Embed Size (px)
Citation preview

Lecture 3Ngrams
Lecture 3Ngrams
Topics Topics Python NLTK N – grams Smoothing
Readings:Readings: Chapter 4 – Jurafsky and Martin
January 23, 2013
CSCE 771 Natural Language Processing

– 2 –CSCE 771 Spring 2013
Last TimeLast Time Slides from Lecture 1 30-
Regular expressions in Python, (grep, vi, emacs, word)?Eliza
Morphology
TodayToday N-gram models for prediction

– 3 –CSCE 771 Spring 2013
Eliza.pyEliza.py
https://github.com/nltk/nltk/blob/master/nltk/chat/eliza.py
• List of re – response pattern pairsList of re – response pattern pairs
• If Regular expression matchesIf Regular expression matches
• Then respond with …Then respond with …pairs = (pairs = ( (r'I need (.*)',(r'I need (.*)', ( "Why do you need %1?",( "Why do you need %1?", "Would it really help you to get %1?","Would it really help you to get %1?", "Are you sure you need %1?")),"Are you sure you need %1?")),
(r'Why don\'t you (.*)',(r'Why don\'t you (.*)', ( "Do you really think I don't %1?",( "Do you really think I don't %1?", "Perhaps eventually I will %1.","Perhaps eventually I will %1.", "Do you really want me to %1?")),"Do you really want me to %1?")),

– 4 –CSCE 771 Spring 2013
http://nltk.org/book/http://nltk.org/book/
Natural Language Processing with PythonNatural Language Processing with Python--- Analyzing Text with the Natural Language Toolkit--- Analyzing Text with the Natural Language Toolkit
Steven Bird, Ewan Klein, and Edward LoperSteven Bird, Ewan Klein, and Edward Loper
Preface ( (extras) 1. ) 1. Language Processing and Python (extras) 2. (extras) 2. Accessing Text Corpora and Lexical Resources (extras) 3. Accessing Text Corpora and Lexical Resources (extras) 3. Processing Raw Text 4. Writing Structured Programs (extras) 5. Processing Raw Text 4. Writing Structured Programs (extras) 5. Categorizing and Tagging Words 6. Learning to Classify Text Categorizing and Tagging Words 6. Learning to Classify Text (extras) 7. Extracting Information from Text 8. Analyzing (extras) 7. Extracting Information from Text 8. Analyzing Sentence Structure (extras) 9. Building Feature Based Sentence Structure (extras) 9. Building Feature Based Grammars 10. Analyzing the Meaning of Sentences (extras) 11. Grammars 10. Analyzing the Meaning of Sentences (extras) 11. Managing Linguistic Data 12. Afterword: Facing the Language Managing Linguistic Data 12. Afterword: Facing the Language ChallengeChallenge
nltk.org/book

– 5 –CSCE 771 Spring 2013
Language Processing and PythonLanguage Processing and Python
>>> from nltk.book import * >>> from nltk.book import *
*** Introductory Examples for the NLTK Book *** *** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9 Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it. Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851 text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811 text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis text3: The Book of Genesis
text4: Inaugural Address Corpustext4: Inaugural Address Corpus
……nltk.org/book

– 6 –CSCE 771 Spring 2013
Simple text processing with NLTKSimple text processing with NLTK
>>> text1.concordance("monstrous")>>> text1.concordance("monstrous")
>>> text1.similar("monstrous")>>> text1.similar("monstrous")
>>> text2.common_contexts(["monstrous", "very"])>>> text2.common_contexts(["monstrous", "very"])
>>> text4.dispersion_plot(["citizens", "democracy", >>> text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])"freedom", "duties", "America"])
>>> text3.generate()>>> text3.generate()
>>> text5[16715:16735]>>> text5[16715:16735]
nltk.org/book

– 7 –CSCE 771 Spring 2013
Counting VocabularyCounting Vocabulary
>>> len(text3)>>> len(text3)
>>> sorted(set(text3))>>> sorted(set(text3))
>>> from __future__ import division >>> from __future__ import division
>>> len(text3) / len(set(text3))>>> len(text3) / len(set(text3))
>>> text3.count("smote")>>> text3.count("smote")
nltk.org/book

– 8 –CSCE 771 Spring 2013
lexical_diversitylexical_diversity
>>> def lexical_diversity(text): >>> def lexical_diversity(text):
... return len(text) / len(set(text)) ... return len(text) / len(set(text))
... ...
>>> def percentage(count, total): >>> def percentage(count, total):
... return 100 * count / total ... return 100 * count / total
......
nltk.org/book

– 9 –CSCE 771 Spring 2013
1.3 Computing with Language: Simple Statistics1.3 Computing with Language: Simple StatisticsFrequency DistributionsFrequency Distributions
>>> fdist1 = FreqDist(text1) >>> fdist1 = FreqDist(text1)
>>> fdist1 <FreqDist with 260819 outcomes> >>> fdist1 <FreqDist with 260819 outcomes>
>>> vocabulary1 = fdist1.keys() >>> vocabulary1 = fdist1.keys()
>>> vocabulary1[:50] >>> vocabulary1[:50]
>>> fdist1['whale']>>> fdist1['whale']
>>> V = set(text1) >>> V = set(text1)
>>> long_words = [w for w in V if len(w) > 15] >>> long_words = [w for w in V if len(w) > 15]
>>> sorted(long_words)>>> sorted(long_words)nltk.org/book

– 10 –CSCE 771 Spring 2013
List constructors in PythonList constructors in Python
>>> V = set(text1) >>> V = set(text1)
>>> long_words = [w for w in V if len(w) > 15] >>> long_words = [w for w in V if len(w) > 15]
>>> sorted(long_words)>>> sorted(long_words)
>>> fdist5 = FreqDist(text5) >>> fdist5 = FreqDist(text5)
>>> sorted([w for w in set(text5) if len(w) > 7 and >>> sorted([w for w in set(text5) if len(w) > 7 and fdist5[w] > 7])fdist5[w] > 7])
nltk.org/book

– 11 –CSCE 771 Spring 2013
Collocations and BigramsCollocations and Bigrams
>>> bigrams(['more', 'is', 'said', 'than', 'done']) >>> bigrams(['more', 'is', 'said', 'than', 'done'])
[('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')][('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')]
>>> text4.collocations() >>> text4.collocations()
Building collocations list Building collocations list
United States; fellow citizens; years ago; Federal United States; fellow citizens; years ago; Federal Government; General Government; American Government; General Government; American people; Vice President; Almighty God; Fellow people; Vice President; Almighty God; Fellow citizens; Chief Magistrate; Chief Justice; God bless; citizens; Chief Magistrate; Chief Justice; God bless; Indian tribes; public debt; foreign nations; political Indian tribes; public debt; foreign nations; political parties; State governments; National Government; parties; State governments; National Government; United Nations; public moneyUnited Nations; public money
nltk.org/book

– 12 –CSCE 771 Spring 2013
Table 1.2Table 1.2Example Description
fdist = FreqDist(samples)create a frequency distribution containing the given samples
fdist.inc(sample) increment the count for this sample
fdist['monstrous']count of the number of times a given sample occurred
fdist.freq('monstrous') frequency of a given sample
fdist.N() total number of samples
fdist.keys() sorted in order of decreasing frequency
for sample in fdist: iterate over the samples, decreasing frequency
fdist.max() sample with the greatest count
fdist.tabulate() tabulate the frequency distribution
fdist.plot() graphical plot of the frequency distribution
fdist.plot(cumulative=True) cumulative plot of the frequency distribution
fdist1 < fdist2test if samples in fdist1 occur less frequently than in fdist2
nltk.org/book

– 13 –CSCE 771 Spring 2013
Quotes from Chapter 4Quotes from Chapter 4
But it must be recognized that the notion “probability of But it must be recognized that the notion “probability of a sentence” is an entirely useless one, under any a sentence” is an entirely useless one, under any known interpretation of this term.known interpretation of this term.
Noam Chomsky 1969Noam Chomsky 1969• http://www.chomsky.info/
Anytime a linguist leaves the group the recognition rate Anytime a linguist leaves the group the recognition rate goes up.goes up.
Fred Jelinek (then of the IBM speech Fred Jelinek (then of the IBM speech group)group)
SLP – Jurafsky and Matrin for the rest of the day

– 14 –CSCE 771 Spring 2013
Predicting WordsPredicting Words
Please turn your homework …Please turn your homework …
What is the next word?What is the next word?
Language models: N-gram modelsLanguage models: N-gram models

– 15 –CSCE 771 Spring 2013
Word/Character prediction UsesWord/Character prediction Uses
1.1. Spelling correction (at character level)Spelling correction (at character level)
2.2. Spelling correction (at a higher level) when the Spelling correction (at a higher level) when the corrector corrects to the wrong wordcorrector corrects to the wrong word
3.3. Augmentative communication – person with Augmentative communication – person with disability chooses words from a menu predicted by disability chooses words from a menu predicted by the systemthe system

– 16 –CSCE 771 Spring 2013
Real-Word Spelling ErrorsReal-Word Spelling Errors
Mental confusionsMental confusions Their/they’re/there To/too/two Weather/whether Peace/piece You’re/your
Typos that result in real wordsTypos that result in real words

– 17 –CSCE 771 Spring 2013
Spelling Errors that are WordsSpelling Errors that are Words
TyposTypos
ContextContext Left context Right context

– 18 –CSCE 771 Spring 2013
Real Word Spelling ErrorsReal Word Spelling Errors
Collect a set of common pairs of confusionsCollect a set of common pairs of confusions
Whenever a member of this set is encountered compute Whenever a member of this set is encountered compute the probability of the sentence in which it appearsthe probability of the sentence in which it appears
Substitute the other possibilities and compute the Substitute the other possibilities and compute the probability of the resulting sentenceprobability of the resulting sentence
Choose the higher oneChoose the higher one

– 19 –CSCE 771 Spring 2013
Word CountingWord Counting
Probability based on countingProbability based on counting
• He stepped out into the hall, was delighted to He stepped out into the hall, was delighted to encounter a water brotherencounter a water brother. (from the Brown corpus). (from the Brown corpus)• Words?• Bi-grams
Frequencies of words, but what words?Frequencies of words, but what words?
Corpora ?Corpora ?• Web everything on it• Shakespeare• Bible/Koran• Spoken transcripts (switchboard)
• Problems with spoken speech “uh” , “um” fillers

– 20 –CSCE 771 Spring 2013
6.2 Bigrams from Berkeley Restaurant Proj.6.2 Bigrams from Berkeley Restaurant Proj.
Berkeley Restaurant Project – a speech based restaurant consultantBerkeley Restaurant Project – a speech based restaurant consultant
Handling requests:Handling requests: I’m looking for Cantonese food. I’m looking for a good place to eat breakfast.

– 21 –CSCE 771 Spring 2013
Chain RuleChain Rule
Recall the definition of Recall the definition of conditional probabilitiesconditional probabilities
RewritingRewriting
Or…Or…
Or… Or…
)(
)^()|(
BP
BAPBAP
)()|()^( BPBAPBAP
)()|()( thePthebigPbigTheP
)|()()( thebigPthePbigTheP

– 22 –CSCE 771 Spring 2013
ExampleExample
The big red dogThe big red dog
P(The)*P(big|the)*P(red|the big)*P(dog|the big red)P(The)*P(big|the)*P(red|the big)*P(dog|the big red)
Better P(The| <Beginning of sentence>) written asBetter P(The| <Beginning of sentence>) written as
P(The | <S>)P(The | <S>)

– 23 –CSCE 771 Spring 2013
General CaseGeneral Case
The word sequence from position 1 to n isThe word sequence from position 1 to n is
So the probability of a sequence isSo the probability of a sequence is
nw1
)|()(
)|()...|()|()()(
112
1
11
2131211
k
kn
k
nn
n
wwPwP
wwPwwPwwPwPwP

– 24 –CSCE 771 Spring 2013
UnfortunatelyUnfortunately
That doesn’t help since its unlikely we’ll ever gather the That doesn’t help since its unlikely we’ll ever gather the right statistics for the prefixes.right statistics for the prefixes.

– 25 –CSCE 771 Spring 2013
Markov AssumptionMarkov Assumption
Assume that the entire prefix history isn’t necessary.Assume that the entire prefix history isn’t necessary.
In other words, an event doesn’t depend on all of its In other words, an event doesn’t depend on all of its history, just a fixed length near historyhistory, just a fixed length near history

– 26 –CSCE 771 Spring 2013
Markov AssumptionMarkov Assumption
So for each component in the product replace each So for each component in the product replace each with its with the approximation (assuming a prefix of with its with the approximation (assuming a prefix of N)N)
)|()|( 11
11
nNnn
nn wwPwwP

– 27 –CSCE 771 Spring 2013
Maximum Likelihood EstimationMaximum Likelihood Estimation
Maximum Likelihood Estimation (MLE) - Method to Maximum Likelihood Estimation (MLE) - Method to estimate probabilities for the n-gram modelsestimate probabilities for the n-gram models
Normalize counts from a corpusNormalize counts from a corpus

– 28 –CSCE 771 Spring 2013
N-Grams: The big red dogN-Grams: The big red dog
Unigrams:Unigrams: P(dog)P(dog)
Bigrams:Bigrams: P(dog|red)P(dog|red)
Trigrams:Trigrams: P(dog|big red)P(dog|big red)
Four-grams:Four-grams: P(dog|the big red)P(dog|the big red)
In general, we’ll be dealing withIn general, we’ll be dealing with
P(Word| Some fixed prefix)P(Word| Some fixed prefix)

– 29 –CSCE 771 Spring 2013
CaveatCaveat
The formulation The formulation P(Word| Some fixed prefix) P(Word| Some fixed prefix) is is notnot really really appropriate in many applications.appropriate in many applications.
It is if we’re dealing with real time speech where we It is if we’re dealing with real time speech where we only have access to prefixes.only have access to prefixes.
But if we’re dealing with text we already have the right But if we’re dealing with text we already have the right and left contexts. There’s no a priori reason to stick and left contexts. There’s no a priori reason to stick to left contexts only.to left contexts only.

– 30 –CSCE 771 Spring 2013
BERP Table: Counts (fig 4.1)BERP Table: Counts (fig 4.1)
Then we can normalize by dividing each row by the unigram counts.

– 31 –CSCE 771 Spring 2013
BERP Table: Bigram ProbabilitiesBERP Table: Bigram Probabilities

– 32 –CSCE 771 Spring 2013
ExampleExample
For this example For this example • P(I | <s>) = .25
• P(food | english) = .5• P (english | want) 0.0011• P (</s> | food) = .68
Now consider “<s> I want English food </s>”Now consider “<s> I want English food </s>”
P(<s> I want English food </s>)P(<s> I want English food </s>)
= P(I | <s>) P(want | i) P(english | want) P(food | english) P(</s>|food)= P(I | <s>) P(want | i) P(english | want) P(food | english) P(</s>|food)

– 33 –CSCE 771 Spring 2013
An Aside on LogsAn Aside on Logs
You don’t really do all those multiplies. The numbers You don’t really do all those multiplies. The numbers are too small and lead to underflowsare too small and lead to underflows
Convert the probabilities to logs and then do additions.Convert the probabilities to logs and then do additions.
To get the real probability (if you need it) go back to the To get the real probability (if you need it) go back to the antilog.antilog.

– 34 –CSCE 771 Spring 2013
Some ObservationsSome Observations
The following numbers are very informative. Think The following numbers are very informative. Think about what they capture.about what they capture. P(want|I) = .32 P(to|want) = .65 P(eat|to) = .26 P(food|Chinese) = .56 P(lunch|eat) = .055

– 35 –CSCE 771 Spring 2013
Some More ObservationsSome More Observations
P(I | I)P(I | I)
P(want | I)P(want | I)
P(I | food)P(I | food)
I I I wantI I I want
I want I want toI want I want to
The food I want isThe food I want is

– 36 –CSCE 771 Spring 2013
GenerationGeneration
Choose N-Grams according to their probabilities and Choose N-Grams according to their probabilities and string them togetherstring them together

– 37 –CSCE 771 Spring 2013
BERPBERP
II want want want to
to eat
eat Chinese
Chinese food
food .

– 38 –CSCE 771 Spring 2013
Some Useful ObservationsSome Useful Observations
A small number of events occur with high frequencyA small number of events occur with high frequency You can collect reliable statistics on these events with
relatively small samples
A large number of events occur with small frequencyA large number of events occur with small frequency You might have to wait a long time to gather statistics on the
low frequency events

– 39 –CSCE 771 Spring 2013
Some Useful ObservationsSome Useful Observations
Some zeroes are really zeroesSome zeroes are really zeroes Meaning that they represent events that can’t or shouldn’t
occur
On the other hand, some zeroes aren’t really zeroesOn the other hand, some zeroes aren’t really zeroes They represent low frequency events that simply didn’t
occur in the corpus

– 40 –CSCE 771 Spring 2013
Shannon’s MethodShannon’s Method
Sentences randomly generated based on the Sentences randomly generated based on the probability models (n-gram models)probability models (n-gram models)
Sample a random bigram (<s>, w) according to its probabilitySample a random bigram (<s>, w) according to its probability
Now sample a random bigram (w, x) according to its probabilityNow sample a random bigram (w, x) according to its probability Where the prefix w matches the suffix of the first.
And so on until we randomly choose a (y, </s>)And so on until we randomly choose a (y, </s>)
Then string the words togetherThen string the words together
<s> I<s> I
II want want want to to eat eat Chinese
Chinese food food </s>
Slide from: Speech and Language Processing Jurafsky and Martin

– 41 –CSCE 771 Spring 2013
Shannon’s method applied to ShakespeareShannon’s method applied to Shakespeare

– 42 –CSCE 771 Spring 2013
Shannon applied to Wall Street JournalShannon applied to Wall Street Journal

– 43 –CSCE 771 Spring 2013
Evaluating N-grams: PerplexityEvaluating N-grams: Perplexity
Training setTraining set
Test set : W = wTest set : W = w11ww22….w….wnn
Perplexity (PP) is a Measure of how good a model is.Perplexity (PP) is a Measure of how good a model is.
PP(W) = P(wPP(W) = P(w11ww22….w….wnn ) )-1/N-1/N
Higher probability Higher probability lower perplexity lower perplexity
Wall Street Journal perplexities of modelsWall Street Journal perplexities of models

– 44 –CSCE 771 Spring 2013
Unknown words: Open versus Closed VocabulariesUnknown words: Open versus Closed Vocabularies<UNK> unrecognized word token<UNK> unrecognized word token

– 45 –CSCE 771 Spring 2013
Google words visualizationGoogle words visualization
http://googlesystem.blogspot.com/2008/05/using-googles-n-gram-corpus.html

– 46 –CSCE 771 Spring 2013
ProblemProblem
Let’s assume we’re using N-gramsLet’s assume we’re using N-grams
How can we assign a probability to a sequence where How can we assign a probability to a sequence where one of the component n-grams has a value of zeroone of the component n-grams has a value of zero
Assume all the words are known and have been seenAssume all the words are known and have been seen Go to a lower order n-gram Back off from bigrams to unigrams Replace the zero with something else

– 47 –CSCE 771 Spring 2013
SmoothingSmoothing
Smoothing - reevaluating some of the zero and low Smoothing - reevaluating some of the zero and low probability N-grams and assigning them non-zero probability N-grams and assigning them non-zero valuesvalues
Add-One (Laplace) Add-One (Laplace)
Make the zero counts 1.Make the zero counts 1.
Rationale: They’re just events you haven’t seen yet. If Rationale: They’re just events you haven’t seen yet. If you had seen them, chances are you would only you had seen them, chances are you would only have seen them once… so make the count equal to have seen them once… so make the count equal to 1.1.

– 48 –CSCE 771 Spring 2013
Add-One SmoothingAdd-One Smoothing
TerminologyTerminology
N – Number of total wordsN – Number of total words
V – vocabulary size == number of distinct wordsV – vocabulary size == number of distinct words
Maximum Likelihood estimateMaximum Likelihood estimate
ii
xx wc
wcwP
)(
)()(

– 49 –CSCE 771 Spring 2013
Adjusted counts “C*”Adjusted counts “C*”
TerminologyTerminology
N – Number of total wordsN – Number of total words
V – vocabulary size == V – vocabulary size == number of distinct wordsnumber of distinct words
VN
Ncc ii
)1(*
Adjusted count C*Adjusted count C*
N
cp ii *
Adjusted probabilitiesAdjusted probabilities

– 50 –CSCE 771 Spring 2013
DiscountingDiscounting
Discounting – lowering some of Discounting – lowering some of the larger non-zero counts to the larger non-zero counts to get the “probability” to assign get the “probability” to assign to the zero entriesto the zero entries
ddcc – the discounted counts – the discounted counts
The discounted probabilities The discounted probabilities can then be directly calculatedcan then be directly calculated
c
cdc
*
VN
cp ii
1*
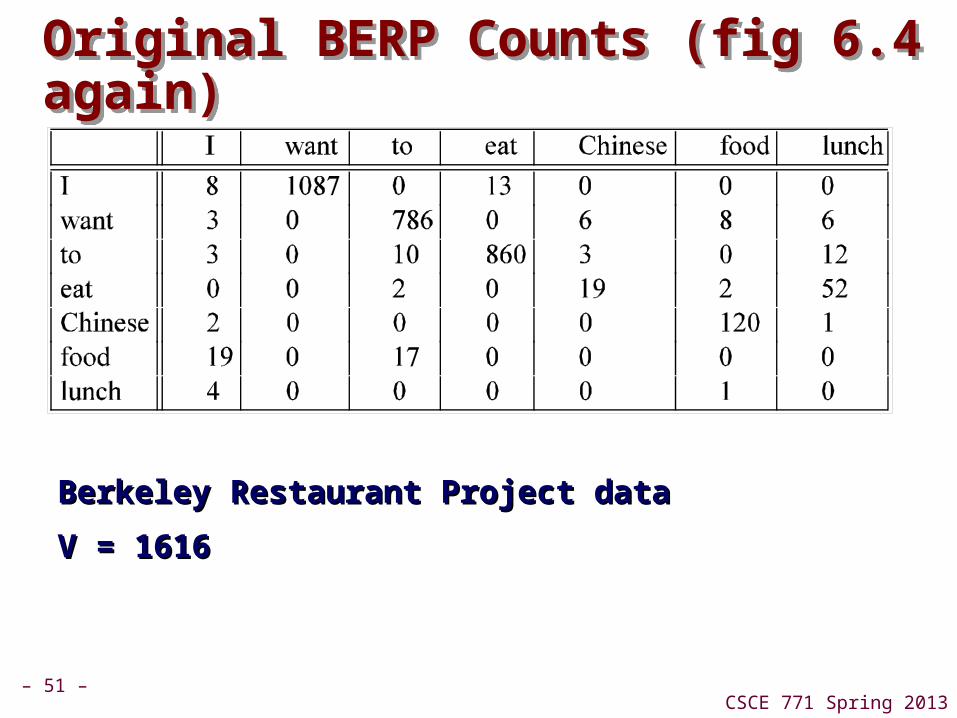
– 51 –CSCE 771 Spring 2013
Original BERP Counts (fig 6.4 again)Original BERP Counts (fig 6.4 again)
Berkeley Restaurant Project dataBerkeley Restaurant Project data
V = 1616V = 1616

– 52 –CSCE 771 Spring 2013
Figure 6.6 Add one countsFigure 6.6 Add one countsCountsCounts
ProbabilitiesProbabilities

– 53 –CSCE 771 Spring 2013
Figure 6.6 Add one counts & prob.Figure 6.6 Add one counts & prob.CountsCounts
ProbabilitiesProbabilities

– 54 –CSCE 771 Spring 2013
Add-One Smoothed bigram countsAdd-One Smoothed bigram counts
Think about the occurrence of an unseen item (Think about the occurrence of an unseen item (

– 55 –CSCE 771 Spring 2013
Witten-BellWitten-Bell
Think about the occurrence of an unseen item Think about the occurrence of an unseen item (word, bigram, etc) as an event.(word, bigram, etc) as an event.
The probability of such an event can be measured The probability of such an event can be measured in a corpus by just looking at how often it in a corpus by just looking at how often it happens.happens.
Just take the single word case first.Just take the single word case first.
Assume a corpus of N tokens and T types.Assume a corpus of N tokens and T types.
How many times was an as yet unseen type How many times was an as yet unseen type encountered?encountered?

– 56 –CSCE 771 Spring 2013
Witten BellWitten Bell
First compute the probability of an unseen eventFirst compute the probability of an unseen event
Then distribute that probability mass equally among the Then distribute that probability mass equally among the as yet unseen eventsas yet unseen events That should strike you as odd for a number of reasons In the case of words… In the case of bigrams

– 57 –CSCE 771 Spring 2013
Witten-BellWitten-Bell
In the case of bigrams, not all conditioning events are In the case of bigrams, not all conditioning events are equally promiscuousequally promiscuous P(x|the) vs P(x|going)
So distribute the mass assigned to the zero count So distribute the mass assigned to the zero count bigrams according to their promiscuitybigrams according to their promiscuity

– 58 –CSCE 771 Spring 2013
Witten-BellWitten-Bell
Finally, renormalize the whole table so that you still Finally, renormalize the whole table so that you still have a valid probabilityhave a valid probability

– 59 –CSCE 771 Spring 2013
Original BERP Counts; Original BERP Counts;
Now the Add 1 counts

– 60 –CSCE 771 Spring 2013
Witten-Bell Smoothed and ReconstitutedWitten-Bell Smoothed and Reconstituted

– 61 –CSCE 771 Spring 2013
Add-One Smoothed BERPReconstitutedAdd-One Smoothed BERPReconstituted





























