Embed Size (px)
Citation preview

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 1
Sound, Mixtures, and Learning
Dan Ellis<[email protected]>
Laboratory for Recognition and Organization of Speech and Audio(Lab
ROSA
)
Electrical Engineering, Columbia Universityhttp://labrosa.ee.columbia.edu/
Outline
Human sound organization
Computational Auditory Scene Analysis
Speech models and knowledge
Sound mixture recognition
Learning opportunities
1
2
3
4
5

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 2
Human sound organization
• Analyzing and describing complex sounds:
- continuous sound mixture
→
distinct events
• Hearing is
ecologically
grounded
- reflects ‘natural scene’ properties- subjective
not
canonical (ambiguity)-
mixture
analysis as primary goal
1
0 2 4 6 8 10 12 time/s
frq/Hz
0
2000
1000
3000
4000
Voice (evil)
Stab
Rumble Strings
Choir
Voice (pleasant)
Analysis
level / dB-60
-40
-20
0

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 3
Sound mixtures
• Sound ‘scene’ is almost always a mixture
- always stuff going on- sound is ‘transparent’ - but big energy range
• Need information related to our ‘world model’
- i.e. separate objects- a wolf howling in a blizzard is the same as
a wolf howling in a rainstorm- whole-signal statistics won’t do this
• ‘Separateness’ is similar to independence
- objects/sounds that change in isolation- but: depends on the situation e.g.
passing car vs. mechanic’s diagnosis
time / s time / s time / s
freq
/ kH
z
0 0.5 10
1
2
3
4
0 0.5 1 0 0.5 1
+ =
Speech Noise Speech + Noise
LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 4
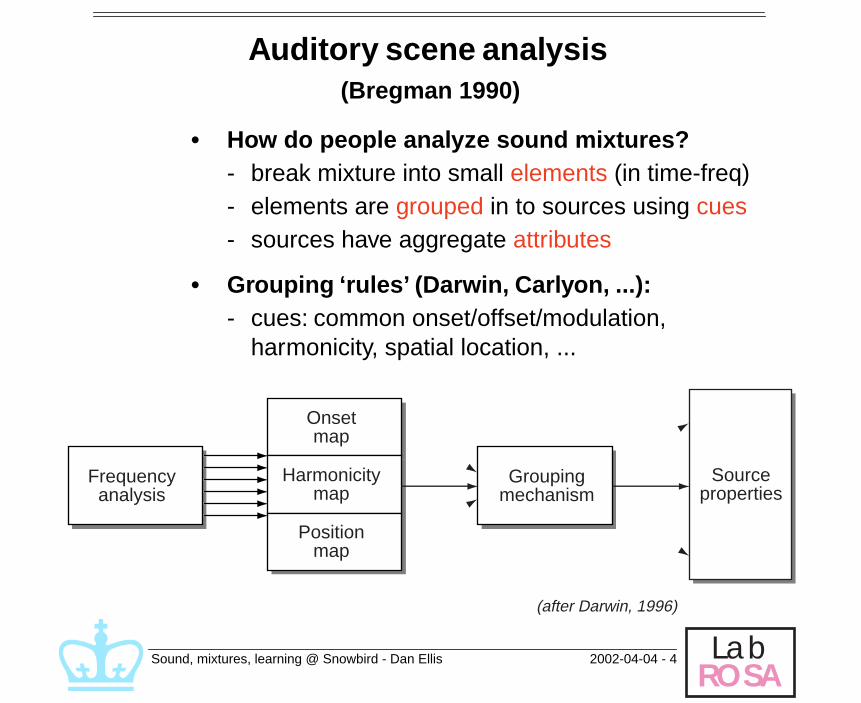
Auditory scene analysis
(Bregman 1990)
• How do people analyze sound mixtures?
- break mixture into small
elements
(in time-freq)- elements are
grouped
in to sources using
cues
- sources have aggregate
attributes
• Grouping ‘rules ’ (Darwin, Carlyon, ...):
- cues: common onset/offset/modulation, harmonicity, spatial location, ...
Frequencyanalysis
Groupingmechanism
Onsetmap
Harmonicitymap
Positionmap
Sourceproperties
(after Darwin, 1996)

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 5
Cues to simultaneous grouping
• Elements + attributes
• Common onset
- simultaneous energy has common source
• Periodicity
- energy in different bands with same cycle
• Other cues
- spatial (ITD/IID), familiarity, ...
time / s
freq
/ H
z
0 1 2 3 4 5 6 7 8 90
2000
4000
6000
8000

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 6
The effect of context
• Context can create an ‘expectation ’: i.e. a bias towards a particular interpretation
• e.g. Bregman ’s “old-plus-new ” principle:
A change in a signal will be interpreted as an
added
source whenever possible
- a different division of the same energy depending on what preceded it
+
time / s
freq
uenc
y / k
Hz
0.0 0.4 0.8
1
2
1.20

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 7
Outline
Human sound organization
Computational Auditory Scene Analysis
- sound source separation- bottom-up models- top-down constraints
Speech models and knowledge
Sound mixture recognition
Learning opportunities
1
2
3
4
5

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 8
Computational Auditory Scene Analysis(CASA)
• Goal: Automatic sound organization ;Systems to ‘pick out ’ sounds in a mixture
- ... like people do
• E.g. voice against a noisy background
- to improve speech recognition
• Approach:
- psychoacoustics describes grouping ‘rules’- ... just implement them?
2
CASAObject 1 descriptionObject 2 descriptionObject 3 description...

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 9
CASA front-end processing
• Correlogram:Loosely based on known/possible physiology
- linear filterbank cochlear approximation- static nonlinearity- zero-delay slice is like spectrogram- periodicity from delay-and-multiply detectors
Cochleafilterbank
sound
envelopefollower
short-timeautocorrelation
delay line
freq
uenc
y ch
anne
ls
Correlogramslice
freq
lag
time
LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 10
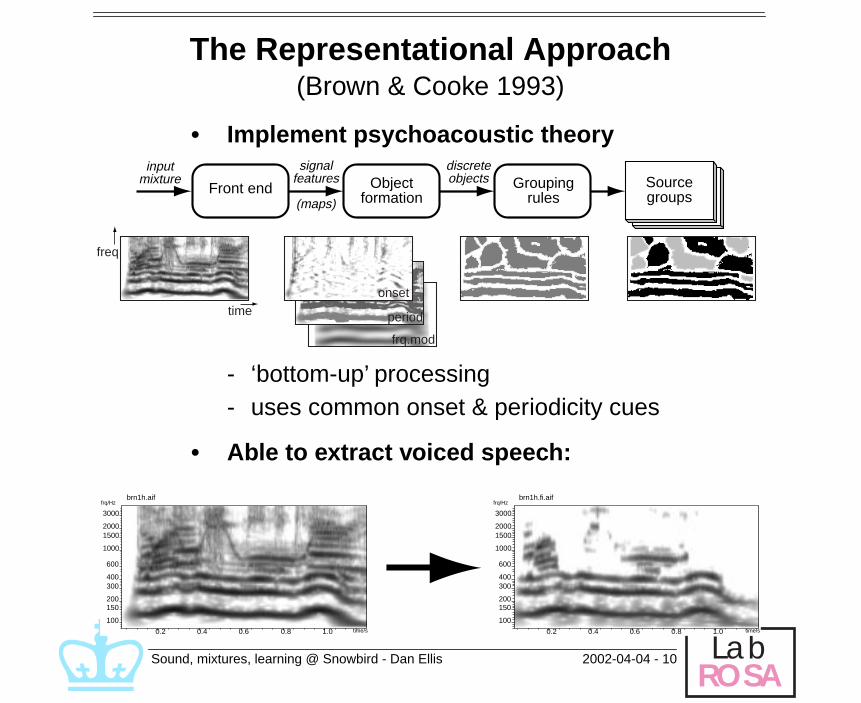
The Representational Approach
(Brown & Cooke 1993)
• Implement psychoacoustic theory
- ‘bottom-up’ processing- uses common onset & periodicity cues
• Able to extract voiced speech:
inputmixture
signalfeatures
(maps)
discreteobjects
Front end Objectformation
Groupingrules
Sourcegroups
onset
period
frq.mod
time
freq
0.2 0.4 0.6 0.8 1.0 time/s
100
150200
300400
600
1000
15002000
3000
frq/Hzbrn1h.aif
0.2 0.4 0.6 0.8 1.0 time/s
100
150200
300400
600
1000
15002000
3000
frq/Hzbrn1h.fi.aif

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 11
Problems with ‘bottom-up ’ CASA
• Circumscribing time-frequency elements
- need to have ‘regions’, but hard to find
• Periodicity is the primary cue
- how to handle aperiodic energy?
• Resynthesis via masked filtering
- cannot separate within a single t-f element
• Bottom-up leaves no ambiguity or context
- how to model illusions?
time
freq

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 12
Restoration in sound perception
• Auditory ‘illusions ’ = hearing what ’s not there
• The continuity illusion
• SWS
- duplex perception
1000
2000
4000
f/Hz ptshort
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4time/s
5
10
15f/Bark S1−env.pf:0
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8
40
60
80

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 13
Adding top-down constraints
Perception is not
direct
but a
search
for
plausible hypotheses
• Data-driven (bottom-up)...
- objects irresistibly appear
vs. Prediction-driven (top-down)
- match observations with parameters of a world-model
- need world-model constraints...
inputmixture
signalfeatures
discreteobjects
Front end Objectformation
Groupingrules
Sourcegroups
inputmixture
signalfeatures
predictionerrors
hypotheses
predictedfeaturesFront end Compare
& reconcile
Hypothesismanagement
Predict& combinePeriodic
components
Noisecomponents

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 14
Aside: Optimal techniques (ICA, ABF)
(Bell & Sejnowski etc.)
• General idea:Drive a parameterized separation algorithm to maximize independence of outputs
• Attractions:
- mathematically rigorous, minimal assumptions
• Problems:
- limitations of separation algorithm (N x N)- essentially bottom-up
m1m2
s1s2
a11a21
a12a22
x
−δ MutInfoδa

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 15
Outline
Human sound organization
Computational Auditory Scene Analysis
Speech models and knowledge- automatic speech recognition- subword states- cepstral coefficients
Sound mixture recognition
Learning opportunities
1
2
3
4
5

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 16
Speech models & knowledge
• Standard speech recognition
• ‘State of the art’ word-error rates (WERs):- 2% (dictation) - 30% (telephone conversations)
3
Featurecalculation
sound
Acousticclassifier
feature vectorsAcoustic model
parameters
HMMdecoder
Understanding/application...
phone probabilities
phone / word sequence
Word models
Language modelp("sat"|"the","cat")p("saw"|"the","cat")
s ah t
D A
T A

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 17
Speech units
• Speech is highly variable- simple templates won’t do- spectral variation (voice quality)- time-warp problems
• Match short segments (states), allow repeats- model with pseudo-stationary slices of ~ 10 ms
• Speech models are distributions
time / s
freq
/ H
z
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.450
1000
2000
3000
4000sil silg w eh n
p X q( )

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 18
Speech features: Cepstra
• Idea: Decorrelate & summarize spectral slices:
- easier to model:
- C0 ‘normalizes out’ average log energy
• Decorrelated pdfs fit diagonal Gaussians- DCT is close to PCA for log spectra
Xm l[ ] IDFT S mH k,[ ]log{ }=
frames
5
10
15
20
25
4
8
12
16
20
5 10 15 20
4
8
12
16
20
-5
-4
-3
-2
50 100 150
Cep
stra
l co
effi
cien
tsA
ud
ito
ry
spec
tru
mCovariance matrixFeatures Example joint distrib (10,15)
2468
1012141618
-5 0 5-4-3-2-10123

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 19
Acoustic model training
• Goal: describe with e.g. GMMs
• Training data labels from:- manual phonetic annotation- ‘best path’ from earlier classifier (Viterbi)- EM: joint estimation of labels & pdfs
p X q( )
Labeledtraining
examples{xn,ωxn}
Sortaccordingto class
Estimateconditional pdf
for class ω1
p(x|ω1)

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 20
HMM decoding
• Feature vectors cannot be reliably classified into phonemes
• Use top-down constraints to get good results- allowable phonemes- dictionary of known words- grammar of possible sentences
• Decoder searches all possible state sequences- at least notionally; pruning makes it possible
time / s
freq
/ kH
z
0 0.5 1 1.5 2 2.50
1
2
3
4
w iy d uwhh aev
jhahs tcl yuw
d ey z l eh n tclh#
w iy dclduw hhaeaw jh ah stcltaxchjhy iyuwdcld ey z l eh f h# dh
WE DO HAVE JUSTA
FEW DAYS LEFTTHE

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 21
Outline
Human sound organization
Computational Auditory Scene Analysis
Speech models and knowledge
Sound mixture recognition- feature invariance- mixtures including- general mixtures
Learning opportunities
1
2
3
4
5

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 22
Sound mixture recognition
• Biggest problem in speech recognition is background noise interference
• Feature invariance approach- use features that reflect only speech- e.g. normalization, mean subtraction- but: non-static noise?
• Or: more complex models of the signal- HMM decomposition- missing-data recognition
• Generalize to other, multiple sounds
4
LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 23
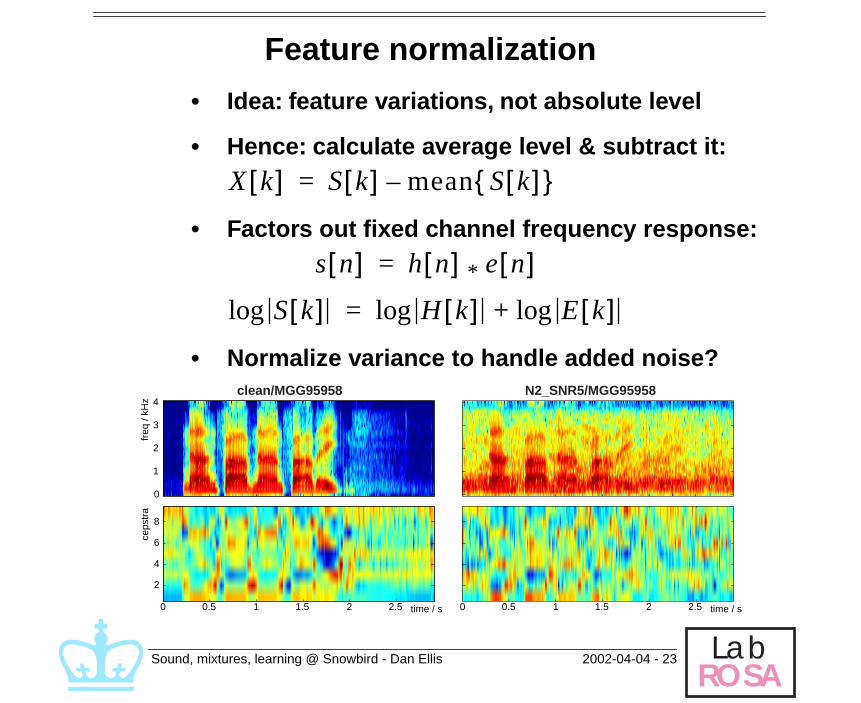
Feature normalization
• Idea: feature variations, not absolute level
• Hence: calculate average level & subtract it:
• Factors out fixed channel frequency response:
• Normalize variance to handle added noise?
X k[ ] S k[ ] mean S k[ ]{ }–=
s n[ ] h n[ ] e n[ ]*=
S k[ ]log H k[ ]log E k[ ]log+=
time / s
freq
/ kH
zce
pstr
a
0 0.5 1 1.5 2 2.5 time / s0 0.5 1 1.5 2 2.5
0
1
2
3
4
8
6
4
2
clean/MGG95958 N2_SNR5/MGG95958

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 24
HMM decomposition(e.g. Varga & Moore 1991, Roweis 2000)
• Total signal model has independent state sequences for 2+ component sources
• New combined state space q' = {q1 q2}
- new observation pdfs for each combination
model 1
model 2
observations / time
p Xi
q1i
q2i,( )

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 25
Problems with HMM decomposition
• O(qk)N is exponentially large...
• Normalization no longer holds!- each source has a different gain
→ model at various SNRs?- models typically don’t use overall energy C0
- each source has a different channel H[k]
• Modeling every possible sub-state combination is inefficient, inelegant and impractical

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 26
Missing data recognition(Cooke, Green, Barker @ Sheffield)
• Energy overlaps in time-freq. hide features- some observations are effectively missing
• Use missing feature theory...- integrate over missing data xm under model M
• Effective in speech recognition
• Problem: finding the missing data mask
p x M( ) p xp xm M,( ) p xm M( ) xmd∫=
-5 0 5 10 15 20 Clean0
10
20
30
40
50
60
70
80
90 AURORA 2000 - Test Set A
WE
RMD Discrete SNRMD Soft SNRHTK clean trainingHTK multi-condition
"1754" + noise
Missing-dataRecognition
stationary noise estimate
"1754"
Mask based on

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 27
Maximum-likelihood data mask(Jon Barker @ Sheffield)
• Search of sound-fragment interpretations
• Decoder searches over data mask K:
- how to estimate p(K)
"1754" + noise
Common Onset/Offset
MultisourceDecoder
Spectro-Temporal Proximity
Mask split into subbands
stationary noise estimate
`Grouping' applied within bands:
"1754"
Mask based on
p M K x,( ) p x K M,( ) p K M( ) p M( )∝

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 28
Multi-source decoding
• Search for more than one source
• Mutually-dependent data masks
• Use CASA processing to propose masks- locally coherent regions- p(K|q)
• Theoretical vs. practical limits
O(t)
K1(t)q1(t)
K2(t)q2(t)

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 29
General sound mixtures
• Search for generative explanation:
Sourcemodels
Sourcesignals
Receivedsignals
Observations
ObservationsO
Modeldependence
Channelparameters
M1 Y1 X1
C1
M2 Y2 X2
C2
O
{Mi}{Ki}
p(X|Mi,Ki)
Θ
Generationmodel
Analysisstructure
Fragmentformation
Maskallocation
Likelihoodevaluation
Modelfitting

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 30
Outline
Human sound organization
Computational Auditory Scene Analysis
Speech models and knowledge
Sound mixture recognition
Opportunities for learning- learnable aspects of modeling- tractable decoding- some examples
1
2
3
4
5

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 31
Opportunities for learning
• Per model feature distributions
- e.g. analyzing isolated sound databases
• Channel modifications
- e.g. by comparing multi-mic recordings
• Signal combinations
- determined by acoustics
• Patterns of model combinations
- loose dependence between sources
• Search for most likely explanations
• Short-term structure: repeating events
5
P Y M( )
P X Y( )
P O Xi{ }( )
P Mi{ }( )
P Mi{ } O( ) P O Xi{ }( )P Xi{ } Mi{ }( )P Mi{ }( )∝

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 32
Source models
• The speech recognition lesson:Use the data as much as possible- what can we do with unlimited data feeds?
• Data sources- clean data corpora- identify near-clean segments in real sound
• Model types- templates- parametric/constraint models- HMMs

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 33
What are the HMM states?
• No sub-units defined for nonspeech sounds
• Final states depend on EM initialization- labels- clusters- transition matrix
• Have ideas of what we’d like to get- investigate features/initialization to get there
s4s7s3s4s3s4s2s3s2s5s3s2s7s3s2s4s2s3s7
1.15 1.20 1.25 1.30 1.35 1.40 1.45 1.50 1.55 1.60 1.65 1.70 1.75 1.80 1.85 1.90 1.95 2.00 2.05 2.10 2.15 2.20 2.25 2
s4s7s3s4s3s4s2s3s2s5s3s2s7s3s2s4s2s3s7
12345678
1.15 1.20 1.30 1.40 1.50 1.60 1.70 1.80 1.90 2.00 2.10 2.20 2time
freq
/ kH
z
dogBarks2

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 34
Tractable decoding
• Speech decoder notionally searches all states
• Parametric models give infinite space- need closed-form partial explanations- examine residual, iterate, converge
• Need general cues to get started- return to Auditory Scene Analysis:
- onsets- harmonic patterns
- then parametric fitting
• Need multiple hypothesis search, pruning, efficiency tricks
• Learning? Parameters for new source events- e.g. from artificial (hence labeled) mixtures

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 35
Example: Alarm sound detection
• Alarm sounds have particular structure- people ‘know them when they hear them’
• Isolate alarms in sound mixtures
- sinusoid peaks have invariant properties
• Learn model parameters from examples
freq
/ H
z
1 1.5 2 2.50
1000
2000
3000
4000
5000
time / sec1 1.5 2 2.5
0
1000
2000
3000
4000
5000 1
1 1.5 2 2.50
1000
2000
3000
4000
5000
time / sec
freq
/ H
zP
r(al
arm
)
0 1 2 3 4 5 6 7 8 9
0
2000
4000
0.5
1
Speech + alarm

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 36
Example: Music transcription(e.g. Masataka Goto)
• High-quality training material:Synthesizer sample kits
• Ground truth available:Musical scores
• Find ML explanations for scores- guide by multiple pitch tracking (hyp. search)
• Applications in similarity matching

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 37
Summary
• Sound contains lots of information... but it’s always mixed up
• Psychologists describe ASA... but bottom-up computer models don’t work
• Speech recognition works for isolated speech... by exploiting top-down, context constraints
• Speech in mixtures via multiple-source models... practical combinatorics are the main problem
• Generalize this idea for all sounds... need models of ‘all sounds’... plus models of channel modification... plus ways to propose segmentations... plus missing-data recognition

LabROSA
Sound, mixtures, learning @ Snowbird - Dan Ellis 2002-04-04 - 38
Further reading[BarkCE00] J. Barker, M.P. Cooke & D. Ellis (2000). “Decoding speech in the
presence of other sound sources,” Proc. ICSLP-2000, Beijing.ftp://ftp.icsi.berkeley.edu/pub/speech/papers/icslp00-msd.pdf
[Breg90] A.S. Bregman (1990). Auditory Scene Analysis: the perceptual organi-zation of sound, MIT Press.
[Chev00] A. de Cheveigné (2000). “The Auditory System as a Separation Machine,” Proc. Intl. Symposium on Hearing.http://www.ircam.fr/pcm/cheveign/sh/ps/ATReats98.pdf
[CookE01] M. Cooke, D. Ellis (2001). “The auditory organization of speech and other sources in listeners and computational models,” Speech Commu-nication (accepted for publication).http://www.ee.columbia.edu/~dpwe/pubs/tcfkas.pdf
[Ellis99] D.P.W. Ellis (1999). “Using knowledge to organize sound: The predic-tion-driven approach to computational auditory scene analysis...,” Speech Communications 27.http://www.ee.columbia.edu/~dpwe/pubs/spcomcasa98.pdf
[Roweis00] S. Roweis (2000). “One microphone source separation.,” Proc. NIPS 2000.http://www.ee.columbia.edu/~dpwe/papers/roweis-nips2000.pdf





























