Embed Size (px)
Citation preview

CSC412/2506Spring2017Probabilis7cGraphicalModels
Lecture3:DirectedGraphicalModels
andLatentVariables
BasedonslidesbyRichardZemel

Learningoutcomes
• Whataspectsofamodelcanweexpressusinggraphicalnotation?
• Whichaspectsarenotcapturedinthisway?• Howdoindependencieschangeasaresultofconditioning?
• Reasonsforusinglatentvariables• Commonmotifssuchasmixturesandchains• Howtointegrateoutunobservedvariables

JointProbabili7es
• Chainruleimpliesthatanyjointdistributionequals
• Directedgraphicalmodelimpliesarestrictedfactorization
p(x1:D) = p(x1)p(x2|x1)p(x3|x1, x2)p(x4|x1, x2, x3)...p(xD|x1:D�1)

Condi7onalIndependence• Notation:xA⊥xB|xC
• DeGinition:two(setsof)variablesxAandxBareconditionallyindependentgivenathirdxCif:
whichisequivalenttosaying
• Onlyasubsetofalldistributionsrespectanygiven(nontrivial)conditionalindependencestatement.ThesubsetofdistributionsthatrespectalltheCIassumptionswemakeisthefamilyofdistributionsconsistentwithourassumptions.
• Probabilisticgraphicalmodelsareapowerful,elegantandsimplewaytospecifysuchafamily.
P (xA,xB |xC) = P (xA|xC)P (xB |xC) ; 8xC
P (xA|xB ,xC) = P (xA|xC) ; 8xC

DirectedGraphicalModels• Considerdirectedacyclicgraphsovernvariables.• Eachnodehas(possiblyempty)setofparentsπi• Wecanthenwrite
• Hencewefactorizethejointintermsoflocalconditionalprobabilities
• Exponentialin“fan-in”ofeachnodeinsteadofinN
P (x1, ...,xN ) =Y
i
P (xi|x⇡i)

Condi7onalIndependenceinDAGs
• Ifweorderthenodesinadirectedgraphicalmodelsothatparentsalwayscomebeforetheirchildrenintheorderingthenthegraphicalmodelimpliesthefollowingaboutthedistribution:
wherearethenodescomingbeforexithatarenotitsparents
• Inotherwords,theDAGistellingusthateachvariableisconditionallyindependentofitsnon-descendantsgivenitsparents.
• Suchanorderingiscalleda“topological”ordering
x⇡i
{xi ? x⇡i |x⇡i} ; 8i
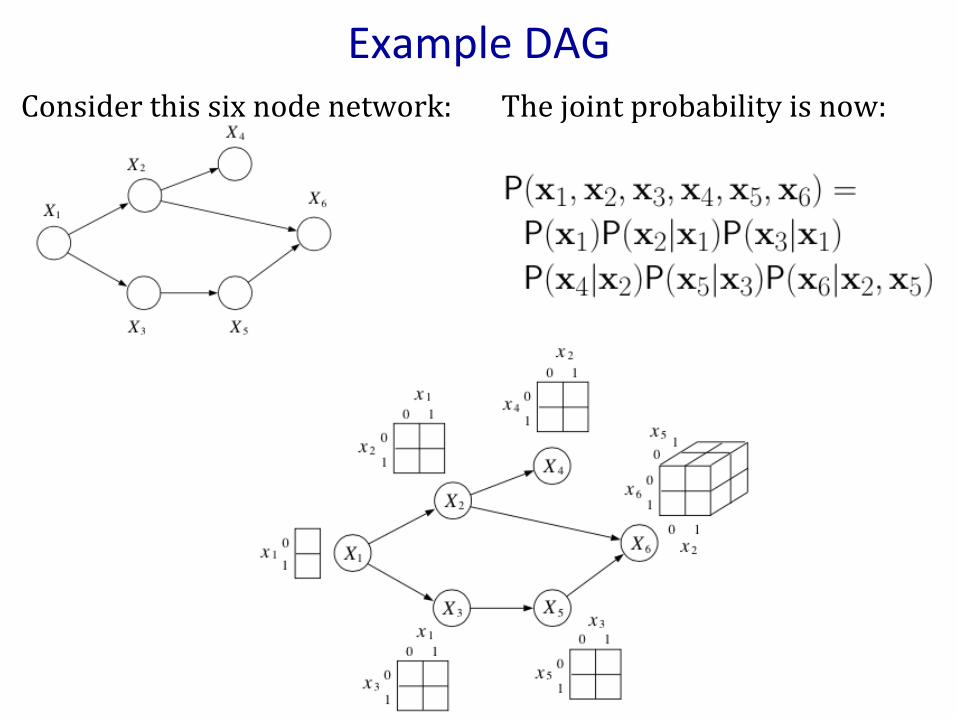
ExampleDAGConsiderthissixnodenetwork:Thejointprobabilityisnow:

MissingEdges• Keypointaboutdirectedgraphicalmodels:
Missingedgesimplyconditionalindependence• Rememberthatbythechainrulewecanalwayswritethefulljointasaproductofconditionals,givenanordering:
• IfthejointisrepresentedbyaDAGM,thensomeoftheconditionedvariablesontherighthandsidesaremissing.
• Thisisequivalenttoenforcingconditionalindependence.• Startwiththe“idiot’sgraph”:eachnodehasallpreviousnodesintheorderingasitsparents.
• NowremoveedgestogetyourDAG.• Removinganedgeintonodeieliminatesanargumentfromtheconditionalprobabilityfactor
P (x1,x2, ...) = P (x1)P (x2|x1)P (x3|x2,x1)P (x4|x3,x2,x1)
P (xi|x1,x2, ...,xi�1)

D-Separa7on• D-separation,ordirected-separationisanotionofconnectednessinDAGMsinwhichtwo(setsof)variablesmayormaynotbeconnectedconditionedonathird(setof)variable.
• D-connectionimpliesconditionaldependenceandd-separationimpliesconditionalindependence.
• Inparticular,wesaythatxA⊥xB|xCifeveryvariableinAisd-separatedfromeveryvariableinBconditionedonallthevariablesinC.
• Tocheckifanindependenceistrue,wecancyclethrougheachnodeinA,doadepth-GirstsearchtoreacheverynodeinB,andexaminethepathbetweenthem.Ifallofthepathsared-separated,thenwecanassertxA⊥xB|xC
• Thus,itwillbesufGicienttoconsidertriplesofnodes.(Why?)• Pictorially,whenweconditiononanode,weshadeitin.

Chain
• Q:Whenweconditionony,arexandzindependent?
whichimpliesandthereforex⊥z|y• Thinkofxasthepast,yasthepresentandzasthefuture.
P (x,y, z) = P (x)P (y|x)P (z|y)
P (z|x,y) = P (x,y, z)
P (x,y)
=P (x)P (y|x)P (z|y)
P (x)P (y|x)= P (z|y)
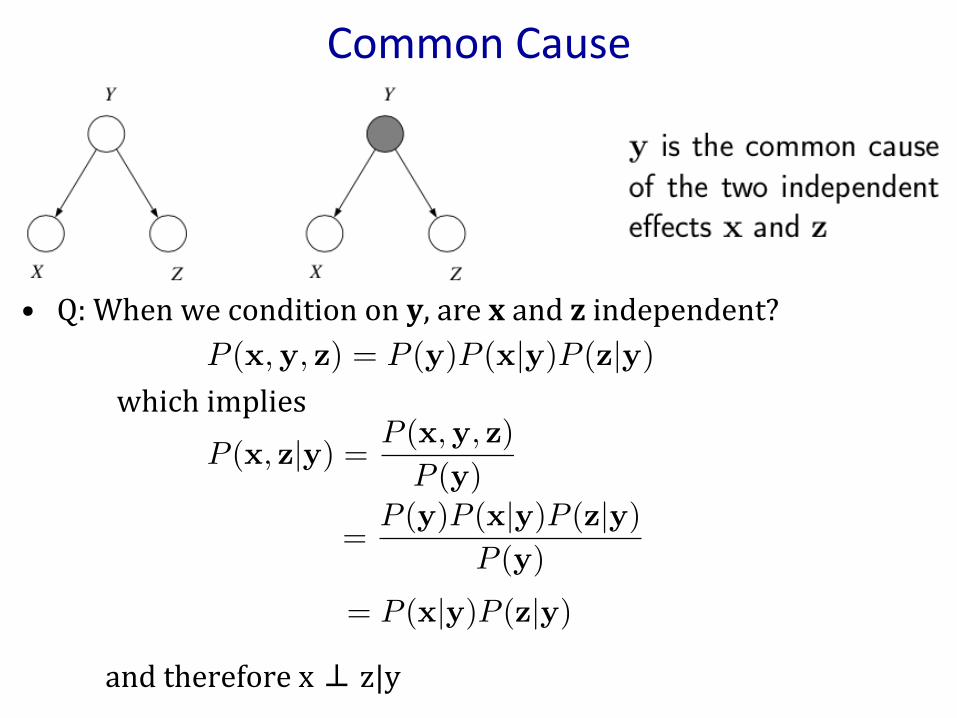
CommonCause
• Q:Whenweconditionony,arexandzindependent?
whichimpliesandthereforex⊥z|y
= P (x|y)P (z|y)
=P (y)P (x|y)P (z|y)
P (y)
P (x, z|y) = P (x,y, z)
P (y)
P (x,y, z) = P (y)P (x|y)P (z|y)

ExplainingAway
• Q:Whenweconditionony,arexandzindependent?• xandzaremarginallyindependent,butgivenytheyareconditionallydependent.
• Thisimportanteffectiscalledexplainingaway(Berkson’sparadox.)
• Forexample,Gliptwocoinsindependently;letx=coin1,z=coin2.• Lety=1ifthecoinscomeupthesameandy=0ifdifferent.• xandzareindependent,butifItellyouy,theybecomecoupled!
P (x,y, z) = P (x)P (z)P (y|x, z)

Bayes-BallAlgorithm• TocheckifxA⊥xB|xCweneedtocheckifeveryvariableinAisd-separatedfromeveryvariableinBconditionedonallvarsinC.
• Inotherwords,giventhatallthenodesinxCareclamped,whenwewigglenodesxAcanwechangeanyofthenodesinxB?
• TheBayes-BallAlgorithmisasuchad-separationtest.• WeshadeallnodesxC,placeballsateachnodeinxA(orxB),letthembouncearoundaccordingtosomerules,andthenaskifanyoftheballsreachanyofthenodesinxB(orxA).
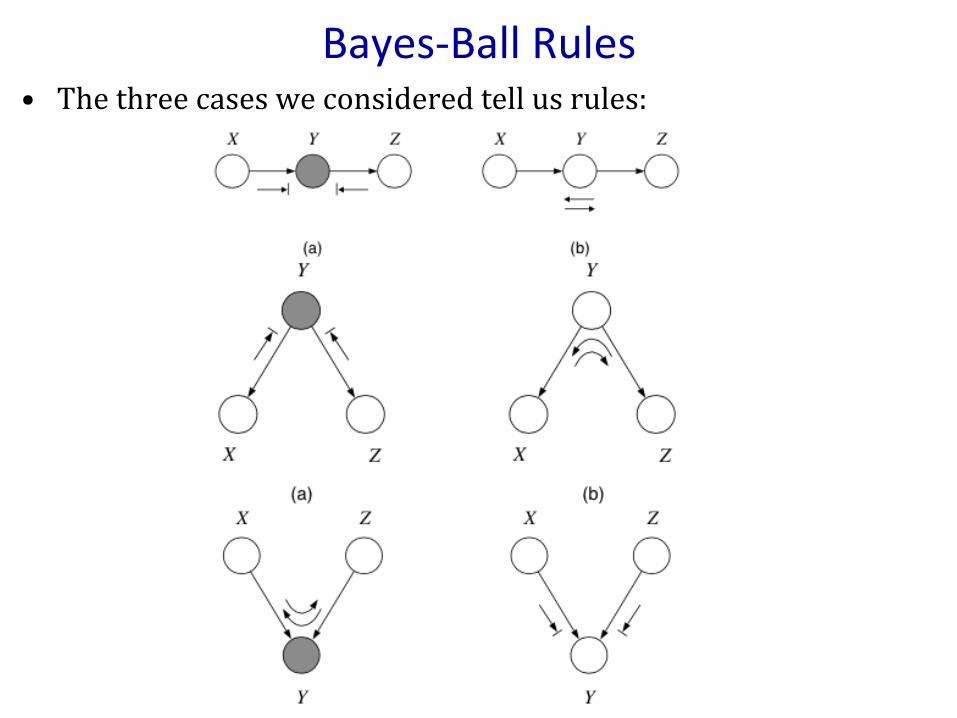
Bayes-BallRules• Thethreecasesweconsideredtellusrules:

Bayes-BallBoundaryRules
• Wealsoneedtheboundaryconditions:
• Here’satrickfortheexplainingawaycase:Ifyoranyofitsdescendantsisshaded,theballpassesthrough.
• Noticeballscantraveloppositetoedgedirections.
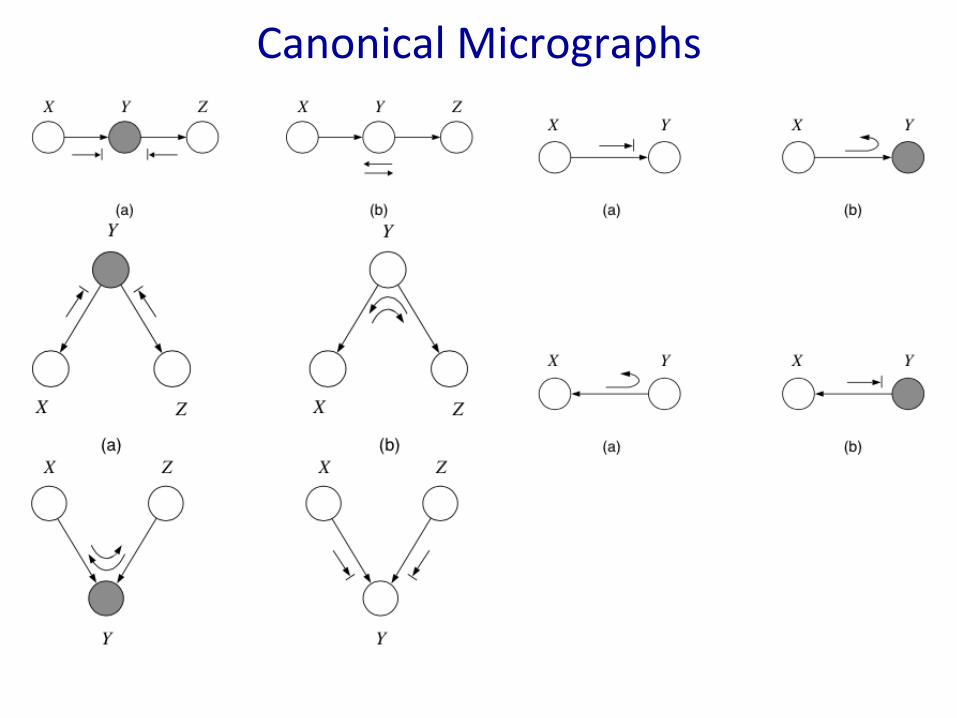
CanonicalMicrographs
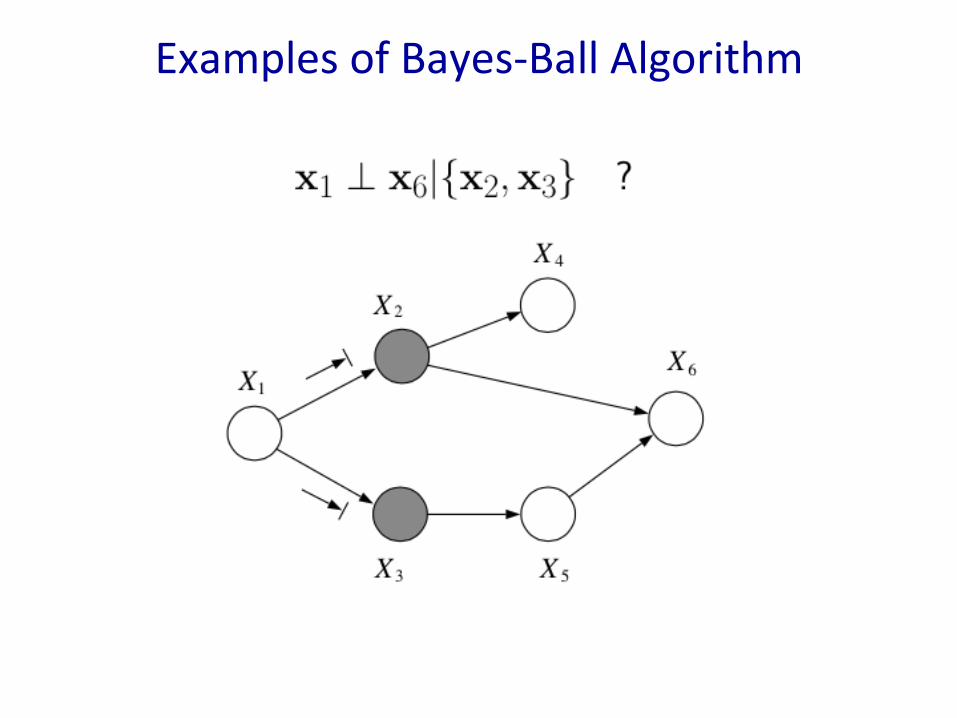
ExamplesofBayes-BallAlgorithm
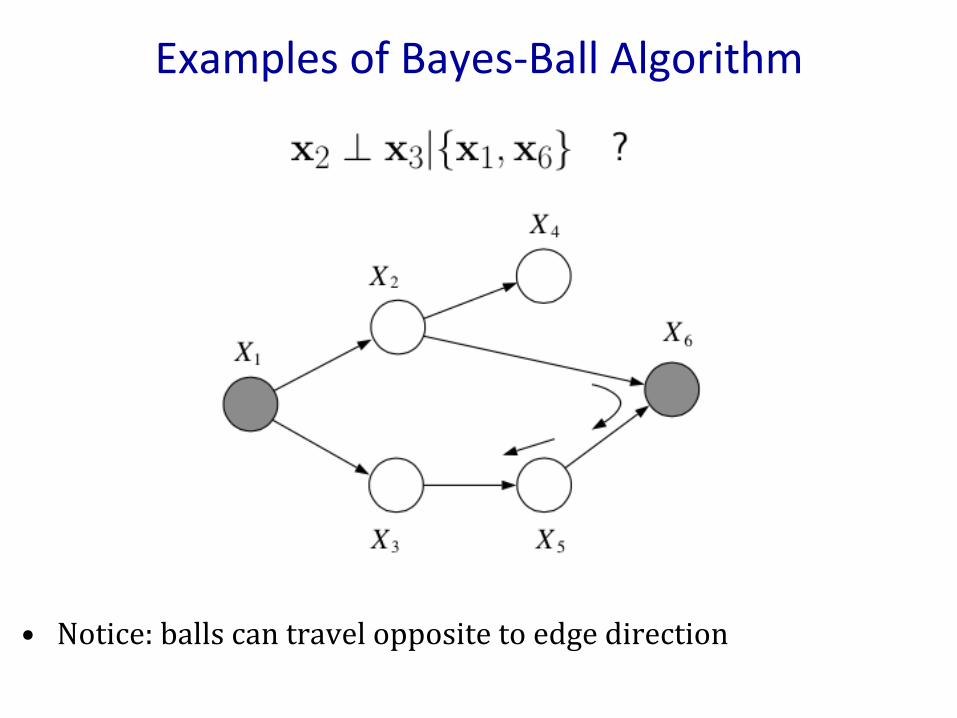
ExamplesofBayes-BallAlgorithm
• Notice:ballscantraveloppositetoedgedirection

Plates

Plates&Parameters
• SinceBayesianmethodstreatparametersasrandomvariables,wewouldliketoincludetheminthegraphicalmodel.
• Onewaytodothisistorepeatalltheiidobservationsexplicitlyandshowtheparameteronlyonce.
• Abetterwayistouseplates,inwhichrepeatedquantitiesthatareiidareputinabox.
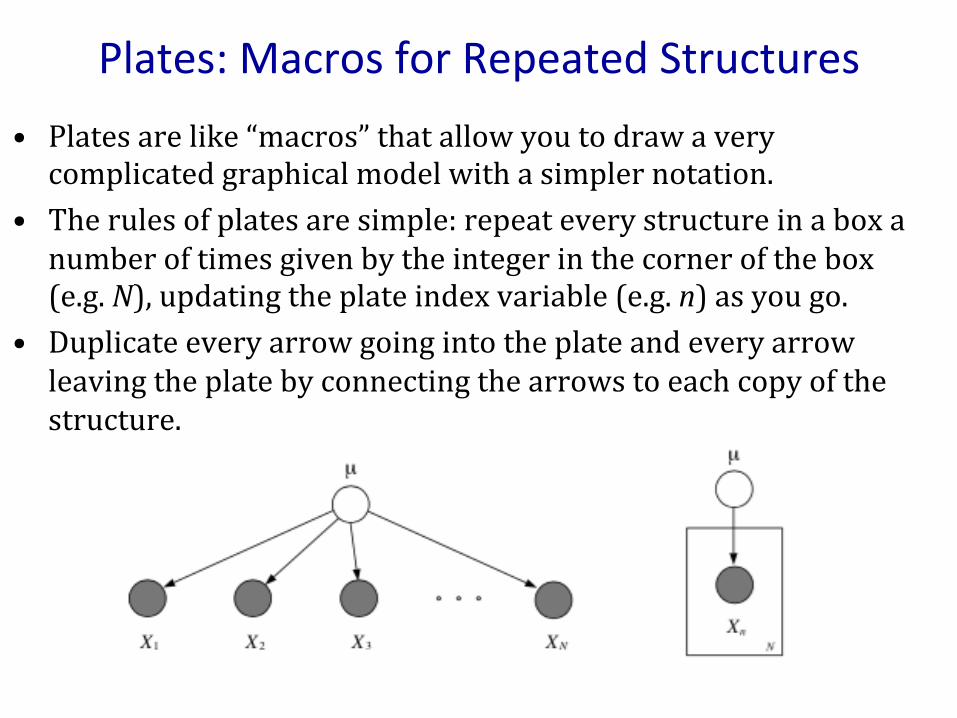
Plates:MacrosforRepeatedStructures• Platesarelike“macros”thatallowyoutodrawaverycomplicatedgraphicalmodelwithasimplernotation.
• Therulesofplatesaresimple:repeateverystructureinaboxanumberoftimesgivenbytheintegerinthecornerofthebox(e.g.N),updatingtheplateindexvariable(e.g.n)asyougo.
• Duplicateeveryarrowgoingintotheplateandeveryarrowleavingtheplatebyconnectingthearrowstoeachcopyofthestructure.

Nested/Intersec7ngPlates
• Platescanbenested,inwhichcasetheirarrowsgetduplicatedalso,accordingtotherule:drawanarrowfromeverycopyofthesourcenodetoeverycopyofthedestinationnode.
• Platescanalsocross(intersect),inwhichcasethenodesattheintersectionhavemultipleindicesandgetduplicatedanumberoftimesequaltotheproductoftheduplicationnumbersonalltheplatescontainingthem.
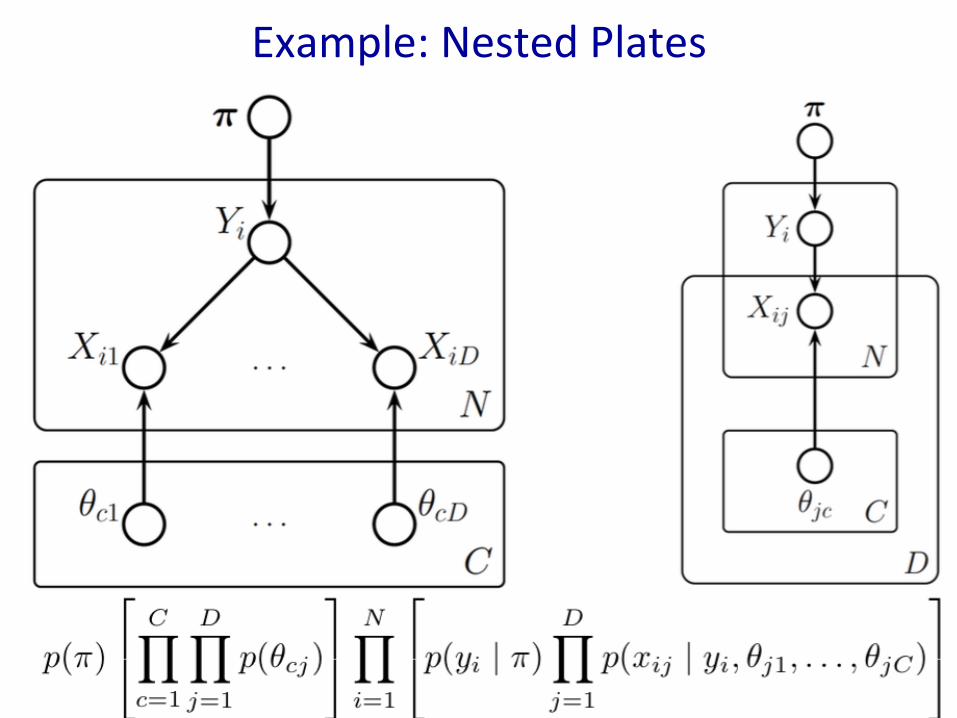
Example:NestedPlates

ExampleDAGM:MarkovChain
• MarkovProperty:Conditionedonthepresent,thepastandfutureareindependent
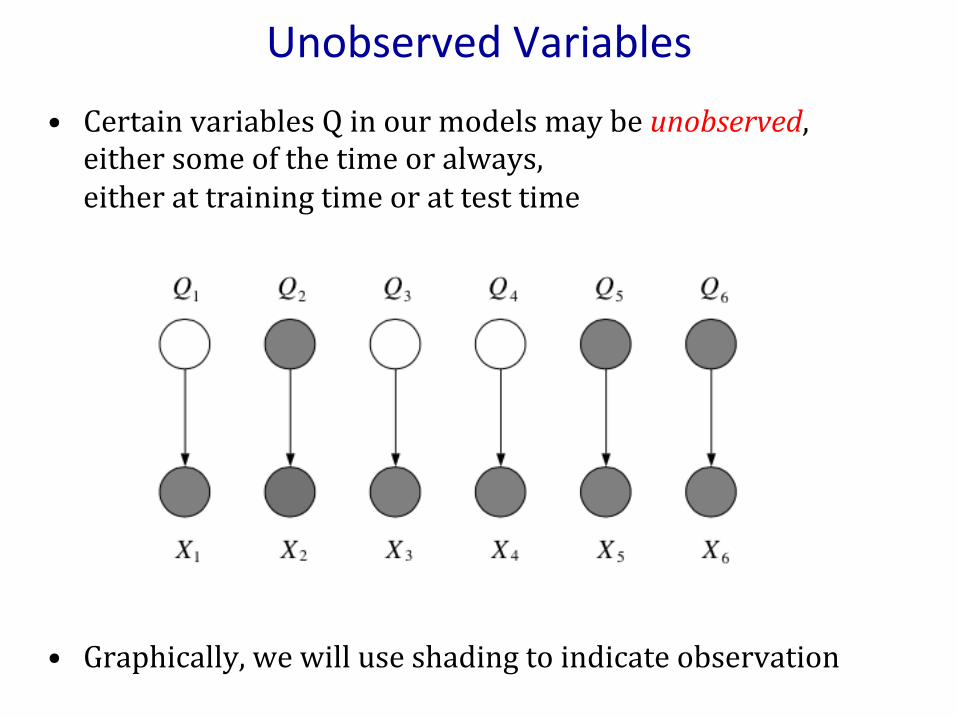
UnobservedVariables• CertainvariablesQinourmodelsmaybeunobserved,eithersomeofthetimeoralways,eitherattrainingtimeorattesttime
• Graphically,wewilluseshadingtoindicateobservation

Par7allyUnobserved(Missing)Variables• Ifvariablesareoccasionallyunobservedtheyaremissingdata,e.g.,undeGinedinputs,missingclasslabels,erroneoustargetvalues
• Inthiscase,wecanstillmodelthejointdistribution,butwedeGineanewcostfunctioninwhichwesumoutormarginalizethemissingvaluesattrainingortesttime:
Recallthat
`(✓;D) =
X
complete
log p(xc,yc|✓) +X
missing
log p(xm|✓)
=
X
complete
log p(xc,yc|✓) +X
missing
log
X
y
p(xm,y|✓)
p(x) =X
q
p(x, q)

LatentVariables• Whattodowhenavariablezisalwaysunobserved?Dependsonwhereitappearsinourmodel.Ifweneverconditiononitwhencomputingtheprobabilityofthevariableswedoobserve,thenwecanjustforgetaboutitandintegrateitout.e.g.,giveny,xGitthemodelp(z,y|x)=p(z|y)p(y|x,w)p(w).(Inotherwordsifitisaleafnode.)
• Butifzisconditionedon,weneedtom odelit:odelit:
e.g.giveny,xGitthemodelp(y|x)=Σzp(y|x,z)p(z)
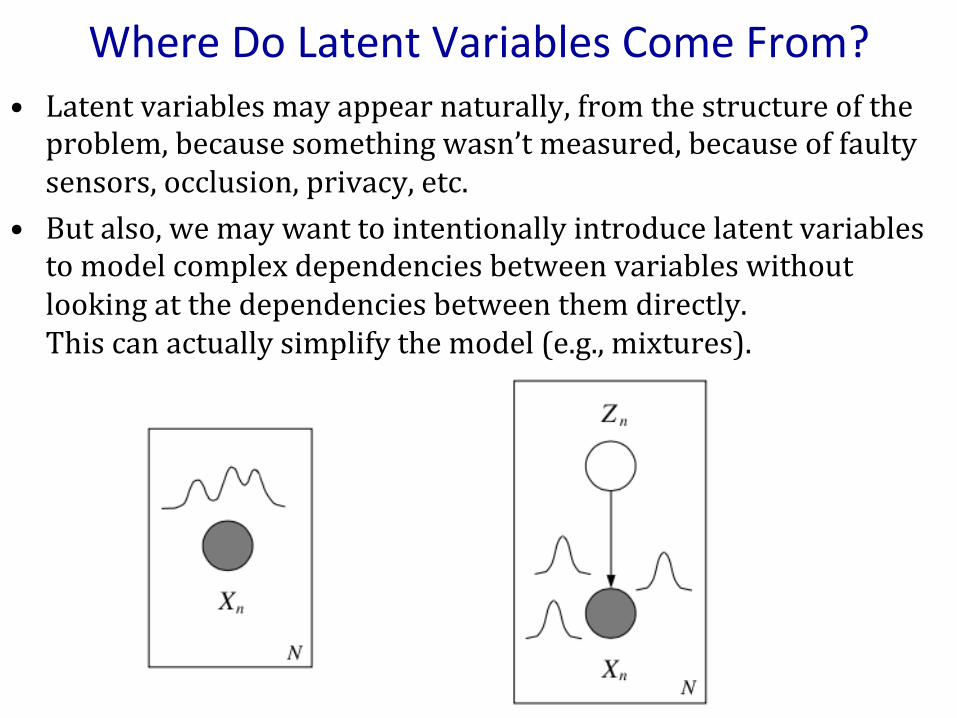
WhereDoLatentVariablesComeFrom?• Latentvariablesmayappearnaturally,fromthestructureoftheproblem,becausesomethingwasn’tmeasured,becauseoffaultysensors,occlusion,privacy,etc.
• Butalso,wemaywanttointentionallyintroducelatentvariablestomodelcomplexdependenciesbetweenvariableswithoutlookingatthedependenciesbetweenthemdirectly.Thiscanactuallysimplifythemodel(e.g.,mixtures).
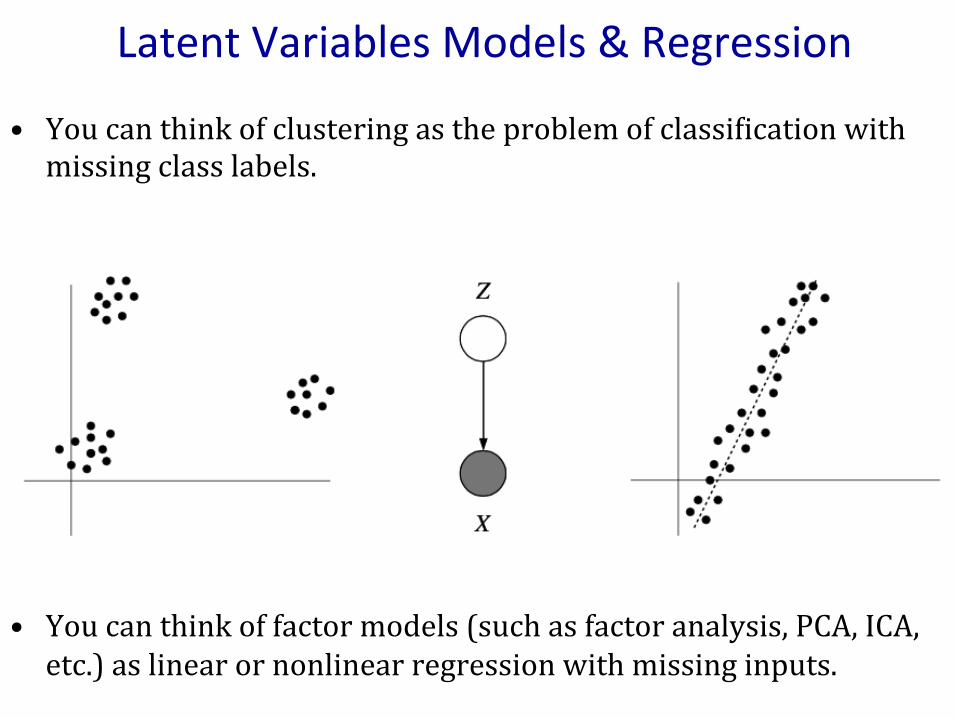
LatentVariablesModels&Regression
• YoucanthinkofclusteringastheproblemofclassiGicationwithmissingclasslabels.
• Youcanthinkoffactormodels(suchasfactoranalysis,PCA,ICA,etc.)aslinearornonlinearregressionwithmissinginputs.

WhyisLearningHarder?
• Infullyobservediidsettings,theprobabilitymodelisaproduct,thustheloglikelihoodisasumwheretermsdecouple.(Atleastfordirectedmodels.)
• Withlatentvariables,theprobabilityalreadycontainsasu m,sotheloglikelihoodhasallparameterscoupledtogetherviaz:rscoupledtogetherviaz:
(Justaswiththepartitionfunctioninundirectedmodels)
`(✓;D) = log p(x, z|✓)
= log p(z|✓z
) + log p(x|z, ✓x
)
`(✓;D) = log
X
z
p(x, z|✓)
= log
X
z
p(z|✓z
) + log p(x|z, ✓x
)
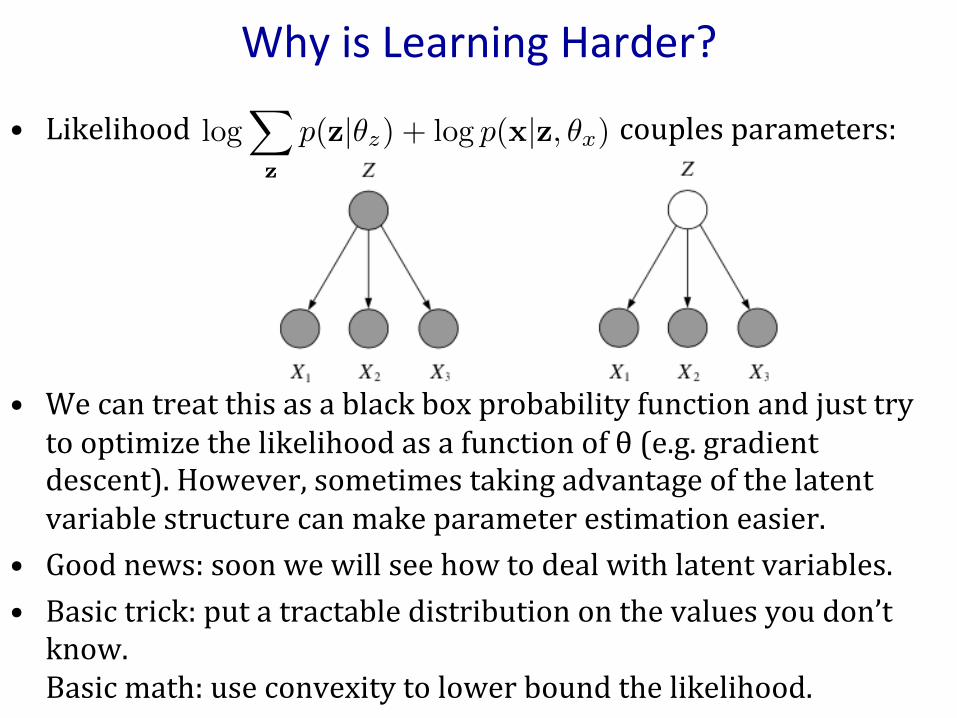
WhyisLearningHarder?
• Likelihood couplesparameters:
• Wecantreatthisasablackboxprobabilityfunctionandjusttrytooptimizethelikelihoodasafunctionofθ(e.g.gradientdescent).However,sometimestakingadvantageofthelatentvariablestructurecanmakeparameterestimationeasier.
• Goodnews:soonwewillseehowtodealwithlatentvariables.• Basictrick:putatractabledistributiononthevaluesyoudon’tknow.Basicmath:useconvexitytolowerboundthelikelihood.
= log
X
z
p(z|✓z
) + log p(x|z, ✓x
)
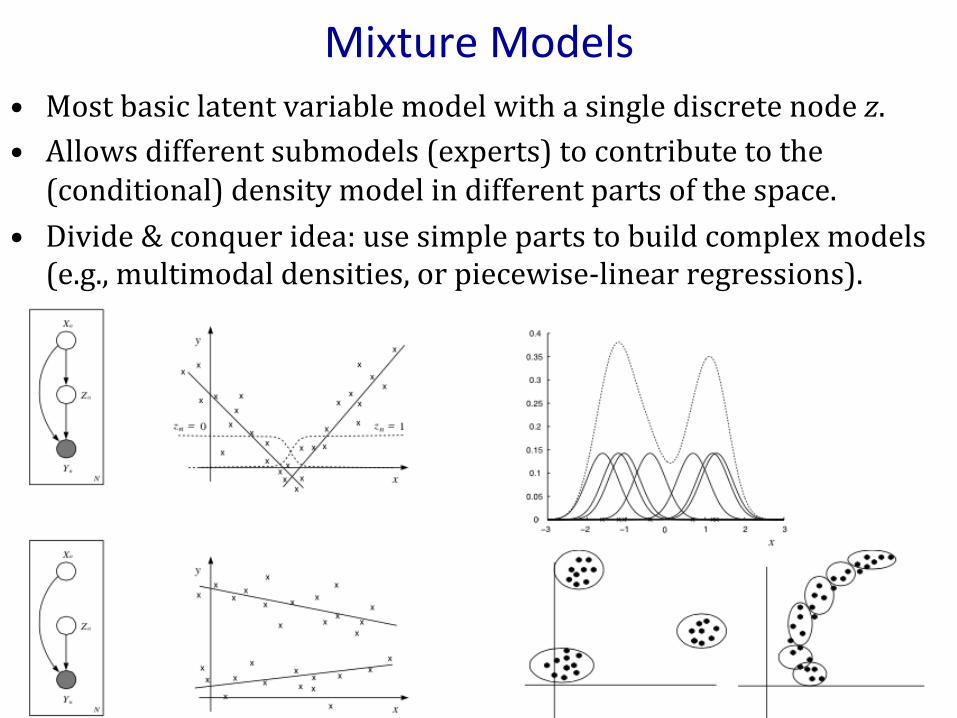
MixtureModels• Mostbasiclatentvariablemodelwithasinglediscretenodez.• Allowsdifferentsubmodels(experts)tocontributetothe(conditional)densitymodelindifferentpartsofthespace.
• Divide&conqueridea:usesimplepartstobuildcomplexmodels(e.g.,multimodaldensities,orpiecewise-linearregressions).

MixtureDensi7es• ExactlylikeaclassiGicationmodelbuttheclassisunobservedandsowesumitout.Whatwegetisaperfectlyvaliddensity:
wherethe“mixingproportions”addtoone:Σkαk=1.• WecanuseBayes’ruletocomputetheposteriorprobabilityofthemixturecomponentgivensomedata:
thesequantitiesarecalledresponsibilities.
p(z = k|x, ✓) = ↵kpk(x|✓k)Pj ↵jpj(x|✓j)
p(x|✓) =KX
k=1
p(z = k|✓z)p(x|z = k, ✓k)
=X
k
↵kpk(x|✓k)

Example:GaussianMixtureModels• ConsideramixtureofKGaussiancomponents:
• Densitymodel:p(x|θ)isafamiliaritysignal.Clustering:p(z|x,θ)istheassignmentrule,−l(θ)isthecost.
p(x|✓) =X
k
↵kN (x|µk,⌃k)
p(z = k|x, ✓) = ↵kN (x|µk,⌃k)Pj ↵jN (x|µj ,⌃j)
`(✓;D) =
X
n
log
X
k
↵kN (x
(n)|µk,⌃k)

Example:MixturesofExperts• Alsocalledconditionalmixtures.Exactlylikeaclass-conditionalmodelbuttheclassisunobservedandsowesumitoutagain:
where
• Harder:mustlearnα(x)(unlesschosezindependentofx).• WecanstilluseBayes’ruletocomputetheposteriorprobabilityofthemixturecomponentgivensomedata:
thisfunctionisoftencalledthegatingfunction.
p(y|x, ✓) =KX
k=1
p(z = k|x, ✓z)p(y|z = k,x, ✓k)
=X
k
↵k(x|✓z)pk(y|x, ✓k)X
k
↵k(x) = 1 8x
p(z = k|x,y, ✓) = ↵k(x)pk(y|x, ✓k)Pj ↵j(x)pj(y|x, ✓j)

Example:MixturesofLinearRegressionExperts• EachexpertgeneratesdataaccordingtoalinearfunctionoftheinputplusadditiveGaussian noise:
• The“gate”functioncanbeasoftmaxclassiGicationmachine
• Remember:wearenotmodelingthedensityoftheinputsx
p(y|x, ✓) =X
k
↵kN (y|�Tk x,�
2k)
↵k(x) = p(z = k|x) = e⌘Tk x
Pj e
⌘Tj x

GradientLearningwithMixtures
• Wecanlearnmixturedensitiesusinggradientdescentonthelikelihoodasusual.Thegradientsarequiteinteresting:
• Inotherwords,thegradientistheresponsibilityweightedsumoftheindividualloglikelihoodgradients
`(✓) = log p(x|✓) = log
X
k
↵kpk(x|✓k)
@`
@✓=
1
p(x|✓)X
k
↵k@pk(x|✓k)
@✓
=
X
k
↵k1
p(x|✓)pk(x|✓k)@ log pk(x|✓k)
@✓
=X
k
↵kpk(x|✓k)p(x|✓)
@`k@✓k
=X
k
↵krk@`k@✓k

ParameterConstraints
• Ifwewanttousegeneraloptimizations(e.g.,conjugategradient)tolearnlatentvariablemodels,weoftenhavetomakesureparametersrespectcertainconstraints(e.g.,Σkαk=1,ΣkαkpositivedeGinite)
• Agoodtrickistore-parameterizethesequantitiesintermsofunconstrainedvalues.Formixingproportions,usethesoftmax:
• Forcovariancematrices,usetheCholeskydecomposition
whereAisupperdiagonalwithpositivediagonal
↵k =
exp(qk)Pj exp(qj)
⌃�1 = ATA |⌃|�1/2 =Y
i
Aii
Aii = exp(ri) > 0 Aij = aij (j > i) Aij = 0 (j < i)

Logsumexp• Oftenyoucaneasilycomputebk=logp(x|z=k,θk),
butitwillbeverynegative,say-106orsmaller.• Now,tocomputel=logp(x|θ)youneedtocompute(e.g.,forcalculatingresponsibilitiesattesttimeorforlearning)
• Careful!Donotcomputethisbydoinglog(sum(exp(b))).YouwillgetunderGlowandanincorrectanswer.
• Insteaddothis:–AddaconstantexponentBtoallthevaluesbksuchthatthe
largestvalueequalszero:B=max(b).–Computelog(sum(exp(b-B)))+B.• Example:iflogp(x|z=1)=−120andlogp(x|z=2)=−120,whatislogp(x)=log[p(x|z=1)+p(x|z=2)]?Answer:log[2e−120]=−120+log2.
• Ruleofthumb:neveruselogorexpbyitself
log
Pk e
bk
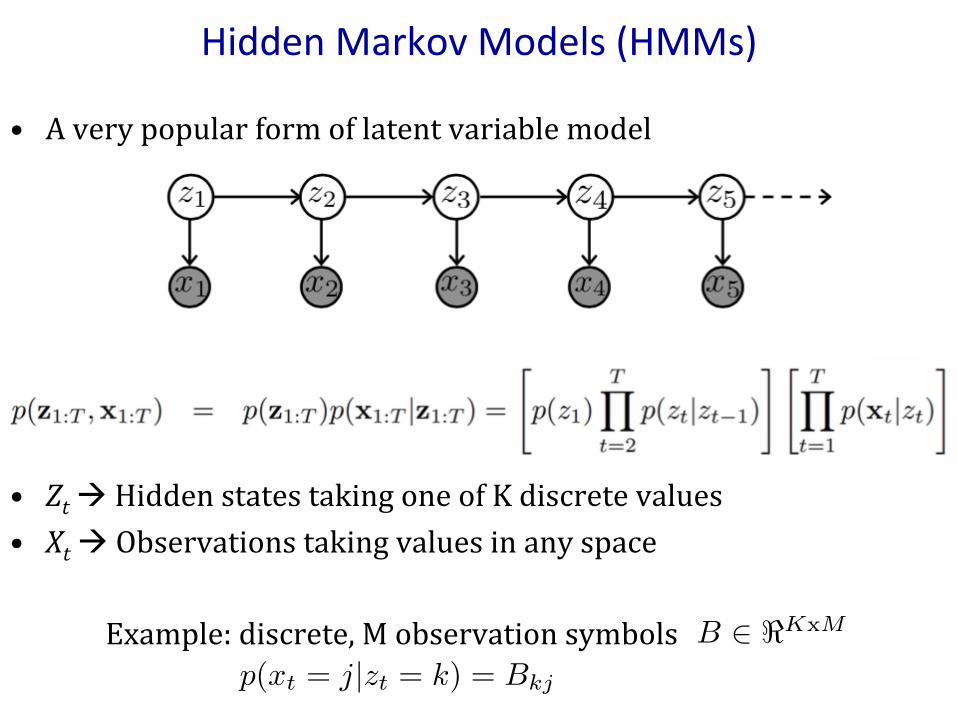
HiddenMarkovModels(HMMs)
• Averypopularformoflatentvariablemodel
• ZtàHiddenstatestakingoneofKdiscretevalues• XtàObservationstakingvaluesinanyspace
Example:discrete,MobservationsymbolsB 2 <KxM
p(xt = j|zt = k) = Bkj

InferenceinGraphicalModels
xEàObservedevidencevariables(subsetofnodes)xFàunobservedquerynodeswe’dliketoinferxRàremainingvariables,extraneoustothisquerybutpartofthegivengraphicalrepresentation
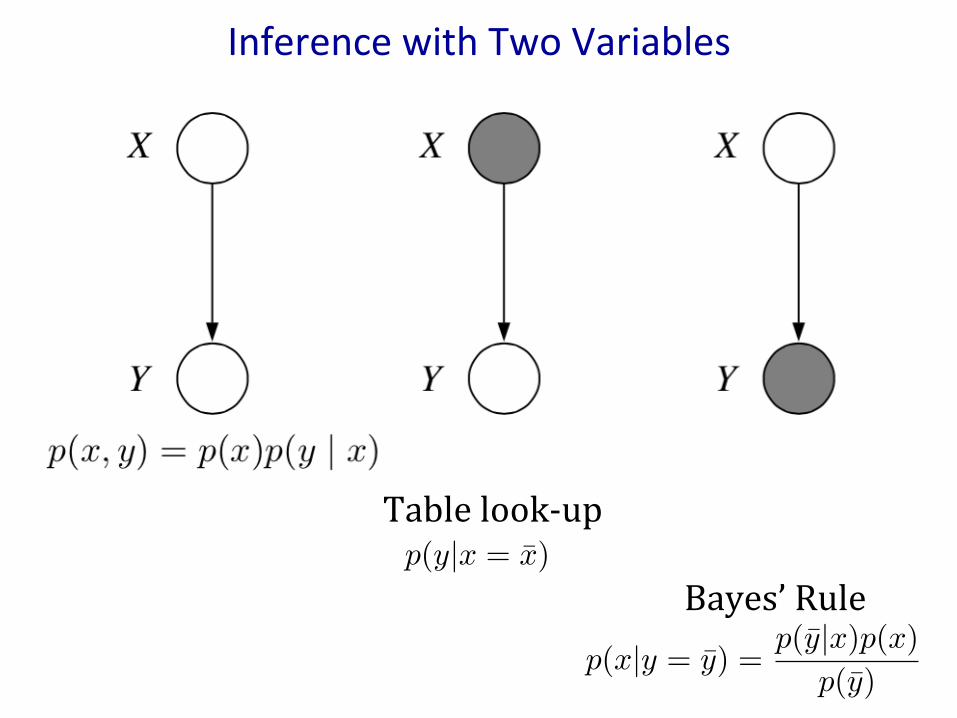
InferencewithTwoVariables
Tablelook-up
Bayes’Rulep(x|y = y) =
p(y|x)p(x)p(y)
p(y|x = x)
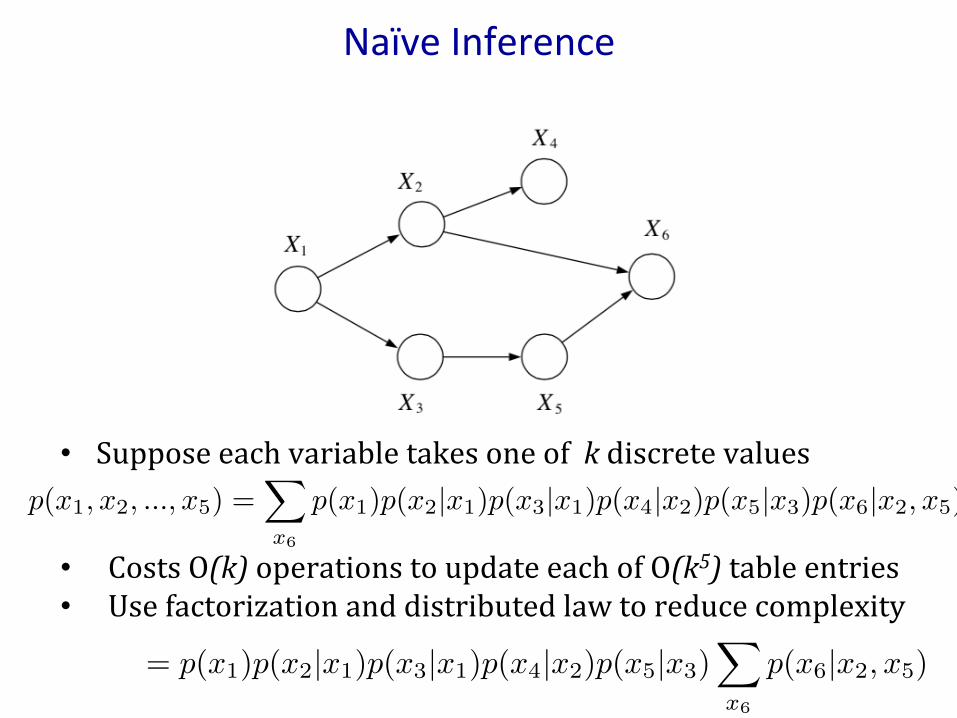
NaïveInference
• Supposeeachvariabletakesoneofkdiscretevalues
• CostsO(k)operationstoupdateeachofO(k5)tableentries• Usefactorizationanddistributedlawtoreducecomplexity
p(x1, x2, ..., x5) =X
x6
p(x1)p(x2|x1)p(x3|x1)p(x4|x2)p(x5|x3)p(x6|x2, x5)
= p(x1)p(x2|x1)p(x3|x1)p(x4|x2)p(x5|x3)X
x6
p(x6|x2, x5)

InferenceinDirectedGraphs
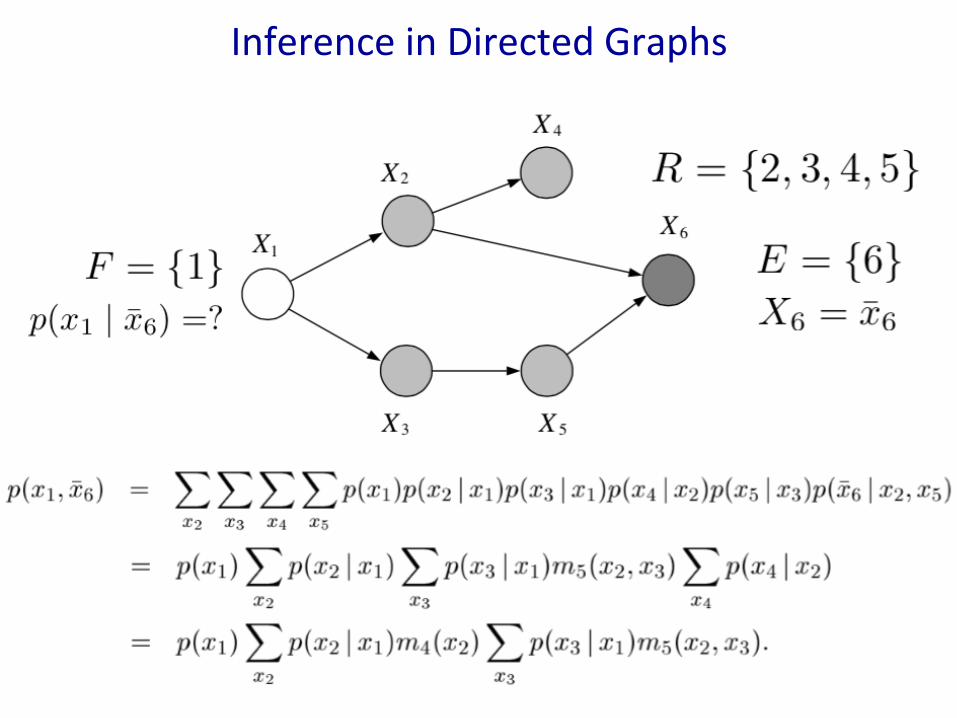
InferenceinDirectedGraphs

InferenceinDirectedGraphs

Learningoutcomes
• Whataspectsofamodelcanweexpressusinggraphicalnotation?
• Whichaspectsarenotcapturedinthisway?• Howdoindependencieschangeasaresultofconditioning?
• Reasonsforusinglatentvariables• Commonmotifssuchasmixturesandchains• Howtointegrateoutunobservedvariables

Ques7ons?
• Thursday:Tutorialonautomaticdifferentiation• Thisweek:Assignment1released





















![LATENT TREE MODELS: AN APPLICATION AND AN EXTENSIONlzhang/paper/pspdf/poon-thesis.pdf · Latent tree models (LTMs) [172] are a class of tree-structured probabilistic graphical models](https://img.pdfslide.us/doc/110x75/5f6bea25e6ded244784e94b3/latent-tree-models-an-application-and-an-lzhangpaperpspdfpoon-thesispdf-latent.jpg)







