Embed Size (px)
Citation preview

John A. Nestor, Kavon Nasabzadeh, and Oliver Bowen
ECE DepartmentLafayette College
Easton, Pennsylvania18042
Supporting Rip-Up and Reroute in an FPGA-Based Multilayer Maze Routing
Accelerator

2 MAPLD 2005/209Nestor
Outline
Background Overview of VLSI CAD Maze Routing with the Lee Algorithm Routing Accelerators The L3 Acclerator Maze Routing with Multiple Nets (Rip up and Reroute)
L4 - Hardware Acclerator with Rip up and Reroute Design Improvements Etching - a new feature to support Rip up and Reroute Control Software Implementation
Results Conclusion

3 MAPLD 2005/209Nestor
The Routing Problem
Given a set desired connections (a netlist) A set of layers available to make connections
Create a set of connections that: Completely connects the terminals of each net Meets timing constraints on delay for critical nets Minimizes the area consumed by routing Minimizes the crossings between each layer Resolves crosstalk and noise issues
4 MAPLD 2005/209Nestor
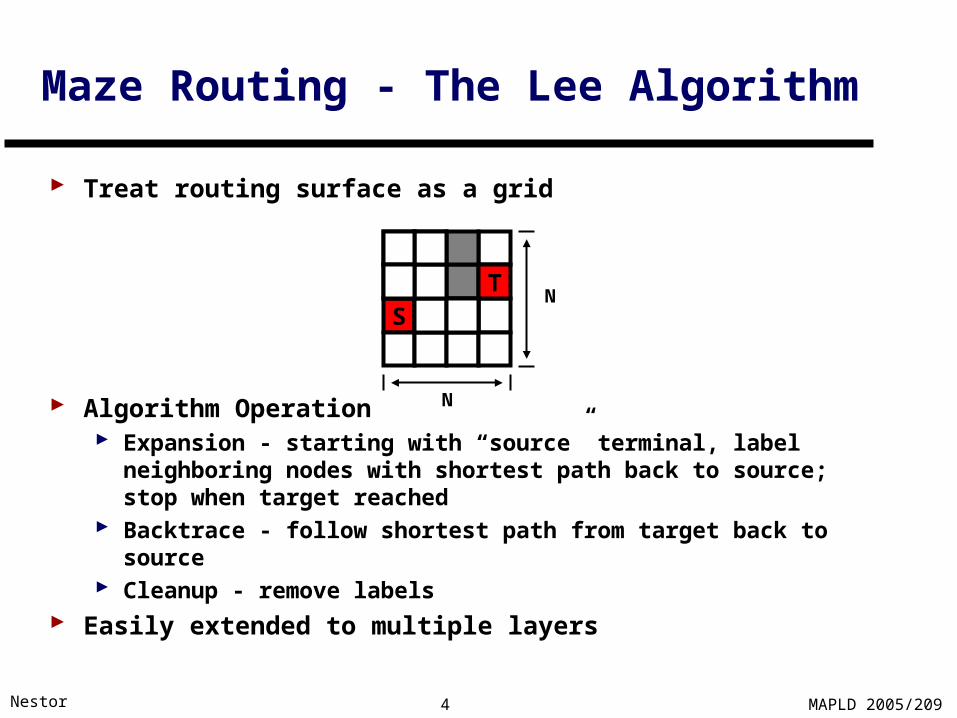
Maze Routing - The Lee Algorithm
Treat routing surface as a grid
Algorithm Operation Expansion - starting with “source” terminal, label neighboring
nodes with shortest path back to source; stop when target reached
Backtrace - follow shortest path from target back to source Cleanup - remove labels
Easily extended to multiple layers
S
T
N
N
5 MAPLD 2005/209Nestor
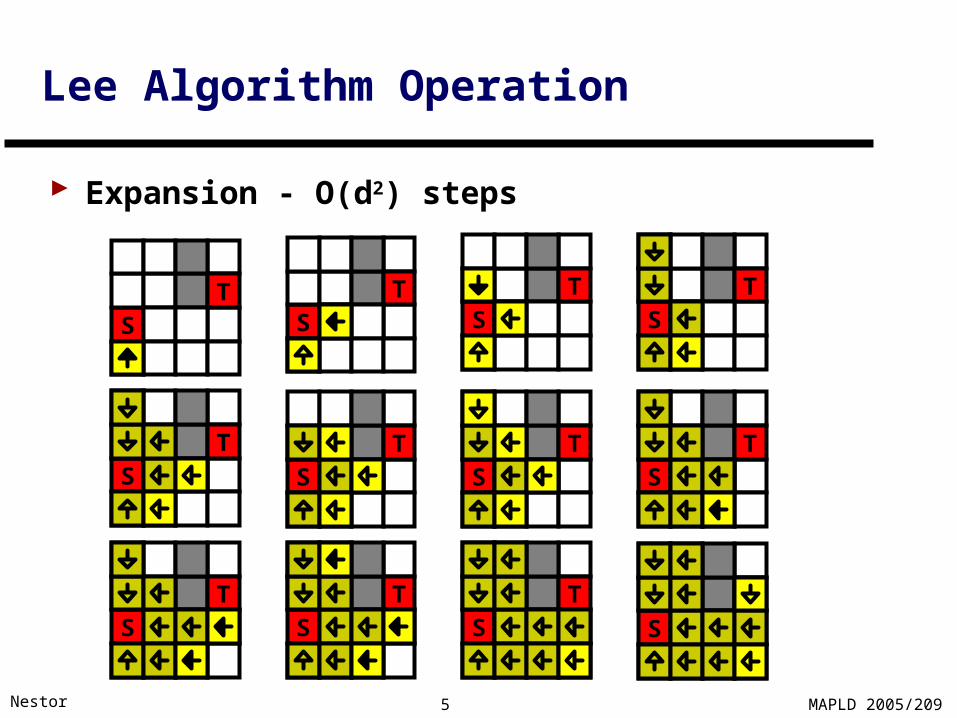
Lee Algorithm Operation
S
TS
T
S
T
S
T
S
TS
T
S
T
S
T
S
T
S
T
S
T
S
T
Expansion - O(d2) steps
6 MAPLD 2005/209Nestor
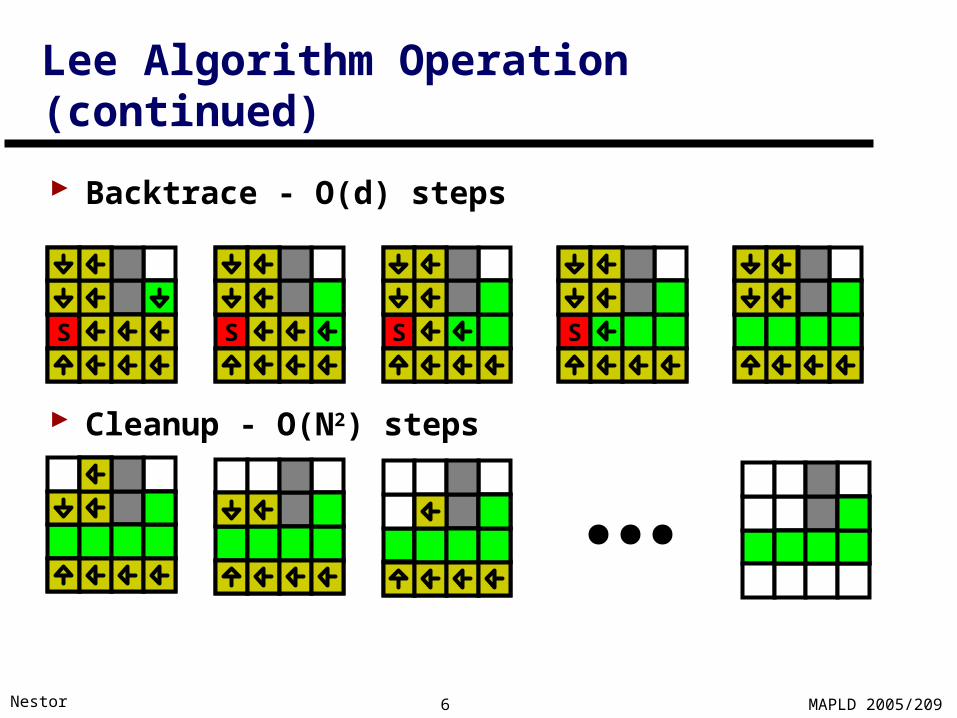
Lee Algorithm Operation (continued)
S
T
S
T
S
T
S
T T
Backtrace - O(d) steps
Cleanup - O(N2) steps
T T T T

7 MAPLD 2005/209Nestor
Lee Algorithm Tradeoffs
Advantage: Guaranteed to find a shortest path connection if one exists
Disadvantages: Slow
• Expansion: O(d2) for connection of distance d
• Backtrace: O(d) for connection of distance d
• Cleanup: O(N2) for an N X N grid
Shortest-path guarantee only for a single connection
8 MAPLD 2005/209Nestor
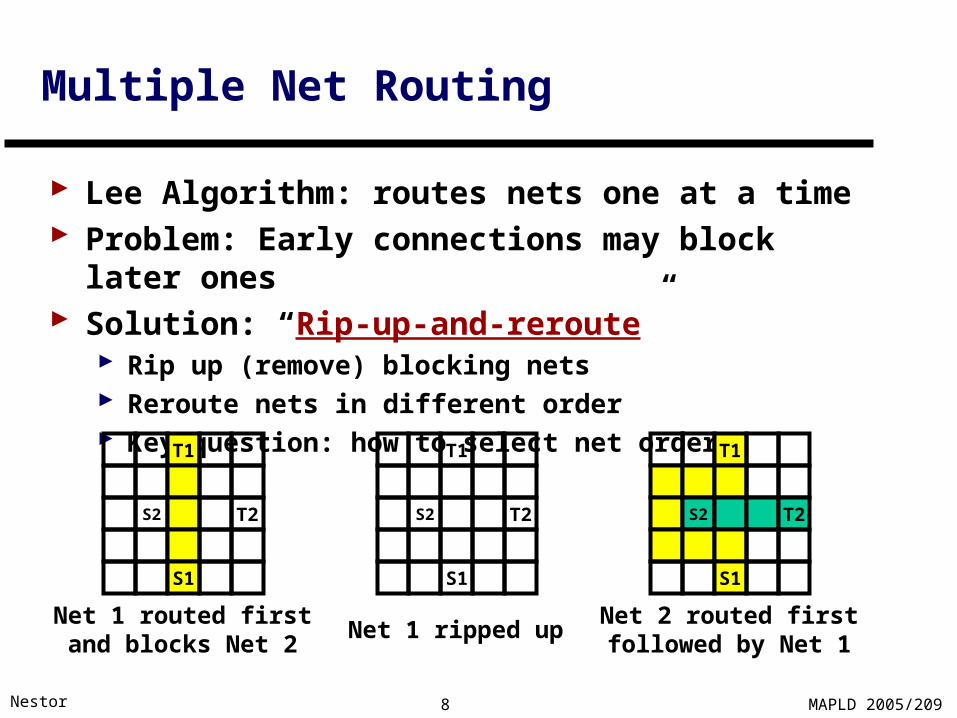
Multiple Net Routing
Lee Algorithm: routes nets one at a time Problem: Early connections may block later ones Solution: “Rip-up-and-reroute”
Rip up (remove) blocking nets Reroute nets in different order Key question: how to select net order?
S2
T1
S1
T2
Net 1 routed firstand blocks Net 2
S2
T1
S1
T2
Net 1 ripped up
S2
T1
S1
T2
Net 2 routed firstfollowed by Net 1
9 MAPLD 2005/209Nestor
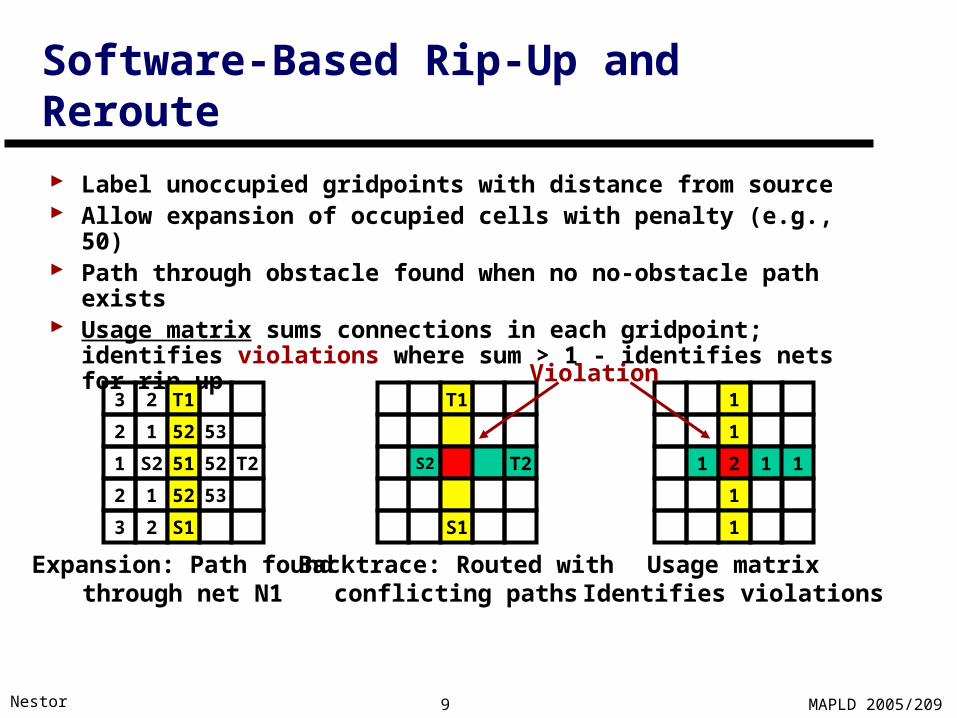
Software-Based Rip-Up and Reroute
Label unoccupied gridpoints with distance from source Allow expansion of occupied cells with penalty (e.g., 50) Path through obstacle found when no no-obstacle path exists Usage matrix sums connections in each gridpoint; identifies
violations where sum > 1 - identifies nets for rip-up
3
2
1
2
3
2
1
S2
1
2
T1
52
51
52
S1
53
52
53
T2
Expansion: Path foundthrough net N1
S2
T1
S1
T2
Backtrace: Routed withconflicting paths
1
1
1
2
1
1
1 1
Usage matrixIdentifies violations
Violation

10 MAPLD 2005/209Nestor
Maze Routing Accelerators
Full grid accelerators(e.g. L-Machine, [Breuer & Shamsa 1981]) One processing element per gridpoint Custom implementation Reduces execution time from O(d2) to O(d) Impractical for multiple layers
Virtual grid acclerators (e.g. HAM [Venkataswaran & Mazumder, 1993]) Each processing element handles multiple gridpoints Custom implementatoin Complex PE design

11 MAPLD 2005/209Nestor
The L3 Maze Routing Accelerator
Modified Direct Grid Approach Use two-dimensional grid to support multiple layers by
time multiplexing PE Operation on each clock cycle
Expansion: • if the cell represented the PE is unexpanded and a
neighboring PE is expanded, enter an “expansion state” that marks the direction of the neighbor (shortest path to source)
• Quit when target enters expansion state Backtrace
• Start with target and follow marked direction• Quite when source is reached
Cleanup: clear expansion states (but not obstacles) of all PEs in parallel - one layer per clock cycle
12 MAPLD 2005/209Nestor
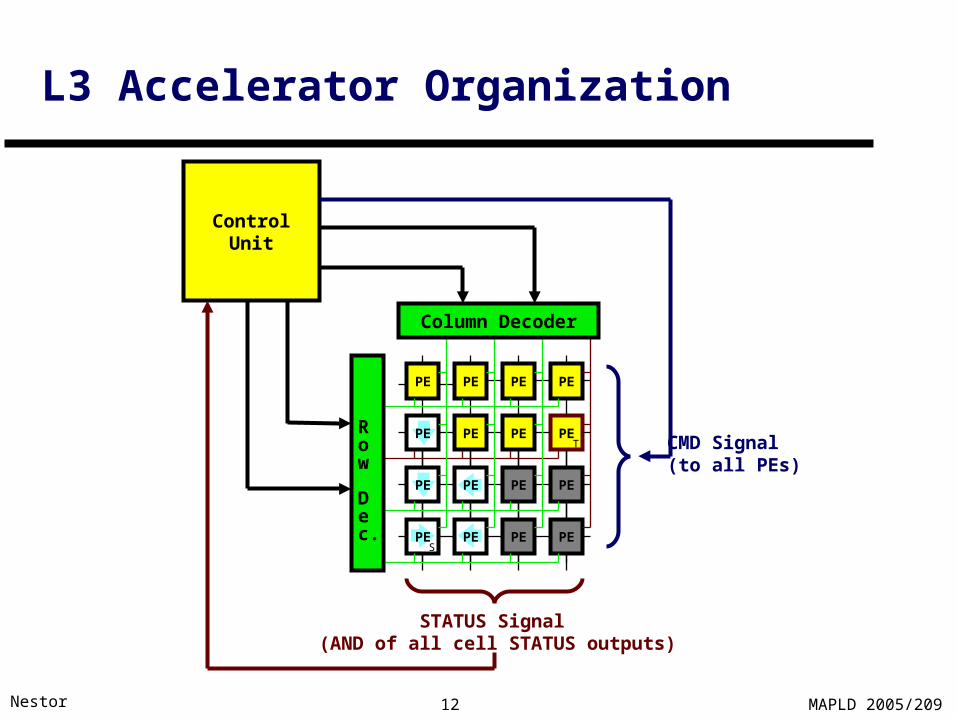
L3 Accelerator Organization
PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
Column Decoder
ControlUnit
STATUS Signal (AND of all cell STATUS outputs)
CMD Signal (to all PEs)
Row
Dec.
S
T

13 MAPLD 2005/209Nestor
L3 - PE Details
Efficient implementation - 32 LUTs in a Xilinx Spartan/Virtex FPGA for each PE Large Xilinx FPGAs can support grids of 32 X 32 PEs
Execution time comparsion: hw vs sw: Expansion: O(L X d) for L layers vs. O(L X d2) Backtrace: O(L X d) vs. O(L X d) Cleanup: O(L) vs. O(L X N2)
Single-net routing speedup of 93X over software for a 16 X 16 4 layer array (2.5GHz Pentum 4)
Drawbacks Limited clock speed due to long timing paths in design No support for multiple net routing

14 MAPLD 2005/209Nestor
L4 - An Improved Routing Accelerator
Support for rip up and reroute using etching Hardware can’t support cost-based routing (unlike SW) Instead, allow expansion of “obstacle” cells Analogy - solvent “etching” through a barrier
Pipelined control unit / array interaction for increased clock rate (50 MHz vs. 24MHz)
Increased implementation cost (44 LUTs), but still feasible for 32 X 32 routing array
Control algorithm in Host Processor supports multiple net routing
15 MAPLD 2005/209Nestor
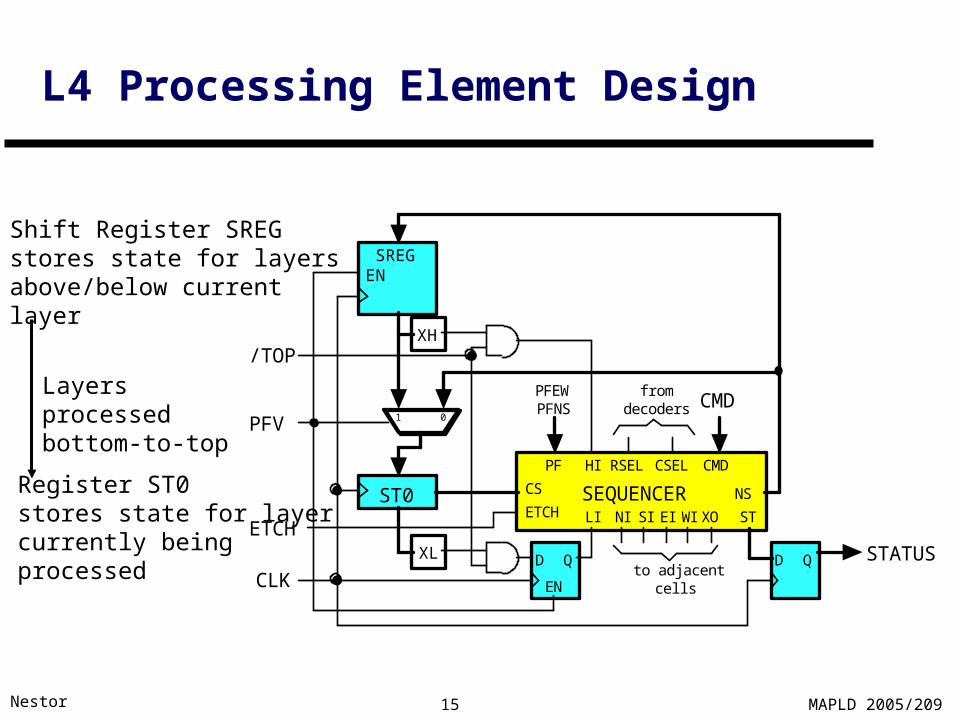
L4 Processing Element Design
Register ST0stores state for layercurrently being processed
Shift Register SREGstores state for layersabove/below current layer
Layers processedbottom-to-top
D QXL
XH/TOP
CLK
SEQUENCERST0
SREG
NSCS
HI
LI NI SI EI WI
RSEL CSEL CMD
ST
to adjacentcells
fromdecoders CMD
STATUS
PFV
EN
1 0
PF
PFEWPFNS
EN
XO
D Q
ETCHETCH

16 MAPLD 2005/209Nestor
L4 Processing Element - States
EMPTY Cell unoccupied and unexpanded
BLOCKED Cell occupied by routed net
XE Expanded - shortest backtrace path to east
XW Expanded - shortest backtrace path to west
XN Expanded - shortest backtrace path to north
XS Expanded - shortest backtrace path to south
XU Expanded - shortest backtrace path upward
XD Expanded - shortest backtrace path downard
Each PE stores the state of each layer at a specific (x,y) coordinate
States:

17 MAPLD 2005/209Nestor
L4 Processing Element - Commands
READ Return state of selected cell(s)
WRITE Write state of selected cell(s)
EXPAND
IF EMPTY or (BLOCKED and ETCH enabled, AND a neighboring cell is expandedTHEN enter corresponding expand state (XN, …)
Commands are broadcast to all cells Decoders select rectangular regions of cells Cell outputs ORed together
CLEARX
Reset expanded cells to EMPTY state Reset etched cells to BLOCKED state
18 MAPLD 2005/209Nestor
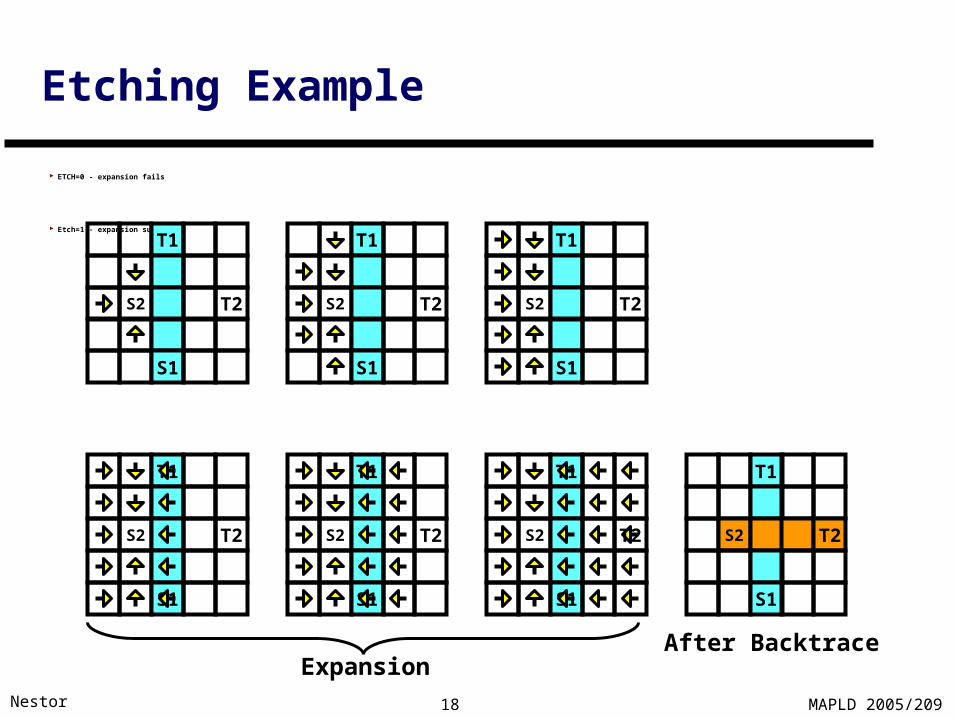
Etching Example
ETCH=0 - expansion fails
Etch=1 - expansion succeeds
S2
T1
S1
T2 S2
T1
S1
T2 S2
T1
S1
T2
S2
T1
S1
T2 S2
T1
S1
T2 S2
T1
S1
T2 S2
T1
S1
T2
After BacktraceExpansion
19 MAPLD 2005/209Nestor
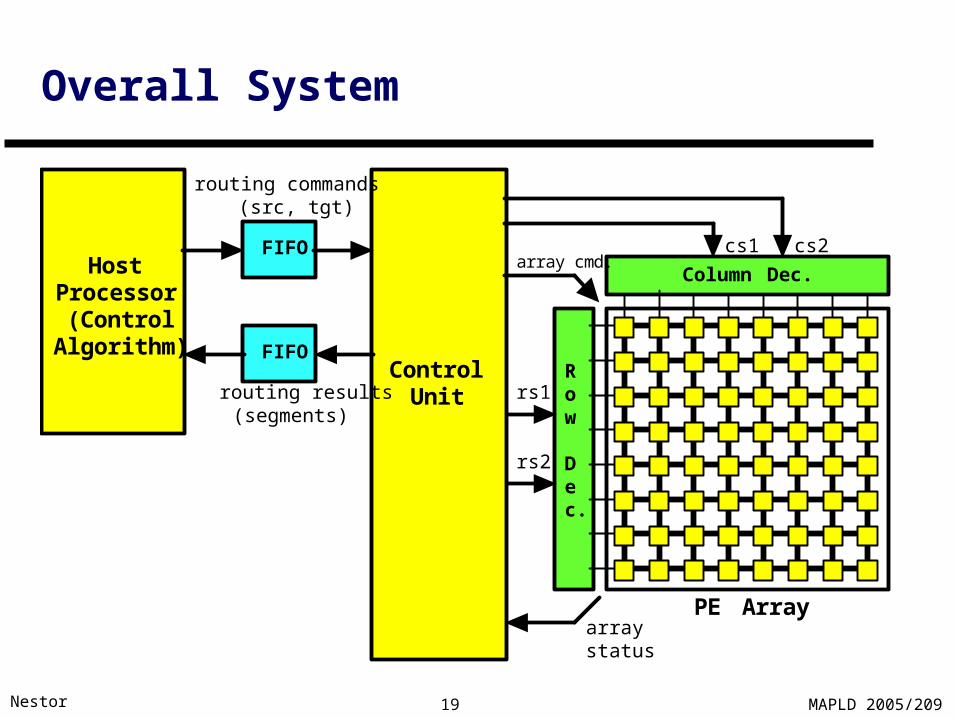
Overall System
Column Dec.
Row Dec.
ControlUnit
arraystatus
array cmd.HostProcessor(Control
Algorithm)
routing commands(src, tgt)
routing results(segments)
rs1
rs2
cs1 cs2
PE Array
FIFO
FIFO

20 MAPLD 2005/209Nestor
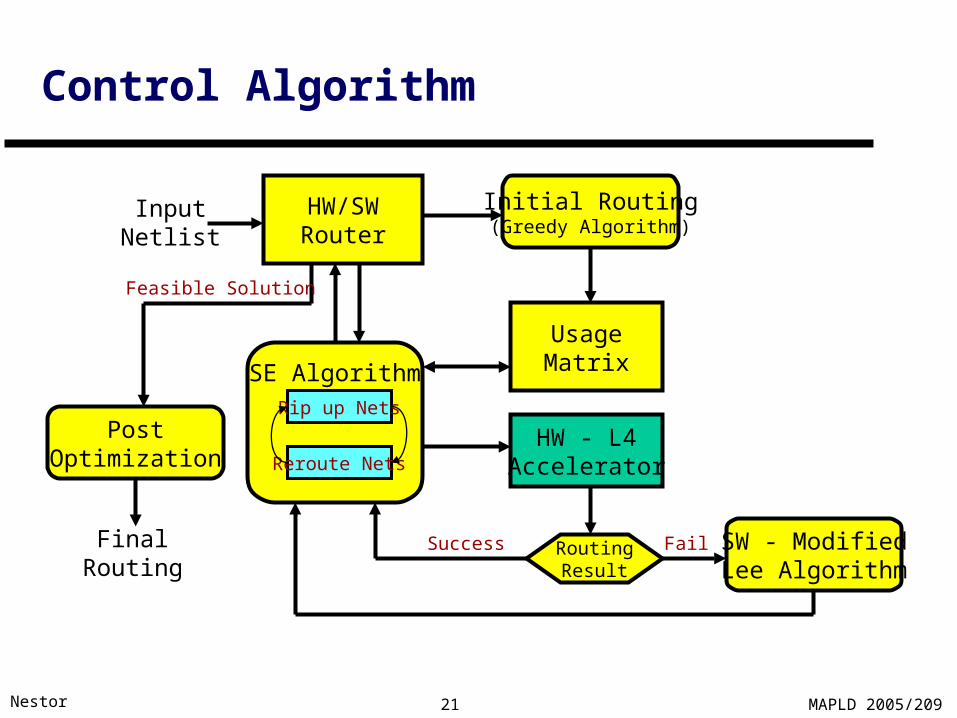
Control Algorithm
Based on the SILK Simulated Evolution router [Lin et. al., 1989]
Key idea: score nets by fitness Score = * (number of violations)
+ * (number of vias – minimum number of vias)
+ * (actual wire length / lower bound of wire length)
Probabilistically select less fit nets for rip-up Use hardware router to find connections Usage matrix (maintained in software) identifies
routing violationsYoun-Long Lin, Yu-Chin Hsu and Fur-Shing Tsai, “SILK: A Simulated Evolution Router”,IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, Vol. 8, No. 10, pp. 1108-1114, October 1989.
21 MAPLD 2005/209Nestor
Control Algorithm
SE AlgorithmRip up Nets
Reroute Nets
HW/SWRouter
Initial Routing(Greedy Algorithm)
HW - L4Accelerator
UsageMatrix
PostOptimization
InputNetlist
RoutingResult
SW - ModifiedLee Algorithm
Success Fail
Feasible Solution
FinalRouting

22 MAPLD 2005/209Nestor
Evaluating the System
Goal: evaluate the best case speedup over software (interface overhead excluded)
Method: Cycle counters in accelerator, host processors
Experiements on two grids 4-layer 8 X 8 4-layer 16 X 16
23 MAPLD 2005/209Nestor
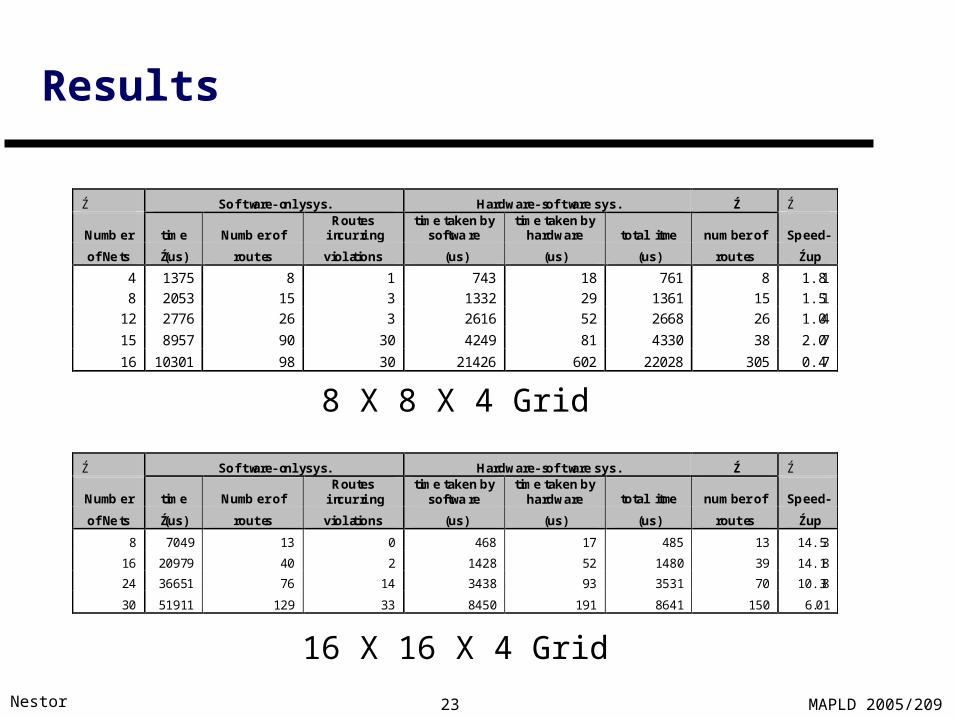
Results
Ź Software-only sys. Hardware-software sys. Ź Ź
Number time Number ofRoutes
incurringtime taken by
softwaretime taken by
hardware total time number of Speed-
of Nets Ź(us) routes violations (us) (us) (us) routes Źup
8 7049 13 0 468 17 485 13 14.53
16 20979 40 2 1428 52 1480 39 14.18
24 36651 76 14 3438 93 3531 70 10.38
30 51911 129 33 8450 191 8641 150 6.01
Ź Software-only sys. Hardware-software sys. Ź Ź
Number time Number ofRoutes
incurringtime taken by
softwaretime taken by
hardware total time number of Speed-
of Nets Ź(us) routes violations (us) (us) (us) routes Źup
4 1375 8 1 743 18 761 8 1.81
8 2053 15 3 1332 29 1361 15 1.51
12 2776 26 3 2616 52 2668 26 1.04
15 8957 90 30 4249 81 4330 38 2.07
16 10301 98 30 21426 602 22028 305 0.47
8 X 8 X 4 Grid
16 X 16 X 4 Grid

24 MAPLD 2005/209Nestor
Conclusions
Extended accelerator for Maze Routing Support for Rip-Up and Reroute Support for multiple net routing Faster clock speed Control algorithm based on simulated evolution
Future Work Larger arrays in a PCI-based accelerator Performance measurements including interface overhead Hardware support to accelerate control algorithm













![Introduction - interoperability.blob.core.windows.netMS-PSOM]-18042… · Web viewThe PSOM Shared Object Messaging Protocol is used to exchange messages between the client and server](https://img.pdfslide.us/doc/110x75/5e107845c9998d7fe8187c1c/introduction-ms-psom-18042-web-viewthe-psom-shared-object-messaging-protocol.jpg)















