Embed Size (px)
Citation preview

Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Learning a Sparse Codebook of Facial and Body Microexpressions for Emotion Recognition
Yale SongMIT CSAIL
Randall DavisMIT CSAIL
Louis‐Philippe MorencyUSC ICTSpeaker
ACM ICMI 2013, Dec 9‐13, Sydney, Australia

Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Same “no”, different emotions
Y. Song, L.‐P. Morency, and R. Davis. 2013
Apathy Disgust
Concealment !!!
Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
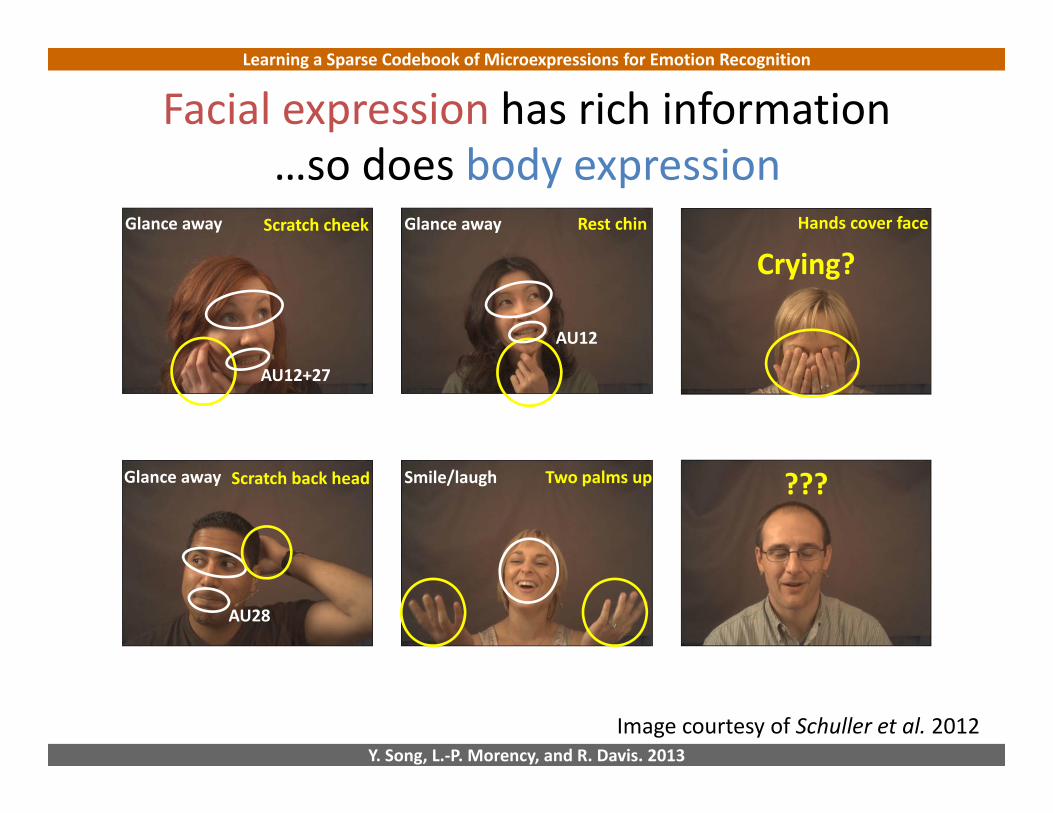
Facial expression has rich information
Glance away Glance away
Glance away
Image courtesy of Schuller et al. 2012
…so does body expression
Smile/laughScratch back head
Scratch cheek Rest chin
Two palms up
Hands cover face
Crying?
???
AU28
AU12+27
AU12

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
… and the devil is in the temporal details
Video courtesy of Schuller et al. 2012
Temporal context provides more information

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
… and the devil is in the temporal details
Video courtesy of Schuller et al. 2012Video courtesy of Schuller et al. 2012
Hands cover face
Shoulder Shrug
How to capture spatio‐temporal patterns of facial and body expressions ?
Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
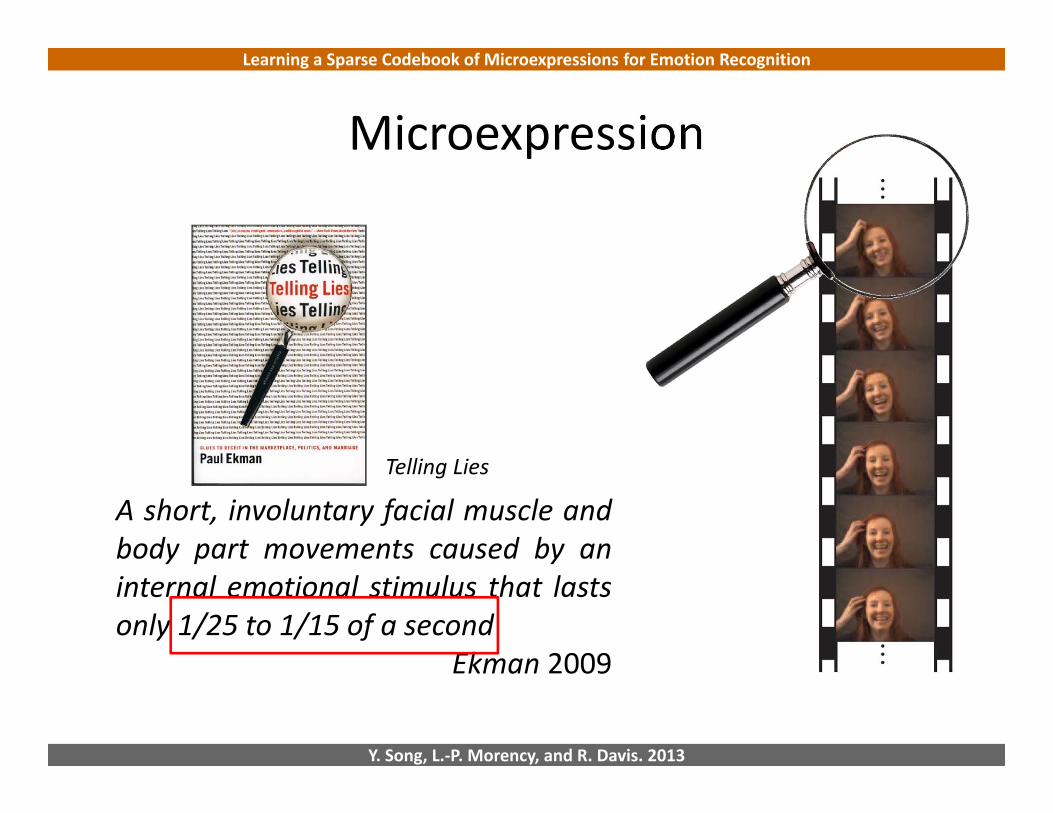
Microexpression
Telling Lies
A short, involuntary facial muscle andbody part movements caused by aninternal emotional stimulus that lastsonly 1/25 to 1/15 of a second
Ekman 2009

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
The goal of this work
We want a representation that captures• both facial and body expressions• both spatial and temporal patterns• patterns at micro‐temporal scale (1/25 to 1/15 sec)

How to extract both face and body features?
• Extract separately, combine later
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Y. Song, L.‐P. Morency, and R. Davis. 2013
Facial feature
Body feature
• How to combine? – “Early vs. late” issue– Feature normalization issue
• Different statistical properties of each channel
Inferenceappearance
appearance/motion

How to extract both face and body features?
• Extract simultaneously
• Simpler, but requires careful feature description
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Y. Song, L.‐P. Morency, and R. Davis. 2013
Facial and body feature Inference
• Extract separately, combine later
Facial feature
Body feature
appearance
appearance/motion
Inference

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
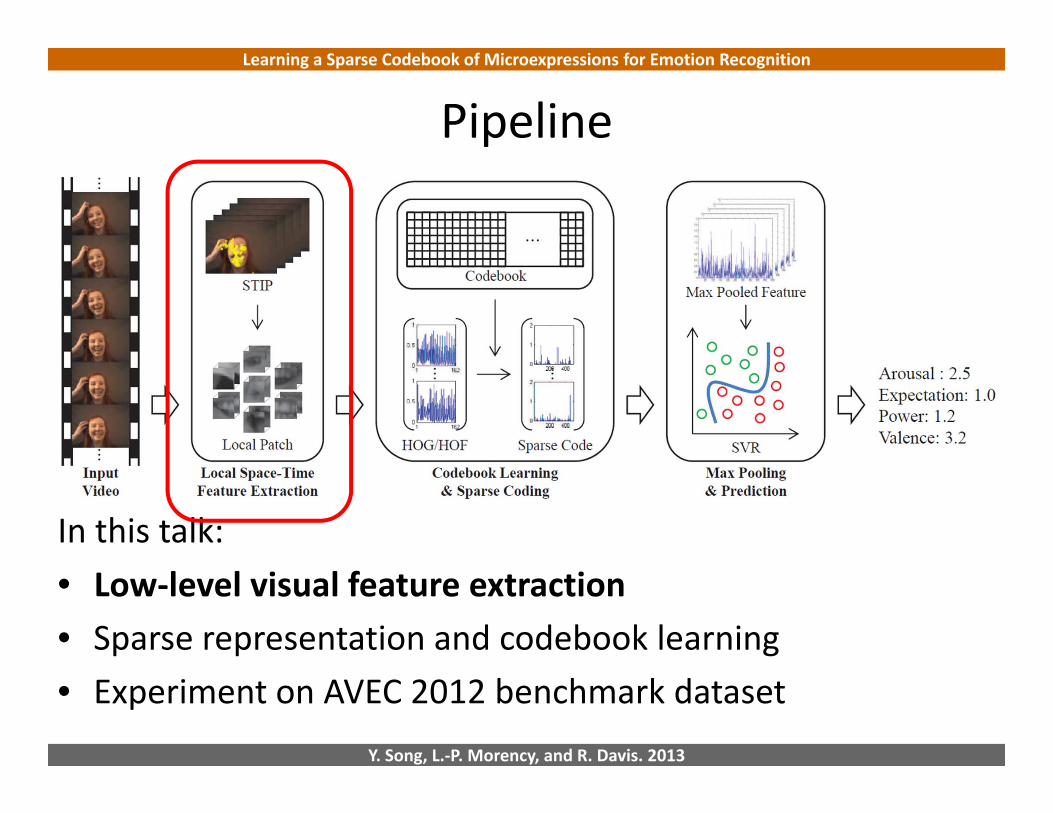
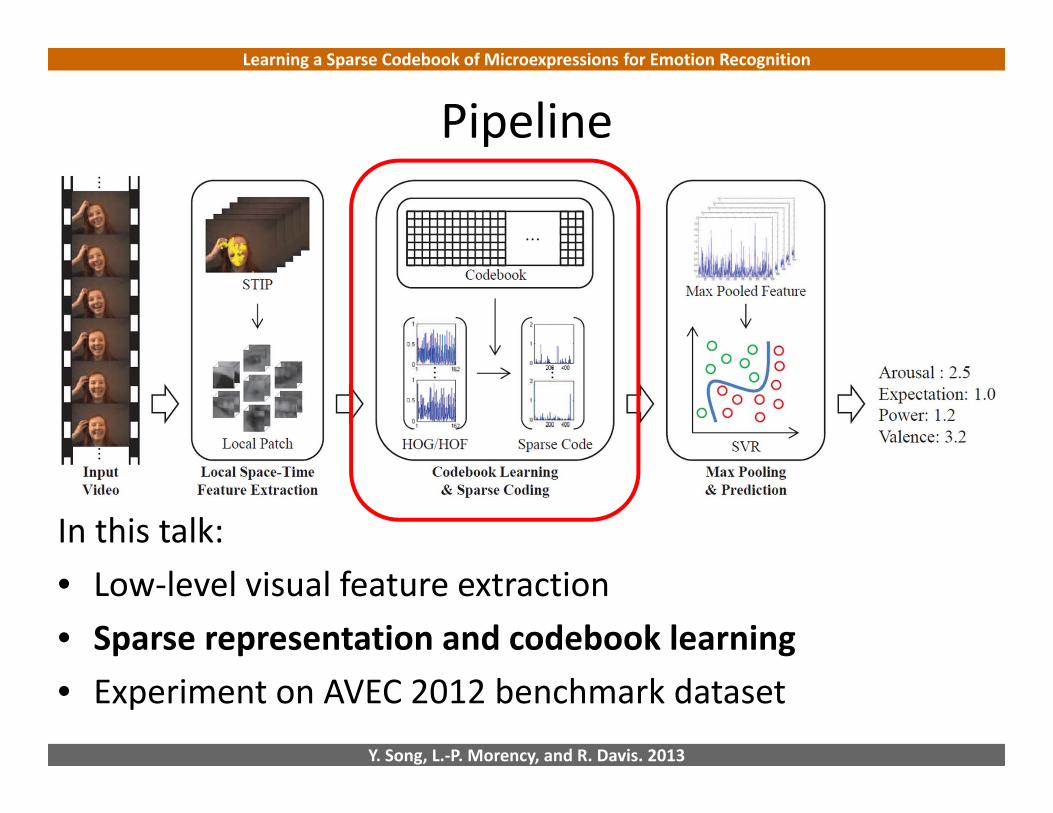
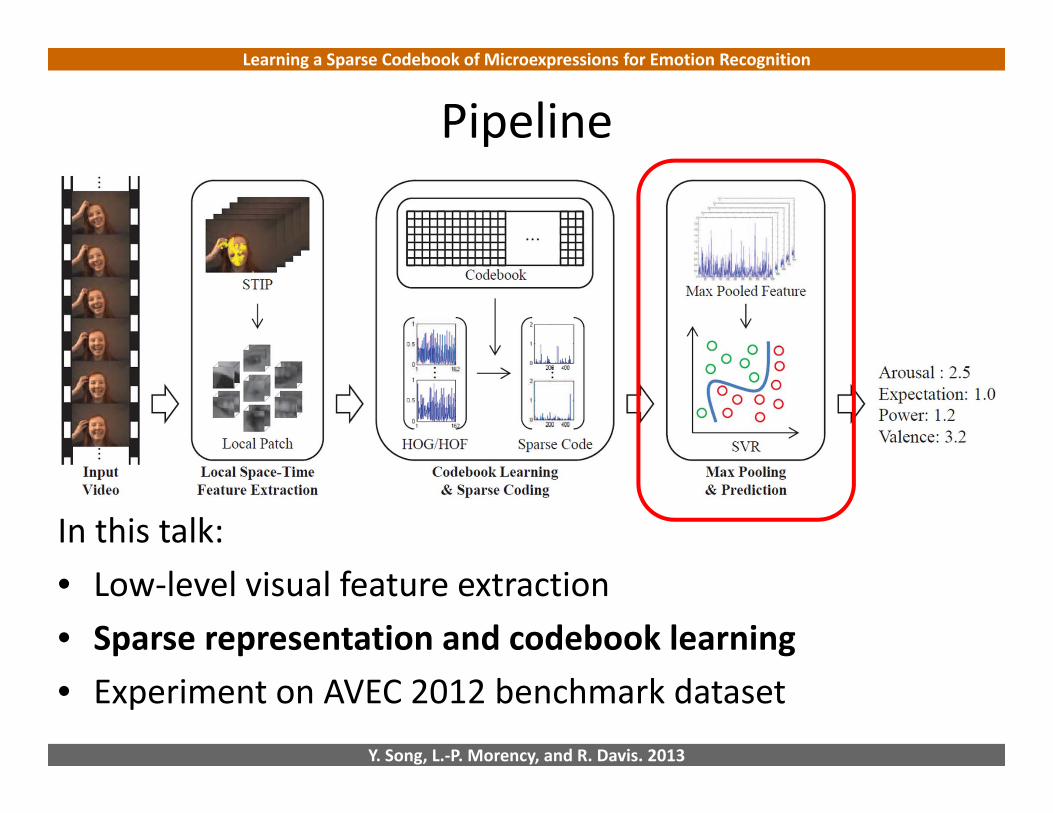
Pipeline
• Successful in object / action recognition[Yang et al. CVPR’09; Laptev et al. CVPR‘08]
• Evaluation on emotion recognition
Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Pipeline
In this talk:• Low‐level visual feature extraction• Sparse representation and codebook learning• Experiment on AVEC 2012 benchmark dataset
Low‐level visual feature extraction

Space‐Time Interest Points (STIPs)Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Y. Song, L.‐P. Morency, and R. Davis. 2013
• Step 1: STIP detection– “Space‐time” corners with high spatio‐temporal variation
• Step 2: Feature extraction– Computed at each STIP– Characterize local appearance (HOG) and motion (HOF)
Ivan Laptev. “On Space‐Time Interest Points”, IJCV’05
Step 1 Step 2 HOG
appearance
HOF
motion

How to extract both face and body features?
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Y. Song, L.‐P. Morency, and R. Davis. 2013
• Extract simultaneously
– Possible, under certain conditions
• Work if video contains upper body shots
AVEC Interview Video blog
conditions granularities

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Video courtesy of Schuller et al. 2012
Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
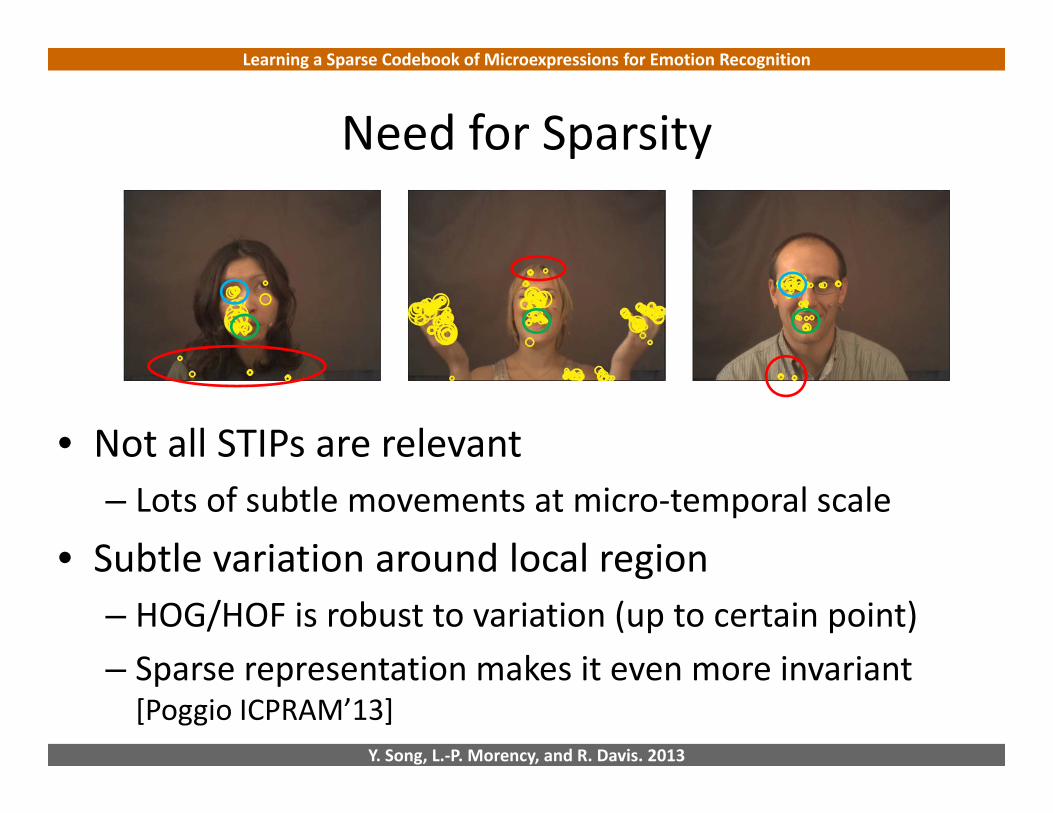
Need for Sparsity
• Not all STIPs are relevant– Lots of subtle movements at micro‐temporal scale
• Subtle variation around local region– HOG/HOF is robust to variation (up to certain point)– Sparse representation makes it even more invariant[Poggio ICPRAM’13]
Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Pipeline
In this talk:• Low‐level visual feature extraction• Sparse representation and codebook learning• Experiment on AVEC 2012 benchmark dataset

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Sparse Coding 101• Represent input signal using only a few codes
Visual Codebook
0 .
0 0
.⋯ 0
. 0
Sparse coefficients
128412452594…521076
Densepixel values
0.23 x + 0.12 x + 0.62 x

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Sparse Coding 101• Represent input signal using only a few codes
128412452594…521076
DenseHOG/HOF
0 .
0 0
.⋯ 0
. 0
Sparse coefficients
Codebook
Codebook Learning

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Codebook Learning
ReconstructionError Measure
SparsityMeasure
While not_converged• Step 1: Given optimize for • Step 2: Fix all and optimize for End

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Codebook Learning
ReconstructionError Measure
SparsityMeasure
Codebook captures canonical bases of input signal

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Codebook Learning
ReconstructionError Measure
SparsityMeasure
Codebook captures canonical micro‐expressions
Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
HOG/HOF Sparse Code
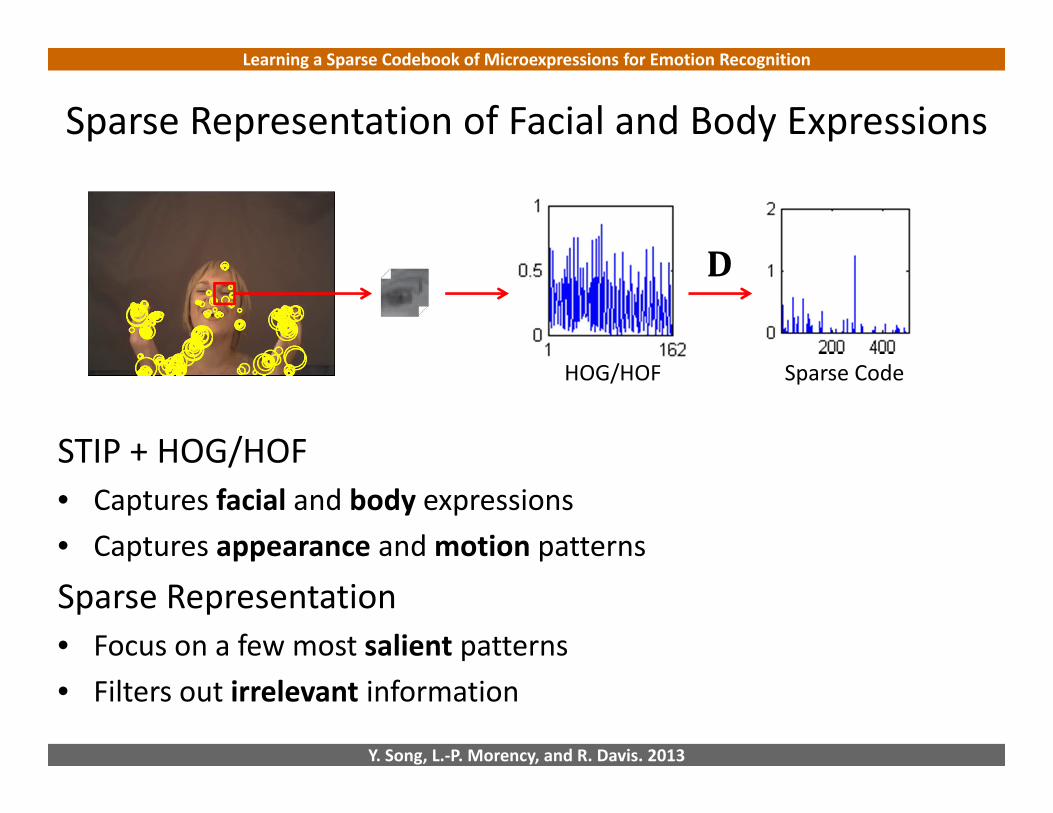
Sparse Representation of Facial and Body Expressions
STIP + HOG/HOF• Captures facial and body expressions• Captures appearance and motion patterns
Sparse Representation• Focus on a few most salient patterns• Filters out irrelevant information
Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Pipeline
In this talk:• Low‐level visual feature extraction• Sparse representation and codebook learning• Experiment on AVEC 2012 benchmark dataset
max
Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
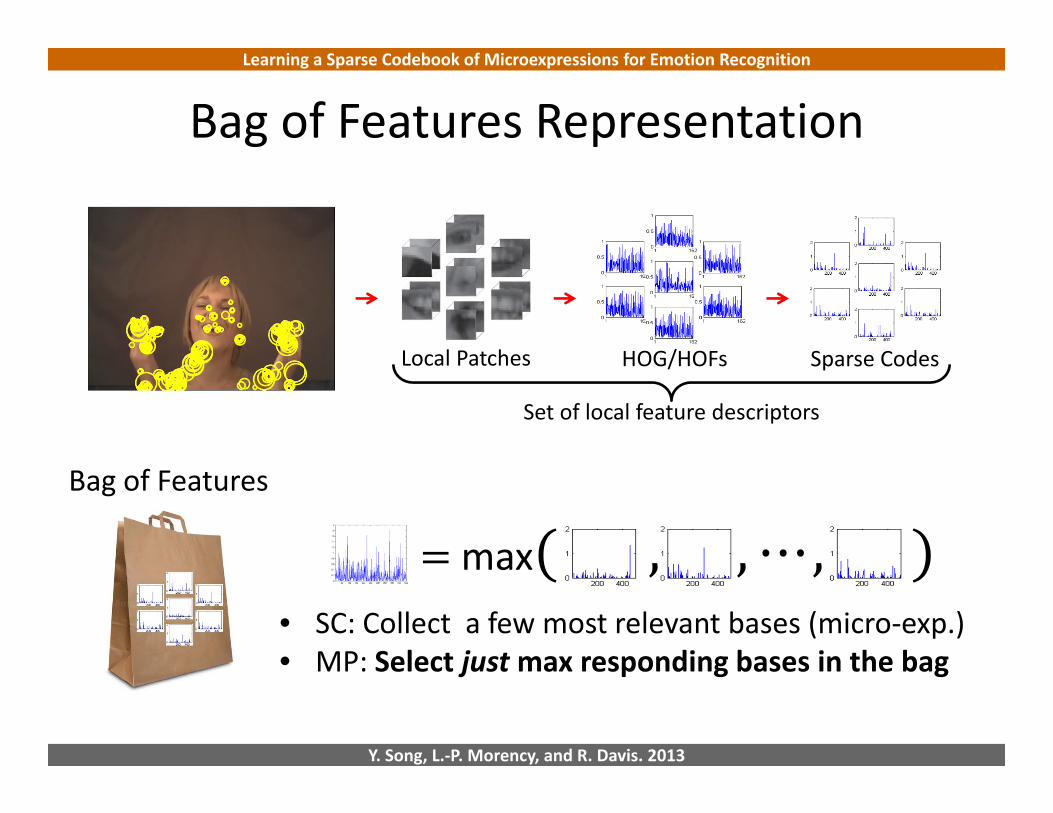
Bag of Features Representation
Local Patches HOG/HOFs Sparse Codes
Set of local feature descriptors
Bag of Features
• SC: Collect a few most relevant bases (micro‐exp.)• MP: Select justmax responding bases in the bag

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Space‐Time Feature Pooling
Goal: Obtain per‐frame feature representation:• Define a window of size one second• Perform feature bagging of sparse codes collected within the window
• Slide the window
1 sec
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 100 200 300 400 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1

Experiments:How far can we go just with visual data?
Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
DatasetAVEC 2012 (in conjunction with ICMI’12)
• Fully Continuous Sub Challenge (FCSC)– For each frame predict real‐valuedemotional states in four dimensions
• Arousal (dynamic vs. lethargic)• Expectation (surprised vs. calm)• Power (dominant vs. impotent)• Valence (positive vs. negative)
• Audio‐visual features are provided – we used the provided audio features

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
MethodologyTwo scenarios:• Visual input only• Audio‐Visual input (using provided audio features)
– Fusion methods: early, late, kernel CCA
Per‐frame prediction• Support Vector Regression (SVR) w/ RBF kernel• Exponential smoothing over time
Cross‐validation• Hyper‐parameters are optimized based on validation set
Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
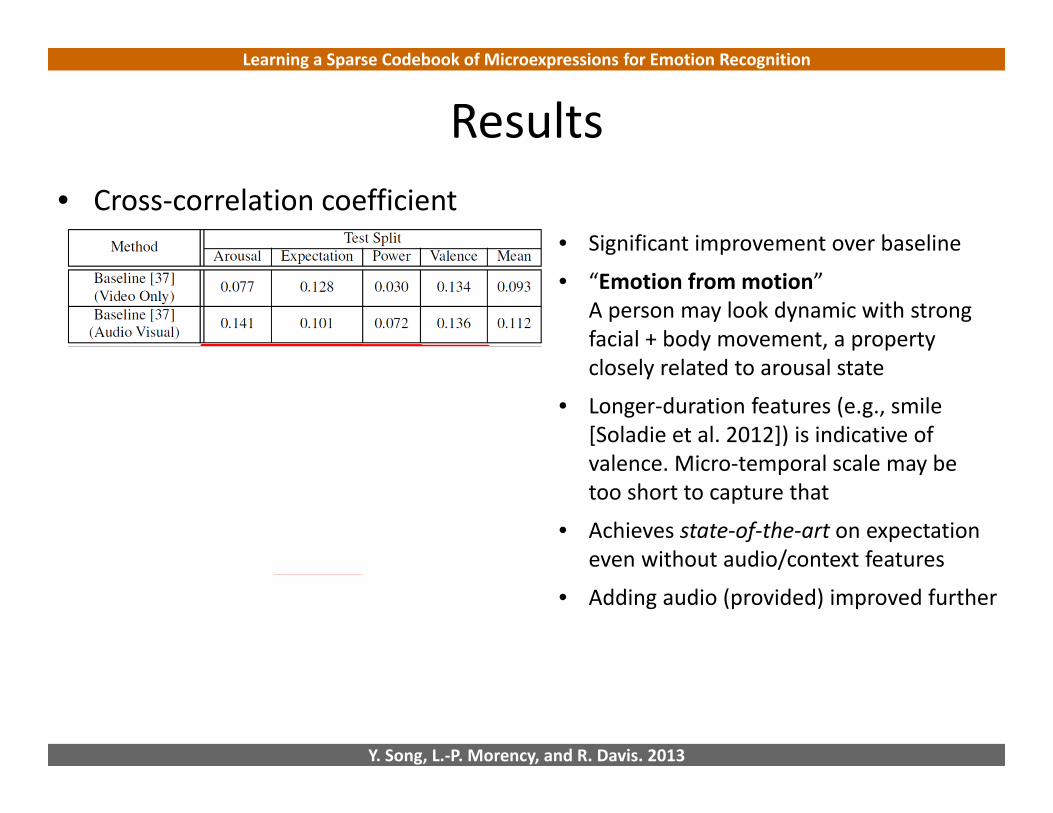
Results• Cross‐correlation coefficient
• Significant improvement over baseline
• “Emotion from motion”A person may look dynamic with strong facial + body movement, a property closely related to arousal state
• Longer‐duration features (e.g., smile [Soladie et al. 2012]) is indicative of valence. Micro‐temporal scale may be too short to capture that
• Achieves state‐of‐the‐art on expectationeven without audio/context features
• Adding audio (provided) improved further

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Results on Audio‐Visual Fusion• Combine audio (provided) and visual features using:
– Early (concatenate), – Early KCCA (max correlation; concatenate)– Late (weighted voting)
Early fusion can harm when audio feature is “missing”• Audio features are set to zero when no vocalization• Late fusion “votes” to visual channel when no vocalization

Y. Song, L.‐P. Morency, and R. Davis. 2013
Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Summary• Our face & body convey rich information about emotion• “The devil is in the temporal details”
– Need both spatial and temporal patterns– But many subtle/irrelevant movements
• We evaluate sparse representation of micro‐expressions– Densely extract local space‐time features– Sparse rep. focus on most salient bases (micro‐exp)– Max‐pooling selects just max responding bases
• Experiments on AVEC 2012 – Performs well on arousal/expectation/power– Less so on valence – need for high‐level features

Learning a Sparse Codebook of Microexpressions for Emotion Recognition
Thank you!
Yale SongMIT CSAIL
Randall DavisMIT CSAIL
Louis‐Philippe MorencyUSC ICTSpeaker
Y. Song, L.‐P. Morency, and R. Davis. 2013





























