Embed Size (px)
Citation preview

Journal of Systems Architecture 58 (2012) 112–125
Contents lists available at SciVerse ScienceDirect
Journal of Systems Architecture
journal homepage: www.elsevier .com/locate /sysarc
Instruction set architectural guidelines for embedded packet-processing engines
Mostafa E. Salehi ⇑, Sied Mehdi Fakhraie, Amir YazdanbakhshNano Electronics Center of Excellence, School of Electrical and Computer Engineering, Faculty of Engineering, University of Tehran, Tehran 14395-515, Iran
a r t i c l e i n f o
Article history:Received 7 September 2009Received in revised form 16 January 2012Accepted 25 February 2012Available online 5 March 2012
Keywords:Packet-processing engineApplication-specific processorBenchmark profilingArchitectural guideline
1383-7621/$ - see front matter � 2012 Elsevier B.V. Adoi:10.1016/j.sysarc.2012.02.004
⇑ Corresponding author.E-mail addresses: [email protected], mostafa.sale
[email protected] (S.M. Fakhraie), a.yazdanbakhsh@ec
a b s t r a c t
This paper presents instruction set architectural guidelines for improving general-purpose embeddedprocessors to optimally accommodate packet-processing applications. Similar to other embedded proces-sors such as media processors, packet-processing engines are deployed in embedded applications, wherecost and power are as important as performance. In this domain, the growing demands for higher band-width and performance besides the ongoing development of new networking protocols and applicationscall for flexible power- and performance-optimized engines.
The instruction set architectural guidelines are extracted from an exhaustive simulation-based profile-driven quantitative analysis of different packet-processing workloads on 32-bit versions of two well-known general-purpose processors, ARM and MIPS. This extensive study has revealed the main perfor-mance challenges and tradeoffs in development of evolution path for survival of such general-purposeprocessors with optimum accommodation of packet-processing functions for future switching-intensiveapplications. Architectural guidelines include types of instructions, branch offset size, displacement andimmediate addressing modes for memory access along with the effective size of these fields, data types ofmemory operations, and also new branch instructions.
The effectiveness of the proposed guidelines is evaluated with the development of a retargetable com-pilation and simulation framework. Developing the HDL model of the optimized base processor for net-working applications and using a logic synthesis tool, we show that enhanced area, power, delay, andpower per watt measures are achieved.
� 2012 Elsevier B.V. All rights reserved.
1. Introduction
High-performance and flexible network processors are expectedto comply the user demands for improved networking services andpacket-processing tasks at different line speeds. According to theever-increasing demand for higher bandwidth, the performancebottleneck of networks has been transferred to the processing ele-ments and consequently there has been a tremendous effort inspeeding these modules. Traditional PEs are either based on cus-tom hardware blocks or general-purpose processors (GPPs). Cus-tom ASIC designs have better performance, higher manufacturingcosts, and lower flexibility; however, GPPs are more flexible butare not speed-power-area optimized for networking applications.According to various performance requirements of network work-loads, there is a plenty of work on the design of network processorarchitecture and instruction set. Some designs exploit the flexibil-ity of GPPs and use as many GPPs as required to satisfy the perfor-mance requirements. For example, Niemann et al. [1] exploit amassive parallel-processing structure of simple processing
ll rights reserved.
[email protected] (M.E. Salehi),e.ut.ac.ir (A. Yazdanbakhsh).
elements, and due to its regularity, the architecture can be scaledto accommodate various performance and throughput require-ments. As an alternative to employing large number of simpleGPPs, Vlachos et al. [2] introduce a high performance packet-pro-cessing engine (PPE) with a three-stage pipeline consisting of threespecial purpose processors (SPPs). The proposed SPPs are micro-programmed processors optimized for header field extraction,header field modification, packet verification, bit and byte process-ing, and leave only some generic software execution to the centralprocessing core.
SPPs are also used in many of the commercial network processors(NPs) to improve packet processing performance. Sixteen program-mable processing units are used in Motorola C-5 [3] in a parallelconfiguration. IBM PowerNP [4] introduce a multi-processor NParchitecture with embedded processor complex (EPC). The EPC hasa PowerPC core and 16 programmable protocol processors. IntelIXP1250 [5] uses six micro-engines (MEs). Each ME is a 32-bit RISCprocessor that do the majority of the network processing tasks suchas packet header inspection and modification, classification, routing,metering, etc. The ME instruction set is a mix of conventional RISCinstructions with additional features specifically tailored for net-work processing. Another NP called FlexPathNP [6,7] exploits thediverse processing requirements of packet flows and sends the

M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125 113
packets with relatively simple processing requirements directly tothe traffic manager unit. By this technique the CPU cluster comput-ing capacity will be used optimally and the processing performanceis increased. A cache-based network processor architecture is pro-posed in [8] that has special process-learning cache mechanism tomemorize every packet-processing activity with all table lookup re-sults of those packets that have the same information such as thesame pair of source and destination addresses. The memorized re-sults are then applied to subsequent packets that have the sameinformation in their headers.
Most of the previously introduced architectures and instructionsets are based on a refined version of a well-known architectureand instruction set. To have a reproducible analysis, we focus ontypical NP workloads and benchmarks and exploit a powerful sim-ulator and profiler [9] to obtain some useful details of network pro-cessing benchmarks on two well-known GPPs. The results indicateperformance bottlenecks of representative packet-processingapplications when GPPs are used as the sole processing engine.Then we use these results in accordance with quantitative studyof different network applications to extract helpful architecturalguidelines for designing optimized instruction set for packet-pro-cessing engines.
To keep up with the demands of increasing performance andevolving network applications, the programmable network-spe-cific PEs should support application changes and meet their heavyprocessing workloads. Therefore considering flexibility for shorttime to market, it is necessary to build on the existing applicationdevelopment environments and users’ background on using gen-eral purpose processors (GPPs). On the other hand, means shouldbe provided for catching up with the increasing demand of higherperformance at affordable power and area. In this paper, we pro-vide a solution for finding the minimum required instructions oftwo most-frequently-used GPPs for packet-processing applica-tions. In addition, a retargetable compilation and simulationframework is developed based upon which the proposed instruc-tion set architectural guidelines are evaluated and compared tothe base architectures.
The proposed guidelines provide a wide variety of design alter-natives available to the instruction set architects including: mem-ory addressing, addressing modes, type and size of operands,operands for packet processing, operations for packet processing,control flow instructions, and also propose special-purposeinstructions for packet-processing applications. These guidelinesdemonstrate what future general-purpose processors need topower-speed optimally respond to the growing number of embed-ded applications with switching demands. Based on the introducedarchitectural guidelines, an embedded packet-processing engineuseful for a wide range of packet-processing applications can bedeveloped, and be used in massively parallel processing architec-tures for cost-sensitive demanding embedded network applica-tions. The proposed guidelines would also be applicable to theprocessing nodes of embedded applications that are responsiblefor packet-processing tasks among others.
2. Analysis of packet-processing applications
Hennessy and Patterson [10] present a quantitative analysis ofinstruction set architectures aimed at processors for desktops,servers and also embedded media processors and introduce a widevariety of design alternatives available to the instruction set archi-tects. In this paper we present comparative results for develop-ment of embedded engines customized for packet-processingtasks in different network applications. According to the IETF(Internet Engineering Task Force), operations of network applica-tions can be functionally categorized into data-plane and control-
plane functions [11]. The data-plane performs packet-processingtasks such as packet fragmentation, encapsulation, editing, classifi-cation, forwarding, lookup, and encryption. While the control-plane performs congestion control, flow management, signaling,handling higher-level protocols, and other control tasks. Thereare a large variety of NP applications that contain a wide rangeof different data-plane and control-plane processing tasks. Toproperly evaluate network-specific processing tasks, it is necessaryto specify a workload that is typical of that environment.
CommBench [12] is composed of eight data-plane programsthat are categorized into four packet-header processing and fourpacket-payload processing tasks. In a similar work NetBench [13]contains nine applications that are representative of commercialapplications for network processors and cover small low-level codefragments as well as large application-level programs. CommBenchand NetBench both introduce data-plane applications. NpBench[14] targets towards both control-plane and data-plane workloads.A tool called PacketBench is presented in [15], which provides aframework for implementing network-processing applicationsand extracting workload characteristics. For statistics collection,PacketBench presents a number of micro-architectural and net-working related metrics for four different networking applicationsranging from simple packet forwarding to complex packet payloadencryption. The profiling results of PacketBench are obtained fromARM-based SimpleScalar [16]. Embedded Microprocessor Bench-marking Consortium (EEMBC) [17] has also developed a network-ing benchmark suite to reflect the performance of client andserver systems (TCPmark), and also functions mostly carried outin infrastructure equipment (IPmark). The IPmark is intended fordevelopers of infrastructure equipment, while the TCPmark, whichincludes the TCP benchmark, focuses on client- and server-basednetwork hardware.
Considering representative benchmark applications for headerand payload processing for IPv4 protocol, we have presented a sim-ulation-based profile-driven quantitative analysis of packet-pro-cessing applications. The selected applications are IPv4-radix andIPv4-trie as look-up and forwarding algorithms, a packet-classifica-tion algorithm called Flow-Class, Internet Protocol Security (IPSec)and Message-Digest algorithm 5 (MD5) as payload-processingapplications. To develop efficient network processing engines, itis important to have a detailed understanding of the workloadsassociated with this processing. PacketBench provides a frame-work for developing network applications and extracting a set ofworkload characteristics on ARM-based SimpleScalar [16] simula-tor. To have an architecture-independent analysis, we have identi-fied and then modified the PacketBench profiling capabilities thatare added to ARM-based SimpleScalar and also developed a com-pound simulation and profiling environment for MIPS-basedSimpleScalar, yielding a MIPS-based profiling platform. MIPS-based SimpleScalar which is augmented with PacketBench profil-ing capabilities, reproduce the PacketBench profiling observationson MIPS processor. The measurements which are indicative of net-work applications reveal the performance challenges of differentprograms. The presented measurements are also dynamic, inwhich, the frequency of a measured event is weighed by the num-ber of times that the event occurs during execution of theapplication.
We present the experimental results of profiling representativenetwork applications on 32-bit versions of ARM and MIPS proces-sors using ARM9 and MIPSR3000 examples. ARM and MIPS familyof processors are two widely-used processors in the network-pro-cessor products. Intel IXP series of network processors use Strong-ARM processors that are based on ARM architecture [18], andBroadcom BCM products [19] have used MIPS processors in com-munication-processor products. The comparative results of bothARM and MIPS platforms then yield architectural guidelines for

114 M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125
developing application-specific processing engines for networkapplications. To have a realistic analysis, we use packet traces ofreal networks. An excellent repository of traces collected at severalmonitoring points is maintained by the National Laboratory for Ap-plied Network Research (NLANR/PMA) [20]. We have selectedmany traces of this trace repository as our input packet tracesand the average value of the results are presented here. For eachapplication, the extracted properties are the frequencies of load,store, and branch instruction, instruction distribution, instructionpatterns, frequent instruction sequences, offset size of branches,rate of the taken branches, execution cycles, and performancebottlenecks.
2.1. Execution time analysis
We use the execution time analysis to evaluate and comparethe performance of MIPS and ARM processors when running eachof the selected applications. To present comparative results, we en-sure the reproducibility principle in reporting performance mea-surements, such that another researcher would duplicate theresults in different platforms. The execution time of an applicationis calculated according to the following formula [21] in terms ofInstruction Count (IC), Clock Per Instruction (CPI), and Clock Period(CP).
Execution time of application ¼ IC � CPI � CP
In our previous work [22], we employ this reproducible analysisfor packet-processing applications as the number of required cy-cles for processing a packet (IC � CPI) and consequently involvethe processor architectural dependencies. IC � CPI is a part of thepresented formula and the remaining parameter is CP, therefore,having known the frequency of different processors, the reportednumber of the required clock cycles of an application simply leadsto calculation of the application execution time. This then makesdifferent architectures universally comparable when running thetarget applications. To find the instruction count and clock countof packet-processing tasks and have a comparative analysis, wehave profiled benchmark applications on both of ARM- andMIPS-based simulators. The results in Table 1 shows the numberof instructions and also the required clock cycles for processing apacket in each of the specified applications using both of the MIPS-and ARM-based SimpleScalar environments.
As shown in Table 1, the computational properties of the se-lected applications vary when they are executed with differentprocessors. Despite the simple instruction set of MIPS, ARM has amore powerful instruction set. In ARM processor, each operationcan be performed conditionally according to the results of the pre-vious instructions [23]. Furthermore, ARM supports complexinstructions that perform shift as well as arithmetic or logic oper-ation in a single instruction. These instructions can lead to lowerinstruction count in loops and also in codes with complicated lo-gic/arithmetic operations. However, these complex instructionscomplicate the pipeline architecture and may cause the reductionof ARM clock frequency that consequently may lead to more exe-cution time and lower performance. A smart compiler can takeadvantage of complex ARM instructions and produce more opti-mized codes in terms of lower number of instructions. Throughout
Table 1Computational complexity of the packet-processing applications based on TSH [20] traces
ARM [22]
IPV4-radix IPV4-trie Flow-Class IPSec M
# of instructions 4205 206 152 100998# of clock cycles 5092 494 340 113108 1
an application compilation with ARM compiler, when the complexinstructions are not applicable, general instructions are used andnumber of instructions in the generated code is expected to be lessthan or equal to when the code is compiled with MIPS compiler.According to the results of compiling selected applications withARM and MIPS compilers, payload processing applications haveabout 18% lower instructions when compiled with ARM compiler.However, in header processing applications ARM results are worsethan MIPS. Both of the selected cross compilers are based ongcc2.95.2. With the same cross compiler, instruction counts ofthe header processing applications in ARM are 10–80% higher thaninstruction counts of these applications in MIPS (Table 1). Whenmultiplying the ‘‘number of clock cycles of running an application’’with a processor, with the ‘‘clock period’’, of a specific implemen-tation of that processor, the total execution or elapsed time isachieved, that would make the results universally comparableamong different implementations of various processors.
2.2. The role of compiler
As shown in Table 1, the instructions count of IPV4-radix, is 80%higher when compiled with ARM cross compiler. The instructioncount of the IPV4-radix based on its containing functions is summa-rized in Table 2. As shown in this table the instruction count of val-idate_packet and inet_ntoa functions are similar but the instructioncount of the lookup_tree in ARM is about six times more than inMIPS.
Table 3 shows the instruction count of the sub-functions of thelookup_tree. The instruction count of the inet_aton function in ARMis about 10 times more than MIPS. This is because of the strtoulfunction generated with ARM compiler which is optimized prop-erly with MIPS cross compiler. This observation shows the effectof cross compiler on the number of generated instructions whenthe same gcc compiler is used.
To reveal the effect of compiler version on instruction count ofthe compiled application codes and to compare different compilerstogether, we obtain the results with another version of gcc for ARMcross compiler and the instruction count of the representativeapplications on both 2.95.2 and 3.4.3 versions of ARM cross com-piler are calculated. According to the results (Table 4), despitethe 80% difference in IPV4-radix results in ARM and MIPS 2.95.2cross compilers, compiling IPV4-radix with MIPS gcc2.95.2 andARM gcc3.4.3 cross compilers yield almost equal instruction countsand for the other applications different versions of MIPS and ARMcross compilers have negligible effects on instruction count of thecompiled application codes. Therefore, from now on we use theoptimum compiler results of each processor for further compari-sons in this paper.
2.3. Instruction set operations
The supported operations by most instruction set architecturesare categorized in Table 5 [10]. All processors must have someinstruction support for basic system functions and generally pro-vide a full set of the first three categories. The amount of supportfor the last categories may vary from none to an extensive set ofspecial instructions. Floating-point instructions will be provided
.
MIPS
D5 IPV4-radix IPV4-trie Flow-Class IPSec MD5
8911 2376 186 113 123394 110434202 3630 398 274 227330 17570
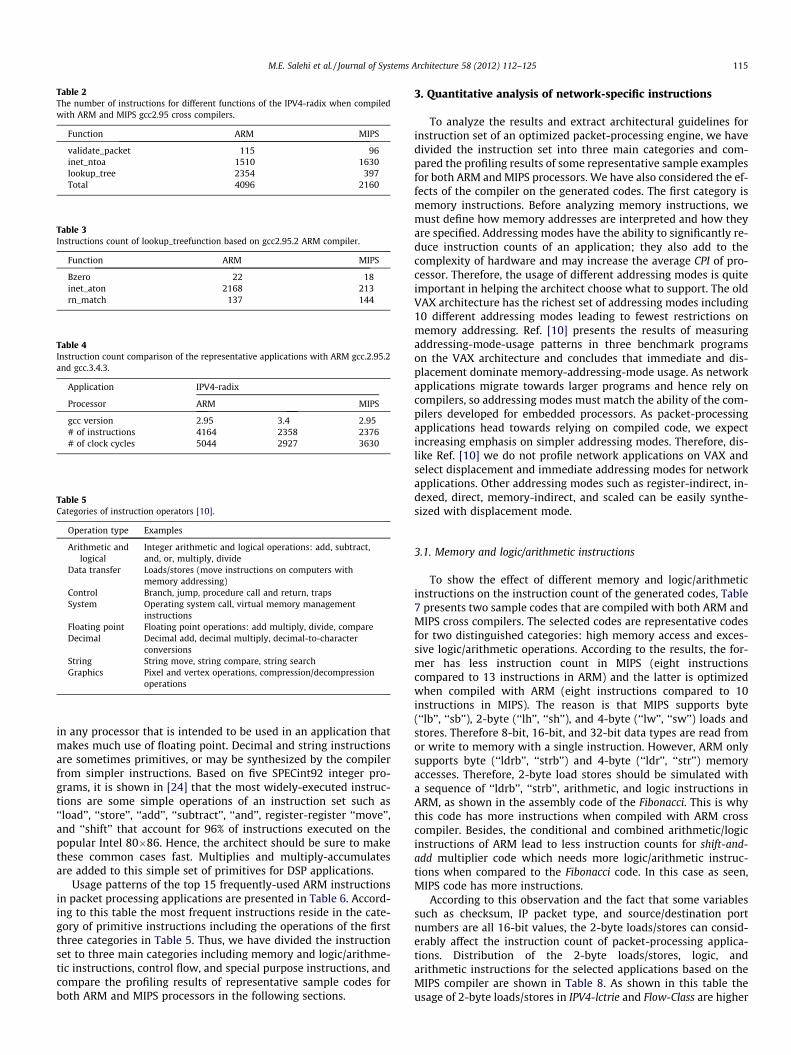
Table 2The number of instructions for different functions of the IPV4-radix when compiledwith ARM and MIPS gcc2.95 cross compilers.
Function ARM MIPS
validate_packet 115 96inet_ntoa 1510 1630lookup_tree 2354 397Total 4096 2160
Table 3Instructions count of lookup_treefunction based on gcc2.95.2 ARM compiler.
Function ARM MIPS
Bzero 22 18inet_aton 2168 213rn_match 137 144
Table 4Instruction count comparison of the representative applications with ARM gcc.2.95.2and gcc.3.4.3.
Application IPV4-radix
Processor ARM MIPS
gcc version 2.95 3.4 2.95# of instructions 4164 2358 2376# of clock cycles 5044 2927 3630
Table 5Categories of instruction operators [10].
Operation type Examples
Arithmetic andlogical
Integer arithmetic and logical operations: add, subtract,and, or, multiply, divide
Data transfer Loads/stores (move instructions on computers withmemory addressing)
Control Branch, jump, procedure call and return, trapsSystem Operating system call, virtual memory management
instructionsFloating point Floating point operations: add multiply, divide, compareDecimal Decimal add, decimal multiply, decimal-to-character
conversionsString String move, string compare, string searchGraphics Pixel and vertex operations, compression/decompression
operations
M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125 115
in any processor that is intended to be used in an application thatmakes much use of floating point. Decimal and string instructionsare sometimes primitives, or may be synthesized by the compilerfrom simpler instructions. Based on five SPECint92 integer pro-grams, it is shown in [24] that the most widely-executed instruc-tions are some simple operations of an instruction set such as‘‘load’’, ‘‘store’’, ‘‘add’’, ‘‘subtract’’, ‘‘and’’, register-register ‘‘move’’,and ‘‘shift’’ that account for 96% of instructions executed on thepopular Intel 80�86. Hence, the architect should be sure to makethese common cases fast. Multiplies and multiply-accumulatesare added to this simple set of primitives for DSP applications.
Usage patterns of the top 15 frequently-used ARM instructionsin packet processing applications are presented in Table 6. Accord-ing to this table the most frequent instructions reside in the cate-gory of primitive instructions including the operations of the firstthree categories in Table 5. Thus, we have divided the instructionset to three main categories including memory and logic/arithme-tic instructions, control flow, and special purpose instructions, andcompare the profiling results of representative sample codes forboth ARM and MIPS processors in the following sections.
3. Quantitative analysis of network-specific instructions
To analyze the results and extract architectural guidelines forinstruction set of an optimized packet-processing engine, we havedivided the instruction set into three main categories and com-pared the profiling results of some representative sample examplesfor both ARM and MIPS processors. We have also considered the ef-fects of the compiler on the generated codes. The first category ismemory instructions. Before analyzing memory instructions, wemust define how memory addresses are interpreted and how theyare specified. Addressing modes have the ability to significantly re-duce instruction counts of an application; they also add to thecomplexity of hardware and may increase the average CPI of pro-cessor. Therefore, the usage of different addressing modes is quiteimportant in helping the architect choose what to support. The oldVAX architecture has the richest set of addressing modes including10 different addressing modes leading to fewest restrictions onmemory addressing. Ref. [10] presents the results of measuringaddressing-mode-usage patterns in three benchmark programson the VAX architecture and concludes that immediate and dis-placement dominate memory-addressing-mode usage. As networkapplications migrate towards larger programs and hence rely oncompilers, so addressing modes must match the ability of the com-pilers developed for embedded processors. As packet-processingapplications head towards relying on compiled code, we expectincreasing emphasis on simpler addressing modes. Therefore, dis-like Ref. [10] we do not profile network applications on VAX andselect displacement and immediate addressing modes for networkapplications. Other addressing modes such as register-indirect, in-dexed, direct, memory-indirect, and scaled can be easily synthe-sized with displacement mode.
3.1. Memory and logic/arithmetic instructions
To show the effect of different memory and logic/arithmeticinstructions on the instruction count of the generated codes, Table7 presents two sample codes that are compiled with both ARM andMIPS cross compilers. The selected codes are representative codesfor two distinguished categories: high memory access and exces-sive logic/arithmetic operations. According to the results, the for-mer has less instruction count in MIPS (eight instructionscompared to 13 instructions in ARM) and the latter is optimizedwhen compiled with ARM (eight instructions compared to 10instructions in MIPS). The reason is that MIPS supports byte(‘‘lb’’, ‘‘sb’’), 2-byte (‘‘lh’’, ‘‘sh’’), and 4-byte (‘‘lw’’, ‘‘sw’’) loads andstores. Therefore 8-bit, 16-bit, and 32-bit data types are read fromor write to memory with a single instruction. However, ARM onlysupports byte (‘‘ldrb’’, ‘‘strb’’) and 4-byte (‘‘ldr’’, ‘‘str’’) memoryaccesses. Therefore, 2-byte load stores should be simulated witha sequence of ‘‘ldrb’’, ‘‘strb’’, arithmetic, and logic instructions inARM, as shown in the assembly code of the Fibonacci. This is whythis code has more instructions when compiled with ARM crosscompiler. Besides, the conditional and combined arithmetic/logicinstructions of ARM lead to less instruction counts for shift-and-add multiplier code which needs more logic/arithmetic instruc-tions when compared to the Fibonacci code. In this case as seen,MIPS code has more instructions.
According to this observation and the fact that some variablessuch as checksum, IP packet type, and source/destination portnumbers are all 16-bit values, the 2-byte loads/stores can consid-erably affect the instruction count of packet-processing applica-tions. Distribution of the 2-byte loads/stores, logic, andarithmetic instructions for the selected applications based on theMIPS compiler are shown in Table 8. As shown in this table theusage of 2-byte loads/stores in IPV4-lctrie and Flow-Class are higher
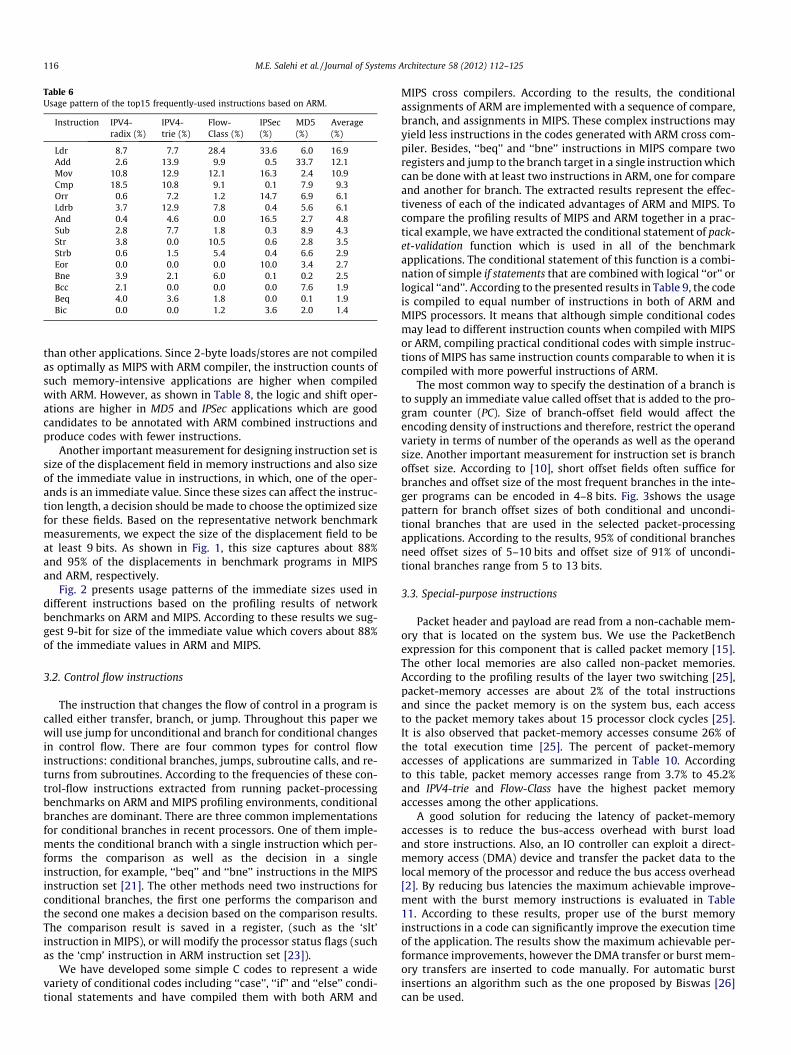
Table 6Usage pattern of the top15 frequently-used instructions based on ARM.
Instruction IPV4-radix (%)
IPV4-trie (%)
Flow-Class (%)
IPSec(%)
MD5(%)
Average(%)
Ldr 8.7 7.7 28.4 33.6 6.0 16.9Add 2.6 13.9 9.9 0.5 33.7 12.1Mov 10.8 12.9 12.1 16.3 2.4 10.9Cmp 18.5 10.8 9.1 0.1 7.9 9.3Orr 0.6 7.2 1.2 14.7 6.9 6.1Ldrb 3.7 12.9 7.8 0.4 5.6 6.1And 0.4 4.6 0.0 16.5 2.7 4.8Sub 2.8 7.7 1.8 0.3 8.9 4.3Str 3.8 0.0 10.5 0.6 2.8 3.5Strb 0.6 1.5 5.4 0.4 6.6 2.9Eor 0.0 0.0 0.0 10.0 3.4 2.7Bne 3.9 2.1 6.0 0.1 0.2 2.5Bcc 2.1 0.0 0.0 0.0 7.6 1.9Beq 4.0 3.6 1.8 0.0 0.1 1.9Bic 0.0 0.0 1.2 3.6 2.0 1.4
116 M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125
than other applications. Since 2-byte loads/stores are not compiledas optimally as MIPS with ARM compiler, the instruction counts ofsuch memory-intensive applications are higher when compiledwith ARM. However, as shown in Table 8, the logic and shift oper-ations are higher in MD5 and IPSec applications which are goodcandidates to be annotated with ARM combined instructions andproduce codes with fewer instructions.
Another important measurement for designing instruction set issize of the displacement field in memory instructions and also sizeof the immediate value in instructions, in which, one of the oper-ands is an immediate value. Since these sizes can affect the instruc-tion length, a decision should be made to choose the optimized sizefor these fields. Based on the representative network benchmarkmeasurements, we expect the size of the displacement field to beat least 9 bits. As shown in Fig. 1, this size captures about 88%and 95% of the displacements in benchmark programs in MIPSand ARM, respectively.
Fig. 2 presents usage patterns of the immediate sizes used indifferent instructions based on the profiling results of networkbenchmarks on ARM and MIPS. According to these results we sug-gest 9-bit for size of the immediate value which covers about 88%of the immediate values in ARM and MIPS.
3.2. Control flow instructions
The instruction that changes the flow of control in a program iscalled either transfer, branch, or jump. Throughout this paper wewill use jump for unconditional and branch for conditional changesin control flow. There are four common types for control flowinstructions: conditional branches, jumps, subroutine calls, and re-turns from subroutines. According to the frequencies of these con-trol-flow instructions extracted from running packet-processingbenchmarks on ARM and MIPS profiling environments, conditionalbranches are dominant. There are three common implementationsfor conditional branches in recent processors. One of them imple-ments the conditional branch with a single instruction which per-forms the comparison as well as the decision in a singleinstruction, for example, ‘‘beq’’ and ‘‘bne’’ instructions in the MIPSinstruction set [21]. The other methods need two instructions forconditional branches, the first one performs the comparison andthe second one makes a decision based on the comparison results.The comparison result is saved in a register, (such as the ‘slt’instruction in MIPS), or will modify the processor status flags (suchas the ‘cmp’ instruction in ARM instruction set [23]).
We have developed some simple C codes to represent a widevariety of conditional codes including ‘‘case’’, ‘‘if’’ and ‘‘else’’ condi-tional statements and have compiled them with both ARM and
MIPS cross compilers. According to the results, the conditionalassignments of ARM are implemented with a sequence of compare,branch, and assignments in MIPS. These complex instructions mayyield less instructions in the codes generated with ARM cross com-piler. Besides, ‘‘beq’’ and ‘‘bne’’ instructions in MIPS compare tworegisters and jump to the branch target in a single instruction whichcan be done with at least two instructions in ARM, one for compareand another for branch. The extracted results represent the effec-tiveness of each of the indicated advantages of ARM and MIPS. Tocompare the profiling results of MIPS and ARM together in a prac-tical example, we have extracted the conditional statement of pack-et-validation function which is used in all of the benchmarkapplications. The conditional statement of this function is a combi-nation of simple if statements that are combined with logical ‘‘or’’ orlogical ‘‘and’’. According to the presented results in Table 9, the codeis compiled to equal number of instructions in both of ARM andMIPS processors. It means that although simple conditional codesmay lead to different instruction counts when compiled with MIPSor ARM, compiling practical conditional codes with simple instruc-tions of MIPS has same instruction counts comparable to when it iscompiled with more powerful instructions of ARM.
The most common way to specify the destination of a branch isto supply an immediate value called offset that is added to the pro-gram counter (PC). Size of branch-offset field would affect theencoding density of instructions and therefore, restrict the operandvariety in terms of number of the operands as well as the operandsize. Another important measurement for instruction set is branchoffset size. According to [10], short offset fields often suffice forbranches and offset size of the most frequent branches in the inte-ger programs can be encoded in 4–8 bits. Fig. 3shows the usagepattern for branch offset sizes of both conditional and uncondi-tional branches that are used in the selected packet-processingapplications. According to the results, 95% of conditional branchesneed offset sizes of 5–10 bits and offset size of 91% of uncondi-tional branches range from 5 to 13 bits.
3.3. Special-purpose instructions
Packet header and payload are read from a non-cachable mem-ory that is located on the system bus. We use the PacketBenchexpression for this component that is called packet memory [15].The other local memories are also called non-packet memories.According to the profiling results of the layer two switching [25],packet-memory accesses are about 2% of the total instructionsand since the packet memory is on the system bus, each accessto the packet memory takes about 15 processor clock cycles [25].It is also observed that packet-memory accesses consume 26% ofthe total execution time [25]. The percent of packet-memoryaccesses of applications are summarized in Table 10. Accordingto this table, packet memory accesses range from 3.7% to 45.2%and IPV4-trie and Flow-Class have the highest packet memoryaccesses among the other applications.
A good solution for reducing the latency of packet-memoryaccesses is to reduce the bus-access overhead with burst loadand store instructions. Also, an IO controller can exploit a direct-memory access (DMA) device and transfer the packet data to thelocal memory of the processor and reduce the bus access overhead[2]. By reducing bus latencies the maximum achievable improve-ment with the burst memory instructions is evaluated in Table11. According to these results, proper use of the burst memoryinstructions in a code can significantly improve the execution timeof the application. The results show the maximum achievable per-formance improvements, however the DMA transfer or burst mem-ory transfers are inserted to code manually. For automatic burstinsertions an algorithm such as the one proposed by Biswas [26]can be used.
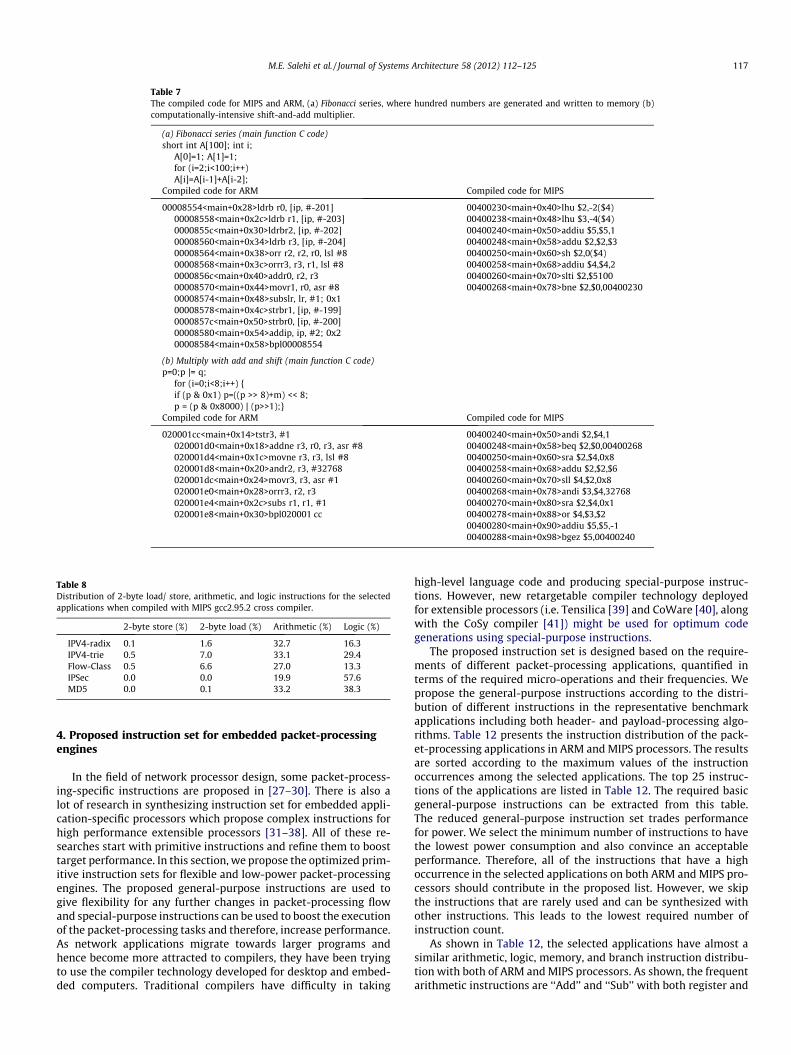
Table 7The compiled code for MIPS and ARM, (a) Fibonacci series, where hundred numbers are generated and written to memory (b)computationally-intensive shift-and-add multiplier.
(a) Fibonacci series (main function C code)short int A[100]; int i;
A[0]=1; A[1]=1;for (i=2;i<100;i++)A[i]=A[i-1]+A[i-2];
Compiled code for ARM Compiled code for MIPS
00008554<main+0x28>ldrb r0, [ip, #-201]00008558<main+0x2c>ldrb r1, [ip, #-203]0000855c<main+0x30>ldrbr2, [ip, #-202]00008560<main+0x34>ldrb r3, [ip, #-204]00008564<main+0x38>orr r2, r2, r0, lsl #800008568<main+0x3c>orrr3, r3, r1, lsl #80000856c<main+0x40>addr0, r2, r300008570<main+0x44>movr1, r0, asr #800008574<main+0x48>subslr, lr, #1; 0x100008578<main+0x4c>strbr1, [ip, #-199]0000857c<main+0x50>strbr0, [ip, #-200]00008580<main+0x54>addip, ip, #2; 0x200008584<main+0x58>bpl00008554
00400230<main+0x40>lhu $2,-2($4)00400238<main+0x48>lhu $3,-4($4)00400240<main+0x50>addiu $5,$5,100400248<main+0x58>addu $2,$2,$300400250<main+0x60>sh $2,0($4)00400258<main+0x68>addiu $4,$4,200400260<main+0x70>slti $2,$510000400268<main+0x78>bne $2,$0,00400230
(b) Multiply with add and shift (main function C code)p=0;p |= q;
for (i=0;i<8;i++) {if (p & 0x1) p=((p >> 8)+m) << 8;p = (p & 0x8000) | (p>>1);}
Compiled code for ARM Compiled code for MIPS
020001cc<main+0x14>tstr3, #1020001d0<main+0x18>addne r3, r0, r3, asr #8020001d4<main+0x1c>movne r3, r3, lsl #8020001d8<main+0x20>andr2, r3, #32768020001dc<main+0x24>movr3, r3, asr #1020001e0<main+0x28>orrr3, r2, r3020001e4<main+0x2c>subs r1, r1, #1020001e8<main+0x30>bpl020001 cc
00400240<main+0x50>andi $2,$4,100400248<main+0x58>beq $2,$0,0040026800400250<main+0x60>sra $2,$4,0x800400258<main+0x68>addu $2,$2,$600400260<main+0x70>sll $4,$2,0x800400268<main+0x78>andi $3,$4,3276800400270<main+0x80>sra $2,$4,0x100400278<main+0x88>or $4,$3,$200400280<main+0x90>addiu $5,$5,-100400288<main+0x98>bgez $5,00400240
Table 8Distribution of 2-byte load/ store, arithmetic, and logic instructions for the selectedapplications when compiled with MIPS gcc2.95.2 cross compiler.
2-byte store (%) 2-byte load (%) Arithmetic (%) Logic (%)
IPV4-radix 0.1 1.6 32.7 16.3IPV4-trie 0.5 7.0 33.1 29.4Flow-Class 0.5 6.6 27.0 13.3IPSec 0.0 0.0 19.9 57.6MD5 0.0 0.1 33.2 38.3
M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125 117
4. Proposed instruction set for embedded packet-processingengines
In the field of network processor design, some packet-process-ing-specific instructions are proposed in [27–30]. There is also alot of research in synthesizing instruction set for embedded appli-cation-specific processors which propose complex instructions forhigh performance extensible processors [31–38]. All of these re-searches start with primitive instructions and refine them to boosttarget performance. In this section, we propose the optimized prim-itive instruction sets for flexible and low-power packet-processingengines. The proposed general-purpose instructions are used togive flexibility for any further changes in packet-processing flowand special-purpose instructions can be used to boost the executionof the packet-processing tasks and therefore, increase performance.As network applications migrate towards larger programs andhence become more attracted to compilers, they have been tryingto use the compiler technology developed for desktop and embed-ded computers. Traditional compilers have difficulty in taking
high-level language code and producing special-purpose instruc-tions. However, new retargetable compiler technology deployedfor extensible processors (i.e. Tensilica [39] and CoWare [40], alongwith the CoSy compiler [41]) might be used for optimum codegenerations using special-purpose instructions.
The proposed instruction set is designed based on the require-ments of different packet-processing applications, quantified interms of the required micro-operations and their frequencies. Wepropose the general-purpose instructions according to the distri-bution of different instructions in the representative benchmarkapplications including both header- and payload-processing algo-rithms. Table 12 presents the instruction distribution of the pack-et-processing applications in ARM and MIPS processors. The resultsare sorted according to the maximum values of the instructionoccurrences among the selected applications. The top 25 instruc-tions of the applications are listed in Table 12. The required basicgeneral-purpose instructions can be extracted from this table.The reduced general-purpose instruction set trades performancefor power. We select the minimum number of instructions to havethe lowest power consumption and also convince an acceptableperformance. Therefore, all of the instructions that have a highoccurrence in the selected applications on both ARM and MIPS pro-cessors should contribute in the proposed list. However, we skipthe instructions that are rarely used and can be synthesized withother instructions. This leads to the lowest required number ofinstruction count.
As shown in Table 12, the selected applications have almost asimilar arithmetic, logic, memory, and branch instruction distribu-tion with both of ARM and MIPS processors. As shown, the frequentarithmetic instructions are ‘‘Add’’ and ‘‘Sub’’ with both register and
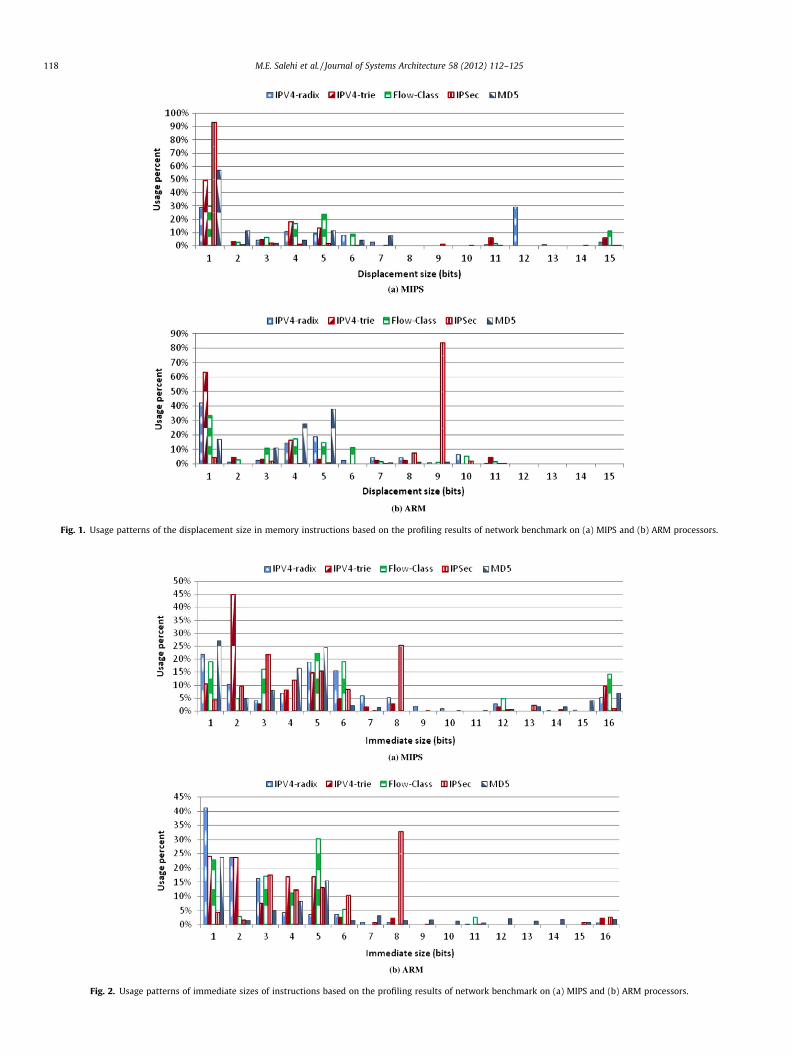
Fig. 1. Usage patterns of the displacement size in memory instructions based on the profiling results of network benchmark on (a) MIPS and (b) ARM processors.
Fig. 2. Usage patterns of immediate sizes of instructions based on the profiling results of network benchmark on (a) MIPS and (b) ARM processors.
118 M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125

Table 9Representative code for condition checking. The code is extracted from the validate-packet function of the IPV4 lookupapplications.
if ((ll_length>MIN_IP_DATAGRAM) &&(in_checksum&&(ip_v == 4) &&(ip_hl>= MIN_IP_DATAGRAM/4) &&(ip_len>= ip_hl))return 1;else return 0;
Compiled code for ARM (gcc3.4) Compiled code for MIPS (gcc. 2.95)
0000866c<validate_packet>cmp r1, #000008670<validate_packet+0x4>cmpne r0, #2000008674<validate_packet+0x8>movr1, r300008678<validate_packet+0xc>ble000086840000867c < validate_packet+0x10>cmp r2, #400008680<validate_packet+0x14>beq 0000868c00008684<validate_packet+0x18>mov r0, #000008688<validate_packet+0x1c>mov pc, lr0000868c<validate_packet+0x20>ldrr3, [sp]00008690<validate_packet+0x24>cmp r3, r100008694<validate_packet+0x28>cmpge r1, #400008698<validate_packet+0x2c>mov r0, #10000869c<validate_packet+0x30>movgt pc, lr000086a0<validate_packet+0x34>b00008684
00400400<validate_packet>addu $2,$0,$000400408<validate_packet+0x8>lw $8,16($29)00400410<validate_packet+0x10>addiu $3,$0,2000400418<validate_packet+0x18>slt $3,$3,$400400420<validate_packet+0x20>beq $3,$0,0040046800400428<validate_packet+0x28>beq $5,$0,0040046800400430<validate_packet+0x30>addiu $3,$0,400400438<validate_packet+0x38>bne $6,$3,0040046800400440<validate_packet+0x40>slti $3,$7,500400448<validate_packet+0x48>bne $3,$0,0040046800400450<validate_packet+0x50>slt $3,$8,$700400458<validate_packet+0x58>bne $3,$0,0040046800400460<validate_packet+0x60>addiu $2,$0,100400468<validate_packet+0x68>jr $31
M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125 119
immediate operands. The ‘‘Slt’’ instructions of MIPS which are usedfor LESS THAN or LESS THAN OR EQUAL comparisons can be omit-ted and substituted with ‘‘Bl’’ and ‘‘Ble’’ instructions. MIPS andARM follow different approaches for implementing the branch.MIPS compares two registers and based on the comparison resultsjumps to the target address in a single instruction called ‘‘Beq’’ or‘‘Bne’’. ARM implements the branch with two separate instruc-tions; the first one does the comparison and the second checksthe flags of the processor and jumps to the target address if thebranch condition is satisfied. Since branch instructions have a highcontribution in the selected applications, we propose the single-instruction comparison-and-jump approach. Therefore, the ‘‘Slt’’and ‘‘Cmp’’ instructions are not included in arithmetic instructionsand ‘‘Beq’’, ‘‘Bne’’, ‘‘Bl’’, and ‘‘Ble’’ are proposed for branch instruc-tions. The other branch instructions can be implemented withthese instructions.
The frequent logic instructions are ‘‘And’’, ‘‘Or’’, and ‘‘Xor’’.‘‘Nor’’ and the immediate modes of logic instructions can be syn-thesized with the corresponding register modes. Table 8 showsthat the 2-byte loads/stores can considerably affect the instructioncount of an application. Since 2-byte load/stores are not compiledoptimally with ARM compiler, the instruction counts of IPV4-trieand Flow_class applications are higher when compiled with ARM.Therefore, the proposed memory access instructions support 8-bit, 16-bit, and 32-bit loads and stores. The frequent shift instruc-tions are ‘‘Sll’’, ‘‘Srl’’, and ‘‘Sra’’. As shown in Table 8, the logic andshift operations are higher in MD5 and IPSec applications which aregood candidates to be synthesized with ARM complex instructionsto produce codes with fewer instructions. Usage patterns of ARMcomplex instructions in the selected benchmark applications aresummarized in Table 13.
According to Table 13, 4.7% and 3.6% of IPSec and MD5 instruc-tions are of these types, respectively. Each of ARM complex instruc-tions would be synthesized with at least two MIPS instructions.Over all, as shown sum of the average values of complex instruc-tion usages for all representative applications is about 10%. There-fore, properly employing these instructions would improve theinstruction count about 10%. However, because of the complexityof these instructions, they would complicate the pipeline designand hence, might elongate the overall clock period of the processor.Therefore, one should decide on using such instructions consider-ing compiler potentials and also architecture design issues.
IPSec and MD5 are two large applications that contain about100,000 and 9000 instruction in ARM. According to the results,the instruction counts of these applications are about 23% higherwhen compiled for MIPS. One reason for this difference in instruc-tion counts is the usage of ARM complex instructions (Table 13). Asanother source for this difference, we have observed the effect ofburst load and store instructions in ARM (‘‘stdmb’’ and ‘‘ldmdb’’)which perform a block transfer to/from memory. These instruc-tions are widely used in function calls and returns for saving andrestoring the function parameters to the stack. These instructionscan also be used for accessing memory for some registers whichshould be ‘‘push’’ to or ‘‘pop’’ from stack. Since the investigatedpayload processing applications are composed of too many smallfunctions, these instructions improve the instruction counts infunction calls and returns. According to our profiling results, theburst memory access instructions of ARM improve the instructioncount of IPSec and MD5 about 3.5% and 9%, respectively. Some ofthe widely-used instructions of MIPS and ARM (according to theprofiling results), and also the proposed optimum instruction setare summarized in Table 14.
5. Retargetable instruction set compilation and simulationframework
To evaluate the proposed instruction set, we have customizedthe gcc compiler [42] and developed a retargetable compilationframework for exploring the instruction set space for packet-pro-cessing applications. The GNU compiler collection (usually short-ened to gcc) is a Linux-based compiler produced by the GNUproject which supports a variety of programming languages. GCChas two distinct sections called machine dependent and machineindependent parts. The machine dependent part is responsiblefor the final compilation process. In this part, the machine-inde-pendent intermediate output is compiled to the target machinecode using the machine definition (MD) file. The general structureof the GCC compiler is shown in Fig. 4 (based on [42]).
The MD codes state all the microarchitectural specificationssuch as: number of registers, supported instructions, instructionset architecture, and execution flow of each instruction. The ma-chine dependent codes consist of two basic files, the MD file thatcontains the instruction patterns of the target processors and a Cfile containing some macro definitions. The MD file defines the
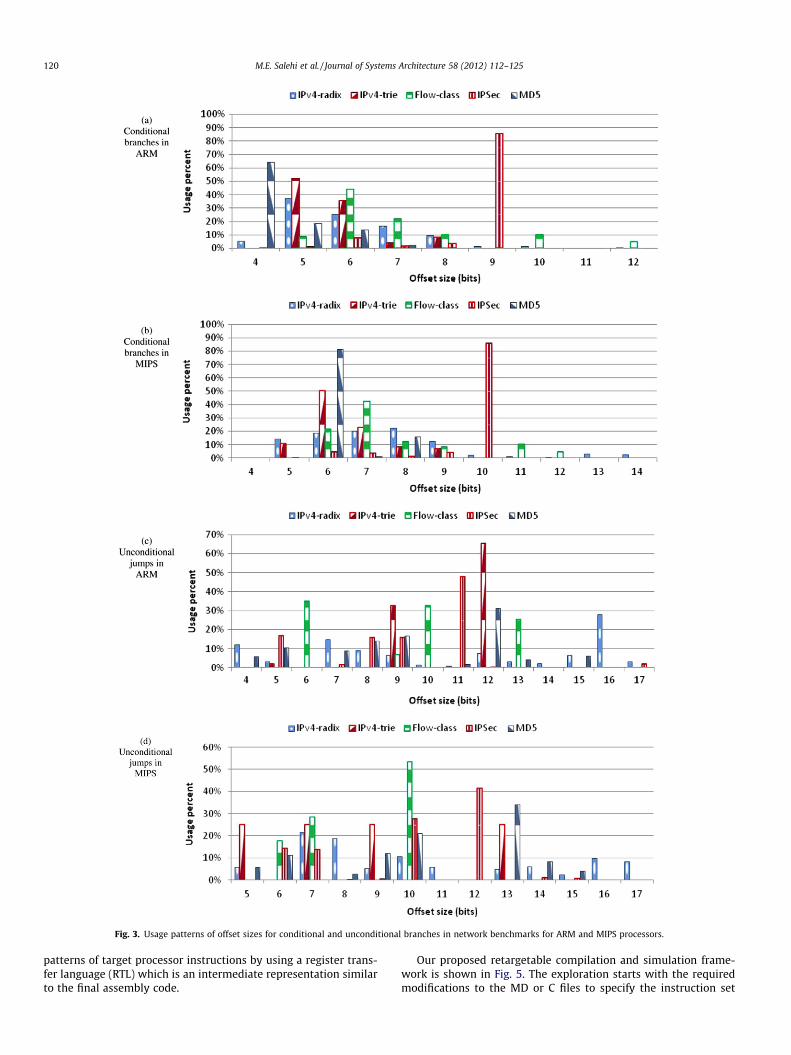
Fig. 3. Usage patterns of offset sizes for conditional and unconditional branches in network benchmarks for ARM and MIPS processors.
120 M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125
patterns of target processor instructions by using a register trans-fer language (RTL) which is an intermediate representation similarto the final assembly code.
Our proposed retargetable compilation and simulation frame-work is shown in Fig. 5. The exploration starts with the requiredmodifications to the MD or C files to specify the instruction set
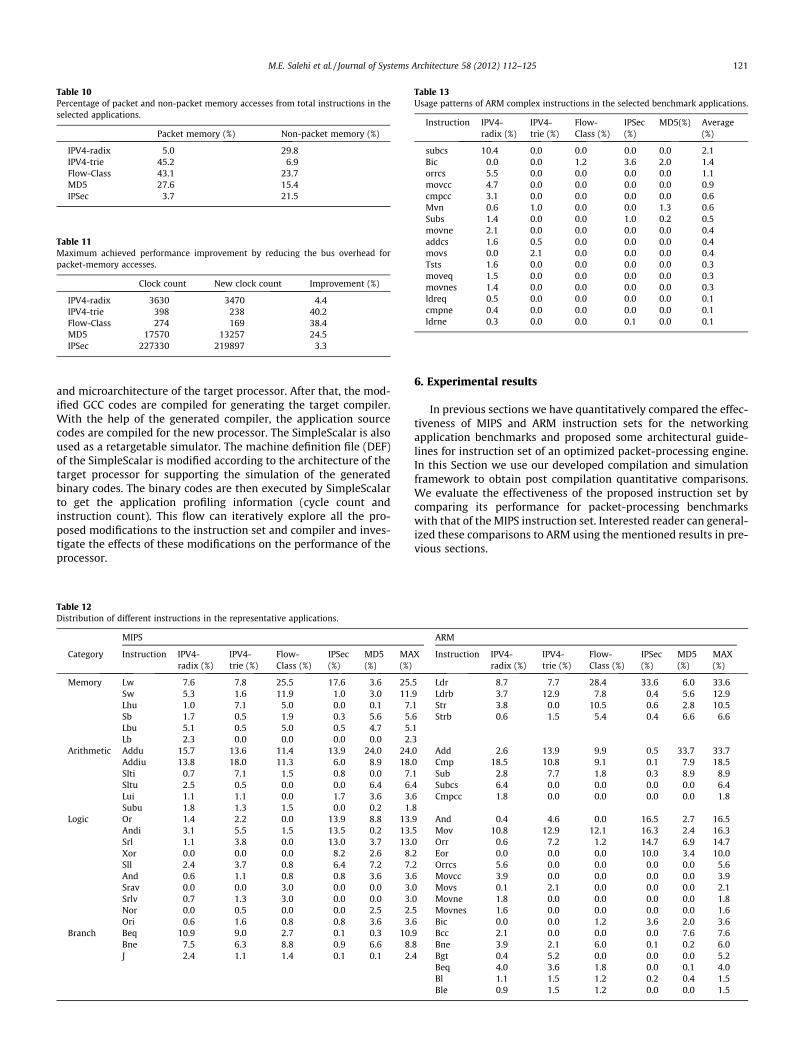
Table 10Percentage of packet and non-packet memory accesses from total instructions in theselected applications.
Packet memory (%) Non-packet memory (%)
IPV4-radix 5.0 29.8IPV4-trie 45.2 6.9Flow-Class 43.1 23.7MD5 27.6 15.4IPSec 3.7 21.5
Table 11Maximum achieved performance improvement by reducing the bus overhead forpacket-memory accesses.
Clock count New clock count Improvement (%)
IPV4-radix 3630 3470 4.4IPV4-trie 398 238 40.2Flow-Class 274 169 38.4MD5 17570 13257 24.5IPSec 227330 219897 3.3
Table 13Usage patterns of ARM complex instructions in the selected benchmark applications.
Instruction IPV4-radix (%)
IPV4-trie (%)
Flow-Class (%)
IPSec(%)
MD5(%) Average(%)
subcs 10.4 0.0 0.0 0.0 0.0 2.1Bic 0.0 0.0 1.2 3.6 2.0 1.4orrcs 5.5 0.0 0.0 0.0 0.0 1.1movcc 4.7 0.0 0.0 0.0 0.0 0.9cmpcc 3.1 0.0 0.0 0.0 0.0 0.6Mvn 0.6 1.0 0.0 0.0 1.3 0.6Subs 1.4 0.0 0.0 1.0 0.2 0.5movne 2.1 0.0 0.0 0.0 0.0 0.4addcs 1.6 0.5 0.0 0.0 0.0 0.4movs 0.0 2.1 0.0 0.0 0.0 0.4Tsts 1.6 0.0 0.0 0.0 0.0 0.3moveq 1.5 0.0 0.0 0.0 0.0 0.3movnes 1.4 0.0 0.0 0.0 0.0 0.3ldreq 0.5 0.0 0.0 0.0 0.0 0.1cmpne 0.4 0.0 0.0 0.0 0.0 0.1ldrne 0.3 0.0 0.0 0.1 0.0 0.1
M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125 121
and microarchitecture of the target processor. After that, the mod-ified GCC codes are compiled for generating the target compiler.With the help of the generated compiler, the application sourcecodes are compiled for the new processor. The SimpleScalar is alsoused as a retargetable simulator. The machine definition file (DEF)of the SimpleScalar is modified according to the architecture of thetarget processor for supporting the simulation of the generatedbinary codes. The binary codes are then executed by SimpleScalarto get the application profiling information (cycle count andinstruction count). This flow can iteratively explore all the pro-posed modifications to the instruction set and compiler and inves-tigate the effects of these modifications on the performance of theprocessor.
Table 12Distribution of different instructions in the representative applications.
MIPS
Category Instruction IPV4-radix (%)
IPV4-trie (%)
Flow-Class (%)
IPSec(%)
MD5(%)
MA(%)
Memory Lw 7.6 7.8 25.5 17.6 3.6 25.Sw 5.3 1.6 11.9 1.0 3.0 11.Lhu 1.0 7.1 5.0 0.0 0.1 7.Sb 1.7 0.5 1.9 0.3 5.6 5.Lbu 5.1 0.5 5.0 0.5 4.7 5.Lb 2.3 0.0 0.0 0.0 0.0 2.
Arithmetic Addu 15.7 13.6 11.4 13.9 24.0 24.Addiu 13.8 18.0 11.3 6.0 8.9 18.Slti 0.7 7.1 1.5 0.8 0.0 7.Sltu 2.5 0.5 0.0 0.0 6.4 6.Lui 1.1 1.1 0.0 1.7 3.6 3.Subu 1.8 1.3 1.5 0.0 0.2 1.
Logic Or 1.4 2.2 0.0 13.9 8.8 13.Andi 3.1 5.5 1.5 13.5 0.2 13.Srl 1.1 3.8 0.0 13.0 3.7 13.Xor 0.0 0.0 0.0 8.2 2.6 8.Sll 2.4 3.7 0.8 6.4 7.2 7.And 0.6 1.1 0.8 0.8 3.6 3.Srav 0.0 0.0 3.0 0.0 0.0 3.Srlv 0.7 1.3 3.0 0.0 0.0 3.Nor 0.0 0.5 0.0 0.0 2.5 2.Ori 0.6 1.6 0.8 0.8 3.6 3.
Branch Beq 10.9 9.0 2.7 0.1 0.3 10.Bne 7.5 6.3 8.8 0.9 6.6 8.J 2.4 1.1 1.4 0.1 0.1 2.
6. Experimental results
In previous sections we have quantitatively compared the effec-tiveness of MIPS and ARM instruction sets for the networkingapplication benchmarks and proposed some architectural guide-lines for instruction set of an optimized packet-processing engine.In this Section we use our developed compilation and simulationframework to obtain post compilation quantitative comparisons.We evaluate the effectiveness of the proposed instruction set bycomparing its performance for packet-processing benchmarkswith that of the MIPS instruction set. Interested reader can general-ized these comparisons to ARM using the mentioned results in pre-vious sections.
ARM
X Instruction IPV4-radix (%)
IPV4-trie (%)
Flow-Class (%)
IPSec(%)
MD5(%)
MAX(%)
5 Ldr 8.7 7.7 28.4 33.6 6.0 33.69 Ldrb 3.7 12.9 7.8 0.4 5.6 12.91 Str 3.8 0.0 10.5 0.6 2.8 10.56 Strb 0.6 1.5 5.4 0.4 6.6 6.6130 Add 2.6 13.9 9.9 0.5 33.7 33.70 Cmp 18.5 10.8 9.1 0.1 7.9 18.51 Sub 2.8 7.7 1.8 0.3 8.9 8.94 Subcs 6.4 0.0 0.0 0.0 0.0 6.46 Cmpcc 1.8 0.0 0.0 0.0 0.0 1.889 And 0.4 4.6 0.0 16.5 2.7 16.55 Mov 10.8 12.9 12.1 16.3 2.4 16.30 Orr 0.6 7.2 1.2 14.7 6.9 14.72 Eor 0.0 0.0 0.0 10.0 3.4 10.02 Orrcs 5.6 0.0 0.0 0.0 0.0 5.66 Movcc 3.9 0.0 0.0 0.0 0.0 3.90 Movs 0.1 2.1 0.0 0.0 0.0 2.10 Movne 1.8 0.0 0.0 0.0 0.0 1.85 Movnes 1.6 0.0 0.0 0.0 0.0 1.66 Bic 0.0 0.0 1.2 3.6 2.0 3.69 Bcc 2.1 0.0 0.0 0.0 7.6 7.68 Bne 3.9 2.1 6.0 0.1 0.2 6.04 Bgt 0.4 5.2 0.0 0.0 0.0 5.2
Beq 4.0 3.6 1.8 0.0 0.1 4.0Bl 1.1 1.5 1.2 0.2 0.4 1.5Ble 0.9 1.5 1.2 0.0 0.0 1.5

Table 14Proposed instruction set for embedded packet-processing engines.
MIPS ARM Proposed instructions
Arithmetic AdduAddiuSltiSltuSubu
AddSubSubcsCmpCmpcc
Add: add two registersAddi: add register and immediateSub: Sub two registersSubi: Sub immediate from register
Logic OrOriAndAndiXorNorSrlSllSravSrlv
OrOrcsAndEorMovMovccMovsMovneMovnesBic
And, Andi: and two operandsOr, Ori: or two operandXor, Xori: xor two operandsSll, Sllv: shift left logicalSrl, Srlv: shift right logicalSra, Srav: shift right arithmeticBic: bit clear
Memory LwLhuLbuLbSwSb
LdrLdrbStrStrbLdmStm
Ldw: load 32-bit from memoryLdh: load 16-bit from memoryLdb: load 8-bit from memoryStw: store 32-bit to memorySth: store 16-bit to memoryStb: store 8-bit to memoryLdm: load a block from memoryStm: store a block to memory
Branch BeqBneJJal
BeqBneBgtBlBleBcc
Beq: branch if registers are equalBne: branch if registers are not equalBlt: branch if a register is less than a registerBle: branch if a register is less than ro equalto a registerB: unconditional branchBr: branch to the address in the registerBal: branch and link
Fig. 4. General structure of the GCC.
Fig. 5. Our retargetable compilation and simulation framework.
Table 15Some of the least-frequently used instructions of MIPS in selected benchmarkapplications.
Instruction IPV4-radix (%)
IPV4-trie (%)
Flow-Class (%)
IPSec(%)
MD5(%)
Average(%)
mult 0.73 0.00 0.00 0.00 0.00 0.15mfhi 0.59 0.00 0.00 0.00 0.00 0.12divu 0.59 0.00 0.00 0.00 0.00 0.12blez 0.30 0.00 0.00 0.00 0.01 0.06bgtz 0.29 0.00 0.00 0.00 0.00 0.06bgez 0.29 0.00 0.00 0.00 0.00 0.06bltz 0.25 0.00 0.00 0.00 0.00 0.05xori 0.17 0.00 0.00 0.00 0.00 0.03slt 0.15 0.00 0.00 0.00 0.02 0.03dsw 0.15 0.00 0.00 0.00 0.00 0.03dlw 0.15 0.00 0.00 0.00 0.00 0.03
122 M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125
Exploiting the proposed exploration framework, we havestarted with the MIPS instruction set [21] as the starting pointand have modified it to converge to the optimized instructionset. We have evaluated the effectiveness of each modification tothe instruction set in terms of execution cycles and instructioncount for each of the representative benchmark applications.According to the results, there are some instructions that areleast-frequently or never used when compiling the selected appli-cations. We have found multiply and divide among these instruc-tions. We have excluded these instructions from the instructionlist with negligible performance degradation. Some of the least-fre-quent-used instructions of MIPS in the selected benchmarkapplications are shown in Table 15.
Decisions on whether excluding or including instructions from/to the instruction set is made based on the profiling results of theexploration framework. Some examples of the effect of excluding(e.g. immediate logical and shift instructions) or including (e.g.branch instructions, and byte- and half-word-loads and stores)new instructions on the performance and code size for the selectedapplications are shown in Fig. 6. As shown, excluding the immedi-ate logical instructions (i.e. ‘‘andi’’, ‘‘ori’’, and ‘‘xori’’) and immedi-ate shifts (i.e. ‘‘sll’’, ‘‘srl’’, and ‘‘sra’’) increases the executioncycles of representative applications about 7% and 11% on average,respectively. Therefore, it is not recommended to exclude theseinstructions from the MIPS instruction set. Including the proposedbranch instructions (i.e. ‘‘blt’’ and ‘‘ble’’) reduces the execution cy-cles of the selected applications by 8% on average. Excluding thehalf word loads/stores (i.e. ‘‘lh’’, ‘‘lhu’’/‘‘sh’’) increases the executioncycles about 3/1% on average, respectively. In addition excludingbyte loads/stores (i.e. ‘‘lb’’, ‘‘lbu’’/‘‘sb’’) reduces the performanceabout 5.4/6.9% on average, respectively. Furthermore, by excludingall half-word- and byte-loads and stores, the maximum degrada-tion in performance is 23% for MD5 and 27% for Flow-Class applica-tions. Comparing to the instruction sets that only support 32-bitloads/stores, the proposed instruction set can provide considerable
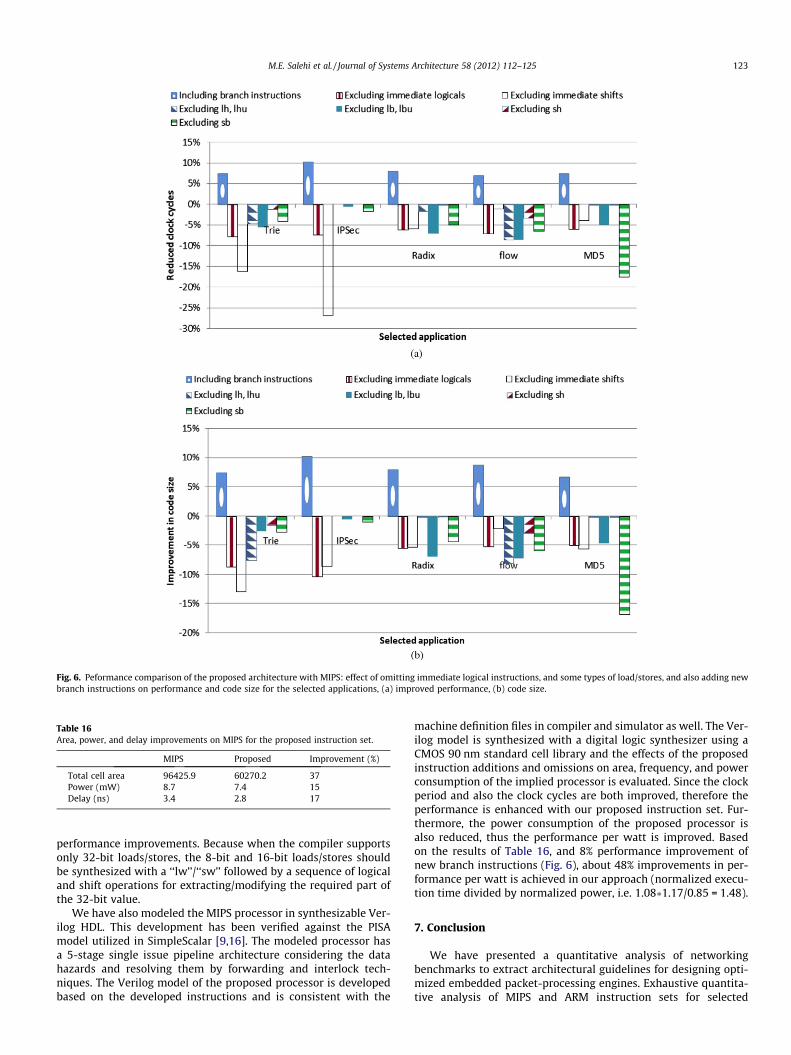
Fig. 6. Peformance comparison of the proposed architecture with MIPS: effect of omitting immediate logical instructions, and some types of load/stores, and also adding newbranch instructions on performance and code size for the selected applications, (a) improved performance, (b) code size.
Table 16Area, power, and delay improvements on MIPS for the proposed instruction set.
MIPS Proposed Improvement (%)
Total cell area 96425.9 60270.2 37Power (mW) 8.7 7.4 15Delay (ns) 3.4 2.8 17
M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125 123
performance improvements. Because when the compiler supportsonly 32-bit loads/stores, the 8-bit and 16-bit loads/stores shouldbe synthesized with a ‘‘lw’’/‘‘sw’’ followed by a sequence of logicaland shift operations for extracting/modifying the required part ofthe 32-bit value.
We have also modeled the MIPS processor in synthesizable Ver-ilog HDL. This development has been verified against the PISAmodel utilized in SimpleScalar [9,16]. The modeled processor hasa 5-stage single issue pipeline architecture considering the datahazards and resolving them by forwarding and interlock tech-niques. The Verilog model of the proposed processor is developedbased on the developed instructions and is consistent with the
machine definition files in compiler and simulator as well. The Ver-ilog model is synthesized with a digital logic synthesizer using aCMOS 90 nm standard cell library and the effects of the proposedinstruction additions and omissions on area, frequency, and powerconsumption of the implied processor is evaluated. Since the clockperiod and also the clock cycles are both improved, therefore theperformance is enhanced with our proposed instruction set. Fur-thermore, the power consumption of the proposed processor isalso reduced, thus the performance per watt is improved. Basedon the results of Table 16, and 8% performance improvement ofnew branch instructions (Fig. 6), about 48% improvements in per-formance per watt is achieved in our approach (normalized execu-tion time divided by normalized power, i.e. 1.08�1.17/0.85 = 1.48).
7. Conclusion
We have presented a quantitative analysis of networkingbenchmarks to extract architectural guidelines for designing opti-mized embedded packet-processing engines. Exhaustive quantita-tive analysis of MIPS and ARM instruction sets for selected

124 M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125
benchmarks has been made. SimpleScalar simulation and profilingenvironments are deployed to obtain comparative results, basedupon which instruction set architectural guidelines are developed.The reproducible profile-driven results are based on representativeheader- and payload-processing tasks. The experiments recom-mend load-store architecture with displacement and immediateaddressing modes supporting 8-, 16-, and 32-bit memory opera-tions for packet-processing tasks. We also recommend new com-pare-and-branch instructions for conditional branches whichsupport registers as operands.
To validate the proposed instruction set guidelines by consider-ing the mutual interaction of architecture and compiler in an inte-grated environment, a retargetable compilation and simulationframework has been developed. This framework utilizes GCC andSimpleScalar machine definition capabilities in the aforementioneddevelopment. It is shown that the proposed basic set of networkinginstructions provides low-power and cost-sensitive operation forembedded packet-processing engines. These optimized enginescan be employed in massively parallel NP architectures or embed-ded processors customized for packet processing in the future pack-etized world. Furthermore, the proposed instructions can also beused as the base set for accommodating application-specific custominstructions for more-complex processors.
References
[1] J.C. Niemann, C. Puttmann, et al., Resource efficiency of the GigaNetIC chipmultiprocessor architecture, Journal of Systems Architecture 53 (2007) 285–299.
[2] K. Vlachos, T. Orphanoudakis, et al., Design and performance evaluation of aprogrammable packet processing engine (PPE) suitable for high-speed networkprocessors units, Microprocessors & Microsystems 31 (3) (2007) 188–199.
[3] Patrick Crowley, Mark A. Franklin, Haldun Hadimioglu, Peter Z. Onufryk,Network Processor Design, Issues and Practices, The Morgan Kaufmann Seriesin Computer Architecture and Design, vol. 1, Elsevier Inc., 2005.
[4] J. Allen, B. Bass, et al., IBM PowerNP network processor: hardware, software,and applications, IBM Journal of Research and Development 47 (2/3) (2003)177–194.
[5] Panos C. Lekkas, Network Processors: Architectures, Protocols, and Platforms,McGraw-Hill Professional Publishing, 2003.
[6] R. Ohlendorf, A. Herkersdorf, T. Wild, FlexPath NP – a network processorconcept with application-driven flexible processing paths, in: third IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System,Synthesis, (CODES+ISSS), September 2005, pp. 279–284.
[7] R. Ohlendorf, T. Wild, M. Meitinger, H. Rauchfuss, A. Herkersdorf, Simulatedand measured performance evaluation of RISC-based SoC platforms in networkprocessing applications, Journal of Systems Architecture 53 (2007) 703–718.
[8] M. Okuno, S. Nishimura, S. Ishida, H. Nishi, Cache-based network processorarchitecture: evaluation with real network traffic, IEICE Transaction onElectron, E89–C (11) (2006) 1620–1628.
[9] D. Burger, T. Austin, The SimpleScalar tool set version 2.0, ComputerArchitecture News 25 (3) (1997) 13–25.
[10] J.L. Hennessy, D.A. Patterson, Computer architecture: a quantitative approach,fourth ed., The Morgan Kaufmann Series in Computer Architecture and Design,Elsevier Inc., 2007.
[11] IETF RFCs, available from: <http://www.ietf.org/>.[12] T. Wolf, M.A. Franklin, CommBench – a telecommunications benchmark for
network processors, in: Proc. of IEEE International Symposium on PerformanceAnalysis of Systems and Software (ISPASS), April 2000, pp. 154–162.
[13] G. Memik, W.H. Mangione-Smith, W. Hu, Net-Bench: a benchmarking suite fornetwork processors, in: Proc. of IEEE/ACM International Conference on,Computer-Aided Design, November 2001, pp. 39–42.
[14] B.K. Lee, L.K. John, NpBench: a benchmark suite for control plane and dataplane applications for network processors, in: Proc. of IEEE InternationalConference on Computer Design (ICCD 03), October 2003, pp. 226–233.
[15] R. Ramaswamy, T. Wolf, PacketBench: a tool for workload characterization ofnetwork processing, in: Proc. of IEEE International Workshop on WorkloadCharacterization, October 2003, pp. 42–50.
[16] SimpleScalar LLC, available from: <http://www.simplescalar.com>.[17] EEMBC, The Embedded Microprocessor Benchmark Consortium, Available
from: <http://www.eembc.org/home.php>.[18] Intel� IXP4XX Product Line of Network Processors, Available from: <http://
www.intel.com/design/network/products/npfamily/ixp4xx.htm>.[19] Broadcom corporation, Communications Processors, available from: <http://
www.broadcom.com/products/Data-Telecom-Networks/Communications-Processors#tab=products-tab>.
[20] National Laboratory for Applied Network Research – Passive Measurement andAnalysis. Passive Measurement and Analysis, available from: <http://pma.nlanr.net/PMA/>.
[21] J.L. Hennessy, D.A. Patterson, Computer organization and design: thehardware/software interface, third ed., The Morgan Kaufmann Series inComputer Architecture and Design, Elsevier Inc., 2005.
[22] M.E. Salehi, S.M. Fakhraie, Quantitative analysis of packet-processingapplications regarding architectural guidelines for network-processing-engine development, Journal of Systems Architecture 55 (2009) 373–386.
[23] ARM Processor Instruction Set Architecture, available from: <http://www.arm.com/products/CPUs/architecture.html>.
[24] Jurij Silc, Borut Robic, Th. Ungerer, Processor Architecture: From Dataflow toSuperscalar and Beyond, Springer-Verlag, 1999.
[25] M.E. Salehi, R. Rafati, F. Baharvand, S.M. Fakhraie, A quantitative study onlayer-2 packet processing on a general purpose processor. in: Proc. ofInternational Conference on Microelectronic (ICM06), December 2006, pp.218–221.
[26] Partha Biswas, Kubilay Atasu, Vinay Choudhary, Laura Pozzi, Nikil Dutt, PaoloIenne, Introduction of local memory elements in instruction set extensions. in:Proc. of the 41st Design Automation Conference, San Diego, CA, June 2004, pp.729–734.
[27] H. Mohammadi, N. Yazdani, A genetic-driven instruction set for high speednetwork processors, in: Proc. of IEEE International Conference on ComputerSystems and Applications (ICCSA 06), March 2006, pp. 1066–1073.
[28] Gary Jones, Elias Stipidis, Architecture and instruction set design of an ATMnetwork processor, Microprocessors and Microsystems 27 (2003) 367–379.
[29] N.T. Clark, H. Zhong, S.A. Mahlke, Automated custom instruction generation fordomain-specific processor acceleration, IEEE Transaction on Computers 54(10) (2005) 1258–1270.
[30] M. Grünewald, D. Khoi Le, et al. Network application driven instruction setextensions for embedded processing clusters, in: Proc. InternationalConference on Parallel Computing in, Electrical Engineering, September2004, pp. 209–214.
[31] Muhammad Omer Cheema, Omar Hammami, Application-specific SIMDsynthesis for reconfigurable architectures, Microprocessors andMicrosystems 30 (2006) 398–412.
[32] Pan Yu, Tulika Mitra, Scalable custom instructions identification for instructionset extensible processors, in: Proc. of International Conference on Compilers,Architecture and Synthesis for Embedded Systems, September 2004, pp. 69–78.
[33] Jason Cong, Yiping Fan, Guoling Han, Zhiru Zhang, Application-specificinstruction generation for configurable processor architectures, in: Proc. ofthe ACM/SIGDA international symposium on Field programmable gate arrays,2004, pp. 183–189.
[34] S.K. Lam, T. Srikanthan, Rapid design of area-efficient custom instructions forreconfigurable embedded processing, Journal of System Architecture 55 (2009)1–14.
[35] K. Atasu, C. Ozturan, G. Dundar, O. Mencer, W. Luk, CHIPS: custom hardwareinstruction processor synthesis, IEEE Transactions on Computer Aided Designof Integrated Circuits and Systems 27 (2008) 528–541.
[36] L. Pozzi, K. Atasu, P. Ienne, Exact and approximate algorithms for the extensionof embedded processor instruction sets, IEEE Transaction on Computer-AidedDesign of Integrated Circuits and Systems 25 (2006) 1209–1229.
[37] F. Sun, S. Ravi, A. Raghunathan, N.K. Jha, A synthesis methodology for hybridcustom instruction and co-processor generation for extensible processors, IEEETransactions on Computer-Aided Design 26 (11) (2007) 2035–2045.
[38] Philip Brisk, Adam Kaplan, Majid Sarrafzadeh, Area-efficient instruction setsynthesis for reconfigurable system-on-chip designs, in: Proc. of the 41stannual Design Automation Conference (DAC 04), 2004, pp. 395–400.
[39] Tensilica: Customizable Processor Cores for the Dataplane, available from:<http://www.tensilica.com/>.
[40] Karl Van Rompaey, DiederikVerkest, Ivo Bolsens, Hugo De Man, ‘‘CoWare – adesign environment for heterogeneous hardware/software systems’’, in: Proc.of European Design Automation Conference, 1996, pp. 252–257.
[41] ACE CoSy compiler development system, available from: <http://www.ace.nl/compiler/cosy.html>.
[42] GCC, the GNU Compiler Collection, available from: <http://gcc.gnu.org/>.
Mostafa Ersali Salehi Nasab was born in Kerman, Iran,in 1978. He received the B.Sc. degree in computerengineering from University of Tehran, Tehran, Iran, andthe M.Sc. degree in computer architecture from Uni-versity of Amirkabir, Tehran, Iran, in 2001 and 2003,respectively. He has received his Ph.D. degree in schoolof Electrical and Computer Engineering, University ofTehran, Tehran, Iran in 2010. He is now an AssistantProfessor in University of Tehran. From 2004 to 2008, hewas a senior digital designer working on ASIC designprojects with SINA Microelectronics Inc., TechnologyPark of University of Tehran, Tehran, Iran. His research
interests include novel techniques for high-speed digital design, low-power logicdesign, and system integration of networking devices.

M.E. Salehi et al. / Journal of Systems Architecture 58 (2012) 112–125 125
Sied Mehdi Fakhraie was born in Dezfoul, Iran, in 1960.He received the M.Sc. degree in electronics from theUniversity of Tehran, Tehran, Iran, in 1989, and the Ph.D.degree in electrical and computer engineering from theUniversity of Toronto, Toronto, ON, Canada in 1995.Since 1995, he has been with the School of Electrical andComputer Engineering, University of Tehran, where heis now an Associate Professor. He is also the Director ofSilicon Intelligence and the VLSI Signal Processing Lab-oratory. From September 2000 to April 2003, he waswith Valence Semiconductor Inc. and has worked inDubai, UAE, and Markham, Canada offices of Valence as
Director of application-specific integrated circuit and system-on-chip (ASIC/SoCDesign) and also technical lead of Integrated Broadband Gateway and Family RadioSystem baseband processors. During the summers of 1998, 1999, and 2000, he was
a Visiting Professor at the University of Toronto, where he continued his work onefficient implementation of artificial neural networks. He is coauthor of the bookVLSI-Compatible Implementation of Artificial Neural Networks (Boston, MA: Kluwer,1997). He has also published more than 200 reviewed conference and journalpapers. He has worked on many industrial IC design projects including design ofnetwork processors and home gateway access devices, digital subscriber line (DSL)modems, pagers, and one- and two-way wireless messaging systems, and digitalsignal processors for personal and mobile communication devices. His researchinterests include system design and ASIC implementation of integrated systems,novel techniques for high-speed digital circuit design, and system-integration andefficient VLSI implementation of intelligent systems.
Amir Yazdanbakhsh was born in Shiraz, Iran, in 1984.He received the B.Sc. degree in computer engineeringfrom Shiraz University, Shiraz, Iran, and the M.Sc.degree in computer architecture from University ofTehran, Tehran, Iran in 2007 and 2010, respectively. Hisresearch interests include novel high-performance andlow-power architecture models for microprocessor andembedded systems and customization for specificapplication domains.





























