Embed Size (px)
Citation preview

Sam Shaojun ZhaoOct 13, 2005
Learn to Answer Contextual Questions

Outline
•Question Answering•Context Question Answering (CQA)
–Information Retrieval Approach–Learning Approach
•Experiments•Conclusion

Question Answering Track
•A large-scale evaluation of systems that return answers, as opposed to lists of documents, in response to a question.–Facts-based, short-answer questions such as
“How many calories are there in a big Mac?”–Document Retrieval and Information
Extraction.–Information Retrieval vs. Document Retrieval

Evaluation
•Return a ranked list of 5 strings per question such that each string was believed to contain an answer to the question.
•Human assessors read each string and made a binary decision as to whether of not the string actually contain an answer to the question.
•Mean reciprocal rank.

Strategies
1. Question type classification– When -> TIME– Who -> PERSON– Why -> REASON
2. Standard document retrieval– SMART
3. Shallow Parsing– Entities Detecting
• WordNet in step 1, 3.• Query Expansion• Search Engine• Shallow Parsing.
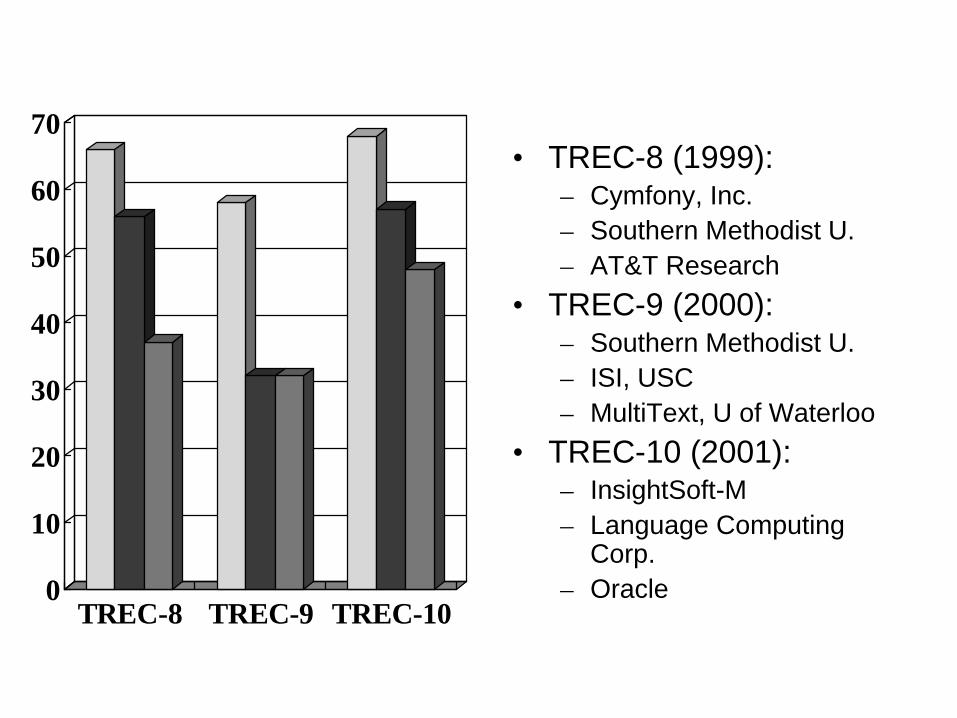
0
10
20
30
40
50
60
70
TREC-8 TREC-9 TREC-10
• TREC-8 (1999):– Cymfony, Inc.– Southern Methodist U.– AT&T Research
• TREC-9 (2000):– Southern Methodist U.– ISI, USC– MultiText, U of Waterloo
• TREC-10 (2001):– InsightSoft-M– Language Computing
Corp.– Oracle

What are Contextual Questions?
Q1. What is the name of the volcano that destroyed the ancient city of Pompeii?
Q2. When did it happen?Q3. How many people were killed?Q4. How tall was this volcano?Q5. Any pictures?Q6. Where is Mount Rainier?
I love contextual questions…

What are Contextual Questions?
Q1. What is the name of the volcano that destroyed the ancient city of Pompeii?
Q2. When did it happen?Q3. How many people were killed?Q4. How tall was this volcano?Q5. Any pictures?Q6. Where is Mount Rainier?

What are Contextual Questions?
Q1. What is the name of the volcano that destroyed the ancient city of Pompeii?
Q2. When did it happen?Q3. How many people were killed?Q4. How tall was this volcano?Q5. Any pictures?Q6. Where is Mount Rainier?

Issues in CQA
•Issues–Reference
•Small context•Refer to the answers
–Ellipsis•Linguistics: underspecified•Special case: Verb-ellipsis

Issues in CQA (Cont’d)
•Deep Understanding of Text–Restricted Domain–Restricted Language


Information Retrieval Approach
•Preprocessing –stemming, stop-words
•Index–Efficiency
•Retrieval–Document–Passage–Feedback

IR Heuristics

Empirical Observations in IR
• Retrieval heuristics are necessary for good retrieval performance.– E.g. TF-IDF weighting, document length
normalization
• Similar formulas may have different performances.
• Performance is sensitive to parameter setting.
Slides from “A Formal Study of Information Retrieval Heuristics”Hui Fang, et al

• Pivoted Normalization Method
• Dirichlet Prior Method
• Okapi Method
1 ln(1 ln( ( , ))) 1( , ) ln
| | ( )(1 )w q d
c w d Nc w q
d df ws savdl
∈ ∩
+ + +⋅ ⋅
− +∑
( , )( , ) ln(1 ) | | ln
( | ) | |w q d
c w dc w q q
p w C dµ
µ µ∈ ∩
× + + ⋅⋅ +∑
31
31
( 1) ( , )( 1) ( , )( ) 0.5ln
| |( ) 0.5 ( , )((1 ) ) ( , )w q d
k c w qk c w dN df wddf w k c w qk b b c w d
avdl∈ ∩
+ ×+ ×− +⋅ ⋅
+ +− + +∑
Inversed Document FrequencyDocument Length NormalizationTerm Frequency
Empirical Observations in IR (Cont.)
1+ln(c(w,d))
Alternative TF transformationParameter sensitivity
Slides from “A Formal Study of Information Retrieval Heuristics”Hui Fang, et al

Research Questions
•How can we formally characterize these necessary retrieval heuristics?
•Can we predict the empirical behavior of a method without experimentation?
Slides from “A Formal Study of Information Retrieval Heuristics”Hui Fang, et al

d2:d1:
),( 1dwc
),( 2dwc
Term Frequency Constraints (TFC1)
• TFC1
TF weighting heuristic I: Give a higher score to a document with more occurrences of a query term.
q : w
If |||| 21 dd =),(),( 21 dwcdwc >and
Let q be a query with only one term w.
).,(),( 21 qdfqdf >then
),(),( 21 qdfqdf >
Slides from “A Formal Study of Information Retrieval Heuristics”Hui Fang, et al

1 2( , ) ( , )f d q f d q>
Term Frequency Constraints (TFC2)
TF weighting heuristic II: Favor a document with more distinct query terms.
2 1( , )c w d
1 2( , )c w d
1 1( , )c w d
d1:
d2:1 2( , ) ( , ).f d q f d q>then
1 2 1 1 2 1( , ) ( , ) ( , )c w d c w d c w d= +If2 2 1 1 2 1( , ) 0, ( , ) 0, ( , ) 0c w d c w d c w d= ≠ ≠
and
1 2| | | |d d=and
Let q be a query and w1, w2 be two query terms.
Assume 1 2( ) ( )idf w idf w=
• TFC2
q:w1 w2
Slides from “A Formal Study of Information Retrieval Heuristics”Hui Fang, et al

Term Discrimination Constraint (TDC)
IDF weighting heuristic:Penalize the words popular in the collection; Give higher weights to discriminative terms.
Query: SVM Tutorial Assume IDF(SVM)>IDF(Tutorial)
...…
SVMSVM TutorialTutorial…
Doc 1……
SVMSVMTutorialTutorial…
Doc 2
( 1) ( 2)f Doc f Doc>
SVM Tutorial

Term Discrimination Constraint (Cont.)
• TDC
Let q be a query and w1, w2 be two query terms.
1 2| | | |,d d=Assume
)()( 21 widfwidf ≥and),(),( 2111 dwcdwc ≥If
).,(),( 21 qdfqdf ≥then
),(),(),(),( 22211211 dwcdwcdwcdwc +=+and
),(),( 21 dwcdwc = for all other words w.and
1 2( ) ( )idf w idf w>q:w1 w2
d2:d1:
),( 11 dwc
),( 21 dwc
),( 12 dwc
),( 22 dwc
1 2( , ) ( , )f d q f d q>
Slides from “A Formal Study of Information Retrieval Heuristics”Hui Fang, et al

Length Normalization Constraints(LNCs)
Document length normalization heuristic:Penalize long documents(LNC1); Avoid over-penalizing long documents (LNC2) .
• LNC2
d2:
q:Let q be a query.
d1:||||,1 21 dkdk ⋅=>∀ ),(),( 21 dwckdwc ⋅=If and
),(),( 21 qdfqdf ≥then
),(),( 21 qdfqdf ≥
d1:d2:
q:Let q be a query.
1),(),(, 12 +=∉ dwcdwcqw),(),(, 12 dwcdwcw =
qw∉
),( 1dwc
),( 2dwc
If for some wordbut for other words
),(),( 21 qdfqdf ≥ ),(),( 21 qdfqdf ≥then
• LNC1

TF-LENGTH Constraint (TF-LNC)
• TF-LNC
TF-LN heuristic:Regularize the interaction of TF and document length.
q: w
),( 2dwc
d2:
),( 1dwc
d1:
Let q be a query with only one term w.
).,(),( 21 qdfqdf >then
),(),( 21 dwcdwc >and
If 1 2 1 2| | | | ( , ) ( , )d d c w d c w d= + −
1 2( , ) ( , )f d q f d q>
Slides from “A Formal Study of Information Retrieval Heuristics”Hui Fang, et al

Information Retrieval Approach
•Link Analysis
Information Retrieval Approach
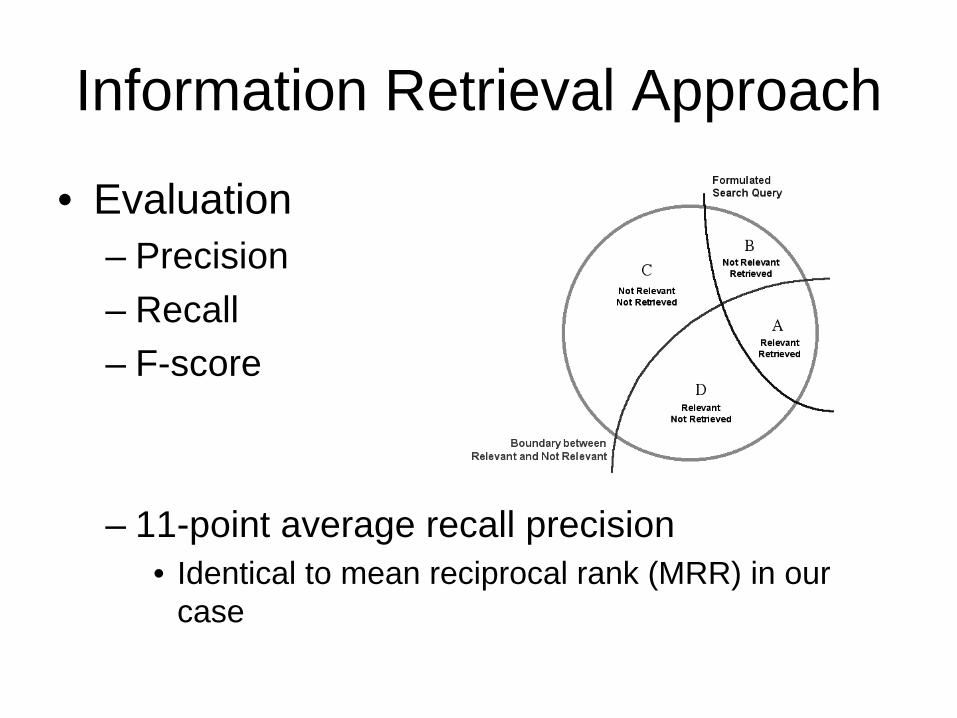
•Evaluation–Precision –Recall–F-score
–11-point average recall precision•Identical to mean reciprocal rank (MRR) in our
case

Results from IR-based Approach
•Data–4 topics
•Tom Cruise•Presidential Debates•Hawaii •Pompeii city
–About 260 questions •About 40 groups

Results of IR-based Approach
•MRR/11-point average precision–19.36% (baseline)
I can find the answer around the 5th result

Heuristics
Q1. What is the name of the volcano that destroyed the ancient city of Pompeii?
Q2. When did it happen?Q3. How many people were killed?Q4. How tall was this volcano?Q5. Any pictures?Q6. Where is Mount Rainier?
Feeding question
Follow questions

Results of IR-based Approach
•MRR/11-point average precision–19.36% (baseline 1)–25.68% (baseline 2)
•Combine feeding question
–21.80% (baseline 3)•Combine previous question
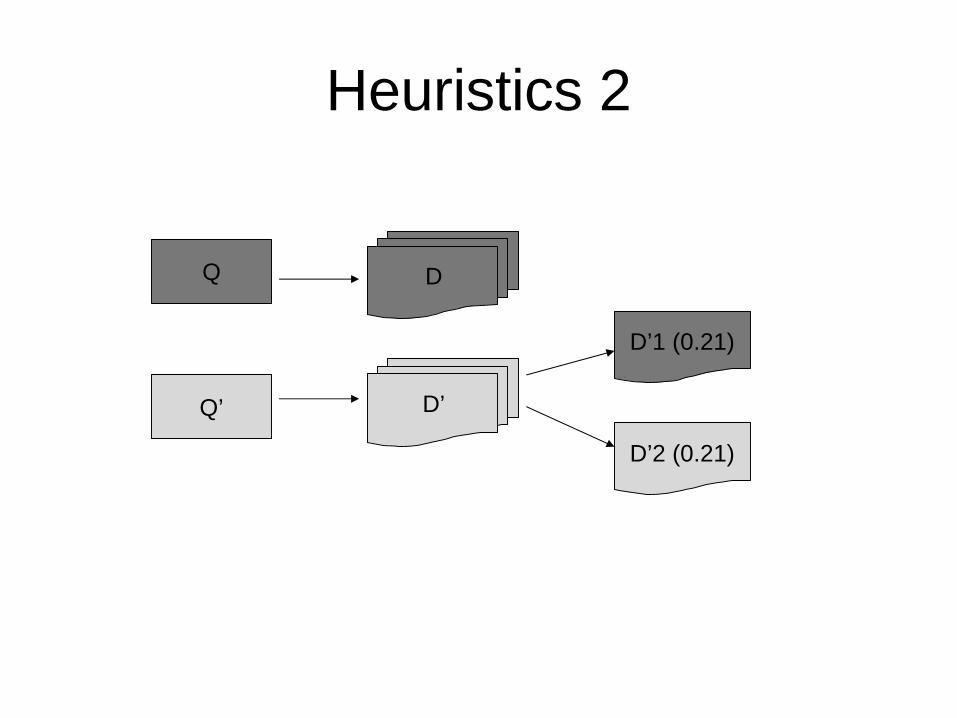
Heuristics 2
Q
Q’
D
D’
D’1 (0.21)
D’2 (0.21)
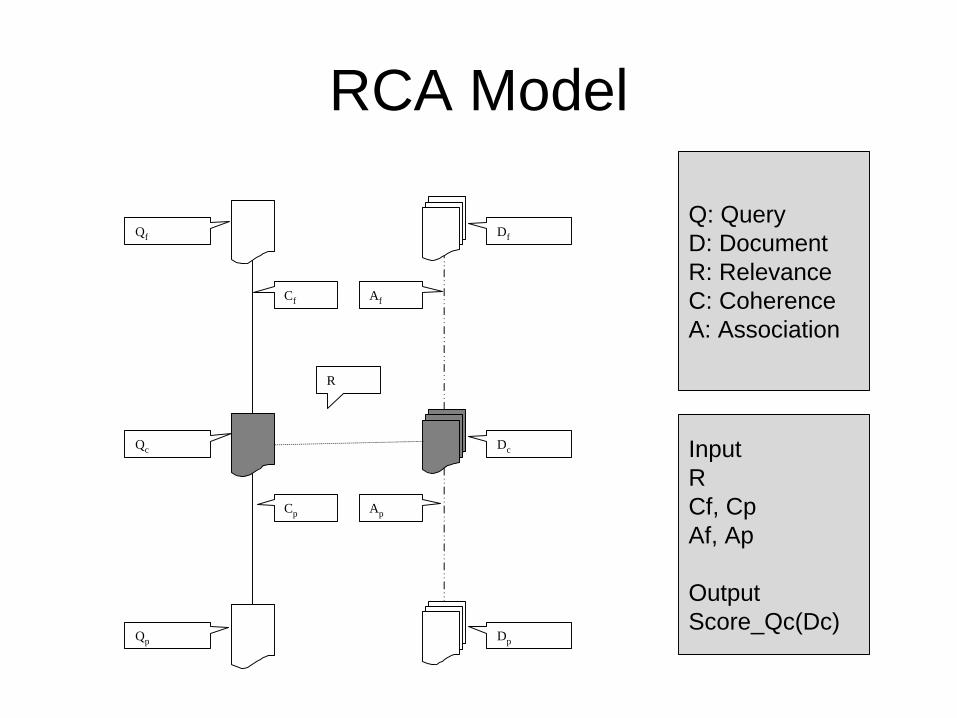
RCA Model
Cf
Ap
Qf
Qc
Qp
Df
Cp
R
Af
Dp
Dc
Q: QueryD: DocumentR: RelevanceC: CoherenceA: Association
InputRCf, CpAf, Ap
OutputScore_Qc(Dc)

Learning
•Purpose–Learn the score
•How–Supervised Learning

Learning•Supervised Learning
–Training data•<Label(+/-), R, Cf, Cp, Af, Af… >
–Testing data•<Label(+/-), R, Cf, Cp, Af, Af… >
–Prediction•<Score(-1~1), Cf, Cp, Af, Af… >

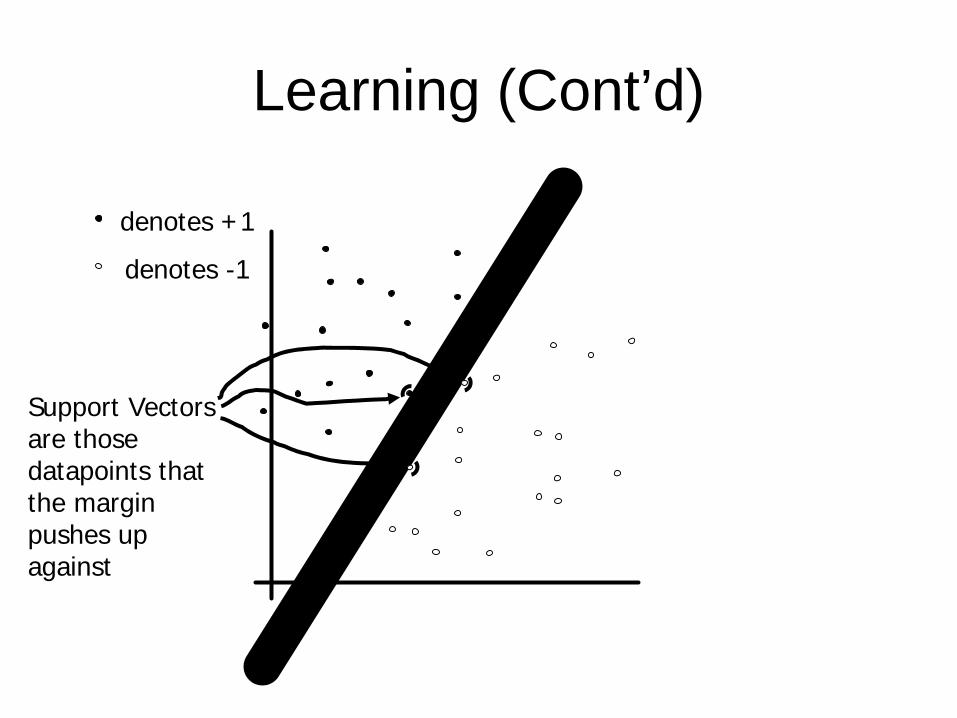
Learning (Cont’d)
•Still how to do it?–Could have many ways to do it–SVM
Learning (Cont’d)
denotes +1
denotes -1
Support Vectors are those datapoints that the margin pushes up against
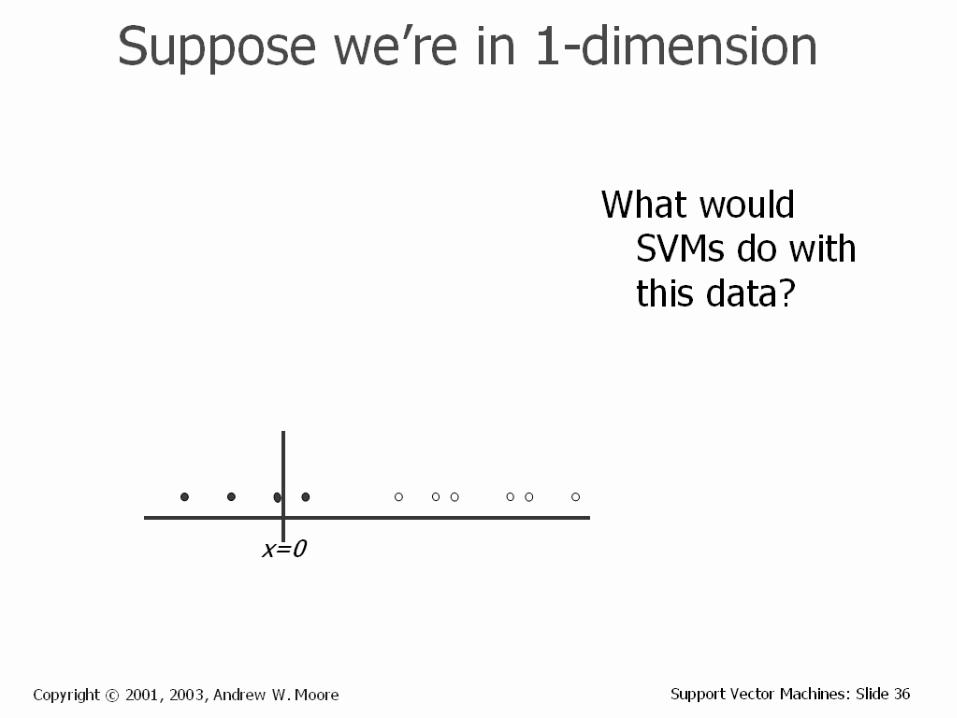

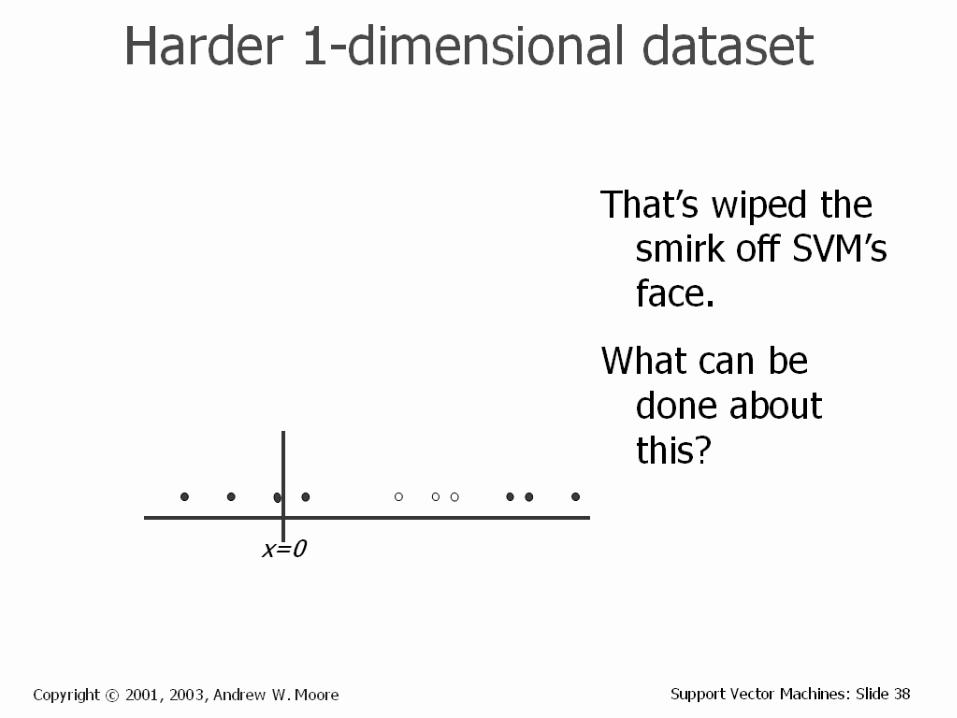
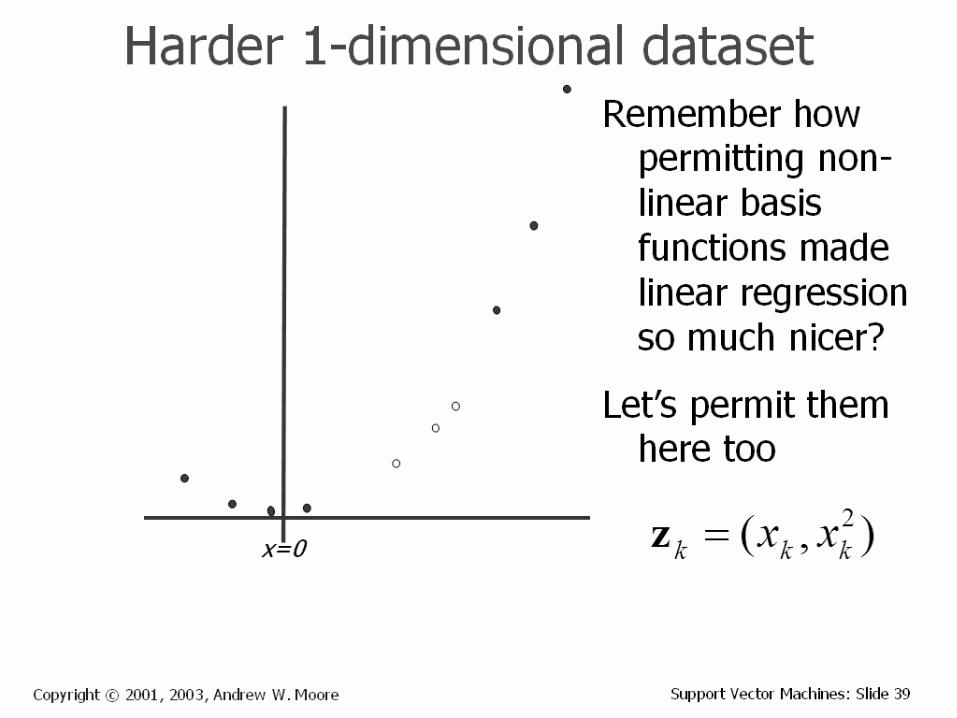


Experiments
0.2979Model 2
0.2837Model 1
0.2180Baseline 3
0.2568Baseline 2
0.1936Baseline 1
MRRModel
Preliminary result, could be improved
further

Conclusion•An Information Retrieval Approach•Learning Approach•Association information between retrieved
documents is helpful












![Classification is a Strong Baseline for Deep Metric ... · ZHAI, WU: CLASSIFICATION IS A STRONG BASELINE FOR DEEP METRIC LEARNING 3. in image retrieval datasets[12,18,25]. Training](https://img.pdfslide.us/doc/110x75/5ec759b54643787e07426e8f/classiication-is-a-strong-baseline-for-deep-metric-zhai-wu-classification.jpg)





![Abstract arXiv:2004.06389v1 [cs.IR] 14 Apr 2020 · Information Retrieval, Contextual Suggestion, Recommender System 1. Introduction Due to easy access to the internet, more than 55%](https://img.pdfslide.us/doc/110x75/5f941176df1c783ca71de7f4/abstract-arxiv200406389v1-csir-14-apr-2020-information-retrieval-contextual.jpg)









