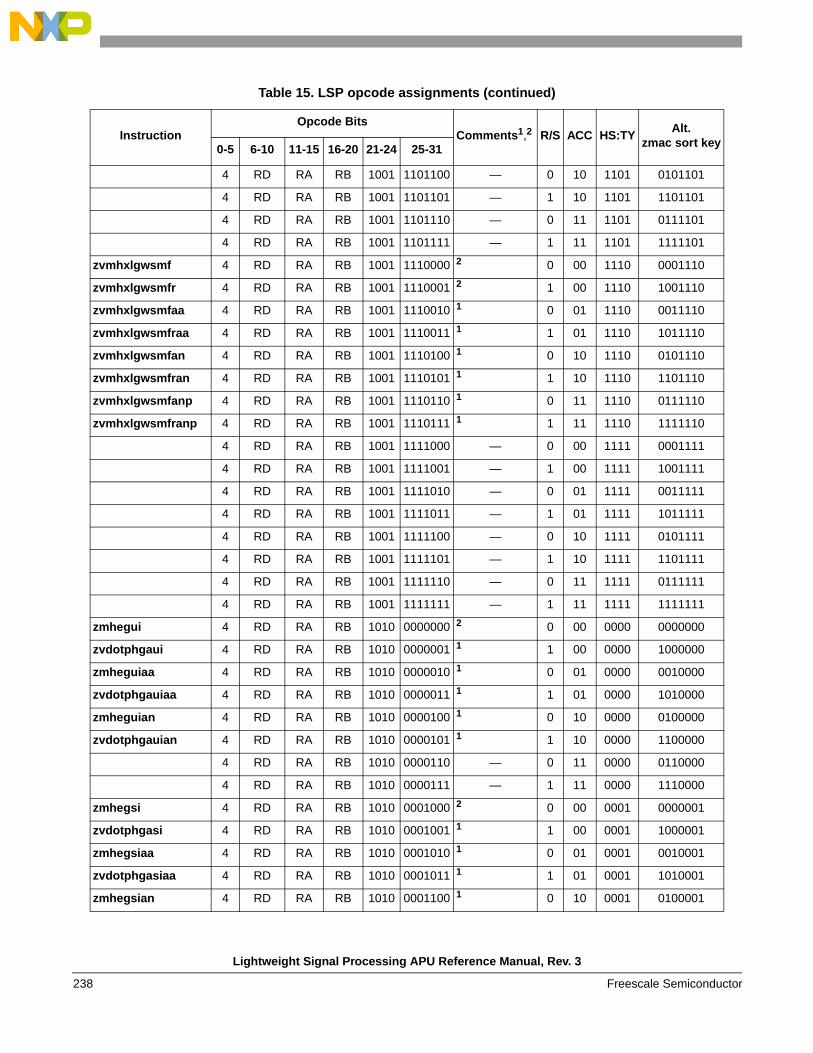
4 RD RA RB 1001 1101100 — 0 10 1101 0101101
4 RD RA RB 1001 1101101 — 1 10 1101 1101101
4 RD RA RB 1001 1101110 — 0 11 1101 0111101
4 RD RA RB 1001 1101111 — 1 11 1101 1111101
zvmhxlgwsmf 4 RD RA RB 1001 1110000 2 0 00 1110 0001110
zvmhxlgwsmfr 4 RD RA RB 1001 1110001 2 1 00 1110 1001110
zvmhxlgwsmfaa 4 RD RA RB 1001 1110010 1 0 01 1110 0011110
zvmhxlgwsmfraa 4 RD RA RB 1001 1110011 1 1 01 1110 1011110
zvmhxlgwsmfan 4 RD RA RB 1001 1110100 1 0 10 1110 0101110
zvmhxlgwsmfran 4 RD RA RB 1001 1110101 1 1 10 1110 1101110
zvmhxlgwsmfanp 4 RD RA RB 1001 1110110 1 0 11 1110 0111110
zvmhxlgwsmfranp 4 RD RA RB 1001 1110111 1 1 11 1110 1111110
4 RD RA RB 1001 1111000 — 0 00 1111 0001111
4 RD RA RB 1001 1111001 — 1 00 1111 1001111
4 RD RA RB 1001 1111010 — 0 01 1111 0011111
4 RD RA RB 1001 1111011 — 1 01 1111 1011111
4 RD RA RB 1001 1111100 — 0 10 1111 0101111
4 RD RA RB 1001 1111101 — 1 10 1111 1101111
4 RD RA RB 1001 1111110 — 0 11 1111 0111111
4 RD RA RB 1001 1111111 — 1 11 1111 1111111
zmhegui 4 RD RA RB 1010 0000000 2 0 00 0000 0000000
zvdotphgaui 4 RD RA RB 1010 0000001 1 1 00 0000 1000000
zmheguiaa 4 RD RA RB 1010 0000010 1 0 01 0000 0010000
zvdotphgauiaa 4 RD RA RB 1010 0000011 1 1 01 0000 1010000
zmheguian 4 RD RA RB 1010 0000100 1 0 10 0000 0100000
zvdotphgauian 4 RD RA RB 1010 0000101 1 1 10 0000 1100000
4 RD RA RB 1010 0000110 — 0 11 0000 0110000
4 RD RA RB 1010 0000111 — 1 11 0000 1110000
zmhegsi 4 RD RA RB 1010 0001000 2 0 00 0001 0000001
zvdotphgasi 4 RD RA RB 1010 0001001 1 1 00 0001 1000001
zmhegsiaa 4 RD RA RB 1010 0001010 1 0 01 0001 0010001
zvdotphgasiaa 4 RD RA RB 1010 0001011 1 1 01 0001 1010001
zmhegsian 4 RD RA RB 1010 0001100 1 0 10 0001 0100001
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor238
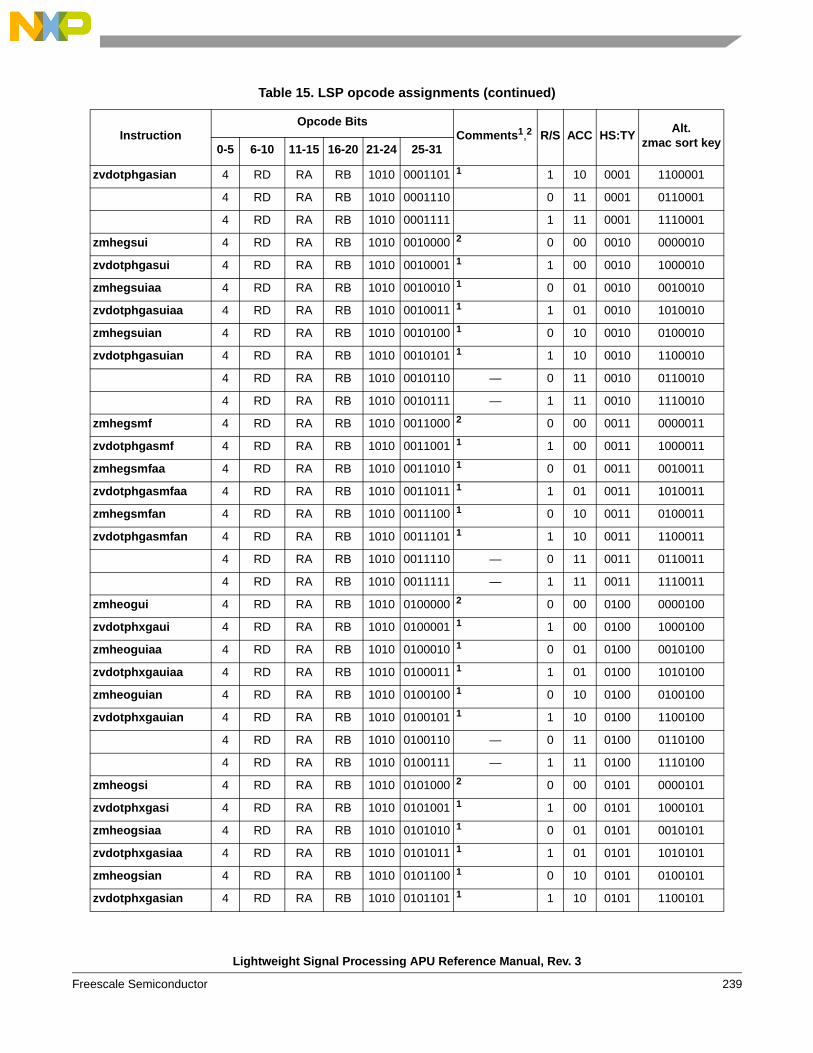
zvdotphgasian 4 RD RA RB 1010 0001101 1 1 10 0001 1100001
4 RD RA RB 1010 0001110 0 11 0001 0110001
4 RD RA RB 1010 0001111 1 11 0001 1110001
zmhegsui 4 RD RA RB 1010 0010000 2 0 00 0010 0000010
zvdotphgasui 4 RD RA RB 1010 0010001 1 1 00 0010 1000010
zmhegsuiaa 4 RD RA RB 1010 0010010 1 0 01 0010 0010010
zvdotphgasuiaa 4 RD RA RB 1010 0010011 1 1 01 0010 1010010
zmhegsuian 4 RD RA RB 1010 0010100 1 0 10 0010 0100010
zvdotphgasuian 4 RD RA RB 1010 0010101 1 1 10 0010 1100010
4 RD RA RB 1010 0010110 — 0 11 0010 0110010
4 RD RA RB 1010 0010111 — 1 11 0010 1110010
zmhegsmf 4 RD RA RB 1010 0011000 2 0 00 0011 0000011
zvdotphgasmf 4 RD RA RB 1010 0011001 1 1 00 0011 1000011
zmhegsmfaa 4 RD RA RB 1010 0011010 1 0 01 0011 0010011
zvdotphgasmfaa 4 RD RA RB 1010 0011011 1 1 01 0011 1010011
zmhegsmfan 4 RD RA RB 1010 0011100 1 0 10 0011 0100011
zvdotphgasmfan 4 RD RA RB 1010 0011101 1 1 10 0011 1100011
4 RD RA RB 1010 0011110 — 0 11 0011 0110011
4 RD RA RB 1010 0011111 — 1 11 0011 1110011
zmheogui 4 RD RA RB 1010 0100000 2 0 00 0100 0000100
zvdotphxgaui 4 RD RA RB 1010 0100001 1 1 00 0100 1000100
zmheoguiaa 4 RD RA RB 1010 0100010 1 0 01 0100 0010100
zvdotphxgauiaa 4 RD RA RB 1010 0100011 1 1 01 0100 1010100
zmheoguian 4 RD RA RB 1010 0100100 1 0 10 0100 0100100
zvdotphxgauian 4 RD RA RB 1010 0100101 1 1 10 0100 1100100
4 RD RA RB 1010 0100110 — 0 11 0100 0110100
4 RD RA RB 1010 0100111 — 1 11 0100 1110100
zmheogsi 4 RD RA RB 1010 0101000 2 0 00 0101 0000101
zvdotphxgasi 4 RD RA RB 1010 0101001 1 1 00 0101 1000101
zmheogsiaa 4 RD RA RB 1010 0101010 1 0 01 0101 0010101
zvdotphxgasiaa 4 RD RA RB 1010 0101011 1 1 01 0101 1010101
zmheogsian 4 RD RA RB 1010 0101100 1 0 10 0101 0100101
zvdotphxgasian 4 RD RA RB 1010 0101101 1 1 10 0101 1100101
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 239
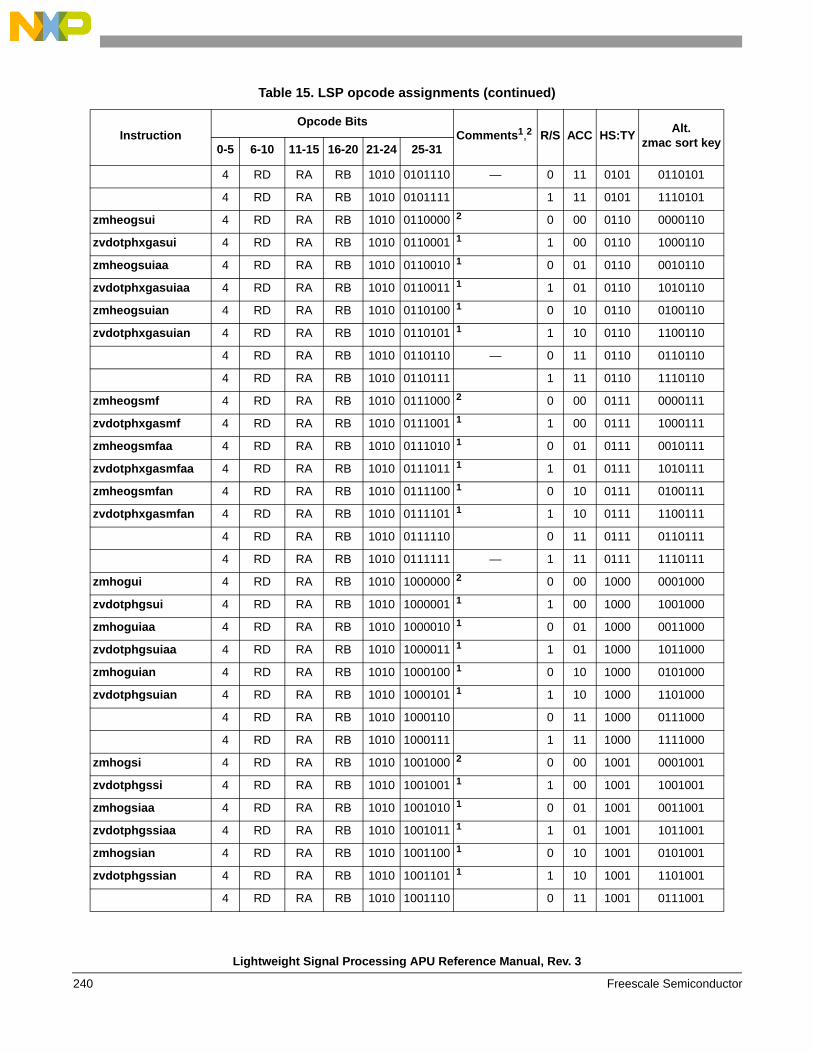
4 RD RA RB 1010 0101110 — 0 11 0101 0110101
4 RD RA RB 1010 0101111 1 11 0101 1110101
zmheogsui 4 RD RA RB 1010 0110000 2 0 00 0110 0000110
zvdotphxgasui 4 RD RA RB 1010 0110001 1 1 00 0110 1000110
zmheogsuiaa 4 RD RA RB 1010 0110010 1 0 01 0110 0010110
zvdotphxgasuiaa 4 RD RA RB 1010 0110011 1 1 01 0110 1010110
zmheogsuian 4 RD RA RB 1010 0110100 1 0 10 0110 0100110
zvdotphxgasuian 4 RD RA RB 1010 0110101 1 1 10 0110 1100110
4 RD RA RB 1010 0110110 — 0 11 0110 0110110
4 RD RA RB 1010 0110111 1 11 0110 1110110
zmheogsmf 4 RD RA RB 1010 0111000 2 0 00 0111 0000111
zvdotphxgasmf 4 RD RA RB 1010 0111001 1 1 00 0111 1000111
zmheogsmfaa 4 RD RA RB 1010 0111010 1 0 01 0111 0010111
zvdotphxgasmfaa 4 RD RA RB 1010 0111011 1 1 01 0111 1010111
zmheogsmfan 4 RD RA RB 1010 0111100 1 0 10 0111 0100111
zvdotphxgasmfan 4 RD RA RB 1010 0111101 1 1 10 0111 1100111
4 RD RA RB 1010 0111110 0 11 0111 0110111
4 RD RA RB 1010 0111111 — 1 11 0111 1110111
zmhogui 4 RD RA RB 1010 1000000 2 0 00 1000 0001000
zvdotphgsui 4 RD RA RB 1010 1000001 1 1 00 1000 1001000
zmhoguiaa 4 RD RA RB 1010 1000010 1 0 01 1000 0011000
zvdotphgsuiaa 4 RD RA RB 1010 1000011 1 1 01 1000 1011000
zmhoguian 4 RD RA RB 1010 1000100 1 0 10 1000 0101000
zvdotphgsuian 4 RD RA RB 1010 1000101 1 1 10 1000 1101000
4 RD RA RB 1010 1000110 0 11 1000 0111000
4 RD RA RB 1010 1000111 1 11 1000 1111000
zmhogsi 4 RD RA RB 1010 1001000 2 0 00 1001 0001001
zvdotphgssi 4 RD RA RB 1010 1001001 1 1 00 1001 1001001
zmhogsiaa 4 RD RA RB 1010 1001010 1 0 01 1001 0011001
zvdotphgssiaa 4 RD RA RB 1010 1001011 1 1 01 1001 1011001
zmhogsian 4 RD RA RB 1010 1001100 1 0 10 1001 0101001
zvdotphgssian 4 RD RA RB 1010 1001101 1 1 10 1001 1101001
4 RD RA RB 1010 1001110 0 11 1001 0111001
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor240
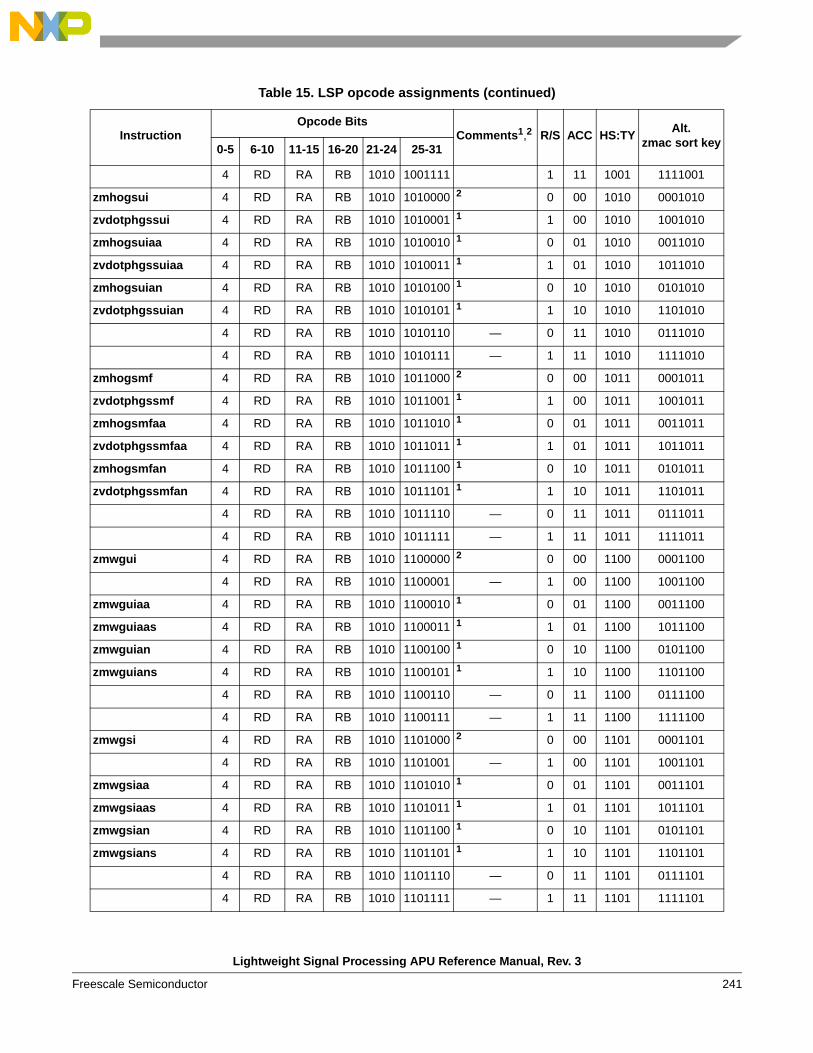
4 RD RA RB 1010 1001111 1 11 1001 1111001
zmhogsui 4 RD RA RB 1010 1010000 2 0 00 1010 0001010
zvdotphgssui 4 RD RA RB 1010 1010001 1 1 00 1010 1001010
zmhogsuiaa 4 RD RA RB 1010 1010010 1 0 01 1010 0011010
zvdotphgssuiaa 4 RD RA RB 1010 1010011 1 1 01 1010 1011010
zmhogsuian 4 RD RA RB 1010 1010100 1 0 10 1010 0101010
zvdotphgssuian 4 RD RA RB 1010 1010101 1 1 10 1010 1101010
4 RD RA RB 1010 1010110 — 0 11 1010 0111010
4 RD RA RB 1010 1010111 — 1 11 1010 1111010
zmhogsmf 4 RD RA RB 1010 1011000 2 0 00 1011 0001011
zvdotphgssmf 4 RD RA RB 1010 1011001 1 1 00 1011 1001011
zmhogsmfaa 4 RD RA RB 1010 1011010 1 0 01 1011 0011011
zvdotphgssmfaa 4 RD RA RB 1010 1011011 1 1 01 1011 1011011
zmhogsmfan 4 RD RA RB 1010 1011100 1 0 10 1011 0101011
zvdotphgssmfan 4 RD RA RB 1010 1011101 1 1 10 1011 1101011
4 RD RA RB 1010 1011110 — 0 11 1011 0111011
4 RD RA RB 1010 1011111 — 1 11 1011 1111011
zmwgui 4 RD RA RB 1010 1100000 2 0 00 1100 0001100
4 RD RA RB 1010 1100001 — 1 00 1100 1001100
zmwguiaa 4 RD RA RB 1010 1100010 1 0 01 1100 0011100
zmwguiaas 4 RD RA RB 1010 1100011 1 1 01 1100 1011100
zmwguian 4 RD RA RB 1010 1100100 1 0 10 1100 0101100
zmwguians 4 RD RA RB 1010 1100101 1 1 10 1100 1101100
4 RD RA RB 1010 1100110 — 0 11 1100 0111100
4 RD RA RB 1010 1100111 — 1 11 1100 1111100
zmwgsi 4 RD RA RB 1010 1101000 2 0 00 1101 0001101
4 RD RA RB 1010 1101001 — 1 00 1101 1001101
zmwgsiaa 4 RD RA RB 1010 1101010 1 0 01 1101 0011101
zmwgsiaas 4 RD RA RB 1010 1101011 1 1 01 1101 1011101
zmwgsian 4 RD RA RB 1010 1101100 1 0 10 1101 0101101
zmwgsians 4 RD RA RB 1010 1101101 1 1 10 1101 1101101
4 RD RA RB 1010 1101110 — 0 11 1101 0111101
4 RD RA RB 1010 1101111 — 1 11 1101 1111101
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 241
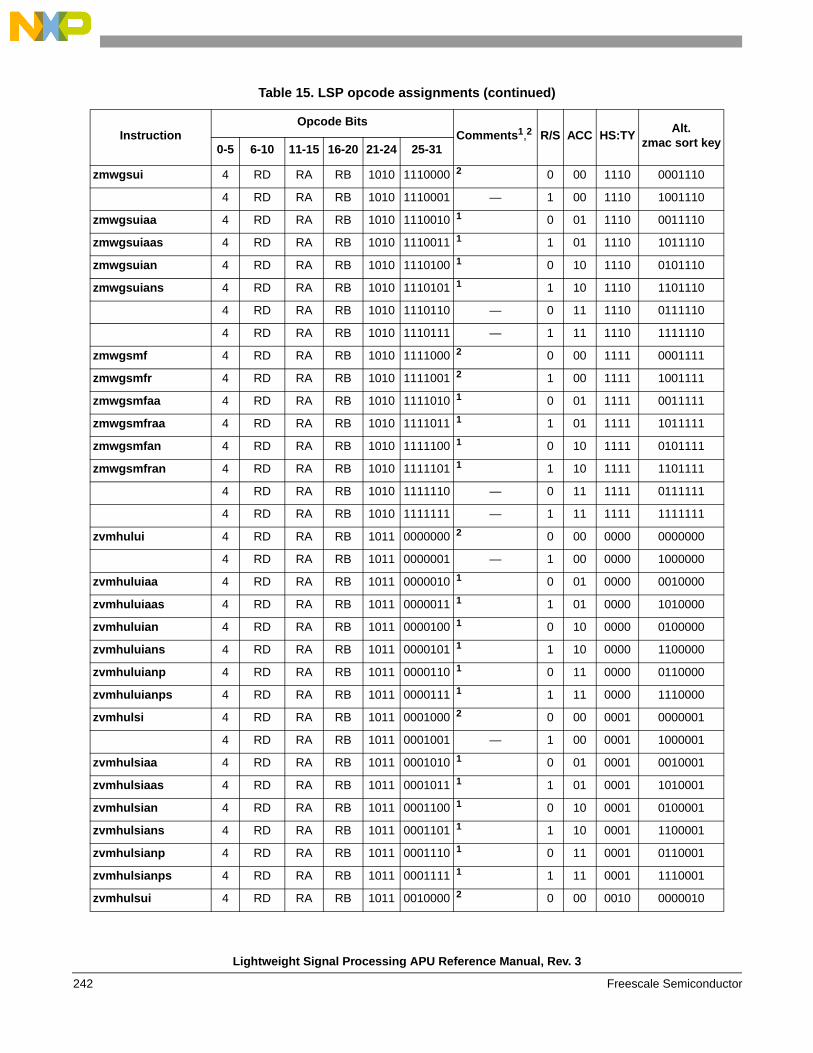
zmwgsui 4 RD RA RB 1010 1110000 2 0 00 1110 0001110
4 RD RA RB 1010 1110001 — 1 00 1110 1001110
zmwgsuiaa 4 RD RA RB 1010 1110010 1 0 01 1110 0011110
zmwgsuiaas 4 RD RA RB 1010 1110011 1 1 01 1110 1011110
zmwgsuian 4 RD RA RB 1010 1110100 1 0 10 1110 0101110
zmwgsuians 4 RD RA RB 1010 1110101 1 1 10 1110 1101110
4 RD RA RB 1010 1110110 — 0 11 1110 0111110
4 RD RA RB 1010 1110111 — 1 11 1110 1111110
zmwgsmf 4 RD RA RB 1010 1111000 2 0 00 1111 0001111
zmwgsmfr 4 RD RA RB 1010 1111001 2 1 00 1111 1001111
zmwgsmfaa 4 RD RA RB 1010 1111010 1 0 01 1111 0011111
zmwgsmfraa 4 RD RA RB 1010 1111011 1 1 01 1111 1011111
zmwgsmfan 4 RD RA RB 1010 1111100 1 0 10 1111 0101111
zmwgsmfran 4 RD RA RB 1010 1111101 1 1 10 1111 1101111
4 RD RA RB 1010 1111110 — 0 11 1111 0111111
4 RD RA RB 1010 1111111 — 1 11 1111 1111111
zvmhului 4 RD RA RB 1011 0000000 2 0 00 0000 0000000
4 RD RA RB 1011 0000001 — 1 00 0000 1000000
zvmhuluiaa 4 RD RA RB 1011 0000010 1 0 01 0000 0010000
zvmhuluiaas 4 RD RA RB 1011 0000011 1 1 01 0000 1010000
zvmhuluian 4 RD RA RB 1011 0000100 1 0 10 0000 0100000
zvmhuluians 4 RD RA RB 1011 0000101 1 1 10 0000 1100000
zvmhuluianp 4 RD RA RB 1011 0000110 1 0 11 0000 0110000
zvmhuluianps 4 RD RA RB 1011 0000111 1 1 11 0000 1110000
zvmhulsi 4 RD RA RB 1011 0001000 2 0 00 0001 0000001
4 RD RA RB 1011 0001001 — 1 00 0001 1000001
zvmhulsiaa 4 RD RA RB 1011 0001010 1 0 01 0001 0010001
zvmhulsiaas 4 RD RA RB 1011 0001011 1 1 01 0001 1010001
zvmhulsian 4 RD RA RB 1011 0001100 1 0 10 0001 0100001
zvmhulsians 4 RD RA RB 1011 0001101 1 1 10 0001 1100001
zvmhulsianp 4 RD RA RB 1011 0001110 1 0 11 0001 0110001
zvmhulsianps 4 RD RA RB 1011 0001111 1 1 11 0001 1110001
zvmhulsui 4 RD RA RB 1011 0010000 2 0 00 0010 0000010
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor242
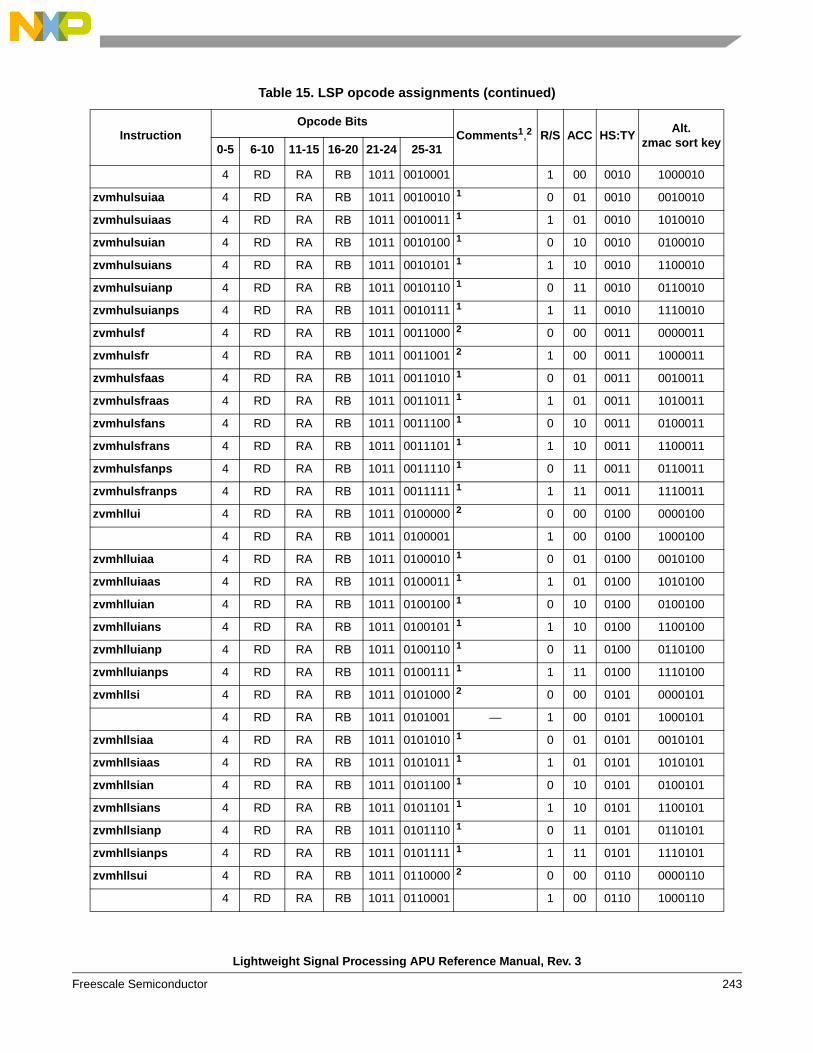
4 RD RA RB 1011 0010001 1 00 0010 1000010
zvmhulsuiaa 4 RD RA RB 1011 0010010 1 0 01 0010 0010010
zvmhulsuiaas 4 RD RA RB 1011 0010011 1 1 01 0010 1010010
zvmhulsuian 4 RD RA RB 1011 0010100 1 0 10 0010 0100010
zvmhulsuians 4 RD RA RB 1011 0010101 1 1 10 0010 1100010
zvmhulsuianp 4 RD RA RB 1011 0010110 1 0 11 0010 0110010
zvmhulsuianps 4 RD RA RB 1011 0010111 1 1 11 0010 1110010
zvmhulsf 4 RD RA RB 1011 0011000 2 0 00 0011 0000011
zvmhulsfr 4 RD RA RB 1011 0011001 2 1 00 0011 1000011
zvmhulsfaas 4 RD RA RB 1011 0011010 1 0 01 0011 0010011
zvmhulsfraas 4 RD RA RB 1011 0011011 1 1 01 0011 1010011
zvmhulsfans 4 RD RA RB 1011 0011100 1 0 10 0011 0100011
zvmhulsfrans 4 RD RA RB 1011 0011101 1 1 10 0011 1100011
zvmhulsfanps 4 RD RA RB 1011 0011110 1 0 11 0011 0110011
zvmhulsfranps 4 RD RA RB 1011 0011111 1 1 11 0011 1110011
zvmhllui 4 RD RA RB 1011 0100000 2 0 00 0100 0000100
4 RD RA RB 1011 0100001 1 00 0100 1000100
zvmhlluiaa 4 RD RA RB 1011 0100010 1 0 01 0100 0010100
zvmhlluiaas 4 RD RA RB 1011 0100011 1 1 01 0100 1010100
zvmhlluian 4 RD RA RB 1011 0100100 1 0 10 0100 0100100
zvmhlluians 4 RD RA RB 1011 0100101 1 1 10 0100 1100100
zvmhlluianp 4 RD RA RB 1011 0100110 1 0 11 0100 0110100
zvmhlluianps 4 RD RA RB 1011 0100111 1 1 11 0100 1110100
zvmhllsi 4 RD RA RB 1011 0101000 2 0 00 0101 0000101
4 RD RA RB 1011 0101001 — 1 00 0101 1000101
zvmhllsiaa 4 RD RA RB 1011 0101010 1 0 01 0101 0010101
zvmhllsiaas 4 RD RA RB 1011 0101011 1 1 01 0101 1010101
zvmhllsian 4 RD RA RB 1011 0101100 1 0 10 0101 0100101
zvmhllsians 4 RD RA RB 1011 0101101 1 1 10 0101 1100101
zvmhllsianp 4 RD RA RB 1011 0101110 1 0 11 0101 0110101
zvmhllsianps 4 RD RA RB 1011 0101111 1 1 11 0101 1110101
zvmhllsui 4 RD RA RB 1011 0110000 2 0 00 0110 0000110
4 RD RA RB 1011 0110001 1 00 0110 1000110
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 243
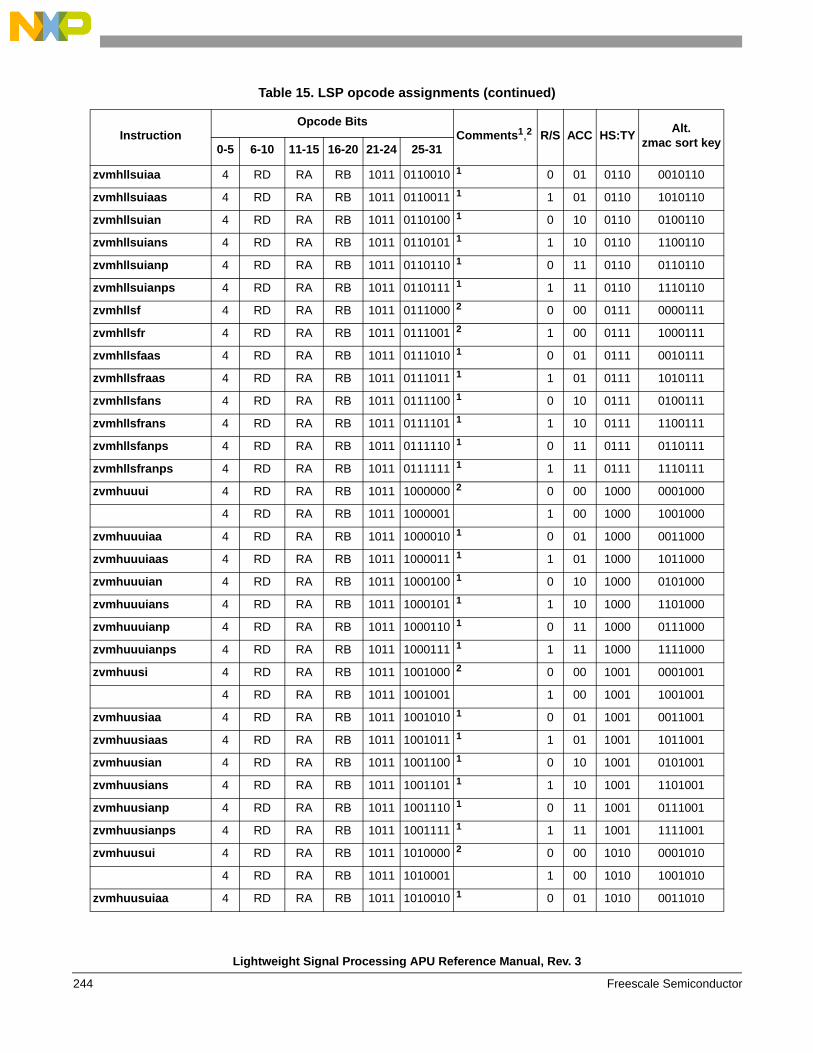
zvmhllsuiaa 4 RD RA RB 1011 0110010 1 0 01 0110 0010110
zvmhllsuiaas 4 RD RA RB 1011 0110011 1 1 01 0110 1010110
zvmhllsuian 4 RD RA RB 1011 0110100 1 0 10 0110 0100110
zvmhllsuians 4 RD RA RB 1011 0110101 1 1 10 0110 1100110
zvmhllsuianp 4 RD RA RB 1011 0110110 1 0 11 0110 0110110
zvmhllsuianps 4 RD RA RB 1011 0110111 1 1 11 0110 1110110
zvmhllsf 4 RD RA RB 1011 0111000 2 0 00 0111 0000111
zvmhllsfr 4 RD RA RB 1011 0111001 2 1 00 0111 1000111
zvmhllsfaas 4 RD RA RB 1011 0111010 1 0 01 0111 0010111
zvmhllsfraas 4 RD RA RB 1011 0111011 1 1 01 0111 1010111
zvmhllsfans 4 RD RA RB 1011 0111100 1 0 10 0111 0100111
zvmhllsfrans 4 RD RA RB 1011 0111101 1 1 10 0111 1100111
zvmhllsfanps 4 RD RA RB 1011 0111110 1 0 11 0111 0110111
zvmhllsfranps 4 RD RA RB 1011 0111111 1 1 11 0111 1110111
zvmhuuui 4 RD RA RB 1011 1000000 2 0 00 1000 0001000
4 RD RA RB 1011 1000001 1 00 1000 1001000
zvmhuuuiaa 4 RD RA RB 1011 1000010 1 0 01 1000 0011000
zvmhuuuiaas 4 RD RA RB 1011 1000011 1 1 01 1000 1011000
zvmhuuuian 4 RD RA RB 1011 1000100 1 0 10 1000 0101000
zvmhuuuians 4 RD RA RB 1011 1000101 1 1 10 1000 1101000
zvmhuuuianp 4 RD RA RB 1011 1000110 1 0 11 1000 0111000
zvmhuuuianps 4 RD RA RB 1011 1000111 1 1 11 1000 1111000
zvmhuusi 4 RD RA RB 1011 1001000 2 0 00 1001 0001001
4 RD RA RB 1011 1001001 1 00 1001 1001001
zvmhuusiaa 4 RD RA RB 1011 1001010 1 0 01 1001 0011001
zvmhuusiaas 4 RD RA RB 1011 1001011 1 1 01 1001 1011001
zvmhuusian 4 RD RA RB 1011 1001100 1 0 10 1001 0101001
zvmhuusians 4 RD RA RB 1011 1001101 1 1 10 1001 1101001
zvmhuusianp 4 RD RA RB 1011 1001110 1 0 11 1001 0111001
zvmhuusianps 4 RD RA RB 1011 1001111 1 1 11 1001 1111001
zvmhuusui 4 RD RA RB 1011 1010000 2 0 00 1010 0001010
4 RD RA RB 1011 1010001 1 00 1010 1001010
zvmhuusuiaa 4 RD RA RB 1011 1010010 1 0 01 1010 0011010
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor244
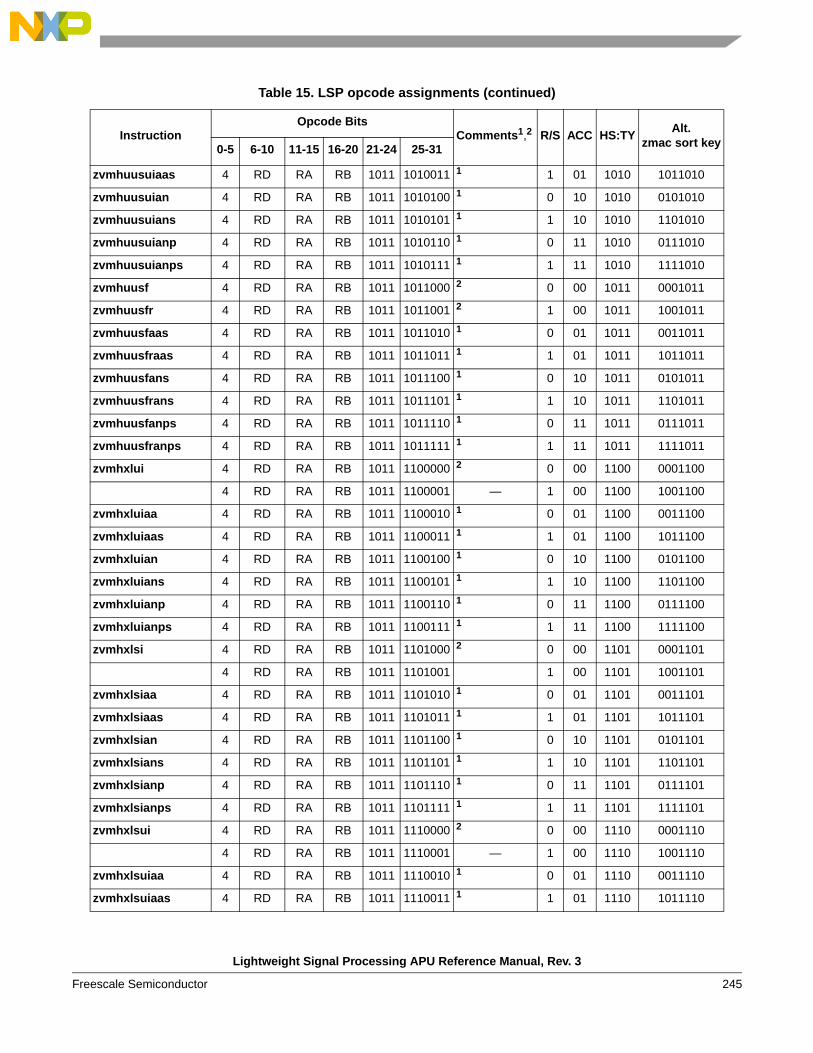
zvmhuusuiaas 4 RD RA RB 1011 1010011 1 1 01 1010 1011010
zvmhuusuian 4 RD RA RB 1011 1010100 1 0 10 1010 0101010
zvmhuusuians 4 RD RA RB 1011 1010101 1 1 10 1010 1101010
zvmhuusuianp 4 RD RA RB 1011 1010110 1 0 11 1010 0111010
zvmhuusuianps 4 RD RA RB 1011 1010111 1 1 11 1010 1111010
zvmhuusf 4 RD RA RB 1011 1011000 2 0 00 1011 0001011
zvmhuusfr 4 RD RA RB 1011 1011001 2 1 00 1011 1001011
zvmhuusfaas 4 RD RA RB 1011 1011010 1 0 01 1011 0011011
zvmhuusfraas 4 RD RA RB 1011 1011011 1 1 01 1011 1011011
zvmhuusfans 4 RD RA RB 1011 1011100 1 0 10 1011 0101011
zvmhuusfrans 4 RD RA RB 1011 1011101 1 1 10 1011 1101011
zvmhuusfanps 4 RD RA RB 1011 1011110 1 0 11 1011 0111011
zvmhuusfranps 4 RD RA RB 1011 1011111 1 1 11 1011 1111011
zvmhxlui 4 RD RA RB 1011 1100000 2 0 00 1100 0001100
4 RD RA RB 1011 1100001 — 1 00 1100 1001100
zvmhxluiaa 4 RD RA RB 1011 1100010 1 0 01 1100 0011100
zvmhxluiaas 4 RD RA RB 1011 1100011 1 1 01 1100 1011100
zvmhxluian 4 RD RA RB 1011 1100100 1 0 10 1100 0101100
zvmhxluians 4 RD RA RB 1011 1100101 1 1 10 1100 1101100
zvmhxluianp 4 RD RA RB 1011 1100110 1 0 11 1100 0111100
zvmhxluianps 4 RD RA RB 1011 1100111 1 1 11 1100 1111100
zvmhxlsi 4 RD RA RB 1011 1101000 2 0 00 1101 0001101
4 RD RA RB 1011 1101001 1 00 1101 1001101
zvmhxlsiaa 4 RD RA RB 1011 1101010 1 0 01 1101 0011101
zvmhxlsiaas 4 RD RA RB 1011 1101011 1 1 01 1101 1011101
zvmhxlsian 4 RD RA RB 1011 1101100 1 0 10 1101 0101101
zvmhxlsians 4 RD RA RB 1011 1101101 1 1 10 1101 1101101
zvmhxlsianp 4 RD RA RB 1011 1101110 1 0 11 1101 0111101
zvmhxlsianps 4 RD RA RB 1011 1101111 1 1 11 1101 1111101
zvmhxlsui 4 RD RA RB 1011 1110000 2 0 00 1110 0001110
4 RD RA RB 1011 1110001 — 1 00 1110 1001110
zvmhxlsuiaa 4 RD RA RB 1011 1110010 1 0 01 1110 0011110
zvmhxlsuiaas 4 RD RA RB 1011 1110011 1 1 01 1110 1011110
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 245
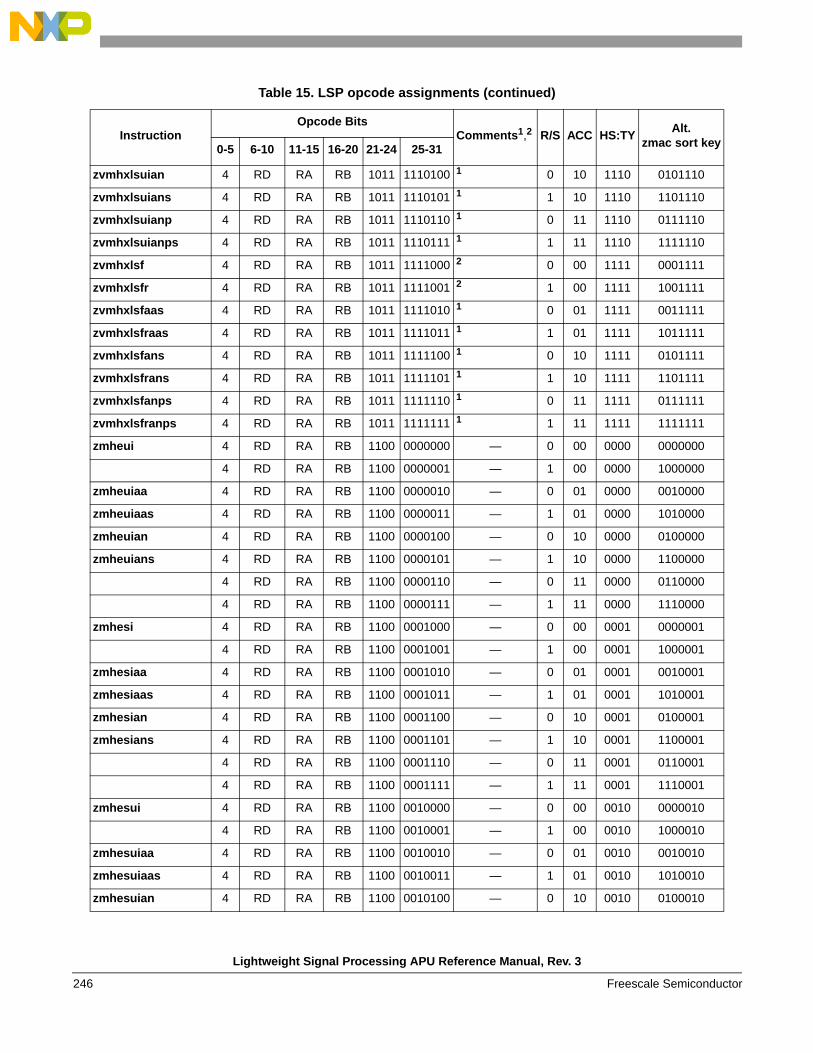
zvmhxlsuian 4 RD RA RB 1011 1110100 1 0 10 1110 0101110
zvmhxlsuians 4 RD RA RB 1011 1110101 1 1 10 1110 1101110
zvmhxlsuianp 4 RD RA RB 1011 1110110 1 0 11 1110 0111110
zvmhxlsuianps 4 RD RA RB 1011 1110111 1 1 11 1110 1111110
zvmhxlsf 4 RD RA RB 1011 1111000 2 0 00 1111 0001111
zvmhxlsfr 4 RD RA RB 1011 1111001 2 1 00 1111 1001111
zvmhxlsfaas 4 RD RA RB 1011 1111010 1 0 01 1111 0011111
zvmhxlsfraas 4 RD RA RB 1011 1111011 1 1 01 1111 1011111
zvmhxlsfans 4 RD RA RB 1011 1111100 1 0 10 1111 0101111
zvmhxlsfrans 4 RD RA RB 1011 1111101 1 1 10 1111 1101111
zvmhxlsfanps 4 RD RA RB 1011 1111110 1 0 11 1111 0111111
zvmhxlsfranps 4 RD RA RB 1011 1111111 1 1 11 1111 1111111
zmheui 4 RD RA RB 1100 0000000 — 0 00 0000 0000000
4 RD RA RB 1100 0000001 — 1 00 0000 1000000
zmheuiaa 4 RD RA RB 1100 0000010 — 0 01 0000 0010000
zmheuiaas 4 RD RA RB 1100 0000011 — 1 01 0000 1010000
zmheuian 4 RD RA RB 1100 0000100 — 0 10 0000 0100000
zmheuians 4 RD RA RB 1100 0000101 — 1 10 0000 1100000
4 RD RA RB 1100 0000110 — 0 11 0000 0110000
4 RD RA RB 1100 0000111 — 1 11 0000 1110000
zmhesi 4 RD RA RB 1100 0001000 — 0 00 0001 0000001
4 RD RA RB 1100 0001001 — 1 00 0001 1000001
zmhesiaa 4 RD RA RB 1100 0001010 — 0 01 0001 0010001
zmhesiaas 4 RD RA RB 1100 0001011 — 1 01 0001 1010001
zmhesian 4 RD RA RB 1100 0001100 — 0 10 0001 0100001
zmhesians 4 RD RA RB 1100 0001101 — 1 10 0001 1100001
4 RD RA RB 1100 0001110 — 0 11 0001 0110001
4 RD RA RB 1100 0001111 — 1 11 0001 1110001
zmhesui 4 RD RA RB 1100 0010000 — 0 00 0010 0000010
4 RD RA RB 1100 0010001 — 1 00 0010 1000010
zmhesuiaa 4 RD RA RB 1100 0010010 — 0 01 0010 0010010
zmhesuiaas 4 RD RA RB 1100 0010011 — 1 01 0010 1010010
zmhesuian 4 RD RA RB 1100 0010100 — 0 10 0010 0100010
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor246
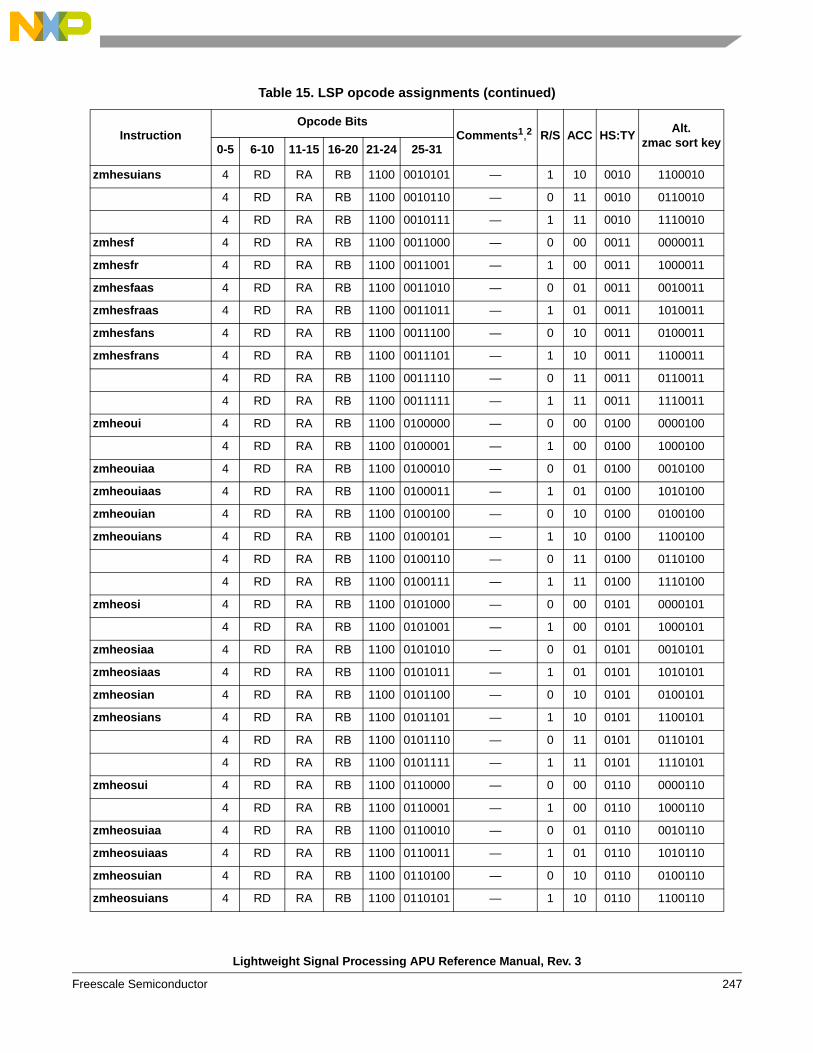
zmhesuians 4 RD RA RB 1100 0010101 — 1 10 0010 1100010
4 RD RA RB 1100 0010110 — 0 11 0010 0110010
4 RD RA RB 1100 0010111 — 1 11 0010 1110010
zmhesf 4 RD RA RB 1100 0011000 — 0 00 0011 0000011
zmhesfr 4 RD RA RB 1100 0011001 — 1 00 0011 1000011
zmhesfaas 4 RD RA RB 1100 0011010 — 0 01 0011 0010011
zmhesfraas 4 RD RA RB 1100 0011011 — 1 01 0011 1010011
zmhesfans 4 RD RA RB 1100 0011100 — 0 10 0011 0100011
zmhesfrans 4 RD RA RB 1100 0011101 — 1 10 0011 1100011
4 RD RA RB 1100 0011110 — 0 11 0011 0110011
4 RD RA RB 1100 0011111 — 1 11 0011 1110011
zmheoui 4 RD RA RB 1100 0100000 — 0 00 0100 0000100
4 RD RA RB 1100 0100001 — 1 00 0100 1000100
zmheouiaa 4 RD RA RB 1100 0100010 — 0 01 0100 0010100
zmheouiaas 4 RD RA RB 1100 0100011 — 1 01 0100 1010100
zmheouian 4 RD RA RB 1100 0100100 — 0 10 0100 0100100
zmheouians 4 RD RA RB 1100 0100101 — 1 10 0100 1100100
4 RD RA RB 1100 0100110 — 0 11 0100 0110100
4 RD RA RB 1100 0100111 — 1 11 0100 1110100
zmheosi 4 RD RA RB 1100 0101000 — 0 00 0101 0000101
4 RD RA RB 1100 0101001 — 1 00 0101 1000101
zmheosiaa 4 RD RA RB 1100 0101010 — 0 01 0101 0010101
zmheosiaas 4 RD RA RB 1100 0101011 — 1 01 0101 1010101
zmheosian 4 RD RA RB 1100 0101100 — 0 10 0101 0100101
zmheosians 4 RD RA RB 1100 0101101 — 1 10 0101 1100101
4 RD RA RB 1100 0101110 — 0 11 0101 0110101
4 RD RA RB 1100 0101111 — 1 11 0101 1110101
zmheosui 4 RD RA RB 1100 0110000 — 0 00 0110 0000110
4 RD RA RB 1100 0110001 — 1 00 0110 1000110
zmheosuiaa 4 RD RA RB 1100 0110010 — 0 01 0110 0010110
zmheosuiaas 4 RD RA RB 1100 0110011 — 1 01 0110 1010110
zmheosuian 4 RD RA RB 1100 0110100 — 0 10 0110 0100110
zmheosuians 4 RD RA RB 1100 0110101 — 1 10 0110 1100110
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 247
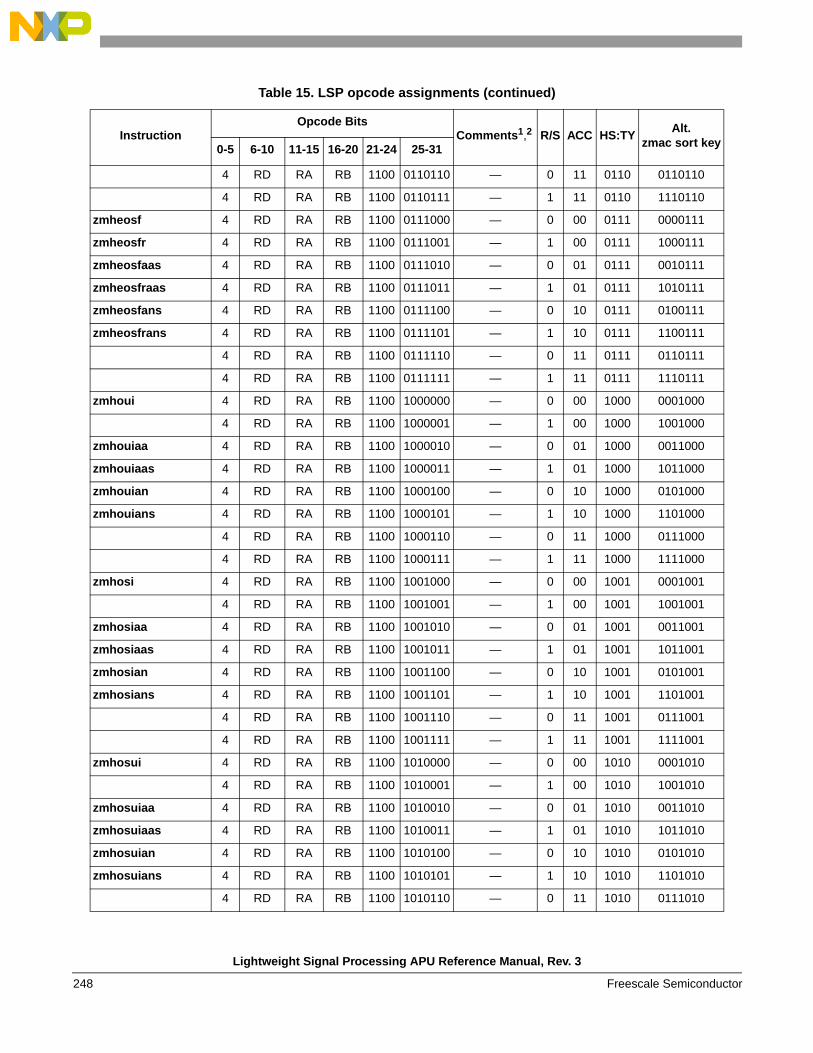
4 RD RA RB 1100 0110110 — 0 11 0110 0110110
4 RD RA RB 1100 0110111 — 1 11 0110 1110110
zmheosf 4 RD RA RB 1100 0111000 — 0 00 0111 0000111
zmheosfr 4 RD RA RB 1100 0111001 — 1 00 0111 1000111
zmheosfaas 4 RD RA RB 1100 0111010 — 0 01 0111 0010111
zmheosfraas 4 RD RA RB 1100 0111011 — 1 01 0111 1010111
zmheosfans 4 RD RA RB 1100 0111100 — 0 10 0111 0100111
zmheosfrans 4 RD RA RB 1100 0111101 — 1 10 0111 1100111
4 RD RA RB 1100 0111110 — 0 11 0111 0110111
4 RD RA RB 1100 0111111 — 1 11 0111 1110111
zmhoui 4 RD RA RB 1100 1000000 — 0 00 1000 0001000
4 RD RA RB 1100 1000001 — 1 00 1000 1001000
zmhouiaa 4 RD RA RB 1100 1000010 — 0 01 1000 0011000
zmhouiaas 4 RD RA RB 1100 1000011 — 1 01 1000 1011000
zmhouian 4 RD RA RB 1100 1000100 — 0 10 1000 0101000
zmhouians 4 RD RA RB 1100 1000101 — 1 10 1000 1101000
4 RD RA RB 1100 1000110 — 0 11 1000 0111000
4 RD RA RB 1100 1000111 — 1 11 1000 1111000
zmhosi 4 RD RA RB 1100 1001000 — 0 00 1001 0001001
4 RD RA RB 1100 1001001 — 1 00 1001 1001001
zmhosiaa 4 RD RA RB 1100 1001010 — 0 01 1001 0011001
zmhosiaas 4 RD RA RB 1100 1001011 — 1 01 1001 1011001
zmhosian 4 RD RA RB 1100 1001100 — 0 10 1001 0101001
zmhosians 4 RD RA RB 1100 1001101 — 1 10 1001 1101001
4 RD RA RB 1100 1001110 — 0 11 1001 0111001
4 RD RA RB 1100 1001111 — 1 11 1001 1111001
zmhosui 4 RD RA RB 1100 1010000 — 0 00 1010 0001010
4 RD RA RB 1100 1010001 — 1 00 1010 1001010
zmhosuiaa 4 RD RA RB 1100 1010010 — 0 01 1010 0011010
zmhosuiaas 4 RD RA RB 1100 1010011 — 1 01 1010 1011010
zmhosuian 4 RD RA RB 1100 1010100 — 0 10 1010 0101010
zmhosuians 4 RD RA RB 1100 1010101 — 1 10 1010 1101010
4 RD RA RB 1100 1010110 — 0 11 1010 0111010
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor248
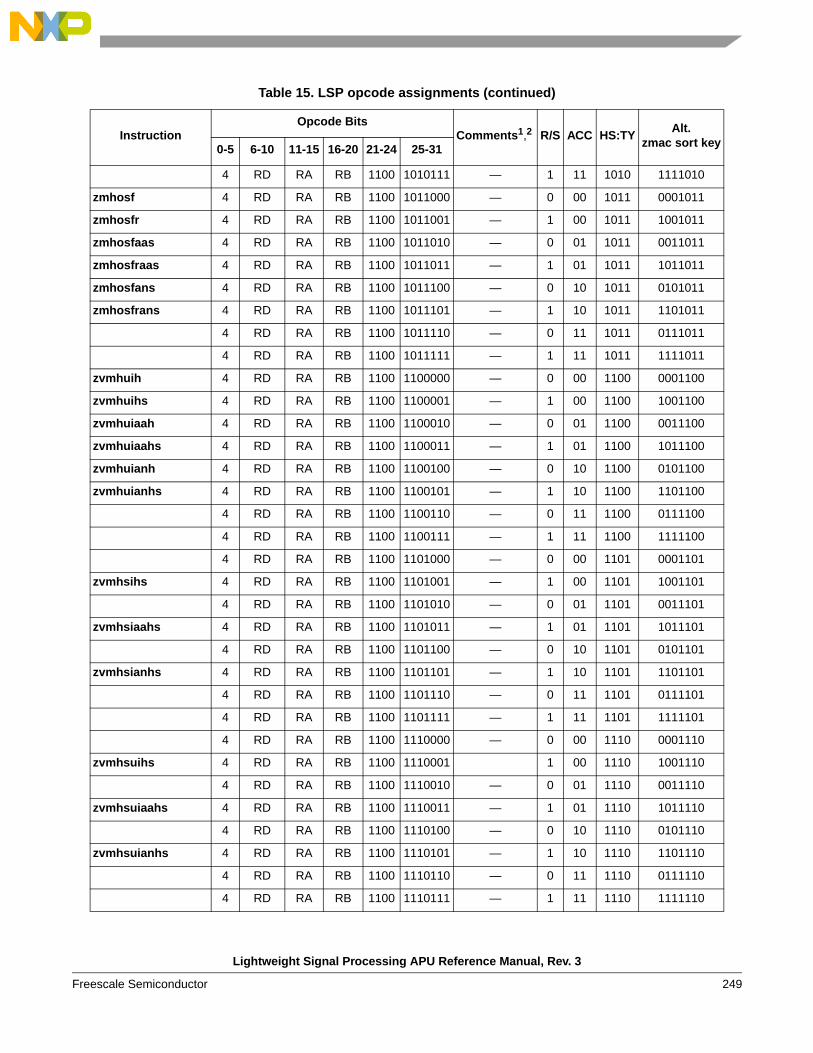
4 RD RA RB 1100 1010111 — 1 11 1010 1111010
zmhosf 4 RD RA RB 1100 1011000 — 0 00 1011 0001011
zmhosfr 4 RD RA RB 1100 1011001 — 1 00 1011 1001011
zmhosfaas 4 RD RA RB 1100 1011010 — 0 01 1011 0011011
zmhosfraas 4 RD RA RB 1100 1011011 — 1 01 1011 1011011
zmhosfans 4 RD RA RB 1100 1011100 — 0 10 1011 0101011
zmhosfrans 4 RD RA RB 1100 1011101 — 1 10 1011 1101011
4 RD RA RB 1100 1011110 — 0 11 1011 0111011
4 RD RA RB 1100 1011111 — 1 11 1011 1111011
zvmhuih 4 RD RA RB 1100 1100000 — 0 00 1100 0001100
zvmhuihs 4 RD RA RB 1100 1100001 — 1 00 1100 1001100
zvmhuiaah 4 RD RA RB 1100 1100010 — 0 01 1100 0011100
zvmhuiaahs 4 RD RA RB 1100 1100011 — 1 01 1100 1011100
zvmhuianh 4 RD RA RB 1100 1100100 — 0 10 1100 0101100
zvmhuianhs 4 RD RA RB 1100 1100101 — 1 10 1100 1101100
4 RD RA RB 1100 1100110 — 0 11 1100 0111100
4 RD RA RB 1100 1100111 — 1 11 1100 1111100
4 RD RA RB 1100 1101000 — 0 00 1101 0001101
zvmhsihs 4 RD RA RB 1100 1101001 — 1 00 1101 1001101
4 RD RA RB 1100 1101010 — 0 01 1101 0011101
zvmhsiaahs 4 RD RA RB 1100 1101011 — 1 01 1101 1011101
4 RD RA RB 1100 1101100 — 0 10 1101 0101101
zvmhsianhs 4 RD RA RB 1100 1101101 — 1 10 1101 1101101
4 RD RA RB 1100 1101110 — 0 11 1101 0111101
4 RD RA RB 1100 1101111 — 1 11 1101 1111101
4 RD RA RB 1100 1110000 — 0 00 1110 0001110
zvmhsuihs 4 RD RA RB 1100 1110001 1 00 1110 1001110
4 RD RA RB 1100 1110010 — 0 01 1110 0011110
zvmhsuiaahs 4 RD RA RB 1100 1110011 — 1 01 1110 1011110
4 RD RA RB 1100 1110100 — 0 10 1110 0101110
zvmhsuianhs 4 RD RA RB 1100 1110101 — 1 10 1110 1101110
4 RD RA RB 1100 1110110 — 0 11 1110 0111110
4 RD RA RB 1100 1110111 — 1 11 1110 1111110
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 249
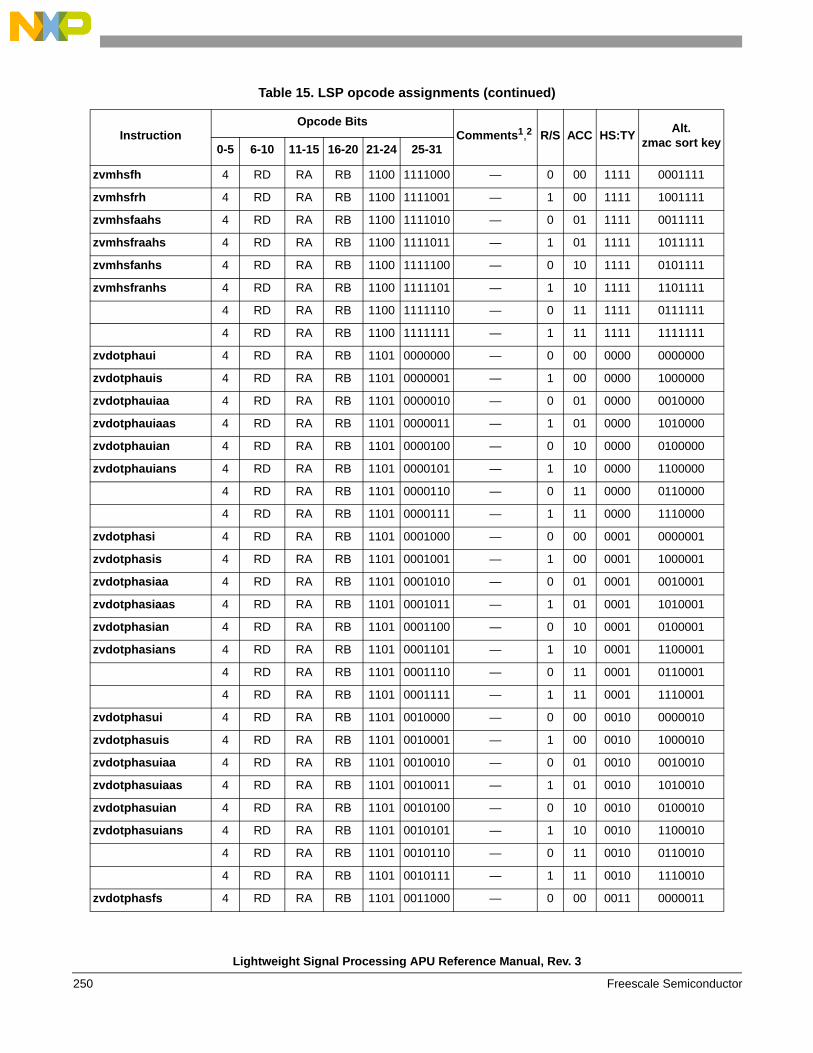
zvmhsfh 4 RD RA RB 1100 1111000 — 0 00 1111 0001111
zvmhsfrh 4 RD RA RB 1100 1111001 — 1 00 1111 1001111
zvmhsfaahs 4 RD RA RB 1100 1111010 — 0 01 1111 0011111
zvmhsfraahs 4 RD RA RB 1100 1111011 — 1 01 1111 1011111
zvmhsfanhs 4 RD RA RB 1100 1111100 — 0 10 1111 0101111
zvmhsfranhs 4 RD RA RB 1100 1111101 — 1 10 1111 1101111
4 RD RA RB 1100 1111110 — 0 11 1111 0111111
4 RD RA RB 1100 1111111 — 1 11 1111 1111111
zvdotphaui 4 RD RA RB 1101 0000000 — 0 00 0000 0000000
zvdotphauis 4 RD RA RB 1101 0000001 — 1 00 0000 1000000
zvdotphauiaa 4 RD RA RB 1101 0000010 — 0 01 0000 0010000
zvdotphauiaas 4 RD RA RB 1101 0000011 — 1 01 0000 1010000
zvdotphauian 4 RD RA RB 1101 0000100 — 0 10 0000 0100000
zvdotphauians 4 RD RA RB 1101 0000101 — 1 10 0000 1100000
4 RD RA RB 1101 0000110 — 0 11 0000 0110000
4 RD RA RB 1101 0000111 — 1 11 0000 1110000
zvdotphasi 4 RD RA RB 1101 0001000 — 0 00 0001 0000001
zvdotphasis 4 RD RA RB 1101 0001001 — 1 00 0001 1000001
zvdotphasiaa 4 RD RA RB 1101 0001010 — 0 01 0001 0010001
zvdotphasiaas 4 RD RA RB 1101 0001011 — 1 01 0001 1010001
zvdotphasian 4 RD RA RB 1101 0001100 — 0 10 0001 0100001
zvdotphasians 4 RD RA RB 1101 0001101 — 1 10 0001 1100001
4 RD RA RB 1101 0001110 — 0 11 0001 0110001
4 RD RA RB 1101 0001111 — 1 11 0001 1110001
zvdotphasui 4 RD RA RB 1101 0010000 — 0 00 0010 0000010
zvdotphasuis 4 RD RA RB 1101 0010001 — 1 00 0010 1000010
zvdotphasuiaa 4 RD RA RB 1101 0010010 — 0 01 0010 0010010
zvdotphasuiaas 4 RD RA RB 1101 0010011 — 1 01 0010 1010010
zvdotphasuian 4 RD RA RB 1101 0010100 — 0 10 0010 0100010
zvdotphasuians 4 RD RA RB 1101 0010101 — 1 10 0010 1100010
4 RD RA RB 1101 0010110 — 0 11 0010 0110010
4 RD RA RB 1101 0010111 — 1 11 0010 1110010
zvdotphasfs 4 RD RA RB 1101 0011000 — 0 00 0011 0000011
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor250
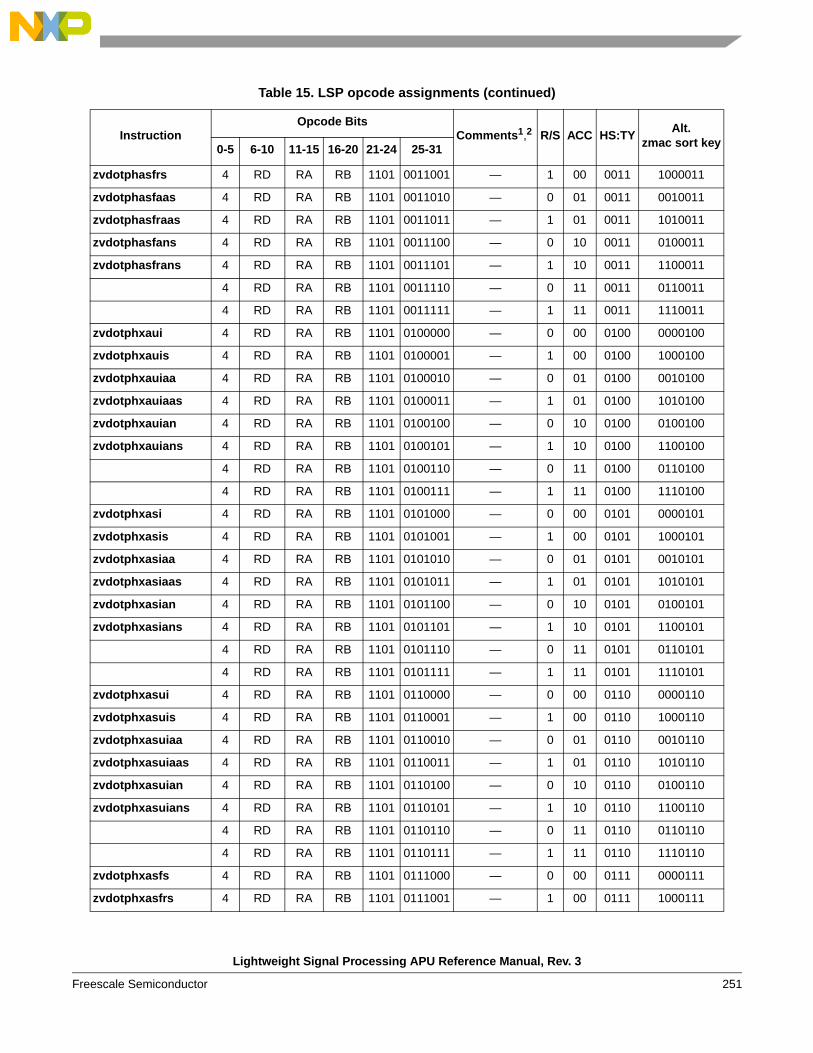
zvdotphasfrs 4 RD RA RB 1101 0011001 — 1 00 0011 1000011
zvdotphasfaas 4 RD RA RB 1101 0011010 — 0 01 0011 0010011
zvdotphasfraas 4 RD RA RB 1101 0011011 — 1 01 0011 1010011
zvdotphasfans 4 RD RA RB 1101 0011100 — 0 10 0011 0100011
zvdotphasfrans 4 RD RA RB 1101 0011101 — 1 10 0011 1100011
4 RD RA RB 1101 0011110 — 0 11 0011 0110011
4 RD RA RB 1101 0011111 — 1 11 0011 1110011
zvdotphxaui 4 RD RA RB 1101 0100000 — 0 00 0100 0000100
zvdotphxauis 4 RD RA RB 1101 0100001 — 1 00 0100 1000100
zvdotphxauiaa 4 RD RA RB 1101 0100010 — 0 01 0100 0010100
zvdotphxauiaas 4 RD RA RB 1101 0100011 — 1 01 0100 1010100
zvdotphxauian 4 RD RA RB 1101 0100100 — 0 10 0100 0100100
zvdotphxauians 4 RD RA RB 1101 0100101 — 1 10 0100 1100100
4 RD RA RB 1101 0100110 — 0 11 0100 0110100
4 RD RA RB 1101 0100111 — 1 11 0100 1110100
zvdotphxasi 4 RD RA RB 1101 0101000 — 0 00 0101 0000101
zvdotphxasis 4 RD RA RB 1101 0101001 — 1 00 0101 1000101
zvdotphxasiaa 4 RD RA RB 1101 0101010 — 0 01 0101 0010101
zvdotphxasiaas 4 RD RA RB 1101 0101011 — 1 01 0101 1010101
zvdotphxasian 4 RD RA RB 1101 0101100 — 0 10 0101 0100101
zvdotphxasians 4 RD RA RB 1101 0101101 — 1 10 0101 1100101
4 RD RA RB 1101 0101110 — 0 11 0101 0110101
4 RD RA RB 1101 0101111 — 1 11 0101 1110101
zvdotphxasui 4 RD RA RB 1101 0110000 — 0 00 0110 0000110
zvdotphxasuis 4 RD RA RB 1101 0110001 — 1 00 0110 1000110
zvdotphxasuiaa 4 RD RA RB 1101 0110010 — 0 01 0110 0010110
zvdotphxasuiaas 4 RD RA RB 1101 0110011 — 1 01 0110 1010110
zvdotphxasuian 4 RD RA RB 1101 0110100 — 0 10 0110 0100110
zvdotphxasuians 4 RD RA RB 1101 0110101 — 1 10 0110 1100110
4 RD RA RB 1101 0110110 — 0 11 0110 0110110
4 RD RA RB 1101 0110111 — 1 11 0110 1110110
zvdotphxasfs 4 RD RA RB 1101 0111000 — 0 00 0111 0000111
zvdotphxasfrs 4 RD RA RB 1101 0111001 — 1 00 0111 1000111
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 251
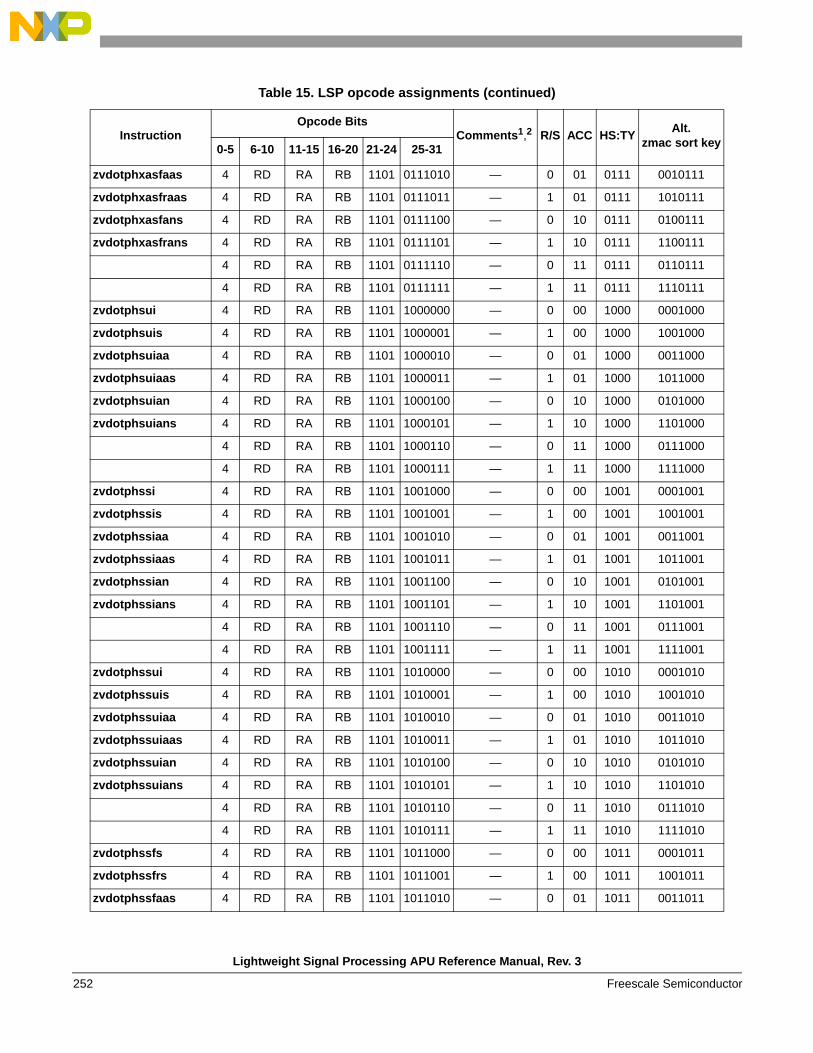
zvdotphxasfaas 4 RD RA RB 1101 0111010 — 0 01 0111 0010111
zvdotphxasfraas 4 RD RA RB 1101 0111011 — 1 01 0111 1010111
zvdotphxasfans 4 RD RA RB 1101 0111100 — 0 10 0111 0100111
zvdotphxasfrans 4 RD RA RB 1101 0111101 — 1 10 0111 1100111
4 RD RA RB 1101 0111110 — 0 11 0111 0110111
4 RD RA RB 1101 0111111 — 1 11 0111 1110111
zvdotphsui 4 RD RA RB 1101 1000000 — 0 00 1000 0001000
zvdotphsuis 4 RD RA RB 1101 1000001 — 1 00 1000 1001000
zvdotphsuiaa 4 RD RA RB 1101 1000010 — 0 01 1000 0011000
zvdotphsuiaas 4 RD RA RB 1101 1000011 — 1 01 1000 1011000
zvdotphsuian 4 RD RA RB 1101 1000100 — 0 10 1000 0101000
zvdotphsuians 4 RD RA RB 1101 1000101 — 1 10 1000 1101000
4 RD RA RB 1101 1000110 — 0 11 1000 0111000
4 RD RA RB 1101 1000111 — 1 11 1000 1111000
zvdotphssi 4 RD RA RB 1101 1001000 — 0 00 1001 0001001
zvdotphssis 4 RD RA RB 1101 1001001 — 1 00 1001 1001001
zvdotphssiaa 4 RD RA RB 1101 1001010 — 0 01 1001 0011001
zvdotphssiaas 4 RD RA RB 1101 1001011 — 1 01 1001 1011001
zvdotphssian 4 RD RA RB 1101 1001100 — 0 10 1001 0101001
zvdotphssians 4 RD RA RB 1101 1001101 — 1 10 1001 1101001
4 RD RA RB 1101 1001110 — 0 11 1001 0111001
4 RD RA RB 1101 1001111 — 1 11 1001 1111001
zvdotphssui 4 RD RA RB 1101 1010000 — 0 00 1010 0001010
zvdotphssuis 4 RD RA RB 1101 1010001 — 1 00 1010 1001010
zvdotphssuiaa 4 RD RA RB 1101 1010010 — 0 01 1010 0011010
zvdotphssuiaas 4 RD RA RB 1101 1010011 — 1 01 1010 1011010
zvdotphssuian 4 RD RA RB 1101 1010100 — 0 10 1010 0101010
zvdotphssuians 4 RD RA RB 1101 1010101 — 1 10 1010 1101010
4 RD RA RB 1101 1010110 — 0 11 1010 0111010
4 RD RA RB 1101 1010111 — 1 11 1010 1111010
zvdotphssfs 4 RD RA RB 1101 1011000 — 0 00 1011 0001011
zvdotphssfrs 4 RD RA RB 1101 1011001 — 1 00 1011 1001011
zvdotphssfaas 4 RD RA RB 1101 1011010 — 0 01 1011 0011011
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor252
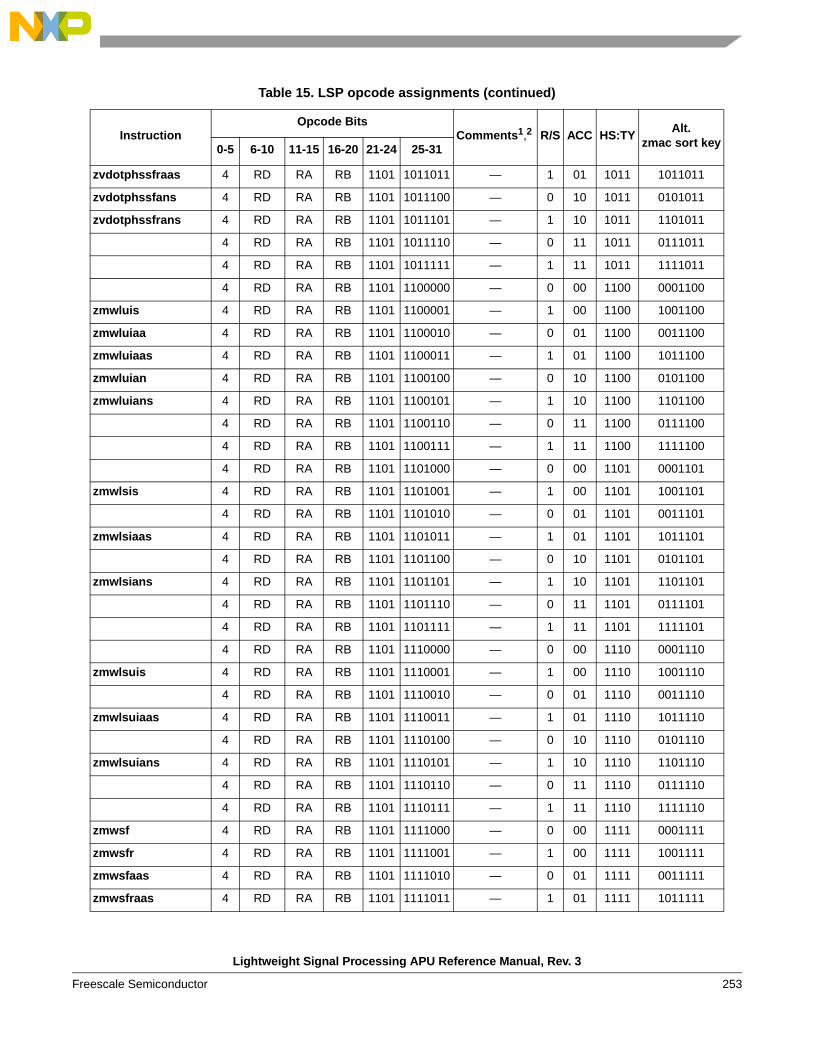
zvdotphssfraas 4 RD RA RB 1101 1011011 — 1 01 1011 1011011
zvdotphssfans 4 RD RA RB 1101 1011100 — 0 10 1011 0101011
zvdotphssfrans 4 RD RA RB 1101 1011101 — 1 10 1011 1101011
4 RD RA RB 1101 1011110 — 0 11 1011 0111011
4 RD RA RB 1101 1011111 — 1 11 1011 1111011
4 RD RA RB 1101 1100000 — 0 00 1100 0001100
zmwluis 4 RD RA RB 1101 1100001 — 1 00 1100 1001100
zmwluiaa 4 RD RA RB 1101 1100010 — 0 01 1100 0011100
zmwluiaas 4 RD RA RB 1101 1100011 — 1 01 1100 1011100
zmwluian 4 RD RA RB 1101 1100100 — 0 10 1100 0101100
zmwluians 4 RD RA RB 1101 1100101 — 1 10 1100 1101100
4 RD RA RB 1101 1100110 — 0 11 1100 0111100
4 RD RA RB 1101 1100111 — 1 11 1100 1111100
4 RD RA RB 1101 1101000 — 0 00 1101 0001101
zmwlsis 4 RD RA RB 1101 1101001 — 1 00 1101 1001101
4 RD RA RB 1101 1101010 — 0 01 1101 0011101
zmwlsiaas 4 RD RA RB 1101 1101011 — 1 01 1101 1011101
4 RD RA RB 1101 1101100 — 0 10 1101 0101101
zmwlsians 4 RD RA RB 1101 1101101 — 1 10 1101 1101101
4 RD RA RB 1101 1101110 — 0 11 1101 0111101
4 RD RA RB 1101 1101111 — 1 11 1101 1111101
4 RD RA RB 1101 1110000 — 0 00 1110 0001110
zmwlsuis 4 RD RA RB 1101 1110001 — 1 00 1110 1001110
4 RD RA RB 1101 1110010 — 0 01 1110 0011110
zmwlsuiaas 4 RD RA RB 1101 1110011 — 1 01 1110 1011110
4 RD RA RB 1101 1110100 — 0 10 1110 0101110
zmwlsuians 4 RD RA RB 1101 1110101 — 1 10 1110 1101110
4 RD RA RB 1101 1110110 — 0 11 1110 0111110
4 RD RA RB 1101 1110111 — 1 11 1110 1111110
zmwsf 4 RD RA RB 1101 1111000 — 0 00 1111 0001111
zmwsfr 4 RD RA RB 1101 1111001 — 1 00 1111 1001111
zmwsfaas 4 RD RA RB 1101 1111010 — 0 01 1111 0011111
zmwsfraas 4 RD RA RB 1101 1111011 — 1 01 1111 1011111
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 253
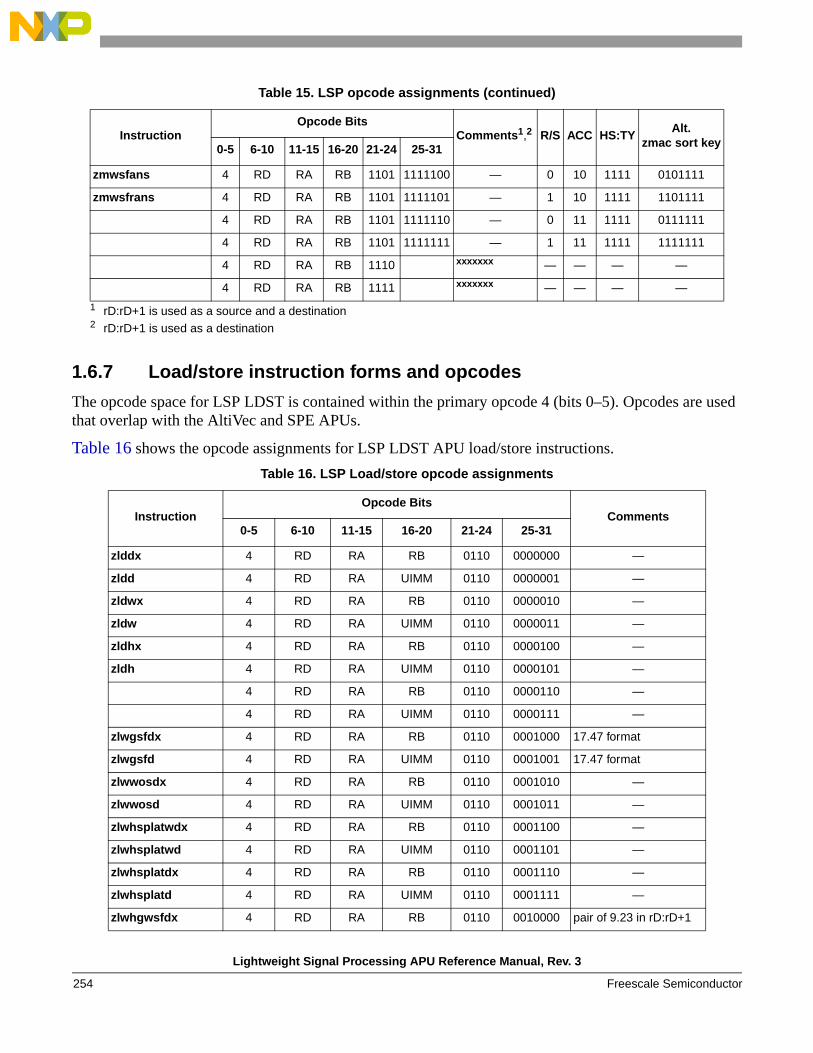
1.6.7 Load/store instruction forms and opcodes
The opcode space for LSP LDST is contained within the primary opcode 4 (bits 0–5). Opcodes are used that overlap with the AltiVec and SPE APUs.
Table 16 shows the opcode assignments for LSP LDST APU load/store instructions.
zmwsfans 4 RD RA RB 1101 1111100 — 0 10 1111 0101111
zmwsfrans 4 RD RA RB 1101 1111101 — 1 10 1111 1101111
4 RD RA RB 1101 1111110 — 0 11 1111 0111111
4 RD RA RB 1101 1111111 — 1 11 1111 1111111
4 RD RA RB 1110 xxxxxxx — — — —
4 RD RA RB 1111 xxxxxxx — — — —
1 rD:rD+1 is used as a source and a destination2 rD:rD+1 is used as a destination
Table 16. LSP Load/store opcode assignments
InstructionOpcode Bits
Comments0-5 6-10 11-15 16-20 21-24 25-31
zlddx 4 RD RA RB 0110 0000000 —
zldd 4 RD RA UIMM 0110 0000001 —
zldwx 4 RD RA RB 0110 0000010 —
zldw 4 RD RA UIMM 0110 0000011 —
zldhx 4 RD RA RB 0110 0000100 —
zldh 4 RD RA UIMM 0110 0000101 —
4 RD RA RB 0110 0000110 —
4 RD RA UIMM 0110 0000111 —
zlwgsfdx 4 RD RA RB 0110 0001000 17.47 format
zlwgsfd 4 RD RA UIMM 0110 0001001 17.47 format
zlwwosdx 4 RD RA RB 0110 0001010 —
zlwwosd 4 RD RA UIMM 0110 0001011 —
zlwhsplatwdx 4 RD RA RB 0110 0001100 —
zlwhsplatwd 4 RD RA UIMM 0110 0001101 —
zlwhsplatdx 4 RD RA RB 0110 0001110 —
zlwhsplatd 4 RD RA UIMM 0110 0001111 —
zlwhgwsfdx 4 RD RA RB 0110 0010000 pair of 9.23 in rD:rD+1
Table 15. LSP opcode assignments (continued)
InstructionOpcode Bits
Comments1,2 R/S ACC HS:TYAlt.
zmac sort key0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor254

zlwhgwsfd 4 RD RA UIMM 0110 0010001 pair of 9.23 in rD:rD+1
zlwhedx 4 RD RA RB 0110 0010010 —
zlwhed 4 RD RA UIMM 0110 0010011 —
zlwhosdx 4 RD RA RB 0110 0010100 —
zlwhosd 4 RD RA UIMM 0110 0010101 —
zlwhoudx 4 RD RA RB 0110 0010110 —
zlwhoud 4 RD RA UIMM 0110 0010111 —
zlwhx 4 RD RA RB 0110 0011000 —
zlwh 4 RD RA UIMM 0110 0011001 —
zlwwx 4 RD RA RB 0110 0011010 —
zlww 4 RD RA UIMM 0110 0011011 —
zlhgwsfx 4 RD RA RB 0110 0011100 9.23 format
zlhgwsf 4 RD RA UIMM 0110 0011101 9.23 format
zlhhsplatx 4 RD RA RB 0110 0011110 —
zlhhsplat 4 RD RA UIMM 0110 0011111 —
zstddx 4 RS RA RB 0110 0100000 —
zstdd 4 RS RA UIMM 0110 0100001 —
zstdwx 4 RS RA RB 0110 0100010 —
zstdw 4 RS RA UIMM 0110 0100011 —
zstdhx 4 RS RA RB 0110 0100100 —
zstdh 4 RS RA UIMM 0110 0100101 —
4 RS RA RB 0110 0100110 —
4 RS RA UIMM 0110 0100111 —
zstwhedx 4 RS RA RB 0110 0101000 —
zstwhed 4 RS RA UIMM 0110 0101001 —
zstwhodx 4 RD RA RB 0110 0101010 —
zstwhod 4 RD RA UIMM 0110 0101011 —
4 RD RA RB 0110 0101100 (stwbe)
4 RD RA UIMM 0110 0101101 (stwbe)
4 RD RA RB 0110 0101110 (stwbo)
4 RD RA UIMM 0110 0101111 (stwbo)
zlhhex 4 RS RA RB 0110 0110000 —
zlhhe 4 RS RA UIMM 0110 0110001 —
Table 16. LSP Load/store opcode assignments (continued)
InstructionOpcode Bits
Comments0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 255
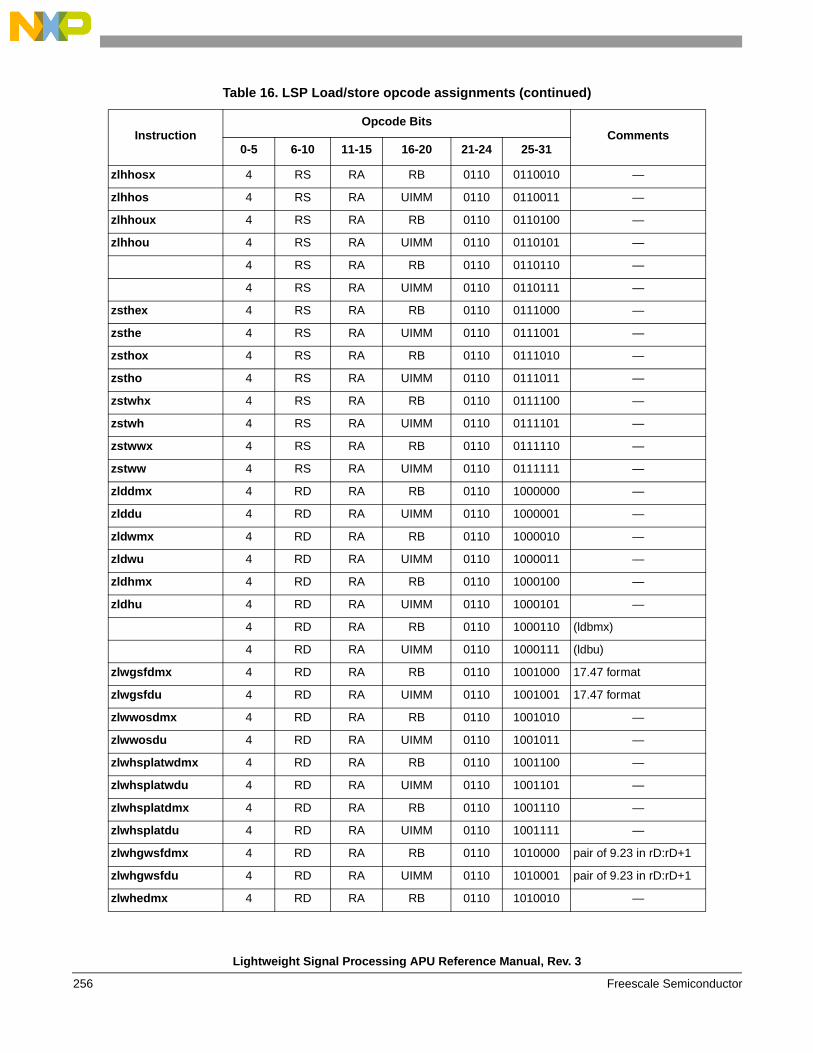
zlhhosx 4 RS RA RB 0110 0110010 —
zlhhos 4 RS RA UIMM 0110 0110011 —
zlhhoux 4 RS RA RB 0110 0110100 —
zlhhou 4 RS RA UIMM 0110 0110101 —
4 RS RA RB 0110 0110110 —
4 RS RA UIMM 0110 0110111 —
zsthex 4 RS RA RB 0110 0111000 —
zsthe 4 RS RA UIMM 0110 0111001 —
zsthox 4 RS RA RB 0110 0111010 —
zstho 4 RS RA UIMM 0110 0111011 —
zstwhx 4 RS RA RB 0110 0111100 —
zstwh 4 RS RA UIMM 0110 0111101 —
zstwwx 4 RS RA RB 0110 0111110 —
zstww 4 RS RA UIMM 0110 0111111 —
zlddmx 4 RD RA RB 0110 1000000 —
zlddu 4 RD RA UIMM 0110 1000001 —
zldwmx 4 RD RA RB 0110 1000010 —
zldwu 4 RD RA UIMM 0110 1000011 —
zldhmx 4 RD RA RB 0110 1000100 —
zldhu 4 RD RA UIMM 0110 1000101 —
4 RD RA RB 0110 1000110 (ldbmx)
4 RD RA UIMM 0110 1000111 (ldbu)
zlwgsfdmx 4 RD RA RB 0110 1001000 17.47 format
zlwgsfdu 4 RD RA UIMM 0110 1001001 17.47 format
zlwwosdmx 4 RD RA RB 0110 1001010 —
zlwwosdu 4 RD RA UIMM 0110 1001011 —
zlwhsplatwdmx 4 RD RA RB 0110 1001100 —
zlwhsplatwdu 4 RD RA UIMM 0110 1001101 —
zlwhsplatdmx 4 RD RA RB 0110 1001110 —
zlwhsplatdu 4 RD RA UIMM 0110 1001111 —
zlwhgwsfdmx 4 RD RA RB 0110 1010000 pair of 9.23 in rD:rD+1
zlwhgwsfdu 4 RD RA UIMM 0110 1010001 pair of 9.23 in rD:rD+1
zlwhedmx 4 RD RA RB 0110 1010010 —
Table 16. LSP Load/store opcode assignments (continued)
InstructionOpcode Bits
Comments0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor256
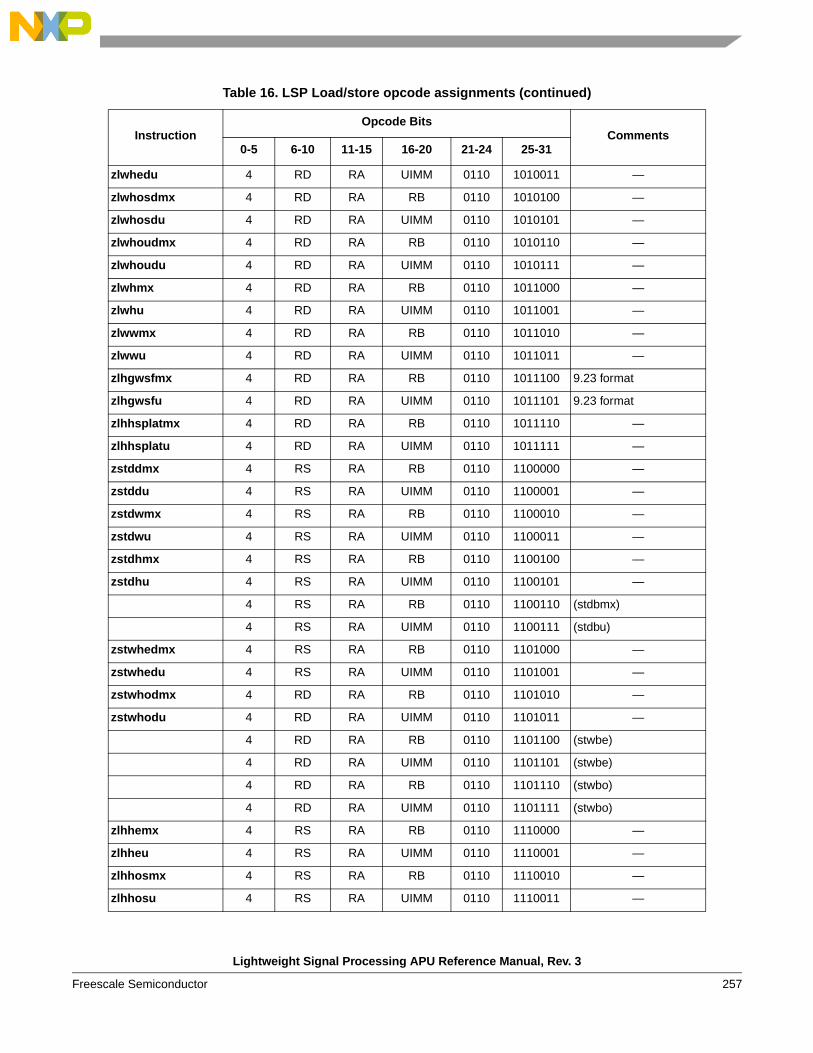
zlwhedu 4 RD RA UIMM 0110 1010011 —
zlwhosdmx 4 RD RA RB 0110 1010100 —
zlwhosdu 4 RD RA UIMM 0110 1010101 —
zlwhoudmx 4 RD RA RB 0110 1010110 —
zlwhoudu 4 RD RA UIMM 0110 1010111 —
zlwhmx 4 RD RA RB 0110 1011000 —
zlwhu 4 RD RA UIMM 0110 1011001 —
zlwwmx 4 RD RA RB 0110 1011010 —
zlwwu 4 RD RA UIMM 0110 1011011 —
zlhgwsfmx 4 RD RA RB 0110 1011100 9.23 format
zlhgwsfu 4 RD RA UIMM 0110 1011101 9.23 format
zlhhsplatmx 4 RD RA RB 0110 1011110 —
zlhhsplatu 4 RD RA UIMM 0110 1011111 —
zstddmx 4 RS RA RB 0110 1100000 —
zstddu 4 RS RA UIMM 0110 1100001 —
zstdwmx 4 RS RA RB 0110 1100010 —
zstdwu 4 RS RA UIMM 0110 1100011 —
zstdhmx 4 RS RA RB 0110 1100100 —
zstdhu 4 RS RA UIMM 0110 1100101 —
4 RS RA RB 0110 1100110 (stdbmx)
4 RS RA UIMM 0110 1100111 (stdbu)
zstwhedmx 4 RS RA RB 0110 1101000 —
zstwhedu 4 RS RA UIMM 0110 1101001 —
zstwhodmx 4 RD RA RB 0110 1101010 —
zstwhodu 4 RD RA UIMM 0110 1101011 —
4 RD RA RB 0110 1101100 (stwbe)
4 RD RA UIMM 0110 1101101 (stwbe)
4 RD RA RB 0110 1101110 (stwbo)
4 RD RA UIMM 0110 1101111 (stwbo)
zlhhemx 4 RS RA RB 0110 1110000 —
zlhheu 4 RS RA UIMM 0110 1110001 —
zlhhosmx 4 RS RA RB 0110 1110010 —
zlhhosu 4 RS RA UIMM 0110 1110011 —
Table 16. LSP Load/store opcode assignments (continued)
InstructionOpcode Bits
Comments0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 257
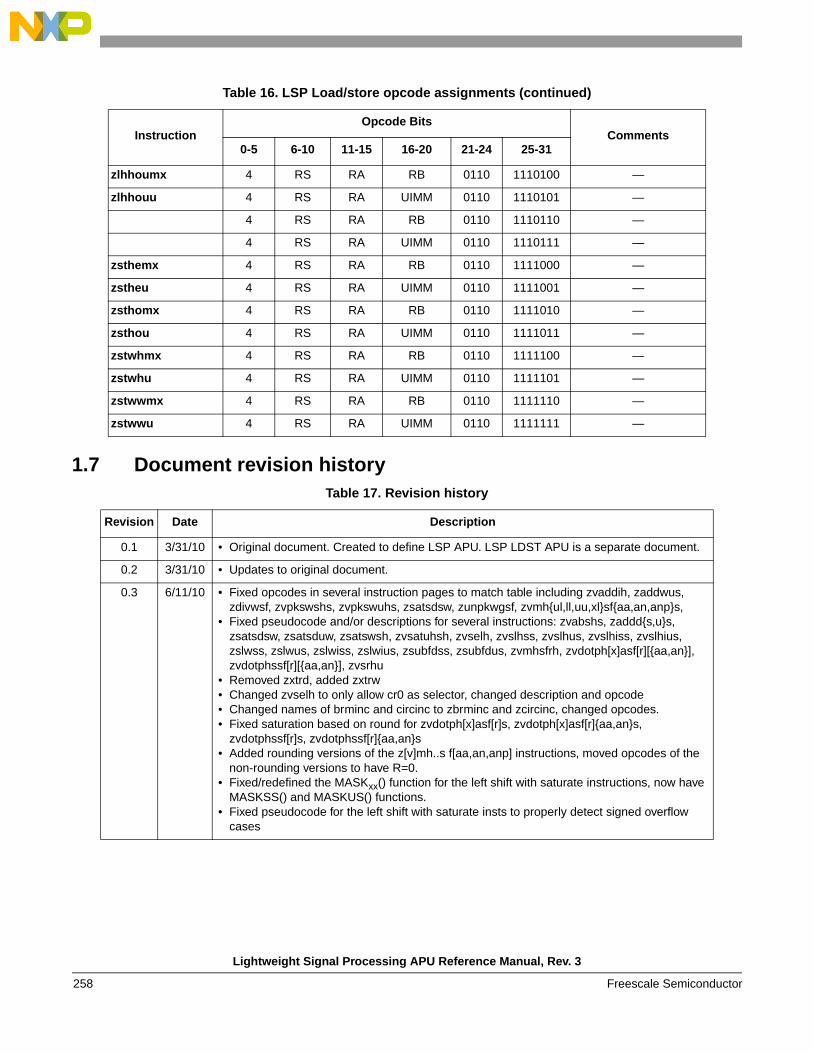
1.7 Document revision history
zlhhoumx 4 RS RA RB 0110 1110100 —
zlhhouu 4 RS RA UIMM 0110 1110101 —
4 RS RA RB 0110 1110110 —
4 RS RA UIMM 0110 1110111 —
zsthemx 4 RS RA RB 0110 1111000 —
zstheu 4 RS RA UIMM 0110 1111001 —
zsthomx 4 RS RA RB 0110 1111010 —
zsthou 4 RS RA UIMM 0110 1111011 —
zstwhmx 4 RS RA RB 0110 1111100 —
zstwhu 4 RS RA UIMM 0110 1111101 —
zstwwmx 4 RS RA RB 0110 1111110 —
zstwwu 4 RS RA UIMM 0110 1111111 —
Table 17. Revision history
Revision Date Description
0.1 3/31/10 • Original document. Created to define LSP APU. LSP LDST APU is a separate document.
0.2 3/31/10 • Updates to original document.
0.3 6/11/10 • Fixed opcodes in several instruction pages to match table including zvaddih, zaddwus, zdivwsf, zvpkswshs, zvpkswuhs, zsatsdsw, zunpkwgsf, zvmh{ul,ll,uu,xl}sf{aa,an,anp}s,
• Fixed pseudocode and/or descriptions for several instructions: zvabshs, zaddd{s,u}s, zsatsdsw, zsatsduw, zsatswsh, zvsatuhsh, zvselh, zvslhss, zvslhus, zvslhiss, zvslhius, zslwss, zslwus, zslwiss, zslwius, zsubfdss, zsubfdus, zvmhsfrh, zvdotph[x]asf[r][{aa,an}], zvdotphssf[r][{aa,an}], zvsrhu
• Removed zxtrd, added zxtrw • Changed zvselh to only allow cr0 as selector, changed description and opcode • Changed names of brminc and circinc to zbrminc and zcircinc, changed opcodes. • Fixed saturation based on round for zvdotph[x]asf[r]s, zvdotph[x]asf[r]{aa,an}s,
zvdotphssf[r]s, zvdotphssf[r]{aa,an}s • Added rounding versions of the z[v]mh..s f[aa,an,anp] instructions, moved opcodes of the
non-rounding versions to have R=0. • Fixed/redefined the MASKxx() function for the left shift with saturate instructions, now have
MASKSS() and MASKUS() functions. • Fixed pseudocode for the left shift with saturate insts to properly detect signed overflow
cases
Table 16. LSP Load/store opcode assignments (continued)
InstructionOpcode Bits
Comments0-5 6-10 11-15 16-20 21-24 25-31
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor258

0.3(cont.)
6/11/10 • Fixed zmheosf in table • Fixed positive comparison value, and saturation result values, and other pseudocode for
zvpkshgwshfrs • Fixed EXTxx function, the signed and unsigned cases were incorrectly swapped • Fixed extension of values to 64 bit to use EXTxx instead of EXTSxx for
zvdotph[x]a{si,ui,sui}s, zvdotphs{si,ui,sui}s • Fixed diagrams to better represent destination and intermediate product sizes • Fixed pseudocode bit numbers for zsubfwg[s,u]i, zsubfwgsf • Fixed pseudocode for zmh{e,eo,o}gwsmf[r], zmh{e,eo,o}gwsmf[r]{aa,an},
zvmh{ul,ll,uu,xl}gwsmf[r], zvmh{ul,ll,uu,xl}gwsmf[r]{aa,an,anp}, zvdotph[x]gwasmf[r], zvdotph[x]gwasmf[r]{aa,an}, zvdotphgwssmf[r], zvdotphgwssmf[r]{aa,an}, zmwgsmf[r]{aa,an} to fix -1 * -1 cases
• Changed rounding on the dotphgw and zvmh{ul,ll,uu,xl}sfr{aa,an,anp}s to round final sum • Fixed pseudocode for zmwl{s,u,su}i{aa,an}, zmwl{s,u,su}i{aa,an}s for 64-bit product usage • Moved opcodes for zsatsduw, zsatsdsw, zsatuduw, zxtrw#x, zbrminc, zcircinc, zdivwsf,
zvselh • Added new instructions zvaddw, zvaddwss, zvaddwus, zvsubfw, zvsubfwss, zvsubfwus,
zvaddsubfw, zvaddsubfwss, zvsubfaddw, zvsubfaddwss • Fixed pseudocode for several zmwgxx instructions to show rD odd illegal • Fixed pseudocode for zunpkhgwsf and fixed diagram for bit #s • Changed underflow references to negative overflow • Moved dotphg, dotphxg opcodes to line 1010 w/ R=1 • Removed dotp xs variants • Added rounding versions of the z[v]mh..s f[aa,an,anp] instructions, moved opcodes of the
non-rounding versions to have R=0. • Changed HS value for odd halfwords to 11 from 10 in mul mac zmac insts (zmhoxxx, etc), and
moved zvmhuih[s], zvmhsf[r]h, zvmhsihs, zvmhsuihs, to HS=11 slots • Added missing zmheguiaa to opmap table • Moved opcodes for zmwg into line with zmhxxg using HS=11 encoding space • Moved opcodes for zmwl, zmwsf into line with zvdotph using HS=11 encoding space • Removed zmwlsi{aa,an} opcodes, now alias to zmwlui{aa,as}. Added zmwlsui{aa,an} aliases • Added zvmhsih, zvmhsuih aliases to zvmhuih • Added rounding ops zvmh{ul,ll,uu,xl}sfr, zmh{e,eo,o}sfr • Swapped lines D and B all opcodes • Added zvmhui{aa,an}h insts and aliases zvmh{si,sui}{aa,an}h • Added zvmh{si,sui,ui}{aa,an}hs insts • Added zvmhsf[r]{aa,an}hs insts • Moved opcodes for zvsplat[f]ih, zvcntl[s,z]h, zcntlsw • Moved line 8 opcodes to line C, then moved DW ops from line 4 to line 8, swapping opcode
bits 29:30 with 27:28 to align decodes for rD;rD+1 as a dest only in line 8 with line 9, A and B • Moved zvunpk xx opcodes again by setting bit 26 to 1 in line 8 after move
Table 17. Revision history (continued)
Revision Date Description
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor 259
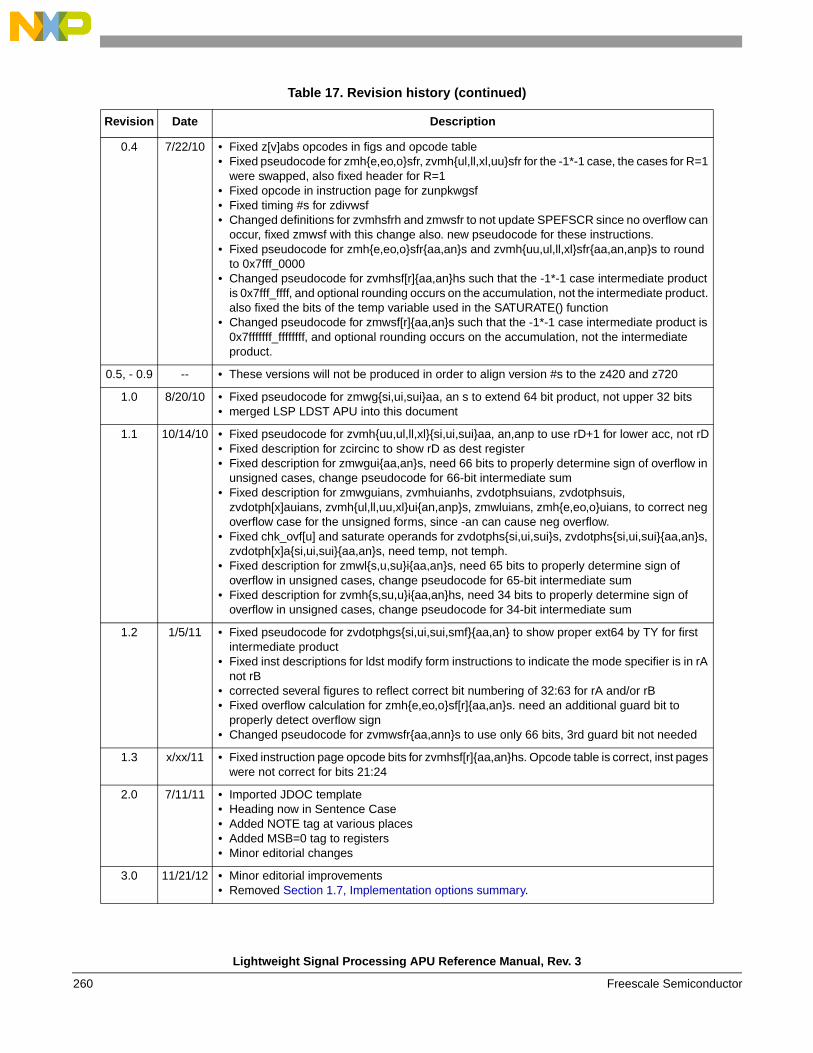
0.4 7/22/10 • Fixed z[v]abs opcodes in figs and opcode table • Fixed pseudocode for zmh{e,eo,o}sfr, zvmh{ul,ll,xl,uu}sfr for the -1*-1 case, the cases for R=1
were swapped, also fixed header for R=1 • Fixed opcode in instruction page for zunpkwgsf • Fixed timing #s for zdivwsf • Changed definitions for zvmhsfrh and zmwsfr to not update SPEFSCR since no overflow can
occur, fixed zmwsf with this change also. new pseudocode for these instructions. • Fixed pseudocode for zmh{e,eo,o}sfr{aa,an}s and zvmh{uu,ul,ll,xl}sfr{aa,an,anp}s to round
to 0x7fff_0000 • Changed pseudocode for zvmhsf[r]{aa,an}hs such that the -1*-1 case intermediate product
is 0x7fff_ffff, and optional rounding occurs on the accumulation, not the intermediate product. also fixed the bits of the temp variable used in the SATURATE() function
• Changed pseudocode for zmwsf[r]{aa,an}s such that the -1*-1 case intermediate product is 0x7fffffff_ffffffff, and optional rounding occurs on the accumulation, not the intermediate product.
0.5, - 0.9 -- • These versions will not be produced in order to align version #s to the z420 and z720
1.0 8/20/10 • Fixed pseudocode for zmwg{si,ui,sui}aa, an s to extend 64 bit product, not upper 32 bits • merged LSP LDST APU into this document
1.1 10/14/10 • Fixed pseudocode for zvmh{uu,ul,ll,xl}{si,ui,sui}aa, an,anp to use rD+1 for lower acc, not rD • Fixed description for zcircinc to show rD as dest register • Fixed description for zmwgui{aa,an}s, need 66 bits to properly determine sign of overflow in
unsigned cases, change pseudocode for 66-bit intermediate sum • Fixed description for zmwguians, zvmhuianhs, zvdotphsuians, zvdotphsuis,
zvdotph[x]auians, zvmh{ul,ll,uu,xl}ui{an,anp}s, zmwluians, zmh{e,eo,o}uians, to correct neg overflow case for the unsigned forms, since -an can cause neg overflow.
• Fixed chk_ovf[u] and saturate operands for zvdotphs{si,ui,sui}s, zvdotphs{si,ui,sui}{aa,an}s, zvdotph[x]a{si,ui,sui}{aa,an}s, need temp, not temph.
• Fixed description for zmwl{s,u,su}i{aa,an}s, need 65 bits to properly determine sign of overflow in unsigned cases, change pseudocode for 65-bit intermediate sum
• Fixed description for zvmh{s,su,u}i{aa,an}hs, need 34 bits to properly determine sign of overflow in unsigned cases, change pseudocode for 34-bit intermediate sum
1.2 1/5/11 • Fixed pseudocode for zvdotphgs{si,ui,sui,smf}{aa,an} to show proper ext64 by TY for first intermediate product
• Fixed inst descriptions for ldst modify form instructions to indicate the mode specifier is in rA not rB
• corrected several figures to reflect correct bit numbering of 32:63 for rA and/or rB • Fixed overflow calculation for zmh{e,eo,o}sf[r]{aa,an}s. need an additional guard bit to
properly detect overflow sign • Changed pseudocode for zvmwsfr{aa,ann}s to use only 66 bits, 3rd guard bit not needed
1.3 x/xx/11 • Fixed instruction page opcode bits for zvmhsf[r]{aa,an}hs. Opcode table is correct, inst pages were not correct for bits 21:24
2.0 7/11/11 • Imported JDOC template • Heading now in Sentence Case • Added NOTE tag at various places • Added MSB=0 tag to registers • Minor editorial changes
3.0 11/21/12 • Minor editorial improvements • Removed Section 1.7, Implementation options summary.
Table 17. Revision history (continued)
Revision Date Description
Lightweight Signal Processing APU Reference Manual, Rev. 3
Freescale Semiconductor260

Document Number: LSPAPURMRev. 312/2012
Information in this document is provided solely to enable system and software
implementers to use Freescale products. There are no express or implied copyright
licenses granted hereunder to design or fabricate any integrated circuits based on the
information in this document.
Freescale reserves the right to make changes without further notice to any products
herein. Freescale makes no warranty, representation, or guarantee regarding the
suitability of its products for any particular purpose, nor does Freescale assume any
liability arising out of the application or use of any product or circuit, and specifically
disclaims any and all liability, including without limitation consequential or incidental
damages. “Typical” parameters that may be provided in Freescale data sheets and/or
specifications can and do vary in different applications, and actual performance may
vary over time. All operating parameters, including “typicals,” must be validated for each
customer application by customer’s technical experts. Freescale does not convey any
license under its patent rights nor the rights of others. Freescale sells products
pursuant to standard terms and conditions of sale, which can be found at the following
address: freescale.com/SalesTermsandConditions.
How to Reach Us:
Home Page: freescale.com
Web Support: freescale.com/support
Freescale, the Freescale logo, AltiVec, C-5, CodeTest, CodeWarrior, ColdFire, C-Ware,
Energy Efficient Solutions logo, Kinetis, mobileGT, PowerQUICC, Processor Expert,
QorIQ, Qorivva, StarCore, Symphony, and VortiQa are trademarks of Freescale
Semiconductor, Inc., Reg. U.S. Pat. & Tm. Off. Airfast, BeeKit, BeeStack, ColdFire+,
CoreNet, Flexis, MagniV, MXC, Platform in a Package, QorIQ Qonverge, QUICC
Engine, Ready Play, SafeAssure, SMARTMOS, TurboLink, Vybrid, and Xtrinsic are
trademarks of Freescale Semiconductor, Inc. All other product or service names are
the property of their respective owners. The Power Architecture and Power.org word
marks and the Power and Power.org logos and related marks are trademarks and
service marks licensed by Power.org.
© 2011–2012 Freescale Semiconductor, Inc.