Embed Size (px)
Citation preview

Knowledge Extraction System from Unstructured Documents
T. Rodríguez, J. Aguilar, Member, IEEE
Abstract. This paper designs and implements a system of
knowledge extraction from unstructured documents in HyperText Markup Language (HTML) format. Basically, the system transforms the content of a text that is in natural language, in structured and organized knowledge, semantically described (Semantic Ontology). Therefore, it is proposed to generate a semantic knowledge based on the extraction of entities and relationships, where entities are something about we can say something, and the relationships are the interactions between the entities. From this model of semantic knowledge, it is possible to infer new knowledge, such as lexicons, taxonomies and databases, with specialized terminology. The system can be used by any application of semantic processing, in its enrichment processes of information and knowledge.
Keywords. Natural Language Processing, Knowledge
Extraction, Semantic Ontology, Semantic Knowledge.
I. INTRODUCCIÓN N la actualidad, existe un gran número de documentos en lenguaje natural, los cuales tienen un gran contenido semántico. Esos documentos, en su gran mayoría, son
generados, almacenados y transmitidos con rapidez a través de Internet. De esta manera, existe una gran cantidad de información no estructurada. Esa información se puede estructurar y organizar semánticamente. La importancia de estructurar y organizar la información, es porque se convierte en conocimiento en un contexto dado. Por ejemplo, el contenido de los documentos no estructurados es interpretado naturalmente por los seres humanos, ya que son capaces de extraer conocimientos a partir de ellos.
El objetivo principal de este trabajo es organizar la información que se encuentre en un texto en formato HTML, para que sea útil en un contexto dado. Es decir, la idea es generar conocimiento semántico a partir de documentos no estructurados, entendiendo por conocimiento semántico a las entidades y relaciones que se encuentran en el texto.
En ese sentido, en este trabajo se propone un sistema para extraer el conocimiento de las entidades y relaciones que están presentes en los documentos no estructurados, de tal manera de poder ser usados por cualquier sistema de procesamiento semántico. El sistema se basa en una ontología semántica, tal que el conocimiento extraído sea organizado ella. La ontología semántica se expresa en los lenguajes Resource Description Framework (RDF) y Ontology Web Language (OWL), y sus instancias representan todo el conocimiento extraído de la colección de documentos. Con esa ontología se pueden hacer procesos de razonamiento, para inferir nuevos conocimientos para generar lexicones, taxonomías, entre otras cosas [14].
T.R. and J. A. Universidad de Los Andes, Facultad de Ingeniería, Escuela de Ingeniería de Sistemas, CEMISID, Mérida, E-mail: [email protected]. and Universidad Autónoma de Chile, Santiago, Chile.
Algunos ejemplos de sistema de procesamiento semántico que podrían usar este servicio son el Marco Ontológico Semántico Dinámico [4, 5, 12], sistemas de Aprendizaje de Ontologías a partir de textos en español, sistemas que generen lexicones computacionales en español, entre otros.
Este sistema se apoya en herramientas de Procesamiento de Lenguaje Natural para su implementación. Además, organiza el conocimiento extraído desde textos no estructurados semánticamente, en un tipo de datos abstracto que llamamos grafo de aprendizaje.
Este trabajo está organizado de la siguiente manera. En la sección II se presentan trabajos previos similares a los nuestros. En la siguiente sección III se presentan los fundamentos teóricos. En la sección IV se presenta el esquema general propuesto del sistema de extracción de conocimiento desde texto no estructurado. En la sección V se presentan varios casos de estudios y se analizan los resultados; y en la sección VI se presentan las conclusiones y los trabajos futuros.
II. ARQUITECTURA BÁSICA DE LOS SISTEMAS DE EXTRACCIÓN DE INFORMACIÓN BASADO EN ONTOLOGÍAS En el ámbito de la extracción de conocimiento existe un
sub-campo basado en ontologías, donde las ontologías son usadas para el proceso de extracción de la información, y también, la salida del proceso es presentada a través de ellas [1, 7, 8]. En [2] presentan la arquitectura de tales sistemas, en un alto nivel de abstracción, la cual está compuesta por un componente de Pre-procesamiento, otro que realiza tareas de Extracción de Información (EI), tales como de reconocimiento de Entidades con nombre (de personas, lugares, entre otros), clasificación de subcadenas de texto, reconocimiento de las relaciones entre entidades, entre otras [2, 9, 10]; otro que es un Lexicón semántico, cuyo objetivo es definir las palabras validas del lenguaje, y un Sistema de Gestión de Ontologías, para editarlas, modificarlas, generarlas y usarlas.
La salida del sistema consiste en la información extraída del texto, que puede estar representada usando una ontología, definida en OWL, por ejemplo. El sistema de extracción de información basado en ontologías propuesto en [2], procesa texto estructurado o no en lenguaje natural, a través de mecanismos guiados por ontologías.
En [3] presentan un método para la extracción de información estructurada desde texto, para el procesamiento de textos en diferentes formatos. Ellos combinan el análisis sintáctico con el análisis de dependencias, para el reconocimiento de entidades, de patrones lingüísticos, entre otros, almacenados en un corpus de Mapas Conceptuales (MC), que es una herramienta para organizar y representar el conocimiento en forma de grafo dirigido etiquetado [3]. Ese sistema, además de reconocer entidades, identifica frases
E
IEEE LATIN AMERICA TRANSACTIONS, VOL. 16, NO. 2, FEB. 2018 639

conceptuales y relaciones entre ellas, las cuales también son representadas en el MC. Por otro lado, OpenCALAIS es un servicio Web que recibe un texto en inglés, y entrega información semántica contenida en el texto en formato RDF [15]. El servicio busca en el texto las entidades, hechos y eventos, y luego los los devuelve en RDF.
III. ESQUEMA GENERAL DE NUESTRO SISTEMA DE EXTRACCIÓN DE CONOCIMIENTO PARA EN TEXTO NO
ESTRUCTURADO A continuación se describe el sistema propuesto en este
trabajo. El procesamiento de texto no estructurado se apoya en los siguientes recursos lingüísticos: lexicones,
diccionarios, corpus y Onomásticon. En la Fig. 1 se presenta el esquema general, cuya entrada es el texto a procesar, y usando los recursos lingüísticos, se genera el grafo de aprendizaje.
Nuestro sistema se diferencia de los trabajos anteriores en cuanto a que es independiente del idioma, reconoce los conceptos por sus acrónimos, es un sistema que puede ser usado como un servicio de acceso libre, genera un grafo cuya información esta representa en RDF, y el servicio puede ser usado por diferentes tipos de sistemas, tales como un generador de base terminológicas o taxonomías, un sistema de actualización de lexicones, entre otros.
Figure 1. Esquema General del procesamiento.
En particular, el proceso de Extracción de Conocimiento se centra en la extracción de entidades y relaciones que se encuentran en los textos de entrada. En específico, los recursos usados son el lexicón, el cual es una ontología de términos del lenguaje español donde se encuentra toda la información morfológica del término, y un Onomásticon, el cual es una ontología de nombres propios utilizados en los diferentes dominios. También, el corpus utilizado es CONLL-2002 (Conference on Computational Natural Language Learning) para el español [13], y el diccionario Online WordReference [16]. Una vez realizado el proceso de Extracción de entidades y relaciones, el resultado se almacena en un grafo de aprendizaje. Pasemos a describir los componentes principales.
A. Modelo Conceptual del Sistema de Tratamiento de Texto El esquema conceptual de todos los elementos
involucrados en el tratamiento del texto que se propone, se basa en la siguiente idea: “los sustantivos son las entidades y los verbos son los eventos, en las oraciones que conforman un texto”. A partir de allí, se define el esquema conceptual del Sistema de Tratamiento del texto (ver Fig. 3):
La interpretación del texto se inicia con el reconocimiento de los términos encontrados en el texto, los cuales pueden ser palabras simples (por ejemplo, universidad, Venezuela) o palabras compuestas (por ejemplo “Universidad de Los Andes”, “San Cristóbal”). Cada palabra simple tiene un lema
(por ejemplo, Universidad tiene como lema Universid). Además, tanto las palabras simples como compuestas tienen una Categoría (representa el tipo de la palabra, si es un verbo, un sustantivo, si el sustantivo es de tipo común (por ejemplo Universidad) o propio (representa los nombres propios, por ejemplo: Universidad de Los Andes), entre otras cosas. Por otro lado, cada una de estas entidades tiene una clasificación semántica (por ejemplo, personas, lugares y organizaciones). También, según la Fig. 2 el verbo es un evento, y los recursos lingüísticos usados son el lexicón y el Onomásticon.
B Formalización del Grafo de Aprendizaje El Grafo de Aprendizaje permite describir
ontológicamente (semánticamente) todo el conocimiento extraído desde el texto, basado en la hipótesis definida en la sección anterior. De esta manera, el Grafo de Aprendizaje es una ontología semántica, que permite describir el conocimiento contenido en un texto (colección de textos). Sus instancias serán ese conocimiento extraído desde el (los) texto(s). Para ello, el Grafo de Aprendizaje se basa en el esquema conceptual mostrado en la Fig. 2, y se define de la siguiente manera: un Grafo de Aprendizaje es una tupla (T, E), donde T es el conjunto de todos los conceptos involucrados en la caracterización de los términos encontrados en el texto, R es el conjunto de sus relaciones.
Para hacer ese proceso de caracterización de los términos en un texto, T contiene las siguientes clases (ver Fig. 3):
640 IEEE LATIN AMERICA TRANSACTIONS, VOL. 16, NO. 2, FEB. 2018

Figure 2. Esquema conceptual del Sistema de Tratamiento del texto
• Término Grafo: Representan todos los sustantivos y verbos que existen en el texto
• Palabra Simples: es una subclase del Término Grafo, que representa todas las palabras atómicas.
• Palabra Compuesta: es una subclase del término Grafo, que representa palabras compuestas por otras palabras.
• Categoría: Representa la categoría gramatical del término Grafo, y está compuesta por Sustantivo y Verbo.
• Entidad: representa las entidades de lugar o ubicación, organización, personas y otros.
• Eventos: representa a los verbos que ejecutan una acción entre las entidades.
• Lexicón: en este caso, el lexicón solo contiene los sustantivos que no son nombre propios.
• Onomásticon: representa todos los nombres propios encontrados en el texto.
Por otro lado, las relaciones entre esos conceptos son
(ver Fig. 4): • TieneGenero: indica si es femenino, masculino o neutro. • TieneNumero: indica si el término del árbol es uno o más
de uno. En específico, en español es singular o plural.
• TieneSemantica: representa la clasificación semántica del término del grafo (si es organización, persona, u otro)
• TieneTipo: representa el tipo del término (si es nombre común, nombre propio)
• esPalabraCompuesta: representa si el término está compuesto por varias palabras.
• esPalabraSimple: representa si el término es una sola palabra.
• esUn: representa si el término del árbol es un verbo • tieneModo: En el caso de que el término del grafo sea un
verbo, el modo se refiere a la actitud del hablante ante lo que dice. Hay tres modos verbales: Indicativo (por ejemplo, yo he llegado a la ciudad), Subjetivo (por ejemplo, quizás llegue a la ciudad), e Imperativo (por ejemplo, venid aquí).
Finalmente, la clase término grafo tiene un conjunto de
propiedades (ver Fig. 5): • tieneEtiquetaEAGLES: es una etiqueta que representa la
información morfológica del término en el Grafo de Aprendizaje. Sirve para la anotación morfosintáctica en los lexicones y corpus.
Figure 4 Las relaciones definidas en GA. Figure 3. Las clases definidas en GA.
RODRÍGUEZ AND AGUILAR : KNOWLEDGE EXTRACTION SYSTEM FROM UNSTRUCTURED 641

• tieneFrecuencia: representa el número de veces que se repite el término grafo en el texto que se procesa. Ella sirve para determina si el término es relevante o no.
• tieneNombre: representa el nombre del término en el Grafo de Aprendizaje.
De esta manera, cada instancia de la clase Término Grafo
se describe de acuerdo a sus características morfológicas. En la Fig. 6 se muestra un ejemplo completo de cómo quedaría la descripción de la clase término grafo, en este caso para el término Académico, el cual se describe de la siguiente manera: es una palabra simple, de tipo nombre propio, singular, masculino, tiene el lema académ, se repite en los documentos dos veces, y el nombre es Académico y posee la etiqueta eagles np00000.
C Proceso general de extracción de Entidades y Relaciones desde texto no estructurado
En la Fig. 7 se presenta el proceso general de extracción de entidades y relaciones en textos no estructurados. Dicho proceso usa el Grafo de Aprendizaje, que tiene por finalidad estructurar los términos del texto en un grafo. El proceso se divide en 3 pasos, y uno de ellos en 4 sub-procesos:
1. Separación del texto en Sentencias: este proceso consiste en dividir el texto en sentencias
2. Análisis de cada sentencia, según los siguientes pasos:
a. Reconocimientos de Nombres Propios: consiste en la detección y clasificación de los términos del texto, como nombres de personas, organizaciones, lugares, expresiones numéricas, de tiempo, de lugar, entre otros. En este proceso se utiliza como recursos lingüísticos el Onomásticon y Corpus. El reconocimiento de nombres propios puede arrojar palabras simples (como por ejemplo, Juan) o palabras compuestas (como por ejemplo, Universidad de Los Andes). Por ejemplo, la sentencia “La Universidad de los Andes es una Universidad pública”, identifica que Universidad de Los Andes es el nombre propio de Universidad.
b. Análisis Morfosintáctico: consiste en etiquetar las palabras de la sentencia con la información morfológica y sintáctica de ellas; es decir, cada una de las palabras de la sentencia se etiqueta según su categoría gramatical (verbos, sustantivos, entre otras categorías). Este proceso utiliza los recursos lingüísticos lexicón, Onomásticon y Corpus.
c. Reconocimiento de Entidades: en este proceso se extraen las palabras (tokens) etiquetadas como nombres propios y nombres comunes en la sentencia, en el análisis morfosintáctico. Ellas serán las entidades candidatas que serán usadas en el Grafo de Aprendizaje. En el reconocimiento de entidades simples se obtiene el lema de la entidad, el cual tiene como objeto normalizar las entidades (por ejemplo, las entidades simples Universitario y Universitarios tienen el lema Universitari, este lema representa el misma entidad)
d. Reconocimientos de Relaciones: en este proceso se extraen las palabras (tokens) tipo verbos de la sentencia, etiquetadas en el análisis morfosintáctico. Ellas son las relaciones candidatas que serán usadas por el Grafo de Aprendizaje.
3. Actualización de Grafo de Aprendizaje: En este proceso se actualizan todas las entidades y relaciones candidatas encontradas en el texto procesado, con sus respectivas relaciones y tipos de datos, en el Grafo de Aprendizaje. Esta fase tiene características específicas, que son indicadas en la siguiente sección.
Texto de Entrada
Separación de Sentencia
Fuentes de Conocimiento
diccionarioon-lineCorpus
Lexicón Onomasticon
Reconocimiento de Nombres Propios
Análisis morfosintactico
Reconocimientos de EntidadesActualización del
Grafo
Reconocimientos de Eventos
Grafo
Figure 7. Proceso de extracción de textos para instanciar el Grafo de Aprendizaje La implementación del sistema combina el uso de
distintas técnicas y herramientas de Procesamiento de Lenguaje Natural, por ejemplo la librería OpenNLP [17], Java Server Pages (JSP), y la librería Apache Jena.
Figure 6. Ejemplo de descripción de la clase Término Grafo instanciada en el término Académico.
Figure 5. Los tipos de datos definidos por defecto en el Grafo de Aprendizaje.
642 IEEE LATIN AMERICA TRANSACTIONS, VOL. 16, NO. 2, FEB. 2018

D Actualización del Grafo de Aprendizaje El paso anterior (análisis de cada sentencia) genera una
colección de palabras (tokens) en un dominio específico, en los cuales se han caracterizado las Entidades Candidatas, que son todos los sustantivos que se encuentran en los textos procesados, y las Relaciones Candidatas, que son todos los verbos que se encuentran en los textos procesados.
En este paso se seleccionan las entidades y relaciones relevantes, que deberán ser incorporadas al Grafo de Aprendizaje. Las Entidades Relevantes son todos los sustantivos que cumplen los criterios de relevancia, y las Relaciones Relevantes son todos los verbos que cumplen los criterios de relevancias. Para ello se proponen las siguientes medidas, que clasifican los términos en los documentos procesados como relevantes o no, basados en [11]: • tf (Frecuencia del término): es la frecuencia de un
término j. Es una medida de relevancia de un término en el Grafo de Aprendizaje. Si el término aparece muchas veces en el Grafo de Aprendizaje, el peso del término es alto. Donde, 〖tf〗_j=tieneFrecuencia_j
• fi (frecuencia inversa): o inverso de la frecuencia de documentos, refleja la importancia de los términos en los textos procesados, primando la precisión y el poder discriminatorio de los mismos. Así, dará mayor importancia a un término cuanto menor sea el número de texto procesados de la colección en los que aparezca dicho término. Fi se calcula como
• wj (peso del término j): indica que entre mayor es para un término j, es porque ese término es más relevante, ya que es muy frecuente y discriminante.
En concreto, el criterio utilizado para determinar si una Entidad o Relación es relevante es: será relevante si su peso es mayor o igual que el promedio de los pesos.
Para la evaluación del Grafo de Aprendizaje generado, se usan los siguientes criterios: • Uso correcto del lenguaje, el cual consiste en evaluar la
calidad del Grafo de Aprendizaje en cuanto a la manera como está escrito. En esta fase se codifico el Grafo de Aprendizaje con el lenguaje OWL-DL, el cual permite máxima expresividad. Una vez codificado. se utilizó el editor Protégé para verificar que el Grafo de Aprendizaje sea un código libre de errores.
• Exactitud de la estructura taxonómica, en esta fase se chequeo con el editor Protégé las inconsistencias, la completitud de conceptos y la existencia de redundancias en clases, instancias y relaciones. Para lograr esto, se realizó junto con el experto de dominio, las siguientes actividades: se observó la estructura jerárquica usada para representar el conocimiento, se visualizó las definiciones y las propiedades de los conceptos y sus relaciones semánticas, y por último, se visualizó las definiciones y las propiedades de las instancias.
Una vez obtenido el Grafo de Aprendizaje, se puede usar para varias cosas, como los casos de estudios de la sección V.
IV. CASO DE ESTUDIOS Y ANÁLISIS DE RESULTADOS
A Caracterización del proceso de extracción de conocimiento desde texto no Estructurado de Internet
En este primer caso de estudio, queremos extraer las entidades y relaciones relevantes que permitirán instanciar al grafo de aprendizaje (ontología semántica), desde un texto tomado de Wikipedia. Con este primer ejemplo, buscamos mostrar las capacidades del grafo de aprendizaje como una ontología, que permite describir semánticamente documentos.
El proceso comienza con un texto de entrada (para nuestro caso, texto que se encuentra en Wikipedia sobre la Universidad de Los Andes (ULA), en goo.gl/Eow5ib). Siguiendo el proceso de la Fig. 7, se separa el texto en sentencias. A continuación se analiza cada sentencia, se reconocen los nombres propios que aparecen en el texto, luego se procede al análisis morfosintáctico de las palabras, y a reconocer las entidades y relaciones candidatas (ver Fig. 8). La fase de análisis de las sentencias, utiliza las diferentes fuentes de conocimientos. Finalmente, se procede a la última fase, que consiste en determinar las entidades y relaciones relevantes (ver Tabla I). Para esta última fase, que consiste en determinar las entidades y relaciones relevantes, se usan las métricas definidas en la sección IV.D sobre este único documento. En este caso, al ser un solo documento, el peso es la frecuencia (ver ec. 2).
Las entidades y relaciones relevantes en la Tabla I, al ser usadas para instanciar la ontología que se deriva del grafo de aprendizaje, permiten hacer una descripción semánticamente del documento de Wikipedia analizado.
TABLA I
ENTIDADES Y RELACIONES RELEVANTES Entidades Peso Relaciones Peso
Escuela 49 EDITAR 26
Mérida 31 ES 25
facultad 29 ESTÁ 9
ciudad 26 CUENTA 8
Universidad 25 ENCUENTRA 8
Laboratorio 23 UBICA 8
Núcleo 23 FUE 7
Facultades 22 SON 6
Investigaciones 21 ENCUENTRAN 5
Sede 20 CONFORMAN 4
Centro 18 CREA 4
ULA 18 POSEE 4
Venezuela 16 SIENDO 4
Ingeniería 16 TIENEN 4
Universitario 15 VE 4
B Caso de estudio Doctorado de Ciencias Aplicadas de la Facultad de Ingeniería
Este segundo caso de estudio tiene como objetivo, mostrar algunos de los posibles usos de la ontología semántica que subyace en el sistema de extracción de conocimiento desde documentos no estructurados, propuesto
RODRÍGUEZ AND AGUILAR : KNOWLEDGE EXTRACTION SYSTEM FROM UNSTRUCTURED 643
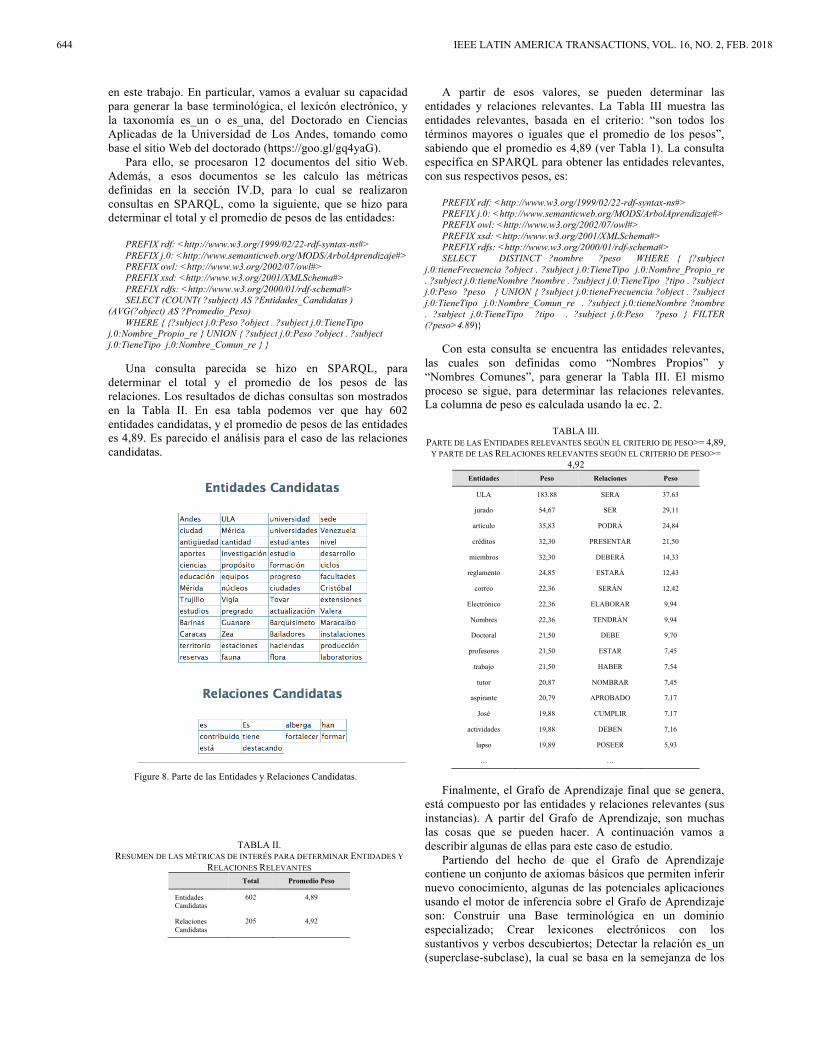
en este trabajo. En particular, vamos a evaluar su capacidad para generar la base terminológica, el lexicón electrónico, y la taxonomía es_un o es_una, del Doctorado en Ciencias Aplicadas de la Universidad de Los Andes, tomando como base el sitio Web del doctorado (https://goo.gl/gq4yaG).
Para ello, se procesaron 12 documentos del sitio Web. Además, a esos documentos se les calculo las métricas definidas en la sección IV.D, para lo cual se realizaron consultas en SPARQL, como la siguiente, que se hizo para determinar el total y el promedio de pesos de las entidades:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX j.0: <http://www.semanticweb.org/MODS/ArbolAprendizaje#> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT (COUNT( ?subject) AS ?Entidades_Candidatas )
(AVG(?object) AS ?Promedio_Peso) WHERE { {?subject j.0:Peso ?object . ?subject j.0:TieneTipo
j.0:Nombre_Propio_re } UNION { ?subject j.0:Peso ?object . ?subject j.0:TieneTipo j.0:Nombre_Comun_re } }
Una consulta parecida se hizo en SPARQL, para
determinar el total y el promedio de los pesos de las relaciones. Los resultados de dichas consultas son mostrados en la Tabla II. En esa tabla podemos ver que hay 602 entidades candidatas, y el promedio de pesos de las entidades es 4,89. Es parecido el análisis para el caso de las relaciones candidatas.
TABLA II. RESUMEN DE LAS MÉTRICAS DE INTERÉS PARA DETERMINAR ENTIDADES Y
RELACIONES RELEVANTES Total Promedio Peso
Entidades Candidatas
602 4,89
Relaciones Candidatas
205 4,92
A partir de esos valores, se pueden determinar las entidades y relaciones relevantes. La Tabla III muestra las entidades relevantes, basada en el criterio: “son todos los términos mayores o iguales que el promedio de los pesos”, sabiendo que el promedio es 4,89 (ver Tabla 1). La consulta específica en SPARQL para obtener las entidades relevantes, con sus respectivos pesos, es:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX j.0: <http://www.semanticweb.org/MODS/ArbolAprendizaje#> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT DISTINCT ?nombre ?peso WHERE { {?subject
j.0:tieneFrecuencia ?object . ?subject j.0:TieneTipo j.0:Nombre_Propio_re . ?subject j.0:tieneNombre ?nombre . ?subject j.0:TieneTipo ?tipo . ?subject j.0:Peso ?peso } UNION { ?subject j.0:tieneFrecuencia ?object . ?subject j.0:TieneTipo j.0:Nombre_Comun_re . ?subject j.0:tieneNombre ?nombre . ?subject j.0:TieneTipo ?tipo . ?subject j.0:Peso ?peso } FILTER (?peso>4.89)}
Con esta consulta se encuentra las entidades relevantes,
las cuales son definidas como “Nombres Propios” y “Nombres Comunes”, para generar la Tabla III. El mismo proceso se sigue, para determinar las relaciones relevantes. La columna de peso es calculada usando la ec. 2.
TABLA III.
PARTE DE LAS ENTIDADES RELEVANTES SEGÚN EL CRITERIO DE PESO>= 4,89, Y PARTE DE LAS RELACIONES RELEVANTES SEGÚN EL CRITERIO DE PESO>=
4,92 Entidades Peso Relaciones Peso
ULA 183.88 SERA 37.63
jurado 54,67 SER 29,11
artículo 35,83 PODRÁ 24,84
créditos 32,30 PRESENTAR 21,50
miembros 32,30 DEBERÁ 14,33
reglamento 24,85 ESTARÁ 12,43
correo 22,36 SERÁN 12,42
Electrónico 22,36 ELABORAR 9,94
Nombres 22,36 TENDRÁN 9,94
Doctoral 21,50 DEBE 9,70
profesores 21,50 ESTAR 7,45
trabajo 21,50 HABER 7,54
tutor 20,87 NOMBRAR 7,45
aspirante 20,79 APROBADO 7,17
José 19,88 CUMPLIR 7,17
actividades 19,88 DEBEN 7,16
lapso 19,89 POSEER 5,93
… …
Finalmente, el Grafo de Aprendizaje final que se genera,
está compuesto por las entidades y relaciones relevantes (sus instancias). A partir del Grafo de Aprendizaje, son muchas las cosas que se pueden hacer. A continuación vamos a describir algunas de ellas para este caso de estudio.
Partiendo del hecho de que el Grafo de Aprendizaje contiene un conjunto de axiomas básicos que permiten inferir nuevo conocimiento, algunas de las potenciales aplicaciones usando el motor de inferencia sobre el Grafo de Aprendizaje son: Construir una Base terminológica en un dominio especializado; Crear lexicones electrónicos con los sustantivos y verbos descubiertos; Detectar la relación es_un (superclase-subclase), la cual se basa en la semejanza de los
Figure 8. Parte de las Entidades y Relaciones Candidatas.
644 IEEE LATIN AMERICA TRANSACTIONS, VOL. 16, NO. 2, FEB. 2018

conceptos (un concepto incluye al otro) para construir taxonomías. A continuación, vamos a describir esos usos.
1. Base terminológica del Doctorado de Ciencias Aplicadas
El Grafo de Aprendizaje permite extraer una lista de términos especializados de un dominio a partir del corpus de los documentos estudiados. Para ello, se tiene en cuenta el criterio de peso antes definido. Por ejemplo, se podrían usar las siguientes reglas sobre el Grafo de Aprendizaje:
• TieneTipo(?x, Nombre_Propio_re), tienePeso(?x, ?pes),
greaterThan(?pes, 4,89 -> Onomasticon(?x), • TieneTipo(?x, Nombre_Comun_re), tienePeso (?x, ?pes),
greaterThan(?pes, 4,89) -> Lexicon(?x) • Onomsticon((?x)or(Lexicon((?x)-> TerminosEspecializados Estas reglas caracterizan los términos (nombres propios,
nombres comunes, entre otros) relevantes (peso 4,89) que caracterizan al doctorado. Esas reglas, al ser ejecutadas por el razonador sobre el Grafo de Aprendizaje, obtendrían términos especializados sobre el doctorado (ver Fig. 9).
Para la evaluación de la base terminológica (términos
especializados) del doctorado, generada por el Grafo de Aprendizaje, se usa el siguiente criterio: verificación si los términos pertenecen al dominio del doctorado. Como se observa en la Fig. 9, todos los términos están vinculados al doctorado.
Esta capacidad de adquisición especializada terminológica, se puede usar en procesamiento de textos, en tareas de minería de texto, en creación de ontologías especializadas, entre otras cosas.
2. Lexicón Electrónico
En el caso de diseño de un lexicón electrónico de sustantivos y verbos, se aplicarían las siguientes reglas sobre el Grafo de Aprendizaje:
• TieneTipo(?x, Nombre_Comun_re), tienePeso(?x, ?pes),
greaterThan(?pes, 4,89) -> Lexicon(?x) • esUn(?x, Verbo_re), tienePeso(?x, ?fre), greaterThan(?fre, 4,92) -
> Evento(?x) • Lexicon(?x)orEvento(?x)->LexiconElectronico
Estas reglas permiten extraer los sustantivos y verbos
guardados en el Grafo de Aprendizaje. Para el caso del doctorado, su resultado (instancias) se muestra en la Fig.10.
Para la evaluación del lexicón, se usó el siguiente criterio:
verificación si los términos son nombres comunes y verbos. Como se observa en la Fig. 10, todos los términos son nombres comunes y verbos.
En este caso, la posibilidad de construir automáticamente (aprendizaje) lexicones, abre un mundo a nivel lingüístico, para actualizar lexicones computacionales ya definidos.
3. Creación de taxonomía es_un o es_una
En los textos analizados del Doctorado, se encontraron varias sentencias que tienen el verbo es, como por ejemplo: • El doctorando es inmerso totalmente en la dinámica del
grupo de investigación al cual pertenece su tutor. • Cualquier investigador cualificado que sea miembro de
un grupo de investigación consolidado de la Universidad de Los Andes es, potencialmente, un tutor del programa.
• Si el Plan de Formación no es aceptado por la Comisión de Admisión, el aspirante con su tutor podrán modificarlo y someterlo una vez más a la consideración de la Comisión, en un lapso de un mes.
Pasemos a describir como se usaría el Grafo de
Aprendizaje para este caso. En el Grafo de Aprendizaje instanciado con los documentos del doctorado, se determina si en él existen relaciones del tipo “es_un” entre dos entidades. Por ejemplo, para las tres sentencias de arriba: • En la sentencia 1 no se puede establecer ninguna relación
“es un” entre entidades.
Figure 9. Términos Especializados del Doctorado de Ciencias Aplicadas
Figure 10. Lexicón electrónico de sustantivos y verbos
RODRÍGUEZ AND AGUILAR : KNOWLEDGE EXTRACTION SYSTEM FROM UNSTRUCTURED 645

• En la sentencia 2 se establece la relación investigador “es un” tutor.
• En la sentencia 3 no se puede establecer la relación “es un”, debido a que el verbo es “es aceptado”.
Por lo tanto, para el caso anterior, solo se podría obtener
la relación taxonómica de la Fig. 11.
Figure 11. Relación taxonómica de las sentencias analizadas
De esta manera, podemos crear automáticamente
taxonomías “es_un”, las cuales son las más comúnmente usadas al construir ontologías, y las mejor soportadas por las herramientas de desarrollo de ontologías (como Protege).
Vemos así, estas tres formas de generación de conocimiento, a partir del Grafo de Aprendizaje generado por el conjunto de documentos no estructurados del doctorado.
V. CONCLUSIONES En este trabajo se presenta un sistema de extracción de
conocimiento desde textos no estructurados, el cual es organizado semántica en un Grafo de Aprendizaje. El Grafo de Aprendizaje es una ontología semántica que puede ser representada en RDF, OWL, entre otros lenguajes, cuyas instancias representan todo el conocimiento extraído de una colección de documentos. A partir de Grafo de Aprendizaje, es posible usar el sistema para generar nuevo conocimiento semántico, como por ejemplo, bases terminológicas especializadas, lexicones, y taxonomías.
Para la construcción del Grafo de Aprendizaje, hemos usado una métrica que permite clasificar los términos contenidos en los documentos procesados, como relevantes o no. Dicha métrica, combina la frecuencia y la capacidad de discriminar de los términos en los documentos procesados. Esto le confiere al Grafo de Aprendizaje una característica fundamental, ser una ontología semántica de documentos procesados, conformada solamente por información (individuos) relevante. Trabajos previos no consideran este aspecto, es decir, el desarrollo de ontologías semánticas que solamente contengan el conocimiento relevante de un conjunto de documentos bajo estudio.
En particular, este sistema es usado como insumo en el aprendizaje semántico del Marco Ontológico Dinámico (MODS) [4, 5, 6, 12]. Este sistema permite actualizar los siguientes componentes del MODS: la ontología interpretativa y el lexicón. Para el primer caso, da el insumo de las entidades y relaciones a incorporar en la ontología nterpretativa; y en el segundo caso, define los nuevos conceptos (verbos y sustantivos) a incorporar en su lexicón.
Uno de los trabajos futuros sobre el sistema, es extraer, además de las relaciones taxonómicas, las no taxonómicas, así como también, reglas lingüísticas, y los atributos que se relacionan con los conceptos, para el procesamiento del lenguaje natural.
REFERENCIAS [1] S. Nirenburg and V. Raskin “Ontological Semantics”. MIT Press, 2004.
Cambridge, Massachusetts, London, England.
[2] D. Wimalasuriya and D. Dou. “Ontology-Based Information Extraction: An Introduction and a Survey of Current Approaches”. Journal of Information Science. vol. 36, no 3, pp. 306-323, 2010.
[3] A. Rodríguez and A. Cuevas. “Método para la extracción de información estructurada desde texto”. Revista Cubana de Ciencias Informaticas. Vol. 7, no. 1, pp. 55-67, 2013.
[4] T. Rodríguez. E. Puerto, J. Aguilar. “Dynamic Semantic Ontological Framework for Web Semantics”. Proceeding of the 9th WSEAS Intl. Conference on Computational Intelligence, Man-Machine Systems and Cybernetics (CIMMACS '10), pp. 91- 98, 2010.
[5] E. Puerto, J. Aguilar, T. Rodríguez. “Automatic Learning of Ontologies for the Semantic Web: experiment lexical learning”. Respuestas: Revista, vol. 17, no. 2, pp. 5-12, 2012.
[6] T. Rodríguez and J. Aguilar. “Aprendizaje ontológico para el marco ontológico dinámico semántico”, DYNA, vol. 81 no. 187, pp. 56-63, 2014.
[7] T. Gruber. “A translation approach to portable ontology specifications”, Knowledge Acquisition, vol. 5, no. 2, pp. 199-220, 1993.
[8] R. Studer, V. Benjamins, D. Fensel. “Knowledge Engineering: Principles and methods”, Data Knowledge Engineering, vol.25, no. 1, pp. 161-197, 1998.
[9] D. Nadeau and S. Sekine, “A survey of named entity recognition and classification”. Lingvisticae Investigationes 30 (1) (2007), 3–26.
[10] L. Ramshaw and R. Weischedel. “Information extraction”, Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, 2005.
[11] J Martínez. “Los modelos clásicos de recuperación de Información y su vigencia”. III Seminario Hispano-Mexicano de Investigación en bibliotecología y documentación, (2006). México. Consultado 12/09/14. http://eprints.ucm.es/5979/1/Modelos_RI_preprint.pdf
[12] T. Rodriguez and J. Aguilar, "Implementación del marco ontológico dinámico semántico", Ingeniare, vol. 25, no. 3, 2017.
[13] E. Sang and T. Sang. “Introduction to the CoNLL-2002 Shared Task: Language-Independent Named Entity Recognition”. Proceedings of CoNLL-2002, pp. 155-158, 2002.
[14] J. Aguilar and J. Altamiranda. “Conceptos sobre Minería Web”, Revista GTI, vol. 3, no. 7, 2004.
[15] http://www.opencalais.com/ [16] http://www.wordreference.com/ [17] http://opennlp.apache.org/
System Engineer, MSc in Computer and PhD in Computer Science at the Universidad de Los Andes. Her interest is include Ontologies, Ontology Learning, Linked Data, Semantic Web, Social Analytics, Big Data, and Processing Language Natural. She works at the Universidad de los Andes, in the Master degree program in Computer Sciences.
Jose Aguilar is a System Engineer from the Universidad de Los Andes, Venezuela. M. Sc. degree in Computer Sciences from the University Paul Sabatier-France. Ph. D degree in Computer Sciences from the University Rene Descartes- France. He completed post-doctorate studies at the Department of Computer Science in the University of Houston,
researcher at the Microcomputer and Distributed Systems Center (CEMISID). Member of the Mérida Science Academy and the International Technical Committee of the IEEE-CIS on Artificial Neural Network.
646 IEEE LATIN AMERICA TRANSACTIONS, VOL. 16, NO. 2, FEB. 2018