Embed Size (px)
Citation preview

LDBC: Benchmarking Graph Data Management
Systems
www.cwi.nl/~boncz/graphta.ppt
Peter Boncz

• make competing products comparable
• accelerate progress, make technology viable
Why Benchmarking?
© Jim Gray, 2005
www.cwi.nl/~boncz/graphta.ppt

What is the LDBC?Linked Data Benchmark Council = LDBC• Industry entity similar to TPC (www.tpc.org)• Focusing on graph and RDF store benchmarking
Kick-started by an EU project• Runs from September 2012 – March 2015• 9 project partners:
www.cwi.nl/~boncz/graphta.ppt

SNB: Social Network Benchmark
www.cwi.nl/~boncz/graphta.ppt

Data Correlations between attributesSELECT personID from person
WHERE firstName = AND addressCountry = ‘Germany’‘Joachim’
SELECT personID from person
WHERE firstName = AND addressCountry = ‘Italy’‘Cesare’
Query optimizers may underestimate or overestimate the result size of conjunctive predicates
Anti-Correlation
Loew PrandelliJoachim CesareCesare Joachim
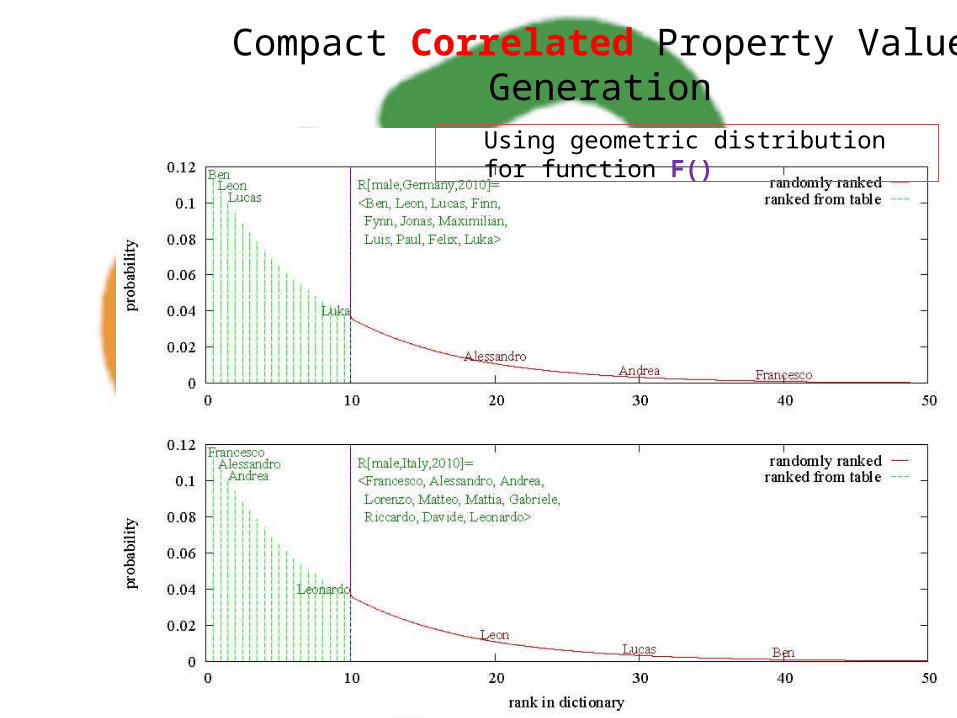
Compact Correlated Property Value GenerationUsing geometric distribution for function F()

Correlated Edge Generation
P4
<knows>
<knows>
<knows> P5
Student“Anna”
<is>
<studyAt>
“University of Leipzig”
<liveAt> “Germany”
“1990”
<birthYear>
<firstname>
<firstname>P1
< studyAt >
“University of Leipzig”
“Laura”
“1990”<birthYear><li
ke>
<Britney Spears>
<Britney Spears>
<like>
<knows>
P3
< studyAt >
“University of Leipzig”
“1990”
<birthYear>P2
<studyAt>“University of Amsterdam”
<liveAt>
“Netherlands”
www.cwi.nl/~boncz/graphta.ppt

How to Generate a Correlated Graph?
P4
P5
Student“Anna”
<is>
<studyAt
>
“University of Leipzig”
<liveAt> “Germany”
“1990”
<birthYear>
<firstname>
<firstname>P1
< studyAt >
“University of Leipzig”
“Laura”
“1990”<birthYear>
<like
>
<Britney Spears>
<Britney Spears><like>
P3
< studyAt >
“University of Leipzig”
“1990”
<birthYear>P2
<studyAt>
“University of Amsterdam”
<liveAt>
“Netherlands”
Danger: this is very expensive to compute on a large graph! (quadratic, random access)
?
??
? ?
• Compute similarity of two nodes based on their (correlated) properties.
• Use a probability density function wrt to this similarity for connecting nodes
• Compute similarity of two nodes based on their (correlated) properties.
• Use a probability density function wrt to this similarity for connecting nodes
connectionprobability
highly similar less similar
?
www.cwi.nl/~boncz/graphta.ppt

Window Optimization
P4
<knows>
<knows>
<knows> P5
Student“Anna”
<is>
<studyAt
>
“University of Leipzig”
<liveAt> “Germany”
“1990”
<birthYear>
<firstname>
<firstname>P1
< studyAt >
“University of Leipzig”
“Laura”
“1990”<birthYear>
<like
>
<Britney Spears>
<Britney Spears><lik
e>
<knows>
P3
< studyAt >
“University of Leipzig”
“1990”
<birthYear>P2
<studyAt>
“University of Amsterdam”
<liveAt>
“Netherlands”
Probability that two nodes are connected is skewed w.r.t the similarity between the nodes (due to probability distr.)
connectionprobability
highly similar less similar
Window
Trick: disregard nodes with too large similarity distance(only connect nodes in a similarity window)
www.cwi.nl/~boncz/graphta.ppt

Workloads by systemSystem Interactive Business Intelligence Graph Analytics
Graph databases Yes Yes Maybe
Graph programming frameworks - Yes Yes
RDF databases Yes Yes -
Relational databases Yes Yes
Maybe, by keeping state in temporary
tables, and using the functional features of
PL-SQL
NoSQL Key-value Maybe Maybe -
NoSQL MapReduce - Maybe Yes
www.cwi.nl/~boncz/graphta.ppt

Plans For 2014• Finishing Interactive workload– updates (transactional)– substitution parameters
• New BI and Graph Analytical Workloads• Data Generator Improvements– improve dictionaries and distributions for BI– Scale factors and dataset (SN graph) validation
• Query Drivers– Parallel update generator
• Auditing Rules for SNB
www.cwi.nl/~boncz/graphta.ppt

Pointers
• Code&Queries: github.com/ldbc– ldbc_socialnet_bm
• ldbc_socialnet_dbgen• ldbc_socialnet_qgen
• Wiki: ldbc.eu:8090/display/TUC– Background & Discussions + Detailed report:ldbc.eu:8090/download/attachments/4325436/LDBC_SNB_Report_Nov2013.pdf
• LDBC Technical User Community (TUC) meeting:– Thursday April 3, CWI Amsterdam (see wiki – next week)
www.cwi.nl/~boncz/graphta.ppt





























