Embed Size (px)
Citation preview

Lecture 1
Huma Israr

Reference Books
1. “Distributed Database Systems” (2nd Edition) by
T.M.,Ozsu, P. Valdusiez
2. “Distributed Database Systems”. By D. Bell, J.
Grimson, Addison-Wesley, 1992
3. Distributed Systems: Concepts and Design, 4th
Edition, by G. Coulouris, J. Dollimore,
T.Kindberg, Addison-Wesley

Prerequisites
Database Management Systems,
Computer Networks

Approach to the course
Introduction to database and Distributed Systems in
general
Architectures and Design Issues of DDBS
Theoretical Aspects of the topic
Technological Treatment

Important term to be revised
Data.
Recorded fact & Figure
Database:
A collection of logically related data.
Distribution.
The act of dispersing

A distributed database (DDB)
A distributed database (DDB) is combination of two contrasting technologies database system computer network.
A distributed database (DDB) is a collection of multiple, logically interrelated databases distributed over a computer network.

Distributed Database Management system
A distributed database management system (D–DBMS) is the software that manages the DDB and provides an access mechanism that makes this distribution transparent to the users.

Strategies of distribution Data replication
Copies of data distributed to different sites
Horizontal partitioning Different rows of a table distributed to different sites
Vertical partitioning Different columns of a table distributed to different sites
Combinations of the above

Replication strategies
Synchronous All copies of the same data are always identical
Data updates are immediately applied to all copies throughout network
Good for data integrity
High overhead slow response times
Asynchronous Some data inconsistency is tolerated
Data update propagation is delayed
Lower data integrity
Less overhead faster response time

User access database via application
Two types of application
Local
Global
Local application do not required data from remote site
Global app required data from remote site

Decentralized database system: A collection of
independent databases on non-networked computers.
Centralized database system: with network
Distributed database system: distributed database
(DDB) is a collection of logically interrelated databases
over computer network.
Distributed computing system: A number of
autonomous processing elements that are connected
through a computer network and that cooperate in
performing their assigned tasks

Types of DDBS
Homogenous DDBS
All sites have identical s/w
Are aware of each other
Appear to user as single database
Heterogeneous DDBS
Use different schema and s/w
Schema difference is problem for query processing
S/w difference for transaction processing
May not aware of each other may provide limited facility.

Advantages
Reduced Communication Overhead Most data access is local, less expensive and performs
better.
Improved Processing Power Instead of one server handling the full database, we now
have a collection of machines handling the same database.
Removal of Reliance on a Central Site If a server fails, then the only part of the system that is
affected is the relevant local site. The rest of the system remains functional and available.

Advantages conti……. Expandability
It is easier to accommodate increasing the size of the global (logical) database.
Local autonomy
Local site can operate with its database when network connections fail . Each site controls its own data, security, logging, recovery.
Location Transparency
User does not have to know the location of the data. Data requests automatically forwarded to appropriate site
Backups,

Disadvantages Architectural complexity.
Cost.
Security.
Integrity control more difficult.
Lack of experience.
Database design more complex.
Software cost and complexity
Slower response for certain queries

Distributed DBMS Vendors Oracle
Microsoft
Informix
Sybase
IBM
Computer Associates
Ingress
Others……

Lecture 2
Huma Israr

Centralized DBMS on a Network
Site 5
Site 1
Site 2
Site 3 Site 4
Communication
Network

Distributed DBMS Environment
Site 5
Site 1
Site 2
Site 3 Site 4
Communication
Network

Distributed DBMS Promises
Transparent management of distributed, fragmented, and replicated data
Improved reliability/availability through distributed transactions
Improved performance
Easier and more economical system expansion

Transparency:
Transparency is the separation of the higher level semantics of a system
from the lower level implementation issues.
A transparent system “hides” the implementation details from the users.
1. Network (distribution) transparency
2. Replication transparency
3. Fragmentation transparency
horizontal fragmentation:
vertical fragmentation:
hybrid

Distributed Database - User View
Distributed Database

Distributed DBMS - Reality
Communication Subsystem
User Query
DBMS Software
DBMS Software
User Application
DBMS Software
User Application User
Query DBMS
Software
User Query
DBMS Software

Network (distribution) transparency
Network/Distribution transparency allows a user to perceive a DDBS
as a single, logical entity
The user is protected from the operational details of the network (or even
does not know about the existence of the network)
The user does not need to know the location of data items and a command
used to perform a task is independent from the location of the data and the
site the task is performed (location transparency)
A unique name is provided for each object in the database (naming
transparency)
– In absence of this, users are required to embed the location name as
part of an identifier

Network transparency con…….. Different ways to ensure naming transparency:
• Solution 1: Create a central name server; however, this results in
– loss of some local autonomy
– central site may become a bottleneck
– low availability (if the central site fails remaining sites cannot create new
objects)
• Solution 2: Prefix object with identifier of site that created it
– e.g., branch created at site S1 might be named S1.BRANCH
– Also need to identify each fragment and its copies
– e.g., copy 2 of fragment 3 of Branch created at site S1 might be referred to as
S1.BRANCH.F3.C2
• An approach that resolves these problems uses aliases for each database object
– Thus, S1.BRANCH.F3.C2 might be known as local branch by user at site S1
– DDBMS has task of mapping an alias to appropriate database object

Replication transparency
Replication transparency ensures that the user is not
involved in the management of copies of some data
The user should even not be aware about the existence of
replicas, rather should work as if there exists a single copy
of the data
Replication of data is needed for various reasons
– e.g., increased efficiency for read-only data access

Fragmentation transparency Fragmentation transparency ensures that the user is not aware of and is
not involved in the fragmentation of the data
The user is not involved in finding query processing strategies over fragments
or formulating queries over fragments
The evaluation of a query that is specified over an entire relation but
now has to be performed on top of the fragments requires an appropriate
query evaluation strategy
Fragmentation is commonly done for reasons of performance, availability, and
reliability
Two fragmentation alternatives
– Horizontal fragmentation: divide a relation into a subsets of tuples
– Vertical fragmentation: divide a relation by columns

Transaction transparency Transaction transparency ensures that all distributed transactions maintain
integrity (assuring the accuracy ) and consistency (A transaction is a correct transformation of the
state) of the DDB and support concurrency.
Each distributed transaction is divided into a number of sub-transactions (a sub-
transaction for each site that has relevant data) that concurrently access data at different
locations
DDBMS must ensure the indivisibility of both the global transaction and each of the
sub-transactions Can be further divided into
– Concurrency transparency
– Failure transparency

Concurrency transparency guarantees that transactions must execute independently and are
logically consistent, i.e., executing a set of transactions in parallel gives the same result as if the
transactions were executed in some arbitrary serial order.
– DDBMS must ensure that global and local transactions do not interfere with each other
– DDBMS must ensure consistency of all sub-transactions of global transaction
Replication makes concurrency even more complicated
– If a copy of a replicated data item is updated, update must be propagated to all copies
– Option 1: Propagate changes as part of original transaction, making it an atomic operation;
however, if one site holding a copy is not reachable, then the transaction is delayed until the site is
reachable.
– Option 2: Limit update propagation to only those sites currently available; remaining sites
are updated when they become available again.
– Option 3: Allow updates to copies to happen asynchronously, sometime after the original
update; delay in regaining consistency may range from a few seconds to several hours.

Failure transparency: Failure transparency: DDBMS must ensure
atomicity (A transaction’s changes to the state are atomic: either all happen or
none happen) and durability (Once a transaction completes successfully
(commits), its changes to the state survive failures) of the global transaction, i.e., the sub-transactions of the global transaction either all commit or all abort.
Thus, DDBMS must synchronize global transaction to ensure that all sub-transactions have completed successfully before recording a final COMMIT for the global transaction
The solution should be robust in presence of site and network failures

Performance transparency: Performance transparency: DDBMS must perform as if it were a centralized DBMS
– DDBMS should not suffer any performance degradation due to the distributed architecture
– DDBMS should determine most cost-effective strategy to execute a request
Distributed Query Processor (DQP) maps data request into an ordered sequence of operations on
local databases
• DQP must consider fragmentation, replication, and allocation schemas
• DQP has to decide:
– which fragment to access
– which copy of a fragment to use
– which location to use
• DQP produces execution strategy optimized with respect to some cost function
Typically, costs associated.

Huma israr

Data Allocation
Data Fragmentation
Distributed Catalogue Management
Distributed Transactions
Distributed Queries –
DISTRIBUTED DATABASES ISSUES

Distributed DBMS Issues
Distributed Database Design
how to distribute the database
replicated & non-replicated database distribution
a related problem in catalog management
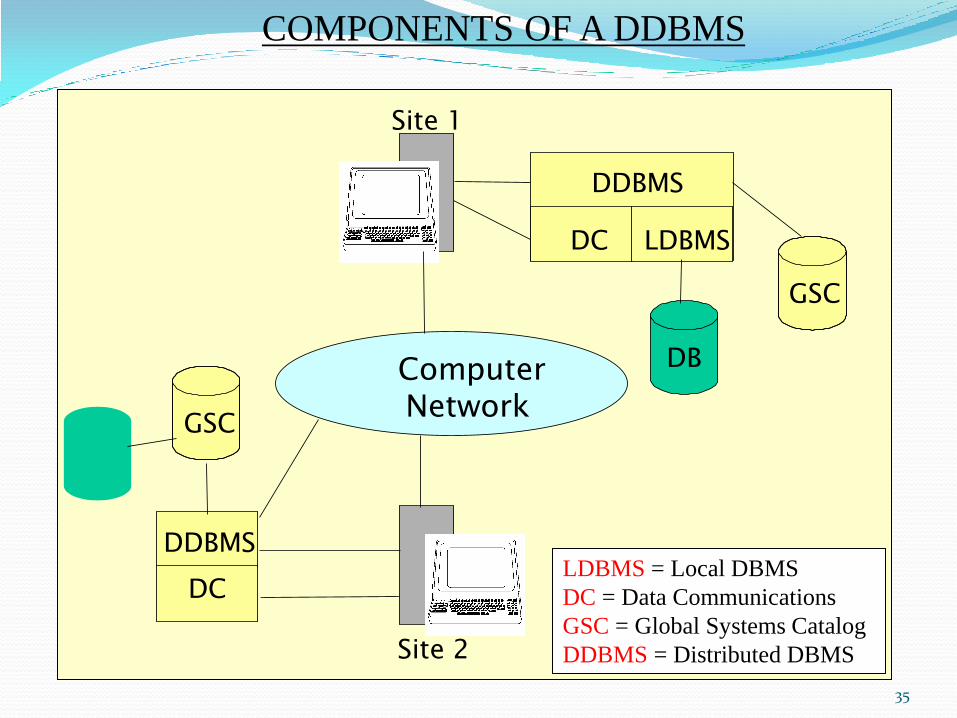
35
DB Computer
Network
Site 2
Site 1
GSC
DDBMS
DC LDBMS
GSC
DDBMS
DC
LDBMS = Local DBMS
DC = Data Communications
GSC = Global Systems Catalog
DDBMS = Distributed DBMS
COMPONENTS OF A DDBMS

36
Distributed catalog management The distributed database catalog entries must specify site(s) at
which data is being stored in addition to data in a system catalog
in a centralized DBMS. Because of data partitioning and
replication, this extra information is needed. There are a number
of approaches.
Centralized - Keep one master copy of the catalog
Fully replicated - Keep one copy of the catalog at each site
Partitioned - Partition and replicate the catalog as usage
patterns demand
Centralized/partitioned - Combination of the above

1. Locality of reference Is the data near to the sites that need it?
2. Reliability and availability Does the strategy improve accessibility?
3. Performance Does the strategy result in bottlenecks or under-utilisation of
resources?
4. Storage costs How does the strategy effect the availability and cost of data storage?
5. Communication costs How much network traffic will result from the strategy?
DISTRIBUTED DATABASES DATA ALLOCATION METRICS

CENTRALISED
DISTRIBUTED DATABASES DATA ALLOCATION STRATEGIES
Locality of Reference
Reliability/Availability
Storage Costs
Performance
Communication Costs
Lowest
Lowest
Lowest
Unsatisfactory
Highest

PARTITIONED/FRAGMENTED
DISTRIBUTED DATABASES DATA ALLOCATION STRATEGIES
Locality of Reference
Reliability/Availability
Storage Costs
Performance
Communication Costs
High
Low (item) – High (system)
Lowest
Satisfactory
Low

COMPLETE REPLICATION
DISTRIBUTED DATABASES DATA ALLOCATION STRATEGIES
Locality of Reference
Reliability/Availability
Storage Costs
Performance
Communication Costs
Highest
Highest
Highest
High
High (update) – Low (read)

SELECTIVE REPLICATION
DISTRIBUTED DATABASES DATA ALLOCATION STRATEGIES
Locality of Reference
Reliability/Availability
Storage Costs
Performance
Communication Costs
High
Average
Satisfactory
Low
Low (item) – High (system)

Comparison of Strategies for Data Distribution

Distributed DBMS Issues
Concurrency Control
synchronization of concurrent accesses
consistency and isolation of transactions' effects
deadlock management. Deadlock management: prevention,
avoidance, detection/recovery

45
Distributed concurrency control
Concurrency control in distributed databases can be done
in several ways. Locking and Time stamping are two
techniques. but time stamping is generally preferred.
The problems of concurrency control in a distributed
DBMS are more severe because of the fact that data may be
replicated and partitioned..

46
Timestamping
Time-stamping is a method of concurrency control where
basically, all transactions are given a timestamp or unique
date/time/site combination and the database management
system uses one of a number of protocols to schedule
transactions which require access to the same piece of data.
While more complex to implement than locking, time-stamping
does avoid deadlock occurring by avoiding it in the first place.

47
Distributed database issues
Distributed query optimizations
Distributed update propagation

48
Distributed query optimization
In a distributed database the optimization of queries
by the DBMS itself is critical to the efficient
performance of the overall system. Query optimization
must take into account the extra communication costs
of moving data from site to site, but can use whatever
replicated copies of data are closest, to execute a query.

49
DISTRIBUTED DATABASES
DATE’S TWELVE RULES FOR A DDBMS
A distributed system looks exactly like
a non-distributed system to the user!
Local autonomy
No reliance on a central site
Continuous operation
Location independence
Fragmentation independence
Replication independence
Distributed query independence
Distributed transaction processing
Hardware independence
Operating system independence
Network independence
Database independence

Distribution/Allocation
Three key Concepts:
Fragmentation,
Allocation,
Replication.

Distributed Database Design
Fragmentation
Relation may be divided into a number of sub-relations,
which are then distributed.
Allocation
Each fragment is stored at site with “optimal” distribution.
Replication
Copy of fragment may be maintained at several sites.

Data Fragmentation
Division of relation r into fragments r1, r2, …, rn which contain sufficient information to reconstruct relation r.
A special attribute, the tuple-id attribute may be added to each schema to serve as a candidate key.

Fragmentation Types Horizontal – subset of rows
Vertical – subset of columns
Each fragment must contain primary key
Other columns can be replicated
Mixed – both horizontal and vertical
Derived – natural join first to get additional information required then fragment
Must be able to reconstruct original table
Can query and update through fragment

HORIZONTAL DATA FRAGMENTATION
333.00 Karachi Saleem 456
500.00 Lahore Irfan 400
340.14 Lahore Saadia 350
23.17 Karachi Noman 345
200.00 Lahore Ali 324
1000.00 Karachi Ahmad 200
BALANCE BRANCH CUSTOMER ACCOUNT
e.g ( branch = ‘Karachi’ Account)

HORIZONTAL DATA FRAGMENTATION
Karachi
Karachi
Karachi
333.00 Saleem 456
23.17 Noman 345
1000.00 Ahmad 200
BALANCE BRANCH CUSTOMER ACCT NO.
Lahore
Lahore
Lahore
500.00 Irfan 400
340.14 Saadia 350
200.00 Ali 324
BALANCE BRANCH CUSTOMER ACCT NO.
STRATFORD BRANCH
BARKING BRANCH

VERTICAL DATA FRAGMENTATION
KJTR78 KHA456T 03005005821 Karachi Saleem 456
ZZEE56 GRA324S 03345457528 Lahore Ali 324
XXYY22 JON200T 03455009000 Karachi Ahmad 200
PASSWORD LOGIN PHONE NO
SITE NAME S#
e.g., ( S#, NAME, SITE, PHONE NO Student)

VERTICAL DATA FRAGMENTATION
Karachi
Lahore
Karachi
Saleem 456
Ali 324 03005005821
03345457528
03455009000 Ahmad 200
PHONE NO. SITE NAME S#
KJTR78
ZZEE56
XXYY22
KHA456T 456
GRA324S 324
JON200T 200
PASSWORD LOGIN-ID S#
STUDENT ADMINISTRATION
NETWORK ADMINISTRATION

Horizontal Fragmentation of account Relation
branch_name account_number balance
Hillside
Hillside
Hillside
A-305
A-226
A-155
500
336
62
account1 = branch_name=“Hillside” (account )
branch_name account_number balance
Valleyview
Valleyview
Valleyview
Valleyview
A-177
A-402
A-408
A-639
205
10000
1123
750
account2 = branch_name=“Valleyview” (account )

Vertical Fragmentation of employee_info Relation
branch_name customer_name tuple_id
Hillside Hillside Valleyview Valleyview Hillside Valleyview Valleyview
Lowman Camp Camp Kahn Kahn Kahn Green
deposit1 = branch_name, customer_name, tuple_id (employee_info )
1 2 3 4 5 6 7
account_number balance tuple_id
500 336 205 10000 62
1123 750
1 2 3 4 5 6 7
A-305 A-226 A-177 A-402 A-155 A-408 A-639
deposit2 = account_number, balance, tuple_id (employee_info )

Why Fragment?
Usage
Applications work with views rather than entire
relations.
Efficiency
Data is stored close to where it is most frequently used.
Data that is not needed by local applications is not
stored.

Why Fragment?
Parallelism
With fragments as unit of distribution,
transaction can be divided into several sub-
queries that operate on fragments.
Security
Data not required by local applications is not
stored and so not available to unauthorized users.

Why Fragment? Disadvantages
Performance,
Integrity.

Correctness of Fragmentation Three correctness rules:
Completeness,
Reconstruction,
Disjointness.

Correctness of Fragmentation Completeness
If a relation instance R is decomposed into fragments R1,R2 …. Rn,
each data item that can be found in R can also be found in one or
more of Ri’s.
Reconstruction
Must be possible to define a relational operation that will reconstruct R
from the fragments.
Reconstruction for horizontal fragmentation is Union operation and Join
for vertical .

Correctness of Fragmentation
Disjointness
If data item di appears in fragment Ri, then it should
not appear in any other fragment.
Exception: vertical fragmentation, where primary key
attributes must be repeated to allow reconstruction.

Data Allocation
Partitioned (or Fragmented)
Database partitioned into disjoint fragments, each fragment assigned to one site.
Selective Replication
Combination of partitioning, replication, and centralization.

Replication Replication is the process of sharing database objects
and data at multiple databases.
To maintain replicated database objects and data at multiple databases, a change to one of these database objects at a database is shared with the other databases

Why Replication? Availability
Performance
Disconnected computing
Network load reduction

Modes Synchronous Replication.
Wait condition
A synchronous Replication.
Not in wait condition

Replication types Three types of Replication(supported by ORACLE)
Materialized View Replication
Muti-mater Replication
Oracle Streaming Replication

Refresh type Complete: Delete or truncate the existing data and
insert new fresh data.
Fast: Only new changes are applied. In this type m.views logs are used.
Force: 1st priority will to apply Fast technique if fail or impossible then apply complete technique. This is default option.

Change Data Capture For incremental data replication there is a need of
change data capture.
Timestamps, Partitioning, Triggers are used.

Timestamps Insert a column of timestamp.
Which shows time and date on which row was last time modified.
We can find latest data by date.

Partitioning Table is partitioned by date key e.g. By week. By day.
New data can be extracted.

Triggers Triggers are normally used with timestamp column.
Triggers will be apply on every column for which we want to capture data.

Major DDBS Architectures Peer-to-Peer Distributed Systems.
Client-Server Architecture.
A Multidatabase System

CLIENT/SERVER DBMS
Manages user interface
Accepts user data
Processes application/business logic
Generates database requests (SQL)
Transmits database requests to server
Receives results from server
Formats results according to application logic
Present results to the user
CLIENT PROCESS

78
CLIENT/SERVER DBMS
Accepts database requests
Processes database requests
Performs integrity check
Handles concurrent access
Optimises queries
Performs security checks
Enacts recovery routines
Transmits result of database request to client
SERVER PROCESS

A Multidatabase System
• Provides access from multiple, autonomous heterogeneous, and distributed databases.
Major DDBS Architectures-III

In Centralized & Distributed Environment

Query processing & Optimization
Query Processing activities involved in retrieving data
from the database:
SQL query translation into low-level language implementing
relational algebra
Query execution
Query Optimization selection of an efficient query
execution plan.

82
Relational Algebra
Relational algebra defines basic operations on relation instances
Results of operations are also relation instances

83
Basic Operations Unary algebra operations:
Selection
Projection
Binary algebra operations:
Union
Set difference
Cross-product

84
Relational Algebra Operations:
select: σ
project: π
union:
difference: -
product: x
join:

85
Selection criterion(I)
where (criterion – selection condition), and I- an instance of a relation.
Result: the same schema
A subset of tuples from the instance I
Criterion: conjunction (AND) and disjunction (OR)
Comparison operators: <,<=,=,,>=,>

Projection Vertical subset of input relation instance
The schema of the result :
is determined by the list of desired fields
a1,a2,…,am(I),
where a1,a2,…,am – desired fields from the relation with the instance I

Joins Join is defined as cross-product followed by selections
Based on the conditions, joins are classified:
Theta-joins
Natural joins
Other…

Query processing
Query processing can be divided into four main phases:
1. decomposition,
2. optimization,
3. code generation, and
4. execution.

Phases of Query Processing

decomposition Analysis
Normalization
Semantic analysis
Simplification
Query restructuring

Analysis The query is lexically and syntactically analyzed using
the techniques of programming language compilers.
Verifies that the relations and attributes specified in
the query are defined in the system catalog.
Verifies that any operations applied to database objects
are appropriate for the object type.

(Cont.)
On completion of the analysis, the high-level query has been transformed into some internal representation (query tree) that is more suitable for processing.
Root
Intermediate operations
leaves

Normalization
Converts the query into a normalized form that can be
more easily manipulated.
There are two different normal forms, conjunctive
normal form and disjunctive normal form.

Conjunctive normal form
A sequence of conjuncts that are connected with the
‘and” operator. Each conjunct contains one or more
terms connected by the “or” operator.
for example
(position=‘Manager’ V salary>20000) ^ branchNo =
‘B003’

Disjunctive normal form A sequence of disjuncts that are connected with the
“or” operator. Each disjunt contains one or more terms
connected by the “and” operator.
for example
(position=‘Manager’ ^ branchNo = ‘B003’) V
(salary>20000 ^ branchNo = ‘B003’)

Semantic analysis
The objective is to reject normalized queries that are incorrectly formulated or contradictory.

Simplification To detect redundant qualifications, eliminate common
sub-expressions , and transform the query to a
semantically equivalent but more easily and efficiently
computed form.
Access restrictions, and integrity constraints are
considered at this stage.

Query restructuring The final stage of query decomposition.
The query is restructured to provide a more efficient implementation.

Query optimization The activity of choosing an efficient execution strategy
for processing a query.
An important aspect of query processing is query optimization.
The aim of query optimization is to choose the one that minimizes resource usage.

Dynamic query optimization Advantage: all information required to select an
optimum strategy is up to date.
Disadvantage: the performance of the query is affected because the query has to be parsed, validated, and optimized before it can be executed.

Static query optimization The query is parsed, validated, and optimized once
that is similar to the approach taken by a compiler for a programming language.
Advantages
1)The runtime overhead is removed
2)More time available to evaluate a larger number of execution strategies.

(cont.) Disadvantage: the execution strategy that is chosen as
being optimal when the query is compiled may no longer be optimal when the query is run.

103
Query Optimization Optimization criteria:
Reduce total execution time of the query:
Minimize the sum of the execution times of all individual operations
Reduce the number of disk access
Reduce response time of the query:
Maximize parallel operations
Dynamic vs. static optimization

104
Estimating Cost What needs to be considered:
Disk I/Os
sequential
random
CPU time
Network communication
What are we going to consider:
Disk I/Os
page reads/writes
Ignoring cost of writing final output



Distributed Query Processing Suppose our data is distributed across multiple machines and we need to process
queries
Parallel DBMSs assume homogeneous nodes and fast networks (sometimes
even shared memory)
Major goal: efficiently utilize all resources, balance load
Distributed DBMSs assume heterogeneous nodes, slower networks, some
sources only available on some machines
Major goal: determine what computation to place where
Our focus here is on the latter

The Data Placement Problem Performance depends on where the data is placed
Partition by relations: each machine gets some tables
Vertical partitioning: each machine gets different columns from the
same table
Horizontal partitioning: each machine gets different rows from the
same table
Also an option to replicate data partitions
Trade-offs between query and update performance!
As with order in a centralized DBMS, data’s location becomes a property the
optimizer needs to explore
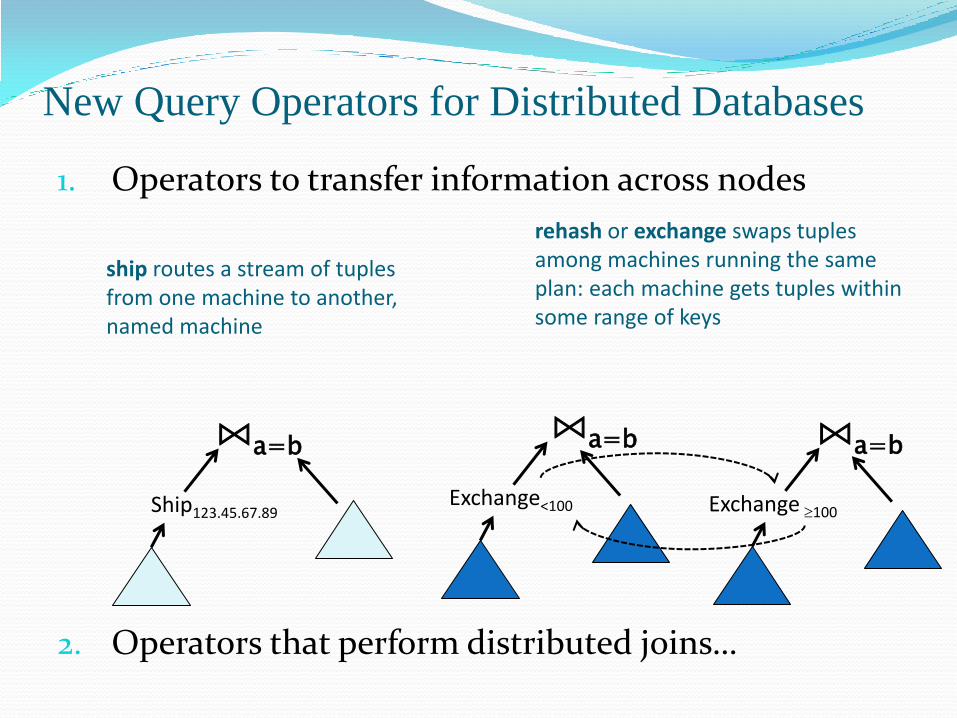
New Query Operators for Distributed Databases
1. Operators to transfer information across nodes
2. Operators that perform distributed joins…
Ship123.45.67.89
⋈a=b
Exchange<100
⋈a=b
Exchange100
⋈a=b
rehash or exchange swaps tuples among machines running the same plan: each machine gets tuples within some range of keys
ship routes a stream of tuples from one machine to another, named machine

Distributed DBMSs Generalize DB Techniques to Handle Communication
Distributed databases contributes three basic sets of
techniques:
1. Different data partitioning methods and their impact on
performance
2. Incorporating data location into cost-based optimization
3. New operators for shipping data and for multi-stage
joins

Centralized & Distributed environment

Introduction to Transaction Processing
A Transaction:
Logical unit of database processing that includes one or more access operations (read -retrieval, write - insert or update, delete).
A transaction (set of operations) may be stand-alone specified in a high level language like SQL submitted interactively, or may be embedded within a program.
Transaction boundaries:
Begin and End transaction.
An application program may contain several transactions separated by the Begin and End transaction boundaries.

Tansaction and System Concepts
A transaction is an atomic unit of work that is either completed in its entirety or not done at all.
For recovery purposes, the system needs to keep track of when the transaction starts, terminates, and commits or aborts.
Transaction states:
Active state Partially committed state Committed state Failed state Terminated State

State transition diagram illustrating the states for transaction execution

Slide 17- 115
Desirable Properties of Transactions
ACID properties:
Atomicity: A transaction is an atomic unit of processing; it is either performed in its entirety or not performed at all.
Consistency preservation: A correct execution of the transaction must take the database from one consistent state to another.
Isolation: A transaction should not make its updates visible to other transactions until it is committed; this property, when enforced strictly, solves the temporary update problem and makes cascading rollbacks of transactions unnecessary (see Chapter 21).
Durability or permanency: Once a transaction changes the database and the changes are committed, these changes must never be lost because of subsequent failure.

Trans Cont…… Basic operations are read and write
read_item(X): Reads a database item named X into a program variable. To simplify our notation, we assume that the program variable is also named X.
write_item(X): Writes the value of program variable X into the database item named X.

Detail of read & Write operation
read_item(X) command includes the following steps: Find the address of the disk block that contains item X. Copy that disk block into a buffer in main memory (if that disk
block is not already in some main memory buffer). Copy item X from the buffer to the program variable named X.
write_item(X) command includes the following steps: Find the address of the disk block that contains item X. Copy that disk block into a buffer in main memory (if that disk
block is not already in some main memory buffer). Copy item X from the program variable named X into its correct
location in the buffer. Store the updated block from the buffer back to disk (either
immediately or at some later point in time).

Two sample transactions Two sample transactions:
(a) Transaction T1 (b) Transaction T2

Introduction to Transaction Processing (6) Why Concurrency Control is needed: The Lost Update Problem
This occurs when two transactions that access the same database items have their operations interleaved in a way that makes the value of some database item incorrect.
The Temporary Update (or Dirty Read) Problem This occurs when one transaction updates a database item and then the
transaction fails for some reason (see Section 17.1.4). The updated item is accessed by another transaction before it is
changed back to its original value.
The Incorrect Summary Problem If one transaction is calculating an aggregate summary function on a
number of records while other transactions are updating some of these records, the aggregate function may calculate some values before they are updated and others after they are updated.

Concurrent execution is uncontrolled: (a) The lost update
problem.

Slide 17- 121
Concurrent execution is uncontrolled: (b) The temporary
update problem.

Slide 17- 122
Concurrent execution is uncontrolled: (c) The incorrect
summary problem.












![1 Galton-Watson Trees - IMPA[Gro07] Misha Gromov. Metric structures for Riemannian and non-Riemannian spaces. Modern Birkh¨auser Classics. Birkh ¨auser Boston Inc., Boston, MA, english](https://img.pdfslide.us/doc/110x75/60e7af2b591a6b44c714e5d6/1-galton-watson-trees-impa-gro07-misha-gromov-metric-structures-for-riemannian.jpg)

















