Embed Size (px)
Citation preview

K2View Data Fabric Technical Whitepaper
Introduction
At Our Core: The Logical Unit
Architecture
Data Model: K2view Fabric Schema
Data Management
Data Services
Consistency, Durability & Availability
Performance
Security
Administration
Total Cost Of Ownership
Conclusion
3
4
6
9
10
12
13
13
15
17
17
18
TABLE OF CONTENTS
THE BIG DATA PROBLEMBig Data. The term is sometimes overused as a catchall for anything that requires massive amount of data processing or storage. The academic definition refers to a collection of data too massive to be handled efficiently by traditional database tools and methods.
Why would traditional database tools and methods not be able to support modern collections of data?
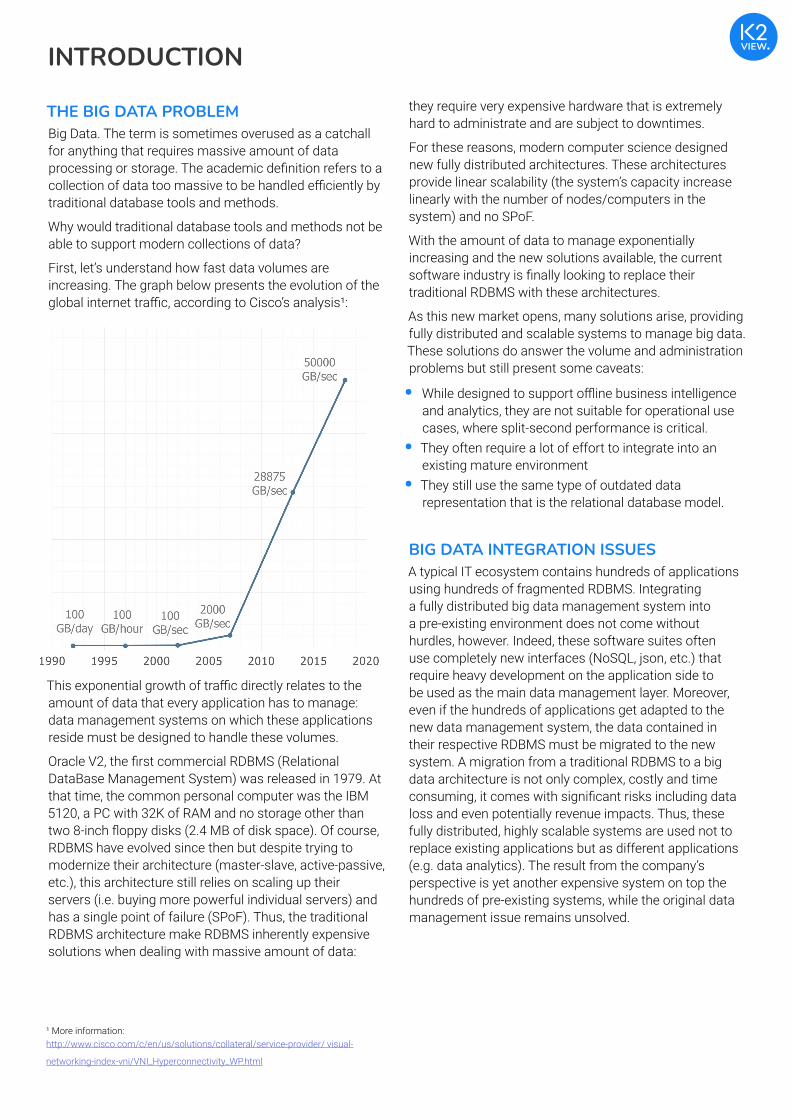
First, let’s understand how fast data volumes are increasing. The graph below presents the evolution of the global internet traffic, according to Cisco’s analysis¹:
This exponential growth of traffic directly relates to the amount of data that every application has to manage: data management systems on which these applications reside must be designed to handle these volumes.
Oracle V2, the first commercial RDBMS (Relational DataBase Management System) was released in 1979. At that time, the common personal computer was the IBM 5120, a PC with 32K of RAM and no storage other than two 8-inch floppy disks (2.4 MB of disk space). Of course, RDBMS have evolved since then but despite trying to modernize their architecture (master-slave, active-passive, etc.), this architecture still relies on scaling up their servers (i.e. buying more powerful individual servers) and has a single point of failure (SPoF). Thus, the traditional RDBMS architecture make RDBMS inherently expensive solutions when dealing with massive amount of data:
they require very expensive hardware that is extremely hard to administrate and are subject to downtimes.
For these reasons, modern computer science designed new fully distributed architectures. These architectures provide linear scalability (the system’s capacity increase linearly with the number of nodes/computers in the system) and no SPoF.
With the amount of data to manage exponentially increasing and the new solutions available, the current software industry is finally looking to replace their traditional RDBMS with these architectures.
As this new market opens, many solutions arise, providing fully distributed and scalable systems to manage big data. These solutions do answer the volume and administration problems but still present some caveats:
• While designed to support offline business intelligence and analytics, they are not suitable for operational use cases, where split-second performance is critical.
• They often require a lot of effort to integrate into an existing mature environment
• They still use the same type of outdated data representation that is the relational database model.
BIG DATA INTEGRATION ISSUESA typical IT ecosystem contains hundreds of applications using hundreds of fragmented RDBMS. Integrating a fully distributed big data management system into a pre-existing environment does not come without hurdles, however. Indeed, these software suites often use completely new interfaces (NoSQL, json, etc.) that require heavy development on the application side to be used as the main data management layer. Moreover, even if the hundreds of applications get adapted to the new data management system, the data contained in their respective RDBMS must be migrated to the new system. A migration from a traditional RDBMS to a big data architecture is not only complex, costly and time consuming, it comes with significant risks including data loss and even potentially revenue impacts. Thus, these fully distributed, highly scalable systems are used not to replace existing applications but as different applications (e.g. data analytics). The result from the company’s perspective is yet another expensive system on top the hundreds of pre-existing systems, while the original data management issue remains unsolved.
INTRODUCTION
¹ More information: http://www.cisco.com/c/en/us/solutions/collateral/service-provider/ visual-
networking-index-vni/VNI_Hyperconnectivity_WP.html

DISTRIBUTED RELATIONAL DATA MODEL, PERFORMANCE, AND COSTAs discussed in the previous paragraph, big data management systems are extremely hard to integrate as the main data management system. But even when they are integrated or used as fringe systems, they still use the same technical approach to represent this data: data is stored by category in extremely large placeholders that get linked to one another.
Some big data systems use files or documents but the most common and easy to use way to store and manipulate data remains tables, just as a traditional RDBMS.
Therefore, when an application queries the big data management system, it goes through the same type of lookup as any RDBMS: scanning through these massive data placeholders to retrieve one piece of information that will link them to another placeholder, and so on and so forth until you reach the line of data that is relevant to the application.
These lookups are extremely resource consuming because they require massive amounts of computation. The way that big data systems try to overcome their computation constraints is by using massive parallel processing or executing them in memory, going as far as storing the entire database in memory. These methods do provide better performance than traditional RDBMS
but can be extremely costly (in the case of a full in-memory database especially). One question arises from this analysis: why isn’t the data stored in a way that is logical to the business application needs?
WHAT IS K2VIEW DATA FABRIC?At K2View, we answered that question and our customers’ Big Data Problem with our flagship product: K2View Data Fabric. K2View Data Fabric provides all the benefits of a big data management system: a distributed, shared-nothing and linearly scalable architecture, massive parallel processing in memory for computation, and disk storage for minimal total cost of ownership. But K2View Data Fabric also solves the two major flaws of the other modern big data management systems:
It requires almost no effort of integration into a mature environment thanks to its embedded ETL layer, and full SQL and standard connectors support.
It uses a revolutionary and patented means to represent and store the data the way that the business needs it - the Digital Entity™ - making it uniquely suitable for operational use cases, where near real-time performance is mandatory.
K2View Data Fabric offers additional features for better security, flexible synchronization and easy administration. The object of this white paper is to detail the K2View Data Fabric architecture and key capabilities.
DEFINITIONAs explained above, most database management systems store data based on the type of data being stored (e.g. customer data, financial data, address data, device data); this model translates into very large tables that must be queried using complex joins every time one wants to access business-relevant data (e.g. how many payments has this customer made within the past three months?).
K2View Data Fabric looks at data a different way: storing and retrieving it based on business logic. This allows the business organize data based on their needs, as opposed to try to fit them into a pre-defined structure.
Indeed, in K2View Data Fabric, every business-related object (e.g. Customer, Merchant, Location, Credit Card) is represented by a data schema - the Digital Entity™.
This schema defines all the relevant data fields, aggregated from all underlying systems, that is associated with the digital entity. Defining the data schema for the digital entity is either automated
using K2View Data Fabric’s Auto-Discovery module, or performed manually using the K2View graphical Studio. The result is a business-oriented structure containing tables and objects from as many systems as needed (e.g. for a Customer digital entity, 3-tables from the CRM system running on MySQL and 5-tables from the billing system residing on Oracle).
This schema is used every time data is accessed in K2View Data Fabric: using embedded ETL capabilities, the data is processed, stored, and distributed into a micro-DB™ – one micro-DB per digital entity instance.
Every micro-DB is compressed and individually encrypted with a unique key, enabling incredible performance, enhanced security, high-availability and configurable data synchronization.
AT OUR CORE: THE DIGITAL ENTITY

WHY IS REPRESENTING DATA AS DIGITAL ENTITIES SO IMPORTANT?The digital entity and associated micro-DB concept is a bridge between scattered, hard to maintain data and high availability, business- oriented data.
By its very nature, it enables split-second performance. Indeed, since the data is organized according to the business needs, around 95% of all data access will occur within a single micro-DB: this means that inherently every K2View Data Fabric query will execute against only one micro-DB (for a single business-related object) instead of having to scan through massive tables like other databases.
And since the data is stored in micro-DBs, it also
enables K2View Data Fabric to restrict access and encrypt data at the micro-DB level. Moreover, it allows for fully flexible data retrieval without interruption of the underlying application systems: data can be retrieved in real time, from in memory when queried instead of having to retrieve all the data from all the massive tables before being able to access that data. Therefore, when describing K2View Data Fabric capabilities, we will heavily rely on this concept.
The diagram below illustrates the difference between traditional data representation and K2View Data Fabric digital entity concept.
TRADITIONAL RDBMS BIG DATA ARCHITECTURE K2VIEW DATA FABRIC
• Data is scattered across multiple systems (e.g. CRM, Billing, etc.)
• Each system is independent
• Very hard to access all data corresponding to one business-related object (e.g. customer)
• Data is stored and distributed in big data system (e.g. Hadoop)
• No business logic in storage
• Data access for one entity requires lookup through massive amount of data
• Data is stored and distributed in K2View Data Fabric
• Data is represented by digital entity and stored in a micro-DB, one micro-DB per business-related object.
• Data access for one entity is a core feature

• CONFIGURATION: This layer contains the versioned configuration of every digital entity. It contains all its parameters: schema, interfaces, optimization parameters, synchronization policies, transformation rules, masking rules, user functions, web services, etc. This layer is accessed through our administration tools (K2 Admin Manager, K2View Studio and Web Admin) and is described in detail in the DATA MODEL: K2VIEW DATA FABRIC SCHEMA section.
• MICROSERVICES: This layer is used to communicate with user applications: either via direct queries (database services) or via web services. It is described in detail in the DATA SERVICES section.
• AUTHENTICATION ENGINE: This layer manages user access control and restrictions. It is detailed in the SECURITY section.
• MASKING LAYER: This layer is an optional layer that allows real-time masking of sensitive data. It is described in detail in the DATA MANAGEMENT section.
• PROCESSING ENGINE: This layer is where every data computation is managed. It uses the principles of massive parallel processing and map-reduce in order execute operations. It is described in detail in the PERFORMANCE section.
• SMART DATA CONTROLLER: This layer drives the real
time synchronization of data to K2View Fabric. It is described in detail in the DATA MANAGEMENT section.
• ETL LAYER: This layer is K2View Fabric’s embedded migration layer, allowing for automated ETL on retrieval. It is described in detail in the DATA MANAGEMENT section.
• ENCRYPTION ENGINE: This layer manages the granular encryption of each data set. It is detailed in the SECURITY section.
• LU STORAGE MANAGER: This layer compresses and sends data to the distributed database for storage. K2View Data Fabric leverages Cassandra as the distributed storage. More details about this layer and the communication between K2View Data Fabric and Cassandra will be detailed later in this section.
ARCHITECTURE
The diagram below illustrates an overview of the K2View Fabric’s architecture:
INSIDE K2VIEW FABRIC

• USER APPLICATIONS: These are the clients and different application using the data. It can be any type of application (java-based, web-based, etc.) or a simple client or script querying K2View Data Fabric.
• SOURCE SYSTEMS: These are the current data management systems (traditional RDBMS or big data management systems). K2View Data Fabric integrates data from and updates to these source systems but also allows gradual retirement of deprecated legacy systems to become the new operational data system that replaces the source system.
• DISTRIBUTED DATABASE: This layer manages the distribution and storage of data. K2View Data Fabric leverages Cassandra as distributed storage, but can be adapted for any other type of distributed data storage.
DISTRIBUTED DATABASE FEATURES
• K2View Data Fabric utilizes Cassandra as a base storage layer to handle the mundane data storage and access functionality. This section details the features enabling this communication:
• KEY-VALUE STORE: Every digital entity’s data is stored in a micro-DB, each with its unique key, using the distributed database native functionalities. For K2View Data Fabric, the key is Logical Unit Instance ID, as defined in its schema (see following section DATA MODEL: K2VIEW DATA FABRIC SCHEMA); the value is a compressed and encrypted database file containing the micro-DB data. This gives K2View Data Fabric a very simple, structured and efficient way to access distributed data.
• COMMUNICATION PROTOCOLS: K2View Data Fabric relies on the distributed database native communication between server and clients. This means that K2View Data Fabric support Cassandra’s SDK out of the box (see the DATA SERVICES section for more details).
• DISTRIBUTED ARCHITECTURE: Cassandra brings together the distributed systems technologies from Dynamo (Amazon’s Highly Available Key-value Store) and the data model from Google’s Big Table. This makes K2View Data Fabric one of the world’s most efficiently distributed, shared-nothing, no Single Point of Failure (no SPoF) backend architectures.
• LINEAR SCALABILITY: The linear scalability of Cassandra has been thoroughly demonstrated, most famously by Netflix that studied and demonstrated its capacities on stage. K2View Data Fabric is therefore a linearly scalable product running on commodity hardware to ensure the lowest Total Cost of Ownership (see the TOTAL COST OF OWNERSHIP section).
COMMUNICATION WITH DISTRIBUTED DATABASE
• Internally, the communication between K2View Data Fabric and the distributed database is very simple. It is driven by three components of the K2View Data Fabric Architecture in three distinct cases:
• CASE A: The Smart Data Controller needs to retrieve data for transactions on single micro-DB
• CASE B: The Smart Data Controller needs to retrieve data for analytics transactions across multiple micro-DBs
• CASE C: The LU Storage Manager needs to push data onto disk after compression
CASE AIn case A, the Smart Data Controller checks if synchronization with other systems than K2View Data Fabric is needed; if not, it triggers the retrieval of data from the distributed database storage for a transaction on one single micro-DB (for details when synchronization is needed, see the DATA MANAGEMENT section). For this type of transaction, K2View Data Fabric simply retrieves the value associated with the corresponding key (Logical Unit Instance ID). This retrieval is executed using the distributed database native capabilities.
OUTSIDE K2VIEW FABRIC

CASE BCase B is the case of large queries over several micro-DBs. In this case, the Processing Engine triggers K2View Data Fabric to send workers distributed across the distributed database nodes. For this type of transaction, each worker in K2View Data Fabric triggers the Smart Data Controller to retrieve the most up to date data. If synchronization with other systems is not needed, the Smart Data Controller retrieves the most up-to-date data from the distributed database using its native communication protocols and sends it to the worker that then executes its individual computation on the node to which it has been dispatched. For more information about this process, refer to the PERFORMANCE section.
CASE CCase C is the last interaction between K2View Data Fabric and the distributed storage: when data is pushed from memory to disk. Every time data is accessed in memory for computation, it is pushed post-computation onto the distributed database key-value storage. As explained previously, the key is the Logical Unit Instance ID and the value is a compressed database file containing the micro-DB data. The LU Storage is responsible for compressing the database file post encryption and sends it for storage on the distributed database using its native communication protocols. More details about a data access flow can be found in the DATA MANAGEMENT section.
As detailed above, the only interactions between K2View Data Fabric and Cassandra are:
• Pulling data from nodes using the distributed database native protocols
• Pushing data to nodes using the distributed database native protocols
By only relying on Cassandra as a distributed storage layer, K2View Data Fabric is very flexible and may be adapted to other distributed databases.

OVERVIEWUsing the digital entity schema definition, K2View Data Fabric features a set of embedded data management functions to populate, store and present data:
• Embedded ETL (Extract-Transform-Load)
• Embedded data masking
• Flexible data synchronizationThese data management features are key differentiators between K2View Data Fabric and other data management systems, even modern distributed systems. They allow data to be retrieved, validated and enriched automatically
- without using any transformation scripts or third-party tools. In traditional data management platforms, data management is cumbersome, risky, and expensive. In K2View Data Fabric, data management is part of the database, as this section will describe.
EMBEDDED ETLTraditional ETL solutions used for data movement to either traditional RDBMS or even new big data stores are not designed to be distributed. That is why K2View’s ETL capabilities have been embedded into K2View Data Fabric. The principles of the ETL are based on the digital entity data representation: once the schema has been defined, K2View Fabric workers launch the retrieval and transformation of data through the supported connectors.
When the K2View Data Fabric ETL layer is activated, it triggers a ‘mini-migration’ from the source interfaces defined in the schema onto K2View Data Fabric for the micro-DB in scope. This ETL is executed in memory and parallelized using K2View Data Fabric’s processing engine. Once retrieved, the data can be used in memory for any operation. After this data is used, it is pushed onto the distributed database layer.
There is no configuration needed for the ETL layer, as any enrichment or validation is simply defined while populating the K2View Data Fabric schema via the K2View Studio.
As a result, K2View Data Fabric embedded ETL offers the following features:
• In-memory digital entity-based migration
• No-interruption; on-the-fly migration
• Full data consistency according to schema
• Low risk flexible phased or full system migration
• Concurrent configuration and versioning
• Full suite of transformation function library for complex transformation and enrichments
• Offline debug capabilities
The embedded ETL layer can be used for data migration. Furthermore, it can also be triggered by the K2View Data Fabric’s Smart Data Controller on data retrieval allowing for legacy systems to either retire into K2View Data
Fabric or remain operational until desired retirement. This no-configuration flexible ETL makes integrating K2View Data Fabric in an existing IT eco- system a risk free alternative.
EMBEDDED DATA MASKINGWhile integrating K2View Data Fabric into an IT eco-system, it can be an interface to different type of applications: staging applications dedicated to internal business testing or production applications for end-user consumption. These applications often contain highly sensitive data (e.g. SSN, Credit Card, etc.). This data must only be accessed by the relevant users and only be stored where absolutely necessary: on the production system, where it is the most secure. Other systems should store masked data.
To solve this issue, K2View Data Fabric provides a fully embedded suite of data masking functions. As in the embedded ETL layer, all masking is based on the digital entity data representation.
K2View Data Fabric embedded masking features:
• In-memory digital entity-based masking
• No-interruption, on-the-fly masking
• User role dependent masking
• Full data consistency according to schema
• Conservation of every application rules while masking for data complete usability
• Full suite of pre-configured libraries masking for most commonly used fields
• Offline debug capabilities
Of course, data masking is an optional component of K2View Data Fabric and does not need to be executed for production use.
While these embedded functionalities are essential to K2View Data Fabric’s data management features, they are driven by K2View Data Fabric’s Smart Data Controller.
SMART DATA CONTROLLERAny time data is accessed in K2View Data Fabric, the Smart Data Controller compares the current state of the data in K2View Data Fabric versus the synchronization parameters - and updates the data if needed (e.g. difference in version, or other synchronization modes triggers).
DATA MANAGEMENT

The most common case is when a change in the version of the K2View Data Fabric schema occurs (e.g. new table added, field enriched): in this case, when the Smart Data Controller is called to access data, it will trigger K2View Data Fabric’s embedded ETL capabilities to connect to the relevant source systems and access that data.
As such, K2View Data Fabric gives immediate access to data without going through a complex, costly and time- consuming migration process by simply defining its schema. Using versioning also allows to enter a
“time machine” and view the micto-DB data as it evolves throughout the different schema versions.
The same principles of synchronization apply for every synchronization mode triggers below.
ON-DEMAND SYNCK2View Data Fabric allows data synchronization to be triggered by on-demand calls. These calls are driven by the web and database layer. They can either be a web service triggering the Smart Data Controller or batch scripts using K2View Data Fabric’s database drivers or directly querying K2View Data Fabric (administrative mode).
EVENT-BASED SYNCAlternatively, K2View Data Fabric synchronization can be triggered using the principles of Change Data Capture (CDC). Using this mode, K2View Data Fabric
automatically captures changes in the source systems that are part of its schema. This synchronization mode granularity is at the table level: when a change occurs on a table from a source system, K2View Data Fabric triggers the Smart Data Controller to change the data only on the corresponding table in the digital entity schema, therefore minimizing irrelevant updates for performance optimization.
ALWAYSYNCK2View Data Fabric features an intelligent and flexible way to synchronize data: AlwaySync. This mode allows complete granularity over the data that needs to be synchronized with source systems.
Using AlwaySync, K2View Data Fabric allows you to configure what data needs to be refreshed automatically, and how frequently. For each element of the digital entity schema, an AlwaySync timer that drives the K2View Data Fabric synchronization is set (e.g., if the usage information from the Customer table needs to be updated every 5 minutes, a timer of 5 minutes is set).
Once configured, K2View Data Fabric synchronizes data with source systems only upon data access - to optimize performance. As such, when retrieved, if the timestamp on the micro-DB data is older than the timer set for this data, K2View Data Fabric triggers synchronization.
The figure below illustrates this synchronization mode, in the case of data access without masking.
1. Web/Database Services layer relays data access request from user application.
2. User is authenticated and authorized to proceed with data access.
3. The Smart Data Controller retrieves data from distributed database storage in memory (if not already).
4. The Smart Data Controller checks the micro-DB data timestamp against AlwaySync timer; the timestamp is older than the AlwaySync timer.
5. The Smart Data Controller triggers ETL layer for data synchronization.
6. ETL layer synchronizes data with source systems and sends it to the processing engine.
7. The processing engine uses data to perform necessary operations.
8. Web/Database Services layer sends processed data to user application.
9. In parallel to this process, the processing engine sends data for encryption.
10. Data is compressed and sent to distributed database for storage.

OVERVIEWAs described in the previous section, K2View Data Fabric uses innovative engines to manage and synchronize data. K2View Data Fabric also provides easy access to this data via its web and database services. The goal of these services is to make the integration of user applications seamless.
This is why K2View Data Fabric provides:
• A query engine supporting full SQL.
• An easy-to-configure web service layer. This section will describe these services in detail. DATABASE SERVICES
The K2View Data Fabric Processing Engine uses two query
Methods, depending on the type of data on which the query is executed:
• Query on single micro-DB (around 95% of overall queries): simple ANSI SQL query.
• Query across micro-DBs for analytics: Leveraging integrated Elastic Search engine
These two methods are described in detail in the PERFORMANCE section. However, both of them support the full capabilities of ANSI SQL.
On top of this SQL language support, K2View Data Fabric is packaged with embedded database drivers:
• Every driver supported by the Cassandra SDK².
• Full JDBC support.
Finally, on top of the standard indexing functionalities provided by its full SQL support, K2View Data Fabric provides a proprietary way to define and utilize indexes in order to optimize queries and enable user access control.
Indexes can be defined for any field of the K2View Data Fabric schema. By defining a field as an index, this field can automatically be used for analytical queries (indexes are not used for single micro-DB queries because they are not needed).
Indexes are stored as reference data and can be used to optimize queries and to define access permissions.
For instance, K2View Data Fabric enables a DBA to define the state field of an address table (contained in the
schema for a particular micro-DB) to be an index, thus enhancing performances of queries selecting all micro-DBs of a particular state.
WEB SERVICESOne of K2View Data Fabric’s core and unique capabilities is its embedded Web Services layer. Indeed, in traditional database management systems (distributed or not), creating a layer of Web Services entails advanced and intricate software development: you need to define communication protocols with the database management system, expose these access methods, define users and security protocols, define the distribution of the Web Services layer, etc. This development is expensive, time-consuming, and requires constant maintenance to cater to the database changes or new functional requests.
In K2View Data Fabric, the web services layer is embedded: it offers an out-of-the-box configuration graphical interface to define Web Services. Any function (which can be as simple as a query) can be created and registered as a Web Service.
These functions can then be re-used and combined by other functions, essentially allowing for any Web Service to be easily re-used by other Web Services.
Once a Web Service function is defined, K2View Data Fabric automatically takes care of user access, distribution, updates due to schema changes, etc. The gain in time and effort is tremendous.
Each Web Service can be restricted per micro-DB and per user. Moreover, as hinted above, indexes can be used to restrict access to a Web Service, making any field of the K2View digital entity schema a potential restriction field.
To reuse the above example, the query selecting all micro-DB data for a particular state can simply be registered as a function and thus a Web Service. This Web Service can then be accessed by any application and the state index can be used to restrict the access of one particular state to one particular set of users.
Therefore, and unlike traditional solutions, by combining embedded Web Services, ETL, and flexible sync capabilities, K2View Data Fabric does not require any custom upstream or downstream development.
DATA SERVICES
² More information: http://planetcassandra.org/client-drivers-tools/

OVERVIEWK2View Data Fabric uniquely ensures full consistency, guaranteed durability, and high availability of the data it manages. Before detailing how K2View Data Fabric supports these capabilities, let’s look at their Wikipedia definitions:
• CONSISTENCY: Consistency in database systems refers to the requirement that any given database transaction must only change affected data in allowed ways. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof.
• DURABILITY: In database systems, durability is the ACID property which guarantees that transactions that have committed will survive permanently.
• HIGH AVAILIBILITY: High availability is a characteristic of a system. It is measured in percentage using the following equation: Ao = (total time - down time) / total time. It relies on three principles: Elimination of SPoF, Reliable crossover, Detection of failures as they occur.
In K2View Data Fabric, durability and high availability are inherent features of the distributed database layer (Cassandra). Cassandra has a flexible consistency mechanism, that K2View Data Fabric leverages to be fully consistent during network partitions, as expected from an ACID compliant database.
CONSISTENCYConsistency is ensured by the Processing engine of K2View Data Fabric. Every time a write on a certain micro-DB occurs, K2View Data Fabric checks against a transaction table stored in the distributed database (thus distributed and
highly available), determines if a concurrent transaction is occurring and if the write should be put on hold. For instance, if two or more concurrent transactions are committed to the same micro-DB, its transaction log is used as a conflict detection and resolution mechanism. This process occurs only in the case of a write transaction for a particular key (micro-DB ID), therefore maintaining fast performance and high availability.
DURABILITYAs mentioned above, durability is inherent to the distributed database layer. K2View provides durability by appending writes to a commitlog first. This means that before performing any write and using it in memory it appends the value into a commitlog. This not only ensures full durability – because data is written on disk first – but since it’s appending a small amount of a file, it is also quasi-instantaneous.
HIGH AVAILIBLITYSimilarly to durability, high availability is driven by the distributed database (Cassandra) architecture. Cassandra’s architecture ensures the elimination of Single Point of Failures by design. In a Cassandra cluster all nodes are equal: there are no masters or coordinators at the cluster level. Moreover, Cassandra provide reliable crossover and detection of failures using an internode communication protocol called Gossip. Gossip is a peer-to-peer communication protocol in which nodes periodically exchange state information about themselves and about other nodes they know about. Therefore, Cassandra and thus K2View Data Fabric, ensure the three principles of high availability. The next section will present how this high availability capability translates into high-end performance.
OVERVIEWK2View Data Fabric’s high performance is rooted its inherent digital entity and micro-DB architecture, running every query on a small amount of data. This makes K2View Data Fabric the fastest high-scale database management system available. On top of this inherent design, K2View Data Fabric optimizes performance using the two following major principles:
• Every query is executed in memory.
• For analytics queries running across several micro-DBs, K2View Data Fabric leverages an integrated Elastic Search engine to scan and search data in multiple micro-DBs.
The following section describes how both principles ensure high-end performance. The purpose of the section is not to establish performance benchmarks; of course, K2View Data Fabric’s actual performance is highly hardware dependent, but since K2View Data Fabric is
linearly scalable, it can be easily adjusted to cater to any desired required speed.
IN MEMORY PROCESSINGThis performance enabler is pretty straightforward: whenever an operation is executed, the computation is executed in memory and not on disk – for faster performances. While certain queries need to be distributed (in the case of analytic queries), the design of K2View Data Fabric does not require complex parallelization for almost any of its operations.
Indeed, provided a proper digital entity schema design, most of the queries are executed against one micro-DB, on a limited amount of data.
Therefore, the amount of data to be retrieved and processed in memory is small enough to provide extremely fast performance without having to implement complex distribution across nodes, the absence of which also contributes to faster performance.
CONSISTENCY, DURABILITY & AVAILIBILITY
PERFORMANCE

OVERVIEWWhile the previous sections discuss the performance, reliability and high availability of data in K2View Data Fabric, one major hurdle of any data management system is ensuring that the data is securely stored. The goal is to eliminate mass data breaches. Since K2View Data Fabric stores data in micro-DBs, it provides two revolutionary protocols to secure data:
• Advanced data encryption via the patented K2View Hierarchical Encryption Key Schema (HEKS)
• Complete user access control using HEKS, data services authorization parameters and index definitions.
As presented in the ARCHITECTURE section, these protocols are used in the Authentication Engine and Encryption Engine. The Authentication Engine ensures user access control upstream while the Encryption Engine encrypts the data downstream before storage.
This section will start by addressing the Encryption Engine before the Authentication Engine, as some of the Authentication Engine relies on the principle of HEKS defined in the Encryption Engine.
ENCRYPTION ENGINEEach user in K2View Data Fabric is created with a set of security attributes that are used to enable K2View Data Fabric security features, as detailed in the figure below.
K2View Data Fabric uses an industry standard public-key cryptography algorithm to encrypt and decrypt data. The user public key is used to encrypt its wallet, which stores resources keys. This data is then only readable using this user’s private key to decrypt. The private key itself has been previously encrypted using the user password. This password is salted before being stored in K2View Data Fabric, and is never stored in clear.
Using this cryptography, a user has access to a set of resource keys stored in their wallet, enabling exclusive,
patented security features: Hierarchical Encryption-Key Schema (HEKS) and user access control.
K2View Data Fabric’s proprietary algorithm, Hierarchical Encryption-Key Schema (HEKS), relies on the resource keys contained in one user’s wallet and provide three level of resource keys:
• Master Key: Generated during K2View Data Fabric’s installation, this is the main key allowing access to every resource of K2View Data Fabric: each user that has access to that key can generate all other key types, and thus encrypt or decrypt any resource within the hierarchy.
• Type Keys: These keys restrict access at the micro-DB level and are a hash of the Master Key. As such, each user that has access to a type key can encrypt and decrypt data belonging to every digital entity type.
• Instance Keys: These keys restrict access at the Logical Unit Instance level and are a hash of their corresponding type key. As such, a user having access to one Logical Unit Instance will not be able to decrypt data from another instance, even though both instances are part of the same schema.
Password Salted before storage.
Private Key (decryption) Unique, encrypted using password.
Public Key (encryption) Unique, public to every user.
Wallet Collection of resource keys used for HEKS.
In the figure above, you can see how HEKS is implemented for two digital entity types.
Indeed, you can see the following keys:
• 1 Master Key allowing full access
• 2 Type Keys restricting access to 2 different digital entity types
• 6 micro-DB keys, 3 for each digital entity types, restricting access at the micro-DB level
Using this hierarchical encryption, K2View Data Fabric enables complete control over the stored data and significantly reduces the risk of data leaks: even if one micro-DB key were to be hacked, only the data of one micro-DB would be breached; all other micro-DBs would remain safely encrypted. Therefore, this design makes K2View Data Fabric an “ultra secure database”, essentially rendering massive data breaches impossible.
SECURITY
Master
Digital Entity Type
Micro-DB
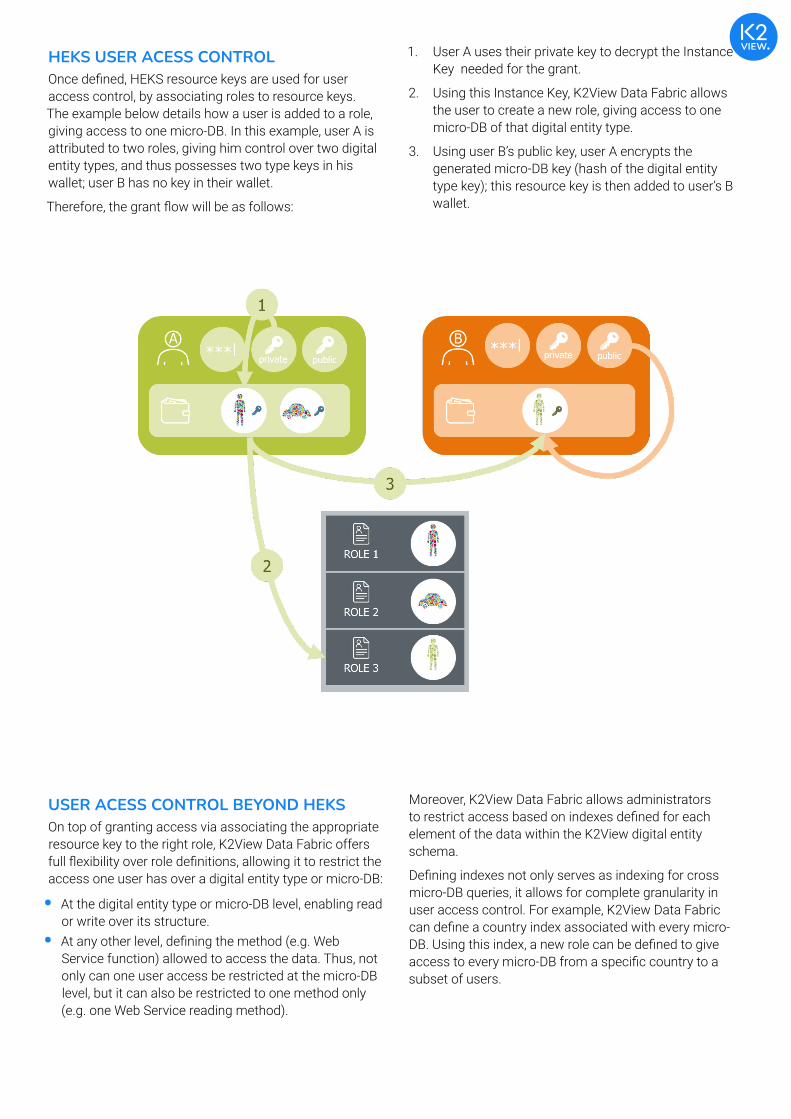
HEKS USER ACESS CONTROLOnce defined, HEKS resource keys are used for user access control, by associating roles to resource keys. The example below details how a user is added to a role, giving access to one micro-DB. In this example, user A is attributed to two roles, giving him control over two digital entity types, and thus possesses two type keys in his wallet; user B has no key in their wallet.
Therefore, the grant flow will be as follows:
1. User A uses their private key to decrypt the Instance Key needed for the grant.
2. Using this Instance Key, K2View Data Fabric allows the user to create a new role, giving access to one micro-DB of that digital entity type.
3. Using user B’s public key, user A encrypts the generated micro-DB key (hash of the digital entity type key); this resource key is then added to user’s B wallet.
USER ACESS CONTROL BEYOND HEKSOn top of granting access via associating the appropriate resource key to the right role, K2View Data Fabric offers full flexibility over role definitions, allowing it to restrict the access one user has over a digital entity type or micro-DB:
• At the digital entity type or micro-DB level, enabling read or write over its structure.
• At any other level, defining the method (e.g. Web Service function) allowed to access the data. Thus, not only can one user access be restricted at the micro-DB level, but it can also be restricted to one method only (e.g. one Web Service reading method).
Moreover, K2View Data Fabric allows administrators to restrict access based on indexes defined for each element of the data within the K2View digital entity schema.
Defining indexes not only serves as indexing for cross micro-DB queries, it allows for complete granularity in user access control. For example, K2View Data Fabric can define a country index associated with every micro-DB. Using this index, a new role can be defined to give access to every micro-DB from a specific country to a subset of users.

OVERVIEWK2View Data Fabric features an easy way to orchestrate data in and out of its scope, while applying the digital entity and micro-DB organization and processing capabilities described above. The goal of K2View Data Orchestration is to provide the ability to design data flows as a succession of Stages. Data processing is executed across Stages by pre-defined data operators that act as the building blocks of the flows and that can be assembled and combined to implement any required data processing.
K2View Data Orchestration provides:
• A flow management staging front-end, built from Stages, which are executed from left to right. A flow can be split into different execution paths based on conditions and loops according to the configurable logic path that matches your business process.
• A comprehensive and growing list of over one hundred pre-built operators (functions) for processing data. New operators can be developed in JavaScript for custom functionality.
• In debug mode, data can be visualized and traced along the different data orchestration flows.
EXTERNAL DATABASE OPERATORSK2View Data Orchestration provides a range of Database functions to interact with external interfaces such as:
• JDBC URLs
• References to predefined interfaces, Schemas,
• tables or fields in coordination with SQL commands
Data Orchestration also supports loading data into databases, with regular commands such as insert, update/upsert, and delete, and using appropriate.
DATA ORCHESTRATION OPERATORSMicro-DBs corresponding to digital entities stored in K2View Data Fabric can be: accessed, used, transformed, and exposed from the Data Orchestration pipeline manager. Once a specific operator is invoked, it sets the scope of the entire pipeline to a specific entity.
This is fully configurable so the same pipeline can be invoked and executed across multiple entities using batch operators.
LOGIC OPERATORSK2View Data Orchestration boasts an exhaustive list of built-in logic operators.
These allow to perform logic operations on operators and return Boolean values depending on the outcome.
Simple mathematical comparison for all type of data can be executed and influence the execution of subsequent stages.
Moreover, mathematic operators can be used, such as power, root, min, max or mod.
RegEX and string manipulations are also supported out-of-the-box to prepare and format data according to business requirements. Many more mathematical and logic functions can be added by creating new custom operators that can be stored and reused across pipelines and projects.
MASKING OPERATORSThese operators are used to mask sensitive information, such as SSN, credit card number, emails, sequences, zip codes, etc. For example:
• SSN masking will mask the original SSN by replacing it with a valid, yet fake SSN.
• Credit card masking will generate a fake (but valid) credit card number.
• Digital entity function masking will mask the input value of the function with the output resulting from the digital entity function execution. If the masked value is found in the masked values storage, the function will not be called.
PARSING & STREAMING OPERATORSVarious stream manipulation functions, such as compression, file reading or HTTPS streaming can be performed.
Data from files stored in a defined interface can be read and processed line by line and parsed according to the scheme corresponding to its format: JSON, XML, CSV, or plain text.
HTTPS streaming operators allow the connection to external web servers, thus providing the ability to enrich Data Orchestration flows with data originating from any external data sources, such as social media, weather, and finance APIs.
MISCELLANEOUSMany more operators for data maps or array creation, systems monitoring and statistics are available, and can be used in tandem with all the operators defined above.
DATA ORCHESTRATION

OVERVIEWK2View Test Data Management (K2View TDM) offers an automated means for provisioning realistic data subsets for digital entities into a test environment. Such data sets are generated from your production systems and provide high-quality data to testing teams.
K2View TDM relies on the K2View Data Fabric, which acts as (1) a test data warehouse for the provisioned test data, and (2) an ETL layer for extracting data from production sources and loading it to the target environment.
One of the main challenges of provisioning test data is that data is often fragmented between different data sources. For example, a Customer’s data may be stored in CRM, Billing, Ordering, Ticketing, Customer Feedback, and Collection systems. To run functional tests on a Customer in an integrative testing environment, their data must be extracted from all relevant source systems while maintaining referential integrity.
The K2View Data Fabric’s patented micro-DB, a data lake for each digital entity instance, ensures smooth data provisioning, based on the company’s business needs rather than extracting a complete copy of each data source.
KEY FEATURES
• Self-service web application where testers can request data to be provisioned on-demand.
• Test data warehouse of provisioned test data.
• Ability to transfer data into live testing environments.
• Data subset requests, re-deployment of data and data appending.
• Provisioning user-defined lists of business entity data from a selected source environment to a selected target environment. All data related to the selected entities is extracted and copied to the relevant data systems. This enables the provisioning of a sub-set of entities based on predefined parameters. For example, copying 10 customers in NY and using small business packages.
• Synthetic data generation, by cloning a given production entity into the target environment, while avoiding sequence duplication and ensuring referential integrity in the test environment.
• Automatic data security and masking on an entity-by-entity basis.
• Updating schemes from selected entities.K2View TDM features a “Data Flux” that provides the ability to roll-back test data from a specific version:
• Testers can save specific versions of a selected list of entities or selected list of metadata (reference) tables.
• Testers can load a selected version of entities or metadata tables to the selected target environment.
• Provisioning of data on-demand or automatic provisioning based on scheduling parameters. For example, provisioning the data automatically every week.
TDM ARCHITECTURE
TEST DATA MANAGEMENT GUI ADMINThe K2View TDM web application offers the testing manager the ability to perform the following activities:
• Defining business entities, environments, roles, and permissions.
• Creating and executing K2View TDM tasks that provide a selected subset of entities or reference tables to the selected environment.
K2VIEW TDM DATABASEK2View TDM settings and tasks are managed in the TDM PostgreSQL DB. Both the K2View TDM GUI and K2View Data Fabric connect to the K2View TDM DB to get or update settings or tasks.
TEST DATA MANAGEMENT

OVERVIEWK2View Data Privacy Management (K2View DPM) provides the tools needed to configure, manage, and audit Data Subject Access Requests associated with data privacy regulations such as GDPR, CCPA, LGPD, and others.
K2View DPM is highly configurable to support regulation rules, workflows, and data access requirements associated with privacy compliance.
K2View DPM is composed of two main components that ensure the end-to-end lifecycle of any data privacy-related requests, from request submission to fulfilment, including SLA management, dashboards, and data audits:
DATA PRIVACY CONFIGURATION Data Privacy policies and rules are managed via the K2View DPM Admin module, to configure the system.
Through this module, the administrator can define all data privacy management aspects:
• Supported regulations
• Types of requests that can be made for each regulation
• Task flows required for the fulfilment of each request, consent configuration, and more.
• DSAR & CONSENT MANAGEMENT
• This is where role-based schemes that serve different users, are defined:
• Call center Representatives, who handle data requests,
• Data Stewards, who execute the requests,
• Case Owners, responsible for the successful completion of the requests under their responsibility
• Supervisors, who distribute requests to Case Owners.
K2View DPM covers the end-to-end lifecycle of Consent management, including:
• Consent configuration
• Customer consent preferences management
• Central consent repository
• Third-parties integration, and moreConsent topic is fully configurable by means of user-friendly web-based user interface.
Customers can review, accept, or withdraw consents using a self-service web-based application. All changes are recorded for monitoring and auditing purposes on a per-customer basis – within a micro-DB, with a full historical view of customer consent actions.
The data can be exposed to authorized users or applications via APIs, files, publish/subscribe technologies such as Kafka and more, or stored for regulation compliancy and evidence management.
DPM ENTITIES K2View DPM require users to define the following objects
in order for the system to learn the rules, roles and policies at play in your data compliancy scheme:
• Regulations – used to capture the rules pertaining to a specific Data Privacy policy
• Activities – used to represent all the actions allowed by customers with regards to their data, as per defined in the legislation (right to be forgotten, right to access or modify data)
• Flows – responsible to execute the request that corresponds to one of the activities above-defined
• Stages – the building block of a flow
• Tasks – lowest granularity for one of the many actions performed in an activity such as:
• Send email to customer
• Gather customer data
• Check request validity
ROLESK2View DPM is a role-based application. Each user is associated with one or more roles. The role determines the Activities the user can perform in the system.
The roles are structured in two layers:
• DPM Application Roles – each application role includes a set of DPM functionality a user can perform.
• Corporate Roles – Configurable roles defined by the corporation to represent the corporate organizational structure for DPM users.
Rich UI AND CONTROLSK2View DPM provides different views and dashboards to display the relevant information and statistics to the role assigned to the user.
DATA PRIVACY MANAGEMENT

OVERVIEWConfiguring, monitoring, and administrating K2View Data Fabric is performed through two set of tools:
• Using K2View Admin Manager, K2View Studio, K2View Web Admin.
• Using the distributed database native administration capabilities.
This section will present the list of functionalities provided by K2View Fabric administration and configuration tools.
K2VIEW ADMIN MANAGER
• Version control administration: define repositories and developer access to K2View Fabric configuration. Developer access is restricted via password, and can be granular to any level of the configuration.
• K2View Data Fabric services control: start/stop of K2View Data Fabric’s services.
K2VIEW FABRIC STUDIO
• Digital entity type definition
• Digital entity schema configuration
• Sync Policy configuration
• Data Enrichment/ETL rules
• Data masking rules
• Index configuration
• Deployment to K2View Data Fabric environment
• Commit/update to and from Version Control repository
K2VIEW WEB ADMIN
• Query executions
• Index definition
• User management
• Role and permission management
• Nodes administration
OVERVIEWK2View Data Fabric does not require storage of all data in memory or expensive hardware for scaling up performance. K2View Data Fabric’s low total cost of ownership (TCO) relies on three simple cornerstones:
• In-Memory performance on commodity hardware
• Complete linear scalability
• Risk-free integrationThis section will reviews this hardware configuration; it is intended to provide a benchmark of performance per hardware type.
MINIMUM REQUIREMENTSAs mentioned, K2View Data Fabric can run on commodity hardware; therefore, the minimum requirements to install K2View Data Fabric are easily accessible.
K2View Data Fabric is installed on two servers:
• One Linux Server to manage the server node.
• One Windows Server to run the administration and configuration tools described in the previous section.
The minimum requirements for the Linux cluster are:
• CentOS 6.5 OS or Redhat 6.5 with latest patches.
• Modern Xeon Processor.
• 4 nodes x 4 cores.
• 32GB RAM.
• HDD, select one of the following two options:
• 2 Physical HDD, 500GB each, RAID0 configuration.
• 2 500GB SSD.
It is very important to note that K2View Data Fabric stores data on disk and not in memory (only current operations are done in memory). Using regular disk storage is a contributing factor to K2View Data Fabric’s low TCO, as opposed to other distributed high-end performances databases that store all data in memory, and thus requiring massive amounts of RAM.
The minimum requirements for the Windows server are:
• Windows Version – Any one of the following:
• Windows Server 2008 r2 64bit Machine
• Windows 7 64Bit or Windows 8 64Bit1 CPU
• 4GB RAM
• 100GB Available Disk Space
ADMINISTRATION
TOTAL COST OF OWNERSHIP

LINEAR SCALABILTYK2View Data Fabric’s linear scalability is ensured by the proven linear scalability of its underlying distributed database (Cassandra).
RISK-FREE INTEGRATIONAs explained at the beginning of this paper, and on top of the actual costs associated with a new system purchase (hardware, licenses, etc.), one major cost component of any data management system is its integration into an existing IT eco-system. Indeed, integrating a new system is not only very costly, it can also present an elevated risk for organizations provisioning applications to millions of its customers.
K2View Fabric inherently drives integration costs to a minimum:
• Data migration is fully automated by the embedded ETL layer without impact on source systems
• Flexible synchronization allows progressive legacy systems retirement
• SQL support does not require any learning curve for database user
• Embedded Web-Services allows integration without changes on database applications
These features make integrating K2View Fabric into any IT environment a risk free operation.
This paper has detailed the key components of the K2View Data Fabric, and how they contribute to making it a next generation distributed data management system – an operational data fabric.
Indeed, while K2View Data Fabric solves the big data problem established in the introduction, it also delivers risk-free integration within an existing IT eco-system and uses a revolutionary business-oriented way to present data: the digital entity. K2View’s patented digital entity and micro-DB technologies lend to the data fabric’s high-scale, high-performance, high-availability, and fully secure architecture.
Moreover, K2View Data Fabric offers unprecedented features: ease of configuration, full SQL support, embedded data services, flexible synchronization, performance-oriented processing engine and complete security granularity.
To learn more about K2View Data Fabric, refer to K2View’s website: www.k2view.com
ABOUT K2VIEWK2View provides an operational data fabric dedicated to making every customer experience personalized and profitable.
The K2View platform continually ingests all customer data from all systems, enriches it with real-time insights, and transforms it into a patented Micro-DB™ - one for every customer. To maximize performance, scale, and security, every micro-DB is compressed and individually encrypted. It is then delivered in milliseconds to fuel quick, effective, and pleasing customer interactions.
Global 2000 companies – including AT&T, Vodafone, Sky, and Hertz – deploy K2View in weeks to deliver outstanding multi-channel customer service, minimize churn, achieve hyper-segmentation, and assure data compliance.
CONTACT INFORMATION
• www.k2view.com
• +1-844-438-2443
CONCLUSION

CONFIDENTIALITYThis document contains copyrighted work and proprietary information belonging to K2View.
This document and information contained herein are delivered to you as is, and K2View makes no warranty whatsoever as to its accuracy, completeness, fitness for a particular purpose, or use. Any use of the documentation and/or the information contained herein, is at the user’s risk, and K2View is not responsible for any direct, indirect, special, incidental, or consequential damages arising out of such use of the documentation. Technical or other inaccuracies, as well as typographical errors, may occur in this Guide.
This document and the information contained herein and any part thereof are confidential and proprietary to K2View. All intellectual property rights (including, without limitation, copyrights, trade secrets, trademarks, etc.) evidenced by or embodied in and/or attached, connected, or related to this Guide, as well as any information contained herein, are and shall be owned solely by K2View. K2View does not convey to you an interest in or to this Guide, to information contained herein, or to its intellectual property rights, but only a personal, limited, fully revocable right to use the Guide solely for reviewing purposes. Unless explicitly set forth otherwise, you may not reproduce by any means any document and/or copyright contained herein.
Information in this Guide is subject to change without notice. Corporate and individual names and data used in examples herein are fictitious unless otherwise noted.
Copyright © 2015 K2View Ltd./K2VIEW LLC. All rights reserved. The following are trademark of K2View:
K2View logo, K2View’s platform.
K2View reserves the right to update this list from time to time.
Other company and brand products and service names in this document are trademarks or registered trademarks of their respective holders.
CONTACT INFORMATION
• www.k2view.com
• +1-844-438-2443





























