Embed Size (px)
Citation preview

Lexical and Syntax Analysis(of Programming Languages)
Lexical Analysis

Lexical and Syntax Analysis(of Programming Languages)
Lexical Analysis
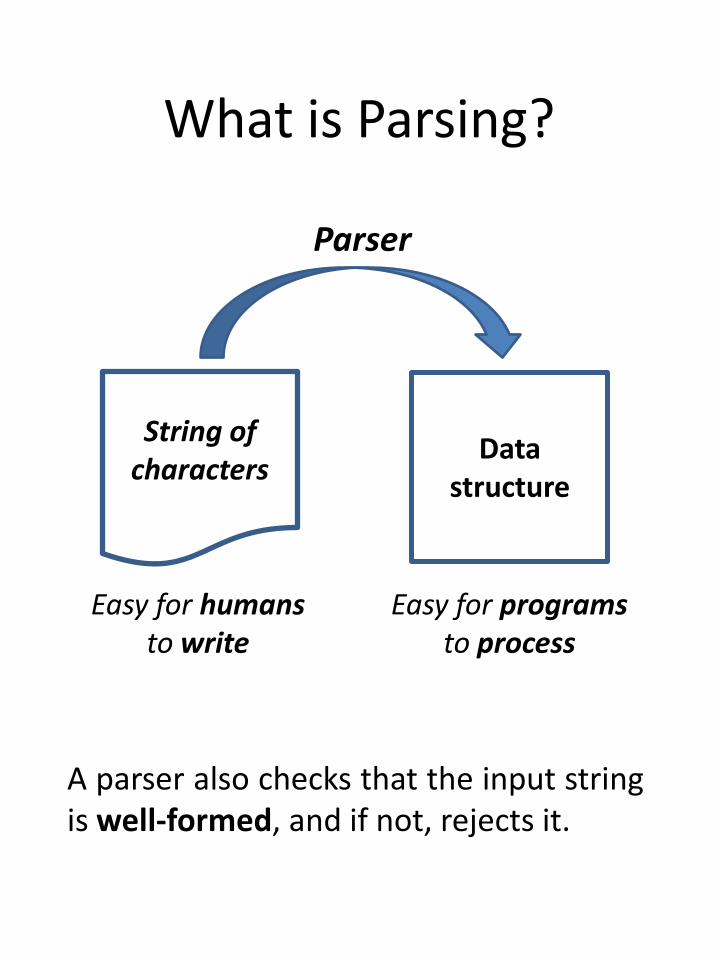
What is Parsing?
String ofcharacters
Easy for humansto write
Easy for programsto process
Parser
A parser also checks that the input stringis well-formed, and if not, rejects it.
Data structure
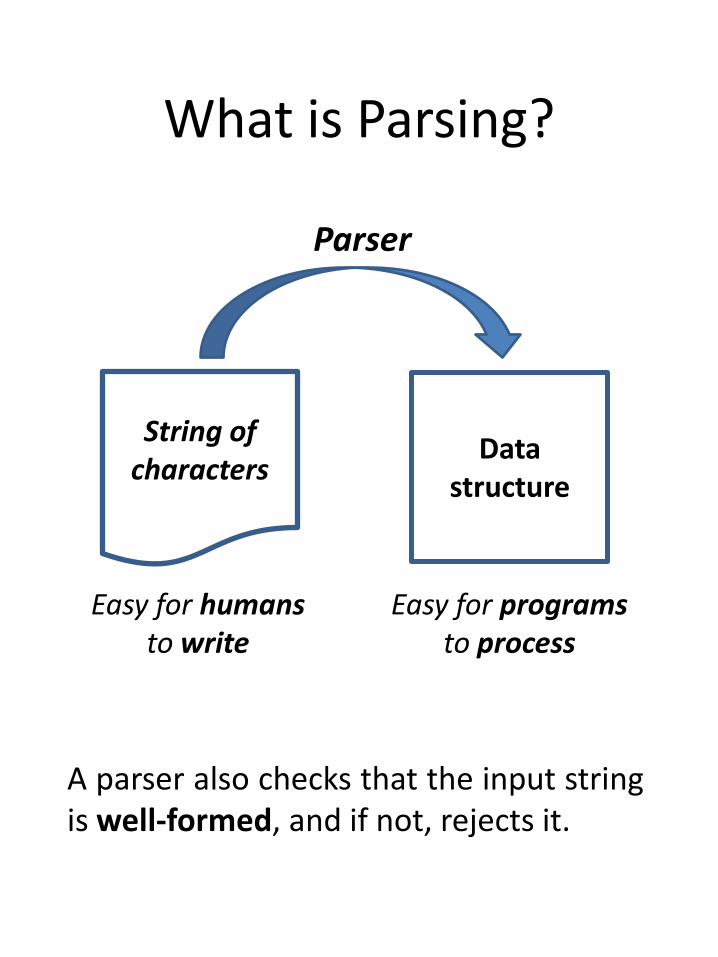
What is Parsing?
String ofcharacters
Easy for humansto write
Easy for programsto process
Parser
A parser also checks that the input stringis well-formed, and if not, rejects it.
Data structure

PARSING
=
LEXICAL ANALYSIS+
SYNTAX ANALYSIS

PARSING
=
LEXICAL ANALYSIS+
SYNTAX ANALYSIS

Lexical Analysis
Identifies the lexemes in asentence.
Lexeme: a minimal meaningfulunit of a language.
Converts each lexeme to atoken.
Throws away ignorable textsuch as spaces, new-lines, andcomments.
(Also known as “scanning”)

Lexical Analysis
Identifies the lexemes in asentence.
Lexeme: a minimal meaningfulunit of a language.
Converts each lexeme to atoken.
Throws away ignorable textsuch as spaces, new-lines, andcomments.
(Also known as “scanning”)

What is a token?
Every token has an identifier,used to denote the kind oflexeme that it represents, e.g.
Token identifier denotes
PLUS a + operator
ASSIGN a := operator
VAR a variable
NUM a number
Some tokens have a componentvalue, conventionally written inparenthesis after the identifier,e.g. VAR(foo), NUM(12).

What is a token?
Every token has an identifier,used to denote the kind oflexeme that it represents, e.g.
Token identifier denotes
PLUS a + operator
ASSIGN a := operator
VAR a variable
NUM a number
Some tokens have a componentvalue, conventionally written inparenthesis after the identifier,e.g. VAR(foo), NUM(12).
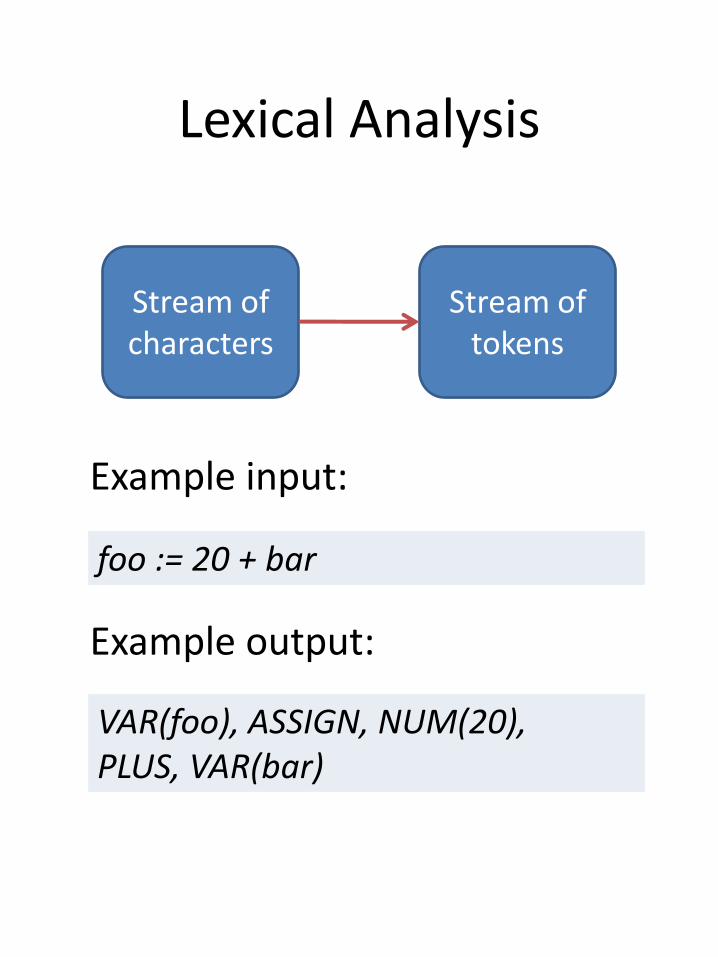
Lexical Analysis
Stream of characters
Stream of tokens
Example input:
foo := 20 + bar
Example output:
VAR(foo), ASSIGN, NUM(20),PLUS, VAR(bar)
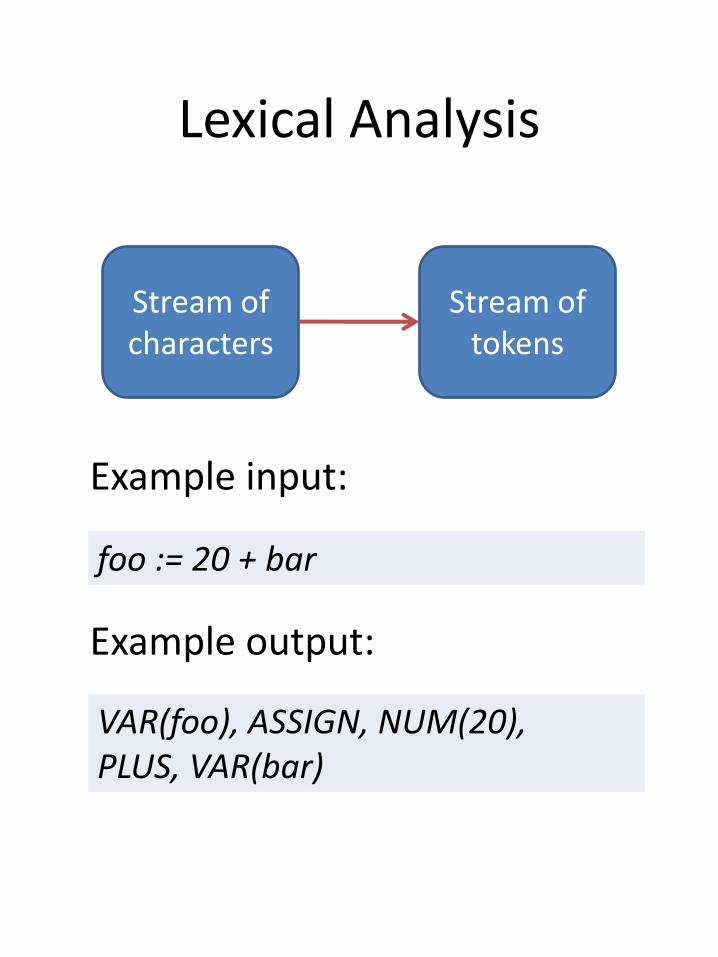
Lexical Analysis
Stream of characters
Stream of tokens
Example input:
foo := 20 + bar
Example output:
VAR(foo), ASSIGN, NUM(20),PLUS, VAR(bar)

Lexical Analysis
Lexemes are specified by regularexpressions. For example:
number = digit⋅ digit*
variable = letter⋅ (letter | digit)*
digit = 0 | ... | 9letter = a | ... | z
1443634
xfoofoo2x1y20
Example numbers: Example variables:

Lexical Analysis
Lexemes are specified by regularexpressions. For example:
number = digit⋅ digit*
variable = letter⋅ (letter | digit)*
digit = 0 | ... | 9letter = a | ... | z
1443634
xfoofoo2x1y20
Example numbers: Example variables:

REGULAR EXPRESSIONS
What exactly is a regular expression?

REGULAR EXPRESSIONS
What exactly is a regular expression?

Notation
Alphabet ∑ is the set of allcharacters that can appear in aninput string.
If a string s matches a regularexpressions r, we write s ∿ r.
Language L(r) = { s ⦁ s ∿ r }, i.e.the set of all strings matchingregular expression r.
We write s1s2 to denote theconcatenation of strings s1 and s2.

Notation
Alphabet ∑ is the set of allcharacters that can appear in aninput string.
If a string s matches a regularexpressions r, we write s ∿ r.
Language L(r) = { s ⦁ s ∿ r }, i.e.the set of all strings matchingregular expression r.
We write s1s2 to denote theconcatenation of strings s1 and s2.
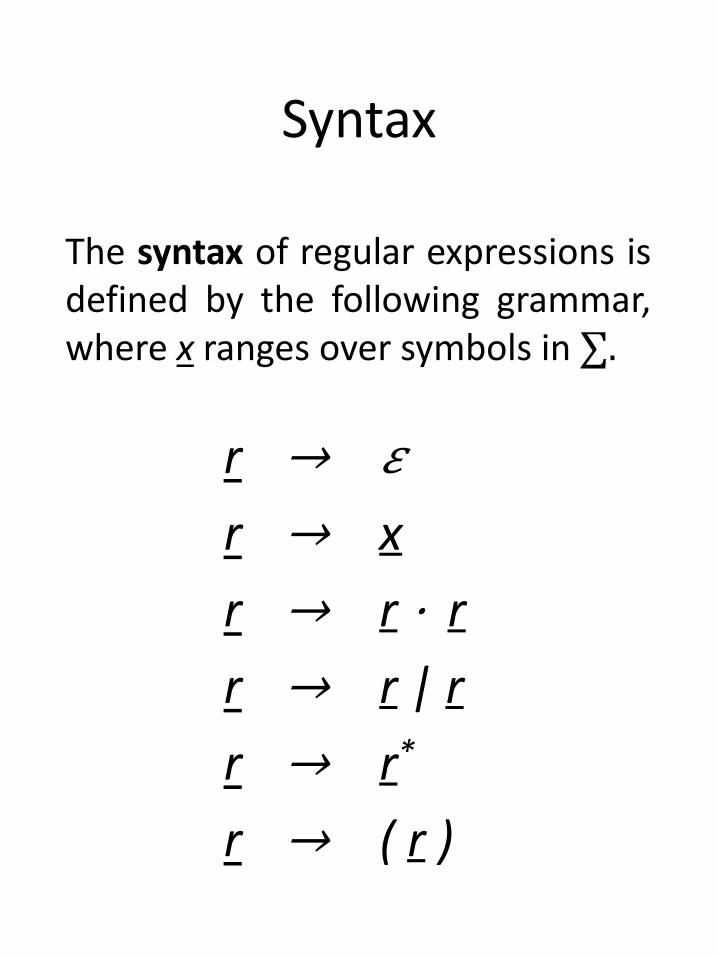
Syntax
r → 𝜀
r → x
r → r ⋅ r
r → r | r
r → r*
r → ( r )
The syntax of regular expressions isdefined by the following grammar,where x ranges over symbols in ∑.
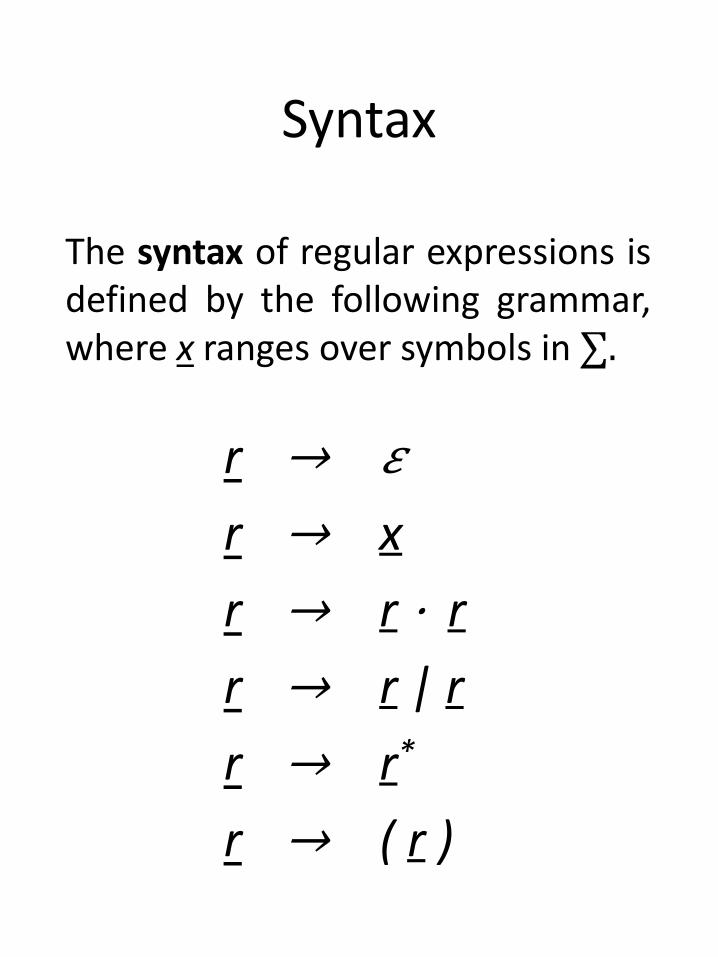
Syntax
r → 𝜀
r → x
r → r ⋅ r
r → r | r
r → r*
r → ( r )
The syntax of regular expressions isdefined by the following grammar,where x ranges over symbols in ∑.

Intuitive definition
Regularexpression
Matching strings are
𝜀 The empty string 𝜀
x The singleton string x if x ∊ ∑
r1 | r2 Any string matching r1 or r2.
r1 ⋅ r2
Any string that can be split intosubstrings s1 and s2 such that s1
matches r1 and s2 matches r2
r*
The empty string or any stringthat can be split into substringss1...sn such that si matches r forall i in 1...n

Intuitive definition
Regularexpression
Matching strings are
𝜀 The empty string 𝜀
x The singleton string x if x ∊ ∑
r1 | r2 Any string matching r1 or r2.
r1 ⋅ r2
Any string that can be split intosubstrings s1 and s2 such that s1
matches r1 and s2 matches r2
r*
The empty string or any stringthat can be split into substringss1...sn such that si matches r forall i in 1...n
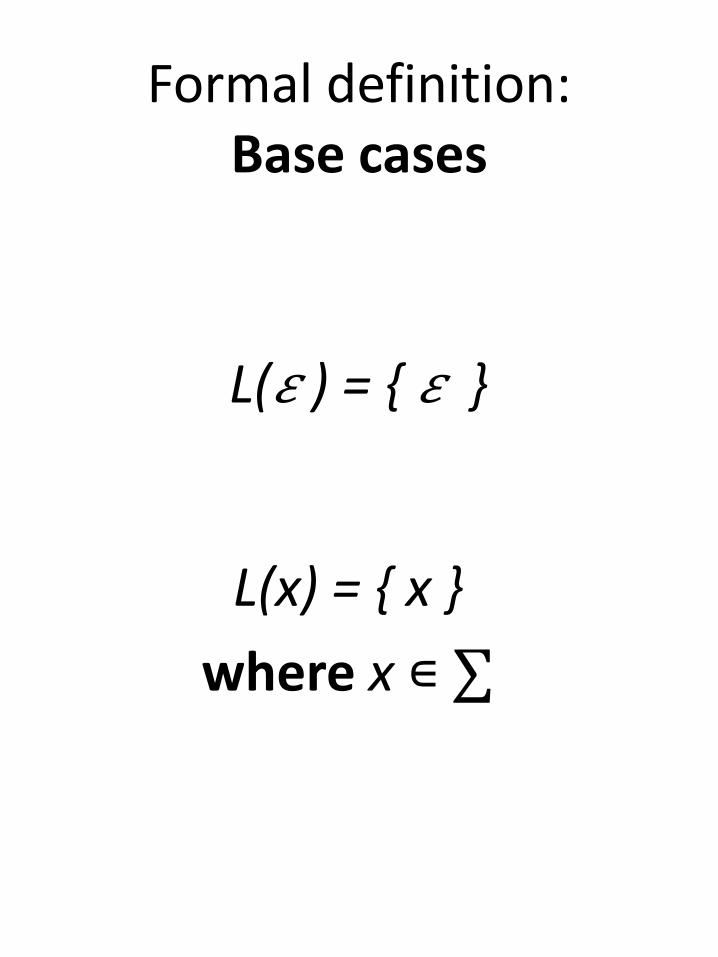
Formal definition:Base cases
L(𝜀 ) = { 𝜀 }
L(x) = { x }
where x ∊ ∑
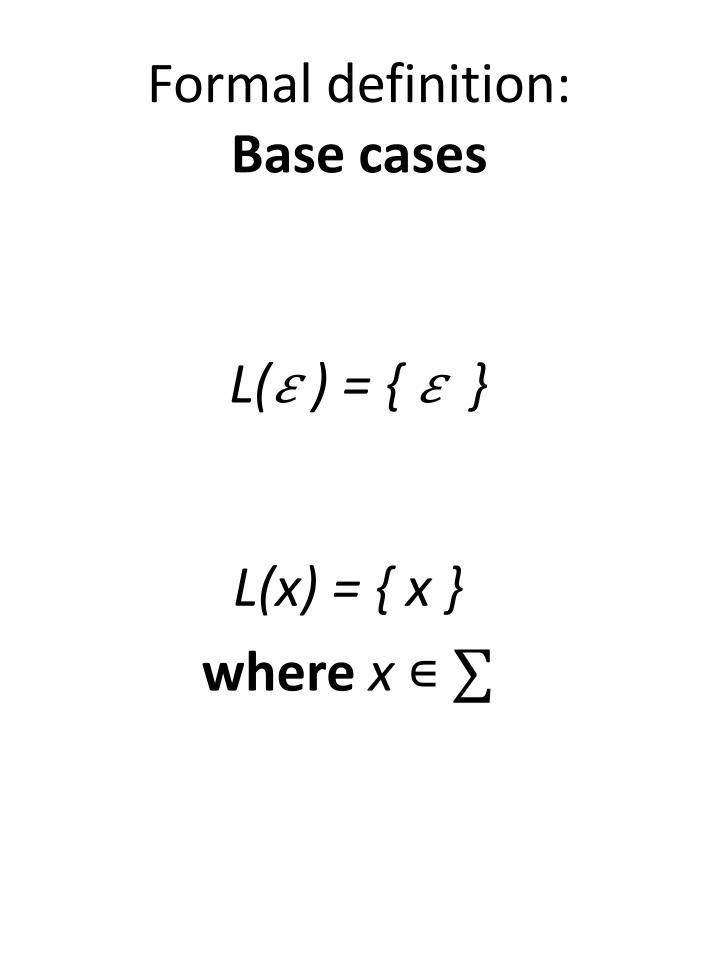
Formal definition:Base cases
L(𝜀 ) = { 𝜀 }
L(x) = { x }
where x ∊ ∑

Formal definition:Choice and Sequence
L(r1 | r2) = L(r1) ∪ L(r2)
L(r1 ⋅ r2) ={ s1s2 ⦁ s1 ∊ L(r1),
s2 ∊ L(r2) }

Formal definition:Choice and Sequence
L(r1 | r2) = L(r1) ∪ L(r2)
L(r1 ⋅ r2) ={ s1s2 ⦁ s1 ∊ L(r1),
s2 ∊ L(r2) }

Formal definition:Kleene closure
L(rn) =
L(r*) =
⋃
{ 𝜀 }, if n = 0L(r ⋅ rn-1), if n > 0
{ L(rn) ⦁ n ∊ { 0⋯ ∞ } }

Formal definition:Kleene closure
L(rn) =
L(r*) =
⋃
{ 𝜀 }, if n = 0L(r ⋅ rn-1), if n > 0
{ L(rn) ⦁ n ∊ { 0⋯ ∞ } }

Example 1
r L(r)
a|b { a, b }
(a|b)⋅ (a|b) { aa, ab, ba, bb }
a* { 𝜀, a, aa, aaa, ... }
(a⋅ b)* { 𝜀, ab, abab, ... }
(a|b)* { 𝜀, a, b, ab, ba, ... }
Suppose ∑ = { a, b }.

Example 1
r L(r)
a|b { a, b }
(a|b)⋅ (a|b) { aa, ab, ba, bb }
a* { 𝜀, a, aa, aaa, ... }
(a⋅ b)* { 𝜀, ab, abab, ... }
(a|b)* { 𝜀, a, b, ab, ba, ... }
Suppose ∑ = { a, b }.

Example 2
Example of a language that cannotbe defined by a regular expression:
{ anbn ⦁ n ∊ ℕ }
The set of strings containing nconsecutive a symbols followed byn consecutive b symbols, for all n.

Example 2
Example of a language that cannotbe defined by a regular expression:
{ anbn ⦁ n ∊ ℕ }
The set of strings containing nconsecutive a symbols followed byn consecutive b symbols, for all n.

Exercise 1
Characterise the languages definedby the following regular expressions
a ⋅ (a|b)* ⋅ a
a* ⋅ b ⋅ a* ⋅ b ⋅ a* ⋅ b ⋅ a*
((𝜀|a) ⋅ b*)*

Exercise 1
Characterise the languages definedby the following regular expressions
a ⋅ (a|b)* ⋅ a
a* ⋅ b ⋅ a* ⋅ b ⋅ a* ⋅ b ⋅ a*
((𝜀|a) ⋅ b*)*

Proof rules:Base cases
If x ∊ ∑ then x matches x.
x ∿ x
x ∊ ∑
The empty string 𝜀 matches 𝜀.
𝜀 ∿ 𝜀 [Empty]
[Single]

Proof rules:Base cases
If x ∊ ∑ then x matches x.
x ∿ x
x ∊ ∑
The empty string 𝜀 matches 𝜀.
𝜀 ∿ 𝜀 [Empty]
[Single]

Proof rules:Sequence
s1s2 ∿ r1 ⋅ r2
s1 ∿ r1 s2 ∿ r2[Seq]
If s1 matches r1 and s2 matches r2
then s1s2 matches r1 ⋅ r2.

Proof rules:Sequence
s1s2 ∿ r1 ⋅ r2
s1 ∿ r1 s2 ∿ r2[Seq]
If s1 matches r1 and s2 matches r2
then s1s2 matches r1 ⋅ r2.

Proof rules:Choice
If s matches r1
then s matches r1 | r2
s ∿ r1 | r2
s ∿ r1[Or1]
If s matches r2
then s matches r1 | r2
s ∿ r1 | r2
s ∿ r2[Or2]

Proof rules:Choice
If s matches r1
then s matches r1 | r2
s ∿ r1 | r2
s ∿ r1[Or1]
If s matches r2
then s matches r1 | r2
s ∿ r1 | r2
s ∿ r2[Or2]

Proof rules:Kleene closure
If s matches 𝜀
then s matches r*.
If s matches r ⋅ r*
then s matches r*.
s ∿ r*
s ∿ 𝜀[Kleene1]
s ∿ r*
s ∿ r ⋅ r*
[Kleene2]

Proof rules:Kleene closure
If s matches 𝜀
then s matches r*.
If s matches r ⋅ r*
then s matches r*.
s ∿ r*
s ∿ 𝜀[Kleene1]
s ∿ r*
s ∿ r ⋅ r*
[Kleene2]

Exercise 2
Proove that the string
cab
matches the regular expression
((a⋅ b)|c)*

Exercise 2
Proove that the string
cab
matches the regular expression
((a⋅ b)|c)*
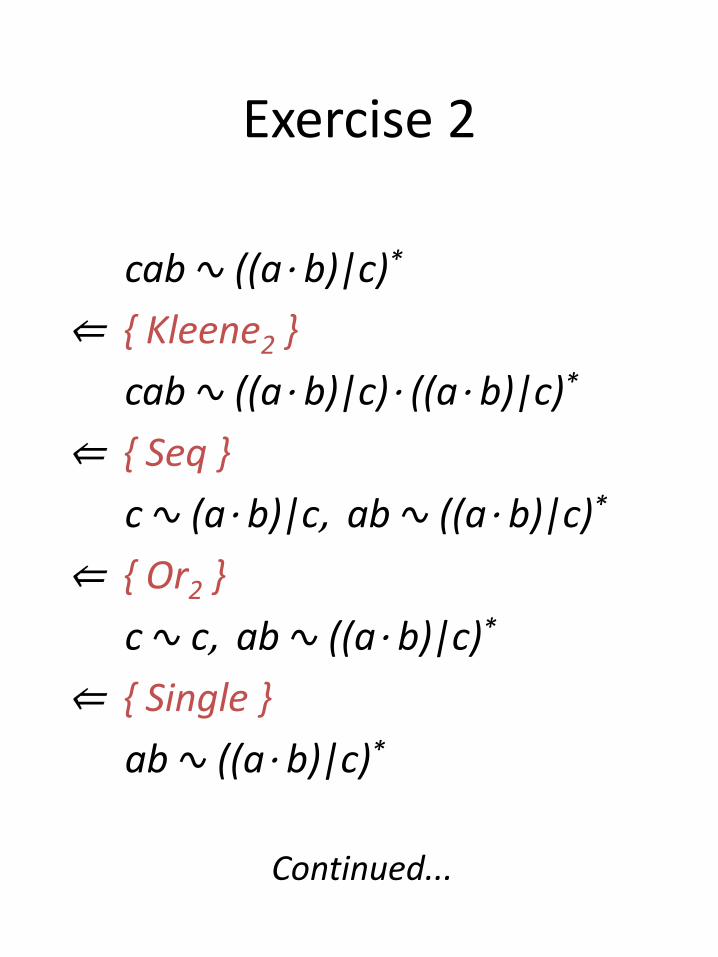
Exercise 2
cab ∿ ((a⋅ b)|c)*
⇐ { Kleene2 }
cab ∿ ((a⋅ b)|c)⋅ ((a⋅ b)|c)*
⇐ { Seq }
c ∿ (a⋅ b)|c, ab ∿ ((a⋅ b)|c)*
⇐ { Or2 }
c ∿ c, ab ∿ ((a⋅ b)|c)*
⇐ { Single }
ab ∿ ((a⋅ b)|c)*
Continued...
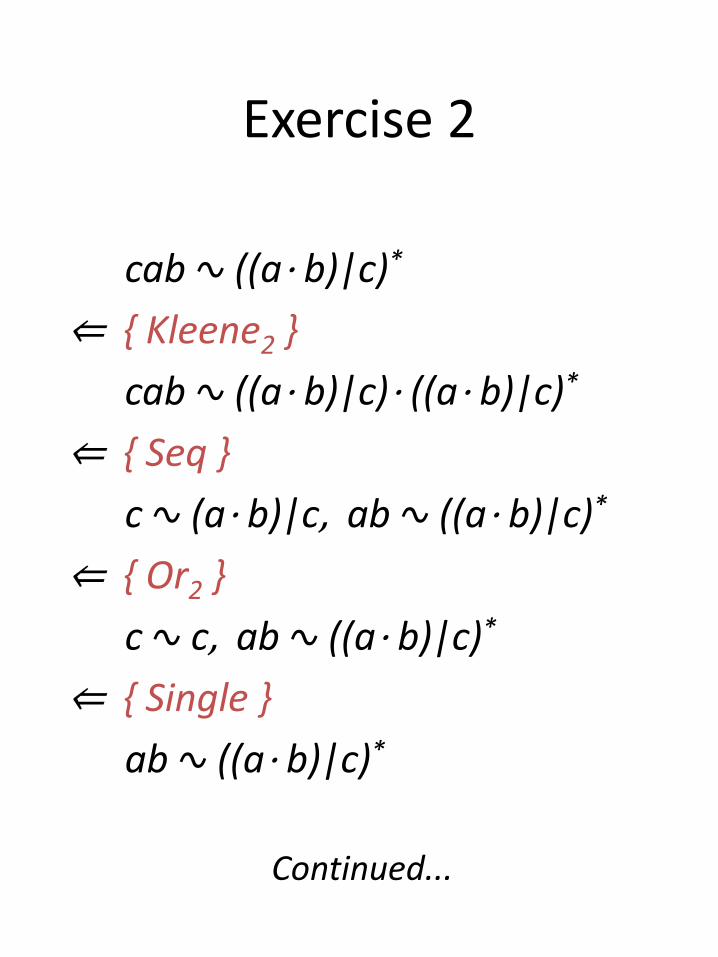
Exercise 2
cab ∿ ((a⋅ b)|c)*
⇐ { Kleene2 }
cab ∿ ((a⋅ b)|c)⋅ ((a⋅ b)|c)*
⇐ { Seq }
c ∿ (a⋅ b)|c, ab ∿ ((a⋅ b)|c)*
⇐ { Or2 }
c ∿ c, ab ∿ ((a⋅ b)|c)*
⇐ { Single }
ab ∿ ((a⋅ b)|c)*
Continued...
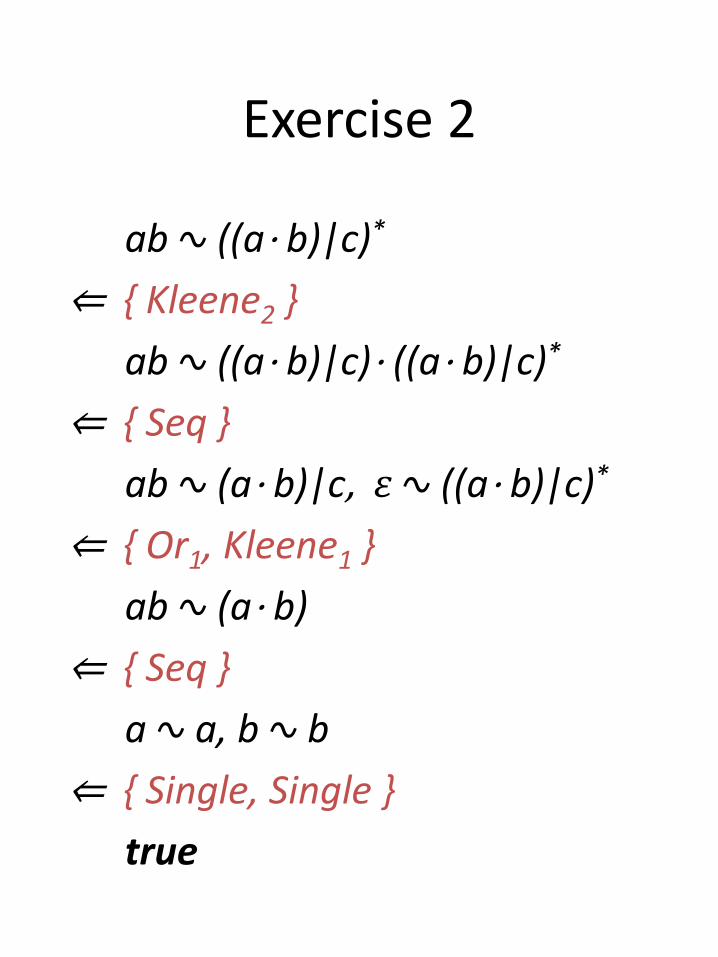
Exercise 2
ab ∿ ((a⋅ b)|c)*
⇐ { Kleene2 }
ab ∿ ((a⋅ b)|c)⋅ ((a⋅ b)|c)*
⇐ { Seq }
ab ∿ (a⋅ b)|c, 𝜀 ∿ ((a⋅ b)|c)*
⇐ { Or1, Kleene1 }
ab ∿ (a⋅ b)
⇐ { Seq }
a ∿ a, b ∿ b
⇐ { Single, Single }
true
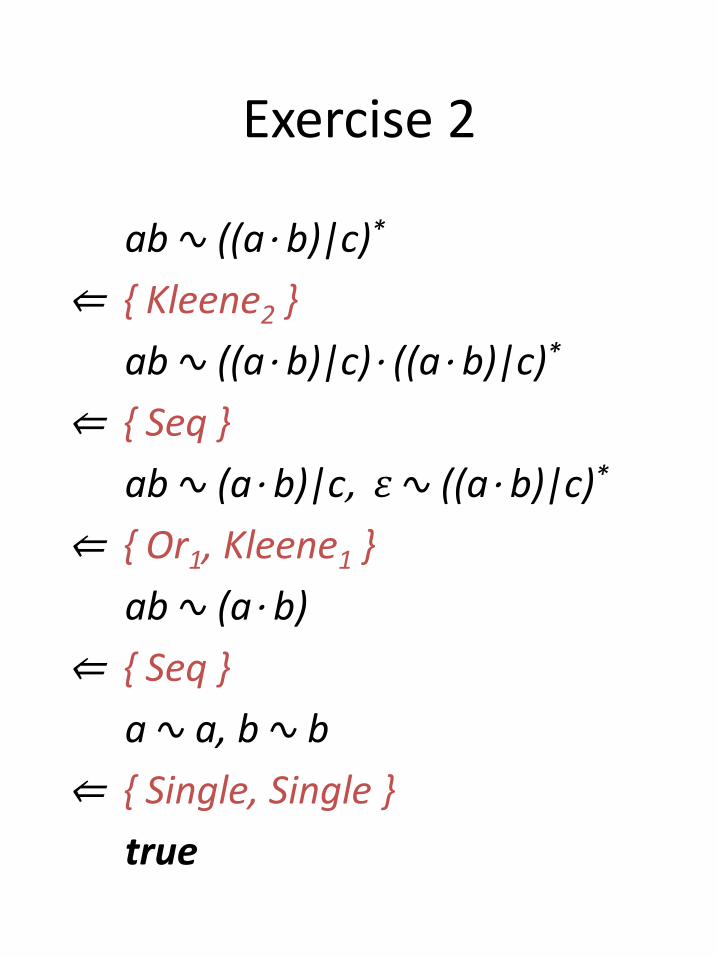
Exercise 2
ab ∿ ((a⋅ b)|c)*
⇐ { Kleene2 }
ab ∿ ((a⋅ b)|c)⋅ ((a⋅ b)|c)*
⇐ { Seq }
ab ∿ (a⋅ b)|c, 𝜀 ∿ ((a⋅ b)|c)*
⇐ { Or1, Kleene1 }
ab ∿ (a⋅ b)
⇐ { Seq }
a ∿ a, b ∿ b
⇐ { Single, Single }
true

Sound and Complete
Complete: if s ∊ L(r) then wecan prove s ∿ r using the rules.
The proof rules are:
Sound: if we can prove s ∿ rusing the rules then s ∊ L(r).

Sound and Complete
Complete: if s ∊ L(r) then wecan prove s ∿ r using the rules.
The proof rules are:
Sound: if we can prove s ∿ rusing the rules then s ∊ L(r).

Prolog
If we define our proof rules inProlog then we get a regularexpression implementation.
[] ∿ [].[X] ∿ X.S ∿ R1!R2 :- S ∿ R1.S ∿ R1!R2 :- S ∿ R2.S ∿ R1.R2 :- append(S1, S2, S),
S1 ∿ R1, S2 ∿ R2 .[] ∿ R*.S ∿ R* :- append(S1, S2, S), S1=[X|Xs],
S1 ∿ R, S2 ∿ R* .
Operator ! used to represent vertical bar. Read “:-” as “if”. Strings represented by lists of symbols. Termination ensured by requiring S1 to be
non-empty in final clause.
NOTES:

Prolog
If we define our proof rules inProlog then we get a regularexpression implementation.
[] ∿ [].[X] ∿ X.S ∿ R1!R2 :- S ∿ R1.S ∿ R1!R2 :- S ∿ R2.S ∿ R1.R2 :- append(S1, S2, S),
S1 ∿ R1, S2 ∿ R2 .[] ∿ R*.S ∿ R* :- append(S1, S2, S), S1=[X|Xs],
S1 ∿ R, S2 ∿ R* .
Operator ! used to represent vertical bar. Read “:-” as “if”. Strings represented by lists of symbols. Termination ensured by requiring S1 to be
non-empty in final clause.
NOTES:

Prolog
Sadly the Prolog implementation isnot very efficient:
when applying the proof rules byhand we used human intuition toknow where to split the string;
Prolog does not have this intuition;
instead, Prolog guesses, trying allpossible ways to split a string, andbacktracks on failure.

Prolog
Sadly the Prolog implementation isnot very efficient:
when applying the proof rules byhand we used human intuition toknow where to split the string;
Prolog does not have this intuition;
instead, Prolog guesses, trying allpossible ways to split a string, andbacktracks on failure.

Common extensions
Regularexpression
is the same as
r+ r⋅ r*
r? 𝜀|r
[c1c2c3-cn] c1|c2|c3|... |cn
[^c1c2] { x ⦁ x ∊ ∑ , x ∊ {c1 , c2} }

Common extensions
Regularexpression
is the same as
r+ r⋅ r*
r? 𝜀|r
[c1c2c3-cn] c1|c2|c3|... |cn
[^c1c2] { x ⦁ x ∊ ∑ , x ∊ {c1 , c2} }

Escaping
What if ∑ contains regularexpression symbols such as
| * ⋅ ( + [ ?
We can escape such symbols byprefixing with a backslash:
\| \* \⋅ \( \[ \?
And if we want \ then write \\.
Example: \[*⋅ \]* means zero orleft brackets followed by zero ormore right brackets.

Escaping
What if ∑ contains regularexpression symbols such as
| * ⋅ ( + [ ?
We can escape such symbols byprefixing with a backslash:
\| \* \⋅ \( \[ \?
And if we want \ then write \\.
Example: \[*⋅ \]* means zero orleft brackets followed by zero ormore right brackets.

Regular definitions
For convenience, we may wishto name a regular expressionso that we can refer to it manytimes:
name = r
number = digit⋅ digit*
digit = 0 | ... | 9
We write name but sometimesthe notation {name} is used(e.g. in Flex). Example:

Regular definitions
For convenience, we may wishto name a regular expressionso that we can refer to it manytimes:
name = r
number = digit⋅ digit*
digit = 0 | ... | 9
We write name but sometimesthe notation {name} is used(e.g. in Flex). Example:

Implementingregular expressions
How do we convert a regularexpression r into an efficientprogram that prints YES whenapplied to any string in L(r) andNO in all other cases?
Two options:
By hand (LSA Lab 1)
Automatically (Chapters 3 & 4of lecture notes, and LSA Lab 2)

Implementingregular expressions
How do we convert a regularexpression r into an efficientprogram that prints YES whenapplied to any string in L(r) andNO in all other cases?
Two options:
By hand (LSA Lab 1)
Automatically (Chapters 3 & 4of lecture notes, and LSA Lab 2)

Outline
Automatic conversion of regularexpressions to efficient string-matching functions:
Step 1: RE ⟶ NFA
Step 2: NFA ⟶ DFA
Step 3: DFA ⟶ C Function
Acronym Meaning
RE Regular Expression
NFA Non-deterministic Finite Automaton
DFA Deterministic Finite Automaton

Outline
Automatic conversion of regularexpressions to efficient string-matching functions:
Step 1: RE ⟶ NFA
Step 2: NFA ⟶ DFA
Step 3: DFA ⟶ C Function
Acronym Meaning
RE Regular Expression
NFA Non-deterministic Finite Automaton
DFA Deterministic Finite Automaton

STEP 1: RE ⟶ NFA
Thompson’s construction

STEP 1: RE ⟶ NFA
Thompson’s construction
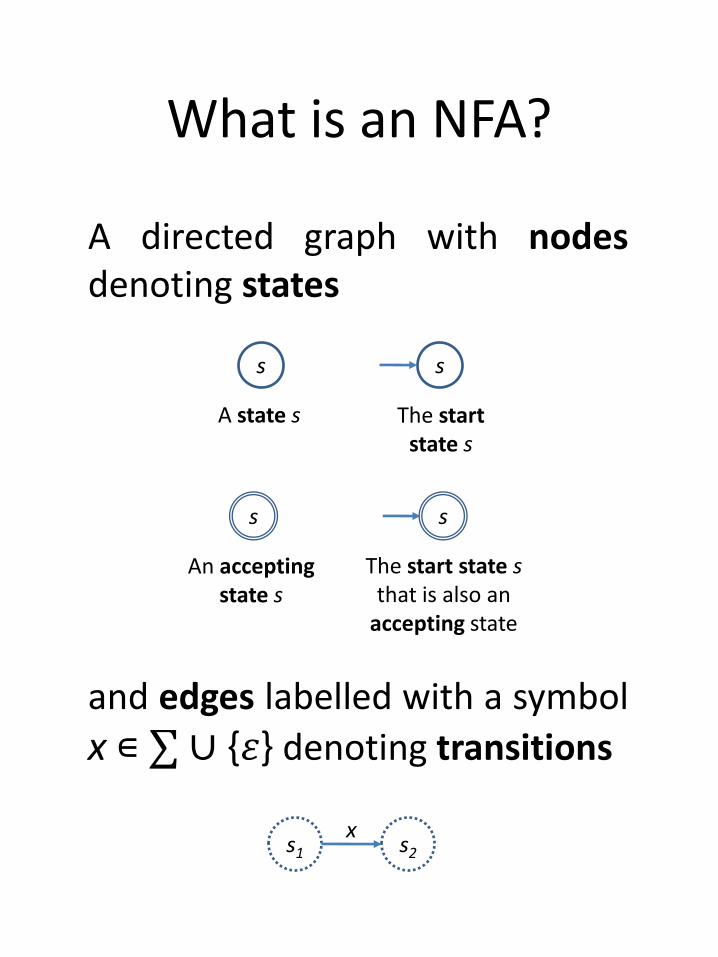
What is an NFA?
s s
s
s1 s2
x
A state s The startstate s
An acceptingstate s
s
The start state sthat is also an
accepting state
A directed graph with nodesdenoting states
and edges labelled with a symbol
x ∊ ∑ ∪ {𝜀} denoting transitions
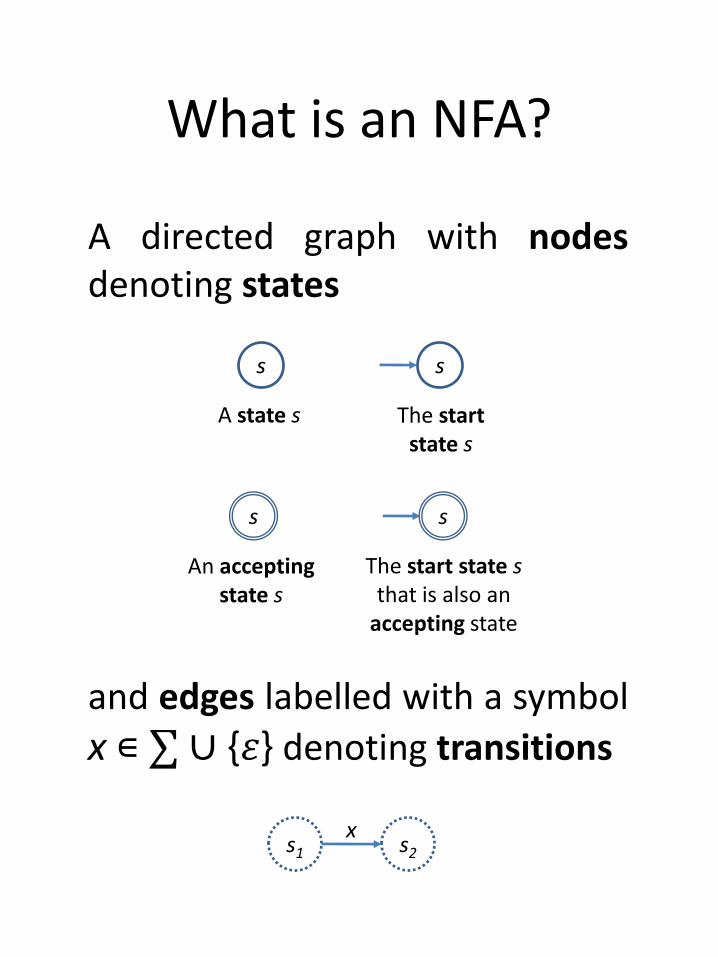
What is an NFA?
s s
s
s1 s2
x
A state s The startstate s
An acceptingstate s
s
The start state sthat is also an
accepting state
A directed graph with nodesdenoting states
and edges labelled with a symbol
x ∊ ∑ ∪ {𝜀} denoting transitions

Meaning of an NFA
A string x1x2...xn is accepted byan NFA if there is a pathlabelled x1,x2,...,xn (includingany number of 𝜀 transitions)from the start state to anaccepting state.

Meaning of an NFA
A string x1x2...xn is accepted byan NFA if there is a pathlabelled x1,x2,...,xn (includingany number of 𝜀 transitions)from the start state to anaccepting state.
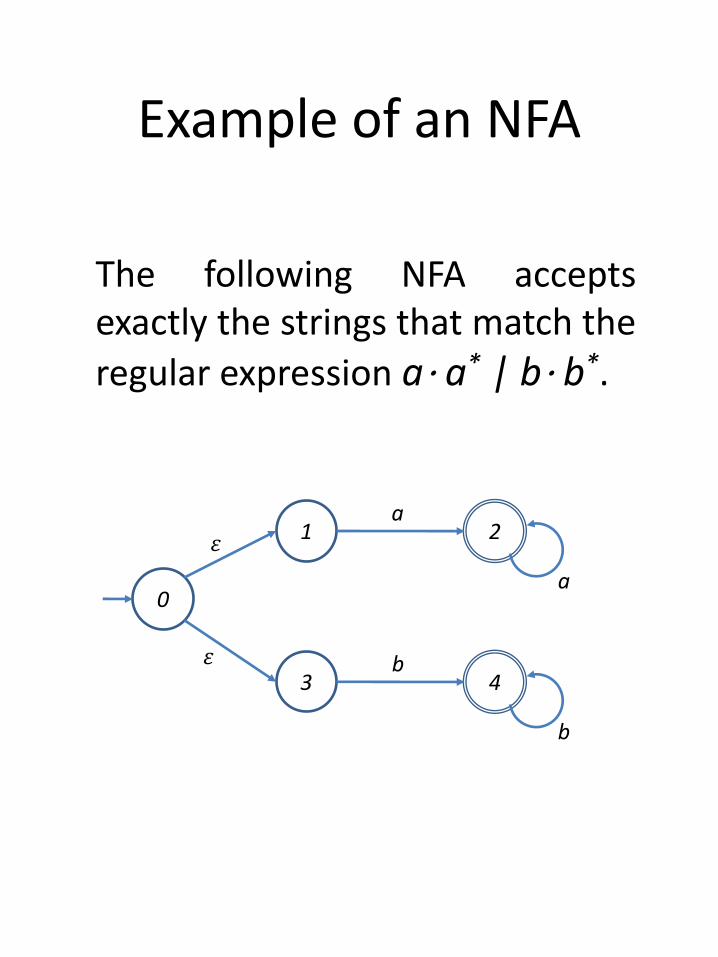
Example of an NFA
The following NFA acceptsexactly the strings that match the
regular expression a⋅ a* | b⋅ b*.
0
2
43
1
b
a
a
b
𝜀
𝜀
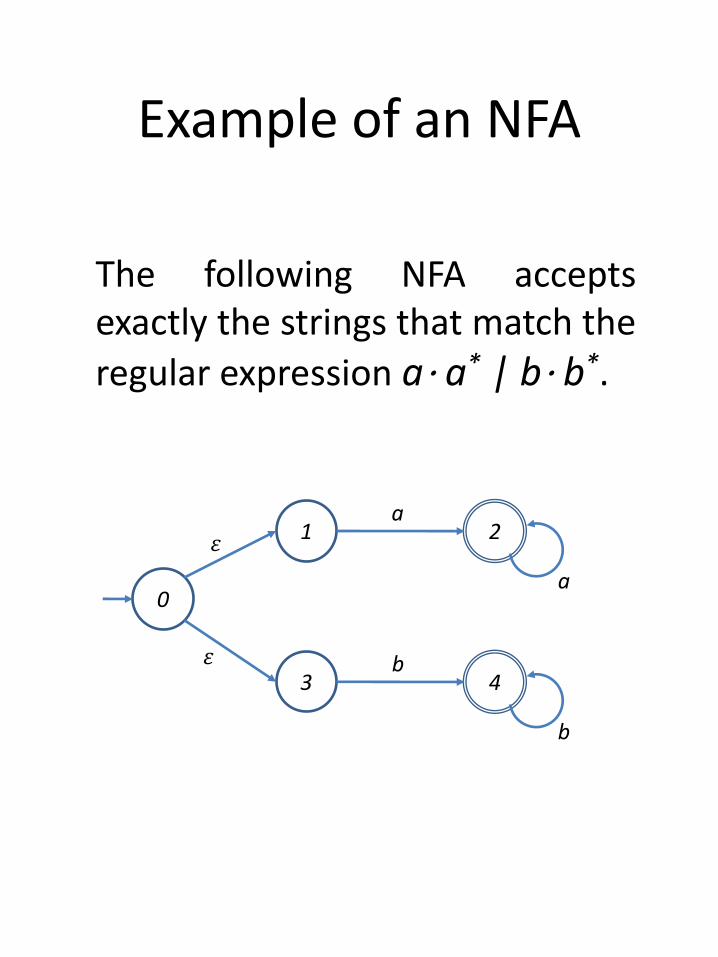
Example of an NFA
The following NFA acceptsexactly the strings that match the
regular expression a⋅ a* | b⋅ b*.
0
2
43
1
b
a
a
b
𝜀
𝜀

Thompson’s construction:Notation
Let N(r) be the NFA acceptingexactly the set of strings in L(r).
We abstractly represent an NFAN(r) with start state s0 and finalstate sa by the diagram:
N(r)s0 sa

Thompson’s construction:Notation
Let N(r) be the NFA acceptingexactly the set of strings in L(r).
We abstractly represent an NFAN(r) with start state s0 and finalstate sa by the diagram:
N(r)s0 sa
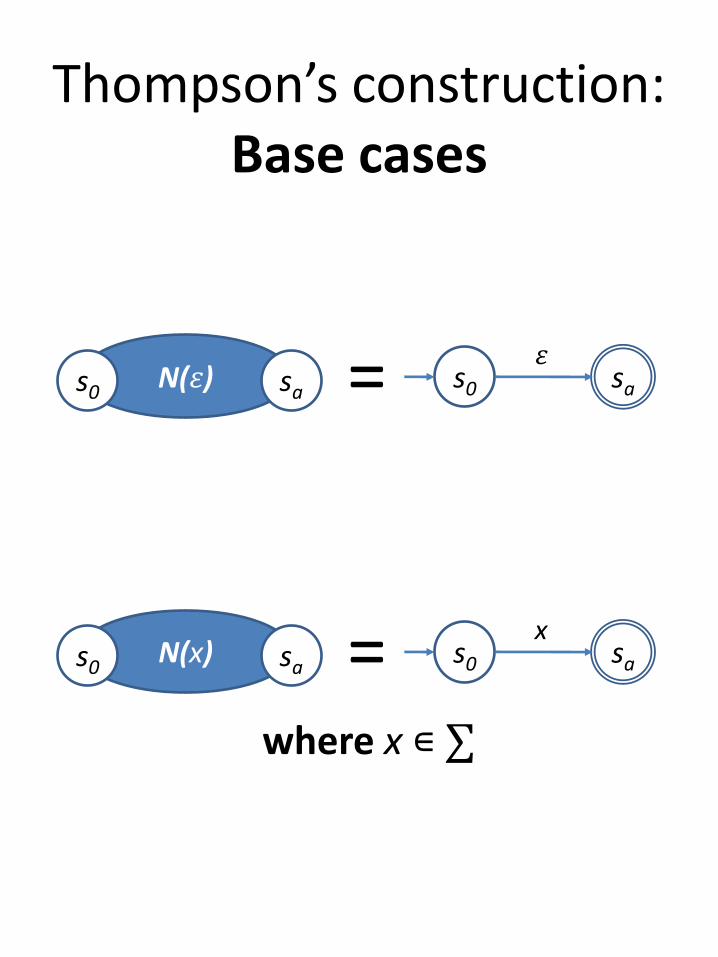
Thompson’s construction:Base cases
s0 saN(𝜀)s0 sa = 𝜀
s0 saN(x)s0 sa = x
where x ∊ ∑
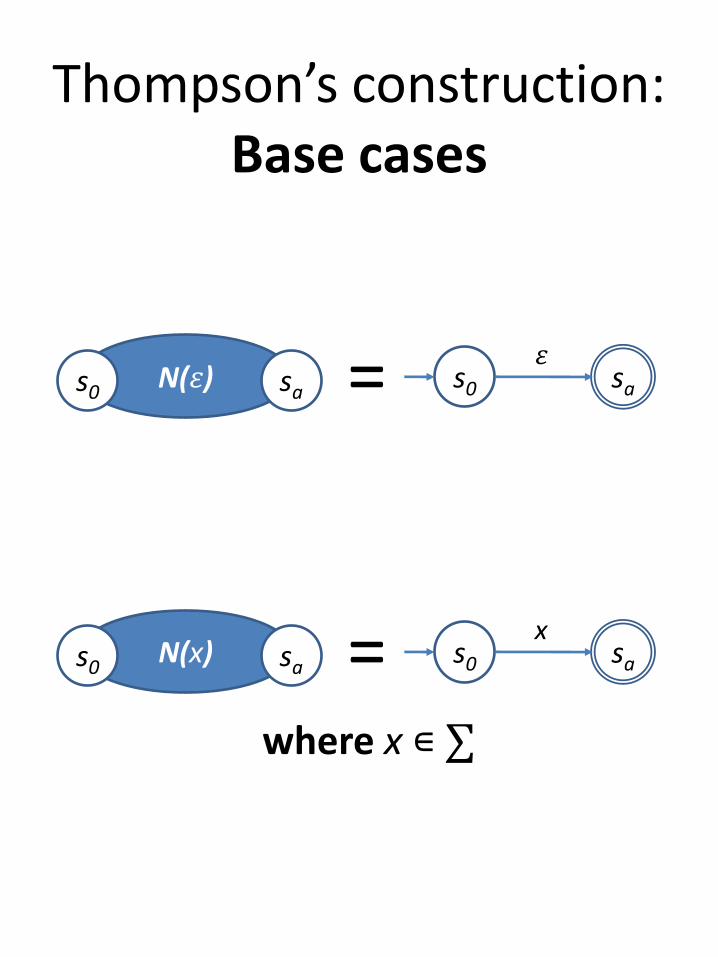
Thompson’s construction:Base cases
s0 saN(𝜀)s0 sa = 𝜀
s0 saN(x)s0 sa = x
where x ∊ ∑
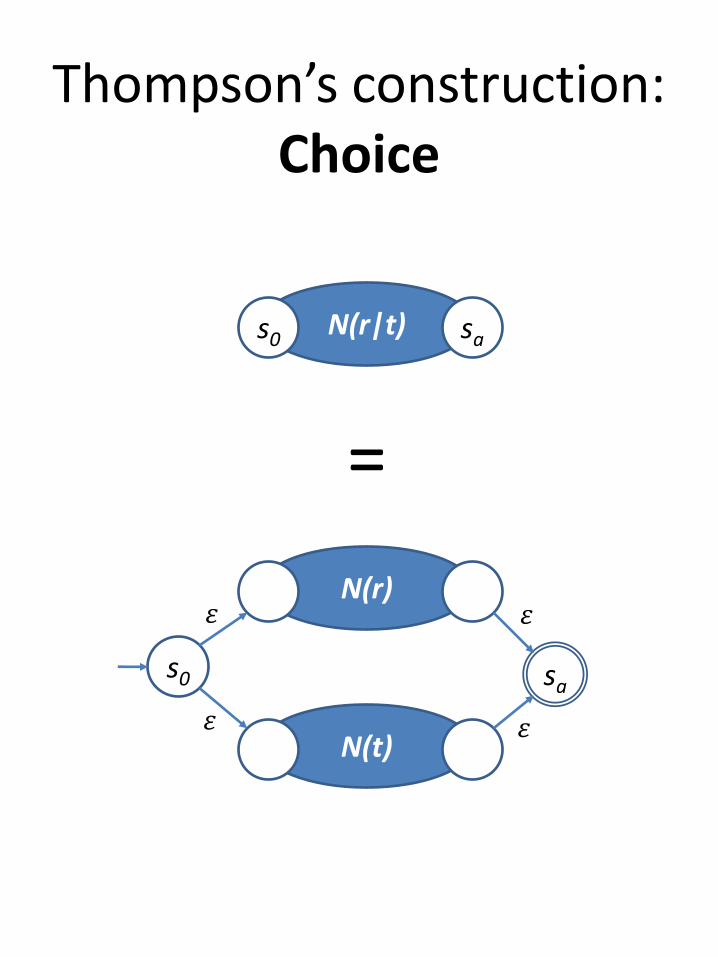
Thompson’s construction:Choice
N(r)
N(t)
s0 sa
N(r|t)s0 sa
=
𝜀
𝜀 𝜀
𝜀
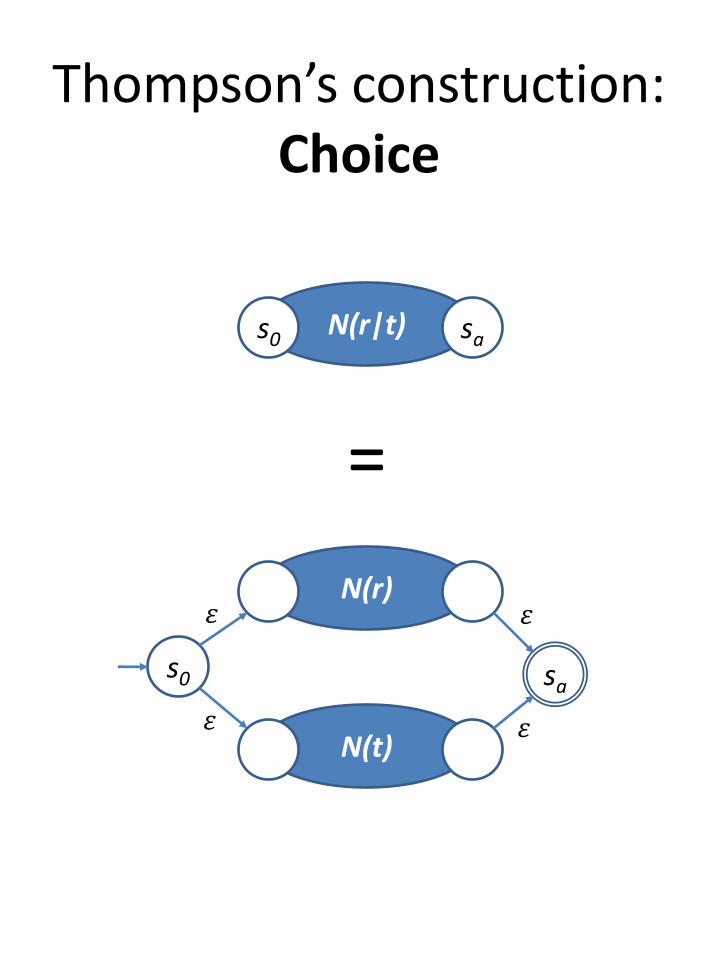
Thompson’s construction:Choice
N(r)
N(t)
s0 sa
N(r|t)s0 sa
=
𝜀
𝜀 𝜀
𝜀
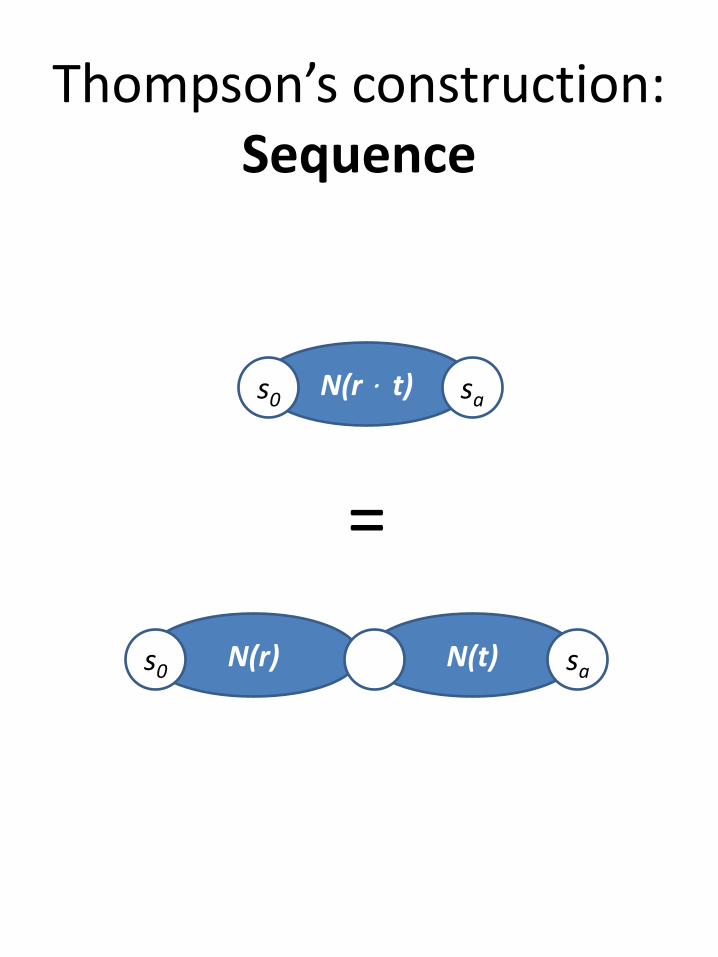
Thompson’s construction:Sequence
N(t) saN(r)s0
N(r ⋅ t)s0 sa
=
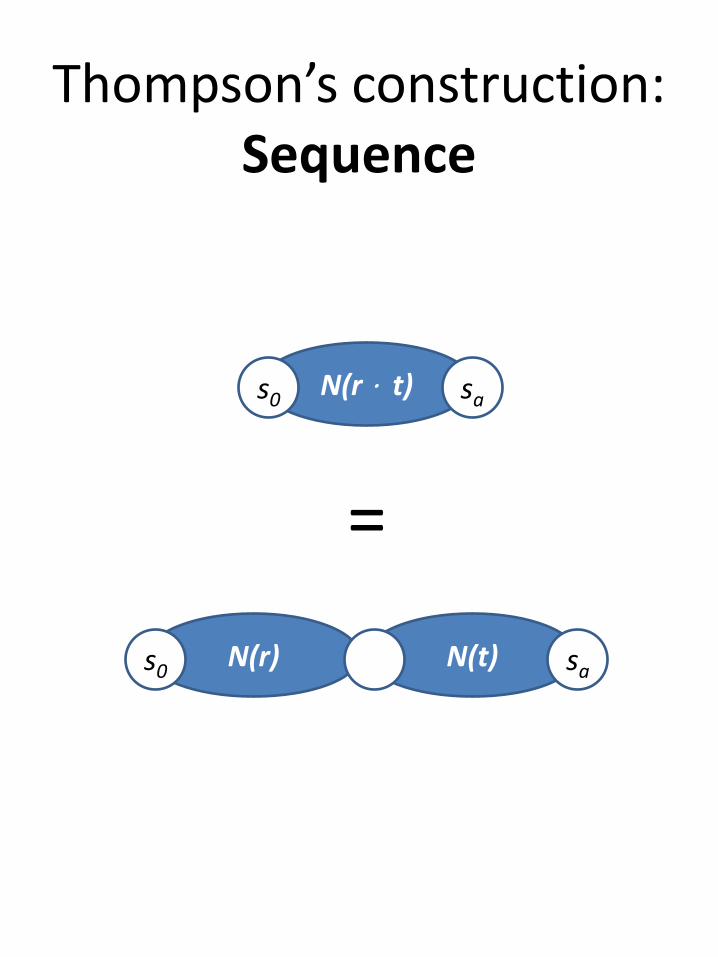
Thompson’s construction:Sequence
N(t) saN(r)s0
N(r ⋅ t)s0 sa
=
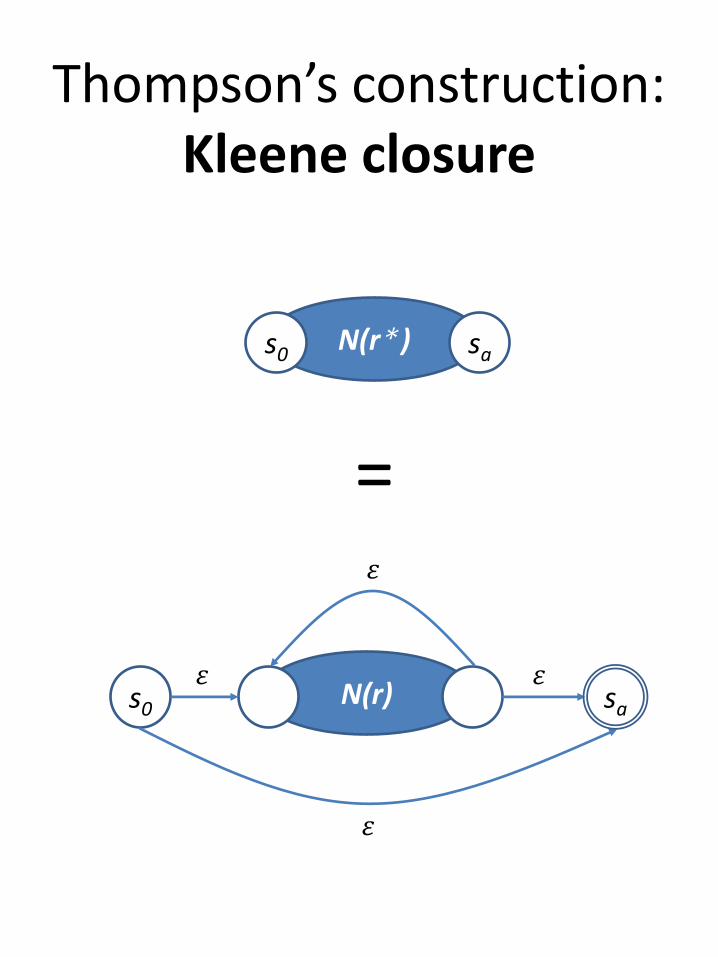
Thompson’s construction:Kleene closure
N(r)
N(r* )s0 sa
=
s0
𝜀
𝜀 𝜀
𝜀
sa
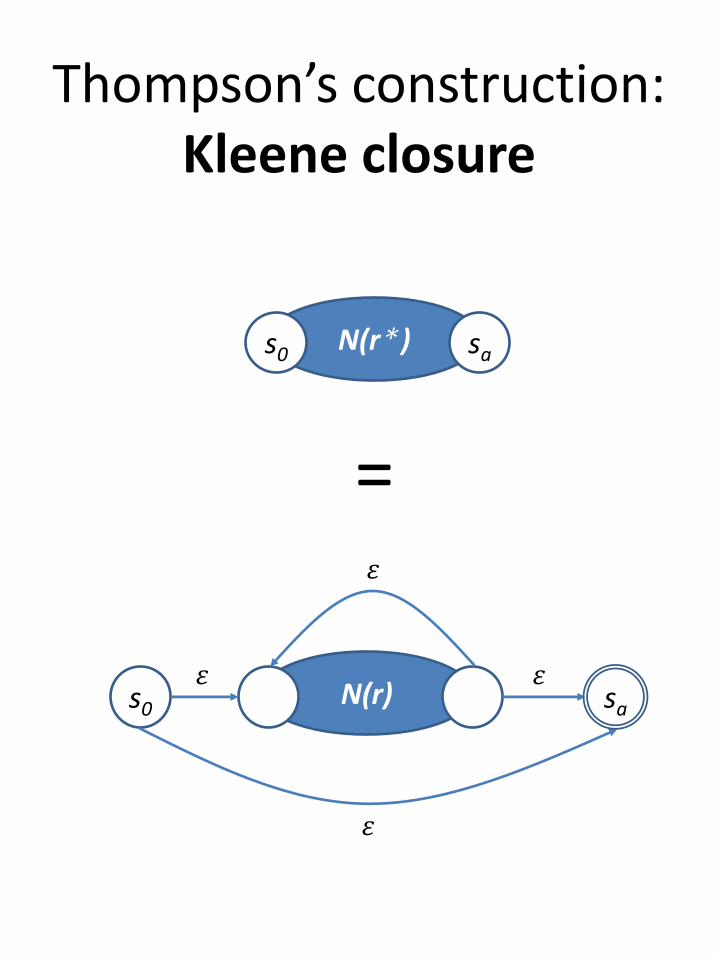
Thompson’s construction:Kleene closure
N(r)
N(r* )s0 sa
=
s0
𝜀
𝜀 𝜀
𝜀
sa

Exercise 3
Apply Thompson’s construction tothe following regular expression.
((a⋅ b)|c)*

Exercise 3
Apply Thompson’s construction tothe following regular expression.
((a⋅ b)|c)*

Problem with NFAs
It is not straightforward to turnan NFA into a deterministicprogram because:
There may be many possiblenext-states for a given input.
Which one do we choose?
Try them all?
Idea: convert an NFA into aDFA: a DFA can be easilyconverted into an efficientexecutable program.

Problem with NFAs
It is not straightforward to turnan NFA into a deterministicprogram because:
There may be many possiblenext-states for a given input.
Which one do we choose?
Try them all?
Idea: convert an NFA into aDFA: a DFA can be easilyconverted into an efficientexecutable program.

STEP 2: NFA ⟶ DFA
The subset construction.

STEP 2: NFA ⟶ DFA
The subset construction.

What is a DFA?
A deterministic finite automaton(DFA) is an NFA in which
there are no 𝜀 transitions, and
for each state s and inputsymbol a there is at most onetransition out of s labelled a.

What is a DFA?
A deterministic finite automaton(DFA) is an NFA in which
there are no 𝜀 transitions, and
for each state s and inputsymbol a there is at most onetransition out of s labelled a.
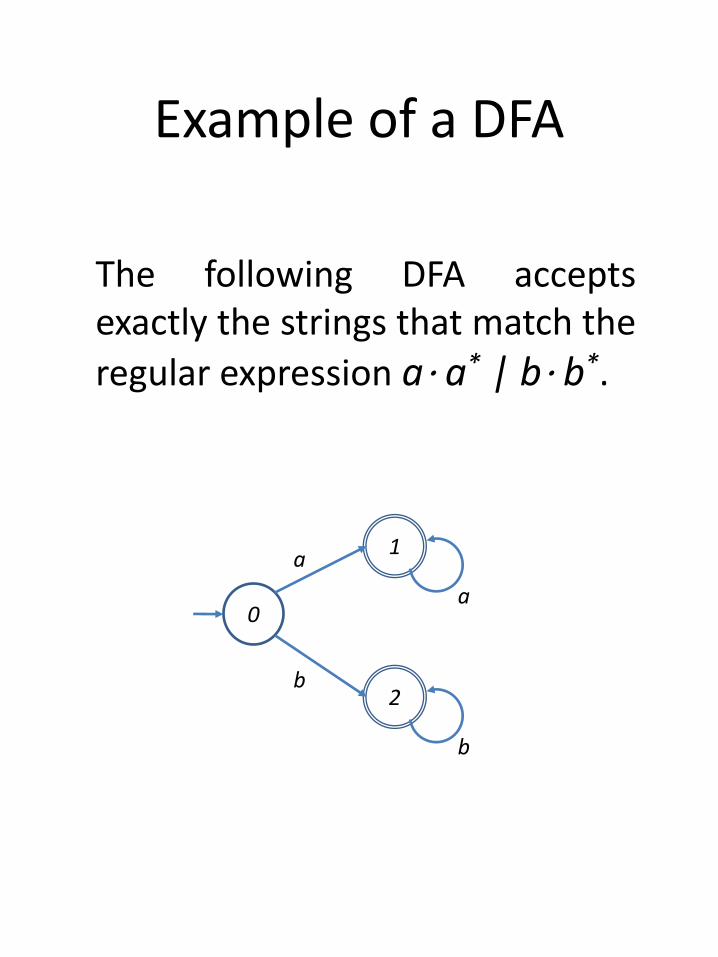
Example of a DFA
The following DFA acceptsexactly the strings that match the
regular expression a⋅ a* | b⋅ b*.
0
1
2b
a
a
b
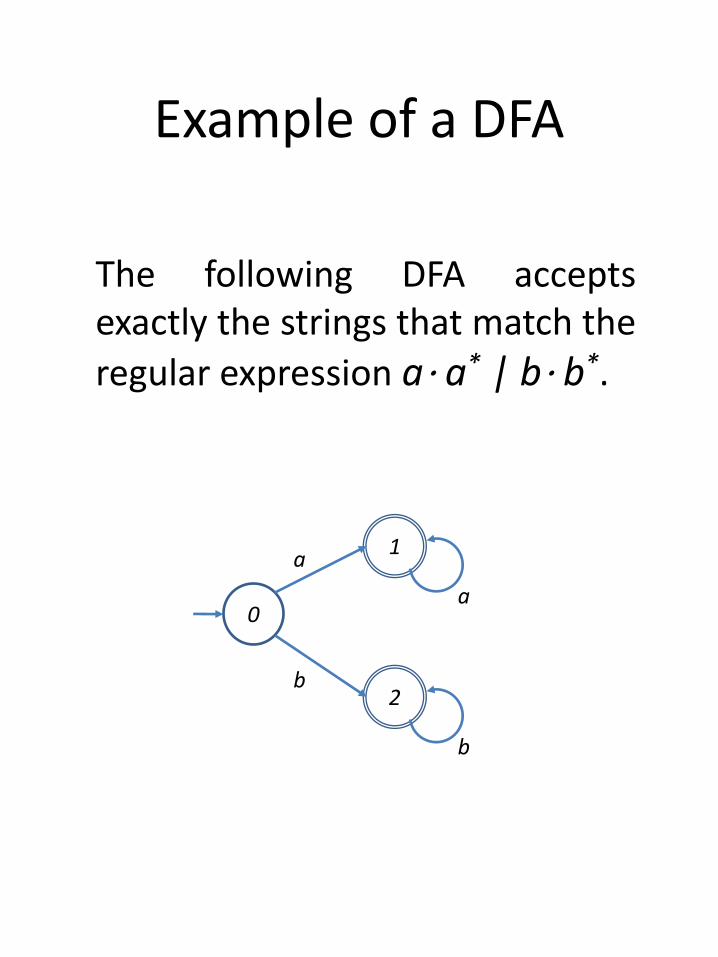
Example of a DFA
The following DFA acceptsexactly the strings that match the
regular expression a⋅ a* | b⋅ b*.
0
1
2b
a
a
b
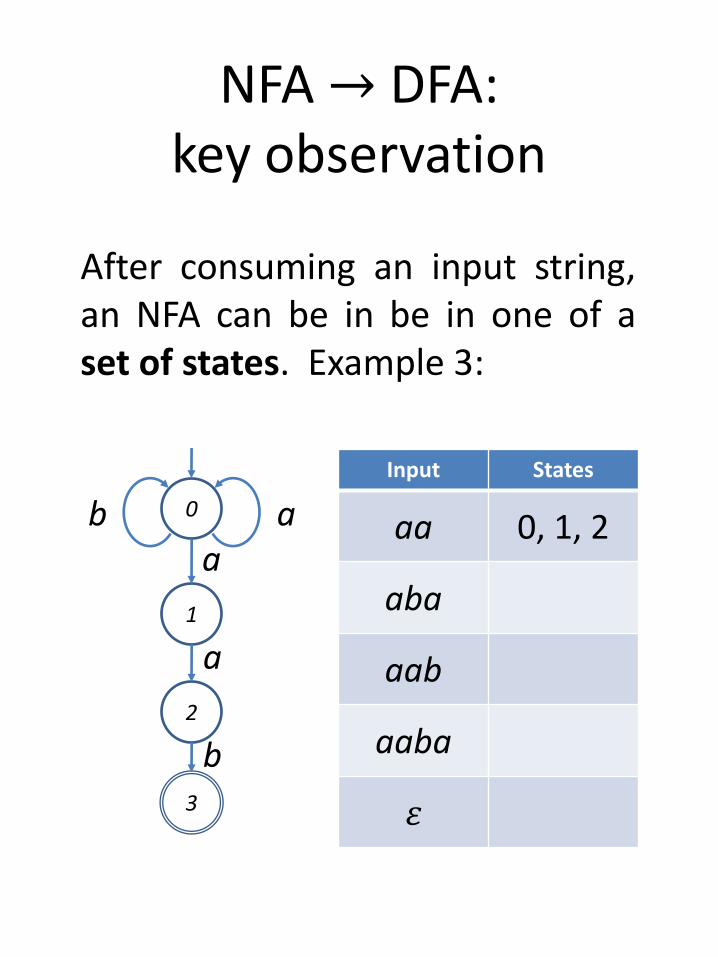
NFA → DFA:key observation
After consuming an input string,an NFA can be in be in one of aset of states. Example 3:
0
3
1
a
b
2
ab
a
Input States
aa 0, 1, 2
aba
aab
aaba
𝜀
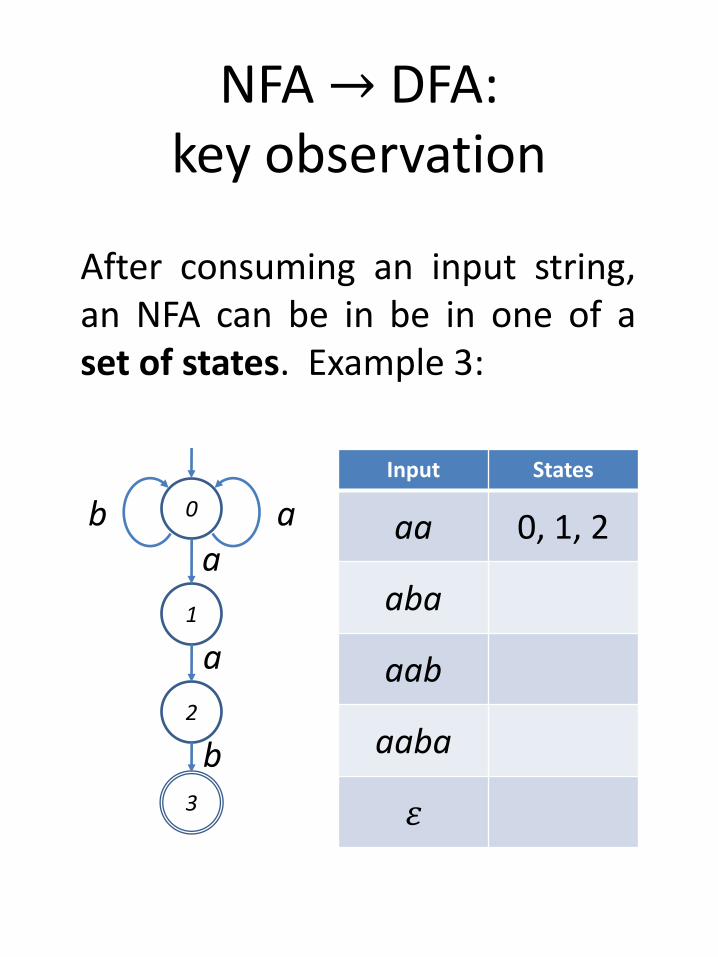
NFA → DFA:key observation
After consuming an input string,an NFA can be in be in one of aset of states. Example 3:
0
3
1
a
b
2
ab
a
Input States
aa 0, 1, 2
aba
aab
aaba
𝜀

NFA → DFA: key idea
Idea: construct a DFA in whicheach state corresponds to a setof NFA states.
After consuming a1⋯ an theDFA is in a state whichcorresponds to the set of statesthat the NFA can reach on inputa1⋯ an.

NFA → DFA: key idea
Idea: construct a DFA in whicheach state corresponds to a setof NFA states.
After consuming a1⋯ an theDFA is in a state whichcorresponds to the set of statesthat the NFA can reach on inputa1⋯ an.

Example 3, revisited
Input NFA States DFA State
aa 0, 1, 2 A
aba 0,1 B
aab 0,3 C
aaba 0,1 B
𝜀 0 D
Create a DFA state correspondingto each set of NFA states.
Question: which states would beinitial and final DFA states?

Example 3, revisited
Input NFA States DFA State
aa 0, 1, 2 A
aba 0,1 B
aab 0,3 C
aaba 0,1 B
𝜀 0 D
Create a DFA state correspondingto each set of NFA states.
Question: which states would beinitial and final DFA states?

Notation
Operation Description
𝜀-closure(s)Set of NFA states reachablefrom NFA state s on zero ormore 𝜀-transitions.
𝜀-closure(T)
move(T, a)Set of NFA states to whichthere is a transition on symbola from some state s in T.
⋃ 𝜀-closure(s)
s ∊ T

Notation
Operation Description
𝜀-closure(s)Set of NFA states reachablefrom NFA state s on zero ormore 𝜀-transitions.
𝜀-closure(T)
move(T, a)Set of NFA states to whichthere is a transition on symbola from some state s in T.
⋃ 𝜀-closure(s)
s ∊ T
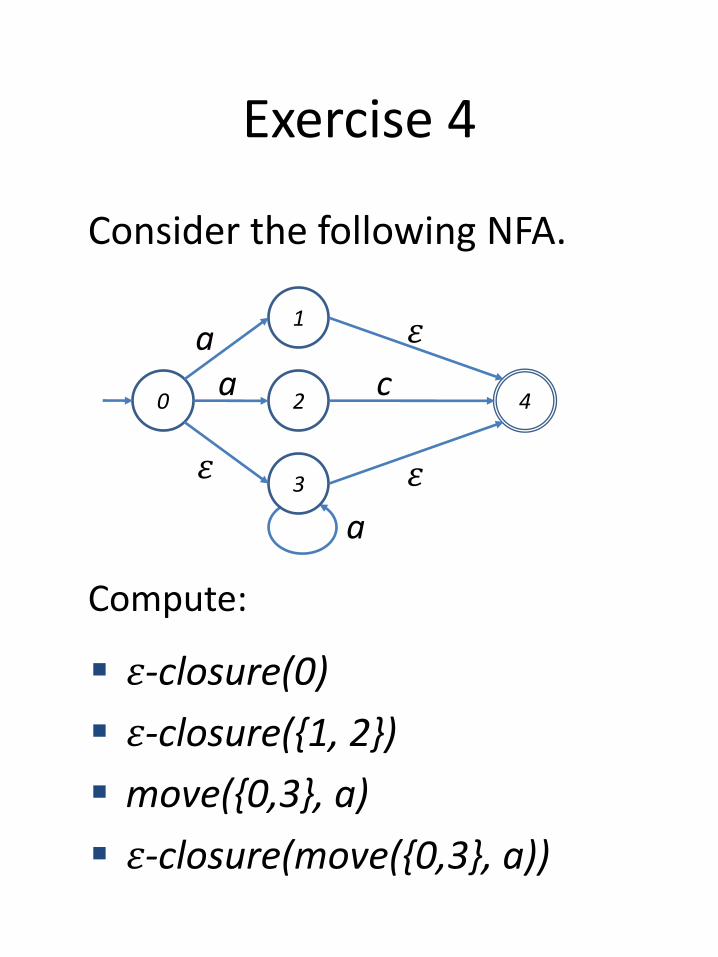
Exercise 4
Consider the following NFA.
Compute:
0 4
1a
𝜀
2
a
a
3 𝜀
𝜀
c
𝜀-closure(0)
𝜀-closure({1, 2})
move({0,3}, a)
𝜀-closure(move({0,3}, a))
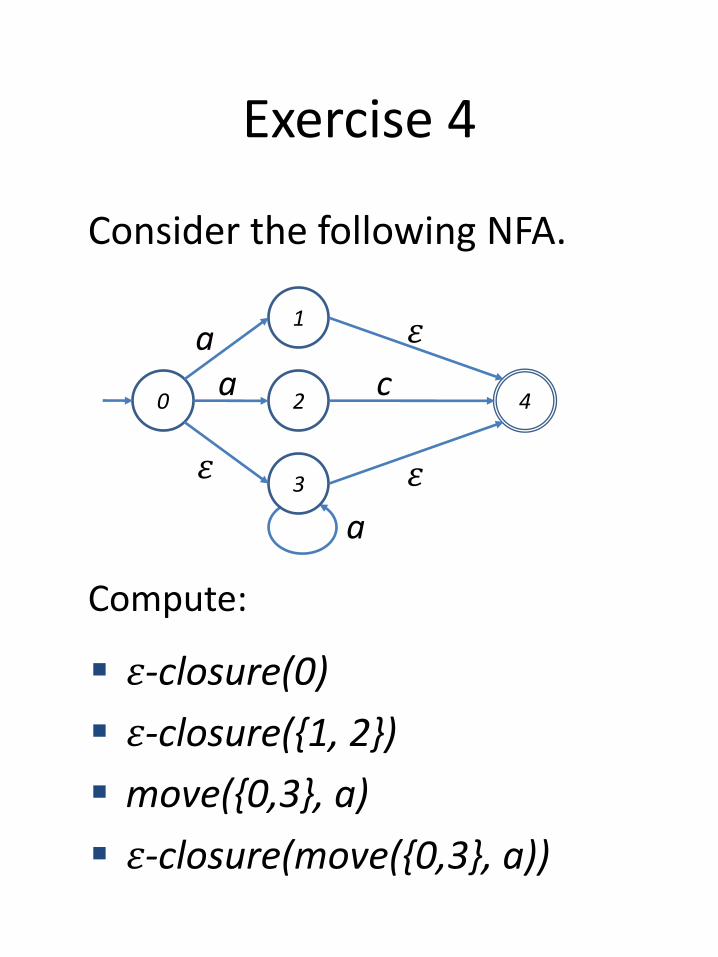
Exercise 4
Consider the following NFA.
Compute:
0 4
1a
𝜀
2
a
a
3 𝜀
𝜀
c
𝜀-closure(0)
𝜀-closure({1, 2})
move({0,3}, a)
𝜀-closure(move({0,3}, a))

Subset construction:input and output
Input: an NFA N.
Output: a DFA D accepting thesame language as N. Specifically,the set of states of D, termedDstates, and its transition functionDtran that maps any state-symbolpair to a next state.

Subset construction:input and output
Input: an NFA N.
Output: a DFA D accepting thesame language as N. Specifically,the set of states of D, termedDstates, and its transition functionDtran that maps any state-symbolpair to a next state.

Subset construction:input and output
Each state in D is denoted by asubset of N’s states.
To ensure termination, every stateis either marked or unmarked.
Initially, Dstates contains a singleunmarked start state 𝜀-closure(s0)where s0 is the start state of N.
The accepting states of D are thestates that contain at least oneaccepting state of N.

Subset construction:input and output
Each state in D is denoted by asubset of N’s states.
To ensure termination, every stateis either marked or unmarked.
Initially, Dstates contains a singleunmarked start state 𝜀-closure(s0)where s0 is the start state of N.
The accepting states of D are thestates that contain at least oneaccepting state of N.

Subset construction:algorithm
while (there is an unmarkedstate T in Dstates) {
mark T;for (each input symbol a) {
U = 𝜀-closure(move(T, a));Dtran[T, a] = Uif (U is not in Dstates)
add U as unmarked state to Dstates;}
}

Subset construction:algorithm
while (there is an unmarkedstate T in Dstates) {
mark T;for (each input symbol a) {
U = 𝜀-closure(move(T, a));Dtran[T, a] = Uif (U is not in Dstates)
add U as unmarked state to Dstates;}
}
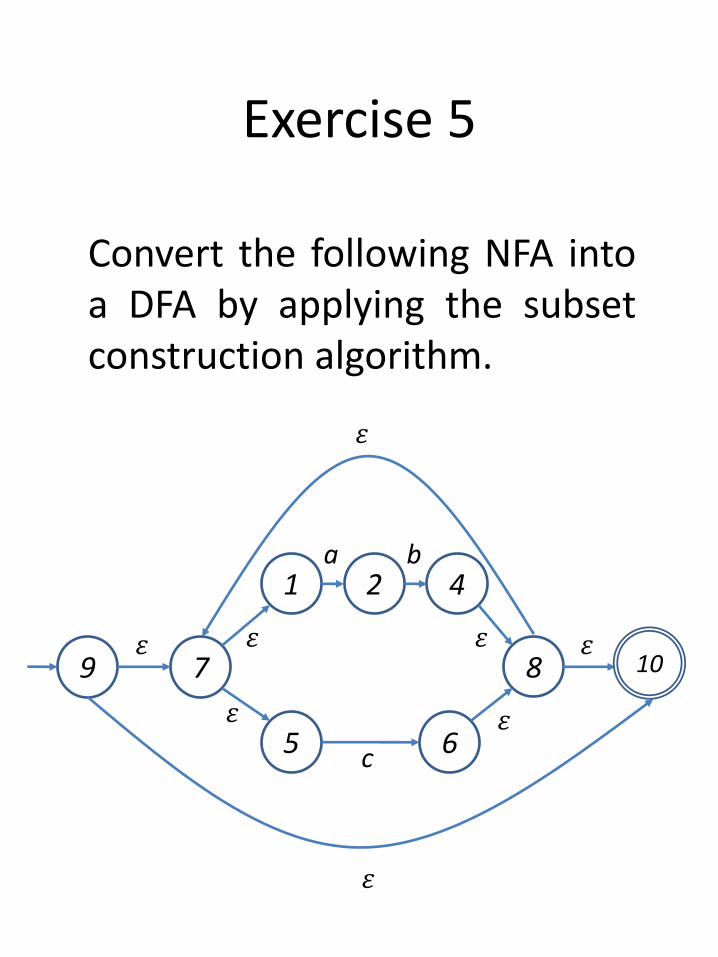
Exercise 5
Convert the following NFA intoa DFA by applying the subsetconstruction algorithm.
2 4b
1a
5 6c
7𝜀
𝜀
8
𝜀
𝜀9
𝜀
𝜀 𝜀
𝜀
10
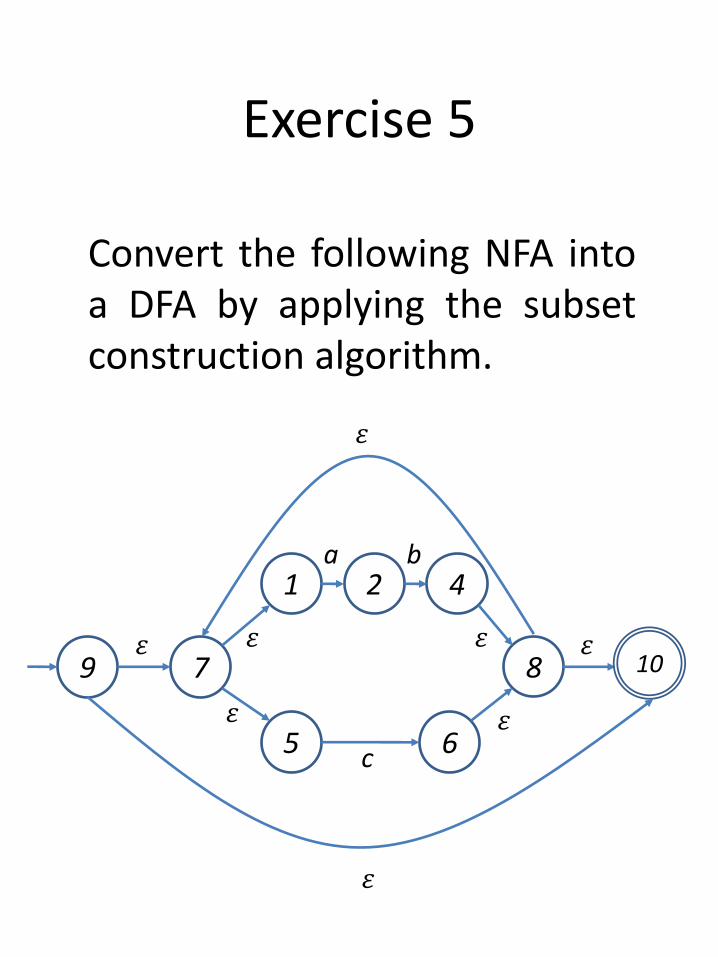
Exercise 5
Convert the following NFA intoa DFA by applying the subsetconstruction algorithm.
2 4b
1a
5 6c
7𝜀
𝜀
8
𝜀
𝜀9
𝜀
𝜀 𝜀
𝜀
10

Exercise 6
It is not obvious how to simulatean NFA in linear time with respectto the length of the input string.
But it may be converted to a DFAthat can be simulated easily inlinear time.
What’s the catch? Can you thinkof any problems with the DFAproduced by subset construction?

Exercise 6
It is not obvious how to simulatean NFA in linear time with respectto the length of the input string.
But it may be converted to a DFAthat can be simulated easily inlinear time.
What’s the catch? Can you thinkof any problems with the DFAproduced by subset construction?

Caveats
Number of DFA states could beexponential in number of NFAstates!
DFA produced is not minimalin number of states. (Can applya minimisation algorithm.)
Often no problem in practice.

Caveats
Number of DFA states could beexponential in number of NFAstates!
DFA produced is not minimalin number of states. (Can applya minimisation algorithm.)
Often no problem in practice.
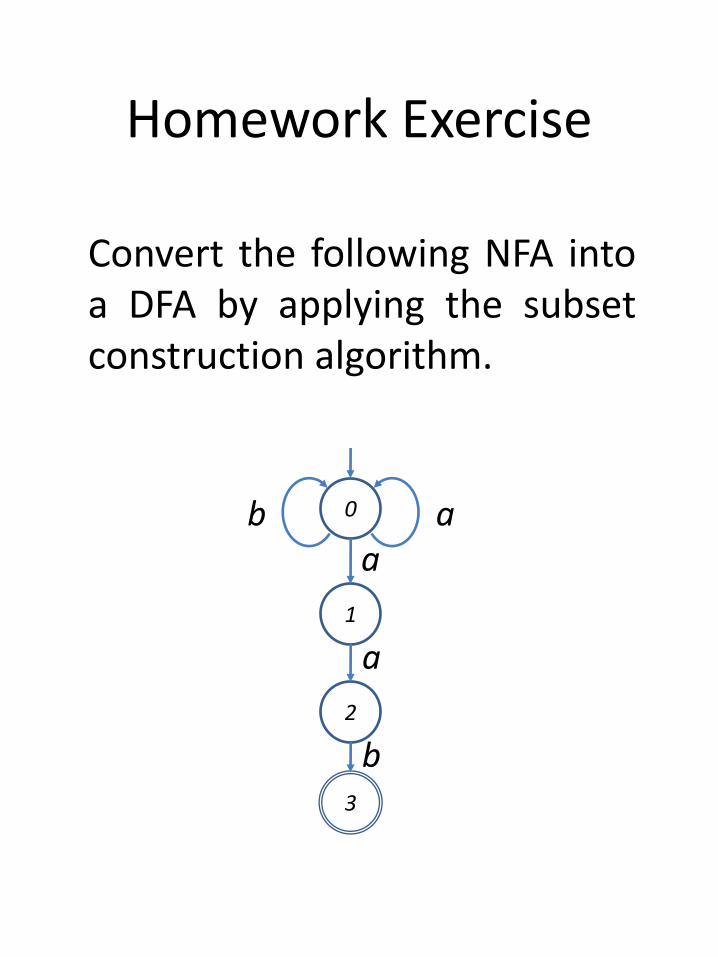
Homework Exercise
Convert the following NFA intoa DFA by applying the subsetconstruction algorithm.
0
3
1
a
b
2
ab
a
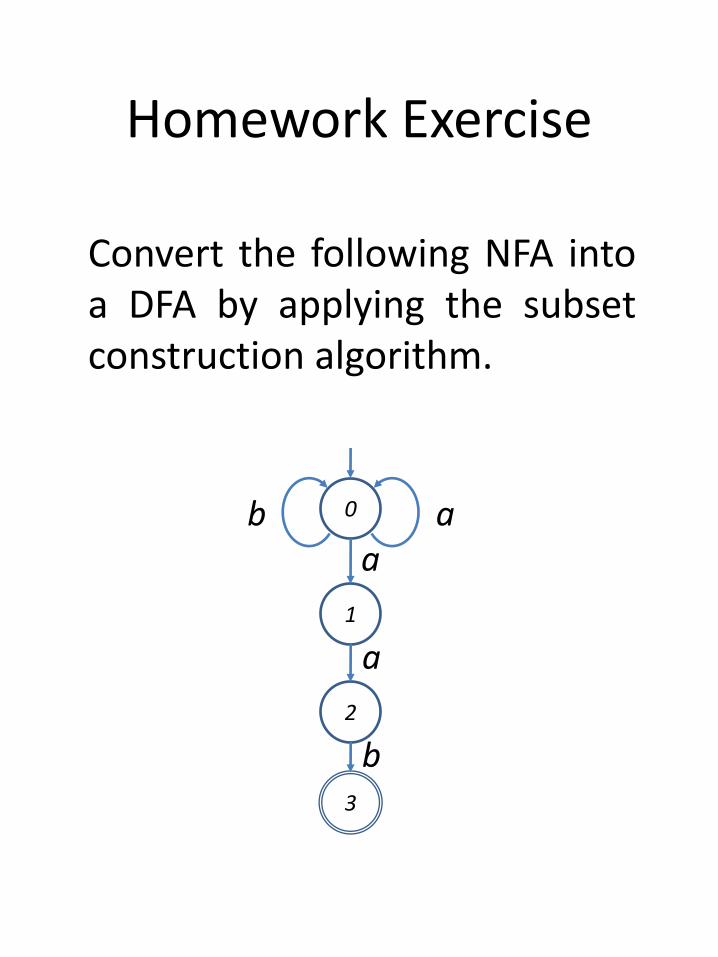
Homework Exercise
Convert the following NFA intoa DFA by applying the subsetconstruction algorithm.
0
3
1
a
b
2
ab
a

STEP 3: DFA ⟶ C CODE

STEP 3: DFA ⟶ C CODE
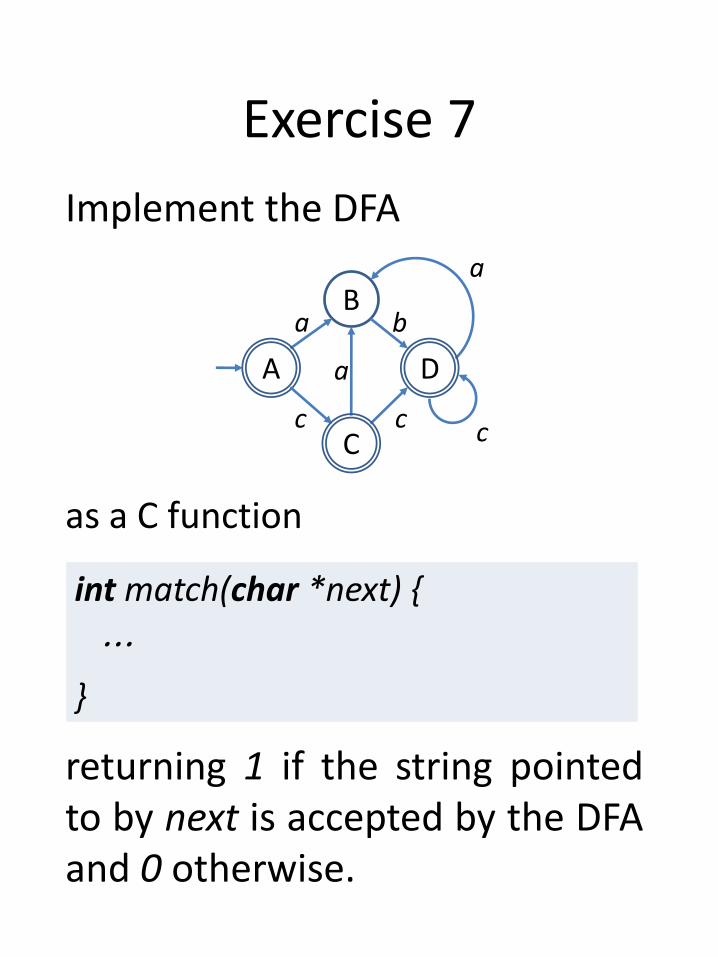
Exercise 7
Implement the DFA
bB
a
c
A a
c
a
C
D
c
int match(char *next) {
⋯
}
returning 1 if the string pointedto by next is accepted by the DFAand 0 otherwise.
as a C function
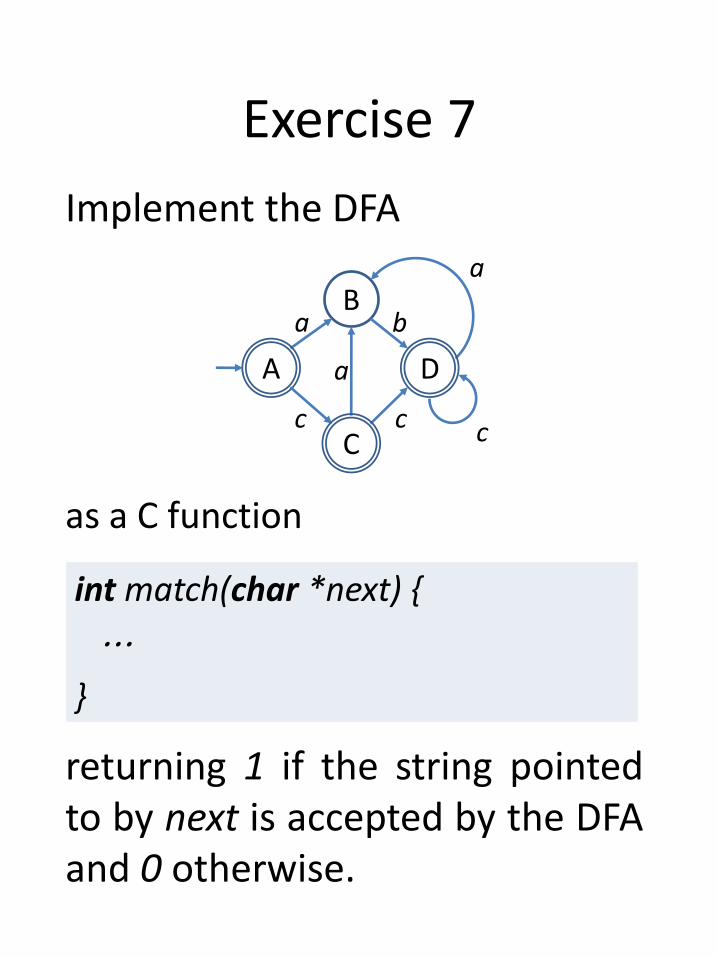
Exercise 7
Implement the DFA
bB
a
c
A a
c
a
C
D
c
int match(char *next) {
⋯
}
returning 1 if the string pointedto by next is accepted by the DFAand 0 otherwise.
as a C function

int match(char* next) {
goto A; /* start state */
A: if (*next == '\0') return 1;if (*next == 'a') { next++; goto B; }if (*next == 'c') { next++; goto C; }return 0;
B: if (*next == '\0') return 0;if (*next == 'b') { next++; goto D; }return 0;
C: if (*next == '\0') return 1;if (*next == 'a') { next++; goto B; }if (*next == 'c') { next++; goto D; }return 0;
D: if (*next == '\0') return 1;if (*next == 'a') { next++; goto B; }if (*next == 'c') { next++; goto D; }return 0;
}

int match(char* next) {
goto A; /* start state */
A: if (*next == '\0') return 1;if (*next == 'a') { next++; goto B; }if (*next == 'c') { next++; goto C; }return 0;
B: if (*next == '\0') return 0;if (*next == 'b') { next++; goto D; }return 0;
C: if (*next == '\0') return 1;if (*next == 'a') { next++; goto B; }if (*next == 'c') { next++; goto D; }return 0;
D: if (*next == '\0') return 1;if (*next == 'a') { next++; goto B; }if (*next == 'c') { next++; goto D; }return 0;
}

SUMMARY

SUMMARY

Summary
In lexical analysis, the lexemesof the language are identifiedand converted into tokens.
Lexemes are typically specifiedby regular expressions.
Matching of regular expressionsformalised by proof rules.
Defining proof rules in Prologgives a simple but inefficientimplementation.

Summary
In lexical analysis, the lexemesof the language are identifiedand converted into tokens.
Lexemes are typically specifiedby regular expressions.
Matching of regular expressionsformalised by proof rules.
Defining proof rules in Prologgives a simple but inefficientimplementation.

Summary
Automatically converting regularexpressions into efficient C codeinvolves three main steps:
1. RE → NFA
(Thompson’s Construction)
2. NFA → DFA
(Subset Construction)
3. DFA → C Function

Summary
Automatically converting regularexpressions into efficient C codeinvolves three main steps:
1. RE → NFA
(Thompson’s Construction)
2. NFA → DFA
(Subset Construction)
3. DFA → C Function

Theory & Practice
In the next lecture, we will learnhow to use a tool called Flexthat puts the regular expressiontheory into practice.





























