Embed Size (px)
Citation preview

Large Scale Server Publishingfor Dynamic Content
Karl Andersson Thunberg
June 7, 2013Master’s Thesis in Computing Science, 30 credits
Supervisor at CS-UmU: Jan-Erik MostromSupervisor at Dohi Sweden: Linus Mahler Lundgren
Examiner: Fredrik Georgsson
UmeaUniversityDepartment of Computing Science
SE-901 87 UMEASWEDEN


Abstract
The number of interactive and dynamic web services on the Internet is growing more andmore and to accommodate as much functionality as possible, many techniques for asyn-chronous web communication are being developed. This thesis report describes the eval-uation of an existing web service that uses bidirectional communication over the web toprovide voting functionality in real-time on web pages. The thesis consists of an assess-ment of problem domains, an evaluation of the system and an implementation of some ofthe identified problems. It focuses on a few core issues of the current solution, namely thecommunication techniques between the client and the server, the setup of the overarchingstructure of the system and the separation of messaging channels for different use cases.
The evaluation of the reference system was motivated by addressing the issue of beingable to packet the service better as a product and create a distinction between the use caseand the underlying system. It was done so that the stakeholders of the product may moreeasily define the way the service can be used and so that a better course of action can betaken for continuing the development of the service. The implemented solution shows anexample of how the messaging channels could be separated and what kind of trade-offs existbetween the current and implemented solution.

ii

Contents
1 Introduction 1
1.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Goals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Purpose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.5 Thesis Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Method 7
2.1 Outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Development Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.1 Planning Sessions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.2 Ongoing Sprint Activities . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.3 Sprint Transitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Evaluation of Existing Software . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4 Results Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.5 In-depth Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.6 Documenting and Tracking Results . . . . . . . . . . . . . . . . . . . . . . . . 12
2.7 System Orientation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3 Assessment of Problem Domains 15
3.1 Web Communication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.1 Communication Techniques . . . . . . . . . . . . . . . . . . . . . . . . 16
3.1.2 Web Servers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.3 Web Application Libraries . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2 Internal Messaging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.1 Messaging Paradigms . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.2 Qualities of Service (QoS) . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2.3 Messaging Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3 Data Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.1 Batch Data Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.2 Stream Data Processing . . . . . . . . . . . . . . . . . . . . . . . . . . 27
iii

iv CONTENTS
3.4 Distributed Coordination with Zookeeper . . . . . . . . . . . . . . . . . . . . 28
4 Evaluation of Reference System 31
4.1 Use Case . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2 System Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.4 Assessment of Issues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4.1 Inseparable Use Case . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4.2 Functionality Not Defined . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4.3 Required Maintenance . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4.4 Single Messaging Channel . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4.5 Complete Replica of Global State . . . . . . . . . . . . . . . . . . . . . 38
4.4.6 Intra-dependencies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.4.7 Simple Messaging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.4.8 State Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.5 System Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.6 Proposal of Improvements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.6.1 System Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.6.2 Messaging Channels . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5 Publish-Subscribe Pattern 45
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.1.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.1.2 Subscription Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2 Problems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.3 Measurements of Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.4 Classification of Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.5 Research Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.5.1 Decentralizing Brokers . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.5.2 Peer-to-peer Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.5.3 Self-managed Self-optimized Methods . . . . . . . . . . . . . . . . . . 59
5.6 Conclusion and discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.6.1 Decentralising Brokers . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.6.2 Peer-to-peer Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.6.3 Self-managed Self-optimised Methods . . . . . . . . . . . . . . . . . . 64
5.6.4 The Future . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
6 Implementation of Improvements 65
6.1 Goals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6.2 Measurements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
6.3 Implementation Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
6.3.1 Channel Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67

CONTENTS v
6.3.2 Components . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
6.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
6.5 Results Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
6.5.1 Separation of Messaging Data . . . . . . . . . . . . . . . . . . . . . . . 72
6.5.2 Separation of Messages . . . . . . . . . . . . . . . . . . . . . . . . . . 74
6.5.3 Initialization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
7 Discussion 75
7.1 Restrictions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
7.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
8 Acknowledgement 77

vi CONTENTS

List of Figures
1.1 A high level representation of the system, outlining three important aspects of
the system; the asynchronous web communication between client and server
(1), the back-end architecture (2) and the separation of the messaging chan-
nels (3). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1 A work-flow overview of a typical sprint planning session. . . . . . . . . . . . 9
2.2 The work-flow during a pre-planned workday. . . . . . . . . . . . . . . . . . . 10
2.3 Work-flow at the end of a sprint. . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4 An overview of the system and its underlying components. The numbers
represents three technical aspects that were deemed important for this thesis.
They are: 1. the asynchronous communication between a web client and
a web server, 2. the back end architecture and 3. the separation of the
messaging channels for events. . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.1 A representation of how a client currently is exposed to the service. It is
exposed to the service on a web page where the static content, such as HTML
and CSS, is downloaded from a static file store. This static content also
contains logic for communicating with the web server that contains the voting
functionality. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2 Overarching components in the reference solution. A web client fetches the
static content from a static file store, which also contains the logic to com-
municate with the web server that contains the voting functionality. A web
client connects to a web server using a load balancer. Any votes are put on
a processing queue so that votes are bufferd to a data processing component
that calculates a result and returns it using a notification system. The service
also uses a database to store the global state of all events. . . . . . . . . . . . 33
4.3 An overview of the service bus architecture describing the way components
interact with each other. This solution proposed the use of a message bus
which all components uses to communicate with each other. . . . . . . . . . . 41
vii

viii LIST OF FIGURES
4.4 An overview of the two-tier architecture presenting the layout of the com-
ponents of the system. This solution divides the service in two parts that
communicate with a message bus in between them. One one side is the client
functionality and on the other side is the use case functionality. . . . . . . . . 42
4.5 Outline of the layered web server solution. It introduces two levels in the web
server where the higher level contains use case specific logic separate from
each other, while the lower level manages these use cases. . . . . . . . . . . . 44
5.1 A description of how types in a type-based publish-subscribe solution may
relate to each other. A subscriber may subscribe to the type sports news, in
which it will receive all sports news, both those that are golf news and those
that are football news. A subscriber may also subscribe to, for example, golf
news, in which it will only receive golf news and not fotball news. . . . . . . . 47
6.1 An overview of the components in the solution which highlights the general
functionality of the messaging channels that is not tied to any use case. It
separates the web server in two levels: a higher level which contains use case
specific functionality in separate modules and a lower level that manages
these modules. It introduces a web client interface that the clients use to
express their interest in events or channels. The client validation cache is
also used directly by the lower level of the web servers. The load balander
and the notification system is also viewed as part of the basic functionality. . 68
6.2 Overarching components in the solution with modified components high-
lighted. Those that were modified during the implementation are the web
client, web server, notification system and database. Other components were
used as they were. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
6.3 Number of messages received by three clients where the first client is publish-
ing and subscribing to channel 1, the second client is subscribing to channel
1 and the third client is subscribing to channel 2. . . . . . . . . . . . . . . . . 71
6.4 The perceived latency for a client when initializing a connection to the service
with one subscription. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
6.5 The perceived latency of ten consecutive client initializations. . . . . . . . . . 73
6.6 The size of the bootstrap when ten channels are added to the service, each
with a bootstrap of 1000B data. The bootstrap is the initial message that
the web server sends to a client when the client first connects. . . . . . . . . . 73

Chapter 1
Introduction
Dynamic web applications are applications that attempt to enhance the web experiencefor users by providing interactive or interchanging content such as video or live chatting.Dynamic content1 could be incorporated client-side which includes the ways a web pagebehaves in response to user input. It can also be present on the server-side which refersto the way a server responds to a client based on its internal state. Combining these twomethods is a third alternative that can provide further functionality by using additionalcommunication between a web client and a web server.
Finding ways to create an asynchronous connection between a web client and a webserver has always been studied because of the additional content such functionality canprovide. Earlier solutions include making use of the HTTP request/response protocol tosimulate a bidirectional connection using polling techniques. Because of HTML5 and thecontinuously improving performance of web browsers, dynamic content is being used moreand more in web application and this has brought forward newer and more efficient ways tocommunicate over the web. Making use of browser plugins and controllers have also beenused to establish further communication functionality but these kinds of solutions are slowlybeing phased out as more regular web communication techniques are standardised.
Today, virtually any larger website provides some dynamic content using asynchronouscommunication. A couple of examples are Facebook’s chat functionality, automatic updateson Twitter feeds and streaming video on Youtube. Games are a large part of the weband as HTML is getting more versatile and web communication is getting faster and morestandardized, it opens more use cases. As web communication develops, existing web appli-cations and their software architecture may need to be revised to support new methods andtechnologies which can be a complex task because of the large scale infrastructure neededof a web application and the higher demand on web application performance.
1.1 Background
Dohi Sweden is a holding company that offers, inter alia, products and services for theinteractive web. The company has developed a web service that makes use of asynchronouscommunication to provide a solution that can send and receive information between a webclient and a web server without the need of a page reload. This service is used for receivinga lot of asynchronous data from the web clients, processing it on the back end and then
1Dynamic content refers to content provided by dynamic web applications.
1

2 Chapter 1. Introduction
pushing the results back to the web clients. It was made for another company that had aspecific use case for it and it includes a web client interface, a web administration interfaceand a back end that serves these two interfaces. The use of this service is tied to specificevents or time intervals where its functionality is provided for these events separately andthe data transmitted during an event is completely decoupled from any other event.
The current service that Dohi Sweden provides was developed completely for this usecase and may be limited to use for other companies or similar use cases. The web clientsfor a specific event cannot be distinguished from web clients for other events and the datathat is received and processed during an event are broadcasted to every connected webclient no matter if a web client is interested in the event or not. The service could be usedin many other ways if it featured a more general functionality, with the specific use caseseparated from the underlying system where also the web clients could be separated basedof the event they are interested in. Making a more versatile solution is of interest for thestakeholders of Dohi Sweden as it enables packeting this solution so that it can be offeredto other companies and applied to other use cases. Supporting multiple use cases that areclearly separated from each other would make a more appealing product as it would letclients focus on the work for the specific use of the product instead of doing redundant workthat may be the same between use cases and events.
1.2 Goals
The overall goal of this thesis project is to evaluate the stakeholders’ current solution andthe underlying technologies in order to improve the service with a solution that may bettersuit their needs. This evaluation addresses the issue of separating the use case with theunderlying system to make a solution that behaves more like a framework that can beused to implement other types of web services and use cases. Web services that are withinthe scope of the desired solution are those that makes use of asynchronous communicationbetween the front end and the back end and those that feature a scalable back end wherereceived data may be processed before a result is sent back. It is assumed that transmitteddata between web clients and the back end are linked to an event and are completelyseparated from data that are transmitted for other events.
To be able to create a base on which decisions for the evaluation can be made, it isnecessary to include an assessment of the problem domains that are relevant for this project.The assessment does not include every part of the overall solution but instead focuses onthree problem domains; client-server communication, internal back-end messaging and back-end data processing. A fourth part, that is at least equally important but is not included inthis work, is the data model of the solution. What kind of data model that should be usedrelies heavily on what kind of use case it should be designed for but the work needed tocreate a data model that suits all targeted use cases is outside the scope of this thesis. Otherparts of the solution are not explicitly evaluated but may differ from the current solution,as replacing one may make it easier to use any of the suggested improvements.
The work also includes an implementation to test and validate the results of the evalu-ation which means that the project can be broken down into the following three goals:
– Make an assessment of already existing techniques and solutions relevant to the projectdomains and describe in what way they are relevant, what they do and how they areused. Solutions for a specific task must be compared and their differences documented.
– Evaluate the current solution and identify problems related to separating the usecase and the system. Make a proposal of improvements for the identified problems

1.3. Purpose 3
and describe in what way they differ from the current solution. This also includesdocumentation of how the the differences from the improvements impacts the currentsolution in terms of scalability, latency, manageability and extendability.
– Test and evaluate a set of the proposed improvements by applying them to the currentimplementation, including tests to validate the behaviour of the original use caseand to document the differences in terms of scalability, latency, manageability andextendability.
An abstract view of the service is presented in Figure 1.1 which does not consider itsindividual components but instead focuses on the higher level functionality and three aspectsthat are of importance for this kind of system. The overview is purposely presented at thishigh level, postponing the detailed description of the components until later chapters.
The three important aspects of the service are the client-server communication, the backend application architecture and the separation of the data transmitted on different events.The client-server communication (1) refers to the service’s ability to uphold an asynchronousconnection that provides a reliable and fast way of transmitting data. It is important thatthe service can be provided to as many clients as possible and do not feature any heavyprocessing on the client-side of the solution so that the service does not degrade performanceof any other web service it is integrated into. The back-end application architecture (2) isof interest as the way the internal components are set up and interact with each other,determines what the solution can be used for. The last aspect (3) addresses the importanceof being able to distinguish between the messaging channels used for the different events asthat makes it much more clear of how the use case can be separated from the system.
1.3 Purpose
These goals, when met, will result in a documented evaluation of the current service whichcontains a list of proposed improvements where a subset of these improvements have beentested and demonstrated. This documentation outlines ways to proceed when continuingwith the development of the service and how this development could be done dependingon the desired path. This report will serve as a documentation for current techniques andsolutions that together with the evaluation and the implementation provide material forgaining more knowledge in this field as well as provide an example of how this type ofservice can be made.
The implemented improvements consists of a back end that contains a clearer distinctionfrom the current use case so that it is more apparent how the system works and what itcould be used for. The solution is able to support more than the current single use case andis able to send data to only the correct clients. This creates a good base that can be usedwhen incorporating this functionality in the current system.
1.4 Related Work
This project is an evaluation of a system that is owned and developed by Dohi Sweden andit is currently still being developed to include more use cases for the initial client. Thismay help during the development of this thesis as it may give further directions of wherethis project is heading and what areas is of interest for this thesis to study. The result ofthis thesis is meant to provide additional information when proceeding with developing thecurrent service so that it may be easier to implement the addressed improvements. The

4 Chapter 1. Introduction
Figure 1.1: A high level representation of the system, outlining three important aspectsof the system; the asynchronous web communication between client and server (1), theback-end architecture (2) and the separation of the messaging channels (3).
current solution is evaluated from the state it was in when this project was started and anyfurther functionality will not be included in this evaluation.
1.5 Thesis Overview
Chapter 2 presents the methodology used during this project to reach the defined goalsof the thesis, including how the steps of the project was planned and documented. This

1.5. Thesis Overview 5
chapter also describes the tools used during the development and how results were measuredand analysed. Chapter 2 concludes with a brief overview of the entire system together withan explanation of how to read subsequent chapters. By presenting the overview as early aspossible, it allows readers to skip uninteresting parts, while still understanding how eachcomponent is related in the actual solution.
Chapter 3 describes an assessment of the problem domains that are relevant for thisthesis work. This chapter is meant to document the base on which future decisions for theimplementation was made on so that the reader may better follow the reasoning behindthe path that was taken. It represent the analysis of existing techniques and solutions thatwas made prior to the evaluation of the current system. Readers that are already confidentin the problem domains that this chapter addresses may skip this chapter completely andcontinue reading without any problems of understanding the other chapters.
Having made an assessment of the problem domains for this thesis, Chapter 4 focuseson the task of evaluating the current solution and identifying problems with regards to theproject goals. It presents the use case for the system and gives an overview of how thesystem is built and how its different components interact with each other. It includes adiscussion about the different components focusing on the problem domains and concludeswith a list of proposed improvements for the identified problems.
Chapter 5 is an in-depth study of scientific research in the area of the publish-subscribepattern. It focuses on ways to build the internal messaging system so that one of theimmediate goals of the thesis can be fulfilled, namely the separation of the use case and theunderlying system. This chapter starts with an overview of the pattern that explains how itworks and what it is used for, including different alternations of it. It contains a summaryof three domains that are of interest for this project and outlines their impact and how theycan be of use in this system.
Chapter 6 presents an implementation that aims to solve some of the addressed problemsusing some of the proposed solutions from chapter 4. It describes the plan that was takenduring the implementation as well as the design of the system with a list of what needs tobe changed from the reference system. It also contains motivation as to why the proposedimprovements was implemented, how they will be tested and what the results from the testsmay conclude.
Chapter 7 addresses the implementation that is made to test and evaluate a set ofproposed improvements. It combines the result provided by the previous chapters andpresents a suggested implementation, viewing the solution in its entirety. It proceeds toevaluate the results of the tests for the implementation in accordance with the evaluationcriteria from Chapter 2. It concludes with some quantitative results derived from the testruns on the complete system based on the goals of this thesis.
Chapter 8 contains an overall discussion and conclusions of both the implementationresults and how ideas derived from the in-depth study in Chapter 5 can be realized with thedeveloped framework as a base. It highlights the restrictions and limitations present in theimplementation and what implications the developed system may have in the future.

6 Chapter 1. Introduction

Chapter 2
Method
The general methodology, used when performing this thesis project, is described in thischapter. Section 2.1 lists the steps performed to divide, implement and analyze each indi-vidual component. The agile development method called Scrum, was used for planning anddocumentation during this work and this method is presented in Section 2.2. This chapterincludes a description how existing software is to be evaluated in Section 2.3. Section 2.4explains how the results related to the system evaluation are to be analyzed and how thetested improvements should be applied to create as fair of a comparison as possible. Theapproach used in the in-depth study is presented in Section 2.5 while Section 2.6 presentshow the general project progress were documented. The chapter concludes with a systemoverview in Section 2.7 that describes the components of the system and which parts arefocused on during the thesis.
2.1 Outline
This section describes a general outline of the steps taken, both for the assessment of do-mains, the theoretical evaluation, the in-depth study and the implementation. It explainshow the work was divided and performed and each step can be related to the thesis in itsentirety as well as to each individual chapter.
1. Create a list of system requirements from the stakeholders, or in the case of currentsoftware analysis, assemble a list of supported features and potential limitations.
2. Split up the project into logical parts. These parts will be addressed individually, witha background focus on how these components make up the entire solution.
3. Do a pre-study related to the addressed subject and areas related to the different partsof the system.
4. Set up quantitative measurements for performance and validation for the thesis’s in-dividual components and the solution as a whole.
5. Produce data for the quantitative measurements by either implementing tests or gatherinformation from other sources.
6. Analyze and document the results and relate these to the list of quantitative measure-ments.
7

8 Chapter 2. Method
2.2 Development Method
Dohi Sweden uses an agile development method called Scrum[40]. Scrum focuses on theiteration of Sprints which is a limited time-frame where the development of a product isincremented to a potentially releasable product. Each Sprint has a clear and decisive goalthat is supposed to be reached in a designated time-frame which usually spans one to a fewweeks. Sprints have generally a consistent duration throughout the development and areimmediately followed by another Sprint when the current is done. Short iterative steps areused to quickly build prototypes which can be tested to make quick decisions on how toproceed. Companies and project groups usually use their own modified version of the Scrumdevelopment method. The version and work-flow used at Dohi Sweden is a compromise ofprevious experiences at the company and the limited time span of the thesis project. Thedaily and weekly Scrum activities that were held with the external supervisor at Dohi Swedenare the following:
– Every day began with a Scrum meeting, including the discussion of:
• What was done yesterday
• Problems that had been encountered
• What had to be done until tomorrow
– Each week concluded with a summary of the following three aspects:
• Completed weekly tasks
• Problems that had been encountered
• Tasks that had to be postponed or modified
– After every month (roughly one iteration) the progress was presented to the externalsupervisor and summarized to provide a detailed project progress report.
From this general activity work-flow there are three central Scrum activities that needto be specified further; the planning sessions, the activities during an ongoing sprint andfinally the transition between two subsequent sprints.
2.2.1 Planning Sessions
Planning sessions is an important part where all requirements are formulated into tasks,subsequently divided to fit a specific time granularity and then grouped into components.Although the development method belongs in the agile class, the planning process canbe considered as a generally iterative process. As each requirement is first formulated intohigh-order tasks, these are iteratively divided into lower-level tasks. As long as the expectedgranularity of these tasks exceed a specified time threshold, they should be divided further.By keeping the tasks at the lowest possible level without specifying implementation details,it ensures that they are conceptually easy, allowing a more steady flow of progress to bereported. By grouping the divided tasks into components they are also easier to order byeither expected difficulty or by the order of dependency on other tasks. Figure 2.1 on thefacing page gives a work-flow overview of how the weekly sprint planning sessions of thethesis project were performed.

2.2. Development Method 9
Figure 2.1: A work-flow overview of a typical sprint planning session.
2.2.2 Ongoing Sprint Activities
These planning sessions produced (at least) a week’s workload divided into 4-hour tasks.The granularity of these tasks varied slightly, but as a consistency measure and to aid inproject progress overview they were all averaging roughly four hours each. The typicalworkday was 8 hours, with five days a week; yielding an expected task completion rate often tasks per week. A work-flow overview of daily activities of a pre-planned sprint areshown in Figure 2.2.
It was not explicitly stated in the planning sessions, but it was considered that the timeassigned to tasks would also include testing and documentation. The completion of anytask (on time or not) results in progress that is either completed and tested or marked forfurther testing. Any task may also be postponed for whatever reason.
2.2.3 Sprint Transitions
A sprint is considered completed, whether the tasks have been completed or not, when anew week begins. Tasks that are not completed in one sprint will carry over to the nextone. As the new sprint begins it starts with a summary of the progress of the completedsprint, where tasks that were not completed may now either be discarded, re-prioritised orpostponed even further in the new planning session that followed directly. Figure 2.3 showshow a recently completed sprint is summarised and its results combined into a new planningsession.
The concept of accepting a weekly progress is related to a measurement of how well theactual progress matched the planned activities. If there were any unplanned interrupts orbugs introduced that consumed a lot of time, this may have led to some tasks not being

10 Chapter 2. Method
Figure 2.2: The work-flow during a pre-planned workday.
Figure 2.3: Work-flow at the end of a sprint.
completed as planned. In these cases, the progress may be considered unacceptable, andsome tasks may have to carry over to the next sprint. Some tasks may have to be discardedcompletely or postponed indefinitely.

2.3. Evaluation of Existing Software 11
The decision to discard or postpone tasks may in projects involving more than one personmay instead be reduced to re-distribution of the workload, allowing other team membersto accumulate more tasks to ease the burden of particularly bug-ridden or difficult tasksassigned to specific persons. Of course, the purpose of having daily Scrum meetings shouldlimit the necessity of this, as the progress of each individual and the team as a whole ismonitored regularly. This makes it easier to make adaptive changes to regulate the progresswith the ultimate ambition to avoid having to resort to discarding or postponing tasks.
Short sprints instead of long iterations does not not only offer the possibility to makeshort-term workload readjustment for particular team members, it also provides naturalmilestones for both iterations and the project road-map as a whole.
2.3 Evaluation of Existing Software
There are several solutions for asynchronous web communication already available on themarket. Companies are providing both complete solutions and software frameworks tosupport web applications with dynamic content. However, many frameworks are customfor a particular use case or application area. This introduces limitations that apply forthe size of the application scope, the general cost of production and the choice of differentsoftware architecture components. By evaluating the current software, it is not only possibleto compare the performance to a proprietary solution but also possible to gain insight onwhat problems exists and how they can be solved, or worked around. This evaluationwill promote feature extension instead of re-iteration of already implemented and well-functioning solutions.
The motivation for developing a proprietary framework is to promote the possibility foreasy continuation of the already existing use case while still being able to extend the systemto other applicable areas. Three main evaluation criteria were used in the evaluation ofcurrent software solutions:
1. The ability to support as many web clients as possible over asynchronous connections,no matter which platform or browser the client uses.
2. The computational complexity and calculation time of vital software procedures, suchas separating the different messaging channels for events.
3. The software architecture, in the context of being able to support different use casesand flows for the application tasks.
2.4 Results Analysis
Since the different goals of the project have been split into three separate chapters, theresults for each goal will be addressed in respective chapter while an analysis and discussionof the overall system as well as the work for this project are presented in chapter 7.
To be able to perform fair comparisons with current software, the implementation willimitate the original behaviour as closely as possible and any differences between the twosystems will be thoroughly analysed and documented in what way they differ and whatimpact that may have on the test results and a future integration of the implementedfunctionality into the current service.

12 Chapter 2. Method
2.5 In-depth Study
The in-depth part of the thesis project (see Chapter 5) makes up the theoretical foundationthat concludes with the thesis project implementation. Focus was on three aspects of thepublish-subscribe pattern and the in-depth study tries to give an overview of how thesework and what they may be used for in the current system. The placement of the in-depthstudy chapter was chosen explicitly to be preceded by the chapter on implementing proposedimprovements, as the techniques and methods described in the in-depth review are closelyrelated to those explained in detail in the development of the improvements.
2.6 Documenting and Tracking Results
Throughout the whole project, a project diary was used and shared online with the internalsupervisor so that he could get a better understanding of the current status of the project.The work for the project diary consisted of noting down the following aspects for each week:
– What I have done.
– What kind of experiences I have gained.
– A status update of the schedule, including a revision when the schedule have not beenfollowed.
– Who I have been communicating with and in what way.
During the thesis project at Dohi Sweden, a project management tool called PivotalTracker1 was used to document the tasks for each sprint and note down what has been doneeach day and how much time that has taken. It was also used to keep track of the milestonesfor the project and to generate various backlog information such as burn-down charts andestimations of when milestones and tasks will be done using a calculated project velocity.
2.7 System Orientation
Figure 2.4 shows an overview of the current system, including the components of the back endand how they communicate with each other. Three important aspects for this evaluationis the communication between the front end and the back end, the architecture of theback end and the separation of messaging channels for different events. The client-servercommunication will focus on the link between the front end and the web server. The setup ofthe overarching system and its components will address most of the components presentedin the figure, excluding the static file store and focusing on the way components relateand interact with each other. The separation of events addresses the problem of logicallydistinguishing between different event data inside the system components as well as on theactual channels of the internal messaging bus.
1www.pivotaltracker.com

2.7. System Orientation 13
Figure 2.4: An overview of the system and its underlying components. The numbers rep-resents three technical aspects that were deemed important for this thesis. They are: 1.the asynchronous communication between a web client and a web server, 2. the back endarchitecture and 3. the separation of the messaging channels for events.

14 Chapter 2. Method

Chapter 3
Assessment of ProblemDomains
This chapter describes an assessment of problems and questions that are relevant for thisthesis work. These problems have been grouped into four domains which are representedwith four sections in this chapter. The first three domains reflect those that were definedby the goals of this work while the last domain centres around a specific problem that isprevalent in the other domains.
Section 3.1 focuses on the problems of creating large scale asynchronous communica-tion over the web. This section addresses underlying communication protocols as well asabstractions of messaging implementations.
Section 3.2 is centered around the internal messaging on the back end. Since the solutionmust be able to scale well there are questions related to how scalable back-end componentsmay synchronise and communicate with each other.
Section 3.3 is an assessment of problems for handling large scale data processing on theback end both distributed and as a distinct logical unit. It addresses ways to manage andprocess data as well as making a clear separation between different use cases.
Section 3.4 refers to the problem of ensuring and managing reliable distributed systems.This section is an assessment of how coordination services can be used to handle componentsof the solution that must be distributed.
3.1 Web Communication
The solution that is addressed in this thesis is defined as a web service since the front endof the system is aimed to be incorporated into a web page or any other container thatdisplays and manages web content. This means that the service needs to use some kind ofweb communication with the clients. Furthermore, since the communication should go bothways, the way a client and the service communicates is of great interest for this study as theHTTP request/response protocol used for web communication is not bidirectional. Becauseof this, this section includes an assessment of commonly used ways to create asynchronousand bidirectional communication between a web client and a web server.
Using web communication between the clients and the service also means that the serviceneeds some kind of web server in the front. The service may also be used as a some kind hostfor web content which also motivates a web server. This section includes a small description
15

16 Chapter 3. Assessment of Problem Domains
of a number of web servers and a summary, based on the studied web servers, of foundproperties that is of importance for this kind of solution.
3.1.1 Communication Techniques
This section describes a comprehensive list of available techniques, in form of methods andprotocols, used to create asynchronous connections between a web server and a web client.This list is aimed to document how these methods and protocols are used and in what waythey differ from each other. An important aspect that is addressed for these techniques isthe ability to conform to a standard for web communication. This includes, for example,the way a technique depends on the client’s web browser, if a protocol uses a common portor if and in what way a technique uses the HTTP request/response protocol.
Three terms that relate heavily to this text is Ajax, Comet (Reverse Ajax) and XML-HttpRequest (XHR). Ajax is a general term that refers to a set of client-side techniquesused to make it possible for a web client to send data to and retrieve data from a web serverwithout reloading the whole page. Comet or Reverse Ajax is a general term that refers toa set of techniques used to make it possible for a web server to push data to a web client.Comet capabilities is usually achieved by using HTTP streaming or by using Ajax with longpolling. XHR is an widely used API that a web client can use inside a web page, usingscripting languages, to communicate with a web server using the HTTP request/responseprotocol without loading a new web page.
Long Polling
Long polling is an HTTP request/response protocol technique used by a client to poll a webserver for new content where the server waits with the HTTP response if it does not haveany data to send to the client. When the server has new data it uses the connection it is stillholding to push the data to the client. After the client receives a response it sends anotherrequest to the server. This makes it so that the server always has a connection to the clientit can use to send data.
Long polling is widely supported by web browsers since it is a technique that has beenaround for very long. This also means that there are a lot of solutions and implementationsavailable that uses this technique so it becomes easier to find a solution that fits into a morespecific use case. This technique is an improvement of regular polling since it has a highprobability to reduce the polling or message exchange frequency and it enables servers torespond immediately when it has new data to send. When many messages are being sentbetween the server and the client there is no real performance improvement from regularpolling[32]. As the server needs to hold a connection open when it does not have anything tosend it creates idle processes which take up some resources on the server[41]. Long polling isusually enabled by loading some kind of library onto the client which could add some delaywhen accessing a page.
HTTP Streaming
HTTP streaming or HTTP server push is a technique for sending data from a web serverto a web client by making the web server hold the HTTP connection open after a responsehas been sent to the client. By holding the connection open the server can push data tothe client whenever the server gets new data to send. HTTP streaming can make use ofXHR to handle ingoing and outgoing events or use page streaming where the server keeps

3.1. Web Communication 17
the client in the ”loading” state and send script tags which gets executed by the client assoon as they are received.
Since a connection is kept open, there is not as much overhead from sending multiplemessages as long polling since there is no need to make an HTTP request/response forevery message. This gives greater performance when exchanging a lot of messages betweena server and a client compared to long polling[14].
WebSocket
WebSocket consists of a protocol and an API that provides full-duplex communication usingTCP over port 80 and is attained with an upgrade handshake from HTTP[59]. This meansthat web servers can communicate with web browsers asynchronously by both letting thebrowser send messages to the server and by letting the server send messages to the browser.Since the connection uses the standard HTTP ports for the web there is no need to open upany additional ports to allow WebSocket communication. What is needed is a web serverand a web browser that supports WebSocket. A WebSocket connection can send both UTF-8encoded text and binary data.
Full duplex communication gives increased efficiency over long polling and HTTP stream-ing because of less overhead with the messages exchanged[49]. With the use of TCP and theability to send message in binary, WebSocket can be used to serve any type of data that aregular program can. WebSocket is supported by a lot of browsers but it is still a fairly newtechnique and its API has still not yet been standardised so there are still some older andused versions of web browsers that do not fully support WebSocket[5]. It may also be moredifficult to find and make use of software architecture solutions such as load balancing sincethey also need to support WebSocket[26]. WebSocket has its own API which lets developersfocus less on the message exchange handling as they have a unified way of communicatingand do not need to learn multiple ways, compare different methods, etc.
Bi-directional Streams Over Synchronous HTTP (BOSH)
BOSH is a transport protocol that uses pairs of HTTP requests and responses to emulatebi-directional communication. It uses long polling to ensure that the server always has aconnection it can send messages to the client. To let the client communicate with the serverit uses an additional HTTP request aside from the long polling request.
BOSH claims to have a very low latency for a protocol that only uses regular HTTPcommunication[17]. This makes it a very viable alternative for WebSocket as it enablesmessages to be sent both ways, with methods that may work when WebSocket do not.BOSH uses a JavaScript library to handle messages on the client-side and that library needsto be loaded into the client before BOSH can be used.
Web Real-Time Communication (WebRTC)
WebRTC is an API designed to make voice calling, video chat and file sharing betweenbrowsers possible without the need of a plugin. It is being drafted by the World Wide WebConsortium (W3C) and even though it is not complete it is still partially supported bydifferent browsers[57]. The WebRTC project includes components such as network modulesand audio and video codecs to make it easier for the developers to create high quality andreal time communication functionality inside the browser.
WebRTC uses the Real-time Transport Protocol (RTP) which makes it a better choicefor serving content such as audio and video. This also makes the WebRTC into a Peer-

18 Chapter 3. Assessment of Problem Domains
to-peer (P2P) solution for transferring data both between a web browser and a web serverbut also between two web browsers which means that communication can be set up towork between two clients without the need of going through a server. This is somethingWebSocket alone cannot do. WebRTC is still being drafted though and is not as supportedby web browsers than WebSocket[57]. WebRTC needs a signalling protocol to set up thecommunication between two clients which is something WebSocket can provide[10].
Server-Sent Events (SSE)
Server-Sent Events is a technology used to provide functionality for sending data from aweb server to a web client[56]. It describes how a server can communicate with a client andcontains a JavaScript API called EventSource that the client can use to request and handlea connection to a data stream on the server. EventSource is being standardised as part ofHTML5 by the W3C.
SSE is unidirectional and does only provide a way for letting a server push messages to aclient and has, bacause of this, not as wide of a use case as WebSocket and other bidirectionalcommunication methods. SSE can be emulated by using JavaScript which makes it possibleto support older browser that do not support SSE natively[38].
Browser Plugins
There are numerous browser plugins that can be used to enable additional communicationtechniques between a web browser and a web server. One possible push technique is tomake use of a one pixel large Adobe Flash movie to establish an additional connection tothe server. This hides the movie from the user while providing the extra communicationlink from the Flash movie. The extra connection is used as a regular TCP connectionwithout the need of HTTP requests or responses. SilverLight is an application frameworkfrom Microsoft that aims to fulfill a similar purpose as Adobe Flash. SilverLight can alsobe incorporated into a web browser as a plugin and provides different ways for a web serverand a browser to communicate. ActiveX is another alternative that gives extra control ofthe browser. These methods use other or additional types of protocols than the HTTPrequest/response and needs extra software and explicit support in the browser which makesthem a secondary solution for this solution. Using these types of browser controllers haveintroduced many extra security problems and many of them are widely known for theirexploitations by malicious web applications.
3.1.2 Web Servers
This section is an assessment of web servers that can be used as the party that explicitlycommunicates with the clients of the service. It focuses on asynchronous, event-driven webservers that can scale and perform well when handling many concurrent clients. A verypopular HTTP web server that hosts a significant amount of web sites (63.7% of all activewebsites[25]) over the world is the Apache web server. This server was not included in thisassessment since it is not an event-driven web server.
Event-driven web servers sees handling all network connections as a single task which issolved by one (most common) or multiple threads in a loop, iterating over the connectionsand reading from them and writing to them asynchronously. This is different from the moretraditional way of creating a separate thread for each connection. The main drawbacksof using the traditional method is its scalability as creating a thread for each connectioncreates a lot more memory and thread management overhead.

3.1. Web Communication 19
Nginx
Nginx is an asynchronous event-driven web server that can also function as a reverse proxyserver for HTTP, SMTP, POP3 and IMAP protocols. It was found to be the second mostused web server for all active sites according to Netcraft’s December 2012 Web ServerSurvey[15] and is used by, for example, Netflix and Wordpress. It is designed to be a verylightweight, scalable and high performance web server and is widely used for load balancingas a front-end server. When using Nginx as web server, 10000 inactive HTTP keep-aliveconnections can be handled with only 2.5MB of memory[29].
Tornado
Tornado is an open source solution for a scalable, non-blocking web server that also providesan application framework written in Python. It contains a set of modules that includes aWebSocket module and has numerous web application implementations built on top of itsuch as Socket.IO1 and SockJS2 as well as many help libraries and frameworks[53]. Thismakes it a good choice when choosing a web server that can support other, perhaps alreadyused, frameworks and libraries. Including libraries in the Python framework might not beas easy as Tornado needs asynchronous libraries to be able to fully use the non-blockingfunctionality.
Jetty
Jetty is an open source, HTTP server, HTTP client and Servlet container based on Java andis used in many products such as Apache Maven, Google App Engine, Eclipse and Hadoop.It supports different embedded solutions, frameworks and clusters. It supports WebSocket,SPDY and the Java Servlet API[19]. Jetty features a very extensive and pluggable function-ality which makes it easier to customize and optimize for different use cases.
Mongrel2
Mongrel2 is an open source web server that supports HTTP, Flash, WebSocket and longpolling communication[28]. It supports 13 different programming languages and can bebuilt on many different platforms. It is built on ZeroMQ3 for concurrency and is thereforeperhaps easier than others to manage when scaling. The ability to implement componentsor functionality using different languages makes it a very versatile server solution that canhandle many types of use cases.
Lighttpd
Lighttpd, pronounced Lighty, is a web server that was designed to be very lightweightand handle 10000 parallel connections on a single web server[24]. It is a very secure andflexible web server that has a very low memory footprint. It is similar to Nginx but is notconsidered to be as stable and easy to use as Nginx but it does feature a full-blown bugtracking system[63] which is of great use during development.
1www.socket.io2www.github.com/sockjs3www.zeromq.org

20 Chapter 3. Assessment of Problem Domains
Node.js
Node.js or Node is a system for deploying fast and scalable network applications written inJavaScript. Node uses event-driven, asynchronous I/O to handle communication and thesystem can be used to create a web server written in JavaScript. Node has a fairly highamount of modules that can provide additional functionality from the Node core such asimplementations of networking techniques, authentication and testing[31].
Event-driven asynchronous I/O generates less overhead than the OS threaded solutionand as Node is not threaded it does not have any dead-locking possibilities. This makesNode more viable for the development of scalable web solutions as developers do not have tospend as much time managing a threaded environment[48]. Applications for Node is writtenin JavaScript which means that a web client and a web server can use the same language.This will make it easier to make web applications as there is no need for interpretationbetween two languages. It is also much easier to make test cases incorporating both sides.JavaScript is a dynamic language where it is possible to compile code into other languagessuch as C or Java.
Vert.x
Vert.x is a Java-based application framework which, similar to Node.js, uses event-driven I/Oand an asynchronous programming model to provide concurrent applications[55]. Vert.x runson a Java Virtual Machine (JVM) and supports a fair amount of programming languagessuch as Ruby, Java, Groovy, JavaScript and Python. One difference from Node.js is thatVert.x can use multiple threads on a single Vert.x instance and does not need to add moreinstances to fully saturate a multicore server solution. Vert.x does also support differentcommunication patterns natively such as the publish/subscribe pattern.
EventMachine
EventMachine is a software system for the Ruby programming language and provides event-driven I/O. It is designed for concurrent programming where scalability and performance isof concern. EventMachine has been around for many years and is a mature and well-testedsystem compared to Node.js and Vert.x who have been around for much less time[12]. Ap-plications for EventMachine are written in Ruby which makes it a less language agnosticsystem compared to, for example, Vert.x and web solutions needs to be written using differ-ent languages on the front end and the back end. EventMachine is also restricted to usingEventMachine libraries and cannot ensure that other types of Ruby functionality works.
Twisted
Twisted is a programming framework for event-driven networking written in Python andsupports many different protocols such as TCP, UDP, SSL/TLS, IP, HTTP, CMPP, SSH,IRC and FTP[54]. Twisted is, like EventMachine, a more mature solution than Node.jsand Vert.x and has a lot of additional functionality. Like the Tornado web server, Twistedcannot directly use any Python library because of the asynchronous nature of Twisted andthe synchronous nature of regular Python languages. Twisted might have a steeper learningcurve than, for example, Node.js because of its additional functionality it supports andperhaps needs more code and time to set up an application with equivalent capabilities asan application for Node.js.

3.1. Web Communication 21
Summary
When looking at event-driven web servers for asynchronous communication there exists someproperties that are used to motivate a specific web server. The programming language thata web server supports is naturally of importance since a certain use case may better fit aspecific language based on factors such as the functionality of the use case and the experienceof the developer. Supporting multiple languages minimizes the risk of a developer choosinganother web server because of the language. Node.js has gained a fair amount of popularitylately because of the use of JavaScript on the server-side, which enables developers to createweb sites that use the same, widely known, language on both sides.
Two aspects that are commonly used as low-level performance indicators of a web serverare the memory footprint and the message throughput when scaling the number of connectedclients. The memory footprint refers to the size of memory a web server needs to handle acertain amount of clients and using an event-driven web server this can be held to a verysmall amount. Message throughput refers to the number of messages a web server can sendand receive for a specific time frame and a specific amount of clients. Both these aspectsrelate to the overhead of managing multiple connected clients which is one of the mainattractions of event-driven servers. They are important as one of the prerequisite of thetargeted solution is to be able to scale well and handle many clients concurrently.
The number of supported libraries and modules for a web server are important as it mayhelp abstract parts so that the developer can focus on the core functionality of the solution.Support for general and well-known libraries are also a factor as previous experience can thenbe used. A prevalent problem with the assessed web servers are the disparity between theasynchronous framework of the web server and the common libraries in the same languagewhich the web server uses. Most of these libraries are not made for asynchronous tasks andmay be difficult to assert whether they are reliable for use with the specific web server.
One way the listed web servers can differ is their take on multi-threading focused onscalability and manageability. Node, for example, uses only one thread to handle client con-nections and instead pushes the responsibility to make full use of a processor to the developerwhere the idea is to use multiple instances of Node. This makes a Node instance much moreeasier to implement since developers do not have to worry about multi-threading[48] whilethe scalability of a Node on a single processing unit needs more work outside of the Nodeinstance implementation.
3.1.3 Web Application Libraries
One important aspect when creating a messaging system is the use of abstraction in thenetworking layer of an implementation. Incorporating a library to use as a higher levelinterface for communication between a client and a server makes it easier for the developerto focus on the core functionality.
Socket.IO and SockJS are two JavaScript libraries that provide the use of multiple com-munication techniques using fallbacks where a second technique could be used if a first onefails. Socket.IO can be used as a wrapper for WebSocket with fallbacks to other techniques,such as Flash and Ajax long polling. SockJS core does not support Flash but providesdifferent streaming protocols instead. Atmosphere is a Java framework that also containscomponents for creating asynchronous web application and has support for WebSocket,Server-side Events, long polling, HTTP Streaming and JSONP[2].
One of the benefits of using JavaScript on the server-side is that the same languagecould be used on both sides. Socket.IO contains two parts: a web-server application thatis supposed to run on Node and a client-side API that can be run in a web browser. This

22 Chapter 3. Assessment of Problem Domains
makes it possible to use the same solution on both sides which minimizes the overhead ofusing two different programming environments. SockJS tries to make its API as similar tothe regular WebSocket API as possible so that there is no need to learn and conform toanother API.
The JavaScript version of SockJS is made for Node but it currently exists implemen-tations for other languages and server solutions such as Tornado, Netty and Twisted.Socket.IO also has a version for Tornado. Providing an API for multiple server solutionsmakes it easier for developers to incorporate SockJS functionality using a web server and alanguage they are familiar with.
The Channel API is an API for Google App Engine (GAE) that enables messagingcapabilities between applications written for Google App Engine and web clients[58]. GoogleApp Engine is a cloud computing platform where applications can be deployed and servedacross multiple servers without the need to manually supervise the infrastructure of theapplication as components such as web servers are provided and managed by GAE usingvirtualization. The Channel API is a way to marshal the different communication techniquesand instead provide an API that is easier to use when implementing messaging functionalitysuch as server to client publishing.
3.2 Internal Messaging
The web service that is studied in this thesis is supposed to serve more than 100000 concur-rent connections and must keep the client-side latency to a minimum. One important aspectof a web service that should both scale and perform well is the internal synchronisation andcommunication between back-end components. It is apparent that it is very important tochoose a messaging solution that properly fits the targeted solution. This section describessome different messaging paradigms to get a better understanding how these work and whenthey should be applied.
3.2.1 Messaging Paradigms
The messaging paradigms that are described are remote procedure call (RPC), distributedshared memory (DSM), message queueing and publish-subscribe. These paradigms differin many ways and have different uses and this study tries to assess when and how theseare applied. The entities in a messaging system are usually called the message sender,the message recipient (receiver) and the messenger (broker). A messenger or broker isan intermediate component that makes sure that a message is routed from a sender to arecipient.
Remote Procedure Call (RPC)
Remote procedure calls or RPC refers to when a software invokes a procedure in anotherprogram environment, commonly over a network[3]. This is usually implemented in a way sothat there is no large difference between coding local functionality and issuing remote invo-cations. RPC tries to make remote processing transparent by treating a distributed systemas a single process. RPC is used to minimize the impedance for accessing local and remotefunctionality and to reduce the complexity of using a full-fledged messaging system and in-terface. Using RPC is problematic when addressing the difficulties of distributed messagingas remote procedure calls faces different problems than local calls such as partial failures,and different memory access models in communicating parties. One of the disadvantages

3.2. Internal Messaging 23
of RPC is that there currently does not exists a general solution which has proven RPC afitting solution for large scale communication over a wide area.
Distributed Shared Memory (DSM)
Distributed Shared Memory or DSM refers to the solution where a virtual address spaceis shared among loosely coupled processes, often over a network[30]. A process views theshared memory as regular local memory and moves the issue of scaling a distributed solutionto mapping a memory access request to a space in shared memory. This method gives avery simple abstraction as implementations using a distributed shared memory do not haveto worry about moving data. This also simplifies process migration as different machines allstill use the same memory. The DSM provides time and space decoupling as processes usinga DSM does not know about each other but does not provide synchronisation decoupling.A DSM is generally not as used for typical client-server models where resources need to beviewed and accessed in an abstract manner because of security and modularity issues[9].
Message Queueing
Message queueing enables buffering of a sent message for later retrieval and decouples thesender and the receiver in respect to space and time[13]. This is commonly done by intro-ducing a messenger between a sender and a receiver that first enqueues sent messages andthen sends them to the receiver when the receiver expresses its interest in it. This paradigmoften provides transactional, timing and ordering guarantees for the messages that are sent.It is used to provide greater resilience between communicating processes and is an appro-priate paradigm where there exists a discrepancy between the number of messages beingsent to a process and the rate of which the process can receive and process messages. Mes-sage queues do not provide synchronization decoupling with well-supported scalability asconsumers synchronously pull messages from the queue.
Publish-subscribe
The publish-subscribe pattern decouples the communicating processes with regards to space,time and synchronisation[13]. Receiving processes address their interest in some kind ofcontent and sending processes address their interest in sending some kind of content. Theimplemented publish-subscribe system is then responsible to route sent messages to processesthat have expressed interest in the content that the message consists of. This is a very similarparadigm to message queueing as they decouple the processing in the same manner. Thepublish-subscribe pattern is more appropriate when there exists a need of more intricaterouting messages than a one way communication path. This paradigm also enables a higherscalability as it can make better use of the underlying network architecture and processtopology.
3.2.2 Qualities of Service (QoS)
This section addresses three qualities of service that may be of importance when implement-ing a messaging system: persistence, reliability and availability.
Persistence
Persistence is a quality of service that is desirable in a messaging system when the sender andreceiver are decoupled in respect to time and there exists a situation where the sender cannot

24 Chapter 3. Assessment of Problem Domains
directly be guaranteed that the message has been delivered to the receiver[13]. Persistenceoften means storing messages on a hard drive or flash memory so that messages are not lostbetween the sender and the receiver if, for example, a messenger would crash. This qualityof service may degrade the performance of a system since messages cannot only be stored,for example, in RAM but must also be put on some persistent, often much slower, storage.This is of concern when facing a system that should be able to perform well while scaling asdistributing more messengers may make the system more complex when trying to guaranteethe delivery of a message in a path of a larger messenger architecture.
Reliability
Reliability is another quality of service related to aspects of guaranteeing the delivery of amessage[13]. Reliability addresses end-to-end delivery guarantees with different propertiessuch as using reliable protocols, persistent messages and message ordering. This is animportant quality of a messaging service when using more loosely coupled messaging systemand the end-to-end participants are not using point-to-point communication. One problemwith distributed systems is the fault tolerance of the distributed architecture and ensuringmessages are delivered in case of a messenger crash.
Availability
Availability refers to the portion of a time interval a service can ensure it operability. Differ-ent systems may have different definitions of operability where, for example in a multi-serverarchitecture, the system may still be considered operational as long as one server is still func-tioning. This is not as much of a messaging aspect as it is a more general quality of servicefor distributed systems[13]. When implementing a solution that gives the internal messaginga central role it is important that the messaging system is robust enough to guarantee afunctional state for as long as much. An example of increasing a messaging system’s ro-bustness and availability is by using replication of messengers so that one messenger couldpick up a delivery should another crash or somehow fail. This is on the expense of increasedresource management and cost as well possible degradation of performance.
3.2.3 Messaging Systems
The following parts of this sections describe a couple of messaging systems that, as of today,have some fairly large support and use. This section tries to highlight the main use cases ofthe messaging systems as well as describe in what way they are used and differ from eachother.
Kafka
Kafka is a distributed publish-subscribe messaging system that is written in Scala and wasmade for managing activity stream processing on a website[22]. It is an explicitly distributedbroker system that was developed for LinkedIn and is currently an open-sourced project byApache. Kafka is designed for persistent messages and focuses on throughput instead offeatures. It offers a JVM-based client and a primitive Python client but supports anylanguage that makes use of standard socket I/O. Kafka can use different data structureswhere some support transactional semantics - this can reduce performance though becauseof the disk operations Kafka uses for persistency.

3.2. Internal Messaging 25
Kafka is a fairly recent messaging system which do not use AMQP4 and does not offeras much functionality or complex routing because of its focus on throughput instead offeatures. Kafka has a low overhead in network transferring and on-disk storage which givesit good performance [36]. It uses a very lightweight API that is simple to use and togetherwith its distributed architecture it performs very well when scaling out. As Kafka uses itsown non-AMQP protocol it is more difficult to replace.
RabbitMQ
RabbitMQ is a widely used open-sourced messaging system that implements a broker ar-chitecture and uses AMQP[35]. It supports HTTP, STOMP and MQTT and provides clientlibraries in many different languages such as Java, Python and Erlang. The rabbitMQbrokers use Erlang to pass messages around. A RabbitMQ messaging solution can be dis-tributed in three different ways, clustering, federation and shovel. Clustering refers to whenmultiple brokers are grouped and act as a single logical broker. Federation is when brokersconnect to each other, typically over the Internet, to exchange and share messages so thatdata is mirrored between them. Shovel refers to when brokers are connected and insteadof mirroring their data they forward it to others. RabbitMQ contains solutions for highavailability and fail-overs using many different techniques such as clustering and mirroringdata.
RabbitMQ is one of the most used solutions for AMQP messaging systems and hasbeen around for some time. Because of this, RabbitMQ has a lot of libraries, tools anddocumentation which makes it a good choice when looking for a reliable messaging system.RabbitMQ is not as focused on performance as Kafka and instead provides additional func-tionality that Kafka does not. It features more different routing capabilities and is highlyconfigurable.
Qpid
Qpid is an open-sourced messaging system from Apache that, similar to RabbitMQ, im-plements AMQP[34]. It provides brokers in Java and C++ and many client libraries suchas Java, C++, Python and Ruby. Qpid contains many features for managing transactions,queueing messages, and distributing brokers. It is very configurable and uses a pluggablelayer to provide additional functionality such as persistency and automatic client fail-over.Qpid does not feature as much functionality for a distributed solution as Kafka and Rab-bitMQ and clustering is only used to mirror all messages between brokers.
Qpid is, similar to RabbitMQ, highly configurable and uses AMQP which makes it agood choice when replacing some other messaging system. Qpid is also very similar to JMSand provides a JMS API as well which may make it easier to implement when already usingJMS.
ActiveMQ
ActiveMQ[43] is an open-sourced message broker from Apache that implements JMS. Ac-tiveMQ supports many languages such as Java, C/C++, Perl, Python and Ruby and awide variety of protocols including AMQP. ActiveMQ supports a lot of clustering optionssuch as a shared database, a shared file system or a master-slave set up. It also supports
4Advanced Message Queuing Protocol, an open standard application layer protocol for message-orientedmiddleware.

26 Chapter 3. Assessment of Problem Domains
four different message stores that can be used for messages persistency. ActiveMQ can bedeployed using peer-to-peer topologies instead of a broker architecture.
ActiveMQ is very highly configurable and contains a lot of additional functionality forsetting up any type of messaging system. One disadvantage with ActiveMQ is its perfor-mance compared to other systems, it has been proven to be slower than other systems andits performance when message stores is used is very low. Scaling an ActiveMQ broker systemhas also been showing some inconsistencies in terms of performance and stability.
3.3 Data Processing
This section describes two data processing models, namely batch data processing and streamdata processing. Instead of taking a general approach to these models, this section focuseson an implementation for both models, named Hadoop and Storm. These two processingmodels are currently the most popular for their problem domain and this section addresseshow these solutions work and are used.
3.3.1 Batch Data Processing
Batch data processing refers to the processing of very large collections of data that is mostlyalready gathered at the start of the procedure[44]. It uses a cluster of worker nodes wherethe work is divided between worker nodes that cooperates to compute a result. This istypically used when there exists some high amount of data that is supposed to be analyzedand reduced to some quantifiable result such as statistics from a database or a log file.
MapReduce[8] is a programming model for batch data processing that uses a masternode and a number of worker nodes. It divides the procedure into three steps: master mapsinput to sub problems and specific worker nodes, worker nodes compute answers for eachproblem and then the master collects and combines the answers into a result. The first andthe third step can also be distributed as long as the different input data and the differentanswers from the worker nodes has an appropriate level of independence. MapReduce isalso the name of an implementation of this type of batch processing made by Google.
Hadoop
Hadoop[18] is a software framework that enables distributed processing by using a program-ming model that was derived from Google’s MapReduce. It is open-source and licensed underthe Apache v2 license. It is made to provide a data-intensive processing solution that canbe run on commodity hardware and instead of relying on hardware it focuses on deliveringa high-availability system that can detect and handle failures at application level.
To be able to handle large files with sequential read/write operations, Hadoop makes useof its own distributed file system called Hadoop Distributed File System (HDFS) derivedfrom the Google File System (GFS). HDFS splits a file into multiple chunks and distributesthem on multiple data nodes[4]. A master node is used to keep track of files that has beendistributed over the data nodes and can tell where a certain chunk of a file is located.The master node also supervises writes to a file on the HDFS. This is done by pushingthe changes from the client to all relevant data nodes and then using the master node todesignate one of the data nodes as primary and send a commit to this node. The primarynode decides on an order to update, synchronises and updates together with all other datanodes and then sends a commit response back to the client.

3.3. Data Processing 27
Hadoop uses a job tracker to submit processing jobs[60] which takes a job configurationthat describes a map, a combine and a reduce function together with the way input and out-put should be managed. The job tracker delegates the work in the map phase to the workernodes which are also called task trackers. Each task tracker is responsible of extracting andapplying the map function on their own part of the input. Applying the map function onthe input will result in a number of key/value pairs which are stored in the memory bufferwhich are periodically sorted using the combine function to to group resulting data withrespect to the corresponding task trackers that will perform the reduce operation. When atask tracker is done it notifies the job tracker and when all are done the job tracker will startthe reduce phase. A task tracker in the reduce phase will then apply the reduce function onits reduce data and output the results. The job tracker will periodically check the health ofthe task trackers to see, for example, if a tracker has crashed, in which the job tracker willissue the map or reduce work on another task tracker.
3.3.2 Stream Data Processing
Stream data processing refers to data-intensive processing where, in contrast to batch dataprocessing, all data is not known at the beginning of the procedure. This model focuses onuse cases where data is continuously being generated and instead of computing a large setof static data, data is computed as it is introduced to the system[27]. This can be seen asa complement to batch data processing as stream data processing focuses on small batchesof rapid data that must be processed in real-time whereas batch processing focuses on a setof data as a whole and typically expects some delay between reading input and returning aresult.
Storm
Storm is an open-source software for distributed real-time data processing[46]. It focuseson computation of smaller data sets that are continuously introduced to the system andcan be used for real-time analytics and online machine learning among others. Its inherentparallelism gives it very high performance in terms of message throughput and it has beenbenchmarked at processing one million 100 byte messages per second and node on two IntelE5645 processors at 2.4Ghz with 24GB of memory[47]. In contrast to Hadoop, Storm is notexpected to terminate and instead be up and running for as long as it is allowed to.
Storm uses a topology of sprouts and bolts in an acyclic directed graph where sprouts areprocessing nodes that introduce data and bolts are the execution points in the system[50].The sprouts are the source from which data is either generated or fetched from somewhereelse. A sprout can be connected to any number of bolts where it can send its data to. Boltsare the computational units that can receive data from any number of sprouts and bolts andtransmit data through to any number of bolts. Except for defining the sprouts and boltsthat are needed for a system, a topology also needs to be specified that describes how thesprouts and bolts should be connected.
Thrift[52] is a software framework for scalable services development that supports a widerange of programming languages. It is used for data serialisation with focus on efficiency andseamless use between languages. Storm uses Thrift to define topologies and a JSON-basedprotocol over stdin/stdout for the communication between sprouts and bolts. This makesStorm more easy to use as its functionality can be implemented in many different languages.
Storm consists of a master node that runs a daemon called Nimbus and a number ofworker nodes were each worker node runs a daemon called supervisor. Nimbus featuressimilar responsibilities as Hadoop’s job tracker where tasks are distributed among worker

28 Chapter 3. Assessment of Problem Domains
nodes and the health of worker nodes are monitored[21]. A supervisor waits for tasks tobe assigned by the Nimbus and is responsible for managing the compute processes on thenode. The interaction between the Nimubs and the supervisors of Storm is done throughZookeeper, see section 3.4 about zookeeper. This separates the coordination of the Stormcluster from the Storm functionality and creates a more distinct definition of what Stormexclusively does.
3.4 Distributed Coordination with Zookeeper
This section focuses on an intermediate service that have been prevalent throughout thewhole assessment for this chapter, namely distributed coordination with Zookeeper. Thissection tries to describe the fundamentals of using Zookeeper in a distributed system.
Zookeeper is a centralised coordination service for distributed solutions that is intendedfor high performance[16]. It tries to take over the responsibilities of distributing an appli-cation from the application itself to improve manageability and make an application easierto implement. It provides services for maintaining configuration information, synchronisingdistributed processes and managing groups in a distributed application. It enables consen-sus, election service, synchronisation and a naming registry among many other distributedfunctionalities.
Zookeeper was in the beginning made for Hadoop before it was turned into a stand-aloneproject by Apache. Hadoop used Zookeeper to coordinate the nodes of Hadoop so thatdistribution functionality could be offloaded from an application for Hadoop to Zookeeper.Zookeeper is used by Storm[21] to coordinate the master and the worker nodes to make iteasier to deploy and manage a Storm cluster. It is also used by Kafka to manage a clusterof brokers.
ZooKeeper uses a shared hierarchical name space of data registers called znodes tocoordinate distributed processes[62]. These znodes are provided with high throughput, lowlatency, high availability and strictly ordered access. The name space is very similar to aregular file system where every znode is identified by a sequence of path elements separatedby a slash (/). This file system was made to store smaller data of coordination informationand is not meant to be used as a large data store. The data tree is also stored in-memorywhich further limits the service to use small data sets.
The service is replicated over a set of machines where a client may connect to any ofthese replicas. One of the replicas is assigned as a master which controls the way data canbe written to the file system to make writes guaranteed to be persisted in-order. It is alsoresponsible for updating the other replicas with the new data. Reads are concurrent and asany replica can be used by a client, reads are eventual consistent. This makes Zookeeperless appropriate when facing a very write-heavy workload as guaranteeing linear writes maytake some time.

Chapter 4
Evaluation of Reference System
This chapter describes an evaluation of the current solution that this thesis aims to improve.It tries to explain how the provided service is used in section 4.1 so that later suggestedimprovements can be more easily understood. Section 4.2 contains an overview of thesolution including how the system components are implemented and how they interact witheach other. Section 4.3 includes a discussion about the motivation and drawbacks of thedifferent components focused on the domains from chapter 3. The last section lists identifiedproblems or issues revolving the immediate goal of this thesis, namely to improve the solutionwith regards to making it a more distinct product.
4.1 Use Case
The system is currently used to provide voting functionality on a website either for ratingsubjects or for answering categorical questions. The functionality is provided during eventswhere the customer wants to ask questions related to the event. There are two ways auser may interact with the system, either as a regular client that can vote on questionsand view results or as an administrator that can create and supervise questions. Thesetwo types of interactions are completely separate from each other on the client-side andtheir functionality are accessed through completely different web pages. The back end isresponsible for receiving votes, processing them and return a result back to the clients. Thisis done using an asynchronous connection between the web client on the front end and theweb server on the back end. The admin interface uses the back end in a RESTful[23] wayto update questions and to control which one is active.
A client gets exposed to the service by visiting a web page that has incorporated the frontend of the service into its context which is currently done using an Iframe, see Figure 4.1.When a question is started, the back end notifies the front end by sending a message in whichthe front end will then update its content so that the client then can vote. When a clientvotes, the front end sends the vote to the back end that processes votes and periodicallysends current result back to all clients. The result basically consists of the current ratingfor a rating question or the number of votes for each choice for a categorical question.
The way an administrator gets access to the system is also via a web page but the contentis provided directly as a standalone page and not in an Iframe.
29

30 Chapter 4. Evaluation of Reference System
Figure 4.1: A representation of how a client currently is exposed to the service. It is exposedto the service on a web page where the static content, such as HTML and CSS, is downloadedfrom a static file store. This static content also contains logic for communicating with theweb server that contains the voting functionality.
4.2 System Overview
This section describes the overall architecture of the current solution and includes a list ofaddressed components describing what they do, how they are implemented and how theyinteract with each other.
Front End
The front end consists of a web page containing both regular web content as well as func-tionality to support asynchronous communication with the back end. It could either consistof a page providing the regular use case for the service i.e. voting functionality or it couldconsist of a page providing administrative functionality. The page for the regular use case isincorporated into another service’s web page using an Iframe. The front end communicateswith the back end using the API from Socket.IO and JavaScript. Messages are sent as plaintext using JavaScript Object Notation (JSON).
Load Balancer
When a client first connects, it speaks with a load balancer that keeps track of all the runninginstances of the web servers and routes the client to one of them. The load balancer onlyroutes the client when it is first connecting, after the client has been assigned a web server,the client speaks directly to the web server. The load balancer makes sure that a previouslyconnected client always gets the same web server to talk to when it is reconnecting to the

4.2. System Overview 31
Figure 4.2: Overarching components in the reference solution. A web client fetches thestatic content from a static file store, which also contains the logic to communicate withthe web server that contains the voting functionality. A web client connects to a web serverusing a load balancer. Any votes are put on a processing queue so that votes are bufferdto a data processing component that calculates a result and returns it using a notificationsystem. The service also uses a database to store the global state of all events.
service. This is done using the load balancer HAProxy on an AWS Elastic Compute Cloud(EC2) instance.
Web Server
The web server consists of a cluster of AWS EC2 instances that are running Tornadio2which is a python implementation of Socket.IO on top of the Tornado web server framework.Socket.IO is used to provide many ways of communicating asynchronously with a client with

32 Chapter 4. Evaluation of Reference System
fallbacks when one does not work because of client limitations, such as web browser supportfor the current techniques. The server instances are horizontally scaled up or down usingAWS Auto Scaling depending on use statistics.
Static File Store
The service uses a file store to host the static web content that is fetched by connectingclients. The file store functions as a regular web server for static web pages and a clientfetches the page directly from the file store using point-to-point file transfer without talkingto the web servers of the back end. The currently used file store is the key/value storeSimple Storage Service or S3 from AWS which can also function as a web server.
Client Validation Cache
The web servers uses a remote cache to store client validation information. The AWSElastiCache is used to store this data outside of a specific web server. When a clientconnects to a web server it first checks with the validation cache to see if there are alreadysome data on that client.
Data Processing Queue
When a web server receives a vote from a client it puts the message on a queue thatconnects to the data processing system. This is used to buffer the messages that is sentto the processing system and decouple space and time between the web servers and theprocessing system. The current system uses AWS Simple Queue Service or SQS to providethis functionality.
Data Processing
The processing of messages that are sent in from the clients are offloaded on a stream dataprocessing system called Storm. This component receives votes from the processing queue,computes a result and sends it to all of the web servers using a notification system. Stormis also responsible for storing the result and other statistics in a database. The results thatare computed are typically the mean value for a voting question or the vote count for acategorical question. Storm is deployed as a cluster on a number of EC2 instances. Stormuses a spout for the interaction with the Simple Queueing Service (SQS) which listens forand receives messages from the queue. It uses a bolt for the Simple Notification Service(SNS) to send results to the notification system and a bolt for the Relational DatabaseService (RDS) to update the database.
Notification System
The notification system is responsible for relaying messages between web servers and thedata processing component. When Storm computes a new result it transmits the resultto all web servers using the notification system. The notification system is also used bythe administrators of the service to relay when a question has been started or stopped tothe other web servers that the administrator is not connected to. AWS Simple NotificationService or SNS is used as the notification system.

4.3. Discussion 33
Database
The reference system uses a database to store the current state as well as log statistics andother data. When a web server are added to the back end cluster, the web server fetchesthe current state from the database and transmits it to the client. The current solution usesAWS Relational Database Service or RDS as the service’s database.
4.3 Discussion
This section focuses on the reference project in the context of the previously assessed do-mains, the web communication between front end and back end, the internal messagingbetween back-end components and the data processing on the back end. It includes a dis-cussion for each domain in how the current solution handles the problems relevant to thedomains.
Web Communication
The service is using the Socket.IO API on both the front end and the back end to com-municate between them. Using a higher level interface makes it easier for developing theservice as abstracting non-core functionality lets developers focus on the use case specificparts. Socket.IO abstracts the specific communication protocols and also supports fallbacksto other protocols when one fails. This is a fast way of enabling support for as many dif-ferent types of clients as possible. Using the same type of API on both sides minimizesthe overhead in time needed to create two frameworks using different APIs. As for usingPython and the Tornado Web Server on the server-side it has been proving to be a veryfast solution[33][37]. One drawback is that the two frameworks are not implemented in thesame language which may highten the impedance as code cannot be reused between the twoframeworks and the developer needs to be familiar with two languages instead of one.
The load balancer uses HAProxy on an AWS EC2 instance instead of using AWS ownElastic Load Balancing (ELB). This is done because ELB does not currently support theWebsocket protocol using ”sticky” sessions, or server affinity, where a client is routed to thesame web server it was previously connected to. The downside is that HAProxy and EC2requires (more) maintenance and do not provide as many additional services such as autoscaling. ELB would also work well with other components in the system as many are alsoAWS services. Making clients only talk to the load balancer at the beginning of a connectionand then directly speaking to the web server is good from a performance point of view as iteliminates another step between the end points of the communication.
The file store that serves the static web content is also only used in the beginning of aclient’s connection with the service. This means that the file transfers do not go throughthe web server which can focus on the exchange of messages after the initial part of theconnection. This solution does not take any explicit bandwidth or performance from theweb servers which makes the load balancing and auto scaling elements simpler to implement.As the static content is only downloaded in the beginning before exchanging messages, theperformance for retrieving static content is less of an issue. Using AWS S3 makes it easy toscale the storage needed and it keeps the maintenance down to a minimum.

34 Chapter 4. Evaluation of Reference System
Internal Messaging
The internal messaging in the reference solution is done using two AWS services, namelySQS and SNS. These two services are used decouple space and time between the web serversand the processing system. This makes components more independent from each other andeasier to replace as well as to update. Using a queue also offloads responsibility for messagingfunctionality from the two components and creates components with more distinct logicalpurposes. SQS and SNS is also used for buffering messages between components so that notall components fall behind when one does.
Using a queue for the incoming messages to the processing system makes sense sinceit may be viewed as a contention point since all (or the majority of) messages receivedby all web servers are sent to the processing system. All messages that are sent to theprocessing system are generally of the same type so there is also no need for any moreadvanced messaging paradigm. No messages need any advanced routing and the processingsystem does not need to express different types of data it is interested in. SQS needs lessmaintenance and can scale automatically. It also provides some security, reliable forwardingwhere SQS guarantees a message will be delivered to at least one recipient. One of thedisadvantages with SQS is that it is slower than most of the non-cloud messaging systemsand can also be more expensive than a messaging implementation placed on EC2[61].
The current notification system can be used to broadcast messages of a specific topic andlisten for notifications of a specific topic. SNS has the same benefits as any Amazon WebService and provides a simple publish-subscribe implementation with built-in scalability andavailability. SNS features a way to be instantly notified when a message of interest is beingbroadcast which means that participants can listen for notifications without needing to pollthe message system for notifications. This reduces overhead in the listening participants aswell as network contention.
Data Processing
The processing of votes is handled using stream data processing where messages or votesare processed as they come in to the system. This should better suit the use case since votesare not all made at the same time and are instead asynchronously sent to the service withno respect to each other in time. A batch data processing model may not be appropriatesince results could be updated based on the new data and the previous results and thereis no need to look at the data as a whole. A batch data processing system may be moresuitable when trying to analyze the statistics that is put in the database by the web serversand the stream data processing system.
Storm is run as a cluster on a number of AWS EC2 instances which takes furtheruse of the underlying help from deploying the overall system on the AWS cloud. It usesZookeeper as a distributed coordinator to synchronize the data between the Nimbus andSupervisor nodes. Offloading the coordination on another system further separates the core-functionality of the processing system from miscellaneous responsibility. Storm guaranteesthat every message introduced to a topology of the system will be processed, even if amachine goes down and the messages it was processing get dropped. This together withZookeeper makes Storm a very reliable distributed solution for stream data processing.

4.4. Assessment of Issues 35
4.4 Assessment of Issues
This section addresses implementation issues of the service focusing on the goal of makinga more complete service which Dohi Sweden may provide as a stand-alone product.
4.4.1 Inseparable Use Case
The main concern for this thesis is that the current solution was built for a specific use caseand were not meant for any other type of functionality. This limits the service greatly interms of extendability and modification as there is not a distinct separation between theuse case and the underlying system. It also makes it difficult to present what the servicecan offer apart from the already existing use case since other types of functionality needs tobe developed with the entire system, and consequently the current use case, in mind. Theservice provides basically two types of questions: rating questions and categorical questionsand if the client wants any other type of question or functionality, it needs to be implementedby the developers at Dohi Sweden.
All components are tightly coupled to the current use case; the web server, for example,handles only messages related to the current question types. This is also true for the dataprocessing component that only processes votes for these two question types. The datamodel also only stores data specific to the voting functionality.
4.4.2 Functionality Not Defined
When trying to improve an implementation so that the core could be separated from theuse case, it is important to know what it should actually be used for. The behaviour of thesolution must be generalised and core functionality needs to be identified. Without definingwhat the system should do, it is hard to extract or focus on the parts that is of importanceas well as identify problems that is relevant for this evaluation. This is also a problem forthis evaluation as this work also needs to identify what exactly constitutes the core of thesystem.
4.4.3 Required Maintenance
The system uses a number of cloud services which includes, for instance, implementedcomponents deployed on AWS EC2. These needs to be supervised and maintained by thedevelopers at Dohi and requires that resources are set aside for this. Some of these are alsoset to scale automatically when facing heavy load or other problems concerning demandson resources. The scaling is not completely automatic and many services need to be shutdown between events to minimize the resources used and consequently keep the cost down.This could be more problematic as the time when an event should occur may not be knowntoo long beforehand.
4.4.4 Single Messaging Channel
The system was built focusing on a single event and did not address multiple and concur-rent events. Even if the system may handle multiple events it does so only because of thestatelessness of system components. Web servers, for example, do not distinguishes betweenvotes from different questions and just forwards all of them to the data processing compo-nent. Web servers also forwards questions to all clients which means that if two events wereoccurring at the same time, all clients would get questions from both of them even if they

36 Chapter 4. Evaluation of Reference System
are only participating in one of the events. Instead, there exists client-side safety checks toensure that only questions from the correct event is handled.
4.4.5 Complete Replica of Global State
When a web server is added to the system, it fetches information from all of the events thatare present in the system and keeps a local replica of the complete global state. This globalstate is also transferred to every client even if a client is not interested in the state of allevents. This poses scalability issues for the web servers and the web clients as they muststore and handle every event that is present in the system. The communication betweena client and a web server must also scale with the complete global state as the web servermust push everything to the client.
4.4.6 Intra-dependencies
The system uses many services from AWS that fall in the cloud service model Infrastructureas a Service (IaaS). These services have separate APIs and protocols which bind the systemto these services and increases intra-dependencies and decreases modularity. While makinga development process more simple, the use of these cloud services make it harder to movethe system and without any interfaces between the different components of the system, thesystem is much less versatile in terms of replacing a component and consequently modifyingand extending the system.
4.4.7 Simple Messaging
One very central part of the system is the messaging between the participants of the service.This currently does not provide any type of message ordering between web clients and webservers and clients may receive messages in different orders. This introduces a race conditionthat may lead to divergent behaviour because of different message orders. The client hasbeen given safety checks to ensure that this divergent behaviour is limited and as long asevents are run one at a time and are manually supervised it may not be a practical problembut it still poses restrictions for any additional use or development of the service.
4.4.8 State Synchronisation
When a web server is added to the system, the web server first fetches the state of the systemfrom the database and then uses this internally as a local replica of the state. This may leadto an inconsistent state between web servers and consequently between clients as the statecould change during synchronisation. This means that when a client connects to an eventit can, for example, receive a question that becomes outdated during the establishment ofthe connection.
4.5 System Definition
A definition of what constitutes the system has been made to be able to better explainand motivate suggestions of different implementation changes. This definition includes adescription of the core parts that the system consists of as well as the core behaviour of thesystem. Most of further suggestions about the system are based on or are influenced by this

4.6. Proposal of Improvements 37
definition. The definition as well as further suggestions assumes that the already existinguse case must also be fully functional in the applicability of any suggestion.
One aspect of the system that is prevalent throughout the whole solution is the focuson or use of messages in the system. Apart from the HTTP GET request at the beginningwhen a users connect to the service, a client relies solely on sending and receiving messagesto interact with the back end and uses it to vote on questions and receive the results forquestions. The web servers as well as the data processing layer, also use an internal mes-saging system to communicate with each other. Messaging in the system enables scalabilityas it further separates different parts in the system and decouples them in terms of space,time and synchronisation. Focusing on the messages in the solution may lead to a betterevaluation of the system as a messaging model fits this solution.
Except for providing messaging functionality for the client, the system also providesstatic web content that the user receives when he connects. This content does not necessarilyneed to be provided directly by the system, it could be separately designed and created bythe customer as long as it featured a messaging channel to the service. This definitionemphasises the complete independence between the static web content and the messagingfunctionality but does not exclude the static content from the core functionality that theservice should be able to provide. This relates to the assumption that the service mustsupport the already existing use case in its entirety. This does not exclude use cases wereonly the messaging functionality is desired by the service but puts a requirement on theservice to be able to provide both messaging functionality as well as static content.
To summarise, the service directly provides two core functionalities for the front end,namely an asynchronous messaging interface for web communication and a regular file storeto serve static web content. The front end is a web front end that uses the messaginginterface to communicate with the service and may also use the file store to fetch staticcontent such as web pages. The idea of using the file store is to group a front-end viewtogether with the communication layer so that it is not necessary to fetch these using twoseparate services.
Except for the messaging bus and the file store, the back end also requires some additionalfunctionality to support the existing use case. This type of functionality could be thoughtof as being internal, where the effect of it is exposed on the front end using the messagingfunctionality. Examples of this kind of functionality in the current solution are the dataprocessing layer and the data model. This type of functionality is not considered being partof the core of the service but they are required to be operable nonetheless for the existinguse case.
4.6 Proposal of Improvements
This section presents a proposal of improvements, taking the previously described issuesin account. Instead of directly solving each problem separately, it focuses on two parts,namely the overall system architecture and the messaging channels for events. This sectiondescribes ways to alter these aspects to create a solution that may better solve the listedproblems.
4.6.1 System Architecture
Using the previous definition of what constitutes the current service, the alterations ofthe current software architecture focuses on the messaging system as a central part of the

38 Chapter 4. Evaluation of Reference System
solution. This section describes how components may be grouped together and how differentcomponents may interact with each other.
Service Bus
One way to view each component of the system is as a separate service that provides somekind of functionality to the system that is not directly tied to any other service or part ofthe system. This puts a messaging bus in the centre of the architecture which is responsiblefor providing communication with the necessary services another service needs. This type ofsoftware architecture, called service bus architecture, focuses on the complete separation ofcomponents or services by interfacing with the central messaging bus and using it to discoverand access other services in the system while providing the functionality of a service overthe bus to anyone that is interested.
Introducing this type of architecture for the current system means that all of the com-ponents would be viewed as separate services that only need to communicate directly withthe messaging bus and a service would only know about the services that itself need toprovide its own functionality. An overview of how this setup would be described can be seenin Figure 4.3. In this architecture, the client validation cache would be a separate servicethat provides its functionality, store and retrieve client validation tokens, over the messagingbus. Another service would be the front end together with the web server cluster that wouldrepresent the user interface of the system, which introduces the input from the user into thesystem. The use case specific parts of the voting functionality would be a standalone servicethat connected the user voting input to other services in the system. The database wouldbe another service which provides the functionality of storing to and retrieving data fromit. The last service would be the data processing functionality that would provide ways toprocess retrieved data and publish the result back on the messaging bus.
The service bus would create a very decoupled system where additional functionality ofthe current use case or a new use case could be implemented without any need to modify anynon-relevant parts of the system and without any possibility of any non-relevant parts failingor otherwise changing its behaviour because of the introduced functionality. This wouldalso put the definition of the system on a very low level where as good as any functionalitycould be provided as long as it is provided over the messaging bus. Possible use caseswould be those that may use messages to communicate between internal components. Thistype of architecture would put extra work on the maintenance of the messaging bus andon implementing components that operates only over the messaging bus and completelyseparate from other services. Defining each service or component would be easier as theywould have a very distinct function in the overall solution.
This solution decouples the different functionality of the system and creates a more scal-able system while introducing a more complex overall solution with a higher end-to-endlatency. As components need to use the message bus to communicate, it is not possibleto explicitly interact with other components without the message bus interface. This in-terface poses additional overhead in handling the provided functionality of components as,the database service for example, cannot use their already well-defined interfaces directlywithout some kind of adapter between the messaging bus and the internal interface.
Two-tier Messaging Bus
The two-tier messaging bus is another software architecture that uses a messaging bus inthe centre. This architecture focuses on the separation of user input and use case specificlogic. It defines two types of components, a client handler and a use case handler, which

4.6. Proposal of Improvements 39
Figure 4.3: An overview of the service bus architecture describing the way components inter-act with each other. This solution proposed the use of a message bus which all componentsuses to communicate with each other.
are all connected using a messaging bus. The messaging bus is responsible for forwardingmessages between a client handler and a use case handler. It is used to separate input fromlogic so that other types of input can be added to a use case or other types of use cases,which uses the same type of user input, can be added.
An overview of the two-tier architecture, including a layout of the components of thecurrent system, is presented in Figure 4.4. This architecture groups the current functionalityinto two parts where one part handles the web communication with the front end and theother part handles the voting use case functionality, including processing votes, fetch andupdate state in database and validate client tokens. These two groups interact with eachother by sending messages over a message bus.
With this type of solution, it is easier to add other types of clients without modifyingany existing code, as the client input functionality is completely separated from any otherfunctionality. Adding another use case to the system is done by adding another use casehandler and modifying the client input so that relevant messages are routed to the handler.A use case handler is completely separated from any other use case handler except for animplicit relation because of the possible sharing of a client input handler. Like the servicebus architecture, this architecture also requires the different services, or handlers in this
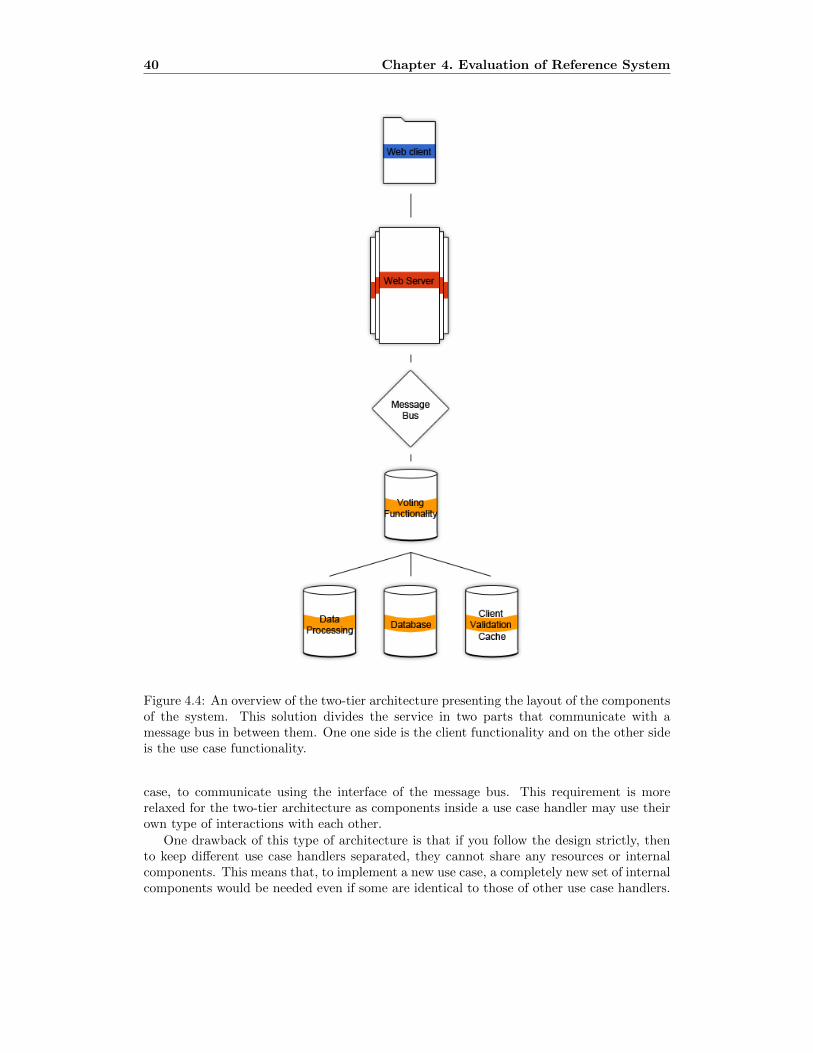
40 Chapter 4. Evaluation of Reference System
Figure 4.4: An overview of the two-tier architecture presenting the layout of the componentsof the system. This solution divides the service in two parts that communicate with amessage bus in between them. One one side is the client functionality and on the other sideis the use case functionality.
case, to communicate using the interface of the message bus. This requirement is morerelaxed for the two-tier architecture as components inside a use case handler may use theirown type of interactions with each other.
One drawback of this type of architecture is that if you follow the design strictly, thento keep different use case handlers separated, they cannot share any resources or internalcomponents. This means that, to implement a new use case, a completely new set of internalcomponents would be needed even if some are identical to those of other use case handlers.

4.6. Proposal of Improvements 41
This introduces overhead for the extra maintenance that needs to be done when managingmultiple logical components for the same or similar functionality.
4.6.2 Messaging Channels
One of the main concerns of this evaluation is the separation of the data that are transmittedfor different events. Being able to distinguish data between different events addresses manyof the previously listed concerns such as complete state replication in the local memoryof all web servers and broadcasting of all messages to all clients no matter if the client isinterested in the message or not. This section describes two parts of the system that areof interest when trying to create a distinction between events, namely the logic in the webserver and the messaging channels for the internal messaging system.
Separation of Logic in Web Servers
The web servers of the solution is one of the core components which the overall performanceof the system depends on heavily. The web servers cannot currently separate data fromdifferent events and treats every client as a client that is interested in every aspect of everyevent. This could be solved by introducing two layers or levels in the web server where themost basic level, level 1, would address the separation of events and level 2 would consistsof the use case specific logic for an event, see Figure 4.5. Defining an event as the messagingchannel that it needs to communicate with the client and the other back end components,would effectively mean that the separation of events does also separate the different usecases that could be used by the system.
Level 1 would be able to directly communicate with the connected clients and, by seeingwhich events each client is interested in, would group clients and expose them togetherwith functionality to communicate with them to the corresponding use case logic on level2. When a message is sent from a client, the level 1 of the web server would then forwardthe message to corresponding event logic on the second level. This would solve the problemof broadcasting every message to everyone as the event logic would be provided means tocommunicate with exactly those that are interested in the corresponding event.
The state of a use case or an event would be stored and managed by the correspondingevent logic module on level 2. This divides the local state of a web server into smaller,separate parts which relate directly to the event logic modules that are present on the webserver. By choosing which event modules that should be present on a web server, it limitsthe local state to only keep the state of those events that are included in the web server.
Separating the logic of the web server into two levels would create a base functionalitythat operates the same no matter the event or the use case. This could be used to defineexactly what kind of functionality the web server can provide in the system and what kindof use cases it supports. The second level of the web server decouples the logic for thedifferent events which gives a higher level of abstraction where specific use case modules canbe implemented and deployed without the need to modify any other module.
Internal Messaging System
This section explains how separating the internal messaging channels for different events mayhelp solving the identified problems of the solution. It focuses on the use of the messagingpattern called publish-subscribe to separate different events as well as separate internalnon-related components in the system. The publish-subscribe pattern is addressed both in

42 Chapter 4. Evaluation of Reference System
Figure 4.5: Outline of the layered web server solution. It introduces two levels in the webserver where the higher level contains use case specific logic separate from each other, whilethe lower level manages these use cases.
chapter 3 and chapter 5 and this section will instead focus on the explicit use and effect ofintroducing such a pattern in the current service.
The currently used internal messaging system is a publish-subscribe pattern implemen-tation but it is currently not used in any way other than to create a single messaging channelthat all messages are sent on. To add support for multiple channels, the setup and tear-down of the channel must be moved from the global scope of the entire web server to thecorresponding event functionality of the channel. This makes a message channel coupledwith the event and can be viewed as a separate part belonging only to the correspondingevent.
By creating a messaging system where components express their interest in differenttypes of messages, components are decoupled in space and do not have to manage any othertype of messages than those that they want. This greatly increases the scalability of thenetwork as well as decouples non-related components from each other so that componentsmay be added, removed or modified in the system without any non-related component wouldchange its behaviour.

Chapter 5
Publish-Subscribe Pattern
This report is a documentation of a thesis project performed at Dohi Sweden that consistsof creating and evaluating a large scale back-end solution for asynchronous communicationbetween a web client and a web server. The publish-subscribe pattern has been aroundfor a long time and it currently exists many different types of known uses for it as wellas a fair amount of research in this area. This chapter aims to make a summary of thepublish-subscribe paradigm focused on an intermediate goal of the main study, namely theseparation of use cases. The area of publish-subscribe is of great interest for this work asthe overall communication for the targeted solution fits this type of pattern.
5.1 Introduction
The publish-subscribe pattern is a messaging pattern that is of great use for message-oriented solutions as it tries to loosely connect messaging participants based on what typeof content they are interested in[51]. The publish-subscribe pattern defines two types ofparticipants: the publisher that produces content and the subscriber that consumes content.The highest benefit from this pattern is its loose coupling between participants as publishersand subscribers do not need to know each other, they do not have to participate at the sametime and messages are sent and received asynchronously. This is a widely used messagingpattern on the Internet and other types of large networks as it enables high scalability fordistributed messaging.
An overview of the publish-subscribe pattern has been made to be able to more easilyaddress relevant aspects of the pattern. This section tries to explain how this patterncommonly works and describe a general framework of an implemented publish-subscribesystem.
5.1.1 Overview
A publish-subscribe solution is usually refered to as a notification service where the pub-lishers and the subscribers are the clients of the service[1]. For the interaction betweencomponents of a notification service, three terms are commonly used: a notification, anevent and a publication. A publisher produces an event which is also often called a pub-lication for the notification service while a subscriber receives and consumes a notificationfrom the service. This thesis will use notification as a general term when addressing anyof them later on. This thesis will also use the expressions of a subscription request and an
43

44 Chapter 5. Publish-Subscribe Pattern
advertisement request to denote when a subscriber expresses its interest in receving certaincontent and when a publisher expresses its interest in publishing certain content.
Furthermore, the type of content that a subscriber expressed its interests in receiving iscalled a pattern and the type of content that a publisher expresses its interests in publishingis called a filter.
In the context of notification passing, nodes that lie ”in between” and forward notifica-tions between a sender and a receiver are commonly refered to as brokers or broker nodes.Brokers can be, for example, intermediate forwarding systems, network routers or other peersdepending on the implemented notification service. Except for making a centralized brokerarchitecture, brokers could be distributed and managed in many ways[20][42][11] which isone of the reasons publish-subscribe is such a well used pattern for scalable messaging.
5.1.2 Subscription Models
One aspect of a notification service that needs to be determined is how subscribers expresstheir interest in content. Choosing a more expressive subscription model often makes theservice more complex and harder to realize and deciding on this trade-off is important asdifferent subscription models result in different solutions for the underlying system.
There are three commonly known subscription models: topic, content and type-basedsubscription models and these will be described in this section.
Topic-based
In a topic-based notification service, a publisher pairs a publication with a topic in whichthen all subscribers that express their interest in that topic will receive the notification.This can be seen as having a separate messaging channel for each topic that does notrelate to any other channel. A topic-based notification service has the least expressivenesscompared to the other two addressed subscription models but it is also the most easy toimplement. Topic-based notifications can be viewed as the equivalence of broadcasting ingroup communication as subscribers of a topic are implicitly static - the recipients do notneed to be calculated when publishing a publication.
Content-based
Content-based publish-subscribe is a more expressive subscription model than topic-basedpublish-subscribe. Instead of connecting publishers and subscribers with an external prop-erty such as a topic, content-based publish-subscribe routes messages that matches a specificpattern that a subscriber has specified. A pattern consists of a number of conditions forproperties of the notification itself and these conditions are used to filter out any notificationthat not fit these conditions. An example of a pattern Θ(S) that subscriber S expresses itsinterest in could be:
Θ(S) = (x > 5) ∨ (y == 0)
which means that S wants to receive a notification if the property x of the notification islarger than 5 or if the property y is zero. This gives a lot expressiveness as subscriptions couldbe based on complex sequences of constraints on the internal properties of the notifications.

5.2. Problems 45
Type-based
In a type-based notification service, a subscriber expresses its interest in a specific typewhich is a unique identifier just like topics in topic-based publish-subscribe. Types-basedpublish-subscribe on the other hand uses a object-oriented approach where a notification canbe seen as an object with a specific object type which can be further derived from anotherobject type. Figure 5.1 describes three types where Sports News could be seen as a base typewith two subtypes: Fotball News and Golf News. Subscribers could express their interestin, for example, Golf News in which they would only receive notifications of type Golf News.Subscribers could also subscribe to Sports News in which they would receive notificationsof all three types. This leads to a higher expressiveness than topic-based publish-subscribetogether with type-safety checks of notifications at compile-time.
Figure 5.1: A description of how types in a type-based publish-subscribe solution may relateto each other. A subscriber may subscribe to the type sports news, in which it will receiveall sports news, both those that are golf news and those that are football news. A subscribermay also subscribe to, for example, golf news, in which it will only receive golf news andnot fotball news.
5.2 Problems
The most common problems related to notification services are listed as the following:
– Expressiveness vs Realisability. The underlying system of a notification service isbased heavily on the expressiveness of the service. A content-based subscription model,for example, requires a filtering process during dissemination compared to a topic-based model where subscribers for a notification are statically retrieved. These modelsuse very different system architectures and the general consensus of the expressivenessfor a publication service is that a higher expressiveness also raises the complexity ofthe implementation. This poses a problem as a more general solution that should fitmore use cases typically also increases the need of a higher expressiveness.
– Throughput vs Reconfigurability. The time it takes for a notification service todisseminate a notification to its subscribers varies depending on the implementation.One aspect that may hinder the performance of a notification service in terms ofthroughput and latency is the reconfigurability of the service. If all subscribers andpublishers where decided beforehand there would be no need to support any reconfig-urability as the exact routing of notifications would already be known. By raising thereconfigurability level to, for example, handle dynamic publishers and subscribers italso lowers the performance of the overall system.
– Decentralization vs Manageability. A common problem for all solutions that isdecentralised for scalability purposes is its decreased manageability. This is even moreproblematic for solutions such as notification services that may not have a clear way

46 Chapter 5. Publish-Subscribe Pattern
of decentralisation. When going from a single broker to multiple brokers questionsarise how these should function since it may be difficult to horizontally scale these.
– Security. Early publish-subscribe implementations were used for mail and news feedsand security was not as high of a priority. Because of the decoupling nature of thepattern it is problematic when facing security concerns such as content authentication,confidentiality and integrity. Since publishers and subscribers do not know each other,the notification service must make sure that these concerns are tended to and ensuredby the service.
– Reliability and Persistence. Message reliability and persistence is two additionalconcerns that may be generally more complex in a notification service because of thedecoupling nature of the publish-subscribe pattern. There is often more than one stepbetween a publisher and a subscriber in a notification service and all steps need toguarantee reliability and persistence. This is not an easy task as, stated in the intro-duction, publishers and subscribers do not need to know each other, they do not haveto participate at the same time and messages are sent and received asynchronously.
5.3 Measurements of Results
Common quantitative measurements related to messaging systems are throughput in termsof number of messages disseminated and latency in terms of time between sending andreceiving. These measurements will be considered in this study and they will be measuredagainst each other as one will affect the other. Aspects of these measurements that will benoted is the size of the messages sent and if there exists any situation where performancevaries greatly. The throughput and latency will also be addressed in the context of scalabilitywhere the performance of these two aspects are measured against the level of scaling used.This is expressed as measuring the increased or decreased throughput and latency whenvarying the number of broker nodes or other quantitative scalable variables.
The rate of failures when disseminating a notification is of interest as it relates to thereliability and persistence of a notification service. This aspect can be expressed as thenumber of messages that may be dropped or somehow lost during the way from a publisherto a subscriber.
5.4 Classification of Methods
There are many existing techniques and methods that address the problems that is of interestin this study. The ones that are considered in this study have been grouped into threecategories to be able to more easily focus on and understand the problems of this study.These do not include all scientific work within this research area but express the onesthat were deemed the most interesting for this specific work. The categories are also notnecessarily completely separate from each other and may overlap in terms of practical usebut the distinct focus for each category is described in this section.
1. Decentralising brokers. This category focuses on the distribution of managed bro-kers to better ensure different qualities of service such as availability and respon-siveness. Distributing managed brokers is probably the most used way of scaling anotification service as it uses the widely known and used client-server model. It isbased on when there exists a separate layer of brokers between the publishers and

5.5. Research Summary 47
subscribers that is owned and handled manually by the notification service. Depend-ing on the desired expressiveness different types of broker topologies may be suitable.These topologies may also work on different levels of the network infrastructure where,for example, topologies that work on a lower level uses functions of the physical net-work to disseminate a notification. Different topologies may also use different routingalgorithms.
2. Peer-to-peer methods. Notification services that only uses the clients of the servicehas been of interest lately because of the growth of smartphones and other highlymobile and lightweight units. This category refers to when there are no brokers ”inbetween” and the problem of disseminating a notification either lies partially on acoordinator or entirely on the clients. Interesting aspects of peer-to-peer solutions thatwill be addressed are how a peer-to-peer topology relates to the underlying physicalnetwork topology and how different routing algorithms for the topologies work.
3. Self-managed self-optimised methods. This category focuses on the properties ofself-managed notification services. Instead of using a broker topology that is staticallyand manually specified beforehand self-managed services are able to dynamically mod-ify its architecture based on the use of the service. This also relates to the capabilitiesof ensuring robustness and availability in a automatic way without the need of a, forexample, manual restart of a node when a node crashes. Being self-optimised refersto the possibilities of a notification service automatically adjusting itself to improveperformance.
5.5 Research Summary
Having introduced the subject, listed reoccurring problems and classified the methods, it istime to present gathered scientific progress, both successful and unsuccessful. One methodwill be presented for each method category (decentralising brokers, peer-to-peer methodsand self-managed methods), clearly describing the proposed idea, identifying and associatingthe problem(s) addressed while highlighting possible limitations and/or assumptions made.Each method, and the selected summarized work, will be concluded by stating the resultsfollowed by a discussion. The last section of this chapter concludes the in-depth study witha more detailed comparative discussion of (dis)advantages of the different approaches aswell as indications of where future research can allow for improvements, generalisation andextensions of proposed ideas.
5.5.1 Decentralizing Brokers
Decentralised brokers relies on managed nodes in the publish-subscribe network to routenotifications. A notification service that uses this kind of solution puts the disseminationfunctionality in a layer separate from its clients where the client-side parts of the serviceonly feature some simple communication with the separate layer. This type of messagingsystem is probably the most used as it follows the common client-server architecture wherethe messaging functionality can be viewed as a separate system that is completely managedby its maker.
Siena[6] is a notification service that makes use of distributed brokers and has beenaround for very long. It features a very extensive theoretical documentation of the publish-subscribe paradigm which is further used in this summary to describe a typical implemen-tation of a publish-subscribe system. The fundamentals of Siena is studied together with a

48 Chapter 5. Publish-Subscribe Pattern
system architecture for publish-subscribe called EventGuard[45]. This system architectureaddresses security concerns such as confidentiality, authentication and fail-overs for an ex-isting publish-subscribe service. The authentication part from EventGuard will be studiedfor the general solution that was extracted from Siena.
Two broker topologies or architectures that will be addressed in this thesis is hierarchicaland peer-to-peer topologies. The hierarchical topology connects a broker with a singlehigher level broker (master) and multiple ”lower level” nodes which could be both brokersand clients. A master can receive notifications from all its clients but will only forwardnotifications to a client that needs it. This makes the master comparable to a gatekeeper,keeping unwanted traffic off the clients. The peer-to-peer topology is a more general topologywhere brokers communicate with neighbours bidirectionally without a hierarchy.
There are two commonly known types of routing algorithms: subscription forwarding andadvertisement forwarding. The former type of routing algorithms propagates subscriptionrequests through the network to create the routing paths for notifications. A routing path isthen used to route a message through the reverse path from which the subscription requestcame from. The latter type of routing algorithms broadcasts advertisements first, creatinga tree of brokers where every broker has information about the advertisers. Subscriptionsare then sent along the reverse path back to relevant advertisers, marking the paths thatnotifications for a subscription will take when published.
The publish-subscribe implementation is, in general terms, pruning spanning trees overa network of brokers to minimize communication, storage and computation costs. A sub-scription request is only propagated along the paths that a previous request has not alreadycovered. This study uses the expression X ≺S
S Y to be able to later denote a relation be-tween subscriptions where subscription X covers subscription Y . The expression X ≺A
A Yis used to denote the equivalent relation between advertisement requests.
To keep track of the relations between subscriptions, a partially ordered set or poset offilters can be used. Siena denotes PS as a poset defined by ≺S
S and PA as a poset definedby ≺A
A. In a poset of subscriptions PS , a filter f1 is an immediate predecessor of anotherfilter f2 and f2 is an immediate successor to f1 if f1 ≺S
S f2 and there is no other filter f3such that f1 ≺S
S f3 ≺SS f2. The filters that do not have any successors in the poset is called
roots and these are the ones that will produce network traffic.
A Hierarchical Architecture
A broker in a hierarchical topology contains a poset PS where the subscribers of filters in theposet represents ”lower level” brokers and clients. This poset is used to route notificationsto subscribers in the ”lower level” where filters for subscriptions covers the classificationof the notification. Because of this, only subscription forwarding is considered for hierar-chical architectures as masters would not be able to respond to an advertisement with thecorresponding subscriptions.
Algorithm 1 and algorithm 2 tries to express the way the poset is used in a broker whenit receives a subscription and a notification. These algorithms uses the expression S(f) todenote the set of subscribers to a filter f and the expressions f and f to denote the sets

5.5. Research Summary 49
containing the immediate successors and the immediate predecessors respectively.
Algorithm 1: Subscription request management in a hierarchical broker topology
Data: A poset PS for the current brokerData: A subscriber X that issued the subscription requestData: A filter f that corresponds to the requested subscription
if ∃f ′ : X ∈ S(f) ∧ f ≺SS f ′ then
terminateelse
if f /∈ PS theninsert f into PS
endinsert X into S(f)if f = ∅ then
forward subscription to masterendif f 6= ∅ then
remove X from filters f ′ in all predecessors of f where f ′ ≺SS f
end
end
Algorithm 2: Notification propagation in a hierarchical broker topology
Data: A queue Q containing the root subscriptions of current broker’s posetData: A notification n that should be routed to matching subscriptions
if this broker has a master and the master did not send n thensend n to master
endfor each element s in Q that has not yet been visited do
visit sif n ≺S
S s thenappend all predecessors of s that has not been visited
elseremove s from Q
end
endfor each element s in Q do
send n to send
When a broker receives a subscription request it manages it in basically three ways:
1. If there already exists a filter that the subscriber also subscribes to and this coversthe new filter, the broker will just do nothing since notifications corresponding to thenew subscription will already be routed to the subscriber.
2. If the filter already exists in the poset the subscriber will be added to the subscriberslist for that filter.
3. If the filter does not exists in the poset the filter will be inserted and the subscriberwill be added to the inserted filter.
For the last two cases where a subscription is inserted into a filter f , the broker needs toremove any previous subscriptions from the same subscriber that the new filter will cover.

50 Chapter 5. Publish-Subscribe Pattern
This is done using a breadth first search starting in f and removing any subscriptions withthe same subscriber as the insterted one. If the filter that the subscription is inserted intois a root i.e. it does not have a successor in the poset the subscription will be sent to themaster as well.
An Acyclic Peer-to-peer Architecture
The peer-to-peer solution covered in this segment is very similar to the hierarchical topologythat were previously described. Instead of keeping track of a master and a set of client nodes,a broker in the peer-to-peer topology uses only a set of neighbours denoting the connectednodes to that broker. It uses a poset PS just like in the hierarchical topology but thisposet also has a set of forwards for a subscription that contains the neighbours that thesubscription already has been forwarded to.
The acyclic peer-to-peer architecture propagates notifications exactly the same way asthe hierarchical architecture. The way a subscription request works is also similar but inthe latter two cases where covered subscriptions needs to be removed, the peer-to-peer usesa different procedure in forwarding the subscription to its neighbours. The set forwards(f)of a subscription f can be defined as the following:
forwards(f) = neighbours−NST (f)−⋃
f ′∈PS∧f≺SSf ′
forwards(f ′) (5.1)
This means that, f is forwarded to all neighbours except those not downstream fromthe server along any spanning tree rooted at an original subscriber of f and those to whichsubscriptions f ′ covering f have been forwarded already by this server.
Authentication
To ensure authentication, EventGuard uses a key management system called Meta Service(MS). When a subscriber S wants to subscribe to a topic w it first sends the request tothe MS. The MS then authorises the subscriber using some central authorisation serviceand then accepts or denies the request based on what the subscriber wants to subscribeto and what is is allowed to subscribe to. If the subscriber is authorised by the MS itreceives a subscription permit from the MS consisting of a key K(w), a token T (w) anda signature sigSMS(T (w)). The key K(w) is used to decrypt received notifications fromthe topic w. The token T (w) is a one-way hash of w and is used as a private identifierof the topic w. The signature sigSMS(T (w)) is ElGamal-encrypted1 and is used to checkthe validity of the subscriber on the publish-subscribe nodes. When a subscriber receives asubscription permit from the MS it then formally subscribes to the publish-subscribe serviceusing T (w) as topic instead of w. Notifications for the topic w will then be routed in thepublish-subscribe topology to all subscribers of T (w).
When a publisher P wants to send an advertisement to be a publisher for for a topic wit first speaks with the MS using a public-key pk(P ). MS then authorises the publisher andsends an advertisement permit to the publisher containing a key K(w), a token T (w) and asignature sigSMS(T (w), P, pk(P )). The key and the token are the same key and token thatsubscribers receive. Except for the token, the signature sigSMS(T (w), P, pk(P )) also includesan identifier for the publisher and the publisher’s public-key. When a publisher receives aadvertisement permit it submits an advertisement to the publish-subscribe service on topic
1http://en.wikipedia.org/wiki/ElGamal encryption

5.5. Research Summary 51
T (w). Subscribers of T (w) will receive the publishers signature which includes the public-keyfor that publisher.
When an authorised publisher wants to send a notification under the topics w1, w2, ..., wm
it first makes a request to the MS that returns a random key Kr. The publisher then encryptsthe content of the notification with Kr and publishes the encrypted content together withan encryption of the random key EK(wi)(Kr) for each topic using the key for correspondingtopic. Subscribers of a topic wi can then use the key K(wi) to decrypt Kr and then use Kr
to decrypt the notification content
Results
The report containing an overview of Siena, includes an evaluation of the fundamentals andtries to test the framework in terms of relative performance, expressiveness and scalability.The tests varied the amount of interested objects and parties while keeping the network sitesconstant. Siena tests four different topologies: centralised, hierarchical, acyclic peer-to-peerand general peer-to-peer. It also includes evaluations of the total cost as well as differentparts of the system such as cost per subscription and notification.
The total cost refers to the message traffic between all sites and it was shown fromthe test results that when there were more than 100 parties, the total cost was essentiallyconstant. This was referred to as the saturation point as there was a high chance that thereexisted a party at every node using every message channel. When the number of interestedparties were below the saturation point, all of the tested topologies scale sub linearly asit was very likely that an object of interest and an interested party was not on the samesite. The hierarchical topology performed worse than the acyclic peer-to-peer solution asthe hierarchical topology is forced to propagate notifications to the root whether or not itis necessary.
The main difference between architectures in terms of cost per subscription and pernotification is in the way each architecture forwards subscriptions. In a network of N sitesthe acyclic peer-to-peer architecture must propagate a subscription using O(N) hops throughthe network while the hierarchical architecture only needs to forward subscriptions up to theroot, with O(log(n)) hops. The cost for propagating notifications are on the other hand infavour of the acyclic peer-to-peer architecture as this kind of propagation keeps a constantlower cost compared to the hierarchical solution with a varying amount of interested parties.
The documentation of EventGuard includes a tested and evaluated implementation ontop of a Siena core. These tests showed that EventGuard could be successfully deployedon a Siena system without the need of modifying Sienas routing or matching functionality.The solution was tested on a binary tree-based hierarchical topology with a varying num-ber of nodes advertising, subscribing and publishing. The tests was used to compare theperformance of the EventGuard, in terms of throughput and latency, and the performanceof the Siena base without EventGuard.
Throughput was measured in terms of maximum number of notifications that the solu-tions can handle per second. Latency was measured using the amount of time it takes for anotification to propagate to a subscriber using maximum throughput in the system. Thesetests showed that Siena with an incorporated EventGuard, scales with the same order ofmagnitude in terms of throughput as the Siena base, with only a small constant decrease.The results from testing the latency showed similar results with only a small constant de-crease between the EventGuard and Siena and a latency difference that was not higher than4% at any given time.

52 Chapter 5. Publish-Subscribe Pattern
Discussion
Distributing managed brokers is a good way of scaling the messaging system while keepingthe control of the system. It fits well into the common client-server model and do notrequire much from its messaging clients. This section makes it clear how brokers can bedistributed using a hierarchical and a peer-to-peer architecture to scale the performance ofthe messaging system.
EventGuard shows how authentication functionality could be incorporated in a publish-subscribe system without changing the fundamentals of the system. This makes it easier totest the differences between a regular messaging system and a system with a security layer.It also makes it easier to modify the publish-subscribe system without the need of modifyingeverything, a system could much easier be replaced while still keeping the security features.The tests shows that the authentication solution presented by EventGuard is practical asan implementation does not decrease performance and scalability.
Siena was made to handle content-based publish-subscribe functionality which gives ahighly expressive messaging system that can be used for many different types of use cases.This shows that a messaging solution could be implemented with scalability features as wellas with a high expressiveness.
5.5.2 Peer-to-peer Methods
This section addresses publish-subscribe solutions that do not use any managed brokers butinstead relies solely on the peers of the system. Peers can be used to create a publish-subscribe solution on top of the application infrastructure building an application-level net-work of peers as brokers. This can be very effectively used to create large-scale informationdissemination that is reliable and cheap as there does not exists any other componentsexcept for the clients.
Pastry
Pastry is an object location and routing substrate for large-scale distributed peer-to-peerapplications. Pastry makes use of peer-to-peer communication to create an application-level topology over the network that can be used to implement a wide range of functionalitysuch as global data storage, group communication and naming. It is used in a notificationinfrastructure, called Scribe, to provide a peer-to-peer publish-subscribe solution.
Pastry uses a 128-bit value to identify each node in its overlay topology. These node idsare assigned randomly to nodes and it is assumed that the generation of ids is uniformlydistributed in the 128-bit space. An id could be generated using a hash function on anode’s public key or IP address which creates a high possibility that neighbouring nodes,those with adjacent ids, are diverse in, for example, geography and network attachment.Messages contains a key K which is the node id of the recipient. Node ids and message keysare seen as a sequence of digits with base 2b. This sequence is used by Pastry to route amessage to a node with a node id that is numerically closest to the message key.
A Pastry node maintains a leaf set and a routing table that it uses to route messagesin the system. The leaf set L contains the |L|/2 nodes which have the numerically closestsmaller node ids to the node and the |L|/2 nodes which have the numerically closest largernode ids to the node. |L| are typically 2b or 2 ∗ 2b. When a node receives a message, it firstchecks if the message key is within range of the leaf set and, if that is the case, routes itto the numerically closest node in the leaf set. The routing table consists of blog2bNc rowswith 2b−1 entries in each row where each entry on a row n shares the node’s id in the first n

5.5. Research Summary 53
Ki = 3110295102146305 12146366 22143746 (3)21544630162975 3(1)567716 32529610 3303144631013514 31(1)890012 31210004 31315406311(0)3514 31114398 31120914 3113607531100414 31101513 3110(2)962 31103052
Table 5.1: Routing table for a node i in a Pastry overlay network.
digits, but do not share the digit at position n+ 1. Each entry in the routing table containsthe IP address of one of the nodes that has fits this prefix. See Table 5.1 for an exampleof a routing table for a node i with id Ki = 31102951. When a message M with key K isreceived on a node A, and the key is not within range of the leaf set, the node checks therouting table and forwards the message to a node that shares a common prefix with the keyby at least one more digit. Pseudo code for the core routing algorithm in Pastry is shownin Algorithm 3.
Algorithm 3: Routing algorithm for a node in a Pastry overlay network.
Data: A message M with key K that has arrived to the node with node id AData: The entry Ri
l at column i, 0 ≤ i < 2b and row l, 0 ≤ l < b128/bc in the routingtable R.
Data: The i-th closest node id Li in the leaf set L, −b|L|/2c ≤ K ≤ b|L|/2c.Data: The value of the digit Kl at position l in the key K.Data: shl(A,B): the length of the prefix shared among A and B, in digits.
if L−b|L|/2c ≤ K ≤ Lb|L|/2c thenforward M to Li so that |K − Li| is minimal
elselet l = shl(K,A)forward M to RKl
l
end
Scribe
Scribe[39] is a peer-to-peer topic-based publish-subscribe solution that is based on Pastry tocreate a fully decentralised application-level network overlay topology. It sets a rendezvouspoint for a topic and uses that to build a multicast tree by joining the Pastry routes fromeach subscriber up to the rendezvous point. Scribe consists of a Pastry network of peerswhere peers have equal responsibilities. Scribe adds two more types of functionality to theeach node, namely the forward and deliver methods. The deliver method is invoked when amessage arrives at a node with a node id numerically closest to the key of the message, orwhen a message was sent to the node with Pastry’s send operation. If a received messageshould not be delivered and instead forwarded, the node invokes the forward method. Thesemethods will carry out a specific task depending on the message type which could be:CREATE, SUBSCRIBE, PUBLISH, and UNSUBSCRIBE. The forward and the delivermethods are described in Algorithm 4 and Algorithm 5 respectively.
Each topic in Scribe has a unique topic id in the same format as a node id and a messagekey. The Scribe node that is numerically closest to the topic id acts as the rendezvouspoint for the topic and forms the root of the topic’s multicast tree. To create a topic, a

54 Chapter 5. Publish-Subscribe Pattern
Algorithm 4: Forwarding algorithm for a Scribe node.
forward(msg, key, nextId):switch msg.type do
case SUBSCRIBEif msg.topic 6⊂ topics then
add msg.topic to topicsmsg.source = thisNodeIdroute(msg, msg.topic)
endadd msg.source to topics[msg.topic].childrennextId = null
endsw
endsw
Algorithm 5: Deliver algorithm for a Scribe Node.
deliver(msg, key):switch msg.type do
case CREATEadd msg.topic to topics
endswcase SUBSCRIBE
add msg.source to topics[msg.topic].childrenendswcase PUBLISH
for every node in topics[msg.topic].children dosend(msg, node)
endif subscribedTo(msg.topic) then
invokeEventHandler(msg.topic, msg)end
endswcase UNSUBSCRIBE
remove msg.source from topics[msg.topic].childrenif |topics[msg.topic].children| == 0 then
invokeEventHandler(msg.topic, msg)msg.source = thisNodeIdsend(msg, topics[msg.topic].parent)
end
endsw
endsw

5.5. Research Summary 55
Scribe node uses Pastry to route a message with message type CREATE and topic id asthe message key. The numerically closest node then adds the topic to the list of topics italready knows about using the deliver method. The id of a topic is hashed so that topic idsand consequently rendezvous points are uniformly distributed over the nodes of the Pastrynetwork.
The multicast tree of a topic is built by joining the Pastry routes from the subscribers tothe rendezvous point and for each node on the way, the forward method will be invoked. Ifa forwarding node is not already a member of the multicast tree of the topic, it will set itselfas a forwarder of the tree and route the message forward to a closer node. The forwarderwill then add the sender to its children of that topic.
When a publisher publishes a notification, it first checks to see if it knows the IP addressof the rendezvous point, in which the publisher just sends the PUBLISH message directlyto it. If the publisher does not know the IP address, it uses Pastry to route a message to therendezvous point, asking for its IP address. When a rendezvous point receives a PUBLISHmessage it disseminates the notification using the constructed multicast tree for that topic.
Authentication
The multicast trees that are built when providing publish-subscribe functionality in anapplication-level overlay network such as Pastry, could provide further security by usinga Merkle tree[64]. A Merkle Tree is a binary tree composed of cryptographic hash values,where leaves contain cryptographic hash values of data blocks, the internal nodes containthe hash concatenation of the children values and the root contains the content public key.
Publishers create a set of private keys and generate a hash tree of these keys where thepaths to the top hash, called public key or root key, is used as authentication paths. Leavescontain the hash values of the private keys and the nodes between the leaves and the rootcontain the hash of the concatenation of their two children. When a publisher wants topublish a notification, he first chooses one of the private keys and signs the notification withit. He then calculates the authentication which is the list of hash values needed to reach thetop hash or the public key. This can later be used by a subscriber to verify the notification.
This type of security model makes use of a separate authentication service where pub-lishers and subscribers of a topic first must authenticate themselves to. This service storesinformation about the topic that is needed by the publishers and subscribers to be able tosecurely send and receive notifications. For each topic it stores the following:
1. Spread function. A mathematical function that lists the sequence of data blocksidentifiers forming the content. It is used to avoid storing all data block IDs in theauthentication service.
2. Root hash. The root hash of the Merkle tree used to authenticate the content.
3. Public Key. The public key of the content provider.
4. Signature. The signature of the content.
Results
The documentation of Pastry includes an evaluation of an implemented version of the so-lution. It was written in Java and uses network emulation environment to be able to testit with up to 100000 Pastry nodes. Each Pastry node were randomly assigned a location

56 Chapter 5. Publish-Subscribe Pattern
on a plane in the emulated environment before the Pastry system were tested for differentperformance aspects such as routing and locating a close node.
In this documentation, the overall routing performance were measured in the number ofrouting hops between two random Pastry nodes using 1000 to 100000 number of nodes inthe network where b = 4 and |L| = 16. From the 200000 trials, it showed that the maximumnumber of hops required to route in a network of N nodes were as expected dlog2bNe. Itfurther showed that the number of route hops scale with the size of the network as predicted.
Another performance aspect that was evaluated in Pastry was the ability to locate oneof the 5 closest nodes near the client. It was tested in an environment of 10000 nodes withb = 3 and |L| = 8, where a randomly selected Pastry node sent a message to a randomlyselected key. The test recorded the first 5 numerically closest nodes to the key that reachedalong the route. The results showed that Pastry is able to locate the closest node 68% ofthe time and one of the top two nodes 87% of the time.
An experimental evaluation of Scribe[7] presented results and conclusions about theperformance of an implementation of Scribe. Three metrics were used to measure theperformance of Scribe, namely the delay to deliver notifications, to group members, thestress on each node and the stress on each physical network link. These were tested usinga simulation of a network with 5050 routers and 100000 end nodes that were randomlyassigned to the routers. Multiple test runs were used with a varying number of groups andgroup sizes.
The delay when disseminate notifications to a group using Pastry were tested and com-pared against the delay of regular IP multicast. The relative delay penalty (RDP) for Scribeagainst IP multicast showed a mean value of 1.81 and more than 80% had an RDP less than2.25. The stress on a node were measured by counting the number of groups that hadnon-empty children tables and the number of entries in children tables in each node. Using1500 groups and 100000 nodes shows a mean number of non-empty children tables per nodeof 2.4 and a mean number of entries in all the children tables of any node of 6.2.
Discussion
Pastry shows a very cheap and effective way of creating an application-level overlay networkfor large peer-to-peer solutions. It scales well with the network without significantly reducinglatency as it do not require more than dlog2bNe for a network with N nodes. This would bea very viable solution when an application can not use a regular client-server model withan intermediate layer of managed components. Scribe shows that Pastry is a powerful toolthat can be used to create highly scalable communication solutions.
Scribe uses Pastry to maintain groups and group membership and creates a very effectiveand scalable publish-subscribe solution that only relies on the peers of the system. Scribecan concurrently support many different types of applications as it can efficiently handlelarge number of nodes, groups and groups sizes. Scribe could be used to leverage a client-server model where clients may want to set up a communication channel between themselvesthat does not need much supervision or participation by the back end.
A publish-subscribe system using Pastry could be successfully used with an authentica-tion solution that do not require different responsibilities of nodes and that keeps the nodesequal. Authenticating the communication channel of a topic makes sure that the contentthat is being delivered in the group are introduced following the rules by a creator or amanager of the group and not just from everyone.

5.5. Research Summary 57
5.5.3 Self-managed Self-optimized Methods
A publish-subscribe solution which uses brokers to disseminate notifications often relies ona broker topology on a higher level than that of the physical network. This may lead to nonoptimal performance of the system as the system does not make use of the inherited localityof brokers that are handling similar types of subscriptions. If the locality of brokers are notconsidered when creating an overlay topology of brokers, the propagation of a notificationmay take longer routes which increases the number of TCP hops and the time it takes forthe solution to disseminate the notification.
What follows is a description of a self-organising algorithm which tries to dynamicallyarrange TCP connections between pairs of brokers using only the routing tables of thebrokers[1]. This preserves the scalability properties of a regular publish-subscribe solutionas the algorithm only relies on local knowledge provided by the brokers. The goal of thisalgorithm is to improve the performance and scalability of a publish-subscribe solution byreducing the number of TCP hops for a notification dissemination. This study focuses onreducing the number of hops by grouping brokers that manages similar subscriptions anddoes not address grouping brokers that are physically close to each other on the underlyingnetwork.
The algorithm defines a measurement for subscription similarity called associativity. Thismetric is used to describe the intersection of two broker’s zones of interest. A notificationmatches a subscription if the point it represents falls inside the geometrical zone identifiedby the subscription. If follows that the larger the intersection between two broker’s zonesof interest, the more notifications that will be received by one broker but not by the otherone. The associativity for a zone Z with respect to another zone Z ′ is defined as:
ASZ(Z ′) = |Z∩Z′||Z|
Let Bi and Bj be two brokers whose zones of interest are Zi and Zj , then the associativityof Bi is defined as ASi(Bj) = ASZi
(Zj). From this, the associativity of a broker Bi withrespect to its neighbours, is defined as:
AS(Bi) =∑
Bj∈NiASi(Bj)
The associativity of the whole publish-subscribe system can similarly be defined as:
AS :∑
Bi∈{B1,...,BN}AS(Bi)N

58 Chapter 5. Publish-Subscribe Pattern
The algorithm is realized the same way in every broker, where the goal, for each broker,is to detect a possible rearrangement of the TCP links to increase its associativity while notdecreasing the overall associativity of the system AS. A possible rearrangement is wheretwo brokers, B and B′, may directly connect to each other with a TCP link instead of usinga path of brokers between them. If a broker B finds a rearrangement that will increase itsassociativity with another broker B′ while not decreasing the overall associativity of AS,then the algorithm proceeds by connecting B and B′ and deciding on a link in the pathbetween B and B′ that must be tear down in order to ensure no cycles.
The algorithm assumes that each broker can open a bounded number F of TCP linksat the same time. The number of links available at broker B is defined as alB where0 ≤ alB < F . Each link li,j between two brokers Bi and Bj is associated with a weight wthat reflects the associativity between the brokers and is used to measure the associativitythat two brokers gain or lose when a link is created or teared down. The weight is a measureof the number of notifications that will pass through that link that are of interest to bothbrokers. The weight wi,j of a link li,j is defined as:
w(li,j) = wi,j = ASi(Bj) + ASj(Bi)
Using the definition of weights for a link, a hop sequence can be defined as an orderedset of pairs of a broker id and a weight denoted as:
HS(B0, Bl) = {(B0, 0), (B1, w0,1), ..., (Bi, wi−1,i), ..., (Bl, wl−1,l)}
which represents the path between B0 and Bl with the associated weights.The algorithm consists of four phases: triggering, tear-up link discovery, tear-down link
selection and reconfiguration. What follows is a description of these phases.
Triggering
Triggering refers to when a broker B detects a possibility of increasing its associativity. LetZi be the zone of broker Bi, before the arrival of a new subscription S, and Z∗i = Zi ∪ S beBi’s new zone of interest. The algorithm is triggered if the following predicate, ActivationPredicate or AP, is verified:
AP : Z∗i ⊃ Zi ∧ ∃li,j : ASZ∗i(Zi,j) > ASZi
(Zi,j)
For each li,j satisfying this predicate, a tear-up discovery procedure is invoked along thatlink, as Bi suspects that behind it could be a broker which can increase its associativity.

5.5. Research Summary 59
Tear-Up Link Discovery
When a tear-up discovery procedure is triggered for a broker Bi, Bi sends a request messagealong the link li,j with the following information: Zi, the new subscription S, and the hopsequence HS, initialised to (Bi, 0). When a broker Bj receives a request message, it computesthe associativity between itself and Bi, it updates HS by adding (Bj , wl) and computes thefollowing Forwarding Predicate, FP:
FP : ∃lj,h 6= l : ASZ∗i(Zli,j ) > ASZ∗i
(Zj)
The predicate is used to indicate whenever there is a possibility that a higher associativitycan be discovered with a broker behind lj,h: if no links exist such that FP is satisfied, thena reply message is sent back to Bi along the path stored in HS. For each lj,h satisfying FP,Bj forwards the request and then waits for the corresponding reply. When Bj receives areply from each link, it computes the maximum among all the values, including its own,and sends back a reply to Bi using the reply message from the broker with the calculatedmaximum.
Tear-Down Link Selection
This phase focuses on identifying and selecting a link that has to be teared down duringthe reconfiguration phase. This phase is started every time a broker Bi receives a reply fora tear-up discovery procedure that itself started. The reply contains the hop path HS andthe identifier Bl of the broker behind the link l that the request was sent on. The link tobe potentially teared-up Bi and Bl as ltu.
If all = 0 ∧ ali = 0 the link ltu cannot be created and thus no links exist that can beteared down and ltd = NULL. If this is not true then there exist two cases:
1. ali > 0 ∧ all > 0: in this case both Bi and Bj have available connections and thusthey can establish the link ltu without removing one of their existing links.
2. all = 0, ali > 0(resp.ali = 0, all > 0): in this case ltd must be one of Bl’s (resp. Bi)links.
Reconfiguration
This phase focuses on tearing down a link that has been selected by the tear-down linkselection phase. As the tear-down procedure must avoid creating a partition of the brokernetwork, the procedure introduces a locking mechanisms that ensures that there is onlyone tear-down happening at a time along the path from Bi to Bl. The locking mechanismworks by first sending a lock message along the path to Bl where a broker B between theendpoints execute the following algorithm:
– When receiving a lock message: if B is involved with another concurrent reconfigura-tion phase on the same link it received the lock message from, it replies with a NACKmessage. Otherwise we have two cases:

60 Chapter 5. Publish-Subscribe Pattern
1. if B = Bl, B sends an ACK message to the next node towards Bi
2. if B 6= Bl, B sends a LOCK message to the next node towards Bl
– When receiving a ACK message: B forwards the ACK message to the next nodetowards Bi
– When receiving a NACK message: B forwards the NACK message to the next nodetowards Bi and removes the lock
Once the path is locked Bi sends a close message to Bj which tears the link down. Afterthat Bj sends back an unlock message where then the routing table for all brokers in thepath are updated.
Results
A report containing an implementation of this study[1], uses Siena as a base for the publish-subscribe functionality and Java with J-Sim to simulate a real-time network which the pro-totype was run on top of. In total, a network of 100 nodes were simulated with one brokerrunning on top of each network node. Simulation scenarios were sequences of subscrip-tions changes and notification publications, over a bi-dimensional space with two numericalattributes. Notifications are generated using an uniform distribution over the space.
One aspect that was tested in this implementation was the routing performance whichreferred to the number of TCP hops per notification required for the dissemination. Thisaspect was tested and compared using the messaging system with and without the self-organising algorithm. This test showed a reduction of forwards by 70% which is close to theminimum.
Another aspect that was tested was the overhead of the self-organising algorithm betterrouting performance comes at the price of additional network traffic introduced by thealgorithm itself. The overhead was measured using the average number of messages peroperation against the pub/sub ratio R. Such messages include all the messages generated bythe system for notification diffusion, subscription routing and self-organisation. For a ratioas low as R = 10:1 the self-organisation cost is not outweighed by its benefits. As the ratioincreases, the cost decreases of about 30% with respect to the case when no self-organisationis performed.
Discussion
The material covered in this section shows that a setup of decentralised brokers can incorpo-rate a self-managing algorithm so that the brokers may autonomously organise themselveswithout the need of any manual intervention. This section serves as a good example of howa decentralised messaging solution can still feature a more manageable system which stillprovides a high expressiveness and throughput.
The test results show on better routing performance when using the algorithm. Thishighlights the problem of using brokers that are not aware of the underlying network system.
The addressed self-organising algorithm is a very simple algorithm that only consists ofsome few, very distinct phases. This bodes well for the continuation of the developmentand introduction of such an algorithm which can be easily implemented using the stepspreviously described.

5.6. Conclusion and discussion 61
5.6 Conclusion and discussion
Having presented the different workings of publish-subscribe for each category, this sectionconcludes the in-depth study chapter of this thesis report with a comparative discussion.The individually summarised methods have been reviewed but this section aims to inspectthese methods in regard to each other by comparing their (dis)advantages and highlighttheir possible applicability in the current solution. This conclusion also includes a discussionabout the future of addressed methods.
5.6.1 Decentralising Brokers
Decentralised brokers are probably the most common way of scaling this type of notificationsystem. It scales well and is completely managed and controlled by the owners. It is alsothe way the current solution is handled and scaled out except for a slight variation of theexplicit control of the notification component, as it is a cloud service owned and providedby AWS.
This notification service that AWS provides, called SNS, is a topic-based publish-subscribesolution that uses intermediate brokers on the AWS cloud to disseminate notification. Thisservice is a part of AWS cloud services and, because of that, it has a lot of extra functionalitysuch as scaling and security. Using a cloud service reduces the need of maintenance while itprovides very many simple ways to monitor and analyze a wide range of information aboutthe service.
One way to make further way for the messaging channels in the service, is to upgrade thetopic-based routing to content-based or type-based notification routing. This would makeit possible for the different components of the system to interact with each other in moreintricate ways. A type-based solution could for example be used to create sub channels withthe possibility to express interest in parent channels where messages from both channelswould be routed to. This would make it possible to, for example, create one sub channel forthe voting functionality and one sub channel for the admin functionality while components,like logging tools, could listen to their parent channel and receive messages from both of thesub channels. Type-based notification systems would also be able to simulate the same typeof hierarchy used by the path component of a HTTP request where messaging channelscould be distinguished using the path component. For example, /voting/client/event1,could denote a channel that consists of two parent channels /voting/client and /voting.This would combine RESTful functionality with the type-based notification functionality sothat the interface between those could be made as minimal as possible.
5.6.2 Peer-to-peer Methods
Pastry and Scribe shows that there exist very viable solutions for creating scalable peer-to-peer publish-subscribe systems on an application-level network. It does however not give asmuch maintainability and other types of notification services, especially those on the cloud,outperforms this kind of solution in many ways. This solution is instead meant for use caseswhere it does not exist any way to provide the functionality of a use case using a centralisedbroker system. This type of notification system could instead be used for when a centralmessaging system is not needed or wanted and the clients of the system should interactdirectly with each other.
Peer-to-peer solutions could be used in the current system to offload the central partson the back end and instead partially move messaging functionality to the peers. Thiscould be used to create a more scalable way of pushing out data to the clients as a web

62 Chapter 5. Publish-Subscribe Pattern
server does not need to keep track of every client and does not need to publish messages toevery client. This would mean that the quality of the provided services are dependent onclients capabilities to route messages. This peer-to-peer network could be used to implementadditional functionality that do not need the back end for any heavy data processing, forexample. This type of functionality may relate to dynamic handling of events where clients,for example, can create their own events. Offloading these types of events on the clientsmakes it possible for the system to handle more concurrent events. This type of notificationsystem also shows that there exists viable security solutions which may further motivatethe creation of dynamic events by the clients and possibilities to create security policies forevents so that, for example, only friends may connect to a channel.
5.6.3 Self-managed Self-optimised Methods
The addressed self-managing algorithm shows a simple and easy to understand procedurethat can be used to add some automation to a messaging system. As the reference projectuses a cloud based service for its internal messages, it is impossible to configure the brokersof the notification system. Therefore it may not have as much value for the current systemif not the messaging system would be replaced with an alternative that could support thesemethods.
If a non-cloud based messaging solution would be implemented for the current system,this algorithm could be a good way to improve the performance of the solution as the systemwould make use of the locality for the different clients. It could be implemented for manytypes of messaging systems as seen on its test cases on top of Siena, a very generic and wellused base for publish-subscribe systems. This fits nicely into the use of peer-to-peer solutionsof publish-subscribe if the messaging would be offloaded onto the clients, as the locality ofthe clients plays a much larger part for peer-to-peer solutions where clients positions maymove much more.
5.6.4 The Future
The use of cloud based services is a great way to skip development of redundant and un-necessary code as cloud services may provide the needed functionality out of the box withalready present and well-tested functionality for, for example, scaling and monitoring. Thesecloud services, on the other hand, cannot often be tailored specifically to the needs of thedeveloped application and cannot, because of that, truly compete with proprietary solutionswhen it comes to performance and if the messaging system would be replaced by a non-cloudbased messaging system, the addressed methods of this chapter would come in great use.
While these methods focuses on the internal messaging system, one way to extend thecurrent use case while offloading the internal system would be to introduce dynamic eventsthat could be created and managed by the users. This added functionality could be usedto create an event that is only relevant for the client and, for example, its friends. Thesemethods is especially of interest for this kind of messaging as it addresses peer-to-peer andself-managed solutions with security in mind where authentication could be used with anypublicly known and used procedure such as authentication with Facebook or Google.
This in-depth study could also be used as a documentation of said methods where anyimplementation of a publish-subscribe system would benefit from addressing the issues inthis chapter. Siena, for example, is a well-known base for publish-subscribe systems thatcould work as a reference solution when designing any type of publish-subscribe functionalitywhere a messaging solution is needed that decouples the sender and the receiver.

Chapter 6
Implementation ofImprovements
This chapter is a documentation of the implementation that was made during this thesis. Itfocuses on applying one of the proposed main improvements on the current system, namelythe separation of messaging channels in the web server. It is not an implementation fromscratch but a modification of the current system which focuses on applying the improvementand changing as little as possible of the behaviour and inner workings of the current service.This implementation can then be seen a good base or reference if this type of functionalityshould be incorporated into the existing system later on. This chapter presents the goalsfor this implementation in section 6.1 and describes how they will be measured in section6.2. It includes an overview of the implementation details in section 6.3 and concludes witha presentation of the results in section 6.4.
6.1 Goals
One of the main goals for this implementation is the modification of the web server so that itis able to distinguish between clients for different events and is able to multicast messages toclients for an event. The proposed improvement defined two levels in the web server wherethe first level addressed the generic functionality of the message channels and the secondlevel addressed the event logic where use case specific functionality would be present. Theselevels will be implemented and will consist of including a way to separate the logic for eachevent inside the web server so that any message that is sent for an event is handled by itsrespective event logic on the second level.
This improvement of the current solution directly addresses two issues, namely sendingeverything to everyone and completely replicating the global state in both clients and webservers. By implementing the two levels in the web server, the web server will be able todistinguish between clients and multicast messages to clients for an event. The second issue,on the other hand, requires use case specific changes to the solution so that the logic foreach event can be used separately. This means that the use case implementation needs tobe modified so that it uses this separation of event logic and does not, for example, fetch thewhole global state and instead only fetches the state for a specific event. This also meansthat the current solution must be changed in the same way on the client where a client onlystores and handles the state of those events that it is interested in. The goal to solve this
63

64 Chapter 6. Implementation of Improvements
second issue can then be broken down to as making sure that the web server only holds theevent logic for those events that it needs, namely those that connected clients are interestedin.
The modifications of the current system must be explicitly documented in which partsof the system it changes and what it changes. This is to make it clear of how these changescan be applied when or if the stakeholders of Dohi Sweden decides to incorporate this intothe system. The implementation must also be able to demonstrate the behaviour of thecurrent use case by incorporating it into the modified solution.
Reaching these goals would not pose any challenges if the performance aspects of thesolution would not be considered. One of the overall goals of this implementation as wellas this thesis is to come up with improvements for the existing service that may betterfit the needs of the stakeholders and that may later be used by the existing service. Thisimplementation will trade usability and performance, in terms of client-server delay, toscalability, generality and complexity, and these trade-offs must be documented so thatreaders may get a good idea of what differs between the two systems.
6.2 Measurements
Demonstrating that the implemented solution only sends messages to the clients of thecorresponding event can be easily done by creating two events, connect a client to eachevent and then send some messages over the events. Showing that the client and the webserver only keeps track of relevant events can be done by logging the data that is storedin both components. The web browser Google Chrome supports ways to log data that istransmitted over asynchronous web connections and this can be used to show that a messagealso only contain data for the corresponding event.
The differences between how the solutions proceeds when a client connects is measuredusing the perceived latency by the client, the number of messages sent and the size ofthe messages sent. The phase for when a client connects is defined as the steps betweenthe first communication with the web server and the consecutive steps until the client haseverything it needs to be able to send and receive messages for the event it is interested in.In the reference solution, this means that the initialization phase consists of fetching thebootstrap from the web server, fetching the token from the web server and then connectingto the web server for the asynchronous communication link. The initialization phase for themodified solution consists of connecting to the web server, receiving a connection response,sending a subscription response and finally receiving a subscription response. The special”quick subscribe” method of the modified solution has also been tested and it consists ofthe steps where the client connects to a special URL and then receives a combined connectand subscribe response.
How the modified solution behaves with its lazy initialization is tested by doing tenconsecutive initializations with ten clients where the previously connected clients stays con-nected. The perceived latency by the connecting client is then noted down.
The bootstrap of the both solutions are also tested. The boostrap is the initial messagethat is sent when a client connects and contains information specific to a channel or, for thereference solution, information about all channels. This information is used by the client toset up the necessary parts of an event so that it can be presented the correct way.

6.3. Implementation Details 65
6.3 Implementation Details
This section describes the modifications that were made on the current system by addressingthe components that has been changed and how they differ from the existing solution. Itpresents the separation between the general functionality and the use case specific logic andoutlines how it works.
6.3.1 Channel Definition
The proposed improvements defines a channel as a separated messaging channel for a singleuse case or, in the case of the reference use case, a single event. Each event or use case getsits own channel which it uses to send and receive messages over for the corresponding usecase or event. These channels represent the core functionality of the generalization that thisimplementation introduces. The idea is that clients subscribes to channels instead of justconnecting to the web server where a client that is a subscriber of a channel can send andreceive messages on that channel. The channel functionality is present in three components,the client interface, the web server and the client validation cache, see Figure 6.1 for anoverview of all components of solution with addressed components highlighted.
The channel id, or reference, is for the voting use case intended to be similar to thatof a path component of a URL. A channel reference is also meant to be a composition ofan account and the name of an event, such as ”/dohi/event1”. This is used for the requesthandlers and the channel manager in the web server to be able to group channel specificlogic and to further minimize overhead by, for example, let a client subscribe to a channelwhen connecting to the server using a certain URL.
6.3.2 Components
There are four components that have been modified to some extent and how these havebeen changed is described in the following subsections. The overall architecture has notbeen changed from the existing solution and components are still only interacting withthose it do in the reference system, see Figure 6.2 for an overview of the system architecturewhere modified components have been highlighted with a wider and rounded border.
Web Server
The web server has been completely reworked from the ground up to accommodate for thecore functionality of the channels. It consists of two levels where the first level consists of thecore functionality and the second level consists of use case specific logic. When a client firstconnects to the web server, the web server directly sends a respond to the client containingthe validation token that the connected client must use in every message to validate itself.A connected client can then send subscription requests to the server which, depending ifthere is any channel module that validates the request, sets the client as a subscriber to thechannel and sends a response back that may contain use case specific information such asinitial state.
The web server holds channel modules which are bound by a mapping expression for howan id or reference to the channel could look. The web server uses these modules to performlazy initialization on channels, triggering when the first client subscribes to a channel. SeeAlgorithm 6 for a step by step description of the subscription procedure used in the webserver. The initialization of a channel includes setting up a topic on SNS for the channel andcall a channel modules initialization method. The SNS topic is used for channel messaging

66 Chapter 6. Implementation of Improvements
between internal components of the system and the module initialization call is used to letthe use case or event specific logic to do an initialization. When the last client unsubscribesfrom an initialized channel on a web server, the web server tears down the channel byunsubscribing to the SNS topic and calling a destructor method on the channel module.
A channel module can hold regular handlers for HTTP request/response logic which donot go through the subscription procedure but is still exposed to the channel module andthe messaging functionality for a channel and can as such still interact with the use case
Figure 6.1: An overview of the components in the solution which highlights the generalfunctionality of the messaging channels that is not tied to any use case. It separates the webserver in two levels: a higher level which contains use case specific functionality in separatemodules and a lower level that manages these modules. It introduces a web client interfacethat the clients use to express their interest in events or channels. The client validationcache is also used directly by the lower level of the web servers. The load balander and thenotification system is also viewed as part of the basic functionality.
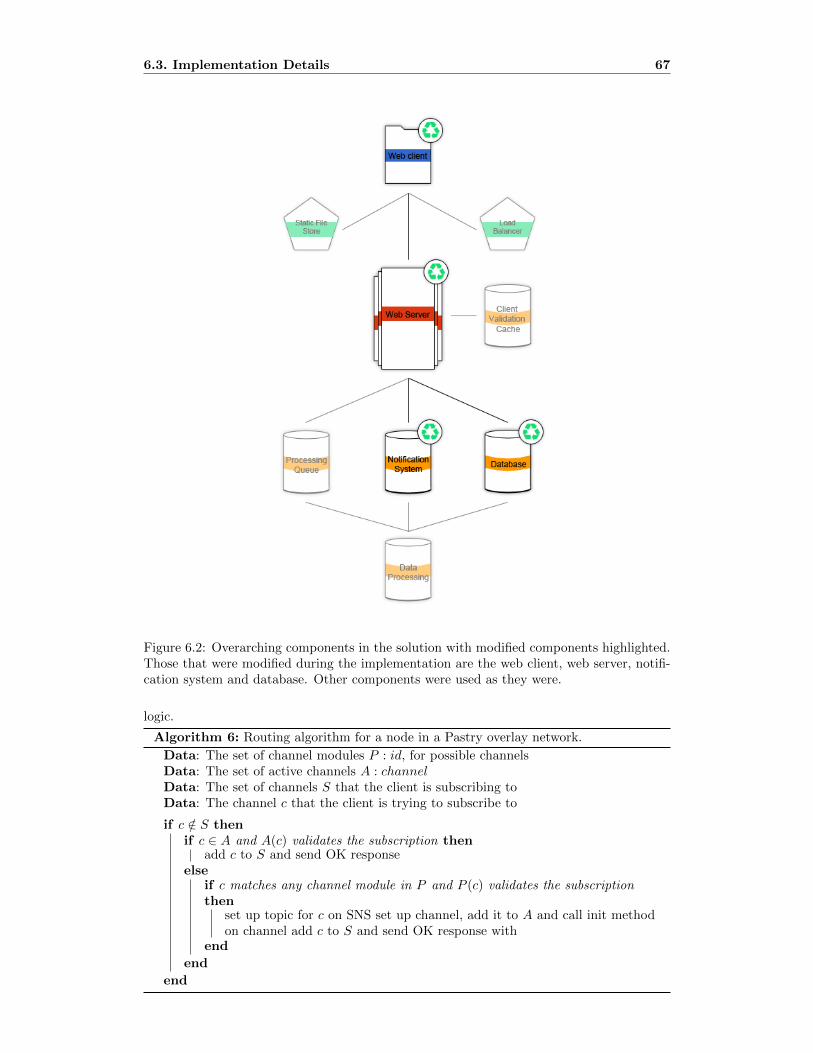
6.3. Implementation Details 67
Figure 6.2: Overarching components in the solution with modified components highlighted.Those that were modified during the implementation are the web client, web server, notifi-cation system and database. Other components were used as they were.
logic.
Algorithm 6: Routing algorithm for a node in a Pastry overlay network.
Data: The set of channel modules P : id, for possible channelsData: The set of active channels A : channelData: The set of channels S that the client is subscribing toData: The channel c that the client is trying to subscribe to
if c /∈ S thenif c ∈ A and A(c) validates the subscription then
add c to S and send OK responseelse
if c matches any channel module in P and P (c) validates the subscriptionthen
set up topic for c on SNS set up channel, add it to A and call init methodon channel add c to S and send OK response with
end
end
end

68 Chapter 6. Implementation of Improvements
The event module for the current use case is similar to the use case functionality in thereference system, except it does not operate on the complete global state but instead onlyon its own channel state. When the channel manager in level 1 asks the event module tovalidate a channel it checks if the channel exists in the database and accepts the validationif it does. When the logic for an event initializes, it fetches the state of the channel fromthe database and stores it locally and then gives it to the channel manager whenever thechannel manager asks for a channel subscription response. The admin interface handling isdone exactly the same by using HTTP request/response handlers and directly querying thedatabase. The data model has been changed, though, from storing happenings to storingchannels and, because of that, the admin handlers has been modified to support the newdata model.
To further minimize the number of steps that needs to taken in the starting phase when aclient connects, a client can, instead of connecting to the root of the server address, connectto the server using a path component that starts with ”/channel/”. The web server willinterpret this as a connection with a single subscription request to a channel whose referenceis represented the remaining part of the path component.
Notification System
The notification system is still SNS and the internal components do still communicate usinga single topic but the web server now also creates a topic for each channel that can be usedto send messages over its own channel and further separate use cases or events.
Database
The data model has been modified to accommodate the new separation of data with chan-nels. When a channel for an event is initialized, the event logic needs to be able to fetch thestate of that single event. Instead of using happenings, surveys, questions and options, thedatabase now stores channels as a substitution for happenings and surveys grouped togetherwhere each channel in the database represents a channel or event for the current use case.A user is no longer tied to a happening but can instead be tied to a number of accountswhere an account represents a group of channels.
Front end
The front end has been divided into two parts where a client interface has been extractedfrom the use case specific web client. The client interface is a Javascript library that pro-vides functionality to connect to a server, disconnect from a server, subscribe to a channel,unsubscribe to a channel and send and receive messages for a channel. This interface hidesthe low level communication with the web server, such as token handling and sending sub-scribe messages, and provides a more abstract functionality where clients can be notifiedabout channel specific information by registering callbacks.
The current voting client has been modified so that it uses the new client interface toconnect to the server and subscribe to a channel. The data model handler has also beenchanged to support the new data model where only the specific event data is stored locally.The client implementation has been limited to the rating functionality where a user can ratea subject and then receive a result, in the form of a sliding window mean value of votes,which it displays in a heatometer.

6.4. Results 69
6.4 Results
The implementation was tested using the reference client, the reference admin interface anda test client which consisted of a web page with a text area that displayed received messagesand a text field that could be used to send messages. Except for the reference channelmodule, another module was added to the web server that accepts every subscriber andbroadcasts any message it receives. The test clients were run on the same machine, runningWindows 7 with processing power close to 2.7GHz and memory of 8GB. All of the servicesused are run either as a AWS service or on an AWS EC2 micro instance. See chapter 4.2for a complete overview of how every component of the service are implemented.
To show that messages are only sent over the corresponding channel, three instances ofthe test client were started where, in the improved solution, the first and second client wereconnected to one channel and the third client was connected to another channel. The firstclient then sent 1000 messages aimed only for the clients of its corresponding channel. Asseen in Figure 6.3, all three clients received every message when tested with the referencesolution, while only the two first clients received the messages in the modified solution.
Figure 6.3: Number of messages received by three clients where the first client is publishingand subscribing to channel 1, the second client is subscribing to channel 1 and the thirdclient is subscribing to channel 2.
The time to connect to the server and initialize a subscription, is shown in Figure 6.4.It presents the time for three versions; the reference solution, the general method for themodified solution and a special method for the modified solution. The time of the referencesolution refers to the time it takes for a client to first fetch the bootstrap by using an AJAXcall, then fetch the token using an AJAX call and lastly connecting to the bi-directionalcommunication link. The general method for the modified solution refers to the time it takesfor a client to connect to the server and then, after it has received a connection response, doa subscription request and receive a subscription response. The special, ”quick subscribe”method , refers to the time it takes for a client to connect to the server using a special URL,
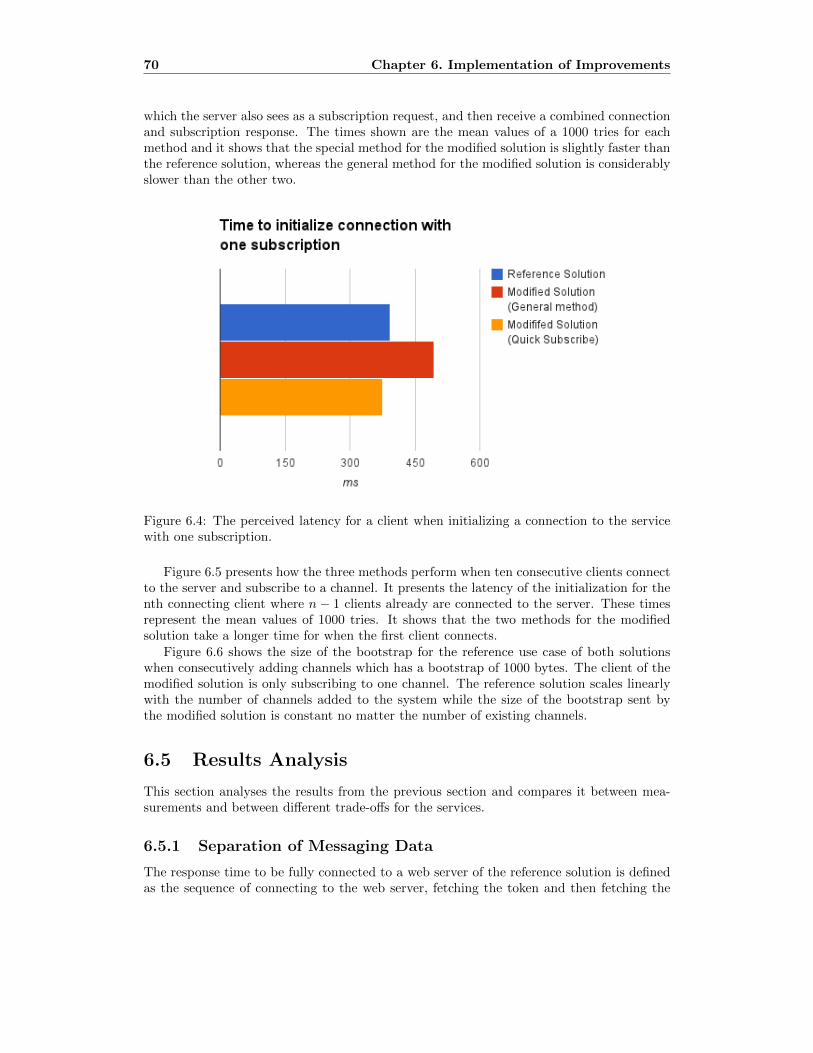
70 Chapter 6. Implementation of Improvements
which the server also sees as a subscription request, and then receive a combined connectionand subscription response. The times shown are the mean values of a 1000 tries for eachmethod and it shows that the special method for the modified solution is slightly faster thanthe reference solution, whereas the general method for the modified solution is considerablyslower than the other two.
Figure 6.4: The perceived latency for a client when initializing a connection to the servicewith one subscription.
Figure 6.5 presents how the three methods perform when ten consecutive clients connectto the server and subscribe to a channel. It presents the latency of the initialization for thenth connecting client where n − 1 clients already are connected to the server. These timesrepresent the mean values of 1000 tries. It shows that the two methods for the modifiedsolution take a longer time for when the first client connects.
Figure 6.6 shows the size of the bootstrap for the reference use case of both solutionswhen consecutively adding channels which has a bootstrap of 1000 bytes. The client of themodified solution is only subscribing to one channel. The reference solution scales linearlywith the number of channels added to the system while the size of the bootstrap sent bythe modified solution is constant no matter the number of existing channels.
6.5 Results Analysis
This section analyses the results from the previous section and compares it between mea-surements and between different trade-offs for the services.
6.5.1 Separation of Messaging Data
The response time to be fully connected to a web server of the reference solution is definedas the sequence of connecting to the web server, fetching the token and then fetching the
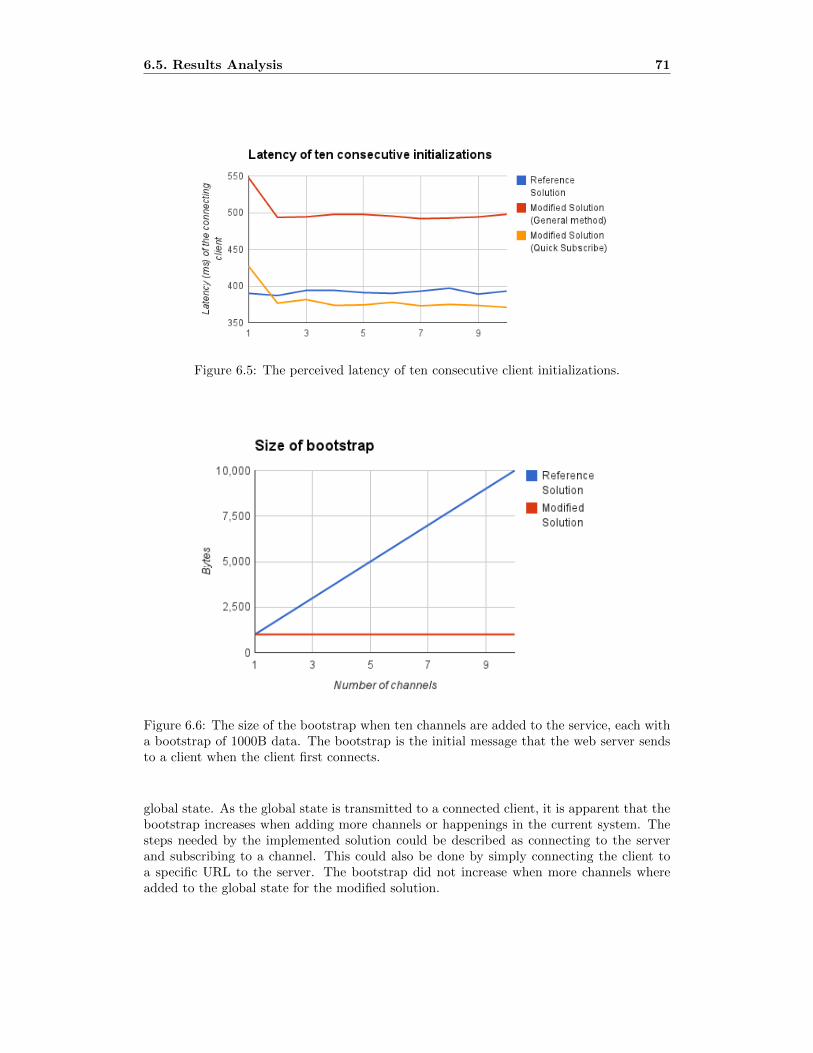
6.5. Results Analysis 71
Figure 6.5: The perceived latency of ten consecutive client initializations.
Figure 6.6: The size of the bootstrap when ten channels are added to the service, each witha bootstrap of 1000B data. The bootstrap is the initial message that the web server sendsto a client when the client first connects.
global state. As the global state is transmitted to a connected client, it is apparent that thebootstrap increases when adding more channels or happenings in the current system. Thesteps needed by the implemented solution could be described as connecting to the serverand subscribing to a channel. This could also be done by simply connecting the client toa specific URL to the server. The bootstrap did not increase when more channels whereadded to the global state for the modified solution.

72 Chapter 6. Implementation of Improvements
6.5.2 Separation of Messages
For the modified solution, as seen in Figure 6.3, clients that are subscribing to the samechannels receive the same messages while clients that are not subscribing to the same chan-nels do not receive the same messages. This means that the neither the clients nor the serverneed to send and receive unnecessary messages which also leads to more efficient networkusage.
6.5.3 Initialization
As the modified solution does a more complex procedure when a client connects, it does notperform as good as the reference solution in terms of the perceived latency by the client.The modified solution must keep track of which clients are subscribing to which channelsand must also provide the functionality to let clients subscribe to channels. When a serverreceives a message, it also has to forward the message to the correct channel. This leads toa longer execution time of the web server and a higher client-perceived latency. The special”quick subscribe” method, which the modified solution provides, outperforms the referencesolution as it only needs to do three things; connect a client, initialize the subscription andsend a response. This works great when a client only wants to subscribe directly to a singlechannel when connecting to the server but if the client would later want to connect to achannel or connect to multiple channels, it would have to use the general and slower method.
The test results also show that both methods for the modified solution performs worsethan the reference solution for the first connecting client. This is the drawback for lazyinitializing messaging channels as more work needs to be done for the first client.

Chapter 7
Discussion
One of the tasks whose planned time was largely overestimated was the definition of thisthesis. Trying to concretize the work for the thesis took roughly double the time than whatwas initially planned. This meant that the planned work for the project was revised manytimes during the start of the thesis and many hours were added to this category instead ofto others.
As the author did not have any knowledge of this subject prior to this study, a pre-studytook many hours to perform instead of using those for the actual evaluation.
7.1 Restrictions
The implemented system that addresses the selected improvements do not entirely reflectthe same behaviour as the reference project. This means that extra time would be needed toincorporate these improvements in the current system so that the current use case behavesas it should. It also means that the effect and the results of the performed tests are morespeculative as the modified system do not work in the same way as the original application.
As there was not enough time, only a very minimal implementation of the improvementswere made. Had there been more time, more improvements could have been tested andmore work could have been added to making sure that the modified version of the solutioncould be used and behave as similar as possible as the current solution. More of the usecase specific functionality could also have been generalised and moved to level 1 in the webserver. The database and the data processing components are currently viewed as votingfunctionality and it is expected that any new use case implements their own functionalityfor those components.
The internal messaging component did not perform as good as expected and the biggestculprit when it comes down to measuring response times for different tasks. The cloud basedmessaging service may be better of for use as a single static messaging channel that is knownbeforehand. As the web server lazy initializes channels and consequently also SNS topics,it introduces additional overhead when the first client of an inactive channel connects.
The modification of the data model did currently not provide any additional informationof use for how to continue with the development of this solution. This step could insteadhave been simulated in the web server so that time could have been used for something moreproductive. There are many components that only features minimal modifications so thatthey can handle channels in the current solution. Even though their participation helps in
73

74 Chapter 7. Discussion
estimating the complete behaviour of the modifications in the reference solution, they couldstill instead have been simulated to give additional time on other matters.
As the general functionality in the web server only addresses lazy initialization of channelsfor the subscription functionality, the request handlers can not directly use the internalmessaging channel as inactive channels would have to initialize the messaging logic for arequest handler.
The messaging channels in the web server do not feature any authentication. Instead itis up to the use case module to implement its own authorization logic and this is only donefor the request handlers in the existing use case. This means that any authorisation has notbeen tested on a messaging channel neither on level 1 or on a channel module.
7.2 Future Work
The idea for this evaluation was to make proposal of improvements for the current systemso that any further development may be able to more easily solve the addressed issues andincorporate the implemented modifications. For this to be possible, work would have to beperformed to implement the addressed issues as the modified solution does not completelyreflect the behaviour of the current solution.
With the use of level 1 in the web server very many different types of use cases could beimplemented. This is a trade-off between generalization and complexity and use cases thatare similar to that of the current use case would have to do more work to add the missingfunctionality.
Further work for the separation of messaging channels should focus on the internal mes-saging system if the performance aspect is not good enough. Completely separate channelson the back end would add extra scalability issues as well as a more decoupled system.An interesting aspect of the messaging service is the use of a type-based publish subscribesystem instead of a topic-based one. This would make it possible to create a hierarchy ofparent channels and sub channels and allow much more intricate ways to send messages.This could be used, for example, to group channels using a parent channel where loggingtools could be deployed on the parent which would be able to receive all messages from thechildren.
Another interesting aspect for future work is the support for dynamic channels for clients.Enabling the functionality so that users can create their own channels would open up muchmore use cases and it is also in line with the direction the current use case is taking with thevoting functionality, being more of a social entertainment. The base for this has also beengiven much time in the in-depth study that focuses on different publish-subscribe solutionswith some focus on authentication in the publish-subscribe solutions.

Chapter 8
Acknowledgement
The author wishes to thank Dohi Sweden for providing the prerequisites for a very interestingand educational thesis that has given the author great insight and experience in how a projectin computer science is performed and managed. The author has been given help by everyoneat Dohi Sweden and could not be more grateful for all their hard work and support. Specialthanks go out to Anton Lundin, Stefan Tingstrom and Olle Haff for their efforts in guidingthe author, and Linus Mahler Lundgren for his immensely valuable help throughout thewhole project.
Finally, thanks to the internal supervisor at Umea University, Jan-Erik Mostrom. Thankyou for the help during the thesis project and for taking the time to read through this lengthyreport.
75

76 Chapter 8. Acknowledgement

References
[1] Virgillito Antonino. Publish/Subscribe Communication Systems: from Mod-els to Applications.http://goo.gl/N4hsT. Visited 20/03/2013.
[2] Atmosphere. Product github.http://goo.gl/QelPc. Visited 14/02/2013.
[3] Andrew D. Birrel and Bruce Jay Nelson. Implementing Remote Procedure Calls.http://goo.gl/yTjni. Visited 22/02/2013.
[4] Dhruba Borthakur. The Hadoop Distributed File System: Architecture andDesign.http://goo.gl/iv0fi. Visited 22/02/2013.
[5] caniuse.com. Can I use Web Sockets?http://goo.gl/kqEgF. Visited 22/02/2013.
[6] Antonio Carzaniga, David S. Rosenblum, and Alexander L. Wolf. Design and Eval-uation of a Wide-Area Event Notification Service.http://goo.gl/rZb19. Visited 18/03/2013.
[7] Miguel Castro et al. SCRIBE: A large-scale and decentralized application-level multicast infrastructure.http://goo.gl/9oVVZ. Visited 20/03/2013.
[8] Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processingon Large Clusters.http://goo.gl/87mH5. Visited 22/02/2013.
[9] Jean Dollimore, Tim Kindberg, and George Coulouris. Distributed Systems: Con-cepts and Design.ISBN: 978-0321263544. Published 14/06/2005.
[10] Sam Dutton. Getting started with WebRTC.http://goo.gl/VCAQd, note = Visited 22/02/2013.
[11] Fidler E. et al. The PADRES Distributed Publish/Subscribe System.http://goo.gl/TcW39. Visited 19/03/2013.
[12] EventMachine. Official homepage.http://goo.gl/3HZf5. Visited 14/02/2013.
[13] Daniel Ford et al. Availability in Globally Distributed Storage Systems.http://goo.gl/h5wQJ. Visited 22/02/2013.
[14] fxn. Why HTTP Streaming?http://goo.gl/xsXg4. Visited 11/02/2013.
77

78 REFERENCES
[15] Netcraft homepage. December 2012 Web Server Survey.http://goo.gl/oVIn6. Visited 15/02/2013.
[16] Patrick Hunt et al. ZooKeeper: Wait-free coordination for Internet-scale sys-tems.http://goo.gl/eQm2L. Visited 22/02/2013.
[17] Peter Saint-Andre Jack Moffitt Ian Paterson Dave Smith. XEP-0124: Bidirectional-streams Over Synchronous HTTP (BOSH).http://goo.gl/wZFwc. Visited 13/02/2013.
[18] Joey Jablonski. Introduction to Hadoop.http://goo.gl/g1dAH. Visited 22/02/2013.
[19] Jetty. Official homepage.http://goo.gl/lZmrz. Visited 22/02/2013.
[20] Chen Jianxia, Ramaswamy Lakshmish, and Lowenthal David. Towards EfficientEvent Aggregation in a Decentralized Publish-Subscribe System.http://goo.gl/Hp9CT. Visited 19/03/2013.
[21] M. Tim Jones and IBM. Process real-time big data with Twitter Storm.http://goo.gl/wWEom. Visited 22/02/2013.
[22] Apache Kafka. A high-throughput distributed messaging system.http://goo.gl/XPpjh. Visited 22/02/2013.
[23] Markku Laine. RESTful Web Services for the Internet of Things.http://goo.gl/axg7K. Visited 05/03/2013.
[24] lighttpd. Official homepage.http://goo.gl/fD0IY. Visited 22/02/2013.
[25] Netcraft LTD. September 2012 Web Server Survey.http://goo.gl/1aiWK. Visited 16/05/2013.
[26] Peter Lubbers. How HTML5 Web Sockets Interact With Proxy Servers.http://goo.gl/9yCtQ. Visited 22/02/2013.
[27] Andrew McGregor. Processing data streams.http://goo.gl/uqNkG. Visited 22/02/2013.
[28] Mongrel2. Official homepage.http://goo.gl/c2nM7. Visited 22/02/2013.
[29] NginX. Official homepage.http://goo.gl/Q85LW. Visited 14/02/2013.
[30] Bill Nitzberg and Virginia Lo. Distributed Shared Memory: A Survey of Issuesand Algorithms.http://goo.gl/jxJpy. Visited 22/02/2013.
[31] Node.js. Official homepage.http://goo.gl/zpsh4. Visited 14/02/2013.
[32] Frank Greco Peter Lubbers. HTML5 Web Sockets: A Quantum Leap in Scal-ability for the Web.http://goo.gl/DysTB. Visited 11/02/2013.
[33] Nicholas Piel. Asynchronous Servers in Python.http://goo.gl/ulToK. Visited 22/02/2013.

REFERENCES 79
[34] Apache Qpid. Open Source AMQP Messaging.http://goo.gl/vRMA3. Visited 22/02/2013.
[35] RabbitMQ. Distributed RabbitMQ brokers.http://goo.gl/jq1S6. Visited 22/02/2013.
[36] Jun Rao. Open-sourcing Kafka, LinkedInas distributed message queue.http://goo.gl/hqgOa. Visited 22/02/2013.
[37] David Recordon. Tornado: Facebook’s Real-Time Web Framework for Python.http://goo.gl/H3PDx. Visited 22/02/2013.
[38] HTML 5 Doctor Remy Sharp. Server-Sent Events.http://goo.gl/BLl0v. Visited 22/02/2013.
[39] Antony Rowstron et al. SCRIBE: The design of a large-scale event notificationinfrastructure.http://goo.gl/AuiDv. Visited 18/03/2013.
[40] Ken Schwaber and Jeff Sutherland. The Scrum Guide.http://goo.gl/JSmQQ. Visited 22/02/2013.
[41] Dmitry Sheiko. WebSockets vs Server-Sent Events vs Long-polling.http://goo.gl/1dSK1. Visited 11/02/2013.
[42] Chien Shih-Chiang, Kao Yung-Wei, and Yuan Shyan-Ming. A GenericPublish/Subscribe Framework for Peer-to-Peer Environment.http://goo.gl/MGZSr. Visited 19/03/2013.
[43] Bruce Snyder, Dejan Bosanac, and Rob Davies. ActiveMQ in action.http://goo.gl/omWIR. Visited 22/02/2013.
[44] Ian Sommerville. Batch data processing systems.http://goo.gl/tFqnp. Visited 22/02/2013.
[45] Mudhakar Srivatsa and Ling Liu. Securing Publish-Subscribe Overlay Serviceswith EventGuard.http://goo.gl/rHGJD. Visited 18/03/2013.
[46] Storm. Official homepage.http://goo.gl/IK2Sd. Visited 22/02/2013.
[47] Storm. Official homepage - Benchmark.http://goo.gl/TBb11. Visited 22/02/2013.
[48] Aater Suleman. What makes parallel programming hard?http://goo.gl/sZl4k. Visited 16/05/2013.
[49] Dio Synodinos. HTML 5 Web Sockets vs. Comet and Ajax.http://goo.gl/rjyps. Visited 22/02/2013.
[50] Datasalt Systems. Real-time feed processing with Storm.http://goo.gl/nOLxb. Visited 22/02/2013.
[51] Sasu Tarkoma. Publish / Subscribe Systems: Design and Principles.ISBN: 9781119951544. Published 13/07/2012.
[52] Apache Thrift. Official homepage.http://goo.gl/pYp5V. Visited 22/02/2013.
[53] Tornado. Official homepage.http://goo.gl/3oWrm. Visited 14/02/2013.

80 REFERENCES
[54] Twisted. Official homepage.http://goo.gl/m0nXr. Visited 14/02/2013.
[55] Vert.x. Official homepage.http://goo.gl/G9iHT. Visited 14/02/2013.
[56] Google Inc. W3C Ian Hickson. Server-Sent Events, W3C Candidate Recom-mendation 11 December 2012.http://goo.gl/NofUz. Visited 13/02/2013.
[57] WebRTC. Official homepage.http://goo.gl/oITWk. Visited 22/02/2013.
[58] Google developers website. Channel API Overview.http://goo.gl/MMpjR. Visited 22/02/2013.
[59] Websocket.org. What is WebSocket?http://goo.gl/Kg4gm. Visited 22/02/2013.
[60] Tom White. Hadoop: The Definitive Guide.ISBN: 9781449311520. Published 05/2012.
[61] Brian Whitman. Replacing Amazon SQS with something faster and cheaper.http://goo.gl/qdmdn. Visited 22/02/2013.
[62] Apache Wiki. ZooKeeper Overview.http://goo.gl/pc0Ih. Visited 22/02/2013.
[63] WikiVS.com. lighttpd vs nginx.http://goo.gl/1Dmnk. Visited 22/02/2013.
[64] Walter Wong. Efficient Content Authentication in Publish/Subscribe Sys-tems.http://goo.gl/p7bQh. Visited 20/03/2013.





























