Embed Size (px)
Citation preview

K-Clustering Coresets
Sagi Hed
9th Dec 2008
, , ,
• “Bi-Criteria Linear-Time Approximations for Generalized k-Mean/Median/Center”(Danny Feldman, Amos Fiat, Micha Sharir, Danny Segev)
• “Smaller Coresets for k-Median an k-Means Clustering”(Sariel Har-Peled, Akash Kushal)

Coresets Approach
• Not exactly sublinear time algorithm!
•
Instead of working on input, work on an alternative, very small, but indistinguishable input
• Create small coreset in streaming algorithm
•
Coreset will allow infinite various queries in sub-linear time..
, , ,
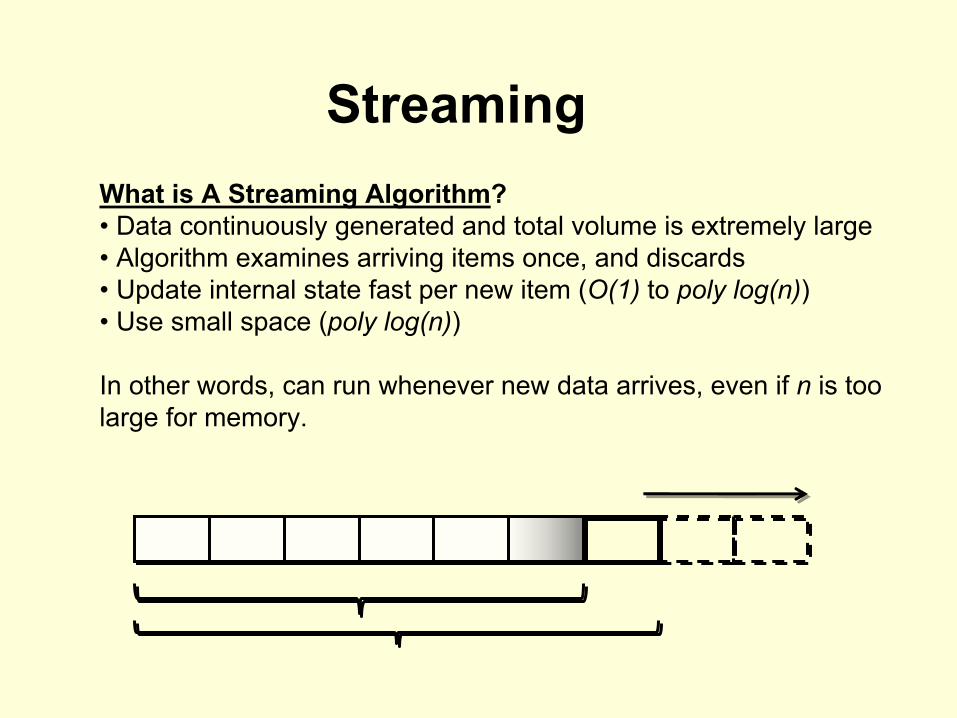
StreamingWhat is A Streaming Algorithm?• Data continuously generated and total volume is extremely large• Algorithm examines arriving items once, and discards• Update internal state fast per new item (O(1)
to poly log(n))• Use small space (poly log(n))
In other words, can run whenever new data arrives, even if n
is too large for memory.

CoresetsWhat is a Coreset?A subset of input, such that we can get a good approximation to the original input by solving the problem directly on the coreset.
Since the coreset is very small, typically poly-logarithmic, we can do this even with exhaustive search.
Coreset
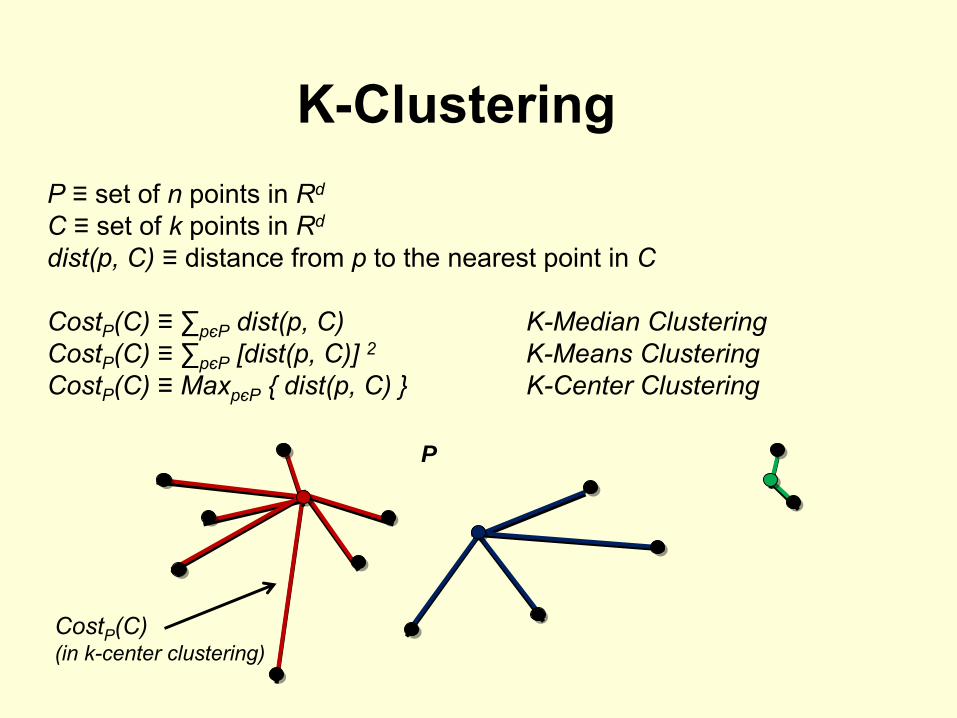
K-ClusteringP
≡
set of n
points in Rd
C
≡
set of k
points in Rd
dist(p, C)
≡
distance from p
to the nearest point in C
CostP
(C) ≡ ∑pєP
dist(p, C)
K-Median ClusteringCostP
(C) ≡ ∑pєP
[dist(p, C)] 2
K-Means ClusteringCostP
(C) ≡
MaxpєP
{ dist(p, C) }
K-Center Clustering
CostP
(C)(in k-center clustering)
P
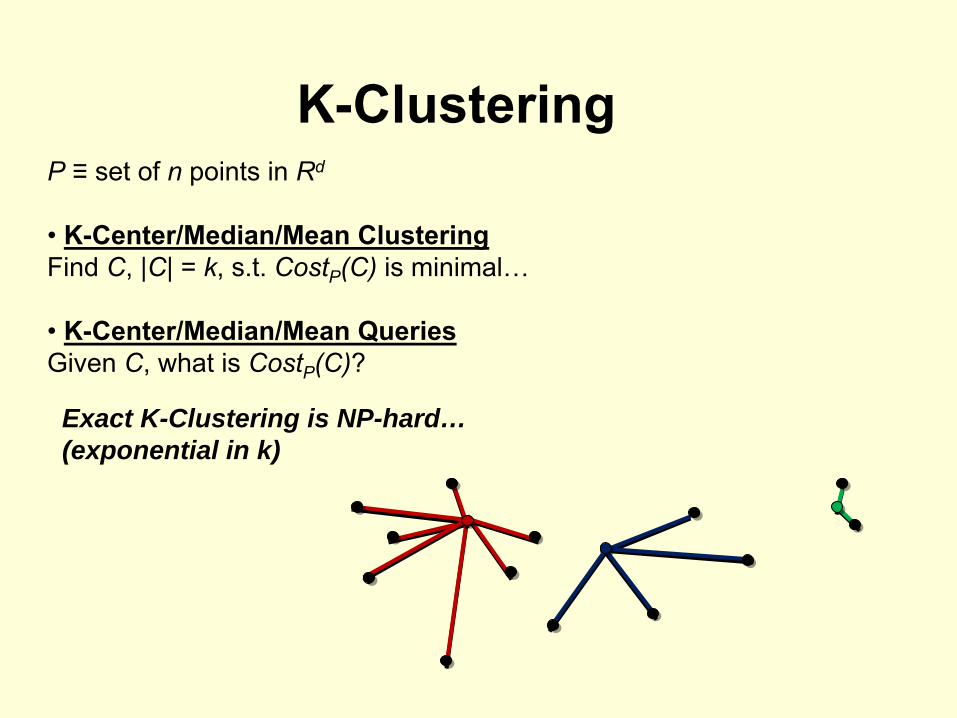
K-ClusteringP
≡
set of n
points in Rd
• K-Center/Median/Mean ClusteringFind C, |C| = k, s.t. CostP
(C)
is minimal…
• K-Center/Median/Mean QueriesGiven C, what is CostP
(C)?
Exact K-Clustering is NP-hard… (exponential in k)
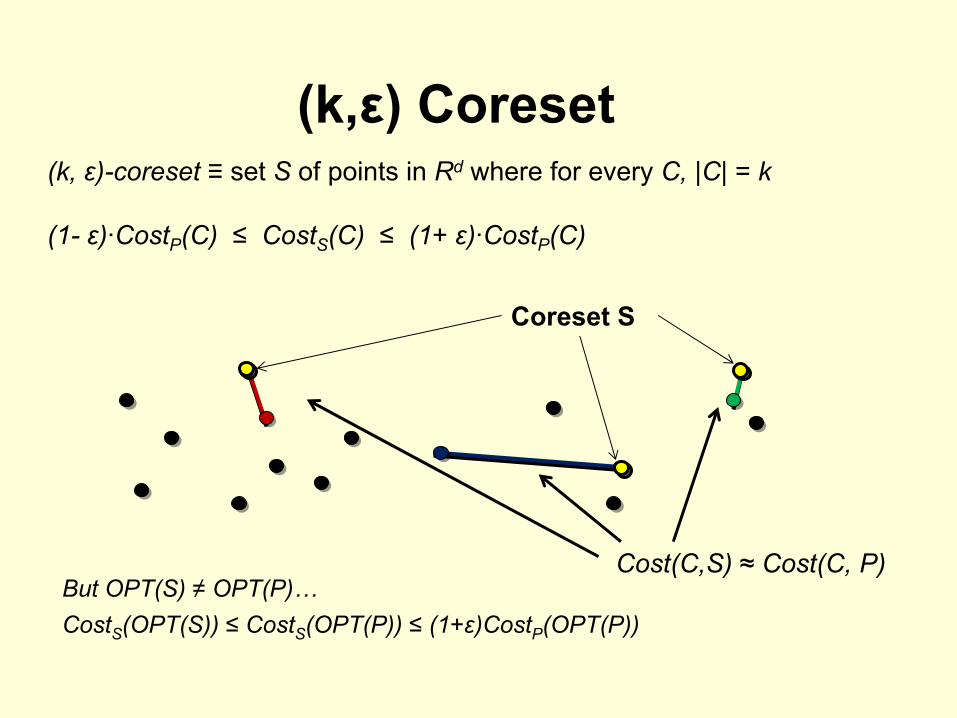
(k,ε) Coreset(k, ε)-coreset ≡
set S
of points in Rd
where for every C, |C| = k
(1-
ε)·CostP
(C) ≤
CostS
(C) ≤
(1+
ε)·CostP
(C)
Coreset S
Cost(C,S) ≈
Cost(C, P)
CostS
(OPT(S)) ≤
CostS
(OPT(P)) ≤
(1+ε)CostP
(OPT(P))But OPT(S) ≠
OPT(P)…
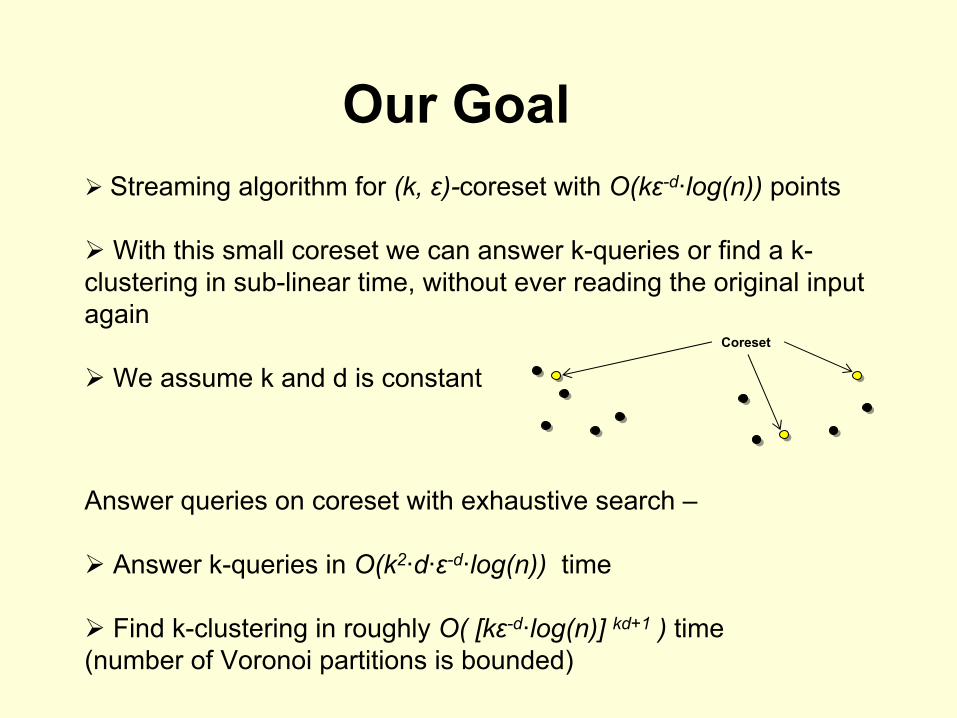
Our GoalStreaming algorithm for (k, ε)-coreset with O(kε-d·log(n)) points
With this small coreset we can answer k-queries or find a k-clustering in sub-linear time, without ever reading the original input again
We assume k and d is constantCoreset
Answer queries on coreset with exhaustive search –
Answer k-queries in O(k2·d·ε-d·log(n)) time
Find k-clustering in roughly O( [kε-d·log(n)] kd+1 ) time (number of Voronoi partitions is bounded)

K-Clustering Coresets
Order Of Business:
1. Coreset Streaming Reduction
2.
Bi-Criteria K-Clustering Approximation
3.
K-Center Coresets Using Bi-Criteria K-Clustering
4.
K-Means/Median Coresets Using Hand Waving

Coreset Streaming Reduction
Input
A (k,ε)-coreset creation algorithm for k-clustering, creating coresets of size O(k(1/ε)d)
in O(d·n·k)
OutputA Streaming (k,ε)-coreset creation algorithm for k-center clustering, creating coresets of size O(k(1/ε)dlog(n)),
that works in time O(polylog(k,1/ε))
per insertion
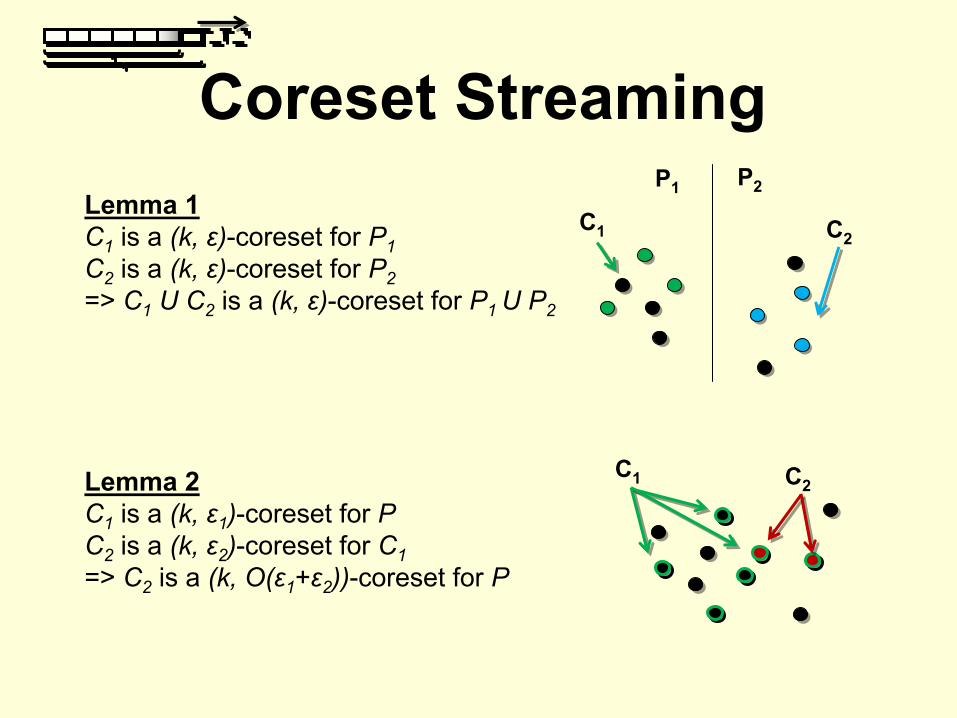
Coreset StreamingLemma 1C1
is a (k, ε)-coreset for P1C2
is a (k, ε)-coreset for P2=> C1
U C2
is a (k, ε)-coreset for P1 U P2
C2C1
P1 P2
C2C1Lemma 2
C1
is a (k, ε1
)-coreset for PC2
is a (k, ε2
)-coreset for C1=> C2
is a (k, O(ε1
+ε2
))-coreset for P
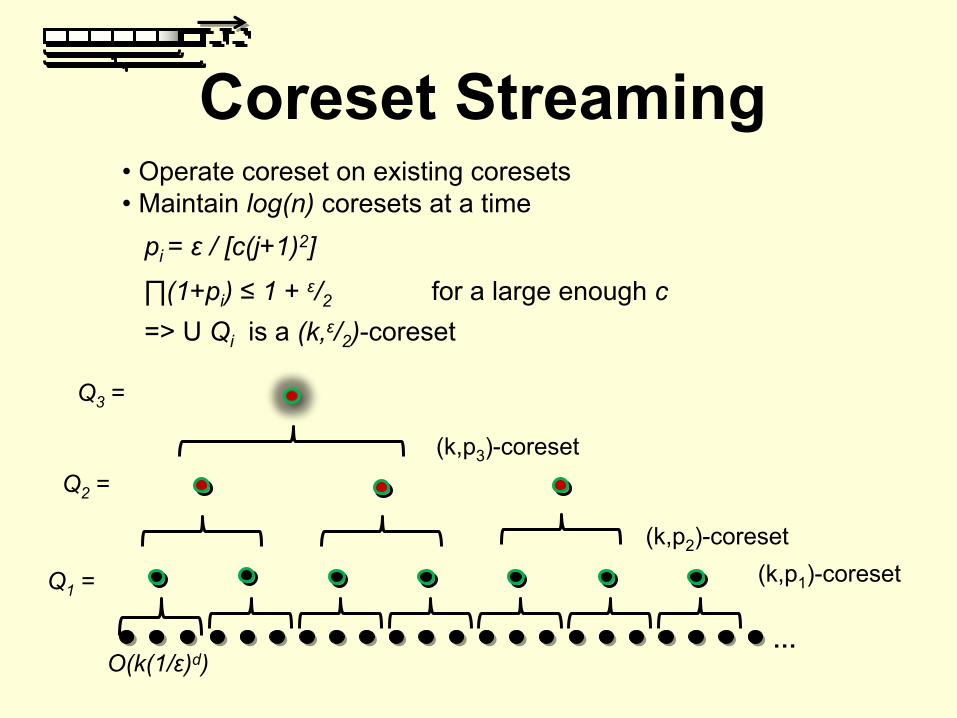
Coreset Streaming
…
• Operate coreset on existing coresets• Maintain log(n) coresets at a time
(k,p1
)-coreset(k,p2
)-coreset
(k,p3
)-coreset
pi = ε
/ [c(j+1)2]
∏(1+pi
) ≤
1 + ε/2
for a large enough c=> U Qi
is a (k,ε/2
)-coreset
O(k(1/ε)d)
Q3
=
Q2
=
Q1
=

Coreset StreamingSpace ComplexitySpace for algorithm is –∑1 ≤
j ≤
log(n)
O([c(j+1)2d] / εd) = O(polylog(n))
Coreset SizeBuild Ri
= (k, ε/6)-coreset from every QiU Ri
= still a (k, ε)-coreset for all points|U Ri
|
= ∑1 ≤
j ≤
log(n)
O((6/ε)d) = O((1/ε)dlog(n))=> actual coreset (for exhaustive search) is smaller
Time ComplexityRequires an amortized analysis similar to that of a binary counter=> O(polylog(k,1/ε))
per insertion
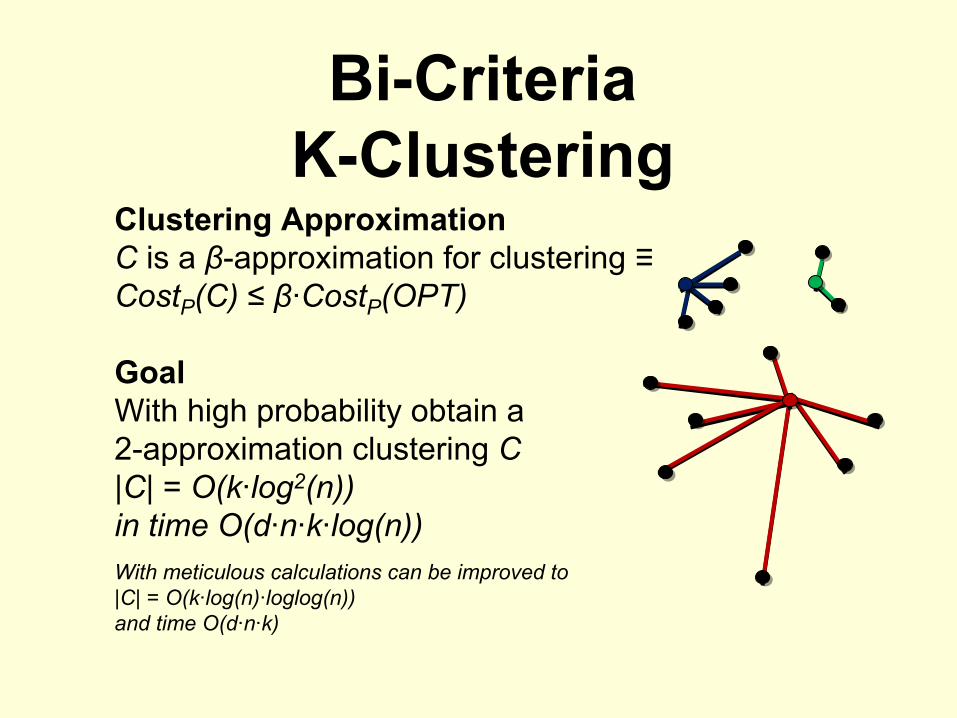
Bi-CriteriaK-Clustering
Clustering ApproximationC
is a β-approximation for clustering ≡
CostP
(C) ≤ β·CostP
(OPT)
GoalWith high probability obtain a2-approximation clustering C|C| = O(k·log2(n))in time O(d·n·k·log(n))With meticulous calculations can be improved to|C| = O(k·log(n)·loglog(n))and time O(d·n·k)
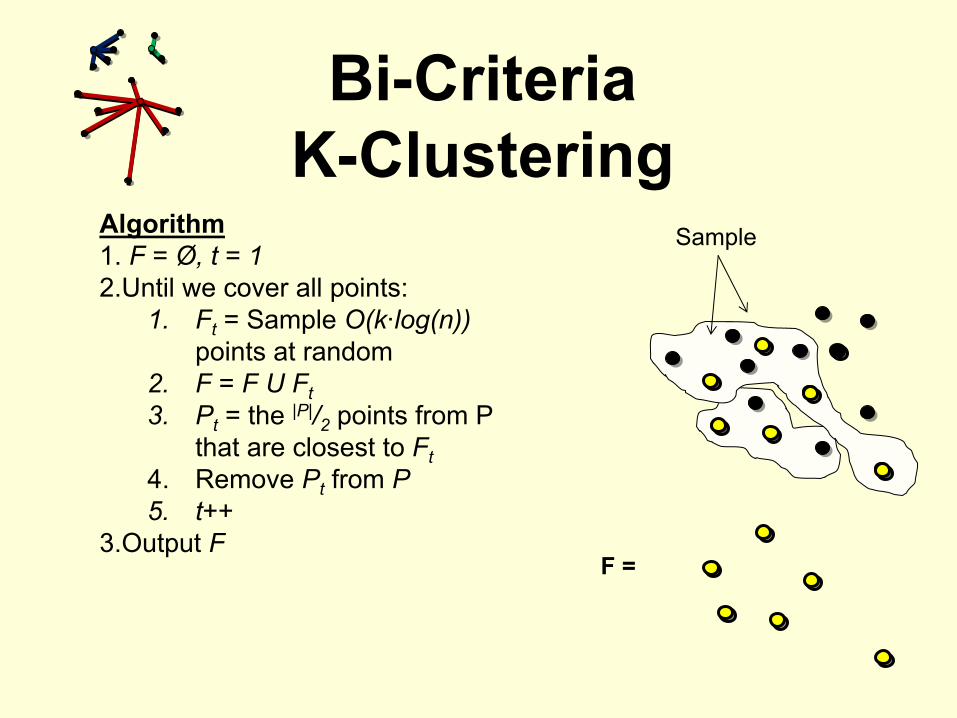
Algorithm1. F = Ø, t = 12.Until we cover all points:
1.
Ft
= Sample O(k·log(n))
points at random2.
F = F U Ft3.
Pt
= the |P|/2
points from P that are closest to Ft
4.
Remove Pt
from P5.
t++3.Output F
Bi-CriteriaK-Clustering
Sample
F =
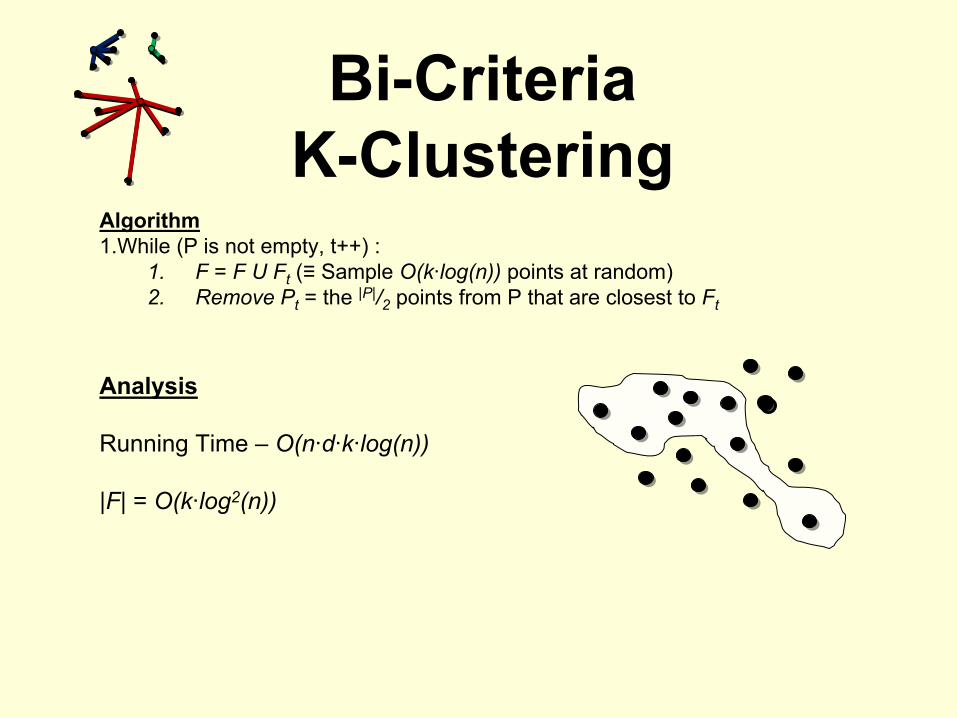
Algorithm1.While (P is not empty, t++) :
1.
F = F U Ft
(≡
Sample O(k·log(n))
points at random)2.
Remove Pt
= the |P|/2
points from P that are closest to Ft
Bi-CriteriaK-Clustering
Analysis
Running Time –
O(n·d·k·log(n))
|F| = O(k·log2(n))
good point
Bi-CriteriaK-Clustering
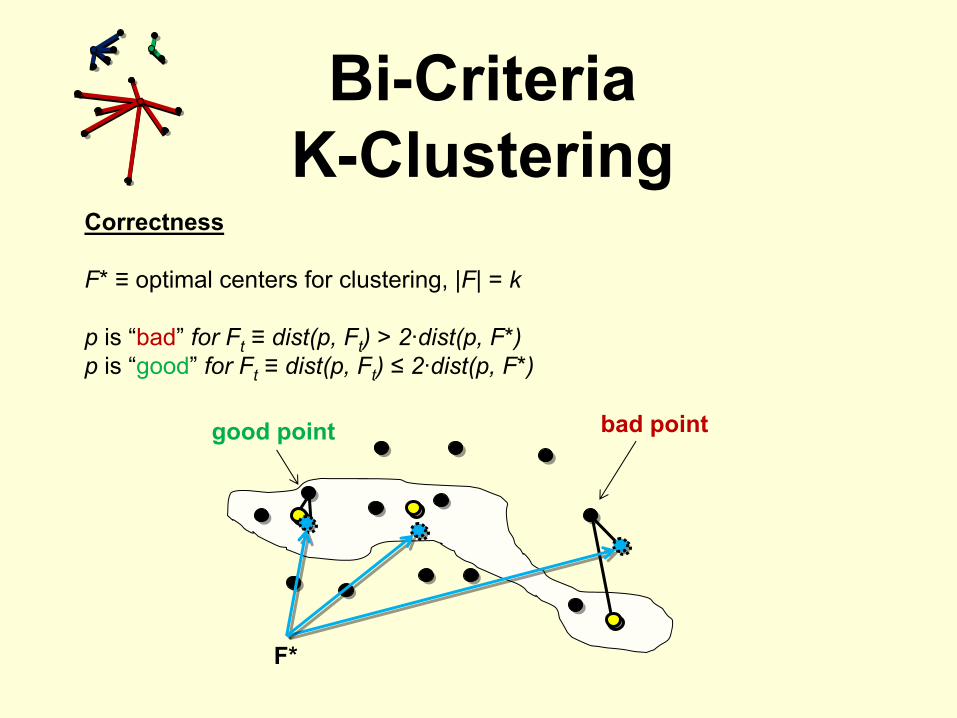
Correctness
F* ≡
optimal centers for clustering, |F| = k
p
is “bad”
for Ft
≡
dist(p, Ft
) > 2·dist(p, F*)p
is “good”
for Ft
≡
dist(p, Ft
) ≤
2·dist(p, F*)
F*
bad point
Bi-CriteriaK-Clustering
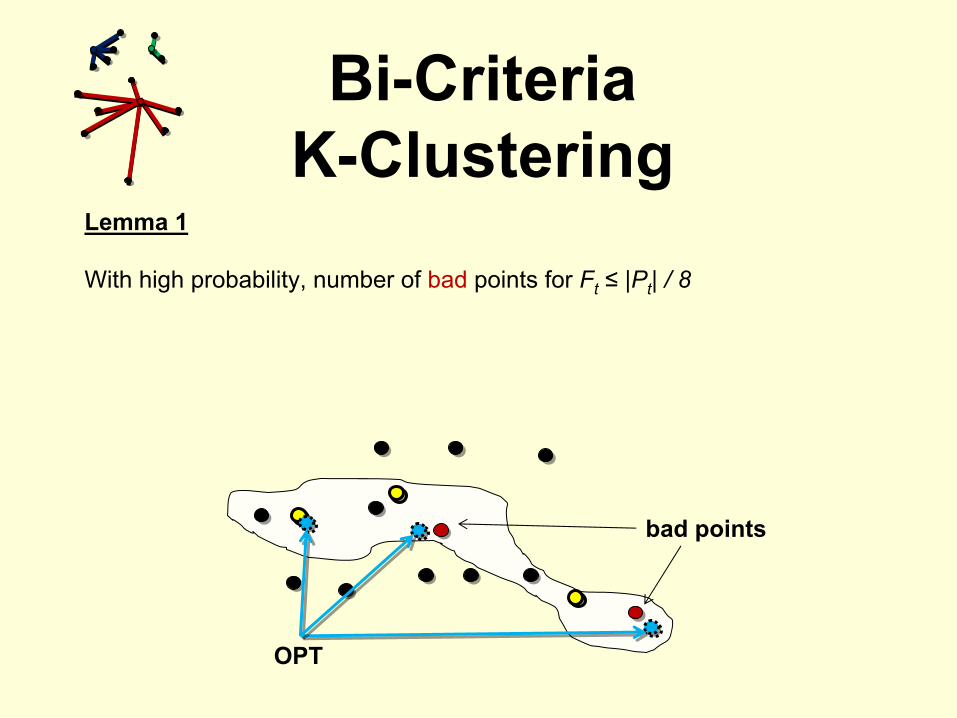
Lemma 1
With high probability, number of bad
points for Ft
≤
|Pt
| / 8
OPT
bad points
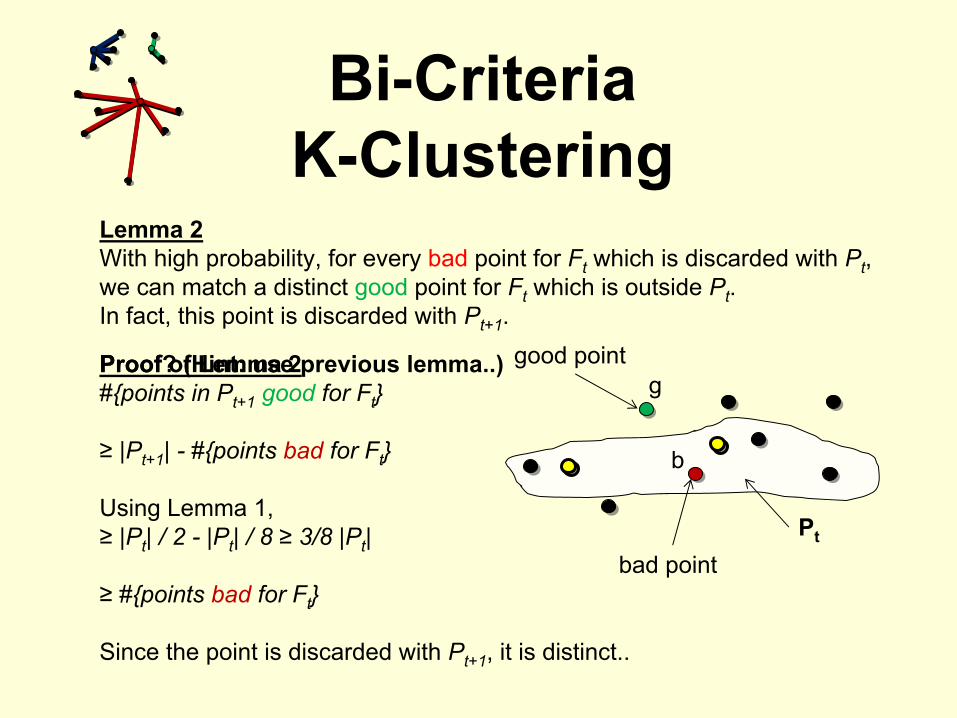
Lemma 2With high probability, for every bad
point for Ft
which is discarded with Pt
, we can match a distinct good
point for Ft
which is outside Pt
.In fact, this point is discarded with Pt+1
.
bad point
good point
Pt
g
b
Bi-CriteriaK-Clustering
Proof of Lemma 2#{points in Pt+1
good
for Ft
}
≥
|Pt+1
| -
#{points bad
for Ft
}
Using Lemma 1,≥
|Pt
| / 2 -
|Pt
| / 8 ≥
3/8 |Pt
|
≥
#{points bad
for Ft
}
Since the point is discarded with Pt+1
, it is distinct..
Proof? (Hint: use previous lemma..)
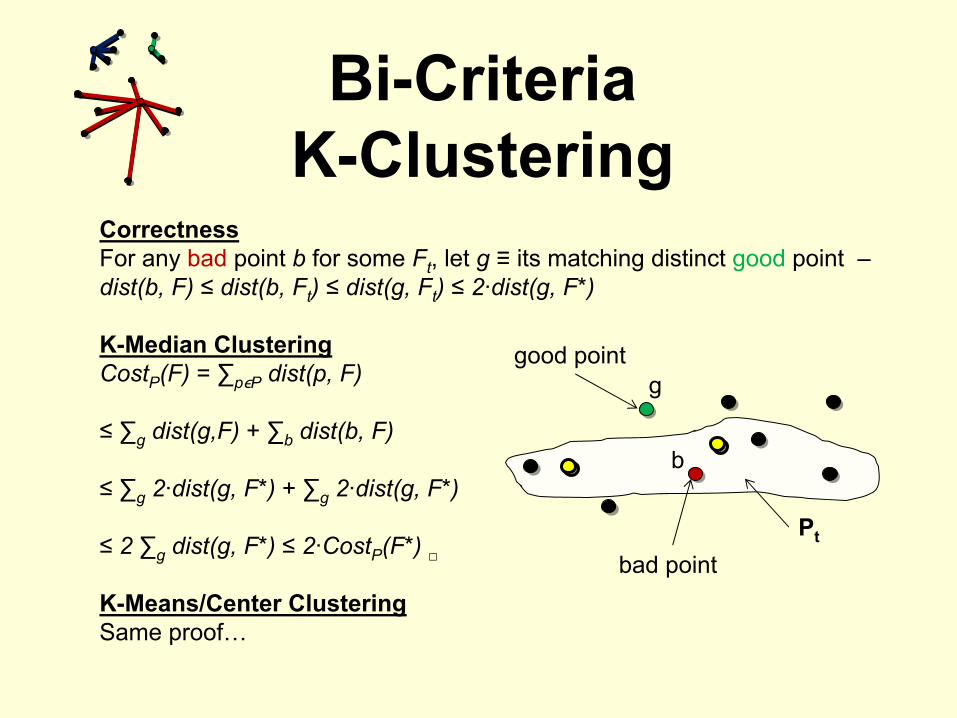
CorrectnessFor any bad
point b
for some Ft
, let g
≡
its matching distinct good
point –dist(b, F) ≤
dist(b, Ft
) ≤
dist(g, Ft
) ≤
2·dist(g, F*)
K-Median ClusteringCostP
(F) = ∑pϵP
dist(p, F)
≤ ∑g
dist(g,F) + ∑b
dist(b, F)
≤ ∑g
2·dist(g, F*) + ∑g
2·dist(g, F*)
≤
2 ∑g
dist(g, F*) ≤
2·CostP
(F*) □
K-Means/Center ClusteringSame proof…
bad point
good point
Pt
g
b
Bi-CriteriaK-Clustering
Bi-CriteriaK-Clustering
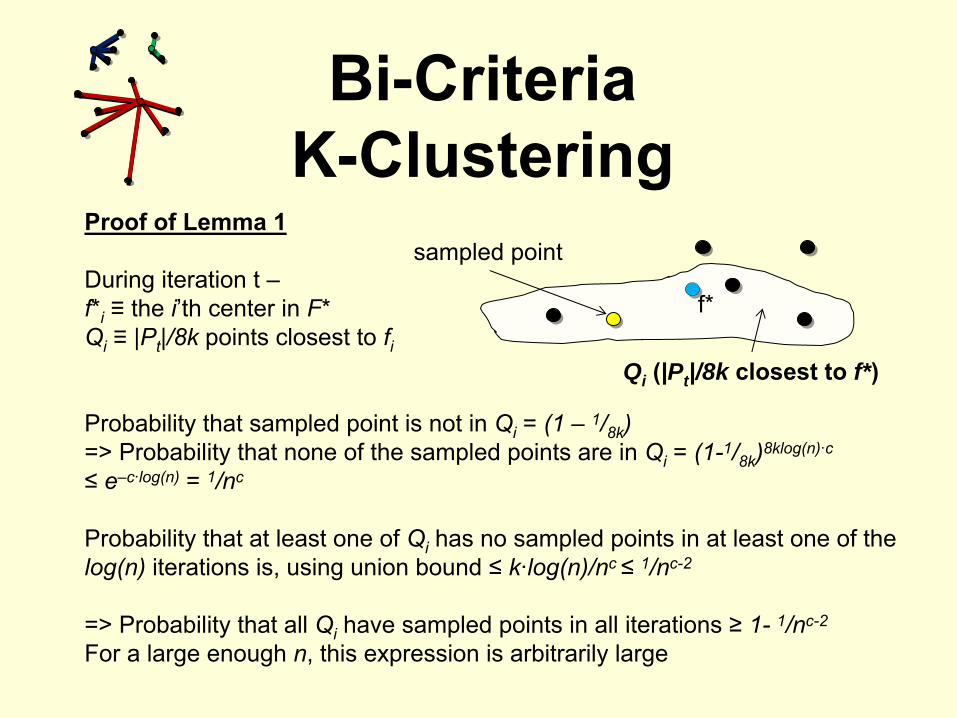
Proof of Lemma 1
During iteration t –f*i
≡
the i’th center in F*Qi
≡
|Pt
|/8k
points closest to fi
Probability that sampled point is not in Qi
= (1 –
1/8k
)=> Probability that none of the sampled points are in Qi
= (1-1/8k
)8klog(n)·c
≤
e–c·log(n)
= 1/nc
Probability that at least one of Qi
has no sampled points in at least one of the log(n)
iterations is, using union bound ≤
k·log(n)/nc ≤
1/nc-2
=> Probability that all Qi
have sampled points in all iterations ≥
1-
1/nc-2
For a large enough n, this expression is arbitrarily large
sampled point
Qi (|Pt |/8k closest to f*)
f*
Bi-CriteriaK-Clustering
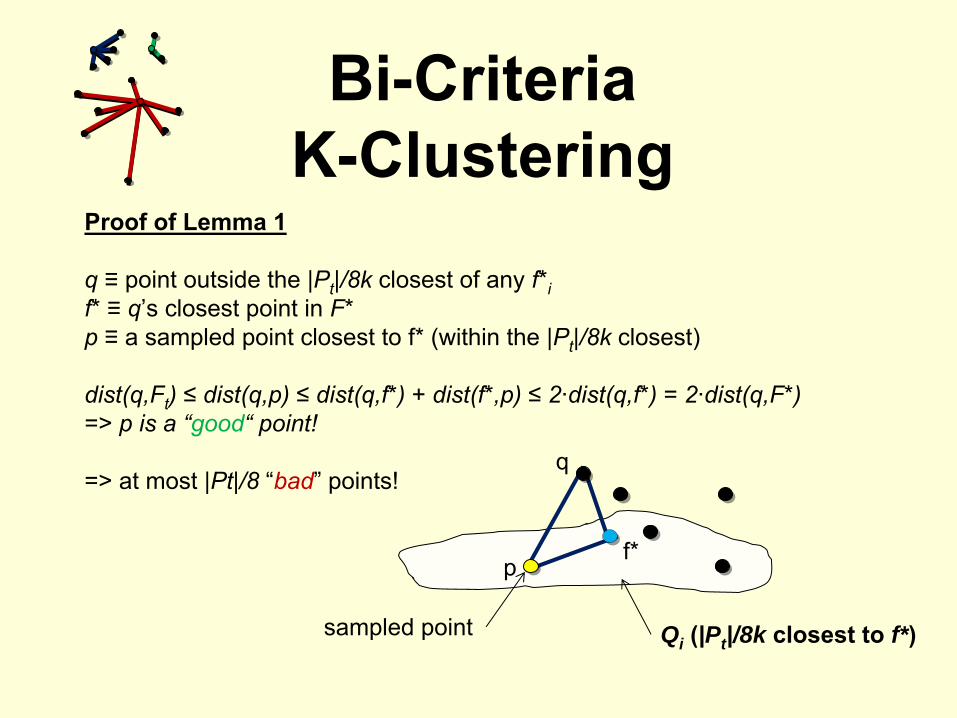
Proof of Lemma 1
q ≡
point outside the |Pt
|/8k
closest of any f*if* ≡
q’s closest point in F*p ≡
a sampled point closest to f* (within the |Pt
|/8k
closest)
dist(q,Ft
) ≤
dist(q,p) ≤
dist(q,f*) + dist(f*,p) ≤
2·dist(q,f*) = 2·dist(q,F*)=> p is a “good“
point!
=> at most |Pt|/8 “bad”
points!
sampled point Qi (|Pt |/8k closest to f*)
q
f*p

Careful
Can amplify the probability more by making attempts and choosing
F
with lowest CostP
(F)..
Need to be careful with probabilities and streaming reduction..
□
Bi-CriteriaK-Clustering
Generalizes to j-flats in d dimensions instead of points (open problem to construct coresets for these)
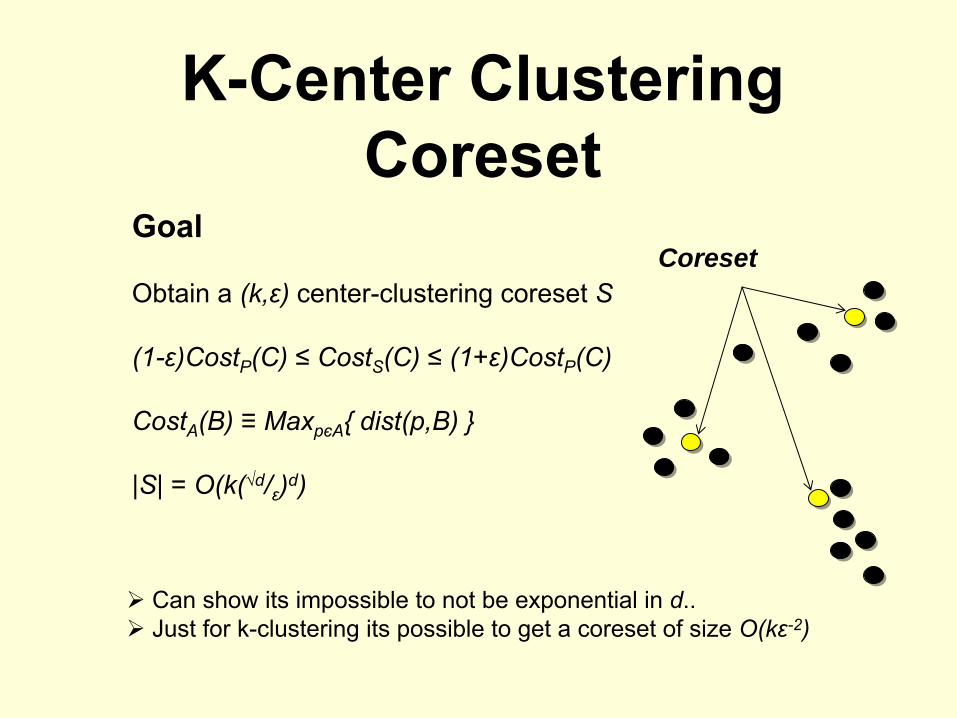
K-Center Clustering Coreset
Goal
Obtain a (k,ε)
center-clustering coreset S
(1-ε)CostP
(C) ≤
CostS
(C) ≤
(1+ε)CostP
(C)
CostA
(B) ≡
MaxpєA
{ dist(p,B) }
|S| = O(k(√d/ε
)d)
Coreset
Can show its impossible to not be exponential in d..Just for k-clustering its possible to get a coreset of size O(kε-2)
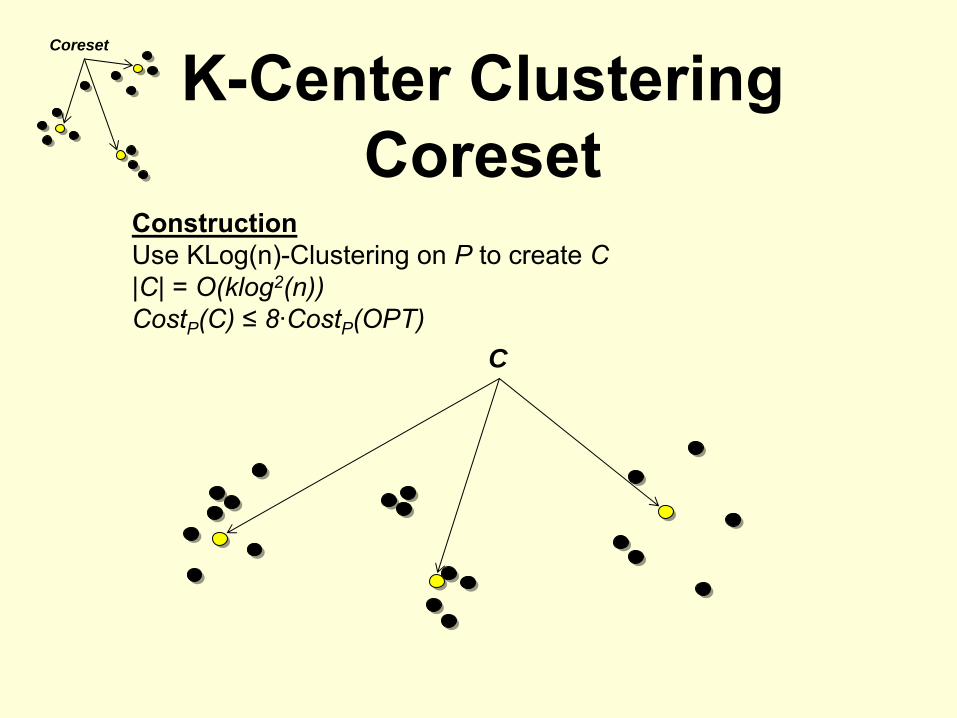
K-Center Clustering Coreset
Coreset
ConstructionUse KLog(n)-Clustering on P
to create C|C| = O(klog2(n))CostP
(C) ≤
8·CostP
(OPT)C
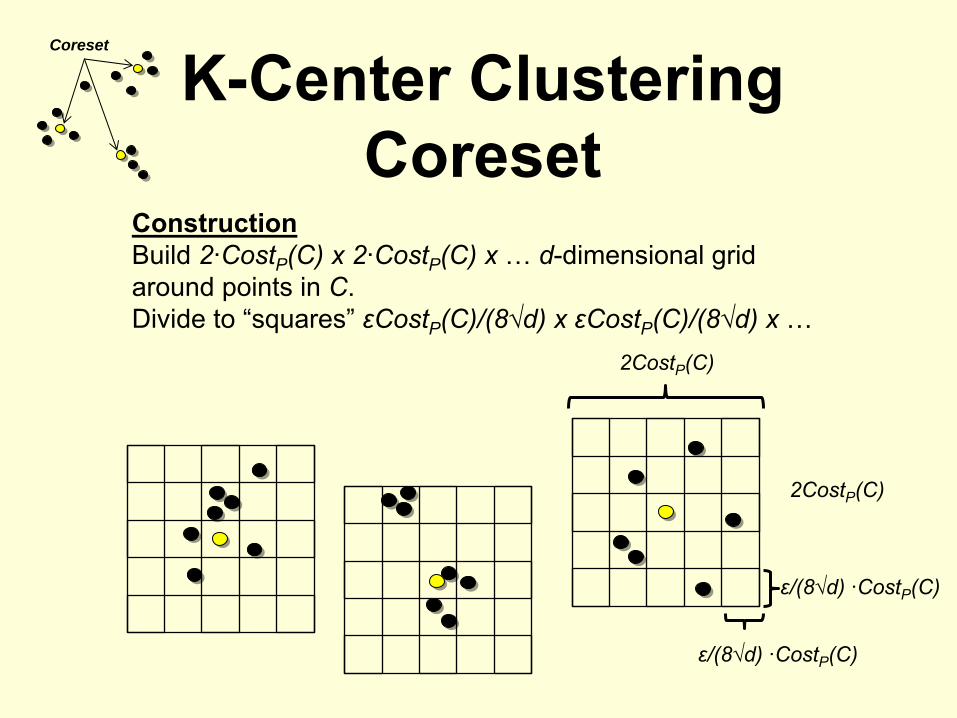
K-Center Clustering Coreset
Coreset
ConstructionBuild 2·CostP
(C) x 2·CostP
(C) x
… d-dimensional grid around points in C.Divide to “squares”
εCostP
(C)/(8√d) x εCostP
(C)/(8√d) x …2CostP
(C)
2CostP
(C)
ε/(8√d) ·CostP
(C)
ε/(8√d) ·CostP
(C)
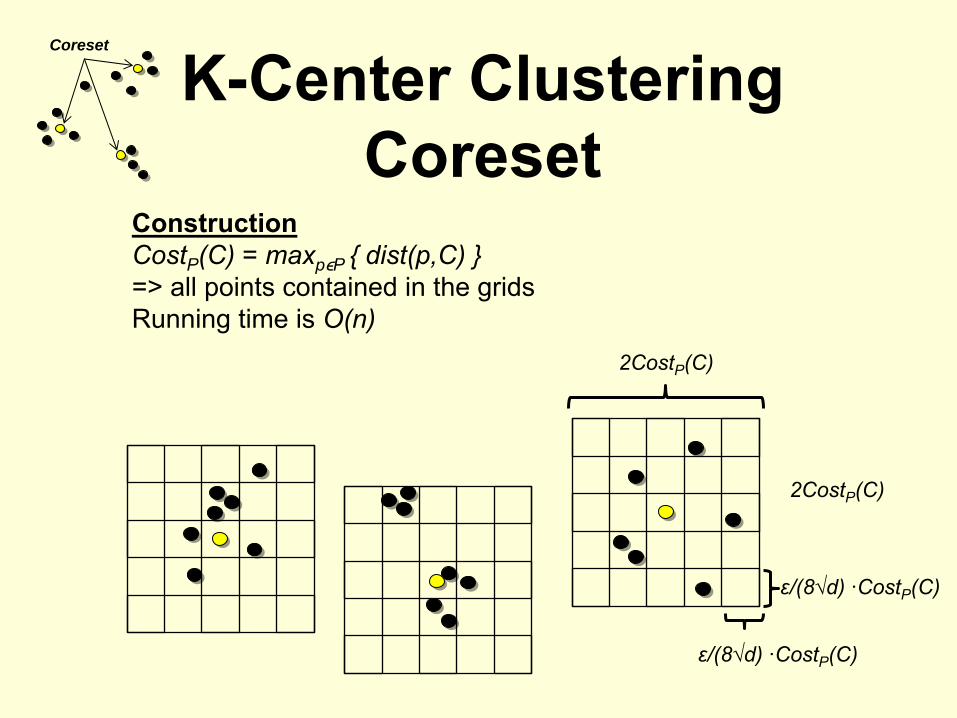
K-Center Clustering Coreset
Coreset
ConstructionCostP
(C) = maxpϵP { dist(p,C) }=> all points contained in the gridsRunning time is O(n)
2CostP
(C)
2CostP
(C)
ε/(8√d) ·CostP
(C)
ε/(8√d) ·CostP
(C)
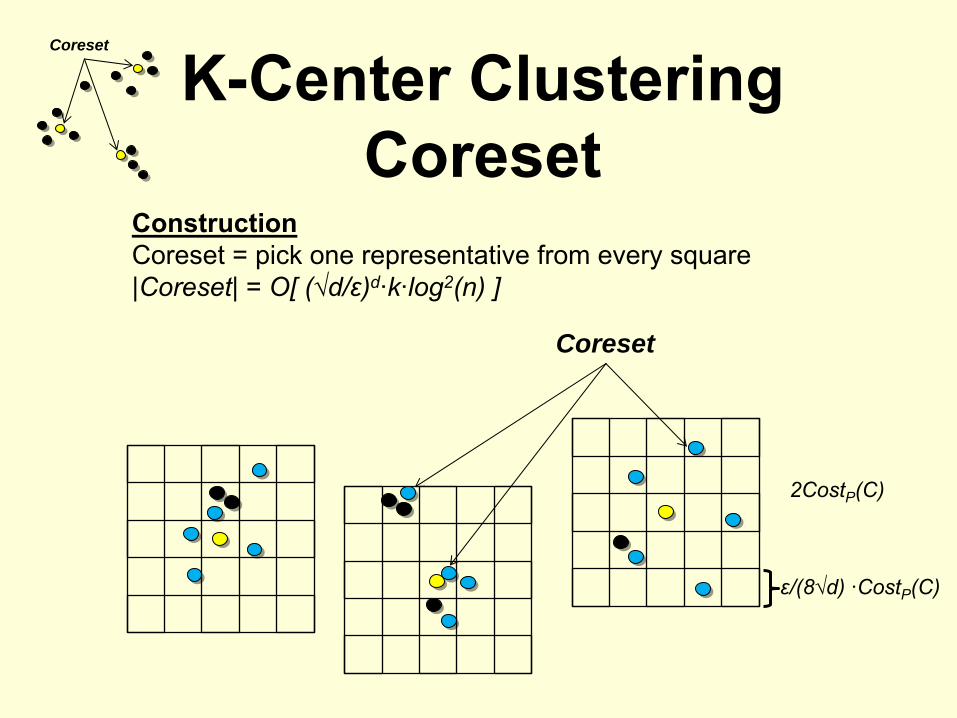
K-Center Clustering Coreset
Coreset
ConstructionCoreset = pick one representative from every square|Coreset| = O[ (√d/ε)d·k·log2(n) ]
2CostP
(C)
Coreset
ε/(8√d) ·CostP
(C)
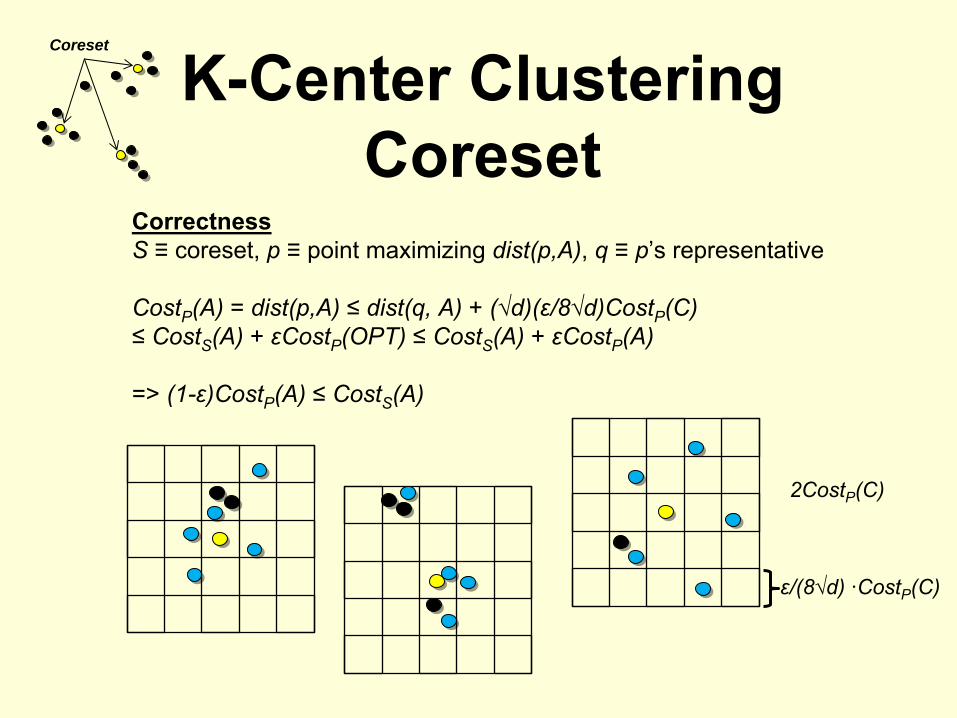
K-Center Clustering Coreset
Coreset
CorrectnessS
≡
coreset, p
≡
point maximizing dist(p,A), q ≡
p’s representative
CostP
(A) = dist(p,A) ≤
dist(q, A) + (√d)(ε/8√d)CostP
(C)≤
CostS
(A) + εCostP
(OPT) ≤
CostS
(A) + εCostP
(A)
=> (1-ε)CostP
(A) ≤
CostS
(A)
2CostP
(C)
ε/(8√d) ·CostP
(C)
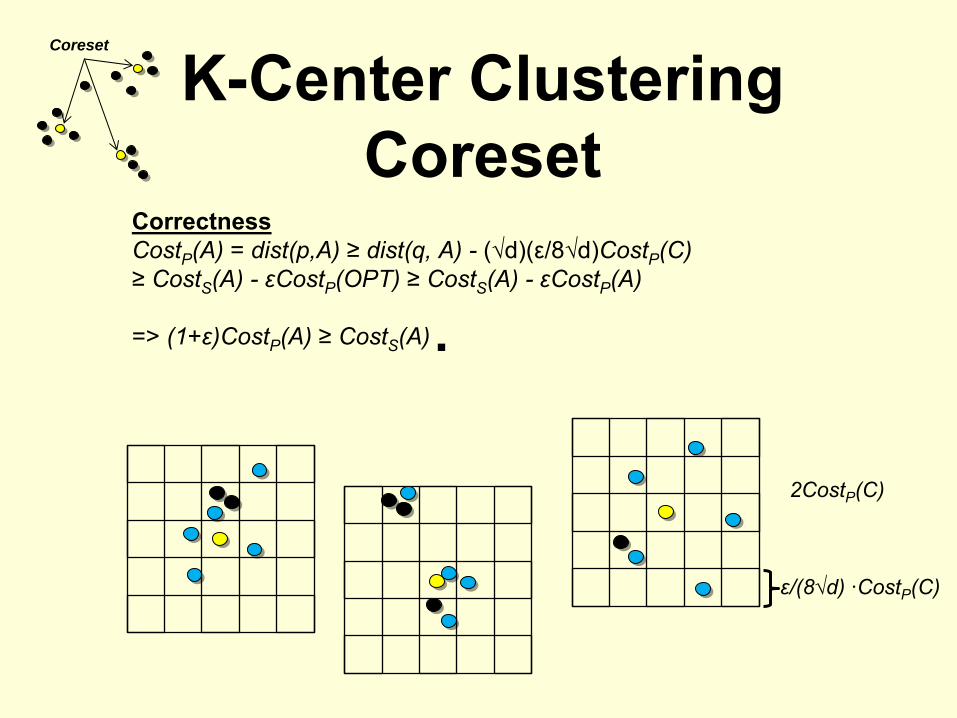
K-Center Clustering Coreset
Coreset
CorrectnessCostP
(A) = dist(p,A) ≥
dist(q, A) -
(√d)(ε/8√d)CostP
(C)≥
CostS
(A) -
εCostP
(OPT) ≥
CostS
(A) -
εCostP
(A)
=> (1+ε)CostP
(A) ≥
CostS
(A)
■
2CostP
(C)
ε/(8√d) ·CostP
(C)

K-Center Clustering Coreset
Coreset
|Coreset| = O[ (√d/ε)d·k·log2(n) ]
How to get rid of the log2(n)?It was inherited from number of cluster centers in the bi-criteria clustering approximation…
Find a k-center clustering (1+ε) approximation using the current coreset, then reassign the clustering (this time with exactly k centers) into the coreset creation…

K-Means/MedianClustering Coreset
Can also create a (k,ε) median/means-clustering coreset S
(1-ε)CostP
(C) ≤
CostS
(C) ≤
(1+ε)CostP
(C)
CostA
(B) ≡ ∑pєA
dist(p,B)orCostA
(B) ≡ ∑pєA
[dist(p,B)]2
|S| = O(k2ε-d)
Was improved to |S| = O(poly(d,k,1/ε)) !! Again, just for k-clustering its possible to get
a coreset of size independent of n or d

K-Means/MedianClustering Coreset
ConstructionIn K-Means/Median the coresets have to be weighted…
Similarly to k-centers, start with a bi-criteria clustering and create squares around each center. The squares are growing by factor 2.
Sample points from every square, but give a weight according to the number of points in that square.

Questions ??
Coreset

Exercises1.
Consider the case of points in R2. Suppose you have an O(log(n))
size coreset. Figure out how to find its optimal clustering using exhaustive search in O(log4k(n))
time.
2.
Consider Bi-Criteria K-Clustering for the case of lines in R2. i.e. we want to find a set C
of O(kclogc(n))
lines s.t. -CostP
(C) ≤
c’
·
CostP
(OPT)where distances are now from points to their nearest line.
Hint: The algorithm stays almost the same.When sampling points think how you should transform them into lines…







![Clustering and Constructing User Coresets to Accelerate ...web.cs.ucla.edu/~chohsieh/papers/cantor_ · proaches. Locality sensitive hashing (LSH) [16] and PCA tree [32] may be applied](https://img.pdfslide.us/doc/110x75/5fabc9afbb04c91ff4236f3a/clustering-and-constructing-user-coresets-to-accelerate-webcsuclaeduchohsiehpaperscantor.jpg)





![On Coresets for Fair Clustering in Metric and Euclidean ...their case, the notion of fairness is captured by the balance parameter t. R osner and Schmidt [77] studied a multicolored](https://img.pdfslide.us/doc/110x75/60c319260cc5ba468b540567/on-coresets-for-fair-clustering-in-metric-and-euclidean-their-case-the-notion.jpg)










![[B19 BS 2102] SAGI RAMA KRISHNAM RAJU ENGINEERING …](https://img.pdfslide.us/doc/110x75/624d84dc8b2d192aeb63a563/b19-bs-2102-sagi-rama-krishnam-raju-engineering-.jpg)


![[B19EC2101] SAGI RAMA KRISHNAM RAJU ENGINEERING …](https://img.pdfslide.us/doc/110x75/61adba21b4d8770c3e472924/b19ec2101-sagi-rama-krishnam-raju-engineering-.jpg)

