Embed Size (px)
Citation preview

Information Systems 26 (2001) 607–633
Learning object identification rules for information integration
Sheila Tejadaa,*, Craig A. Knoblocka, Steven Mintonb
aUniversity of Southern California, Information Sciences Institute, 4676 Admiralty Way, Marina del Rey, CA 90292, USAbFetch Technologies 4676 Admiralty Way, Marina del Rey, CA 90292, USA
Abstract
When integrating information from multiple websites, the same data objects can exist in inconsistent text formatsacross sites, making it difficult to identify matching objects using exact text match. We have developed an object
identification system called Active Atlas, which compares the objects’ shared attributes in order to identify matchingobjects. Certain attributes are more important for deciding if a mapping should exist between two objects. Previousmethods of object identification have required manual construction of object identification rules or mapping rules fordetermining the mappings between objects. This manual process is time consuming and error-prone. In our approach.
Active Atlas learns to tailor mapping rules, through limited user input, to a specific application domain. Theexperimental results demonstrate that we achieve higher accuracy and require less user involvement than previousmethods across various application domains. r 2001 Elsevier Science Ltd. All rights reserved.
Keywords: Information integration; Machine learning; Data cleaning; Record linkage; Object identification; Active learning
1. Introduction
Many problems arise when integrating informa-tion from multiple information sources on the web[1]. One of these problems is that data objects canexist in inconsistent text formats across severalsources. An example application of informationintegration involves integrating all the reviews ofrestaurants from the Zagat’s Restaurants webpagewith the current restaurant health ratings from theDepartment of Health’s website. To integrate thesesources requires comparing the objects from bothsources and identifying which restaurants are thesame.Examples of the object identification problem
are shown in Fig. 1. In the first example therestaurant referred to as ‘‘Art’s Deli’’ on the
Zagat’s webpage may appear as ‘‘Art’s Delicates-sen’’ on the Health Department’s site. Because ofthis problem, the objects’ instances cannot becompared using equality, they must be judgedaccording to text similarity in order to determine ifthe objects are the same. When two objects aredetermined to be the same, a mapping is createdbetween them.The examples in Fig. 1 are each representative of
a type of example found in the restaurant domain.Together, these types of examples demonstrate theimportance of certain attributes or combinationsof attributes for deciding mappings betweenobjects. Both sources list a restaurant named‘‘Teresa’s’’, and even though they match exactlyon the Name attribute, we would not considerthem the same restaurant. These restaurantsbelong to the same restaurant chain, but theymay not share the same health rating. In this*Corresponding author.
0306-4379/01/$ - see front matter r 2001 Elsevier Science Ltd. All rights reserved.
PII: S 0 3 0 6 - 4 3 7 9 ( 0 1 ) 0 0 0 4 2 - 4

restaurant application the Name attribute alonedoes not provide enough information to determinethe mappings.The ‘‘Steakhouse The’’ and ‘‘Binion’s Coffee
Shop’’ restaurants are located in the same foodcourt of a shopping mall. Although they match onthe Street and Phone attributes, they may not havethe same health rating and should not beconsidered the same restaurant. In the lastexample, due to errors and unreliability of thedata values of the Street attribute, the restaurantobjects match only on the Name and Phone
attributes. Therefore, in order for objects to becorrectly mapped together in this application, theobjects must match highly on both the Name andthe Street attributes (‘‘Art’s Deli’’) or on both theName and Phone attributes (‘‘Les Celebrites’’).This type of attribute information is captured inthe form of object identification rules (mappingrules), which are used to determine the mappingsbetween the objects.This paper presents an object identification
system called Active Atlas that learns to tailormapping rules to a specific application domain inorder to determine with high accuracy the set ofmappings between the objects of two sources. Themain goal of this research is to achieve the highestpossible accuracy in object identification withminimal user interaction in order to properly
integrate data from multiple information sources.Active Atlas is a tool that can be used inconjunction with information mediators, such asSIMS [2] and Ariadne [3], to properly handle theobject identification problem for informationintegration.
1.1. Ariadne information mediator
The Ariadne information mediator [4] is asystem for extracting and integrating informationfrom sources on the web. Ariadne provides a singleinterface to multiple information sources forhuman users or applications programs. Queriesto Ariadne are in a uniform language, independentof the distribution of information over sources, thesource query languages, and the location ofsources. Ariadne determines which data sourcesto use and how to efficiently retrieve the data fromthe sources.Ariadne has a set of modeling tools that allow
the user to rapidly construct and maintaininformation integration applications for specificinformation sources, such as the restaurant appli-cation shown in Fig. 2. This application integratesinformation about restaurants from Zagat’s Res-taurants with information from the Department ofHealth. In order to retrieve data objects from theseweb sources, wrappers are created for each source.
Fig. 1. Matching restaurant objects.
S. Tejada et al. / Information Systems 26 (2001) 607–633608

A wrapper is software that extracts informa-tion from a website and provides a database-like interface. In this restaurant applicationtwo wrappers are created. Application buildingtools are provided with the Ariadne system,including a wrapper building tool, which gene-rates a wrapper to properly extract informationfrom a website. When the application hasbeen constructed, the Ariadne information med-iator can answer queries from the user by breakingthem into individual queries to the appropriatewrapper.Data objects extracted from websites by these
wrappers can be stored in the form of records in arelational table or database (Fig. 3). These objects(records) represent entities in the real world, likerestaurants. Each object has a set of attributes(e.g., Name, Street, Phone). A specific restaurantobject, for example, may have the following set ofvalues for its attributes: the value ‘‘Art’s Deli’’ forthe Name attribute, the value ‘‘12224 VenturaBoulevard’’ for the Street attribute, and the value‘‘818-756-4124’’ for the Phone attribute. As shownin Fig. 3 the attribute values of objects can have
different text formats and values across websites orinformation sources.To allow the user to properly query the
information mediator about these objects, there isa unifying domain model created for each Ariadneapplication, which provides a single ontology. Thedomain model (Fig. 4) is used to describe thecontents of the individual sources. Given a query interms of the concepts (e.g. Restaurant) andattributes (e.g. Name and Phone) described in themodel, the system dynamically selects an appro-priate set of sources and then generates a plan toefficiently produce the requested data.Unfortunately, due to the object identification
problem described in Fig. 1, the given domainmodel (Fig. 4) does not provide enough informa-tion for the mediator to properly integrate theinformation from the sources. To address thisproblem, Active Atlas can be applied to determinewith high accuracy the mappings between theobjects of the sources and add new informationsources to the domain model that include thenecessary information for integrating the sources(Fig. 5).
Fig. 2. Restaurant application.
S. Tejada et al. / Information Systems 26 (2001) 607–633 609
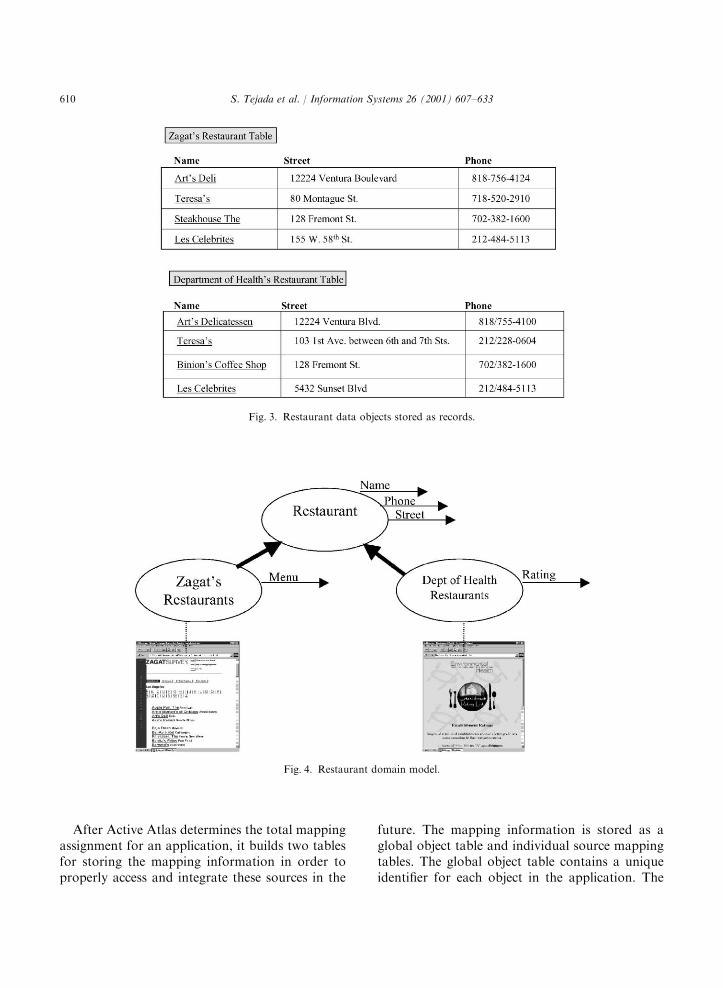
After Active Atlas determines the total mappingassignment for an application, it builds two tablesfor storing the mapping information in order toproperly access and integrate these sources in the
future. The mapping information is stored as aglobal object table and individual source mappingtables. The global object table contains a uniqueidentifier for each object in the application. The
Fig. 3. Restaurant data objects stored as records.
Fig. 4. Restaurant domain model.
S. Tejada et al. / Information Systems 26 (2001) 607–633610
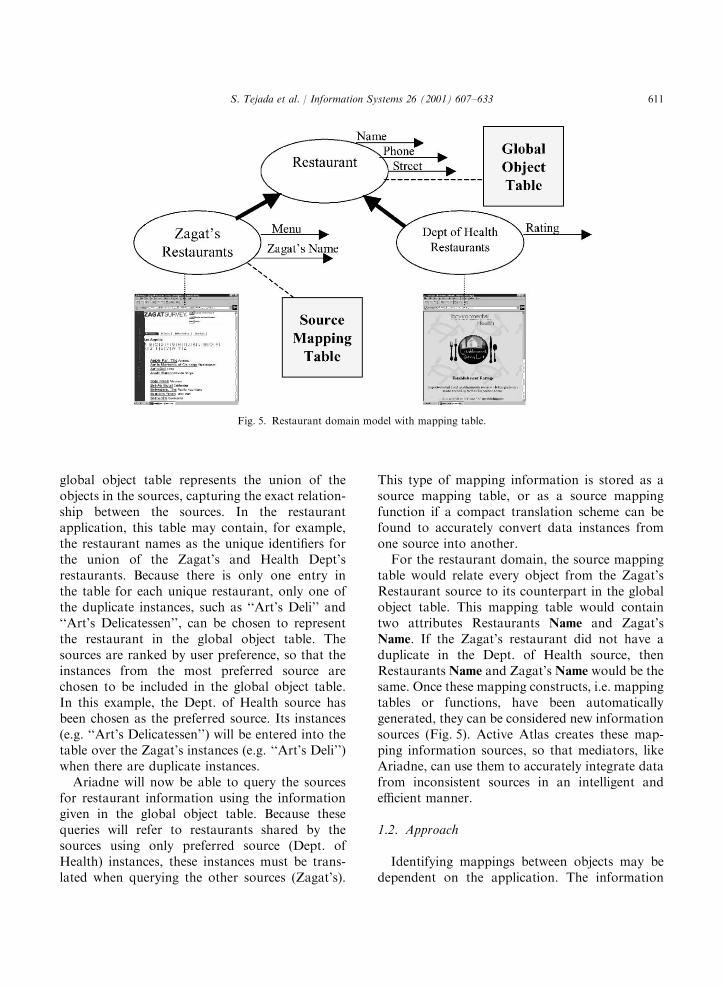
global object table represents the union of theobjects in the sources, capturing the exact relation-ship between the sources. In the restaurantapplication, this table may contain, for example,the restaurant names as the unique identifiers forthe union of the Zagat’s and Health Dept’srestaurants. Because there is only one entry inthe table for each unique restaurant, only one ofthe duplicate instances, such as ‘‘Art’s Deli’’ and‘‘Art’s Delicatessen’’, can be chosen to representthe restaurant in the global object table. Thesources are ranked by user preference, so that theinstances from the most preferred source arechosen to be included in the global object table.In this example, the Dept. of Health source hasbeen chosen as the preferred source. Its instances(e.g. ‘‘Art’s Delicatessen’’) will be entered into thetable over the Zagat’s instances (e.g. ‘‘Art’s Deli’’)when there are duplicate instances.Ariadne will now be able to query the sources
for restaurant information using the informationgiven in the global object table. Because thesequeries will refer to restaurants shared by thesources using only preferred source (Dept. ofHealth) instances, these instances must be trans-lated when querying the other sources (Zagat’s).
This type of mapping information is stored as asource mapping table, or as a source mappingfunction if a compact translation scheme can befound to accurately convert data instances fromone source into another.For the restaurant domain, the source mapping
table would relate every object from the Zagat’sRestaurant source to its counterpart in the globalobject table. This mapping table would containtwo attributes Restaurants Name and Zagat’sName. If the Zagat’s restaurant did not have aduplicate in the Dept. of Health source, thenRestaurants Name and Zagat’s Name would be thesame. Once these mapping constructs, i.e. mappingtables or functions, have been automaticallygenerated, they can be considered new informationsources (Fig. 5). Active Atlas creates these map-ping information sources, so that mediators, likeAriadne, can use them to accurately integrate datafrom inconsistent sources in an intelligent andefficient manner.
1.2. Approach
Identifying mappings between objects may bedependent on the application. The information
Fig. 5. Restaurant domain model with mapping table.
S. Tejada et al. / Information Systems 26 (2001) 607–633 611

necessary for deciding a mapping may not beevident by solely evaluating the data itself becausethere might be knowledge about the task that isnot represented in the data. For example, the sameGovernment Census data can be grouped byhousehold or by each individual (Fig. 6) dependingon the task. In the figure below the objectscorresponding to Mrs. Smith and Mr. Smith
would not be mapped together if the applicationis to retrieve information about an individual, suchas their personal income, from the Govern-ment Census data. But, if the application is todetermine the household mailing addresses inorder to mail the new Census 2000 form to eachhousehold, then the objects Mrs. Smith and Mr.Smith would be mapped together, so that theSmith household would only receive a singleCensus 2000 form.In the restaurant domain (Fig. 1), because we
are retrieving information about health ratings, weare interested in finding the same physical restau-rant between the sources. In other words, wewould not map together restaurants belonging tothe same chain, like the ‘‘Teresa’s’’ restaurants inFig. 1, or the restaurants in the same food court ofa shopping mall, like ‘‘Steakhouse The’’ &‘‘Binion’s Coffee Shop’’. Because of these typesof examples, a combination of the Name attributeand either the Street or Phone attributes isnecessary to determine whether the objects shouldbe mapped together. But, for example, telemark-eters trying to sell long distance phone service tothese restaurants, would only be interested in therestaurant phone number matchingFthe otherattributes would be irrelevant. Because the map-ping assignment can depend on the application,the data itself is not enough to decide themappings between the sets of objects. The user’sknowledge is needed to increase the accuracy ofthe total mapping assignment. We have adopted ageneral domain-independent approach for incor-
porating the user’s knowledge into the objectidentification system.There are two types of knowledge necessary for
handling object identification: (1) the importanceof the different attributes for deciding a mapping,and (2) the text formatting differences or transfor-mations that may be relevant to the applicationdomain. It is very expensive, in terms of the user’stime, to manually encode these types of knowledgefor an object identification system. Also, due toerrors that can occur in the data, a user may not beable to provide comprehensive information with-out thoroughly reviewing the data in all sources.Our approach is to learn a set of mapping rules fora specific application domain, through limited userinput. We accomplish this by first determining thetext formatting transformations, and then learningdomain-specific mapping rules.The focus of this paper is to present a general
method of learning mapping rules for objectidentification. This paper consists of five sections.Section 2 provides a detailed description of ourobject identification system Active Atlas. Section 3presents the experimental results of the system.Section 4 discusses related work, and Section 5concludes with a description of future work.
2. Learning object identification rules
We have developed an object identificationmethod that learns the mapping informationnecessary to properly integrate web sources withhigh accuracy. As shown in Fig. 7, there are twostages in our method, computing the similarityscores and mapping-rule learning. In the firststage, the candidate generator is used to proposethe set of possible mappings between the two setsof objects by comparing the attribute values andcomputing the similarity scores for the proposedmappings. In the next stage, the mapping rule
Fig. 6. Example census data.
S. Tejada et al. / Information Systems 26 (2001) 607–633612

learner determines which of the proposed map-pings are correct by learning the appropriatemapping rules for the application domain.The objects from the sources are given as input
in the first stage of processing. The candidategenerator compares all of the shared attributes ofthe given objects by applying a set of domain-independent functions to resolve text transforma-tions, e.g., substring, acronym, abbreviation, etc.to determine which objects are possibly mappedtogether. It then computes the similarity scores foreach of attributes of the proposed mapped pairs ofobjects or candidate mappings. The output of the
candidate generator is the set of candidate map-pings, each with their corresponding set of attributesimilarity scores and combined total score.The second stage (Fig. 7) is learning the map-
ping rules. This component determines whichattribute or combinations of attributes (Name,Street, Phone) are most important for mappingobjects by learning the thresholds on the attributesimilarity scores computed in the first stage. Thepurpose of learning the mapping rules is to achievethe highest possible accuracy for object mappingacross various application domains. The user’sinput is necessary for learning these mapping rules.The main idea behind our approach is for themapping rule learner to actively choose the mostinformative candidate mappings, or training ex-amples, for the user to classify as mapped or notmapped. The learner constructs high accuracymapping rules based on these examples, while atthe same time limiting the amount of userinvolvement. Once the rules have been learned,they are applied to the set of candidate mappingsto determine the set of mapped objects.
2.1. Computing similarity scores
When comparing objects, the alignment of theattributes is determined by the domain model(Fig. 4). The values for each attribute are com-pared individually (Fig. 8FName with Name,Street with Street, and Phone with Phone).Comparing the attributes individually is importantin reducing the confusion that can arise whencomparing the objects as a whole. Words canoverlap between the attribute values. For example,some words in the Name of the restaurant ‘‘TheBoulevard Cafe’’ can appear in the Street attributevalue of another restaurant. Comparing theattributes individually saves computation and
Fig. 7. General system architecture. Fig. 8. Comparing objects by attributes.
S. Tejada et al. / Information Systems 26 (2001) 607–633 613

decreases mapping error by reducing the numberof candidate mappings considered.Given the two sets of objects, the candidate
generator is responsible for generating the set ofcandidate mappings by comparing the attributevalues of the objects. The output of this compo-nent is a set of attribute similarity scores for eachcandidate mapping. A candidate mapping has acomputed similarity score for each attribute pair.The process for computing these scores is de-scribed in detail later in this section.Example attribute similarity scores for the
candidate mapping of the ‘‘Art’s Deli’’ and ‘‘Art’sDelicatessen’’ objects are displayed in Fig. 9. Thesimilarity scores for the Name and Street attributevalues are relatively high. This is because the textvalues are similar and the text formatting differ-ences between them can be resolved. The Phoneattribute score is low because the two phonenumbers only have the same area code in common,and since the dataset contains many restaurants inthe same city as ‘‘Art’s Deli’’, the area code occursfrequently.
2.1.1. General transformation functionsIncluded in our framework is a set of general
domain-independent transformation functions toresolve the different text formats used by theobjects (Fig. 10). These transformation functions(e.g. abbreviation, acronym, substring, etc.) aredomain-independent and are applied to all of theattribute values in every application domain.These functions determine if text transformationsexist between words (tokens) in the attributevalues, e.g. (abbreviationF‘‘Deli’’, ‘‘Delicates-sen’’) or between phrases, e.g. (acronymF‘‘California Pizza Kitchen’’, ‘‘CPK’’). If transfor-mations exist between the tokens, then a candidatemapping is proposed between the correspondingobjects.There are two basic types of the transformation
functions. Type I transformations require only a
single token as input in order to compute itstransformation. Type II transformations comparetokens from two objects.
Type I transformations
* Stemming converts a token into its stem orroot.
* Soundex converts a token into a Soundexcode. Tokens that sound similar have the samecode.
* Abbreviation replaces token with correspondingabbreviation (e.g., 3rd or third).
Type II transformations
* Equality compares two tokens to determine ifeach token contains the same characters in thesame order.
* Initial computes if one token is equal to the firstcharacter of the other.
* Prefix computes if one token is equal to acontinuous subset of the other starting at thefirst character.
* Suffix computes if one token is equal to acontinuous subset of the other starting at thelast character.
* Substring computes if one token is equal to acontinuous subset of the other, but does notinclude the first or last character.
* Abbreviation computes if one token is equal to asubset of the other (e.g., Blvd, Boulevard).
* Acronym computes if all characters of onetoken are initial letters of all tokens from theother object (e.g., CPK, California PizzaKitchen).
2.1.2. Information retrieval engineThe candidate generator is a modified informa-
tion retrieval engine [5] that can apply a varietyof transformation functions to resolve text
Fig. 9. Set of computed similarity scores.
Fig. 10. Transformations.
S. Tejada et al. / Information Systems 26 (2001) 607–633614

formatting inconsistencies and generate the candi-date mappings. The information retrieval engine isused to apply the transformation functions be-tween sets of attribute values individually, i.e.Name with Name, Street with Street and Phoneand Phone in the restaurant application (Fig. 8).Most information retrieval systems, such as the
Whirl system [6], apply only the stemmingtransformation function to compare the words ofthe attribute values. The stemming transformationfunction compares the stem or root of the words todetermine similarity. In our approach we haveincluded a set of general transformation functions,so that the system is able to resolve a variety oftext formatting differences.For the candidate generator, the attribute values
are considered short documents. These documentsare divided into tokens. These tokens are com-pared using the transformation functions. If atransformation exists between the tokens or if thetokens match exactly, then a candidate mapping isgenerated for the corresponding objects. For theexample below, a candidate mapping is generatedfor the objects ‘‘Art’s Deli’’ and ‘‘Art’s Delicates-sen’’., because there are transformations betweentheir tokens: (equalityF‘‘Art’s’’, ‘‘Art’s’’), i.e.exact text match, and (abbreviationF‘‘Deli’’,‘‘Delicatessen’’) (Fig. 11).The information retrieval (IR) engine has
been modified in order to apply the transforma-tions in a three-step process. The first step is toapply all of the Type I transformations to the data.The second step after applying the Type Itransformations is to determine the set of objectpairs that are related. And the third step is toapply the Type II transformations in order tofurther strengthen the relationship between thetwo data objects.
In step 1, the Type I transformations are appliedto one attribute dataset, such as the Department ofHealth’s restaurant names. Like a traditional IRengine the data is first tokenized, the transforma-tions are applied to each token (Stemming,Soundex, etc.) and then stored in a hash-table.Therefore, each token can have more than oneentry in the hash-table. In this modified IR engine,information about which transformation wasapplied is stored, as well as the token frequencyand tuple (object) number.Now the other dataset for this attribute
(Zagat’s restaurant names) is used as a queryset against this hash-table. Each object in theZagat’s dataset is tokenized and the trans-formations are applied to each of the tokens.The object’s tokens and the new transformationtokens are both used to query the hash-table. Thehash-table entries returned contain the tuplenumbers of the related objects from the otherdataset (Department of Health). This processis completed for every attribute (Name, Street,and Phone).At the end of the first step, the set of related
objects and the transformations used to relatethem are known for each attribute. The secondstep is to determine the total set of related objectsby combining the sets computed for each of theattributes. Once this is done, then the morecomputationally expensive transformations (TypeII) are applied to the remaining unmatched tokensof the attribute values for the related object pairsin order to improve the match. When this step isfinished, it will output the set of related objectpairs with their corresponding set of transforma-tions used to relate them, along with the tokenfrequency information needed for computing thesimilarity scores.
2.1.3. Computing attribute similarity scoresEach transformation function has an initial
probability score or transformation weight that isused in the calculation of the attribute similarityscores. For the example in Fig. 11 the totalsimilarity score for the Name attribute values‘‘Art’s Deli’’ and ‘‘Art’s Delicatessen’’, is calcu-lated with the weights for the two transformations(equalityF‘‘Art’s’’ ‘‘Art’s’’), and (abbreviationFig. 11. Applying transformation functions.
S. Tejada et al. / Information Systems 26 (2001) 607–633 615

F‘‘Deli’’, ‘‘Delicatessen’’). In this section wediscuss in detail how the transformation weightsare used to calculate the attribute similarity scores.Fig. 12 shows how attribute values, (Z1, Z2, Z3)
and (D1, D2, D3), are compared in order togenerate the set of attribute similarity scores(Sname;Sstreet;Sphone). In Fig. 12, Z1 and D1 repre-sent Name attribute values, e.g. ‘‘Art’s Deli’’ and‘‘Art’s Delicatessen’’. These values are comparedusing general transformation functions and thentheir transformation weights are used to calculatethe similarity score Sname:To calculate the similarity scores for the
attribute values of the candidate mappings, wehave employed the cosine measure commonly usedin information retrieval engines with an alteredform of the TFIDF (Term Frequency� InverseDocument Frequency) weighting scheme [7]. Be-cause the attribute values of the object are veryshort, the term frequency weighting is not relevant.In place of the term frequency, we have substitutedthe initial probability score of the applied trans-formation function, which represents the transfor-mation weight (TWIDF). The similarity score fora pair of attribute values is computed using thefollowing attribute similarity formula:
Similarity ðA;BÞ ¼Pt
i¼1 ðwiawibÞffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiPti¼1 w
2ia
Pti¼1 w
2ib
q ;
where wia ¼ ð0:5þ 0:5 tweightia=max tweightaÞ �IDF; wib ¼ freqib � IDFi; tweightia is the transfor-mation function weight i for attribute value a;max tweighta the maximum transformation func-tion weight, IDFi the IDF (Inverse DocumentFrequency) of token i in the entire collection
and freqib the frequency of token i in attributevalue b:In this formula a and b represent the two
documents (attribute values) being compared and trepresents the number of tokens in the documents.The terms wia and wib correspond to the weightscomputed by the TWIDF weighting function. Thisformula measures the similarity by computing thedistance between two attribute values.
2.1.4. Calculating the total object similarity scoresWhen the candidate generator is finished, it
outputs all of the candidate mappings it hasgenerated along with each of their correspondingset of attribute similarity scores. Example sets ofattribute similarity scores from the candidategenerator are shown in Fig. 13. For each candidatemapping, the total object similarity score iscalculated as a weighted sum of the attributesimilarity scores.Each attribute has a uniqueness weight that is a
heuristic measure of the importance of thatattribute. This is to reflect the idea that we aremore likely to believe mappings between uniqueattributes because the values are rarer. Theuniqueness weight of an attribute is measured bythe total number of unique attribute valuescontained in the attribute set divided by the totalnumber of values for that attribute set. There aretwo uniqueness weights for each attribute similar-ity score, because we are comparing pairs ofattribute valuesFone from each of the twosources being integrated. To calculate the totalobject similarity score, each attribute similarityscore is multiplied by its associated uniquenessweights, and then summed together. Once the total
Fig. 13. Output of the candidate generator.
Fig. 12. Computing similarity scores.
S. Tejada et al. / Information Systems 26 (2001) 607–633616

object scores are computed, the candidate map-ping information is then given as input to themapping-rule learner (Fig. 13).
2.2. Mapping-rule learning
The mapping-rule learner determines whichattribute, or combinations of attributes (Name,Street, Phone), are most important for mappingobjects. The purpose of learning the mapping rulesis to achieve the highest possible accuracy forobject mapping across various application do-mains. In our approach, the system activelychooses the most informative candidate mappings(training examples) for the user to classify asmapped or not mapped in order to minimize thenumber of user-labeled examples required to learnhigh accuracy mapping rules.
2.2.1. Decision tree learningMapping rules contain information about which
combination of attributes are important fordetermining the mapping between two objects, aswell as, the thresholds on the similarity scores foreach attribute. Several mapping rules may benecessary to properly classify the objects for aspecific domain application. Examples of mappingrules for the restaurant domain are:
* Rule 1: Name > 0:859 and Street > 0:912 )mapped
* Rule 2: Name > 0:859 and Phone > 0:95 )mapped
These rules are obtained through decision treelearning [8]. Decision tree learning is an inductivelearning technique, where a learner constructs adecision tree (Fig. 14) to correctly classify givenpositive and negative labeled examples. Decisiontrees classify an example by starting at the topnode and traversing the tree down to a leaf, whichis the classification for the given example. Eachnode of the tree contains a test to perform on anattribute, and each branch is labeled with apossible outcome of the test.To classify for the candidate mapping of the
objects ‘‘Art’s Deli’’ and ‘‘Art’s Delicatessen’’,which has the attribute similarity scores (0.967
0.953 0.3), we can use the decision tree shown inFig. 14. First, the Name attribute is tested. Itsresults is positive, so the Street attribute is testednext. Its results is also positive, and we follow thepositive branch to reach a leaf node with a mappedclassification; therefore, this example is classifiedas mapped.Decision trees are created by determining which
are the most useful attributes to classify theexamples. A metric called information gain mea-sures how well an attribute divides the given set oftraining examples by their classification (mapped/not mapped). Creating the decision tree is aniterative process, where the attribute with thegreatest information gain is chosen at each level.Once a decision tree is created, it can be convertedinto mapping rules, like those described above.
2.2.2. Active learningA single decision tree learner on its own can
learn the necessary mapping rules to properlyclassify the data with high accuracy, but mayrequire a large number of user-labeled examples,as shown in the Experimental Results section. Toefficiently learn the mapping rules for a particulartask or domain, we are currently applying asupervised learning technique, which uses acombination of several decision tree learners,called query by bagging [9]. This techniquegenerates a committee of decision tree learnersthat vote on the most informative example orcandidate mapping for the user to classify next.The query by bagging technique is considered an
Fig. 14. Example decision tree for restaurant domain.
S. Tejada et al. / Information Systems 26 (2001) 607–633 617
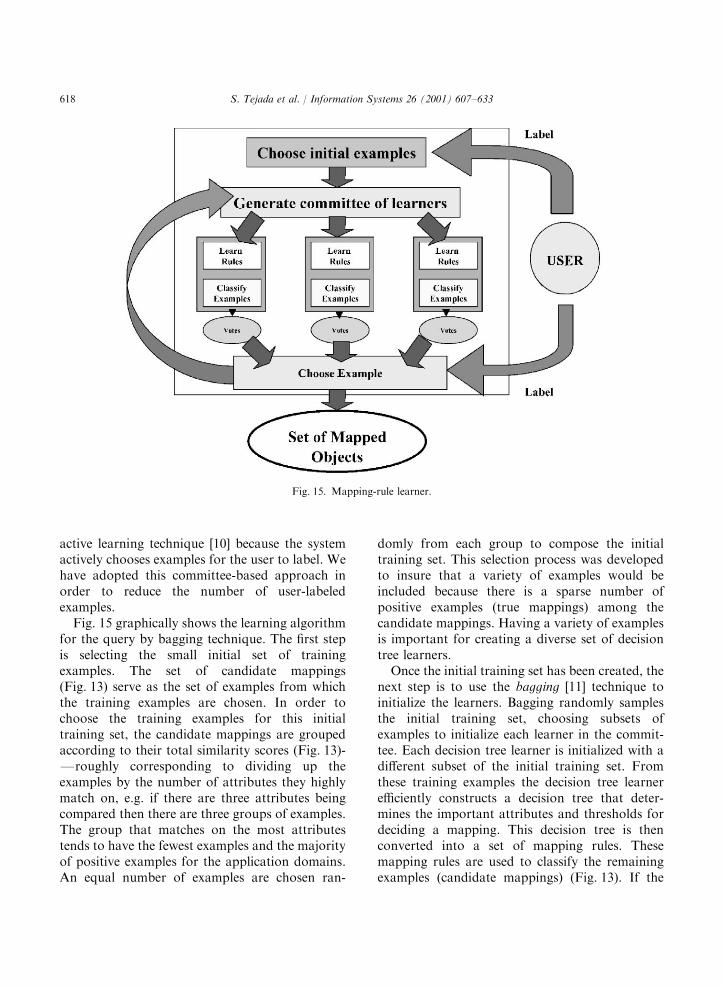
active learning technique [10] because the systemactively chooses examples for the user to label. Wehave adopted this committee-based approach inorder to reduce the number of user-labeledexamples.Fig. 15 graphically shows the learning algorithm
for the query by bagging technique. The first stepis selecting the small initial set of trainingexamples. The set of candidate mappings(Fig. 13) serve as the set of examples from whichthe training examples are chosen. In order tochoose the training examples for this initialtraining set, the candidate mappings are groupedaccording to their total similarity scores (Fig. 13)-Froughly corresponding to dividing up theexamples by the number of attributes they highlymatch on, e.g. if there are three attributes beingcompared then there are three groups of examples.The group that matches on the most attributestends to have the fewest examples and the majorityof positive examples for the application domains.An equal number of examples are chosen ran-
domly from each group to compose the initialtraining set. This selection process was developedto insure that a variety of examples would beincluded because there is a sparse number ofpositive examples (true mappings) among thecandidate mappings. Having a variety of examplesis important for creating a diverse set of decisiontree learners.Once the initial training set has been created, the
next step is to use the bagging [11] technique toinitialize the learners. Bagging randomly samplesthe initial training set, choosing subsets ofexamples to initialize each learner in the commit-tee. Each decision tree learner is initialized with adifferent subset of the initial training set. Fromthese training examples the decision tree learnerefficiently constructs a decision tree that deter-mines the important attributes and thresholds fordeciding a mapping. This decision tree is thenconverted into a set of mapping rules. Thesemapping rules are used to classify the remainingexamples (candidate mappings) (Fig. 13). If the
Fig. 15. Mapping-rule learner.
S. Tejada et al. / Information Systems 26 (2001) 607–633618

similarity scores of a candidate mapping fulfill theconditions of a rule then the candidate mapping isclassified as mapped.With a committee of decision tree learners, the
classification of an example or candidate mappingby one decision tree learner is considered its voteon the example. The votes of the committee oflearners determine which examples are to belabeled by the user. The choice of an example isbased on the disagreement of the query committeeon its classification (Fig. 16). The maximal dis-agreement occurs when there is an equal numberof mapped (yes) and not mapped (no) votes on theclassification of an example. This example has thehighest guaranteed information gain, becauseregardless of the example’s label, half of thecommittee will need to update their hypothesis.As shown in Fig. 16 the example CPK, CaliforniaPizza Kitchen is the most informative example forthe committee (L1, L2, L3, L4, L5, L6, L7, L8, L9,and L10).There are cases where the committee disagrees
the most on several examples. In order to break atie and choose an example, the total objectsimilarity score, associated with each example(Fig. 13), is used as the deciding factor. Sincethere is a sparse number of positive examples inthe set of candidate mappings, we would like toincrease the chances of choosing a positiveexample for the committee to learn from. There-fore, the example with the greatest totalobject similarity score is chosen from the pro-posed set.Once an example is chosen, the user is asked to
label the example, and the system updates thecommittee. This learning process is repeated untileither all learners in the committee converge to the
same decision tree or the user threshold forlabeling examples has been reached. When learn-ing has ended, the mapping-rule learner outputs amajority-vote classifier that can be used to classifythe remaining pairs as mapped or not mapped.After the total mapping assignment is complete,new information sources (mapping tables) can becreated for use by an information mediator.
3. Experimental results
In this section we present the experimentalresults that we have obtained from running ActiveAtlas across three different application domains:restaurants, companies and airports. For eachdomain, we also ran experiments for a systemcalled Passive Atlas. The Passive Atlas systemincludes the candidate generator for proposingcandidate mappings and a single C4.5 decision treelearner for learning the mapping rules.We also include results from two baseline
experiments as well. The first baseline experimentruns the candidate generator to compare all of theshared attributes of the objects separately, whilethe second baseline experiment compares theobjects as a whole, with all of the shared attributesconcatenated into one attribute. Both baselineexperiments require choosing an optimal mappingthreshold from a ranked list of candidate map-pings, and they use only the stemming transforma-tion function.
3.1. Restaurant domain
For the restaurant domain, the shared objectattributes are Name, Street, and Phone. Many of
Fig. 16. Choosing the next example.
S. Tejada et al. / Information Systems 26 (2001) 607–633 619
the data objects in this domain match almostexactly on all attributes, but there are types ofexamples that do not, as shown in Fig. 1. Becauseof these four types of examples, the system learnstwo mapping rules: if the restaurants match highlyon the Name & Street or on the Name & Phone
attributes then the objects should be mappedtogether. The example ‘‘Art’s Deli’’ is an exampleof the first type of mapping rule because its Nameand Street attribute values match highly. The ‘‘LesCelebrites’’ example is an example of the secondtype of mapping rule, because its Name and Phoneattribute values match highly. These two mappingrules are used to classify all of the candidatemappings. Any candidate mapping that fulfills theconditions of these rules, will be mapped. Becausein our application we are looking for the correcthealth rating of a specific restaurant, examplesmatching only on the Name attribute, like the‘‘Teresa’s’’ example, or only on the Street or Phoneattribute, like ‘‘Steakhouse The’’ are not consid-ered mapped.
3.1.1. Experimental resultsIn this domain the Zagat’s website has 331
objects and the Dept of Health has 533 objects.There are 112 correct mappings between the twosites. When running the baseline experiments, thesystem returns a ranked set of all the candidatemappings. The user must scan the mappings anddecide on the mapping threshold or cutoff point inthe returned ranked list. Every candidate mappingabove the threshold is classified as mapped andevery candidate mapping below the threshold isnot mapped. The optimal mapping threshold hasthe highest accuracy. Accuracy is measured as the
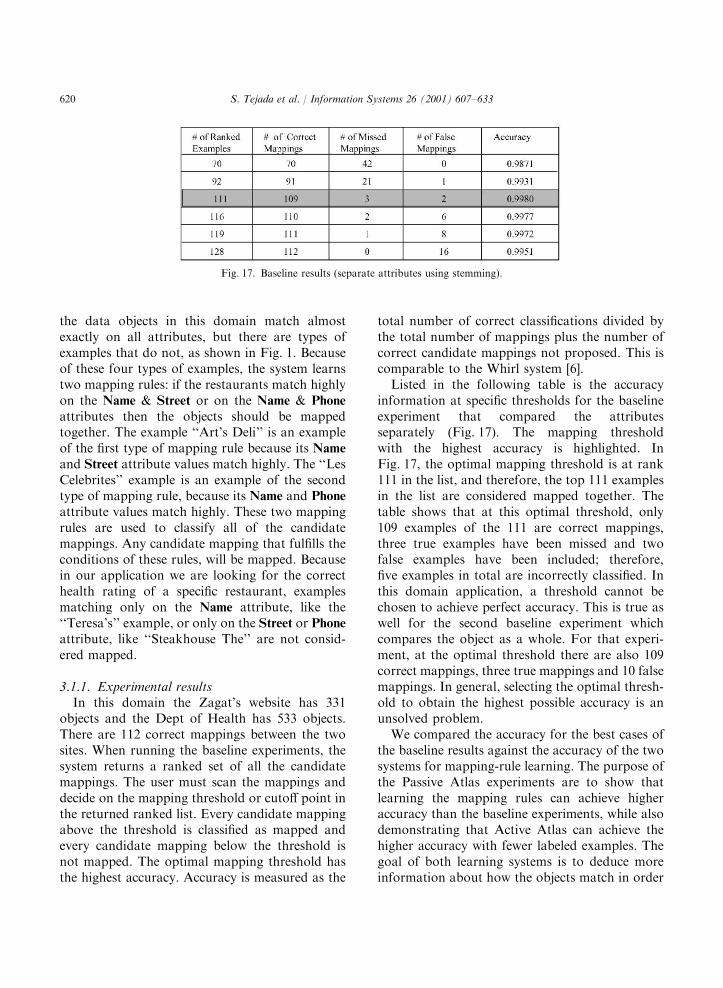
total number of correct classifications divided bythe total number of mappings plus the number ofcorrect candidate mappings not proposed. This iscomparable to the Whirl system [6].Listed in the following table is the accuracy
information at specific thresholds for the baselineexperiment that compared the attributesseparately (Fig. 17). The mapping thresholdwith the highest accuracy is highlighted. InFig. 17, the optimal mapping threshold is at rank111 in the list, and therefore, the top 111 examplesin the list are considered mapped together. Thetable shows that at this optimal threshold, only109 examples of the 111 are correct mappings,three true examples have been missed and twofalse examples have been included; therefore,five examples in total are incorrectly classified. Inthis domain application, a threshold cannot bechosen to achieve perfect accuracy. This is true aswell for the second baseline experiment whichcompares the object as a whole. For that experi-ment, at the optimal threshold there are also 109correct mappings, three true mappings and 10 falsemappings. In general, selecting the optimal thresh-old to obtain the highest possible accuracy is anunsolved problem.We compared the accuracy for the best cases of
the baseline results against the accuracy of the twosystems for mapping-rule learning. The purpose ofthe Passive Atlas experiments are to show thatlearning the mapping rules can achieve higheraccuracy than the baseline experiments, while alsodemonstrating that Active Atlas can achieve thehigher accuracy with fewer labeled examples. Thegoal of both learning systems is to deduce moreinformation about how the objects match in order
Fig. 17. Baseline results (separate attributes using stemming).
S. Tejada et al. / Information Systems 26 (2001) 607–633620
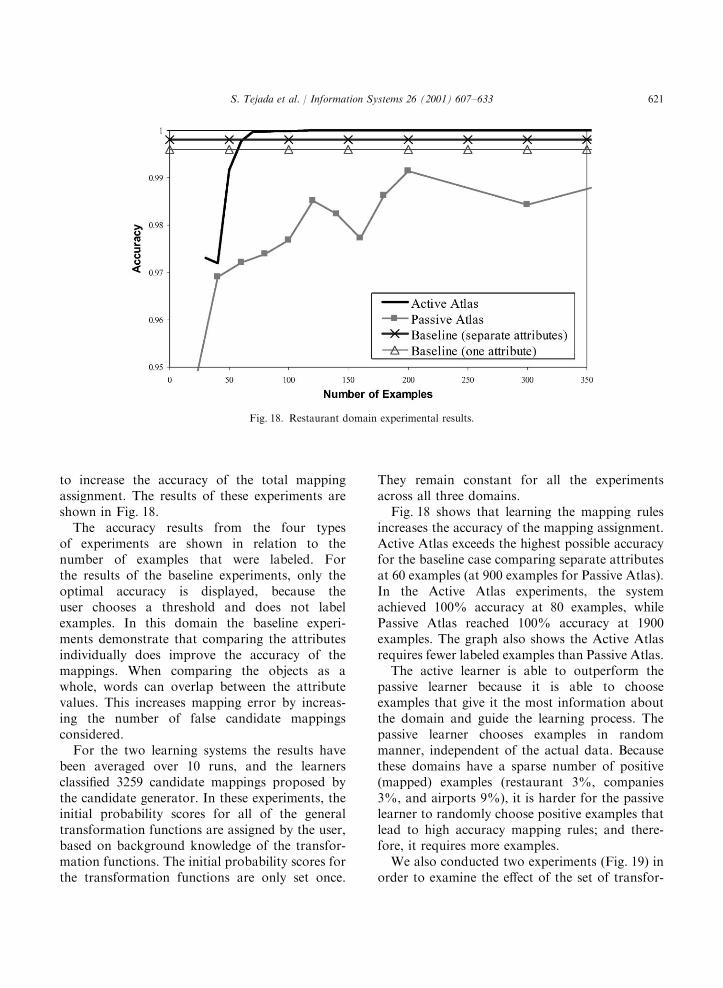
to increase the accuracy of the total mappingassignment. The results of these experiments areshown in Fig. 18.The accuracy results from the four types
of experiments are shown in relation to thenumber of examples that were labeled. Forthe results of the baseline experiments, only theoptimal accuracy is displayed, because theuser chooses a threshold and does not labelexamples. In this domain the baseline experi-ments demonstrate that comparing the attributesindividually does improve the accuracy of themappings. When comparing the objects as awhole, words can overlap between the attributevalues. This increases mapping error by increas-ing the number of false candidate mappingsconsidered.For the two learning systems the results have
been averaged over 10 runs, and the learnersclassified 3259 candidate mappings proposed bythe candidate generator. In these experiments, theinitial probability scores for all of the generaltransformation functions are assigned by the user,based on background knowledge of the transfor-mation functions. The initial probability scores forthe transformation functions are only set once.
They remain constant for all the experimentsacross all three domains.Fig. 18 shows that learning the mapping rules
increases the accuracy of the mapping assignment.Active Atlas exceeds the highest possible accuracyfor the baseline case comparing separate attributesat 60 examples (at 900 examples for Passive Atlas).In the Active Atlas experiments, the systemachieved 100% accuracy at 80 examples, whilePassive Atlas reached 100% accuracy at 1900examples. The graph also shows the Active Atlasrequires fewer labeled examples than Passive Atlas.The active learner is able to outperform the
passive learner because it is able to chooseexamples that give it the most information aboutthe domain and guide the learning process. Thepassive learner chooses examples in randommanner, independent of the actual data. Becausethese domains have a sparse number of positive(mapped) examples (restaurant 3%, companies3%, and airports 9%), it is harder for the passivelearner to randomly choose positive examples thatlead to high accuracy mapping rules; and there-fore, it requires more examples.We also conducted two experiments (Fig. 19) in
order to examine the effect of the set of transfor-
Fig. 18. Restaurant domain experimental results.
S. Tejada et al. / Information Systems 26 (2001) 607–633 621
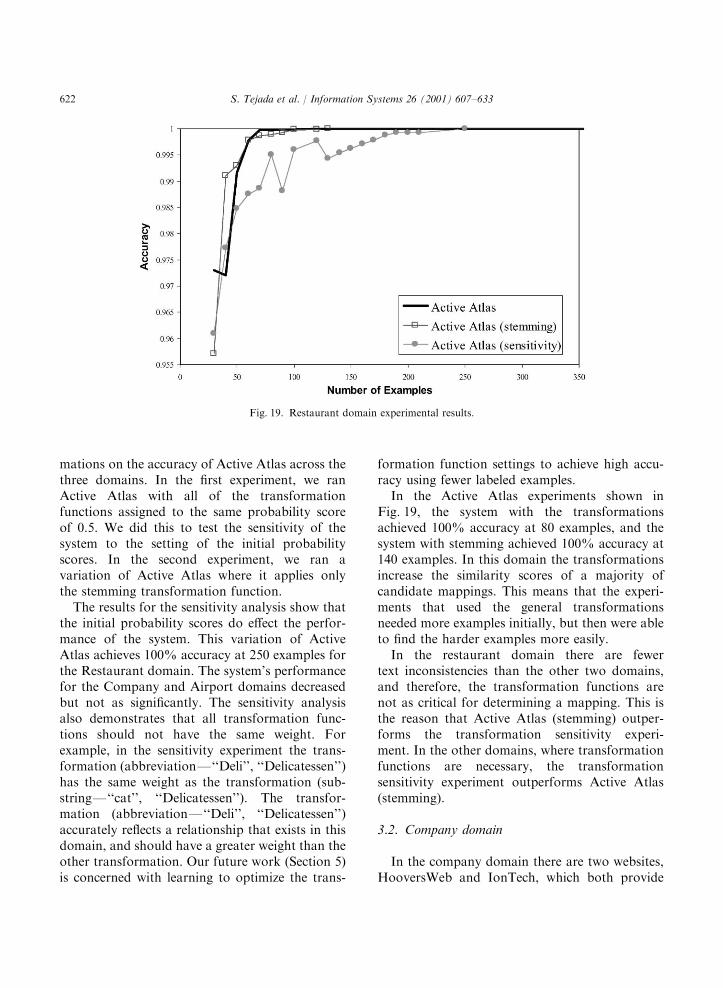
mations on the accuracy of Active Atlas across thethree domains. In the first experiment, we ranActive Atlas with all of the transformationfunctions assigned to the same probability scoreof 0.5. We did this to test the sensitivity of thesystem to the setting of the initial probabilityscores. In the second experiment, we ran avariation of Active Atlas where it applies onlythe stemming transformation function.The results for the sensitivity analysis show that
the initial probability scores do effect the perfor-mance of the system. This variation of ActiveAtlas achieves 100% accuracy at 250 examples forthe Restaurant domain. The system’s performancefor the Company and Airport domains decreasedbut not as significantly. The sensitivity analysisalso demonstrates that all transformation func-tions should not have the same weight. Forexample, in the sensitivity experiment the trans-formation (abbreviationF‘‘Deli’’, ‘‘Delicatessen’’)has the same weight as the transformation (sub-stringF‘‘cat’’, ‘‘Delicatessen’’). The transfor-mation (abbreviationF‘‘Deli’’, ‘‘Delicatessen’’)accurately reflects a relationship that exists in thisdomain, and should have a greater weight than theother transformation. Our future work (Section 5)is concerned with learning to optimize the trans-
formation function settings to achieve high accu-racy using fewer labeled examples.In the Active Atlas experiments shown in
Fig. 19, the system with the transformationsachieved 100% accuracy at 80 examples, and thesystem with stemming achieved 100% accuracy at140 examples. In this domain the transformationsincrease the similarity scores of a majority ofcandidate mappings. This means that the experi-ments that used the general transformationsneeded more examples initially, but then were ableto find the harder examples more easily.In the restaurant domain there are fewer
text inconsistencies than the other two domains,and therefore, the transformation functions arenot as critical for determining a mapping. This isthe reason that Active Atlas (stemming) outper-forms the transformation sensitivity experi-ment. In the other domains, where transformationfunctions are necessary, the transformationsensitivity experiment outperforms Active Atlas(stemming).
3.2. Company domain
In the company domain there are two websites,HooversWeb and IonTech, which both provide
Fig. 19. Restaurant domain experimental results.
S. Tejada et al. / Information Systems 26 (2001) 607–633622
information on companies (Name, Url and De-
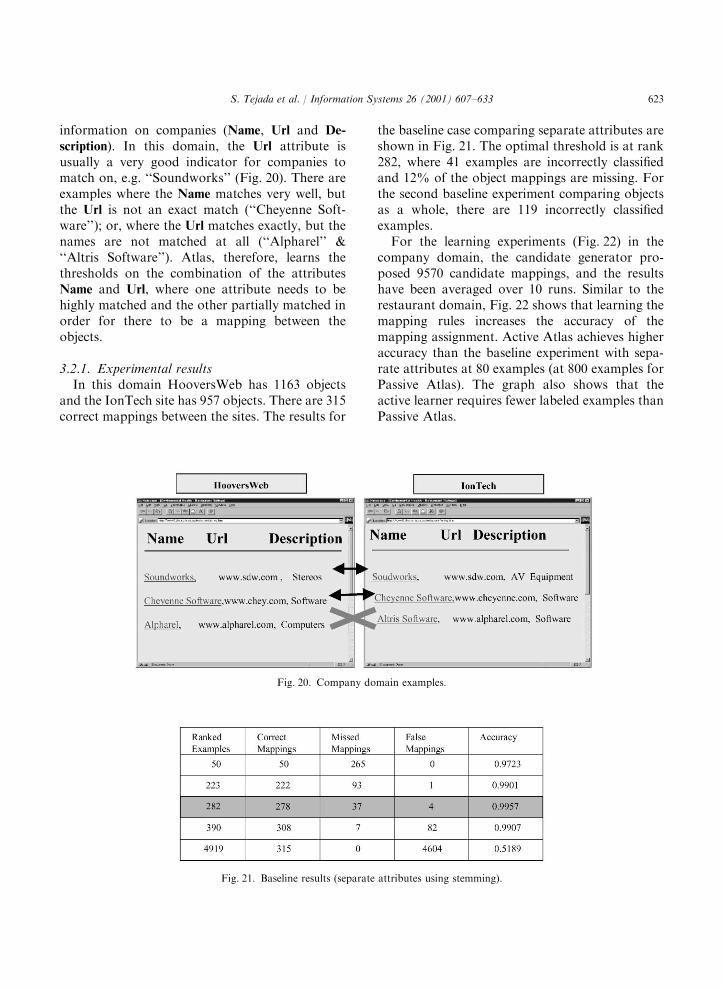
scription). In this domain, the Url attribute isusually a very good indicator for companies tomatch on, e.g. ‘‘Soundworks’’ (Fig. 20). There areexamples where the Name matches very well, butthe Url is not an exact match (‘‘Cheyenne Soft-ware’’); or, where the Url matches exactly, but thenames are not matched at all (‘‘Alpharel’’ &‘‘Altris Software’’). Atlas, therefore, learns thethresholds on the combination of the attributesName and Url, where one attribute needs to behighly matched and the other partially matched inorder for there to be a mapping between theobjects.
3.2.1. Experimental resultsIn this domain HooversWeb has 1163 objects
and the IonTech site has 957 objects. There are 315correct mappings between the sites. The results for
the baseline case comparing separate attributes areshown in Fig. 21. The optimal threshold is at rank282, where 41 examples are incorrectly classifiedand 12% of the object mappings are missing. Forthe second baseline experiment comparing objectsas a whole, there are 119 incorrectly classifiedexamples.For the learning experiments (Fig. 22) in the
company domain, the candidate generator pro-posed 9570 candidate mappings, and the resultshave been averaged over 10 runs. Similar to therestaurant domain, Fig. 22 shows that learning themapping rules increases the accuracy of themapping assignment. Active Atlas achieves higheraccuracy than the baseline experiment with sepa-rate attributes at 80 examples (at 800 examples forPassive Atlas). The graph also shows that theactive learner requires fewer labeled examples thanPassive Atlas.
Fig. 21. Baseline results (separate attributes using stemming).
Fig. 20. Company domain examples.
S. Tejada et al. / Information Systems 26 (2001) 607–633 623
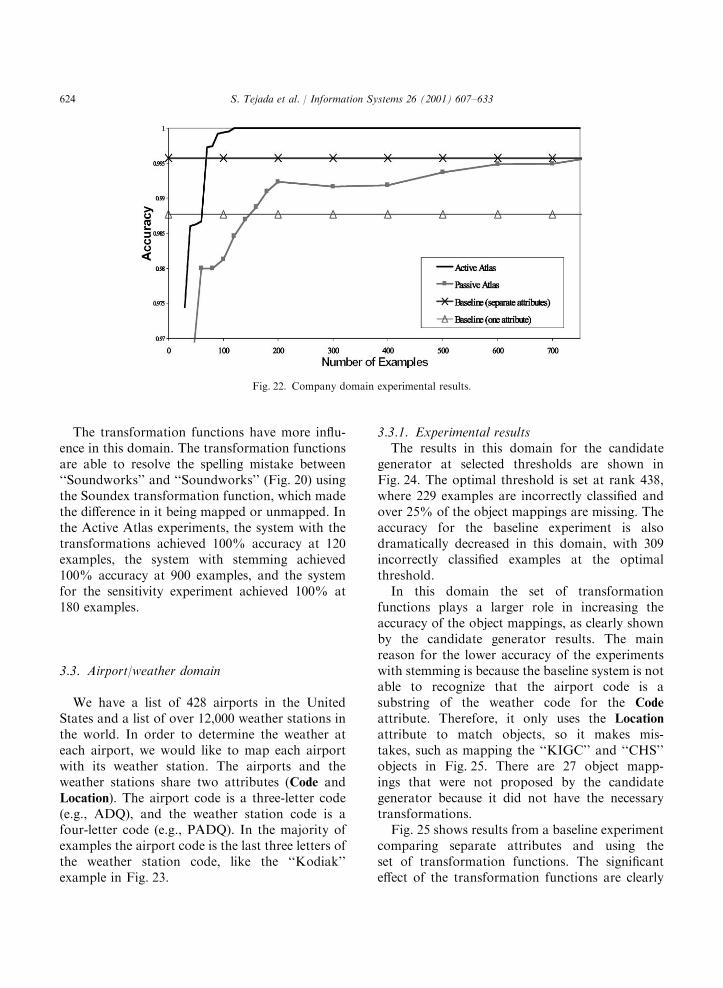
The transformation functions have more influ-ence in this domain. The transformation functionsare able to resolve the spelling mistake between‘‘Soundworks’’ and ‘‘Soundworks’’ (Fig. 20) usingthe Soundex transformation function, which madethe difference in it being mapped or unmapped. Inthe Active Atlas experiments, the system with thetransformations achieved 100% accuracy at 120examples, the system with stemming achieved100% accuracy at 900 examples, and the systemfor the sensitivity experiment achieved 100% at180 examples.
3.3. Airport/weather domain
We have a list of 428 airports in the UnitedStates and a list of over 12,000 weather stations inthe world. In order to determine the weather ateach airport, we would like to map each airportwith its weather station. The airports and theweather stations share two attributes (Code andLocation). The airport code is a three-letter code(e.g., ADQ), and the weather station code is afour-letter code (e.g., PADQ). In the majority ofexamples the airport code is the last three letters ofthe weather station code, like the ‘‘Kodiak’’example in Fig. 23.
3.3.1. Experimental resultsThe results in this domain for the candidate
generator at selected thresholds are shown inFig. 24. The optimal threshold is set at rank 438,where 229 examples are incorrectly classified andover 25% of the object mappings are missing. Theaccuracy for the baseline experiment is alsodramatically decreased in this domain, with 309incorrectly classified examples at the optimalthreshold.In this domain the set of transformation
functions plays a larger role in increasing theaccuracy of the object mappings, as clearly shownby the candidate generator results. The mainreason for the lower accuracy of the experimentswith stemming is because the baseline system is notable to recognize that the airport code is asubstring of the weather code for the Code
attribute. Therefore, it only uses the Location
attribute to match objects, so it makes mis-takes, such as mapping the ‘‘KIGC’’ and ‘‘CHS’’objects in Fig. 25. There are 27 object mapp-ings that were not proposed by the candidategenerator because it did not have the necessarytransformations.Fig. 25 shows results from a baseline experiment
comparing separate attributes and using theset of transformation functions. The significanteffect of the transformation functions are clearly
Fig. 22. Company domain experimental results.
S. Tejada et al. / Information Systems 26 (2001) 607–633624
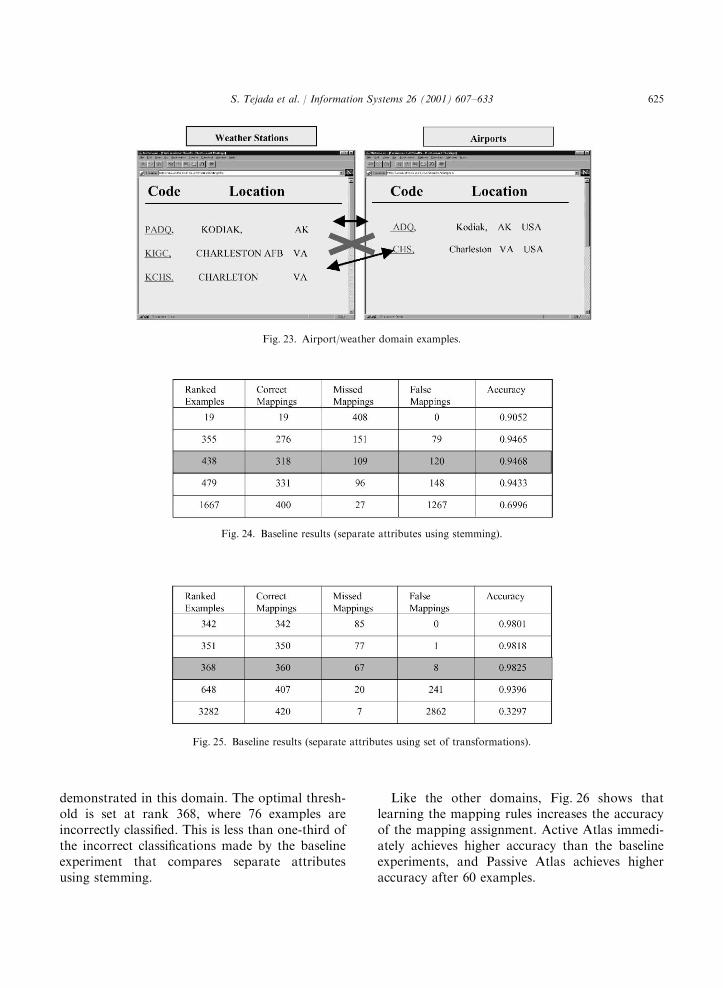
demonstrated in this domain. The optimal thresh-old is set at rank 368, where 76 examples areincorrectly classified. This is less than one-third ofthe incorrect classifications made by the baselineexperiment that compares separate attributesusing stemming.
Like the other domains, Fig. 26 shows thatlearning the mapping rules increases the accuracyof the mapping assignment. Active Atlas immedi-ately achieves higher accuracy than the baselineexperiments, and Passive Atlas achieves higheraccuracy after 60 examples.
Fig. 23. Airport/weather domain examples.
Fig. 24. Baseline results (separate attributes using stemming).
Fig. 25. Baseline results (separate attributes using set of transformations).
S. Tejada et al. / Information Systems 26 (2001) 607–633 625
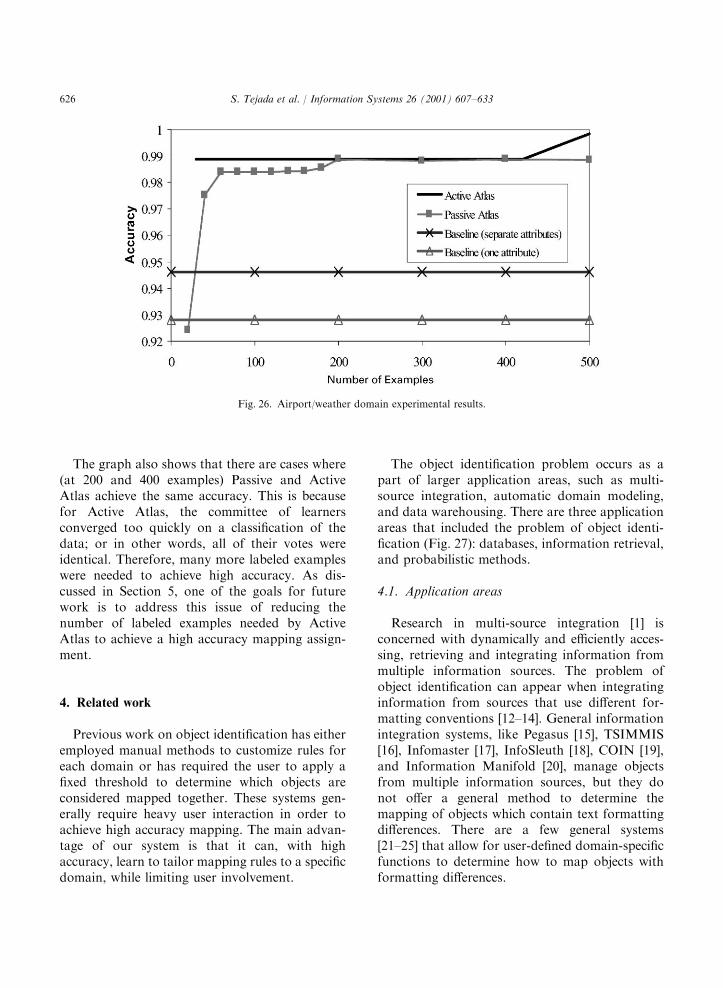
The graph also shows that there are cases where(at 200 and 400 examples) Passive and ActiveAtlas achieve the same accuracy. This is becausefor Active Atlas, the committee of learnersconverged too quickly on a classification of thedata; or in other words, all of their votes wereidentical. Therefore, many more labeled exampleswere needed to achieve high accuracy. As dis-cussed in Section 5, one of the goals for futurework is to address this issue of reducing thenumber of labeled examples needed by ActiveAtlas to achieve a high accuracy mapping assign-ment.
4. Related work
Previous work on object identification has eitheremployed manual methods to customize rules foreach domain or has required the user to apply afixed threshold to determine which objects areconsidered mapped together. These systems gen-erally require heavy user interaction in order toachieve high accuracy mapping. The main advan-tage of our system is that it can, with highaccuracy, learn to tailor mapping rules to a specificdomain, while limiting user involvement.
The object identification problem occurs as apart of larger application areas, such as multi-source integration, automatic domain modeling,and data warehousing. There are three applicationareas that included the problem of object identi-fication (Fig. 27): databases, information retrieval,and probabilistic methods.
4.1. Application areas
Research in multi-source integration [1] isconcerned with dynamically and efficiently acces-sing, retrieving and integrating information frommultiple information sources. The problem ofobject identification can appear when integratinginformation from sources that use different for-matting conventions [12–14]. General informationintegration systems, like Pegasus [15], TSIMMIS[16], Infomaster [17], InfoSleuth [18], COIN [19],and Information Manifold [20], manage objectsfrom multiple information sources, but they donot offer a general method to determine themapping of objects which contain text formattingdifferences. There are a few general systems[21–25] that allow for user-defined domain-specificfunctions to determine how to map objects withformatting differences.
Fig. 26. Airport/weather domain experimental results.
S. Tejada et al. / Information Systems 26 (2001) 607–633626

Current work on the problem of automaticdomain modeling or schema integration [26–30]focuses on generating a global model of thedomain for single, as well as multiple infor-mation sources. Domain models contain informa-tion about the relationships in the data. Tocreate an abstract model or set of classificationrules, these domain modeling tools compare thedata objects in the sources using statisticalmeasurements. When the information sourcescontain text formatting differences, these toolsare not able to generate the correct domain modelbecause the data objects cannot be mappedproperly. The text formatting differences must beresolved before using the domain modeling toolsor capabilities to handle these formatting differ-ences. In this context the objection identificationproblem can be considered a data cleaningtechnique [31].Data warehousing creates a repository of data
retrieved and integrated from multiple informationsources given a common domain model or globalschema. Research on data warehousing concen-trates on efficient methods to merge and maintainthe data [32–35]. When merging the data from thetarget information sources, problems can occur ifthere are errors and inconsistencies in the data. Toimprove the integrity of the data warehouse, thedata can be first filtered or cleaned before therepository is created [36]. Object identificationtechniques can be applied here to assist in cleaningthe data [37].
4.2. Solution approaches
The following solution approaches for objectidentification were developed by the database,information retrieval and statistical communities.
4.2.1. DatabasesIn the database community the problem of
object identification is also known as the merge/purge problem, a form of data cleaning. Domain-specific techniques for correcting format incon-sistencies [38–43] have been applied by manyobject identification systems to measure textsimilarity [37,44–49]. The main concern withdomain-specific transformation rules is that it isvery expensive, in terms of user involvement, togenerate a set of comprehensive rules that arespecific not only to the domain, but also to thedata in the two information sources that are beingintegrated.There are also approaches [50–54] that have
used a single very general transformation function,like edit distance, to address the format incon-sistencies. In our research we show that having asingle general transformation function is notflexible enough to optimize the mappings acrossseveral domains. The same format inconsistenciescan occur in many different domains, but they maynot be appropriate or correct for all of thosedomains.Recent work by Hernandez and Stolfo [45–47],
Lu et al. [55–57]. Chatterjee and Segev [58], and Pu
Fig. 27. Related work graph.
S. Tejada et al. / Information Systems 26 (2001) 607–633 627

[59] have used mapping rules or templates todetermine mapped objects, but these rules arehand tailored to each specific domain or limited toonly the primary key. Work conducted byPinheiro and Sun [53,54] and Ganesh et al.[37,44] used supervised learning techniques tolearn which combinations of attributes are im-portant to generate a mapping. Both of thesetechniques assume that most objects in thedata have at least one duplicate or matchingobject. They also require that the user providespositive examples of mapped objects, and in somecases the user labels as much as 50% of the data.These techniques are most similar to the passiveAtlas system, because they require either that theuser choose the examples or they are randomlyselected.Another form of object identification focuses on
comparing objects using attribute value conflictresolution rules [24,34,35,60–64]. These rules donot judge attributes by their textual similarities,but by knowledge that they contain about how tocompare attribute values when there is a conflict.For example, an object from one source may havethe attribute Age; which holds the value for the ageof a person, and an object from the other sourcemay have the attribute BirthDate; which holds thevalue for the person’s birthday. If there was anattribute value conflict resolution rule that couldconvert the BirthDate to Age; then the attributevalues could be compared. This type of domain-specific data translation rule would be helpful forobject identification, but is not the focus of ourwork. In our system a user-defined transformationfunction must be added for the two attributesBirthDate and Age to be correctly compared.
4.2.2. Information retrievalThe problem of object identification has also
appeared in the information retrieval community[65,66]. When determining relevant documents tosatisfy a user’s query, words or tokens from thedocuments are compared. If there are text format-ting differences in the documents, then relevantdocuments can be missed. Closely related work onthe Whirl object identification system by Cohen[6,67–70] views data objects from informationsources as short documents. In this work the object
mappings are determined by using the informationretrieval vector space model to perform similarlyjoins on the shared attributes. A single transforma-tion Stemming [71] is the only transformation usedto calculate similarity between strings; therefore, inFig. 10 ‘‘CPK’’ would not match ‘‘California PizzaKitchen’’. The similarity scores from each of theshared attributes are multiplied together in order tocalculate the total similarity score of a possiblemapping. This requires that objects must matchwell on all attributes. The total similarity scores arethen ranked and the user is required to set athreshold determining the set of mappings. To setthe threshold the user scans the ranked set ofobjects [6, p. 9]. Setting a threshold to obtainoptimal accuracy is not always a straightforwardtask for the user.Work by Huffman and Steier [72,73] on
integrating information sources for an informationretrieval system, uses domain-specific normaliza-tion techniques to convert data objects into astandard form for performing the mapping. Thiswork involves maintaining a dictionary of domain-specific normalizations to apply when appropriate.The Citeseer project [74,75] is an informationretrieval system that finds relevant and similarpapers and articles, where similarity is based onthe set of citations listed in the articles. Citeseeralso uses domain-specific normalization techni-ques to standardize article citations.
4.2.3. Probabilistic methodsRelated work conducted by Huang and Russell
[76,77] on mapping objects across informationsources uses a probabilistic appearance model.Their approach also compares the objects basedon all of the shared attributes. To determinesimilarity between two objects, they calculate theprobability that given one object it will appear likethe second object in the other relation. Calculatingthese probabilities requires a training set ofcorrectly paired objects (like the objects inFig. 8). Unfortunately, appearance probabilitieswill not be helpful for an attribute with a uniqueset of objects, like restaurant Name. Since ‘‘Art’sDeli’’ only occurs once in the set of objects,knowing that it appears like ‘‘Art’s Delicatessen’’
S. Tejada et al. / Information Systems 26 (2001) 607–633628

does not help in mapping any other objects, like‘‘CPK’’ and ‘‘California Pizza Kitchen’’.In our approach we use a general set of
transformations to handle this problem. Thetransformations are able to compare the textualsimilarity of two attribute values independent ofother attribute value matches. If the transforma-tion exists between the two attribute values,e.g. (abbreviationF‘‘Deli’’ ‘‘Delicatessen’’), thenit has a transformation weight associated with it.Transformation weights should reflect the impor-tance of the rule for the matching of the attributevalues. One of the future goals of our system is tolearn to adjust these weights to fit the specificdomain.Probabilistic models of the data are also used
within the record linkage community [78–82].Work in the record linkage community grew fromthe need to integrate government census data;therefore, they have developed domain-specifictransformations for handling names and ad-dresses. In a record linkage system, the user isrequired to make several initial passes reviewingthe data in order to improve and verify theaccuracy of the transformations. Once the user issatisfied with the accuracy of the transformations,‘‘blocking’’ attributes are chosen. Choosing block-ing attributes is a way to reduce the set ofcandidate mappings by only including the pairsthat match on the chosen attributes. The EMalgorithm is then applied to learn the attributeweightings and classify the candidate mappingsinto one of three classes: mapped, not mapped, orto be reviewed by the user. The main problem thatthe record linkage community [80,82] found withthe use of the EM algorithm is that because it is anunsupervised learning technique it may not dividethe data into the desired classes.
5. Conclusions and future work
This paper has presented the Active Atlas objectidentification system that addresses the problem ofmapping objects between structured web sources,where the same objects can appear in similar yetinconsistent text formats. The experimental resultsfor the system have shown that Active Atlas can
achieve high accuracy, while limiting user involve-ment. For our future work in this area we wouldlike to reduce user interaction even further.We found that some transformations can be
more appropriate for a specific application domainthan others; therefore, in order to increase themapping accuracy, it is important to learn how toweight the transformation appropriately for theapplication domain. In some domains very specifictransformations should be weighted more, e.g.(abbreviationF‘‘Deli’’, ‘‘Delicatessen’’), and inother domains a general transformation function,such as Substring, should be weighted more. Inour approach we are planning to combine both themapping-rule and the transformation weightinglearning in order to create a high accuracy objectidentification system.The purpose of optimizing the transformation
weights is to reduce the number of labeledexamples needed by the system. The transforma-tion weight learner must learn how to increase thesimilarity scores for the correct mappings, whiledecreasing the scores for the incorrect mappings.Having the correct mapping scores higher than theincorrect mapping scores will allow the mapping-rule learner to construct higher accuracy decisiontrees with fewer labeled examples.We plan to combine these two learners (the
mapping-rule learner and the transformationweight learner) into one active learning systemcalled the match learner (Fig. 28). The matchlearner will offer the user one example to label at atime, and from that example be able to learn boththe mapping rules, as well as, the transformationweights.In this hybrid system, there will be two types of
learning. One type of learning is the transforma-tion weight learning, which can recognize possiblerelationships between tokens of object attributes.The second type of learning is mapping-rulelearning, which determines the importance ofobject attributes for generating a mapping. Theadvantage of this learning system will be that itcan intelligently reason and combine informationgathered about each of the proposed objectmappings in order to decide the total mappingassignment. By simultaneously tailoring bothtypes of learning and efficiently utilizing user input
S. Tejada et al. / Information Systems 26 (2001) 607–633 629

we hope to achieve high accuracy mapping withminimal user input.
Acknowledgements
The research reported here was supported inpart by the Defense Advanced Research ProjectsAgency (DARPA) and Air Force Research La-boratory, Air Force Material Command, USAF,under agreement number F30602-00-1-0504, inpart by the Rome Laboratory of the Air ForceSystems Command and the Defense AdvancedResearch Projects Agency (DARPA) under con-tract number F30602-98-2-0109, in part by theUnited States Air Force under contract numberF49620-98-1-0046, in part by the IntegratedMedia Systems Center, a National ScienceFoundation Engineering Research Center, Coop-erative Agreement No. EEC-9529152, and inpart by a research grant from NCR. The U.S.Government is authorized to reproduce anddistribute reports for Governmental purposesnotwithstanding any copyright annotation there-on. The views and conclusions contained herein arethose of the authors and should not be interpretedas necessarily representing the official policies orendorsements, either expressed or implied, of anyof the above organizations or any person connectedwith them.
References
[1] G. Wiederhold, Intelligent integration of information,
SIGMOD Record (1993) 434–437.
[2] J.L. Ambite, Y. Arens, N. Ashish, C.A. Knoblock,
S. Minton, J. Modi, M. Muslea, A. Philpot, W.-M. Shen,
S. Tejada, W. Zhang, The SIMS Manual: Version2.0,
Working Draft, USC/ISI, 1997.
[3] C.A. Knoblock, S. Minton, J.L. Ambite, N. Ashish,
P.J. Modi, I. Muslea, A.G. Philpot, S. Tejada, Modeling
web sources for information integration, in: Proceedings of
the Fifteenth National Conference on Artificial Intelli-
gence, Madison, WI, 1998.
[4] C.A. Knoblock, S. Minton, J.L. Ambite, N. Ashish,
I. Muslea, A.G. Philpot, S. Tejada, The ariadne approach
to web-based information integration, to appear. Int.
J. Cooperative Inf. Systems (IJCIS) Special Issue on
Intell. Inf. Agents: Theory and Applications, Forthcoming,
2001.
[5] T.C. Bell, A. Moffat, I.H. Witten, J. Zobel, The mg
retrieval system: compressing for space and speed, Com-
mun. Assoc. Comput. Mach. 38 (4) (1995) 41–42.
[6] W.W. Cohen, Integration of heterogeneous databases
without common domains using queries based on textual
similarity, in: SIGMOD Conference, 1998, pp. 201–212.
[7] W. Frakes, R. Baeza-Yates, Information Retrieval: Data
Structures and Algorithms, Prentice-Hall, Englewood
Cliffs, NJ, 1992.
[8] J.R. Quinlan, Improved use of continuous attributes in
c4.5, J. Artif. Intell. Res. 4 (1996) 77–90.
[9] N. Abe, H. Mamitsuka, Query learning strategies using
boosting and bagging, in: Proceedings of the Fifteenth
International Conference on Machine Learning, 1998.
[10] D. Angluin, Queries and concept learning, Mach. Learning
2 (1988) 319–342.
Fig. 28. Match learner.
S. Tejada et al. / Information Systems 26 (2001) 607–633630

[11] L. Breiman, Bagging predictors, Mach. Learning 24 (2)
(1996) 123–140.
[12] C. Batini, M. Lenzerini, S. Navathe, A comparative
analysis of methodologies for database schema integration,
ACM Comput. Surveys 18 (4) (1986) 323–364.
[13] H.G. Goldberg, T.E. Senator, Restructuring databases for
knowledge discovery by consolidation and link formation,
in: Second International Conference on Knowledge
Discovery and Data Mining, 1996.
[14] T. Senator, H. Goldberg, J. Wooton, A. Cottini, A. Umar,
C. Klinger, W. Llamas, M. Marrone, R. Wong, The fincen
artificial intelligence system: identifying potential money
laundering from reports of large cash transactions, in:
Proceedings of the Seventh Conference on Innovative
Applications of AI, 1995.
[15] R. Ahmed, P.D. Smedt, W.M. Du, W. Kent, M. Ketabchi,
W.A. Litwin, A. Rafii, M.C. Shan, The pegasus hetero-
geneous multidatabase system, Computer ð1991Þ:[16] H. Garcia-Molina, D. Quass, Ya. Papakonstantinou,
A. Rajaraman, Y. Sagiv, J.D. Ullman, J. Widom, The
tsimmis approach to mediation: data models and lan-
guages, in: NGITS (Next Generation Information Tech-
nologies and Systems), Naharia, Israel, 1995.
[17] M.R. Genesereth, A.M. Keller, O.M. Duschka, Info-
master: an information integration system, in: Proceedings
of the ACM SIGMOD International Conference on
Management of Data, Tucson, AZ, 1997.
[18] R. Bayardo, Jr., B. Bohrer, R.S. Brice, A. Cichocki,
J. Fowler, A. Helal, V. Kashyap, T. Ksiezyk, G. Martin,
M.H. Nodine, M. Rashid, M. Rusinkiewicz,
R. Shea, C. Unnikrishnan, A. Unruh, D. Woelk,
Infosleuth: semantic integration of information in open
and dynamic, in: SIGMOD Conference, 1997, pp.
195–206.
[19] S. Bressan, K. Fynn, C.H. Goh, M. Jakobisiak,
K. Hussein, H. Kon, T. Lee, S. Madnick, T. Pena,
J. Qu, A. Shum, M. Siegel, The context interchange
mediator prototype, in: Proceedings of ACM SIGMOD/
PODS Joint Conference, Tucson, AZ, 1997.
[20] A.Y. Levy, A. Rajaraman, J.J. Ordille, Query answering
algorithms for information agents, in: Proceedings of the
AAAI Thirteenth National Conference on Artificial
Intelligence, 1996.
[21] M. Perkowitz, R.B. Doorenbos, O. Etzoni, D.S. Weld,
Learning to understand information on the internet: an
example-based approach, J. Intell. Inf. Systems 8 (2)
(1997).
[22] M. Perkowitz, O. Etzioni, Category translation: learning
to understand information on the internet, in: IJCAI’95,
1995, pp. 930–936.
[23] G. Zhou, R. Hull, R. King J.-C. Franchitti, Using object
matching and materialization to integrate heterogeneous
databases, in: Proceedings of Third International Con-
ference on Cooperative Information Systems (CoopIS-95),
Vienna, Austria, 1995.
[24] W. Kim, I. Choi, S. Gala, M. Scheevel, On resolving
schematic heterogeneity in multidatabase systems, Dis-
tributed Parallel Databases 1 (3) (1993) 251–279.
[25] D. Fang, J. Hammer, D. McLeod, The identification and
resolution of semantic heterogeneity in multidatabase
systems, Multidatabase Systems: An Advanced Solution
for Global Information Sharing, 1994.
[26] S. Dao, B. Perry, Applying a data miner to heterogeneous
schema integration, in: Proceedings of the First Interna-
tional Conference on Knowledge Discovery and Data
Mining (KDD-95), Menlo Park, CA, 1995.
[27] D.J. DeWitt, J.F. Naughton, D.A. Schneider, An evalua-
tion of non-equijoin algorithms, in: VLDB, 1991, pp.
443–452.
[28] W.-S. Li, Semantic integration in heterogeneous databases
using neural networks, in: Proceedings of the 20th VLDB
Conference, 1994, pp. 1–12.
[29] S. McKearney, H. Roberts, Reverse engineering databases
for knowledge discovery, in: Proceedings of the Second
International Conference on Knowledge Discovery and
Data Mining, 1996.
[30] J.S. Ribeiro, K.A. Kaufman, L. Kerschberg, Knowledge
discovery for multiple databases, in: Knowledge Discovery
and Data mining, Menlo Park, CA, 1995.
[31] U. Fayyad, G. Piatetsky-Shapiro, P. Smyth. Knowledge
discovery and data mining toward a unifying framework,
in: Proceedings of The Second International Conference on
Knowledge Discovery and Data Mining, 1996, pp. 82–88.
[32] J. Hammer, H. Garcia-Molina, J. Widom, W. Labio,
Y. Zhuge, The stanford data warehousing project, IEEE
Data Eng. Bull. 18 (2) (1995) 41–48.
[33] A.P. Sheth, J.A. Larson, Federated database systems for
managing distributed, heterogeneous and autonomous
databases, ACM Comput. Surveys 22 (1990) 183–236.
[34] D. Calvanese, G. De Giacomo, M. Lenzerini, D. Nardi,
R. Rosati, A principled approach to data integration and
reconciliation in data warehousing, in: Proceedings of the
International Workshop on Design and Management of
Data Warehouses (DMDW’99), 1999.
[35] D. Calvanese, G. De Giacomo, M. Lenzerini, D. Nardi,
R. Rosati, Data integration in data warehousing, Int.
J. Cooperative Inf. Systems ð2000Þ:[36] E. Simoudis, B. Livezey, R. Kerber, Using recon for data
cleaning, in: Knowledge Discovery and Datamining,
Menlo Park, CA, 1995, pp. 282–287.
[37] M. Ganesh, J. Srivastava, T. Richardson, Mining
entity-identification rules for database integration, in:
Proceedings of the Second International Conference on
DataMining and Knowledge Discovery, 1996, pp. 291–294.
[38] K.W. Church, W.A. Gale, Probability scoring for spelling
correction, Statist. Comput. 1 (1991) 93–103.
[39] M.A. Bickel, Automatic correction to misspelled names: a
fourthgeneration language approach, Commun. ACM 30
(3) (1987) 224–228.
[40] D. Bitton, D.J. DeWitt, Duplicate record elimination in
large data files, ACM Trans. Database Systems 8 (2) (1983)
255–265.
S. Tejada et al. / Information Systems 26 (2001) 607–633 631

[41] J.T. Grudin, Error patterns in novice and skilled transcrip-
tion typing, in: W.E. Cooper (Ed.), Cognitive Aspects of
Skilled Typewriting, Springer, Berlin, 1983, pp. 121–142.
[42] K. Kukich, Techniques for automatically correcting words
in text, ACM Comput. Surveys 24 (4) (1992) 377–439.
[43] J.J. Pollock, A. Zamora, Automatic spelling correction in
scientific and scholarly text, ACM Comput. Surveys 27 (4)
(1987) 358–368.
[44] M. Ganesh, Mining Entity-Identification Rules for Data-
base Integration, Ph.D. Thesis, Technical Report TR
97-041. University of Minnesota, 1997.
[45] M. Hernandez, S.J. Stolfo, Real-world data is dirty: data
cleansing and the merge/purge problem, in: Data Mining
and Knowledge Discovery, 1998, pp. 1–31.
[46] M. Hernandez, S.J. Stolfo, An generalization of band joins
and the merge/purge problem, IEEE Trans. Knowledge
Data Eng. (1996).
[47] M. Hernandez, S.J. Stolfo, The merge/purge problem for
large databases, in: Proceedings of the 1995 ACM-
SIGMOD Conference, 1995.
[48] J.A. Hylton, Identifying and merging related bibliographic
records, M.S. Thesis, MIT Laboratory for Computer
Science, Technical Report, 678, 1996.
[49] T.W. Yan, H. Garcia-Molina, Duplicate removal in
information dissemination, in: Proceedings of VLDB-95,
1995.
[50] A. Monge, C.P. Elvan, An efficient domain-independent
algorithm for detecting approximately duplicate database
records, in: The Proceedings of the SIGMOD 1997 Work-
shop on Data Mining and Knowledge Discovery, 1997.
[51] A. Monge, C.P. Elvan, The webfind tool for finding
scientific papers over the worldwide web, in: Third Interna-
tional Congress on Computer Science Research, 1996.
[52] A. Monge, C.P. Elkan, The field matching problem:
algorithms and applications, in: Proceedings of the Second
International Conference on Knowledge Discovery and
Data Mining, 1996.
[53] J.C. Pinheiro, D.X. Sun, Methods for linking and mining
massive heterogeneous databases, in: Fourth International
Conference on Knowledge Discovery and Data Mining,
1998.
[54] J.C. Pinheiro, D.X. Sun, Methods for linking and mining
massive heterogeneous databases, Technical memoran-
dum, Bell Laboratories, Lucent Technologies, 1998.
[55] M.L. Lee, H. Lu, T.W. Ling, Y.T. Ko, Cleansing data for
mining and warehousing, in: 10th International Confer-
ence on Database and Expert Systems Applications
(DEXA99), Florence, Italy, 1999.
[56] H. Lu, W. Fan, C.-H. Gob, S. Madnick, D. Cheung,
Discovering and reconciling semantic conflicts: a data
mining prospective, in: IFIP Working Conference on Data
Semantics (DS-7). Switzerland, 1997.
[57] H. Lu, B. Ooi, C. Goh, Multidatabase query optimization:
issues and solutions, in: Proceedings of RIDE-IMS ’93,
1993, pp. 137–143.
[58] A. Chatterjee, A. Segev, Data manipulation in hetero-
geneous databases, SIGMOD Record 20 (4) (1991).
[59] C. Pu, Key equivalence in heterogeneous databases, in:
Proceedings of the First International Workshop on
Interoperability in Multidatabase Systems, 1991, pp.
314–316.
[60] E.-P. Lim, J. Srivastava, S. Shekhar, Resolving attribute
incompatibility in database integration: an evidential
reasoning approach, in: Proceedings of 10th IEEE Data
Engineering Conference, 1994.
[61] E.-P. Lim, J. Srivastava, S. Prabhakar, J. Richardson,
Entity identification in database integration, in: Proceed-
ings Ninth International Conference on Data Engineering,
Vienna, Austria, 1993, pp. 294–301.
[62] E.-P. Lim, J. Srivastava, S. Prabhakar, J. Richardson,
Entity identification in database integration, Technical
Report TR 92-62, University of Minnesota, 1992.
[63] E.-P. Lim, J. Srivastava, S. Shekhar, An evidential
reasoning approach to attribute value conflict resolution
in database integration, IEEE Trans. Knowledge Data
Eng. 8 (5) (1996).
[64] Y.R. Wang, S.E. Madnick, The inter-database instance
identification problem in integrating autonomous systems,
in: Proceedings of the International Conference on Data
Engineering, 1989.
[65] E. Sciore, M. Siegel, A. Rosenthal, Using semantic values
to facilitate interoperability among heterogeneous infor-
mation systems, ACM Trans. Database Systems 19 (2)
(1994) 254–290.
[66] D. O’Leary, Internet-based information and retrieval
systems, Decision Support Systems 27 (3) (1999).
[67] W.W. Cohen, A web-based information system that
reasons with structured collections of text, Autonomous
Agents, 1998.
[68] W.W. Cohen, The whirl approach to integration: an
overview, in: AAAI-98 Workshop on AI and Information
Integration, 1998.
[69] W.W. Cohen, Knowledge integration for structured
information sources containing text, in: SIGIR-97 Work-
shop on Networked Information Retrieval, 1997.
[70] W.W. Cohen, H. Hirsh, Joins that generalize: text
classification using whirl, in: Proceedings of the Fourth
International Conference on Knowledge Discovery and
Data Mining, 1998.
[71] M.F. Porter, An algorithm for suffix stripping, Program 14
(3) (1980) 130–137.
[72] S.B. Huffman, D. Steier, A navigation assistant for data
source selection and integration, in: 1995 AAAI Fall
Symposium on AI Application in Knowledge Navigation
and Retrieval, 1995.
[73] S.B. Huffman, D. Steier, Heuristic joins to integrate
structured heterogeneous data, in: 1995 AAAI Spring
Symposium on Information Gathering in Distributed,
Heterogeneous Environment, 1995.
[74] K.D. Bollacker, S. Lawrence, C.L. Giles, Citeseer: an
autonomous web agent for automatic retrieval and
identification of interesting publications, in: Proceedings
of Second International Conference on Autonomous
Agents, Minneapolis, USA, 1998.
S. Tejada et al. / Information Systems 26 (2001) 607–633632

[75] C.L. Giles, K. Bollacker, S. Lawrence, Citeseer: an
automatic citation indexing system, in: The Third ACM
Conference on Digital Libraries, Pittsburgh, PA, 1998,
pp. 89–98.
[76] T. Huang, S. Russell, Object identification in Bayesian
context, in: Proceedings of IJCAI-97, Nagoya, Japan,
1997.
[77] T. Huang, S. Russell, Object identification: a Bayesian
analysis with application to traffic surveillance, Artif.
Intell. 103 (1998) 1–17.
[78] W. Alvey, B. Jamerson, Record linkage techniques, in:
Proceedings of an International Workshop and Exposi-
tion, Arlington, VA, Washington, DC. Federal Committee
on Statistical Methodology, Office of Management and
Budget, 1997.
[79] I.P. Fellegi, A.B. Sunter, A theory for record-linkage,
J. Am. Statist. Assoc. 64 (1969) 1183–1210.
[80] M.A. Jaro, Advances in record-linkage methodology as
applied to matching the 1985 census of tampa, Florida,
J. Am. Statist. Assoc. 84 (1989) 414–420.
[81] H.B. Newcombe, J.M. Kenedy, Record linkage, Commun.
Assoc. Comput. Mach. 5 (1962) 563–566.
[82] W.E. Winkler, Matching and record linkage, Survey
Methods for Businesses, Farms, and Institutions, 1994.
S. Tejada et al. / Information Systems 26 (2001) 607–633 633



























