Embed Size (px)
Citation preview

Lecture #2:Lecture #2:quantitative quantitative
regionalization and regionalization and cluster detection, cluster detection,
with special with special reference to local reference to local
statisticsstatistics
Spatial statistics in Spatial statistics in practicepractice
Center for Tropical Ecology and Center for Tropical Ecology and Biodiversity, Tunghai University & Fushan Biodiversity, Tunghai University & Fushan
Botanical GardenBotanical Garden

Topics for today’s lecture• Multivariate grouping, and location-allocation
modeling.
• Going from the global to the local: variability and heterogeneity.
• Impacts of spatial autocorrelation on histograms.
• The LISA and Getis-Ord statistics.
• Cluster analysis: multivariate analysis, cluster detection, and spider diagrams.
– An overview of geographic and space-time clusters.
• Regression diagnostics and geographic clusters

Multivariate grouping goals
• If groups are unknown, to identify the latent natural groups of areal units
• If groups are known, to assess similarities and differences among the groups
• To determine the group centroids and groups of geographical points that result from minimizing some function of standard distance

Conventional cluster analysis distances to minimize
• Single linkage – distances are measured between pairs of closest (nearest neighbor) areal units, one from each of two clusters, in attribute space
• Complete linkage – distances are measured between pairs of most distant (furthest neighbor) areal units, one from each of two clusters, in attribute space– This criterion often gives the best grouping
results

• Average linkage – distances are measured between all possible pairs of areal units, one from each of two clusters, in attribute space, and then averaged
• Centroid method – squared distances are measured between each areal unit and all cluster means, in attribute space
• Ward’s algorithm – based upon ANOVA, areal units are allocated to clusters in order to minimize within cluster variances, and maximize between cluster variance– This criterion relates to location-allocation

Contemporary cluster analysis criteria• One- or two-stage density – areal unit groupings are based
upon nonparametric probability density estimation (kth nearest neighbor, uniform kernel, Wong’s hybrid); utilizes single linkage
• EML (equal variance maximum likelihood) – areal unit groupings are based upon maximizing the likelihood of mixtures of identical spherical multivariate normal distributions, possibly with unequal mixing proportions (i.e., sampling probabilities)
• Flexible-beta – areal unit groupings are based upon a weighting involving scalar beta, which usually falls between 0 and -1 (a common default value is -0.25, with -0.5 appearing to be more suitable for data with many outliers)
• McQuitty’s method – areal unit groupings are based upon weighted average linkage, the weighted pair-group arithmetic averages
• Gower's median method – areal unit groupings are based upon weighted pair-group centroids, where distance may or may not be squared

Ward’s algorithm and location-allocation
jcluster toallocated is ilocation
notor er upon wheth depending 0/1, λ
j centroidfor coordinate theis )V,(U
ilocation for coordinate theis )v,(u
ilocation for weight theis w where
)V(v)U(uwλ :MIN
ij
jj
ii
i
P
1j
n
1i
2ji
2jiiij
LA
(weights) variable_FREQ_ awith
criterion) distance (standard variables vandu ecluster th
algorithm sWard'

Clustering with PCA/FA
• Although PCA & FA are used most frequently to deal with multicollinearity across attribute variables (R-mode), these techniques also can be used to handle redundant information across areal units (Q-mode; e.g., the eigenfunctions of geographic weight matrix C)
• Linear combinations extracted from matrix(I-11T/n)C(I-11T/n) or (I-11T/n)D*(I-11T/n)
identify the range of possible distinct map patterns (i.e., uncorrelated and orthogonal)

Legendre et al. method• A comparison of the two procedures is in
• Links directly to the semivariogram plot
• D* is a truncated distance-based matrix, where the truncation is determined by the length of a minimum spanning tree articulating the set of locations

jTj λn
MCC11
Ej is the map pattern with spatial autocorrelation level MCj
Properties
• The extreme eigenvalues define MCmax and MCmin (not necessarily 1, -1)
• As eigenvalues go from the largest positive to the largest negative value, map patterns become more fragmented
• Positive eigenvalues denote:– Global trends with relatively large values– Regional trends with intermediate values– Local trends with relatively small values

Selected ideal map patterns
MC ~ 1 MC = 0.9 MC = 0.7
MC = 0.5 MC = 0.25 MC = -0.6
global
local
regional
regional

SA impacts on Gaussian RVsPrincipal impact: variance inflation
SA map pattern:MC = 1.12, GR = 0.08
MC = 1.00GR = 0.18
MC = 0.00GR = 1.00
MC = 0.28GR = 0.77
heaviertails
increasedkurtosis
MCmax = 1.18
standardnormal curves

Unstandardized normal curve
Kurtosis increases from 0.01(roughly 0) to 0.73. The variance
of kurtosis is 24/n.Therefore, here spatialspatial
autocorrelation has inducedautocorrelation has inducedincreased relative peakednessincreased relative peakedness
(from the sign of the kurtosisstatistic) whose z = 7.3.
autoregressivegenerated
map patterngenerated
Kurtosis increases from 0.04(roughly 0) to 2.79. The variance
of kurtosis is 24/n.Therefore, here spatialspatial
autocorrelation has inducedautocorrelation has inducedincreased relative peakednessincreased relative peakedness
(from the sign of the kurtosisstatistic) whose z = 27.8.

Typical case: MC/MCmax = 0.6
map patternMC = 0.61GR = 0.50 map pattern
MC = 0.80GR = 0.34
attribute correlations
E3 0.004
E4 0.002 0
X E3
E(MC) = -0.00042E(GR) = 1

Torturing the data – conforming to a bell-shaped curve
1. Box-Cox power transformations
2. Manly’s exponential transformation
3. Percentage adjustments (also arcsine)
Transformations to normal approximations
0 γδ),LN(Y*Y
0 γ,δ)(YY* γ
γYeY*
δb)a)/(T(Y1
b)a)/(T(YLN

China data example: births/females
0.4344-15 0.04)(B/FY*

China data example: pop/area
279)LN(P/AY*

China data example: births/deaths
0.24B/DeY*

A China example: % F15-44
empirical probability mean min median max
F/P 0.247 0.193 0.247 0.416
(F+a)/(P+b) 0.270 0.216 0.257 0.407
(1-c)(F+a)/(P+b)+c 0.168 0.107 0.153 0.324
δb)a)/(T(Y1
b)a)/(T(YLN

Constant variance• Attribute: variable transformations often
stabilize the variance of a variable across its measurement range
• Mean/median split gives a heuristic assessment of constant variance (equal variability of high and low values)


Constant variance
• Geographic: variable transformations often stabilize the variance of a variable across the geographic landscape over which it is distributed
• Quadrants of the plane/established areal unit groupings give a heuristic assessment of constant variance across a geographic landscape
Plane quadrants provinces


Non-normal random variables (RVs)
• Poisson: the mean equals the variance (built-in heterogeneity)
– overdispersion: the variance is greater than the mean
– assuming a gamma-distributed mean results in a negative binomial random variable
• binomial: variance equals (1-p) times the mean [i.e., Np(1-p)]
– overdispersion: the variance is greater than Np(1-p)
– employ a quasi-likelihood estimation

overdispersion occurs when:
var(Y) >
weak positivespatial autocorrelation
strong positivespatial autocorrelation
Spatial autocorrelation impacts on Poisson RVs
iid
μ2.2512s
4.9560x
2.23615σ
5μ
2.5874s
4.9930x
6.9475s
5.0045x

Impacts of typical spatial autocorrelation levels
3.1007s
4.9914x
4.0098s
4.9875x
Poissonnessplots
hexagonaltessellation
irregulartessellation

• variance increases
• shape goes to uniform, then to sinusoidal
Spatial auto-correlation impacts
on binomial RVsglobal
global&
regional
global&
regional&
local
autoregressive

Paralleling statistics concerning data outliers, and leverage and influential points, spatial heterogeneity in georeferenced data is addressed by focusing on individual areal units. The emphasis shift is from global trends to local exceptions, to better understand local deviations from global model descriptions by exploiting tensions between global trends and informative local details latent in empirical data:
• adaptation of conventional diagnostic statistics (e.g., Unwin and Wrigley, 1987)
• spatializing existing statistical techniques (e.g., Fotheringham et al., 2002)
• Anselin’s (1995) seminal paper about indices of spatial association (i.e., LISA statistics)
• Getis and Ord’s (1992, 1995) Gi and Gi* statistics
Going from the global to the local

Goals of global versus local analysis
• Identify clustering • Identify particular clusters (significant
local clusters in the absence of global autocorrelation)
• distinguish between homogeneity and heterogeneity (e.g., spatial outliers - highs surrounded by lows, and vice versa)
• identify hot/cold spots• analyze local instability (local deviations
from global pattern of spatial autocorrelation)

LISA: local indicators of spatial autocorrelation
1)/n(n
zcz
c
1
)y(y
)y)(yy(yc
c
nMC
n
1i
n
1jjY,ijiY,
n
1i
n
1jij
n
1i
2i
n
1i
n
1jjiij
n
1i
n
1jij
ionrandomizat from VAR(LISA);1n
nE(LISA)
1)/n(n
zcz
:LISA
cn
z versuszc :tscatterploMoran
i
i
n
1jjY,ijiY,
n
1jiji
iY,
n
1jjY,ij
area competition
selevation

Goal: to assess spatial correlation heterogeneity
LISA z-score
color dark green
Light green
gray Light red
Dark red
# counties 16 2016 200 145 14z-score range -3.6 – 1.2 -1.2 – 3.25 3.25 – 6.4 6.4 – 9.6 9.6+
ANOVAF = 2845
Pr(>X2) = 0.4

The randomization perspective

Conditional randomization
iesprobabilit test multiple ]α)-(1 - [1 adjustedSidak
and/or /n)(α adjusted Bonferroni with z ofy probabilit thecompare :5 Step
s
1)/(nnzcz
z compute :4 Step
nsreplicatio R for the )(s variance then theand ,zcz I compute :3 Step
timesR scores-z 1)-(n remaining theof nselect randomly :2 Step
constant z hold :Step1
1/n
i
I
n
1jiijY,ijiY,
i
I
n
1jjY,ijiY,r
i
iY,
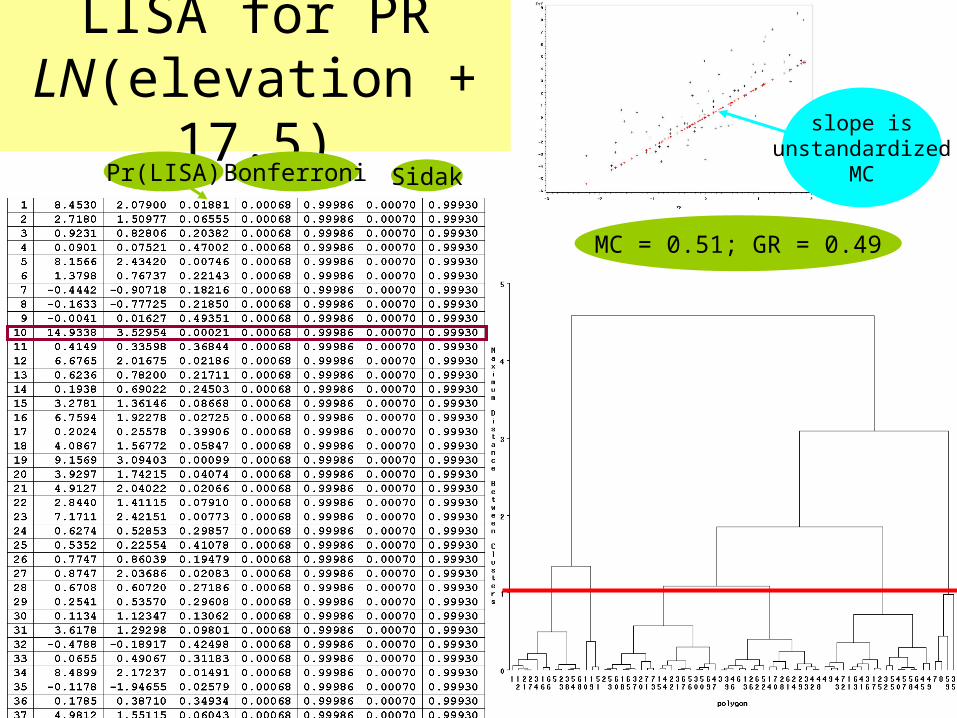
LISA for PR LN(elevation + 17.5)
MC = 0.51; GR = 0.49
Bonferroni SidakPr(LISA)
slope isunstandardized
MC

LISA maps
• Cannot distinguish between H-H and L-L clusters
• Conventional clustering fails to preserve contiguity
significant LISA

… with contiguity proclivity
Clustering geocoding coordinate pair coupled withcoupled with zLISA values
Clustering geocoding coordinate pair with frequencies proportional tofrequencies proportional to zLISA values

Getis-Ord Gi [ Gi* includes i (i.e., j = i)]
ij ,
2n
)(dc)(dc1)(n
s
)(dcy)y(dc
)(dG2
n
1jrij
n
1jr
2ij
(i)
n
1jrij(i)
n
1jjrij
ri
• contiguity based upon distance band defined by dr
• dr may be obtained from a semivariogram plot• one statistic for each areal unit
• Gi(dr) > 0 signifies clustering of high values• Gi(dr) < 0 signifies clustering of lows values• LISA fails to make this particular distinction
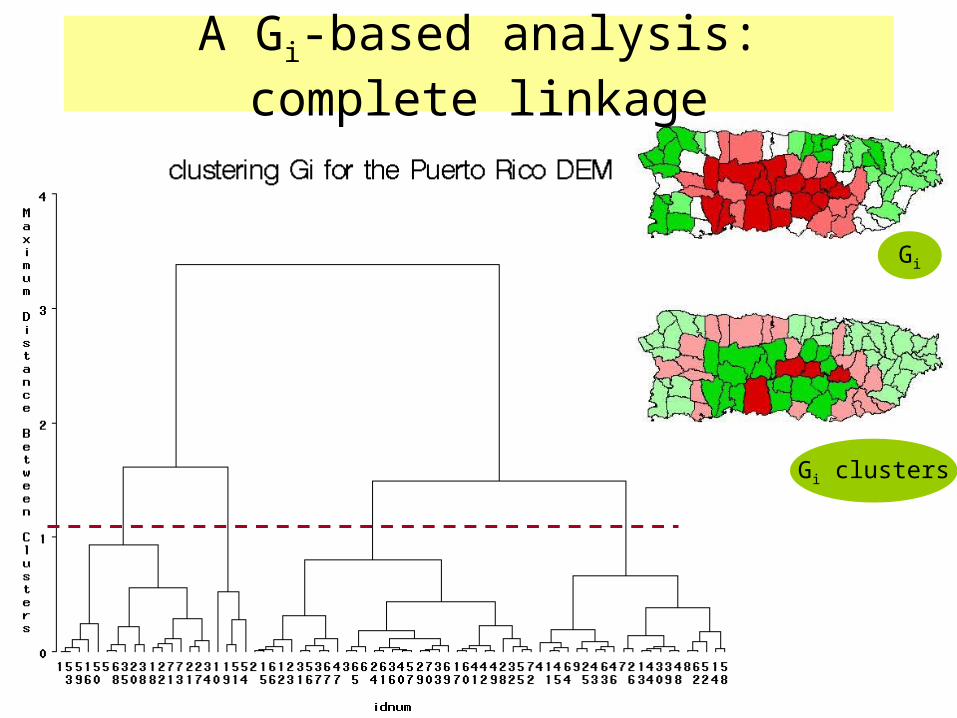
A Gi-based analysis: complete linkage
Gi
Gi clusters
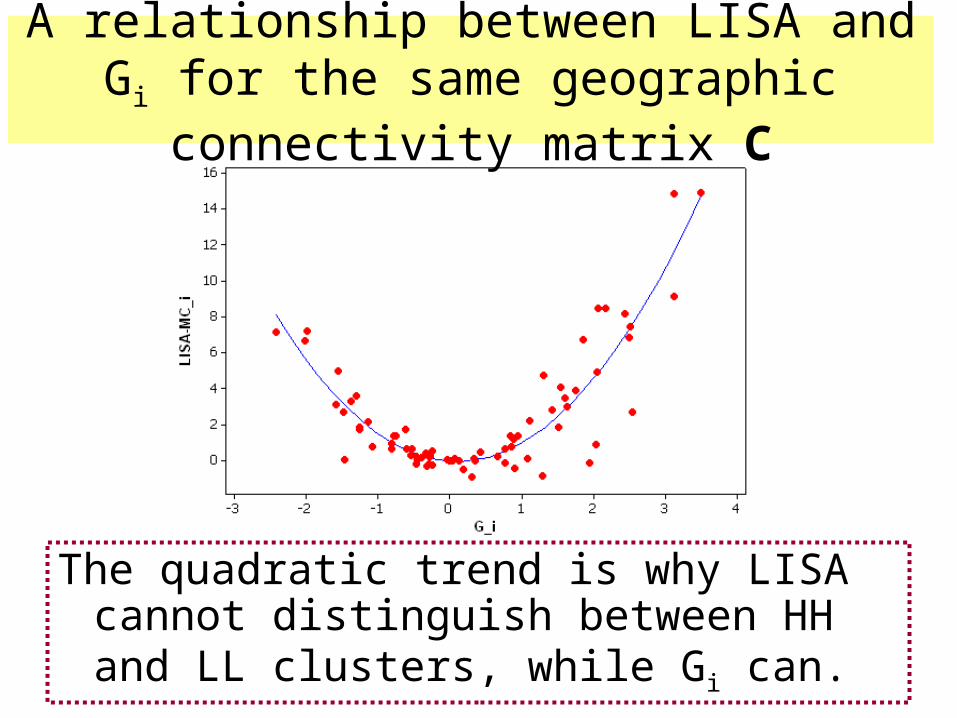
A relationship between LISA and Gi for the same geographic connectivity matrix C
The quadratic trend is why LISA cannot distinguish between HH and LL clusters, while Gi can.

geographic & space-time clusters: an overview
• Global cluster tests search for spatial clusters anywhere in a study area but do not necessarily identify where the clusters occur, and are used to identify departures from spatial randomness when overall spatial pattern is considered.
• Local cluster tests identify locations at which there is some excess/deficit—a hot/cold spot—anywhere within a study area.
• Focused cluster tests determine whether there is an excess near a pre-specified location, called a focus, and are used to detect clustering near, say, putative hazards (e.g., a toxic waste dump).

Cluster detection techniques

Spider diagrams
• allocation to AAR centroids
• allocation to cluster (U, V, z-LISA) centroids

Regression diagnostics: each observation’s influence
on parameter estimates and predicted values • PRESS – global measure that should roughly equal
the mean squared error (MSE) for a trend line (equivalent to cross-validation)
• Leverage – measures degree of influence of areal unit CzY,i value on an MC trend line (marked: > 2/n)
• Studentized residual – measures whether ith areal unit causes a significant shift in its corresponding regression intercept (i.e., is an outlier; marked: > 2)
• Cook’s D – measures influence of ith areal unit on an MC estimate (analogous to DFFITS;
marked: > 2 )n
1

Moran scatterplot for LN(elevation + 17.5)
1.97055PRESS/n
1.94759RMSE
marked values
Barranquitas is a spatialoutlier, again!
mean ofC1

Spatial autocorrelation in diagnostic statistics: eigenvector covariates
MC(E2) = 1.04926
zLISA H rstudentDFFITS
2 2 2* 2
4*
6
13
23
25 25
69
0.439 0.274 0.303 0.109
0.0014α * 0.01;α adj
R2MC = 1.04926
Dark red: very highLight red: highGray: medium
Light green: lowDark green: very low