Embed Size (px)
Citation preview

ECE 451/566 - Intro. to Parallel & Distributed Prog.
1
ECE-451/ECE-566 - Introduction to Parallel and Distributed Programming
Lecture 2: Parallel ArchitecturesLecture 2: Parallel Architectures and Programming Models
Department of Electrical & Computer Engineering
Rutgers University
Machine Architectures andMachine Architectures and Interconnection Networks

ECE 451/566 - Intro. to Parallel & Distributed Prog.
2
Architecture SpectrumShared-Everything
S t i M lti– Symmetric MultiprocessorsShared Memory– NUMA, CC-NUMA
Distributed Memory– DSM, Message Passing
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 3
Shared-Nothing– Clusters, NOW’s
Client/Server
Pros and ConsShared Memory
P– Pros flexible, easier to program
– Consnot scalable, synchronization/coherency issues
Distributed Memory– Pros
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 4
osscalable
– Consdifficult to program, require explicit message passing

ECE 451/566 - Intro. to Parallel & Distributed Prog.
3
Conventional ComputerConsists of a processor executing a program stored in a (main) memory:
Main memory
Processor
Instructions (to processor)Data (to or from processor)
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 5
Each main memory location located by its address. Addresses start at 0 and extend to 2b - 1 when there are b bits (binary digits) in address.
Shared Memory Multiprocessor System
Natural way to extend single processor model - have multiple processors connected to multiple memory modules, such that each processor can access any memory module
Interconnectiont k
Memory modulesOneaddressspace
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 6
Processors
network
ECE 451/566 - Intro. to Parallel & Distributed Prog.
4
Simplistic view of a small shared memory multiprocessor
Processors Shared memory
Examples:Dual Pentiums
Bus
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 7
Quad Pentiums
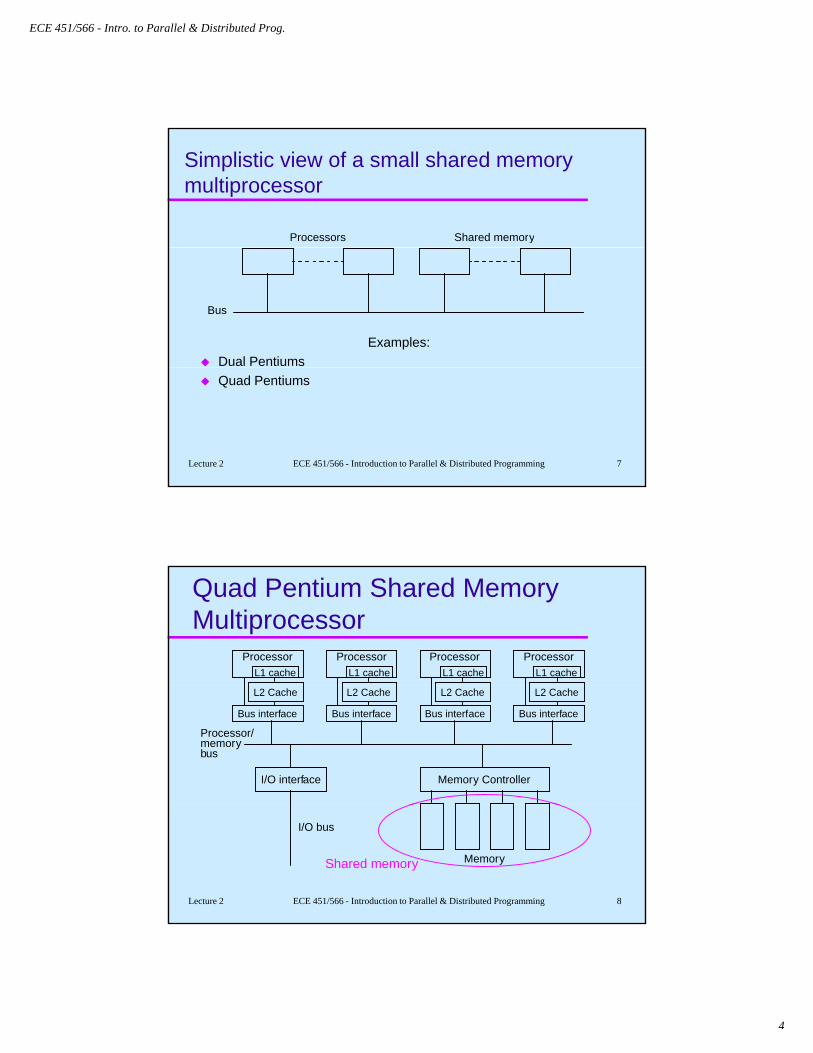
Quad Pentium Shared Memory Multiprocessor
ProcessorL1 cache
ProcessorL1 cache
ProcessorL1 cache
ProcessorL1 cache
L2 Cache
Bus interface
L2 Cache
Bus interface
L2 Cache
Bus interface
L2 Cache
Bus interface
Memory ControllerI/O interface
Processor/memorybus
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 8
Memory
I/O bus
Shared memory

ECE 451/566 - Intro. to Parallel & Distributed Prog.
5
Programming Shared Memory MultiprocessorsUse:
Threads - programmer decomposes program into individual parallel sequences, (threads) each being able to access variables declared outside threads(threads), each being able to access variables declared outside threads.
Example PthreadsSequential programming language with preprocessor compiler directives to declare shared variables and specify parallelism.
Example OpenMP - industry standard - needs OpenMP compilerSequential programming language with added syntax to declare shared variables and specify parallelism.
Example UPC (Unified Parallel C) - needs a UPC compiler.
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 9
Example UPC (Unified Parallel C) needs a UPC compiler.Parallel programming language with syntax to express parallelism - compiler creates executable code for each processor (not now common)Sequential programming language and ask parallelizing compiler to convert it into parallel executable code. - also not now common
Distributed Shared Memory Making main memory of group of interconnected computers
look as though a single memory with single address space.g g y g pShared memory programming techniques can then be used.
Processor
Interconnectionnetwork
Messages
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 10
Shared
Computers
memory

ECE 451/566 - Intro. to Parallel & Distributed Prog.
6
Message-Passing MulticomputerComplete computers connected through an
interconnection network
Processor
Interconnectionnetwork
Messages
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 11
Local
Computers
memory
Interconnection NetworksLimited and exhaustive interconnections2 d 3 di i l h2- and 3-dimensional meshesHypercube (not now common)Using Switches– Crossbar– Trees– Multistage interconnection networks
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 12

ECE 451/566 - Intro. to Parallel & Distributed Prog.
7
Two-dimensional array (mesh)Links Computer/
processor
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 13
Also three-dimensional - used in some large high performance systems.
Three-dimensional hypercube
110 111
010 011
100 101
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 14
000 001

ECE 451/566 - Intro. to Parallel & Distributed Prog.
8
Four-dimensional hypercube
1110
0000 0001
0010 0011
0100
0110
0101
0111
1000 1001
1010 1011
1100
1110
1101
1111
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 15
Hypercubes popular in 1980’s - not now
0001 00
Crossbar switch
Memories
SwitchesProcessors
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 16

ECE 451/566 - Intro. to Parallel & Distributed Prog.
9
Tree
R t
Switchelement
Root
Links
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 17
Processors
Multistage Interconnection NetworkExample: Omega network
2 × 2 switch elements(straight-through or
crossover connections)
000001
010011
000001
010011
Inputs Outputs
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 18
100101
110111
100101
110111

ECE 451/566 - Intro. to Parallel & Distributed Prog.
10
Taxonomy ofTaxonomy of HPC Architectures
Taxonomy of Architectures
Flynn (1966) created a simple classification f t b d b ffor computers based upon number of instruction streams and data streams– SISD - conventional– SIMD - data parallel, vector computing– MISD - systolic arrays
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 20
– MIMD - very general, multiple approaches.Current focus on MIMD model, using general purpose processors or multicomputers

ECE 451/566 - Intro. to Parallel & Distributed Prog.
11
HPC Architecture Examples SISD - mainframes, workstations, PCs. SIMD Shared Memory Vector machines CraySIMD Shared Memory - Vector machines, Cray... MIMD Shared Memory - Sequent, KSR, Tera, SGI, SUN.SIMD Distributed Memory - DAP, TMC CM-2... MIMD Distributed Memory - Cray T3D, Intel, Transputers, TMC CM-5, plus recent workstation clusters (IBM SP2, DEC, Sun, HP).Note: Modern sequential machines are not purely SISD – advanced
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 21
Note: Modern sequential machines are not purely SISD advanced RISC processors use many concepts from vector and parallel architectures (pipelining, parallel execution of instructions, prefetching of data, etc) in order to achieve one or more arithmetic operations per clock cycle.
SISD : A Conventional Computer
Instruc
Si l t i l t f i t ti
ProcessorData Input Data Output
ctions
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 22
Single processor computer - single stream of instructions generated from program. Instructions operate upon a single stream of data items.Speed is limited by the rate at which computer can transfer information internally.
e.g. PC, Macintosh, Workstations

ECE 451/566 - Intro. to Parallel & Distributed Prog.
12
The MISD ArchitectureInstructionStream A
InstructionStream B
Data InputStream
Data OutputStream
ProcessorA
ProcessorB
Stream BInstruction Stream C
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 23
More of an intellectual exercise than a practical configuration. Few built, but commercially not available
ProcessorC
Single Instruction Stream-Multiple Data Stream (SIMD) Computer
A specially designed computer - a single instructionA specially designed computer a single instruction stream from a single program, but multiple data streams exist.Single source program written and each processor executes its personal copy of this program, although independently and not in synchronism.Developed because a number of important applications th t tl t f d t
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 24
that mostly operate upon arrays of data.Source program can be constructed so that parts of the program are executed by certain computers and not others depending upon the identity of the computer.

ECE 451/566 - Intro. to Parallel & Distributed Prog.
13
SIMD ArchitectureInstruction
Stream
ProcessorA
ProcessorB
Data Inputstream A
Data Inputstream B
Data Outputstream A
Data Outputstream B
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 25
e.g. CRAY machine vector processing, Thinking machine cm*
Ci<= Ai * Bi
ProcessorCData Input
stream C
Data Outputstream C
Multiple Instruction Stream-Multiple Data Stream (MIMD) Computer
General-purpose multiprocessor system. Each processor has a separate program and one instructionprocessor has a separate program and one instruction stream is generated from each program for each processor. Each instruction operates upon different data
Program Program
InstructionsInstructions
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 26
Processor
Data
Processor
Data

ECE 451/566 - Intro. to Parallel & Distributed Prog.
14
MIMD ArchitectureInstructionStream A
InstructionStream B
InstructionStream C
ProcessorA
ProcessorB
Processor
Data Inputstream A
Data Inputstream B
Data Outputstream A
Data Outputstream B
Data Output
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 27
Unlike SISD, MISD, MIMD computer works asynchronously.» Shared memory (tightly coupled) MIMD» Distributed memory (loosely coupled) MIMD
ProcessorCData Input
stream C
Data Outputstream C
Shared Memory MIMD machineComm: Source PE writes data to GM &
destination retrieves it Easy to build conventional OSes of
ProcessorA
ProcessorB
ProcessorCEasy to build, conventional OSes of
SISD can be easily be portedLimitation : reliability & expandability. A memory component or any processor failure affects the whole system.Increase of processors leads to memory contention
MEMORY
BUS
MEMORY
BUS
A B C
MEMORY
BUS
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 28
memory contention.E.g. : SGI machines.... Global Memory System

ECE 451/566 - Intro. to Parallel & Distributed Prog.
15
Distributed Memory MIMDIPC
channelIPC
channel
Communication : IPC on HighSpeed Network.Network can be configured to... Tree, Mesh, Cube, etc.Unlike Shared MIMD
easily/ readily expandableHighly reliable (any CPU
MEMORY
BUS
ProcessorA
ProcessorB
ProcessorC
MEMORY
BUS
MEMORY
BUS
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 29
Highly reliable (any CPU failure does not affect the whole system)
MemorySystem A
MemorySystem B
MemorySystem C
Towards Cluster andTowards Cluster and Distributed Computing

ECE 451/566 - Intro. to Parallel & Distributed Prog.
16
Parallel Processing Paradox
Time required to develop a parallel application for solving GCA is equal to:
– Half Life of Parallel Supercomputers.
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 31
An Alternative Supercomputing Resource
Vast numbers of under utilised workstations il bl tavailable to use.
Huge numbers of unused processor cycles and resources that could be put to good use in a wide variety of applications areas.Reluctance to buy Supercomputer due to th i t d h t lif
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 32
their cost and short life span.Distributed compute resources “fit” better into today's funding model.

ECE 451/566 - Intro. to Parallel & Distributed Prog.
17
Networked Computers as a Computing Platform
A network of computers became a very attractive alternative to p yexpensive supercomputers and parallel computer systems for high-performance computing in early 1990’s.
Several early projects. Notable:
– Berkeley NOW (network of workstations) project.
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 33
– NASA Beowulf project. (Will look at this one later)
Key advantagesVery high performance workstations and PCs readily available at low costavailable at low cost.
The latest processors can easily be incorporated into the system as they become available.
Existing software can be used or modified.
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 34

ECE 451/566 - Intro. to Parallel & Distributed Prog.
18
Software Tools for ClustersBased upon Message Passing Parallel Programming
Parallel Virtual Machine (PVM) - developed in late 1980’s. Became very popular.
Message-Passing Interface (MPI) - standard defined in 1990s.
Both provide a set of user-level libraries for message passing.
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 35
Use with regular programming languages (C, C++, ...).
Beowulf Clusters*A group of interconnected “commodity” computers achieving high performance with low costachieving high performance with low cost.
Typically using commodity interconnects - high speed Ethernet, and Linux OS.
* Beowulf comes from name given by NASA Goddard
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 36
Space Flight Center cluster project.

ECE 451/566 - Intro. to Parallel & Distributed Prog.
19
Cluster Interconnects
Originally fast Ethernet on low cost clustersg yGigabit Ethernet - easy upgrade path
More Specialized/Higher PerformanceMyrinet - 2.4 Gbits/sec - disadvantage: single vendorcLanSCI (Scalable Coherent Interface)
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 37
( )QNetInfiniband - may be important as infininband interfaces may be integrated on next generation PCs
Dedicated cluster with a master node
Dedicated Cluster User
Switch
Master node
Compute nodes
Up link
2nd Ethernetinterface
External network
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 38

ECE 451/566 - Intro. to Parallel & Distributed Prog.
20
Scalable Parallel Computers
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 39
Design Space of Competing Computer Architecture
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 40
ECE 451/566 - Intro. to Parallel & Distributed Prog.
21
Machine and Programming ModelsMachine and Programming Models applied to Parallel Systems
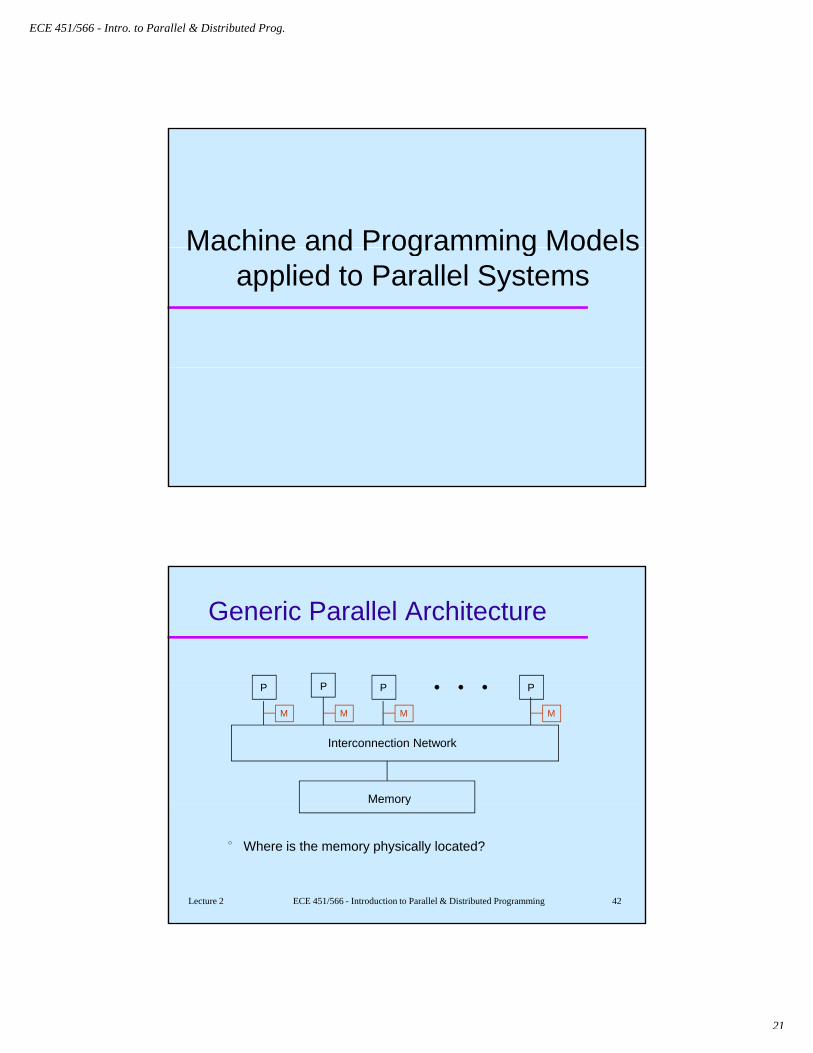
Generic Parallel Architecture
P P P PP P P P
Interconnection Network
M M MM
Memory
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 42
° Where is the memory physically located?
y

ECE 451/566 - Intro. to Parallel & Distributed Prog.
22
Parallel Programming Models
Control– How is parallelism created?p– What orderings exist between operations?– How do different threads of control synchronize?
Data– What data is private vs. shared?– How is logically shared data accessed or communicated?
Operations
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 43
Operations– What are the atomic operations?
Cost– How do we account for the cost of each of the above?
Trivial Example
Parallel Decomposition:
f A ii
n
( [ ] )=
−
∑0
1
a a e eco pos t o– Each evaluation and each partial sum is a task.
Assign n/p numbers to each of p processors– Each computes independent “private” results and partial sum.– One (or all) collects the p partial sums and computes the global sum.
Two Classes of Data: – Logically Shared
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 44
– Logically Shared» The original n numbers, the global sum.
– Logically Private» The individual function evaluations.» What about the individual partial sums?

ECE 451/566 - Intro. to Parallel & Distributed Prog.
23
Programming Model 1: Shared Address Space
Program consists of a collection of threads of controlEach has a set of private variables, e.g. local variables on the stack.C ll ti l ith t f h d i bl t ti i bl h dCollectively with a set of shared variables, e.g., static variables, shared common blocks, global heapThreads communicate implicitly by writing and reading shared variablesThreads coordinate explicitly by synchronization operations on shared variables -- writing and reading flags, locks or semaphoresLike concurrent programming on a uniprocessor
Address:
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 45
iressPPP
iress. . .
x = ...y = ..x ...
Shared
Private
Machine Model 1: Shared Memory Multiprocessor
Processors all connected to a large shared memory“Local” memory is not (usually) part of the hardware
P1 P2 Pn
$ $ $
oca e o y s ot (usua y) pa t o t e a d a e– Sun, DEC, Intel SMPs in Millennium, SGI Origin
Cost: much cheaper to access data in cache than in main memory
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 46
network
memory

ECE 451/566 - Intro. to Parallel & Distributed Prog.
24
Shared Memory Code for Computing a Sum
Thread 1 Thread 2
[s = 0 initially]local_s1= 0for i = 0, n/2-1
local_s1 = local_s1 + f(A[i])s = s + local_s1
[s = 0 initially]local_s2 = 0for i = n/2, n-1
local_s2= local_s2 + f(A[i])s = s +local_s2
What could go wrong?
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 47
Pitfall and Solution via Synchronization° Pitfall in computing a global sum s = local_s1 + local_s2:
Thread 1 (initially s=0)load s [from mem to reg]
Thread 2 (initially s=0)
s = s+local_s1 [=local_s1, in reg]store s [from reg to mem]
Time
load s [from mem to reg; initially 0]s = s+local_s2 [=local_s2, in reg]store s [from reg to mem]
° Instructions from different threads can be interleaved arbitrarily.° What can final result s stored in memory be?° Problem: race condition.° Possible solution: mutual exclusion with locks
Thread 1 Thread 2
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 48
Thread 1lockload ss = s+local_s1store sunlock
Thread 2lockload ss = s+local_s2store sunlock
° Locks must be atomic (execute completely without interruption).

ECE 451/566 - Intro. to Parallel & Distributed Prog.
25
Programming Model 2: Message PassingProgram consists of a collection of named processes.Thread of control plus local address space -- NO shared data.Local variables, static variables, common blocks, heap.pProcesses communicate by explicit data transfers -- matching send and receive pair by source and destination processors.Coordination is implicit in every communication event.Logically shared data is partitioned over local processes.Like distributed programming – program with MPI, PVM.
send P0,X
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 49PPP
iress. . .
iress
recv Pn,Y
XYA: A:
n0 1
Machine Model 2: Distributed MemoryCray XT, IBM SP2, BlueGene, Roadrunner, NOW, etc.Each processor is connected to its own memory and cache ac p ocesso s co ected to ts o e o y a d cac e
but cannot directly access another processor’s memoryEach “node” has a network interface (NI) for all
communication and synchronization
P1
memory
NI P2
memory
NI Pn NI
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 50
interconnect
memory memory memory. . .

ECE 451/566 - Intro. to Parallel & Distributed Prog.
26
Computing s = x(1)+x(2) on each processor
Processor 1 Processor 2i t 1
° First possible solution:
send xlocal, proc2[xlocal = x(1)]
receive xremote, proc2s = xlocal + xremote
receive xremote, proc1send xlocal, proc1
[xlocal = x(2)]s = xlocal + xremote
° Second possible solution -- what could go wrong?
Processor 1 Processor 2
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 51
send xlocal, proc2[xlocal = x(1)]
receive xremote, proc2s = xlocal + xremote
send xlocal, proc1[xlocal = x(2)]
receive xremote, proc1s = xlocal + xremote
° What if send/receive acts like the telephone system? The post office?
Programming Model 3: Data ParallelSingle sequential thread of control consisting of parallel operationsParallel operations applied to all (or a defined subset) of a data structureC i ti i i li it i ll l t d “ hift d” d tCommunication is implicit in parallel operators and “shifted” data structuresElegant and easy to understand and reason aboutLike marching in a regimentUsed by Matlab, Accelerators, GPUs, etc.Drawback: not all problems fit this model
A:
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 52
A:
fA:f
sum
A = array of all datafA = f(A)s = sum(fA)
s:

ECE 451/566 - Intro. to Parallel & Distributed Prog.
27
Machine Model 3: SIMD SystemA large number of (usually) small processors.A single “control processor” issues each instruction.Each processor executes the same instructionEach processor executes the same instruction.Some processors may be turned off on some instructions.Machines are not popular (CM2), but programming model isApplicable to emerging accelerators (GPGPUs, CellBE, etc.)
control processor
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 53
interconnect
P1
memory
NI P2
memory
NI Pn
memory
NI
. . .
Machine Model 4: Clusters of SMPsSince small shared memory machines (SMPs) are the
fastest commodity machine, why not build a larger machine by connecting many of them with a network?CLUMP = Cluster of SMPs.Shared memory within one SMP, but message passing
outside of an SMP.Two programming models:
– Treat machine as “flat”, always use message passing, even within SMP
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 54
Treat machine as flat , always use message passing, even within SMP (simple, but ignores an important part of memory hierarchy).
– Expose two layers: shared memory and message passing (usually higher performance, but ugly to program).

ECE 451/566 - Intro. to Parallel & Distributed Prog.
28
Programming Model 4: Bulk SynchronousUsed within the message passing or shared memory
models as a programming convention.models as a programming convention.Phases are separated by global barriers:– Compute phases: all operate on local data (in distributed memory) or read
access to global data (in shared memory).– Communication phases: all participate in rearrangement or reduction of
global data.
Generally all doing the “same thing” in a phase:
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 55
y g g– all do f, but may all do different things within f.
Features the simplicity of data parallelism, but without the restrictions of a strict data parallel model.
Summary So FarHistorically, each parallel machine was unique, along with
its programming model and programming languageIt was necessary to throw away software and start over with
each new kind of machine – ugh !!!Now we distinguish the programming model from the
underlying machine, so we can write portably correct codes that run on many machines
– MPI now the most portable option, but can be tedious
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 56
Writing portably fast code requires tuning for architecture– Algorithm design challenge is to make this process easy– Example: picking a block size, not rewriting whole algorithm

ECE 451/566 - Intro. to Parallel & Distributed Prog.
29
Steps in Writing p gParallel Programs
Creating a Parallel ProgramIdentify work that can be done in parallel.
Partition work and perhaps data among logical processesPartition work and perhaps data among logical processes (threads).
Manage the data access, communication, synchronization.
Goal: maximize speedup due to parallelismSpeedupprob(P procs) = Time to solve prob with “best” sequential solution
Time to solve prob in parallel on P processors<= P (?)
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 58
<= P (?)Efficiency(P) = Speedup(P) / P
<= 1
° Key question is when you can solve each piece:• statically, if information is known in advance.• dynamically, otherwise.
ECE 451/566 - Intro. to Parallel & Distributed Prog.
30
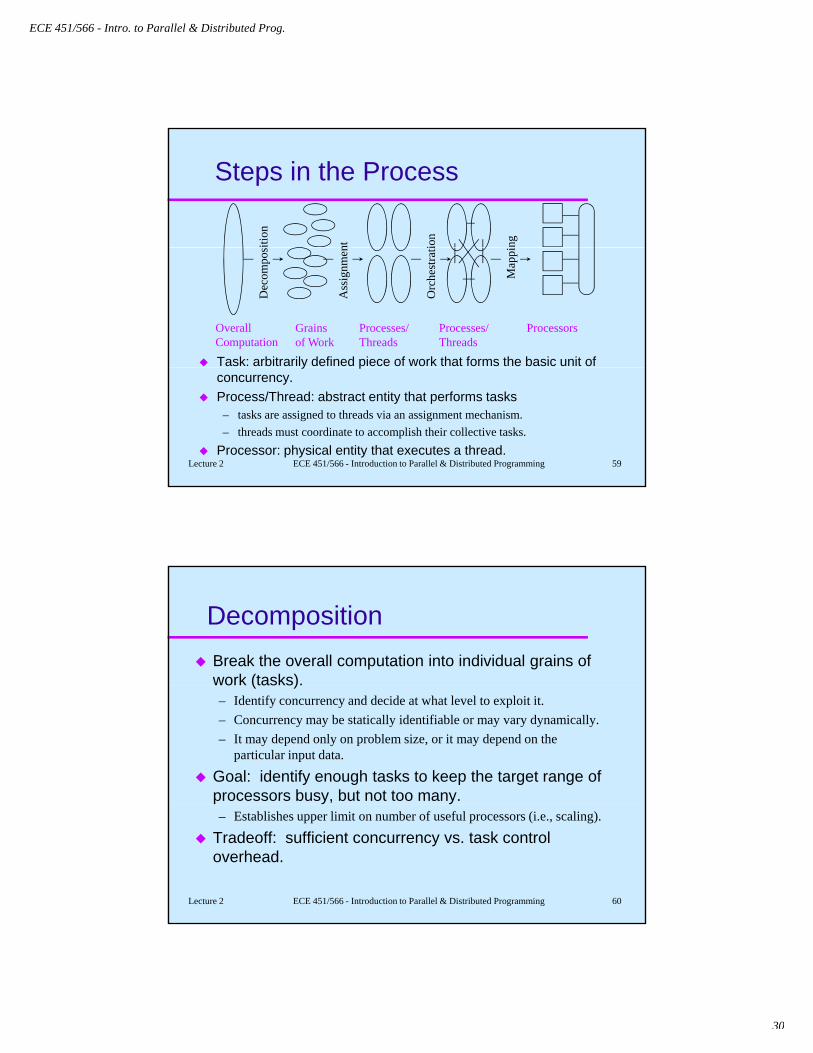
Steps in the Process
ition
nt ion
ng
Task: arbitrarily defined piece of work that forms the basic unit of
OverallComputation
Dec
ompo
s
Grainsof Work
Ass
ignm
enProcesses/Threads
Orc
hest
rati
Processes/Threads
Map
pi
Processors
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 59
y pconcurrency.Process/Thread: abstract entity that performs tasks– tasks are assigned to threads via an assignment mechanism.– threads must coordinate to accomplish their collective tasks.
Processor: physical entity that executes a thread.
DecompositionBreak the overall computation into individual grains of work (tasks).work (tasks).– Identify concurrency and decide at what level to exploit it.– Concurrency may be statically identifiable or may vary dynamically.– It may depend only on problem size, or it may depend on the
particular input data.
Goal: identify enough tasks to keep the target range of processors busy, but not too many.
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 60
– Establishes upper limit on number of useful processors (i.e., scaling).
Tradeoff: sufficient concurrency vs. task control overhead.

ECE 451/566 - Intro. to Parallel & Distributed Prog.
31
AssignmentDetermine mechanism to divide work among threads– Functional partitioning:
A i l i ll di ti t t f k t diff t th d i li i» Assign logically distinct aspects of work to different thread, e.g. pipelining.– Structural mechanisms:
» Assign iterations of “parallel loop” according to a simple rule, e.g. proc j gets iterates j*n/p through (j+1)*n/p-1.
» Throw tasks in a bowl (task queue) and let threads feed.– Data/domain decomposition:
» Data describing the problem has a natural decomposition.k h d d i k i d i h i f
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 61
» Break up the data and assign work associated with regions, e.g. parts of physical system being simulated.
Goals:– Balance the workload to keep everyone busy (all the time).– Allow efficient orchestration.
OrchestrationProvide a means of – Naming and accessing shared data.– Communication and coordination among threads of control.
Goals:– Correctness of parallel solution -- respect the inherent dependencies
within the algorithm.– Avoid serialization.
R d t f i ti h i ti d t
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 62
– Reduce cost of communication, synchronization, and management. – Preserve locality of data reference.

ECE 451/566 - Intro. to Parallel & Distributed Prog.
32
MappingBinding processes to physical processors.Time to reach processor across network does not depend on which processor (roughly)which processor (roughly).– lots of old literature on “network topology”, no longer so important.
Basic issue is how many remote accesses.
Proc
Cache
Proc
Cachefast
l
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 63
Memory Memory
Network
slowreallyslow
Examples = f(A[1]) + … + f(A[n])f(A[1]) + … + f(A[n])DecompositionDecomposition
i h f(A[j])i h f(A[j])–– computing each f(A[j])computing each f(A[j])–– nn--fold parallelism, where n may be >> pfold parallelism, where n may be >> p–– computing sum scomputing sum s
AssignmentAssignment–– thread k sums sthread k sums skk = f(A[k*n/p]) + … + f(A[(k+1)*n/p= f(A[k*n/p]) + … + f(A[(k+1)*n/p--1]) 1]) –– thread 1 sums s = sthread 1 sums s = s11+ … + s+ … + spp (for simplicity of this example)–– thread 1 communicates s to other threadsthread 1 communicates s to other threads
Lecture 2 ECE 451/566 - Introduction to Parallel & Distributed Programming 64
Orchestration Orchestration – starting up threads– communicating, synchronizing with thread 1
MappingMapping– processor j runs thread j

















![HFSS tutorial[2nd draft] - emlab.uiuc.eduemlab.uiuc.edu/ece451/HFSS_tutorial_451.pdf · ANSYS HFSS is an industry standard tool for simulating 3-D full-wave electromagnetic fields](https://img.pdfslide.us/doc/110x75/5d17ed7888c9933b0b8bce20/hfss-tutorial2nd-draft-emlabuiuc-ansys-hfss-is-an-industry-standard-tool.jpg)











