Embed Size (px)
Citation preview

Lecture 2
Probabilityand what it has to do with
data analysis

Abstraction
Random variable, x
it has no set value, until you ‘realize’ it
its properties are described by a probability, P
pot of an infinite number of x’s
Drawing one x from the pot “realizes” x
One way to think about it
p(x)
x

Describing P
If x can take on only discrete values,
say (1, 2, 3, 4, or 5)
then a table would work:
x 1 2 3 4 5
P 10% 30% 40% 15% 5%
Probabilitiesshould sum to
100%
40% probability that x=4
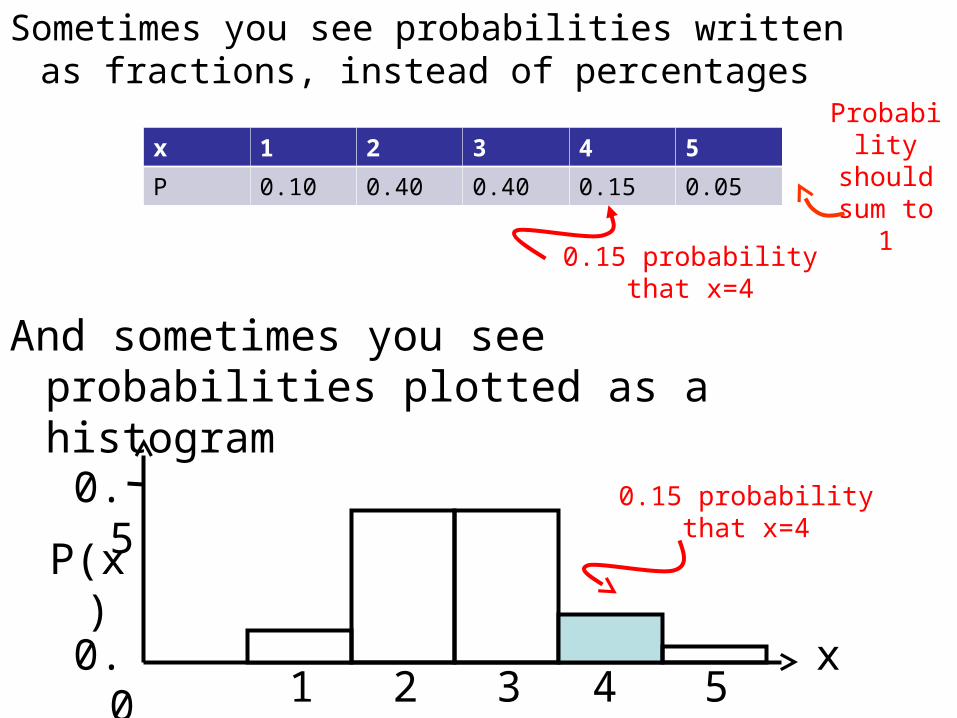
Sometimes you see probabilities written as fractions, instead of percentages
x 1 2 3 4 5
P 0.10 0.40 0.40 0.15 0.05
Probabilityshould sum
to 1
0.15 probability that x=4
x
P(x)
0.0
0.5
1 2 3 4 5
And sometimes you see probabilities plotted as a histogram
0.15 probability that x=4
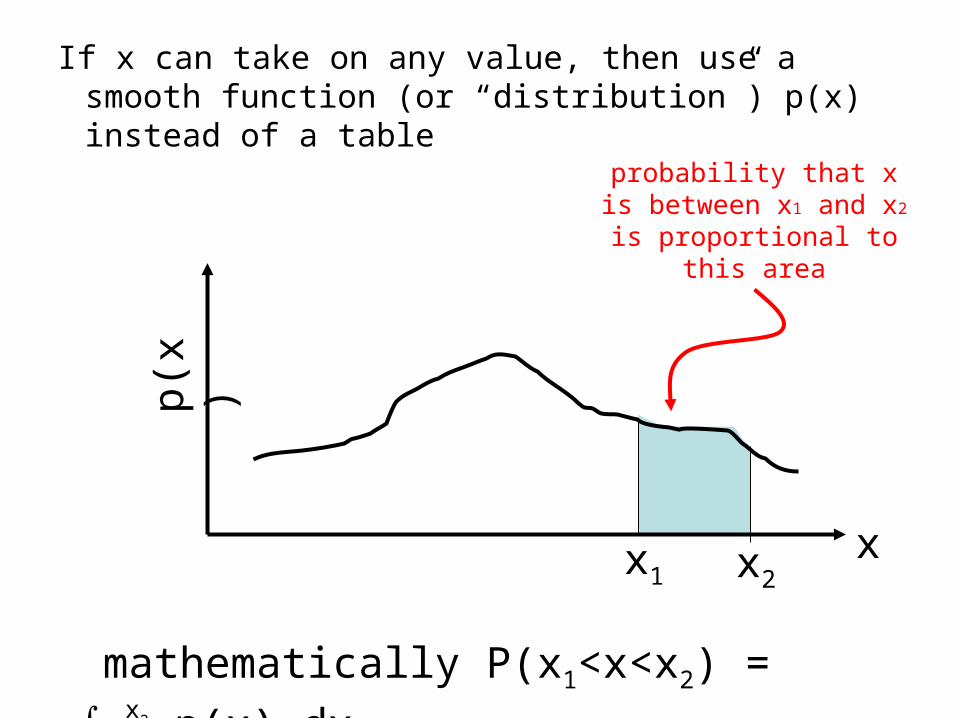
If x can take on any value, then use a smooth function (or “distribution”) p(x) instead of a table
p(x)
xx1 x2
probability that x is between x1 and x2 is proportional to
this area
mathematically P(x1<x<x2) = x1
x2 p(x) dx

p(x)
x
Probability that x is between - and + is 100%, so total area = 1
Mathematically -+ p(x) dx = 1

One Reason Why all this is relevant …
Any measurement of data that contains noise is treated as a random variable, d
and …

The distribution p(d) embodies both the ‘true value’ of the datum being measured and the measurement noise
and …

All quantities derived from a random variable are themselves random variables,
so …

The algebra of random variables allows you to understand how …
… measurement noise affects inferences made from the data

Basic Description of Distributions
want two basic numbers
1) something that describes what x’s commonly occur
2) something that describes the variability of the x’s

1) something that describes what x’s e commonly occur
that is, where the distribution is centered

p(x)
xxmode
Mode
x at which distribution has peak
most-likely value of x
peak

The most popular car in the US is the Honda CR-V
But the next car you see on the highway will probably not be a Honda CR-V
Where’s a CV-R?
Honda CV-R

But modes can be deceptive …p(
x)
xxmode
peak
0 10
x N0-1 31-2 182-3 113-4 84-5 115-6 146-7 87-8 78-9 119-10 9
Sure, the 1-2 range has the most counts, but most of the measurements are bigger than 2!
100 realizations of x

p(x)
xxmedian
Median
50% chance x is smaller than xmedian
50% chance x is bigger than xmedian
No special reason the median needs to coincide with the peak
50% 50%
P(x
)
x
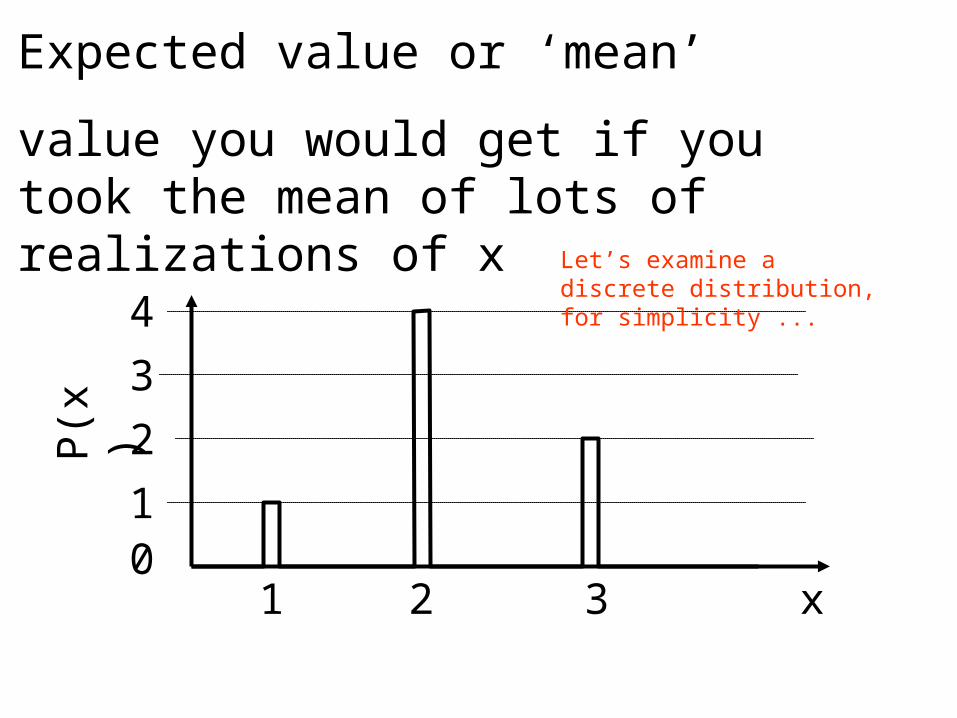
Expected value or ‘mean’
value you would get if you took the mean of lots of realizations of x
01
2
3
4
1 2 3
Let’s examine a discrete distribution, for simplicity ...

x N
1 20
2 80
3 40
Total 140
mean = [ 20 1 + 80 2 + 40 3 ] / 140
= (20/140) 1 + (80/140) 2 + (40/140) 3
= p(1) 1 + p(2) 2 + p(3) 3
= Σi p(xi) xi
Hypothetical table of 140 realizations of x

by analogyfor a smooth distribution
Expected (or mean) value of x
E(x) = -+ x p(x) dx

2) something that describes the variability of the x’s
that is, the width of the distribution
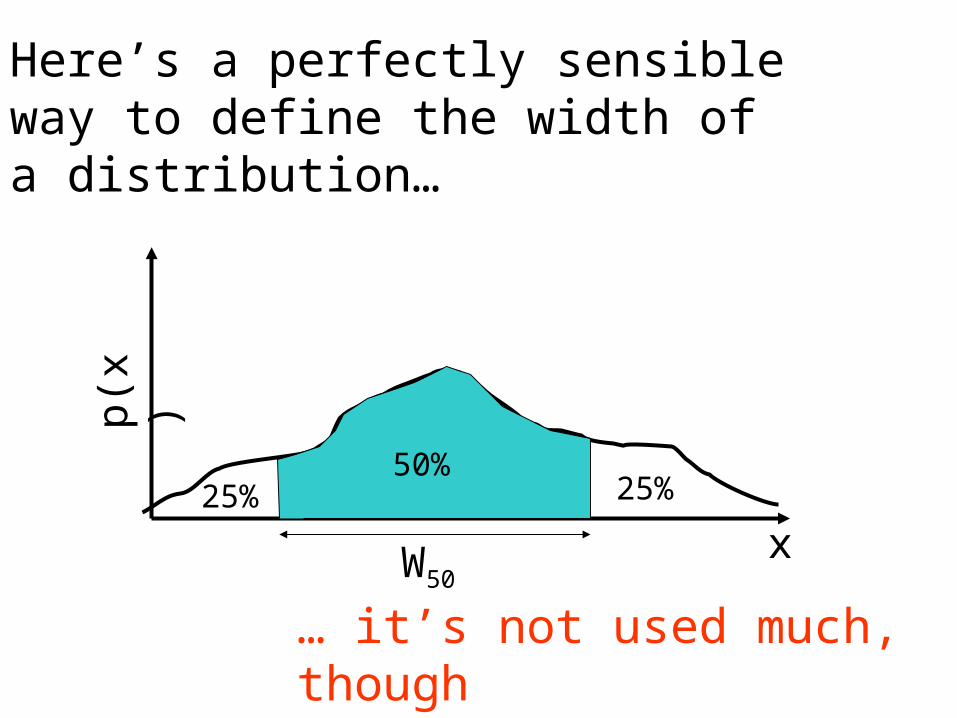
p(x)
x
Here’s a perfectly sensible way to define the width of a distribution…
50%25%25%
W50
… it’s not used much, though

p(x)
x
Width of a distribution
Here’s another way…
… multiply and integrate
E(x)
Parabola [x-E(x)]2

p(x)
x
Variance = 2 = -+ [x-E(x)]2 p(x) dx
E(x)
[x-E
(x)]
2
[x-E
(x)]
2 p(x
)
xE(x)
Compute this total area …
Idea is that if distribution is narrow, then most of the probability lines up with the low spot of the parabola
But if it is wide, then some of the probability lines up with the high parts of the parabola

p(x)
x
variance =
A measure of width …
we don’t immediately know its relationship to area, though …
E(x)

the Gaussian or normal distribution
p(x) = exp{ - (x-x)2 / 22 ) 1(2)
x is expected value
2 is variance
Memorize me !
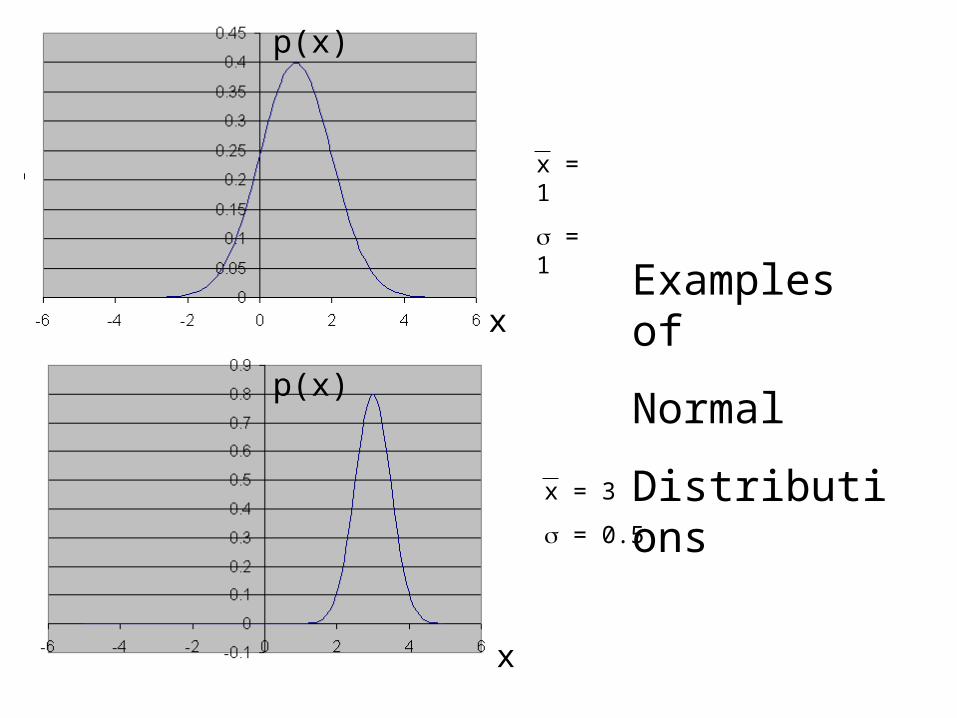
x = 1
= 1
x = 3
= 0.5
x
x
p(x)
p(x)
Examples of
Normal
Distributions
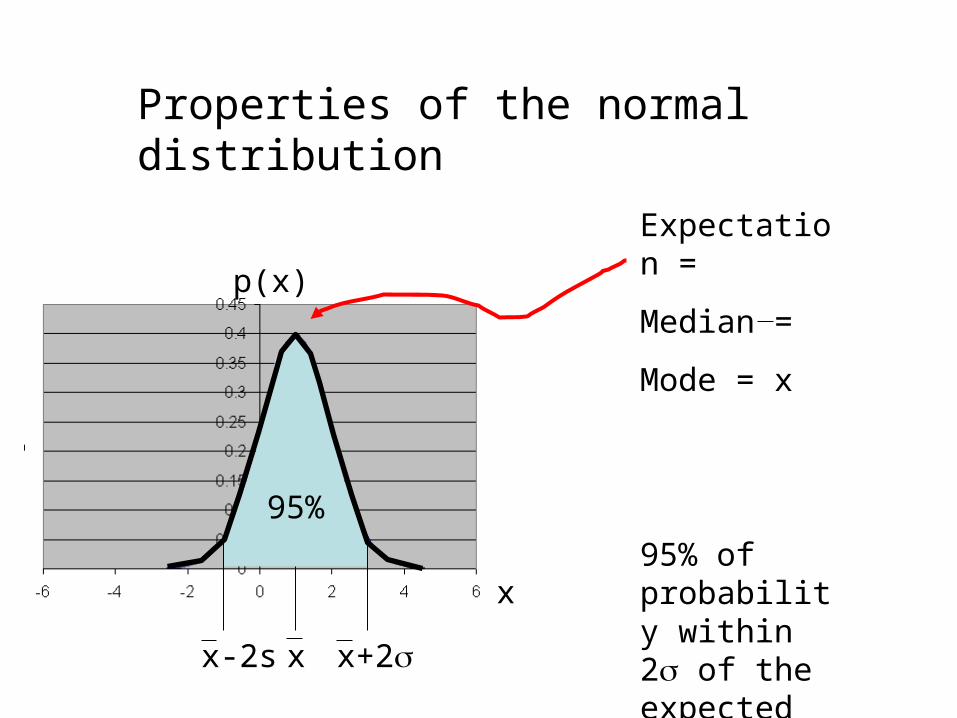
x
p(x)
x x+2x-2s
95%
Expectation =
Median =
Mode = x
95% of probability within 2 of the expected value
Properties of the normal distribution

Again, Why all this is relevant …
Inference depends on data …
You use measurement, d, to deduce the values of some underlying parameter of interest, m.
e.g.use measurements of travel time, d, to deduce the seismic velocity, m, of the earth

model parameter, m, depends on measurement, d
so m is a function of d, m(d)
so …

If data, d, is a random variable
then so is model parameter, m
All inferences made from uncertain data are themselves uncertain
Model parameters are described by a distribution, p(m)

Functions of a random variable
any function of a random variable is itself a random variable

Special case of a linear relationship and a normal distribution
Normal p(d) with mean d and variance 2d
Linear relationship m = a d + b
Normal p(m) with mean ad+b and variance a22
d

multivariate distributions

Example
Liberty island is inhabited by both pigeons and seagulls
40% of the birds are pigeonsand 60% of the birds are gulls
50% of pigeons are white and 50% are grey100% of gulls are white

Two variables
species s takes two values
pigeon p
and gull g
color c takes two values
white w
and tan t
Of 100 birds,
20 are white pigeons
20 are grey pigeons
60 are white gulls
0 are grey gulls
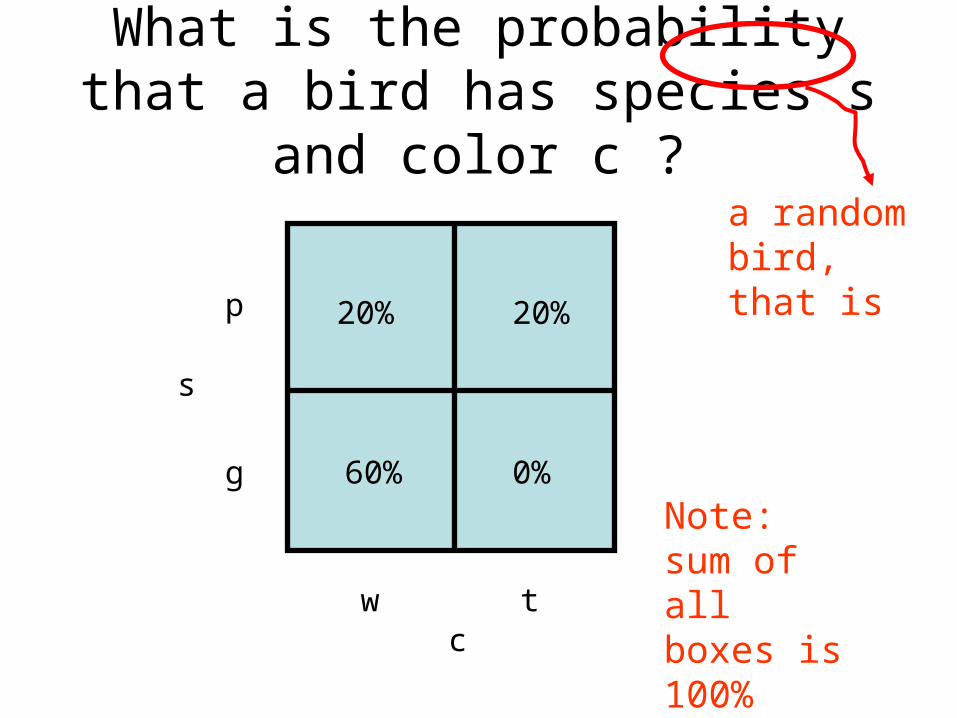
What is the probability that a bird has species s and color c ?
cw t
p
g
s
20% 20%
60% 0%
Note: sum of all boxes is 100%
a random bird, that is

This is called theJoint Probability
and is written
P(s,c)

Two continuous variablessay x1 and x2
have a joint probability distributionand written
p(x1, x2)
with p(x1, x2) dx1 dx2 = 1

You would contour a joint probability distribution
and it would look something like
x2
x1

What is the probability that a bird has color c ?
cw t
p
g
s
20% 20%
60% 0%
start with P(s,c)
80% 20%
and sum columns
To get P(c)
Of 100 birds,
20 are white pigeons
20 are grey pigeons
60 are white gulls
0 are grey gulls

What is the probability that a bird has species s ?
cw t
p
g
s
20% 20%
60% 0%
start with P(s,c)
60%
40%
and sum rows
To get P(s)
Of 100 birds,
20 are white pigeons
20 are grey pigeons
60 are white gulls
0 are grey gulls

These operations make sense with distributions, too
x2
x1
x2
x1
x1
p(x1)
p(x1) = p(x1,x2) dx2
x2
p(x2)
p(x2) = p(x1,x2) dx1
distribution of x1
(irrespective of x2)distribution of x2
(irrespective of x1)

Given that a bird is species swhat is the probability that it has color c ?
cw t
p
g
s
50% 50%
100% 0%
Note, all rows sum to 100
Of 100 birds,
20 are white pigeons
20 are grey pigeons
60 are white gulls
0 are grey gulls

This is called theConditional Probability of c given s
and is writtenP(c|s)
similarly …

Given that a bird is color cwhat is the probability that it has species s ?
cw t
p
g
s
25% 100%
75% 0%
Note, all columns sum to 100
Of 100 birds,
20 are white pigeons
20 are grey pigeons
60 are white gulls
0 are grey gulls
So 25% of white birds are pigeons

This is called theConditional Probability of s given c
and is written
P(s|c)
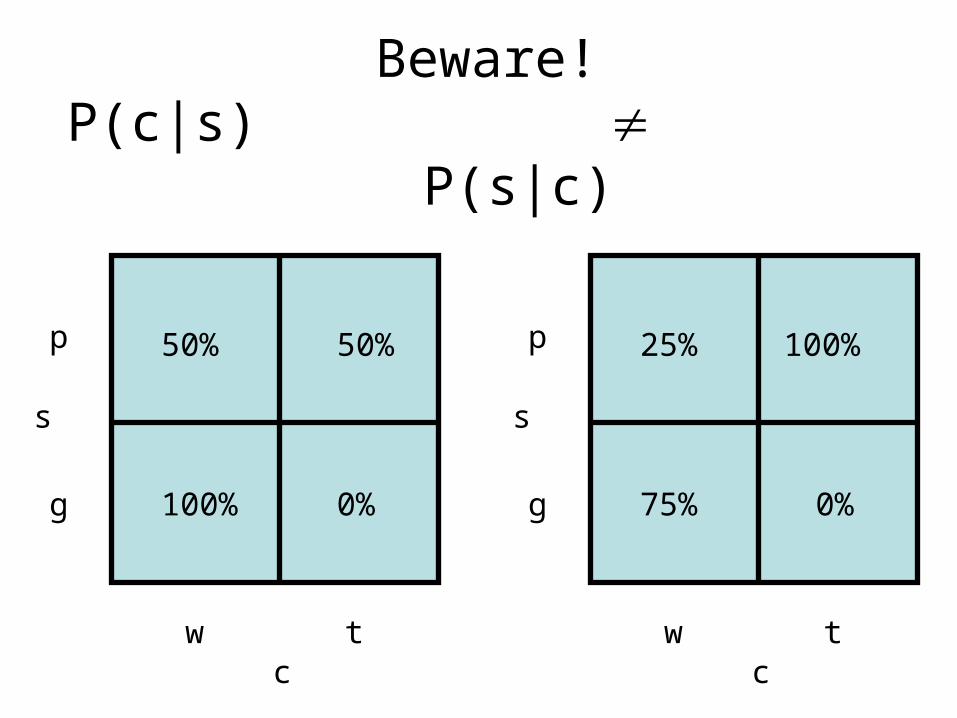
Beware!P(c|s) P(s|c)
cw t
p
g
s
50% 50%
100% 0%
cw t
p
g
s
25% 100%
75% 0%

Actor Patrick Swaysepancreatic cancer victim
Lot of errors occur from confusing the two:
Probability that, if you have pancreatic cancer, that you
will die from it
90%
Probability that, if you die, you will have died of
pancreatic cancer
1.4%
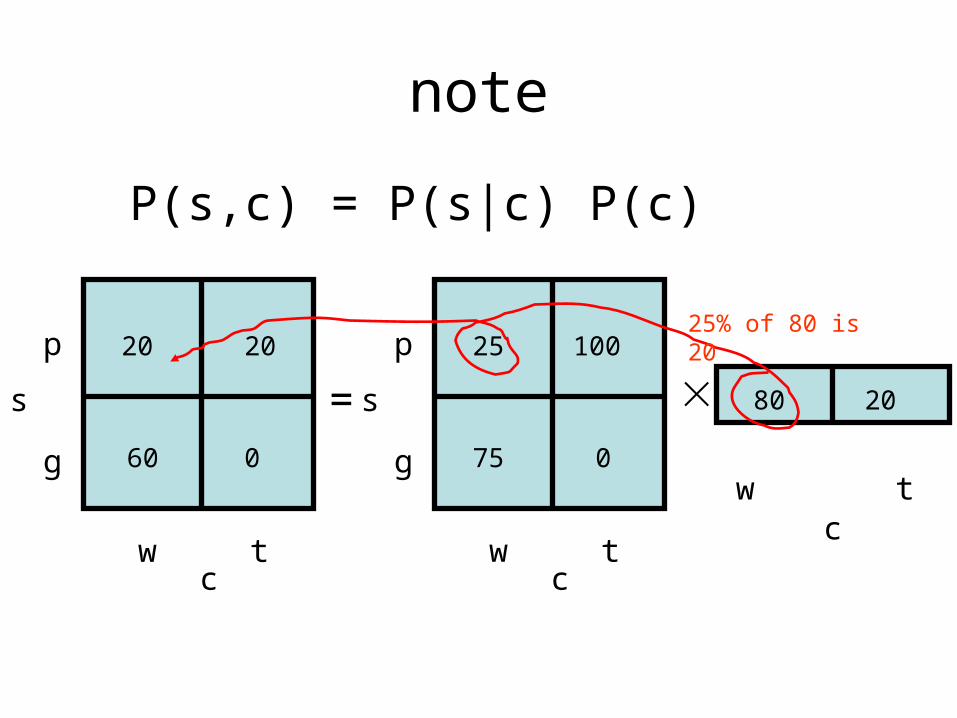
note
P(s,c) = P(s|c) P(c)
cw t
p
g
s
20 20
60 0
cw t
p
g
s
25 100
75 0
= 80 20
cw t
25% of 80 is 20

and
P(s,c) = P(c|s) P(s)
cw t
p
g
s
20 20
60 0
=
cw t
p
g
s
50 50
100 0 60
40p
g
s
50% of 40 is 20

and if
P(s,c) = P(s|c) P(c) = P(c|s) P(s)
then
P(s|c) = P(c|s) P(s) / P(c)
and
P(c|s) = P(s|c) P(c) / P(s)
… which is called Bayes Theorem

In this example
bird color is the observable, the “data”
bird species is the “model parameter”
P(c|s) “color given species” or P(d|m) is
“making a prediction based on the model”Given a pigeon, what the probability that it’s grey?
P(s|c), “species given color” or P(m|d) is
“making an inference from the data”Given a grey bird, what the probability that it’s a pigeon?

Why Bayes Theorem is important
It provides a framework for relating
making a prediction from the model, P(d|m)
to
making an inference from the data, P(m|d)

Bayes Theorem also implies that the joint distribution of data and model parameters
p(d, m)
is the fundamental quantity
If you know p(d, m), you know everything there is to know …

Expectation
Variance
And
Covariance
Of a multivariate distribution
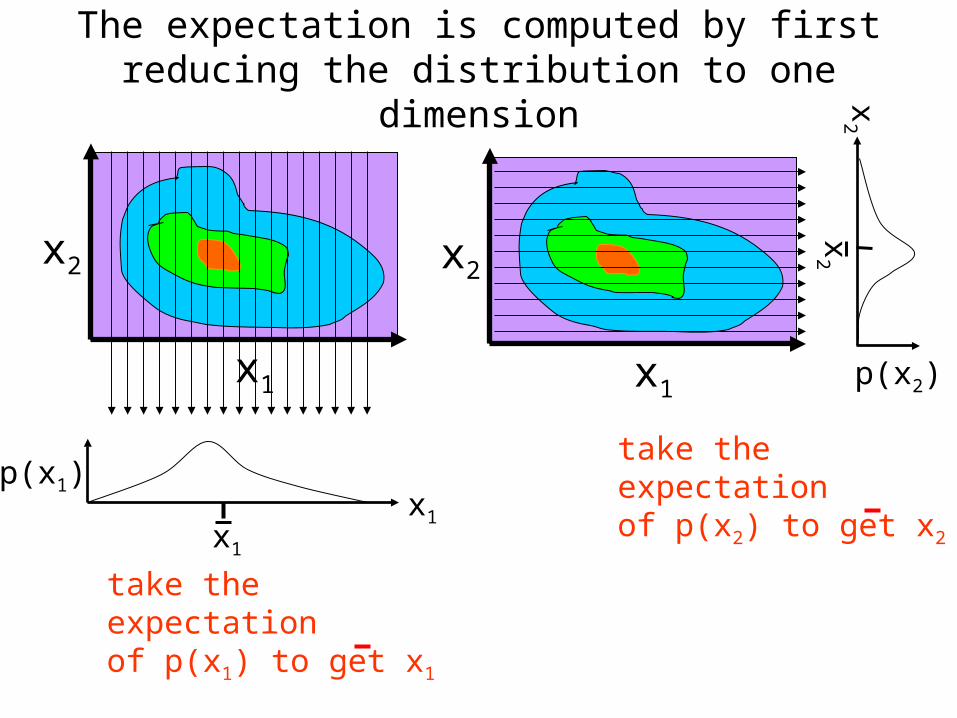
The expectation is computed by first reducing the distribution to one dimension
x2
x1
x2
x1
x1
p(x1)
x2
p(x2)
take theexpectationof p(x1) to get x1
x1
x2
take theexpectationof p(x2) to get x2

The varaince is also computed by first reducing the distribution to one dimension
x2
x1
x2
x1
x1
p(x1)
x2
p(x2)
take thevarianceof p(x1) to get 1
2
x1
x2
take thevarianceof p(x2) to get 2
2
1
2

Note that in this distributionif x1 is bigger than x1, then x2 is bigger than x2 and if x1 is smaller than x1, then x2 is smaller than x2
x2
x1Expected value
x1
x2
This is a
positive correlation

Conversely, in this distributionif x1 is bigger than x1, then x2 is smaller than x2 and if x1 is smaller than x1, then x2 is smaller than x2
x2
x1Expected value
x1
x2
This is a
negative correlation
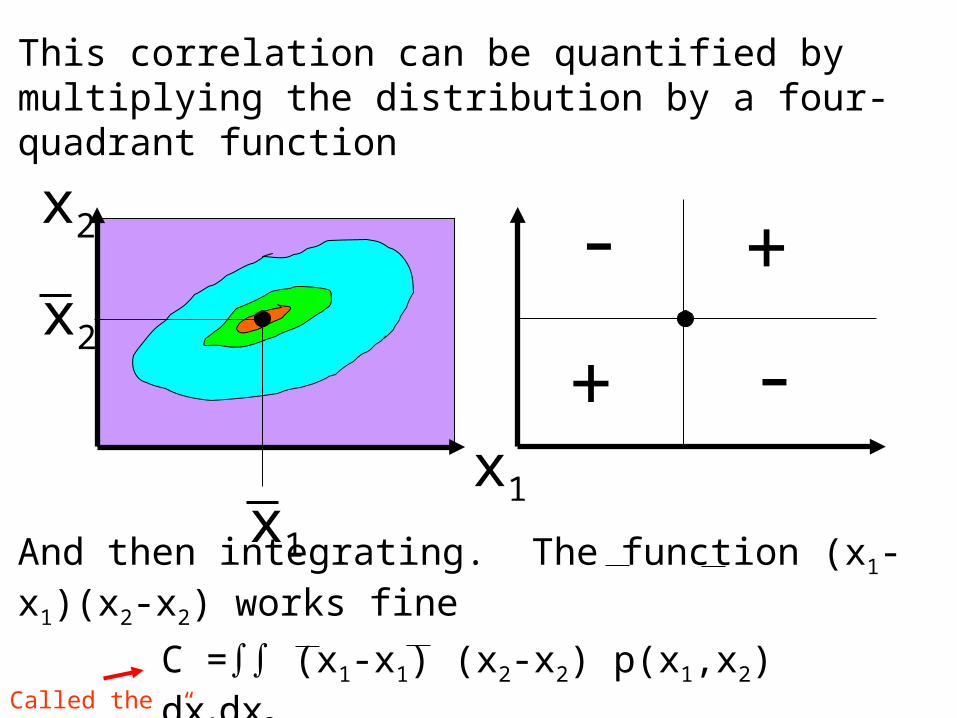
This correlation can be quantified by multiplying the distribution by a four-quadrant function
x2
x1
x1
x2
+
+ -
-
And then integrating. The function (x1-x1)(x2-x2) works fine
C = (x1-x1) (x2-x2) p(x1,x2) dx1dx2Called the “covariance”

Note that the matrix C with elements
Cij = (xi-xi) (xj-xj) p(x1,x2) dx1dx2
has diagonal elements of xi2 the variance of xi
andoff-diagonal elements of cov(xi,xj) the covariance of xi and xj
C =
12 cov(x1,x2) cov(x1,x3)
cov(x1,x2) 22 cov(x2,x2)
cov(x1,x3) cov(x2,x2) 32

The “vector of means” of multivatiate distribution
x
and the “Covariance matrix” of multivariate distribution
Cx
summarized a lot – but not everything –about a multivariate distribution

Functions of a set of random variables, x
A vector of of N random variables in a vector, x

Special Case
linear function y=Mx
the expectation of y is
y=Mx
Memorize!

the covariance of y is
So Cy = M Cx MT
Memorize!

Note that these rules work regardless of the distribution of x
if y is linearly related to x, y=Mx then
y=Mx (rule for means)
Cy = M Cx MT
(rule for propagating error)
Memorize!





























