Embed Size (px)
DESCRIPTION
Authors:. Balamurali A R *,+ Subhabrata Mukherjee + Akshat Malu + Pushpak Bhattacharyya + * IITB- Monash Research Academy, IIT Bombay + Dept. of Computer Science and Engineering, IIT Bombay. Leveraging Sentiment to Compute Word Similarity. GWC 2012, Matsue, Japan. - PowerPoint PPT Presentation
Citation preview

Leveraging Sentiment to Compute Word Similarity
GWC 2012, Matsue, Japan
Balamurali A R*,+ Subhabrata Mukherjee+ Akshat Malu+ Pushpak Bhattacharyya+
*IITB-Monash Research Academy, IIT Bombay+Dept. of Computer Science and Engineering, IIT Bombay
Authors:
Slides Acknowledgement: Akshat Malu

Roadmap
Similarity MetricsSenSim Metric: Our ApproachEvaluationResults & Conclusion

Similarity Metrics

Similarity Metrics
An unavoidable component in an NLP system Example :Word Sense disambiguation (Banerjee &
Pedersen 2002), malapropism detection (Hirst & St-Onge,1997)
Underlying principle: Distributional similarity in terms of their meaning. Example: Refuge and Asylum are similar
Existing approaches: Finding the similarity between a word pair based on their meaning (definition)

Similarity Metrics – Is meaning alone enough?
RefugeMad
house
Asylum
Mad house

Similarity & Sentiment
Our hypothesis
“Knowing the sentiment content of the words is beneficial in measuring their similarity”

SenSim Metric: Our Approach

SenSim Metric
Using sentiment along with the meaning of the words to calculate their similarity
The gloss of the synset is the most informative piece
We leverage it in calculating both, the meaning based similarity as well as the sentiment similarity of the word pair
We use a gloss-vector based approach with cosine similarity in our metric

Gloss Vector Gloss vector is created by representing all the
words of the gloss in the form of a vector Assumption: Synset for the word is already
known Each dimension of the gloss vector represents
a sentiment score of the respective content word
Sentiment scores are obtained from different scoring functions based on an external lexicon
SentiWordNet 1.0 is used as the external lexicon
Problem: The vector thus formed is too sparse

Augmenting Gloss Vector To counter sparsity of gloss vectors, they are
augmented with the gloss of the related synsets
The context is further extended by adding the gloss of synsets of the words present in the gloss of the original word
Refuge
a shelter from danger or hardship
Area
CountryHarbora
ge
a shelter from danger or hardshipa shelter from danger or hardship; a particular geographical region of
indefinite boundarya shelter from danger or hardship; a particular geographical region of indefinite boundary; a place of refuge
a shelter from danger or hardship; a particular geographical region of indefinite boundary; a place of refuge; a structure that provides privacy and protection from danger
a shelter from danger or hardship; a particular geographical region of indefinite boundary; a place of refuge; a structure that provides privacy and protection from danger; the condition of being susceptible to harm or injury
a shelter from danger or hardship; a particular geographical region of indefinite boundary; a place of refuge; a structure that provides privacy and protection from danger; the condition of being susceptible to harm or injury; a state of misfortune or affliction
a shelter from danger or hardship; a particular geographical region of indefinite boundary; a place of refuge; a structure that provides privacy and protection from danger; the condition of being susceptible to harm or injury; a state of misfortune or affliction
a shelter from danger or hardshipa shelter from danger or hardshipa shelter from danger or hardshipa shelter from danger or hardship
Hyponymy Hypernymy
Hyponymy

Scoring Functions Sentiment Difference (SD)
Difference between the positive and negative sentiment values
Sentiment Max (SM) The greater of the positive and negative sentiment
values Sentiment Threshold Difference (TD)
Same as SD but with a minimum threshold value Sentiment Threshold Max (TM)
Same as SM but with a minimum threshold valueScoreSD(A) = SWNpos(A) – SWNneg(A)ScoreSM(A) = max(SWNpos(A), SWNneg(A))
ScoreTD(A) = sign(max(SWNpos(A) , SWNneg(A)) )* (1+abs(SWNpos(A) – SWNneg(A)))
ScoreTM(A) = sign(max(SWNpos(A), SWNneg(A))) * (1+abs(max(SWNpos(A), SWNneg(A))))

SenSim Metric
SenSim_x(A,B) =
cosine(glossvec(sense(A),glossvec(sense(B))
glossvec = 1:score_x(1) 2:score_x(2)............ n:score_x(n)Score_X (Y) = Sentiment score of word Y using scoring function x
x = Scoring function of type SD/SM/TD/TM

Evaluation

Synset Replacemen
t using Similarity
metrics
Comparing scores* given by SenSim with those given by human annotators
* all scores normalized to a scale of 1-5 (1-least similar, 5-most similar)
Evaluation
Evaluation
Intrinsic Extrinsic
Correlation with
Human Annotators
Annotation based on meaning
Annotation based on
sentiment and meaning combined
Correlation between
other Metrics
Correlation with Human
Annotators
Correlation
between other
Metrics
Synset Replaceme
nt using Similarity metrics

Synset Replacement using Similarity metrics Unknown feature problem in supervised
classification–
If Test_Synset T is not in
Train_synset_list
Get Train_Synset_L
ist
Get Test_Synset_Li
st
Training corpus(Synset
)Test
corpus(Synset)
Using similarity metric S find a
similar synset R
Replace T with RNew Test
corpus(Syns
et)
Yes
No
Metrics used:LIN (Lin, 1998) ,LCH (Leacock and Chodorow 1998), Lesk (Banerjee and Pedersen, 2002)

Results & Conclusion

Results – Intrinsic Evaluation (1/4) Sentiment as a parameter for finding
similarity (1/2)
Adding sentiment to the context yields better correlation among the annotators
The decrease in correlation on adding sentiment in case of NOUN can be because sentiment does not play that important role in this case
Annotation Strategy
Overall
NOUN VERB ADJECTIVE ADVERB
Meaning 0.768 0.803 0.750 0.527 0.759
Meaning+Sentiment
0.799 0.750 0.889 0.720 0.844
Pearson Correlation Coefficient between two annotators for various annotation strategies
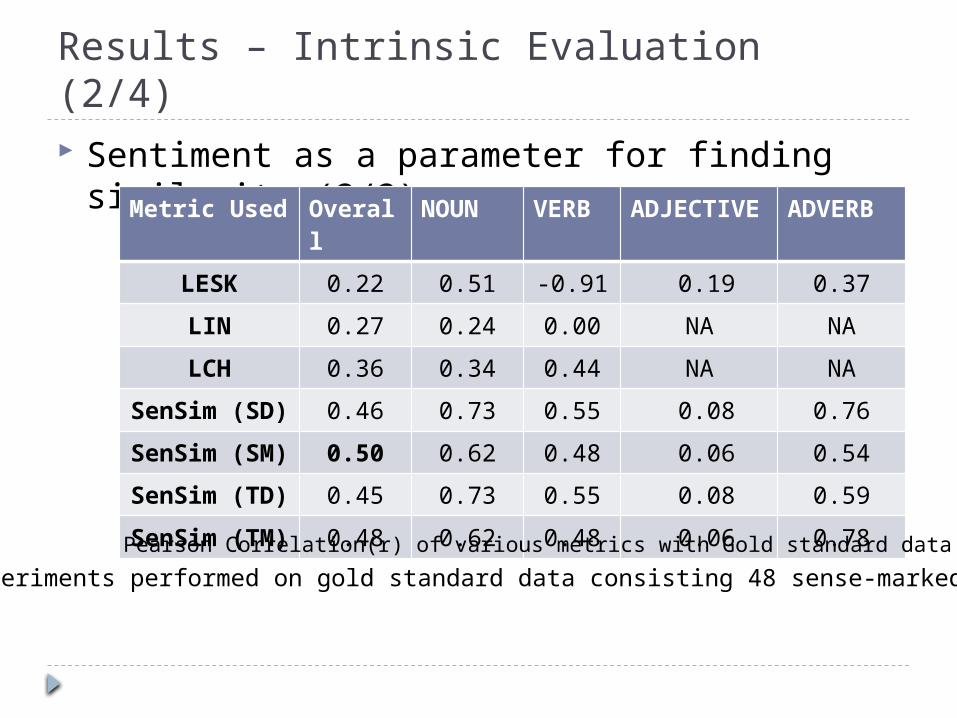
Results – Intrinsic Evaluation (2/4) Sentiment as a parameter for finding
similarity (2/2)Metric Used
Overall
NOUN VERB ADJECTIVE
ADVERB
LESK 0.22 0.51 -0.91 0.19 0.37
LIN 0.27 0.24 0.00 NA NA
LCH 0.36 0.34 0.44 NA NA
SenSim (SD)
0.46 0.73 0.55 0.08 0.76
SenSim (SM)
0.50 0.62 0.48 0.06 0.54
SenSim (TD)
0.45 0.73 0.55 0.08 0.59
SenSim (TM)
0.48 0.62 0.48 0.06 0.78
Pearson Correlation(r) of various metrics with Gold standard data* all experiments performed on gold standard data consisting 48 sense-marked word pairs

Results- Extrinsic Evaluation (3/4) Effect of SenSim on synset replacement
strategy
Baseline signifies the experiment where in there are no synset replacements
Metric Used
Accuracy (%)
PP NP PR NR
Baseline 89.10 91.50 87.07 85.18 91.24
LESK 89.36 91.57 87.46 85.68 91.25
LIN 89.27 91.24 87.61 85.85 90.90
LCH 89.64 90.48 88.86 86.47 89.63
SenSim (SD)
89.95 91.39 88.65 87.11 90.93
SenSim (SM)
90.06 92.01 88.38 86.67 91.58
SenSim (TD)
90.11 91.68 88.69 86.97 91.23
SenSim (TM)
90.17 91.81 88.71 87.09 91.36
Classification results of synset replacement experiment using different similarity metrics; * PP-Positive Precision (%), NP-Negative Precision(%), PR-Positive Recall (%), NR-Negative Recall (%)

Results- Extrinsic Evaluation (4/4) Effect of SenSim on synset replacement
strategy
Improvement is only marginal as no complex features are used for training the classifier
Metric Used
Accuracy (%)
PP NP PR NR
Baseline 89.10 91.50 87.07 85.18 91.24
LESK 89.36 91.57 87.46 85.68 91.25
LIN 89.27 91.24 87.61 85.85 90.90
LCH 89.64 90.48 88.86 86.47 89.63
SenSim (SD)
89.95 91.39 88.65 87.11 90.93
SenSim (SM)
90.06 92.01 88.38 86.67 91.58
SenSim (TD)
90.11 91.68 88.69 86.97 91.23
SenSim (TM)
90.17 91.81 88.71 87.09 91.36
Classification results of synset replacement experiment using different similarity metrics; * PP-Positive Precision (%), NP-Negative Precision(%), PR-Positive Recall (%), NR-Negative Recall (%)

Conclusions Proposed that sentiment content can aid in
similarity measurement, which to date has been done on the basis of meaning alone.
Verified this hypothesis by taking the correlation between annotators using different annotation strategies
Annotator correlation on including sentiment as an additional parameter for similarity measurement was higher than just semantic similarity
SenSim, based on this hypothesis, performs better than the existing metrics, which fail to account for sentiment while calculating similarity

References

References (1/2) Balamurali, A., Joshi, A. & Bhattacharyya, P. (2011), Harnessing wordnet senses for
supervised sentiment classification, in ‘Proc. Of EMNLP-2011’. Banerjee, S. & Pedersen, T. (2002), An adapted lesk algorithm for word sense
disambiguation using wordnet, in ‘Proc. of CICLing-02’. Banerjee, S. & Pedersen, T. (2003), Extended gloss overlaps as a measure of semantic relatedness, in ‘Proc. of IJCAI-03’.
Esuli, A. & Sebastiani, F. (2006), SentiWordNet: A publicly available lexical resource for opinion mining, in ‘Proceedings of LREC-06’, Genova, IT.
Grishman, R. (2001), Adaptive information extraction and sublanguage analysis, in ‘Proc. Of IJCAI-01’.
Hirst, G. & St-Onge, D. (1997), ‘Lexical chains as representation of context for the detection and correction malapropisms’.
Jiang, J. J. & Conrath, D. W. (1997), Semantic Similarity Based on Corpus Statistics and Lexical Taxonomy, in ‘Proc. of ROCLING X’.
Leacock, C. & Chodorow, M. (1998), Combining local context with wordnet similarity for word sense identification, in ‘WordNet: A Lexical Reference System and its Application’.
Leacock, C., Miller, G. A. & Chodorow, M. (1998), ‘Using corpus statistics and wordnet relations for sense identification’, Comput. Linguist. 24.
Lin, D. (1998), An information-theoretic definition of similarity, in ‘Proc. of ICML ’98’. Partington, A. (2004), ‘Utterly content in each others company semantic prosody and semantic preference’, International Journal of Corpus Linguistics 9(1).

Patwardhan, S. (2003), Incorporating dictionary and corpus information into a context vector measure of semantic relatedness, Master’s thesis, University of Minnesota, Duluth.
Pedersen, T., Patwardhan, S. & Michelizzi, J. (2004), Wordnet::similarity: measuring the relatedness of concepts, in ‘Demonstration Papers at HLT-NAACL’04’.
Rada, R., Mili, H., Bicknell, E. & Blettner, M. (1989), ‘Development and application of a metric on semantic nets’, IEEE Transactions on Systems Management and Cybernetics 19(1).
Resnik, P. (1995a), Disambiguating noun groupings with respect to Wordnet senses, in ‘Proceedings of the Third Workshop on Very Large Corpora’, Somerset, New Jersey.
Resnik, P. (1995b), Using information content to evaluate semantic similarity in a taxonomy, in ‘Proc. of IJCAI-95’.
Richardson, R., Smeaton, A. F. & Murphy, J. (1994), Using wordnet as a knowledge base for measuring semantic similarity between words, Technical report, Proc. of AICS-94.
Sinclair, J. (2004), Trust the Text: Language, Corpus and Discourse, Routledge. Wan, S. & Angryk, R. A. (2007), Measuring semantic similarity using wordnet-based context
vectors., in ‘Proc. of SMC’07’. Wu, Z. & Palmer, M. (1994), Verb semantics and lexical selection, in ‘Proc. of ACL-94’, New
Mexico State University, Las Cruces, New Mexico. Zhong, Z. & Ng, H. T. (2010), It makes sense: A wide-coverage word sense disambiguation
system for free text., in ‘ACL (System Demonstrations)’ 10’.
References (2/2)

Back up Slides…

Metrics used for Comparison LIN
uses the information content individually possessed by two concepts in addition to that shared by them.
Lesk based on the overlap of words in their
individual glosses Leacock & Chodorow (LCH)
the shortest path through hypernymy relation
simLIN (A,B) = 2 X log Pr (lso (A,B))
log Pr (A) + log Pr (B)
simLCH (A,B) = -log ( len (A,B)
2D )

How? Use of WordNet Similarity Metrics
If Test_Synset T is not in
Train_synset_list
Get Train_Synset_L
ist
Get Test_Synset_Li
st
Training corpus(Synset
)Test
corpus(Synset)
Using similarity metric S find a
similar synset R
Replace T with RNew Test
corpus(Syns
et)
Yes
No
Metrics used:LIN (Lin, 1998) ,LCH (Leacock and Chodorow 1998), Lesk (Banerjee and Pedersen, 2002)

Synset Replacement using Similarity Metric

Experimental Setup Datasets Used
Intrinsic Evaluation Gold Standard Data containing 48 sense-marked word pairs
Extrinsic Evaluation Dataset provided by Balamurali et al (2011)
Word Sense Disambiguation carried out using the WSD engine by Zhong & Ng (2010) (82% accuracy)
WordNet::Similarity 2.05 package used for computing similarity by other metric scores
Pearson Correlation Coefficient used to find inter-annotator agreement
Sentiment Classification done using C-SVM; all results are average of five-fold cross-validation accuracies







![Gradient Magnitude Similarity Deviation: A Highly ... · Most gradient based FR-IQA models [5-7, 15] were inspired by SSIM [8]. Th ey first compute the similarity between the gradients](https://img.pdfslide.us/doc/110x75/5fe55d6acb3e875c024199a3/gradient-magnitude-similarity-deviation-a-highly-most-gradient-based-fr-iqa.jpg)





![Similarity Dependency Dirichlet Process for Aspect-Based ... · system, aspect-based sentiment analysis is an important component[1],[2] to make it function, because it can e ciently](https://img.pdfslide.us/doc/110x75/5f5ffb9c10016e4d1148548a/similarity-dependency-dirichlet-process-for-aspect-based-system-aspect-based.jpg)













![TI-CNN: Convolutional Neural Networks for Fake News Detection · Liu et.al. [19] analyzed fake reviews on Amazon these years based on the sentiment analysis, lexical, content similarity,](https://img.pdfslide.us/doc/110x75/5f2d3ef5d5fe9b2a895eb626/ti-cnn-convolutional-neural-networks-for-fake-news-detection-liu-etal-19-analyzed.jpg)

