Embed Size (px)
Citation preview

1
Indexing Methods
Lecture 9
Storage Requirements of Databases
• Need data to be stored “permanently” or persistently for long periods of time
• Usually too big to fit in main memory• Low cost of storage per unit of data and the
definition of “very large databases”• Main cost incurred after storage is of
searching the database• Primary and secondary (auxiliary) file
organizations

2
File Organizations
• Relations usually stored in files as logical “records”and read in terms of physical “blocks”
• File organization refers to the way records are stored in terms of blocks and the way blocks are placed on the storage medium and interlinked.
• Types of organizations– Unsorted– Sorted– Hashing
Records
• Represents a tuple in a relation • A file is a sequence of records • Records could be either fixed-length or
variable-length• Records comprise of a sequence of
fields (column, attribute)

3
Blocks• Refer to physical units of storage in storage
devices (Example: Sectors in hard disks, page in virtual memory)
• Of fixed length, based on physical characteristics of the storage/computing device and operating system
• Storage device is either defragmented or fragmented depending on whether contiguous sets of records lie in contiguous blocks
Blocking FactorThe number of records that are stored in a block is called the “blocking factor”. Blocking factor is constant across blocks if record length is fixed, or variable otherwise.
If B is block size and R is record size, then blocking factor is:
bfr = ⎣B/R⎦
Since R may not exactly divide B, there could be some left-over space in each block equal to:
B – (bfr * R) bytes.

4
Spanned and UnspannedRecords
When extra space in blocks are left unused, the record organization is said to be “unspanned”.
Record 1 Record 2 Record 3
Unused
Spanned and UnspannedRecords
In “spanned” record storage, records can be split so that the “span” across blocks.
Record 1 Record 2 Record 3
Record 4 (part)
Record 4(remaining)
Block m
Block p
p

5
Spanned and UnspannedRecords
When record size is greater than block size (i.e. R > B), use of“spanned” record storage is compulsory.
Indexes• Index Files
– Secondary or auxiliary files that help speed up data access in primary files
• Indexes or access structures.– Data structures (and search methods) used for
fast access• Single level index
– index file maps directly to the block or the address of the record
• Multi-level index– multiple levels of indirection among indexes

6
Definitions
• Indexing field (indexing attribute): The field on which an index structure is built (searching is fast on this field)
• Primary index: An index structure that is defined on the ordering key field (the field that is used to physically order records on disk in sorted file organizations)
Definitions
• Clustering index: When the ordering field is not a key field (i.e. not unique) a clustering index is used instead of a primary index
• Secondary index: An index structure defined on a non-ordering field.

7
Primary Indexes
• Comprises of an ordered file of fixed length records having two fields
• The first field of same data type as ordering key (primary key), and second field is of the type block address.
Primary index records are represented by a pair:
(k(i), a(i))
–Where k(i) is the key for the ith record and a(i) is the block address containing the ith record.
Primary Index
.
.
.
Index File2003-01012003-0121
2003-0181
…..…..
…..2003-0201
2003-0241
2003-0221…..
RollNo Name Age Gender Grade2003-0101
2003-0121
2003-0262
2003-0120
…..
.
.
2003-0140
2003-0221
2003-0262
…..…..
…..…..
…..…..
…..…..
2003-0240
2003-0280K(i) a(i)
.
.

8
Primary Index
• The number of entries in the index is equal to the number of disk blocks in the ordered data file
• The first record in each block of the file is indexed (in sparse indexes). These records are called anchor records
• A sparse index has index entries for only some of the search values
• A dense index has an index for every search key value (every record in the data file). Dense indexes are not beneficial on ordered data files.
Primary Index
• Search: – Easy. Perform Binary Search on index file to
identify block containing required record• Insertion / Deletion:
– Easy if key values in records are fixed length and statically allocated to blocks without block spanning (results in wasted space however).
– Else, re-computation of index required on insertion / deletion. Use of overflow buffers may be necessary.

9
Clustering Index
• Clustering field: A non-key ordering field. That is, blocks are ordered on this field which does not have the UNIQUE constraint
• Structure of index file similar to primary index file, but each index points to the first blockhaving the given value in its clustering field.
• One index entry for every distinct value of the clustering field.
Clustering Index
.
.
.
K(I) A(I)12
30
3…..
…..
39
…..
80…..
…..
.
.
90
Dept No Name Gender DOB Job11122233
808081
898990

10
Clustering Index
• A sparse index, since only distinctvalues are indexed
• Insertion and deletion cause problems when a block can hold more than one value for clustering field
• Alternative solution: Allocate blocks for each value of clustering field.
Clustering Index
.
.
.
K(I) A(I)12
30
3…..
…..
39
…..
80…..
…..
.
.
90
Dept No Name Gender DOB Job111
222
8080
898989
More 1 fields
More 2 fields
More 89 fields

11
Secondary Index
• Used to index fields that are neither ordering fields nor key fields.
• Many secondary indexes possible on a single file.
• One index entry for the every record in the data file (dense index), containing the value of the indexed attribute, and a pointer to the block / record.
Secondary Index on Key Field
K(i), A(i)2003-01012003-01022003-01032003-0104
2003-01062003-0105
RollNo Name Age Dept No Job2003-01012003-0107
2003-0107
2003-01032003-0102
2003-01052003-01042003-0106
…
Has as many index entries as the number of records…

12
Secondary Index on Key Field
• Since key fields are unique, number of index entries equal to number of records
• Data file need not be sorted on disk• Fixed length records for index file
Secondary Index on non-key Field
• When a non-key field is indexed, duplicate values have to be handled.
• There are three different techniques for handling duplicates: – Duplicate index entries– Variable length records– Extra redirection levels

13
Duplicate Index Entries
K(i) A(i)2003-01012003-01022003-01022003-0102
2003-01032003-0102
2003-0103
…
Index entries are repeated for each duplicate occurrence of the non-keyattribute.
Binary search becomes more complicated. Mid-point of a search may have duplicate entries on eitherside.
Insertion of records may need restructuring of index table.
Variable Length Records
• Use variable length records for index table in order to accommodate duplicate key entries
• For a given key K(i), there is a set of address pointers instead of a single address pointer
• Binary search becomes complicated since address mid points cannot be computed efficiently
• Insertion of records may need restructuring of the index table
14
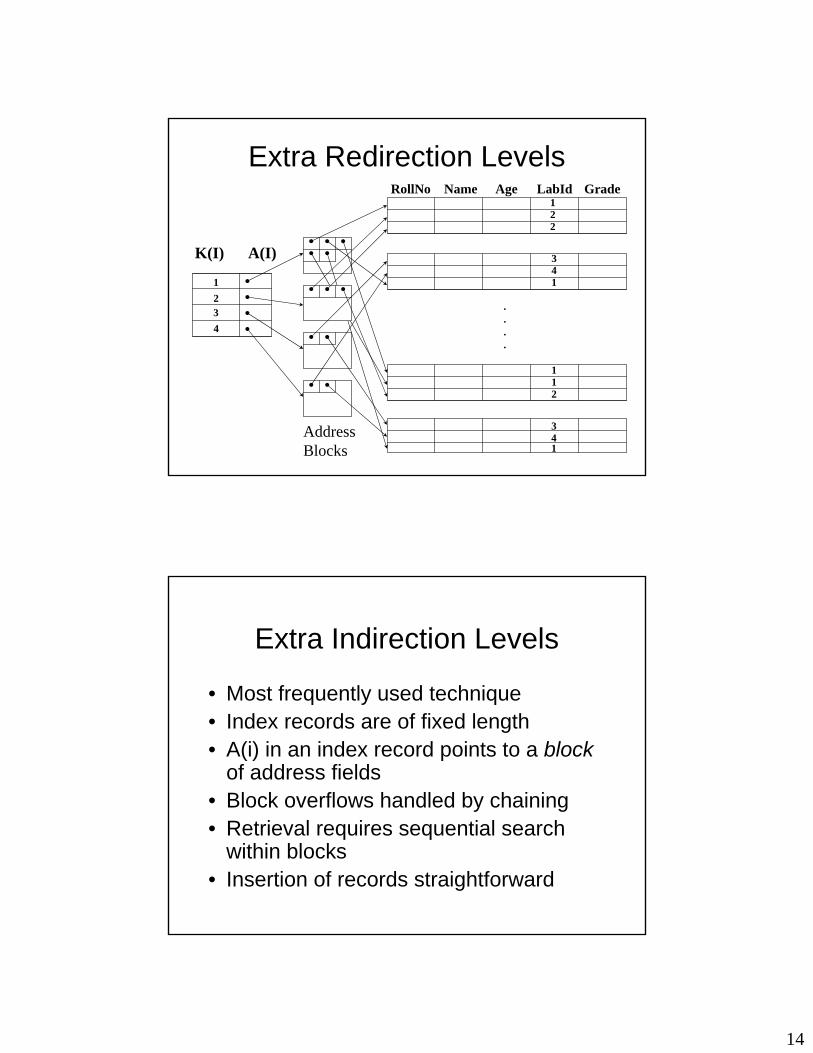
Extra Redirection Levels
K(I) A(I)
1234
RollNo Name Age LabId Grade1
3
.
.
.
.
22
1
2
3
14
41
1
AddressBlocks
Extra Indirection Levels
• Most frequently used technique• Index records are of fixed length• A(i) in an index record points to a block
of address fields • Block overflows handled by chaining • Retrieval requires sequential search
within blocks• Insertion of records straightforward

15
Multi-level Indexes
• Binary search in single-level indexes require a search time of the order of log2b number of block accesses. Here b is the number of blocks in the index file
• If the bfr of the index file is greater than 2, number of block accesses can be reduced even further
• Multi-level indexes are meant for such a reduction.
Multi-level Indexes
• Contains several levels of the index file• Each index block at a given level
connects to a maximum of fo number of blocks at the next level. Here fo is called the “fan out” of the index structure
• Block accesses reduced from log2b to logfob on an average.
16
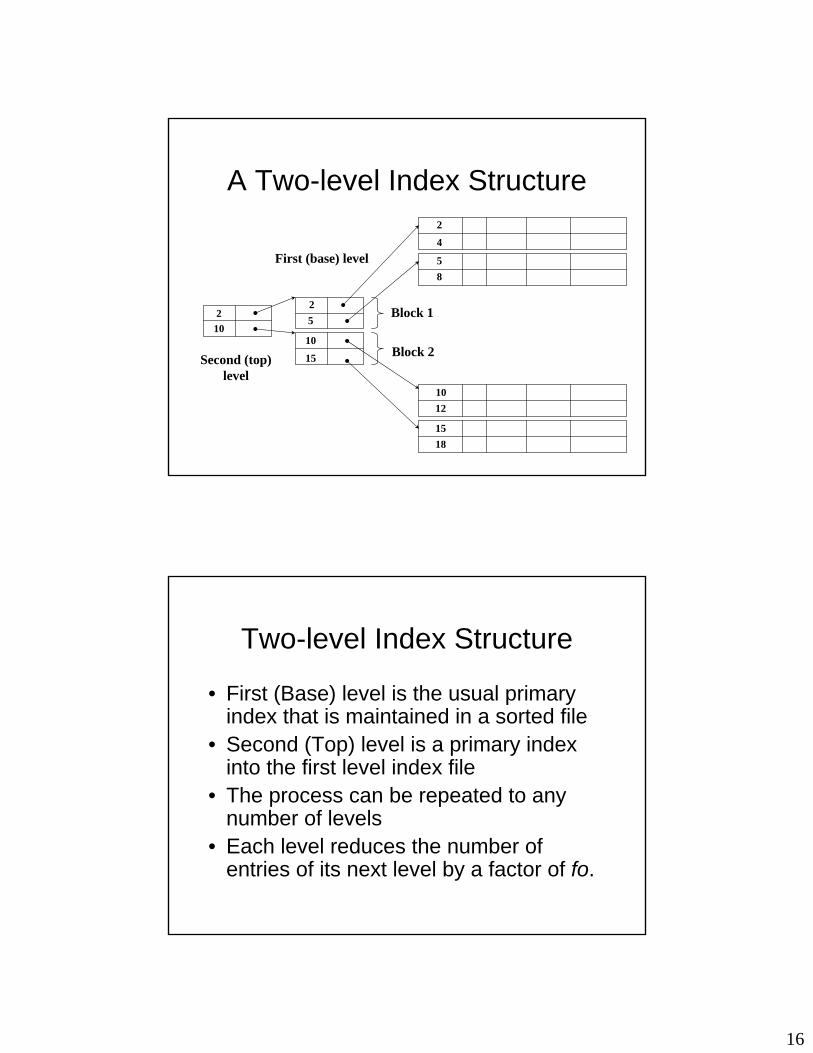
A Two-level Index Structure
210
25
10
15
2
4
58
1012
1518
First (base) level
Second (top)level
Block 1
Block 2
Two-level Index Structure
• First (Base) level is the usual primary index that is maintained in a sorted file
• Second (Top) level is a primary index into the first level index file
• The process can be repeated to any number of levels
• Each level reduces the number of entries of its next level by a factor of fo.
17
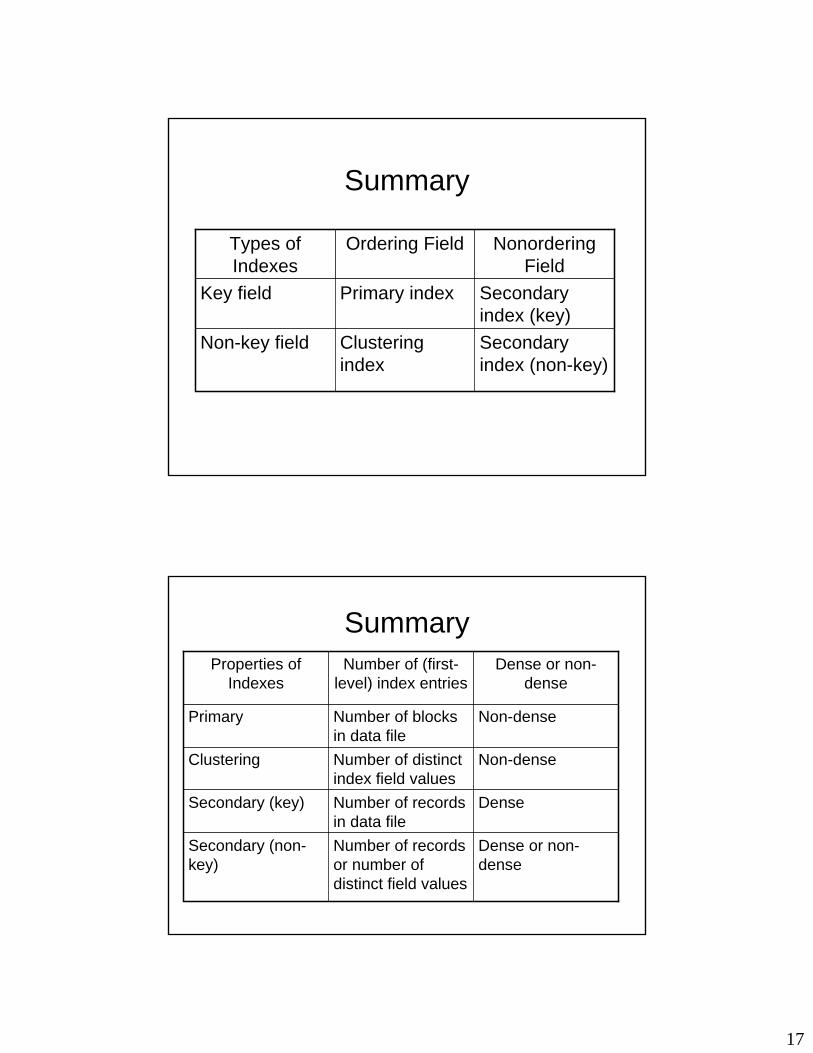
Summary
Secondary index (non-key)
Clustering index
Non-key field
Secondary index (key)
Primary indexKey field
NonorderingField
Ordering FieldTypes of Indexes
Summary
Dense or non-dense
Number of records or number of distinct field values
Secondary (non-key)
DenseNumber of records in data file
Secondary (key)
Non-denseNumber of distinct index field values
Clustering
Non-denseNumber of blocks in data file
Primary
Dense or non-dense
Number of (first-level) index entries
Properties of Indexes

18
Summary
• Multi-level indexes: Several level of index files
• Characteristic “fan out” property. Fan out fo preferably greater than 2
• Reduces number of block accesses to order of logfob.
Dynamic Multi-level Indexes

19
Overview of Index Structures• Index Files
– Secondary or auxiliary files that help speed up data access in primary files
• Indexes or access structures– Data structures (and search methods) used for
fast access• Single level index
– index file maps directly to the block or the address of the record
• Multi-level index– multiple levels of indirection among indexes
Definitions
• Indexing field (indexing attribute): The field on which an index structure is built (searching is fast on this field)
• Primary index: An index structure that is defined on the ordering key field (the field that is used to physically order records on disk in sorted file organizations)

20
Definitions
• Clustering index: When the ordering field is not a key field (i.e. not unique) a clustering index is used instead of a primary index
• Secondary index: An index structure defined on a non-ordering field.
Primary Index Illustration
.
.
.
Index File2003-01012003-0121
2003-0181
…..…..
…..2003-0201
2003-0241
2003-0221…..
RollNo Name Age Gender Grade2003-0101
2003-0121
2003-0262
2003-0120
…..
.
.
2003-0140
2003-0221
2003-0262
…..…..
…..…..
…..…..
…..…..
2003-0240
2003-0280K(i) a(i)
.
.

21
Clustering Index Illustration
.
.
.
K(I) A(I)12
30
3…..
…..
39
…..
80…..
…..
.
.
90
Dept No Name Gender DOB Job11122233
808081
898990
Secondary Index on Key Field
K(i), A(i)2003-01012003-01022003-01032003-0104
2003-01062003-0105
RollNo Name Age Dept No Job2003-01012003-0107
2003-0107
2003-01032003-0102
2003-01052003-01042003-0106
…
Has as many index entries as the number of records…

22
Secondary Index on non-Key Field
K(I) A(I)
1234
RollNo Name Age LabId Grade1
3
.
.
.
.
22
1
2
3
14
41
1
AddressBlocks
Summary
Secondary index (non-key)
Clustering index
Non-key field
Secondary index (key)
Primary indexKey field
NonorderingField
Ordering FieldTypes of Indexes

23
Summary
Dense or non-dense
Number of records or number of distinct field values
Secondary (non-key)
DenseNumber of records in data file
Secondary (key)
Non-denseNumber of distinct index field values
Clustering
Non-denseNumber of blocks in data file
Primary
Dense or non-dense
Number of (first-level) index
entries
Properties of Indexes
Multi-level Indexes
• Binary search in single-level indexes require a search time of the order of log2b number of block accesses. Here b is the number of blocks in the index file
• If the bfr of the index file is greater than 2, number of block accesses can be reduced even further
• Multi-level indexes are meant for such a reduction.

24
Multi-level Indexes
• Contains several levels of the index file• Each index block at a given level
connects to a maximum of fo number of blocks at the next level. Here fo is called the “fan out” of the index structure
• Block accesses reduced from log2b to logfob on an average.
A Two-level Index Structure
210
25
10
15
2
4
58
1012
1518
First (base) level
Second (top)level
Block 1
Block 2

25
Two-level Index Structure
• First (Base) level is the usual primary index that is maintained in a sorted file
• Second (Top) level is a primary index into the first level index file
• The process can be repeated to any number of levels
• Each level reduces the number of entries of its next level by a factor of fo.
A Two-level Index Structure
210
25
10
15
2
4
58
1012
1518
First (base) level
Second (top)level
Block 1
Block 2
26
Two-level Index Structure
• First (Base) level is the usual primary index that is maintained in a sorted file
• Second (Top) level is a primary index into the first level index file
• The process can be repeated to any number of levels
• Each level reduces the number of entries of its next level by a factor of fo.
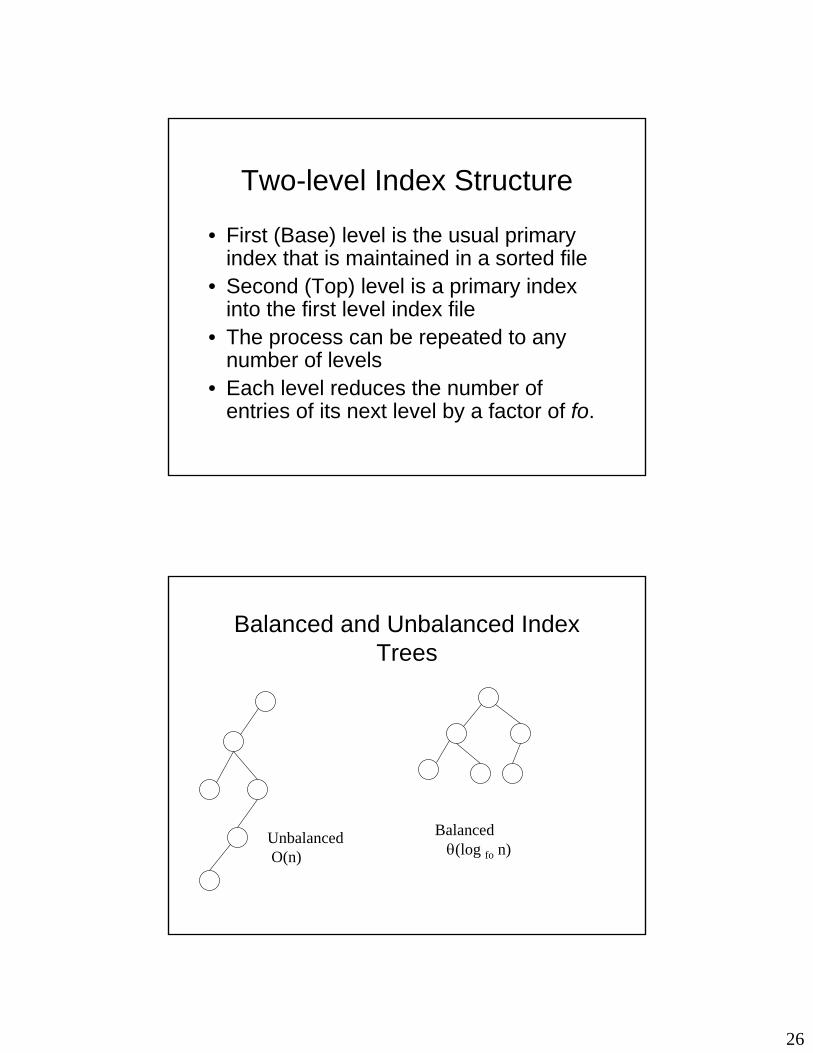
Balanced and Unbalanced Index Trees
UnbalancedO(n)
Balanced θ(log fo n)

27
Insertions and Deletions
• Balanced property of index trees should be maintained during insertions and deletions
• Insertions and deletions are problematic in multi-level index, since all index files are physically sorted files
• An approach to overcome this is to use dynamic multi-level indexes
B-Trees
• A Tree data structure where each node has a predetermined maximum fan-out p
• Terminologies: root node, leaf nodes, internal nodes, parent, children
28
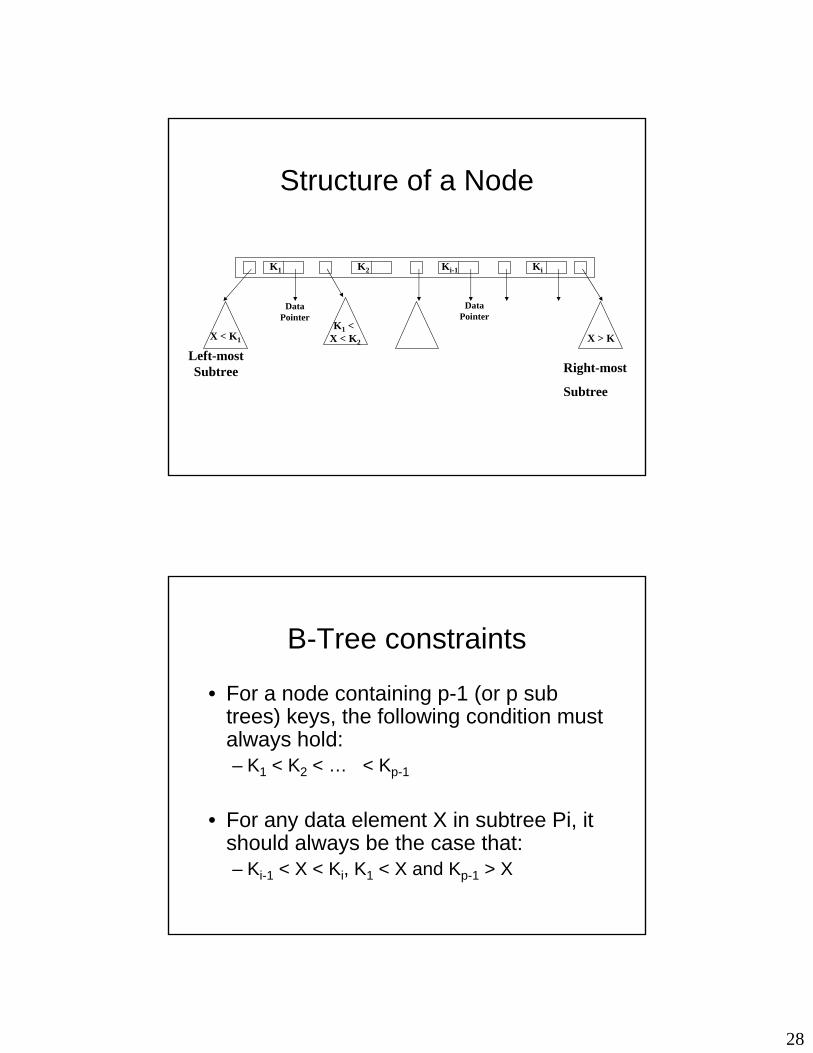
Structure of a Node
DataPointer
Left-mostSubtree
K1 K2 Ki-1 Ki
X > K
DataPointer
X < K1
K1 < X < K2
Right-most
Subtree
B-Tree constraints
• For a node containing p-1 (or p sub trees) keys, the following condition must always hold: – K1 < K2 < … < Kp-1
• For any data element X in subtree Pi, it should always be the case that: – Ki-1 < X < Ki, K1 < X and Kp-1 > X

29
B-Tree Constraints
• Each node has at most p tree pointers• Each node, except the root and leaf nodes,
has at least ⎡p/2⎤ tree pointers (tree balancing constraint)
• The root node has at least 2 tree pointers unless it is the only node in the tree
• All leaf nodes are at the same level. In a leaf node, all tree pointers are null.
B+ Trees
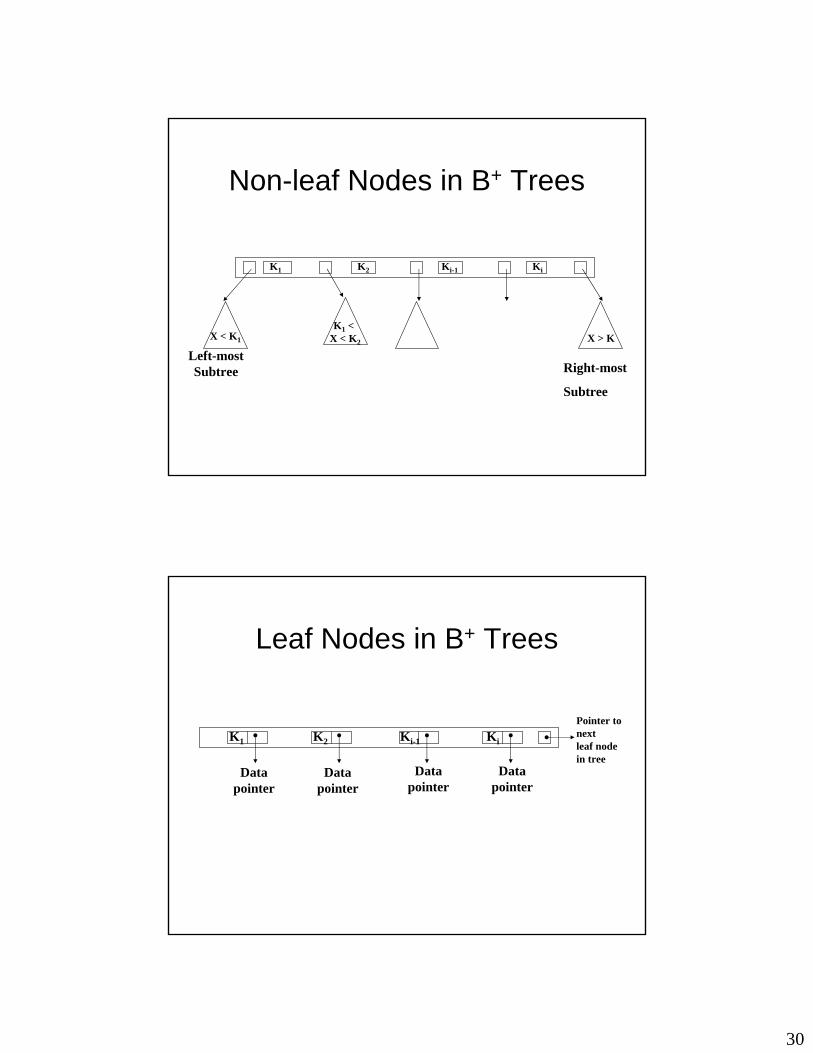
• Most common index structures in RDBMS.• Leaf and non-leaf nodes have different structures:
data pointers are stored only at the leaf nodes• Leaf nodes form a “sense index” containing every
entry for the search field and its corresponding record pointer
• Leaf nodes linked to provide ordered access to data file records.
30
Non-leaf Nodes in B+ Trees
Left-mostSubtree
K1 K2 Ki-1 Ki
X > K X < K1
K1 < X < K2
Right-most
Subtree
Leaf Nodes in B+ Trees
K1 K2 Ki-1 Ki
Datapointer
Datapointer
Datapointer
Datapointer
Pointer tonextleaf nodein tree

31
Properties of Leaf Nodes
• Keys along the leaf nodes chain is organized in sorted order– K1 < K2 < … < Kn
• Each leaf node has at least ⎡p/2⎤ values
• All leaf nodes are at the same level
Searching in B+ TreesGeneralization of Binary Search.
1. Given a search key k start from the root node2. If key is present in current node then success; else 3. If current node is a leaf node and key not present
in node, then key not in the database4. Search for a tree pointer Pi such that Ki-1 < k ≤ ki5. Return to step 2 to continue search.

32
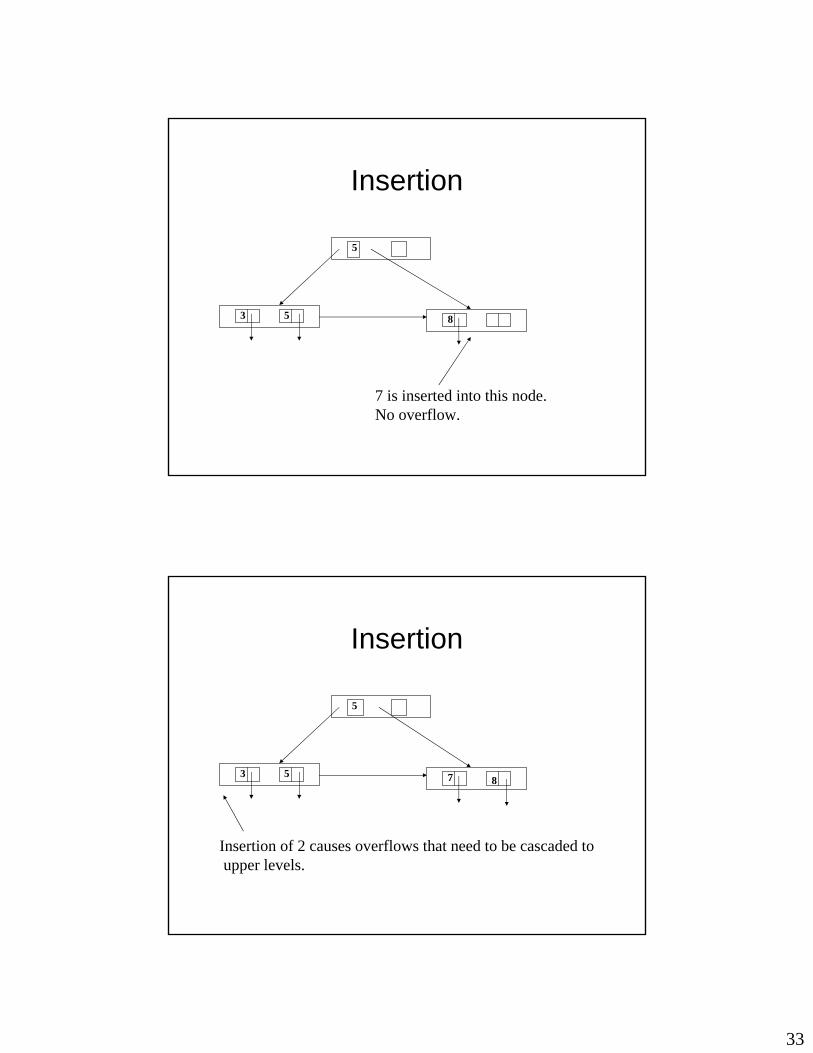
Insertion
• Originally, tree begins with only the root node.
• As and when nodes fill up, they are “split” and made children of a new node.
• Keys are split uniformly across the three nodes.
Insertion
85
Let p = 2.
Let insertion sequence of keys be: 5, 8, 3, 7, 2, 9, 17, 10, …
Tree, after insertion of 5 and 8.
Insertion of next key 3 causes overflow requiring a split.
33
Insertion
53
5
8
7 is inserted into this node. No overflow.
Insertion
53
5
7 8
Insertion of 2 causes overflows that need to be cascaded to upper levels.
34
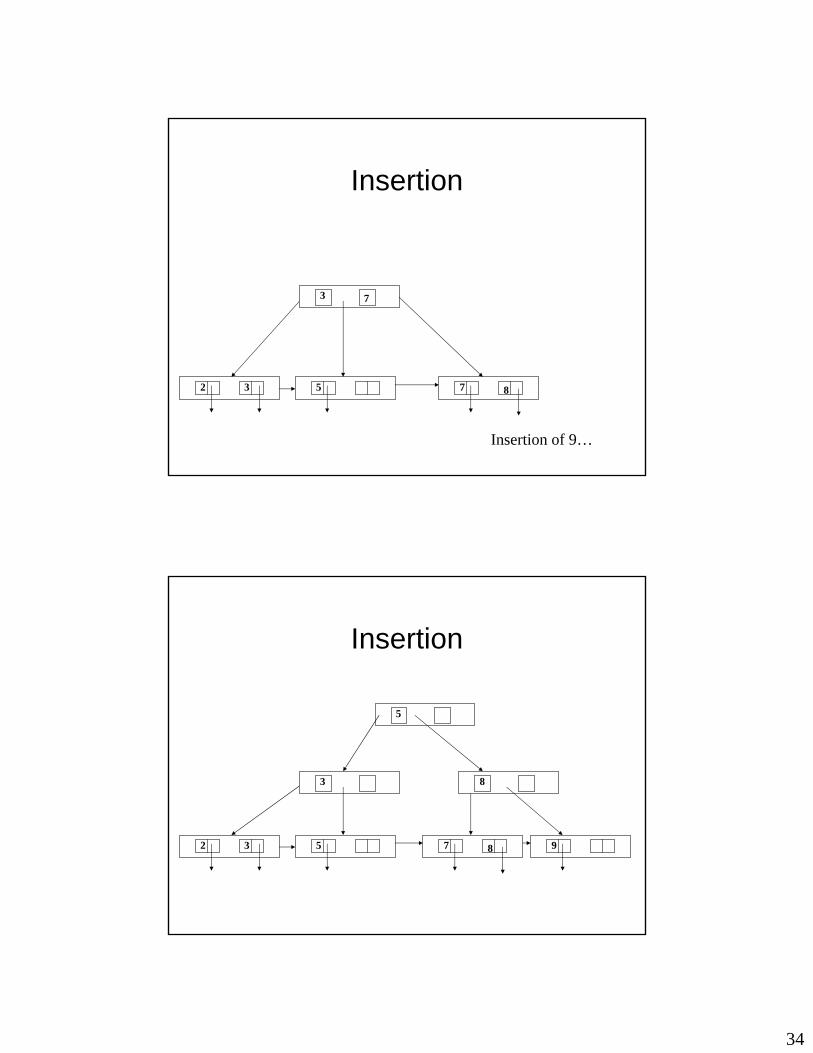
Insertion
5 7 832
3 7
Insertion of 9…
Insertion
5 7 832
3
9
8
5

35
Deletion
• Deletion of keys may cause underflows which have to be handled separately
• An underflow occurs when a node contains less than ⎣p/2⎦ keys
• Nodes are merged with their siblings when underflows occur
Indexes on Multiple Attributes
• All index structures explored till now assumes simple attributes: comprising of only one value
• Many applications require multi-attribute (composite) keys

36
Ordered Index on Multi-attributes
• Considers a composite key as a tuple of simple keys (k1, k2, …kn)
• Ordered index files maintained by ordering each key in sequence.
Partitioned Hashing
• Given a composite key (k1, k2, …kn), partitioned hashing returns n different bucket numbers
• Hash bucket is determined by concatenating the n numbers.

37
Grid Files
• Partitions the range of key values for each key into several buckets
• Combinations of buckets of each key forms a “grid”
• A grid file stores a grid in either a row major or a column major form.
Grid Files
Roll No. 1 2 3 4 5
Grade
A
B
C
D
Roll No.
1 001– 0252 026 – 0503 051 – 0754 076 – 1005 101 – 125
Bucket Pool

38
Summary
• Multi-level Indexes• Trees, root node, leaf nodes, non-leaf
(internal) nodes • Dynamic multi-level indexes, B-trees
and B+ trees• Insertion and deletion in B+ trees• Indexes on multiple attributes.





























