Embed Size (px)
Citation preview

Learning and inference using complex generative models in aspatial localization task
Vikranth R Bejjanki
Department of Brain amp Cognitive Sciences and Center forVisual Science University of Rochester
Rochester NY USADepartment of Psychology and Princeton Neuroscience
Institute Princeton University Princeton NJ USA
David C Knill
Department of Brain amp Cognitive Sciences and Center forVisual Science University of Rochester
Rochester NY USA
Richard N Aslin $
Department of Brain amp Cognitive Sciences and Center forVisual Science University of Rochester
Rochester NY USA
A large body of research has established that underrelatively simple task conditions human observersintegrate uncertain sensory information with learnedprior knowledge in an approximately Bayes-optimalmanner However in many natural tasks observersmust perform this sensory-plus-prior integrationwhen the underlying generative model of theenvironment consists of multiple causes Here we askif the Bayes-optimal integration seen with simpletasks also applies to such natural tasks when thegenerative model is more complex or whetherobservers rely instead on a less efficient set ofheuristics that approximate ideal performanceParticipants localized a lsquolsquohiddenrsquorsquo target whoseposition on a touch screen was sampled from alocation-contingent bimodal generative model withdifferent variances around each mode Over repeatedexposure to this task participants learned the apriori locations of the target (ie the bimodalgenerative model) and integrated this learnedknowledge with uncertain sensory information on atrial-by-trial basis in a manner consistent with thepredictions of Bayes-optimal behavior In particularparticipants rapidly learned the locations of the twomodes of the generative model but the relativevariances of the modes were learned much moreslowly Taken together our results suggest thathuman performance in a more complex localizationtask which requires the integration of sensoryinformation with learned knowledge of a bimodalgenerative model is consistent with the predictions
of Bayes-optimal behavior but involves a muchlonger time-course than in simpler tasks
Introduction
Humans (and other animals) operate in a world ofsensory uncertainty created by noise or processinginefficiencies within each sensory modality or byvariability in the environment (Knill amp Pouget 2004)Given the presence of such internal and externaluncertainty task performance is limited by the qualityof sensory information that is available on a given trialConsider for example the task of estimating thelocation of a target based on visual information suchas the problem faced by a baseball player trying to hit arapidly approaching ball Due to uncertainty in thevisual signal available to the observer an idealapproach to estimating the ballrsquos location at the pointof impact with the bat would be to combine theuncertain sensory information available on each pitchwith prior knowledge about the likely locations of theball such as the areas in the strike zone that a givenpitcher prefers to target learned over prior encounterswith that pitcher Bayesian inference provides aprincipled approach for accomplishing this in astatistically efficient fashion that is in a manner thatmaximally utilizes the available information (Bernardoamp Smith 1994 Cox 1946 Yuille amp Bulthoff 1996)
Citation Bejjanki V R Knill D C amp Aslin R N (2016) Learning and inference using complex generative models in a spatiallocalization task Journal of Vision 16(5)9 1ndash13 doi1011671659
Journal of Vision (2016) 16(5)9 1ndash13 1
doi 10 1167 16 5 9 ISSN 1534-7362Received August 29 2015 published March 10 2016
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 40 International LicenseDownloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
Several studies have shown that human observerscombine prior information with uncertain sensoryinformation in a manner predicted by Bayes-optimalbehavior in tasks including visual motion perception(Stocker amp Simoncelli 2006 Weiss Simoncelli ampAdelson 2002) visuo-motor integration (Kording ampWolpert 2004 OrsquoReilly Jbabdi Rushworth amp Beh-rens 2013 Sato amp Kording 2014 Tassinari Hudsonamp Landy 2006 Vilares Howard Fernandes Gottfriedamp Kording 2012) timing behavior (Jazayeri ampShadlen 2010 Miyazaki Nozaki amp Nakajima 2005)cue combination (Adams Graf amp Ernst 2004 Jacobs1999 Kording et al 2007) categorical judgments(Bejjanki Clayards Knill amp Aslin 2011 HuttenlocherHedges amp Vevea 2000) and movement planning(Hudson Maloney amp Landy 2007 Kwon amp Knill2013) For example considering the task of estimatingthe spatial location of a target based on uncertainvisual information previous studies have shown thathuman observers combine visually presented priorinformation (in the form of a Gaussian blob) withuncertain sensory information in a Bayes-optimalfashion (Tassinari et al 2006) Furthermore severalstudies have shown that human observers are alsocapable of learning prior distributions over repeatedexposure to a task (when receiving a single sample fromthe prior distribution on each trial) and integrating thislearned knowledge with uncertain sensory informationin a Bayes-optimal fashion (Berniker Voss amp Kording2010 Kording amp Wolpert 2004 OrsquoReilly et al 2013Vilares et al 2012) It is important to note that thesestudies used tasks in which observers were faced withuncertain sensory information about stimuli drawnfrom relatively simple prior distributions or generativemodels in the language of Bayesian analysis such asunimodal Gaussian distributions An example of a taskwith such a simple generative model would consist ofsearching for a reward at a single hiding place wherethe reward is replenished according to a Gaussian delayinterval Even in cases where the distributionalproperties of the generative model were changed overthe course of the experiment (Berniker et al 2010OrsquoReilly et al 2013 Vilares et al 2012) this was donein a blocked manner such that in a given block oftrials observers were faced with stimuli drawn from aunimodal Gaussian distribution
In contrast to the tasks considered by these previousstudies in the natural environment human observersare typically faced with tasks involving more complexgenerative models Specifically the stimulus of intereston each trial is usually drawn from one of a number ofpotential environmental causes in a randomly inter-leaved (ie not blocked) fashion If we assume that thestatistical properties of the stimulus distributionassociated with a given environmental cause arerepresented by a Gaussian distribution then such a
complex generative model is best described by amixture model over multiple Gaussian distributionsAn example of a task with such a complex generativemodel would consist of searching for a reward insideone of several hiding places each of which has its ownGaussian delay interval Furthermore the sensoryinformation available to observers in their naturalenvironment typically includes several levels of uncer-tainty again in a randomly interleaved fashion Giventhese task properties ideal behavior involves learningthe complex generative model (ie the mixture modelover all possible causes) for the task by learning theunderlying distributions pertaining to each causeassociating the uncertain sensory information availableon each trial with the relevant cause that might havegenerated it and efficiently integrating the sensoryinformation with the learned generative model on atrial-by-trial basis
Given the significant increase in complexity associ-ated with learning and efficiently using such complexgenerative models it remains an open question as towhether human observers continue to behave in aBayes-optimal manner For instance as the number ofcauses goes up it might be prohibitively expensive froma computational perspective (ie the combinatorialexplosion problem) to track and learn the completegenerative model for the task Observers might insteadchoose to employ suboptimal heuristics or strategies tosimplify task performance such as basing theirperformance on only the mean of the sensoryinformation available across a series of trials and noton the variance of that sensory information It is worthnoting that results from a prior study using a bimodalgenerative model (ie simulating a mixture model overtwo environmental causes) suggest that human ob-servers can learn and utilize such complex generativemodels in an approximately Bayes-optimal manner(Kording amp Wolpert 2004) However this experimentonly involved one level of sensory uncertainty and thetwo mixture components of the generative model didnot differ in their variance (ie in the reliability withwhich they signaled the underlying cause-specificstimulus information) As a result since it did not varythe reliability of either the sensory information or theprior information this experiment was not amenable tofully testing the predictions of the Bayesian model intasks involving complex generative models that is theprediction that the weight assigned to the two sourcesof information should vary on a trial-by-trial basis inproportion to the reliability of each source ofinformation Furthermore this experiment did notexamine the dynamics of the process by which thecomplex generative model was learned
In the current study we examined human behaviorwhen faced with stimuli drawn from a complexgenerative model using a spatial localization task that
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 2
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
allowed us to vary the uncertainty implicit in both thesensory information and the prior information on atrial-by-trial basis Our design simulated a mixturemodel over two environmental causes and as a firstlogical step considered the scenario in which theparticipant is perfectly cued as to the underlying causeon each trial We implemented this using a location-contingent generative modelmdashthe task-relevant stimu-lus on each trial was drawn from a mixture of twounderlying Gaussian distributions with one distribu-tion always centered at one location on the screen andthe other always centered at a distinct second locationon the screen and with one distribution being morevariable (ie representing a less reliable a priori signalabout the likely location of a target drawn from thatdistribution) than the other On each trial the locationof the target was drawn randomly from this bimodalspatial distribution and participants were presentedwith a cluster of dots that was randomly drawn from aseparate Gaussian distribution centered on this truelsquolsquohiddenrsquorsquo location The cluster of dots depending on itsvariance (which could be low medium or high)provided a more or less reliable estimate of the targetrsquoshidden location on each trial (reliability being inverselyproportional to the variance of the dot cluster) Acrosstrials observers could integrate information from theobserved cluster of dots (ie the likelihood) with trial-by-trial feedback they received on previous trials aboutthe underlying bimodal distribution governing thelikely locations of the target (ie the lsquolsquopriorrsquorsquo) Thisexperimental design allowed us to better study thecomputational mechanisms used by human observersin tasks involving complex generative models than waspossible with previous studies Specifically whileaspects of our task are similar to those used in previousstudies (especially Berniker et al 2010 Kording ampWolpert 2004 Tassinari et al 2006 and Vilares et al2012) by randomly interleaving multiple underlyingdistributions (which varied in their reliability) andmultiple levels of sensory uncertainty on a trial-by-trialbasis our design allows us to fully test the predictionsof the Bayesian model in tasks involving complexgenerative models and to rule out alternative subop-timal strategies that could potentially be used to carryout the task
There are several computational models that partic-ipants could potentially use to estimate the location ofthe hidden target on each trial of this task Asmentioned above for example due to the complexityinherent in the statistics that govern target locationacross trials participants might choose to ignore thislsquolsquolatentrsquorsquo source of information and instead base theirestimates solely on the sensory information availableon each trial For instance they might simply choosethe centroid of the cluster of dots as their estimate forthe target location on each trial An alternate strategy
might be to learn some summary statistic such as theaverage location that describes each mixture compo-nent of the generative model and to bias their estimatestoward that source of information Both these kinds ofstrategies would however be statistically suboptimalbecause they would not maximally exploit all thesources of information available to the observerInstead a statistically optimal approach would entaillearning the distributional statistics (both the mean andthe variance) characterizing each mixture component ofthe generative model and integrating this informationwith the sensory information available on each trial ina manner consistent with the predictions of Bayes-optimal behavior This approach predicts that theweight assigned by participants to the sensory infor-mation should drop as the reliability of the sensoryinformation goes down (ie the variance of the clusterof dots goes up) and crucially this drop should begreater when the stimulus is drawn from the mixturecomponent that has lower variance (ie greaterreliability) By following this strategy participantswould maximally utilize all the sources of informationavailable on each trial by appropriately weighting eachsource of information by the uncertainty implicit in it
We provide evidence from two experiments thatover multiple exposures to the task of estimating thelocation of a hidden target human observers not onlylearn the complex distributional statistics about the apriori locations of the target (ie they learn thelocation-contingent bimodal generative model) butalso integrate this knowledge with uncertain sensoryinformation on a trial-by-trial basis in a mannerconsistent with the predictions of Bayes-optimalbehavior Importantly our experimental design al-lowed us to validate the predictions of the Bayesianmodel in a very specific manner and thus rule outalternative suboptimal strategies that could be used tocarry out the task Consistent with the predictions ofthe Bayesian model we found that participantsassigned a smaller weight to the sensory information asthe reliability of sensory information went down andthat this drop was greater when the stimulus was drawnfrom the more reliable mixture component of thecomplex generative model used in the task Our designalso allowed us to examine the dynamics underlying theprocess by which participants learned the complexgenerative model Extending prior work using simplegenerative models (Berniker et al 2010) we found thatparticipants quickly learned the mean locations for thebimodal generative model (ie the centers of the twodistributions that made up the mixture components ofthe generative model for the task) but it took themmuch longer to learn the relative variances of themixture components of these two modes Furthermoreour results show that in tasks with such complexgenerative models the learning rate is dramatically
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 3
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
slower than that observed previously with simplegenerative models presumably due to the significantlyincreased complexity involved in tracking and learningthe means and variances of the generative modelespecially when sensory uncertainty was also variableTaken together our results therefore provide compel-ling evidence in support of the hypothesis that whenfaced with complex environmental statistics humanobservers are capable of learning such distributionsand utilizing this learned knowledge in a statisticallyefficient fashion
General methods
We developed a spatial localization task where theparticipantsrsquo goal on each trial was to estimate thelocation of a hidden target by touching the appropriatelocation on a touch-sensitive display (Figure 1A)Several aspects of our task were similar to the task usedin Kording and Wolpert (2004) Tassinari et al (2006)and Vilares et al (2012) The horizontal and verticalcoordinates of the target location on each trial wereindependently drawn from a complex generative modela location-contingent mixture distribution over twounderlying isotropic two-dimensional Gaussian distri-
butions These Gaussian distributions differed in theirmean locations (one of them was always centered in theleft half of the display while the other was alwayscentered in the right half of the display) and theirrelative variances (one of them had a standarddeviation of 40 pixels while the other had a standarddeviation of 20 pixels) Across participants thedistributions were always centered at the same loca-tions on the left and right of the display but thevariance assigned to each was counterbalanced with thehigher variance distribution centered in the left half ofthe display for 50 of the participants and in the righthalf of the display for the other 50
On each trial participants were not shown the truetarget location instead they were presented withuncertain sensory information about the target locationin the form of a two-dimensional cloud of eight smalldots (Figure 1A) This cloud was independentlygenerated on each trial by drawing samples from aseparate two-dimensional isotropic Gaussian distribu-tion centered at the true target location for that trial(ie the location of the target drawn for that trial fromthe complex generative model) The variance of thiscloud of dots was manipulated to generate sensoryinformation with three levels of reliability withreliability inversely proportional to the variance of thedot distribution Specifically the dots were drawn from
Figure 1 Learning and inference in a spatial localization task (A) An illustration of a typical trial After participants touched a lsquolsquoGOrsquorsquobutton they were presented with uncertain sensory information in the form of a cloud of dots (the likelihood) with one of three
levels of variance (low variance shown here see inset for an illustration of the three levels) Participants estimated the location of a
hidden target drawn from a complex generative model (a mixture over two Gaussian distributions the prior) by touching a location
on the display Feedback was provided posttouch (B) An illustration of Bayes-optimal behavior Considering the example of a target
drawn from the broad prior distribution the ideal observer would learn the mean and variance of the prior and integrate this learned
knowledge with the likelihood on each trial to estimate the location of the hidden target
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 4
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
a distribution that either had low variance (SD of 10pixels) medium variance (SD of 60 pixels) or highvariance (SD of 100 pixels see inset of Figure 1A for anillustration of the three levels of variance) Afterparticipants provided their response by touching alocation on the display feedback on their accuracy onthat trial was provided by displaying a new dot at thetouched location and a second new dot at the truetarget location In addition participants receivedfeedback in the form of numerical points with themagnitude of the points varying based on theiraccuracy
Experiment 1 Can human observerslearn and efficiently use complexprior knowledge
In Experiment 1 participants were exposed to 1200trials of the spatial localization task with half the trialsinvolving targets drawn from each of the two under-lying Gaussian distributions (the mixture componentsof the location-contingent generative model) Thesetwo sets of 600 trials were randomly intermixed andwithin each set 200 trials were randomly presentedwith one of the three levels of reliability in other wordssix total conditions were randomly interleavedthroughout the experiment In each trial participantstherefore had access to two sources of informationmdashthe uncertain sensory information available on thattrial (ie the cloud of dots that corresponded to thelikelihood) and any knowledge they might have learnedup to that point in the experiment based on feedbackreceived in previous trials about the likely locations ofthe target (ie the mixture distribution over the twounderlying Gaussian distributions that corresponded tothe prior) Participants received two cues on each trialas to which of the two underlying Gaussian distribu-tions the target on that trial was drawn from the sideof the display in which the sensory information waspresented (the two underlying distributions were alwayscentered in opposite halves of the display) and the colorof the sensory information (the color of the dot cloudwas set either to green or white depending on the targetdistribution) Since the components of the complexgenerative model were perfectly separable given thelocation contingent cues on each trial we cancharacterize the prior as involving two separabledistributions conditioned on the trial-specific locationand color of the sensory information Accordingly inthe rest of this article we refer to the two Gaussiandistributions that make up the mixture components ofthe complex generative model as the lsquolsquobroadrsquorsquo priordistribution (the distribution with the larger standard
deviation) and the lsquolsquonarrowrsquorsquo prior distribution (thedistribution with the smaller standard deviation)
There are several computational models that partic-ipants could potentially use to carry out this task Onepossibility is that participants just ignore the underlyingprior distributions and base their estimates solely onthe sensory information available on each trial That isgiven the complexity implicit in the generative modelgoverning target location participants can ignore thissource of information (rather than expend the compu-tational resources to track and learn the location-contingent prior distributions) and instead just choosethe centroid of the cluster of dots (which are visible oneach trial) as their estimate for the hidden targetlocation This strategy would predict that participantswould assign a weight of one to the likelihood (ie basetheir responses solely on the sensory information)irrespective of the reliability of the sensory informationor the reliability (or inverse variance) of the priordistribution for that trial Furthermore we wouldexpect to see no change in participantsrsquo weights as afunction of exposure to the task since this strategy doesnot involve any learning (cf the likelihood distributionis drawn independently on each trial) Importantlyhowever such a computational strategy (henceforthreferred to as Model 1) would be suboptimal for tworeasons first as the reliability of the sensory informa-tion goes down the probability that the centroid of thesensory information will correspond exactly to the truetarget location also goes down and second by ignoringthe information provided by the prior distributionsparticipants cannot take advantage of the fact that notall spatial locations are a priori equally likely
A second possibility is that participants are sensitiveto the underlying generative model but given thecomplexity involved in the task they choose to learnonly the mean locations for the two prior distributionswhile ignoring their relative variances (ie their relativereliability)mdashlearning only the means is statisticallyeasier and requires exposure to far fewer trials Bylearning the average position for where the target tendsto be for each prior distribution participants can usethis knowledge to bias their estimates particularly asthe reliability of the sensory information goes downThis model (Model 2) predicts a smaller weight to thelikelihood as the reliability of the sensory informationgoes down and it also predicts that as participants gaingreater exposure to the underlying distributions (thusallowing them to better learn the two prior means)their behavior should show a greater sensitivity to theunderlying prior distributions However a key predic-tion of this model is that for each level of sensoryreliability we should see identical weights beingassigned to the likelihood for targets drawn from thetwo different prior distributions because the variancesof the prior distributions are ignored by this model
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 5
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
Thus this model is still suboptimal since the narrowprior distribution is a more reliable indicator of thelikely target location across trials compared to thebroad prior distribution and an optimal observershould take this into account
Finally a third possibility is that participants learnboth the mean positions and the relative reliabilities ofthe two prior distributions and integrate this learnedknowledge with the sensory information available oneach trial in a manner that is consistent with thepredictions of Bayes-optimal behavior (Model 3) Ifparticipants use such a strategy we should see a smallerweight to the likelihood as the reliability of the sensoryinformation goes down and this drop should be greaterfor trials in which the target is drawn from the narrowprior than when the target is drawn from the broadprior Furthermore this model predicts that asparticipants gain greater exposure to and thus learnmore about the underlying distributions participantsrsquobehavior should show a greater sensitivity to thestatistical properties (both mean location and relativevariance) of the underlying distributions (see Figure 1Bfor an illustration) Formally if the mean and thevariance of the sensory information on a given trial isgiven by ll and r2
l and the mean and the variance ofthe underlying target distribution for that trial is givenby lp and r2
p then the target location t predicted by thismodel would be (Bernardo amp Smith 1994 Cox 1946Jacobs 1999 Yuille amp Bulthoff 1996)
t frac14 wlll thorn eth1 wlTHORNlp eth1THORN
where wl the weight assigned by the observer to thesensory information should be
wl frac141=r2
l
1=r2l thorn 1=r2
p
eth2THORN
By examining the weights assigned by participants tothe likelihood on each trial given the relative reliabilityof the sensory information and the prior informationon that trial we sought to distinguish between the threepotential strategies described above (ie Models 1 2and 3) In addition we sought to characterize learning-induced changes in participantsrsquo weights as a functionof exposure to the task by splitting the total number oftrials into four temporal bins each of which included300 trials of exposure to the task (with the sixconditions randomly interleaved in each bin)
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to the
purpose of the study and provided informed writtenconsent The University of Rochesterrsquos institutionalreview board approved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with the following task instructions
In this study you will be playing a game on theiPad The story behind this game is that you are ata fair and there is an invisible bucket that you aretrying to locate Sometimes the bucket is going tobe located on the left side of the display and atother times the bucket is going to be located onthe right side of the display Now given that thebucket is invisible you canrsquot see where it isHowever on each trial you will see some locationsthat other people have previously guessed thebucket is located at These lsquolsquoguessesrsquorsquo will show upas white or green dots on the screen Now it isimportant to note that you donrsquot know which (ifany) of the dots actually correspond to thelocation of the bucket Indeed all of the dotscould be just random guesses Your job on eachtrial is to try to figure out where the bucket isactually located Once you decide on a locationyou can just touch it at which point you will seetwo more dots a red dot which shows you thetrue location of the bucket on that trial and a bluedot which shows you the location that youtouched If the blue dot is right on the red dotthen you correctly guessed the location of thebucket and you will get 20 points If you donrsquotexactly guess the location of the bucket but youstill get close then you will get 5 points When yousee this it means that you need to try just a littleharder to get the right locationmdashyou are closeFinally if your guess is very far away you will getno points
Participants were seated at a comfortable viewingdistance from a touch-sensitive display (iPad 2 AppleInc Cupertino CA) with a resolution of 768 pixels(vertical) 3 1024 pixels (horizontal) Participantsprovided responses using their finger having beeninstructed to pick a favorite finger and to consistentlyuse that finger throughout the experiment At the startof each trial they were presented with a lsquolsquoGOrsquorsquo buttoncentered at the bottom of the display Once theytouched this button the trial started with the presen-tation of a cluster of white or green dots (thelsquolsquoguessesrsquorsquo) Participants were told to estimate thelocation of the hidden target as rapidly and accuratelyas possible by touching a location on the screen Afterparticipants provided a response the cluster of dots
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 6
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
disappeared and feedback was provided The gameincluded multiple levels once a participant accumu-lated a total of 600 points on each level they wereshown a congratulatory screen and allowed to lsquolsquoleveluprsquorsquo Progress toward the next level was always shownat the top of the screen using a progress bar Thisability to level up was used solely to motivateparticipants and did not represent any change in theexperimental procedure Participants carried out a totalof 1200 trials split across four experimental blocksShort breaks were allowed between blocks and thetotal experimental duration including breaks wasapproximately 50 min
Data analysis
To quantify the computational mechanisms used byparticipants in this experiment we estimated the extentto which their behavior depended on the likelihoodversus the prior on each trial Specifically we usedlinear regression to compute the weight (wl) assigned tothe centroid of the cluster of dots (the likelihood) withthe weight assigned to the mean of the underlyingtarget distribution for that trial (the prior) beingdefined as (1 wl) Thus on each trial given thecentroid of the sensory information (ll) the mean ofthe underlying target distribution (lp) and participantsrsquoestimate for the target location (t ) the weight assignedby participants to the centroid of the sensory infor-mation (wl) was estimated using
t frac14 wlll thorn eth1 wlTHORNlp thorn noise eth3THORN
We focused on participantsrsquo performance in thevertical dimension to eliminate the potential influenceof variability that may have been introduced by aninteraction between participantsrsquo handedness and thehorizontal separation of the prior locations Moreovertheir performance in the horizontal dimension wassimilar to their performance in the vertical dimensionmdashwe found no interaction between dimension (horizontalvs vertical) and exposure bin across prior andlikelihood conditions (all ps 005)
Results and discussion
Consistent with the predictions of the Bayes-optimalmodel (Model 3) by the end of exposure to the task(ie in the final temporal bin) observers assigned areliably smaller weight to the likelihood (and thus agreater weight to the prior) as the sensory informationdecreased in reliability (Figure 2) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 1889 p 0001
Furthermore for each prior condition there was areliable interaction between exposure and likelihoodvariance as participants gained more exposure to thetask they assigned a smaller weight to the likelihoodand this drop in weight was greater as the likelihoodvariance increased (Figure 3) Specifically in a 4(temporal bin) 3 3 (likelihood variance) repeatedmeasures ANOVA carried out over participantsrsquoweights in the broad prior condition there was a maineffect of temporal bin F(3 21)frac14 400 pfrac14 002 a main
Figure 2 Data from the final temporal bin for a representative participant in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior as likelihood variance increased (blue to green to red) participants shifted from selecting the centroid of the
sensory information as their estimate for the target location (the gray dashed line) toward selecting the mean of the underlying prior
distribution (zero on the y-axis) This was true in both the broad (A) and narrow (B) prior conditions but the shift was more
pronounced for the narrow prior condition than for the broad prior condition For illustrative purposes the mean of the underlying
prior distribution was removed from participantsrsquo response locations and from the locations of the centroid of the sensory
information Each dot represents a trial and solid lines represent the best-fit regression lines in each condition
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 7
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
effect of likelihood variance F(2 14) frac14 2117 p
00001 and an interaction between the two factorsF(6 42)frac14 522 p 0001 Similarly in a 4 (temporalbin) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thenarrow prior condition there was a main effect oftemporal bin F(3 21)frac14 906 p 0001 a main effectof likelihood variance F(2 14)frac141224 p 0001 andan interaction between the two factors F(6 42)frac14547p 0001 These findings are inconsistent with Model1 which predicts a weight of 1 to the sensoryinformation across all the likelihood and priorconditions and no change in participantsrsquo weights as afunction of exposure to the task Furthermore incontrast to the predictions of Model 2 we found thatthe drop in the weight assigned by participants to thelikelihood as a function of exposure to the taskparticularly in the high likelihood variance conditionwas greater for trials in which the target was drawnfrom the narrow prior than when the target wasdrawn from the broad prior In a 4 (temporal bin)3 2(prior variance) repeated measures ANOVA carriedout over participantsrsquo weights in the high likelihoodvariance condition we saw a main effect of temporalbin F(3 21) frac14 829 p 0001 and an interactionbetween temporal bin and prior variance F(3 21) frac14307 p frac14 005 This finding suggests that participantsare sensitive to and learn both the means and therelative variances of the underlying prior distribu-tions Taken together this pattern of results providesclear evidence in support of Model 3mdashthe hypothesisthat human observers learn the complex generativemodel and use this learned knowledge in a manner
that is consistent with the predictions of Bayes-optimal behavior
Experiment 2 Exploring thedynamics of learning
While the results from Experiment 1 support thehypothesis that participants learn the complex gener-ative model and use this knowledge in a statisticallyefficient manner the dynamics of this learning remainunclear For instance prior work (Berniker et al2010) has shown that when presented with stimulidrawn from simple generative models human ob-servers rapidly learn the prior mean but it takes themmany more trials to learn the prior variance InExperiment 2 with a new group of participants weexamined the dynamics of learning with complexgenerative models by including an extra conditionrandomly interleaved with all the conditions used inthe first experiment in which no sensory informationwas presented In this condition observers thus had toestimate the position of the target based solely on theirlearned knowledge (up to that point) about where thetarget was likely to occur (ie based on their priorknowledge) thereby allowing us to analyze theirevolving learned knowledge of the location-contingentgenerative model as a function of exposure to the taskParticipants carried out 400 trials of this conditionsplit evenly between the two prior distributions Oneach trial they were cued to estimate the location ofthe target on either the left or the right of the display
Figure 3 Weights assigned to the centroid of the sensory information in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior participants in Experiment 1 relied less on the sensory information and more on the priors as the variance of the
sensory information increased This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to the
sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin included 300 trials split between the two prior conditions and the four bins of trials are depicted in
temporal order Columns represent means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 8
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
(with a box that was colored green or white) thusrequiring them to draw on their learned knowledge ofthe location-contingent prior distribution associatedwith that trial As in Experiment 1 the 1600 trials inExperiment 2 (all conditions from Experiment 1 plus400 trials in this extra condition) were again split upinto the relevant prior and likelihood conditions (theno sensory information condition is statisticallyequivalent to a likelihood condition with infiniteuncertainty) and with each condition being furthersplit into four temporal bins to study the influence oftask exposure
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to thepurpose of the study provided informed writtenconsent and did not participate in Experiment 1 TheUniversity of Rochesterrsquos institutional review boardapproved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with task instructions that were nearlyidentical to those provided to participants in Experi-ment 1 Specifically in addition to the instructions fromExperiment 1 they were also provided with thefollowing instructions
There will also be some trials in which you willbe the first person to guess the location of thebucket In these trials rather than seeing dots onthe screen you will see a briefly flashed white orgreen rectangle which will indicate the side of thescreen that the invisible bucket is located atmdashthebucket could be located anywhere inside thatrectangle Again your job is to try to figure outwhere the bucket is actually located
On each trial of the experiment the procedure wasidentical to that used in Experiment 1 except for theextra condition in which no sensory information waspresented In the trials corresponding to this conditionafter participants touched the GO button they saw abriefly flashed green or white rectangle spanning eitherthe left half or the right half of the display Afterparticipants provided a response feedback was pro-vided as in all the other conditions Participants carriedout a total of 1600 trials split across four experimentalblocks Short breaks were allowed between blocks and
the total experimental duration including breaks wasapproximately an hour
Data analysis
As in Experiment 1 for the trials in which sensoryinformation was available we used linear regression tocompute the weight (wl) assigned to the centroid of thecluster of dots (the likelihood) with the weightsassigned to the mean of the underlying location-contingent target distribution for that trial (the prior)being defined as (1 wl) For the trials in which nosensory information was available we computedparticipantsrsquo mean responses across all trials in eachtemporal bin As in Experiment 1 we again focused onperformance in the vertical dimension
Results and discussion
We first examined the weights assigned by partici-pants to the likelihood and the prior for the trials inwhich sensory information was available and foundthat their behavior was similar to that in Experiment 1(Figure 3) Specifically in line with the Bayes-optimalmodel (Model 3) by the end of exposure to the task inExperiment 2 (ie in the final temporal bin) observersassigned a reliably smaller weight to the likelihood (anda greater weight to the prior) as the sensory informa-tion decreased in reliability (Figure 4) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 4584 p 00001 and aninteraction between the two factors F(2 14)frac14 383 pfrac140047 Furthermore for each prior condition we againfound an interaction between exposure and likelihoodvariance Specifically in a 4 (temporal bin) 3 3(likelihood variance) repeated measures ANOVAcarried out over participantsrsquo weights in the broad priorcondition there was a main effect of temporal bin F(321)frac14 749 pfrac14 0001 a main effect of likelihoodvariance F(2 14)frac14 3421 p 00001 and aninteraction between the two factors F(6 42)frac14 284 pfrac14002 Similarly in a 4 (temporal bin) 3 3 (likelihoodvariance) repeated measures ANOVA carried out overparticipantsrsquo weights in the narrow prior conditionthere was a marginal main effect of temporal bin F(321)frac14 287 pfrac14 006 a main effect of likelihoodvariance F(2 14)frac14 1772 p 0001 and a marginalinteraction between the two factors F(6 42)frac14 230 pfrac140052 Finally participants assigned a smaller weight tothe likelihood particularly in the high likelihoodvariance condition when the target was drawn fromthe narrow prior than when the target was drawn fromthe broad prior In a 4 (temporal bin) 3 2 (prior
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 9
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
variance) repeated measures ANOVA carried out overparticipantsrsquo weights in the high likelihood variancecondition there was a main effect of temporal bin F(321)frac14 555 p 0001 and a main effect of priorvariance F(1 7) frac14 789 p frac14 0026 These findingstherefore represent a replication of our results fromExperiment 1 To further confirm that these resultsreplicate the results from Experiment 1 we carried outa 2 (experiment) 3 4 (temporal bin) 3 3 (likelihoodvariance) mixed ANOVA with experiment as abetween-participants factor and temporal bin andlikelihood variance as within-participant factors overparticipantsrsquo weights in both the broad and narrowprior conditions In each case we found no interactionbetween experiment and any other factor (all ps 017)
Importantly in the conditions in which no sensoryinformation was available (ie no cluster of dots waspresented) we found that within the first temporal bin(the first 100 of the 400 prior-only trials) participantsrsquoestimates of the target location were on averageindistinguishable from the true prior mean locations(plus or minus motor noise estimated from the lowlikelihood variance conditions broad prior t7frac14 173 pfrac14 013 narrow prior t7 frac14 124 p frac14 025) Participantswere therefore able to rapidly learn the prior meanseven when presented with a complex generative model(Figure 5) extending results from previous workexamining such behavior in the presence of simplergenerative models It is important to note howeverthat in the conditions where sensory information wasavailable which were randomly interleaved with theprior-only conditions participantsrsquo weights continue tochange throughout the experiment (Figure 4) This
Figure 4 Weights assigned to the centroid of the sensory information in Experiment 2 As in Experiment 1 participants in Experiment
2 relied less on the sensory information and more on the priors as the variance of the sensory information increased in line with the
predictions of Bayes-optimal behavior This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to
the sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin again included 300 trials split between the two prior conditions and the four bins of trials are depicted
in temporal order Columns represent means and error bars represent SEM across participants
Figure 5 Mean response location in the absence of sensory
information Participants in Experiment 2 rapidly learned the
true prior mean for both the broad (top) and narrow prior
conditions (bottom) Participantsrsquo mean response location in
the trials in which no sensory information was available was
indistinguishable from the true prior means plus or minus
motor noise within the first temporal bin For illustrative
purposes the y-axis represents the mean deviation from the
true mean in each prior condition Each temporal bin included
100 trials split between the two prior conditions and the four
bins of trials are depicted in temporal order Columns represent
means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 10
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016

Several studies have shown that human observerscombine prior information with uncertain sensoryinformation in a manner predicted by Bayes-optimalbehavior in tasks including visual motion perception(Stocker amp Simoncelli 2006 Weiss Simoncelli ampAdelson 2002) visuo-motor integration (Kording ampWolpert 2004 OrsquoReilly Jbabdi Rushworth amp Beh-rens 2013 Sato amp Kording 2014 Tassinari Hudsonamp Landy 2006 Vilares Howard Fernandes Gottfriedamp Kording 2012) timing behavior (Jazayeri ampShadlen 2010 Miyazaki Nozaki amp Nakajima 2005)cue combination (Adams Graf amp Ernst 2004 Jacobs1999 Kording et al 2007) categorical judgments(Bejjanki Clayards Knill amp Aslin 2011 HuttenlocherHedges amp Vevea 2000) and movement planning(Hudson Maloney amp Landy 2007 Kwon amp Knill2013) For example considering the task of estimatingthe spatial location of a target based on uncertainvisual information previous studies have shown thathuman observers combine visually presented priorinformation (in the form of a Gaussian blob) withuncertain sensory information in a Bayes-optimalfashion (Tassinari et al 2006) Furthermore severalstudies have shown that human observers are alsocapable of learning prior distributions over repeatedexposure to a task (when receiving a single sample fromthe prior distribution on each trial) and integrating thislearned knowledge with uncertain sensory informationin a Bayes-optimal fashion (Berniker Voss amp Kording2010 Kording amp Wolpert 2004 OrsquoReilly et al 2013Vilares et al 2012) It is important to note that thesestudies used tasks in which observers were faced withuncertain sensory information about stimuli drawnfrom relatively simple prior distributions or generativemodels in the language of Bayesian analysis such asunimodal Gaussian distributions An example of a taskwith such a simple generative model would consist ofsearching for a reward at a single hiding place wherethe reward is replenished according to a Gaussian delayinterval Even in cases where the distributionalproperties of the generative model were changed overthe course of the experiment (Berniker et al 2010OrsquoReilly et al 2013 Vilares et al 2012) this was donein a blocked manner such that in a given block oftrials observers were faced with stimuli drawn from aunimodal Gaussian distribution
In contrast to the tasks considered by these previousstudies in the natural environment human observersare typically faced with tasks involving more complexgenerative models Specifically the stimulus of intereston each trial is usually drawn from one of a number ofpotential environmental causes in a randomly inter-leaved (ie not blocked) fashion If we assume that thestatistical properties of the stimulus distributionassociated with a given environmental cause arerepresented by a Gaussian distribution then such a
complex generative model is best described by amixture model over multiple Gaussian distributionsAn example of a task with such a complex generativemodel would consist of searching for a reward insideone of several hiding places each of which has its ownGaussian delay interval Furthermore the sensoryinformation available to observers in their naturalenvironment typically includes several levels of uncer-tainty again in a randomly interleaved fashion Giventhese task properties ideal behavior involves learningthe complex generative model (ie the mixture modelover all possible causes) for the task by learning theunderlying distributions pertaining to each causeassociating the uncertain sensory information availableon each trial with the relevant cause that might havegenerated it and efficiently integrating the sensoryinformation with the learned generative model on atrial-by-trial basis
Given the significant increase in complexity associ-ated with learning and efficiently using such complexgenerative models it remains an open question as towhether human observers continue to behave in aBayes-optimal manner For instance as the number ofcauses goes up it might be prohibitively expensive froma computational perspective (ie the combinatorialexplosion problem) to track and learn the completegenerative model for the task Observers might insteadchoose to employ suboptimal heuristics or strategies tosimplify task performance such as basing theirperformance on only the mean of the sensoryinformation available across a series of trials and noton the variance of that sensory information It is worthnoting that results from a prior study using a bimodalgenerative model (ie simulating a mixture model overtwo environmental causes) suggest that human ob-servers can learn and utilize such complex generativemodels in an approximately Bayes-optimal manner(Kording amp Wolpert 2004) However this experimentonly involved one level of sensory uncertainty and thetwo mixture components of the generative model didnot differ in their variance (ie in the reliability withwhich they signaled the underlying cause-specificstimulus information) As a result since it did not varythe reliability of either the sensory information or theprior information this experiment was not amenable tofully testing the predictions of the Bayesian model intasks involving complex generative models that is theprediction that the weight assigned to the two sourcesof information should vary on a trial-by-trial basis inproportion to the reliability of each source ofinformation Furthermore this experiment did notexamine the dynamics of the process by which thecomplex generative model was learned
In the current study we examined human behaviorwhen faced with stimuli drawn from a complexgenerative model using a spatial localization task that
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 2
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
allowed us to vary the uncertainty implicit in both thesensory information and the prior information on atrial-by-trial basis Our design simulated a mixturemodel over two environmental causes and as a firstlogical step considered the scenario in which theparticipant is perfectly cued as to the underlying causeon each trial We implemented this using a location-contingent generative modelmdashthe task-relevant stimu-lus on each trial was drawn from a mixture of twounderlying Gaussian distributions with one distribu-tion always centered at one location on the screen andthe other always centered at a distinct second locationon the screen and with one distribution being morevariable (ie representing a less reliable a priori signalabout the likely location of a target drawn from thatdistribution) than the other On each trial the locationof the target was drawn randomly from this bimodalspatial distribution and participants were presentedwith a cluster of dots that was randomly drawn from aseparate Gaussian distribution centered on this truelsquolsquohiddenrsquorsquo location The cluster of dots depending on itsvariance (which could be low medium or high)provided a more or less reliable estimate of the targetrsquoshidden location on each trial (reliability being inverselyproportional to the variance of the dot cluster) Acrosstrials observers could integrate information from theobserved cluster of dots (ie the likelihood) with trial-by-trial feedback they received on previous trials aboutthe underlying bimodal distribution governing thelikely locations of the target (ie the lsquolsquopriorrsquorsquo) Thisexperimental design allowed us to better study thecomputational mechanisms used by human observersin tasks involving complex generative models than waspossible with previous studies Specifically whileaspects of our task are similar to those used in previousstudies (especially Berniker et al 2010 Kording ampWolpert 2004 Tassinari et al 2006 and Vilares et al2012) by randomly interleaving multiple underlyingdistributions (which varied in their reliability) andmultiple levels of sensory uncertainty on a trial-by-trialbasis our design allows us to fully test the predictionsof the Bayesian model in tasks involving complexgenerative models and to rule out alternative subop-timal strategies that could potentially be used to carryout the task
There are several computational models that partic-ipants could potentially use to estimate the location ofthe hidden target on each trial of this task Asmentioned above for example due to the complexityinherent in the statistics that govern target locationacross trials participants might choose to ignore thislsquolsquolatentrsquorsquo source of information and instead base theirestimates solely on the sensory information availableon each trial For instance they might simply choosethe centroid of the cluster of dots as their estimate forthe target location on each trial An alternate strategy
might be to learn some summary statistic such as theaverage location that describes each mixture compo-nent of the generative model and to bias their estimatestoward that source of information Both these kinds ofstrategies would however be statistically suboptimalbecause they would not maximally exploit all thesources of information available to the observerInstead a statistically optimal approach would entaillearning the distributional statistics (both the mean andthe variance) characterizing each mixture component ofthe generative model and integrating this informationwith the sensory information available on each trial ina manner consistent with the predictions of Bayes-optimal behavior This approach predicts that theweight assigned by participants to the sensory infor-mation should drop as the reliability of the sensoryinformation goes down (ie the variance of the clusterof dots goes up) and crucially this drop should begreater when the stimulus is drawn from the mixturecomponent that has lower variance (ie greaterreliability) By following this strategy participantswould maximally utilize all the sources of informationavailable on each trial by appropriately weighting eachsource of information by the uncertainty implicit in it
We provide evidence from two experiments thatover multiple exposures to the task of estimating thelocation of a hidden target human observers not onlylearn the complex distributional statistics about the apriori locations of the target (ie they learn thelocation-contingent bimodal generative model) butalso integrate this knowledge with uncertain sensoryinformation on a trial-by-trial basis in a mannerconsistent with the predictions of Bayes-optimalbehavior Importantly our experimental design al-lowed us to validate the predictions of the Bayesianmodel in a very specific manner and thus rule outalternative suboptimal strategies that could be used tocarry out the task Consistent with the predictions ofthe Bayesian model we found that participantsassigned a smaller weight to the sensory information asthe reliability of sensory information went down andthat this drop was greater when the stimulus was drawnfrom the more reliable mixture component of thecomplex generative model used in the task Our designalso allowed us to examine the dynamics underlying theprocess by which participants learned the complexgenerative model Extending prior work using simplegenerative models (Berniker et al 2010) we found thatparticipants quickly learned the mean locations for thebimodal generative model (ie the centers of the twodistributions that made up the mixture components ofthe generative model for the task) but it took themmuch longer to learn the relative variances of themixture components of these two modes Furthermoreour results show that in tasks with such complexgenerative models the learning rate is dramatically
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 3
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
slower than that observed previously with simplegenerative models presumably due to the significantlyincreased complexity involved in tracking and learningthe means and variances of the generative modelespecially when sensory uncertainty was also variableTaken together our results therefore provide compel-ling evidence in support of the hypothesis that whenfaced with complex environmental statistics humanobservers are capable of learning such distributionsand utilizing this learned knowledge in a statisticallyefficient fashion
General methods
We developed a spatial localization task where theparticipantsrsquo goal on each trial was to estimate thelocation of a hidden target by touching the appropriatelocation on a touch-sensitive display (Figure 1A)Several aspects of our task were similar to the task usedin Kording and Wolpert (2004) Tassinari et al (2006)and Vilares et al (2012) The horizontal and verticalcoordinates of the target location on each trial wereindependently drawn from a complex generative modela location-contingent mixture distribution over twounderlying isotropic two-dimensional Gaussian distri-
butions These Gaussian distributions differed in theirmean locations (one of them was always centered in theleft half of the display while the other was alwayscentered in the right half of the display) and theirrelative variances (one of them had a standarddeviation of 40 pixels while the other had a standarddeviation of 20 pixels) Across participants thedistributions were always centered at the same loca-tions on the left and right of the display but thevariance assigned to each was counterbalanced with thehigher variance distribution centered in the left half ofthe display for 50 of the participants and in the righthalf of the display for the other 50
On each trial participants were not shown the truetarget location instead they were presented withuncertain sensory information about the target locationin the form of a two-dimensional cloud of eight smalldots (Figure 1A) This cloud was independentlygenerated on each trial by drawing samples from aseparate two-dimensional isotropic Gaussian distribu-tion centered at the true target location for that trial(ie the location of the target drawn for that trial fromthe complex generative model) The variance of thiscloud of dots was manipulated to generate sensoryinformation with three levels of reliability withreliability inversely proportional to the variance of thedot distribution Specifically the dots were drawn from
Figure 1 Learning and inference in a spatial localization task (A) An illustration of a typical trial After participants touched a lsquolsquoGOrsquorsquobutton they were presented with uncertain sensory information in the form of a cloud of dots (the likelihood) with one of three
levels of variance (low variance shown here see inset for an illustration of the three levels) Participants estimated the location of a
hidden target drawn from a complex generative model (a mixture over two Gaussian distributions the prior) by touching a location
on the display Feedback was provided posttouch (B) An illustration of Bayes-optimal behavior Considering the example of a target
drawn from the broad prior distribution the ideal observer would learn the mean and variance of the prior and integrate this learned
knowledge with the likelihood on each trial to estimate the location of the hidden target
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 4
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
a distribution that either had low variance (SD of 10pixels) medium variance (SD of 60 pixels) or highvariance (SD of 100 pixels see inset of Figure 1A for anillustration of the three levels of variance) Afterparticipants provided their response by touching alocation on the display feedback on their accuracy onthat trial was provided by displaying a new dot at thetouched location and a second new dot at the truetarget location In addition participants receivedfeedback in the form of numerical points with themagnitude of the points varying based on theiraccuracy
Experiment 1 Can human observerslearn and efficiently use complexprior knowledge
In Experiment 1 participants were exposed to 1200trials of the spatial localization task with half the trialsinvolving targets drawn from each of the two under-lying Gaussian distributions (the mixture componentsof the location-contingent generative model) Thesetwo sets of 600 trials were randomly intermixed andwithin each set 200 trials were randomly presentedwith one of the three levels of reliability in other wordssix total conditions were randomly interleavedthroughout the experiment In each trial participantstherefore had access to two sources of informationmdashthe uncertain sensory information available on thattrial (ie the cloud of dots that corresponded to thelikelihood) and any knowledge they might have learnedup to that point in the experiment based on feedbackreceived in previous trials about the likely locations ofthe target (ie the mixture distribution over the twounderlying Gaussian distributions that corresponded tothe prior) Participants received two cues on each trialas to which of the two underlying Gaussian distribu-tions the target on that trial was drawn from the sideof the display in which the sensory information waspresented (the two underlying distributions were alwayscentered in opposite halves of the display) and the colorof the sensory information (the color of the dot cloudwas set either to green or white depending on the targetdistribution) Since the components of the complexgenerative model were perfectly separable given thelocation contingent cues on each trial we cancharacterize the prior as involving two separabledistributions conditioned on the trial-specific locationand color of the sensory information Accordingly inthe rest of this article we refer to the two Gaussiandistributions that make up the mixture components ofthe complex generative model as the lsquolsquobroadrsquorsquo priordistribution (the distribution with the larger standard
deviation) and the lsquolsquonarrowrsquorsquo prior distribution (thedistribution with the smaller standard deviation)
There are several computational models that partic-ipants could potentially use to carry out this task Onepossibility is that participants just ignore the underlyingprior distributions and base their estimates solely onthe sensory information available on each trial That isgiven the complexity implicit in the generative modelgoverning target location participants can ignore thissource of information (rather than expend the compu-tational resources to track and learn the location-contingent prior distributions) and instead just choosethe centroid of the cluster of dots (which are visible oneach trial) as their estimate for the hidden targetlocation This strategy would predict that participantswould assign a weight of one to the likelihood (ie basetheir responses solely on the sensory information)irrespective of the reliability of the sensory informationor the reliability (or inverse variance) of the priordistribution for that trial Furthermore we wouldexpect to see no change in participantsrsquo weights as afunction of exposure to the task since this strategy doesnot involve any learning (cf the likelihood distributionis drawn independently on each trial) Importantlyhowever such a computational strategy (henceforthreferred to as Model 1) would be suboptimal for tworeasons first as the reliability of the sensory informa-tion goes down the probability that the centroid of thesensory information will correspond exactly to the truetarget location also goes down and second by ignoringthe information provided by the prior distributionsparticipants cannot take advantage of the fact that notall spatial locations are a priori equally likely
A second possibility is that participants are sensitiveto the underlying generative model but given thecomplexity involved in the task they choose to learnonly the mean locations for the two prior distributionswhile ignoring their relative variances (ie their relativereliability)mdashlearning only the means is statisticallyeasier and requires exposure to far fewer trials Bylearning the average position for where the target tendsto be for each prior distribution participants can usethis knowledge to bias their estimates particularly asthe reliability of the sensory information goes downThis model (Model 2) predicts a smaller weight to thelikelihood as the reliability of the sensory informationgoes down and it also predicts that as participants gaingreater exposure to the underlying distributions (thusallowing them to better learn the two prior means)their behavior should show a greater sensitivity to theunderlying prior distributions However a key predic-tion of this model is that for each level of sensoryreliability we should see identical weights beingassigned to the likelihood for targets drawn from thetwo different prior distributions because the variancesof the prior distributions are ignored by this model
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 5
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
Thus this model is still suboptimal since the narrowprior distribution is a more reliable indicator of thelikely target location across trials compared to thebroad prior distribution and an optimal observershould take this into account
Finally a third possibility is that participants learnboth the mean positions and the relative reliabilities ofthe two prior distributions and integrate this learnedknowledge with the sensory information available oneach trial in a manner that is consistent with thepredictions of Bayes-optimal behavior (Model 3) Ifparticipants use such a strategy we should see a smallerweight to the likelihood as the reliability of the sensoryinformation goes down and this drop should be greaterfor trials in which the target is drawn from the narrowprior than when the target is drawn from the broadprior Furthermore this model predicts that asparticipants gain greater exposure to and thus learnmore about the underlying distributions participantsrsquobehavior should show a greater sensitivity to thestatistical properties (both mean location and relativevariance) of the underlying distributions (see Figure 1Bfor an illustration) Formally if the mean and thevariance of the sensory information on a given trial isgiven by ll and r2
l and the mean and the variance ofthe underlying target distribution for that trial is givenby lp and r2
p then the target location t predicted by thismodel would be (Bernardo amp Smith 1994 Cox 1946Jacobs 1999 Yuille amp Bulthoff 1996)
t frac14 wlll thorn eth1 wlTHORNlp eth1THORN
where wl the weight assigned by the observer to thesensory information should be
wl frac141=r2
l
1=r2l thorn 1=r2
p
eth2THORN
By examining the weights assigned by participants tothe likelihood on each trial given the relative reliabilityof the sensory information and the prior informationon that trial we sought to distinguish between the threepotential strategies described above (ie Models 1 2and 3) In addition we sought to characterize learning-induced changes in participantsrsquo weights as a functionof exposure to the task by splitting the total number oftrials into four temporal bins each of which included300 trials of exposure to the task (with the sixconditions randomly interleaved in each bin)
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to the
purpose of the study and provided informed writtenconsent The University of Rochesterrsquos institutionalreview board approved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with the following task instructions
In this study you will be playing a game on theiPad The story behind this game is that you are ata fair and there is an invisible bucket that you aretrying to locate Sometimes the bucket is going tobe located on the left side of the display and atother times the bucket is going to be located onthe right side of the display Now given that thebucket is invisible you canrsquot see where it isHowever on each trial you will see some locationsthat other people have previously guessed thebucket is located at These lsquolsquoguessesrsquorsquo will show upas white or green dots on the screen Now it isimportant to note that you donrsquot know which (ifany) of the dots actually correspond to thelocation of the bucket Indeed all of the dotscould be just random guesses Your job on eachtrial is to try to figure out where the bucket isactually located Once you decide on a locationyou can just touch it at which point you will seetwo more dots a red dot which shows you thetrue location of the bucket on that trial and a bluedot which shows you the location that youtouched If the blue dot is right on the red dotthen you correctly guessed the location of thebucket and you will get 20 points If you donrsquotexactly guess the location of the bucket but youstill get close then you will get 5 points When yousee this it means that you need to try just a littleharder to get the right locationmdashyou are closeFinally if your guess is very far away you will getno points
Participants were seated at a comfortable viewingdistance from a touch-sensitive display (iPad 2 AppleInc Cupertino CA) with a resolution of 768 pixels(vertical) 3 1024 pixels (horizontal) Participantsprovided responses using their finger having beeninstructed to pick a favorite finger and to consistentlyuse that finger throughout the experiment At the startof each trial they were presented with a lsquolsquoGOrsquorsquo buttoncentered at the bottom of the display Once theytouched this button the trial started with the presen-tation of a cluster of white or green dots (thelsquolsquoguessesrsquorsquo) Participants were told to estimate thelocation of the hidden target as rapidly and accuratelyas possible by touching a location on the screen Afterparticipants provided a response the cluster of dots
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 6
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
disappeared and feedback was provided The gameincluded multiple levels once a participant accumu-lated a total of 600 points on each level they wereshown a congratulatory screen and allowed to lsquolsquoleveluprsquorsquo Progress toward the next level was always shownat the top of the screen using a progress bar Thisability to level up was used solely to motivateparticipants and did not represent any change in theexperimental procedure Participants carried out a totalof 1200 trials split across four experimental blocksShort breaks were allowed between blocks and thetotal experimental duration including breaks wasapproximately 50 min
Data analysis
To quantify the computational mechanisms used byparticipants in this experiment we estimated the extentto which their behavior depended on the likelihoodversus the prior on each trial Specifically we usedlinear regression to compute the weight (wl) assigned tothe centroid of the cluster of dots (the likelihood) withthe weight assigned to the mean of the underlyingtarget distribution for that trial (the prior) beingdefined as (1 wl) Thus on each trial given thecentroid of the sensory information (ll) the mean ofthe underlying target distribution (lp) and participantsrsquoestimate for the target location (t ) the weight assignedby participants to the centroid of the sensory infor-mation (wl) was estimated using
t frac14 wlll thorn eth1 wlTHORNlp thorn noise eth3THORN
We focused on participantsrsquo performance in thevertical dimension to eliminate the potential influenceof variability that may have been introduced by aninteraction between participantsrsquo handedness and thehorizontal separation of the prior locations Moreovertheir performance in the horizontal dimension wassimilar to their performance in the vertical dimensionmdashwe found no interaction between dimension (horizontalvs vertical) and exposure bin across prior andlikelihood conditions (all ps 005)
Results and discussion
Consistent with the predictions of the Bayes-optimalmodel (Model 3) by the end of exposure to the task(ie in the final temporal bin) observers assigned areliably smaller weight to the likelihood (and thus agreater weight to the prior) as the sensory informationdecreased in reliability (Figure 2) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 1889 p 0001
Furthermore for each prior condition there was areliable interaction between exposure and likelihoodvariance as participants gained more exposure to thetask they assigned a smaller weight to the likelihoodand this drop in weight was greater as the likelihoodvariance increased (Figure 3) Specifically in a 4(temporal bin) 3 3 (likelihood variance) repeatedmeasures ANOVA carried out over participantsrsquoweights in the broad prior condition there was a maineffect of temporal bin F(3 21)frac14 400 pfrac14 002 a main
Figure 2 Data from the final temporal bin for a representative participant in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior as likelihood variance increased (blue to green to red) participants shifted from selecting the centroid of the
sensory information as their estimate for the target location (the gray dashed line) toward selecting the mean of the underlying prior
distribution (zero on the y-axis) This was true in both the broad (A) and narrow (B) prior conditions but the shift was more
pronounced for the narrow prior condition than for the broad prior condition For illustrative purposes the mean of the underlying
prior distribution was removed from participantsrsquo response locations and from the locations of the centroid of the sensory
information Each dot represents a trial and solid lines represent the best-fit regression lines in each condition
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 7
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
effect of likelihood variance F(2 14) frac14 2117 p
00001 and an interaction between the two factorsF(6 42)frac14 522 p 0001 Similarly in a 4 (temporalbin) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thenarrow prior condition there was a main effect oftemporal bin F(3 21)frac14 906 p 0001 a main effectof likelihood variance F(2 14)frac141224 p 0001 andan interaction between the two factors F(6 42)frac14547p 0001 These findings are inconsistent with Model1 which predicts a weight of 1 to the sensoryinformation across all the likelihood and priorconditions and no change in participantsrsquo weights as afunction of exposure to the task Furthermore incontrast to the predictions of Model 2 we found thatthe drop in the weight assigned by participants to thelikelihood as a function of exposure to the taskparticularly in the high likelihood variance conditionwas greater for trials in which the target was drawnfrom the narrow prior than when the target wasdrawn from the broad prior In a 4 (temporal bin)3 2(prior variance) repeated measures ANOVA carriedout over participantsrsquo weights in the high likelihoodvariance condition we saw a main effect of temporalbin F(3 21) frac14 829 p 0001 and an interactionbetween temporal bin and prior variance F(3 21) frac14307 p frac14 005 This finding suggests that participantsare sensitive to and learn both the means and therelative variances of the underlying prior distribu-tions Taken together this pattern of results providesclear evidence in support of Model 3mdashthe hypothesisthat human observers learn the complex generativemodel and use this learned knowledge in a manner
that is consistent with the predictions of Bayes-optimal behavior
Experiment 2 Exploring thedynamics of learning
While the results from Experiment 1 support thehypothesis that participants learn the complex gener-ative model and use this knowledge in a statisticallyefficient manner the dynamics of this learning remainunclear For instance prior work (Berniker et al2010) has shown that when presented with stimulidrawn from simple generative models human ob-servers rapidly learn the prior mean but it takes themmany more trials to learn the prior variance InExperiment 2 with a new group of participants weexamined the dynamics of learning with complexgenerative models by including an extra conditionrandomly interleaved with all the conditions used inthe first experiment in which no sensory informationwas presented In this condition observers thus had toestimate the position of the target based solely on theirlearned knowledge (up to that point) about where thetarget was likely to occur (ie based on their priorknowledge) thereby allowing us to analyze theirevolving learned knowledge of the location-contingentgenerative model as a function of exposure to the taskParticipants carried out 400 trials of this conditionsplit evenly between the two prior distributions Oneach trial they were cued to estimate the location ofthe target on either the left or the right of the display
Figure 3 Weights assigned to the centroid of the sensory information in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior participants in Experiment 1 relied less on the sensory information and more on the priors as the variance of the
sensory information increased This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to the
sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin included 300 trials split between the two prior conditions and the four bins of trials are depicted in
temporal order Columns represent means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 8
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
(with a box that was colored green or white) thusrequiring them to draw on their learned knowledge ofthe location-contingent prior distribution associatedwith that trial As in Experiment 1 the 1600 trials inExperiment 2 (all conditions from Experiment 1 plus400 trials in this extra condition) were again split upinto the relevant prior and likelihood conditions (theno sensory information condition is statisticallyequivalent to a likelihood condition with infiniteuncertainty) and with each condition being furthersplit into four temporal bins to study the influence oftask exposure
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to thepurpose of the study provided informed writtenconsent and did not participate in Experiment 1 TheUniversity of Rochesterrsquos institutional review boardapproved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with task instructions that were nearlyidentical to those provided to participants in Experi-ment 1 Specifically in addition to the instructions fromExperiment 1 they were also provided with thefollowing instructions
There will also be some trials in which you willbe the first person to guess the location of thebucket In these trials rather than seeing dots onthe screen you will see a briefly flashed white orgreen rectangle which will indicate the side of thescreen that the invisible bucket is located atmdashthebucket could be located anywhere inside thatrectangle Again your job is to try to figure outwhere the bucket is actually located
On each trial of the experiment the procedure wasidentical to that used in Experiment 1 except for theextra condition in which no sensory information waspresented In the trials corresponding to this conditionafter participants touched the GO button they saw abriefly flashed green or white rectangle spanning eitherthe left half or the right half of the display Afterparticipants provided a response feedback was pro-vided as in all the other conditions Participants carriedout a total of 1600 trials split across four experimentalblocks Short breaks were allowed between blocks and
the total experimental duration including breaks wasapproximately an hour
Data analysis
As in Experiment 1 for the trials in which sensoryinformation was available we used linear regression tocompute the weight (wl) assigned to the centroid of thecluster of dots (the likelihood) with the weightsassigned to the mean of the underlying location-contingent target distribution for that trial (the prior)being defined as (1 wl) For the trials in which nosensory information was available we computedparticipantsrsquo mean responses across all trials in eachtemporal bin As in Experiment 1 we again focused onperformance in the vertical dimension
Results and discussion
We first examined the weights assigned by partici-pants to the likelihood and the prior for the trials inwhich sensory information was available and foundthat their behavior was similar to that in Experiment 1(Figure 3) Specifically in line with the Bayes-optimalmodel (Model 3) by the end of exposure to the task inExperiment 2 (ie in the final temporal bin) observersassigned a reliably smaller weight to the likelihood (anda greater weight to the prior) as the sensory informa-tion decreased in reliability (Figure 4) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 4584 p 00001 and aninteraction between the two factors F(2 14)frac14 383 pfrac140047 Furthermore for each prior condition we againfound an interaction between exposure and likelihoodvariance Specifically in a 4 (temporal bin) 3 3(likelihood variance) repeated measures ANOVAcarried out over participantsrsquo weights in the broad priorcondition there was a main effect of temporal bin F(321)frac14 749 pfrac14 0001 a main effect of likelihoodvariance F(2 14)frac14 3421 p 00001 and aninteraction between the two factors F(6 42)frac14 284 pfrac14002 Similarly in a 4 (temporal bin) 3 3 (likelihoodvariance) repeated measures ANOVA carried out overparticipantsrsquo weights in the narrow prior conditionthere was a marginal main effect of temporal bin F(321)frac14 287 pfrac14 006 a main effect of likelihoodvariance F(2 14)frac14 1772 p 0001 and a marginalinteraction between the two factors F(6 42)frac14 230 pfrac140052 Finally participants assigned a smaller weight tothe likelihood particularly in the high likelihoodvariance condition when the target was drawn fromthe narrow prior than when the target was drawn fromthe broad prior In a 4 (temporal bin) 3 2 (prior
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 9
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
variance) repeated measures ANOVA carried out overparticipantsrsquo weights in the high likelihood variancecondition there was a main effect of temporal bin F(321)frac14 555 p 0001 and a main effect of priorvariance F(1 7) frac14 789 p frac14 0026 These findingstherefore represent a replication of our results fromExperiment 1 To further confirm that these resultsreplicate the results from Experiment 1 we carried outa 2 (experiment) 3 4 (temporal bin) 3 3 (likelihoodvariance) mixed ANOVA with experiment as abetween-participants factor and temporal bin andlikelihood variance as within-participant factors overparticipantsrsquo weights in both the broad and narrowprior conditions In each case we found no interactionbetween experiment and any other factor (all ps 017)
Importantly in the conditions in which no sensoryinformation was available (ie no cluster of dots waspresented) we found that within the first temporal bin(the first 100 of the 400 prior-only trials) participantsrsquoestimates of the target location were on averageindistinguishable from the true prior mean locations(plus or minus motor noise estimated from the lowlikelihood variance conditions broad prior t7frac14 173 pfrac14 013 narrow prior t7 frac14 124 p frac14 025) Participantswere therefore able to rapidly learn the prior meanseven when presented with a complex generative model(Figure 5) extending results from previous workexamining such behavior in the presence of simplergenerative models It is important to note howeverthat in the conditions where sensory information wasavailable which were randomly interleaved with theprior-only conditions participantsrsquo weights continue tochange throughout the experiment (Figure 4) This
Figure 4 Weights assigned to the centroid of the sensory information in Experiment 2 As in Experiment 1 participants in Experiment
2 relied less on the sensory information and more on the priors as the variance of the sensory information increased in line with the
predictions of Bayes-optimal behavior This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to
the sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin again included 300 trials split between the two prior conditions and the four bins of trials are depicted
in temporal order Columns represent means and error bars represent SEM across participants
Figure 5 Mean response location in the absence of sensory
information Participants in Experiment 2 rapidly learned the
true prior mean for both the broad (top) and narrow prior
conditions (bottom) Participantsrsquo mean response location in
the trials in which no sensory information was available was
indistinguishable from the true prior means plus or minus
motor noise within the first temporal bin For illustrative
purposes the y-axis represents the mean deviation from the
true mean in each prior condition Each temporal bin included
100 trials split between the two prior conditions and the four
bins of trials are depicted in temporal order Columns represent
means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 10
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016

allowed us to vary the uncertainty implicit in both thesensory information and the prior information on atrial-by-trial basis Our design simulated a mixturemodel over two environmental causes and as a firstlogical step considered the scenario in which theparticipant is perfectly cued as to the underlying causeon each trial We implemented this using a location-contingent generative modelmdashthe task-relevant stimu-lus on each trial was drawn from a mixture of twounderlying Gaussian distributions with one distribu-tion always centered at one location on the screen andthe other always centered at a distinct second locationon the screen and with one distribution being morevariable (ie representing a less reliable a priori signalabout the likely location of a target drawn from thatdistribution) than the other On each trial the locationof the target was drawn randomly from this bimodalspatial distribution and participants were presentedwith a cluster of dots that was randomly drawn from aseparate Gaussian distribution centered on this truelsquolsquohiddenrsquorsquo location The cluster of dots depending on itsvariance (which could be low medium or high)provided a more or less reliable estimate of the targetrsquoshidden location on each trial (reliability being inverselyproportional to the variance of the dot cluster) Acrosstrials observers could integrate information from theobserved cluster of dots (ie the likelihood) with trial-by-trial feedback they received on previous trials aboutthe underlying bimodal distribution governing thelikely locations of the target (ie the lsquolsquopriorrsquorsquo) Thisexperimental design allowed us to better study thecomputational mechanisms used by human observersin tasks involving complex generative models than waspossible with previous studies Specifically whileaspects of our task are similar to those used in previousstudies (especially Berniker et al 2010 Kording ampWolpert 2004 Tassinari et al 2006 and Vilares et al2012) by randomly interleaving multiple underlyingdistributions (which varied in their reliability) andmultiple levels of sensory uncertainty on a trial-by-trialbasis our design allows us to fully test the predictionsof the Bayesian model in tasks involving complexgenerative models and to rule out alternative subop-timal strategies that could potentially be used to carryout the task
There are several computational models that partic-ipants could potentially use to estimate the location ofthe hidden target on each trial of this task Asmentioned above for example due to the complexityinherent in the statistics that govern target locationacross trials participants might choose to ignore thislsquolsquolatentrsquorsquo source of information and instead base theirestimates solely on the sensory information availableon each trial For instance they might simply choosethe centroid of the cluster of dots as their estimate forthe target location on each trial An alternate strategy
might be to learn some summary statistic such as theaverage location that describes each mixture compo-nent of the generative model and to bias their estimatestoward that source of information Both these kinds ofstrategies would however be statistically suboptimalbecause they would not maximally exploit all thesources of information available to the observerInstead a statistically optimal approach would entaillearning the distributional statistics (both the mean andthe variance) characterizing each mixture component ofthe generative model and integrating this informationwith the sensory information available on each trial ina manner consistent with the predictions of Bayes-optimal behavior This approach predicts that theweight assigned by participants to the sensory infor-mation should drop as the reliability of the sensoryinformation goes down (ie the variance of the clusterof dots goes up) and crucially this drop should begreater when the stimulus is drawn from the mixturecomponent that has lower variance (ie greaterreliability) By following this strategy participantswould maximally utilize all the sources of informationavailable on each trial by appropriately weighting eachsource of information by the uncertainty implicit in it
We provide evidence from two experiments thatover multiple exposures to the task of estimating thelocation of a hidden target human observers not onlylearn the complex distributional statistics about the apriori locations of the target (ie they learn thelocation-contingent bimodal generative model) butalso integrate this knowledge with uncertain sensoryinformation on a trial-by-trial basis in a mannerconsistent with the predictions of Bayes-optimalbehavior Importantly our experimental design al-lowed us to validate the predictions of the Bayesianmodel in a very specific manner and thus rule outalternative suboptimal strategies that could be used tocarry out the task Consistent with the predictions ofthe Bayesian model we found that participantsassigned a smaller weight to the sensory information asthe reliability of sensory information went down andthat this drop was greater when the stimulus was drawnfrom the more reliable mixture component of thecomplex generative model used in the task Our designalso allowed us to examine the dynamics underlying theprocess by which participants learned the complexgenerative model Extending prior work using simplegenerative models (Berniker et al 2010) we found thatparticipants quickly learned the mean locations for thebimodal generative model (ie the centers of the twodistributions that made up the mixture components ofthe generative model for the task) but it took themmuch longer to learn the relative variances of themixture components of these two modes Furthermoreour results show that in tasks with such complexgenerative models the learning rate is dramatically
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 3
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
slower than that observed previously with simplegenerative models presumably due to the significantlyincreased complexity involved in tracking and learningthe means and variances of the generative modelespecially when sensory uncertainty was also variableTaken together our results therefore provide compel-ling evidence in support of the hypothesis that whenfaced with complex environmental statistics humanobservers are capable of learning such distributionsand utilizing this learned knowledge in a statisticallyefficient fashion
General methods
We developed a spatial localization task where theparticipantsrsquo goal on each trial was to estimate thelocation of a hidden target by touching the appropriatelocation on a touch-sensitive display (Figure 1A)Several aspects of our task were similar to the task usedin Kording and Wolpert (2004) Tassinari et al (2006)and Vilares et al (2012) The horizontal and verticalcoordinates of the target location on each trial wereindependently drawn from a complex generative modela location-contingent mixture distribution over twounderlying isotropic two-dimensional Gaussian distri-
butions These Gaussian distributions differed in theirmean locations (one of them was always centered in theleft half of the display while the other was alwayscentered in the right half of the display) and theirrelative variances (one of them had a standarddeviation of 40 pixels while the other had a standarddeviation of 20 pixels) Across participants thedistributions were always centered at the same loca-tions on the left and right of the display but thevariance assigned to each was counterbalanced with thehigher variance distribution centered in the left half ofthe display for 50 of the participants and in the righthalf of the display for the other 50
On each trial participants were not shown the truetarget location instead they were presented withuncertain sensory information about the target locationin the form of a two-dimensional cloud of eight smalldots (Figure 1A) This cloud was independentlygenerated on each trial by drawing samples from aseparate two-dimensional isotropic Gaussian distribu-tion centered at the true target location for that trial(ie the location of the target drawn for that trial fromthe complex generative model) The variance of thiscloud of dots was manipulated to generate sensoryinformation with three levels of reliability withreliability inversely proportional to the variance of thedot distribution Specifically the dots were drawn from
Figure 1 Learning and inference in a spatial localization task (A) An illustration of a typical trial After participants touched a lsquolsquoGOrsquorsquobutton they were presented with uncertain sensory information in the form of a cloud of dots (the likelihood) with one of three
levels of variance (low variance shown here see inset for an illustration of the three levels) Participants estimated the location of a
hidden target drawn from a complex generative model (a mixture over two Gaussian distributions the prior) by touching a location
on the display Feedback was provided posttouch (B) An illustration of Bayes-optimal behavior Considering the example of a target
drawn from the broad prior distribution the ideal observer would learn the mean and variance of the prior and integrate this learned
knowledge with the likelihood on each trial to estimate the location of the hidden target
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 4
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
a distribution that either had low variance (SD of 10pixels) medium variance (SD of 60 pixels) or highvariance (SD of 100 pixels see inset of Figure 1A for anillustration of the three levels of variance) Afterparticipants provided their response by touching alocation on the display feedback on their accuracy onthat trial was provided by displaying a new dot at thetouched location and a second new dot at the truetarget location In addition participants receivedfeedback in the form of numerical points with themagnitude of the points varying based on theiraccuracy
Experiment 1 Can human observerslearn and efficiently use complexprior knowledge
In Experiment 1 participants were exposed to 1200trials of the spatial localization task with half the trialsinvolving targets drawn from each of the two under-lying Gaussian distributions (the mixture componentsof the location-contingent generative model) Thesetwo sets of 600 trials were randomly intermixed andwithin each set 200 trials were randomly presentedwith one of the three levels of reliability in other wordssix total conditions were randomly interleavedthroughout the experiment In each trial participantstherefore had access to two sources of informationmdashthe uncertain sensory information available on thattrial (ie the cloud of dots that corresponded to thelikelihood) and any knowledge they might have learnedup to that point in the experiment based on feedbackreceived in previous trials about the likely locations ofthe target (ie the mixture distribution over the twounderlying Gaussian distributions that corresponded tothe prior) Participants received two cues on each trialas to which of the two underlying Gaussian distribu-tions the target on that trial was drawn from the sideof the display in which the sensory information waspresented (the two underlying distributions were alwayscentered in opposite halves of the display) and the colorof the sensory information (the color of the dot cloudwas set either to green or white depending on the targetdistribution) Since the components of the complexgenerative model were perfectly separable given thelocation contingent cues on each trial we cancharacterize the prior as involving two separabledistributions conditioned on the trial-specific locationand color of the sensory information Accordingly inthe rest of this article we refer to the two Gaussiandistributions that make up the mixture components ofthe complex generative model as the lsquolsquobroadrsquorsquo priordistribution (the distribution with the larger standard
deviation) and the lsquolsquonarrowrsquorsquo prior distribution (thedistribution with the smaller standard deviation)
There are several computational models that partic-ipants could potentially use to carry out this task Onepossibility is that participants just ignore the underlyingprior distributions and base their estimates solely onthe sensory information available on each trial That isgiven the complexity implicit in the generative modelgoverning target location participants can ignore thissource of information (rather than expend the compu-tational resources to track and learn the location-contingent prior distributions) and instead just choosethe centroid of the cluster of dots (which are visible oneach trial) as their estimate for the hidden targetlocation This strategy would predict that participantswould assign a weight of one to the likelihood (ie basetheir responses solely on the sensory information)irrespective of the reliability of the sensory informationor the reliability (or inverse variance) of the priordistribution for that trial Furthermore we wouldexpect to see no change in participantsrsquo weights as afunction of exposure to the task since this strategy doesnot involve any learning (cf the likelihood distributionis drawn independently on each trial) Importantlyhowever such a computational strategy (henceforthreferred to as Model 1) would be suboptimal for tworeasons first as the reliability of the sensory informa-tion goes down the probability that the centroid of thesensory information will correspond exactly to the truetarget location also goes down and second by ignoringthe information provided by the prior distributionsparticipants cannot take advantage of the fact that notall spatial locations are a priori equally likely
A second possibility is that participants are sensitiveto the underlying generative model but given thecomplexity involved in the task they choose to learnonly the mean locations for the two prior distributionswhile ignoring their relative variances (ie their relativereliability)mdashlearning only the means is statisticallyeasier and requires exposure to far fewer trials Bylearning the average position for where the target tendsto be for each prior distribution participants can usethis knowledge to bias their estimates particularly asthe reliability of the sensory information goes downThis model (Model 2) predicts a smaller weight to thelikelihood as the reliability of the sensory informationgoes down and it also predicts that as participants gaingreater exposure to the underlying distributions (thusallowing them to better learn the two prior means)their behavior should show a greater sensitivity to theunderlying prior distributions However a key predic-tion of this model is that for each level of sensoryreliability we should see identical weights beingassigned to the likelihood for targets drawn from thetwo different prior distributions because the variancesof the prior distributions are ignored by this model
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 5
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
Thus this model is still suboptimal since the narrowprior distribution is a more reliable indicator of thelikely target location across trials compared to thebroad prior distribution and an optimal observershould take this into account
Finally a third possibility is that participants learnboth the mean positions and the relative reliabilities ofthe two prior distributions and integrate this learnedknowledge with the sensory information available oneach trial in a manner that is consistent with thepredictions of Bayes-optimal behavior (Model 3) Ifparticipants use such a strategy we should see a smallerweight to the likelihood as the reliability of the sensoryinformation goes down and this drop should be greaterfor trials in which the target is drawn from the narrowprior than when the target is drawn from the broadprior Furthermore this model predicts that asparticipants gain greater exposure to and thus learnmore about the underlying distributions participantsrsquobehavior should show a greater sensitivity to thestatistical properties (both mean location and relativevariance) of the underlying distributions (see Figure 1Bfor an illustration) Formally if the mean and thevariance of the sensory information on a given trial isgiven by ll and r2
l and the mean and the variance ofthe underlying target distribution for that trial is givenby lp and r2
p then the target location t predicted by thismodel would be (Bernardo amp Smith 1994 Cox 1946Jacobs 1999 Yuille amp Bulthoff 1996)
t frac14 wlll thorn eth1 wlTHORNlp eth1THORN
where wl the weight assigned by the observer to thesensory information should be
wl frac141=r2
l
1=r2l thorn 1=r2
p
eth2THORN
By examining the weights assigned by participants tothe likelihood on each trial given the relative reliabilityof the sensory information and the prior informationon that trial we sought to distinguish between the threepotential strategies described above (ie Models 1 2and 3) In addition we sought to characterize learning-induced changes in participantsrsquo weights as a functionof exposure to the task by splitting the total number oftrials into four temporal bins each of which included300 trials of exposure to the task (with the sixconditions randomly interleaved in each bin)
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to the
purpose of the study and provided informed writtenconsent The University of Rochesterrsquos institutionalreview board approved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with the following task instructions
In this study you will be playing a game on theiPad The story behind this game is that you are ata fair and there is an invisible bucket that you aretrying to locate Sometimes the bucket is going tobe located on the left side of the display and atother times the bucket is going to be located onthe right side of the display Now given that thebucket is invisible you canrsquot see where it isHowever on each trial you will see some locationsthat other people have previously guessed thebucket is located at These lsquolsquoguessesrsquorsquo will show upas white or green dots on the screen Now it isimportant to note that you donrsquot know which (ifany) of the dots actually correspond to thelocation of the bucket Indeed all of the dotscould be just random guesses Your job on eachtrial is to try to figure out where the bucket isactually located Once you decide on a locationyou can just touch it at which point you will seetwo more dots a red dot which shows you thetrue location of the bucket on that trial and a bluedot which shows you the location that youtouched If the blue dot is right on the red dotthen you correctly guessed the location of thebucket and you will get 20 points If you donrsquotexactly guess the location of the bucket but youstill get close then you will get 5 points When yousee this it means that you need to try just a littleharder to get the right locationmdashyou are closeFinally if your guess is very far away you will getno points
Participants were seated at a comfortable viewingdistance from a touch-sensitive display (iPad 2 AppleInc Cupertino CA) with a resolution of 768 pixels(vertical) 3 1024 pixels (horizontal) Participantsprovided responses using their finger having beeninstructed to pick a favorite finger and to consistentlyuse that finger throughout the experiment At the startof each trial they were presented with a lsquolsquoGOrsquorsquo buttoncentered at the bottom of the display Once theytouched this button the trial started with the presen-tation of a cluster of white or green dots (thelsquolsquoguessesrsquorsquo) Participants were told to estimate thelocation of the hidden target as rapidly and accuratelyas possible by touching a location on the screen Afterparticipants provided a response the cluster of dots
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 6
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
disappeared and feedback was provided The gameincluded multiple levels once a participant accumu-lated a total of 600 points on each level they wereshown a congratulatory screen and allowed to lsquolsquoleveluprsquorsquo Progress toward the next level was always shownat the top of the screen using a progress bar Thisability to level up was used solely to motivateparticipants and did not represent any change in theexperimental procedure Participants carried out a totalof 1200 trials split across four experimental blocksShort breaks were allowed between blocks and thetotal experimental duration including breaks wasapproximately 50 min
Data analysis
To quantify the computational mechanisms used byparticipants in this experiment we estimated the extentto which their behavior depended on the likelihoodversus the prior on each trial Specifically we usedlinear regression to compute the weight (wl) assigned tothe centroid of the cluster of dots (the likelihood) withthe weight assigned to the mean of the underlyingtarget distribution for that trial (the prior) beingdefined as (1 wl) Thus on each trial given thecentroid of the sensory information (ll) the mean ofthe underlying target distribution (lp) and participantsrsquoestimate for the target location (t ) the weight assignedby participants to the centroid of the sensory infor-mation (wl) was estimated using
t frac14 wlll thorn eth1 wlTHORNlp thorn noise eth3THORN
We focused on participantsrsquo performance in thevertical dimension to eliminate the potential influenceof variability that may have been introduced by aninteraction between participantsrsquo handedness and thehorizontal separation of the prior locations Moreovertheir performance in the horizontal dimension wassimilar to their performance in the vertical dimensionmdashwe found no interaction between dimension (horizontalvs vertical) and exposure bin across prior andlikelihood conditions (all ps 005)
Results and discussion
Consistent with the predictions of the Bayes-optimalmodel (Model 3) by the end of exposure to the task(ie in the final temporal bin) observers assigned areliably smaller weight to the likelihood (and thus agreater weight to the prior) as the sensory informationdecreased in reliability (Figure 2) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 1889 p 0001
Furthermore for each prior condition there was areliable interaction between exposure and likelihoodvariance as participants gained more exposure to thetask they assigned a smaller weight to the likelihoodand this drop in weight was greater as the likelihoodvariance increased (Figure 3) Specifically in a 4(temporal bin) 3 3 (likelihood variance) repeatedmeasures ANOVA carried out over participantsrsquoweights in the broad prior condition there was a maineffect of temporal bin F(3 21)frac14 400 pfrac14 002 a main
Figure 2 Data from the final temporal bin for a representative participant in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior as likelihood variance increased (blue to green to red) participants shifted from selecting the centroid of the
sensory information as their estimate for the target location (the gray dashed line) toward selecting the mean of the underlying prior
distribution (zero on the y-axis) This was true in both the broad (A) and narrow (B) prior conditions but the shift was more
pronounced for the narrow prior condition than for the broad prior condition For illustrative purposes the mean of the underlying
prior distribution was removed from participantsrsquo response locations and from the locations of the centroid of the sensory
information Each dot represents a trial and solid lines represent the best-fit regression lines in each condition
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 7
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
effect of likelihood variance F(2 14) frac14 2117 p
00001 and an interaction between the two factorsF(6 42)frac14 522 p 0001 Similarly in a 4 (temporalbin) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thenarrow prior condition there was a main effect oftemporal bin F(3 21)frac14 906 p 0001 a main effectof likelihood variance F(2 14)frac141224 p 0001 andan interaction between the two factors F(6 42)frac14547p 0001 These findings are inconsistent with Model1 which predicts a weight of 1 to the sensoryinformation across all the likelihood and priorconditions and no change in participantsrsquo weights as afunction of exposure to the task Furthermore incontrast to the predictions of Model 2 we found thatthe drop in the weight assigned by participants to thelikelihood as a function of exposure to the taskparticularly in the high likelihood variance conditionwas greater for trials in which the target was drawnfrom the narrow prior than when the target wasdrawn from the broad prior In a 4 (temporal bin)3 2(prior variance) repeated measures ANOVA carriedout over participantsrsquo weights in the high likelihoodvariance condition we saw a main effect of temporalbin F(3 21) frac14 829 p 0001 and an interactionbetween temporal bin and prior variance F(3 21) frac14307 p frac14 005 This finding suggests that participantsare sensitive to and learn both the means and therelative variances of the underlying prior distribu-tions Taken together this pattern of results providesclear evidence in support of Model 3mdashthe hypothesisthat human observers learn the complex generativemodel and use this learned knowledge in a manner
that is consistent with the predictions of Bayes-optimal behavior
Experiment 2 Exploring thedynamics of learning
While the results from Experiment 1 support thehypothesis that participants learn the complex gener-ative model and use this knowledge in a statisticallyefficient manner the dynamics of this learning remainunclear For instance prior work (Berniker et al2010) has shown that when presented with stimulidrawn from simple generative models human ob-servers rapidly learn the prior mean but it takes themmany more trials to learn the prior variance InExperiment 2 with a new group of participants weexamined the dynamics of learning with complexgenerative models by including an extra conditionrandomly interleaved with all the conditions used inthe first experiment in which no sensory informationwas presented In this condition observers thus had toestimate the position of the target based solely on theirlearned knowledge (up to that point) about where thetarget was likely to occur (ie based on their priorknowledge) thereby allowing us to analyze theirevolving learned knowledge of the location-contingentgenerative model as a function of exposure to the taskParticipants carried out 400 trials of this conditionsplit evenly between the two prior distributions Oneach trial they were cued to estimate the location ofthe target on either the left or the right of the display
Figure 3 Weights assigned to the centroid of the sensory information in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior participants in Experiment 1 relied less on the sensory information and more on the priors as the variance of the
sensory information increased This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to the
sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin included 300 trials split between the two prior conditions and the four bins of trials are depicted in
temporal order Columns represent means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 8
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
(with a box that was colored green or white) thusrequiring them to draw on their learned knowledge ofthe location-contingent prior distribution associatedwith that trial As in Experiment 1 the 1600 trials inExperiment 2 (all conditions from Experiment 1 plus400 trials in this extra condition) were again split upinto the relevant prior and likelihood conditions (theno sensory information condition is statisticallyequivalent to a likelihood condition with infiniteuncertainty) and with each condition being furthersplit into four temporal bins to study the influence oftask exposure
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to thepurpose of the study provided informed writtenconsent and did not participate in Experiment 1 TheUniversity of Rochesterrsquos institutional review boardapproved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with task instructions that were nearlyidentical to those provided to participants in Experi-ment 1 Specifically in addition to the instructions fromExperiment 1 they were also provided with thefollowing instructions
There will also be some trials in which you willbe the first person to guess the location of thebucket In these trials rather than seeing dots onthe screen you will see a briefly flashed white orgreen rectangle which will indicate the side of thescreen that the invisible bucket is located atmdashthebucket could be located anywhere inside thatrectangle Again your job is to try to figure outwhere the bucket is actually located
On each trial of the experiment the procedure wasidentical to that used in Experiment 1 except for theextra condition in which no sensory information waspresented In the trials corresponding to this conditionafter participants touched the GO button they saw abriefly flashed green or white rectangle spanning eitherthe left half or the right half of the display Afterparticipants provided a response feedback was pro-vided as in all the other conditions Participants carriedout a total of 1600 trials split across four experimentalblocks Short breaks were allowed between blocks and
the total experimental duration including breaks wasapproximately an hour
Data analysis
As in Experiment 1 for the trials in which sensoryinformation was available we used linear regression tocompute the weight (wl) assigned to the centroid of thecluster of dots (the likelihood) with the weightsassigned to the mean of the underlying location-contingent target distribution for that trial (the prior)being defined as (1 wl) For the trials in which nosensory information was available we computedparticipantsrsquo mean responses across all trials in eachtemporal bin As in Experiment 1 we again focused onperformance in the vertical dimension
Results and discussion
We first examined the weights assigned by partici-pants to the likelihood and the prior for the trials inwhich sensory information was available and foundthat their behavior was similar to that in Experiment 1(Figure 3) Specifically in line with the Bayes-optimalmodel (Model 3) by the end of exposure to the task inExperiment 2 (ie in the final temporal bin) observersassigned a reliably smaller weight to the likelihood (anda greater weight to the prior) as the sensory informa-tion decreased in reliability (Figure 4) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 4584 p 00001 and aninteraction between the two factors F(2 14)frac14 383 pfrac140047 Furthermore for each prior condition we againfound an interaction between exposure and likelihoodvariance Specifically in a 4 (temporal bin) 3 3(likelihood variance) repeated measures ANOVAcarried out over participantsrsquo weights in the broad priorcondition there was a main effect of temporal bin F(321)frac14 749 pfrac14 0001 a main effect of likelihoodvariance F(2 14)frac14 3421 p 00001 and aninteraction between the two factors F(6 42)frac14 284 pfrac14002 Similarly in a 4 (temporal bin) 3 3 (likelihoodvariance) repeated measures ANOVA carried out overparticipantsrsquo weights in the narrow prior conditionthere was a marginal main effect of temporal bin F(321)frac14 287 pfrac14 006 a main effect of likelihoodvariance F(2 14)frac14 1772 p 0001 and a marginalinteraction between the two factors F(6 42)frac14 230 pfrac140052 Finally participants assigned a smaller weight tothe likelihood particularly in the high likelihoodvariance condition when the target was drawn fromthe narrow prior than when the target was drawn fromthe broad prior In a 4 (temporal bin) 3 2 (prior
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 9
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
variance) repeated measures ANOVA carried out overparticipantsrsquo weights in the high likelihood variancecondition there was a main effect of temporal bin F(321)frac14 555 p 0001 and a main effect of priorvariance F(1 7) frac14 789 p frac14 0026 These findingstherefore represent a replication of our results fromExperiment 1 To further confirm that these resultsreplicate the results from Experiment 1 we carried outa 2 (experiment) 3 4 (temporal bin) 3 3 (likelihoodvariance) mixed ANOVA with experiment as abetween-participants factor and temporal bin andlikelihood variance as within-participant factors overparticipantsrsquo weights in both the broad and narrowprior conditions In each case we found no interactionbetween experiment and any other factor (all ps 017)
Importantly in the conditions in which no sensoryinformation was available (ie no cluster of dots waspresented) we found that within the first temporal bin(the first 100 of the 400 prior-only trials) participantsrsquoestimates of the target location were on averageindistinguishable from the true prior mean locations(plus or minus motor noise estimated from the lowlikelihood variance conditions broad prior t7frac14 173 pfrac14 013 narrow prior t7 frac14 124 p frac14 025) Participantswere therefore able to rapidly learn the prior meanseven when presented with a complex generative model(Figure 5) extending results from previous workexamining such behavior in the presence of simplergenerative models It is important to note howeverthat in the conditions where sensory information wasavailable which were randomly interleaved with theprior-only conditions participantsrsquo weights continue tochange throughout the experiment (Figure 4) This
Figure 4 Weights assigned to the centroid of the sensory information in Experiment 2 As in Experiment 1 participants in Experiment
2 relied less on the sensory information and more on the priors as the variance of the sensory information increased in line with the
predictions of Bayes-optimal behavior This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to
the sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin again included 300 trials split between the two prior conditions and the four bins of trials are depicted
in temporal order Columns represent means and error bars represent SEM across participants
Figure 5 Mean response location in the absence of sensory
information Participants in Experiment 2 rapidly learned the
true prior mean for both the broad (top) and narrow prior
conditions (bottom) Participantsrsquo mean response location in
the trials in which no sensory information was available was
indistinguishable from the true prior means plus or minus
motor noise within the first temporal bin For illustrative
purposes the y-axis represents the mean deviation from the
true mean in each prior condition Each temporal bin included
100 trials split between the two prior conditions and the four
bins of trials are depicted in temporal order Columns represent
means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 10
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
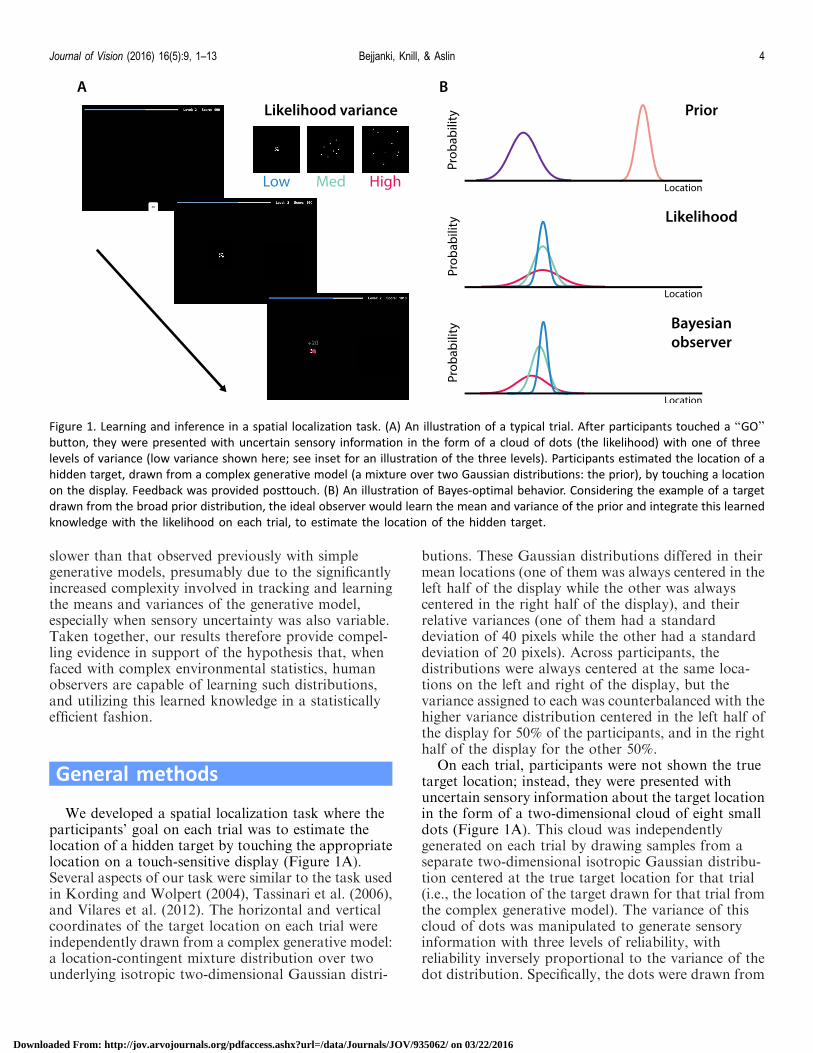
slower than that observed previously with simplegenerative models presumably due to the significantlyincreased complexity involved in tracking and learningthe means and variances of the generative modelespecially when sensory uncertainty was also variableTaken together our results therefore provide compel-ling evidence in support of the hypothesis that whenfaced with complex environmental statistics humanobservers are capable of learning such distributionsand utilizing this learned knowledge in a statisticallyefficient fashion
General methods
We developed a spatial localization task where theparticipantsrsquo goal on each trial was to estimate thelocation of a hidden target by touching the appropriatelocation on a touch-sensitive display (Figure 1A)Several aspects of our task were similar to the task usedin Kording and Wolpert (2004) Tassinari et al (2006)and Vilares et al (2012) The horizontal and verticalcoordinates of the target location on each trial wereindependently drawn from a complex generative modela location-contingent mixture distribution over twounderlying isotropic two-dimensional Gaussian distri-
butions These Gaussian distributions differed in theirmean locations (one of them was always centered in theleft half of the display while the other was alwayscentered in the right half of the display) and theirrelative variances (one of them had a standarddeviation of 40 pixels while the other had a standarddeviation of 20 pixels) Across participants thedistributions were always centered at the same loca-tions on the left and right of the display but thevariance assigned to each was counterbalanced with thehigher variance distribution centered in the left half ofthe display for 50 of the participants and in the righthalf of the display for the other 50
On each trial participants were not shown the truetarget location instead they were presented withuncertain sensory information about the target locationin the form of a two-dimensional cloud of eight smalldots (Figure 1A) This cloud was independentlygenerated on each trial by drawing samples from aseparate two-dimensional isotropic Gaussian distribu-tion centered at the true target location for that trial(ie the location of the target drawn for that trial fromthe complex generative model) The variance of thiscloud of dots was manipulated to generate sensoryinformation with three levels of reliability withreliability inversely proportional to the variance of thedot distribution Specifically the dots were drawn from
Figure 1 Learning and inference in a spatial localization task (A) An illustration of a typical trial After participants touched a lsquolsquoGOrsquorsquobutton they were presented with uncertain sensory information in the form of a cloud of dots (the likelihood) with one of three
levels of variance (low variance shown here see inset for an illustration of the three levels) Participants estimated the location of a
hidden target drawn from a complex generative model (a mixture over two Gaussian distributions the prior) by touching a location
on the display Feedback was provided posttouch (B) An illustration of Bayes-optimal behavior Considering the example of a target
drawn from the broad prior distribution the ideal observer would learn the mean and variance of the prior and integrate this learned
knowledge with the likelihood on each trial to estimate the location of the hidden target
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 4
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
a distribution that either had low variance (SD of 10pixels) medium variance (SD of 60 pixels) or highvariance (SD of 100 pixels see inset of Figure 1A for anillustration of the three levels of variance) Afterparticipants provided their response by touching alocation on the display feedback on their accuracy onthat trial was provided by displaying a new dot at thetouched location and a second new dot at the truetarget location In addition participants receivedfeedback in the form of numerical points with themagnitude of the points varying based on theiraccuracy
Experiment 1 Can human observerslearn and efficiently use complexprior knowledge
In Experiment 1 participants were exposed to 1200trials of the spatial localization task with half the trialsinvolving targets drawn from each of the two under-lying Gaussian distributions (the mixture componentsof the location-contingent generative model) Thesetwo sets of 600 trials were randomly intermixed andwithin each set 200 trials were randomly presentedwith one of the three levels of reliability in other wordssix total conditions were randomly interleavedthroughout the experiment In each trial participantstherefore had access to two sources of informationmdashthe uncertain sensory information available on thattrial (ie the cloud of dots that corresponded to thelikelihood) and any knowledge they might have learnedup to that point in the experiment based on feedbackreceived in previous trials about the likely locations ofthe target (ie the mixture distribution over the twounderlying Gaussian distributions that corresponded tothe prior) Participants received two cues on each trialas to which of the two underlying Gaussian distribu-tions the target on that trial was drawn from the sideof the display in which the sensory information waspresented (the two underlying distributions were alwayscentered in opposite halves of the display) and the colorof the sensory information (the color of the dot cloudwas set either to green or white depending on the targetdistribution) Since the components of the complexgenerative model were perfectly separable given thelocation contingent cues on each trial we cancharacterize the prior as involving two separabledistributions conditioned on the trial-specific locationand color of the sensory information Accordingly inthe rest of this article we refer to the two Gaussiandistributions that make up the mixture components ofthe complex generative model as the lsquolsquobroadrsquorsquo priordistribution (the distribution with the larger standard
deviation) and the lsquolsquonarrowrsquorsquo prior distribution (thedistribution with the smaller standard deviation)
There are several computational models that partic-ipants could potentially use to carry out this task Onepossibility is that participants just ignore the underlyingprior distributions and base their estimates solely onthe sensory information available on each trial That isgiven the complexity implicit in the generative modelgoverning target location participants can ignore thissource of information (rather than expend the compu-tational resources to track and learn the location-contingent prior distributions) and instead just choosethe centroid of the cluster of dots (which are visible oneach trial) as their estimate for the hidden targetlocation This strategy would predict that participantswould assign a weight of one to the likelihood (ie basetheir responses solely on the sensory information)irrespective of the reliability of the sensory informationor the reliability (or inverse variance) of the priordistribution for that trial Furthermore we wouldexpect to see no change in participantsrsquo weights as afunction of exposure to the task since this strategy doesnot involve any learning (cf the likelihood distributionis drawn independently on each trial) Importantlyhowever such a computational strategy (henceforthreferred to as Model 1) would be suboptimal for tworeasons first as the reliability of the sensory informa-tion goes down the probability that the centroid of thesensory information will correspond exactly to the truetarget location also goes down and second by ignoringthe information provided by the prior distributionsparticipants cannot take advantage of the fact that notall spatial locations are a priori equally likely
A second possibility is that participants are sensitiveto the underlying generative model but given thecomplexity involved in the task they choose to learnonly the mean locations for the two prior distributionswhile ignoring their relative variances (ie their relativereliability)mdashlearning only the means is statisticallyeasier and requires exposure to far fewer trials Bylearning the average position for where the target tendsto be for each prior distribution participants can usethis knowledge to bias their estimates particularly asthe reliability of the sensory information goes downThis model (Model 2) predicts a smaller weight to thelikelihood as the reliability of the sensory informationgoes down and it also predicts that as participants gaingreater exposure to the underlying distributions (thusallowing them to better learn the two prior means)their behavior should show a greater sensitivity to theunderlying prior distributions However a key predic-tion of this model is that for each level of sensoryreliability we should see identical weights beingassigned to the likelihood for targets drawn from thetwo different prior distributions because the variancesof the prior distributions are ignored by this model
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 5
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
Thus this model is still suboptimal since the narrowprior distribution is a more reliable indicator of thelikely target location across trials compared to thebroad prior distribution and an optimal observershould take this into account
Finally a third possibility is that participants learnboth the mean positions and the relative reliabilities ofthe two prior distributions and integrate this learnedknowledge with the sensory information available oneach trial in a manner that is consistent with thepredictions of Bayes-optimal behavior (Model 3) Ifparticipants use such a strategy we should see a smallerweight to the likelihood as the reliability of the sensoryinformation goes down and this drop should be greaterfor trials in which the target is drawn from the narrowprior than when the target is drawn from the broadprior Furthermore this model predicts that asparticipants gain greater exposure to and thus learnmore about the underlying distributions participantsrsquobehavior should show a greater sensitivity to thestatistical properties (both mean location and relativevariance) of the underlying distributions (see Figure 1Bfor an illustration) Formally if the mean and thevariance of the sensory information on a given trial isgiven by ll and r2
l and the mean and the variance ofthe underlying target distribution for that trial is givenby lp and r2
p then the target location t predicted by thismodel would be (Bernardo amp Smith 1994 Cox 1946Jacobs 1999 Yuille amp Bulthoff 1996)
t frac14 wlll thorn eth1 wlTHORNlp eth1THORN
where wl the weight assigned by the observer to thesensory information should be
wl frac141=r2
l
1=r2l thorn 1=r2
p
eth2THORN
By examining the weights assigned by participants tothe likelihood on each trial given the relative reliabilityof the sensory information and the prior informationon that trial we sought to distinguish between the threepotential strategies described above (ie Models 1 2and 3) In addition we sought to characterize learning-induced changes in participantsrsquo weights as a functionof exposure to the task by splitting the total number oftrials into four temporal bins each of which included300 trials of exposure to the task (with the sixconditions randomly interleaved in each bin)
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to the
purpose of the study and provided informed writtenconsent The University of Rochesterrsquos institutionalreview board approved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with the following task instructions
In this study you will be playing a game on theiPad The story behind this game is that you are ata fair and there is an invisible bucket that you aretrying to locate Sometimes the bucket is going tobe located on the left side of the display and atother times the bucket is going to be located onthe right side of the display Now given that thebucket is invisible you canrsquot see where it isHowever on each trial you will see some locationsthat other people have previously guessed thebucket is located at These lsquolsquoguessesrsquorsquo will show upas white or green dots on the screen Now it isimportant to note that you donrsquot know which (ifany) of the dots actually correspond to thelocation of the bucket Indeed all of the dotscould be just random guesses Your job on eachtrial is to try to figure out where the bucket isactually located Once you decide on a locationyou can just touch it at which point you will seetwo more dots a red dot which shows you thetrue location of the bucket on that trial and a bluedot which shows you the location that youtouched If the blue dot is right on the red dotthen you correctly guessed the location of thebucket and you will get 20 points If you donrsquotexactly guess the location of the bucket but youstill get close then you will get 5 points When yousee this it means that you need to try just a littleharder to get the right locationmdashyou are closeFinally if your guess is very far away you will getno points
Participants were seated at a comfortable viewingdistance from a touch-sensitive display (iPad 2 AppleInc Cupertino CA) with a resolution of 768 pixels(vertical) 3 1024 pixels (horizontal) Participantsprovided responses using their finger having beeninstructed to pick a favorite finger and to consistentlyuse that finger throughout the experiment At the startof each trial they were presented with a lsquolsquoGOrsquorsquo buttoncentered at the bottom of the display Once theytouched this button the trial started with the presen-tation of a cluster of white or green dots (thelsquolsquoguessesrsquorsquo) Participants were told to estimate thelocation of the hidden target as rapidly and accuratelyas possible by touching a location on the screen Afterparticipants provided a response the cluster of dots
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 6
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
disappeared and feedback was provided The gameincluded multiple levels once a participant accumu-lated a total of 600 points on each level they wereshown a congratulatory screen and allowed to lsquolsquoleveluprsquorsquo Progress toward the next level was always shownat the top of the screen using a progress bar Thisability to level up was used solely to motivateparticipants and did not represent any change in theexperimental procedure Participants carried out a totalof 1200 trials split across four experimental blocksShort breaks were allowed between blocks and thetotal experimental duration including breaks wasapproximately 50 min
Data analysis
To quantify the computational mechanisms used byparticipants in this experiment we estimated the extentto which their behavior depended on the likelihoodversus the prior on each trial Specifically we usedlinear regression to compute the weight (wl) assigned tothe centroid of the cluster of dots (the likelihood) withthe weight assigned to the mean of the underlyingtarget distribution for that trial (the prior) beingdefined as (1 wl) Thus on each trial given thecentroid of the sensory information (ll) the mean ofthe underlying target distribution (lp) and participantsrsquoestimate for the target location (t ) the weight assignedby participants to the centroid of the sensory infor-mation (wl) was estimated using
t frac14 wlll thorn eth1 wlTHORNlp thorn noise eth3THORN
We focused on participantsrsquo performance in thevertical dimension to eliminate the potential influenceof variability that may have been introduced by aninteraction between participantsrsquo handedness and thehorizontal separation of the prior locations Moreovertheir performance in the horizontal dimension wassimilar to their performance in the vertical dimensionmdashwe found no interaction between dimension (horizontalvs vertical) and exposure bin across prior andlikelihood conditions (all ps 005)
Results and discussion
Consistent with the predictions of the Bayes-optimalmodel (Model 3) by the end of exposure to the task(ie in the final temporal bin) observers assigned areliably smaller weight to the likelihood (and thus agreater weight to the prior) as the sensory informationdecreased in reliability (Figure 2) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 1889 p 0001
Furthermore for each prior condition there was areliable interaction between exposure and likelihoodvariance as participants gained more exposure to thetask they assigned a smaller weight to the likelihoodand this drop in weight was greater as the likelihoodvariance increased (Figure 3) Specifically in a 4(temporal bin) 3 3 (likelihood variance) repeatedmeasures ANOVA carried out over participantsrsquoweights in the broad prior condition there was a maineffect of temporal bin F(3 21)frac14 400 pfrac14 002 a main
Figure 2 Data from the final temporal bin for a representative participant in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior as likelihood variance increased (blue to green to red) participants shifted from selecting the centroid of the
sensory information as their estimate for the target location (the gray dashed line) toward selecting the mean of the underlying prior
distribution (zero on the y-axis) This was true in both the broad (A) and narrow (B) prior conditions but the shift was more
pronounced for the narrow prior condition than for the broad prior condition For illustrative purposes the mean of the underlying
prior distribution was removed from participantsrsquo response locations and from the locations of the centroid of the sensory
information Each dot represents a trial and solid lines represent the best-fit regression lines in each condition
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 7
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
effect of likelihood variance F(2 14) frac14 2117 p
00001 and an interaction between the two factorsF(6 42)frac14 522 p 0001 Similarly in a 4 (temporalbin) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thenarrow prior condition there was a main effect oftemporal bin F(3 21)frac14 906 p 0001 a main effectof likelihood variance F(2 14)frac141224 p 0001 andan interaction between the two factors F(6 42)frac14547p 0001 These findings are inconsistent with Model1 which predicts a weight of 1 to the sensoryinformation across all the likelihood and priorconditions and no change in participantsrsquo weights as afunction of exposure to the task Furthermore incontrast to the predictions of Model 2 we found thatthe drop in the weight assigned by participants to thelikelihood as a function of exposure to the taskparticularly in the high likelihood variance conditionwas greater for trials in which the target was drawnfrom the narrow prior than when the target wasdrawn from the broad prior In a 4 (temporal bin)3 2(prior variance) repeated measures ANOVA carriedout over participantsrsquo weights in the high likelihoodvariance condition we saw a main effect of temporalbin F(3 21) frac14 829 p 0001 and an interactionbetween temporal bin and prior variance F(3 21) frac14307 p frac14 005 This finding suggests that participantsare sensitive to and learn both the means and therelative variances of the underlying prior distribu-tions Taken together this pattern of results providesclear evidence in support of Model 3mdashthe hypothesisthat human observers learn the complex generativemodel and use this learned knowledge in a manner
that is consistent with the predictions of Bayes-optimal behavior
Experiment 2 Exploring thedynamics of learning
While the results from Experiment 1 support thehypothesis that participants learn the complex gener-ative model and use this knowledge in a statisticallyefficient manner the dynamics of this learning remainunclear For instance prior work (Berniker et al2010) has shown that when presented with stimulidrawn from simple generative models human ob-servers rapidly learn the prior mean but it takes themmany more trials to learn the prior variance InExperiment 2 with a new group of participants weexamined the dynamics of learning with complexgenerative models by including an extra conditionrandomly interleaved with all the conditions used inthe first experiment in which no sensory informationwas presented In this condition observers thus had toestimate the position of the target based solely on theirlearned knowledge (up to that point) about where thetarget was likely to occur (ie based on their priorknowledge) thereby allowing us to analyze theirevolving learned knowledge of the location-contingentgenerative model as a function of exposure to the taskParticipants carried out 400 trials of this conditionsplit evenly between the two prior distributions Oneach trial they were cued to estimate the location ofthe target on either the left or the right of the display
Figure 3 Weights assigned to the centroid of the sensory information in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior participants in Experiment 1 relied less on the sensory information and more on the priors as the variance of the
sensory information increased This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to the
sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin included 300 trials split between the two prior conditions and the four bins of trials are depicted in
temporal order Columns represent means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 8
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
(with a box that was colored green or white) thusrequiring them to draw on their learned knowledge ofthe location-contingent prior distribution associatedwith that trial As in Experiment 1 the 1600 trials inExperiment 2 (all conditions from Experiment 1 plus400 trials in this extra condition) were again split upinto the relevant prior and likelihood conditions (theno sensory information condition is statisticallyequivalent to a likelihood condition with infiniteuncertainty) and with each condition being furthersplit into four temporal bins to study the influence oftask exposure
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to thepurpose of the study provided informed writtenconsent and did not participate in Experiment 1 TheUniversity of Rochesterrsquos institutional review boardapproved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with task instructions that were nearlyidentical to those provided to participants in Experi-ment 1 Specifically in addition to the instructions fromExperiment 1 they were also provided with thefollowing instructions
There will also be some trials in which you willbe the first person to guess the location of thebucket In these trials rather than seeing dots onthe screen you will see a briefly flashed white orgreen rectangle which will indicate the side of thescreen that the invisible bucket is located atmdashthebucket could be located anywhere inside thatrectangle Again your job is to try to figure outwhere the bucket is actually located
On each trial of the experiment the procedure wasidentical to that used in Experiment 1 except for theextra condition in which no sensory information waspresented In the trials corresponding to this conditionafter participants touched the GO button they saw abriefly flashed green or white rectangle spanning eitherthe left half or the right half of the display Afterparticipants provided a response feedback was pro-vided as in all the other conditions Participants carriedout a total of 1600 trials split across four experimentalblocks Short breaks were allowed between blocks and
the total experimental duration including breaks wasapproximately an hour
Data analysis
As in Experiment 1 for the trials in which sensoryinformation was available we used linear regression tocompute the weight (wl) assigned to the centroid of thecluster of dots (the likelihood) with the weightsassigned to the mean of the underlying location-contingent target distribution for that trial (the prior)being defined as (1 wl) For the trials in which nosensory information was available we computedparticipantsrsquo mean responses across all trials in eachtemporal bin As in Experiment 1 we again focused onperformance in the vertical dimension
Results and discussion
We first examined the weights assigned by partici-pants to the likelihood and the prior for the trials inwhich sensory information was available and foundthat their behavior was similar to that in Experiment 1(Figure 3) Specifically in line with the Bayes-optimalmodel (Model 3) by the end of exposure to the task inExperiment 2 (ie in the final temporal bin) observersassigned a reliably smaller weight to the likelihood (anda greater weight to the prior) as the sensory informa-tion decreased in reliability (Figure 4) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 4584 p 00001 and aninteraction between the two factors F(2 14)frac14 383 pfrac140047 Furthermore for each prior condition we againfound an interaction between exposure and likelihoodvariance Specifically in a 4 (temporal bin) 3 3(likelihood variance) repeated measures ANOVAcarried out over participantsrsquo weights in the broad priorcondition there was a main effect of temporal bin F(321)frac14 749 pfrac14 0001 a main effect of likelihoodvariance F(2 14)frac14 3421 p 00001 and aninteraction between the two factors F(6 42)frac14 284 pfrac14002 Similarly in a 4 (temporal bin) 3 3 (likelihoodvariance) repeated measures ANOVA carried out overparticipantsrsquo weights in the narrow prior conditionthere was a marginal main effect of temporal bin F(321)frac14 287 pfrac14 006 a main effect of likelihoodvariance F(2 14)frac14 1772 p 0001 and a marginalinteraction between the two factors F(6 42)frac14 230 pfrac140052 Finally participants assigned a smaller weight tothe likelihood particularly in the high likelihoodvariance condition when the target was drawn fromthe narrow prior than when the target was drawn fromthe broad prior In a 4 (temporal bin) 3 2 (prior
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 9
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
variance) repeated measures ANOVA carried out overparticipantsrsquo weights in the high likelihood variancecondition there was a main effect of temporal bin F(321)frac14 555 p 0001 and a main effect of priorvariance F(1 7) frac14 789 p frac14 0026 These findingstherefore represent a replication of our results fromExperiment 1 To further confirm that these resultsreplicate the results from Experiment 1 we carried outa 2 (experiment) 3 4 (temporal bin) 3 3 (likelihoodvariance) mixed ANOVA with experiment as abetween-participants factor and temporal bin andlikelihood variance as within-participant factors overparticipantsrsquo weights in both the broad and narrowprior conditions In each case we found no interactionbetween experiment and any other factor (all ps 017)
Importantly in the conditions in which no sensoryinformation was available (ie no cluster of dots waspresented) we found that within the first temporal bin(the first 100 of the 400 prior-only trials) participantsrsquoestimates of the target location were on averageindistinguishable from the true prior mean locations(plus or minus motor noise estimated from the lowlikelihood variance conditions broad prior t7frac14 173 pfrac14 013 narrow prior t7 frac14 124 p frac14 025) Participantswere therefore able to rapidly learn the prior meanseven when presented with a complex generative model(Figure 5) extending results from previous workexamining such behavior in the presence of simplergenerative models It is important to note howeverthat in the conditions where sensory information wasavailable which were randomly interleaved with theprior-only conditions participantsrsquo weights continue tochange throughout the experiment (Figure 4) This
Figure 4 Weights assigned to the centroid of the sensory information in Experiment 2 As in Experiment 1 participants in Experiment
2 relied less on the sensory information and more on the priors as the variance of the sensory information increased in line with the
predictions of Bayes-optimal behavior This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to
the sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin again included 300 trials split between the two prior conditions and the four bins of trials are depicted
in temporal order Columns represent means and error bars represent SEM across participants
Figure 5 Mean response location in the absence of sensory
information Participants in Experiment 2 rapidly learned the
true prior mean for both the broad (top) and narrow prior
conditions (bottom) Participantsrsquo mean response location in
the trials in which no sensory information was available was
indistinguishable from the true prior means plus or minus
motor noise within the first temporal bin For illustrative
purposes the y-axis represents the mean deviation from the
true mean in each prior condition Each temporal bin included
100 trials split between the two prior conditions and the four
bins of trials are depicted in temporal order Columns represent
means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 10
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016

a distribution that either had low variance (SD of 10pixels) medium variance (SD of 60 pixels) or highvariance (SD of 100 pixels see inset of Figure 1A for anillustration of the three levels of variance) Afterparticipants provided their response by touching alocation on the display feedback on their accuracy onthat trial was provided by displaying a new dot at thetouched location and a second new dot at the truetarget location In addition participants receivedfeedback in the form of numerical points with themagnitude of the points varying based on theiraccuracy
Experiment 1 Can human observerslearn and efficiently use complexprior knowledge
In Experiment 1 participants were exposed to 1200trials of the spatial localization task with half the trialsinvolving targets drawn from each of the two under-lying Gaussian distributions (the mixture componentsof the location-contingent generative model) Thesetwo sets of 600 trials were randomly intermixed andwithin each set 200 trials were randomly presentedwith one of the three levels of reliability in other wordssix total conditions were randomly interleavedthroughout the experiment In each trial participantstherefore had access to two sources of informationmdashthe uncertain sensory information available on thattrial (ie the cloud of dots that corresponded to thelikelihood) and any knowledge they might have learnedup to that point in the experiment based on feedbackreceived in previous trials about the likely locations ofthe target (ie the mixture distribution over the twounderlying Gaussian distributions that corresponded tothe prior) Participants received two cues on each trialas to which of the two underlying Gaussian distribu-tions the target on that trial was drawn from the sideof the display in which the sensory information waspresented (the two underlying distributions were alwayscentered in opposite halves of the display) and the colorof the sensory information (the color of the dot cloudwas set either to green or white depending on the targetdistribution) Since the components of the complexgenerative model were perfectly separable given thelocation contingent cues on each trial we cancharacterize the prior as involving two separabledistributions conditioned on the trial-specific locationand color of the sensory information Accordingly inthe rest of this article we refer to the two Gaussiandistributions that make up the mixture components ofthe complex generative model as the lsquolsquobroadrsquorsquo priordistribution (the distribution with the larger standard
deviation) and the lsquolsquonarrowrsquorsquo prior distribution (thedistribution with the smaller standard deviation)
There are several computational models that partic-ipants could potentially use to carry out this task Onepossibility is that participants just ignore the underlyingprior distributions and base their estimates solely onthe sensory information available on each trial That isgiven the complexity implicit in the generative modelgoverning target location participants can ignore thissource of information (rather than expend the compu-tational resources to track and learn the location-contingent prior distributions) and instead just choosethe centroid of the cluster of dots (which are visible oneach trial) as their estimate for the hidden targetlocation This strategy would predict that participantswould assign a weight of one to the likelihood (ie basetheir responses solely on the sensory information)irrespective of the reliability of the sensory informationor the reliability (or inverse variance) of the priordistribution for that trial Furthermore we wouldexpect to see no change in participantsrsquo weights as afunction of exposure to the task since this strategy doesnot involve any learning (cf the likelihood distributionis drawn independently on each trial) Importantlyhowever such a computational strategy (henceforthreferred to as Model 1) would be suboptimal for tworeasons first as the reliability of the sensory informa-tion goes down the probability that the centroid of thesensory information will correspond exactly to the truetarget location also goes down and second by ignoringthe information provided by the prior distributionsparticipants cannot take advantage of the fact that notall spatial locations are a priori equally likely
A second possibility is that participants are sensitiveto the underlying generative model but given thecomplexity involved in the task they choose to learnonly the mean locations for the two prior distributionswhile ignoring their relative variances (ie their relativereliability)mdashlearning only the means is statisticallyeasier and requires exposure to far fewer trials Bylearning the average position for where the target tendsto be for each prior distribution participants can usethis knowledge to bias their estimates particularly asthe reliability of the sensory information goes downThis model (Model 2) predicts a smaller weight to thelikelihood as the reliability of the sensory informationgoes down and it also predicts that as participants gaingreater exposure to the underlying distributions (thusallowing them to better learn the two prior means)their behavior should show a greater sensitivity to theunderlying prior distributions However a key predic-tion of this model is that for each level of sensoryreliability we should see identical weights beingassigned to the likelihood for targets drawn from thetwo different prior distributions because the variancesof the prior distributions are ignored by this model
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 5
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
Thus this model is still suboptimal since the narrowprior distribution is a more reliable indicator of thelikely target location across trials compared to thebroad prior distribution and an optimal observershould take this into account
Finally a third possibility is that participants learnboth the mean positions and the relative reliabilities ofthe two prior distributions and integrate this learnedknowledge with the sensory information available oneach trial in a manner that is consistent with thepredictions of Bayes-optimal behavior (Model 3) Ifparticipants use such a strategy we should see a smallerweight to the likelihood as the reliability of the sensoryinformation goes down and this drop should be greaterfor trials in which the target is drawn from the narrowprior than when the target is drawn from the broadprior Furthermore this model predicts that asparticipants gain greater exposure to and thus learnmore about the underlying distributions participantsrsquobehavior should show a greater sensitivity to thestatistical properties (both mean location and relativevariance) of the underlying distributions (see Figure 1Bfor an illustration) Formally if the mean and thevariance of the sensory information on a given trial isgiven by ll and r2
l and the mean and the variance ofthe underlying target distribution for that trial is givenby lp and r2
p then the target location t predicted by thismodel would be (Bernardo amp Smith 1994 Cox 1946Jacobs 1999 Yuille amp Bulthoff 1996)
t frac14 wlll thorn eth1 wlTHORNlp eth1THORN
where wl the weight assigned by the observer to thesensory information should be
wl frac141=r2
l
1=r2l thorn 1=r2
p
eth2THORN
By examining the weights assigned by participants tothe likelihood on each trial given the relative reliabilityof the sensory information and the prior informationon that trial we sought to distinguish between the threepotential strategies described above (ie Models 1 2and 3) In addition we sought to characterize learning-induced changes in participantsrsquo weights as a functionof exposure to the task by splitting the total number oftrials into four temporal bins each of which included300 trials of exposure to the task (with the sixconditions randomly interleaved in each bin)
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to the
purpose of the study and provided informed writtenconsent The University of Rochesterrsquos institutionalreview board approved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with the following task instructions
In this study you will be playing a game on theiPad The story behind this game is that you are ata fair and there is an invisible bucket that you aretrying to locate Sometimes the bucket is going tobe located on the left side of the display and atother times the bucket is going to be located onthe right side of the display Now given that thebucket is invisible you canrsquot see where it isHowever on each trial you will see some locationsthat other people have previously guessed thebucket is located at These lsquolsquoguessesrsquorsquo will show upas white or green dots on the screen Now it isimportant to note that you donrsquot know which (ifany) of the dots actually correspond to thelocation of the bucket Indeed all of the dotscould be just random guesses Your job on eachtrial is to try to figure out where the bucket isactually located Once you decide on a locationyou can just touch it at which point you will seetwo more dots a red dot which shows you thetrue location of the bucket on that trial and a bluedot which shows you the location that youtouched If the blue dot is right on the red dotthen you correctly guessed the location of thebucket and you will get 20 points If you donrsquotexactly guess the location of the bucket but youstill get close then you will get 5 points When yousee this it means that you need to try just a littleharder to get the right locationmdashyou are closeFinally if your guess is very far away you will getno points
Participants were seated at a comfortable viewingdistance from a touch-sensitive display (iPad 2 AppleInc Cupertino CA) with a resolution of 768 pixels(vertical) 3 1024 pixels (horizontal) Participantsprovided responses using their finger having beeninstructed to pick a favorite finger and to consistentlyuse that finger throughout the experiment At the startof each trial they were presented with a lsquolsquoGOrsquorsquo buttoncentered at the bottom of the display Once theytouched this button the trial started with the presen-tation of a cluster of white or green dots (thelsquolsquoguessesrsquorsquo) Participants were told to estimate thelocation of the hidden target as rapidly and accuratelyas possible by touching a location on the screen Afterparticipants provided a response the cluster of dots
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 6
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
disappeared and feedback was provided The gameincluded multiple levels once a participant accumu-lated a total of 600 points on each level they wereshown a congratulatory screen and allowed to lsquolsquoleveluprsquorsquo Progress toward the next level was always shownat the top of the screen using a progress bar Thisability to level up was used solely to motivateparticipants and did not represent any change in theexperimental procedure Participants carried out a totalof 1200 trials split across four experimental blocksShort breaks were allowed between blocks and thetotal experimental duration including breaks wasapproximately 50 min
Data analysis
To quantify the computational mechanisms used byparticipants in this experiment we estimated the extentto which their behavior depended on the likelihoodversus the prior on each trial Specifically we usedlinear regression to compute the weight (wl) assigned tothe centroid of the cluster of dots (the likelihood) withthe weight assigned to the mean of the underlyingtarget distribution for that trial (the prior) beingdefined as (1 wl) Thus on each trial given thecentroid of the sensory information (ll) the mean ofthe underlying target distribution (lp) and participantsrsquoestimate for the target location (t ) the weight assignedby participants to the centroid of the sensory infor-mation (wl) was estimated using
t frac14 wlll thorn eth1 wlTHORNlp thorn noise eth3THORN
We focused on participantsrsquo performance in thevertical dimension to eliminate the potential influenceof variability that may have been introduced by aninteraction between participantsrsquo handedness and thehorizontal separation of the prior locations Moreovertheir performance in the horizontal dimension wassimilar to their performance in the vertical dimensionmdashwe found no interaction between dimension (horizontalvs vertical) and exposure bin across prior andlikelihood conditions (all ps 005)
Results and discussion
Consistent with the predictions of the Bayes-optimalmodel (Model 3) by the end of exposure to the task(ie in the final temporal bin) observers assigned areliably smaller weight to the likelihood (and thus agreater weight to the prior) as the sensory informationdecreased in reliability (Figure 2) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 1889 p 0001
Furthermore for each prior condition there was areliable interaction between exposure and likelihoodvariance as participants gained more exposure to thetask they assigned a smaller weight to the likelihoodand this drop in weight was greater as the likelihoodvariance increased (Figure 3) Specifically in a 4(temporal bin) 3 3 (likelihood variance) repeatedmeasures ANOVA carried out over participantsrsquoweights in the broad prior condition there was a maineffect of temporal bin F(3 21)frac14 400 pfrac14 002 a main
Figure 2 Data from the final temporal bin for a representative participant in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior as likelihood variance increased (blue to green to red) participants shifted from selecting the centroid of the
sensory information as their estimate for the target location (the gray dashed line) toward selecting the mean of the underlying prior
distribution (zero on the y-axis) This was true in both the broad (A) and narrow (B) prior conditions but the shift was more
pronounced for the narrow prior condition than for the broad prior condition For illustrative purposes the mean of the underlying
prior distribution was removed from participantsrsquo response locations and from the locations of the centroid of the sensory
information Each dot represents a trial and solid lines represent the best-fit regression lines in each condition
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 7
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
effect of likelihood variance F(2 14) frac14 2117 p
00001 and an interaction between the two factorsF(6 42)frac14 522 p 0001 Similarly in a 4 (temporalbin) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thenarrow prior condition there was a main effect oftemporal bin F(3 21)frac14 906 p 0001 a main effectof likelihood variance F(2 14)frac141224 p 0001 andan interaction between the two factors F(6 42)frac14547p 0001 These findings are inconsistent with Model1 which predicts a weight of 1 to the sensoryinformation across all the likelihood and priorconditions and no change in participantsrsquo weights as afunction of exposure to the task Furthermore incontrast to the predictions of Model 2 we found thatthe drop in the weight assigned by participants to thelikelihood as a function of exposure to the taskparticularly in the high likelihood variance conditionwas greater for trials in which the target was drawnfrom the narrow prior than when the target wasdrawn from the broad prior In a 4 (temporal bin)3 2(prior variance) repeated measures ANOVA carriedout over participantsrsquo weights in the high likelihoodvariance condition we saw a main effect of temporalbin F(3 21) frac14 829 p 0001 and an interactionbetween temporal bin and prior variance F(3 21) frac14307 p frac14 005 This finding suggests that participantsare sensitive to and learn both the means and therelative variances of the underlying prior distribu-tions Taken together this pattern of results providesclear evidence in support of Model 3mdashthe hypothesisthat human observers learn the complex generativemodel and use this learned knowledge in a manner
that is consistent with the predictions of Bayes-optimal behavior
Experiment 2 Exploring thedynamics of learning
While the results from Experiment 1 support thehypothesis that participants learn the complex gener-ative model and use this knowledge in a statisticallyefficient manner the dynamics of this learning remainunclear For instance prior work (Berniker et al2010) has shown that when presented with stimulidrawn from simple generative models human ob-servers rapidly learn the prior mean but it takes themmany more trials to learn the prior variance InExperiment 2 with a new group of participants weexamined the dynamics of learning with complexgenerative models by including an extra conditionrandomly interleaved with all the conditions used inthe first experiment in which no sensory informationwas presented In this condition observers thus had toestimate the position of the target based solely on theirlearned knowledge (up to that point) about where thetarget was likely to occur (ie based on their priorknowledge) thereby allowing us to analyze theirevolving learned knowledge of the location-contingentgenerative model as a function of exposure to the taskParticipants carried out 400 trials of this conditionsplit evenly between the two prior distributions Oneach trial they were cued to estimate the location ofthe target on either the left or the right of the display
Figure 3 Weights assigned to the centroid of the sensory information in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior participants in Experiment 1 relied less on the sensory information and more on the priors as the variance of the
sensory information increased This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to the
sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin included 300 trials split between the two prior conditions and the four bins of trials are depicted in
temporal order Columns represent means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 8
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
(with a box that was colored green or white) thusrequiring them to draw on their learned knowledge ofthe location-contingent prior distribution associatedwith that trial As in Experiment 1 the 1600 trials inExperiment 2 (all conditions from Experiment 1 plus400 trials in this extra condition) were again split upinto the relevant prior and likelihood conditions (theno sensory information condition is statisticallyequivalent to a likelihood condition with infiniteuncertainty) and with each condition being furthersplit into four temporal bins to study the influence oftask exposure
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to thepurpose of the study provided informed writtenconsent and did not participate in Experiment 1 TheUniversity of Rochesterrsquos institutional review boardapproved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with task instructions that were nearlyidentical to those provided to participants in Experi-ment 1 Specifically in addition to the instructions fromExperiment 1 they were also provided with thefollowing instructions
There will also be some trials in which you willbe the first person to guess the location of thebucket In these trials rather than seeing dots onthe screen you will see a briefly flashed white orgreen rectangle which will indicate the side of thescreen that the invisible bucket is located atmdashthebucket could be located anywhere inside thatrectangle Again your job is to try to figure outwhere the bucket is actually located
On each trial of the experiment the procedure wasidentical to that used in Experiment 1 except for theextra condition in which no sensory information waspresented In the trials corresponding to this conditionafter participants touched the GO button they saw abriefly flashed green or white rectangle spanning eitherthe left half or the right half of the display Afterparticipants provided a response feedback was pro-vided as in all the other conditions Participants carriedout a total of 1600 trials split across four experimentalblocks Short breaks were allowed between blocks and
the total experimental duration including breaks wasapproximately an hour
Data analysis
As in Experiment 1 for the trials in which sensoryinformation was available we used linear regression tocompute the weight (wl) assigned to the centroid of thecluster of dots (the likelihood) with the weightsassigned to the mean of the underlying location-contingent target distribution for that trial (the prior)being defined as (1 wl) For the trials in which nosensory information was available we computedparticipantsrsquo mean responses across all trials in eachtemporal bin As in Experiment 1 we again focused onperformance in the vertical dimension
Results and discussion
We first examined the weights assigned by partici-pants to the likelihood and the prior for the trials inwhich sensory information was available and foundthat their behavior was similar to that in Experiment 1(Figure 3) Specifically in line with the Bayes-optimalmodel (Model 3) by the end of exposure to the task inExperiment 2 (ie in the final temporal bin) observersassigned a reliably smaller weight to the likelihood (anda greater weight to the prior) as the sensory informa-tion decreased in reliability (Figure 4) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 4584 p 00001 and aninteraction between the two factors F(2 14)frac14 383 pfrac140047 Furthermore for each prior condition we againfound an interaction between exposure and likelihoodvariance Specifically in a 4 (temporal bin) 3 3(likelihood variance) repeated measures ANOVAcarried out over participantsrsquo weights in the broad priorcondition there was a main effect of temporal bin F(321)frac14 749 pfrac14 0001 a main effect of likelihoodvariance F(2 14)frac14 3421 p 00001 and aninteraction between the two factors F(6 42)frac14 284 pfrac14002 Similarly in a 4 (temporal bin) 3 3 (likelihoodvariance) repeated measures ANOVA carried out overparticipantsrsquo weights in the narrow prior conditionthere was a marginal main effect of temporal bin F(321)frac14 287 pfrac14 006 a main effect of likelihoodvariance F(2 14)frac14 1772 p 0001 and a marginalinteraction between the two factors F(6 42)frac14 230 pfrac140052 Finally participants assigned a smaller weight tothe likelihood particularly in the high likelihoodvariance condition when the target was drawn fromthe narrow prior than when the target was drawn fromthe broad prior In a 4 (temporal bin) 3 2 (prior
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 9
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
variance) repeated measures ANOVA carried out overparticipantsrsquo weights in the high likelihood variancecondition there was a main effect of temporal bin F(321)frac14 555 p 0001 and a main effect of priorvariance F(1 7) frac14 789 p frac14 0026 These findingstherefore represent a replication of our results fromExperiment 1 To further confirm that these resultsreplicate the results from Experiment 1 we carried outa 2 (experiment) 3 4 (temporal bin) 3 3 (likelihoodvariance) mixed ANOVA with experiment as abetween-participants factor and temporal bin andlikelihood variance as within-participant factors overparticipantsrsquo weights in both the broad and narrowprior conditions In each case we found no interactionbetween experiment and any other factor (all ps 017)
Importantly in the conditions in which no sensoryinformation was available (ie no cluster of dots waspresented) we found that within the first temporal bin(the first 100 of the 400 prior-only trials) participantsrsquoestimates of the target location were on averageindistinguishable from the true prior mean locations(plus or minus motor noise estimated from the lowlikelihood variance conditions broad prior t7frac14 173 pfrac14 013 narrow prior t7 frac14 124 p frac14 025) Participantswere therefore able to rapidly learn the prior meanseven when presented with a complex generative model(Figure 5) extending results from previous workexamining such behavior in the presence of simplergenerative models It is important to note howeverthat in the conditions where sensory information wasavailable which were randomly interleaved with theprior-only conditions participantsrsquo weights continue tochange throughout the experiment (Figure 4) This
Figure 4 Weights assigned to the centroid of the sensory information in Experiment 2 As in Experiment 1 participants in Experiment
2 relied less on the sensory information and more on the priors as the variance of the sensory information increased in line with the
predictions of Bayes-optimal behavior This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to
the sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin again included 300 trials split between the two prior conditions and the four bins of trials are depicted
in temporal order Columns represent means and error bars represent SEM across participants
Figure 5 Mean response location in the absence of sensory
information Participants in Experiment 2 rapidly learned the
true prior mean for both the broad (top) and narrow prior
conditions (bottom) Participantsrsquo mean response location in
the trials in which no sensory information was available was
indistinguishable from the true prior means plus or minus
motor noise within the first temporal bin For illustrative
purposes the y-axis represents the mean deviation from the
true mean in each prior condition Each temporal bin included
100 trials split between the two prior conditions and the four
bins of trials are depicted in temporal order Columns represent
means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 10
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016

Thus this model is still suboptimal since the narrowprior distribution is a more reliable indicator of thelikely target location across trials compared to thebroad prior distribution and an optimal observershould take this into account
Finally a third possibility is that participants learnboth the mean positions and the relative reliabilities ofthe two prior distributions and integrate this learnedknowledge with the sensory information available oneach trial in a manner that is consistent with thepredictions of Bayes-optimal behavior (Model 3) Ifparticipants use such a strategy we should see a smallerweight to the likelihood as the reliability of the sensoryinformation goes down and this drop should be greaterfor trials in which the target is drawn from the narrowprior than when the target is drawn from the broadprior Furthermore this model predicts that asparticipants gain greater exposure to and thus learnmore about the underlying distributions participantsrsquobehavior should show a greater sensitivity to thestatistical properties (both mean location and relativevariance) of the underlying distributions (see Figure 1Bfor an illustration) Formally if the mean and thevariance of the sensory information on a given trial isgiven by ll and r2
l and the mean and the variance ofthe underlying target distribution for that trial is givenby lp and r2
p then the target location t predicted by thismodel would be (Bernardo amp Smith 1994 Cox 1946Jacobs 1999 Yuille amp Bulthoff 1996)
t frac14 wlll thorn eth1 wlTHORNlp eth1THORN
where wl the weight assigned by the observer to thesensory information should be
wl frac141=r2
l
1=r2l thorn 1=r2
p
eth2THORN
By examining the weights assigned by participants tothe likelihood on each trial given the relative reliabilityof the sensory information and the prior informationon that trial we sought to distinguish between the threepotential strategies described above (ie Models 1 2and 3) In addition we sought to characterize learning-induced changes in participantsrsquo weights as a functionof exposure to the task by splitting the total number oftrials into four temporal bins each of which included300 trials of exposure to the task (with the sixconditions randomly interleaved in each bin)
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to the
purpose of the study and provided informed writtenconsent The University of Rochesterrsquos institutionalreview board approved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with the following task instructions
In this study you will be playing a game on theiPad The story behind this game is that you are ata fair and there is an invisible bucket that you aretrying to locate Sometimes the bucket is going tobe located on the left side of the display and atother times the bucket is going to be located onthe right side of the display Now given that thebucket is invisible you canrsquot see where it isHowever on each trial you will see some locationsthat other people have previously guessed thebucket is located at These lsquolsquoguessesrsquorsquo will show upas white or green dots on the screen Now it isimportant to note that you donrsquot know which (ifany) of the dots actually correspond to thelocation of the bucket Indeed all of the dotscould be just random guesses Your job on eachtrial is to try to figure out where the bucket isactually located Once you decide on a locationyou can just touch it at which point you will seetwo more dots a red dot which shows you thetrue location of the bucket on that trial and a bluedot which shows you the location that youtouched If the blue dot is right on the red dotthen you correctly guessed the location of thebucket and you will get 20 points If you donrsquotexactly guess the location of the bucket but youstill get close then you will get 5 points When yousee this it means that you need to try just a littleharder to get the right locationmdashyou are closeFinally if your guess is very far away you will getno points
Participants were seated at a comfortable viewingdistance from a touch-sensitive display (iPad 2 AppleInc Cupertino CA) with a resolution of 768 pixels(vertical) 3 1024 pixels (horizontal) Participantsprovided responses using their finger having beeninstructed to pick a favorite finger and to consistentlyuse that finger throughout the experiment At the startof each trial they were presented with a lsquolsquoGOrsquorsquo buttoncentered at the bottom of the display Once theytouched this button the trial started with the presen-tation of a cluster of white or green dots (thelsquolsquoguessesrsquorsquo) Participants were told to estimate thelocation of the hidden target as rapidly and accuratelyas possible by touching a location on the screen Afterparticipants provided a response the cluster of dots
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 6
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
disappeared and feedback was provided The gameincluded multiple levels once a participant accumu-lated a total of 600 points on each level they wereshown a congratulatory screen and allowed to lsquolsquoleveluprsquorsquo Progress toward the next level was always shownat the top of the screen using a progress bar Thisability to level up was used solely to motivateparticipants and did not represent any change in theexperimental procedure Participants carried out a totalof 1200 trials split across four experimental blocksShort breaks were allowed between blocks and thetotal experimental duration including breaks wasapproximately 50 min
Data analysis
To quantify the computational mechanisms used byparticipants in this experiment we estimated the extentto which their behavior depended on the likelihoodversus the prior on each trial Specifically we usedlinear regression to compute the weight (wl) assigned tothe centroid of the cluster of dots (the likelihood) withthe weight assigned to the mean of the underlyingtarget distribution for that trial (the prior) beingdefined as (1 wl) Thus on each trial given thecentroid of the sensory information (ll) the mean ofthe underlying target distribution (lp) and participantsrsquoestimate for the target location (t ) the weight assignedby participants to the centroid of the sensory infor-mation (wl) was estimated using
t frac14 wlll thorn eth1 wlTHORNlp thorn noise eth3THORN
We focused on participantsrsquo performance in thevertical dimension to eliminate the potential influenceof variability that may have been introduced by aninteraction between participantsrsquo handedness and thehorizontal separation of the prior locations Moreovertheir performance in the horizontal dimension wassimilar to their performance in the vertical dimensionmdashwe found no interaction between dimension (horizontalvs vertical) and exposure bin across prior andlikelihood conditions (all ps 005)
Results and discussion
Consistent with the predictions of the Bayes-optimalmodel (Model 3) by the end of exposure to the task(ie in the final temporal bin) observers assigned areliably smaller weight to the likelihood (and thus agreater weight to the prior) as the sensory informationdecreased in reliability (Figure 2) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 1889 p 0001
Furthermore for each prior condition there was areliable interaction between exposure and likelihoodvariance as participants gained more exposure to thetask they assigned a smaller weight to the likelihoodand this drop in weight was greater as the likelihoodvariance increased (Figure 3) Specifically in a 4(temporal bin) 3 3 (likelihood variance) repeatedmeasures ANOVA carried out over participantsrsquoweights in the broad prior condition there was a maineffect of temporal bin F(3 21)frac14 400 pfrac14 002 a main
Figure 2 Data from the final temporal bin for a representative participant in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior as likelihood variance increased (blue to green to red) participants shifted from selecting the centroid of the
sensory information as their estimate for the target location (the gray dashed line) toward selecting the mean of the underlying prior
distribution (zero on the y-axis) This was true in both the broad (A) and narrow (B) prior conditions but the shift was more
pronounced for the narrow prior condition than for the broad prior condition For illustrative purposes the mean of the underlying
prior distribution was removed from participantsrsquo response locations and from the locations of the centroid of the sensory
information Each dot represents a trial and solid lines represent the best-fit regression lines in each condition
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 7
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
effect of likelihood variance F(2 14) frac14 2117 p
00001 and an interaction between the two factorsF(6 42)frac14 522 p 0001 Similarly in a 4 (temporalbin) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thenarrow prior condition there was a main effect oftemporal bin F(3 21)frac14 906 p 0001 a main effectof likelihood variance F(2 14)frac141224 p 0001 andan interaction between the two factors F(6 42)frac14547p 0001 These findings are inconsistent with Model1 which predicts a weight of 1 to the sensoryinformation across all the likelihood and priorconditions and no change in participantsrsquo weights as afunction of exposure to the task Furthermore incontrast to the predictions of Model 2 we found thatthe drop in the weight assigned by participants to thelikelihood as a function of exposure to the taskparticularly in the high likelihood variance conditionwas greater for trials in which the target was drawnfrom the narrow prior than when the target wasdrawn from the broad prior In a 4 (temporal bin)3 2(prior variance) repeated measures ANOVA carriedout over participantsrsquo weights in the high likelihoodvariance condition we saw a main effect of temporalbin F(3 21) frac14 829 p 0001 and an interactionbetween temporal bin and prior variance F(3 21) frac14307 p frac14 005 This finding suggests that participantsare sensitive to and learn both the means and therelative variances of the underlying prior distribu-tions Taken together this pattern of results providesclear evidence in support of Model 3mdashthe hypothesisthat human observers learn the complex generativemodel and use this learned knowledge in a manner
that is consistent with the predictions of Bayes-optimal behavior
Experiment 2 Exploring thedynamics of learning
While the results from Experiment 1 support thehypothesis that participants learn the complex gener-ative model and use this knowledge in a statisticallyefficient manner the dynamics of this learning remainunclear For instance prior work (Berniker et al2010) has shown that when presented with stimulidrawn from simple generative models human ob-servers rapidly learn the prior mean but it takes themmany more trials to learn the prior variance InExperiment 2 with a new group of participants weexamined the dynamics of learning with complexgenerative models by including an extra conditionrandomly interleaved with all the conditions used inthe first experiment in which no sensory informationwas presented In this condition observers thus had toestimate the position of the target based solely on theirlearned knowledge (up to that point) about where thetarget was likely to occur (ie based on their priorknowledge) thereby allowing us to analyze theirevolving learned knowledge of the location-contingentgenerative model as a function of exposure to the taskParticipants carried out 400 trials of this conditionsplit evenly between the two prior distributions Oneach trial they were cued to estimate the location ofthe target on either the left or the right of the display
Figure 3 Weights assigned to the centroid of the sensory information in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior participants in Experiment 1 relied less on the sensory information and more on the priors as the variance of the
sensory information increased This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to the
sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin included 300 trials split between the two prior conditions and the four bins of trials are depicted in
temporal order Columns represent means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 8
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
(with a box that was colored green or white) thusrequiring them to draw on their learned knowledge ofthe location-contingent prior distribution associatedwith that trial As in Experiment 1 the 1600 trials inExperiment 2 (all conditions from Experiment 1 plus400 trials in this extra condition) were again split upinto the relevant prior and likelihood conditions (theno sensory information condition is statisticallyequivalent to a likelihood condition with infiniteuncertainty) and with each condition being furthersplit into four temporal bins to study the influence oftask exposure
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to thepurpose of the study provided informed writtenconsent and did not participate in Experiment 1 TheUniversity of Rochesterrsquos institutional review boardapproved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with task instructions that were nearlyidentical to those provided to participants in Experi-ment 1 Specifically in addition to the instructions fromExperiment 1 they were also provided with thefollowing instructions
There will also be some trials in which you willbe the first person to guess the location of thebucket In these trials rather than seeing dots onthe screen you will see a briefly flashed white orgreen rectangle which will indicate the side of thescreen that the invisible bucket is located atmdashthebucket could be located anywhere inside thatrectangle Again your job is to try to figure outwhere the bucket is actually located
On each trial of the experiment the procedure wasidentical to that used in Experiment 1 except for theextra condition in which no sensory information waspresented In the trials corresponding to this conditionafter participants touched the GO button they saw abriefly flashed green or white rectangle spanning eitherthe left half or the right half of the display Afterparticipants provided a response feedback was pro-vided as in all the other conditions Participants carriedout a total of 1600 trials split across four experimentalblocks Short breaks were allowed between blocks and
the total experimental duration including breaks wasapproximately an hour
Data analysis
As in Experiment 1 for the trials in which sensoryinformation was available we used linear regression tocompute the weight (wl) assigned to the centroid of thecluster of dots (the likelihood) with the weightsassigned to the mean of the underlying location-contingent target distribution for that trial (the prior)being defined as (1 wl) For the trials in which nosensory information was available we computedparticipantsrsquo mean responses across all trials in eachtemporal bin As in Experiment 1 we again focused onperformance in the vertical dimension
Results and discussion
We first examined the weights assigned by partici-pants to the likelihood and the prior for the trials inwhich sensory information was available and foundthat their behavior was similar to that in Experiment 1(Figure 3) Specifically in line with the Bayes-optimalmodel (Model 3) by the end of exposure to the task inExperiment 2 (ie in the final temporal bin) observersassigned a reliably smaller weight to the likelihood (anda greater weight to the prior) as the sensory informa-tion decreased in reliability (Figure 4) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 4584 p 00001 and aninteraction between the two factors F(2 14)frac14 383 pfrac140047 Furthermore for each prior condition we againfound an interaction between exposure and likelihoodvariance Specifically in a 4 (temporal bin) 3 3(likelihood variance) repeated measures ANOVAcarried out over participantsrsquo weights in the broad priorcondition there was a main effect of temporal bin F(321)frac14 749 pfrac14 0001 a main effect of likelihoodvariance F(2 14)frac14 3421 p 00001 and aninteraction between the two factors F(6 42)frac14 284 pfrac14002 Similarly in a 4 (temporal bin) 3 3 (likelihoodvariance) repeated measures ANOVA carried out overparticipantsrsquo weights in the narrow prior conditionthere was a marginal main effect of temporal bin F(321)frac14 287 pfrac14 006 a main effect of likelihoodvariance F(2 14)frac14 1772 p 0001 and a marginalinteraction between the two factors F(6 42)frac14 230 pfrac140052 Finally participants assigned a smaller weight tothe likelihood particularly in the high likelihoodvariance condition when the target was drawn fromthe narrow prior than when the target was drawn fromthe broad prior In a 4 (temporal bin) 3 2 (prior
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 9
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
variance) repeated measures ANOVA carried out overparticipantsrsquo weights in the high likelihood variancecondition there was a main effect of temporal bin F(321)frac14 555 p 0001 and a main effect of priorvariance F(1 7) frac14 789 p frac14 0026 These findingstherefore represent a replication of our results fromExperiment 1 To further confirm that these resultsreplicate the results from Experiment 1 we carried outa 2 (experiment) 3 4 (temporal bin) 3 3 (likelihoodvariance) mixed ANOVA with experiment as abetween-participants factor and temporal bin andlikelihood variance as within-participant factors overparticipantsrsquo weights in both the broad and narrowprior conditions In each case we found no interactionbetween experiment and any other factor (all ps 017)
Importantly in the conditions in which no sensoryinformation was available (ie no cluster of dots waspresented) we found that within the first temporal bin(the first 100 of the 400 prior-only trials) participantsrsquoestimates of the target location were on averageindistinguishable from the true prior mean locations(plus or minus motor noise estimated from the lowlikelihood variance conditions broad prior t7frac14 173 pfrac14 013 narrow prior t7 frac14 124 p frac14 025) Participantswere therefore able to rapidly learn the prior meanseven when presented with a complex generative model(Figure 5) extending results from previous workexamining such behavior in the presence of simplergenerative models It is important to note howeverthat in the conditions where sensory information wasavailable which were randomly interleaved with theprior-only conditions participantsrsquo weights continue tochange throughout the experiment (Figure 4) This
Figure 4 Weights assigned to the centroid of the sensory information in Experiment 2 As in Experiment 1 participants in Experiment
2 relied less on the sensory information and more on the priors as the variance of the sensory information increased in line with the
predictions of Bayes-optimal behavior This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to
the sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin again included 300 trials split between the two prior conditions and the four bins of trials are depicted
in temporal order Columns represent means and error bars represent SEM across participants
Figure 5 Mean response location in the absence of sensory
information Participants in Experiment 2 rapidly learned the
true prior mean for both the broad (top) and narrow prior
conditions (bottom) Participantsrsquo mean response location in
the trials in which no sensory information was available was
indistinguishable from the true prior means plus or minus
motor noise within the first temporal bin For illustrative
purposes the y-axis represents the mean deviation from the
true mean in each prior condition Each temporal bin included
100 trials split between the two prior conditions and the four
bins of trials are depicted in temporal order Columns represent
means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 10
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
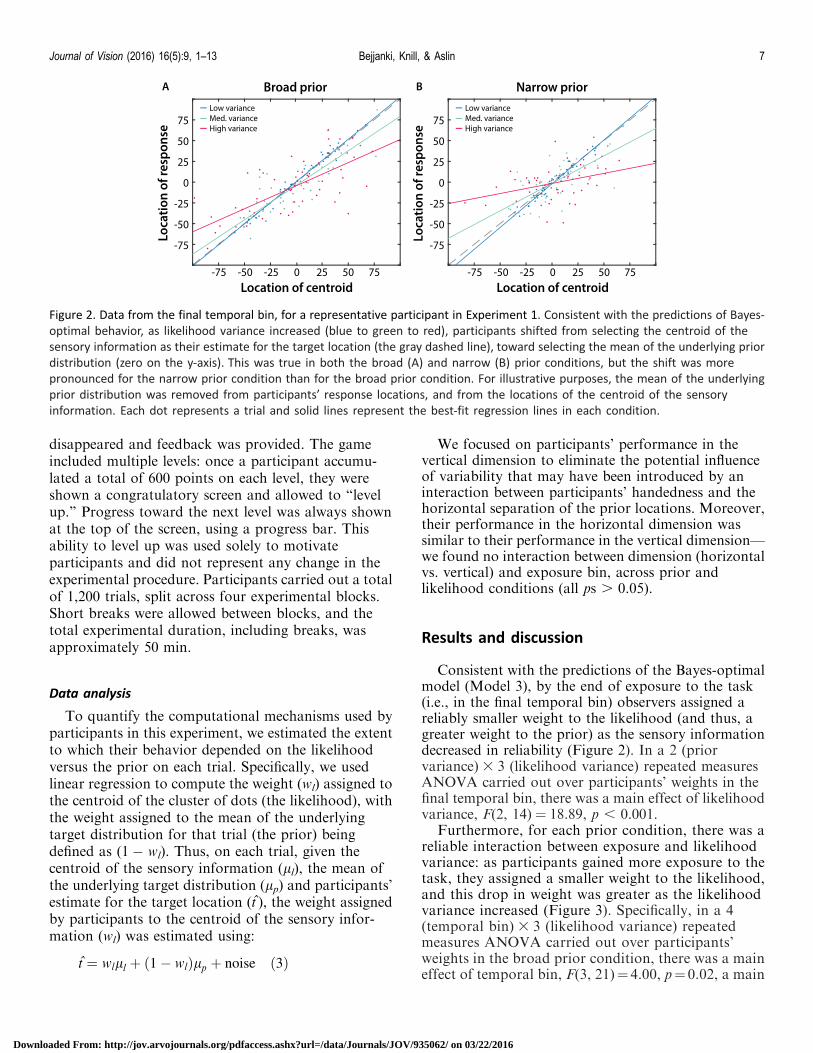
disappeared and feedback was provided The gameincluded multiple levels once a participant accumu-lated a total of 600 points on each level they wereshown a congratulatory screen and allowed to lsquolsquoleveluprsquorsquo Progress toward the next level was always shownat the top of the screen using a progress bar Thisability to level up was used solely to motivateparticipants and did not represent any change in theexperimental procedure Participants carried out a totalof 1200 trials split across four experimental blocksShort breaks were allowed between blocks and thetotal experimental duration including breaks wasapproximately 50 min
Data analysis
To quantify the computational mechanisms used byparticipants in this experiment we estimated the extentto which their behavior depended on the likelihoodversus the prior on each trial Specifically we usedlinear regression to compute the weight (wl) assigned tothe centroid of the cluster of dots (the likelihood) withthe weight assigned to the mean of the underlyingtarget distribution for that trial (the prior) beingdefined as (1 wl) Thus on each trial given thecentroid of the sensory information (ll) the mean ofthe underlying target distribution (lp) and participantsrsquoestimate for the target location (t ) the weight assignedby participants to the centroid of the sensory infor-mation (wl) was estimated using
t frac14 wlll thorn eth1 wlTHORNlp thorn noise eth3THORN
We focused on participantsrsquo performance in thevertical dimension to eliminate the potential influenceof variability that may have been introduced by aninteraction between participantsrsquo handedness and thehorizontal separation of the prior locations Moreovertheir performance in the horizontal dimension wassimilar to their performance in the vertical dimensionmdashwe found no interaction between dimension (horizontalvs vertical) and exposure bin across prior andlikelihood conditions (all ps 005)
Results and discussion
Consistent with the predictions of the Bayes-optimalmodel (Model 3) by the end of exposure to the task(ie in the final temporal bin) observers assigned areliably smaller weight to the likelihood (and thus agreater weight to the prior) as the sensory informationdecreased in reliability (Figure 2) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 1889 p 0001
Furthermore for each prior condition there was areliable interaction between exposure and likelihoodvariance as participants gained more exposure to thetask they assigned a smaller weight to the likelihoodand this drop in weight was greater as the likelihoodvariance increased (Figure 3) Specifically in a 4(temporal bin) 3 3 (likelihood variance) repeatedmeasures ANOVA carried out over participantsrsquoweights in the broad prior condition there was a maineffect of temporal bin F(3 21)frac14 400 pfrac14 002 a main
Figure 2 Data from the final temporal bin for a representative participant in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior as likelihood variance increased (blue to green to red) participants shifted from selecting the centroid of the
sensory information as their estimate for the target location (the gray dashed line) toward selecting the mean of the underlying prior
distribution (zero on the y-axis) This was true in both the broad (A) and narrow (B) prior conditions but the shift was more
pronounced for the narrow prior condition than for the broad prior condition For illustrative purposes the mean of the underlying
prior distribution was removed from participantsrsquo response locations and from the locations of the centroid of the sensory
information Each dot represents a trial and solid lines represent the best-fit regression lines in each condition
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 7
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
effect of likelihood variance F(2 14) frac14 2117 p
00001 and an interaction between the two factorsF(6 42)frac14 522 p 0001 Similarly in a 4 (temporalbin) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thenarrow prior condition there was a main effect oftemporal bin F(3 21)frac14 906 p 0001 a main effectof likelihood variance F(2 14)frac141224 p 0001 andan interaction between the two factors F(6 42)frac14547p 0001 These findings are inconsistent with Model1 which predicts a weight of 1 to the sensoryinformation across all the likelihood and priorconditions and no change in participantsrsquo weights as afunction of exposure to the task Furthermore incontrast to the predictions of Model 2 we found thatthe drop in the weight assigned by participants to thelikelihood as a function of exposure to the taskparticularly in the high likelihood variance conditionwas greater for trials in which the target was drawnfrom the narrow prior than when the target wasdrawn from the broad prior In a 4 (temporal bin)3 2(prior variance) repeated measures ANOVA carriedout over participantsrsquo weights in the high likelihoodvariance condition we saw a main effect of temporalbin F(3 21) frac14 829 p 0001 and an interactionbetween temporal bin and prior variance F(3 21) frac14307 p frac14 005 This finding suggests that participantsare sensitive to and learn both the means and therelative variances of the underlying prior distribu-tions Taken together this pattern of results providesclear evidence in support of Model 3mdashthe hypothesisthat human observers learn the complex generativemodel and use this learned knowledge in a manner
that is consistent with the predictions of Bayes-optimal behavior
Experiment 2 Exploring thedynamics of learning
While the results from Experiment 1 support thehypothesis that participants learn the complex gener-ative model and use this knowledge in a statisticallyefficient manner the dynamics of this learning remainunclear For instance prior work (Berniker et al2010) has shown that when presented with stimulidrawn from simple generative models human ob-servers rapidly learn the prior mean but it takes themmany more trials to learn the prior variance InExperiment 2 with a new group of participants weexamined the dynamics of learning with complexgenerative models by including an extra conditionrandomly interleaved with all the conditions used inthe first experiment in which no sensory informationwas presented In this condition observers thus had toestimate the position of the target based solely on theirlearned knowledge (up to that point) about where thetarget was likely to occur (ie based on their priorknowledge) thereby allowing us to analyze theirevolving learned knowledge of the location-contingentgenerative model as a function of exposure to the taskParticipants carried out 400 trials of this conditionsplit evenly between the two prior distributions Oneach trial they were cued to estimate the location ofthe target on either the left or the right of the display
Figure 3 Weights assigned to the centroid of the sensory information in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior participants in Experiment 1 relied less on the sensory information and more on the priors as the variance of the
sensory information increased This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to the
sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin included 300 trials split between the two prior conditions and the four bins of trials are depicted in
temporal order Columns represent means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 8
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
(with a box that was colored green or white) thusrequiring them to draw on their learned knowledge ofthe location-contingent prior distribution associatedwith that trial As in Experiment 1 the 1600 trials inExperiment 2 (all conditions from Experiment 1 plus400 trials in this extra condition) were again split upinto the relevant prior and likelihood conditions (theno sensory information condition is statisticallyequivalent to a likelihood condition with infiniteuncertainty) and with each condition being furthersplit into four temporal bins to study the influence oftask exposure
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to thepurpose of the study provided informed writtenconsent and did not participate in Experiment 1 TheUniversity of Rochesterrsquos institutional review boardapproved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with task instructions that were nearlyidentical to those provided to participants in Experi-ment 1 Specifically in addition to the instructions fromExperiment 1 they were also provided with thefollowing instructions
There will also be some trials in which you willbe the first person to guess the location of thebucket In these trials rather than seeing dots onthe screen you will see a briefly flashed white orgreen rectangle which will indicate the side of thescreen that the invisible bucket is located atmdashthebucket could be located anywhere inside thatrectangle Again your job is to try to figure outwhere the bucket is actually located
On each trial of the experiment the procedure wasidentical to that used in Experiment 1 except for theextra condition in which no sensory information waspresented In the trials corresponding to this conditionafter participants touched the GO button they saw abriefly flashed green or white rectangle spanning eitherthe left half or the right half of the display Afterparticipants provided a response feedback was pro-vided as in all the other conditions Participants carriedout a total of 1600 trials split across four experimentalblocks Short breaks were allowed between blocks and
the total experimental duration including breaks wasapproximately an hour
Data analysis
As in Experiment 1 for the trials in which sensoryinformation was available we used linear regression tocompute the weight (wl) assigned to the centroid of thecluster of dots (the likelihood) with the weightsassigned to the mean of the underlying location-contingent target distribution for that trial (the prior)being defined as (1 wl) For the trials in which nosensory information was available we computedparticipantsrsquo mean responses across all trials in eachtemporal bin As in Experiment 1 we again focused onperformance in the vertical dimension
Results and discussion
We first examined the weights assigned by partici-pants to the likelihood and the prior for the trials inwhich sensory information was available and foundthat their behavior was similar to that in Experiment 1(Figure 3) Specifically in line with the Bayes-optimalmodel (Model 3) by the end of exposure to the task inExperiment 2 (ie in the final temporal bin) observersassigned a reliably smaller weight to the likelihood (anda greater weight to the prior) as the sensory informa-tion decreased in reliability (Figure 4) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 4584 p 00001 and aninteraction between the two factors F(2 14)frac14 383 pfrac140047 Furthermore for each prior condition we againfound an interaction between exposure and likelihoodvariance Specifically in a 4 (temporal bin) 3 3(likelihood variance) repeated measures ANOVAcarried out over participantsrsquo weights in the broad priorcondition there was a main effect of temporal bin F(321)frac14 749 pfrac14 0001 a main effect of likelihoodvariance F(2 14)frac14 3421 p 00001 and aninteraction between the two factors F(6 42)frac14 284 pfrac14002 Similarly in a 4 (temporal bin) 3 3 (likelihoodvariance) repeated measures ANOVA carried out overparticipantsrsquo weights in the narrow prior conditionthere was a marginal main effect of temporal bin F(321)frac14 287 pfrac14 006 a main effect of likelihoodvariance F(2 14)frac14 1772 p 0001 and a marginalinteraction between the two factors F(6 42)frac14 230 pfrac140052 Finally participants assigned a smaller weight tothe likelihood particularly in the high likelihoodvariance condition when the target was drawn fromthe narrow prior than when the target was drawn fromthe broad prior In a 4 (temporal bin) 3 2 (prior
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 9
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
variance) repeated measures ANOVA carried out overparticipantsrsquo weights in the high likelihood variancecondition there was a main effect of temporal bin F(321)frac14 555 p 0001 and a main effect of priorvariance F(1 7) frac14 789 p frac14 0026 These findingstherefore represent a replication of our results fromExperiment 1 To further confirm that these resultsreplicate the results from Experiment 1 we carried outa 2 (experiment) 3 4 (temporal bin) 3 3 (likelihoodvariance) mixed ANOVA with experiment as abetween-participants factor and temporal bin andlikelihood variance as within-participant factors overparticipantsrsquo weights in both the broad and narrowprior conditions In each case we found no interactionbetween experiment and any other factor (all ps 017)
Importantly in the conditions in which no sensoryinformation was available (ie no cluster of dots waspresented) we found that within the first temporal bin(the first 100 of the 400 prior-only trials) participantsrsquoestimates of the target location were on averageindistinguishable from the true prior mean locations(plus or minus motor noise estimated from the lowlikelihood variance conditions broad prior t7frac14 173 pfrac14 013 narrow prior t7 frac14 124 p frac14 025) Participantswere therefore able to rapidly learn the prior meanseven when presented with a complex generative model(Figure 5) extending results from previous workexamining such behavior in the presence of simplergenerative models It is important to note howeverthat in the conditions where sensory information wasavailable which were randomly interleaved with theprior-only conditions participantsrsquo weights continue tochange throughout the experiment (Figure 4) This
Figure 4 Weights assigned to the centroid of the sensory information in Experiment 2 As in Experiment 1 participants in Experiment
2 relied less on the sensory information and more on the priors as the variance of the sensory information increased in line with the
predictions of Bayes-optimal behavior This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to
the sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin again included 300 trials split between the two prior conditions and the four bins of trials are depicted
in temporal order Columns represent means and error bars represent SEM across participants
Figure 5 Mean response location in the absence of sensory
information Participants in Experiment 2 rapidly learned the
true prior mean for both the broad (top) and narrow prior
conditions (bottom) Participantsrsquo mean response location in
the trials in which no sensory information was available was
indistinguishable from the true prior means plus or minus
motor noise within the first temporal bin For illustrative
purposes the y-axis represents the mean deviation from the
true mean in each prior condition Each temporal bin included
100 trials split between the two prior conditions and the four
bins of trials are depicted in temporal order Columns represent
means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 10
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
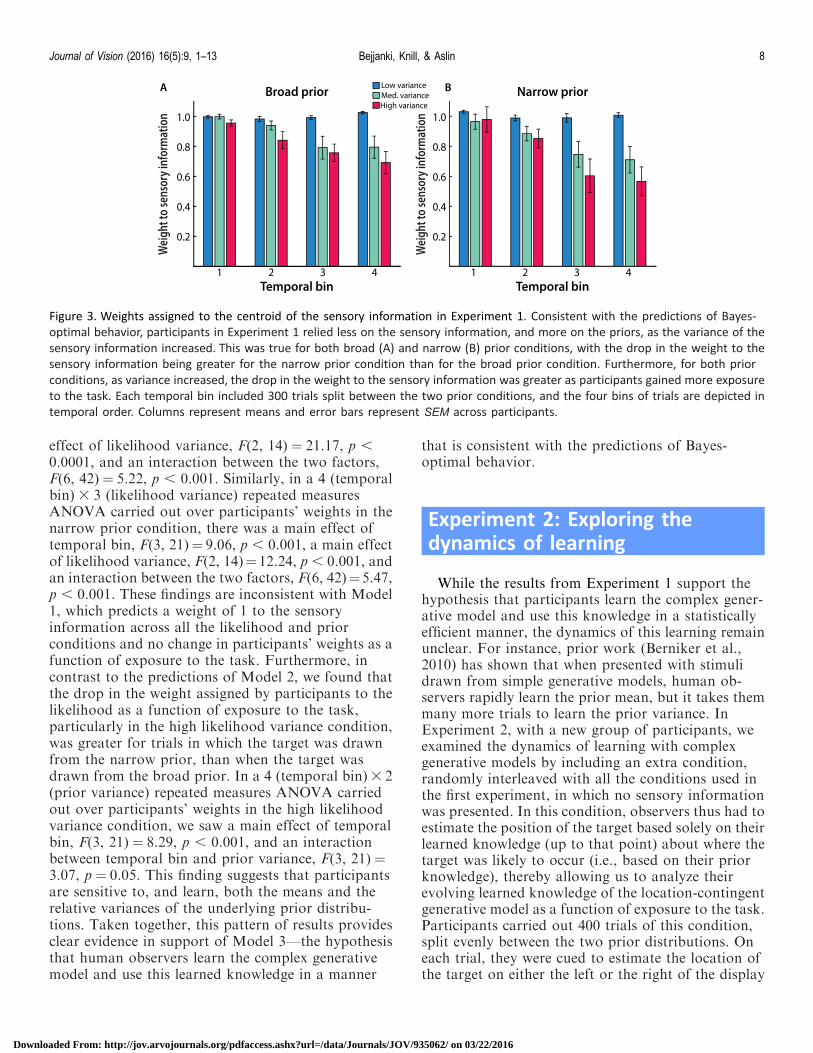
effect of likelihood variance F(2 14) frac14 2117 p
00001 and an interaction between the two factorsF(6 42)frac14 522 p 0001 Similarly in a 4 (temporalbin) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thenarrow prior condition there was a main effect oftemporal bin F(3 21)frac14 906 p 0001 a main effectof likelihood variance F(2 14)frac141224 p 0001 andan interaction between the two factors F(6 42)frac14547p 0001 These findings are inconsistent with Model1 which predicts a weight of 1 to the sensoryinformation across all the likelihood and priorconditions and no change in participantsrsquo weights as afunction of exposure to the task Furthermore incontrast to the predictions of Model 2 we found thatthe drop in the weight assigned by participants to thelikelihood as a function of exposure to the taskparticularly in the high likelihood variance conditionwas greater for trials in which the target was drawnfrom the narrow prior than when the target wasdrawn from the broad prior In a 4 (temporal bin)3 2(prior variance) repeated measures ANOVA carriedout over participantsrsquo weights in the high likelihoodvariance condition we saw a main effect of temporalbin F(3 21) frac14 829 p 0001 and an interactionbetween temporal bin and prior variance F(3 21) frac14307 p frac14 005 This finding suggests that participantsare sensitive to and learn both the means and therelative variances of the underlying prior distribu-tions Taken together this pattern of results providesclear evidence in support of Model 3mdashthe hypothesisthat human observers learn the complex generativemodel and use this learned knowledge in a manner
that is consistent with the predictions of Bayes-optimal behavior
Experiment 2 Exploring thedynamics of learning
While the results from Experiment 1 support thehypothesis that participants learn the complex gener-ative model and use this knowledge in a statisticallyefficient manner the dynamics of this learning remainunclear For instance prior work (Berniker et al2010) has shown that when presented with stimulidrawn from simple generative models human ob-servers rapidly learn the prior mean but it takes themmany more trials to learn the prior variance InExperiment 2 with a new group of participants weexamined the dynamics of learning with complexgenerative models by including an extra conditionrandomly interleaved with all the conditions used inthe first experiment in which no sensory informationwas presented In this condition observers thus had toestimate the position of the target based solely on theirlearned knowledge (up to that point) about where thetarget was likely to occur (ie based on their priorknowledge) thereby allowing us to analyze theirevolving learned knowledge of the location-contingentgenerative model as a function of exposure to the taskParticipants carried out 400 trials of this conditionsplit evenly between the two prior distributions Oneach trial they were cued to estimate the location ofthe target on either the left or the right of the display
Figure 3 Weights assigned to the centroid of the sensory information in Experiment 1 Consistent with the predictions of Bayes-
optimal behavior participants in Experiment 1 relied less on the sensory information and more on the priors as the variance of the
sensory information increased This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to the
sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin included 300 trials split between the two prior conditions and the four bins of trials are depicted in
temporal order Columns represent means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 8
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
(with a box that was colored green or white) thusrequiring them to draw on their learned knowledge ofthe location-contingent prior distribution associatedwith that trial As in Experiment 1 the 1600 trials inExperiment 2 (all conditions from Experiment 1 plus400 trials in this extra condition) were again split upinto the relevant prior and likelihood conditions (theno sensory information condition is statisticallyequivalent to a likelihood condition with infiniteuncertainty) and with each condition being furthersplit into four temporal bins to study the influence oftask exposure
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to thepurpose of the study provided informed writtenconsent and did not participate in Experiment 1 TheUniversity of Rochesterrsquos institutional review boardapproved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with task instructions that were nearlyidentical to those provided to participants in Experi-ment 1 Specifically in addition to the instructions fromExperiment 1 they were also provided with thefollowing instructions
There will also be some trials in which you willbe the first person to guess the location of thebucket In these trials rather than seeing dots onthe screen you will see a briefly flashed white orgreen rectangle which will indicate the side of thescreen that the invisible bucket is located atmdashthebucket could be located anywhere inside thatrectangle Again your job is to try to figure outwhere the bucket is actually located
On each trial of the experiment the procedure wasidentical to that used in Experiment 1 except for theextra condition in which no sensory information waspresented In the trials corresponding to this conditionafter participants touched the GO button they saw abriefly flashed green or white rectangle spanning eitherthe left half or the right half of the display Afterparticipants provided a response feedback was pro-vided as in all the other conditions Participants carriedout a total of 1600 trials split across four experimentalblocks Short breaks were allowed between blocks and
the total experimental duration including breaks wasapproximately an hour
Data analysis
As in Experiment 1 for the trials in which sensoryinformation was available we used linear regression tocompute the weight (wl) assigned to the centroid of thecluster of dots (the likelihood) with the weightsassigned to the mean of the underlying location-contingent target distribution for that trial (the prior)being defined as (1 wl) For the trials in which nosensory information was available we computedparticipantsrsquo mean responses across all trials in eachtemporal bin As in Experiment 1 we again focused onperformance in the vertical dimension
Results and discussion
We first examined the weights assigned by partici-pants to the likelihood and the prior for the trials inwhich sensory information was available and foundthat their behavior was similar to that in Experiment 1(Figure 3) Specifically in line with the Bayes-optimalmodel (Model 3) by the end of exposure to the task inExperiment 2 (ie in the final temporal bin) observersassigned a reliably smaller weight to the likelihood (anda greater weight to the prior) as the sensory informa-tion decreased in reliability (Figure 4) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 4584 p 00001 and aninteraction between the two factors F(2 14)frac14 383 pfrac140047 Furthermore for each prior condition we againfound an interaction between exposure and likelihoodvariance Specifically in a 4 (temporal bin) 3 3(likelihood variance) repeated measures ANOVAcarried out over participantsrsquo weights in the broad priorcondition there was a main effect of temporal bin F(321)frac14 749 pfrac14 0001 a main effect of likelihoodvariance F(2 14)frac14 3421 p 00001 and aninteraction between the two factors F(6 42)frac14 284 pfrac14002 Similarly in a 4 (temporal bin) 3 3 (likelihoodvariance) repeated measures ANOVA carried out overparticipantsrsquo weights in the narrow prior conditionthere was a marginal main effect of temporal bin F(321)frac14 287 pfrac14 006 a main effect of likelihoodvariance F(2 14)frac14 1772 p 0001 and a marginalinteraction between the two factors F(6 42)frac14 230 pfrac140052 Finally participants assigned a smaller weight tothe likelihood particularly in the high likelihoodvariance condition when the target was drawn fromthe narrow prior than when the target was drawn fromthe broad prior In a 4 (temporal bin) 3 2 (prior
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 9
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
variance) repeated measures ANOVA carried out overparticipantsrsquo weights in the high likelihood variancecondition there was a main effect of temporal bin F(321)frac14 555 p 0001 and a main effect of priorvariance F(1 7) frac14 789 p frac14 0026 These findingstherefore represent a replication of our results fromExperiment 1 To further confirm that these resultsreplicate the results from Experiment 1 we carried outa 2 (experiment) 3 4 (temporal bin) 3 3 (likelihoodvariance) mixed ANOVA with experiment as abetween-participants factor and temporal bin andlikelihood variance as within-participant factors overparticipantsrsquo weights in both the broad and narrowprior conditions In each case we found no interactionbetween experiment and any other factor (all ps 017)
Importantly in the conditions in which no sensoryinformation was available (ie no cluster of dots waspresented) we found that within the first temporal bin(the first 100 of the 400 prior-only trials) participantsrsquoestimates of the target location were on averageindistinguishable from the true prior mean locations(plus or minus motor noise estimated from the lowlikelihood variance conditions broad prior t7frac14 173 pfrac14 013 narrow prior t7 frac14 124 p frac14 025) Participantswere therefore able to rapidly learn the prior meanseven when presented with a complex generative model(Figure 5) extending results from previous workexamining such behavior in the presence of simplergenerative models It is important to note howeverthat in the conditions where sensory information wasavailable which were randomly interleaved with theprior-only conditions participantsrsquo weights continue tochange throughout the experiment (Figure 4) This
Figure 4 Weights assigned to the centroid of the sensory information in Experiment 2 As in Experiment 1 participants in Experiment
2 relied less on the sensory information and more on the priors as the variance of the sensory information increased in line with the
predictions of Bayes-optimal behavior This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to
the sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin again included 300 trials split between the two prior conditions and the four bins of trials are depicted
in temporal order Columns represent means and error bars represent SEM across participants
Figure 5 Mean response location in the absence of sensory
information Participants in Experiment 2 rapidly learned the
true prior mean for both the broad (top) and narrow prior
conditions (bottom) Participantsrsquo mean response location in
the trials in which no sensory information was available was
indistinguishable from the true prior means plus or minus
motor noise within the first temporal bin For illustrative
purposes the y-axis represents the mean deviation from the
true mean in each prior condition Each temporal bin included
100 trials split between the two prior conditions and the four
bins of trials are depicted in temporal order Columns represent
means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 10
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016

(with a box that was colored green or white) thusrequiring them to draw on their learned knowledge ofthe location-contingent prior distribution associatedwith that trial As in Experiment 1 the 1600 trials inExperiment 2 (all conditions from Experiment 1 plus400 trials in this extra condition) were again split upinto the relevant prior and likelihood conditions (theno sensory information condition is statisticallyequivalent to a likelihood condition with infiniteuncertainty) and with each condition being furthersplit into four temporal bins to study the influence oftask exposure
Methods
Participants
Eight undergraduate students at the University ofRochester participated in this experiment in exchangefor monetary compensation Each participant hadnormal or corrected-to-normal vision was naıve to thepurpose of the study provided informed writtenconsent and did not participate in Experiment 1 TheUniversity of Rochesterrsquos institutional review boardapproved all experimental protocols
Procedure
Before the start of the experiment participants wereprovided with task instructions that were nearlyidentical to those provided to participants in Experi-ment 1 Specifically in addition to the instructions fromExperiment 1 they were also provided with thefollowing instructions
There will also be some trials in which you willbe the first person to guess the location of thebucket In these trials rather than seeing dots onthe screen you will see a briefly flashed white orgreen rectangle which will indicate the side of thescreen that the invisible bucket is located atmdashthebucket could be located anywhere inside thatrectangle Again your job is to try to figure outwhere the bucket is actually located
On each trial of the experiment the procedure wasidentical to that used in Experiment 1 except for theextra condition in which no sensory information waspresented In the trials corresponding to this conditionafter participants touched the GO button they saw abriefly flashed green or white rectangle spanning eitherthe left half or the right half of the display Afterparticipants provided a response feedback was pro-vided as in all the other conditions Participants carriedout a total of 1600 trials split across four experimentalblocks Short breaks were allowed between blocks and
the total experimental duration including breaks wasapproximately an hour
Data analysis
As in Experiment 1 for the trials in which sensoryinformation was available we used linear regression tocompute the weight (wl) assigned to the centroid of thecluster of dots (the likelihood) with the weightsassigned to the mean of the underlying location-contingent target distribution for that trial (the prior)being defined as (1 wl) For the trials in which nosensory information was available we computedparticipantsrsquo mean responses across all trials in eachtemporal bin As in Experiment 1 we again focused onperformance in the vertical dimension
Results and discussion
We first examined the weights assigned by partici-pants to the likelihood and the prior for the trials inwhich sensory information was available and foundthat their behavior was similar to that in Experiment 1(Figure 3) Specifically in line with the Bayes-optimalmodel (Model 3) by the end of exposure to the task inExperiment 2 (ie in the final temporal bin) observersassigned a reliably smaller weight to the likelihood (anda greater weight to the prior) as the sensory informa-tion decreased in reliability (Figure 4) In a 2 (priorvariance) 3 3 (likelihood variance) repeated measuresANOVA carried out over participantsrsquo weights in thefinal temporal bin there was a main effect of likelihoodvariance F(2 14)frac14 4584 p 00001 and aninteraction between the two factors F(2 14)frac14 383 pfrac140047 Furthermore for each prior condition we againfound an interaction between exposure and likelihoodvariance Specifically in a 4 (temporal bin) 3 3(likelihood variance) repeated measures ANOVAcarried out over participantsrsquo weights in the broad priorcondition there was a main effect of temporal bin F(321)frac14 749 pfrac14 0001 a main effect of likelihoodvariance F(2 14)frac14 3421 p 00001 and aninteraction between the two factors F(6 42)frac14 284 pfrac14002 Similarly in a 4 (temporal bin) 3 3 (likelihoodvariance) repeated measures ANOVA carried out overparticipantsrsquo weights in the narrow prior conditionthere was a marginal main effect of temporal bin F(321)frac14 287 pfrac14 006 a main effect of likelihoodvariance F(2 14)frac14 1772 p 0001 and a marginalinteraction between the two factors F(6 42)frac14 230 pfrac140052 Finally participants assigned a smaller weight tothe likelihood particularly in the high likelihoodvariance condition when the target was drawn fromthe narrow prior than when the target was drawn fromthe broad prior In a 4 (temporal bin) 3 2 (prior
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 9
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
variance) repeated measures ANOVA carried out overparticipantsrsquo weights in the high likelihood variancecondition there was a main effect of temporal bin F(321)frac14 555 p 0001 and a main effect of priorvariance F(1 7) frac14 789 p frac14 0026 These findingstherefore represent a replication of our results fromExperiment 1 To further confirm that these resultsreplicate the results from Experiment 1 we carried outa 2 (experiment) 3 4 (temporal bin) 3 3 (likelihoodvariance) mixed ANOVA with experiment as abetween-participants factor and temporal bin andlikelihood variance as within-participant factors overparticipantsrsquo weights in both the broad and narrowprior conditions In each case we found no interactionbetween experiment and any other factor (all ps 017)
Importantly in the conditions in which no sensoryinformation was available (ie no cluster of dots waspresented) we found that within the first temporal bin(the first 100 of the 400 prior-only trials) participantsrsquoestimates of the target location were on averageindistinguishable from the true prior mean locations(plus or minus motor noise estimated from the lowlikelihood variance conditions broad prior t7frac14 173 pfrac14 013 narrow prior t7 frac14 124 p frac14 025) Participantswere therefore able to rapidly learn the prior meanseven when presented with a complex generative model(Figure 5) extending results from previous workexamining such behavior in the presence of simplergenerative models It is important to note howeverthat in the conditions where sensory information wasavailable which were randomly interleaved with theprior-only conditions participantsrsquo weights continue tochange throughout the experiment (Figure 4) This
Figure 4 Weights assigned to the centroid of the sensory information in Experiment 2 As in Experiment 1 participants in Experiment
2 relied less on the sensory information and more on the priors as the variance of the sensory information increased in line with the
predictions of Bayes-optimal behavior This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to
the sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin again included 300 trials split between the two prior conditions and the four bins of trials are depicted
in temporal order Columns represent means and error bars represent SEM across participants
Figure 5 Mean response location in the absence of sensory
information Participants in Experiment 2 rapidly learned the
true prior mean for both the broad (top) and narrow prior
conditions (bottom) Participantsrsquo mean response location in
the trials in which no sensory information was available was
indistinguishable from the true prior means plus or minus
motor noise within the first temporal bin For illustrative
purposes the y-axis represents the mean deviation from the
true mean in each prior condition Each temporal bin included
100 trials split between the two prior conditions and the four
bins of trials are depicted in temporal order Columns represent
means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 10
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
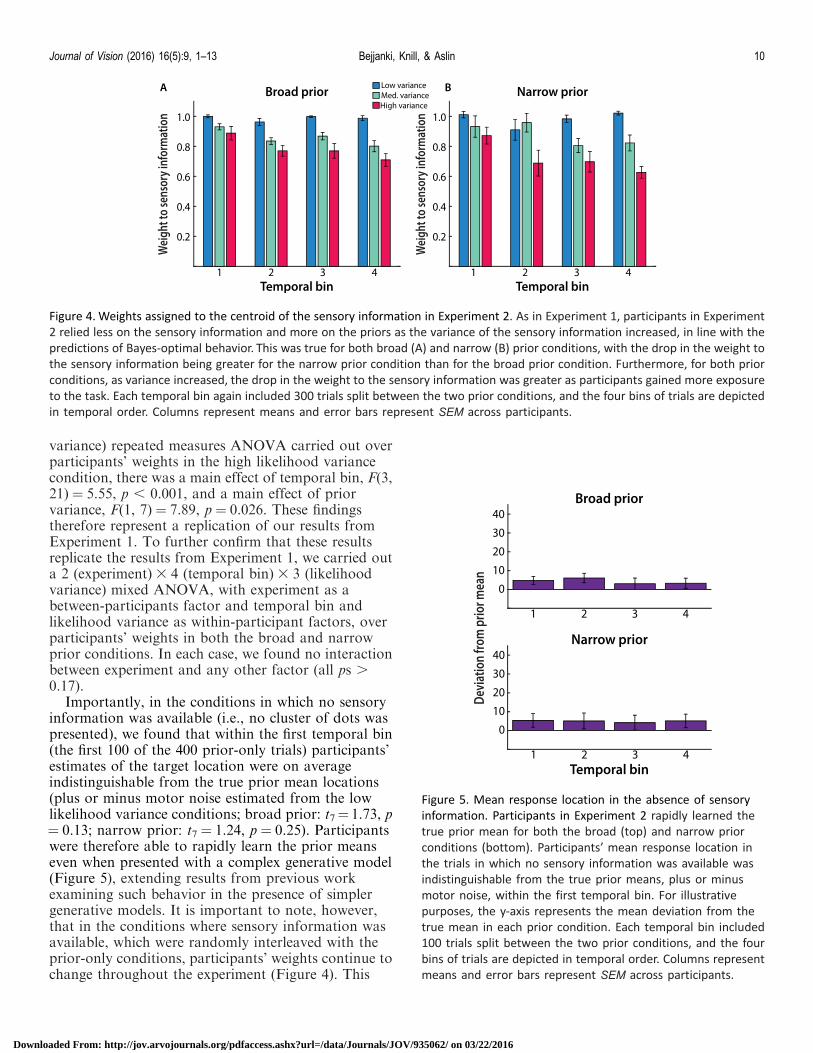
variance) repeated measures ANOVA carried out overparticipantsrsquo weights in the high likelihood variancecondition there was a main effect of temporal bin F(321)frac14 555 p 0001 and a main effect of priorvariance F(1 7) frac14 789 p frac14 0026 These findingstherefore represent a replication of our results fromExperiment 1 To further confirm that these resultsreplicate the results from Experiment 1 we carried outa 2 (experiment) 3 4 (temporal bin) 3 3 (likelihoodvariance) mixed ANOVA with experiment as abetween-participants factor and temporal bin andlikelihood variance as within-participant factors overparticipantsrsquo weights in both the broad and narrowprior conditions In each case we found no interactionbetween experiment and any other factor (all ps 017)
Importantly in the conditions in which no sensoryinformation was available (ie no cluster of dots waspresented) we found that within the first temporal bin(the first 100 of the 400 prior-only trials) participantsrsquoestimates of the target location were on averageindistinguishable from the true prior mean locations(plus or minus motor noise estimated from the lowlikelihood variance conditions broad prior t7frac14 173 pfrac14 013 narrow prior t7 frac14 124 p frac14 025) Participantswere therefore able to rapidly learn the prior meanseven when presented with a complex generative model(Figure 5) extending results from previous workexamining such behavior in the presence of simplergenerative models It is important to note howeverthat in the conditions where sensory information wasavailable which were randomly interleaved with theprior-only conditions participantsrsquo weights continue tochange throughout the experiment (Figure 4) This
Figure 4 Weights assigned to the centroid of the sensory information in Experiment 2 As in Experiment 1 participants in Experiment
2 relied less on the sensory information and more on the priors as the variance of the sensory information increased in line with the
predictions of Bayes-optimal behavior This was true for both broad (A) and narrow (B) prior conditions with the drop in the weight to
the sensory information being greater for the narrow prior condition than for the broad prior condition Furthermore for both prior
conditions as variance increased the drop in the weight to the sensory information was greater as participants gained more exposure
to the task Each temporal bin again included 300 trials split between the two prior conditions and the four bins of trials are depicted
in temporal order Columns represent means and error bars represent SEM across participants
Figure 5 Mean response location in the absence of sensory
information Participants in Experiment 2 rapidly learned the
true prior mean for both the broad (top) and narrow prior
conditions (bottom) Participantsrsquo mean response location in
the trials in which no sensory information was available was
indistinguishable from the true prior means plus or minus
motor noise within the first temporal bin For illustrative
purposes the y-axis represents the mean deviation from the
true mean in each prior condition Each temporal bin included
100 trials split between the two prior conditions and the four
bins of trials are depicted in temporal order Columns represent
means and error bars represent SEM across participants
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 10
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016

pattern of results suggests that while participants learnthe prior means very rapidly it takes much moreexposure to learn the relative variances of the two priordistributions Moreover the finding that participantslearn the true prior means within the first temporal binbut their weights continue to change throughout theexperiment further contradicts the predictions ofModel 2 If participants were only learning and usingthe prior means and not the relative variances of theprior distributions (as predicted by Model 2) then wewould expect to see no change in participantsrsquo weightsbeyond the first temporal bin since they show nochange in their knowledge of the prior means beyondthis bin (as determined by performance in the no-sensory information condition)
Taken together the results from Experiments 1 and2 provide compelling evidence in support of thehypothesis that observers in our study learn and utilizecomplex generative models in combination withsensory information in a manner that is consistentwith the predictions of Bayes-optimal behavior (ieModel 3)
General discussion
Across two experiments we used a spatial localiza-tion task to examine the computational mechanismsemployed by human observers when faced with tasksinvolving complex generative models We obtainedcompelling evidence in support of the hypothesis thathuman observers learn such complex generative mod-els and integrate this learned knowledge with uncertainsensory information in a manner consistent with thepredictions of Bayes-optimal behavior At the outset ofour experiments participantsrsquo behavior was primarilydriven by sensory information (ie the centroid of thecluster of dots) and we saw no difference in the weightsassigned to sensory information across likelihood (iedifferences in cluster variance) and prior conditionsHowever by the end of both experiments (ie the finaltemporal bin) when participants had gained extensiveexposure to the complex generative model theyassigned a significantly lower weight to the sensoryinformation (and thus a greater weight to the mean ofthe trial-specific prior distribution) as the sensoryinformation decreased in reliability in a mannerconsistent with the predictions of the Bayesian modelThis pattern of performance rules out alternativesuboptimal strategies that could be used in this taskFurthermore extending prior findings with simplegenerative models (Berniker et al 2010) we found thateven when faced with a complex generative modelparticipants were able to rapidly learn the true priormeans based on just a few hundred trials of exposure
but it took them much longer to learn and use therelative variances of the prior distributions To ourknowledge this is the first study that has explicitlyexamined the extent to which human observers behavein a manner consistent with the predictions of theBayesian model in tasks that have the degree ofcomplexity approaching that encountered in theirnatural environment that is tasks involving multiplerandomly interleaved levels of sensory uncertainty andwhere the stimulus of interest is drawn from a mixturedistribution over multiple randomly interleaved envi-ronmental causes
In addition to demonstrating that our participantsrsquobehavior is consistent with the predictions of theBayesian model we can also evaluate the extent towhich participantsrsquo empirical weights approach theideal weights that would be assigned by a Bayes-optimal observer given the uncertainty implicit in thetwo sources of information available to the participantthe noisy sensory information and the learned knowl-edge of the location-contingent generative model Howclose are our participantsrsquo weights to this quantitativeideal In order to accurately compute these idealweights however we would need to characterize theuncertainty implicit in participantsrsquo internal estimatesof the prior and likelihood distributions therebyensuring that the ideal observer has access to the samequality of information as our participants Sinceparticipants were presented with multiple samples fromthe likelihood distribution (ie the cloud of dots) onevery trial the uncertainty implicit in it is computableby the participant on a trial-by-trial basis (see Sato ampKording 2014 for a scenario in which this was nottrue) It is therefore reasonable to approximateparticipantsrsquo internal estimate of likelihood uncertaintyby the true uncertainty implicit in the distributions usedto generate the cloud of dots on each trial (ie thestandard deviation of the dot-cloud distributiondivided by the square root of the number of dots)
Approximating the uncertainty implicit in partici-pantrsquos internal estimates of the prior distributions is amuch more challenging endeavor Participantsrsquo internalestimates of the prior distributions could only beobtained by integrating across trials since feedback oneach trial only provided a single sample from the trial-specific prior distribution Thus we would expectparticipantsrsquo internal estimates of the true priordistributions to evolve over the course of the experi-ment and only when participants had received enoughsamples from the underlying distributions to attainperfect knowledge of the prior distributions could weapproximate their internal estimates of these distribu-tions with the true prior distributions The challengestems from the fact that we had no independent way ofassaying participantsrsquo internal estimates of the priordistributions and thereby determining at what point in
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 11
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016

the experiment a given participant had received enoughsamples to attain such perfect knowledge
Despite the foregoing limitation we can computethe ideal weights that a Bayes-optimal observer whois assumed to have perfect knowledge of the priordistributions might assign to the sensory informationin Experiment 2 and evaluate the extent to whichparticipantsrsquo weights approach this quantitative idealThe ideal observer in this analysis is therefore assumedto have knowledge about the underlying targetdistributions that is an upper bound on the knowledgethat participants could learn during the course of theexperiment Comparing the ideal weights computed inthis manner to participantsrsquo empirical weights acrossprior and likelihood conditions we found that theirempirical weights moved closer to the ideal weights asa function of exposure to the task Furthermore bythe final temporal bin which represented the mostexposure to the underlying generative model partic-ipantsrsquo weights showed the same qualitative trends asthe ideal observer but they differed quantitativelyfrom the ideal weights in a manner that interactedwith both prior and likelihood variance Specificallywhile participantsrsquo weights matched the ideal weightsin the low likelihood variance condition they assigneda greater weight to the sensory information incomparison to the ideal observer in the medium andhigh likelihood variance conditions with the differ-ence increasing with an increase in likelihood variance(ie the change in participantsrsquo weights as a functionof likelihood variance was shallower than thatpredicted by the ideal observer see Tassinari et al2006 for a similar finding) Indeed this difference wasalso greater for the narrow prior condition than forthe broad prior condition (Supplementary Fig S1)This pattern of results suggests that even by the endof Experiment 2 participants may not have receivedenough exposure to samples from the underlyingtarget distributions to attain the perfect knowledge ofthe prior distributions assumed by the ideal observerin this analysis Indeed if participants began theexperiment with flat internal estimates for the priors(which is reasonable given that they did not have apriori reason to prefer one location on the display toanother) and sharpened these internal estimates as aresult of exposure we would expect to see exactly thispattern of results Consistent with this hypothesis in afollow-up experiment (see supplementary informa-tion) we found that when participants were providedwith double the number of samples from each priordistribution their weights moved significantly closerto the ideal weights (Supplementary Fig S2) Takentogether these results suggest that when faced withtasks involving such complex generative models therate at which human observers learn the generativemodel is dramatically slower than that observed
previously with simple generative models This slow-down is most likely due to the significantly increasedcomplexity involved in tracking and learning thecomplex generative model
Going forward a logical next step to furtherunderstanding of the computational mechanisms usedby human observers to learn from and use complexgenerative models would be to introduce uncertainty inthe environmental causes that make up the mixturecomponents of the generative model In the currentstudy as a first step we made the environmentaldistribution perfectly location contingent (ie predict-able) with one Gaussian distribution being centered onthe left of the display and the other being centered onthe right of the display As a next step includinguncertainty with regard to the underlying mixturecomponent that the target on each trial is drawn from(ie removing the location contingency) would intro-duce further complexity in the generative model andmake the task even more representative of real-worldtasks Ideal behavior in such tasks can still be modeledin the Bayesian framework by considering a hierarchi-cal process where the ideal observer first solves thelsquolsquocausal inferencersquorsquo problem (what underlying causeproduced the sample Kayser amp Shams 2015 Knill2007 Rohe amp Noppeney 2015 Shams amp Beierholm2010) and then uses the estimated sample to (a) build amodel of the underlying distribution for the inferredcause and (b) integrate that inferred causal distributionwith sensory information on subsequent trials to finallyinfer the target location
Keywords learning complex models Bayesian mod-eling spatial localization
Acknowledgments
This work was supported by research grants fromONR (MURI-N00014-07-1-0937 Daphne Bavelier PI)and NIH (HD-037082 Richard Aslin PI) We aregrateful to Holly Palmeri for help with recruiting andrunning participants
Our dear friend and collaborator David Knill diedtragically while this research project was in progressWe hope our conceptual approach analytic methodsand write-up of the results lives up to his highstandards He will be sorely missed
Commercial relationships noneCorresponding author Vikranth R BejjankiEmail bejjankiprincetoneduAddress Department of Psychology amp PrincetonNeuroscience Institute Princeton University Prince-ton NJ USA
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 12
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016
References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016

References
Adams W J Graf E W amp Ernst M O (2004)Experience can change the lsquolsquolight-from-aboversquorsquoprior Nature Neuroscience 7 1057ndash1058 doi101038nn1312
Bejjanki V R Clayards M Knill D C amp Aslin RN (2011) Cue integration in categorical tasksInsights from audio-visual speech perception PLoSONE 6(5) e19812 doi101371journalpone0019812
Bernardo J M amp Smith A F M (1994) Bayesiantheory New York Wiley
Berniker M Voss M amp Kording K (2010)Learning priors for Bayesian computations in thenervous system PLoS ONE 5(9) e12686 doi101371journalpone0012686
Cox R T (1946) Probability frequency and reason-able expectation American Journal of Physics14(1) 1ndash13 doi10111911990764
Hudson T E Maloney L T amp Landy M S (2007)Movement planning with probabilistic target in-formation Journal of Neurophysiology 98 3034ndash3046 doi101152jn008582007
Huttenlocher J Hedges L V amp Vevea J L (2000)Why do categories affect stimulus judgmentJournal of Experimental Psychology General 129220ndash241 doi1010370096-34451292220
Jacobs R A (1999) Optimal integration of textureand motion cues to depth Vision Research 393621ndash3629
Jazayeri M amp Shadlen M N (2010) Temporalcontext calibrates interval timing Nature Neuro-science 13 1020ndash1026 doi101038nn2590
Kayser C amp Shams L (2015) Multisensory causalinference in the brain PLoS Biology 13(2)e1002075 doi101371journalpbio1002075
Knill D C amp Pouget A (2004) The Bayesian brainThe role of uncertainty in neural coding andcomputation Trends in Neurosciences 27 712ndash719
Knill D C (2007) Robust cue integration A Bayesianmodel and evidence from cue-conflict studies withstereoscopic and figure cues to slant Journal ofVision 7(7)5 1ndash24 doi101167775 [PubMed][Article]
Kording K P Beierholm U Ma W J Quartz STenenbaum J B amp Shams L (2007) Causalinference in multisensory perception PLoS ONE2(9) e943 doi101371journalpone0000943
Kording K P amp Wolpert D M (2004) Bayesianintegration in sensorimotor learning Nature427(6971) 244ndash247 doi101038nature02169
Kwon O-S amp Knill D C (2013) The brain usesadaptive internal models of scene statistics forsensorimotor estimation and planning Proceedingsof the National Academy of Sciences USA 110(11)E1064ndashE1073 doi101073pnas1214869110
Miyazaki M Nozaki D amp Nakajima Y (2005)Testing Bayesian models of human coincidencetiming Journal of Neurophysiology 94 395ndash399doi101152jn011682004
OrsquoReilly J X Jbabdi S Rushworth M F S ampBehrens T E J (2013) Brain systems forprobabilistic and dynamic prediction Computa-tional specificity and integration PLoS Biology11(9) e1001662 doi101371journalpbio1001662
Rohe T amp Noppeney U (2015) Cortical hierarchiesperform Bayesian causal inference in multisensoryperception PLoS Biology 13(2) e1002073 doi101371journalpbio1002073
Sato Y amp Kording K P (2014) How much to trustthe senses Likelihood learning Journal of Vision14(13)13 1ndash13 doi101167141313 [PubMed][Article]
Shams L amp Beierholm U R (2010) Causal inferencein perception Trends in Cognitive Sciences 14 425ndash432
Stocker A A amp Simoncelli E P (2006) Noisecharacteristics and prior expectations in humanvisual speed perception Nature Neuroscience 9578ndash585
Tassinari H Hudson T E amp Landy M S (2006)Combining priors and noisy visual cues in a rapidpointing task The Journal of Neuroscience 2610154ndash10163 doi101523JNEUROSCI2779-062006
Vilares I Howard J D Fernandes H L GottfriedJ A amp Kording K P (2012) Differentialrepresentations of prior and likelihood uncertaintyin the human brain Current Biology 22 1641ndash1648 doi101016jcub201207010
Weiss Y Simoncelli E P amp Adelson E H (2002)Motion illusions as optimal percepts NatureNeuroscience 5 598ndash604
Yuille A L amp Bulthoff H H (1996) Bayesiandecision theory and psychophysics In D C KnillW Richards (Eds) Perception as Bayesian infer-ence (pp 123ndash161) Cambridge UK CambridgeUniversity Press
Journal of Vision (2016) 16(5)9 1ndash13 Bejjanki Knill amp Aslin 13
Downloaded From httpjovarvojournalsorgpdfaccessashxurl=dataJournalsJOV935062 on 03222016




















![Inference in generative models using the Wasserstein distance [[INI]](https://img.pdfslide.us/doc/110x75/5aad84a27f8b9a3a238b4c8f/inference-in-generative-models-using-the-wasserstein-distance-ini.jpg)








