Embed Size (px)
Citation preview

Learning Learning AutomataAutomata
Presented by:Presented by:
Seyyed Alireza MotevallianSeyyed Alireza Motevallian
Iran Artificial Life Society

Learning AutomataLearning Automata
HistoryHistory LearningLearning Reinforcement LearningReinforcement Learning EnvironmentEnvironment Learning AutomataLearning Automata Norms of BehaviorNorms of Behavior TypesTypes ApplicationsApplications

Learning AutomataLearning Automata
Interests in learning Automata began with the
outstanding work of Tsetlin in the early in 1960s in
the Soviet Union.
Eden brings the automaton theory used by Tsetlin in
the field of learning.
During last two decades, “Learning Automaton”
term has been consistently used by researchers.

Learning AutomataLearning Automata
Learning:
Ability of a system to improve its responses based on past experience
Reinforcement learning:
Choosing the best response based on the rewards or punishments token from environment

Learning AutomataLearning Automata
Learning Automata:
An Automaton which selects on of it’s acions
related to its past experiences and rewards or
punishments from the Environment.
An Automaton Approach to Learning, specially
Reinforcement Learning.
Definition:

Learning AutomataLearning Automata
Environment:
Aggregate of all the external conditions and influences
affecting the life and development of an organism.
Environment can be defined by triple: {a,c,b}
a = {a1,a2,...,ar} : Set of inputsb = {b1,b2,...,br} : Set of outputsc = {c1,c2,..., cr} : Set of penalty probabilities
Environmentc = {c1,c2,..., cr}
Actionsa = {a1,a2,...,ar}
Outputsb = {b1,b2,...,br}

Learning AutomataLearning Automata
b = {0,1}ci = Pr [ b(n) = 1 | a(n) = ai ) (i=1,2,...,r)
Environment Models:
P-Model: The output can take only two values, 0 or 1
Q-Model: Finite output set with more than two values,
between 0 and 1
S-Model: The output is a continuous random variable in
the range [0,1]
In the P-Model we assume:

Learning AutomataLearning Automata
Automaton: {Φ,a ,b ,F ,G}
Φ = {Φ1, Φ2,..., Φs}: Set of automaton states
a = { a1, a2,..., as }: Set of Actions
b = { b1, b2,..., bs }: Set of inputs
F(.,.) : Φ*b→Φ : The Transition function
G(.) : Φ→a : The Output function
The StateΦ = {Φ1, Φ2,..., Φr}
Input Set bb = {b1,b2,...,br}
Output Set aa = {a1,a2,...,ar}

Learning AutomataLearning AutomataDeterministic Automaton
Stochastic Automaton
fbij = 1 if Φ → Φ for an input b
= 0 otherwise
gij = 1 if G(Φi) = aj
= 0 otherwise.
fbij = Pr{Φ(n+1) = Φj | Φ(n) = Φi, b(n)=b}
gij = Pr{a(n) = aj | Φ(n) = Φi}
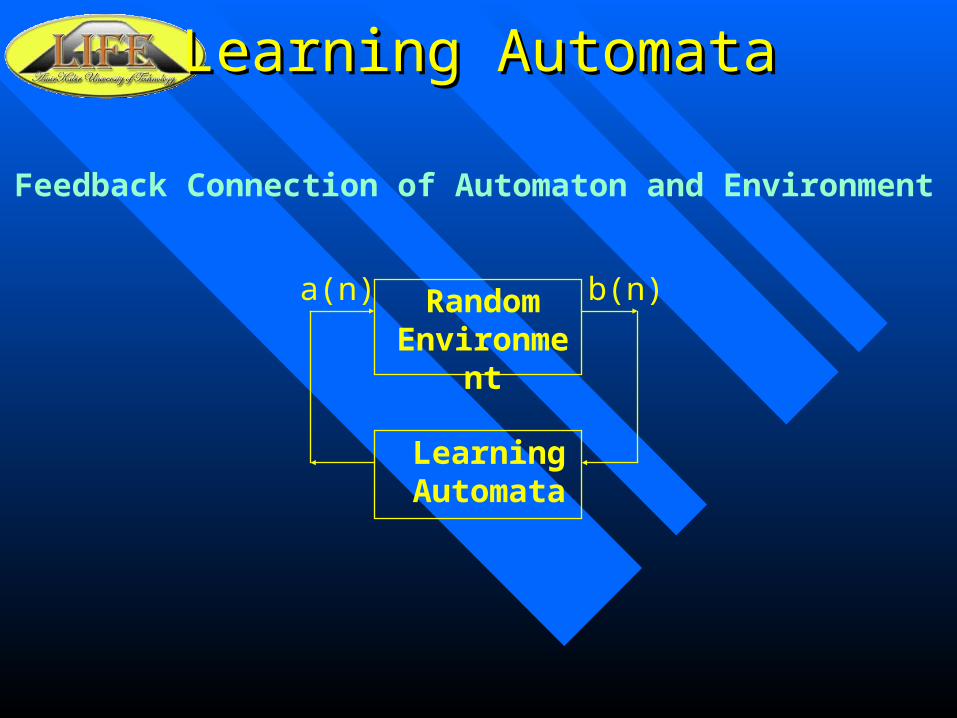
Learning AutomataLearning Automata
Feedback Connection of Automaton and Environment
Random Environment
Learning Automata
a(n) b(n)

Learning AutomataLearning Automata
Fixed-Structures:
1) L2,2 :
1 0F(0)= 0 1
0 1F(1)= 1 0
{Φ1, Φ2} , {a1, a2} , {c1, c2} , {0,1}
Lim M(n) = 2c1c2 / (c1+c2) n → ∞
M0 = 1/2(c1+c2)
a1 a2b=1 a1 a2
b=0
If c1<>c2 then L2,2 is an expedient automaton.
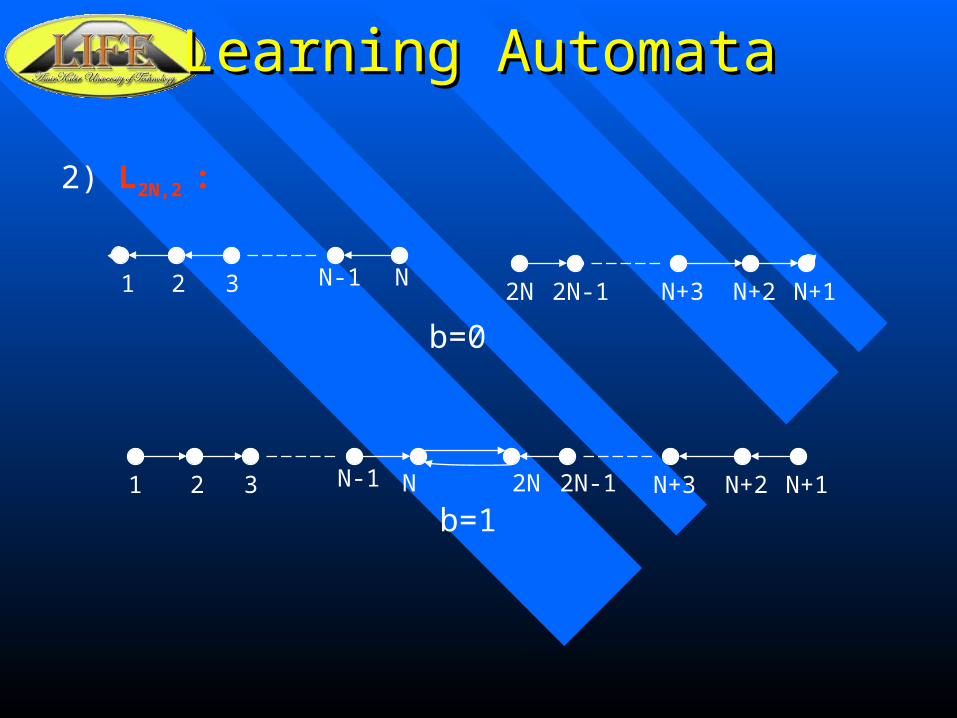
Learning AutomataLearning Automata
2) L2N,2 :
1 N-1 N2 3 2N N+2 N+12N-1 N+3
b=0
1 N-1 N2 3 2N N+2 N+12N-1 N+3
b=1

Learning AutomataLearning Automata
3) G2N,2 :
1 N-1 N2 3 2N N+2 N+12N-1 N+3
b=1
After a change from one action to another, N failures are needed for another change

Learning AutomataLearning Automata
4) Krinsky :
N-1 N2 3 2N N+2N+1
2N-1 N+3
b=0
1
N failures are needed to have a state change

Learning AutomataLearning Automata
5) Krylov :
1 N-1 N2 2N N+2 N+12N-1
b=1
0.5 0.5 0.5 0.5 0.5 0.50.5
When Automaton encountered with a failure,Each state Φi is changed to Φi+1 with probability ½ orto Φi-1 with probability ½.
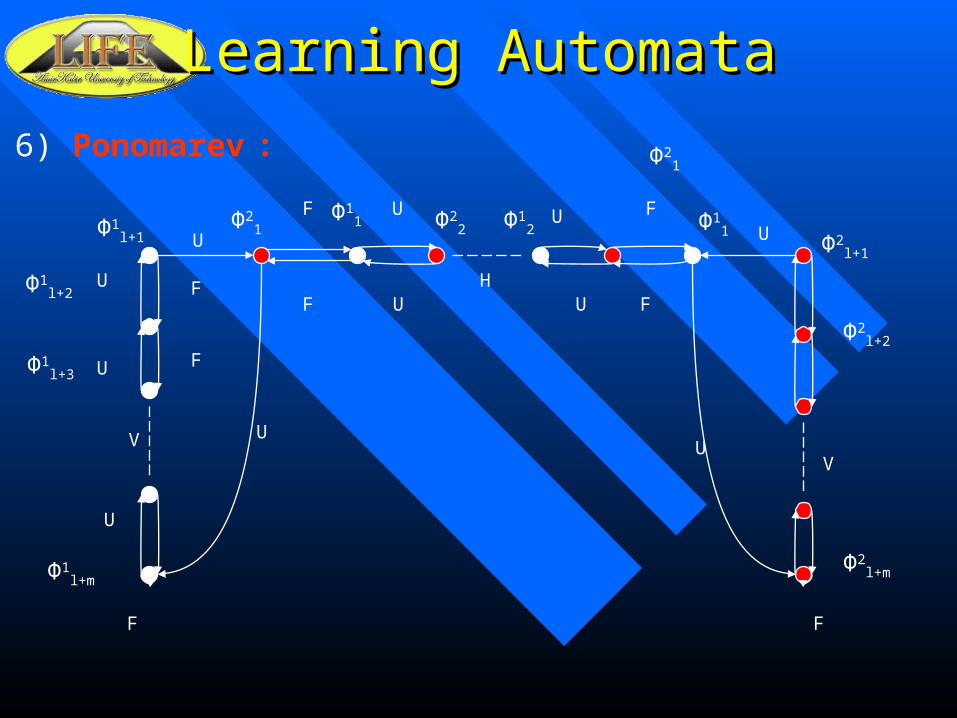
Learning AutomataLearning Automata
6) Ponomarev : Φ21
UU
U
UU
U
U
U
F
F
FF
F
F
F
U
U
U
F
VV
H
Φ2l+2
Φ2l+mΦ1
l+m
Φ1l+2
Φ1l+3
Φ1l+1
Φ21
Φ11 Φ2
2 Φ11Φ1
2Φ2
l+1

Learning AutomataLearning Automata
Variable-Structure Automaton:
a = { a1, a2,..., as }: Set of Actions
b = { b1, b2,..., bs }: Set of inputs
p = { p1, p2,..., ps }: Set of inputs
T : p(n+1) = T[a(n),b(n),p(n)] : Learning Algorithmc = {c1,c2,..., cr} : Set of penalty probabilities
LA = {a,b,p,T,c}
This automaton updates it’s action probabilities according to environments responses
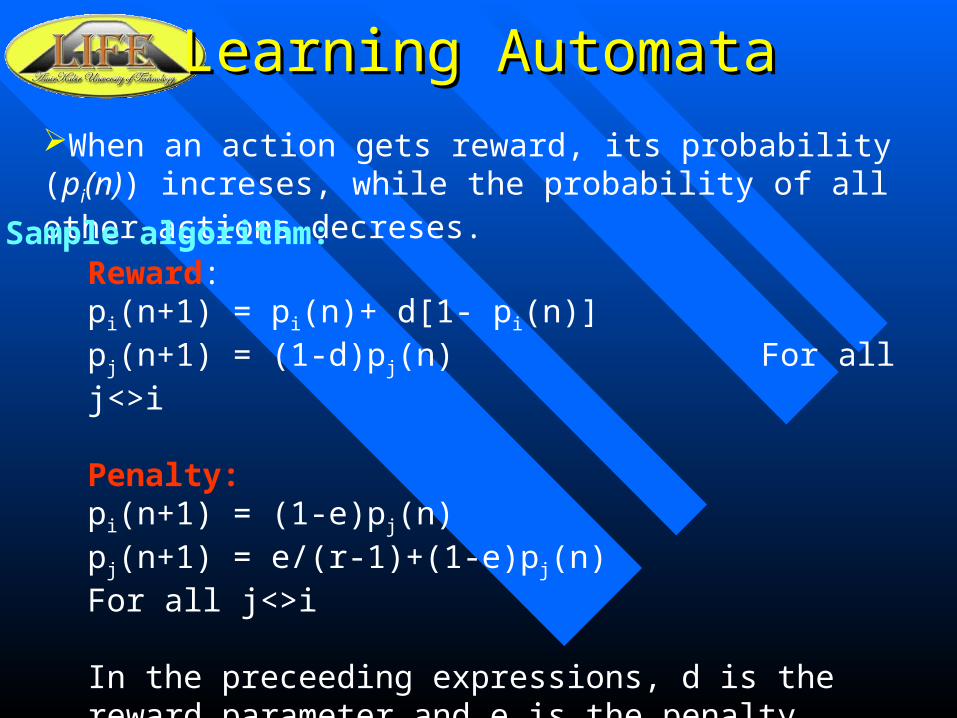
Learning AutomataLearning Automata
When an action gets reward, its probability (pi(n)) increses, while the probability of all other actions decreses.
Sample algorithm:Reward:pi(n+1) = pi(n)+ d[1- pi(n)]pj(n+1) = (1-d)pj(n) For all j<>i
Penalty:pi(n+1) = (1-e)pj(n)pj(n+1) = e/(r-1)+(1-e)pj(n) For all j<>i
In the preceeding expressions, d is the reward parameter and e is the penalty parameter.

Learning AutomataLearning Automata
When d and e are equal, the algorithm is said LRP
When e is much less than d, the algorithm is said LRεP
When e is 0, the algorithm is said LRI

Learning AutomataLearning Automata
Average Penalty for a given action probability vector:
M(n) = E[b(n) | p(n)] = Σri=1
cipi(n)
Pure-Chance Automaton:An Automaton which choose each of its actions with equal probability.
M0 = 1/r Σri=1ci

Learning AutomataLearning Automata
Norms Of Behavior
Expedient: Lim E[M(n)] < M0
n → ∞Optimal:
Lim E[M(n)] = cl , cl=mini{ci} n → ∞
ε-Optimal:Lim E[M(n)] < cl+ ε , cl=mini{ci}
n → ∞
Absolutely Expedient:E [ M(n+1) | p(n) ] < M(n)
Learning AutomataLearning Automata
Applications:
Network Routing
Priority assignment in Queueing System
Task Scheduling
Multiple-Access Networks
Image Compression
Pattern Classification

Learning AutomataLearning Automata
References:
[1] Learning Automata: An Introduction. Kumpati S. Narendra, PRintice Hall,1989
[2] Cellular Learning Automata. Meibodi, Taherkhani, Amir Kabir University of technology





























![[Seyyed Hossein Nasr] Knowledge and the Sacred (Gi(BookZZ.org)](https://img.pdfslide.us/doc/110x75/577cb0fe1a28aba7118b668a/seyyed-hossein-nasr-knowledge-and-the-sacred-gibookzzorg.jpg)