Embed Size (px)
Citation preview

Komparasi Algoritma Non-Parametrik k-Nearest Neighbour ClassifierMenggunakan Euclidean Distance dan Manhattan Distance
untuk Klasifikasi Multispektral Tutupan Lahan
Syamani a)
a) Fakultas Kehutanan Universitas Lambung MangkuratJl. A. Yani, Km. 35, Banjarbaru, Kode Pos 70714
email: syamani [email protected]
Ringkasan
This research is based on the fact that K-Nearest Neighbour Classifier algorithm has amain limitation in classification processing time. One of solution to solve this limitation isto modify the distance measure algorithm in K-Nearest Neighbour Classifier. Commonly,K-Nearest Neighbour Classifier using Euclidean Distance. But, another distance measu-re algorithm, such as Manhattan (City Block) Distance was capable to replace EuclideanDistance. Manhattan Distance has simpler formula than Euclidean Distance, which can in-dicate more efficient classification processing time. The aims of this research are to modifythe distance measure method in K-Nearest Neighbour Classifier using Euclidean Distanceand Manhattan Distance, and then compare the accuracy and eficiency of these algorithmin landcover multispectral classification using digital satellite imagery.
K-Nearest Neighbour Classifier algorithm has been implemented using Interactive DataLanguage (IDL) in order to become an integrated tool in digital image processing software.More than 300 lines code has been written to transform K-Nearest Neighbour Classifier al-gorithm become an interactive Graphical User Interface tool. The implementation result ofK-Nearest Neighbour Classifier algorithm has been tested on various dimensions of multispe-ctral Landsat ETM+ imagery, with 5, 10 and 15 landcover classes. The classification resultsof K-Nearest Neighbour Classifier algorithm accuracy then have had tested using ConfusionMatrix method. Furthermore, the classification processing time had also been tested tosee the efficiency of Euclidean Distance and Manhattan Distance in K-Nearest NeighbourClassifier.
The classification results have shown that Euclidean Distance accuracy was generallymore accurate than Manhattan Distance. But, in several cases, Manhattan Distance canalso more accurate than Euclidean Distance. The different of the accuracy between Eucli-dean Distance and Manhattan Distance was decrease when image dimension and number oflandcover classes increase (Manhattan Distance ability was closely to Euclidean Distance).But, the different of the classification processing time of these both algorithm was increasewhen image dimension and number of landcover classes increase. Certainly, Manhattan Dis-tance was always more efficient than Euclidean Distance. This research has also shown thatas a machine learning algorithm, K-Nearest Neighbour Classifier was very sensitive to pixelnumber in training area. A little difference of pixel number in training area can result alarge difference in classification output. Thus, K-Nearest Neighbour Classifier was absolutlyneed an optimal sampling design.
1 Pendahuluan
Sejauh ini, sejumlah metode komputasi statistik telah diperkenalkan untuk mengekstrak infor-masi tutupan lahan secara digital dari citra penginderaan jauh. Beberapa di antaranya mampubekerja tanpa didasarkan pada training area (unsupervised classification), akan tetapi beberapametode menuntut adanya daerah sampel atau training area untuk mengekstrak informasi tu-tupan lahan tersebut, metode seperti ini disebut supervised classification. Algoritma supervisedclassification terlebih dahulu mengidentifikasi daerah sampel sebelum melakukan penunjukkan
1

kelas. Dalam proses identifikasi daerah-daerah sampel ini, sebagian algoritma akan mengam-bil beberapa parameter statistik tertentu dari masing-masing kelas daerah sampel, seperti nilairata-rata, variasi, dan sebagainya. Algoritma-algoritma seperti ini dikenal sebagai algoritma kla-sifikasi parametrik (parametric classifier). Namun demikian, juga terdapat beberapa algoritmastatistik yang sama sekali tidak mengambil parameter apa-apa dari daerah sampel yang telahditentukan. Algoritma-algoritma seperti ini dikenal sebagai algoritma klasifikasi non-parametrik(non-parametric classifier).
Algoritma klasifikasi parametrik biasanya disertai dengan sejumlah asumsi tertentu, yang se-penuhnya telah ditentukan sebelum proses klasifikasi berlangsung. Misalnya sebagian classifierberasumsi bahwa data (nilai spektral) homogen atau terdistribusi menurut pola tertentu. Dika-renakan algoritma klasifikasi parametrik berdasarkan atas asumsi tertentu yang dibuat sebelumproses klasifikasi, algoritma-algoritma ini dinilai memiliki keterbatasan jika kemudian asumsiyang digunakan tidak sesuai dengan keadaan atau kondisi data yang sebenarnya. Sejumlah ahlipenginderaan jauh menyatakan bahwa seringkali asumsi dasar yang digunakan oleh algoritmaklasifikasi parametrik tertentu tidak sesuai dengan kondisi data yang sebenarnya.
Lu et. al. (2003) mengemukakan sebuah pernyataan yang mengindikasikan keterbatasan bebe-rapa algoritma klasifikasi parametrik yang berasumsi data/nilai spektral terdistribusi normal,”However, MLC (Maximum Likelihood Classifier) and FLD (Fisher Linear Discriminant atauMahalanobis Distance) assume that the histograms of the classes are normally distributed andsuch assumptions are not always true”. Brown et. al. (2006) juga mengemukakan pernyataanserupa, ”Limitations to the ML (Maximum Likelihood) approach include the assumptions thatdata distribution is Gaussian and data layers are not correlated”.
Algoritma klasifikasi non-parametrik dinilai lebih siap untuk dihadapkan pada berbagai kondisidata (nilai spektral). Algoritma klasifikasi non-parametrik memiliki asumsi dasar yang relatiflebih sedikit dibandingkan algoritma klasifikasi parametrik, lebih jauh lagi algoritma ini tidakmemerlukan parameter statistik tertentu dari daerah sampel, seperti rata-rata atau variasi.Dalam proses klasifikasi, metode klasifikasi non-parametrik akan mempelajari dan menggunakansetiap pixel yang berada di bawah daerah sampel sebagai dasar dalam penunjukan kelas. Metodeseperti ini sering dikenal sebagai machine learning.
Salah satu algoritma klasifikasi non-parametrik yang memiliki formulasi statistik paling seder-hana dan paling mudah diimplementasikan adalah K-Nearest Neighbour Classifier (KNN Clas-sifier). K-Nearest Neighbour Classifier berasumsi bahwa pixel-pixel yang saling berdekatan satusama lain (dikenal sebagai pixel-pixel bertetangga) di dalam feature space akan tergolong kedalam kelas yang sama (Richards and Jia, 2006). Dalam proses klasifikasinya, K-Nearest Nei-ghbour Classifier akan mengukur jarak spektral (spectral distance) setiap pixel yang ada padacitra terhadap pixel-pixel yang berada di bawah daerah sampel. Fungsi diskriminan K-NearestNeighbour Classifier sendiri diformulasikan sebagai berikut (Richards and Jia, 2006):
gi(x) =
∑kij=11/d(x, xj
i )∑Mi=1
∑kij=1 1/d(x, xj
i ), x ∈ ωi jika gi(x) > gj(x),∀ 6= i (1)
d(x, x′i) (2)
adalah jarak spektral suatu nilai pixel ke nilai pixel tetangganya. ki menyatakan jumlah pixel
2

sampel pada kelas yang ke i dan
M∑i=1
ki = K (3)
, dan M adalah jumlah kelas.
Seperti algoritma-algoritma machine learning lainnya, K-Nearest Neighbour Classifier dihadap-kan pada satu masalah utama, yaitu lamanya waktu proses klasifikasi. Hal ini dikarenakanK-Nearest Neighbour Classifier mengukur jarak spektral setiap pixel ke semua pixel yang adadalam daerah sampel. Waktu proses klasifikasi akan semakin lama seiring semakin banyaknyajumlah saluran (band), bertambah besarnya ukuran daerah sampel dan bertambahnya jumlahkelas yang akan diklasifikasikan. Seperti yang diungkapkan oleh Richards and Jia (2006) ”...that(K-Nearest Neighbour Classifier) requires an impractically high computational load, especiallywhen the number of spectral bands and/or the number of training samples is large”.
Kemungkinan metode yang dapat dilakukan untuk mengefisiensikan waktu eksekusi K-NearestNeighbour Classifier adalah dengan memodifikasi algoritma pengukur jarak spektral pada algo-ritma ini. Umumnya K-Nearest Neighbour Classifier menggunakan Euclidean Distance sebagaimetode pengukur jarak spektral (Richards and Jia, 2006). Akan tetapi, metode pengukur jarakspektral lainnya seperti Manhattan Distance juga dapat digunakan dalam K-Nearest NeighbourClassifier. Manhattan Distance memiliki bentuk formulasi yang lebih sederhana dibandingkandengan Euclidean Distance. Dilihat dari bentuk persamaan matematisnya, sudah dapat dip-rediksi bahwa algoritma pengukur jarak spektral ini akan memiliki waktu kalkulasi yang lebihcepat dibanding Euclidean Distance. Meskipun demikian, tentunya akurasi hasil klasifikasinyamasih perlu dipertanyakan.
Euclidean Distance atau terkadang juga disebut L2 Distance, ada juga yang menyebutnya Eu-clidean Metric memiliki bentuk persamaan sebagai berikut (Landgrebe, 2003; Folio, 2008):
d(x, xji ) =
√√√√ n∑i=0
(x− xji )2 (4)
Euclidean Distance pada dasarnya merupakan bentuk perluasan dari Teorema Pythagoras padadata multidimensional. Persamaan Euclidean Distance di atas juga dapat ditransformasi kedalam persamaan vektor berikut (Richards and Jia, 2006):
d(x, xji ) =
√(x− xj
i )t(x− xji ) (5)
Manhattan Distance atau terkadang juga disebut L1 Distance, nama lainnya adalah City BlockDistance atau Rectilinear Distance diformulasikan ke dalam bentuk persamaan berikut (Lan-dgrebe, 2003; Folio, 2008):
d(x, xji ) =
n∑i=0
∣∣∣x− xji
∣∣∣ (6)
3

Gambar 1: Ilustrasi perbedaan Euclidean Distance dan Manhattan Distance
2 Maksud dan tujuan
Tujuan penelitian eksperimental ini adalah memodifikasi algoritma K-Nearest Neighbour Classi-fier menggunakan algoritma pengukur jarak Euclidean Distance dan Manhattan Distance, kemu-dian membandingkan akurasi dan efisiensi waktu proses klasifikasi digital tutupan lahan antaraK-Nearest Neighbour Classifier yang menggunakan Euclidean Distance dan yang menggunakanManhattan Distance. Hasil penelitian ini diharapkan mampu memberikan gambaran menge-nai perbandingan kemampuan, khususnya akurasi dan efisiensi algoritma K-Nearest NeighbourClassifier dengan menggunakan Euclidean Distance dan Manhattan Distance.
3 Metode penelitian
Algoritma K-Nearest Neighbour Classifier diimplementasikan menggunakan bahasa pemrogram-an berorientasi objek ENVI Interactive Data Language (ENVI IDL), sehingga menjadi sebuahperangkat lunak (tool) yang terintegrasi dengan software pengolah citra digital ENVI. Lebih dari300 baris kode program ditulis untuk mentransformasi persamaan K-Nearest Neighbour Clas-sifier menjadi sebuah perangkat lunak antarmuka grafis (Graphical User Interface) interaktif.Perangkat lunak hasil implementasi K-Nearest Neighbour Classifier diujicoba pada subset Ci-tra Landsat ETM+ multispektral (daerah Kota Semarang dan sekitarnya), path/row: 120/065,level 1 G, dengan tanggal perekaman 20 Mei 2003.
Pertimbangan utama yang dijadikan dasar dalam pemilihan lokasi penelitian adalah variasikenampakan tutupan lahan (landcover). Daerah Kota Semarang dan sekitarnya (yang termasukdalam scene Landsat ETM+ path/row: 120/065) memperlihatkan variasi kenampakan tutupanlahan yang sangat variatif, dan masing-masing karakter atau tipe tutupan lahan memiliki luasanwilayah yang relatif kecil. Topografi, aksesibilitas wilayah, dan kondisi atmosferik juga dijadikanbahan pertimbangan dalam pemilihan lokasi penelitian. Gangguan atmosferik seperti awansangat berpengaruh terhadap hasil klasifikasi. Oleh karena itu, dalam penelitian ini sengajadipilih subset citra yang memiliki gangguan atmosferik paling minimum.
Pengujian K-Nearest Neighbour Classifier untuk kedua algoritma pengukur jarak spektral di-lakukan pada beberapa variasi dimensi citra. Dimensi citra yang ditentukan adalah 500x500pixel, 1.000x1.000 pixel, dan 2.000x2.000 pixel (dengan jumlah saluran tetap sama). Jumlahkelas tutupan lahan (landcover) yang diklasifikasikan juga dibuat bervariasi, yaitu 5 kelas, 10
4

kelas dan 15 kelas tutupan lahan. Pembuatan daerah sampel (training area) untuk klasifikasidan untuk uji akurasi hasil klasifikasi dilakukan berdasarkan data hasil survey lapangan (gro-und check) yang dilakukan pada tanggal 20, 22 dan 23 Maret 2008. Uji akurasi hasil klasifikasidilakukan menggunakan metode Confusion Matrix (Rossiter, 2004), dan uji efisiensi (lamanyawaktu proses klasifikasi) dinyatakan dalam satuan detik.
Eksekusi algoritma dijalankan pada mesin (portable computer) dengan konfigurasi Intel CentrinoCore 2 Duo T5750 2.00 GHz (L2 Cache 2 MB), Memory 2 GB DDR2, SATA Harddisk 5.400rpm (200 GB), Sistem Operasi Genuine Microsoft Windows Vista Home Basic. Perangkatlunak pengolah citra (image processing software) yang digunakan adalah ENVI 4.5, bahasapemrograman yang digunakan untuk implementasi algoritma K-Nearest Neighbour Classifiersendiri adalah Interactive Data Language (IDL) versi 6.4.1.
4 Hasil dan Pembahasan
Hasil uji akurasi klasifikasi K-Nearest Neighbour Classifier menggunakan Euclidean Distance danManhattan Distanvce, pada berbagai dimensi citra dan jumlah kelas tutupan lahan selengkapnyadapat dilihat pada Tabel 1 berikut:
Tabel 1. Perbandingan Akurasi Keseluruhan (dan Koefisian Kappa)
Secara umum, K-Nearest Neighbour Classifier yang menggunakan metode pengukur jarak Eu-clidean Distance memiliki akurasi keseluruhan (overall accuracy) yang lebih tinggi dari padaManhattan Distance. Akurasi keseluruhan tertinggi dicapai pada dimensi citra 1.000x1.000 pi-xel dengan 5 (lima) kelas tutupan lahan. Akan tetapi, pada dimensi citra 1.000x1.000 pixelterjadi hal yang cukup mengejutkan, yaitu akurasi keseluruhan K-Nearest Neighbour Classifieryang menggunakan Manhattan Distance lebih tinggi dari Euclidean Distance. Akurasi keselu-ruhan yang dihasilkan Manhattan Distance untuk dimensi citra 1.000x1.000 pixel adalah 99,7852untuk 5 (lima) kelas tutupan lahan dan 94,4655 untuk 10 (sepuluh) kelas tutupan lahan, se-
5
mentara Euclidean Distance 99,6778 untuk 5 (lima) kelas tutupan lahan dan 93,9348 untuk 10(sepuluh) kelas tutupan lahan. Hal ini menunjukkan bahwa metode pengukur jarak spektralEuclidean Distance, yang merupakan metode pengukur jarak dalam arti yang sebenarnya (jaraklurus) (”The Euclidean distance or Euclidean metric is the ”ordinary” distance between twopoints that one would measure with a ruler,...” (Folio, 2008)) tidak selalu memberikan hasilyang lebih baik, khususnya jika dibandingkan dengan Rectilinear (Manhattan) Distance. De-ngan kata lain, output klasifikasi yang dihasilkan oleh K-Nearest Neighbour Classifier denganpengukur jarak Euclidean Distance dan Manhattan Distance masih sangat kondisional dari segiakurasi.
Di samping itu, perbedaan akurasi keseluruhan antara metode pengukur jarak Euclidean Dis-tance dan Manhattan Distance tidak terlalu jauh. Perbedaan akurasi seperti ini tidak terlaluberpengaruh terhadap kenampakan peta yang dihasilkan. Kita dapat melihatnya dari peta ha-sil klasifikasi kedua metode pengukur jarak ini, tidak ada perbedaan kenampakan yang sangatsignifikan pada kedua algoritma pengukur jarak ini. Hasil uji akurasi menunjukkan, bahwaperbedaan terbesar akurasi keseluruhan antara Euclidean Distance dan Manhattan Distanceterjadi pada dimensi citra terkecil dan jumlah kelas paling sedikit. Semakin besar dimensi citradan semakin banyak jumlah kelas justru perbedaan akurasi keseluruhan ini relatif tidak terla-lu signifikan. Kondisi di atas ternyata berkebalikan dengan lamanya waktu proses klasifikasi,sebagaimana terlihat pada Tabel 2 dan Gambar 2 di bawah.
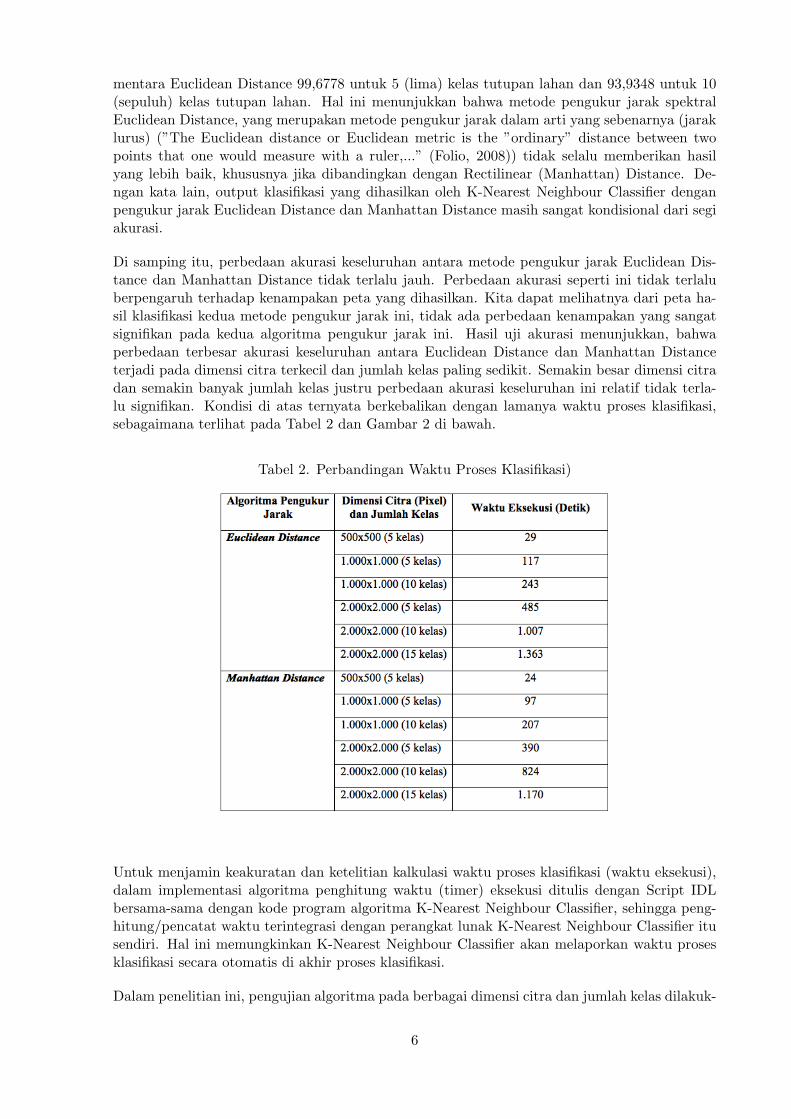
Tabel 2. Perbandingan Waktu Proses Klasifikasi)
Untuk menjamin keakuratan dan ketelitian kalkulasi waktu proses klasifikasi (waktu eksekusi),dalam implementasi algoritma penghitung waktu (timer) eksekusi ditulis dengan Script IDLbersama-sama dengan kode program algoritma K-Nearest Neighbour Classifier, sehingga peng-hitung/pencatat waktu terintegrasi dengan perangkat lunak K-Nearest Neighbour Classifier itusendiri. Hal ini memungkinkan K-Nearest Neighbour Classifier akan melaporkan waktu prosesklasifikasi secara otomatis di akhir proses klasifikasi.
Dalam penelitian ini, pengujian algoritma pada berbagai dimensi citra dan jumlah kelas dilakuk-
6
an atas dasar asumsi bahwa semakin besar dimensi citra, maka intensitas kehadiran atau jumlahkelas tutupan lahan akan semakin banyak. Dan pada kenyataannya, dalam konteks penelitianini memang terjadi seperti itu. Terlalu sulit untuk membuat 15 (lima belas) kelas tutupan lahanpada dimensi citra (Landsat ETM+) 500x500 pixel. Jika dipaksakan maka hasilnya tidak sepertiyang diharapkan (omission error dan commission error menjadi sangat besar).
Sejalan dengan hal itu, penelitian ini menunjukkan bahwa sebagai algoritma non-parametrikyang menggunakan teknologi machine learning, K-Nearest Neighbour Classifier sangat sensitifterhadap perbedaan dimensi training area (jumlah pixel sampel) per kelas. Kondisi sepertiini relatif tidak ditemukan pada algoritma parametrik seperti Maximum Likelihood. Pada K-Nearest Neighbour Classifier, perbedaan jumlah pixel sampel per kelas sangat berpengaruh padaoutput klasifikasi. Jumlah pixel sampel suatu kelas yang lebih banyak dari kelas-kelas lannya,meskipun hanya lebih banyak 50 pixel, maka kelas itu akan mendominasi peta hasil klasifikasi(commission error untuk kelas itu akan sangat besar). Sehingga K-Nearest Neighbour Classifierbenar-benar memerlukan sebuah desain sampel yang optimal, dimana jumlah pixel sampel antarkelas relatif harus seragam. Dalam penelitian ini, jumlah pixel sampel per kelas untuk klasifikasidiusahakan berkisar 50 pixel, sementara pixel sampel untuk uji akurasi berada pada kisaran 100hingga 150 pixel per kelas tutupan lahan.
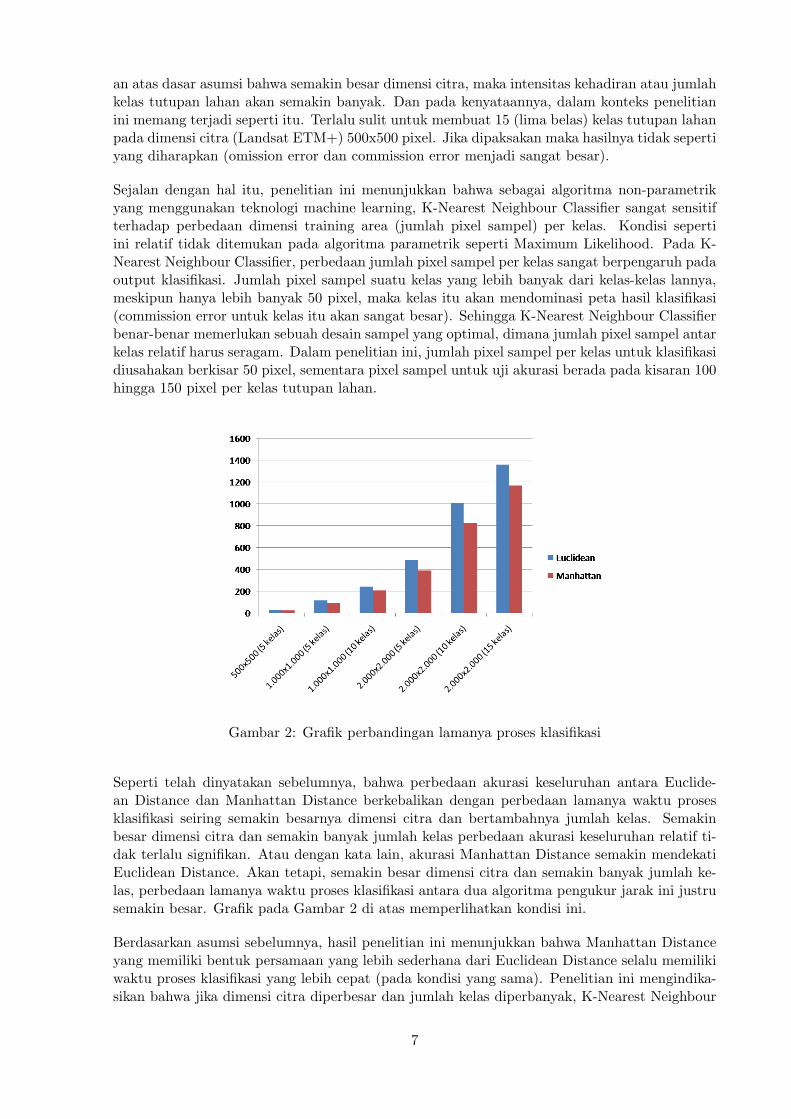
Gambar 2: Grafik perbandingan lamanya proses klasifikasi
Seperti telah dinyatakan sebelumnya, bahwa perbedaan akurasi keseluruhan antara Euclide-an Distance dan Manhattan Distance berkebalikan dengan perbedaan lamanya waktu prosesklasifikasi seiring semakin besarnya dimensi citra dan bertambahnya jumlah kelas. Semakinbesar dimensi citra dan semakin banyak jumlah kelas perbedaan akurasi keseluruhan relatif ti-dak terlalu signifikan. Atau dengan kata lain, akurasi Manhattan Distance semakin mendekatiEuclidean Distance. Akan tetapi, semakin besar dimensi citra dan semakin banyak jumlah ke-las, perbedaan lamanya waktu proses klasifikasi antara dua algoritma pengukur jarak ini justrusemakin besar. Grafik pada Gambar 2 di atas memperlihatkan kondisi ini.
Berdasarkan asumsi sebelumnya, hasil penelitian ini menunjukkan bahwa Manhattan Distanceyang memiliki bentuk persamaan yang lebih sederhana dari Euclidean Distance selalu memilikiwaktu proses klasifikasi yang lebih cepat (pada kondisi yang sama). Penelitian ini mengindika-sikan bahwa jika dimensi citra diperbesar dan jumlah kelas diperbanyak, K-Nearest Neighbour
7

Classifier yang menggunakan metode pengukur jarak Manhattan Distance akan semakin opti-mal. Dalam batasan, waktu proses klasifikasi yang semakin cepat dan perbedaan akurasi tidakterlalu besar (kemampuan Manhattan Distance semakin mendekati Euclidean Distance).
Jika kita mendasarkan evaluasi efisiensi waktu proses klasifikasi pada asumsi yang dinyatakansebelumnya, bahwa semakin besar dimensi citra maka intensitas kehadiran atau jumlah kelastutupan lahan akan semakin banyak, maka kenaikan waktu proses klasifikasi yang terjadi meng-ikuti pola yang tidak linier, melainkan lebih mendekati pola eksponensial. Hal ini terjadi baikpada Euclidean Distance maupun Manhattan Distance. Grafik perbandingan lamanya prosesklasifikasi (Gambar 2) di atas dengan jelas menunjukkan hal ini. Bahkan jika kita berasumsibahwa jumlah kelas tidak terpengaruh oleh dimensi citra, maka kenaikan waktu proses klasifi-kasi masih cenderung mendekati pola eksponensial dari pada linier. Hal ini dapat dilihat padakenampakan grafik 3 (tiga) variasi dimensi citra dengan 5 (lima) kelas tutupan lahan pada Gam-bar 2 di atas. Akan tetapi, jika dimensi citra sama tetapi jumlah kelas berbeda, maka kenaikanwaktu proses klasifikasi cenderung linier. Hal ini dapat dilihat pada kenampakan grafik dimensicitra 2.000x2.000 pixel dengan jumlah kelas 5, 10, dan 15 pada Gambar 2 di atas.sectionKesimpulan dan Saran Secara umum, K-Nearest Neighbour Classifier yang menggunak-an Euclidean Distance memiliki akurasi yang lebih tinggi dari pada Manhattan Distance. Akantetapi, pada beberapa kondisi Manhattan Distance ternyata juga mampu lebih akurat dari padaEuclidean Distance. Hasil penelitian menunjukkan bahwa semakin besar dimensi citra dan sema-kin banyak jumlah kelas, kemampuan Manhattan Distance akan semakin mendekati EuclideanDistance dari segi akurasi. Hal ini berkebalikan dengan lamanya waktu proses klasifikasi. Se-makin besar dimensi citra dan semakin banyak jumlah kelas, perbedaan waktu proses klasifikasiantara Euclidean Distance dan Manhattan Distance justru semakin besar. Dimana ManhattanDistance selalu lebih efisien (lebih cepat) dari pada Euclidean Distance.
Kenaikan waktu proses klasifikasi K-Nearest Neighbour Classifier jika didasarkan pada perubah-an dimensi citra, cenderung lebih mengikuti pola eksponensial dari pada linier. Akan tetapi, jikadidasarkan pada perubahan jumlah kelas tanpa merubah dimensi citra, kenaikan waktu prosesklasifikasi ini cenderung lebih mendekati linier. Penelitian ini juga menunjukkan bahwa sebagaialgoritma non-parametrik yang menggunakan teknologi machine learning, ternyata K-NearestNeighbour Classifier sangat sensitif terhadap jumlah pixel sampel. Perbedaan jumlah pixel sam-pel yang tidak terlalu signifikan akan membawa kepada perbedaan hasil klasifikasi yang cukupsignifikan. Oleh karena itu, K-Nearest Neighbour Classifier benar-benar memerlukan sebuahdesain sampel yang optimal, dimana jumlah pixel sampel yang relatif seragam.
Uji coba algoritma K-Nearest Neighbour Classifier dalam penelitian ini masih terbatas pada satujenis citra, dengan satu karakter resolusi spasial dan resolusi spektral. Selain itu, uji coba padavariasi jumlah pixel sampel per kelas juga tidak di lakukan. Ke depannya perlu dipertimbangkanuntuk menguji kembali algoritma K-Nearest Neighbour Classifier ini pada berbagai jenis citradan variasi jumlah pixel sampel. Terkait dengan objektifitas hasil klasifikasi, untuk selanjutnyajuga perlu dipertimbangkan untuk menambahkan logika thresholding (dalam konteks K-NearestNeighbour Classifier berarti pembatasan jarak spektral) pada algoritma ini.
Pustaka
[1] Brown, K.M., Foody, G.M. and Atkinson, P.M. . 2006, Deriving Thematic Uncertain-ty Measures in Remote Sensing using Classification Outputs, 7th International Symposi-um on Spatial Accuracy Assessment in Natural Resources and Environmental Sciences.http://www.spatial-accuracy.org
8

[2] Folio, E. . 2008, Distance Transform, Technical Report no0806, June 2008, revision 1748,Laboratoire de Recherche et Dveloppement de l’Epita. Le Kremlin-Bictre cedex - France,http://www.lrde.epita.fr
[3] Landgrebe, D.A. . 2003, Signal Theory Methods in Multispectral Remote Sensing, JohnWiley & Sons, Inc. Hoboken, New Jersey
[4] Lu, D., Mausel, P., Batistella, M. and Moran, E. . 2003, Comparison of Land-CoverClassification Methods in The Brazilian Amazon Basin, ASPRS 2003 Annual ConferenceProceedings. http://www.asprs.org
[5] Richards, J.A. and Jia, X. . 2006, Remote Sensing Digital Image Analysis: An Introduction(Fourth Edition), Springer-Verlag. Berlin
[6] Rossiter, D.G. . 2004, Technical Note: Statistical Methods for Accuracy Assesment ofClassified Thematic Maps, Department of Earth Systems Analysis, International Institutefor Geo-information Science and Earth Observation (ITC). Enschede
9
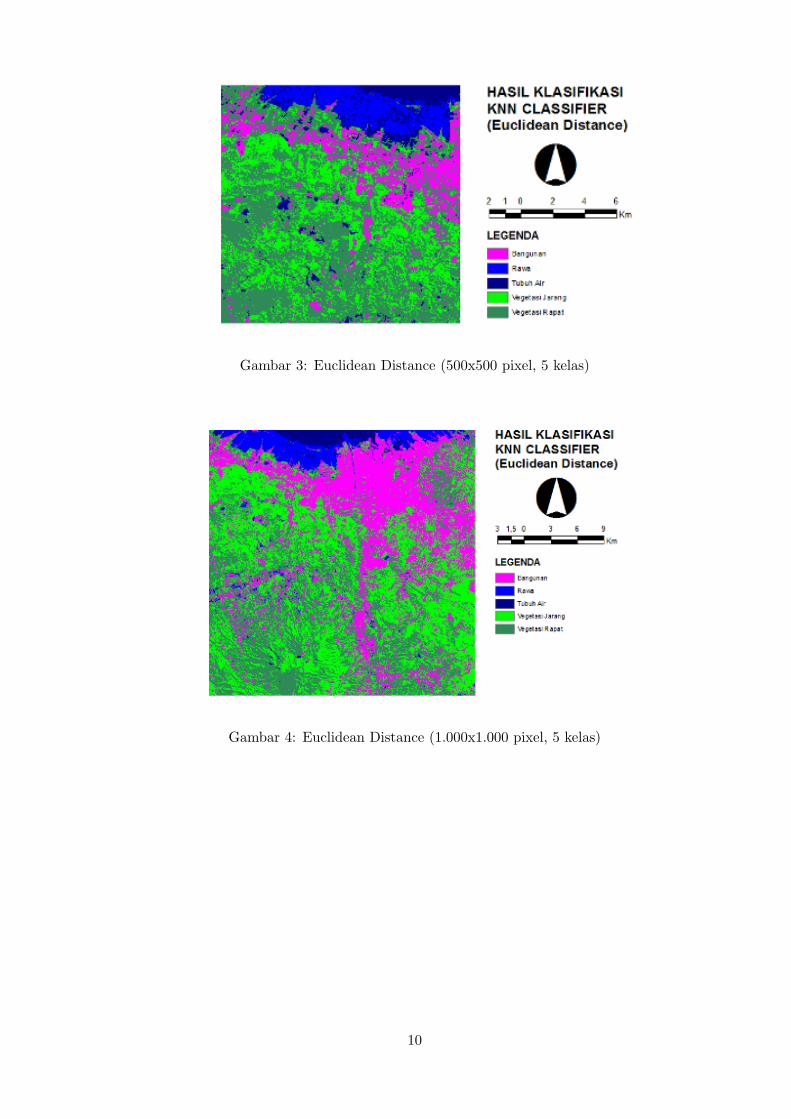
Gambar 3: Euclidean Distance (500x500 pixel, 5 kelas)
Gambar 4: Euclidean Distance (1.000x1.000 pixel, 5 kelas)
10
Gambar 5: Euclidean Distance (1.000x1.000 pixel, 10 kelas)
Gambar 6: Euclidean Distance (2.000x2.000 pixel, 5 kelas)
11

Gambar 7: Euclidean Distance (2.000x2.000 pixel, 10 kelas)
Gambar 8: Euclidean Distance (2.000x2.000 pixel, 15 kelas)
12
Gambar 9: Manhattan Distance (500x500 pixel, 5 kelas)
Gambar 10: Manhattan Distance (1.000x1.000 pixel, 5 kelas)
13
Gambar 11: Manhattan Distance (1.000x1.000 pixel, 10 kelas)
Gambar 12: Manhattan Distance (2.000x2.000 pixel, 5 kelas)
14

Gambar 13: Manhattan Distance (2.000x2.000 pixel, 10 kelas)
Gambar 14: Manhattan Distance (2.000x2.000 pixel, 15 kelas)
15





























