Embed Size (px)
Citation preview

Joint Learning of Phonetic Units and Word Pronunciations for ASR
Chia-ying (Jackie) Lee, Yu Zhang and James Glass
Spoken Language Systems GroupMIT Computer Science and Artificial Intelligence Lab
Cambridge, MA
1
2
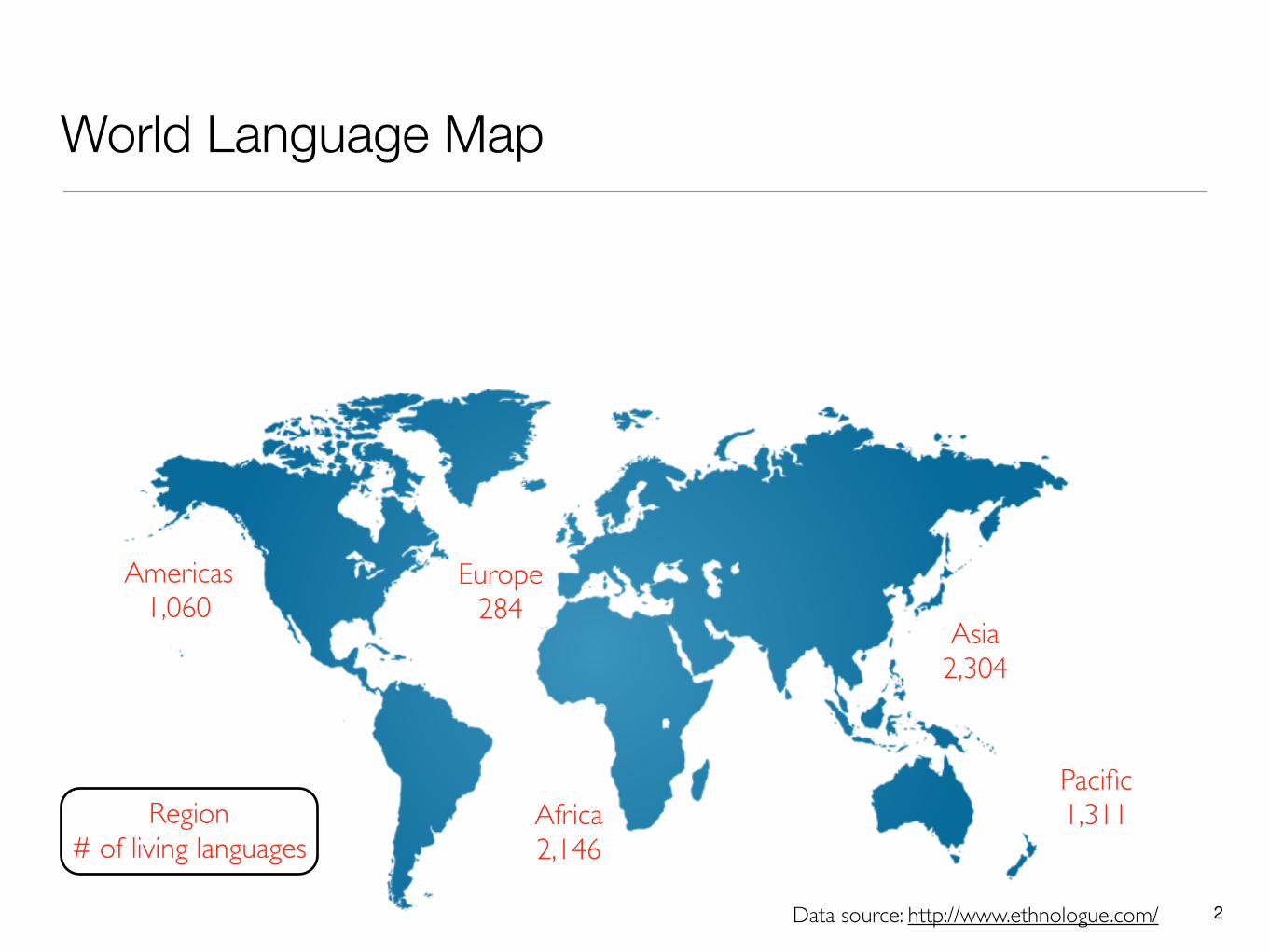
World Language Map
Data source: http://www.ethnologue.com/
• Roughly 7,000 living languages all around the world
- Only 2% are supported by automatic speech recognition (ASR) technology
Region# of living languages
Americas1,060
Africa2,146
Europe284
Asia2,304
Pacific1,311
2
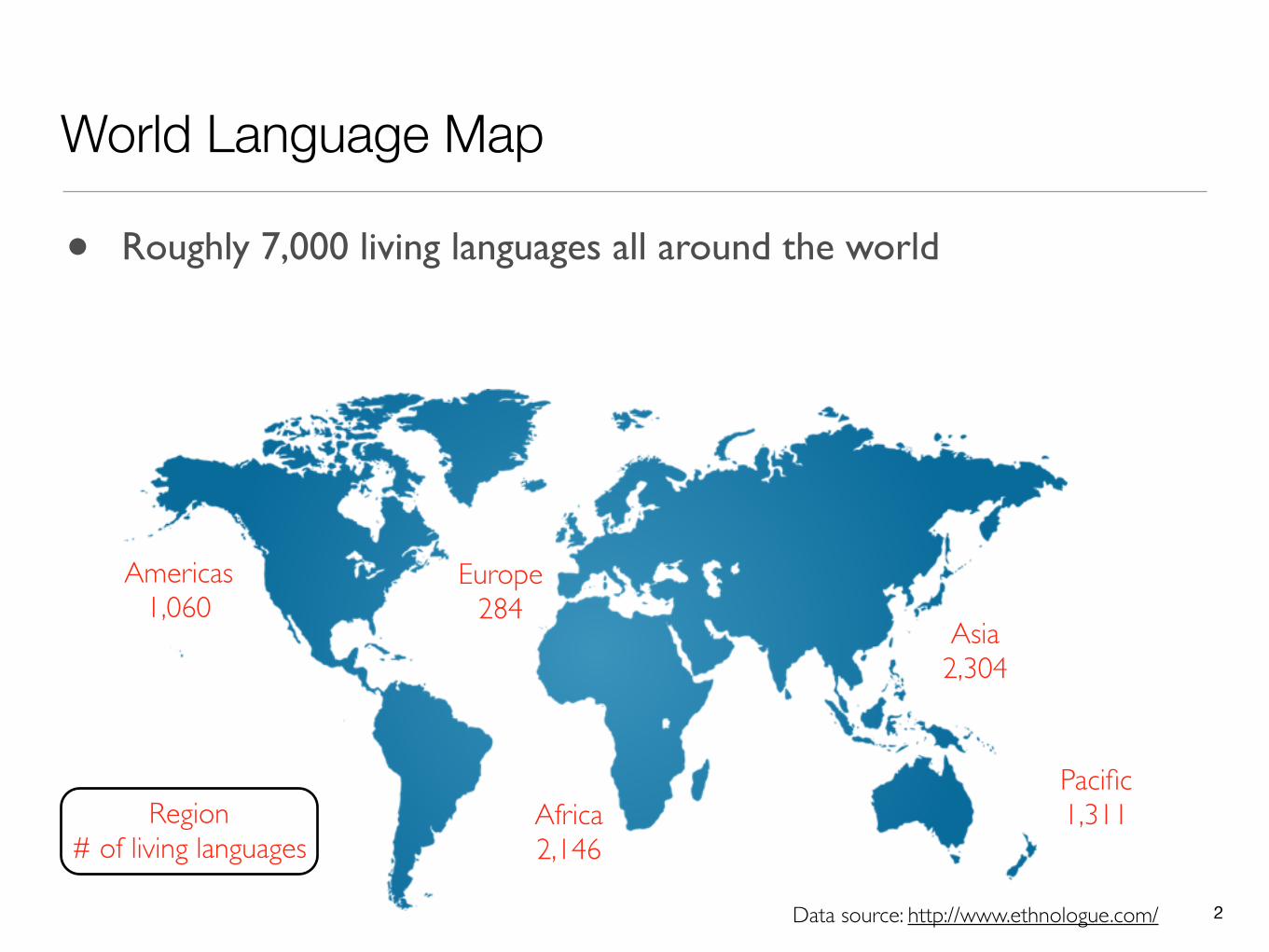
World Language Map
Data source: http://www.ethnologue.com/
• Roughly 7,000 living languages all around the world
- Only 2% are supported by automatic speech recognition (ASR) technology
Region# of living languages
Americas1,060
Africa2,146
Europe284
Asia2,304
Pacific1,311
2
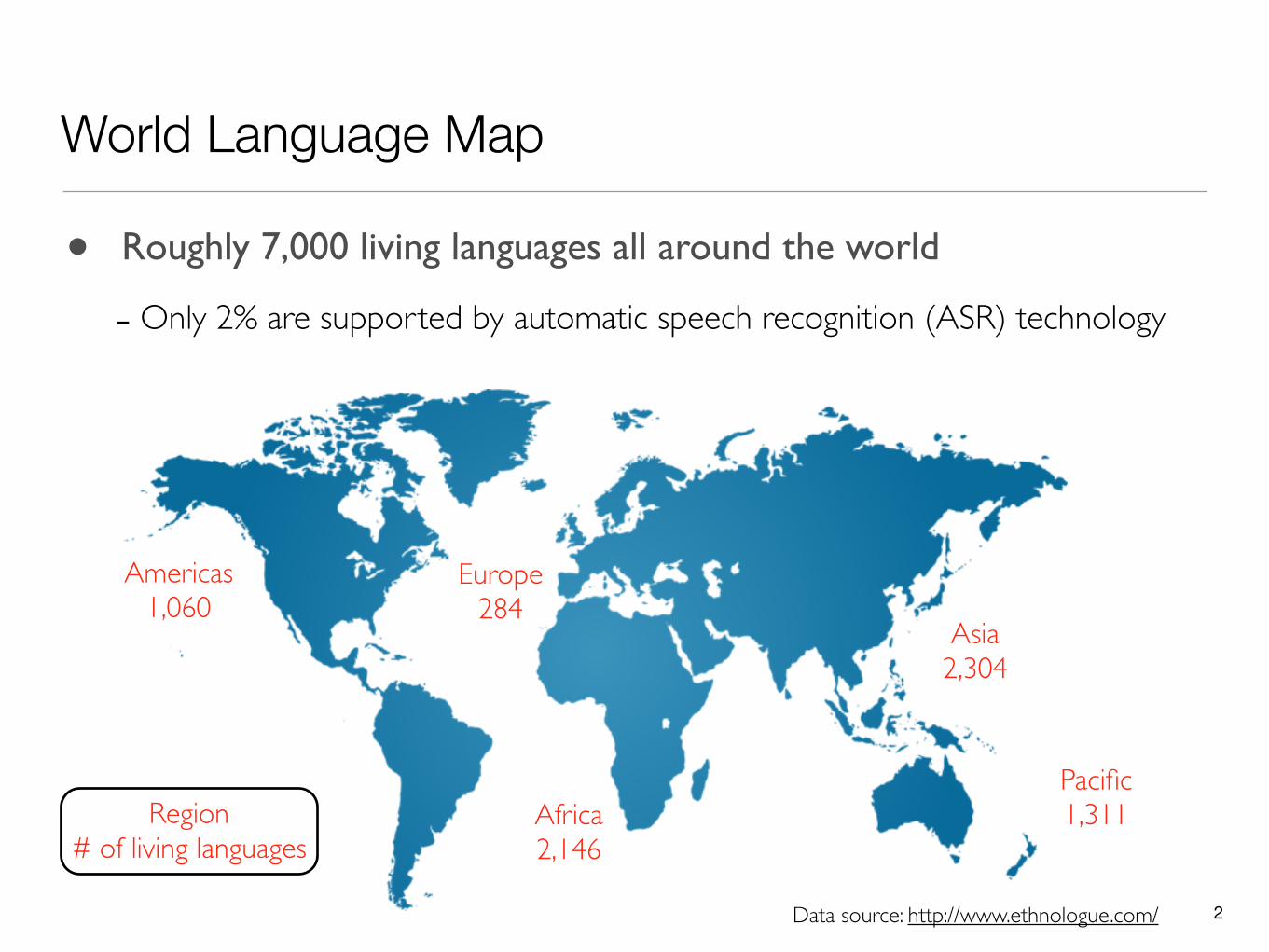
World Language Map
Data source: http://www.ethnologue.com/
• Roughly 7,000 living languages all around the world
- Only 2% are supported by automatic speech recognition (ASR) technology
Region# of living languages
Americas1,060
Africa2,146
Europe284
Asia2,304
Pacific1,311

3
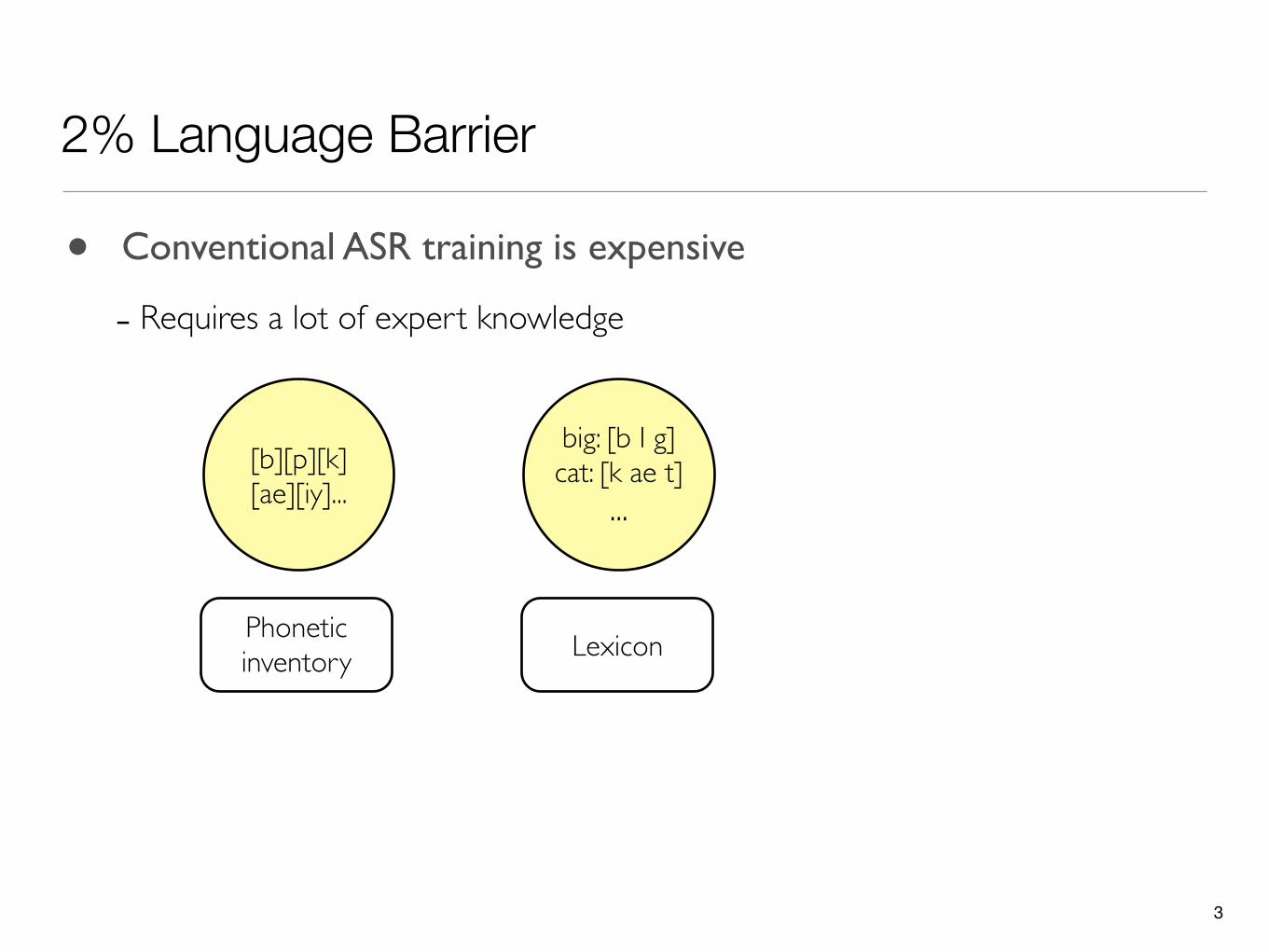
2% Language Barrier
• Conventional ASR training is expensive
- Requires a lot of expert knowledge

3
2% Language Barrier
[b][p][k][ae][iy]...
Phonetic inventory
• Conventional ASR training is expensive
- Requires a lot of expert knowledge
3
2% Language Barrier
[b][p][k][ae][iy]...
Phonetic inventory
big: [b I g]cat: [k ae t]
...
Lexicon
• Conventional ASR training is expensive
- Requires a lot of expert knowledge
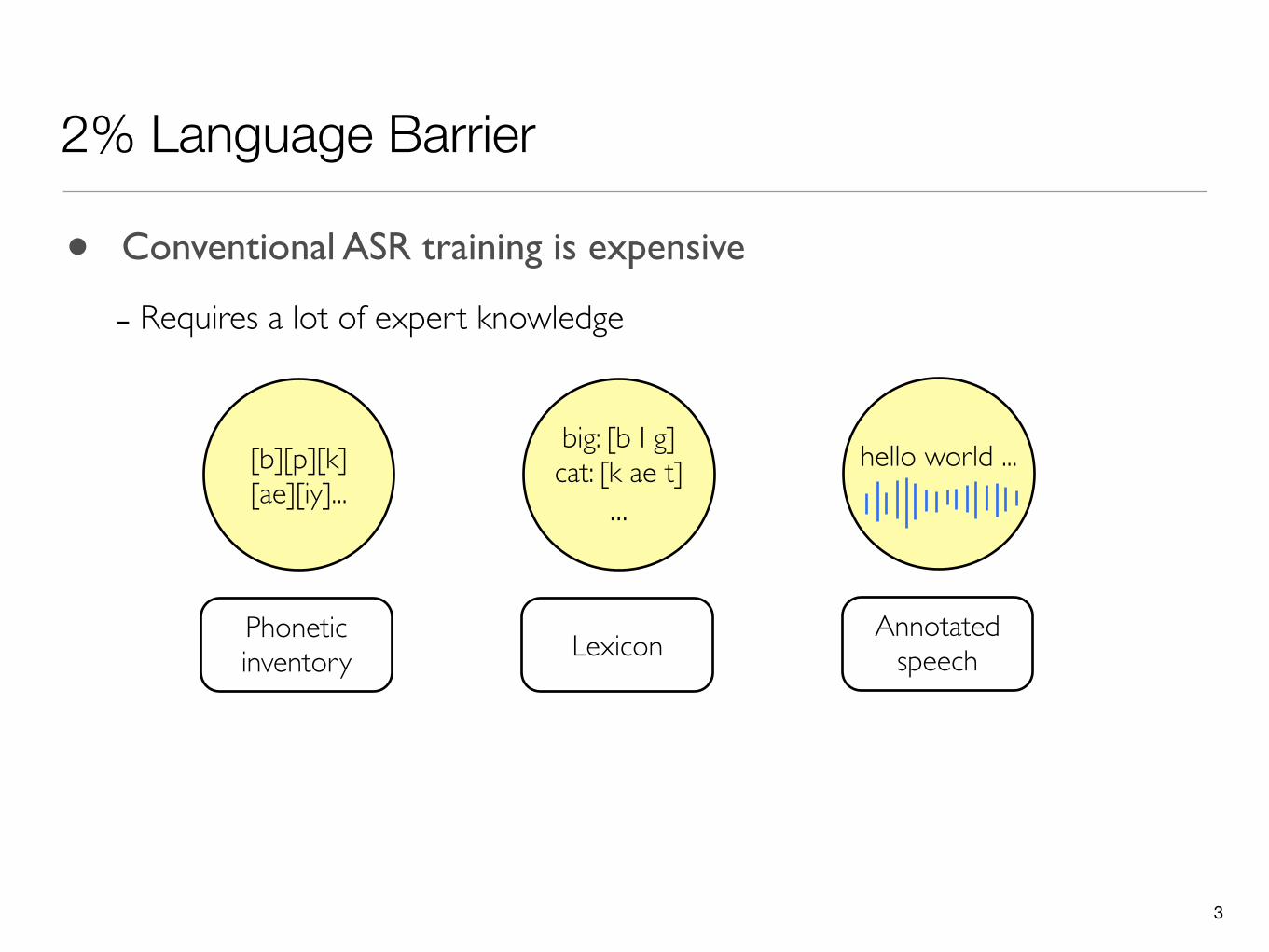
3
2% Language Barrier
[b][p][k][ae][iy]...
Phonetic inventory
big: [b I g]cat: [k ae t]
...
Lexicon
hello world ...
Annotated speech
• Conventional ASR training is expensive
- Requires a lot of expert knowledge
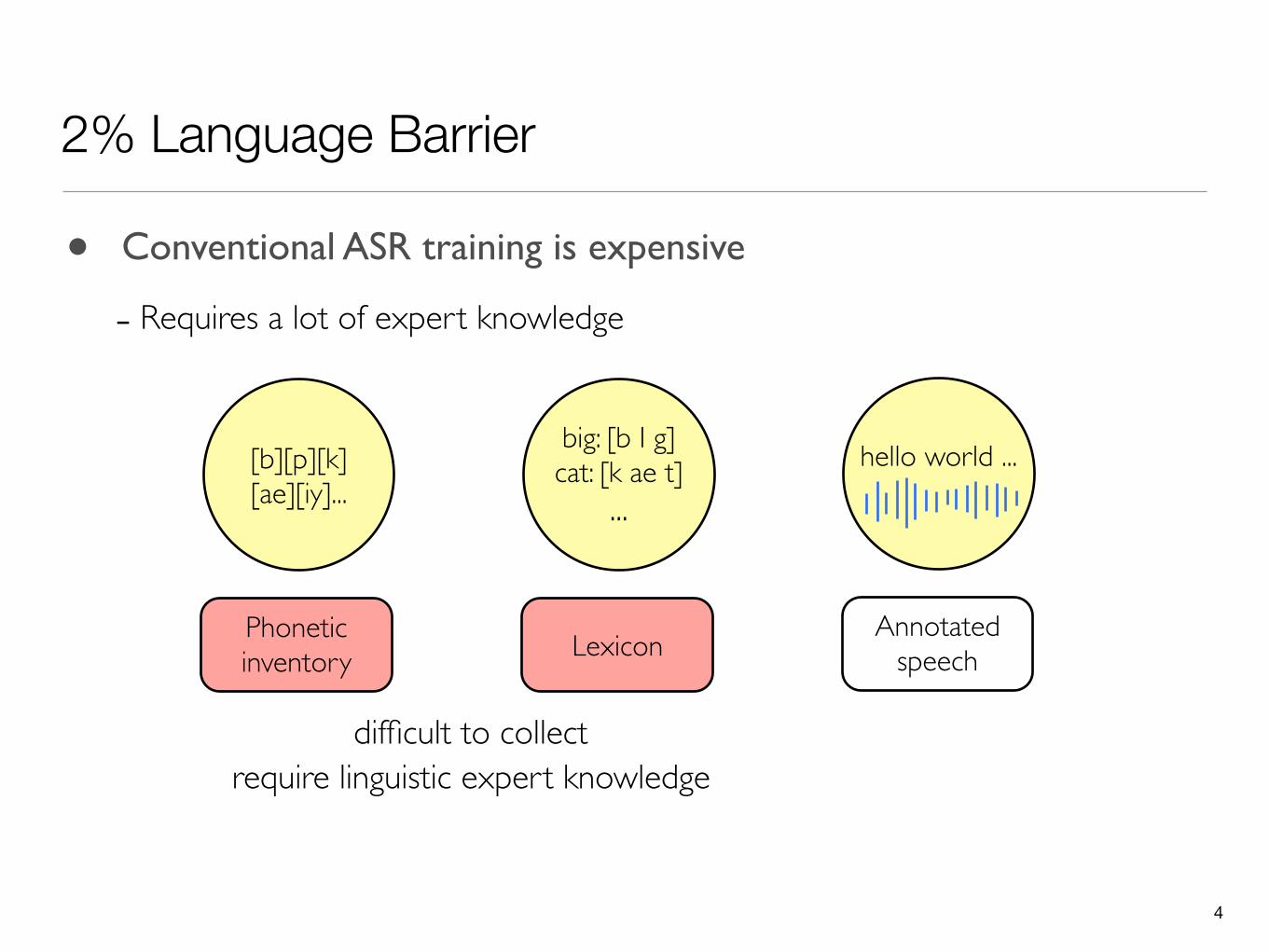
4
2% Language Barrier
big: [b I g]cat: [k ae t]
...hello world ...[b][p][k]
[ae][iy]...
Phonetic inventory Lexicon
require linguistic expert knowledgedifficult to collect
Annotated speech
• Conventional ASR training is expensive
- Requires a lot of expert knowledge
5
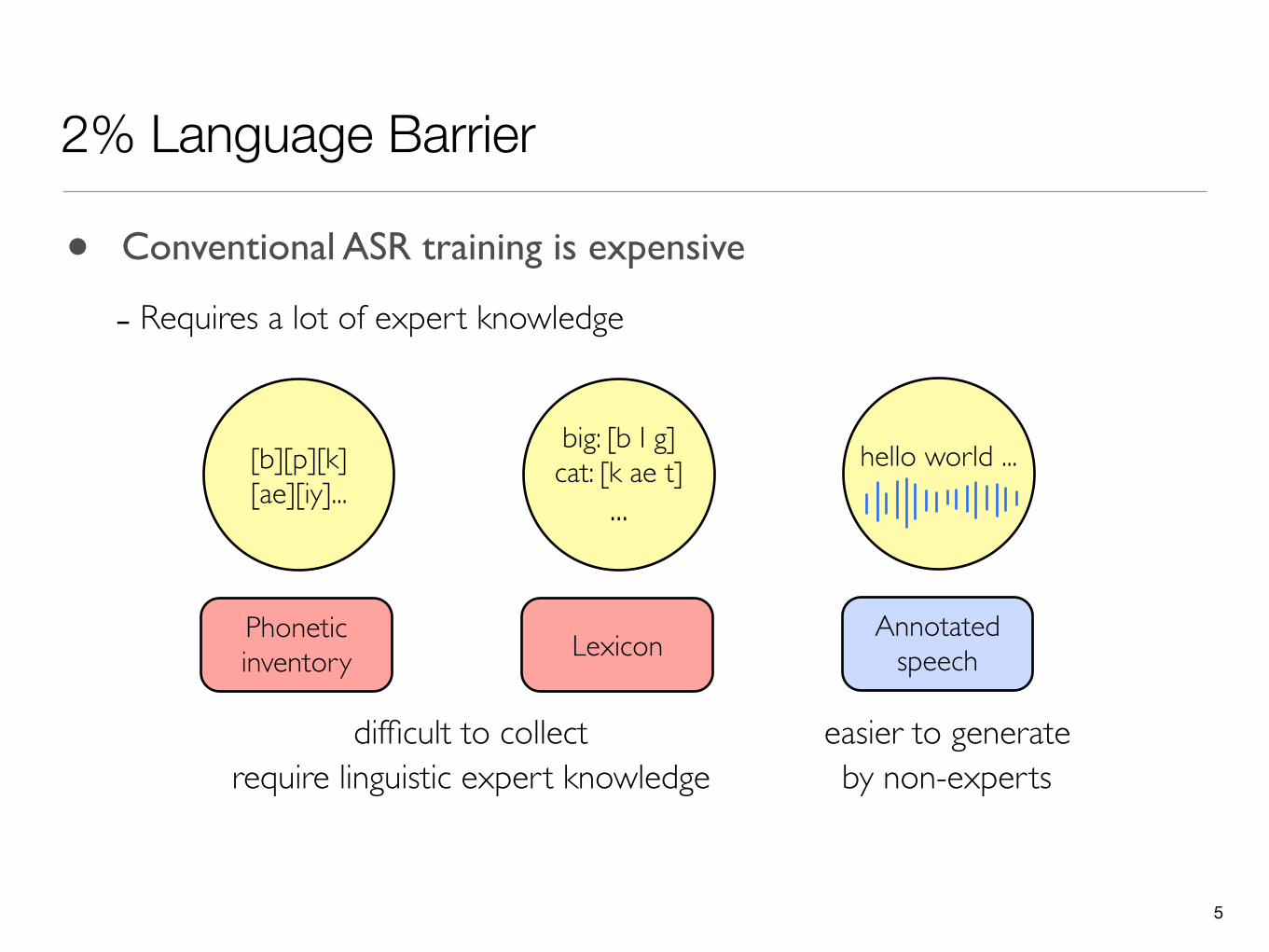
2% Language Barrier
big: [b I g]cat: [k ae t]
...hello world ...[b][p][k]
[ae][iy]...
• Conventional ASR training is expensive
- Requires a lot of expert knowledge
Annotated speech
easier to generateby non-experts
Phonetic inventory Lexicon
require linguistic expert knowledgedifficult to collect
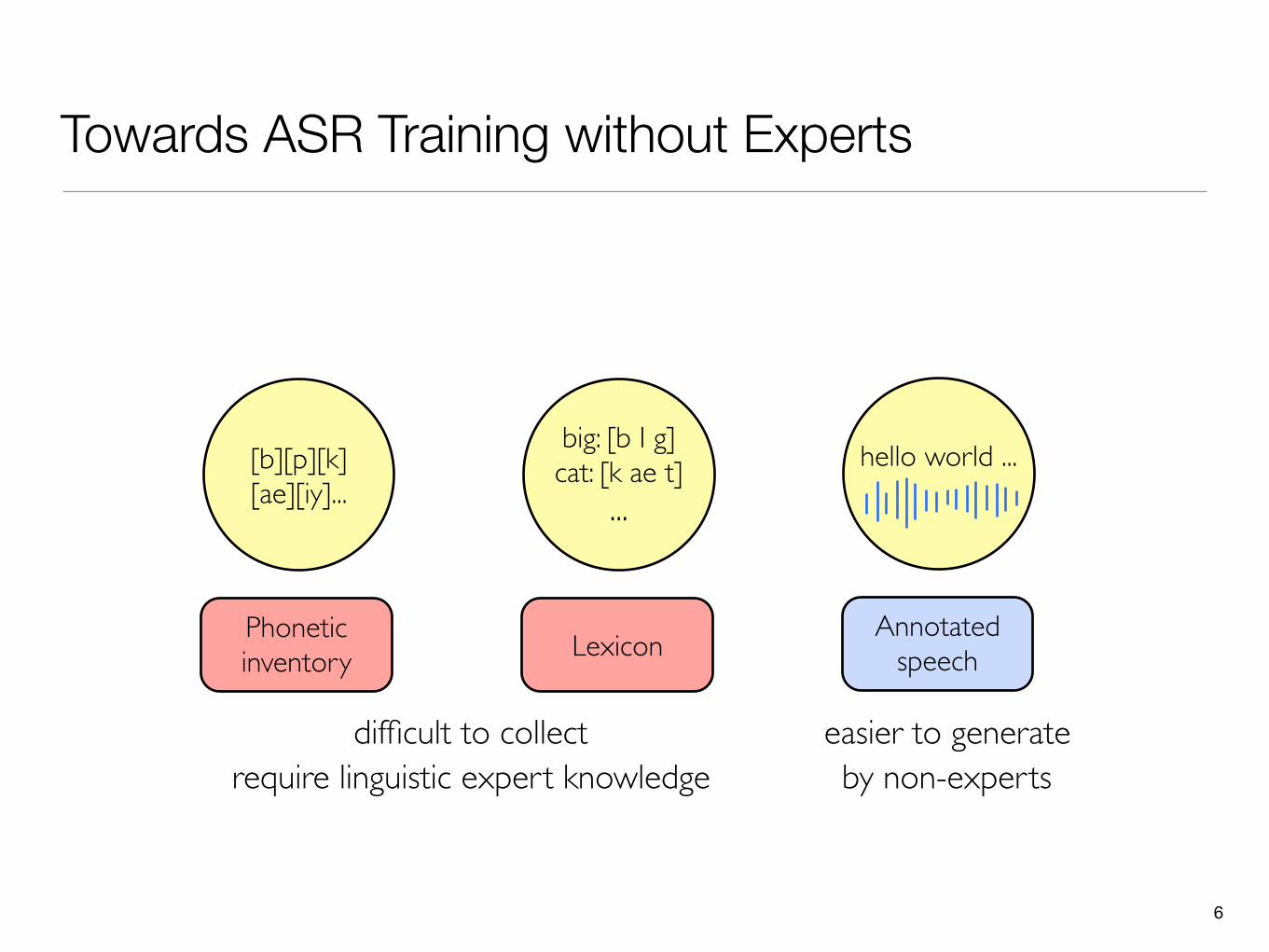
Towards ASR Training without Experts
6
big: [b I g]cat: [k ae t]
...hello world ...[b][p][k]
[ae][iy]...
Phonetic inventory Lexicon Annotated
speech
require linguistic expert knowledgedifficult to collect easier to generate
by non-experts

Towards ASR Training without Experts
7
big: [b I g]cat: [k ae t]
...hello world ...[b][p][k]
[ae][iy]...
Phonetic inventory Lexicon Annotated
speech
require linguistic expert knowledgedifficult to collect easier to generate
by non-experts
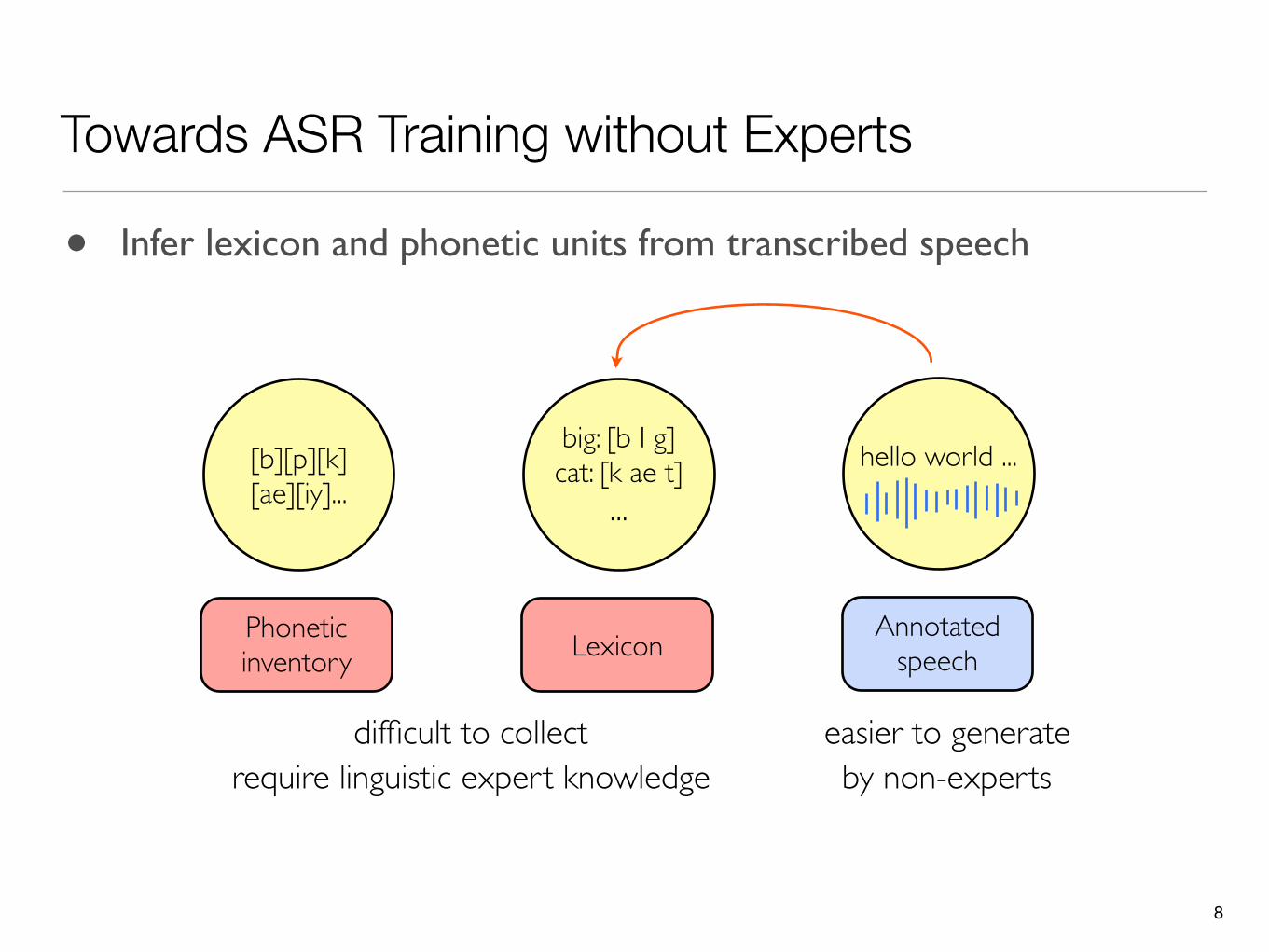
Towards ASR Training without Experts
8
big: [b I g]cat: [k ae t]
...hello world ...[b][p][k]
[ae][iy]...
Phonetic inventory Lexicon Annotated
speech
require linguistic expert knowledgedifficult to collect easier to generate
by non-experts
• Infer lexicon and phonetic units from transcribed speech
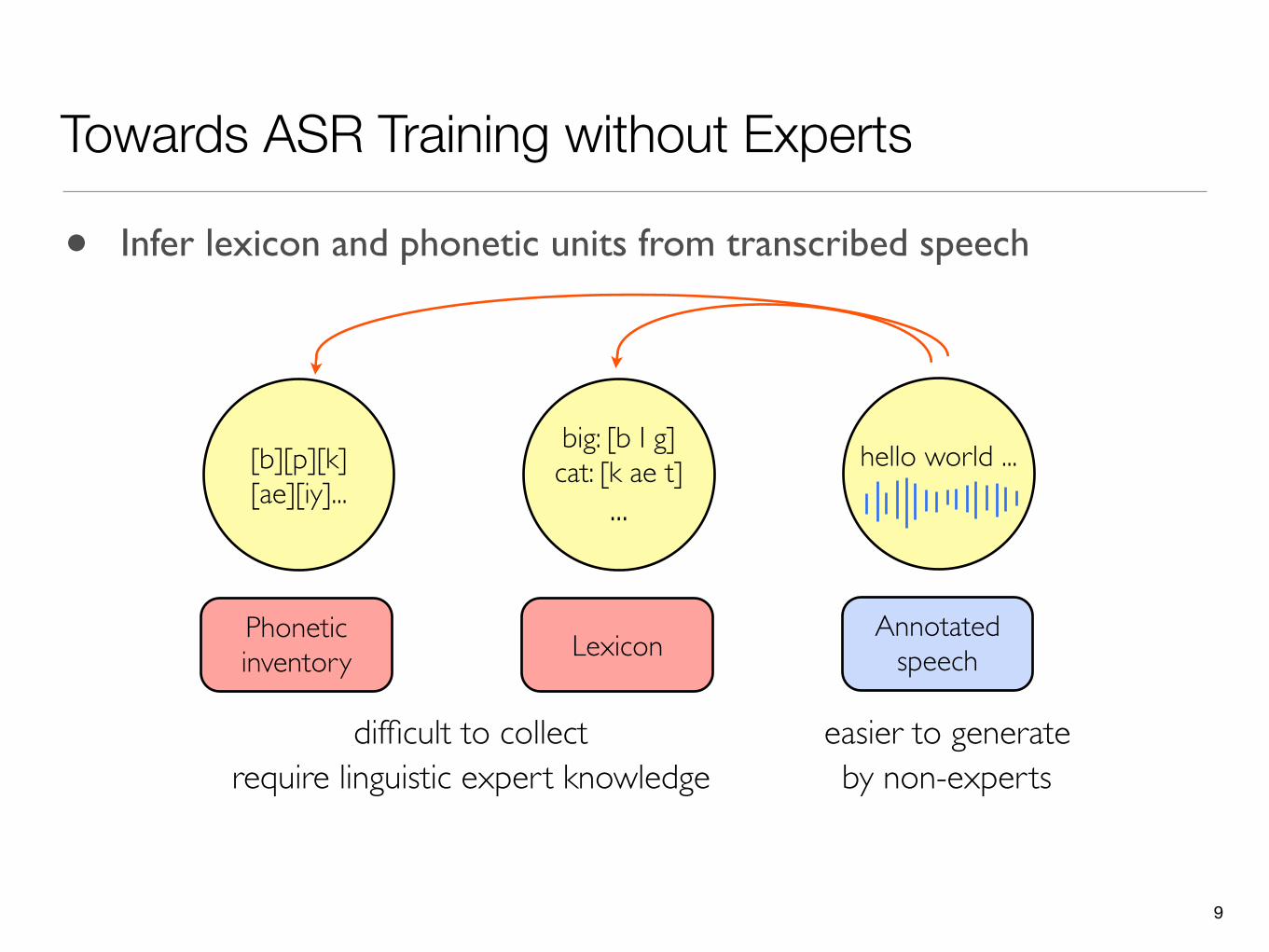
Towards ASR Training without Experts
9
big: [b I g]cat: [k ae t]
...hello world ...[b][p][k]
[ae][iy]...
Phonetic inventory Lexicon Annotated
speech
require linguistic expert knowledgedifficult to collect
• Infer lexicon and phonetic units from transcribed speech
easier to generateby non-experts

Discover Pronunciation Lexicon
10
• Learn word pronunciations from transcribed speech
I need to fly to Texas

Discover Pronunciation Lexicon
11
[n] [iy] [d] [t][ux] [f] [l] [ay] [t] [ux] [t] [e] [k] [s] [ax] [s][ay]
I need to fly to Texas
• Learn word pronunciations from transcribed speech
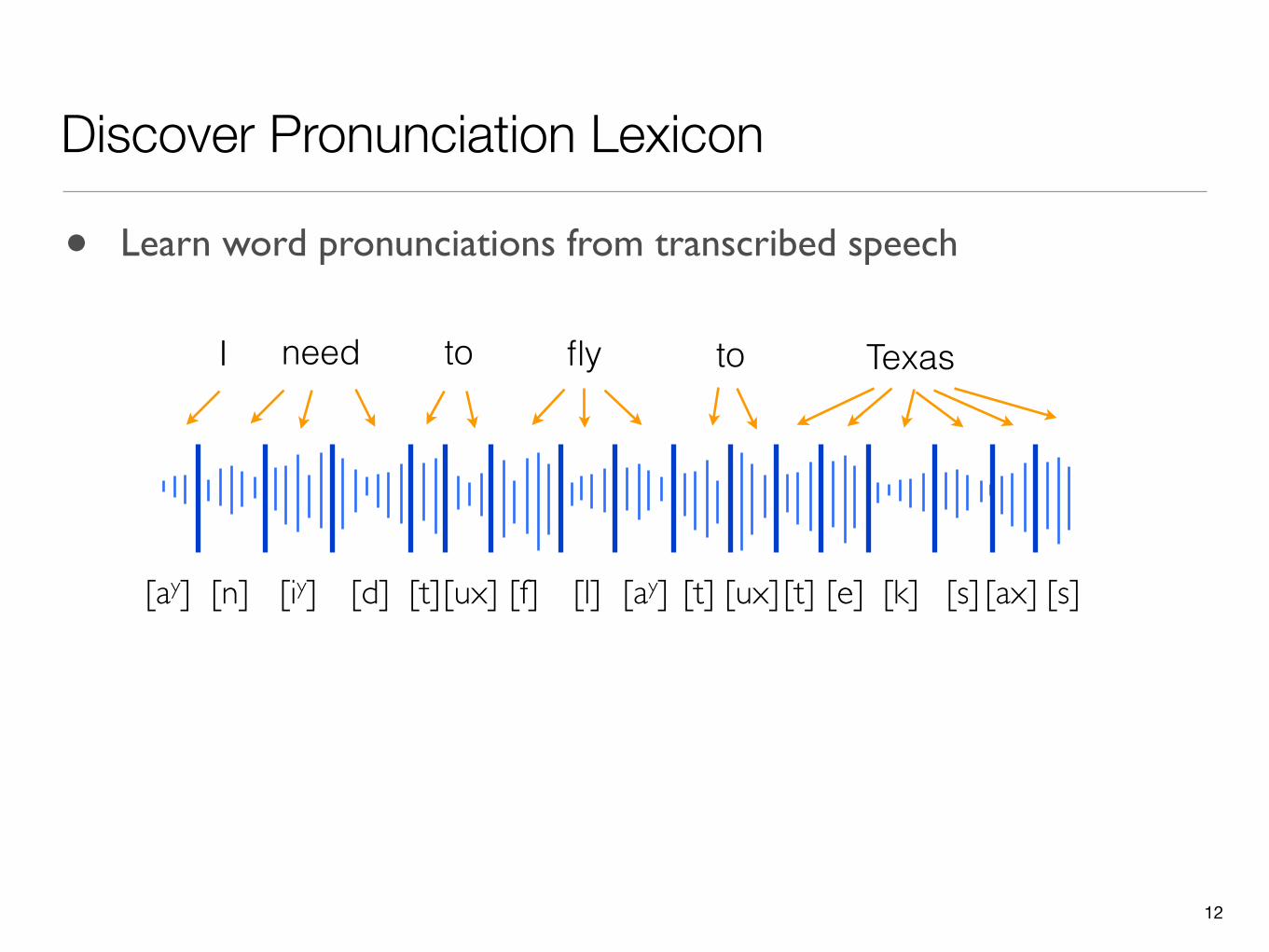
Discover Pronunciation Lexicon
12
[n] [iy] [d] [t][ux] [f] [l] [ay] [t] [ux] [t] [e] [k] [s] [ax] [s][ay]
I need to fly to Texas
• Learn word pronunciations from transcribed speech

Discover Pronunciation Lexicon
12
[n] [iy] [d] [t][ux] [f] [l] [ay] [t] [ux] [t] [e] [k] [s] [ax] [s][ay]
I need to fly to Texas
I : need :
to : fly :
[ay][n iy d][t ux][f l ay]
...
• Learn word pronunciations from transcribed speech
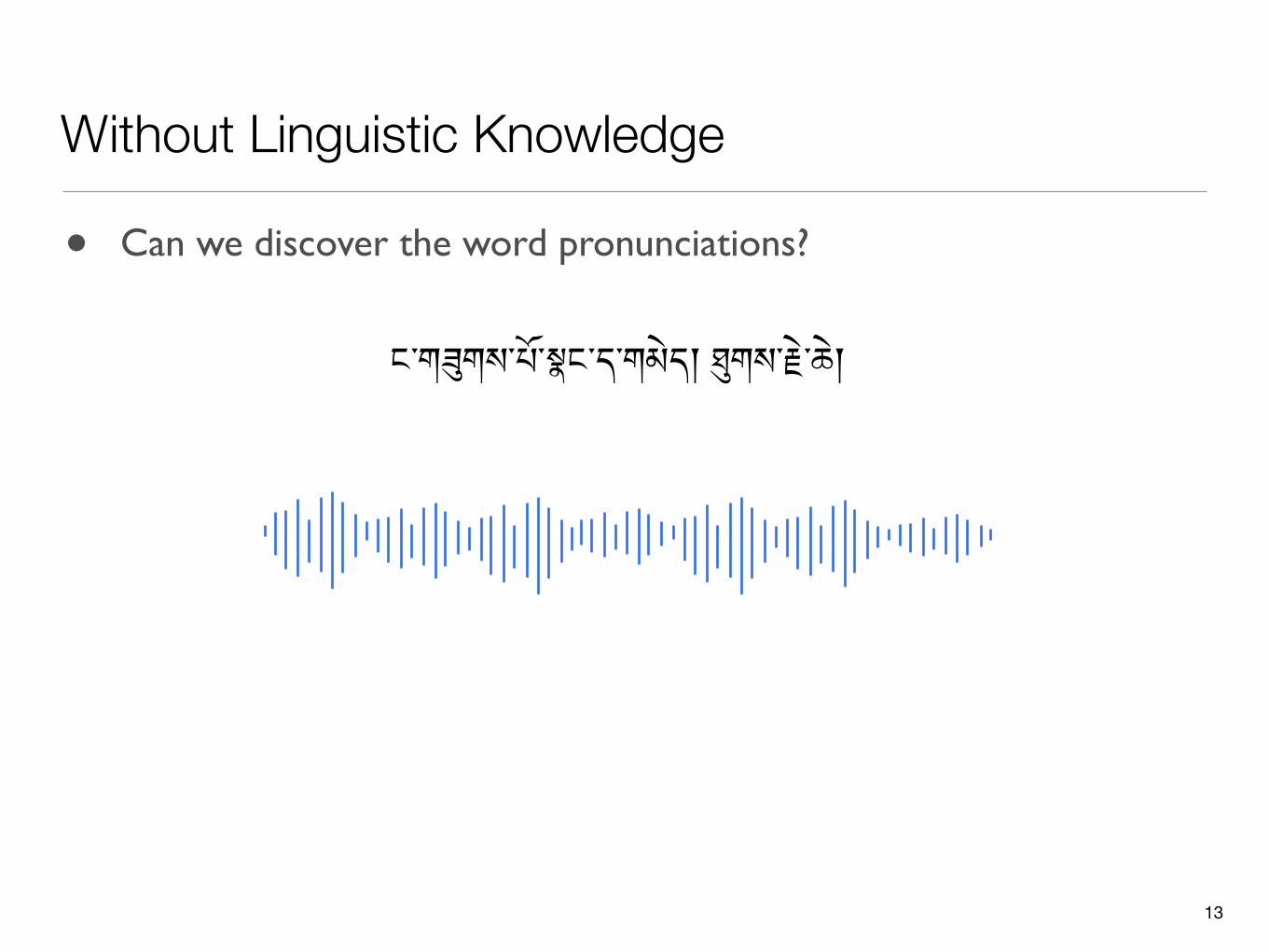
Without Linguistic Knowledge
13
ང་ག$གས་པོ་(ང་ད་གམེད། -གས་.ེ་ཆེ།
• Can we discover the word pronunciations?
Without Linguistic Knowledge
14
• Can we discover the word pronunciations?
ང་ག$གས་པོ་(ང་ད་གམེད། -གས་.ེ་ཆེ།
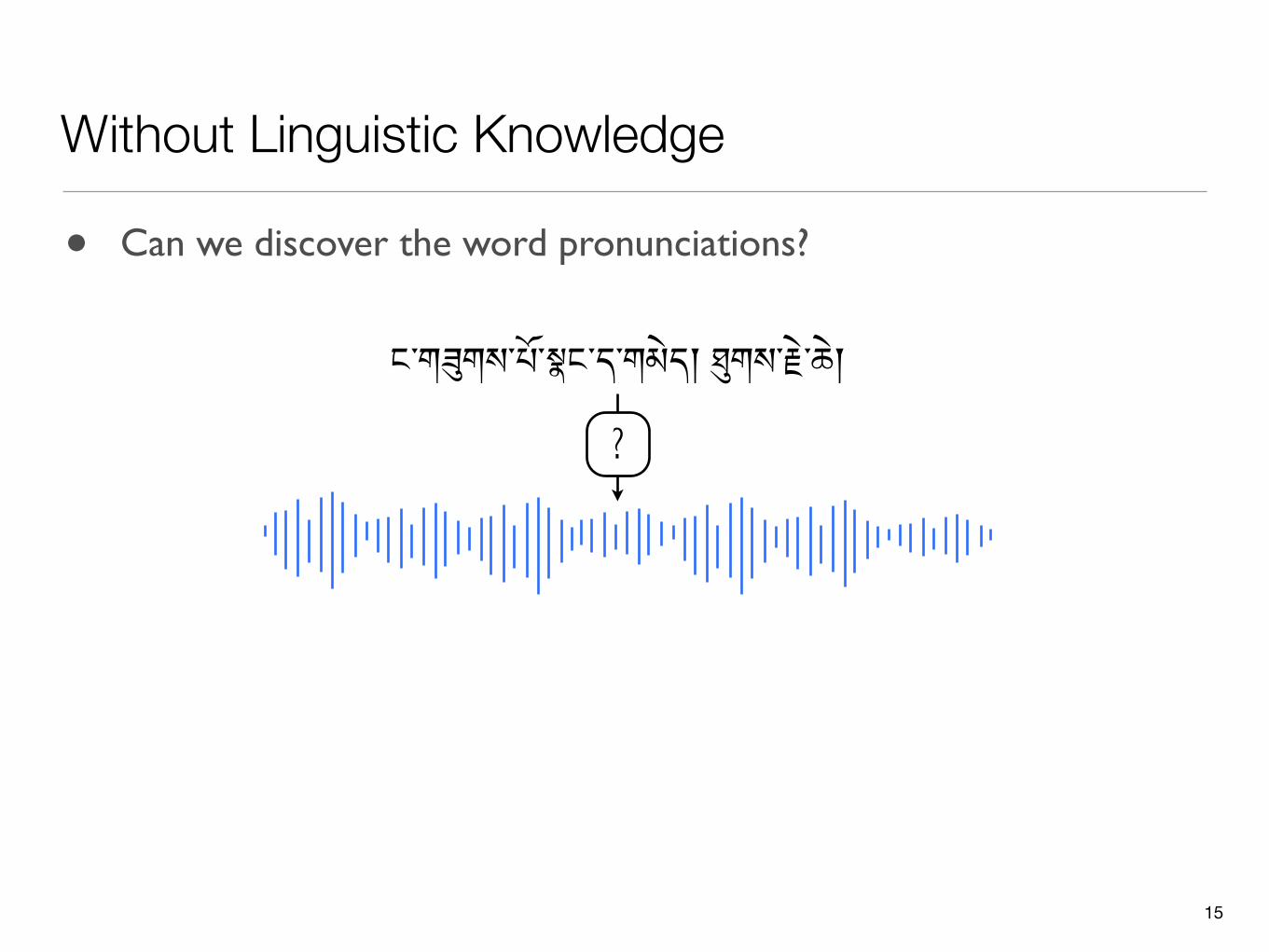
Without Linguistic Knowledge
15
ང་ག$གས་པོ་(ང་ད་གམེད། -གས་.ེ་ཆེ།
?
• Can we discover the word pronunciations?
16
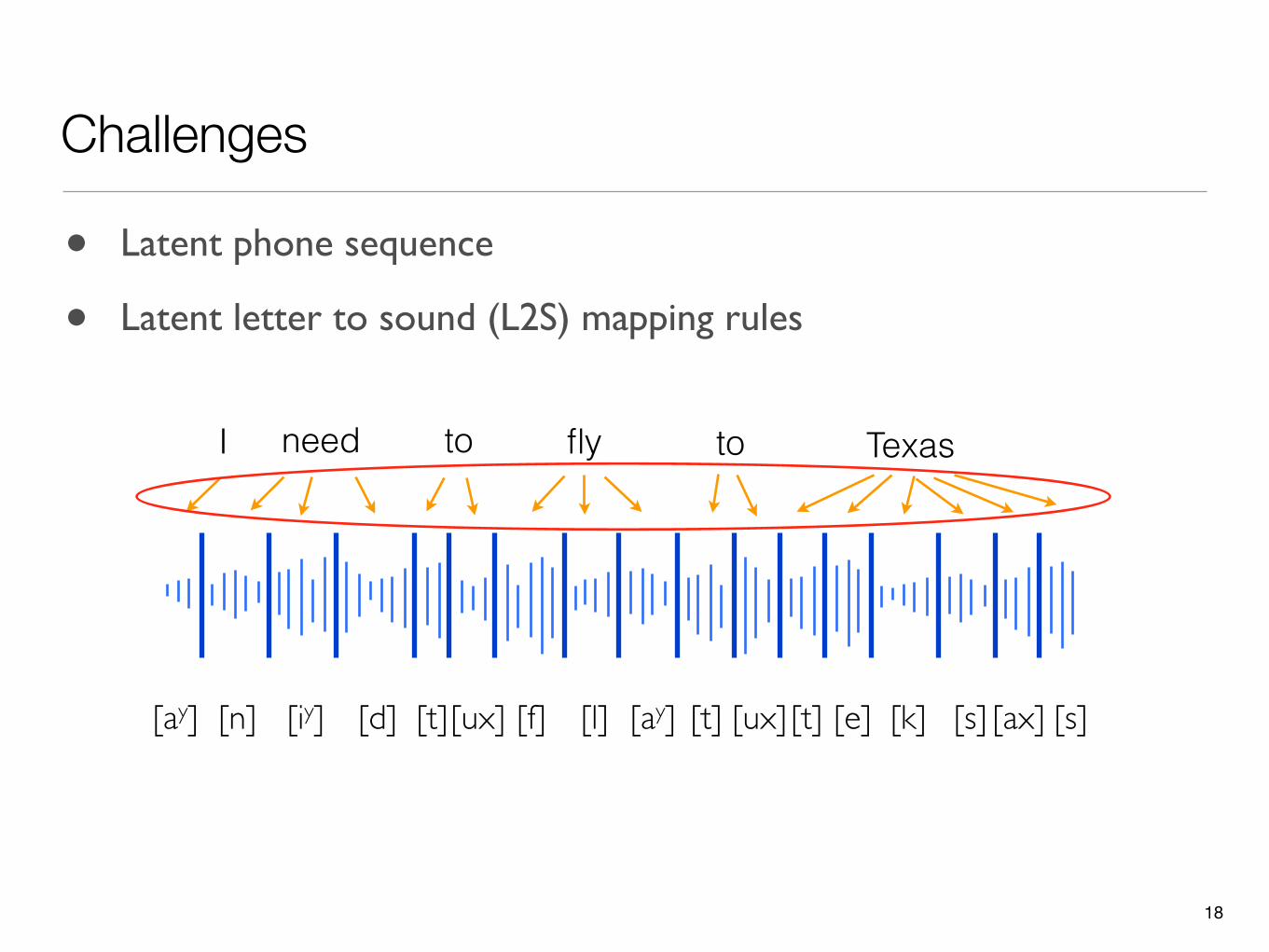
I need to fly to Texas
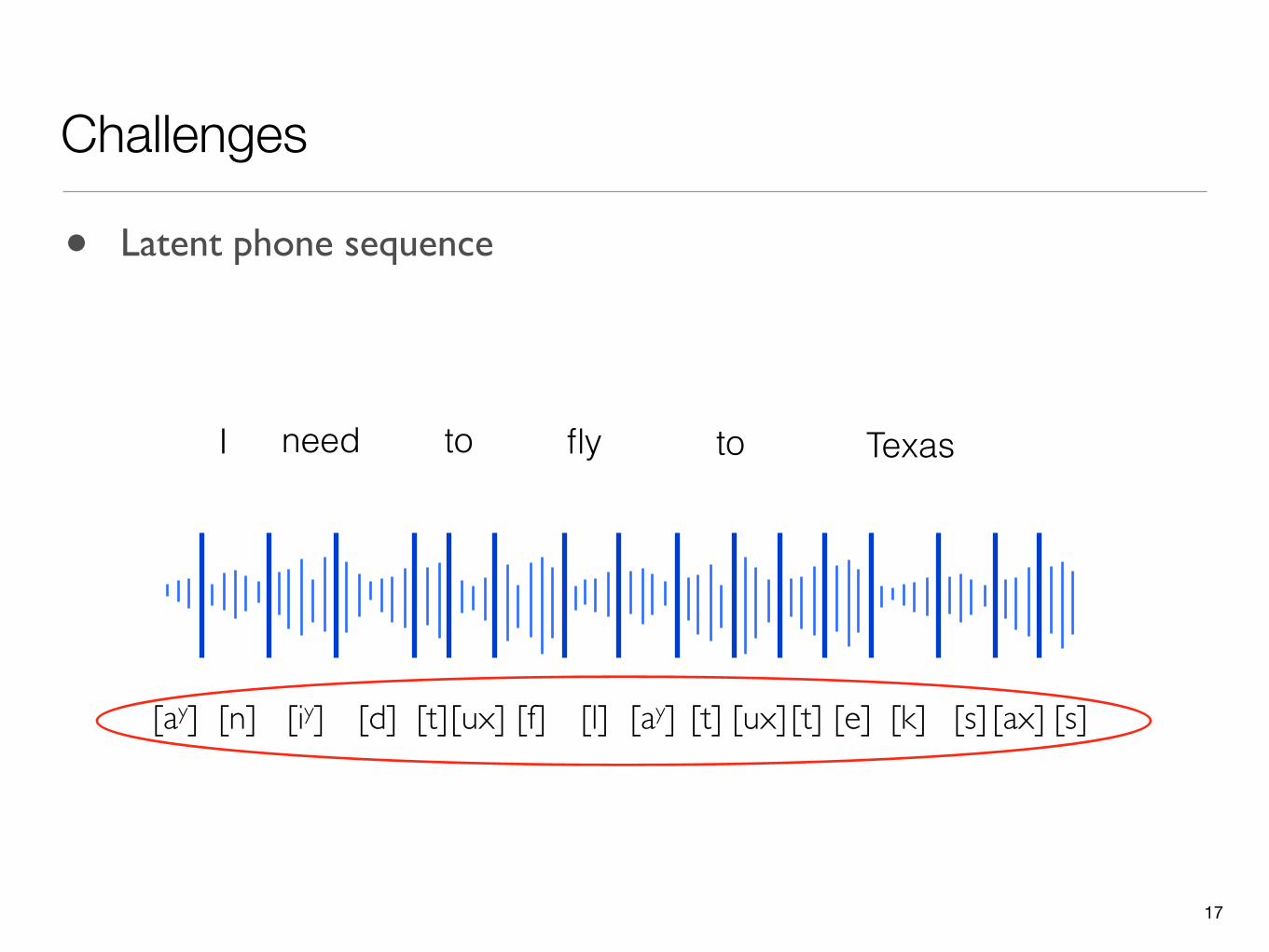
• Latent phone sequence
• Latent letter to sound (L2S) mapping rules
Challenges
Challenges
17
I need to fly to Texas
[n] [iy] [d] [t][ux] [f] [l] [ay] [t] [ux] [t] [e] [k] [s] [ax] [s][ay]
• Latent phone sequence
• Latent letter to sound (L2S) mapping rules
18
I need to fly to Texas
[n] [iy] [d] [t][ux] [f] [l] [ay] [t] [ux] [t] [e] [k] [s] [ax] [s][ay]
• Latent phone sequence
• Latent letter to sound (L2S) mapping rules
Challenges

19
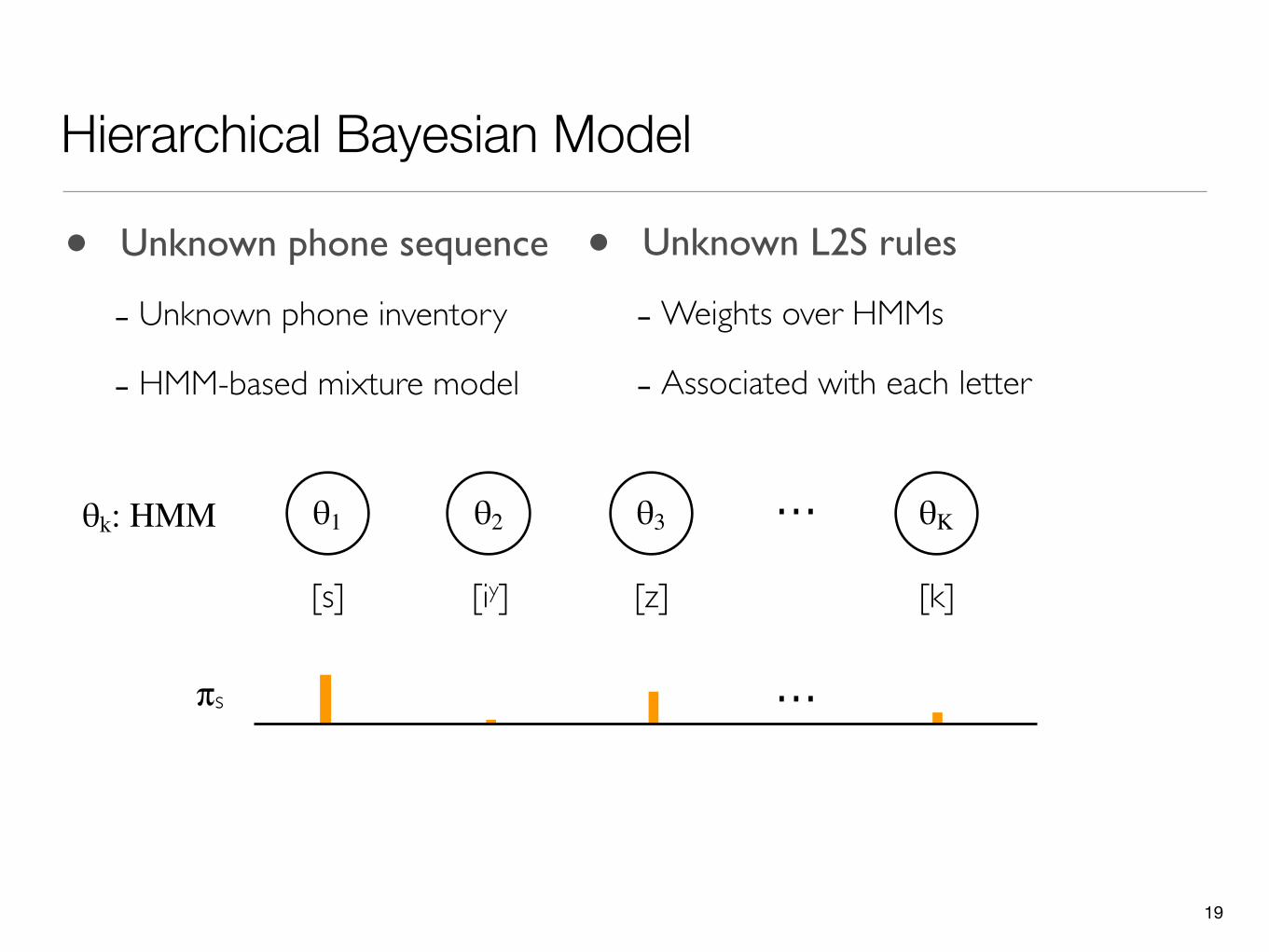
Hierarchical Bayesian Model
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model

19
Hierarchical Bayesian Model
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model

19
Hierarchical Bayesian Model
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model

19
Hierarchical Bayesian Model
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model

19
Hierarchical Bayesian Model
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model
[s] [iy] [z] [k]
θ1 ...θ2 θ3 θKθk: HMM

19
Hierarchical Bayesian Model
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model
[s] [iy] [z] [k]
θ1 ...θ2 θ3 θKθk: HMM

19
Hierarchical Bayesian Model
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model
[s] [iy] [z] [k]
θ1 ...θ2 θ3 θKθk: HMM

19
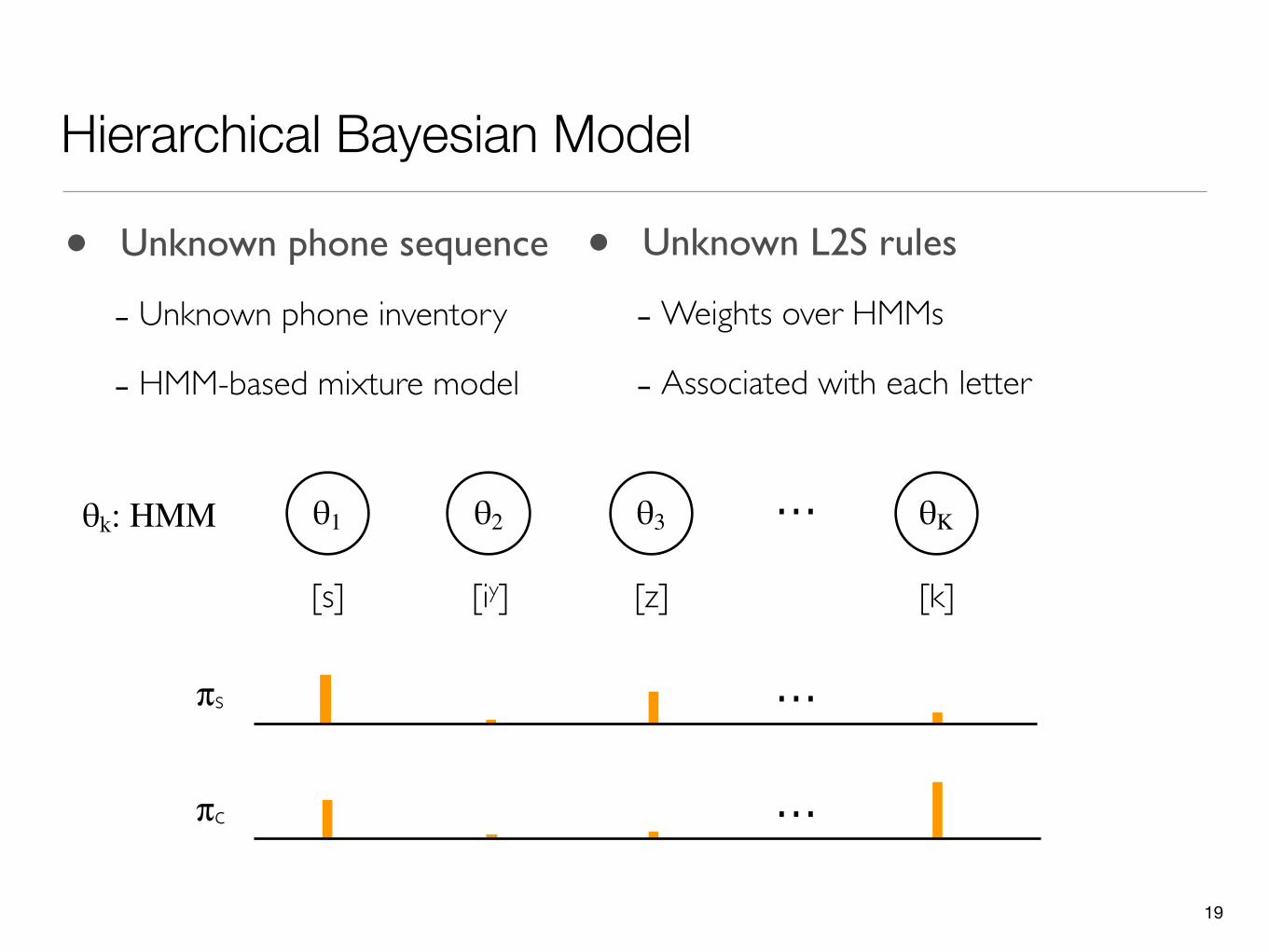
Hierarchical Bayesian Model
πs
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model
[s] [iy] [z] [k]
θ1 ...θ2 θ3 θKθk: HMM
19
Hierarchical Bayesian Model
πs ...
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model
[s] [iy] [z] [k]
θ1 ...θ2 θ3 θKθk: HMM

19
Hierarchical Bayesian Model
πc
πs ...
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model
[s] [iy] [z] [k]
θ1 ...θ2 θ3 θKθk: HMM
19
Hierarchical Bayesian Model
πc ...
πs ...
• Unknown L2S rules
-Weights over HMMs
- Associated with each letter
• Unknown phone sequence
- Unknown phone inventory
- HMM-based mixture model
[s] [iy] [z] [k]
θ1 ...θ2 θ3 θKθk: HMM
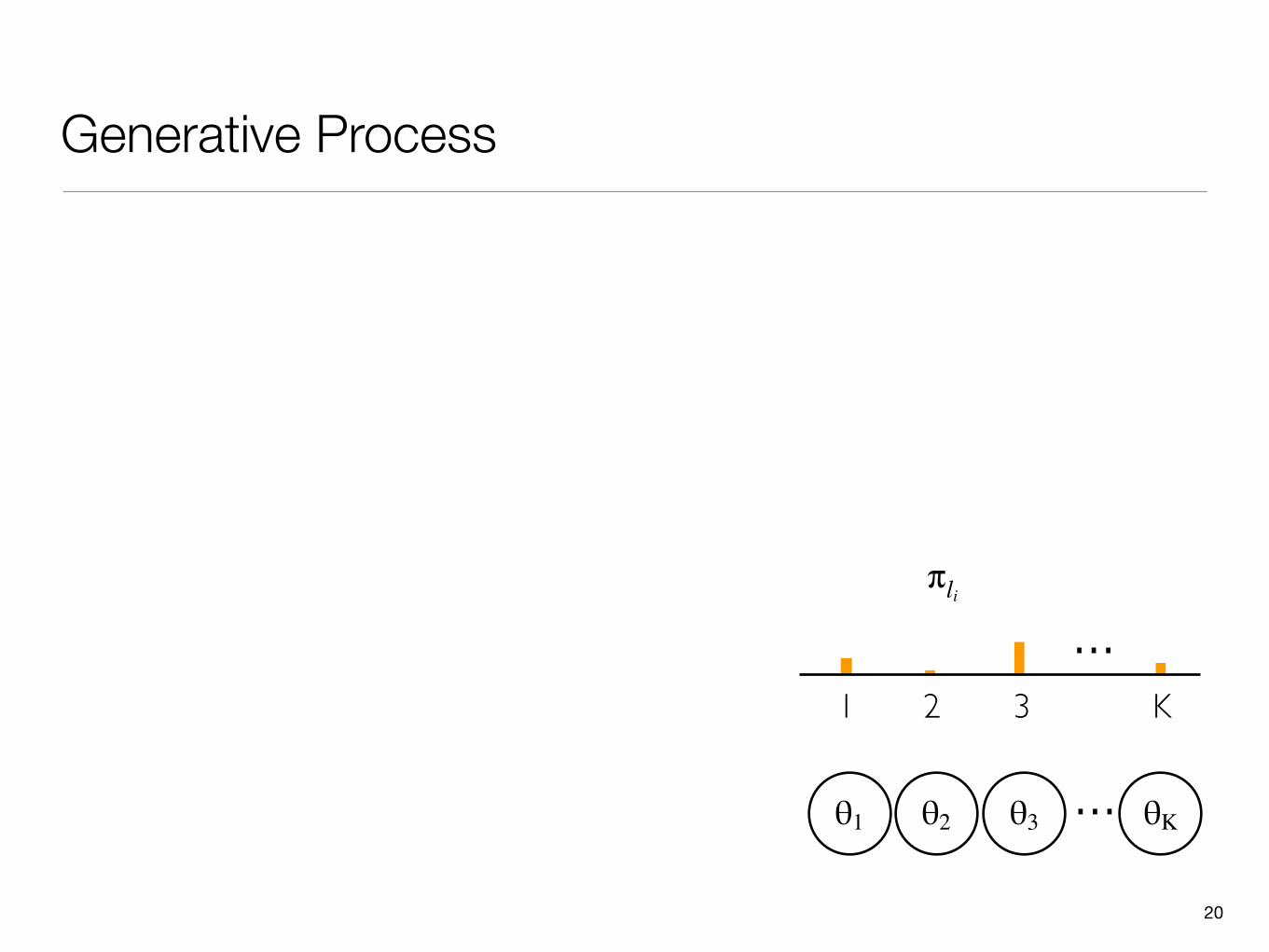
20
Generative Process
θ1 ...θ2 θ3 θK
...1 2 3 K
π li
21
Generative Process
θ1 ...θ2 θ3 θK
li red sox
xt
...1 2 3 K
π li
21
Generative Process
θ1 ...θ2 θ3 θK
li red sox
xt
...1 2 3 K
π li
22
Generative Process
θ1 ...θ2 θ3 θK
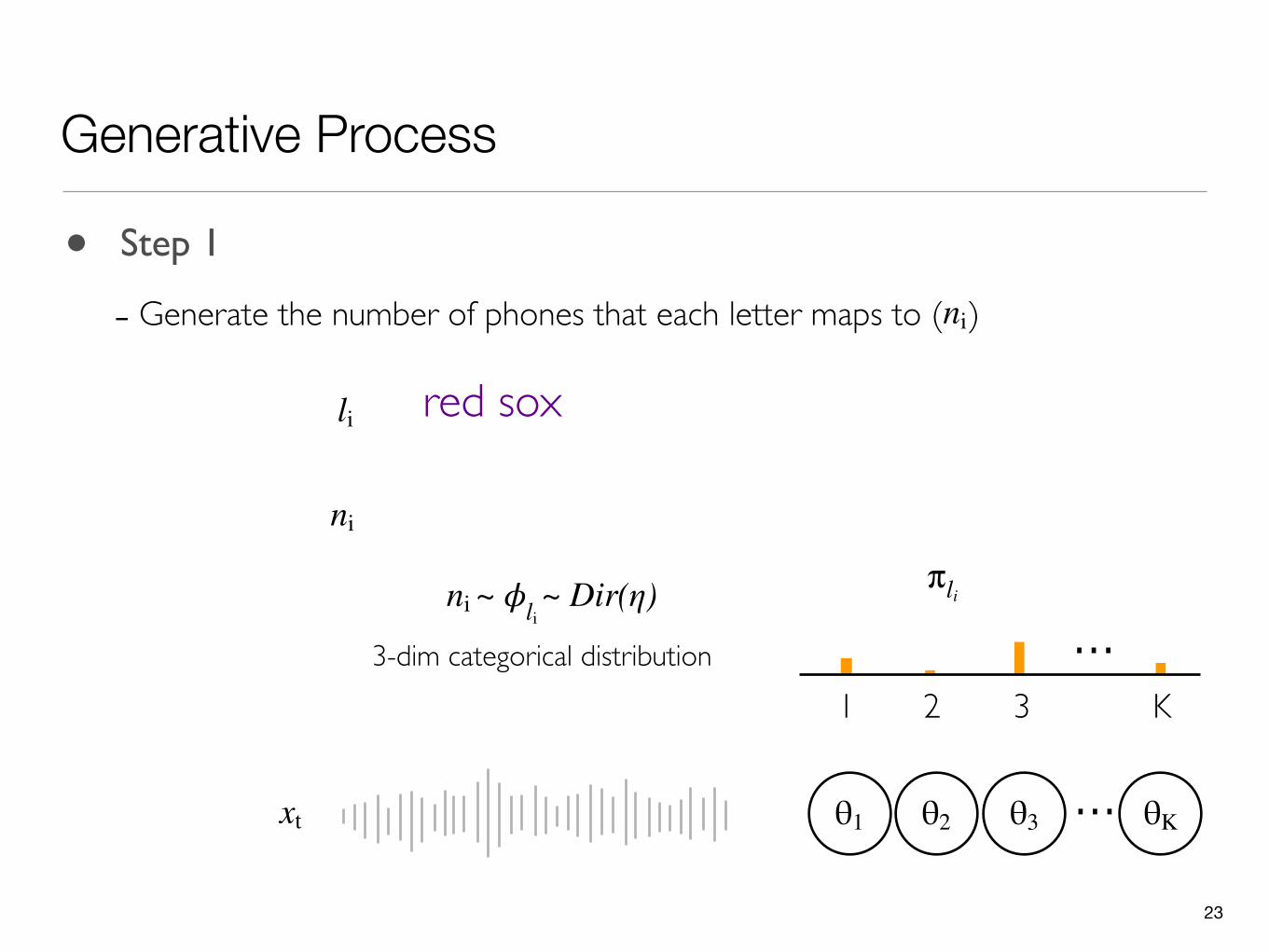
• Step 1
- Generate the number of phones that each letter maps to ( )ni
li red sox
ni
xt
...1 2 3 K
π li
23
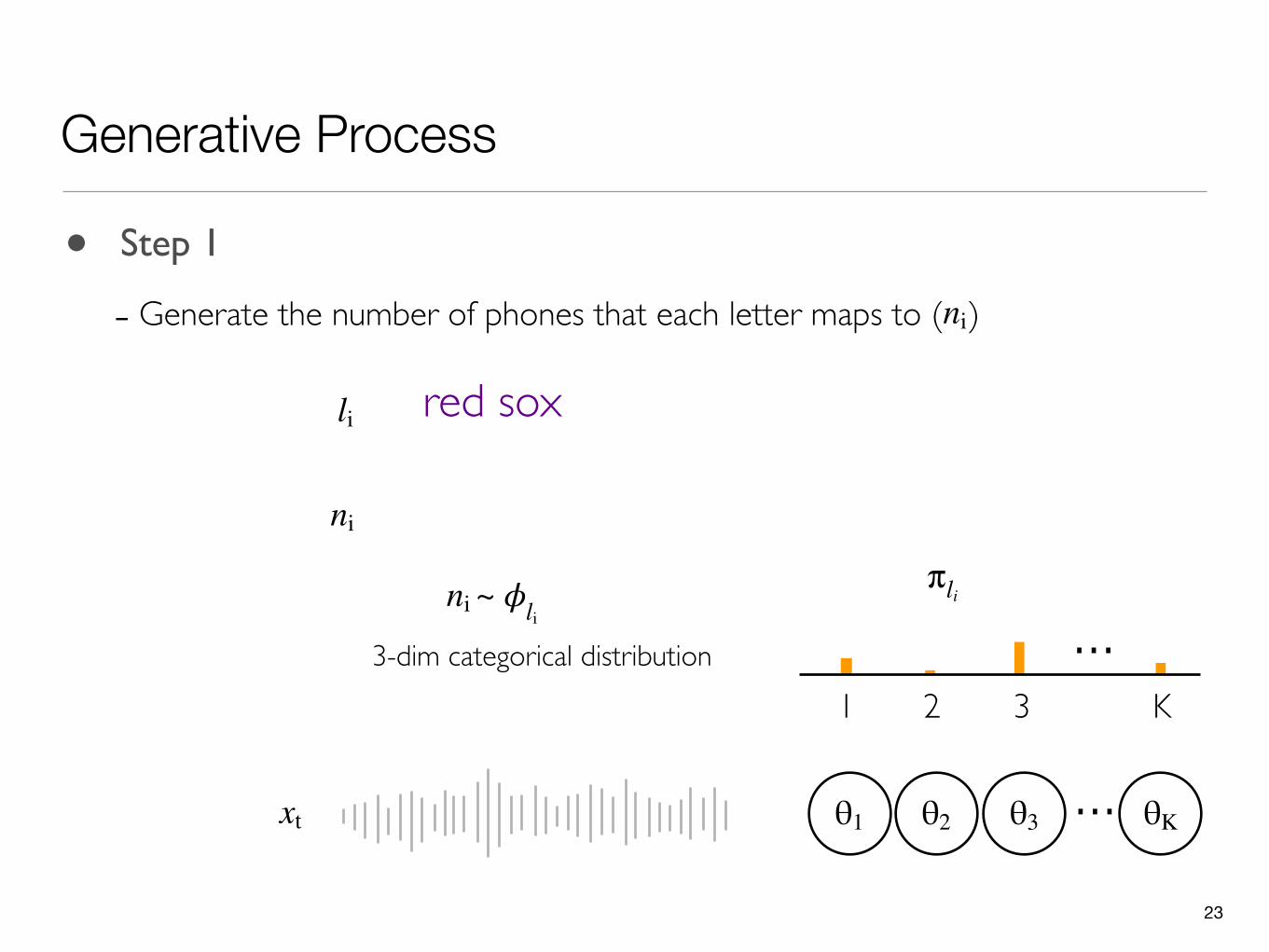
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
ni ~ 𝜙li
li red sox
ni
3-dim categorical distribution
xt
...1 2 3 K
π li
23
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
ni ~ 𝜙li
li red sox
ni
3-dim categorical distribution
xt
~ Dir(η)...
1 2 3 K
π li
24
Generative Process
θ1 ...θ2 θ3 θK
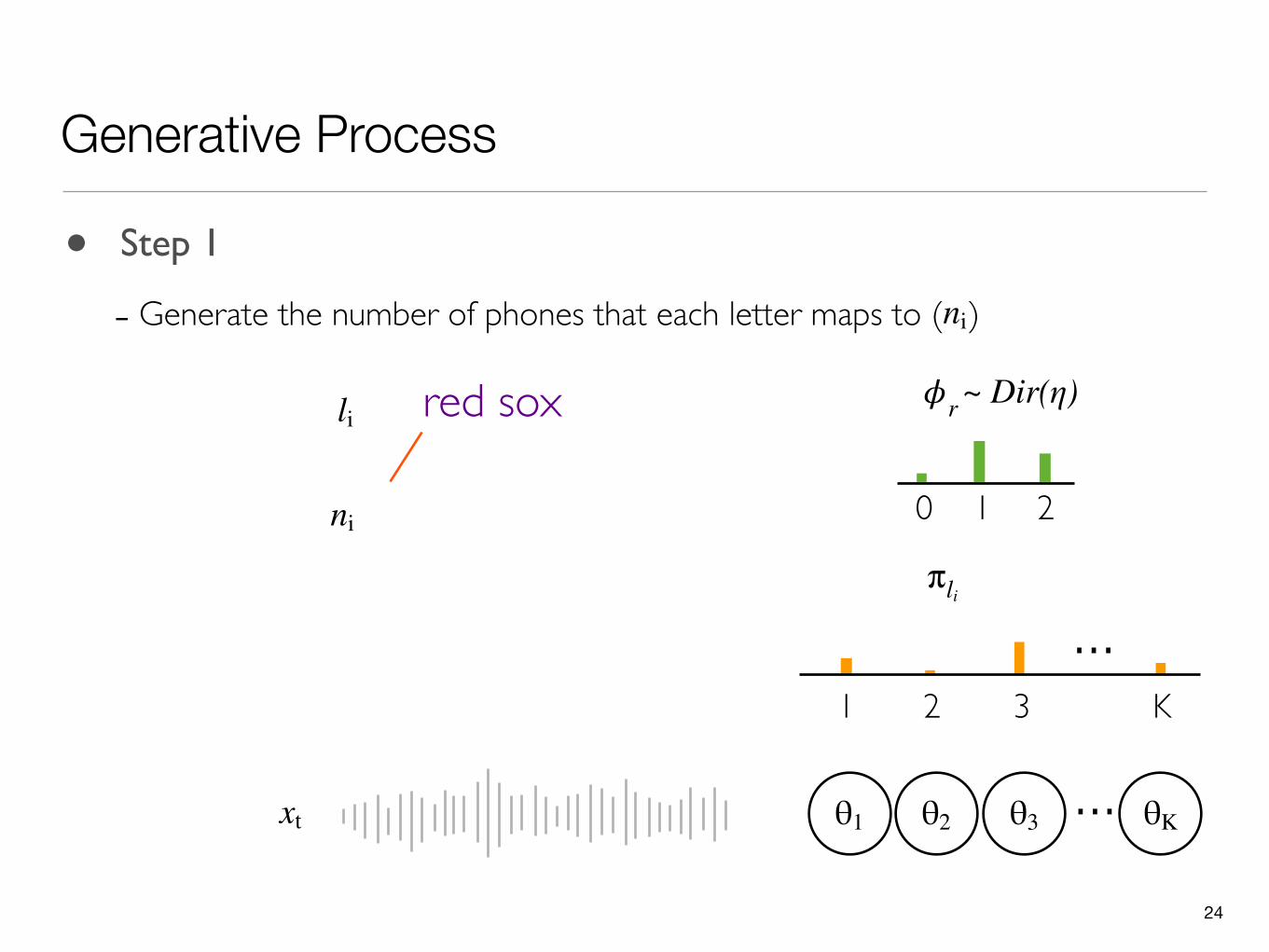
• Step 1
- Generate the number of phones that each letter maps to ( )ni
li red sox
ni 0 1 2
𝜙r
xt
~ Dir(η)
...1 2 3 K
π li

24
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
li red sox
ni 0 1 2
𝜙r
xt
~ Dir(η)
...1 2 3 K
π li
25
Generative Process
θ1 ...θ2 θ3 θK
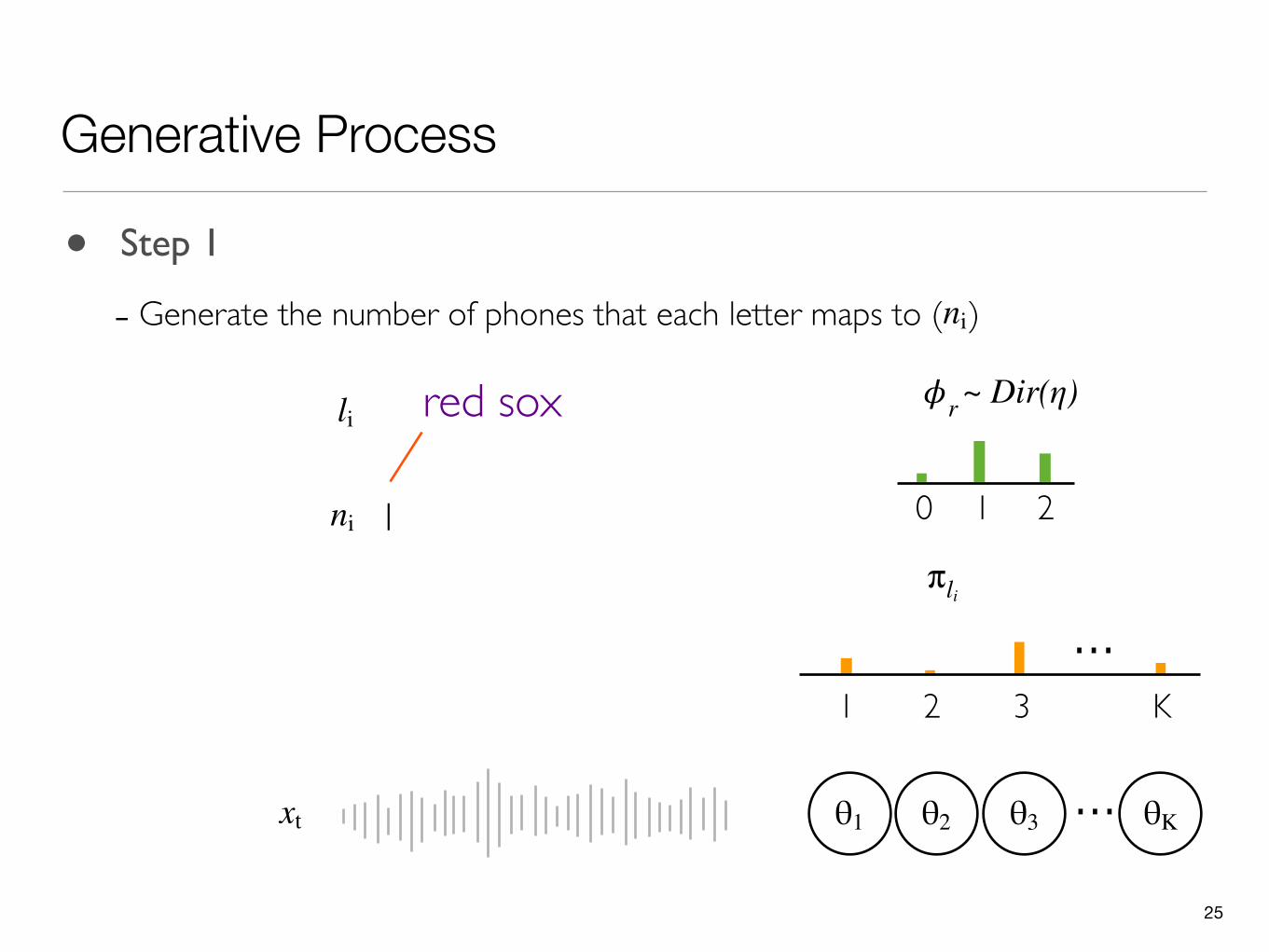
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙rli red sox
1ni
xt
...1 2 3 K
π li
~ Dir(η)
26
Generative Process
θ1 ...θ2 θ3 θK
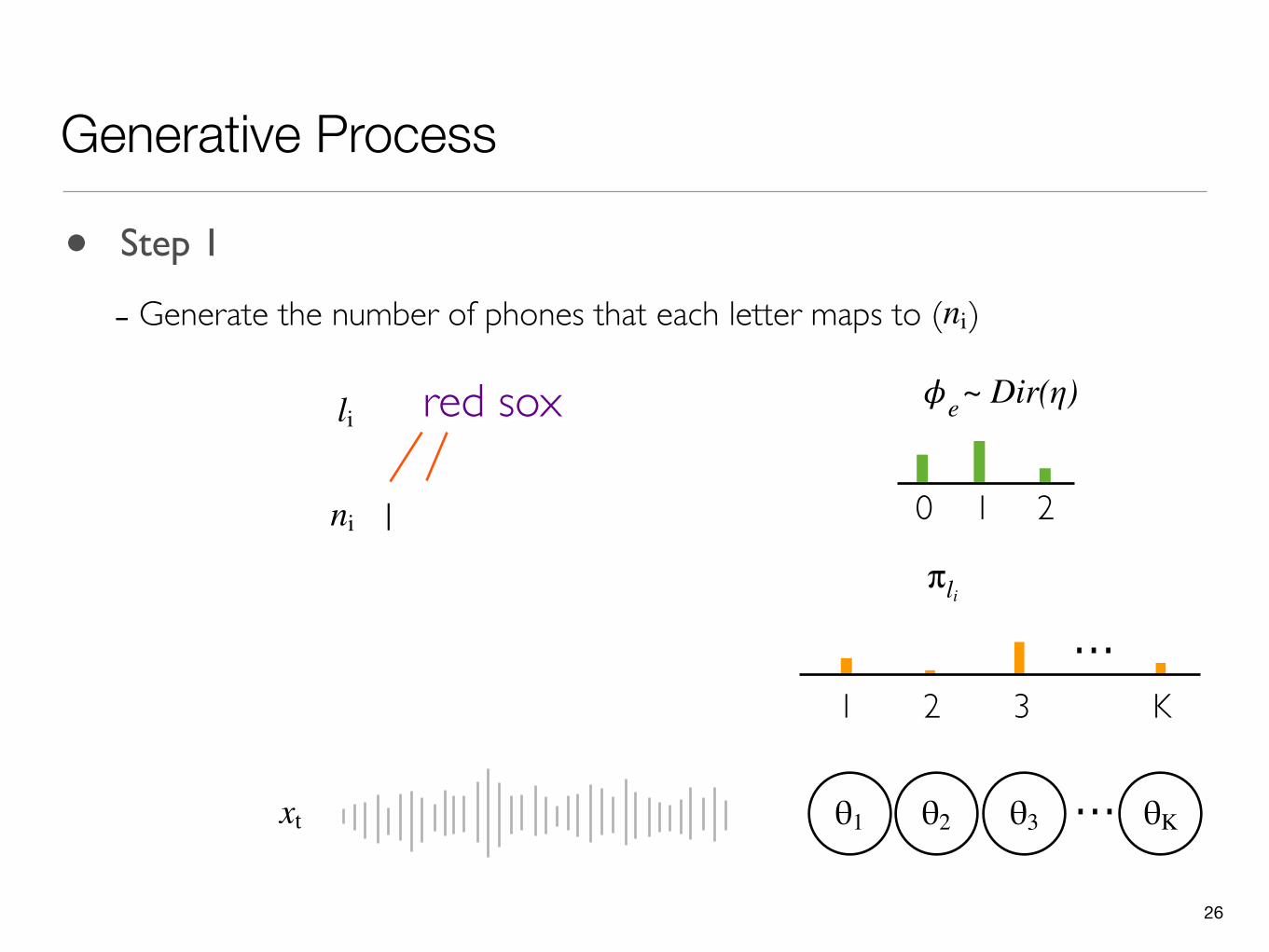
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙eli red sox
1ni
xt
...1 2 3 K
π li
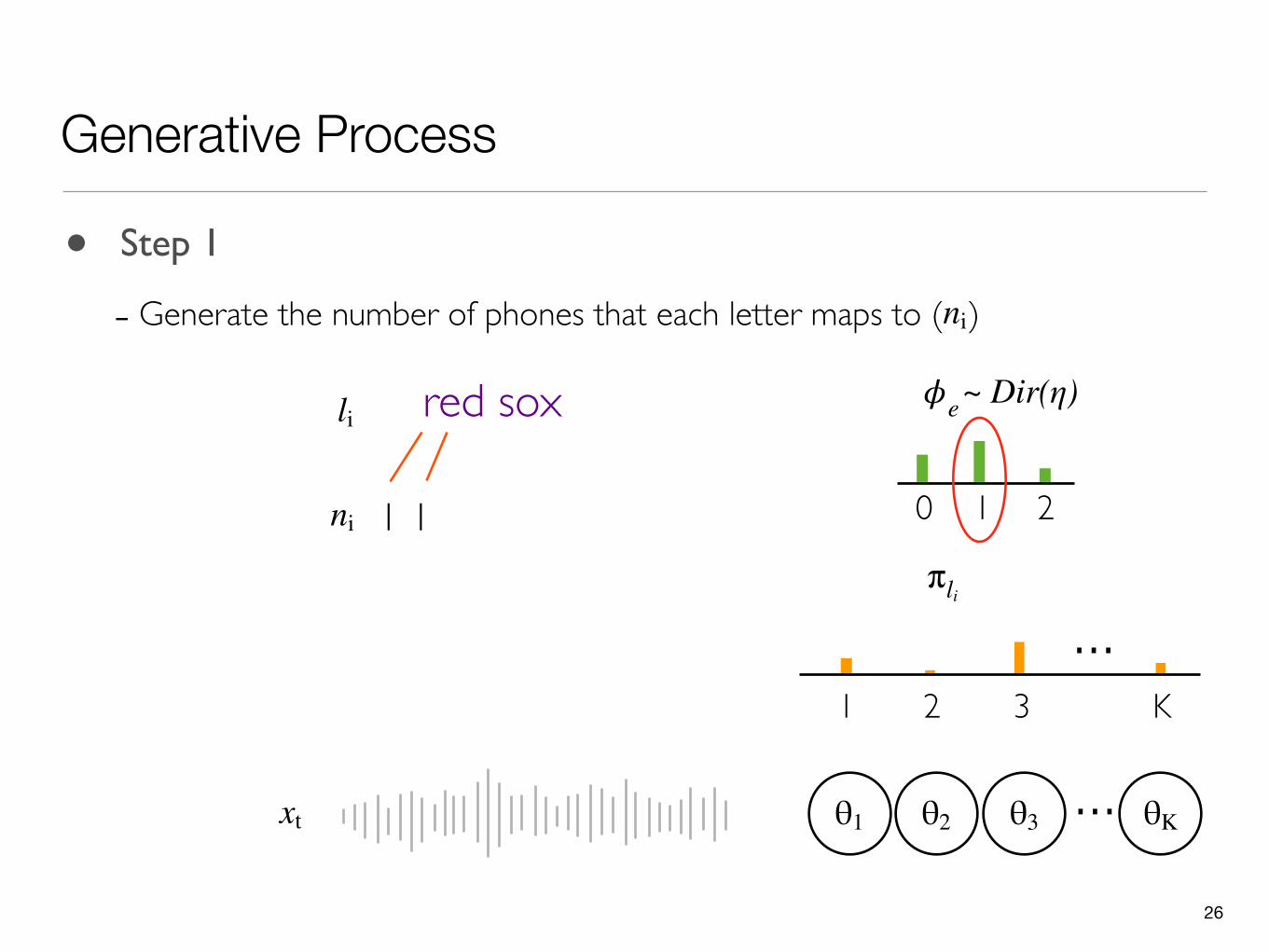
~ Dir(η)
26
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙eli red sox
1ni 1
xt
...1 2 3 K
π li
~ Dir(η)
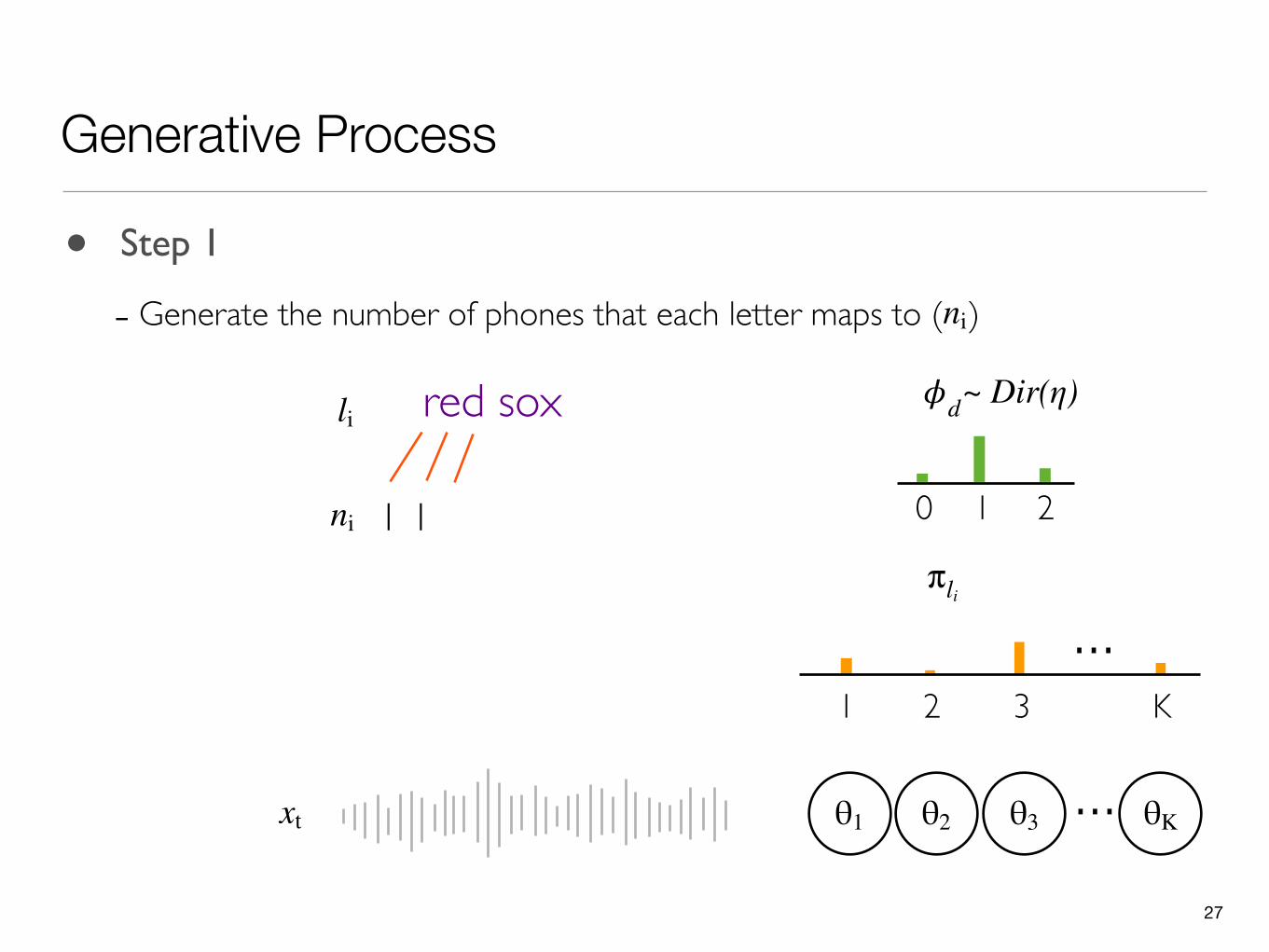
27
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙dli red sox
1 1ni
xt
...1 2 3 K
π li
~ Dir(η)
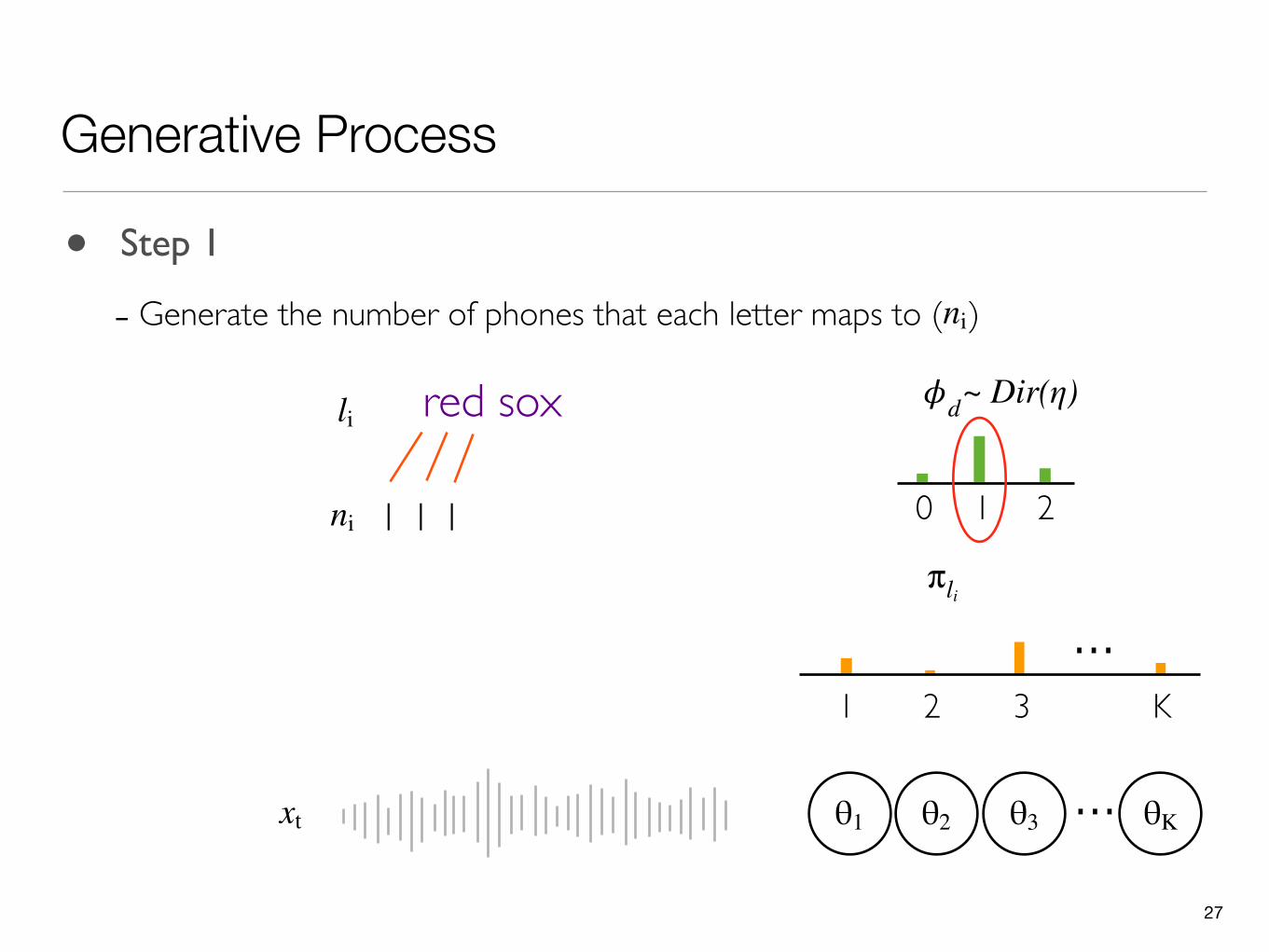
27
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙dli red sox
1 1ni
xt
1
...1 2 3 K
π li
~ Dir(η)
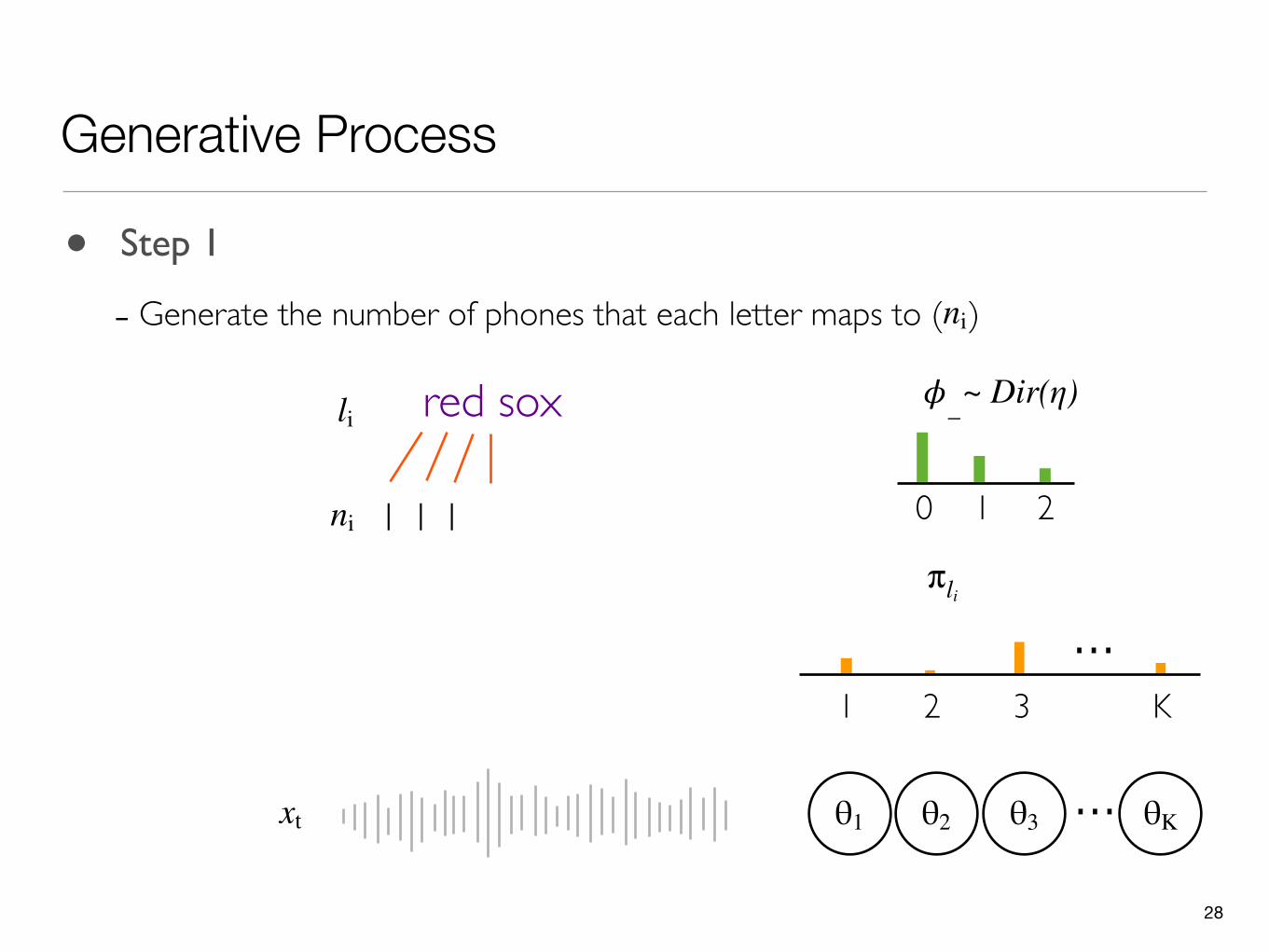
28
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙_li red sox
1 1 1ni
xt
...1 2 3 K
π li
~ Dir(η)
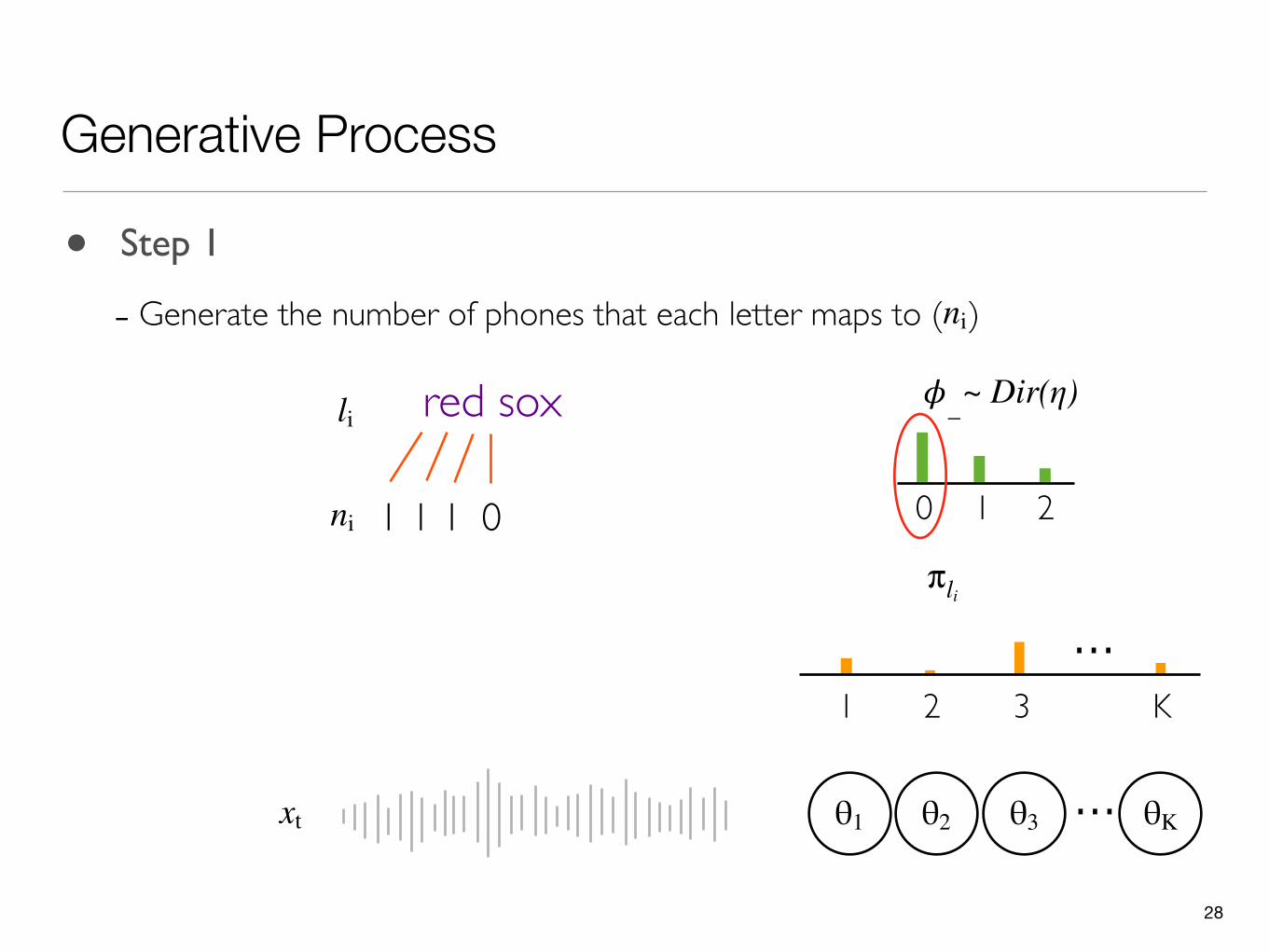
28
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙_li red sox
1 1 1ni
xt
0
...1 2 3 K
π li
~ Dir(η)
29
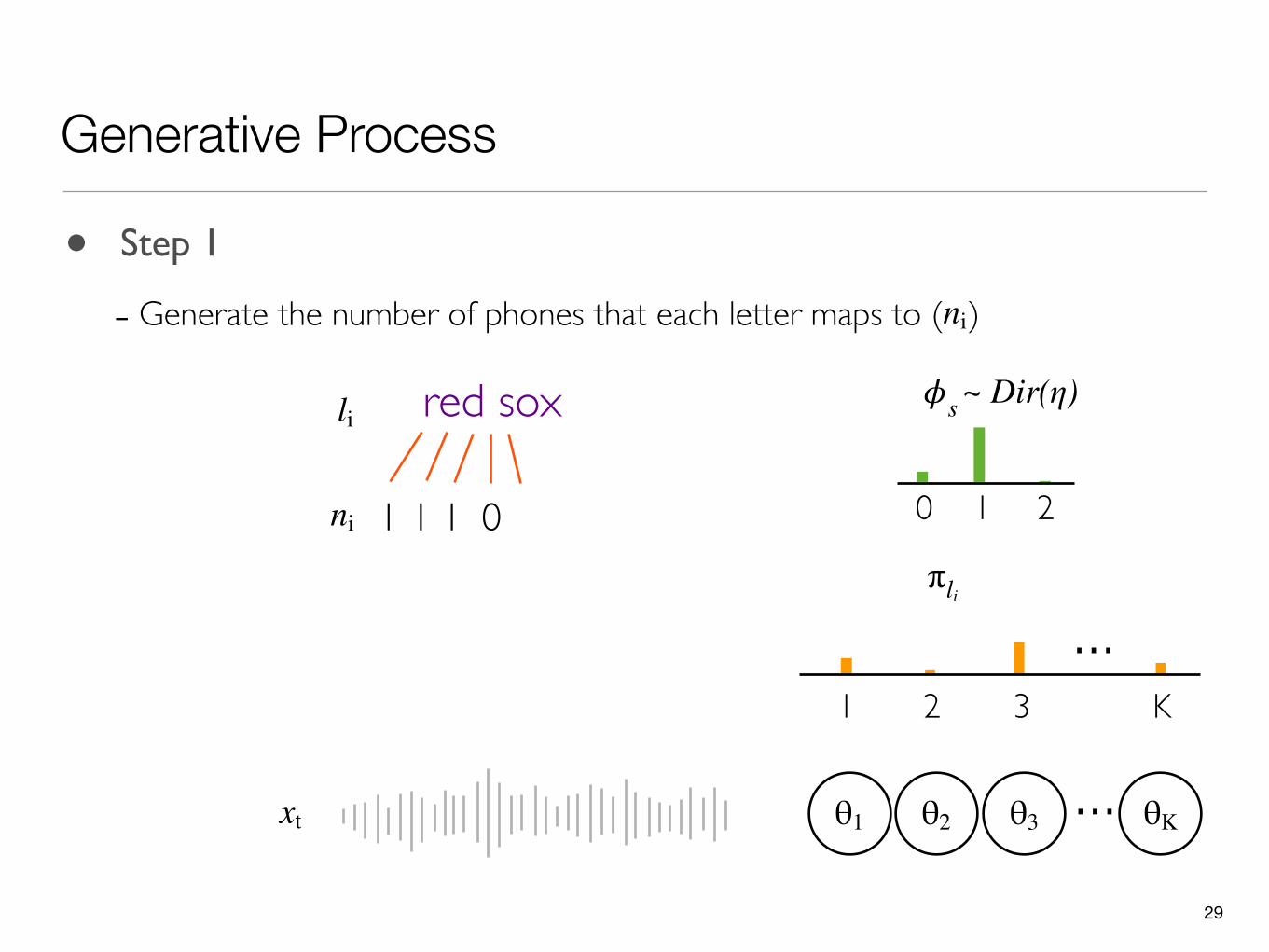
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙sli red sox
1 1 1 0ni
xt
...1 2 3 K
π li
~ Dir(η)
29
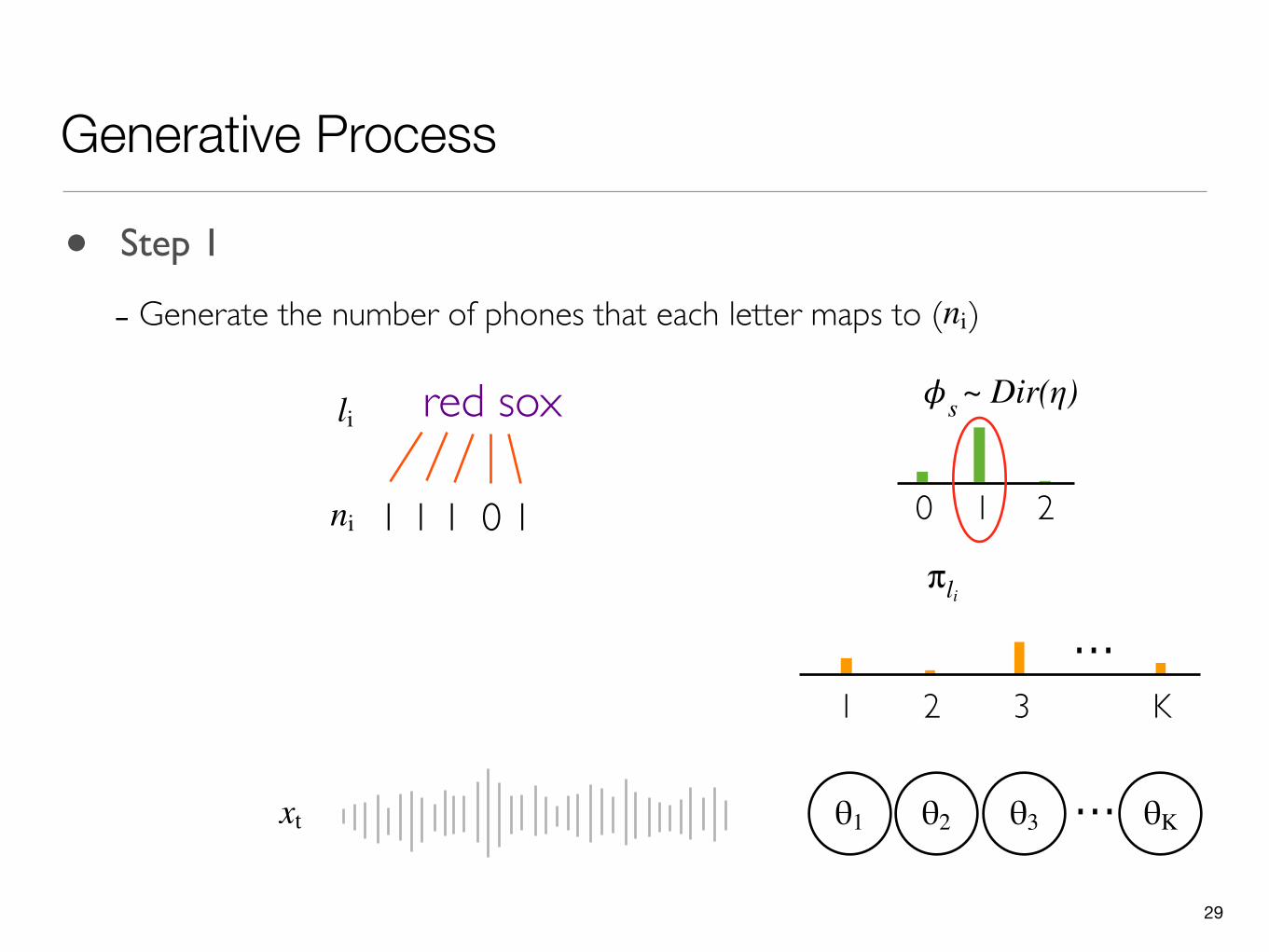
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙sli red sox
1 1 1 0ni
xt
1
...1 2 3 K
π li
~ Dir(η)
30
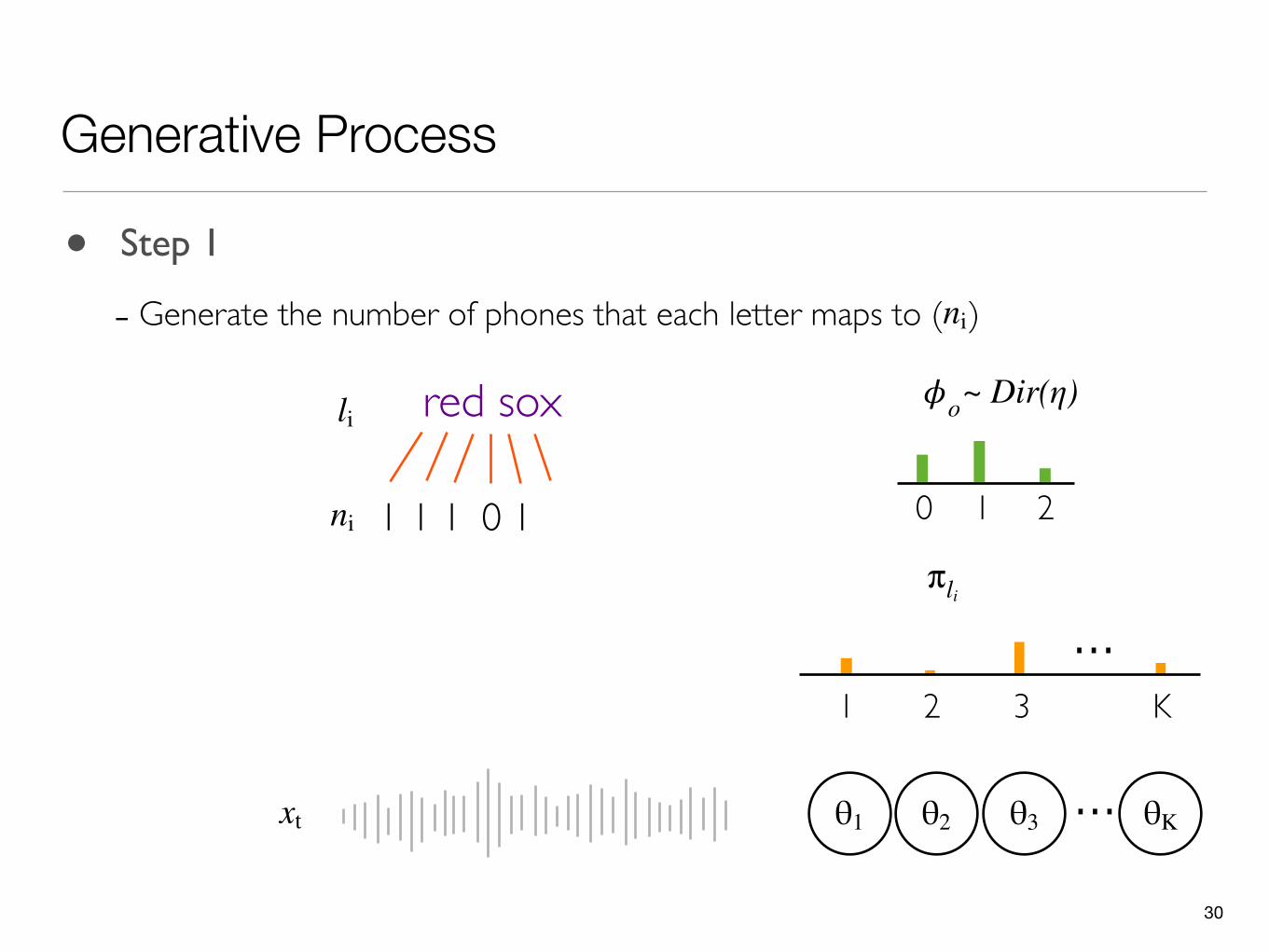
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙oli red sox
11 1 1 0ni
xt
...1 2 3 K
π li
~ Dir(η)
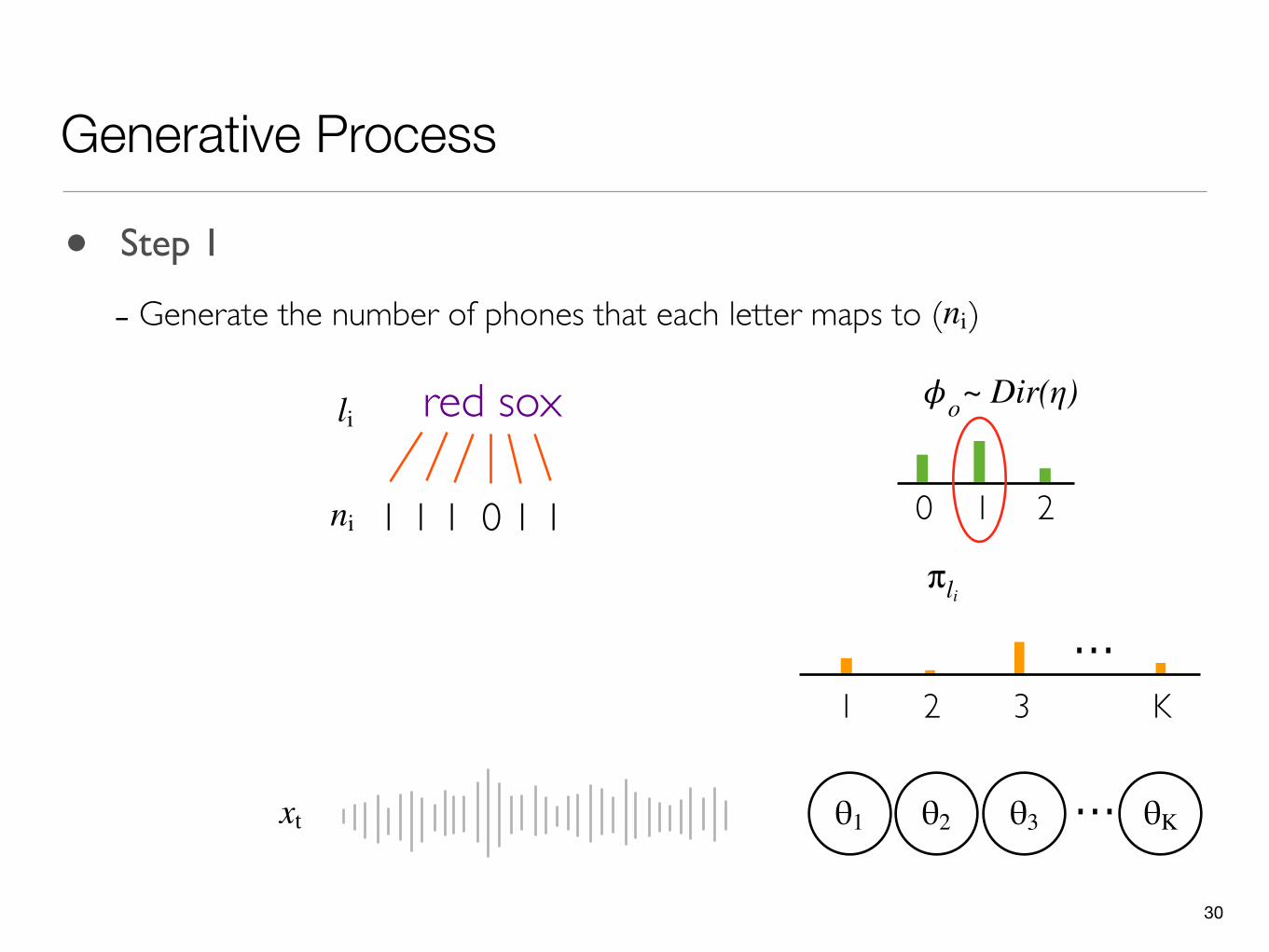
30
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1 2
𝜙oli red sox
11 1 1 0ni
xt
1
...1 2 3 K
π li
~ Dir(η)
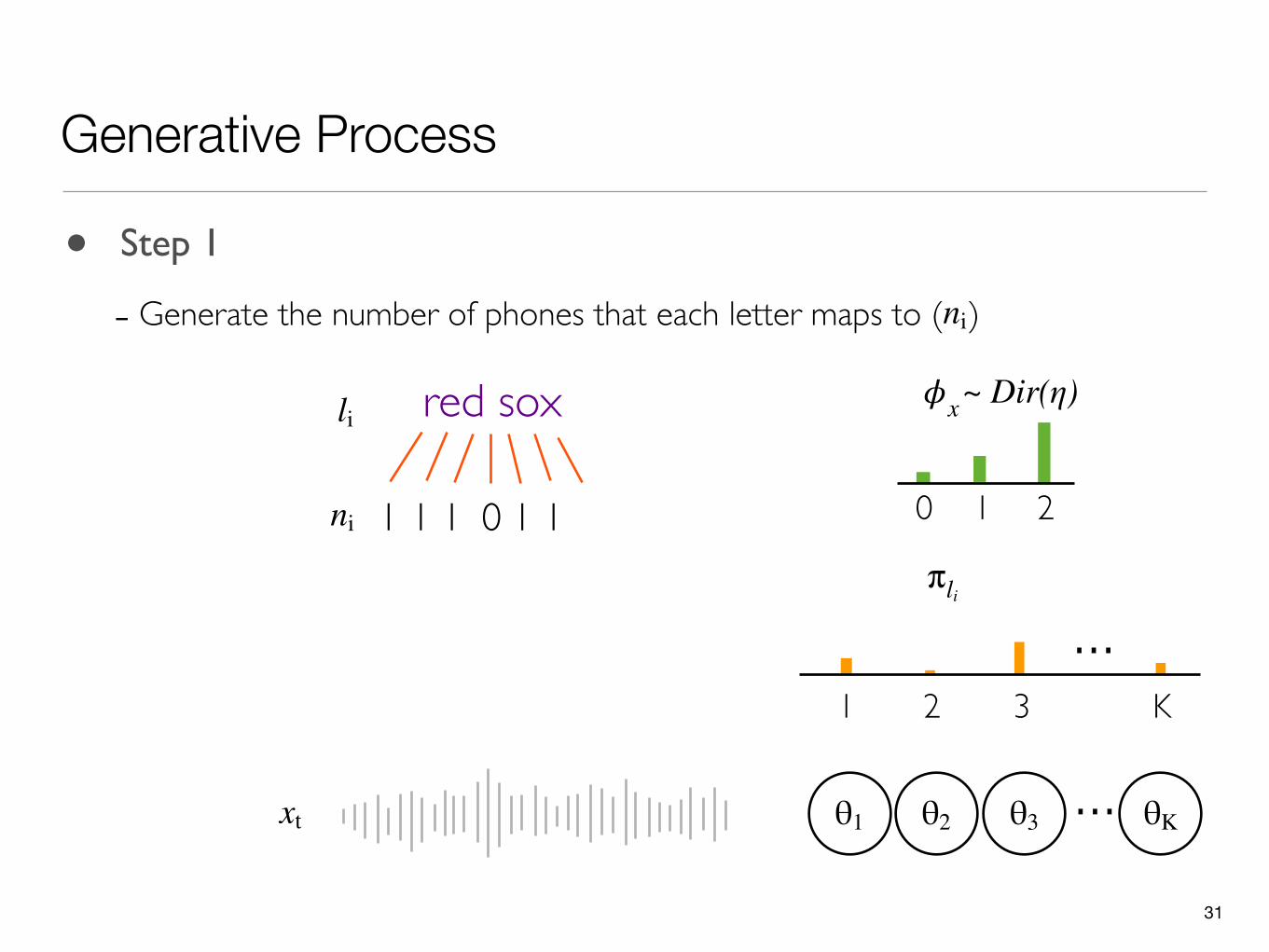
31
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1
𝜙xli red sox
211 1 1 0 1ni
xt
...1 2 3 K
π li
~ Dir(η)
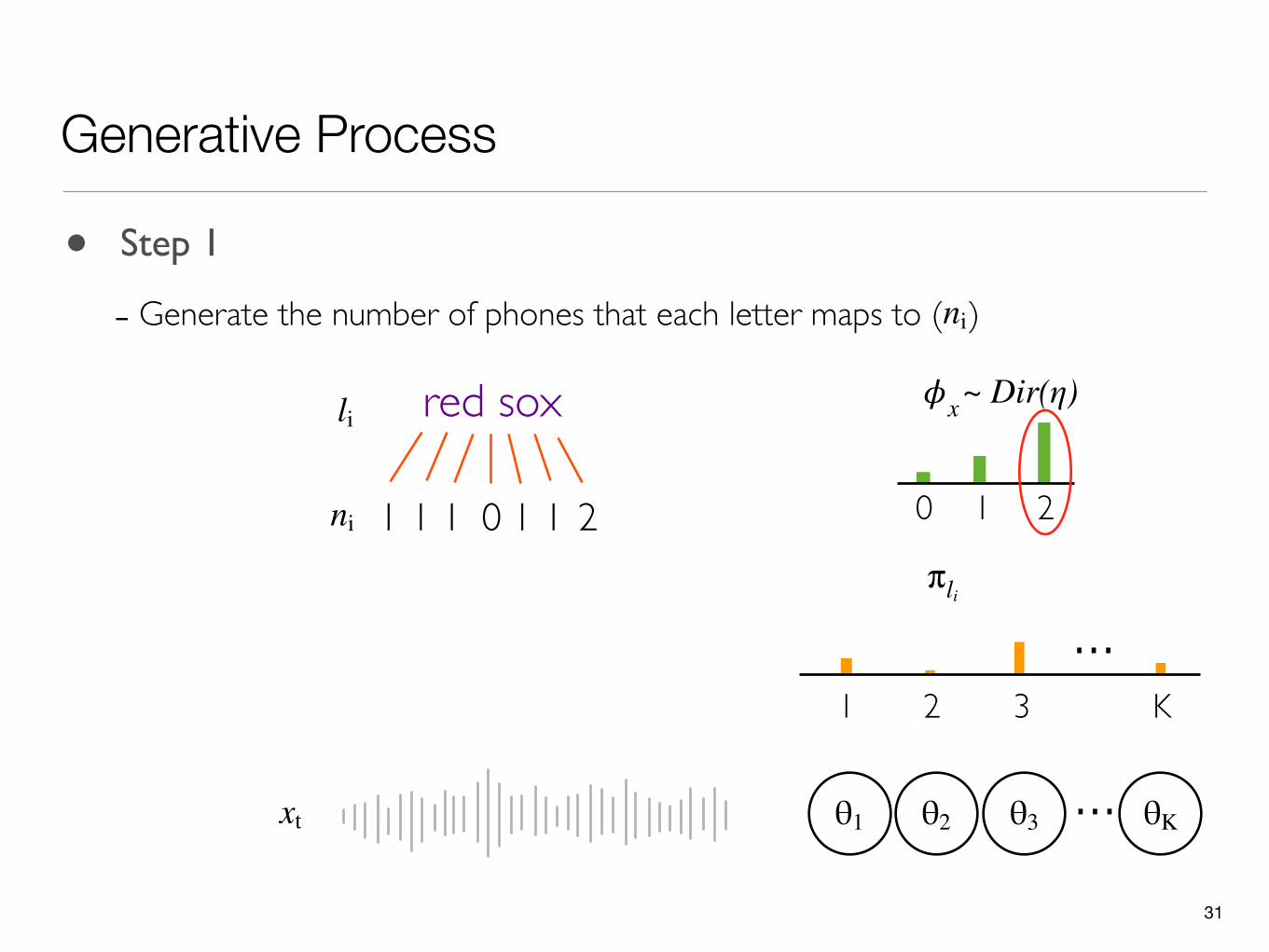
31
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1
𝜙xli red sox
211 1 1 0 1ni
xt
2
...1 2 3 K
π li
~ Dir(η)
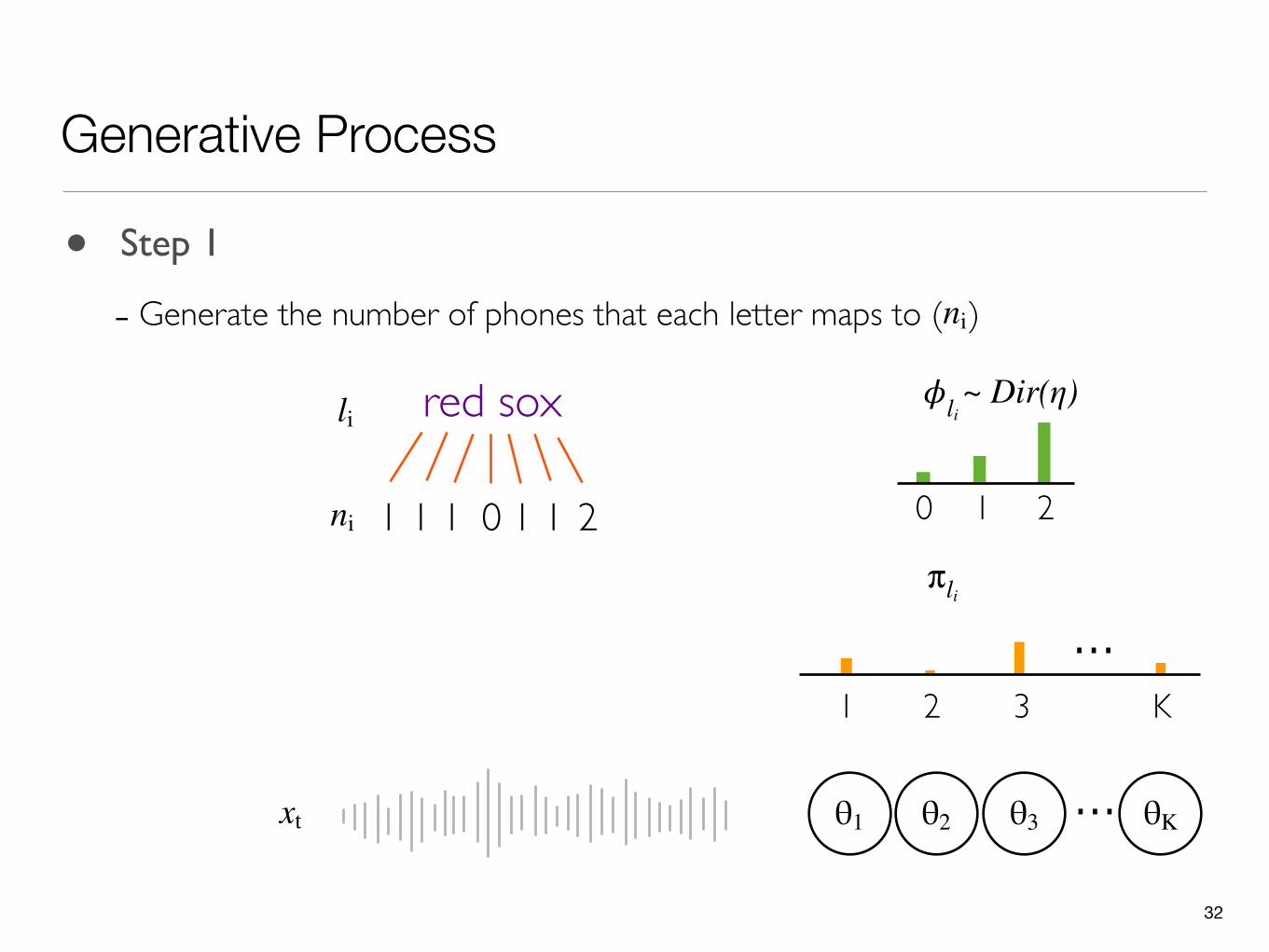
32
Generative Process
θ1 ...θ2 θ3 θK
• Step 1
- Generate the number of phones that each letter maps to ( )ni
0 1
𝜙li red sox
211 1 1 0 1ni
xt
2
...1 2 3 K
π li
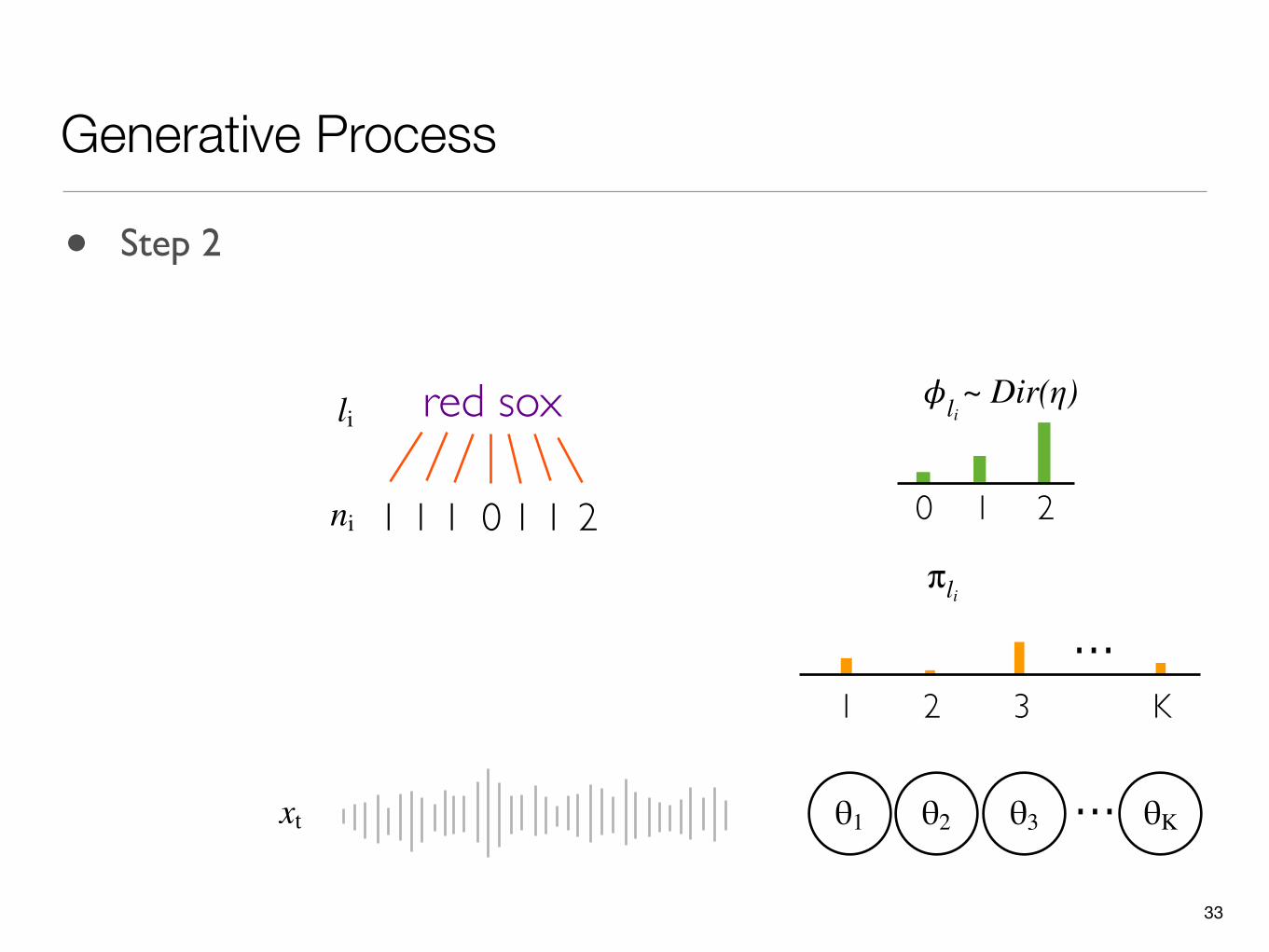
~ Dir(η)li
33
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
li red sox
211 1 1 0 1ni
xt
~ Dir(η)𝜙li
...1 2 3 K
π li
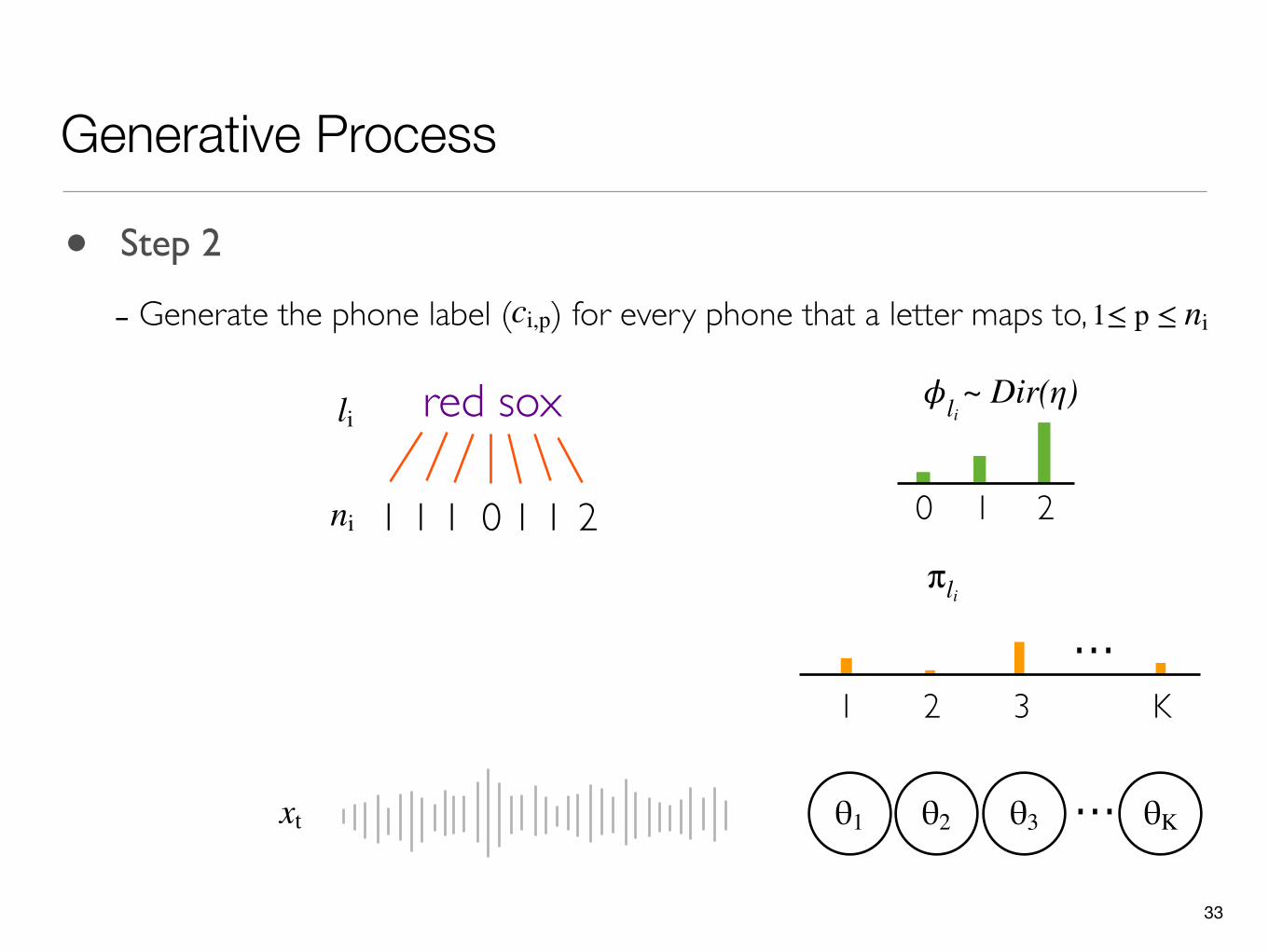
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
33
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
li red sox
211 1 1 0 1ni
xt
~ Dir(η)𝜙li
...1 2 3 K
π li
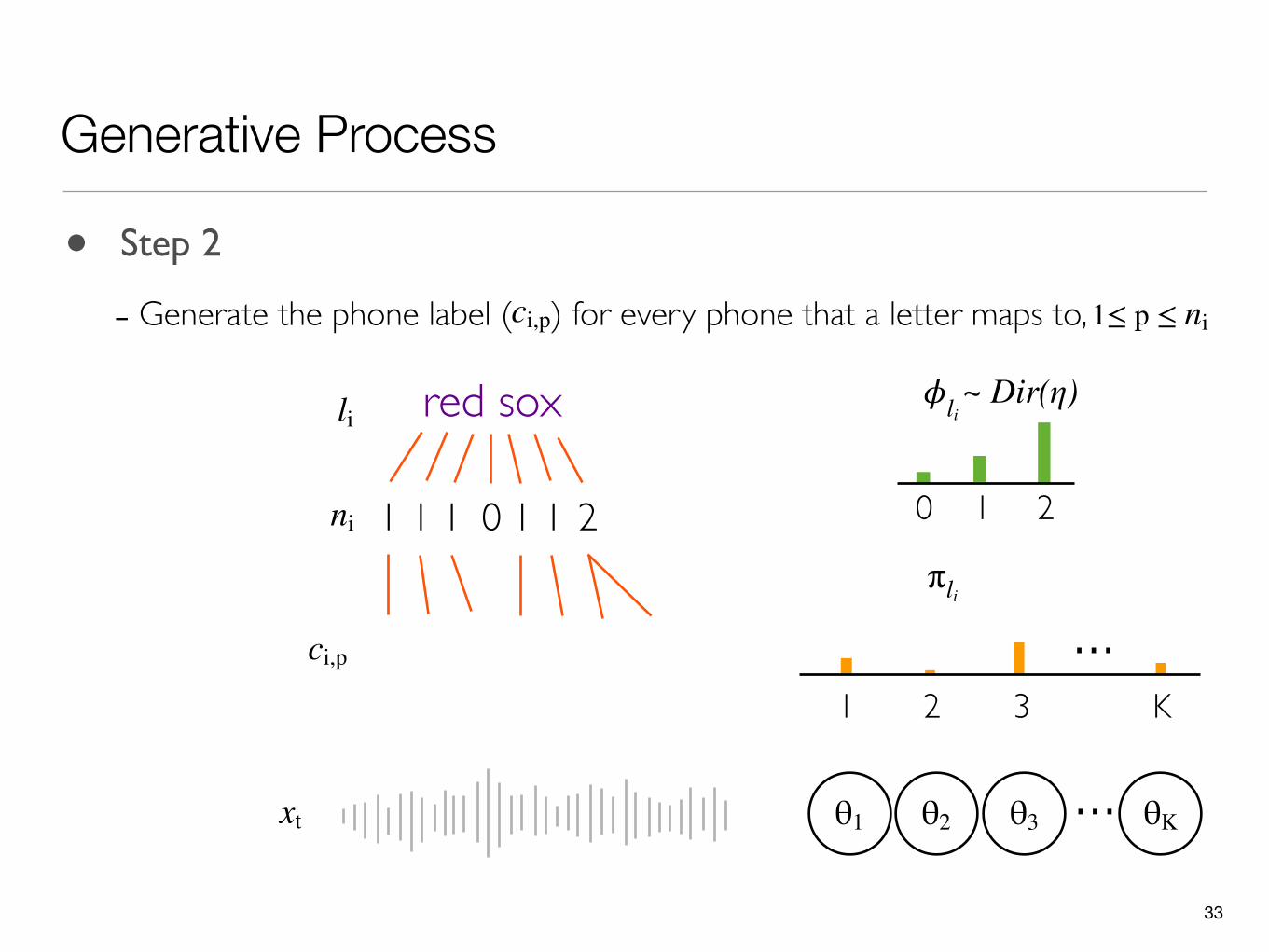
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
33
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
li red sox
211 1 1 0 1ni
xt
ci,p
~ Dir(η)𝜙li
...1 2 3 K
π li
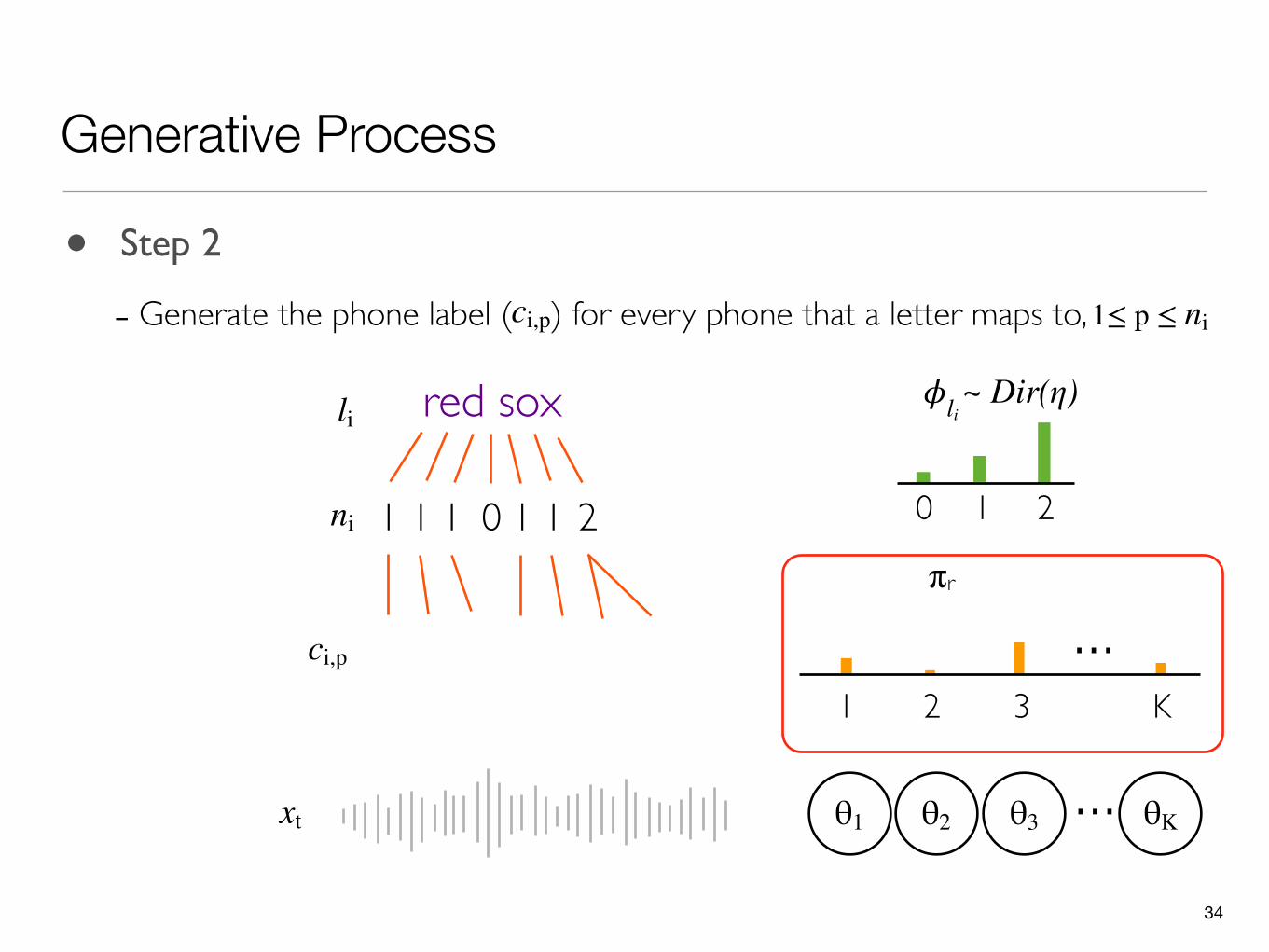
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
34
Generative Process
θ1 ...θ2 θ3 θK
2
xt
0 1
li red sox
211 1 1 0 1ni
ci,p
~ Dir(η)𝜙li
...1 2 3 K
πr
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
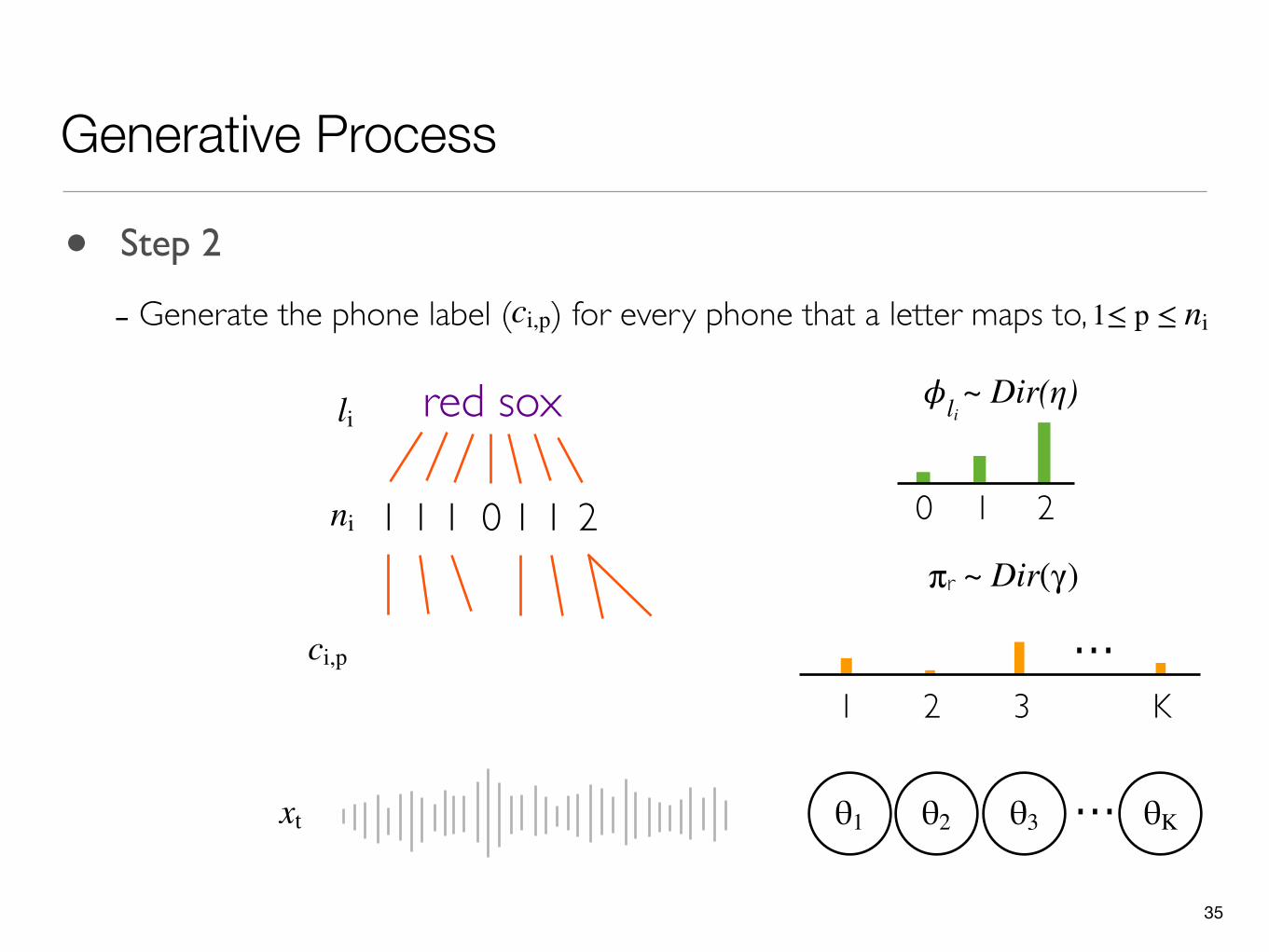
35
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
πr
...1 2 3 K
li red sox
211 1 1 0 1ni
ci,p
xt
~ Dir(η)𝜙li
~ Dir(γ)
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
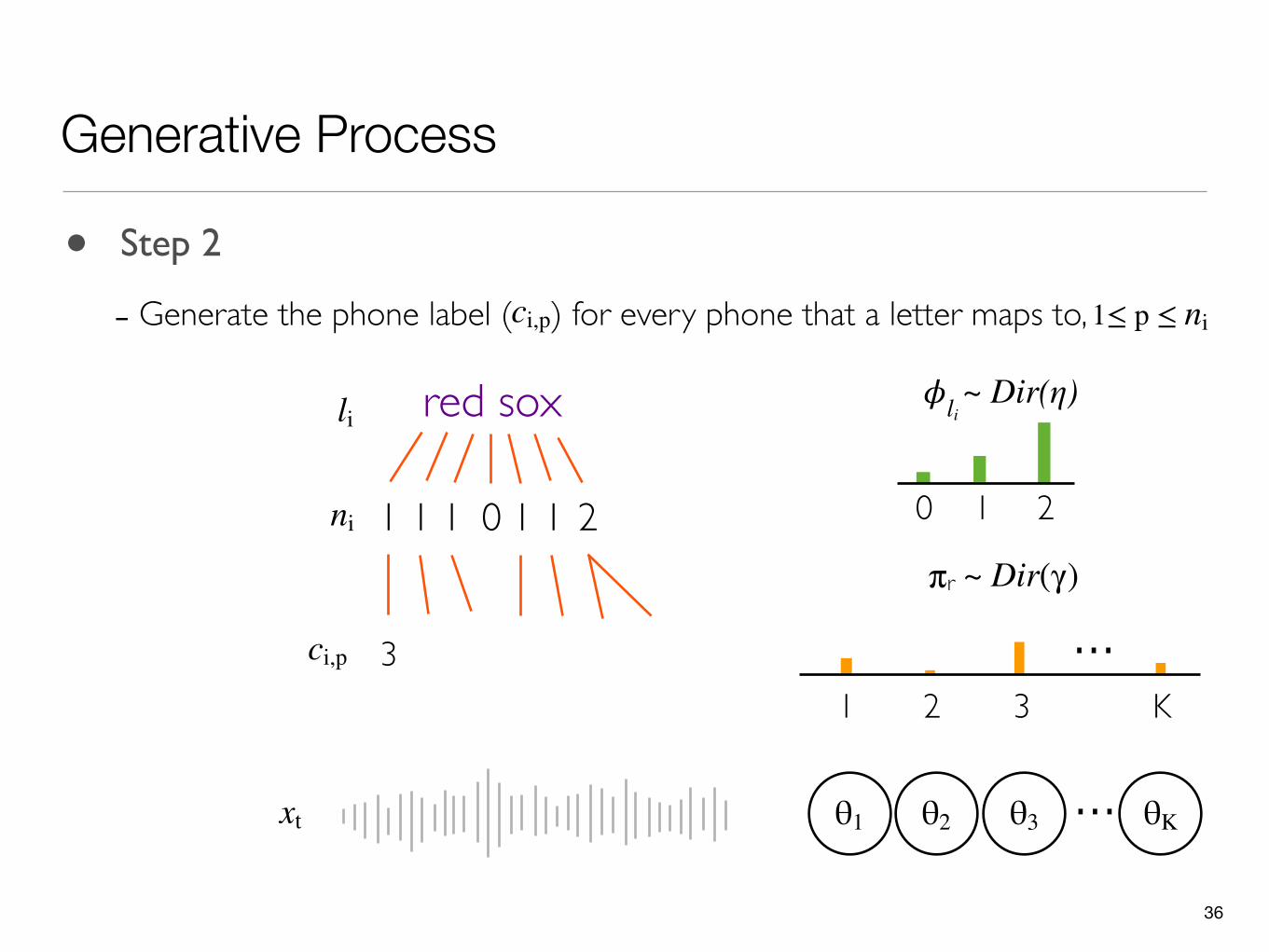
36
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
πr
...1 2 3 K
li red sox
211 1 1 0 1ni
3ci,p
xt
~ Dir(η)𝜙li
~ Dir(γ)
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
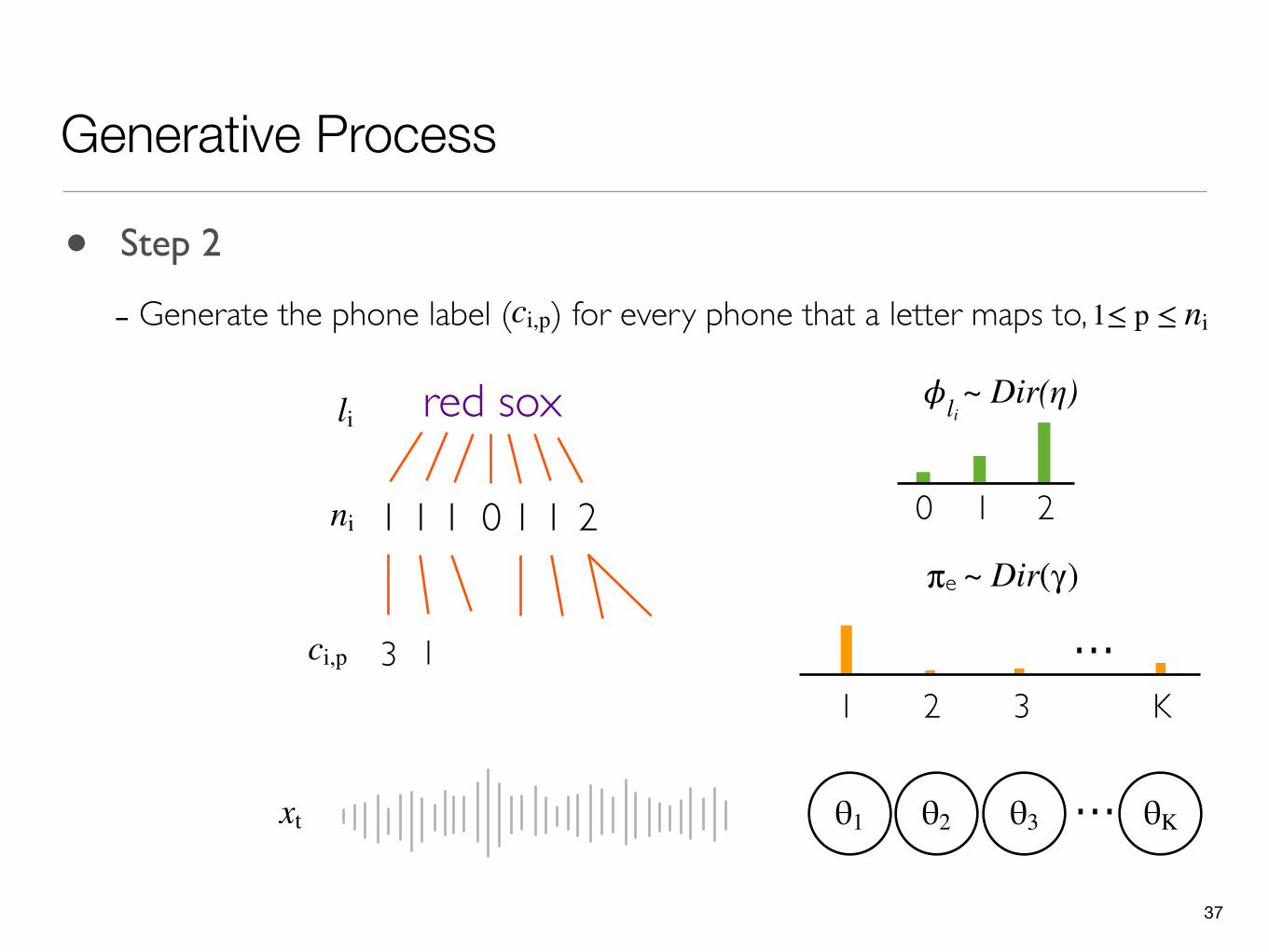
37
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
πe
...1 2 3 K
li red sox
211 1 1 0 1ni
3 1ci,p
xt
~ Dir(η)𝜙li
~ Dir(γ)
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
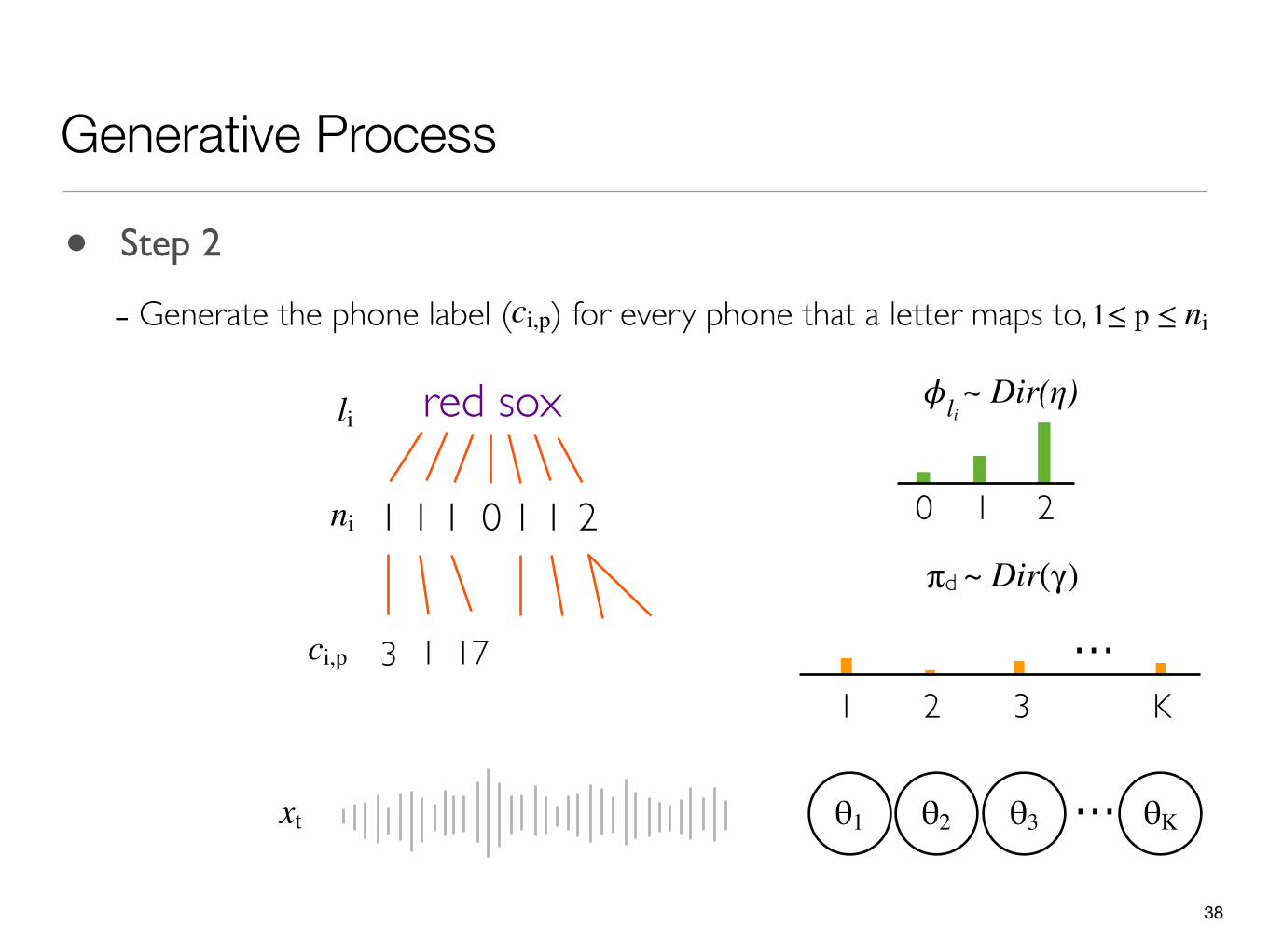
38
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
πd
...1 2 3 K
li red sox
211 1 1 0 1ni
3 1 17ci,p
xt
~ Dir(η)𝜙li
~ Dir(γ)
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
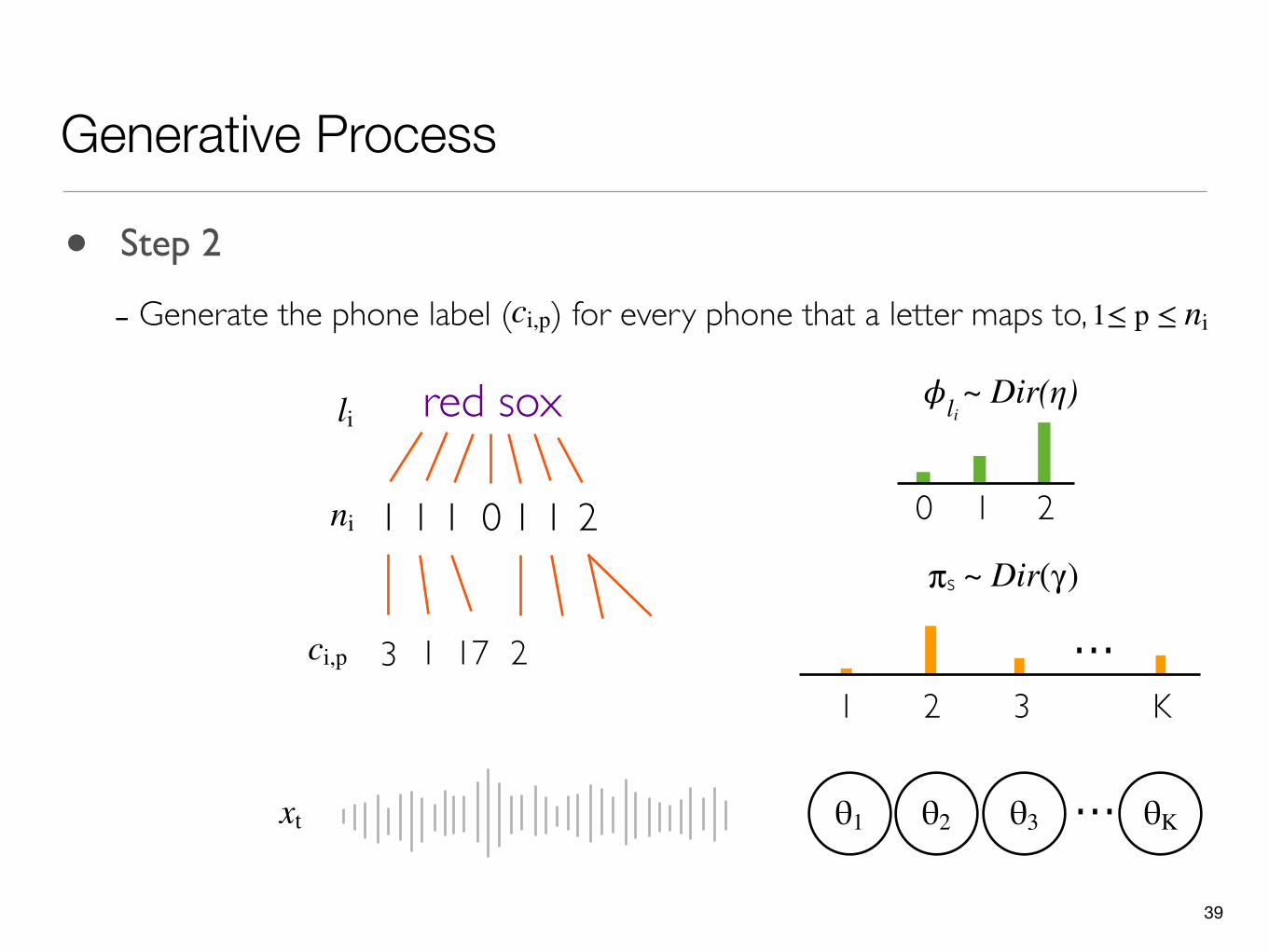
39
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
πs
...1 2 3 K
li red sox
211 1 1 0 1ni
23 1 17ci,p
xt
~ Dir(η)𝜙li
~ Dir(γ)
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
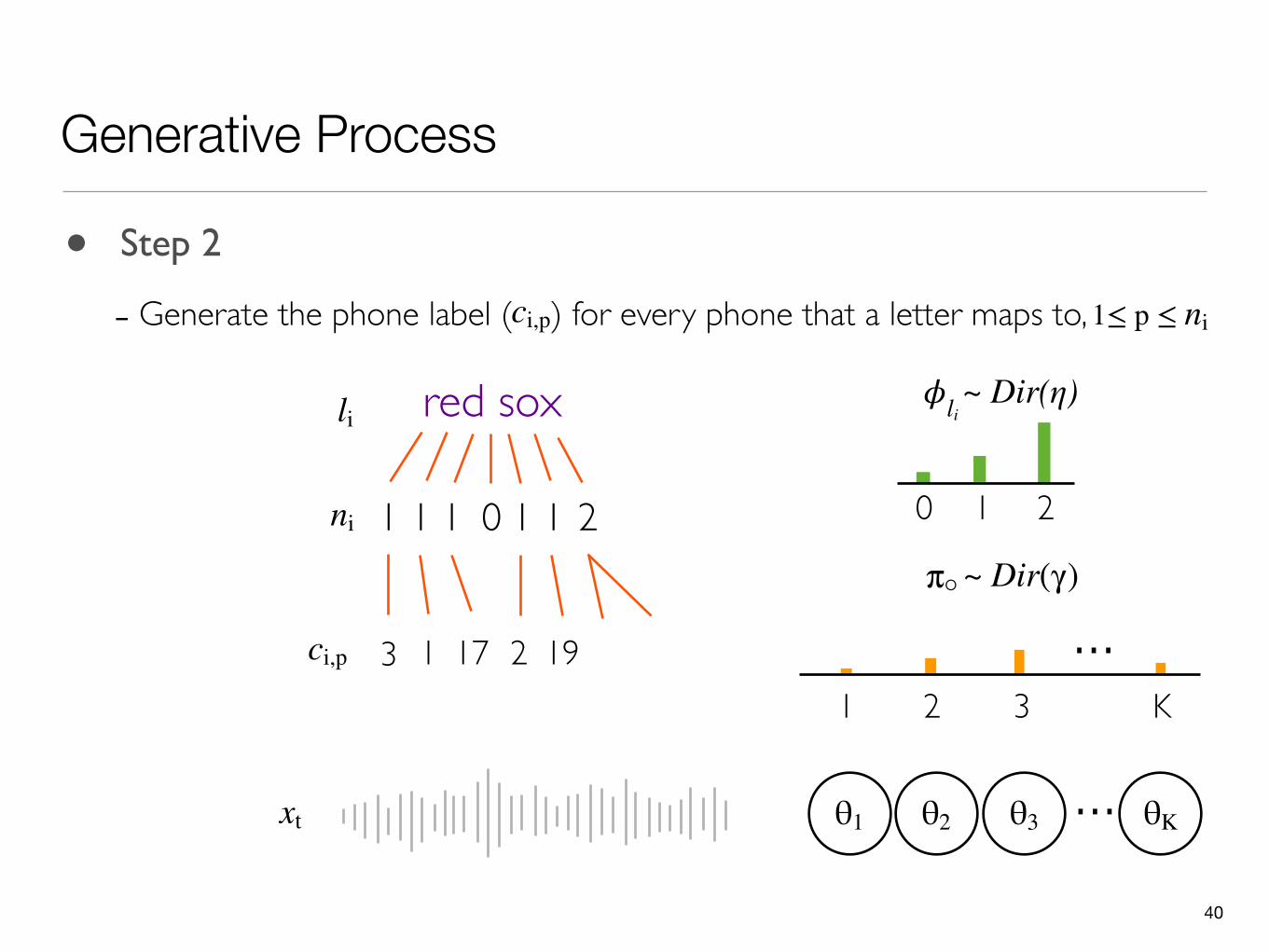
40
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
πo
...1 2 3 K
li red sox
211 1 1 0 1ni
23 1 17 19ci,p
xt
~ Dir(η)𝜙li
~ Dir(γ)
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
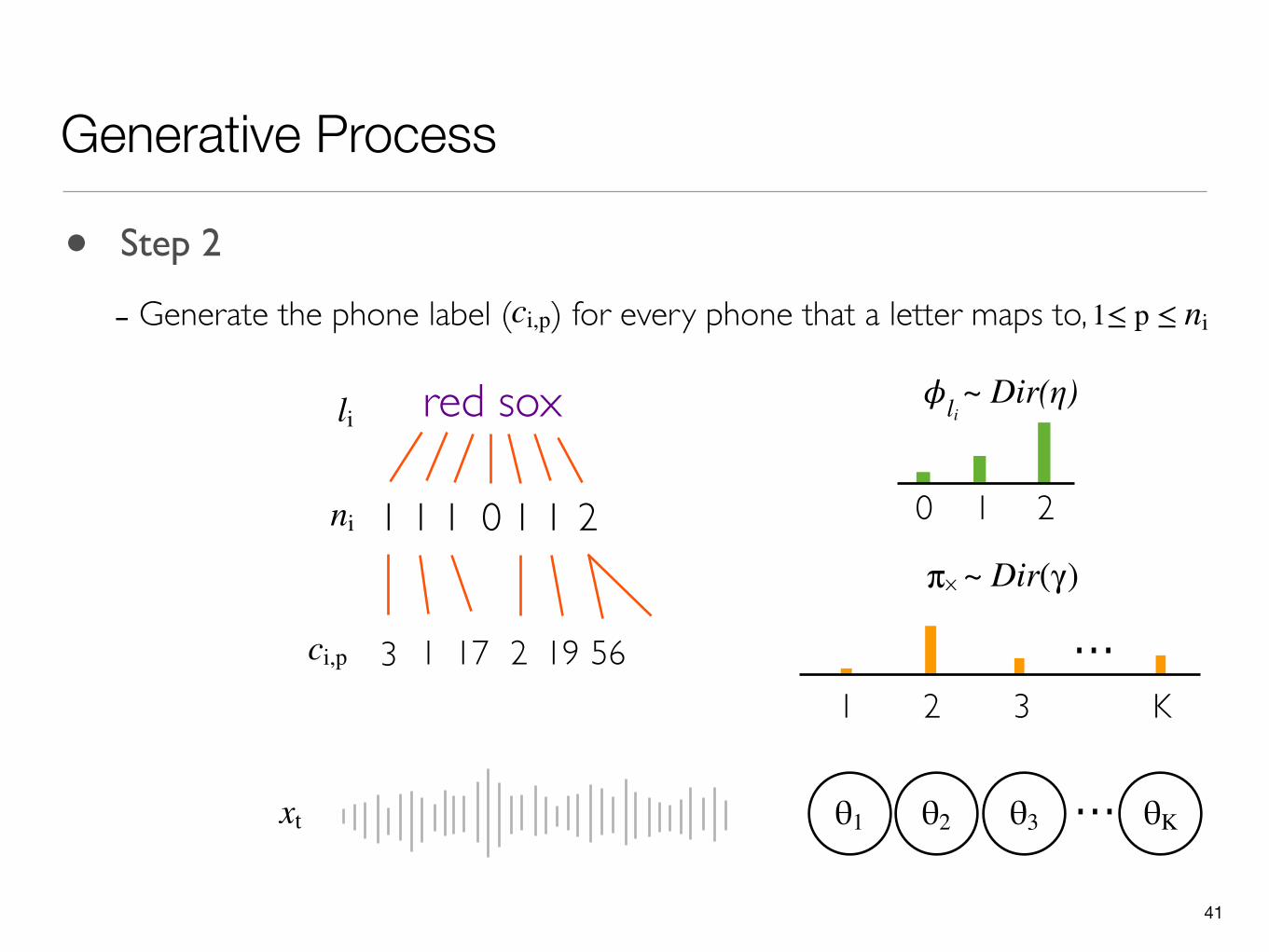
41
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
πx
li red sox
211 1 1 0 1ni
5623 1 17 19 ...1 2 3 K
ci,p
xt
~ Dir(η)𝜙li
~ Dir(γ)
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
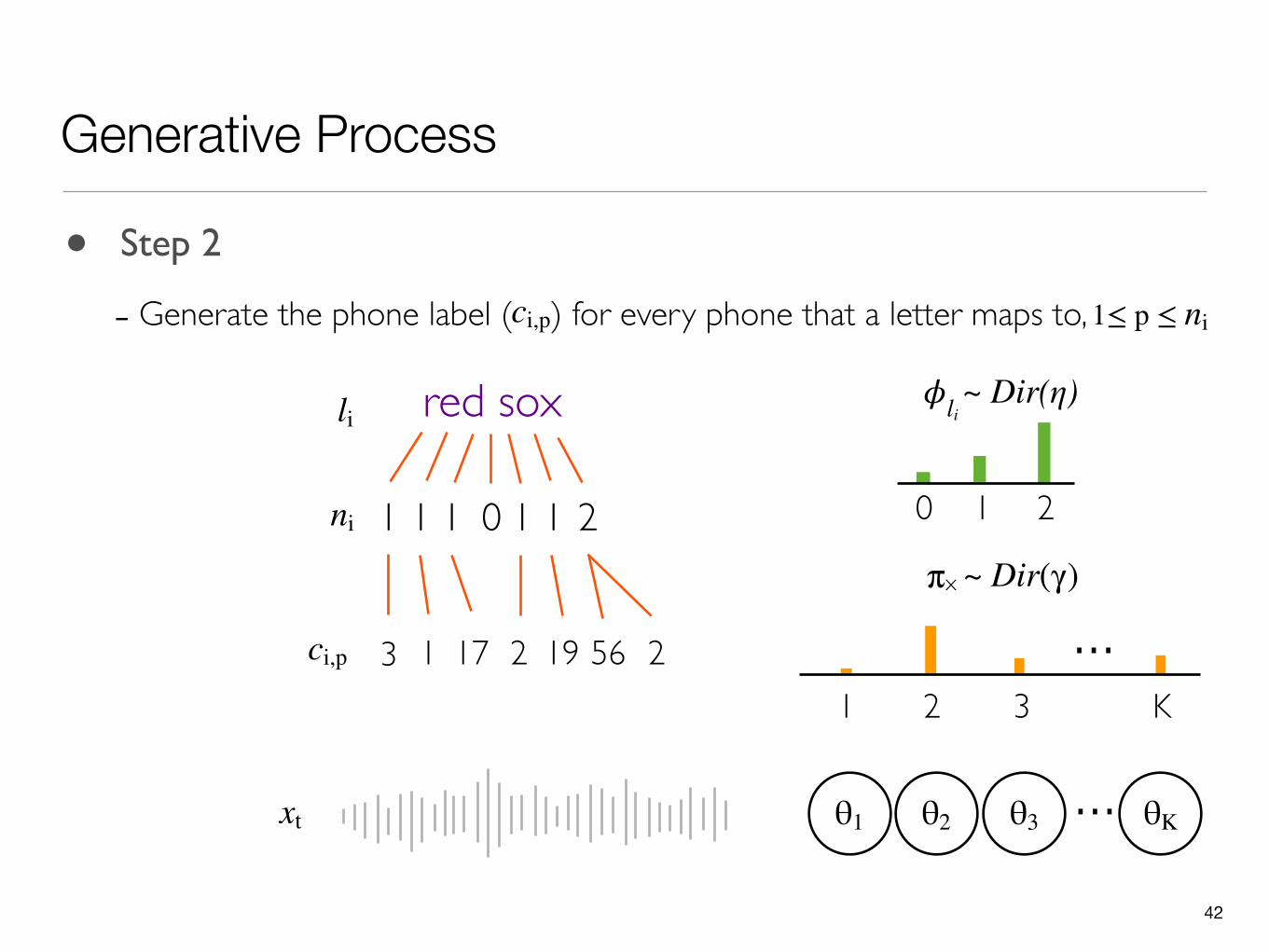
42
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
πx
...1 2 3 K
li red sox
211 1 1 0 1ni
5623 1 17 19 2ci,p
xt
~ Dir(η)𝜙li
~ Dir(γ)
• Step 2
- Generate the phone label ( ) for every phone that a letter maps to,ci,p 1≤ p ≤ ni
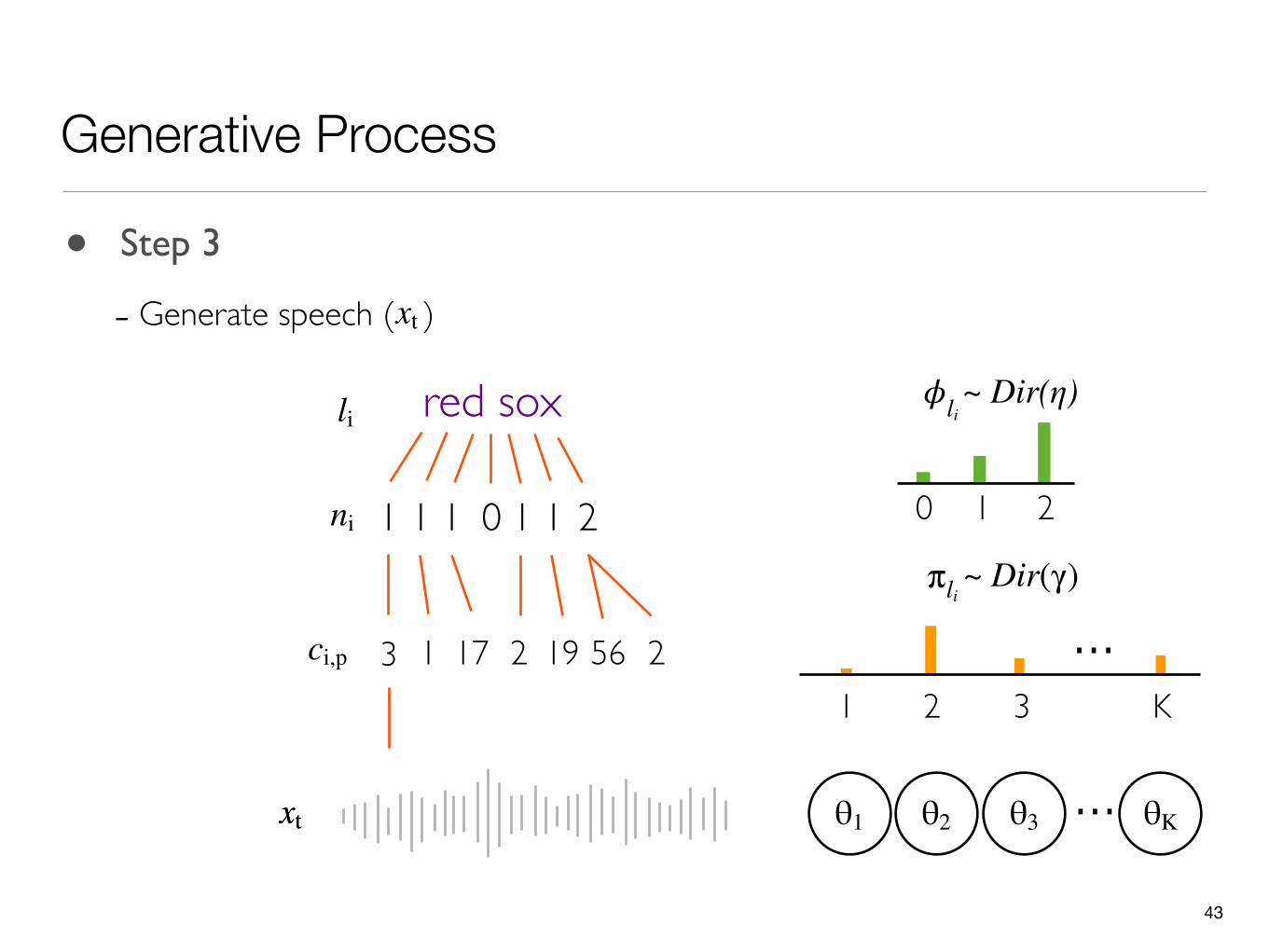
• Step 3
- Generate speech ( )
43
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
...1 2 3 K
xt
li red sox
211 1 1 0 1ni
5623 1 17 19 2
xt
ci,p
xt
~ Dir(η)𝜙li
π li~ Dir(γ)

• Step 3
- Generate speech ( )
44
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
...1 2 3 K
xt
li red sox
211 1 1 0 1ni
5623 1 17 19 2
xt
ci,p
xt
~ Dir(η)𝜙li
π li~ Dir(γ)
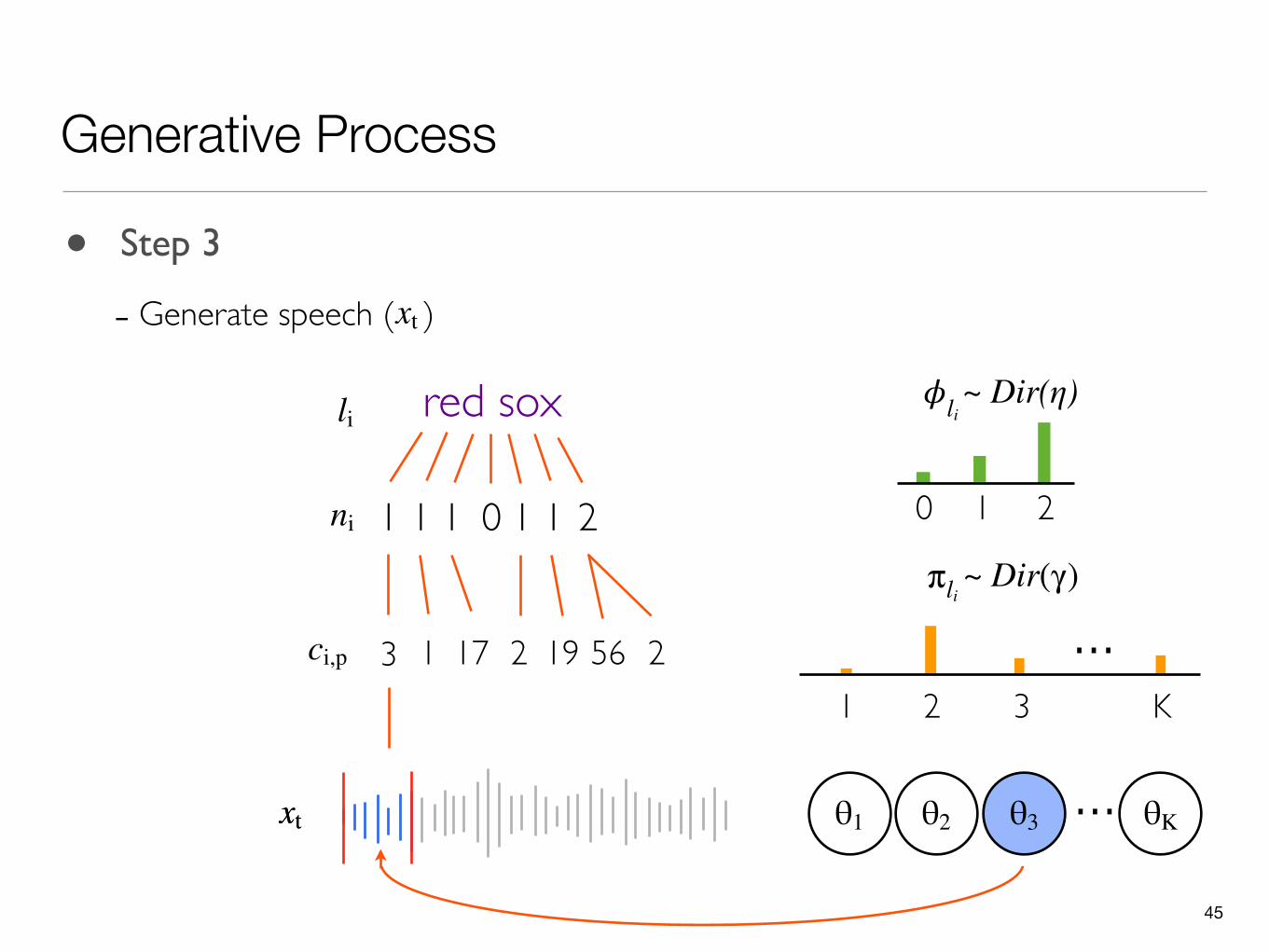
• Step 3
- Generate speech ( )
45
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
...1 2 3 K
xt
li red sox
211 1 1 0 1ni
5623 1 17 19 2
xtxt
~ Dir(η)𝜙li
π li~ Dir(γ)
ci,p
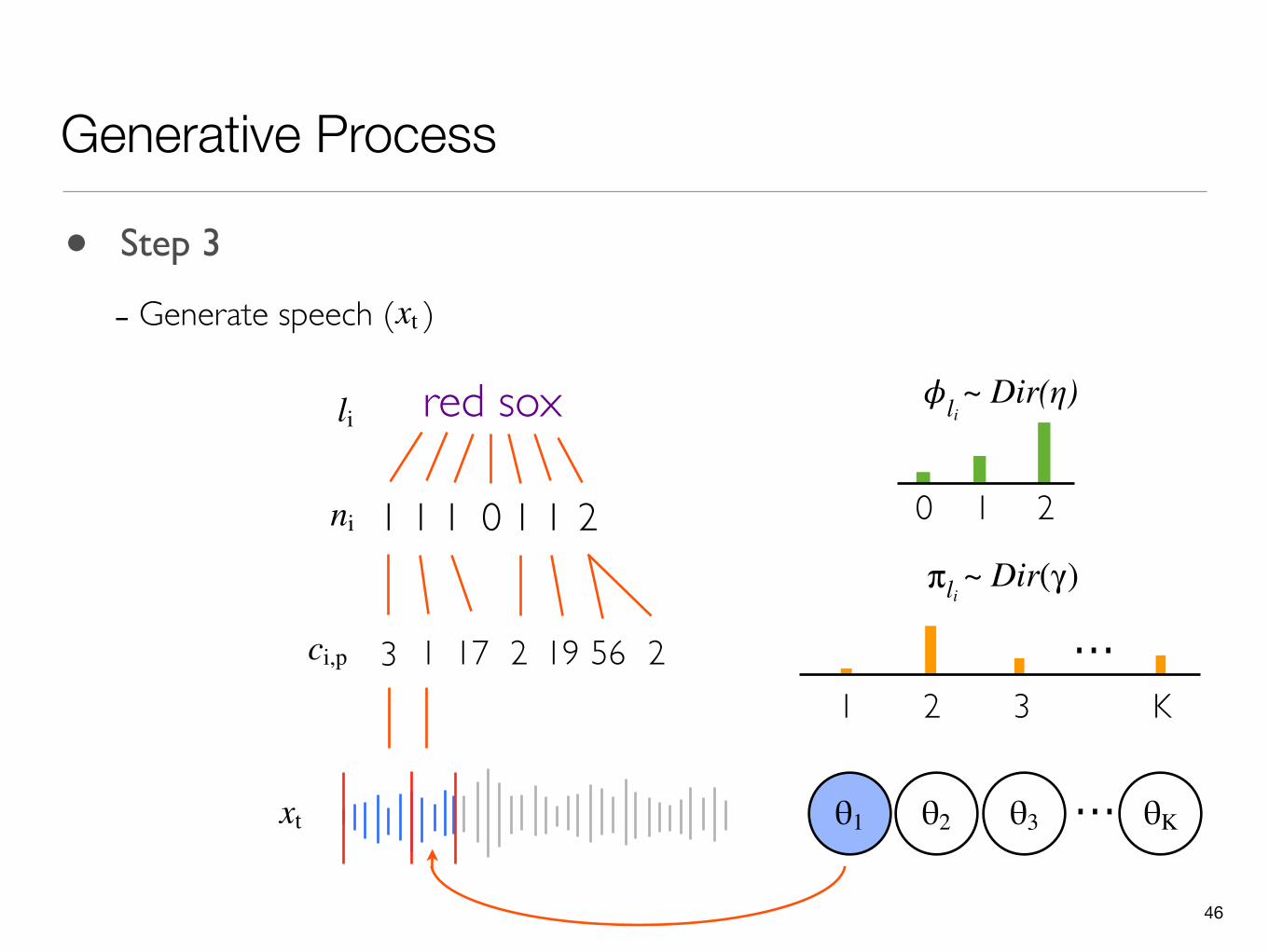
• Step 3
- Generate speech ( )
46
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
...1 2 3 K
xt
li red sox
211 1 1 0 1ni
5623 1 17 19 2
xt
~ Dir(η)𝜙li
π li~ Dir(γ)
ci,p

• Step 3
- Generate speech ( )
47
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
...1 2 3 K
xt
li red sox
211 1 1 0 1ni
5623 1 17 19 2
xt
~ Dir(η)𝜙li
π li~ Dir(γ)
ci,p

• Step 3
- Generate speech ( )
48
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
...1 2 3 K
xt
li red sox
211 1 1 0 1ni
5623 1 17 19 2
xt
~ Dir(η)𝜙li
π li~ Dir(γ)
ci,p
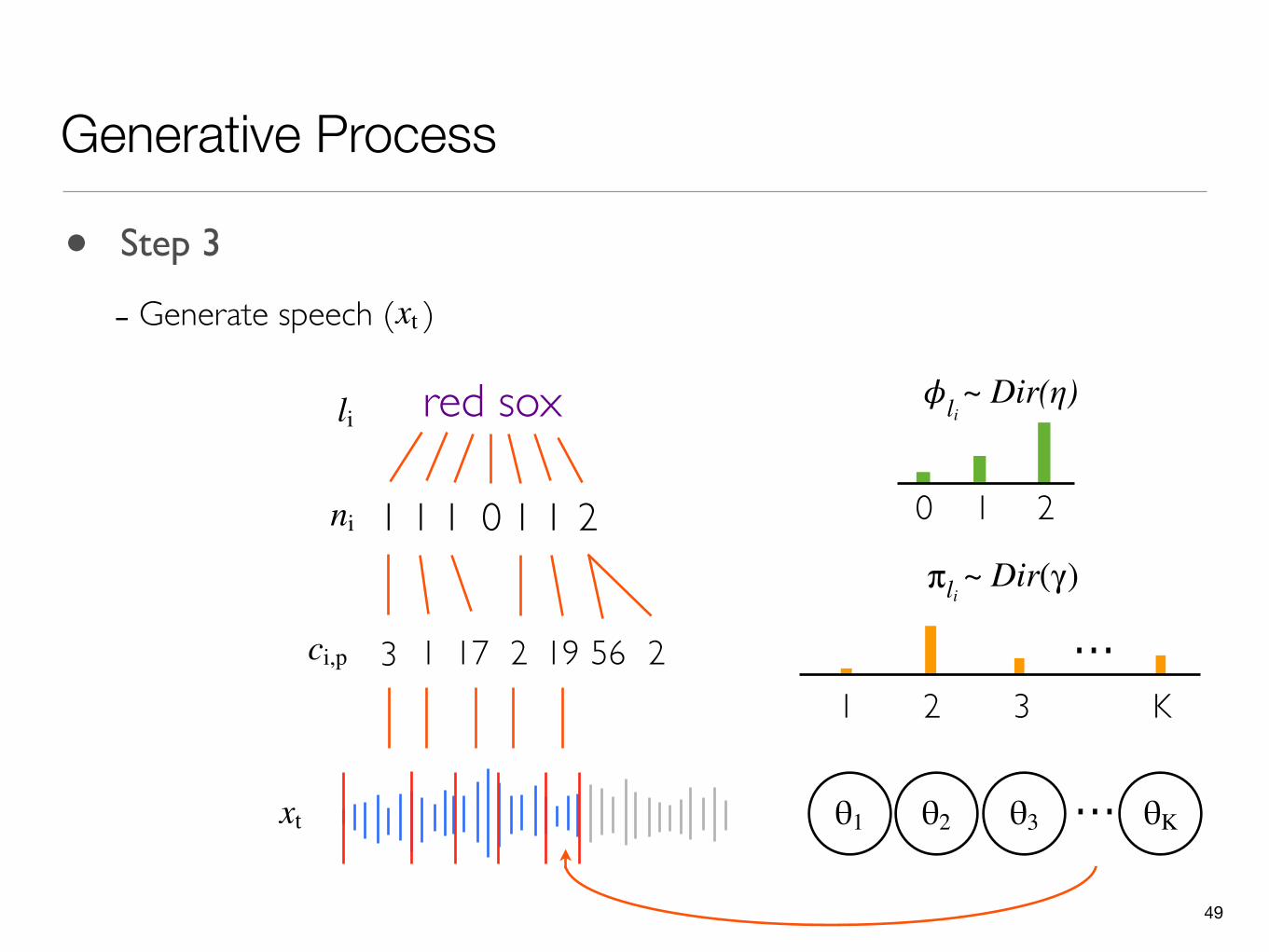
• Step 3
- Generate speech ( )
49
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
...1 2 3 K
xt
li red sox
211 1 1 0 1ni
5623 1 17 19 2
xt
~ Dir(η)𝜙li
π li~ Dir(γ)
ci,p
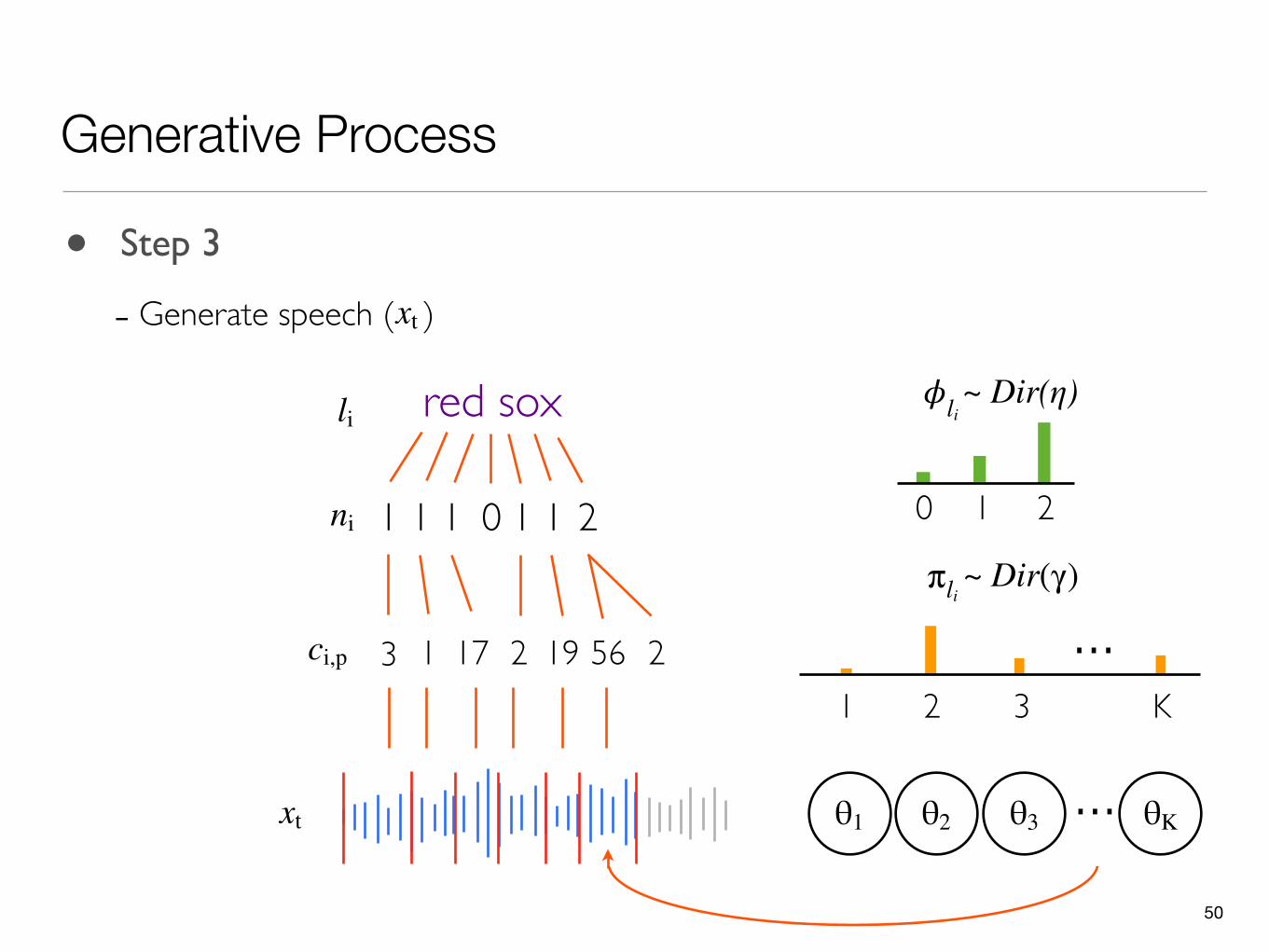
• Step 3
- Generate speech ( )
50
Generative Process
θ1 ...θ2 θ3 θK
0 1 2
...1 2 3 K
xt
li red sox
211 1 1 0 1ni
5623 1 17 19 2
xt
~ Dir(η)𝜙li
π li~ Dir(γ)
ci,p
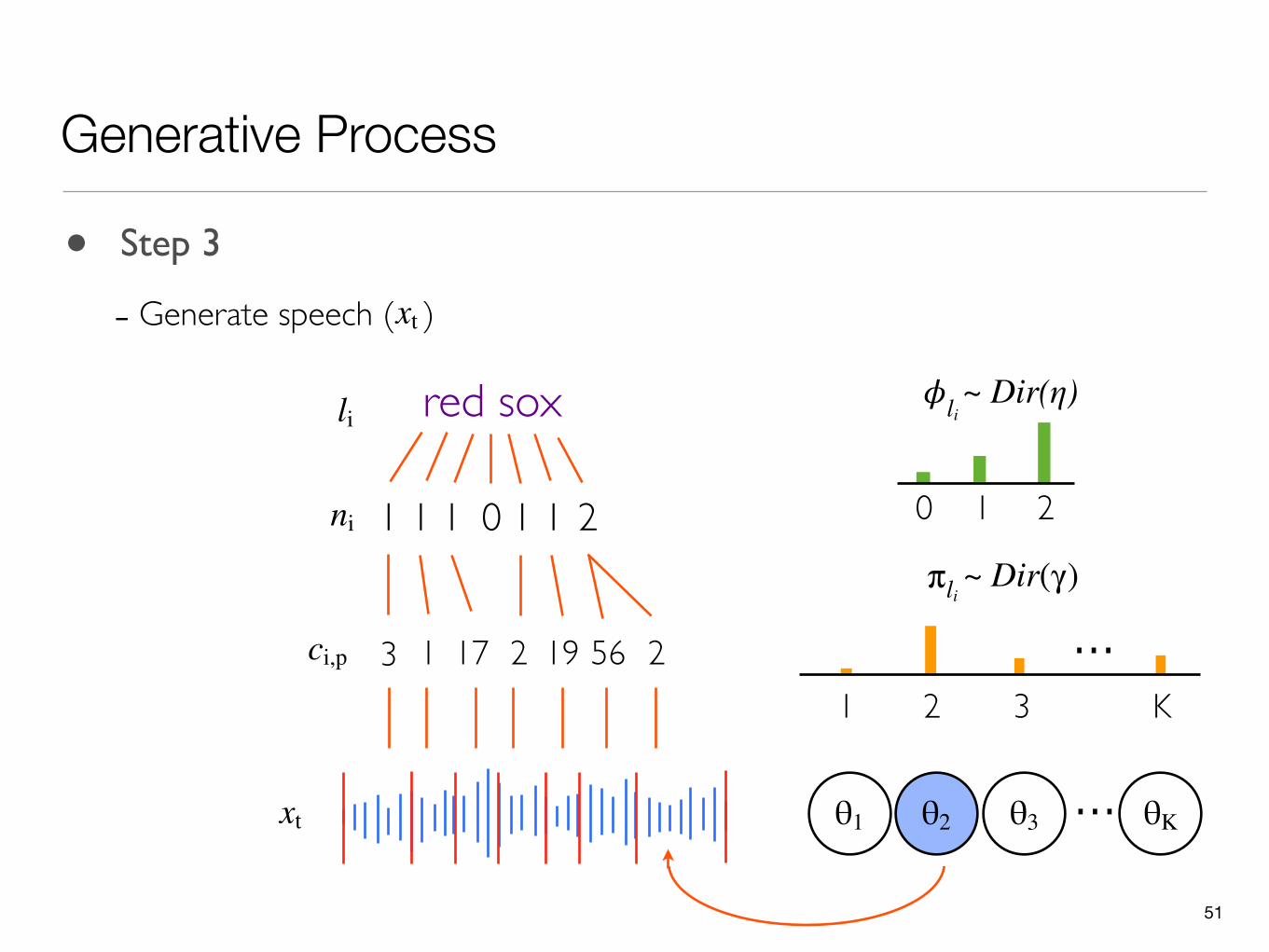
• Step 3
- Generate speech ( )
51
Generative Process
li red sox
211 1 1 0 1
θ1 ...θ2 θ3 θK
ni 0 1 2
5623 1 17 19 2 ...1 2 3 K
xt
xt
~ Dir(η)𝜙li
π li~ Dir(γ)
ci,p
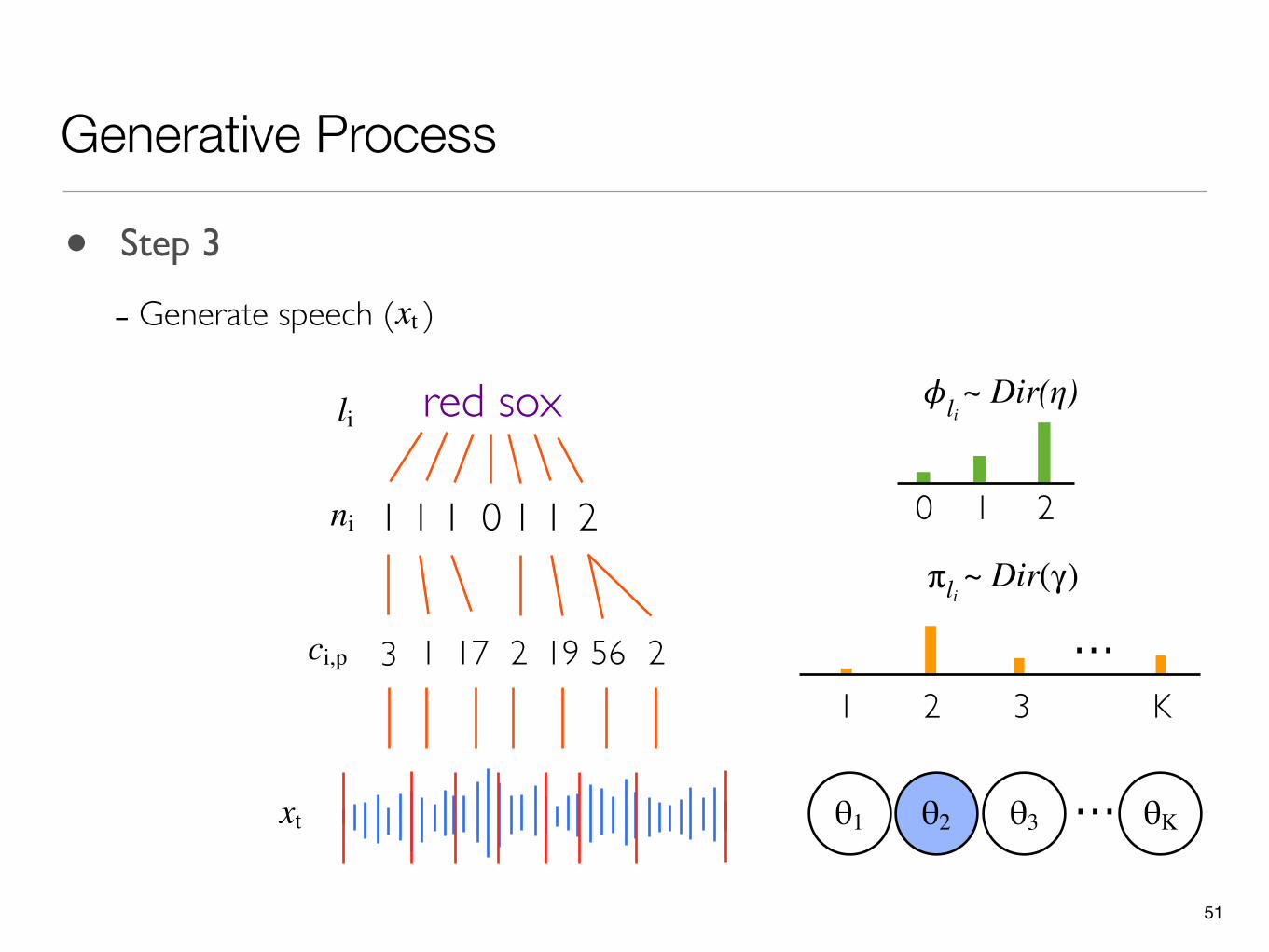
• Step 3
- Generate speech ( )
51
Generative Process
li red sox
211 1 1 0 1
θ1 ...θ2 θ3 θK
ni 0 1 2
5623 1 17 19 2 ...1 2 3 K
xt
xt
~ Dir(η)𝜙li
π li~ Dir(γ)
ci,p

• Take context into account for learning L2S mapping rules
- More specific rules
- Natural back-off mechanism
Context-dependent L2S Rules
52
θ1 θ2 θ3 θ4 ......
~DP(γ, )𝜙sox 𝜙o
~ ci πo
red sox πo
...1 2 3 K

• Take context into account for learning L2S mapping rules
- More specific rules
- Natural back-off mechanism
Context-dependent L2S Rules
53
θ1 θ2 θ3 θ4 ......
~DP(γ, )𝜙sox 𝜙o
red sox...
1 2 3 K
πsox
...1 2 3 K
~ ci πsox
πo

• Take context into account for learning L2S mapping rules
- More specific rules
- Back-off mechanism through hierarchy
Context-dependent L2S Rules
54
...1 2 3 K
πsox
...1 2 3 K
πo

• Take context into account for learning L2S mapping rules
- More specific rules
- Back-off mechanism through hierarchy
Context-dependent L2S Rules
55
...1 2 3 K
...1 2 3 K
~ Dir(απo)πsox
πo

• Take context into account for learning L2S mapping rules
- More specific rules
- Back-off mechanism through hierarchy
Context-dependent L2S Rules
56
...1 2 3 K
...1 2 3 K
• View as the prior of
- If sox appears frequently
- If sox is rarely observed
πo
πsox empirical distribution
πsox
πsox πo
~ Dir(απo)πsox
πo

• Take context into account for learning L2S mapping rules
- More specific rules
- Back-off mechanism through hierarchy
Context-dependent L2S Rules
57
...1 2 3 K
...1 2 3 K
~ Dir(λβ)
~ Dir(𝛾)β
• View as the prior of
- If sox appears frequently
- If sox is rarely observed
πo
πsox empirical distribution
πsox
πsox πo
πo
~ Dir(απo)πsox
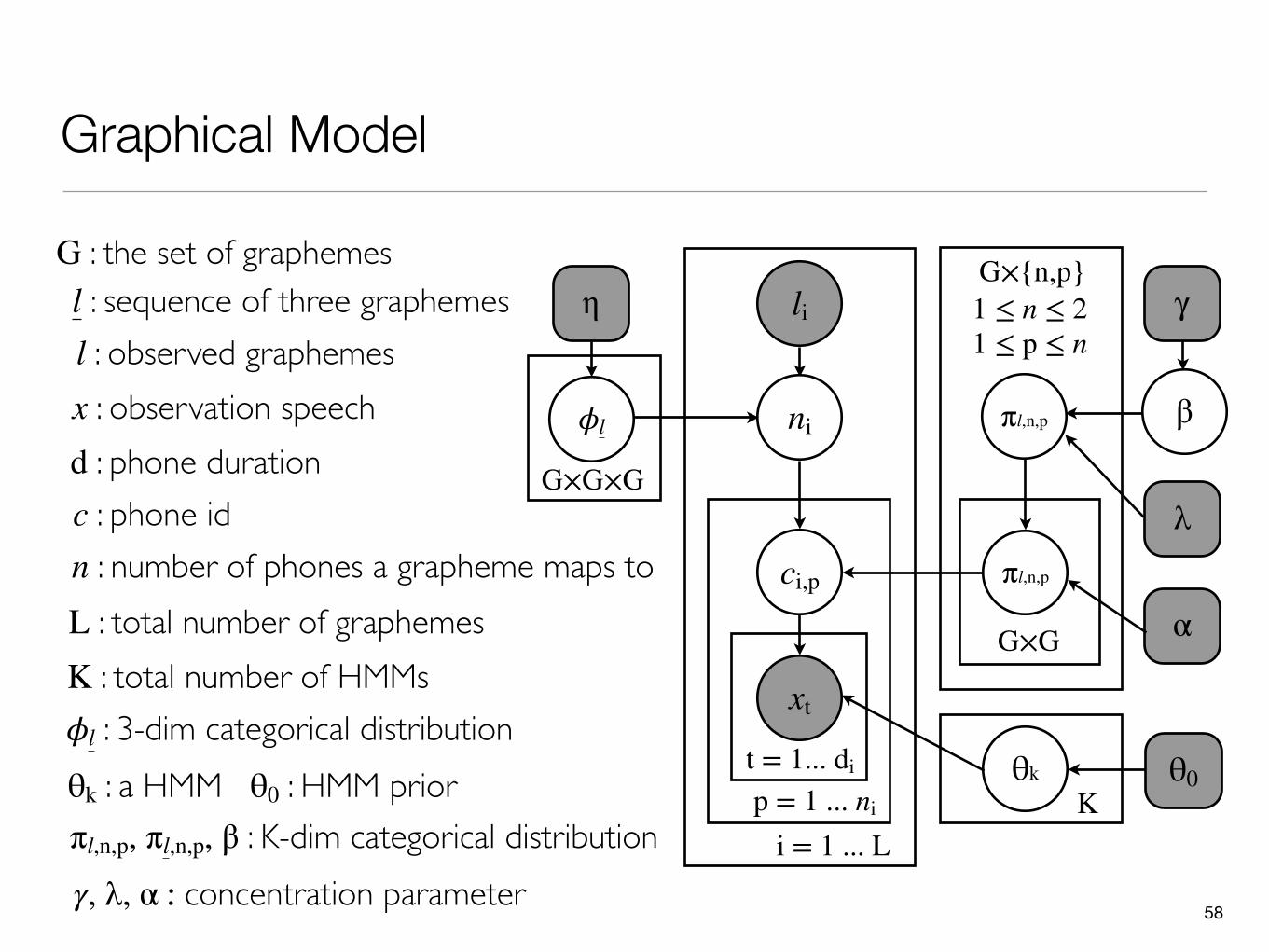
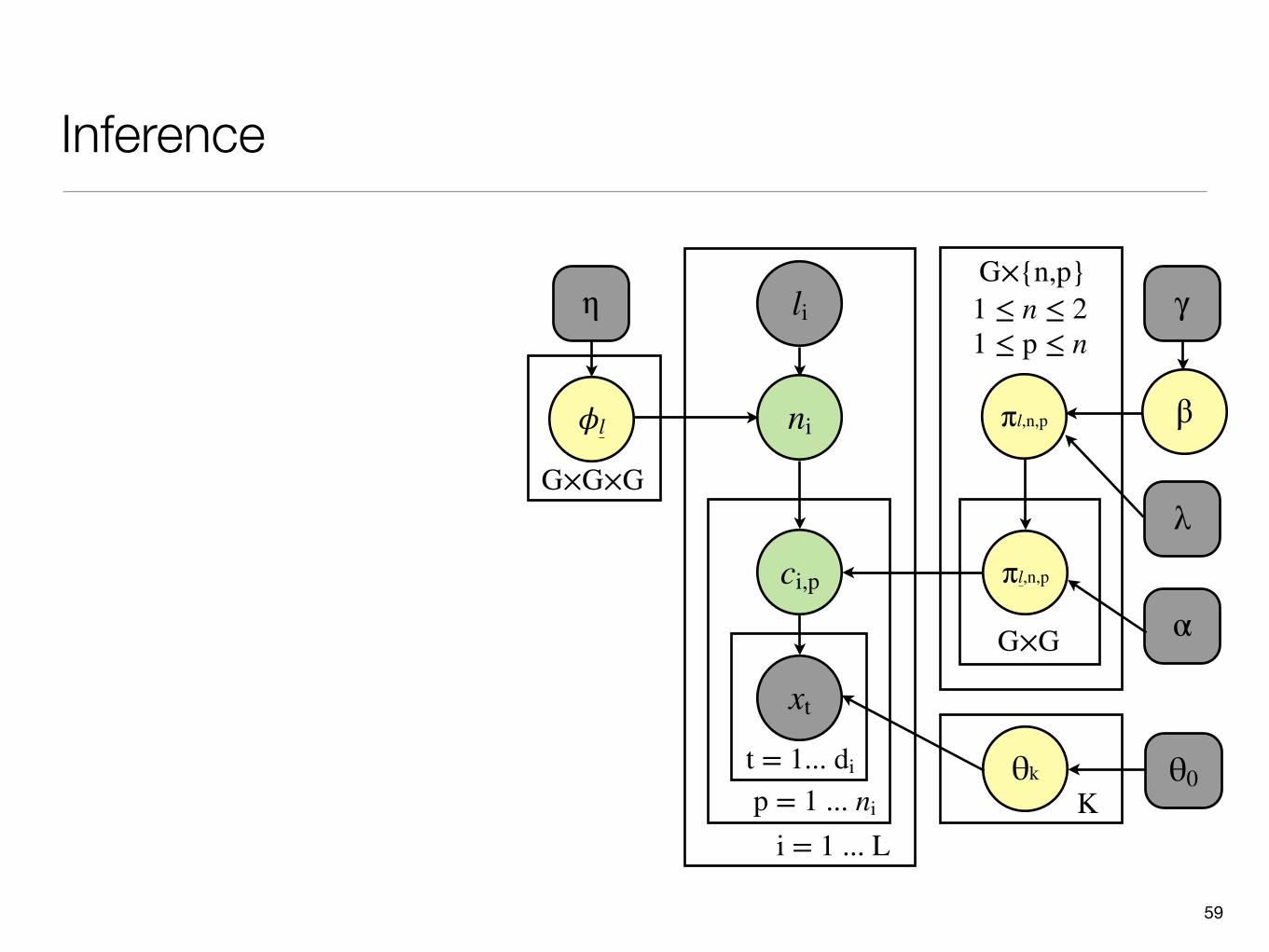
Graphical Model
58𝛾, λ, α : concentration parameter
x : observation speech
li
ni
γη
xt
t = 1... di θk
Kθ0
p = 1 ... ni
β
πl,n,p
G×G
𝜙l
G×G×G
ci,p
πl,n,p
λ
1 ≤ p ≤ n1 ≤ n ≤ 2G×{n,p}
α
i = 1 ... L
G : the set of graphemesl : sequence of three graphemesl : observed graphemes
d : phone duration
n : number of phones a grapheme maps toL : total number of graphemesK : total number of HMMs
c : phone id
𝜙l : 3-dim categorical distribution
πl,n,p, πl,n,p, β : K-dim categorical distributionθk : a HMM θ0 : HMM prior
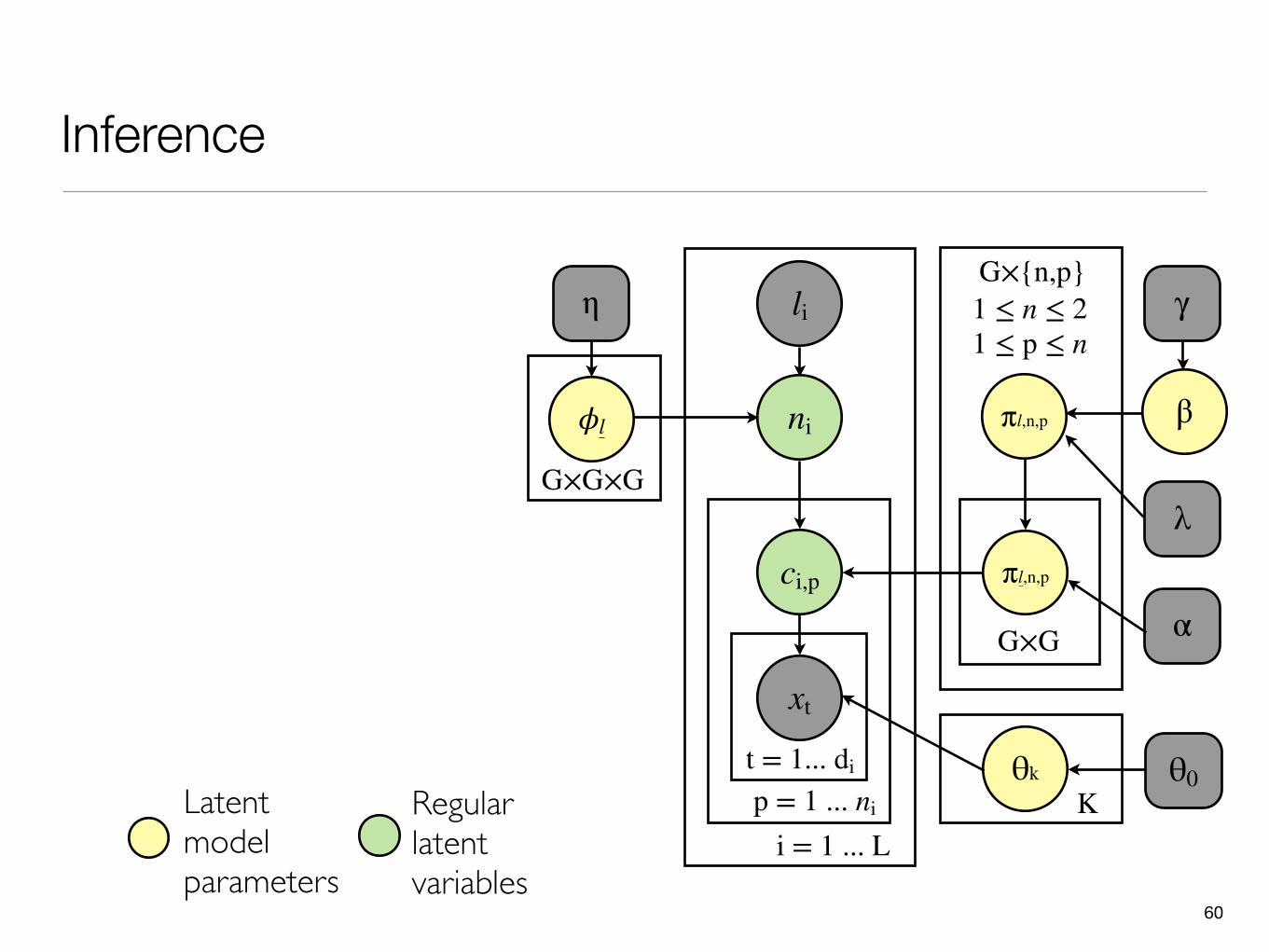
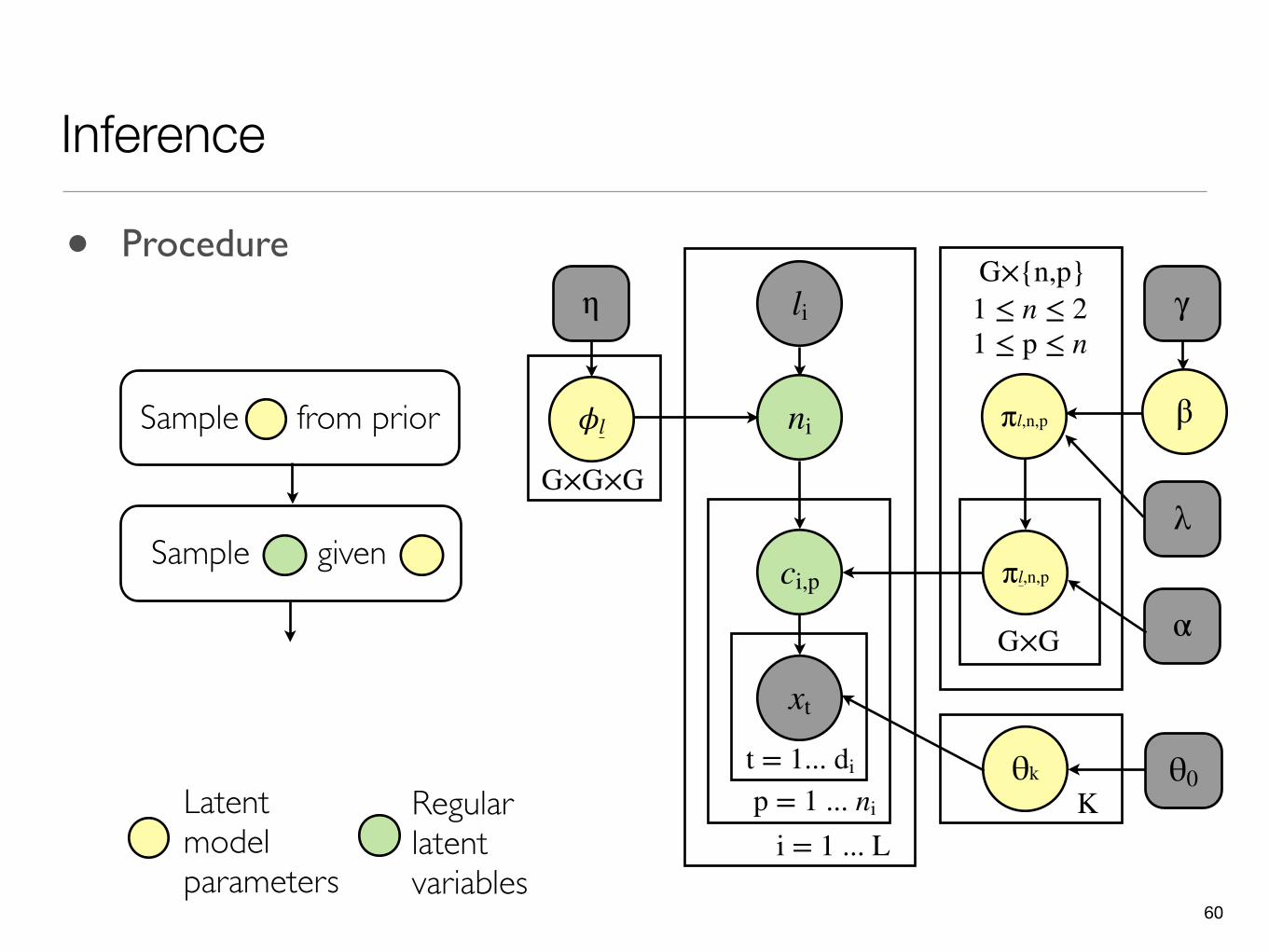
Inference
59
li
ni
γη
xt
t = 1... di θk
Kθ0
p = 1 ... ni
β
πl,n,p
G×G
𝜙l
G×G×G
ci,p
πl,n,p
λ
1 ≤ p ≤ n1 ≤ n ≤ 2G×{n,p}
α
i = 1 ... L
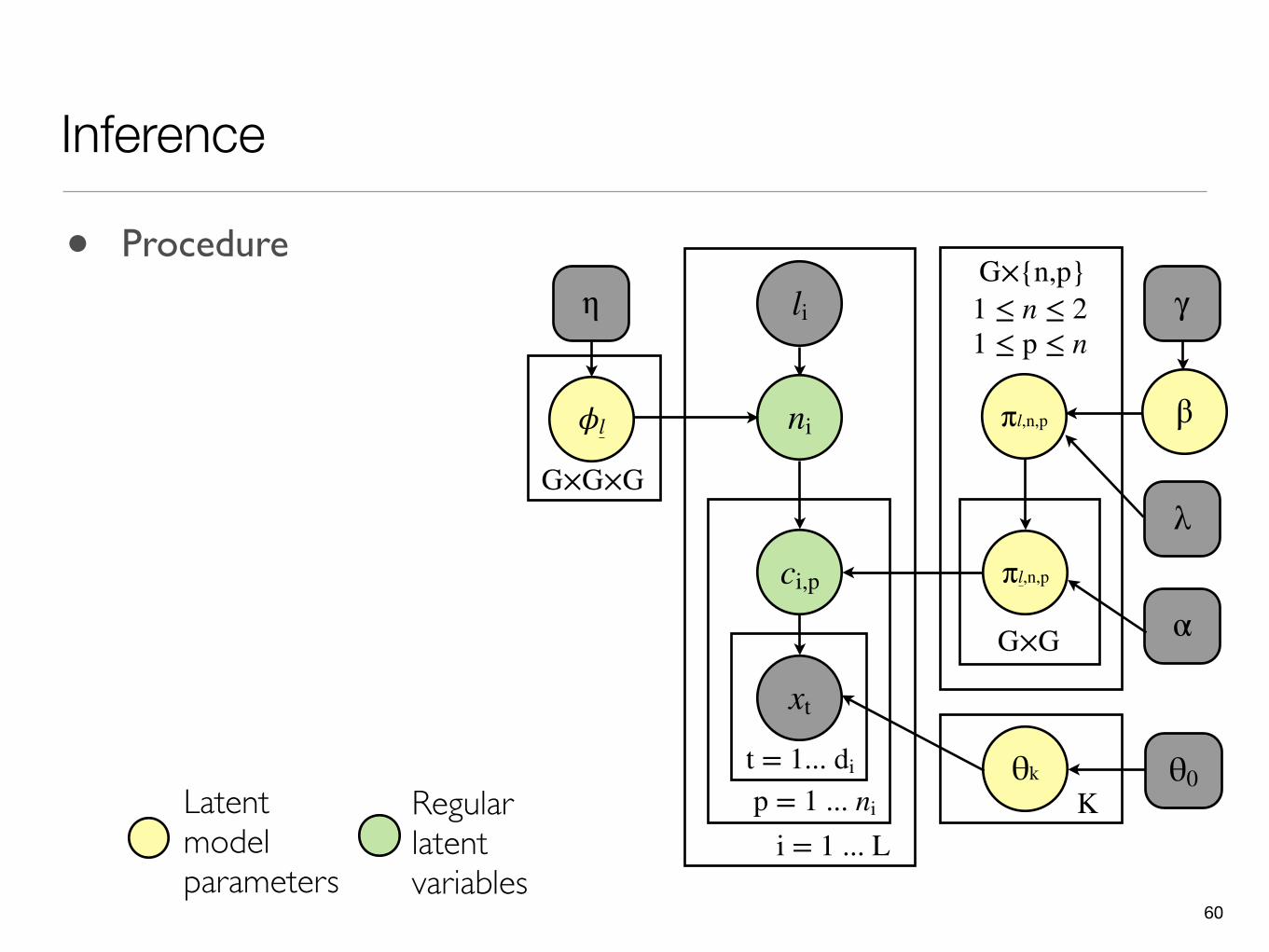
Inference
60
Latent model parameters
Regular latent variables
li
ni
γη
xt
t = 1... di θk
Kθ0
p = 1 ... ni
β
πl,n,p
G×G
𝜙l
G×G×G
ci,p
πl,n,p
λ
1 ≤ p ≤ n1 ≤ n ≤ 2G×{n,p}
α
i = 1 ... L
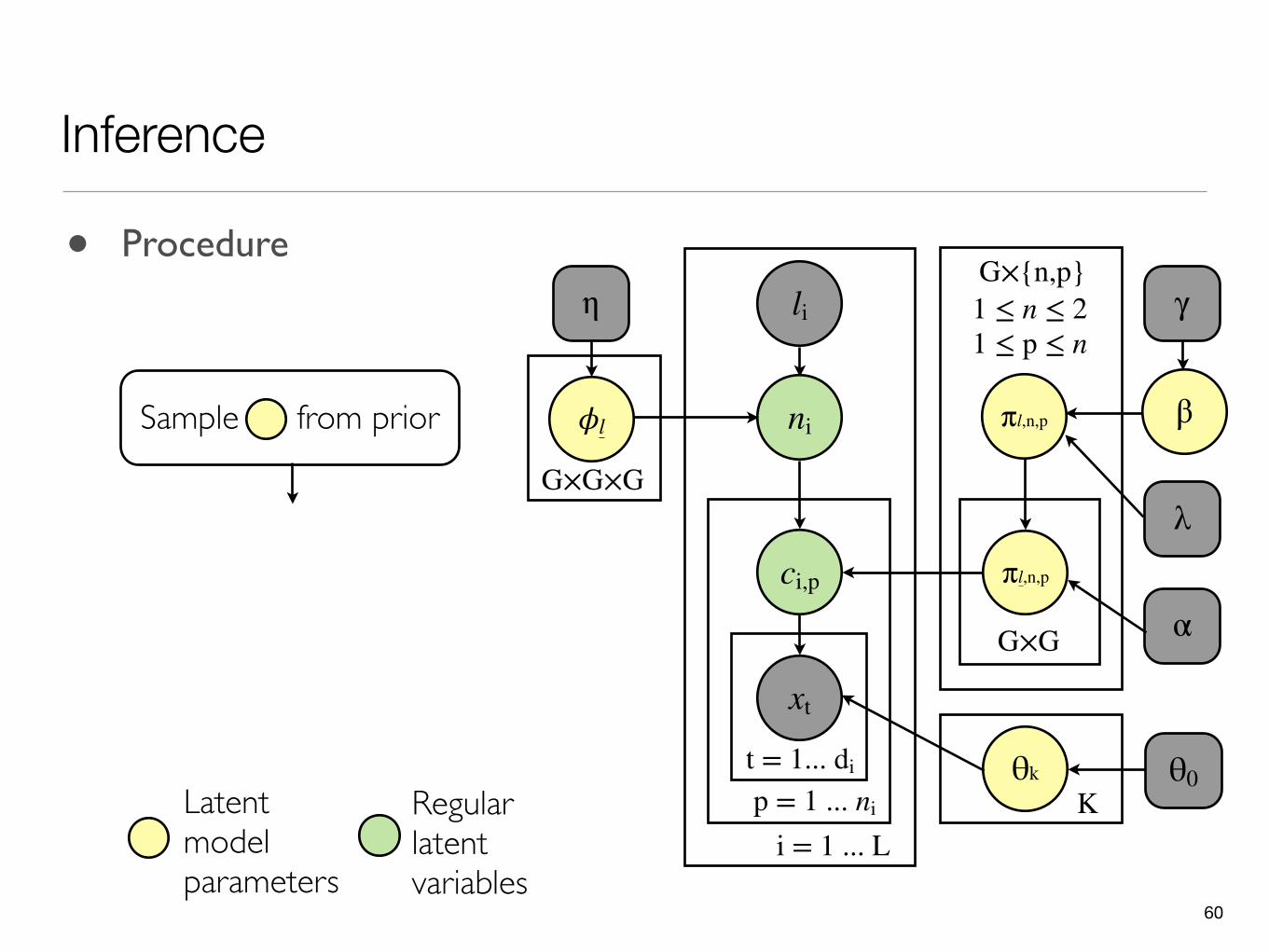
Inference
60
Latent model parameters
Regular latent variables
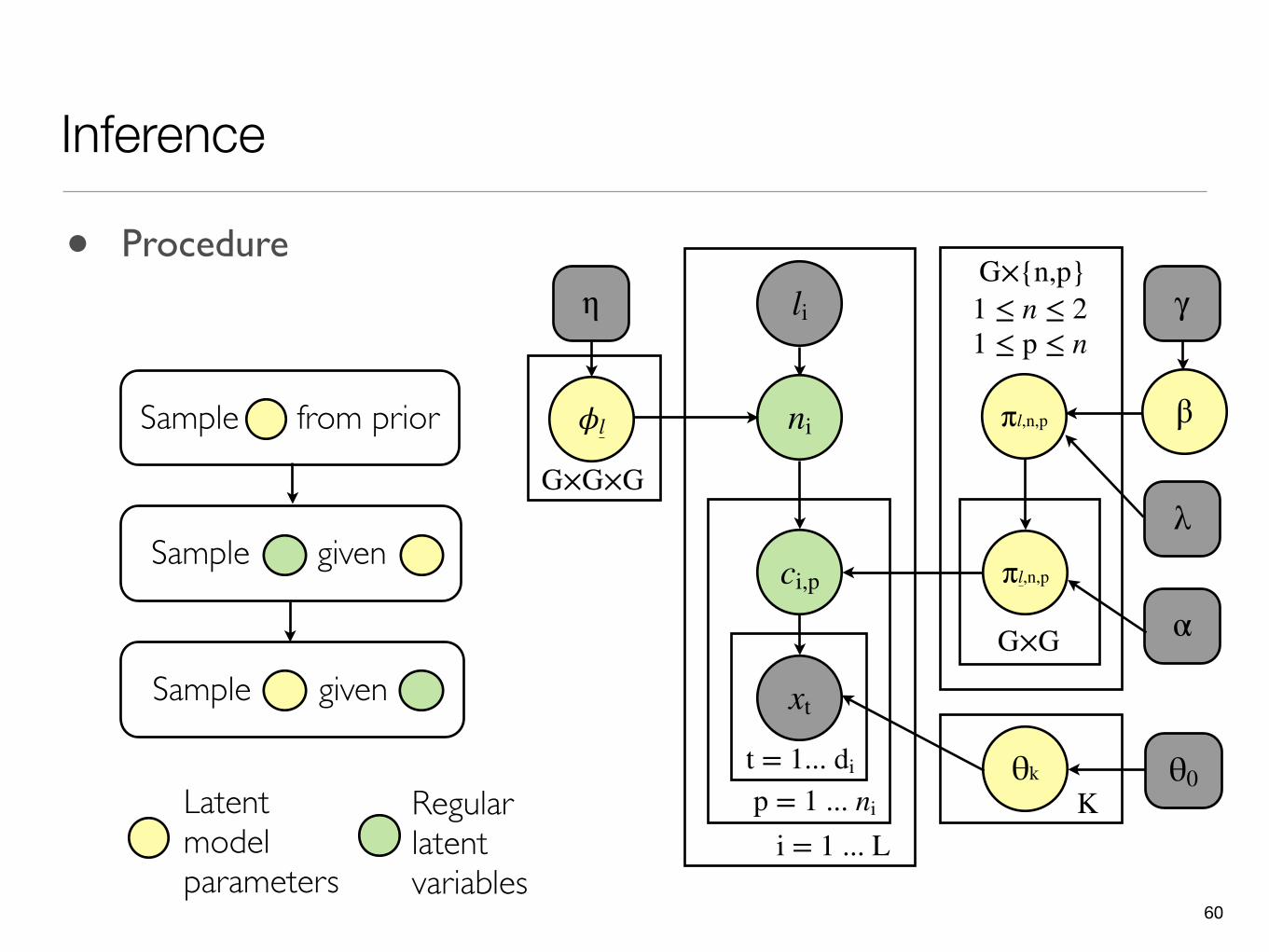
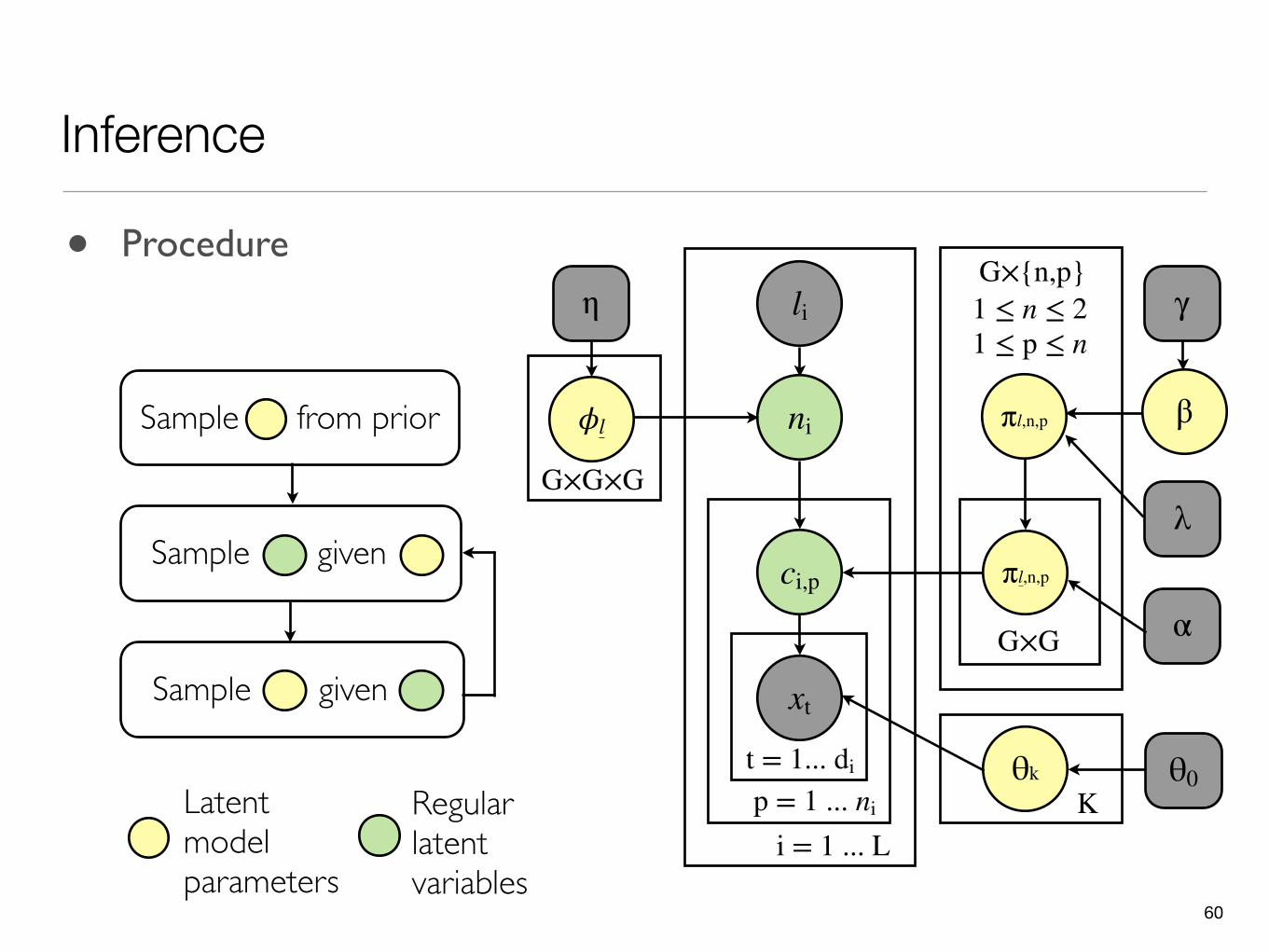
• Procedure
- 20,000 iterations li
ni
γη
xt
t = 1... di θk
Kθ0
p = 1 ... ni
β
πl,n,p
G×G
𝜙l
G×G×G
ci,p
πl,n,p
λ
1 ≤ p ≤ n1 ≤ n ≤ 2G×{n,p}
α
i = 1 ... L
Inference
60
Latent model parameters
Regular latent variables
Sample from prior
• Procedure
- 20,000 iterations li
ni
γη
xt
t = 1... di θk
Kθ0
p = 1 ... ni
β
πl,n,p
G×G
𝜙l
G×G×G
ci,p
πl,n,p
λ
1 ≤ p ≤ n1 ≤ n ≤ 2G×{n,p}
α
i = 1 ... L
Inference
60
Latent model parameters
Regular latent variables
Sample given a
Sample from prior
• Procedure
- 20,000 iterations li
ni
γη
xt
t = 1... di θk
Kθ0
p = 1 ... ni
β
πl,n,p
G×G
𝜙l
G×G×G
ci,p
πl,n,p
λ
1 ≤ p ≤ n1 ≤ n ≤ 2G×{n,p}
α
i = 1 ... L
Inference
60
Latent model parameters
Regular latent variables
Sample given a
Sample given a
Sample from prior
• Procedure
- 20,000 iterations li
ni
γη
xt
t = 1... di θk
Kθ0
p = 1 ... ni
β
πl,n,p
G×G
𝜙l
G×G×G
ci,p
πl,n,p
λ
1 ≤ p ≤ n1 ≤ n ≤ 2G×{n,p}
α
i = 1 ... L
Inference
60
Latent model parameters
Regular latent variables
Sample given a
Sample given a
Sample from prior
• Procedure
- 20,000 iterations li
ni
γη
xt
t = 1... di θk
Kθ0
p = 1 ... ni
β
πl,n,p
G×G
𝜙l
G×G×G
ci,p
πl,n,p
λ
1 ≤ p ≤ n1 ≤ n ≤ 2G×{n,p}
α
i = 1 ... L
Inference
61
Latent model parameters
Regular latent variables
Sample given a
Sample given a
Sample from prior
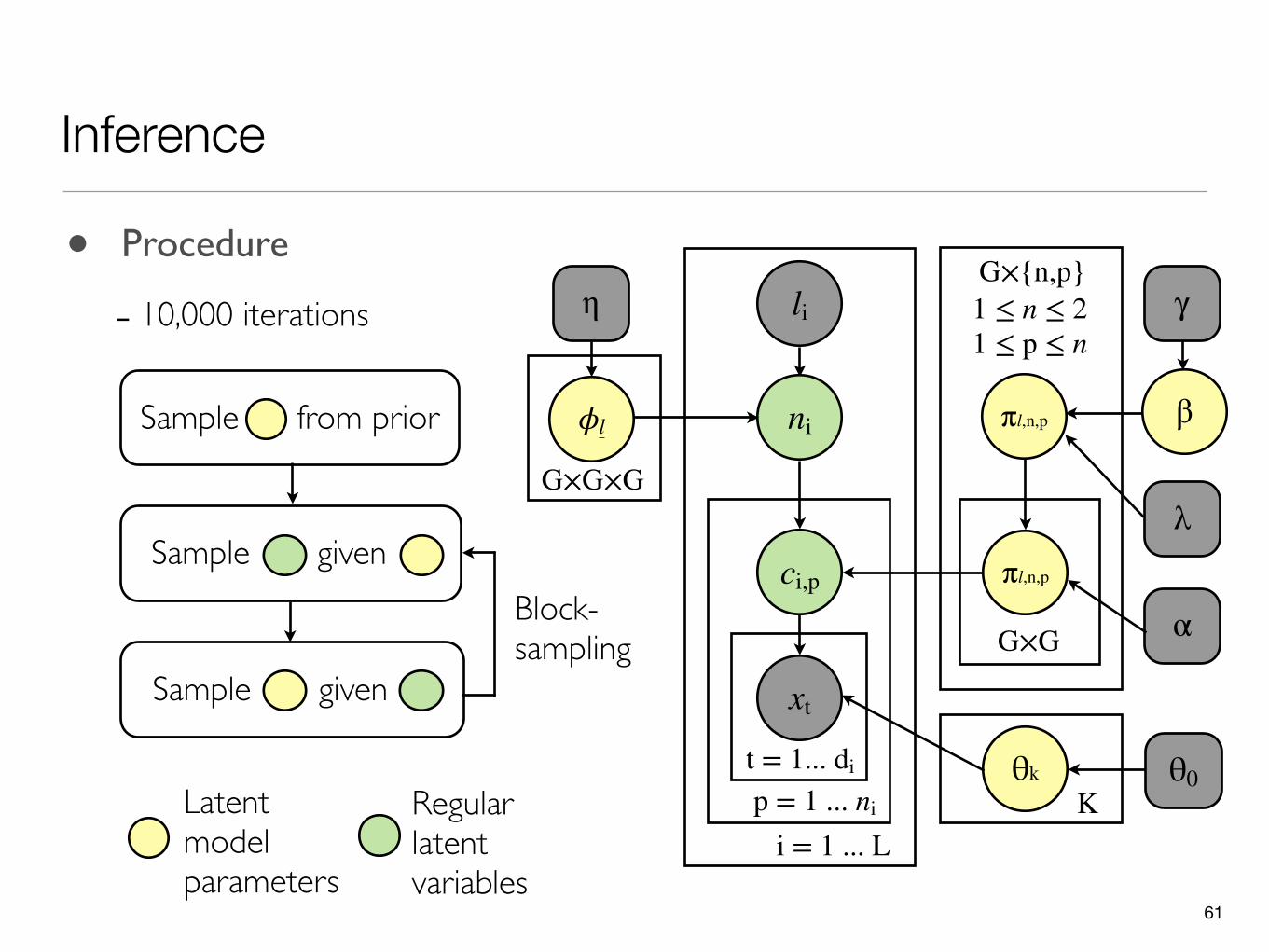
• Procedure
- 10,000 iterations li
ni
γη
xt
t = 1... di θk
Kθ0
p = 1 ... ni
β
πl,n,p
G×G
𝜙l
G×G×G
ci,p
πl,n,p
λ
1 ≤ p ≤ n1 ≤ n ≤ 2G×{n,p}
α
i = 1 ... L
Block-sampling

62
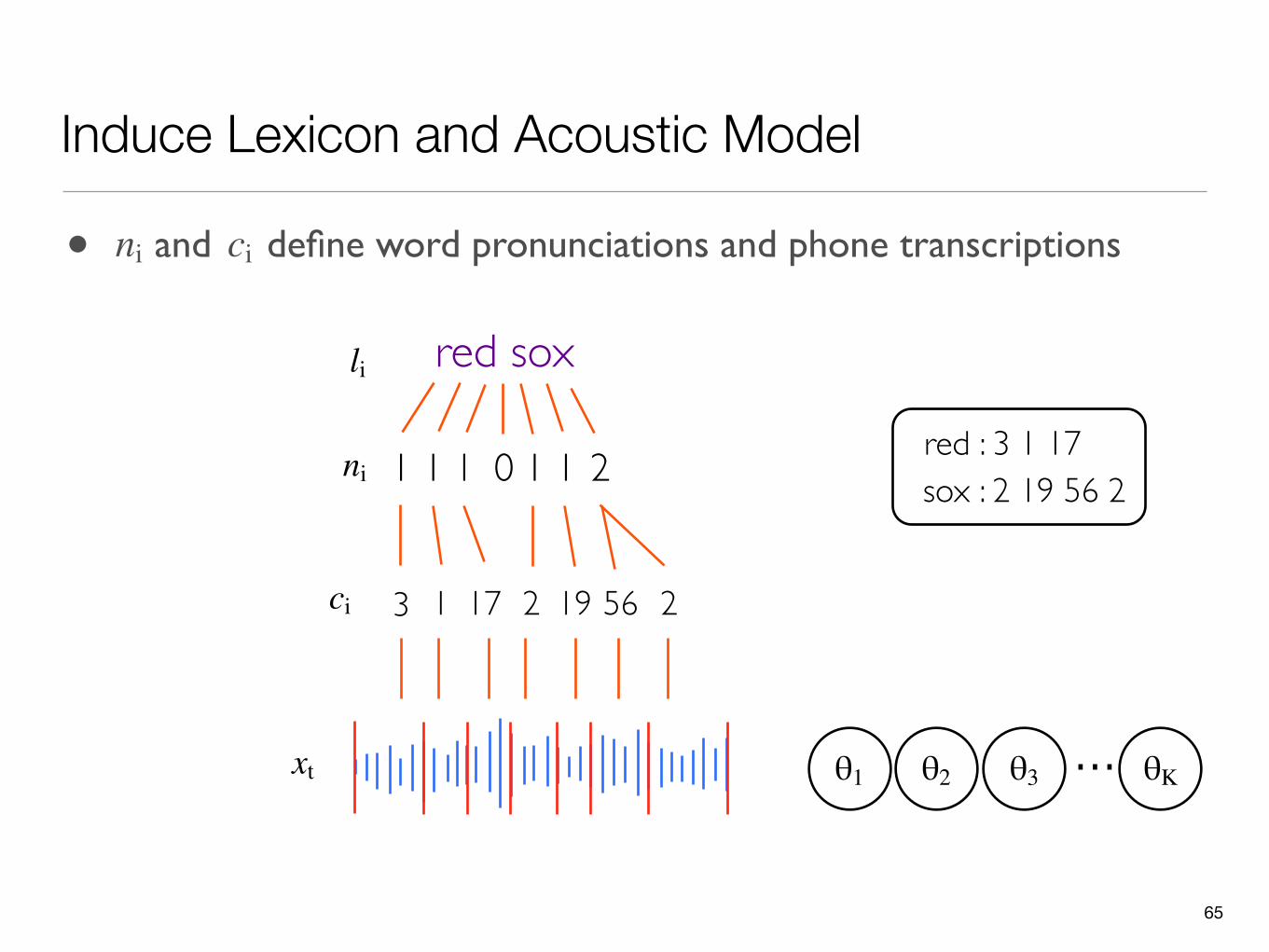
Induce Lexicon and Acoustic Model
li red sox
xt
• and define word pronunciations and phone transcriptionsni ci

63
Induce Lexicon and Acoustic Model
• and define word pronunciations and phone transcriptionsni ci
li red sox
211 1 1 0 1ni
ci 5623 1 17 19 2
xt

64
Induce Lexicon and Acoustic Model
li red sox
211 1 1 0 1ni
5623 1 17 19 2
xt
• and define word pronunciations and phone transcriptionsni ci
ci

64
Induce Lexicon and Acoustic Model
red : 3 1 17sox : 2 19 56 2
li red sox
211 1 1 0 1ni
5623 1 17 19 2
xt
• and define word pronunciations and phone transcriptionsni ci
ci

65
Induce Lexicon and Acoustic Model
red : 3 1 17sox : 2 19 56 2
5623 1 17 19 2
xt
li red sox
211 1 1 0 1ni
• and define word pronunciations and phone transcriptionsni ci
ci
65
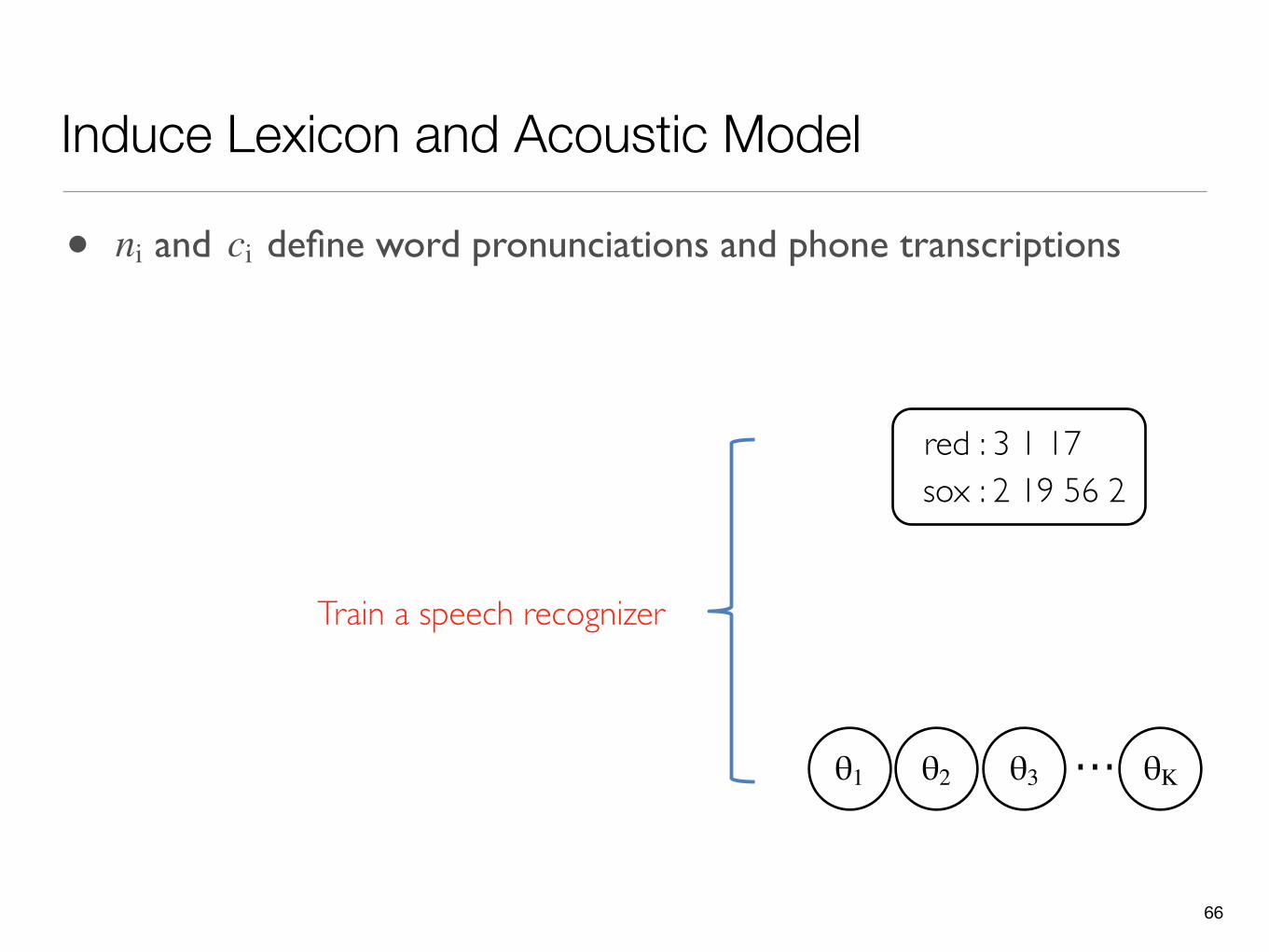
Induce Lexicon and Acoustic Model
red : 3 1 17sox : 2 19 56 2
5623 1 17 19 2
xt θ1 ...θ2 θ3 θK
li red sox
211 1 1 0 1ni
• and define word pronunciations and phone transcriptionsni ci
ci
66
Induce Lexicon and Acoustic Model
red : 3 1 17sox : 2 19 56 2
θ1 ...θ2 θ3 θK
Train a speech recognizer
• and define word pronunciations and phone transcriptionsni ci

Experimental Setup
67
• Dataset
- Jupiter [Zue et al., IEEE Trans. on Speech and Audio Processing, 2000]
- Conversational telephone weather information queries
- 72 hours of training data and 3.2 hours of test data
- A subset of 8 hours of the training data used for training our model

Experimental Setup
67
• Benchmark and baseline
- A speech recognizer trained with an expert-crafted lexicon (Supervised)
- A grapheme-based recognizer (Grapheme)
• Dataset
- Jupiter [Zue et al., IEEE Trans. on Speech and Audio Processing, 2000]
- Conversational telephone weather information queries
- 72 hours of training data and 3.2 hours of test data
- A subset of 8 hours of the training data used for training our model

Experimental Setup
67
• Benchmark and baseline
- A speech recognizer trained with an expert-crafted lexicon (Supervised)
- A grapheme-based recognizer (Grapheme)
• A 3-gram language model is used for all experiments
• Dataset
- Jupiter [Zue et al., IEEE Trans. on Speech and Audio Processing, 2000]
- Conversational telephone weather information queries
- 72 hours of training data and 3.2 hours of test data
- A subset of 8 hours of the training data used for training our model
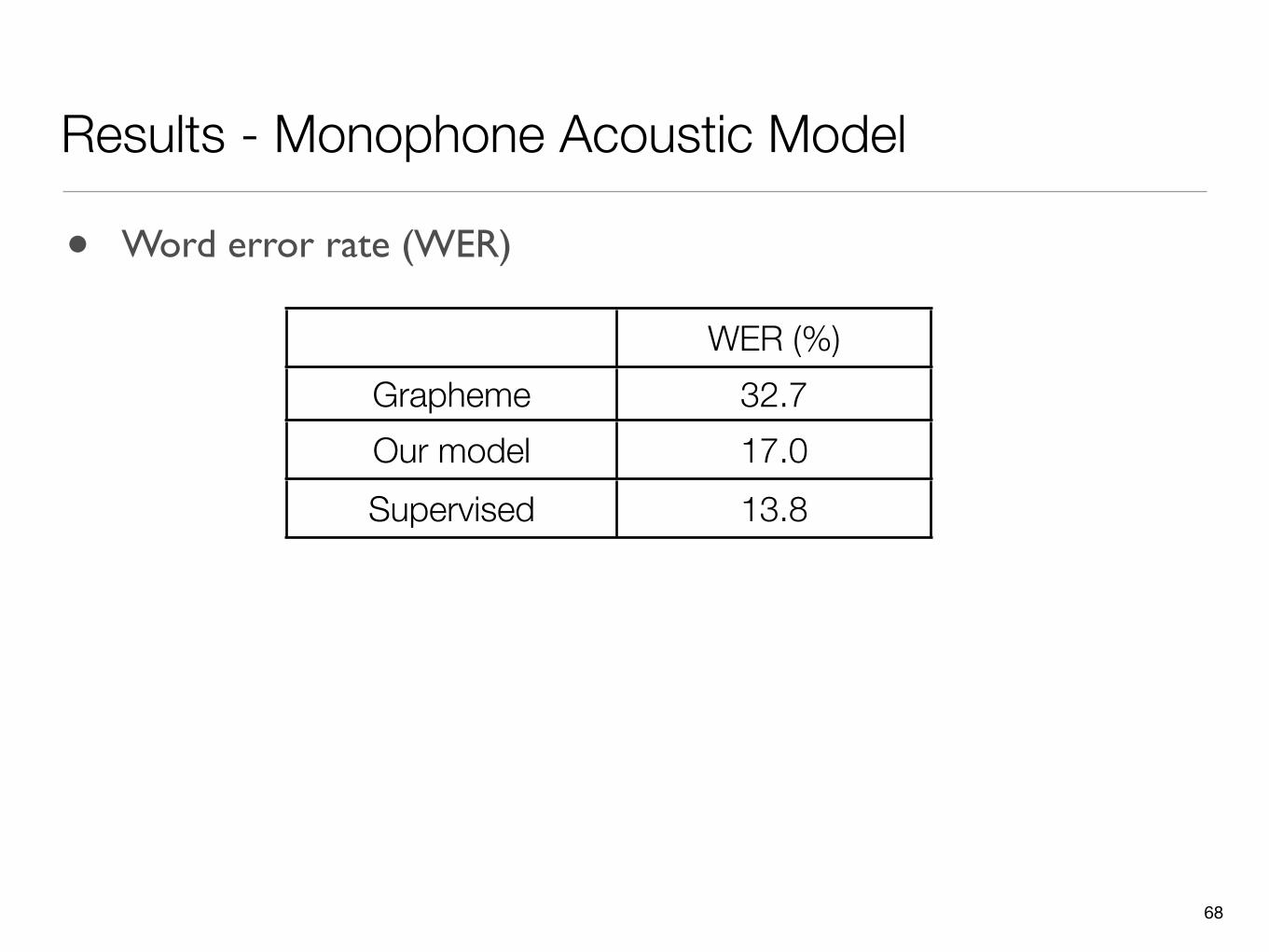
Results - Monophone Acoustic Model
68
WER (%)Grapheme 32.7Our model 17.0Supervised 13.8
• Word error rate (WER)
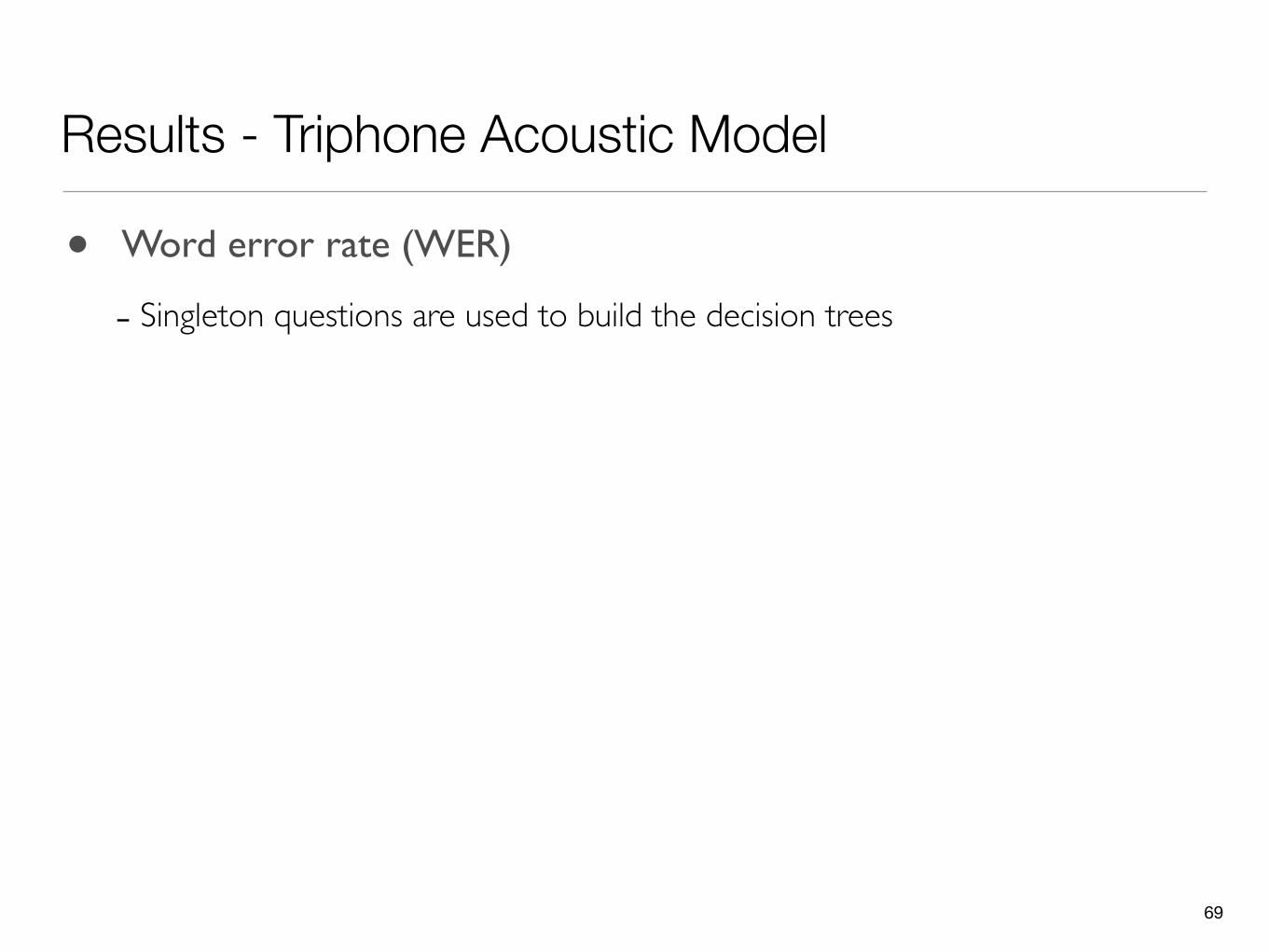
Results - Triphone Acoustic Model
69
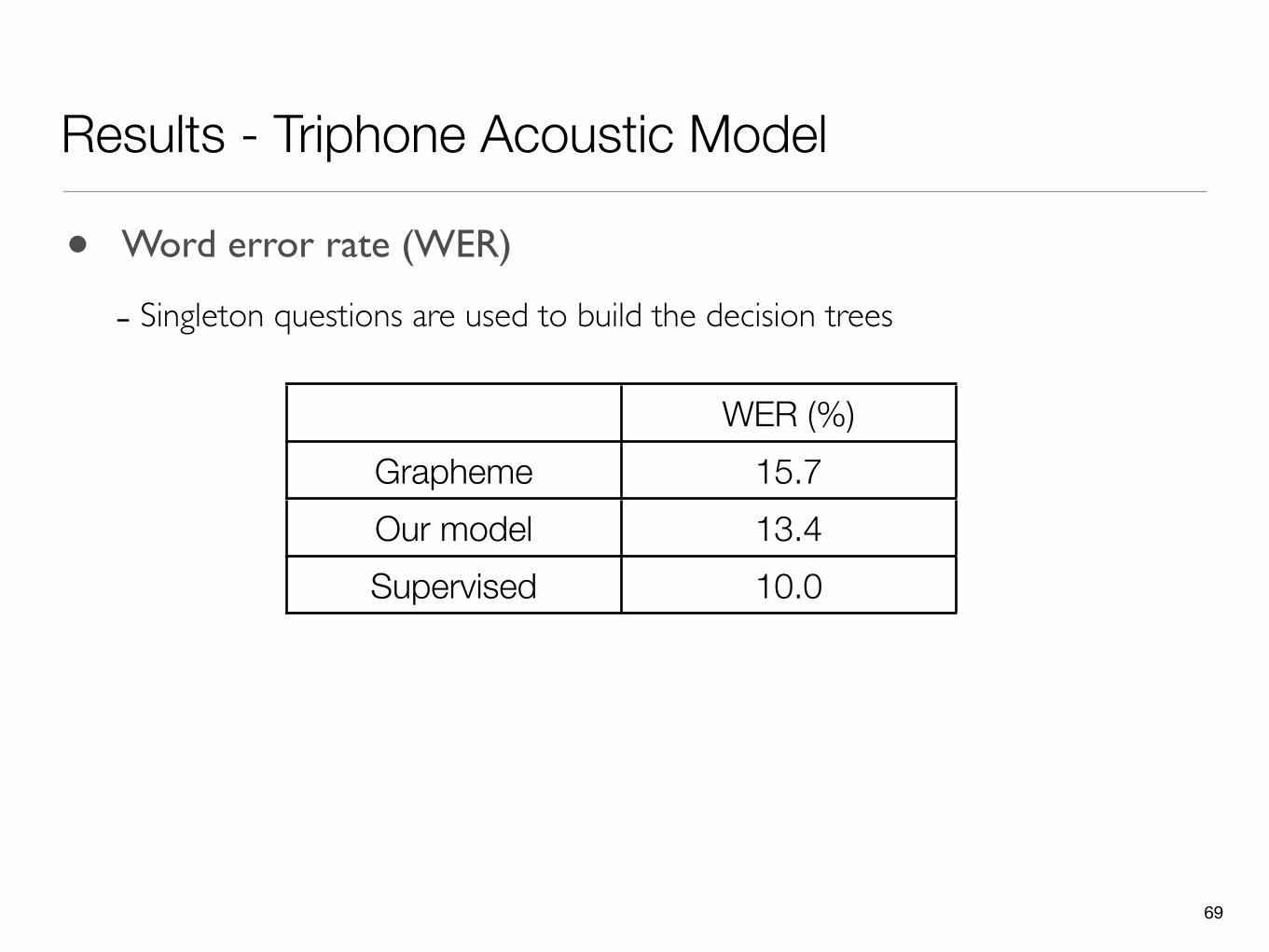
• Word error rate (WER)
- Singleton questions are used to build the decision trees
Results - Triphone Acoustic Model
69
WER (%)Grapheme 15.7Our model 13.4Supervised 10.0
• Word error rate (WER)
- Singleton questions are used to build the decision trees

Related Work
70
• Word pronunciation learning
- A segment model based approach to speech recognition [Lee et al., ICASSP 1988]
- Lexicon-building methods for an acoustic sub-word based speech recognizer [Paliwal, ICASSP 1990]
- Speech recognition based on acoustically derived segment units [Fukuda et al., ICSLP 1996]
- Joint lexicon, acoustic unit inventory and model design [Bacchiani and Ostendorf, Speech Communication 1999]

Related Work
70
• Word pronunciation learning
- A segment model based approach to speech recognition [Lee et al., ICASSP 1988]
- Lexicon-building methods for an acoustic sub-word based speech recognizer [Paliwal, ICASSP 1990]
- Speech recognition based on acoustically derived segment units [Fukuda et al., ICSLP 1996]
- Joint lexicon, acoustic unit inventory and model design [Bacchiani and Ostendorf, Speech Communication 1999]
• Grapheme recognizer
- Grapheme based speech recognition [Killer et al., Eurospeech 2003]
- A grapheme based speech recognizer for Russian [Stuker and Schultz, SPECOM 2004]

Conclusion
71
• A joint learning framework for discovering pronunciation lexicon and acoustic model
- Phonetic units are modeled by a HMM-based mixture model
- L2S mapping rules are captured by weights over mixtures
- L2S rules are tied together through a hierarchical structure

Conclusion
71
• A joint learning framework for discovering pronunciation lexicon and acoustic model
- Phonetic units are modeled by a HMM-based mixture model
- L2S mapping rules are captured by weights over mixtures
- L2S rules are tied together through a hierarchical structure
• Automatic speech recognition experiments
- Outperforms a grapheme-based speech recognizer
- Approaches the performance of a recognizer trained with an expert lexicon

Conclusion
71
• A joint learning framework for discovering pronunciation lexicon and acoustic model
- Phonetic units are modeled by a HMM-based mixture model
- L2S mapping rules are captured by weights over mixtures
- L2S rules are tied together through a hierarchical structure
• Automatic speech recognition experiments
- Outperforms a grapheme-based speech recognizer
- Approaches the performance of a recognizer trained with an expert lexicon
• Apply the lexicon and phone units to existing ASR training methods
- Use our model as an initialization
72
Thank you.
73
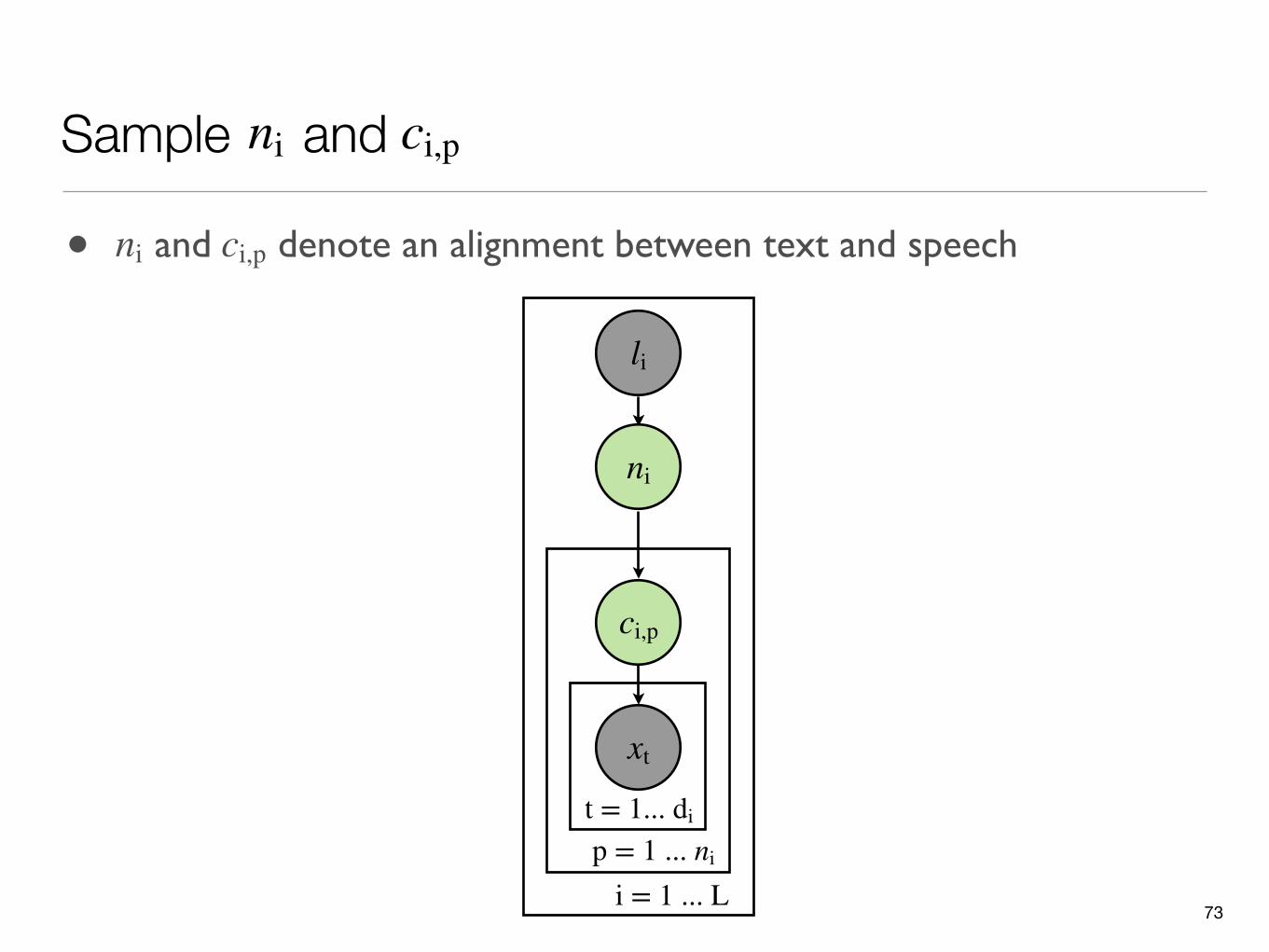
li
ni
xt
t = 1... di
p = 1 ... ni
ci,p
i = 1 ... L
• and denote an alignment between text and speechni ci,p
Sample andni ci,p
74
• Sample a new alignment
- Compute the probabilities of all possible alignments
- Backward message passing with dynamic programming
- Forward block-sample new and
- Similar to inference for hidden semi-Markov models
• and denote an alignment between text and speechni ci,p
ni ci,p
Sample andni ci,p

74
• Sample a new alignment
- Compute the probabilities of all possible alignments
- Backward message passing with dynamic programming
- Forward block-sample new and
- Similar to inference for hidden semi-Markov models
• and denote an alignment between text and speechni ci,p
ni ci,p
Sample andni ci,p

74
• Sample a new alignment
- Compute the probabilities of all possible alignments
- Backward message passing with dynamic programming
- Forward block-sample new and
- Similar to inference for hidden semi-Markov models
• and denote an alignment between text and speechni ci,p
ni ci,p
Sample andni ci,p

74
• Sample a new alignment
- Compute the probabilities of all possible alignments
- Backward message passing with dynamic programming
- Forward block-sample new and
- Similar to inference for hidden semi-Markov models
• and denote an alignment between text and speechni ci,p
ni ci,p
Sample andni ci,p

74
• Sample a new alignment
- Compute the probabilities of all possible alignments
- Backward message passing with dynamic programming
- Forward block-sample new and
- Similar to inference for hidden semi-Markov models
• and denote an alignment between text and speechni ci,p
ni ci,p
Sample andni ci,p

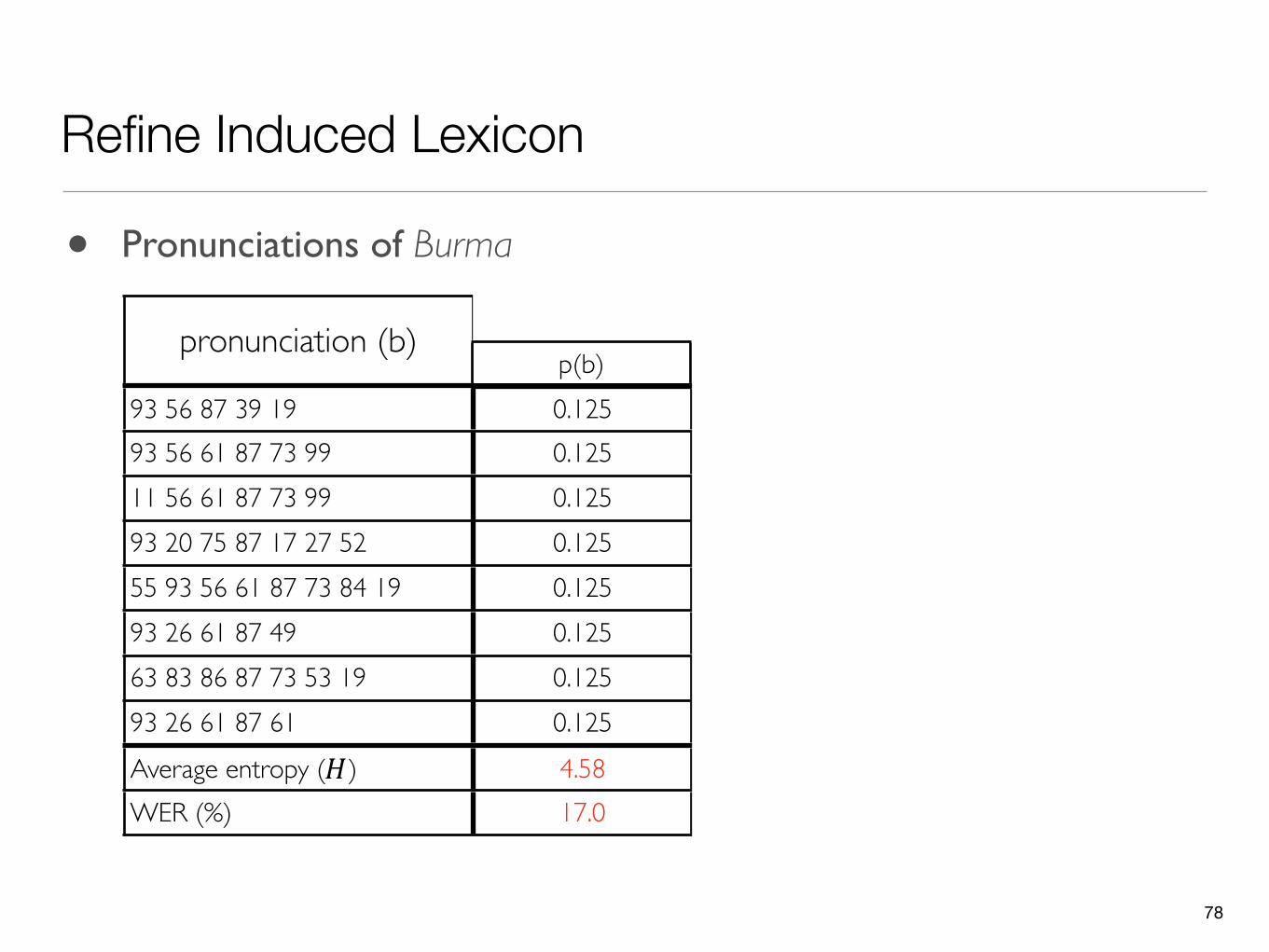
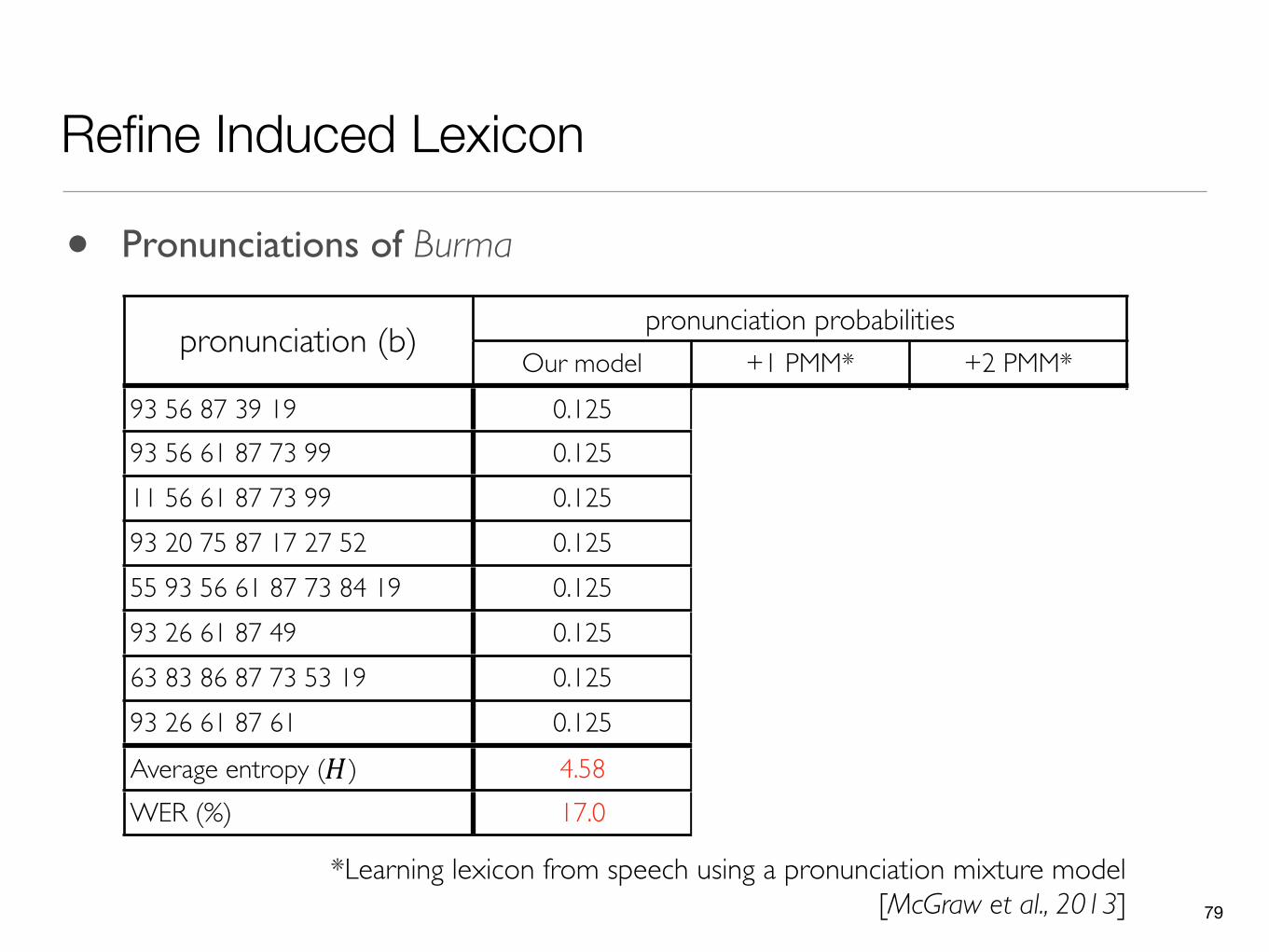
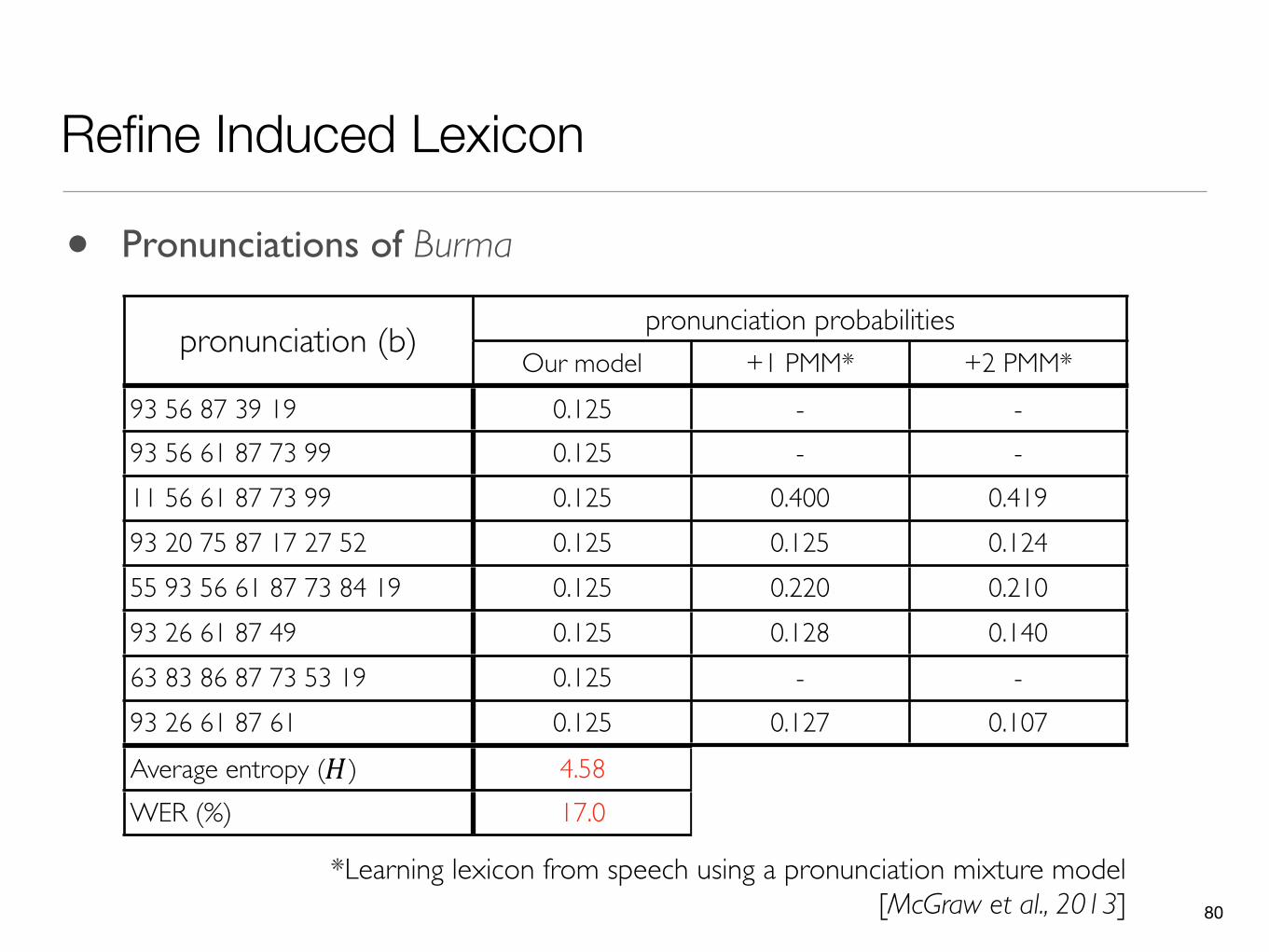
pronunciation (b) pronunciation probabilitiespronunciation probabilitiespronunciation probabilitiespronunciation (b)Our model +1 PMM* +2 PMM*
93 56 87 39 19 0.125 - -93 56 61 87 73 99 0.125 - -11 56 61 87 73 99 0.125 0.400 0.41993 20 75 87 17 27 52 0.125 0.125 0.12455 93 56 61 87 73 84 19 0.125 0.220 0.21093 26 61 87 49 0.125 0.128 0.14063 83 86 87 73 53 19 0.125 - -93 26 61 87 61 0.125 0.127 0.107Average entropy (H) 4.58 3.47 3.03WER (%) 17.0 16.6 15.9
Refine Induced Lexicon
• Pronunciations of Burma
75
B(w)p(b)
: all pronunciations of a word: pronunciation probability
! ≡ −1|!| ! ! !"#$(!)
!∈!(!)!∈!!
!
p(b)

pronunciation (b) pronunciation probabilitiespronunciation probabilitiespronunciation probabilitiespronunciation (b)Our model +1 PMM* +2 PMM*
93 56 87 39 19 0.125 - -93 56 61 87 73 99 0.125 - -11 56 61 87 73 99 0.125 0.400 0.41993 20 75 87 17 27 52 0.125 0.125 0.12455 93 56 61 87 73 84 19 0.125 0.220 0.21093 26 61 87 49 0.125 0.128 0.14063 83 86 87 73 53 19 0.125 - -93 26 61 87 61 0.125 0.127 0.107Average entropy (H) 4.58 3.47 3.03WER (%) 17.0 16.6 15.9
Refine Induced Lexicon
• Pronunciations of Burma
V : vocabulary of the data
76
B(w)p(b)
: all pronunciations of a word: pronunciation probability
! ≡ −1|!| ! ! !"#$(!)
!∈!(!)!∈!!
!
p(b)

pronunciation (b) pronunciation probabilitiespronunciation probabilitiespronunciation probabilitiespronunciation (b)Our model +1 PMM* +2 PMM*
93 56 87 39 19 0.125 - -93 56 61 87 73 99 0.125 - -11 56 61 87 73 99 0.125 0.400 0.41993 20 75 87 17 27 52 0.125 0.125 0.12455 93 56 61 87 73 84 19 0.125 0.220 0.21093 26 61 87 49 0.125 0.128 0.14063 83 86 87 73 53 19 0.125 - -93 26 61 87 61 0.125 0.127 0.107Average entropy (H) 4.58 3.47 3.03WER (%) 17.0 16.6 15.9
Refine Induced Lexicon
• Pronunciations of Burma
V : vocabulary of the data
76
B(w)p(b)
: all pronunciations of a word: pronunciation probability
! ≡ −1|!| ! ! !"#$(!)
!∈!(!)!∈!!
!
p(b)

! ≡ −1|!| ! ! !"#$(!)
!∈!(!)!∈!!
!
pronunciation (b) pronunciation probabilitiespronunciation probabilitiespronunciation probabilitiespronunciation (b)Our model +1 PMM* +2 PMM*
93 56 87 39 19 0.125 - -93 56 61 87 73 99 0.125 - -11 56 61 87 73 99 0.125 0.400 0.41993 20 75 87 17 27 52 0.125 0.125 0.12455 93 56 61 87 73 84 19 0.125 0.220 0.21093 26 61 87 49 0.125 0.128 0.14063 83 86 87 73 53 19 0.125 - -93 26 61 87 61 0.125 0.127 0.107Average entropy ( ) 4.58 3.47 3.03WER (%) 17.0 16.6 15.9
Refine Induced Lexicon
• Pronunciations of Burma
77
p(b)
! ≡ −1|!| ! ! !"#$(!)
!∈!(!)!∈!!
!
pronunciation (b) pronunciation probabilitiespronunciation probabilitiespronunciation probabilitiespronunciation (b)Our model +1 PMM* +2 PMM*
93 56 87 39 19 0.125 - -93 56 61 87 73 99 0.125 - -11 56 61 87 73 99 0.125 0.400 0.41993 20 75 87 17 27 52 0.125 0.125 0.12455 93 56 61 87 73 84 19 0.125 0.220 0.21093 26 61 87 49 0.125 0.128 0.14063 83 86 87 73 53 19 0.125 - -93 26 61 87 61 0.125 0.127 0.107Average entropy ( ) 4.58 3.47 3.03WER (%) 17.0 16.6 15.9
Refine Induced Lexicon
• Pronunciations of Burma
78
p(b)
! ≡ −1|!| ! ! !"#$(!)
!∈!(!)!∈!!
!
pronunciation (b) pronunciation probabilitiespronunciation probabilitiespronunciation probabilitiespronunciation (b)Our model +1 PMM* +2 PMM*
93 56 87 39 19 0.125 - -93 56 61 87 73 99 0.125 - -11 56 61 87 73 99 0.125 0.400 0.41993 20 75 87 17 27 52 0.125 0.125 0.12455 93 56 61 87 73 84 19 0.125 0.220 0.21093 26 61 87 49 0.125 0.128 0.14063 83 86 87 73 53 19 0.125 - -93 26 61 87 61 0.125 0.127 0.107Average entropy ( ) 4.58 3.47 3.03WER (%) 17.0 16.6 15.9
Refine Induced Lexicon
• Pronunciations of Burma
79
*Learning lexicon from speech using a pronunciation mixture model [McGraw et al., 2013]
! ≡ −1|!| ! ! !"#$(!)
!∈!(!)!∈!!
!
Refine Induced Lexicon
80
pronunciation (b) pronunciation probabilitiespronunciation probabilitiespronunciation probabilitiespronunciation (b)Our model +1 PMM* +2 PMM*
93 56 87 39 19 0.125 - -93 56 61 87 73 99 0.125 - -11 56 61 87 73 99 0.125 0.400 0.41993 20 75 87 17 27 52 0.125 0.125 0.12455 93 56 61 87 73 84 19 0.125 0.220 0.21093 26 61 87 49 0.125 0.128 0.14063 83 86 87 73 53 19 0.125 - -93 26 61 87 61 0.125 0.127 0.107Average entropy ( ) 4.58 3.47 3.03WER (%) 17.0 16.6 15.9
• Pronunciations of Burma
*Learning lexicon from speech using a pronunciation mixture model [McGraw et al., 2013]

! ≡ −1|!| ! ! !"#$(!)
!∈!(!)!∈!!
!
Refine Induced Lexicon
81
pronunciation (b) pronunciation probabilitiespronunciation probabilitiespronunciation probabilitiespronunciation (b)Our model +1 PMM* +2 PMM*
93 56 87 39 19 0.125 - -93 56 61 87 73 99 0.125 - -11 56 61 87 73 99 0.125 0.400 0.41993 20 75 87 17 27 52 0.125 0.125 0.12455 93 56 61 87 73 84 19 0.125 0.220 0.21093 26 61 87 49 0.125 0.128 0.14063 83 86 87 73 53 19 0.125 - -93 26 61 87 61 0.125 0.127 0.107Average entropy ( ) 4.58 3.47 3.03WER (%) 17.0 16.6 15.9
• Pronunciations of Burma
*Learning lexicon from speech using a pronunciation mixture model [McGraw et al., 2013]
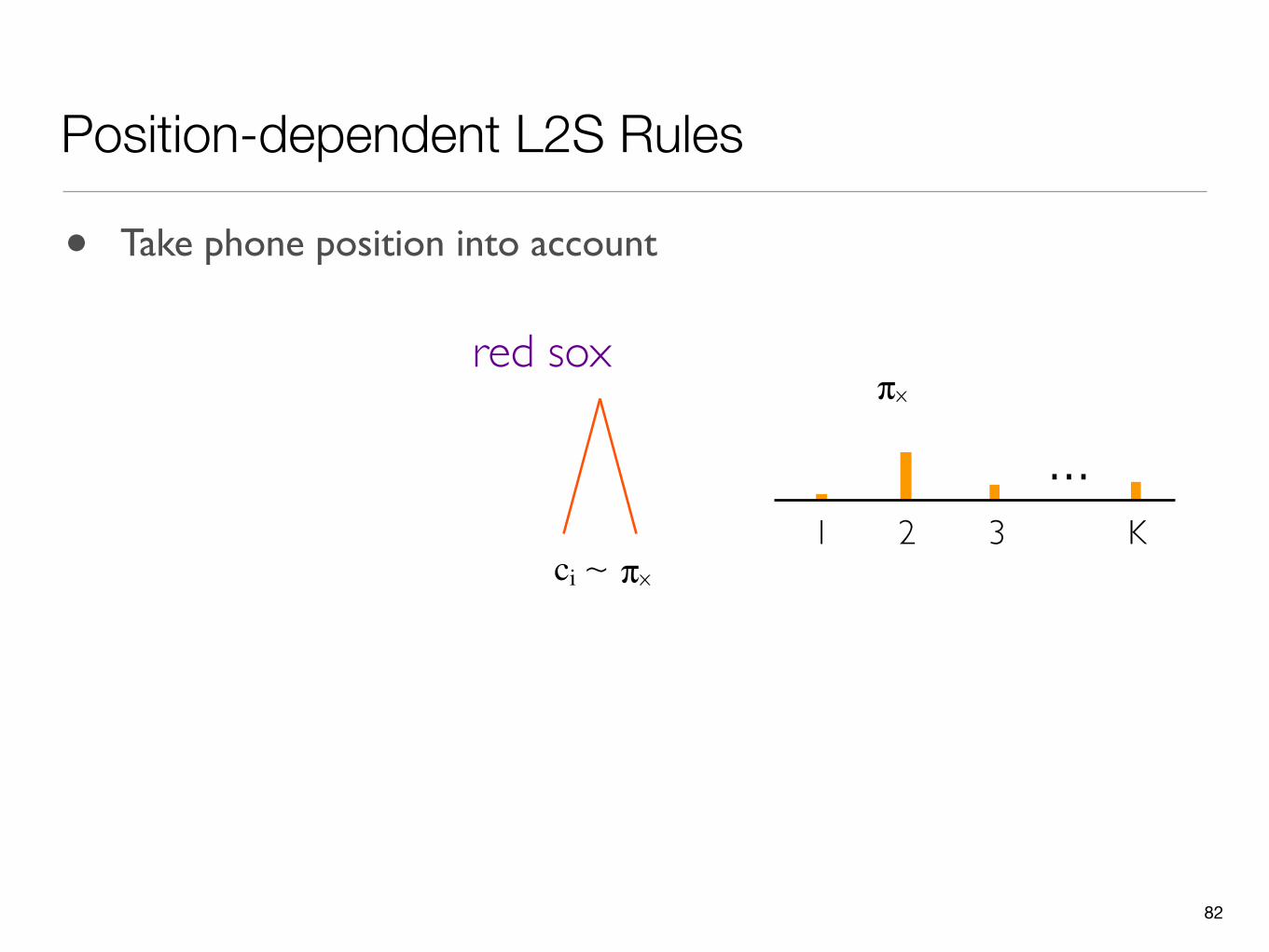
• Take phone position into account
Position-dependent L2S Rules
82
πx
...1 2 3 K
~ ci πx
red sox

• Take phone position into account
Position-dependent L2S Rules
82
πx
...1 2 3 K
~ ci πx
red sox
(2,1) (2,2)

• Take phone position into account
83
red sox
(2,1) (2,2)
~ ci πx,2,1 ~ ci πx,2,2
Position-dependent L2S Rules

• Take phone position into account
83
red sox
(2,1) (2,2)
~ ci πx,2,1 ~ ci πx,2,2
πx,2,1
...1 2 3 K
Position-dependent L2S Rules

• Take phone position into account
83
red sox
(2,1) (2,2)
~ ci πx,2,1 ~ ci πx,2,2
πx,2,1
...1 2 3 K
56
Position-dependent L2S Rules

• Take phone position into account
83
red sox
(2,1) (2,2)
~ ci πx,2,1 ~ ci πx,2,2
πx,2,2
...1 2 3 K
πx,2,1
...1 2 3 K
56
Position-dependent L2S Rules

• Take phone position into account
83
red sox
(2,1) (2,2)
~ ci πx,2,1 ~ ci πx,2,2
πx,2,2
...1 2 3 K
πx,2,1
...1 2 3 K
56 2
Position-dependent L2S Rules





























