Embed Size (px)
Citation preview

Joint Marathi Character Recognition using KNN
Classifier
(1) S. D. Bhosale (2) Dr. U. B. Shinde
(1) Research Scholar, National Institute of Electronics & Information Technology, Aurangabad, India. (2)Department of Electronics and Telecommunication Engineering, CSMSS. Chh.. Shahu College of Engineering,
Aurangabad, India.
ABSTRACT
Compound characters which are one of the features of
Marathi script, derived from Devanagari, occur
frequently used in Marathi Language in daily use.
Recognition of these characters is difficult challenge
to the researchers due to their complex structure. This
paper presents a approach for recognition of
compound Marathi compound characters. Compound
characters itself complex in structure in Marathi due
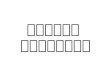
to various parameters. It is written with combination
of two or more characters in alphabets. The character
may be formed with different sequence of
combinations of basic characters, such as vowels and
consonants or both. The recognition of compound
characters makes this task more challenging to the
researchers for Marathi language. The frequency of
use of compound characters in Marathi language is
more as compared to other languages. The various
researchers used different classification techniques
such as Neural Network, Soft Computing, Multiclass
SVM Classifier etc. The recognition is carried out
using KNN. The initial stages of feature extraction
are based upon the structural features and the
classification of the characters is done accordingly.
Keywords:
Digital image processing, Marathi compound character,
OCR, Segmentation, classification, KNN, Neural network
I. INTRODUCTION:
Handwritten character recognition, irrespective of the
script, finds potential application areas for automation
in various fields like postal automation bank
automation, form filling and other apllications.. Joint
character recognition for Marathi scripts is quite a
challenging task for the researchers. This is due to the
various characteristics of these scripts like their large
character set, complex shape, presence of modifiers,
presence of compound characters and similarity
between characters as many compound characters looks
like the same as other. Marathi script derived from
Devanagari, and it is official language of Maharashtra.
It is the fourth most spoken language in India and
fifteenth most spoken language in the world. Marathi
script consists of 16 vowels and 36 consonants total 52
alphabets. Marathi is written from left to right. It has no
upper and lower case characters like English. Every
character has a horizontal line at the top named as the
header line. The header line joins various characters in a
word. Vowels are combined with consonants with
specific characteristic marks. These marks occur in line,
at the top, at the bottom of a character in a word.
Marathi language also has a complex system of
compound characters in which two or more consonants
are combined forming a new special character.
Compound characters in Marathi script occur more
frequently in the script as compared to other same
languages.
Joint character classification is a form of pattern
recognition process. Presence of unwanted objects or
disoriented patterns will affect the percentage accuracy
of recognition. The most basic way of recognizing
patterns is by using the probabilistic methods. It is very
difficult to achieve 100% accuracy in recognition of
joint characters. There are verities of writing styles
because different peoples will write the same character
differently and using different methods. Joint character
recognition has many possible application areas in
various fields like postal automation, bank automation,
form filling etc.
Joint character recognition is an important field of
Optical Character Recognition (OCR). The objective of
OCR is automatic reading of optically sensed document
text materials to translate human readable characters to
machine understandable codes in the document. OCR is
popular for its various application potentials in banks,
library automation post-offices and various
organizations. Joint character recognition aims at
converting handwritten characters in images into text
that can be stored, edited.
This field of research finds applications in various areas
that aim in automation so as to reduce the human efforts
like postal automation bank automation form filling etc.
Joint character recognition for Indian scripts is quite a
challenging task due to several reasons. One of the
Indian Script is Marathi Script. Marathi is forth most
widely used and is used by more than 50 million
people. Unconstrained Marathi writing language is
more complex than English language due to the
possible variations in the shape, number and direction
of the constituent strokes. Marathi Character
recognition is complicated process due to presence of
multiple conjuncts, lower and upper modifiers and the
JASC: Journal of Applied Science and Computations
Volume VI, Issue I, January/2019
ISSN NO: 1076-5131
Page No:1403

number of disconnected and multistroke characters, in a
word where all characters are connected through
Shirorekha.
The consonants in compound characters are joined in
various patterns in Marathi. One way of creating
compound character is by removing the vertical line of
a character and then joining to other on its left hand
side. This type of joining is more commonly used.
Another way of writing a compound character is to join
the characters side by side or one above the other. In
some compound characters, one of the consonants
completely changes its form and then gets joined to the
other consonant. The compound characters not only
exhibit a variation in the shape of the character but also
in the aspect ratio as per the joining strategy it changes
its characterastics. The features like aspect ratio or
number of end points cannot serve as efficient features
due to these various joining strategies in order to attain
acceptable accuracy of recognition. There can be two
ways of recognition of compound character.
II. BLOCK DIAGRAM OF
PROPOSED WORK:
Fig1: Block Diagram of proposed method
Recognition can be done by separating the characters in
the consonant character while the other way is
recognition without separation. If we attempt for
recognition of the compound character after separation
of the characters in it, it would certainly pose more
difficulties as there are number of joining strategies as
studied earlier survey. This paper propose a system for
compound character recognition without separation of
the characters. But, in case if the consonants in the
compound characters get separated or split during pre-
processing, still the compound characters can be
recognized in our proposed system.
In our proposed system, we aim at recognizing
compound characters in Marathi language. This is done
by KNN. The above figure shows the block diagram of
the proposed system, which consist different phases
starting with character input, pre-processing, structural
classification, resized character
III. ALGORITHM & DESCRIPTION:
1. Image Acquisition
Image acquisition in image processing can be broadly
defined as the action of getting an image from some
source, a hardware-based source, so it can be passed
through processes need to occur afterward performing
image acquisition in image processing is always the
first step in the workflow sequence. The Input Image
that we get is completely unprocessed like original one.
One of the ultimate goals of this process is to have a
source of input that operates within such controlled and
measured guidelines that the same image can
reproduced under the same conditions so various
corresponding factors are easier to locate.
2. Preprocessing
A point operator converts gray scale character images to
binary. This operator separates pixels that have values
within specified range means the object from the rest or
the background. This is done by choosing a threshold
that separates object and the background. Here, the
threshold is chosen by using uniform thresholding after
normalization in our method. In uniform thresholding,
pixels above a threshold are set to white and those
below the threshold are set to black and that threshold
we have to choose. Uniform thresholding requires the
knowledge of the gray levels otherwise the target
features might not get selected or may get misclassified
after thresholding process. The joint characters were
tested and checked for the global features for various
threshold values before finalization of a threshold. On
testing about one third of the characters in the database,
the normalized threshold value of 0.75 was found to be
an optimum value that gave correct feature selection of
global features in most of the cases. Pre-processing
plays very important role in handwritten character
recognition as in any other pattern recognition task.
Joint characters show various undesirable effects like
unwanted strokes, gaps or breaks which occur due to
binarization. Many a times when a character is joint
JASC: Journal of Applied Science and Computations
Volume VI, Issue I, January/2019
ISSN NO: 1076-5131
Page No:1404

character, it exhibits lesser width at the curvature than
at other parts of the character. This point is more likely
to break during binarization process.
A system is proposed to recognize compound Marathi
characters in this paper. Character recognition is very
vast field. Various methods are used for the same.
Marathi characters are more complex than English
characters due to various characterastics. Classical
methods of character recognition are not considered to
be as successful for recognition of Marathi characters as
Marathi characters differ in size, shape and style from
person to person and from time to time with same
person writing. Hence this project uses the KNN
technique using evolutionary computational algorithm
for character recognition.
The main advantage of using this technique is that it
provides features extraction and detection that is
suitable for character recognition and improved
efficiency over earlier methods. Neural network gains
more successful in character recognition as compared
with other classical methods as it functions like neural
network with evolutionary computational algorithms.
Preprocessing aims to produce data that are easy for the
computer related system accurately. Preprocessing
enhances the image features thus reducing the effect of
variations in method & rendering it suitable for further
processing. In this project the various operations
performed during preprocessing are noise reduction,
normalization, binarization, edge detection, dilation &
filling. Initially load the dataset image. Then crop the
required character image (i.e. character to be
recognized) manually. Then cropped image is converted
into gray scaled image for further processing. After that
binarization is carried out. After this step, edge of the
binary image is detected. Image dilation & filling of
holes is performed after binarization.
3. Segmentation
The text line segmentation methods can be normally
classified into two types bottom-up and top-down. In
the bottom-up approach, the neighboring components
are grouped using some easy rules depending on the
geometric relationship between neighboring blocks. The
projection based methods are the top-down algorithms
which is one of most successful methods for machine
printed text. The projection based methods are also
successful for handwritten text where text lines are
straight or easily separable. But due to different writing
styles of the people, the text line segmentation is still
very challenging task. In general, text-line segmentation
techniques are script independent methods. In the
proposed system we have used projection based method
for segmentation of lines and characters.
4. Feature Extraction
KNN is used for feature extraction. Features are
extracted using single level decomposition as discusses
earlier. The approximation coefficients obtained for
every character after single level decomposition. The
modified KNN features are also generated in order to
improve the recognition results. Feature extraction is
the next step after preprocessing the data. After the
preprocessing the feature set is extracted with various
properties. Extracted features from the character images
are used to train the neural network and with the help of
various algorithms. In this stage, the features of the
characters that are used for classifying them at
recognition stage are extracted. The edges & end points
of the image are detected & are considered as features
for neural network.
Features are extracted using KNN as discusses earlier.
The single level decomposition leads approximation
features. The modified features are also generated in
order to improve the recognition results. The modified
features are obtained by convolving the approximation
features with themselves.
5. Recognition
Finally character recognition is carried out using neural
network in our proposed paper. In this process a
character to be recognized is assigned to the network
and label is given to next step. Several other patterns of
the same character are taught to neural network under
the computational algorithm under the same name and
characterastics. Hence system learns several variations
in the handwritten characters and these variations gets
adaptive to it. At this time of training of the neural
network weight matrix is initialized to 0. During the
training process the input assigned to matrix is defined.
Each character processes corresponding weight matrix.
As the learning of the character progresses, the weight
of the character is to be updated. In order to train the
network, features of the character which are previously
extracted from the character are given to neural
network. To recognize these patterns, the instructions
are then given to the network. In accordance with this,
the weight matrix is updated. Every time, the weights
are adjusted in such a way as to give an output closer to
the desired output than before used. In this project, feed
KNN is used If the features of the character are not
matched with target, the error is back propagated &
weights are updated with similar one. The process is
continues till features of selected character are matched
with target. Finally output is displayed. The work is
carried out in MATLAB.
IV. RESULT & CONCLUSION:
Compound character is one of the features of the
Marathi script and commonly used. This paper presents
JASC: Journal of Applied Science and Computations
Volume VI, Issue I, January/2019
ISSN NO: 1076-5131
Page No:1405

a system for compound character recognition for
Marathi script. For this we used Marathi language OCR
and used KNN for better results. The recognition of
characters is done using KNN recognition scheme.
Fig2: GUI design for project work
Fig3: Importing an image
Fig4: Binarization Process
Fig5: Line by line segmentation
Fig6: Word to word segmentation
Fig7: Recognition and displaying of compound
characters
This approach is KNN approach is presented for the
recognition of compound Marathi character. So using
KNN we get better results as compared to other
methods.
V. REFERENCES [1] H. S. Baird,” Anatomy of a versatile page reader”,. Proc.
of the IEEE, 80(7):1059-1065, 1992.
[2] G. Nagy. “Twenty years of document image analysis”,
PAMI. IEEE Trans. On Pattern Analysis and Machine
Intelligence, 22(1):38-62, 2000.
JASC: Journal of Applied Science and Computations
Volume VI, Issue I, January/2019
ISSN NO: 1076-5131
Page No:1406

[3] C. Y. Suen, S. Mori, S. H. Kim, and C. H. Leung.,”
Analysis and recognition of Asian scripts - The state of
the art.”, Proc. of the 6th Int. Conf. on Document
Analysis and Recognition (ICDAR), pages 866-878,
2003.
[4] U. Pal and BB Chaudhuri. “Indian script character
recognition: A survey. Pattern Recognition,” 37(9):1887-
1899, 2004.
[5] V. K. Govindan and A. P. Shivprasad, “Character
Recognition - A Review,”Pattern Recognition, vol.23
no.7,pp 671-683, 1990.
[6] SuryaPrakash Kompalli, Srirangaraj Setlur, Venugopal
Govindaraju, Ramanaprasad Vemulapati ,”Creation of
data resources and design of an evaluation test bed for
Devanagari script recognition.”,13th International
Workshop on Research Issues on Data Engineering:
Multi-lingual Information Management
[7] SuryaPrakash Kompalli, Srirangaraj Setlur, Venugopal
Govindaraju, Ramanaprasad Vemulapati ”Creation of
data resources and evaluation tool for multi-lingual
OCR.”,.
Symposium on Document Image Understanding
Technology - 2003 .
[8] D. Trier, A. K. Jain, T. Taxt, “Feature Extraction
Method for Character Recognition - A Survey”, Pattern
recognition, vol.29, no.4, pp.641-662, 1996.
[9] Huang YS, Suen CY. A method of combining multiple
experts for the recognition of unconstrained handwritten
numerals. 1EEE Transactions on Pattern Analysis and
Machine Intelligence 1995; 17(1): 90-94
[10] R.M.K. Sinha, H. Mahabala,,”Machine recognition of
Devanagri script”, IEEE Trans. System, Man Cybern.
9(1979) 435-441.
[11] Plamondon, R. Srihari, S.N. ,Ecole Polytech.,Montreal,
Que.; Online and Offline HandwritingRecognition : A
comprehensive Survey,1EEE Transactions On Pattern
Analysis And Machine Intelligence. VOL. 22, NO. 1.
JANUARY 2000 63
[12] U. Pal , B.B. Chaudhuri , “Printed Devanagri script OCR
system”, Vivek 10 (1997) 12-24.
[13] S. Palit, B.B. Chaudhuri,,”A feature-based scheme for
the machine recognition of printed Devanagri script”,
P.P. Das, B.N. Chatterjee (Eda.) Pattern Recognition,
Image Processing and Computer Vision, Narosa
Publishing House: New Delhi, India 1995, pp. 163-168.
[14] I.K. Sethi, B. Chatterjee, “Machine recognition of
constrained hand-printed Devanagri numerals”, J.
Inst.Electron. Telecom. Eng. 22 (1976) 532-535.
[15] R.M..K. Sinha, “A syntactic pattern analysis system and
its application to Devanagri script recognition”, Ph.D.
Thesis , Electrical Engineering Department, Indian
Institute of Technology, India, 1973.
[16] V. Bansal, R.M.K. Sinha, “Partitioning and searching
dictionary for correction of optically read Devanagri
characters strings”, Proceedings of the Fifth International
Conference on Document Analysis and Recognition ,
1999, pp. 653-656.
[17] S. Arora, D.Bhattacharya, M. Nasipuri, L.Malik, “A
Novel Approach for Handwritten Devanagari Character
Recognition” in IEEE –International Conference on
Signal And Image Processing, Hubli, Karnataka, Dec 7-
9, 2006.
[18] M. Hanmandlu and O.V. Ramana Murthy, “Fuzzy Model
Based Recognition of Handwritten Hindi Numerals”, In
Proc. Intl. Conf. on Cognition and Recognition, pp. 490-
496, 2005.
[19] R. Bajaj, L. Dey, and S. Chaudhury, “Devanagri numeral
recognition by combining decision of multiple
connectionist classifiers”, Sadhana, Vol.27, pp.-59-72,
2002.
[20] U. Bhattacharya, S. K .Parui, B. Shaw, K. Bhattacharya,
“Neural combination of ANN and HMM for handwritten
Devanagri Numeral Recognition”, In Proc. 10th IWFHR,
pp.613-618, 2006.
[21] S. Kumar and C. Singh, “A Study of Zernike Moments
and its use in Devanagri Handwritten Character
Recognition”, In Proc. Intl. Conf. on Cognition and
Recognition, pp. 514-520, 2005.
[22] N. Sharma, U. Pal, F. Kimura and S. Pal, “Recognition
of Offline Handwritten Devanagri Characters using
Quadratic Classifier”, In Proc. Indian Conference on
Computer Vision Graphics and Image Processing, pp-
805-816, 2006.
[23] Feature Extraction Techniques Implementation
Review and Case Study
Uma Bhati Department of Computer Science &
Engineering JSS Academy of Technical Education
Noida-201301
[24] A Review of Research on Devnagari Character
Recognition
Vikas J Dongre Vijay H Mankar Department of
Electronics & Telecommunication, Government
Polytechnic, Nagpur, India
[25] Segmentation of Marathi Handwritten Characters
and Numerals
Ratnashil N Khobragade Assistant Professor, P G
Dept of CS, SGB Amravati University, Amravati,
Maharastra, India
[26] A Streamlined OCR System for Handwritten
Marathi Text Document Classification and
Recognition Using SVM-ACS Algorithm
Surendra Pandurang Ramteke Department of
Electronics & Telecommunication Engineering,
Shram Sadhana Bombay Trust College of
JASC: Journal of Applied Science and Computations
Volume VI, Issue I, January/2019
ISSN NO: 1076-5131
Page No:1407

Engineering and Technology, Bambhori,
Maharashtra, India
[27] Feature Extraction for Marathi Compound
Character Using Edge Map
Mrs.Snehal S.Golait Research Scholar ,Department
of Computer Science and Engineering,
G.H.Raisoni College of Engineering,Nagpur,
JASC: Journal of Applied Science and Computations
Volume VI, Issue I, January/2019
ISSN NO: 1076-5131
Page No:1408