Embed Size (px)
Citation preview

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 1
Fast Closed-form Matting Using HierarchicalData Structure
Chunxia Xiao, Meng Liu, Donglin Xiao, Zhao Dong, and Kwan-Liu Ma, Fellow, IEEE
Abstract—Image/video matting is one of the key operationsin many image/video editing applications. Although previousmethods can generate high-quality matting results, their highcomputational cost in processing high-resolution image andvideo data often limits their usability. In this paper, wepresent a unified acceleration method for closed-form imageand video matting using a hierarchical data structure, whichachieves an excellent compromise between quality and speed.We first apply Gaussian KD-tree to adaptively cluster theinput high-dimensional image and video feature space into alow-dimensional feature space. Then, we solve the affinity-weighted Laplacian alpha matting in the reduced featurespace. The final matting results are derived using detail-awarealpha interpolation. Our algorithm can be fully parallelizedby exploiting advanced graphics hardware, which can furtheraccelerate the matting computation. Our method acceleratesexisting methods by at least an order of magnitude with goodquality, and also greatly reduces the memory consumption.This acceleration strategy is also extended to support otheraffinity-based matting approaches, which makes it a moregeneral accelerating framework for a variety of mattingmethods. Finally, we apply the presented method to accelerateimage and video dehazing, and image shadow detection andremoval.
Index Terms—Gaussian KD-tree, matting, dehazing, accel-eration, GPU
I. INTRODUCTION
MATTING aims at accurately extracting foregroundobjects from input image or video, which is an
important technique in image and video processing andfilm production applications. Although matting has beenextensively studied (refer to [1], [2] for a survey), itsaccuracy and efficiency still need to be improved, so asto develop intelligent, user-friendly, computationally effi-cient matting tools. Recently, several affinity-based mattingmethods [3], [4], [5], [6], [7], [8], [9] succeed in generatingmore accurate results than early approaches. However, thesemethods are generally expensive to compute, as they needto solve a large linear system. Moreover, the high memoryconsumption of these methods also limit their performance
Chunxia Xiao, Meng Liu and Donglin Xiao are with the ComputerSchool, Wuhan University, Wuhan, Hubei, China, 430072. E-mail: [email protected], [email protected], [email protected].
Zhao Dong is with the program of computer graphics, Cornell Univer-sity, NY, USA, 14853. E-mail:[email protected]
Kwan-Liu Ma is with the department of computer science, Universityof California-Davis, CA, USA, 95616-8562. E-mail: [email protected]
Copyright (c) 2013 IEEE. Personal use of this material is permit-ted. However, permission to use this material for any other purpos-es must be obtained from the IEEE by sending an email to [email protected].
Corresponding to Chunxia Xiao: [email protected]
especially when dealing with gigapixel images or videosequences.
Closed-form matting (CFM) [3] is one representativeaffinity-based matting approach and its matting qualityranks top among the methods in the online image mattingbenchmark list [10]. The CFM method derives a cost func-tion from local smoothness assumption on foreground andbackground colors. By eliminating the foreground color (F)and background color (B), this cost function can be deducedto a quadratic cost function only containing alpha value.The globally optimal alpha matte can then be computedby solving a sparse linear system of equations. Althoughthe CFM method [3] works well for image matting, itshigh time and memory consumption for solving a largelinear system make it intractable to process high-resolutionimages or videos.
However, for the natural image and video matting, mostpixels are definite foreground or background, and there aremany clusters of pixels that are highly similar in featurespace. Thus, it is wasteful to perform the CFM optimizationfor every pixel. Motivated by it, we accelerate the CFMmethod [3] using a hierarchical data structure. Firstly, theinput pixels are grouped into clusters based on feature simi-larity metric using the affinity-based Gaussian KD-tree [11].Hence, a much smaller number of Gaussian weightedfeature samples of the original data set are obtained, whichforms the reduced feature space approximating the originaldata set. Then we construct an affinity-weighted Laplacianmatrix with the feature samples to obtain the matting alphavalues in the reduced feature space. Finally, we generate thematting results using a new detail-aware alpha interpolationmethod. With such a hierarchical strategy, we can constructthe Laplacian matrix using a small number of samples andsolve it in low-resolution space, which breaks the timeand memory consumption bottleneck in the original CFMmethod. By applying the Gaussian KD-tree on video inputand constructing affinity-weighted Laplacian matrix basedon 3D local neighboring samples, our method can be easilyextended to efficiently handle video matting. Hence, ourmethod is a unified acceleration strategy for both imageand video matting.
Our method can be further applied as a general accel-eration approach for various other affinity-based mattingmethods [3], [4], [5], [6], [12], [9] with slight modifications.We apply the presented strategy to spectral matting [5] androbust matting [9], which demonstrates that although theunderlying energy functions for these methods are quitedifferent from each other, they can share our method as a

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 2
general matting acceleration framework.We notice that the haze imaging equation has a similar
form as the matting equation [13], where a transmissionmap is exactly an alpha map. As an application, weapply the accelerated CFM as a fast extrapolation tool torefine the computed transmission using prior-dark channelprior [13] for fast image and video dehazing. As shadowdetection and removal is important in image/video editingand segmentation [14], [15], we further apply our methodto accelerate and refine this application.
The Gaussian KD-tree strategy for CFM acceleration hasthe following advantages: Firstly, high image/video mattingquality as the CFM method can be obtained, while thecomputation and memory costs are significantly reduced.Secondly, CFM can be further accelerated by one order ofmagnitude via the evolving graphics hardware, since thethree main steps of the acceleration procedure, includingGaussian KD-tree construction, affinity-based Laplacianmatrix construction, and alpha interpolation, can be imple-mented in parallel. Thirdly, it can be further applied asa general acceleration approach for various other affinity-based matting methods with slight modifications.
In summary, our major contributions are:• A unified acceleration method for the closed-form
image/video matting using hierarchical data structure,which achieves both good quality and high perfor-mance.
• Extending the acceleration method to support otheraffinity-based matting methods, which makes it a moregeneral matting acceleration framework.
• Accelerating the image/video dehazing and imageshadow removal by applying the presented acceleratedCFM as a fast interpolation tool.
II. RELATED WORKS
A complete review of all existing image and videomatting methods is beyond the scope of this article andwe refer the reader to [1] for a detailed introduction. Here,we only discuss the most relevant works.
Image and Video Matting: Existing image mattingmethods can be roughly classified into three categories:affinity-based, sampling-based, and approaches combiningsampling with affinity. Affinity-based matting methodscompute the alpha values for unknown region based onthe alpha interpolation from the known regions determinedby user inputs. It defines the affinities between neighboringpixels by modeling the matte gradient for each pixel inits local neighbor window. The interpolation can thereforebe achieved by solving an affinity matrix [16], [4], [3],[17], [18]. However, the complex computations incurred byaffinity-based matting always becomes the bottleneck whendealing with high-resolution images. The affinity-basedmethods compute alpha value without explicitly accountingfor the foreground and background colors. In contrast, thesampling-based methods [19], [20], [21], [22] assume thatthe true foreground and background colors of a pixel inunknown region can be explicitly estimated by analyzingnearby pixels in known region.
Both sampling-based and affinity-based approaches havepros and cons. The sampling-based methods work betterwhen dealing with distinct foreground and backgroundcolor distributions along with carefully specified trimaps,but tend to generate large errors when their underlyingassumptions are violated. Comparatively, the affinity-basedapproaches are relatively insensitive to different user inputsand always generate smooth mattes, although their resultsmight not be accurate enough for long and thin (i.e. furry)foreground structures. Moreover, they are usually time-consuming. Matting approaches combining sampling withaffinity have been developed [8], [7], [9], which achievea good trade-off between accuracy and robustness. Thesemethods normally defines an energy function taking theform of a “Gibbs” energy to be minimized. Although thesemethods produce satisfactory mattes, their performance isstill low for handling high-resolution image.
Video matting is inherently a more challenging task andthe difficulties mainly arise from the following aspects:(1) large data size, (2) difficulty in maintaining temporalcoherence, and (3) tedious user interactions. Many videomatting methods have been presented [12], [23]–[26], andmost of them extends an image matting method to handle3D video data with time as the third dimension. Forexample, Bayesian video matting [23], [24] follows thetechnical routine of Bayesian image matting [20], andadopts a bidirectional optical flow algorithm to interpolatethe trimaps in key frames. Please refer to [1] for morediscussions about video matting methods.
CFM acceleration: The optimization problem of closed-form matting (CFM) [3] is to minimize a quadratic costfunction subject to linear constraints, and the solution canbe obtained by solving a large set of sparse linear equations.Solving linear system with this structure is a well-studiedproblem with various solutions, such as preconditioning[27] and multigrid [28] methods. Levin et al. [3] applieda simple multi-resolution solver to accelerate matte extrac-tion. Although multi-resolution solver can perform CFM ina couple of seconds for a low-resolution image, this methodwill degrade the matte quality. He et al. [18] presented alarge kernel matting Laplacian matrices to speed up theCFM. Although this method can receive pleasing mattingresults, matting efficiency is still too low for interac-tive applications. To apply GPU acceleration strategy forCFM, Huang et al. [29] proposed a multi-scale windowingscheme, which first computes solutions in local windowsone at a time, and then combines the local solutions toachieve the global results. Although this method is efficientfor accelerating CFM, our acceleration method based onhierarchical data structure is much more general comparedwith it, which can be applied to accelerate various affinity-based matting methods [4], [5], [6], [12], [9], not just CFM.
KD-tree Acceleration: As an efficient hierarchical datastructure for accelerating data clustering, KD-tree has beenwidely applied in computer graphics and vision applica-tions. Utilizing the massive parallelism of modern GPU,it is possible to construct a KD-tree on GPU in real-

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 3
(a) (b) (c) (d)
Fig. 1. Comparison of different clustering techniques: (a) Input image,and clustering results using Gaussian KD-tree (b), k-means (c) and mean-shift (d).
time. Horn et al. [30] and Zhou et al. [31] presentedGPU-based KD-tree construction algorithms achieving real-time performance. KD-Tree also has been used in imageand video processing [32]. Adam et al. [11] developedGaussian KD-tree to accelerate a class of non-linear filters,including bilateral image filtering, bilateral mesh filtering,and image denoising with nonlocal means. This method[11] achieved both magnificent performance improvementand high-quality results. Our method adopts Gaussian KD-tree as the hierarchical data structure to accelerate theimage and video matting. Note, although sharing the similarmotivation with [11], we developed different accelerationstrategies in our method for fast matting applications, whichinclude (1) constructing a new affinity-weighted Laplacianmatrix for the feature samples to obtain the matting alphavalues in the reduced feature space, and (2) generating thematting results using a new detail-aware alpha interpolation.
Many clustering methods have been proposed, such asthe popular k-means clustering (KMC) [33], and mean-shift clustering (MSC) [34]. Although KMC works fastfor data clustering, for the image/video matting task, k-means clustering may not generate accurate and fine sam-pling/clustering result along the image edges, which is criti-cal for extracting accurate matte along the boundaries of theforeground object, e.g. the fine hair in Fig.1. MSC works bydefining a Gaussian kernel density estimate for underlyingdata, and then clustering the similar points together througha fixed-point iterative process until converging to the samemode. MSC works well for small-scale data clustering andsegmentation, while its performance is slow for clusteringlarge data set. Further, MSC cannot produce accurate andfine sampling along the image edges, either. In compar-ison, the Gaussian KD-tree clustering (GKDC) generatesaccurate and fine enough results along the image edges. Asshown in Fig.1, the result using GKDC produces finer andmore accurate sampling along the image edge comparedwith both KMC and MSC. The GKDC also greatly reducesboth time and memory consumption, and hence easily dealswith large data set. Moreover, using the KD-tree structure,it is more convenient to control the hierarchical clusteringscheme, which helps accelerating the matting process usinghierarchical data structure.
III. CLOSED-FORM MATTING
The closed-form matting (CFM) approach [3] explicitlyderives a cost function using local smoothness assumption
on foreground and background colors, referred to as Fand B, respectively. During the derivation, it is possible toanalytically eliminate F and B to finally obtain a quadraticcost function of matte α , which can be further solved as asparse linear system. The underlying assumption made inCFM is that each F and B is a linear mixture of two colorsover a small window wj (typically 3× 3 or 5× 5) aroundeach pixel, which is referred to as the color line model.Under this assumption, the alpha value in a small windowcan be expressed as
αi =∑c
acIci + b,∀i ∈ w (1)
where c refers to color channels, and ac and b are constantsin local window. The matting cost function is then definedas
J(α, a, b) =∑j∈I
(∑i∈w
(αi − acjIci − bj)2 + εacj
)(2)
ac and b can be further eliminated from the cost function,yielding a quadratic cost with α alone:
J(α) = αTLα (3)
where L is an n × n Laplacian matrix (n pixels in theimage). The optimal alpha value is then computed as
α = argmin(αTLα) (4)
which is essentially a problem of minimizing a quadraticerror, and can be solved by a linear system solver. AlthoughCFM achieves very good image matting quality, it works onthe per-pixel basis and hence introduces a large linear sys-tem for high-dimension image and video, the computationalcost and memory consumption of which are prohibitive.
IV. FAST CLOSED-FORM MATTING
In this section, we describe how to accelerate theCFM [3] method using the Gaussian KD-tree [11]. Ourmethod takes an image I (or video sequence) with n pixelsand the interactive user strokes as input. It consists ofthe following major steps: (a) Building the affinity-basedKD-tree for input image/video while maintaining the localsmooth assumption. (b) Propagating the input user strokesto each tree leaf node. (c) Constructing and solving theaffinity-based Laplacian matrix in low-dimensional space.(d) Restoring the matte result for input image using up-sampling. In the following subsections, we introduce thealgorithmic details for each step.
A. Gaussian KD-tree partitioning
Affinity space definition: We adopt the affinity mea-sure from [35], [32] to define the affinity space of theimage/video data. For each pixel i, we represent it using a5-dimensional feature vector fi = (pi, vi) where pi and viare the 2D position and the color (appearance) of i, respec-tively. For video data, the feature vector can be expanded toinclude the frame index (i.e. time) ti of i, which becomesa 6-dimensional vector fi = (pi, vi, ti). Further weighting
JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 4
(a) (b) (c) (d) (e)
(f) (g) (h)
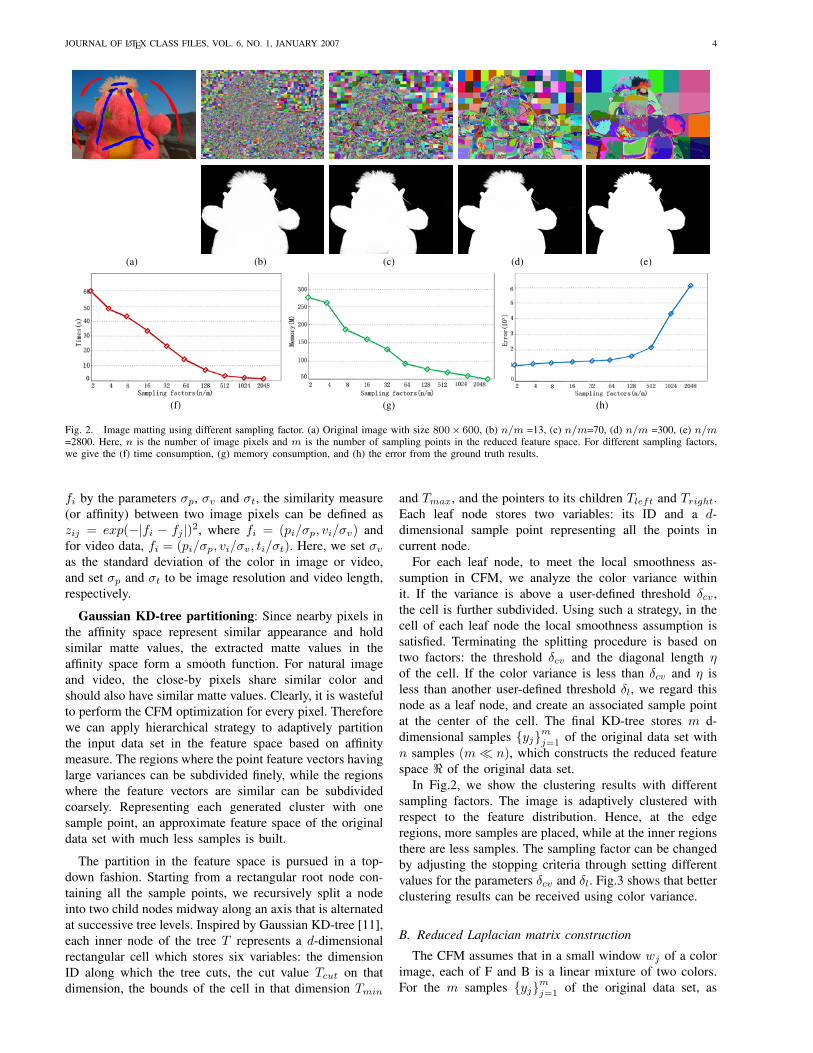
Fig. 2. Image matting using different sampling factor. (a) Original image with size 800× 600, (b) n/m =13, (c) n/m=70, (d) n/m =300, (e) n/m=2800. Here, n is the number of image pixels and m is the number of sampling points in the reduced feature space. For different sampling factors,we give the (f) time consumption, (g) memory consumption, and (h) the error from the ground truth results.
fi by the parameters σp, σv and σt, the similarity measure(or affinity) between two image pixels can be defined aszij = exp(−|fi − fj |)2, where fi = (pi/σp, vi/σv) andfor video data, fi = (pi/σp, vi/σv, ti/σt). Here, we set σvas the standard deviation of the color in image or video,and set σp and σt to be image resolution and video length,respectively.
Gaussian KD-tree partitioning: Since nearby pixels inthe affinity space represent similar appearance and holdsimilar matte values, the extracted matte values in theaffinity space form a smooth function. For natural imageand video, the close-by pixels share similar color andshould also have similar matte values. Clearly, it is wastefulto perform the CFM optimization for every pixel. Thereforewe can apply hierarchical strategy to adaptively partitionthe input data set in the feature space based on affinitymeasure. The regions where the point feature vectors havinglarge variances can be subdivided finely, while the regionswhere the feature vectors are similar can be subdividedcoarsely. Representing each generated cluster with onesample point, an approximate feature space of the originaldata set with much less samples is built.
The partition in the feature space is pursued in a top-down fashion. Starting from a rectangular root node con-taining all the sample points, we recursively split a nodeinto two child nodes midway along an axis that is alternatedat successive tree levels. Inspired by Gaussian KD-tree [11],each inner node of the tree T represents a d-dimensionalrectangular cell which stores six variables: the dimensionID along which the tree cuts, the cut value Tcut on thatdimension, the bounds of the cell in that dimension Tmin
and Tmax, and the pointers to its children Tleft and Tright.Each leaf node stores two variables: its ID and a d-dimensional sample point representing all the points incurrent node.
For each leaf node, to meet the local smoothness as-sumption in CFM, we analyze the color variance withinit. If the variance is above a user-defined threshold δcv ,the cell is further subdivided. Using such a strategy, in thecell of each leaf node the local smoothness assumption issatisfied. Terminating the splitting procedure is based ontwo factors: the threshold δcv and the diagonal length ηof the cell. If the color variance is less than δcv and η isless than another user-defined threshold δl, we regard thisnode as a leaf node, and create an associated sample pointat the center of the cell. The final KD-tree stores m d-dimensional samples {yj}mj=1 of the original data set withn samples (m� n), which constructs the reduced featurespace < of the original data set.
In Fig.2, we show the clustering results with differentsampling factors. The image is adaptively clustered withrespect to the feature distribution. Hence, at the edgeregions, more samples are placed, while at the inner regionsthere are less samples. The sampling factor can be changedby adjusting the stopping criteria through setting differentvalues for the parameters δcv and δl. Fig.3 shows that betterclustering results can be received using color variance.
B. Reduced Laplacian matrix construction
The CFM assumes that in a small window wj of a colorimage, each of F and B is a linear mixture of two colors.For the m samples {yj}mj=1 of the original data set, as

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 5
(a) (b) (c)
(d) (e) (f)
Fig. 3. Clustering using color variance. (a) Input image, (b) (c) thevariance visualization before and after leaf nodes adjustment, (d) (f)matting result before and after leaf nodes adjustment, (e) is zoom in results.
we do not have regular lattice for each sample, we replacethe local window by the nearest neighborhood θj aroundeach sample yj with neighborhood size θ. For each sample,we apply feature affinity-based KD-tree query to find itsnearest neighborhood θj in the feature vector space <.The query takes a query sample yj , a standard deviationδ around this sample, and a number |θj |, which is thenumber of the samples in θ, as input, and returns a list of|θj | nearest points yis with the corresponding weights wis.wi = exp(−|fi − fj |2/2δ2)), where fi and fj are featurevectors of sample yi and sample yj . In our experiments,we set δ in the same way as σ in zij .
As the samples {yj}mj=1 are sampled non-uniformly fromthe original data, the density distribution of samples ineach neighborhood θj may vary. For the samples at theobject boundaries, the samples in θj are densely sampled,while in the inner regions, the samples in θj are coarselysampled. To make the color linear model work well inthe neighborhood, we introduce the affinity weight factorzij = exp(−‖fi−fj‖2) into Eq.(2). Hence, we can get thefollowing energy formula:
J(α, a, b) =∑j∈I
(∑i∈θj
zji(αi − acjIci − bj)2 + εa2j
)(5)
Define J(α, a, b) = mina,bJ(α, a, b), and the followingequation can be obtained:
J(α) = αTLα (6)
where L is a m×m matrix, and each matrix element Lijis defined as:∑k|(i,j)∈θk
zij
(δij−
1
|θk|
((Ii−µk)(Σk+
zijε
|θk|I3)−1(Ij−µk)
))(7)
The matrix L is so-called affinity weighted matting Lapla-cian, where Σk is a 3 × 3 covariance matrix, µk is a3 × 1 vector of the mean color in the neighborhood θk,I3 is the 3 × 3 identity matrix, and |θk| is the number ofpoints in this window. In the matrix L, besides imposingthe local smoothness assumption in local neighborhoodof the reduced feature space, we further impose that in
the neighborhood, the local smoothness assumption alsoaccounts for feature variation, which is captured by theaffinities zij . Thus, the matrix L is more robust for non-uninformly sampled feature space.
From Eq.(7) we observe that the following three terms1|θk| , µk, (Σk +
zijε|θk| I3)−1 are independent of index i, j
for computing Lij . Hence, we first precompute and storethese three terms for each θk, then construct the Laplacianmatrix L, making the construction of Laplacian matrix Lmore efficient.
This affinity-weighted matting Laplacian can be easilyextended to deal with video data. If applying the Laplacianmatting naively for each frame, it may generate temporalincoherent result. To maintain temporal coherence, we treatthe whole video sequence as a 3D volume. We sample mfeature points {yj}mj=1 from the original video data set.Then in each small 3D window typically 15 nearest pointsare sampled around each sample, similar to the image case.Assuming that within each window, each of F and Bis a linear mixture of two colors, thus, the color linearmodel also holds in 3D window. We then build the mattingcost function for the video sequence and obtain affinity-weighted Laplacian matrix similar to Eq.7, where Σk andµk are defined as the covariance matrix and mean vectorof the colors in a 3D window θk.
C. Reduced linear system constructionWithout any additional constraint, directly minimizing
the energy function Eq.6 will lead to a trivial solution.To properly extract semantically meaningful foreground ob-jects, almost all matting approaches, including the CFM [3],start by having the user to segment the input image intothree regions: definite foreground Rf , definite backgroundRb and unknown Ru. Such inputs from user are referredto as a trimap. Instead of requiring a carefully specifiedtrimap, our method allows the user to just specify a fewforeground and background scribbles as inputs to pursuematting. These scribbles define a very coarse trimap bymarking the majority of the pixels as unknowns. Forvideo matting, we apply volume-based approaches [26] tocompute video trimap.
Having the specified trimap on the input data, to performCFM in the reduced feature space using the tripmap asthe constraints, we must map the trimap into the reducedfeature space. The trimap is mapped using the followingsteps: (1) for each scribbled pixel p with feature vectorf , we search its nearest sample Lf in the reduced featurespace <, (2) if pixel p is a foreground or background pixel,then Lf is set to be foreground or background sample.As the reduced feature space contains much less pointsthan original data, the mapped foreground and backgroundsamples in the reduced space may be too coarse to provideenough training examples for effective matting. To resolvethis issue, for each scribbled pixel p, we find several nearestsamples in the feature space < as the corresponding set ofsamples.
After constructing the reduced feature space < andproject the trimap into it, the matting problem is thus

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 6
reduced to estimate F , B and α for pixels within theunknown region in the reduced feature space, based on themapped foreground and background samples. We provideuser-supplied constraints on Eq.6 to extract the alpha matte.We set α = 1 for user specified foreground points, andα = 0 for user specified background points. We minimizethe following energy function to extract the alpha matte,matching the user’s constraints in the reduced feature space:
J∗(α, a, b) = J(α, a, b) + λ1∑θk
∑(i,j)∈θk
zij(αi − αj)2+
λ2(αT − bTS )DS(α− bs)(8)
This energy function consists of three terms. The first termJ(α, a, b) is a cost function. The second term enforces thatthe matte values α are similar for regions with similarappearances f , which is captured by the affinity zij . Thesecond term also helps to avoid the incorrect mattes dif-fusion, especially in the edges regions, since the affinityzij accounts for both the position and color of the sampledpoints. The third one is responsible for satisfying the user-specified constraints, where Ds is a diagonal matrix whosediagonal elements are 1 for constrained pixels and 0 for allother pixels, and bs is the vector containing the specifiedalpha values for the constrained pixels, and bs = 1 forforeground pixels and bs = 0 for background pixels. Therelative contributions of these three terms are controlled byλ1 and λ2. Based on our experiments, λ1 = 0.5 and λ2 = 3are optimal in usual cases.
By eliminating a and b from the first term, to extract analpha matte matching the user’s constraints, we solve for
α = argminαTLα+ λ1∑θk
∑(i,j)∈θk
zij(αi − αj)2+
λ2(αT − bTS )DS(α− bS)
(9)
Since the above cost function is quadratic in alpha α, theglobal minimum can be found by differentiating it andsetting the derivatives to be zero. This amounts to solvingthe following sparse linear system:
(L+ 2λ1D − 2λ1Z + λ2DS)α = λ2bS (10)
where L is the affinity-weighted Laplacian matrix (Eq.7),Z is the affinity matrix whose elements are zij , and D isa diagonal matrix with Dij =
∑j zij . As we construct the
energy function in the reduced feature space, the matrix L,Z, D and Ds are much smaller than the matrix built uponoriginal data set. Hence, the computational complexity isgreatly reduced by solving a much smaller linear system,which can be solved by various linear solvers, such asconjugate gradient descent method [28].
D. Alpha Interpolation
The popular interpolation methods, such as Gaussian orBicubic interpolation, typically suffer from blurring thesharp alpha edges. To achieve better quality, we developa new multi-scale detail-aware alpha interpolation method.Let I be the input image, using an edge preserving filter
[36], [37], we compute M progressively coarser versionI1, ..., IM of I , which suppress the noises while preservingthe strong features in all the subsequent decompositioniterations. We then compute M (M = 3 in our exper-iments) subsequent image detail levels:{Dj}Mj=1, whereDj = Ij−Ij−1. The final matting result for original imageI is restored by upsampling the alpha solution α∗ computedin the reduced feature space using the detail-guided alphainterpolation.
The method works as follows: (1) For each pixel p inI with feature vector f , we search a set of its nearestsamples N∗(p) in feature space, and compute the affinityweight wi = e−|f−fi|
2/2σ between each sample p∗i andp. Then, the weighted details sum of p is computed as:D =
∑Mj=1 φjDj/
∑Mj=1Dj , where the weight φj =
gσ ∗ (j · e− 1n
∑|∇Ij |), n is the number of the image
pixels, and the Gaussian convolution gσ is used to locallysmooth the weight. This weighted details sum D prefersthe coarser detail levels by assigning them larger weights,since the noises are smoothed out and also the prominentedges are better preserved in the coarser levels. Hence,the alpha edge information is recovered by suppressing thenoises in the final matte value. We then define the weightωi = e−|D−Di|2/2σ , where Di is the enhanced detail of apixel in I which corresponds to p∗i in the reduced featurespace. (2) The final alpha value for pixel p is computed as aweighted average of the alpha values αis of all the nearestsamples in N∗(p): αp =
∑i∈N∗(p) αiwiωi/
∑i wiωi. The
interpolation artifacts such as alpha edges blurring, alphanoises, etc, can be efficiently alleviated.
Fig.4 shows the results using two different interpola-tions, one is the Gaussian interpolation, and the other isour detail-aware alpha interpolation. Clearly, our methodproduces smoother and more accurate results. Not only theinterpolation blurring artifact is attenuated, but also the finestructures and features are better enhanced.
E. Incremental refinement
Current matting approaches can achieve good resultswhen the foreground and background are smooth and well-separable in the color space. However, if the foregroundand/or background contain (s) highly-textured regions withcomplex color patterns, existing approaches tend to gener-ate noisy results with noticeable artifacts. This is a difficultopen problem [1] for matting. Levin et al. [3] applied incre-mental refinement technique by adding additional scribblesin the regions containing mixed pixels to address this issue.Our method further improves this incremental refinementscheme [3] using our hierarchical data structure. Whenthere are some regions where the matting results are unsat-isfactory, the user can add new background or foregroundscribbles in these regions. Instead of re-computing the CFMfor every unknown pixel with an unreliable initial value, weuse the previously computed alpha matte as the initial valueto solve the Eq.10, which is much faster and generate moreaccurate results in a progressive style.
Fig.5 shows the incremental matting refinement process.
JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 7
(a) (b) (c) (d)
Fig. 4. (a) Input image with coarse trimap, matting results using (b) Gaussian and (c) detail-aware interpolation, (d) the close-ups in results.
Fig. 5. Incremental refinement results including the incremental trimaps(left) and the incremental matting results (right).
First, the user scribbles a small subset of pixels in the fuzzyregions or regions with incorrect matting values needed tobe re-estimated, and sets constrained value for these pixels.Then, we map the constrained values of these pixels tothe samples in the reduced feature space, and update thevalues of Ds and bs in Eq.10. We use the alpha valuecomputed in previous computation as the initial value toresolve the Eq.10, with the new constrained values Ds andbs, we achieve better matting results.
Our incremental method is fast and accurate due to thefollowing reasons:
• KD-tree partition and Laplacian matrix reconstructiononly need to be performed once and can been reusedin following incremental refinement.
• The Eq.10 is solved in a reduced feature space.• We use the previously computed α value as the initial
value for solving Eq.10, which makes the solutionconverge much faster, and produce more accurateresult.
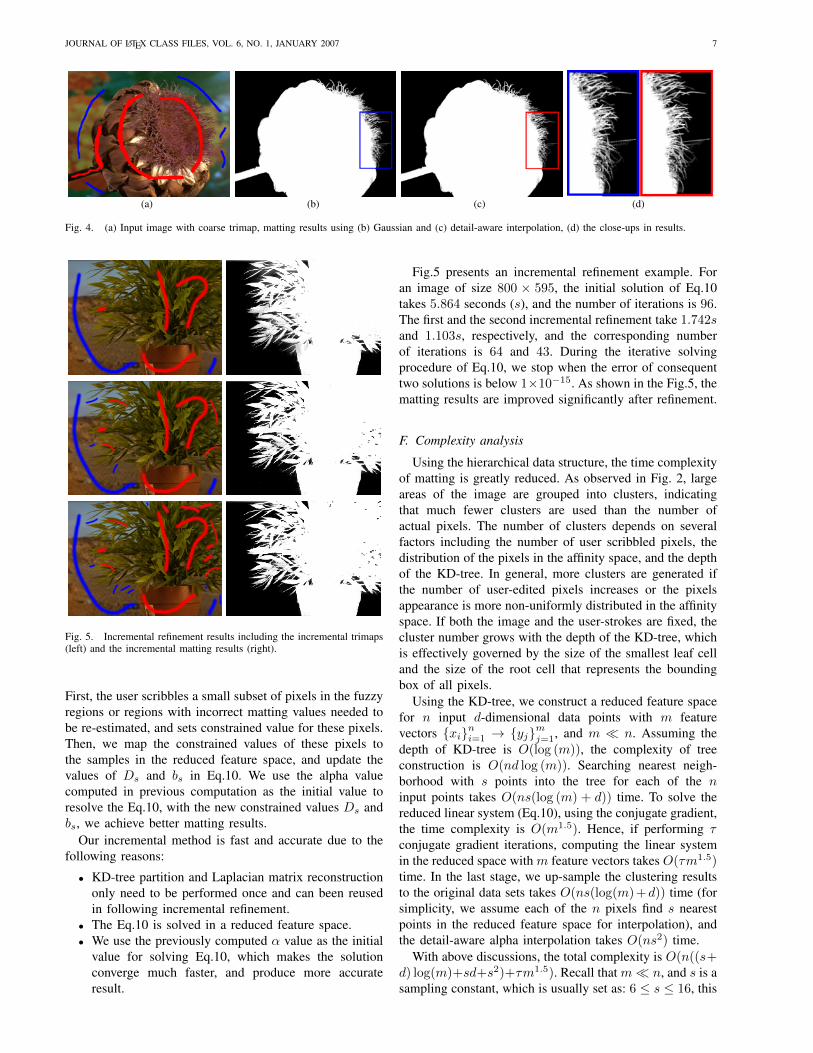
Fig.5 presents an incremental refinement example. Foran image of size 800 × 595, the initial solution of Eq.10takes 5.864 seconds (s), and the number of iterations is 96.The first and the second incremental refinement take 1.742sand 1.103s, respectively, and the corresponding numberof iterations is 64 and 43. During the iterative solvingprocedure of Eq.10, we stop when the error of consequenttwo solutions is below 1×10−15. As shown in the Fig.5, thematting results are improved significantly after refinement.
F. Complexity analysis
Using the hierarchical data structure, the time complexityof matting is greatly reduced. As observed in Fig. 2, largeareas of the image are grouped into clusters, indicatingthat much fewer clusters are used than the number ofactual pixels. The number of clusters depends on severalfactors including the number of user scribbled pixels, thedistribution of the pixels in the affinity space, and the depthof the KD-tree. In general, more clusters are generated ifthe number of user-edited pixels increases or the pixelsappearance is more non-uniformly distributed in the affinityspace. If both the image and the user-strokes are fixed, thecluster number grows with the depth of the KD-tree, whichis effectively governed by the size of the smallest leaf celland the size of the root cell that represents the boundingbox of all pixels.
Using the KD-tree, we construct a reduced feature spacefor n input d-dimensional data points with m featurevectors {xi}ni=1 → {yj}
mj=1, and m � n. Assuming the
depth of KD-tree is O(log (m)), the complexity of treeconstruction is O(nd log (m)). Searching nearest neigh-borhood with s points into the tree for each of the ninput points takes O(ns(log (m) + d)) time. To solve thereduced linear system (Eq.10), using the conjugate gradient,the time complexity is O(m1.5). Hence, if performing τconjugate gradient iterations, computing the linear systemin the reduced space with m feature vectors takes O(τm1.5)time. In the last stage, we up-sample the clustering resultsto the original data sets takes O(ns(log(m) +d)) time (forsimplicity, we assume each of the n pixels find s nearestpoints in the reduced feature space for interpolation), andthe detail-aware alpha interpolation takes O(ns2) time.
With above discussions, the total complexity is O(n((s+d) log(m)+sd+s2)+τm1.5). Recall that m� n, and s is asampling constant, which is usually set as: 6 ≤ s ≤ 16, this

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 8
(a) (b) (c) (d) (e) (f)
(g) (h) (i) (j) (k) (l)
Fig. 6. Accelerating Spectral matting [5]. (a) Input image with coarse trimap, (b) Gaussian Kd-tree partition, (c)-(j) eight matting components, (k)the final matte, (l) the result of [5].
results in a total complexity O(n(s+ d) log(m) + τm1.5).Compared with solving linear system for the original n pix-els with complexity O(τn1.5), our method is significantlyfaster. Further, the memory consumption is greatly reduceddue to construct a much smaller matrix. The much less timeand memory consumption enable our method to efficientlyprocess high-resolution image and video data.
V. GPU ACCELERATION
All the algorithmic steps of our method, includingpartitioning affinity-based KD-tree, preprocessing matrixelement, constructing Laplacian matrix, solving the linearsystem and interpolating matte values, can be fully par-allelized on GPU. Applying the existing techniques from[31], [35], the affinity-based KD-tree can be efficiently builton GPU for the sampling points with high-dimensionalfeature vector. Once the tree is built, the steps of pre-processing matrix element and interpolating matte valuesare inherently parallel, since the high-dimensional nearestneighbor search can be fully implemented in parallel usingGPU [11]. Hence, these two steps are efficient for handlinglarge data set with high-dimensional feature vectors.
When preprocessing the matrix element, for each sample,we need to compute three terms: 1
|θk| , µk, and (Σk +zijε|θk| I3)−1. As every term can be computed independentlyfor each sample, these steps can be processed in parallel.Using GPU-based nearest neighborhood queries, computingthese terms can be further accelerated. When constructingthe Laplacian matrix L, we treat the construction of eachrow of elements as an independent thread block and per-form searching in parallel (i.e. the task of computing eachrow of elements can be processed using one thread block,and using all threads in the thread block to complete thesearch processing). We apply the conjugate gradient methodto solve the linear system (Eq.10), which is acceleratedby the GPU-based CUBLAS library [38] from NVIDIA R©.Interpolating matte values is achieved by computing theweighted average of the nearest alpha values in the re-duced feature space for each pixel from original image.Performing the nearest neighborhood queries and matteinterpolation for each pixel in parallel on GPU, this stepcan also achieve real-time performance.
Our method is implemented in CUDA, and realizesa typical speedup of 20x over the single-threaded CPUimplementation, which allows our method to be a real-time image matting framework for moderate-sized images,and applicable to perform video matting with moderatesize in an acceptable speed. For example, our video mat-ting method costs about 8 seconds for a video with size632× 268× 76.
VI. ACCELERATING AFFINITY-BASED MATTINGMETHODS
Using the same acceleration framework, our hierarchicalstrategy can be extended to many other affinity-basedmatting approaches [4], [5], [6], [12], [8], [9]. Similarly,we first adaptively sample the data set, and then definethe energy functions on the samples. By using the pre-sented hierarchical strategy, the size of data set is greatlyreduced, and the computational complexity of optimizingthe energy function is reduced accordingly. In this section,to show the generality of our method, we extend the presentacceleration framework to spectral matting [5] and robustmatting [9]. Although the underlying energy functions ofother affinity-based methods [4], [6], [8], [12] are quitedifferent, these approaches can share the same optimizationframework with CFM, and hence can be accelerated in thesimilar way, with only minor modifications.
Fast spectral matting: Spectral matting [5] is a mattingapproach that tries to pull out a foreground matte in anautomatic fashion. In this approach, the input image ismodeled as a convex combination of K image layers asIz =
∑Kk=1 a
kzF
kz , where F kz is the kth matting component
of the image. The most important conclusion from thisapproach is that the smallest eigenvectors of the mat-ting Laplacian matrix L [3] span the individual mattingcomponents of the image. Thus, recovering the mattingcomponents of the image is equivalent to finding a lineartransformation of the eigenvectors.
The spectral matting approach is inspired by spectralimage hard segmentation. However, the matting Lapla-cian L is constructed in the same way as CFM, thusit is very slow to compute the smallest eigenvectors Lof for a high-resolution image. Computing an optimallinear transformation of the eigenvectors to find the final

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 9
(a) (b) (c) (d)
Fig. 7. Accelerating robust matting method [9]. (a) Input image with coarse trimap, (b) the result of [9], (c) our result, (d) the ground truth mattingresult.
matting components of the image hence becomes time-consuming. Using our matting acceleration framework, byconstructing the Gaussian KD-tree for the input image, andcomputing and transforming the smallest eigenvectors ina low-dimensional feature space, the matting computationbecomes much faster with much less memory consumption.As illustrated in Fig.6, with the same user interactions,we receive nearly the same matting quality compared withthe standard spectral matting. The standard method takes185.21 seconds to complete the matting extraction, whileour accelerated version only costs 8.45 seconds.
Fast robust matting: The robust matting method [9]combines the advantages of both sampling-based andaffinity-based matting, and is a well-balanced approach thatcan generate high quality mattes while maintaining reason-able robustness against different user inputs. Specifying atrimap for the underlying image, this method minimizes thefollowing energy function:
E =∑z∈w
[fz(αz − αz)2 + (1− fz)(αz − δ(αz > 0.5))2]
+λ · J(α, a, b)(11)
where αz and fz are, respectively, the estimated alphaand confidence values in the color sampling step usingtrimap, and J(α, a, b) is the neighborhood energy definedalready in CFM. The energy function can be minimized asa quadratic function of α, which can be solved by solving alinear system LA = B. The matrix L is a sparse, positive-definite Laplacian matrix.
Robust matting [9] can also be accelerated using ourframework. After specifying a coarse trimap for the image,we subsample the image data, and generate a reducedfeature space. Then we estimate the αz and fz in thereduced feature space, and solve a much simpler linearsystem. Using the detail-aware interpolation, we receive thefinal mattes. As illustrated in Fig.7, with the same coarsetrimap, the accelerated robust matting achieves very similarmatte quality as the standard robust matting [9]. For animage of size 800 × 618, it takes the standard method35 seconds to extract the matte, while our method onlyspends 5 seconds. Further, the memory cost is reduced from0.085G to 0.012G.
(a) (b) (c) (d)
Fig. 8. Image dehazing acceleration: (a) Input haze image, and imagedehazing results of [39] (b), [13] (c), and our method (d).
VII. APPLICATIONS
Our method can be further applied to accelerate theimage and video dehazing, and image shadow detectionand removal.
Image and video dehazing: In computer vision andcomputer graphics, the formation of a haze image is usuallydefined as follows: I(x) = J(x)t(x) + A(1 − t(x)) [13],where I is the observed intensity, J is the scene radiance,A is the global atmospheric light, and t is the mediumtransmission. The goal of haze removal is to recover J , Aand t from I . He et al. [13] proposed the dark channel prior(DCP), a kind of statistics of the haze-free outdoor images,to directly estimate the thickness t(x) of the haze andrecover a high quality haze-free image. The DCP methodestimates the transmission map t(x) from an input hazeimage using the patch (with size 15 × 15). Its dehazingquality is roughly good but contains some blocky effectssince the transmission is not always constant within a patch.Hence, the DCP method refines the transmission map usinga similar Laplacian matrix based interpolation as CFM [3],which is also time-consuming for high-resolution image.
We apply the presented method to accelerate the refine-ment of the transmission map. We first compute the roughtransmission map t(x), and cluster both the input imageI(x) and t(x) using the Gaussian KD-tree to produce thereduced feature space I(x) and map t(x). We then computethe Laplacian matrix L and haze thickness t(x) in I(x).Finally, by using affinity-based interpolation, we interpolate

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 10
Fig. 9. Video dehazing acceleration. Top row, the input video, bottomrow, dehazed video. From left to right, the 3th, 45th and 80th frame.
t(x) to get the final smooth transmission map.We further employ our method for fast video trans-
mission map interpolation to accelerate video dehazing.To maintain temporal coherence, we estimate transmissionmap T (x, t) from an input haze video using a spatio-temporal patch (e.g. 15×15×12). Similarly, the generatedspatio-temporal transmission map T (x, t) also contain-s some blocky effects since the transmission is usuallynonuniform within a patch. Similar to the image case,we compute the transmission map in the reduced featurespace by solving a much simpler sparse linear system.By performing affinity-based interpolation, the temporallycoherent transmission map for the input video is generated.The final dehazing video can be recovered from the refinedtransmission map.
Fig.8 shows the dehazing results using our method,which only exhibit minor visual differences with [13]. Thecomputation time of the standard DCP method [13] is18.905s for this image with size 441 × 450, while ourmethod takes 2.223s. We also compare our method withTarel et al. [39], which is a fast dehazing algorithm usingmedian filter. It take [39] 1.623s to finish the dehazingprocess. The speed of our method is comparable with Tarelet al. [39], while our quality is better.
Fig.9 shows the video dehazing results using our method.For input video with size 512 × 280 × 82, it is difficultto directly apply the CFM for interpolating transmissionmap due to the large memory requirement. Using ouracceleration strategy, it only takes about 0.25G memoryand 8.5s on GPU to complete the dehazing process. Thevideo dehazing results are satisfactory, and the temporallyincoherent artifacts are avoided effectively.
Shadow detection and removal: Image shadow detec-tion and removal are important research topics in computervision. The shadow in an image can described with thefollowing formula: It = (ticosϕiLd + La)Ri, where Ii isthe intensity value of ith pixel, Ld is the direction illumi-
nation, La is the ambient illumination, Ri is the surfacereflectance of ith pixel, ϕi is the angle between directionillumination and the surface norm, and ti (0 < ti < 1 ) isa value determining how much direct illumination gets tocurrent pixel, which is referred to as shadow coefficient.
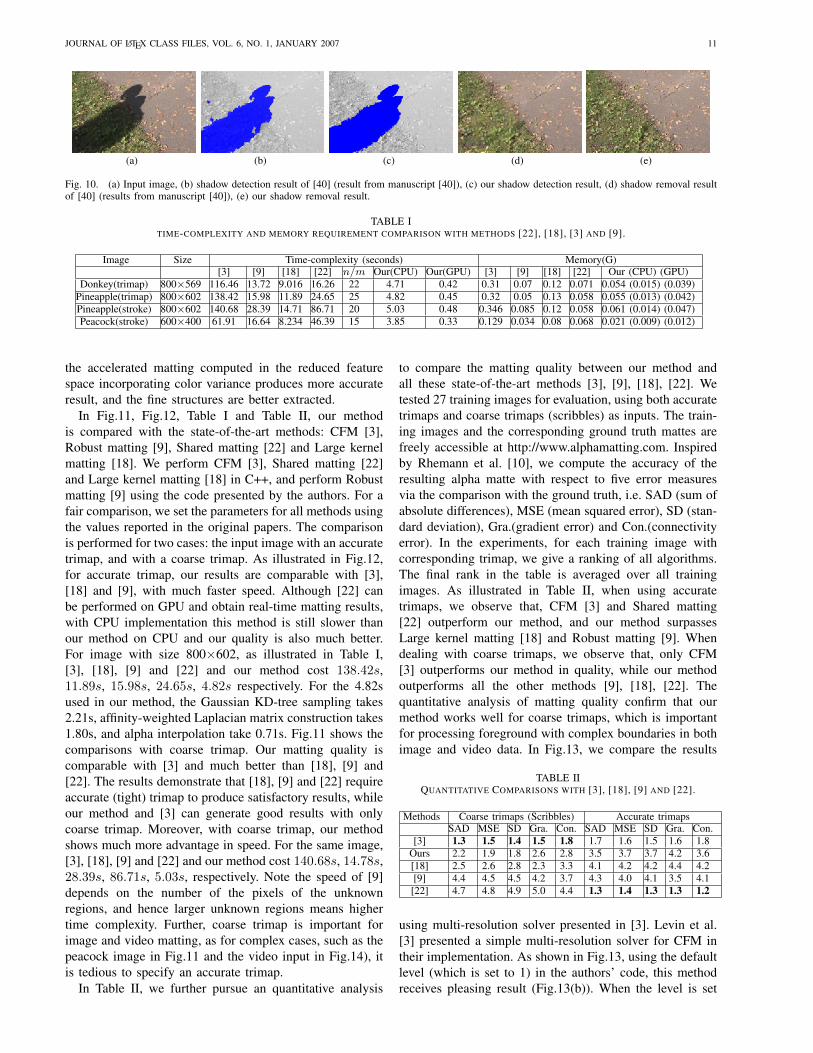
The CFM [3] can be used to improve shadow detectionand removal [40], [41]. With the detected coarse shadows,we treat shadowed pixels as foreground and lit pixels asbackground. Similar as the transmission map interpolationused in image dehazing, the CFM can be applied forinterpolation to obtain more smooth shadow coefficientsti, which can used for further accurate shadow detection.Based on the shadow coefficients, we calculate the ratio be-tween direct light and environment light [40], and then per-form shadow removal by relighting each pixel. Obviously,we can also apply the accelerated closed-form interpolationmethod to efficiently estimate the shadow coefficients ti. Asshown in Fig. 10, in comparison with [40] on both shadowdetection and removal, our results achieve very competitivequality with much less time and memory consumption. Thetime for interpolation is reduced from about 8 seconds to0.56s for the shadowed regions in a image with size of523× 348.
VIII. RESULTS AND DISCUSSIONS
Performance data of all the results is reported on a PCwith Intel R© Pentium Dual-Core CPU [email protected] GHzand 2 GB memory, and a NVIDIA R© GeForce GTX 285(1 GB) graphics card. Our method is implemented usingCUDA 4.1. In this section, we present various experimentalresults, and the comparisons with the state-of-art method-s [22], [18], [3], [9], for the matting quality, time complexi-ty and memory requirement. For a fair comparison, all thesefour methods are implemented in the same environment asours. The limitations of our method are also discussed.
Fig.2 gives the matting results generated applying ourfast CFM method with different sampling factors. As shownin Fig.2, for an image with size 800×600, even with veryhigh sampling factor, such as n/m = 300, the matting resultis still pleasing. However, when using too high samplingfactor such as n/m = 2800, the matte values in the complexregions, like hair, can not be effectively extracted. In Fig.2,for each sampling factor, we also give the correspondingtime and memory consumption, and also the errors from theground truth. Obviously, with gradually higher samplingfactor n/m, the matting speed is faster and the memoryconsumption is less, while the error is increasing. Weapply the perceptually motivated gradient-based MSE errorfunction [10] to measure the errors from the ground truth.
Fig.3 gives the clustering result comparison betweenusing and without using color variance. We map the colorvariance value into the color range between blue (mini-mum) and red (maximum). The pixels in each leaf node arerepresented using the color variance of the cell. As shownin Fig.3 (c), we get leaf nodes with lower color variancecompared with adjustment, which better satisfy the localsmoothness assumption. As shown in Fig.3 (d), (e) and (f),
JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 11
(a) (b) (c) (d) (e)
Fig. 10. (a) Input image, (b) shadow detection result of [40] (result from manuscript [40]), (c) our shadow detection result, (d) shadow removal resultof [40] (results from manuscript [40]), (e) our shadow removal result.
TABLE ITIME-COMPLEXITY AND MEMORY REQUIREMENT COMPARISON WITH METHODS [22], [18], [3] AND [9].
Image Size Time-complexity (seconds) Memory(G)[3] [9] [18] [22] n/m Our(CPU) Our(GPU) [3] [9] [18] [22] Our (CPU) (GPU)
Donkey(trimap) 800×569 116.46 13.72 9.016 16.26 22 4.71 0.42 0.31 0.07 0.12 0.071 0.054 (0.015) (0.039)Pineapple(trimap) 800×602 138.42 15.98 11.89 24.65 25 4.82 0.45 0.32 0.05 0.13 0.058 0.055 (0.013) (0.042)Pineapple(stroke) 800×602 140.68 28.39 14.71 86.71 20 5.03 0.48 0.346 0.085 0.12 0.058 0.061 (0.014) (0.047)Peacock(stroke) 600×400 61.91 16.64 8.234 46.39 15 3.85 0.33 0.129 0.034 0.08 0.068 0.021 (0.009) (0.012)
the accelerated matting computed in the reduced featurespace incorporating color variance produces more accurateresult, and the fine structures are better extracted.
In Fig.11, Fig.12, Table I and Table II, our methodis compared with the state-of-the-art methods: CFM [3],Robust matting [9], Shared matting [22] and Large kernelmatting [18]. We perform CFM [3], Shared matting [22]and Large kernel matting [18] in C++, and perform Robustmatting [9] using the code presented by the authors. For afair comparison, we set the parameters for all methods usingthe values reported in the original papers. The comparisonis performed for two cases: the input image with an accuratetrimap, and with a coarse trimap. As illustrated in Fig.12,for accurate trimap, our results are comparable with [3],[18] and [9], with much faster speed. Although [22] canbe performed on GPU and obtain real-time matting results,with CPU implementation this method is still slower thanour method on CPU and our quality is also much better.For image with size 800×602, as illustrated in Table I,[3], [18], [9] and [22] and our method cost 138.42s,11.89s, 15.98s, 24.65s, 4.82s respectively. For the 4.82sused in our method, the Gaussian KD-tree sampling takes2.21s, affinity-weighted Laplacian matrix construction takes1.80s, and alpha interpolation take 0.71s. Fig.11 shows thecomparisons with coarse trimap. Our matting quality iscomparable with [3] and much better than [18], [9] and[22]. The results demonstrate that [18], [9] and [22] requireaccurate (tight) trimap to produce satisfactory results, whileour method and [3] can generate good results with onlycoarse trimap. Moreover, with coarse trimap, our methodshows much more advantage in speed. For the same image,[3], [18], [9] and [22] and our method cost 140.68s, 14.78s,28.39s, 86.71s, 5.03s, respectively. Note the speed of [9]depends on the number of the pixels of the unknownregions, and hence larger unknown regions means highertime complexity. Further, coarse trimap is important forimage and video matting, as for complex cases, such as thepeacock image in Fig.11 and the video input in Fig.14), itis tedious to specify an accurate trimap.
In Table II, we further pursue an quantitative analysis
to compare the matting quality between our method andall these state-of-the-art methods [3], [9], [18], [22]. Wetested 27 training images for evaluation, using both accuratetrimaps and coarse trimaps (scribbles) as inputs. The train-ing images and the corresponding ground truth mattes arefreely accessible at http://www.alphamatting.com. Inspiredby Rhemann et al. [10], we compute the accuracy of theresulting alpha matte with respect to five error measuresvia the comparison with the ground truth, i.e. SAD (sum ofabsolute differences), MSE (mean squared error), SD (stan-dard deviation), Gra.(gradient error) and Con.(connectivityerror). In the experiments, for each training image withcorresponding trimap, we give a ranking of all algorithms.The final rank in the table is averaged over all trainingimages. As illustrated in Table II, when using accuratetrimaps, we observe that, CFM [3] and Shared matting[22] outperform our method, and our method surpassesLarge kernel matting [18] and Robust matting [9]. Whendealing with coarse trimaps, we observe that, only CFM[3] outperforms our method in quality, while our methodoutperforms all the other methods [9], [18], [22]. Thequantitative analysis of matting quality confirm that ourmethod works well for coarse trimaps, which is importantfor processing foreground with complex boundaries in bothimage and video data. In Fig.13, we compare the results
TABLE IIQUANTITATIVE COMPARISONS WITH [3], [18], [9] AND [22].
Methods Coarse trimaps (Scribbles) Accurate trimapsSAD MSE SD Gra. Con. SAD MSE SD Gra. Con.
[3] 1.3 1.5 1.4 1.5 1.8 1.7 1.6 1.5 1.6 1.8Ours 2.2 1.9 1.8 2.6 2.8 3.5 3.7 3.7 4.2 3.6[18] 2.5 2.6 2.8 2.3 3.3 4.1 4.2 4.2 4.4 4.2[9] 4.4 4.5 4.5 4.2 3.7 4.3 4.0 4.1 3.5 4.1[22] 4.7 4.8 4.9 5.0 4.4 1.3 1.4 1.3 1.3 1.2
using multi-resolution solver presented in [3]. Levin et al.[3] presented a simple multi-resolution solver for CFM intheir implementation. As shown in Fig.13, using the defaultlevel (which is set to 1) in the authors’ code, this methodreceives pleasing result (Fig.13(b)). When the level is set

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 12
(a) (b) (c) (d) (e) (f)
Fig. 11. Matting results comparison based on coarse trimap specified by a few foreground and background scribbles. (a) Input image, (b) result of[22], (c) result of [3], (d) result of [18], (e) result of [9], (f) our result.
(a) (b) (c) (d) (e) (f)
Fig. 12. Matting results comparison based on accurate trimap.(a) Input image, (b) result of [22], (c) result of [3], (d) result of [18], (e) result of [9],(f) our result.
(a) (b) (c) (d) (e)
Fig. 13. Limitation: (a) Original image with trimap, (b) result of multi-resolution solver [3] using 1 levels, (c) result of multi-resolution solver [3]using 3 levels, (d) our result using sampling factor n/m=200, (e) the generated clusters in our method with sampling factor n/m=200.
to 3 (Fig.13(c)), the fine features such as the hair are noteffectively extracted. Using our method, even when we setsampling factor n/m =200, the result (Fig.13(d)) is stillmuch better than Fig.13(c).
Fig.14 presents the video matting results using ourmethod. It is usually time and memory prohibitive to direct-ly apply CFM to process video matting. In comparison, ourfast CFM method can process video matting efficiently. Asshown in Fig.14, by sampling the video data into reducedfeature space, and performing video matting incorporatingboth the spatial and temporal information, we producetemporally coherent video matting results. Note that, forinput video whose foreground and/or background contain(s)highly-textured regions with complex color patterns, weapply the presented incremental refinement techniques toproduce more pleasing results, which incrementally im-
prove the matting quality.As our method can be performed in parallel, we process
video matting on GPU. For the Maria video in Fig.14 withsize of 400× 300× 77, our method takes 1.105s for KD-tree construction, 6.629s for matrix solution, and 2.251s formatting alpha interpolation, and in total around 10s finishmatting. In comparison, applying Bayesian video matting[23], [24], which is a dominant video matting method, tofinish the matting of the same video costs more than onehour on CPU. Moreover, considering the matte quality, ourmethod produces visually comparable results as [20]. Theseexperiments demonstrate that our system is computationallyefficient to extract dynamic matting values from videos withmoderate size.
Limitations: Although our hierarchical subsamplingmethod captures the image features and produces repre-

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 13
Fig. 14. Video matting acceleration. Top row, the input video with size632 × 268 × 76; the second row, our matting acceleration results, fromleft to right is the 2th, 50th and 63th frame; the third row, the input videowith size 400× 300× 77; the fourth row, video matting results of [23];bottom row, our matting results. From the left to right is the 12th, 25thand 76th frame.
sentative samples in the feature space, when the samplesare extremely sparse, our method still fails to extract thematting value in the complex regions, or from the fine andthin features, such as the hair in Fig.13. To address thisissue, one possible solution is to put more user interactionson these regions, and another strategy is to increase thesampling ratio. However, the latter strategy may increasethe time complexity and require relatively more memoryfor the KD-tree construction. We have to leverage betweenmatting quality and the time-memory consumption. Com-pared with the Bayesian video matting [23] that processvideo matting frame by frame, our method is inconvenientto process very long video sequence. One potential solutionis to divide the input video into several subsequences, whilemaking some overlap between the adjacent parts. Finallythe matte value for each part can be extracted using thematte value on the overlap regions as the constrained value.
IX. CONCLUSION AND FUTURE WORK
In this paper, we present a unified acceleration methodfor closed-from image and video matting using hierarchicaldata structure. By downsampling the large data set adaptive-ly into much smaller feature space, and solve the mattingoptimization on such a reduced space, we greatly reducethe time and memory consumption, while maintaining thematting quality. Another advantage of our method is that itcan be further accelerated by exploiting the evolving graph-ics hardware. We also extend our acceleration strategies toother affinity-based matting methods and demonstrate that
it can be considered as a general acceleration frameworkfor a variety of matting methods.
In the future, we plan to work on automatically determin-ing the optimal sampling factors n/m to achieve better bal-ance between quality and performance for different inputs.In most experiments, to compromise between quality andperformance, we set the sampling factor n/m between 50and 80 and receive satisfactory results. Defining guidelinesto automatically choose optimal n/m is an important andinteresting future research direction. Extending our methodto sample-based matting methods is also an interestingfuture research topic.
ACKNOWLEDGMENT
We would like to thank the anonymous reviewers fortheir valuable comments and insightful suggestions. Thiswork was partly supported by the National Basic ResearchProgram of China (No. 2012CB725303), the NSFC (Nos.61070081 and 41271431), the Open Project Program ofthe State Key Lab of CAD&CG (Grant No. A1208), andthe Luojia Outstanding Young Scholar Program of WuhanUniversity.
REFERENCES
[1] J. Wang and M. Cohen, “Image and video matting: a survey,”Foundations and Trends R© in Computer Graphics and Vision, vol. 3,no. 2, pp. 97–175, 2007.
[2] D. Singaraju and R. Vidal, “Estimation of alpha mattes for multipleimage layers,” Pattern Analysis and Machine Intelligence, IEEETransactions on, vol. 33, no. 7, pp. 1295–1309, 2011.
[3] A. Levin, D. Lischinski, and Y. Weiss, “A closed-form solution tonatural image matting,” IEEE Trans. Pattern Anal. Mach. Intell.,vol. 30, no. 2, pp. 228–242, 2008.
[4] L. Grady, T. Schiwietz, S. Aharon, and R. Westermann, “Randomwalks for interactive alpha-matting,” in Proc. of VIIP, vol. 2005,2005, pp. 423–429.
[5] A. Levin, A. Rav-Acha, and D. Lischinski, “Spectral matting,” inProc. of CVPR. IEEE, 2007, pp. 1–8.
[6] Y. Zheng, C. Kambhamettu, J. Yu, T. Bauer, and K. Steiner, “Fuzzy-matte: A computationally efficient scheme for interactive matting,”in Proc. of CVPR. IEEE, 2008, pp. 1–8.
[7] Y. Guan, W. Chen, X. Liang, Z. Ding, and Q. Peng, “Easy matting-astroke based approach for continuous image matting,” in ComputerGraphics Forum, vol. 25, no. 3, 2006, pp. 567–576.
[8] J. Wang and M. Cohen, “An iterative optimization approach forunified image segmentation and matting,” in Proc. of ICCV, vol. 2.IEEE, 2005, pp. 936–943.
[9] J. Wang and M. F. Cohen, “Optimized color sampling for robustmatting,” in Proc. of CVPR. IEEE, 2007, pp. 1–8.
[10] C. Rhemann, C. Rother, J. Wang, M. Gelautz, P. Kohli, and P. Rott,“A perceptually motivated online benchmark for image matting,” inProc. of CVPR. IEEE, 2009, pp. 1826–1833.
[11] A. Adams, N. Gelfand, J. Dolson, and M. Levoy, “Gaussian kd-treesfor fast high-dimensional filtering,” in ACM Trans. Graph., vol. 28,no. 3, 2009, p. 21.
[12] X. Bai and G. Sapiro, “Geodesic matting: A framework for fastinteractive image and video segmentation and matting,” Internationaljournal of computer vision, vol. 82, no. 2, pp. 113–132, 2009.
[13] K. He, J. Sun, and X. Tang, “Single image haze removal using darkchannel prior,” in Proc. of CVPR. IEEE, 2009, pp. 1956–1963.
[14] D. Xu, J. Liu, X. Li, Z. Liu, and X. Tang, “Insignificant shadowdetection for video segmentation,” IEEE Trans. Circuits Syst. VideoTechnol., vol. 15, no. 8, pp. 1058–1064, 2005.
[15] T. Shih, N. Tang, and J. Hwang, “Exemplar-based video inpaintingwithout ghost shadow artifacts by maintaining temporal continuity,”IEEE Trans. Circuits Syst. Video Technol., vol. 19, no. 3, pp. 347–360, 2009.

JOURNAL OF LATEX CLASS FILES, VOL. 6, NO. 1, JANUARY 2007 14
[16] J. Sun, J. Jia, C. Tang, and H. Shum, “Poisson matting,” in ACMTrans. Graph., vol. 23, no. 3, 2004, pp. 315–321.
[17] D. Singaraju, C. Rother, and C. Rhemann, “New appearance modelsfor natural image matting,” in Proc. of CVPR. IEEE, 2009, pp.659–666.
[18] K. He, J. Sun, and X. Tang, “Fast matting using large kernel mattinglaplacian matrices,” in Proc. of CVPR. IEEE, 2010, pp. 2165–2172.
[19] M. Ruzon and C. Tomasi, “Alpha estimation in natural images,” inProc. of CVPR, vol. 1. IEEE, 2000, pp. 18–25.
[20] Y. Chuang, B. Curless, D. Salesin, and R. Szeliski, “A bayesianapproach to digital matting,” in Proc. of CVPR, vol. 2. IEEE,2001, pp. II–264.
[21] C. Rhemann, C. Rother, and M. Gelautz, “Improving color modelingfor alpha matting,” in Proc. of BMVC, 2008.
[22] E. Gastal and M. Oliveira, “Shared sampling for real-time alphamatting,” in Computer Graphics Forum, vol. 29, no. 2, 2010, pp.575–584.
[23] Y. Chuang, A. Agarwala, B. Curless, D. Salesin, and R. Szeliski,“Video matting of complex scenes,” in ACM Trans. Graph., vol. 21,no. 3, 2002, pp. 243–248.
[24] N. Apostoloff and A. Fitzgibbon, “Bayesian video matting usinglearnt image priors,” in Proc. of CVPR, vol. 1. IEEE, 2004, pp.I–407.
[25] Y. Li, J. Sun, and H. Shum, “Video object cut and paste,” ACMTrans. Graph., vol. 24, no. 3, pp. 595–600, 2005.
[26] J. Wang, P. Bhat, R. Colburn, M. Agrawala, and M. Cohen, “Inter-active video cutout,” in ACM Trans. Graph., vol. 24, no. 3. ACM,2005, pp. 585–594.
[27] R. Szeliski, “Locally adapted hierarchical basis preconditioning,” inACM Transactions on Graphics (TOG), vol. 25, no. 3. ACM, 2006,pp. 1135–1143.
[28] Y. Saad and Y. Saad, Iterative methods for sparse linear systems.PWS publishing company Boston, 1996, vol. 20.
[29] M. Huang, F. Liu, and E. Wu, “A gpu-based matting laplacian solverfor high resolution image matting,” The Visual Computer, vol. 26,no. 6, pp. 943–950, 2010.
[30] D. Horn, J. Sugerman, M. Houston, and P. Hanrahan, “Interactivekd tree gpu raytracing,” in Proc. of I3D. ACM, 2007, pp. 167–174.
[31] K. Zhou, Q. Hou, R. Wang, and B. Guo, “Real-time kd-treeconstruction on graphics hardware,” in ACM Trans. Graph., vol. 27,no. 5, 2008, p. 126.
[32] K. Xu, Y. Li, T. Ju, S. Hu, and T. Liu, “Efficient affinity-based editpropagation using kd tree,” in ACM Trans. Graph., vol. 28, no. 5,2009, p. 118.
[33] J. MacQueen et al., “Some methods for classification and analysisof multivariate observations,” in Proceedings of the fifth Berkeleysymposium on mathematical statistics and probability, vol. 1, no.281-297. California, USA, 1967, p. 14.
[34] D. Comaniciu and P. Meer, “Mean shift: A robust approach towardfeature space analysis,” Pattern Analysis and Machine Intelligence,IEEE Transactions on, vol. 24, no. 5, pp. 603–619, 2002.
[35] X. An and F. Pellacini, “Appprop: all-pairs appearance-space editpropagation,” in ACM Trans. Graph., vol. 27, no. 3, 2008, p. 40.
[36] C. Tomasi and R. Manduchi, “Bilateral filtering for gray and colorimages,” in Proc. of ICCV. IEEE, 1998, pp. 839–846.
[37] R. Fattal, M. Agrawala, and S. Rusinkiewicz, “Multiscale shape anddetail enhancement from multi-light image collections,” ACM Trans.Graph., vol. 26, no. 3, p. 51, 2007.
[38] CUBLAS Library, NVIDIA, Feburary 2012.[39] J.-P. Tarel and N. Hautiere, “Fast visibility restoration from a single
color or gray level image,” in ICCV. IEEE, 2009, pp. 2201–2208.[40] R. Guo, Q. Dai, and D. Hoiem, “Single-image shadow detection and
removal using paired regions,” in Proc. of CVPR. IEEE, 2011, pp.2033–2040.
[41] Y. Shor and D. Lischinski, “The shadow meets the mask: Pyramid-based shadow removal,” in Computer Graphics Forum, vol. 27, no. 2,2008, pp. 577–586.
Chunxia Xiao received his BSc and MSc de-grees from the Mathematics Department of Hu-nan Normal University in 1999 and 2002, re-spectively, and received his Ph.D. from the StateKey Lab of CAD & CG of Zhejiang Universityin 2006, China. He is currently a professor atthe Computer School, Wuhan University, China.His research interests include digital geometryprocessing, image and video processing, andcomputational photography.
Meng Liu received a B.S. degree in 2009 anda M.S. degree in 2011, both from the School ofComputer, Wuhan University. His research in-terests include image and video editing, GPGPUapplications.
Donglin Xiao received the BS degree from theSchool of Computer, Wuhan University in 2011,is currently a master student at School of Com-puter, Wuhan University, China. His researchinterests include image and video processing.
Zhao Dong is a postdoc researcher at Programof Computer Graphics of Cornell University. Hereceived his Ph.D. degree in Computer Graphicsfrom Max-Planck-Institut Informatik, Germanyin 2011, and M.S. and B.S degrees from Zhe-jiang University, China, in 2005 and 2001, re-spectively. His current research interests includephysically-based material modelling and render-ing, real-time global illumination rendering andvolume graphics.
Kwan-Liu Ma is a professor of computer sci-ence and the chair of the Graduate Group inComputer Science (GGCS) at the University ofCalifornia, Davis. He leads the VIDi researchgroup and directs the UC Davis Center forVisualization. Professor Ma received his PhDdegree in computer science from the Universityof Utah in 1993. He was a recipient of thePECASE award in 2000. His research interestsinclude visualization, high-performance comput-ing, computer graphics, and user interface de-
sign. Professor Ma was a paper chair of the IEEE Visualization Conferencein 2008 and 2009, and an associate editor of IEEE TVCG (2007-2011). Heis a founding member of the IEEE Pacific Visualization Symposium andthe IEEE Symposium on Large Data Analysis and Visualization. ProfessorMa presently serves on the editorial boards of the IEEE CG&A, theJournal of Computational Science and Discoveries, and the Journal ofVisualization. Professor Ma is an IEEE Fellow.
























![[06]Image Composition and Matting](https://img.pdfslide.us/doc/110x75/552899da55034675588b47fd/06image-composition-and-matting.jpg)




