Embed Size (px)
Citation preview

Java programmingfor high-performancenumerical computing
by J. E. MoreiraS. P. MidkiffM. GuptaP. V. ArtigasM. SnirR. D. Lawrence
First proposed as a mechanism for enhancingWeb content, the JavaTM language has taken offas a serious general-purpose programminglanguage. Industry and academia alike haveexpressed great interest in using the Javalanguage as a programming language forscientific and engineering computations.Applications in these domains are characterizedby intensive numerical computing and often havevery high performance requirements. In thispaper we discuss programming techniques thatlead to Java numerical codes with performancecomparable to FORTRAN or C, the moretraditional languages for this field. Thetechniques are centered around the use of ahigh-performance numerical library, writtenentirely in the Java language, and on compilertechnology. The numerical library takes the formof the Array package for Java. Proper use of thispackage, and of other appropriate tools forcompiling and running a Java application, resultsin code that is clean, portable, and fast. Weillustrate the programming and performanceissues through case studies in data mining andelectromagnetism.
The Java** language is an attractive general-pur-pose programming language for many funda-
mental reasons: clean and simple object semantics,cross-platform portability, security, and an increas-ingly large pool of adept programmers. In both in-dustry and academia, using the Java language as aprogramming language for scientific and engineer-ing computations is of great interest. Applications
in these domains are characterized by intensive nu-merical computing. The goal of this paper is to showthat the major impediment to the use of Java as avehicle for numerical computing—performance—isnot intrinsic to the language and can be solved usingtechniques we describe.
It is true that, when commercial Java environmentsare used, the performance of numerically intensiveJava programs falls woefully short of the perfor-mance of FORTRAN programs. As shown later in thecase study of an electromagnetics application, theperformance of numerically intensive Java programs,developed and compiled without the benefit of thetechniques described in this paper, can be as low as1 percent of the performance of equivalent FORTRANprograms. Although anecdotal evidence suggests thatperformance degradations of up to 50 percent rel-ative to FORTRAN 90 might be tolerated in numer-ically intensive Java programs in order to gain itsother benefits, a 100-fold performance slowdown isunacceptable.
The Java Grande Forum,1 reflecting in part resultsfrom our own research, has identified five critical
rCopyright 2000 by International Business Machines Corpora-tion. Copying in printed form for private use is permitted with-out payment of royalty provided that (1) each reproduction is donewithout alteration and (2) the Journal reference and IBM copy-right notice are included on the first page. The title and abstract,but no other portions, of this paper may be copied or distributedroyalty free without further permission by computer-based andother information-service systems. Permission to republish anyother portion of this paper must be obtained from the Editor.
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 0018-8670/00/$5.00 © 2000 IBM MOREIRA ET AL. 21

Java language and Java virtual machine issues re-lated to the applicability of the Java language to solv-ing large computational problems in science and en-gineering. Unless these issues are resolved, it isunlikely that the Java language will be successful fornumerical computing. The five critical issues are:
1. Multidimensional arrays—True rectangular mul-tidimensional arrays are the most important datastructures for scientific and engineering comput-ing. A large fraction of this paper is dedicated toexplaining the problem with the existing Java ap-proach to multidimensional arrays. We also de-scribe our solution to the problem, through thedesign of a package implemented entirely in theJava language for multidimensional arrays, whichwe call the Array package for Java.
2. Complex arithmetic—Complex numbers are anessential tool in many areas of science and en-gineering. Computations with complex numbersneed to be supported as efficiently as computa-tions with the primitive real number types, floatand double. The issue of high-performance com-puting with complex numbers is directly tied tothe next issue.
3. Lightweight classes—The excessive overhead as-sociated with manipulation of objects in the Javalanguage makes it difficult to efficiently supportalternative arithmetic systems, such as complexnumbers, interval arithmetic, and decimal arith-metic. The ability to manipulate certain objectsas having just value semantics is absolutely fun-damental to achieve high performance with thesealternative arithmetic systems. In this paper, wedescribe how we were able to treat complexnumbers in Java as values, thus achievingFORTRAN-like performance, without making anychanges to the language. The same approach canbe extended to other numerical types.
4. Use of floating-point hardware—Achieving thehighest-possible level of performance on numer-ical codes typically requires exploiting uniquefloating-point features in each processor. This ex-ploitation is often at odds with the Java goal ofexact reproducibility of results in every platform.In this paper we specifically consider the perfor-mance impact of utilizing the POWER and Pow-erPC* fused multiply-add (fma) instruction in Java.
5. Operator overloading—If multidimensional ar-rays and complex numbers (and other arithmeticsystems) are to be implemented in Java as a setof standard packages, then operator overloadingis necessary to make the use of these packagesmore attractive to the application programmer.
Although operator overloading is a feature pri-marily related to code usability and readability,it does have performance implications. We dis-cuss these implications in the context of complexnumbers.
This paper discusses our efforts and lists our accom-plishments in addressing the performance problemsassociated with using the Java language for numer-ical computing. We focus mostly on multidi-mensional arrays and complex numbers, but our dis-cussion touches all of the previously mentioned fiveissues. We show that, when our techniques areapplied, Java code can achieve between 55 and 90percent of the performance of highly optimizedFORTRAN code in a variety of engineering andscientific benchmarks. We illustrate the details ofthese performance results through detailed casestudies in data mining and electromagnetism. Wealso provide a summary of results for other bench-marks. The compiler optimizations we discuss havebeen implemented in our research prototype versionof the IBM High-Performance Compiler for Java(HPCJ).2
The remainder of this paper is organized as follows.The next section is an overview of the problems as-sociated with the current Java approaches to mul-tidimensional arrays and nonprimitive numericaltypes. The third section describes the detailsof the Array package for Java, which supportsFORTRAN-like performance for multidimensional ar-ray computations in Java code. The subsequent sec-tion is a case study of a data mining computationillustrating the performance benefits that result fromusing the Array package. The fifth section is a casestudy of an electromagnetics application that makesheavy use of complex numbers. The sixth sectionsummarizes performance results from a larger setof numerically intensive benchmarks, showing thatJava implementations can be performance-compet-itive with the best FORTRAN implementations. Theseventh section discusses some related work, and fi-nally, the last section presents our conclusions, dis-cusses the impact of our work, and elaborates onsome future research.
The Array package is freely available from alpha-Works*, at http://www.alphaworks.ibm.com/tech/ninja. Our project Web page, with additional infor-mation on the Array package and our research ingeneral, is located at http://www.research.ibm.com/ninja.
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200022

Java approach to multidimensional arraysand complex numbers
In this section, we explain the performance problemsassociated with the existing Java approaches to im-plementing multidimensional arrays and alternativearithmetic systems, particularly complex numbers.We also discuss why the corresponding FORTRAN 90approaches are so much more efficient. We give ataste of our solutions to Java performance problems,which are discussed in more detail in later sections.We show how FORTRAN-like performance can beachieved with 100 percent Java code while remain-ing within the philosophy and spirit of the language.
Java arrays. Although the specification of Java ar-rays does not mandate their exact organization, itplaces sufficient constraints so that all implementa-tions we know of appear as shown in Figure 1. Thefigure shows how two-dimensional arrays would belaid out, and accessed, in a Java implementation.
The Java language does not directly support arraysof rank greater than one. Thus, a two-dimensionalarray is represented as an array-of-arrays: an arraywhose elements are, in turn, references to one-di-mensional row arrays. Each array is represented asan array object descriptor followed by a chunk of stor-age that contains the elements of the array. The ar-ray object descriptor contains the fields that arepresent in all objects (lock bits, bits used by the gar-bage collector, type information, etc.), as well as theupper bound of the array. If a two-dimensional ar-ray of type T is being represented, the elements ofeach row array are either of type T, if T is a Javaprimitive type, or references to objects of type T. InFigure 1, each element is a Java primitive of typedouble. Although the layout of the elements of thearray are not specified, they are typically containedin a contiguous chunk of storage.
The advantages of this layout for an array are: verygeneral structures can be created, and the necessary
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 23

information to perform bounds checking is alwaysavailable. As seen in Figure 1, it is not required thatevery row have the same length. Figure 1 is an ex-ample of a ragged array. It is not even necessary forevery row to be unique—rows 2 and n 2 2 of arrayA point to the same row array object, and thusA[2][4] and A[n 2 2][4] name exactly the same el-ement. Even more generality is possible with arraysof Objects. In that case, each element can be an ar-bitrary Java object, even another array of any rankand type. All this generality comes with a perfor-mance price—a price that is too high for numericalprograms that do not need the supplied generality.
First, consider array bounds checking. The Java lan-guage specification requires that any access to an ar-ray element that is not in bounds must throw an ex-ception. The job of checking for out-of-boundsexceptions exacts a significant toll on Java perfor-mance. In Reference 3 it is shown that eliminatingarray bounds checks alone produced speedups onthe IBM POWER and PowerPC processors three tofour times over keeping the checks. On some pro-cessors, this overhead is less. The real impact on per-formance, however, comes from having one or morepotential exceptions for every data access. BecauseJava exceptions are precise, operations cannot bemoved past a potential exception. This limitation ef-fectively precludes almost all optimizations tradition-ally applied to numerical programs4,5—optimizationsthat are necessary for good performance.
In Reference 3, techniques for creating program re-gions free of array bounds exceptions are presented.Even with these techniques, the Java array modelinterferes with good optimization. Optimizingbounds checks for an array reference A[i][ j] insidea loop structure requires: (1) determining the rangeof values that i and j can take during execution ofthe loop and (2) being able to test, before startingloop execution, that those ranges will be within thelegal bounds of the array. Since a Java two-dimen-sional array can have rows of different lengths, asshown in Figure 1, the test has to be performed forall rows of the array. A much simpler test could beused if the array were guaranteed to be rectangular(i.e., all rows of the same length).
Another major impediment to optimization in Javais the ability to alias rows of an array. Aliasing oc-curs when two or more apparently different varia-bles or references actually refer to the same datum.An example of aliasing is shown in Figure 1, whereA[2] and A[n 2 2] refer to the same row. More-
over, B[1], B[2], A[2] and A[n 2 2] all refer to thesame row. The problem with aliasing is that manyoptimizations rely on moving data reads and writesrelative to one another. For this rearrangement tobe legal, it is necessary that (1) all writes to a datumbe kept in order; (2) that no write to a datum bemoved prior to a read of the same datum; and (3)that no read from a datum be moved after a writeto the same datum. Essential to determining the le-gality of a transformation is the ability to determinewhen two operations are to different data and, there-fore, independent. Aliasing makes this more diffi-cult because it is no longer possible to say that justbecause two variables have different names, or be-cause different array elements have different coor-dinates, they must refer to different memory loca-tions.
The final problem with Java arrays that we discussis the cost of accessing an element. Accessing ele-ment A[2][4] requires the following steps: (1) getthe reference to the array object A; (2) determinethat A is not a null pointer; (3) determine that “2”is an in-bounds index for A; (4) get the reference tothe array object that is row 2; (5) determine that thisobject reference is not a null pointer; (6) determinethat “4” is an in-bounds index for A[2]; and (7) getthe data element A[2][4]. In contrast, as we will see,FORTRAN 90 requires only two steps.
FORTRAN 90 arrays. The structure of a FORTRAN90 two-dimensional array is shown in Figure 2. It hastwo major components: a block of dense, contigu-ous storage that holds the data elements of the ar-ray, and a descriptor that contains the address of theblock of dense storage, bounds information for eachdimension, the size of individual data elements, andother information used to index the array. This in-dexing information is used to access array elementsand implement array sections. Accessing an elementof the array is straightforward: the base address ofthe storage is extracted from the descriptor, and thesubscript, along with the indexing information con-tained in the descriptor, is used to compute an off-set into the data storage.
Because of the information contained in the descrip-tor, array sections (see array B in Figure 2, whichcorresponds to the shaded elements of A) can beimplemented efficiently. A section of a FORTRAN 90array A is a view of A that accesses some subset ofthe elements of A. The section has the followingproperties: (1) it (logically) utilizes the same stor-age as the original array, thus a change of an ele-
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200024

ment value contained in A and the section is reflectedin both; (2) the section has rank less than or equalto the rank of A; (3) the elements in the section aredefined by enumerating element indices along eachaxis; and (4) each element enumerated must be avalid, in-bounds element of the original array axis.Let A be an array of shape 8 3 8. Then B fA(2 ; 8 ; 2, ;) associates B with rows 2, 4, 6, 8, andall columns of the original array A. The referenceB(3, 4) accesses row 6 and column 4 of the originalarray A. This example is illustrated in Figure 2.
The design of FORTRAN 90 arrays has several advan-tages. First, because the storage is dense and con-tiguous, access requires a single pointer dereferenceand offset computation, regardless of the rank or di-mensionality of the array being accessed. Second, theability to take sections allows great flexibility in pass-ing portions of arrays to library functions. Third, arich set of intrinsic functions (i.e., built-in operatorsexpressed syntactically as functions) that operate onarrays can be supported. Fourth, most primitive op-erations in the language (e.g., 1, 2, p, and /) are over-loaded and specify the operation applied element-wise over the entire array. Finally, despite its supportof array sections, aliasing disambiguation withFORTRAN 90 arrays is much simpler than with Javaarrays. Given two two-dimensional FORTRAN 90 ar-ray sections A(lA
1 ; uA1 ; sA
1 , lA2 ; uA
2 ; sA2) and
B(lB1 ; uB
1 ; sB1 , lB
2 ; uB2 ; sB
2), alias disambiguationis a matter of showing that A Þ B or that the in-tersection of the ranges is empty: (lA
1 ; uA1 ; sA
1) ù(lB
1 ; uB1 ; sB
1) 5 À or (lA2 ; uA
2 ; sA2) ù (lB
2 ; uB2
; sB2) 5 À. Even if disambiguation cannot be done
at compile time, the run-time test is trivial. In com-parison, the disambiguation of two two-dimensionalJava arrays, with their unrestricted pointers as shownin Figure 1, is almost always impossible at compiletime (without extensive interprocedural analysis) andvery expensive at run time.
FORTRAN 90 arrays are not, however, without theirfaults. Storage association exposes the programmerto the fact that data elements are contiguous in mem-ory, and that the next logical element of the arrayis also adjacent in storage to the previous element.Quite frequently, FORTRAN programs rely on stor-age association to execute correctly. In addition, op-timizations that alter the layout of an array6–9 areglobally visible. As a consequence, data typically haveto be copied to and from the original layout. Copy-ing makes these optimizations more fragile and lessuseful, since the overhead of copying the arrays twicemust be factored into the cost model for determin-ing whether the optimization should be performed.
A solution for true multidimensional arrays in Java.To overcome the performance deficiencies inherentto Java arrays, we developed the Array package forJava. The Array package is a class library that im-plements true rectangular multidimensional arraysthat combine (1) the efficiency of FORTRAN 90 ar-rays, (2) the flexibility of data layout of Java arrays,and (3) the safety and security features provided bythe Java requirement for bounds checking. With theArray package, multidimensional arrays are created
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 25

using standard Java constructs. For example, thecode
doubleArray2D A 5 new doubleArray2D(m,n);
doubleArray2D B 5 new doubleArray2D(m,n);
declares two two-dimensional arrays A and B of (rect-angular) shape m 3 n. Elements of these arrays canbe accessed using set and get methods from the classdoubleArray2D. For example,
A.set(j,i,B.get(i,j));
copies element (i, j) of array B into element ( j, i)of array A. A more detailed description of the Arraypackage appears in the next section. For now,suffice it to say that the Array package has
FORTRAN-like semantics to facilitate compiler op-timizations.
Complex numbers in the Java and FORTRAN 90languages. In the FORTRAN programming language,complex numbers are supported as primitive types.Arithmetic operations with complex numbers can becoded as easily as with real numbers. Multidimen-sional arrays of complex numbers are directly sup-ported in FORTRAN. Java, in contrast, does not sup-port primitive complex types. The typical approachfor implementing complex numbers and complexarithmetic in Java is through the definition of a Com-plex class. Some components of such a class, whichis being proposed for standardization by the JavaGrande Forum,1 are shown in Figure 3. Objects ofthis class are used to represent complex numbers.We note that a Complex object typically requires 32
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200026

bytes for representation: a 16-byte object descriptor(present in all Java objects) and two 8-byte fields forthe real and imaginary parts.
The operation a 3 b 1 c, where a, b, and c arecomplex numbers, can be coded in Java as
a.times(b).plus(c)
where a, b, and c are references to objects of classComplex. Note that the evaluation of a.times(b) cre-ates a new Complex object to hold this intermediateresult. Method plus is then invoked on this interme-diate result, creating yet another object with the re-sult of a 3 b 1 c.
The approach of representing complex numbers asobjects of class Complex, and the associated creationof objects to represent the output of computations,results in a very high cost for using complex num-bers in Java. As seen in the MICROSTRIP benchmarkresults (in the case study on electromagnetics, wherea detailed analysis of this benchmark is given), ap-plications using a Java Complex class (to representcomplex numbers) can be 100 times slower than theequivalent applications in FORTRAN 90. These per-formance problems can be addressed by using thetechnique of semantic expansion, 10 as implementedin our research prototype HPCJ.
Semantic expansion treats standard classes as lan-guage primitives. Unlike traditional procedure ormethod “inlining,” which (intuitively) treats the in-lined method as a macro, semantic expansion usesthe compiler’s built-in knowledge of the class seman-tics to directly generate efficient, legal code. Withsemantic expansion, Complex objects and operationson those objects are recognized by the compiler andtreated essentially as language primitives (largely asFORTRAN 90 would treat them). The arithmeticmethods of class Complex are treated by semanticexpansion as operating and returning complex val-ues (pairs of [real, imaginary] doubles). If the con-sumers of theses values are other arithmetic meth-ods of Complex, they are semantically expanded todirectly use the complex values. That is, only the re-sulting value of an operation is propagated from onestep to the next. Otherwise, the value is converted toa Complex object, with all the properties of a regularJava object. By treating complex numbers as valueswhenever possible, temporary Complex objects do nothave to be created for arithmetic operations, thusreducing the allocation and garbage collection over-head. This approach delivers the same performance
benefit for complex numbers as the proposed valueobject extension for Java,1 without requiring lan-guage changes. We show in the section on the elec-tromagnetics case study and in the subsequent sec-tion that semantic expansion can sometimes improvethe performance of Java applications using complexarithmetic to approximately 80 percent of the per-formance of corresponding FORTRAN 90 programs.
The problems we described earlier associated withJava multidimensional arrays are exacerbated witharrays of complex numbers. A Java two-dimensionalarray of Complex, declared as Complex[ ][ ] C, is justa collection of pointers to Complex objects. Optimiz-ing null-pointer checks requires, in general, an in-spection of the entire array. In addition to the in-discriminate row-level aliasing shown in Figure 1,Java arrays of Complex objects are subject to indis-criminate element-level aliasing, making the issue ofalias disambiguation even harder.
We address the problems related to Java arrays ofcomplex numbers by including in the Array packageclasses that represent true rectangular arrays of com-plex numbers (e.g., ComplexArray2D). These arraysalways have a complex number associated with eachelement, and there is no aliasing between two dif-ferent elements.
The role of operator overloading. The Array pack-age, the Complex class, semantic expansion, andother compiler techniques we developed can success-fully achieve high levels of performance with numer-ical computing in Java. However, we are still left withthe difficulty of writing, maintaining, and reading pro-grams that make extensive use of classes to repre-sent numerical and array types. Some form (maybelimited) of operator overloading is necessary to al-low application programmers to write their codes ina clear and intuitive notation. At a minimum, it isnecessary to support operator overloading of the ba-sic arithmetic (1, 2, p, /, %) and relational (55,!5, ,5, ,, ., .5) operators, as well as of the ar-ray indexing operator ([ ]).
As an example, consider the evaluation of b[i, j] 5a[i 1 1, j] 1 a[i 2 1, j], where b and a are two-dimensional arrays of complex numbers (implement-ed as ComplexArray2D). Ideally, we would like to codethis operation as
b[i,j] 5 a[i11,j] 1 a[i21,j] (1)
which is an operator-overloaded representation for
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 27

b.set(i,j,a.get(i11,j).plus(a.get(i21,j))) (2)
The set and get methods correspond to the over-loaded array indexing operator ([ ]) and the plusmethod corresponds to the overloaded addition op-erator (1). Operator overloading is fundamental forproductivity and clarity of numerical codes using non-primitive arithmetic systems and array classes. (Analternative to defining operator overloading in thelanguage is to make use of visual editors that presenta more convenient interface to numerical program-mers. Unfortunately, it binds the programmer to aparticular development environment.)
Operator overloading also has an impact on perfor-mance. Rules for the semantics of operator overload-ing must be simple, and code written with overloadedoperators (e.g., code fragment 1) is typically equiv-alent to code that creates temporary objects (e.g.,code fragment 2). In other words, object reuse incode with overloaded operators is difficult. Thus, thekind of optimizations through semantic expansionthat we describe for complex numbers is even moreimportant.
The Array package for Java
The goal of the Array package for Java is to over-come the limitations inherent in Java arrays in termsof performance and ease of use, as compared to ar-ray implementations in other languages. A major de-sign principle of the Array package is to define a setof classes implementing FORTRAN 90-like multidi-mensional arrays that are highly optimizable, ame-nable to compiler analysis techniques, and that con-tain the functionality necessary for numericallyintensive computing. We have modeled the Java Ar-ray package along features of the FORTRAN 90 lan-guage11 and the A11/P11 libraries.12,13 Not sur-prisingly, the reader will also find similarities withAPL, since that programming language undoubtedlyinfluenced the design of FORTRAN 90. However, APLis a much more dynamic language, with strong sup-port for polymorphism of data and functions. Thedesign of the Java Array package, particularly as de-scribed in this paper, follows the more static natureof FORTRAN 90. This design allows us to leveragemature compiler technologies that have been devel-oped for FORTRAN over the course of many years.It is important to emphasize that the Array packageis written entirely in the Java language. Its use doesnot require any code preprocessing steps, just theappropriate import statements.
A word about notation: From now on, when we usethe term Array (with an uppercase A) we refer tothe constructs provided by the Array package. Thestandard arrays in the Java language will be referredto as Java arrays (with a lowercase a).
The functionality provided by the Array package isimplemented by a set of basic methods and oper-ations that are highly optimizable. The class hier-archy inside the Array package has been defined toenable aggressive compiler optimization. As an ex-ample, we make extensive use of final classes, sincemost Java compilers (and, in particular, javac) aremore easily able to apply method inlining to meth-ods of final classes. This approach also statically bindsthe semantics of methods, thus facilitating semanticexpansion. In the most commonly used methods ofthe Array package (i.e., simple element-wise oper-ations) the cost of a method call dominates the costof the computation done by the method. Therefore,inlining those methods is essential for good perfor-mance.
In contrast to Java arrays discussed in the previoussection, Arrays defined by the Array package haveproperties (e.g., a nonragged rectangular shape andconstant bounds over their lifetime) that are easy todetect and use by an optimizing compiler. Thus, forproblems that map well to rectangular multidimen-sional structures, the Array package provides bothfunctionality and performance and is the obviouschoice over Java arrays.
Arrays are n-dimensional rectangular collections ofelements. An Array is characterized by its rank (num-ber of dimensions or axes), its elemental data type(all elements of an array are of the same type), andits shape (the extents along its axes). Rank, type, andshape are immutable properties of an Array. All Ar-ray classes are named using the following scheme:^type&Array^rank&D. As an example, floatArray3D is athree-dimensional Array of single precision floating-point numbers. In the current version of the Arraypackage, type can be any of the Java primitive types(boolean,byte,char,short,int,long,float,double), Com-plex (for complex numbers), or Object for generalobjects. The currently supported values for rank are0, 1, 2, and 3.
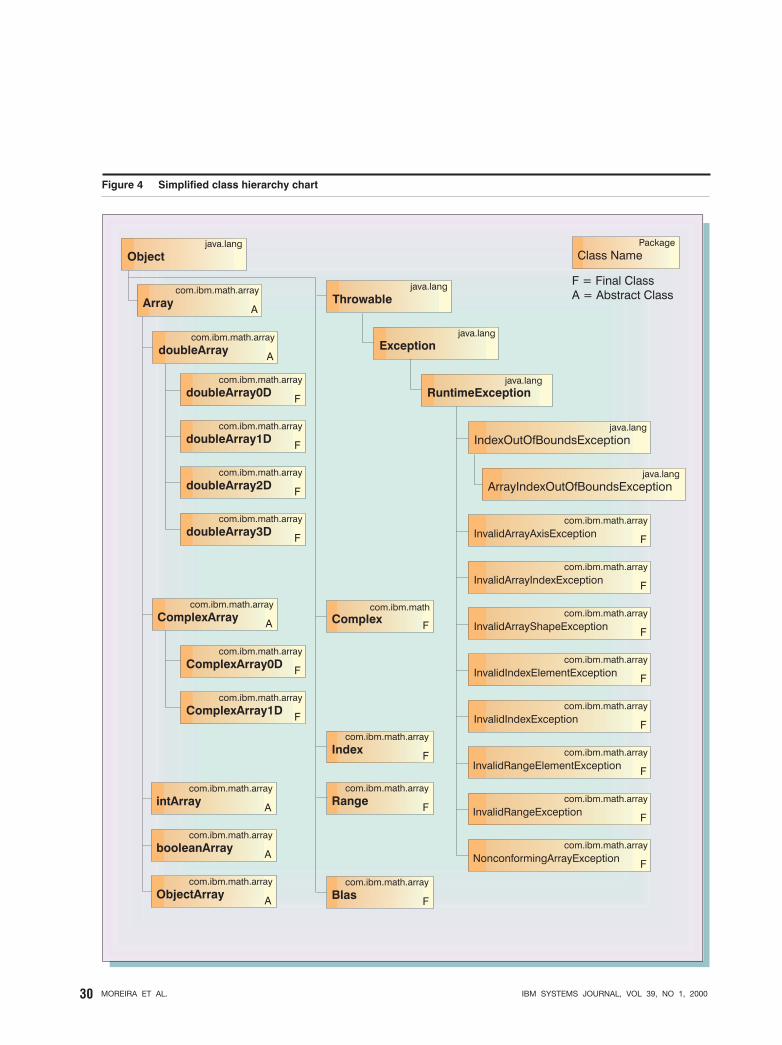
Class hierarchy. All Array classes are derived froma base abstract class Array, which defines the com-mon methods for all types of Arrays. Arrays are fur-ther subdivided according to their (elemental) typeand rank. We also define the Index and Range helper
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200028

classes for indexing and sectioning an Array (see thelater subsection on indexing for more details). Var-ious exception classes are also provided by the Ar-ray package for reporting errors that occur duringarray operations. Figure 4 shows the class hierarchyof the Array package.
We note that the fully qualified name of the Arraypackage for Java, in accordance with Java standards,is com.ibm.math.array. Use of this fully qualified nameallows us to build knowledge about the Array pack-age into our compiler.
Transactional behavior, array semantics, and excep-tions. All operations (methods and constructors) ofthe Array package have, in the absence of Java vir-tual machine (Jvm) failure, transactional behavior.That is, only two outcomes of an array operation arepossible: (1) the operation completes without anyerror, or (2) the operation is aborted, in which casean exception is thrown before any user-visible dataare changed.
If a Jvm failure occurs (e.g., it runs out of stack space)during the execution of an Array package operation,the program enters an unrecoverable error state, andthe results of the partial operation are observableonly by postmortem tools. Therefore, the fact thatthe transactional behavior is violated in this partic-ular case is irrelevant.
In order to clearly identify what was the cause foraborting an Array package operation, exceptions arethrown. These exceptions have descriptive namesthat make the cause of the exception clear to theuser. For example, a NonconformingArrayException isthrown if the user attempts to add two Arrays of dif-ferent shapes, indicating that the add operation can-not be performed because the Arrays do not match.Other exceptions are thrown in other scenarios. Thenumber of methods that might throw a particular ex-ception is very large, so we do not cover all casesextensively in this paper.
All exception classes are derived from the Runtime-Exception class. In Java, exceptions derived from theRuntimeException class are not required to be caughtby user code. Hence, it is not an error for a pieceof code to invoke an Array package method but notdeclare (using a throws clause) or catch an excep-tion that may be thrown by that method. In currentnumerical algorithms, conditions that would raise anexception typically result from programming bugs.The expectation is that the programmer will fix the
bug rather than add exception-handling code to han-dle it at run time. Nevertheless, if the programmerwould like to catch the exception, it can still be done,and so no limitations have been placed on excep-tion handling.
Array operations also implement array semantics: Inevaluating an expression (e.g., A 5 A p B 1 C), alldata are first fetched (i.e., A, B, and C are read frommemory), the computation is performed (i.e., A pB 1 C is evaluated), and only then are the resultsstored (i.e., A is modified). Of course, a high-per-formance system should implement array semanticswhile optimizing to avoid unnecessary copying. (Seethe subsection on internal optimizations for moredetails.)
Array constructors. The shape of an array is spec-ified at its creation through a constructor, and it isimmutable. The Array package defines three con-structors for each Array class, illustrated in Figure5. The first constructor shown builds a new Arraywhose shape is specified by the parameters. The sec-ond constructor shown builds a new Array that is acopy of the Array input parameter. The new Arrayhas its own storage and shares no data with the in-put Array. Finally, the third constructor shown buildsa new Array with elements copied from a conven-tional Java array. If the Java array is multidimen-sional, it must be rectangular. Again, the new Arrayhas its own storage area.
Indexing elements of an array. Elements of an ar-ray are identified by their indices (coordinates) alongeach axis. Let a k-dimensional array A of elementaltype T have extent nj along its jth axis, j 5 0, . . . ,k 2 1. Then, a valid index i j along the jth axis mustbe greater than or equal to zero and less than nj . Anattempt to reference an element A[i0 , i1 , . . . , i k21]with any invalid index i j causes an ArrayIndexOutOf-BoundsException to be thrown.
The Array package allows an axis of an Array to beindexed by either an integer, a Range object or anIndex object. Indexing with an integer specifies a sin-gle element along an axis. Indexing with a Range ob-ject is like addressing using triplets in FORTRAN: afirst element, a last element, and an optional stride(which defaults to one) specify a regular pattern ofelements. An Index object is a list of numbers thatis used by the Array package method to select theenumerated elements along the given axis. Index ob-jects are convenient for scatter-gather operations andfor operations on sparse data in general. When in-
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 29
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200030

dexing with an Index or Range object, all the indicesmust be valid (i.e., within bounds), or an ArrayIndex-OutOfBoundsException is thrown.
Indexing operations are used in accessor methods thatread or write data from or to an array, and in sec-tioning methods that create views of an array. Ac-cessor methods support all possible combinations ofinteger, Range, and Index indices. That is, the sub-script along any given dimension can be either aninteger, a Range object, or an Index object. Section-ing methods only support combinations of integerand Range indices. Supporting sections defined withIndex objects would require a complicated and slowdescriptor for the Array and impair efficient accessto Array elements in the common cases. Array ac-cessors can be implemented efficiently even with In-dex objects.
Defined methods. The Array package defines fourgroups of methods that are always present in any Ar-ray package class: Array operation, Array manipu-lation, Array accessor, and Array inquiry. A groupof methods is just a collection of methods with sim-ilar functionality. The complexity of operations is,in most cases, similar for methods of a group.
Array operations. Array operations are scalar oper-ations applied element-wise to a whole Array. Themethods in this category include assignment, arith-metic and arithmetic-assign operations (analogous,for example, to 15 and p5 operators in Java), re-
lational operations, and logic operations (where ap-propriate for the elemental data type). These oper-ations are further subdivided as Scalar-Array andArray-Array operations. Scalar-Array operations ap-ply the operation to a scalar and each element ofthe Array. Array-Array operations apply the oper-ation to all equivalent elements of two Arrays. If bothArrays in an Array-Array operation do not have thesame shape, a NonconformingArrayException isthrown. These operations are highly optimizable andparallel in nature.
In Figure 6 we compare some elementary Array op-erations described using a math notation and the no-tation defined by the Array package. When there ismore than one Array package version for the expres-sion, the first expression is the most straightforwardand intuitive form. The alternative forms for an op-eration lead to better performance, as they avoid cre-ating (at least some) intermediate objects. (Theforms are semantically equivalent, if the whole op-eration is legal.) It is unrealistic to expect users ofthe Array package to write all Array expressions inthe less intuitive but more efficient form. An intel-ligent compiler should be able to automatically trans-late the Array expressions to the best-performing ver-sion.
Array manipulation. Methods in this group includesection, permuteAxes, and reshape. These methodsoperate on the array as a whole, creating a new viewof the data and returning a new Array object express-
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 31

ing this view. A new Array object is needed becausean Array object always has constant properties, andthe new Array view may have different basic prop-erties than the original array (e.g., a different rankor shape). This new Array object shares its data withthe old object when possible to avoid the overheadof data copying.
Sectioning an Array means obtaining a new view tosome elements of a given Array. A section is a newArray object that shares its data with the original Ar-
ray, as a FORTRAN 90 section shares its data with thebase array. Since data are shared, only a descriptorneeds to be created, resulting in a fast sectioning op-eration. Figure 7 illustrates how a sectioning oper-ation works. For two-dimensional Arrays, the firstindex applies to rows, and the second index appliesto columns. This example creates a section B cor-responding to rows 1 and 2 and columns 1 and 3 ofA. Because sections are first-class Array objects, op-erating on an Array section is indistinguishable fromoperating on any other Array object.
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200032

The permuteAxes method implements generic axis in-terchange. Although permuteAxes(1,0) returns a trans-posed two-dimensional array, permuteAxes is moregeneral than a simple transpose because any axis canbe replaced by any other axis, as long as all axes thatexist in the original Array also exist in the permutedArray. If this condition is not met, the method callis illegal and an exception is thrown. For example,B 5 A.permuteAxes(2,1,0) exchanges axes 0 and 2 ofa three-dimensional Array A. That is, B(i,j,k) 5 A(k,j,i).The expression B 5 A.permuteAxes(1,1,0) is illegal,and throws a run-time InvalidArrayAxisException, sinceaxis 1 appears twice and axis 2 is missing. Permutingthe axis of a given array is a fast operation that onlycreates a new descriptor. No data copy is needed asthe data are shared with the original array. If the userwants data copy to take place, the copy constructoralways guarantees that the data are actually copied,as in the example in Figure 8.
The reshape method returns a new Array with thesame data as the old Array but with a different shape.Every element in the old Array is mapped to an el-ement of the new Array. Therefore, the new Arrayhas the same number of elements as the old Array.The algorithm used to map Array elements is thefollowing. The data are first (logically) linearized byvisiting all axes in order and all elements within anaxis in index order. The logically linearized elementsare then copied into a new Array with the shape spec-ified in the reshape call, again by visiting all axes andall elements within an axis in order. Figure 9 gives
examples of reshape method calls. The reshapemethod throws an InvalidArrayShapeException if thespecified shape does not have the right number ofelements.
Because Array objects have immutable shape, re-shaping an Array implies creating a new Array ob-ject. A copy of data is needed because our descrip-tor, which is designed to be fast for commonoperations, is not rich enough to express the ef-fect of a reshape. We choose not to have a com-plex descriptor that supports fast reshaping for tworeasons: First, the complex descriptor would slowdown most other methods. Second, a common pur-pose of an Array reshape operation is to reorga-nize the data in order to obtain faster access, andso data copying is a desirable consequence of the re-shape operation.
Array accessor methods. The methods of this groupare get, set, and toJava. These are methods thatallow the user to extract and change the array data.Figure 10 contains examples of uses of the meth-ods in this group. The get and set methods arestraightforward. The programmer is provided in-dexing methods (described earlier) to select oneor more elements. A get returns the specified el-ements, and a set updates the specified elements.The method toJava allows a user to extract a Javaarray from an Array package Array. This feature,together with constructors that convert Java ar-rays into Array package Arrays, allows pieces of
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 33

code that work with Java arrays to coexist with (i.e.,exchange data with) pieces of code that use theArray package.
Because the basic purpose of this group of methodsis to move data in and out of Arrays, data copy is
always performed. The common operations arefast—for example, extracting a single element froman array. Extracting an entire subarray (e.g., a rowof a two-dimensional array) using a single Array classoperation is typically faster than extracting one el-ement at a time.
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200034

Array inquiry methods. This group contains methodslast, size, rank, and shape. They are fast, descriptor-only operations that return information about theconstant properties of the Array.
The method last (used as an example in Figure 10)returns the last valid index along a given axis. Themethod size, when invoked without arguments, re-turns the number of elements in the Array; if invokedwith an int argument, it returns the number of el-ements along this given axis. The method rank re-turns the rank of the Array (i.e., the number of axesor dimensionality of the Array). Finally, the shapemethod returns a Java array of integers whose el-ements are the sizes of the Array along each indi-vidual axis.
Comparing array operations in FORTRAN 90 and withthe Array package for Java. As previously mentioned,we have patterned our design of the Array packagealong the lines of the FORTRAN 90 language. Figure11 provides a side-by-side comparison of equivalentFORTRAN 90 and Java Array package constructs.
Readers familiar with FORTRAN 90 will notice an al-most one-to-one correspondence between the twoapproaches. This correspondence has both perfor-mance as well as usability implications. From a per-formance perspective, optimization techniques de-veloped for FORTRAN 90 can be applied to the Arraypackage. From a usability perspective, programmersused to FORTRAN 90 features will find correspond-ing functionality in the Array package.
Internal optimizations. The semantics of Array op-erations imply that they are performed on Arrays asthey would be performed on scalars. That is, the re-sult is computed before assignment into the targetarray. Therefore, execution of an Array operationlogically follows the sequence: (1) all operands arefetched from memory, (2) all computation is per-formed, and (3) the result is stored to memory. Theordering between steps (2) and (3) implies that, ingeneral, the result of the operation must be firststored in a temporary Array and then copied to thefinal target.
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 35

To provide good performance, the supplied Arrayoperations avoid data copying—a costly opera-tion—as much as possible. For example, consider thecode in Figure 12. A naive implementation wouldperform the plusAssign method in two steps: First,a new Array object is created to store the sum of thetwo Arrays. Then, the contents of the new object arecopied back to the first Array. The unnecessary copy-ing degrades performance. The result of an Arrayoperation can be written directly to the target Array(thus eliminating the need for the temporary Arrayand the copy operation) if doing so does not over-write any memory location before its use as an op-erand. The Array package uses a form of dynamicdependence analysis14 to determine when this con-dition holds. It then bypasses the unnecessary tem-porary Array and copy.
BLAS routines. The Basic Linear Algebra Subpro-grams (BLASs)15 are the building blocks of efficientlinear algebra codes. BLAS implements a variety ofelementary vector-vector (level 1), matrix-vector(level 2), and matrix-matrix (level 3) operations. Wehave designed a Blas class as part of the Arraypackage. It provides the functionality of the BLAS op-erations for the multidimensional Arrays in thatpackage. Note that this is a 100 percent Java imple-mentation of BLAS and not an interface to alreadyexisting native libraries. Therefore, we have a com-pletely portable parallel implementation of BLAS thatworks well with the Array package. The code in theBlas class is optimized to take advantage of the in-ternals of the Array package implementation. Ap-plication code making use of these methods will haveaccess to tuned BLAS routines with no programmingeffort.
Figure 13 illustrates several features of the Arraypackage by comparing two straightforward imple-
mentations of the basic BLAS operation dgemm. Thedgemm operation computes C 5 aA* 3 B* 1 bC,where A, B, and C are matrices and a and b arescalars. A* can be either A or A T . The same holdsfor B*. In Figure 13A the matrices are representedas doubleArray2D objects from the Array package.In Figure 13B the matrices are represented as dou-ble[ ][ ]. For simplicity, in both cases we omit the testfor aliasing between C and A or B. Nevertheless, wewant to emphasize that such a test is much simplerand cheaper for the Array package version.
The first difference is apparent in the interfaces ofthe two versions. The dgemm version for the Arraypackage transparently handles operations on sectionsof a matrix. Sections are extracted by the caller andpassed on to dgemm as doubleArray2D objects. Sec-tion descriptors have to be explicitly passed to theJava arrays version, using the m, n, p, i0, j0, and k0parameters. The calling format for computing C(0; 9, 10 ; 19) 5 A(0 ; 9, 20 ; 39) 3 B(20 ; 39,10 ; 19) using the Array package is
dgemm(NoTranspose,NoTranspose,1.0,A.section(new Range(0,9),
new Range(20,39)),B.section(new Range(20,39),
new Range(10,19)),0.0,C.section(new Range(0,9),
new Range(10,19)))
and using Java arrays is
dgemm(NoTranspose,NoTranspose,10,20,10,0,10,20,1.0,A,B,0.0,C)
Next, we note that the computational code in theArray package version is independent of the orien-
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200036

tation of A or B. We just perform a (very cheap)transposition, if necessary, by creating a new descrip-tor for the data using the permuteAxes method. Incomparison, the code in the Java arrays version hasto be specialized for each combination of the ori-
entation of A and B. (We only show the two casesin which A is not transposed.)
Finally, in the Array package version, we can easilyperform some shape consistency verifications before
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 37

entering the computational loop. If we pass that ver-ification, we know we will execute the entire loopiteration space without exceptions. This verificationguarantees the transactional behavior of the method.Such verifications would be more expensive for theJava arrays, because we would have to traverse eachrow of the array to make sure they are all of the ap-propriate length. Furthermore, at least the row-pointer part of each array would have to be privat-ized inside the method to guarantee that no otherthread changes the shape of the array.
This example illustrates some of the benefits, bothfor the programmer and the compiler, of operatingwith the true multidimensional rectangular Arraysof the Array package. We summarize the benefitsthe Array package brings to compiler optimizationsin the subsection that follows the next one.
Arrays of complex numbers. Figure 14 shows somecomponents of class ComplexArray2D that imple-ments two-dimensional Arrays of complex numbers.Inside the Array, values are stored in a packed form,with (real, imaginary) pairs in adjacent locations ofthe data array. This is similar to the FORTRAN stylefor representing arrays of complex numbers and onlyrequires 16 bytes of storage per complex value. Thedeclaration
ComplexArray2D a 5 new ComplexArray2D(m,n);
creates and initializes to zero an m 3 n Array of com-plex values, not complex objects. The equivalentstructure with Java arrays would be created with
Complex[ ][ ] b 5 new Complex[m][n];for (i50; i,m; i11)
for (j50; j,n; j11)b[i][j] 5 new Complex(0, 0);
We note that, in the latter case, b is an array of ref-erences to Complex objects. Each entry has to be cre-ated individually and occupies a full 32 bytes.
The get operation of class ComplexArray2D returnsa new Complex object with the same value as thespecified Array element. The set operation assignsthe value of a Complex object to the specified Arrayelement. Semantic expansion can be used to opti-mize the execution of operations involving Arraysof complex numbers. In particular, the set and getoperations can be recognized and translated to codethat operates directly on complex values. Let us goback to the example in the subsection on the role ofoperator overloading that evaluates
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200038

b.set(i,j,a.get(i11,j).plus(a.get(i21,j)))
where a and b are objects of class ComplexArray2D.The compiler can emit code that directly retrievesthe values associated with elements (i 1 1, j) and(i 2 1, j) of Array a, computes the sum of thosevalues, and stores the result in element (i, j) of Ar-ray b. Not a single object creation needs to be per-formed.
The Array package and compiler optimizations. Inthis subsection we summarize the features of the Ar-ray package that play a strong role in enabling im-portant compiler optimizations. We want to empha-size that there is a strong synergy here, since theArray package would be of little value if code usingit could not be optimized to achieve high perfor-mance.
First, all classes in the Array package that implementmultidimensional Arrays (e.g., intArray1D, double-Array3D, ComplexArray2D) are final. As a result, thesemantics of code using those classes are staticallybound at compile time. In particular, the compiler,using semantic expansion, can recognize set and getmethods and emit code that directly accesses ele-ments of Arrays. Obviously, such code must containthe necessary checks to guarantee that the indicesare in bounds. This optimization has been imple-mented in our research prototype compiler.16
Second, all Arrays in the Array package have rect-angular and immutable shape. This is particularlyuseful for the bounds checks optimizations describedin References 3 and 17. The rectangular shape ofArrays makes it trivial to identify extents along eachaxis. The immutability property makes it unneces-sary to perform a (potentially costly) privatizationto safeguard against another thread changing theshape of an Array. The rectangular shape also re-sults in a more restrictive form of aliasing, which canbe trivially disambiguated at run time. Bounds check-ing optimization has also been implemented in ourresearch prototype compiler.16
Finally, the transactional behavior of Array opera-tions allows them to be extensively optimized. Oncethe initial validation tests have been performed suc-cessfully, an Array operation always executes to theend. This implies that aggressive optimizations likeloop transformations and parallelization can be ap-plied without concern for the semantics of the oper-ation under exceptions. The main computational partof an Array operation is totally free of exceptions.
Support for implicit parallelism in the Array pack-age. We conclude this section on the Array packageby describing how the package provides support forimplicit parallelism. We note that the version of theArray package in alphaWorks does not have any ofthe parallelism features described here. We call theversion with support for parallelism the parallel Ar-ray package. The parallel Array package allows a userprogram written in a completely sequential style toobtain the performance benefits of parallelism trans-parently. The user program does retain control overthe extent of parallelism desired by calling an ini-tializer method of the parallel Array package thatsets the number of parallel threads to be used forthe application.
The parallel Array package employs a master-slavemechanism in the implicitly parallel routines and usesthe multithreading facilities available in Java. Ourdesign principles in developing this mechanism were:(1) create threads only once and reuse them in dif-ferent operations; and (2) allow the master to con-trol the assignment of work to helper threads. Thefirst principle eliminates the cost of creating newthreads for each parallel operation. The second prin-ciple supports better exploitation of data locality be-tween operations.
Figure 15 shows the basic actions performed whenan operation is executed in parallel. Solid boxes in-dicate mutex operations performed on per-threaddata structures, and dashed boxes indicate mutex op-erations performed on a global shared data struc-ture. Solid arrows indicate flow of control, and dashedarrows indicate notify events. The master thread ini-tially creates the number of helper threads specifiedby an initialization call from the application program.It then begins executing the program. Each newlycreated helper thread marks itself as idle and waitsfor work on a synchronization object associated withit. This allows the Java notify method to be used torestart a specific thread.
When the master thread encounters a parallel op-eration, it computes T, the desired number of threadsto perform the operation. It then notifies helperthreads 1, . . . , T 2 1 to start work. All of thethreads, including the master, perform their part ofthe computation. When each thread finishes workon the parallel operation, it signals its completionby decrementing a shared counter. If the masterthread is not the last thread to finish work (as canbe determined by examining the shared counter tosee whether it is zero), it marks itself as idle and waits
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 39

on its synchronization object. If a helper thread isthe last thread to finish, it notifies the master to con-tinue. All helper threads, when finished with the op-eration, mark themselves as idle and wait for the nextparallel operation.
Case study: Data mining
In this section, we present a case study, using a datamining application, that illustrates some of the pit-falls and opportunities in using the Java language todevelop a numerically intensive application. Datamining18 is the process of discovering useful and pre-viously unknown information in very large databases,with applications that span both scientific and com-mercial computing. Although typical data mining ap-plications access large volumes of data from eitherflat files or relational databases, such applicationsoften involve a significant amount of computationabove the data access layer. High-performance datamining applications, therefore, require both fast dataaccess and fast computation. The details of the spe-
cific data mining problem we considered are de-scribed in Appendix A.
Although Java is an attractive vehicle for develop-ing and deploying data mining applications acrossdifferent computing platforms, a major concern hasbeen its performance. We show that this concern iswell-founded but can be dealt with by using well-de-signed class libraries, such as the Array package de-scribed in the last section. In particular, we show thata plain Java implementation suffers from the follow-ing major performance problems, both of which areexacerbated by its lack of support for true multidi-mensional arrays:
● Bounds checking and null pointer checks on arrayaccesses—The overhead of checking each array ac-cess for a null pointer or out-of-bounds access vi-olation takes its toll on performance. To make mat-ters worse, a single reference to a d-dimensionalarray in Java translates into d references to one-dimensional arrays, requiring d null pointer checks
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200040

and d out-of-bounds checks. The algorithm to op-timize these checks away in a compiler by creatingsafe regions17 is significantly simpler for a true mul-tidimensional array because its shape is constantalong all axes, and there is no need to copy arraysto the working memory of a thread for thread-safetyof the transformation.
● Poor data locality and instruction scheduling—Looptransformations, such as interchange, tiling, andouter loop unrolling, typically used by optimizingcompilers to improve data locality and instructionscheduling, cannot be readily applied to loops inwhich an exception may be thrown. This restric-tion is a consequence of the need to support pre-cise exceptions in Java. Furthermore, different ar-rays constituting a multidimensional array in Javaare not necessarily stored together in a single con-tiguous block of memory, leading to inherentlypoor data locality.
Using the Array package allows us to deal with theseproblems quite effectively. The methods in our im-plementation of this package perform all checks forpossible exceptions before the main part of the com-putation. As a result, the main computation canbe optimized in the same manner as equivalentFORTRAN or C11 code, while still remaining strictlyJava-compliant. The main loops in the methods ofthe Blas class are transformed manually using well-known techniques15 to get better uniprocessorperformance through improved data locality, in-struction scheduling, and register utilization.Furthermore, the Array package internally uses con-tiguous memory for all of the data of a multidimen-sional Array, leading to improved data locality andmore efficient indexing of elements.
The data mining implementations. We experi-mented with five different implementations of thescoring algorithm described in Appendix A. The firstversion is a plain Java implementation of the scor-ing algorithm. That is, it does not make use of theArray package described in the previous section. In-stead, it uses standard Java arrays. The second im-plementation is our enhanced Java code, which im-plements the scoring using classes from the Arraypackage. The third implementation is an implicitlyparallel version of the application that is derived fromthe enhanced Java code but uses the parallel Arraypackage. The implicitly parallel Java version is iden-tical to the enhanced Java version, except for a callat the beginning of main to an initializer method ofthe parallel Array package, indicating the numberof threads to be used. We also derive an explicitly
parallel version of the application, which explicitlyuses the multithreading facilities in Java togetherwith the sequential version of the Array package. Fi-nally, we also use a FORTRAN 90 version, with callsto the Engineering and Scientific Subroutine Library(ESSL), of the scoring algorithm. The FORTRAN901ESSL version serves as a reference: It helps usevaluate how well Java is doing relative to a languageand library known for high performance.
Experimental results. We now describe the perfor-mance results obtained for the different implemen-tations of the data mining code on an IBM RS/6000*Model F50 four-way SMP (symmetric multiproces-sor) using 332 MHz PowerPC 604e processors. Weshow the performance of the scoring algorithm,which is the bulk of the computation in the data min-ing code. We used the IBM XLF 6.1 compiler (with-O3 optimization level) for the FORTRAN 90 pro-gram. Results for Java code represent the best ob-tained using both the IBM HPCJ2 (with -O optimiza-tion level) and IBM Java Developer Kit (DK) 1.1.6with the IBM JIT (just-in-time) compiler. (The IBM DKwith JIT compiler delivered the better performancefor Java arrays, while the IBM HPCJ was better withthe Array package.)
Figure 16 shows the serial performance of the Javaand FORTRAN 90 codes as a fraction of the perfor-mance obtained by the FORTRAN 90 version. Thenumbers at the top of the bars indicate million float-ing-point operations per second (Mflops). The plainJava program (with Java arrays) achieves 25.8Mflops, which is 22 percent of the FORTRAN 90 per-formance. The enhanced Java version (with the Ar-ray package) performs significantly better, achiev-ing 109.2 Mflops, or 91 percent of the FORTRAN 90performance.
Figure 17 shows the performance of the parallelcodes for different numbers of threads. Again, thenumbers at the top of the bars indicate Mflops. Theimplicitly parallel code achieves a speedup of 2.7 withfour threads, reaching a performance of 292.4Mflops. The explicitly parallel code consistently de-livers better performance, achieving 343.7 Mflops onfour threads, which represents a speedup of 3.1 overthe enhanced Java version.
Discussion. We now present the reasons for the per-formance differences we have seen in the various im-plementations of the data mining code. We also drawsome general conclusions about writing numericallyintensive Java applications. Finally, we compare the
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 41

two approaches to exploiting parallelism: writing ex-plicitly parallel code, and using a parallel subsystemto extract parallelism out of an application writtenin a completely sequential style.
Performance of serial versions. The Array packageprovides a higher level of abstraction to the program-mer than the primitive operations on arrays currentlydefined in the Java language specification. Our ex-perimental results demonstrate that using this pack-age also leads to better performance. There are twomain reasons for the difference in performance be-tween the plain Java version (that uses primitive ar-ray operations) and the enhanced Java version (thatuses the Array package): (1) greater negative impactof array bounds checking on the performance of theplain Java version, and (2) better data locality andinstruction scheduling of the Blas class library code,used by the enhanced Java version.
In the plain Java program, bounds checking is per-formed for all array accesses. Since the Java languagerequires precise exceptions, all code-reorderingtransformations must be disabled in loops that havebounds checking. An additional measurementshowed that the performance of this program jumpsto 36.5 Mflops if all array bounds checks are opti-
mized away. As discussed earlier, it is easier for thecompiler to apply transformations17 to deal with thisproblem if the program uses the Array package. Infact, for the scatter and gather operations over sparsearrays in our data mining application, static tech-niques, such as those discussed in Reference 17, areinsufficient to optimize the bounds checks, becausethey cannot handle subscripted subscripts. In con-trast, when using the Array package, bounds check-ing on an Array dimension accessed using an Indexobject is performed simply by comparing the min-imum and maximum elements of the Index objectwith zero and the dimension length, respectively. Theminimum and maximum elements for each Index ob-ject are computed at creation time in its constructorto enable efficient bounds checking later.
The Blas class provides the benefit of making a tunedimplementation of commonly needed operations,such as matrix multiplication, available to the pro-grammer. This is similar to the approach adoptedby providers of high-performance libraries such asLAPACK19 and ESSL.20 As with the implementationof the rest of the Array package, all checks for con-ditions leading to exceptions are performed at thebeginning, so that compiler optimizations can be ap-
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200042
plied effectively to performance-critical sections ofthe code.
We observe that by using the Array package, whichdoes not use any native libraries, the Java versionof the data mining code achieves a level of perfor-mance close to that delivered by the FORTRAN901ESSL version. Thus, we show that it is possibleto obtain competitive performance, even on a nu-merically intensive production quality code, withpure Java.
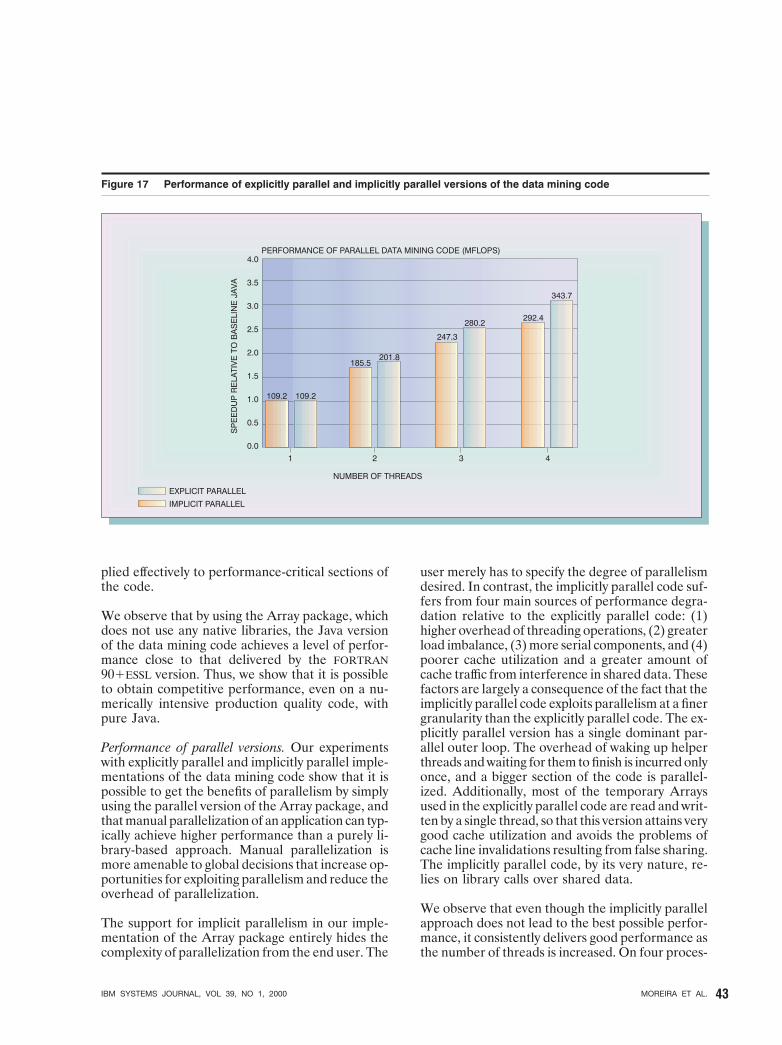
Performance of parallel versions. Our experimentswith explicitly parallel and implicitly parallel imple-mentations of the data mining code show that it ispossible to get the benefits of parallelism by simplyusing the parallel version of the Array package, andthat manual parallelization of an application can typ-ically achieve higher performance than a purely li-brary-based approach. Manual parallelization ismore amenable to global decisions that increase op-portunities for exploiting parallelism and reduce theoverhead of parallelization.
The support for implicit parallelism in our imple-mentation of the Array package entirely hides thecomplexity of parallelization from the end user. The
user merely has to specify the degree of parallelismdesired. In contrast, the implicitly parallel code suf-fers from four main sources of performance degra-dation relative to the explicitly parallel code: (1)higher overhead of threading operations, (2) greaterload imbalance, (3) more serial components, and (4)poorer cache utilization and a greater amount ofcache traffic from interference in shared data. Thesefactors are largely a consequence of the fact that theimplicitly parallel code exploits parallelism at a finergranularity than the explicitly parallel code. The ex-plicitly parallel version has a single dominant par-allel outer loop. The overhead of waking up helperthreads and waiting for them to finish is incurred onlyonce, and a bigger section of the code is parallel-ized. Additionally, most of the temporary Arraysused in the explicitly parallel code are read and writ-ten by a single thread, so that this version attains verygood cache utilization and avoids the problems ofcache line invalidations resulting from false sharing.The implicitly parallel code, by its very nature, re-lies on library calls over shared data.
We observe that even though the implicitly parallelapproach does not lead to the best possible perfor-mance, it consistently delivers good performance asthe number of threads is increased. On four proces-
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 43

sors, it leads to a respectable speedup of 2.7 overthe sequential code, as compared with a speedup of3.1 obtained using the explicitly parallel approach.For many users, this performance level would be ac-ceptable, given the ease with which it is obtained.
Case study: MICROSTRIP
Our second case study comes from the (much sim-plified) electromagnetics application MICROSTRIP.21
This example is representative of many applicationsthat deal with physical phenomena. It implementsa numerical iterative solver for the partial differen-tial equation that describes the behavior of a phys-ical system. MICROSTRIP makes heavy use ofcomplex arithmetic. We use it to illustrate someadditional Java performance issues, not discussedin the data mining case study:
● Complex numbers—Java does not support complexnumbers as primitive types. The typical approachis to define a Complex class and then use Complexobjects to implement complex numbers. We willsee that this approach leads to enormous objectcreation and destruction overhead.
● Storage efficiency—This issue is related to imple-menting complex numbers as Complex objects.Each Complex object includes, in addition to thedouble fields for the real and imaginary parts, datathat describe the object. It results in a 100 percentstorage overhead. Also, Java arrays of Complex (e.g.,Complex[ ],Complex[ ][ ]) are actually arrays of ref-erences to Complex objects. This leads to poor mem-ory locality and poor memory system performance.
In the case of MICROSTRIP, we achieve high perfor-mance through a combination of semantic expan-sion (discussed earlier) and features of the Arraypackage. Semantic expansion is a compilation tech-nique that replaces method calls by code that directlyimplements the semantics of those methods. Thistechnique allows us to support complex numbers inJava as efficiently as in FORTRAN. The Array pack-age has a strong synergy with semantic expansion.Multidimensional Arrays of complex numbers (e.g.,ComplexArray1D and ComplexArray2D) deliver bet-ter locality than Java arrays of Complex objects. How-ever, semantic expansion is absolutely necessary toallow efficient access to elements of these arrays.
The MICROSTRIP implementations. We experi-mented with three different implementations of theiterative solver for MICROSTRIP. The first version isa plain Java implementation that uses Java arrays of
Complex objects. The second implementation is ourenhanced Java code that uses classes from the Arraypackage. Each of the two Java versions can be com-piled with or without the semantic expansion tech-nique. As we shall see in the following subsection,semantic expansion has a significant impact on per-formance. Finally, we use a FORTRAN 90 version ofthe solver, which serves as a yardstick for evaluatingthe performance of Java. This FORTRAN versionachieves approximately 50 percent of the peak per-formance of our benchmark machine. (It achieves140 out of a 266 peak Mflops.) Therefore, it con-stitutes a good reference point against which we com-pare our Java performance.
Experimental results. We now discuss the perfor-mance results obtained for the different implemen-tations of the MICROSTRIP code on an IBM RS/6000Model 590 workstation. This machine has a 67-MHzPOWER2* processor with a 256-KB single-level datacache and 512 MB of main memory. The peak com-putational speed is 266 Mflops. To execute the Javaversions, we used both the IBM HPCJ (with -O op-timization level) and IBM DK 1.1.8 with the IBM JITcompiler. (We report the best result achieved in eachcase.) We used the IBM XLF 6.1 compiler (with -O3optimization level) for the FORTRAN version.
Figure 18 shows five different results for theMICROSTRIP benchmark. The problem parametersare those described in Reference 21 and AppendixB. The numbers at the top of the bars indicateMflops. The bars labeled “plain” and “enhanced”show the performance for the plain (Java arrays) andenhanced (Array package) Java implementations, re-spectively, without semantic expansion. (The best re-sults for these cases were achieved with IBM DK 1.1.8.)Both versions achieve approximately 1 Mflop. Thisperformance would typically be delivered by currentJava environments. The bars “plain 1 exp” and “en-hanced 1 exp” show the performance for the plainand enhanced Java implementations, respectively,with semantic expansion (using our research proto-type compiler). The plain Java version achieves 45.6Mflops with semantic expansion, whereas the en-hanced Java version achieves 75.8 Mflops. Finally,the bar labeled “FORTRAN” shows the performanceof the FORTRAN implementation. The FORTRAN ver-sion achieves 139.5 Mflops, or 52 percent of the peakcomputational speed of the machine.
Discussion. We now discuss why the performanceof the Java versions without semantic expansion isso poor. We also discuss why, with semantic expan-
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200044
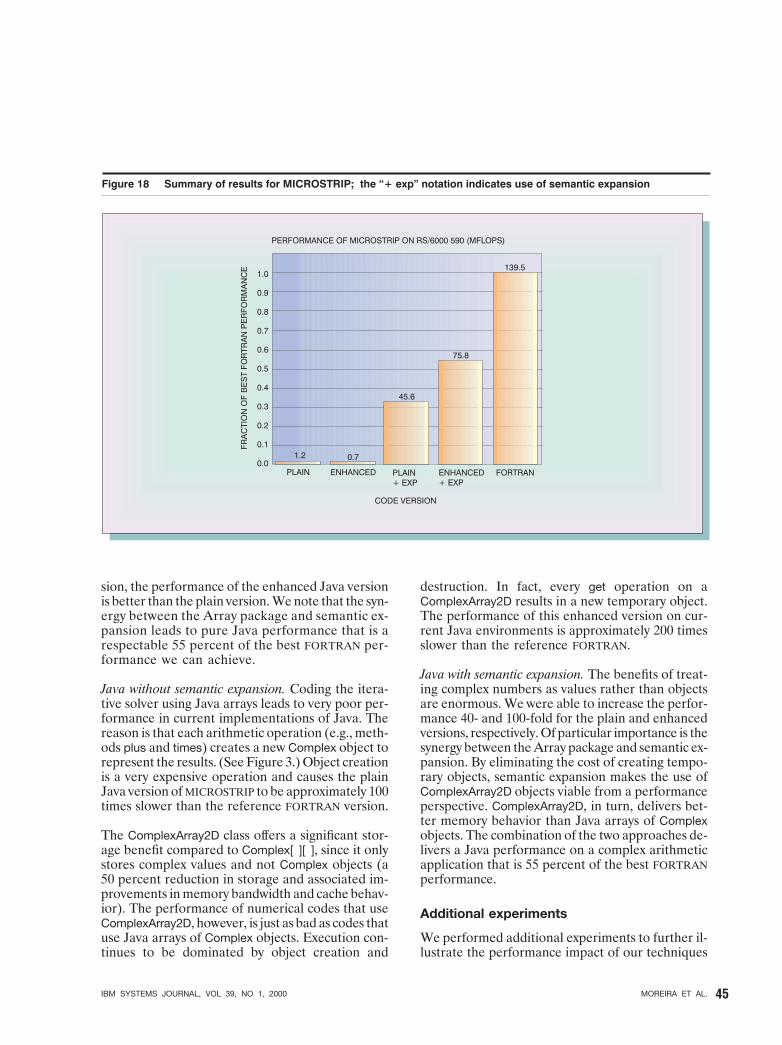
sion, the performance of the enhanced Java versionis better than the plain version. We note that the syn-ergy between the Array package and semantic ex-pansion leads to pure Java performance that is arespectable 55 percent of the best FORTRAN per-formance we can achieve.
Java without semantic expansion. Coding the itera-tive solver using Java arrays leads to very poor per-formance in current implementations of Java. Thereason is that each arithmetic operation (e.g., meth-ods plus and times) creates a new Complex object torepresent the results. (See Figure 3.) Object creationis a very expensive operation and causes the plainJava version of MICROSTRIP to be approximately 100times slower than the reference FORTRAN version.
The ComplexArray2D class offers a significant stor-age benefit compared to Complex[ ][ ], since it onlystores complex values and not Complex objects (a50 percent reduction in storage and associated im-provements in memory bandwidth and cache behav-ior). The performance of numerical codes that useComplexArray2D, however, is just as bad as codes thatuse Java arrays of Complex objects. Execution con-tinues to be dominated by object creation and
destruction. In fact, every get operation on aComplexArray2D results in a new temporary object.The performance of this enhanced version on cur-rent Java environments is approximately 200 timesslower than the reference FORTRAN.
Java with semantic expansion. The benefits of treat-ing complex numbers as values rather than objectsare enormous. We were able to increase the perfor-mance 40- and 100-fold for the plain and enhancedversions, respectively. Of particular importance is thesynergy between the Array package and semantic ex-pansion. By eliminating the cost of creating tempo-rary objects, semantic expansion makes the use ofComplexArray2D objects viable from a performanceperspective. ComplexArray2D, in turn, delivers bet-ter memory behavior than Java arrays of Complexobjects. The combination of the two approaches de-livers a Java performance on a complex arithmeticapplication that is 55 percent of the best FORTRANperformance.
Additional experiments
We performed additional experiments to further il-lustrate the performance impact of our techniques
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 45

for optimizing Java numerical codes. In this sectionwe present a summary of results from eight bench-marks. Four of these benchmarks perform real arith-metic, and the other four complex arithmetic. Wecompare the performance of Java and FORTRAN ver-sions of the benchmarks. We perform all our exper-iments on an IBM RS/6000 Model 590 workstation. Thismachine has a 67-MHz POWER2 processor with a256-KB single-level data cache and 512 MB of mainmemory. The peak computational speed is 266Mflops.
FORTRAN programs are compiled using version 6.1of the IBM XLF compiler with the highest level of op-timization (-O3 -qhot, which performs high-orderloop transformations4). Results for two different Javaversions of each benchmark are reported. One ver-sion, which we call plain, is an implementation ofthe benchmark using Java arrays. The numbers re-ported for this version correspond to the best ob-tained using IBM DK 1.1.8 with the IBM JIT compiler.(The JIT compiler, which incorporates many advancedoptimizations such as bounds checking and null pointerchecking elimination, performs better than HPCJ whenJava arrays are used.) The other Java version, whichwe call best, represents the best result we achieved froma pure Java implementation of the benchmark. It usesmultidimensional Arrays from the Array package andaggressive compiler optimizations in our research pro-totype version of IBM HPCJ to generate safe regions ofcode (i.e., regions without potential exceptions) andperform semantic expansion. For the real arithmeticbenchmarks, we also enabled the use of the fused-mul-tiply add (fma) instruction of the POWER2 hardware forboth the Java and FORTRAN versions of the benchmark(the default for FORTRAN is to use the fma). This rep-resents the performance that can be achieved with Javaif the current proposals for relaxed floating-point arith-metic are approved.1 Because of some technical dif-ficulties, we could not enable the use of the fma in Javafor the complex arithmetic benchmarks. In that case,we chose to also disable the use of fma in FORTRAN.
To guarantee a fair comparison, all three versionsof each benchmark (FORTRAN, Java arrays, and Ar-ray package) were automatically generated from acommon representation. We use an internallydeveloped language, z-code—a very simplifiedFORTRAN-like language, to code each of the bench-marks. From the representation in z-code, an auto-matic translator generates all three versions of abenchmark. The translator takes care of adjustingarray indexing to guarantee that arrays are accessed
in their preferred mode (column-major for FORTRANand row-major for Java).
Real arithmetic benchmarks. The real arithmeticbenchmarks are: CHOLESKY, BSOM, SHALLOW, andTOMCATV. CHOLESKY is a straightforward imple-mentation of the Cholesky decomposition algorithm,as described, for example, in References 22 and 23.It computes the upper triangular factor U of a sym-metric positive definite matrix A such that A 5 UTU.We implemented our code so that the factorizationis performed in place, with the upper half of matrixA being replaced by the factor U. For our experi-ments, we factor a matrix of size 1000 3 1000. TheBSOM (batch self-organizing map) benchmark is adata-mining kernel representative of technologies in-corporated into Version 2 of the IBM Intelligent Min-er*. (It was not used in the data mining applicationdescribed earlier.) It implements a neural-network-based algorithm to determine clusters of input rec-ords that exhibit similar attributes of behavior. Wetime the execution of the training phase of this al-gorithm, which actually builds the neural network.This phase consists of 25 epochs. Each epoch updatesa neural network with 16 nodes using 256 recordsof 256 fields each. SHALLOW is a computational ker-nel from a shallow water simulation code from theNational Center for Atmospheric Research. Thedata structures in SHALLOW consist of 14 matrices(two-dimensional arrays) of size n 3 m each. Thecomputational part of the code is organized as a time-step loop, with several array operations executed ineach time step. For our measurements, we fix thenumber of time steps T 5 20 and use n 5 m 5 256.TOMCATV is part of the SPECfp95 suite (availableat http://www.spec.org). It is a vectorized mesh gen-eration with Thompson solver code. The benchmarkconsists of a main loop that iterates until convergenceor until a maximum number of iterations is executed.At each iteration of the main loop, the major com-putation consists of a series of stencil operations ontwo (coupled) grids, X and Y, of size n 3 n. In ad-dition, a set of tridiagonal systems is solved throughLU decomposition. For our experiments, we use aproblem size of n 5 513.
Results for these four benchmarks are summarizedin Figure 19. The height of each bar is proportionalto the best FORTRAN performance achieved in thecorresponding benchmark. The numbers at the topof the bars indicate actual Mflops. For the “plain” Javaversion, two-dimensional arrays of doubles were rep-resented using a Java double[ ][ ] array. The “best” Javaversion uses doubleArray2D Arrays from the Array
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200046
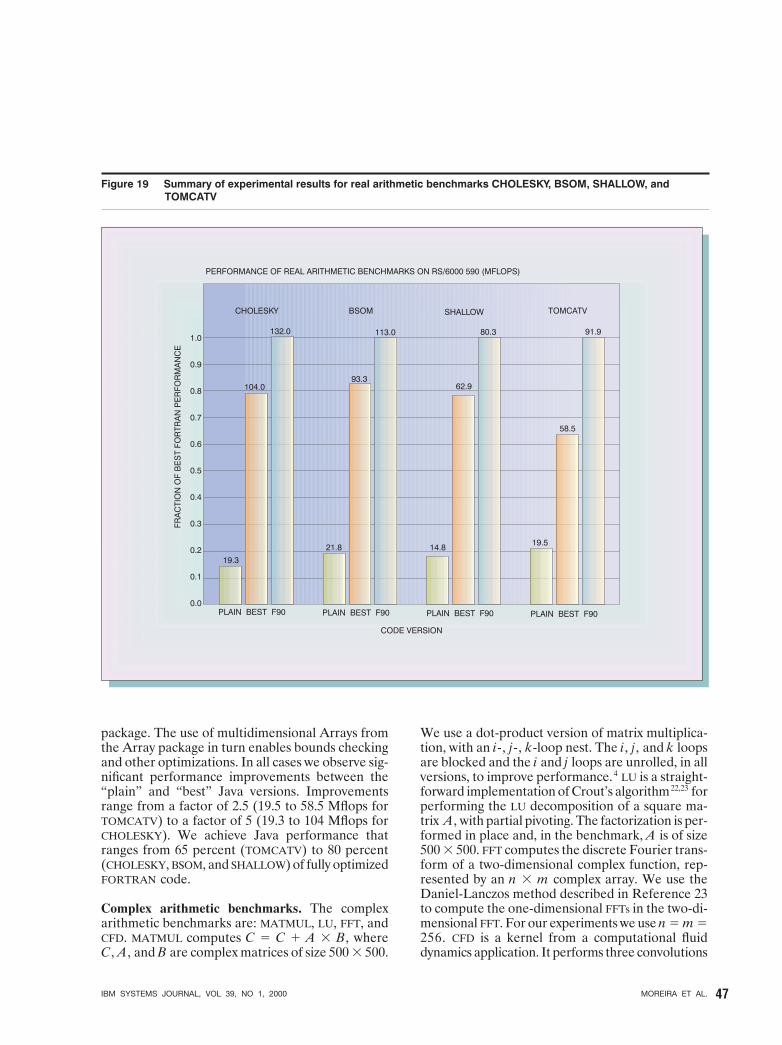
package. The use of multidimensional Arrays fromthe Array package in turn enables bounds checkingand other optimizations. In all cases we observe sig-nificant performance improvements between the“plain” and “best” Java versions. Improvementsrange from a factor of 2.5 (19.5 to 58.5 Mflops forTOMCATV) to a factor of 5 (19.3 to 104 Mflops forCHOLESKY). We achieve Java performance thatranges from 65 percent (TOMCATV) to 80 percent(CHOLESKY, BSOM, and SHALLOW) of fully optimizedFORTRAN code.
Complex arithmetic benchmarks. The complexarithmetic benchmarks are: MATMUL, LU, FFT, andCFD. MATMUL computes C 5 C 1 A 3 B, whereC, A, and B are complex matrices of size 500 3 500.
We use a dot-product version of matrix multiplica-tion, with an i-, j-, k-loop nest. The i, j, and k loopsare blocked and the i and j loops are unrolled, in allversions, to improve performance.4 LU is a straight-forward implementation of Crout’s algorithm22,23 forperforming the LU decomposition of a square ma-trix A, with partial pivoting. The factorization is per-formed in place and, in the benchmark, A is of size500 3 500. FFT computes the discrete Fourier trans-form of a two-dimensional complex function, rep-resented by an n 3 m complex array. We use theDaniel-Lanczos method described in Reference 23to compute the one-dimensional FFTs in the two-di-mensional FFT. For our experiments we use n 5 m 5256. CFD is a kernel from a computational fluiddynamics application. It performs three convolutions
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 47

between pairs of two-dimensional complex functions.Each function is represented by an n 3 m complexarray. The computation performed in this benchmarkis similar to a two-dimensional version of the NASParallel Benchmark FT. Again, for our experimentswe use n 5 m 5 256.
Results for these four benchmarks are summarizedin Figure 20. Again, the height of each bar is pro-portional to the best FORTRAN performance achievedin the corresponding benchmark, and the numbersat the top of the bars indicate actual Mflops. For the“plain” Java version, complex arrays were repre-sented using a Complex[ ][ ] array of Complex objects.No semantic expansion was applied. The “best” Javaversion uses ComplexArray2D Arrays from the Ar-ray package and semantic expansion. In all cases we
observe significant performance improvements be-tween the “plain” and “best” Java versions. Improve-ments range from a factor of 24 (2.5 to 60.2 Mflopsfor FFT) to a factor of 53 (1.7 to 89.5 Mflops forMATMUL). We achieve Java performance that rangesfrom 60 percent (LU) to 85 percent (FFT and CFD)of fully optimized FORTRAN code.
Related work
The importance of having high-performance librar-ies for numerical computing in the Java language hasbeen recognized by many authors. In particular, Ref-erences 24–26 describe projects to develop such li-braries entirely in Java. In addition, there are ap-proaches in which access to existing numericallibraries (typically coded in C and FORTRAN) is pro-
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200048

vided to Java applications.27–29 The Array packageincludes a Blas class, so that efficient linear algebralibraries can be developed for it.
It is well known that programming with libraries hasits limitations. Certain classes of applications can beeffectively expressed in terms of linear algebra op-erations. These applications can be efficiently imple-mented on top of (very successful) linear algebra li-braries such as LAPACK and ESSL. Other classes ofapplications are not so well-structured. In thosecases, the programmer has to develop the applica-tion from scratch, counting on minimal library sup-port. For this reason, the Array package is more thanjust a library: It is a mechanism to represent arrayoperations in a manner that can be highly optimizedby compilers. Linear algebra code can be developedwith the Array package using the BLAS primitives.Less-structured code can use the Array operationsdirectly. With the appropriate compiler support, Javacode built on top of the most basic set and getoperations of the Array package can achieveFORTRAN-like performance.
Cierniak and Li30 describe a global analysis techniquefor determining that the shape of a Java array of ar-rays (e.g., double[ ][ ]) is indeed rectangular and notmodified. The array representation is then trans-formed to a dense storage, and element access is per-formed through index arithmetic. This approach canlead to results that are as good as those obtained fromusing multidimensional Arrays in the Array pack-age. We differ in that we do not need global anal-ysis: Arrays from the Array package are intrinsicallyrectangular and can always be stored in a dense form.We have also integrated support for complex num-bers in our true multidimensional Arrays.
The technique of semantic expansion we use is sim-ilar to the approach taken by FORTRAN compilersin implementing some intrinsic procedures.11 Intrin-sic procedures can be treated by the FORTRAN com-piler as language primitives, just as we treated theComplex class in Java. Semantic expansion differsfrom the handling of intrinsics in FORTRAN in thatboth new data types and operations on the new datatypes are treated as language primitives. Still regard-ing semantic expansion, the work by Wu and Padua31
targets standard container classes for semantic ex-pansion. In their paper, the container semantics arenot used for local optimizations or transformationsinside the container. Instead, the semantics are usedto help data flow analysis and detect parallelizableloops. Their work illustrates how semantic informa-
tion about standard classes exposes new optimiza-tion and parallelization opportunities.
Array operations are natural candidates for the ex-ploitation of parallelism. Exploiting parallelism hasbeen done extensively before both at the lan-guage32–34 and subsystem12,35,36 levels, with differentdegrees of transparency to the application program-mer. So far, we have successfully exploited parallel-ism inside the Array package operations whileachieving total transparency to the programmer. Acombination of the Array package with semantic ex-pansion can lead to programs that are amenable toautomatic parallelization using techniques devel-oped, for example, for FORTRAN. This will result intransparent parallelization of the user code itself.
The efficacy of the Array package in supporting ap-plications of a varied nature is demonstrated by theresults described in the sections containing the twocase studies and the additional experiments. Thestrong synergy between the Java Array package formultidimensional Arrays and the aggressive compileroptimizations is the main differentiator in our work.
Conclusion
We have demonstrated that high-performance nu-merical codes can be developed in the Java language.The benefits of using Java from a productivity anddemographics point of view have been known for awhile. Many people have advocated the developmentof large, computationally intensive Java applicationsbased on those benefits. However, Java performancehas consistently been considered an impediment toits applicability to numerical codes. This paper haspresented a set of techniques that lead to Java per-formance that is competitive with the best FORTRANimplementations available today.
We have used a class library approach to introducein Java features of FORTRAN 90 that are of great im-portance to numerical computing. These features in-clude complex numbers, multidimensional arrays,and libraries for linear algebra. These features havea strong synergy with the compiler optimizations thatwe have developed, particularly bounds checking op-timization and semantic expansion. We have dem-onstrated this synergy, and the resulting performanceimpact, through two detailed case studies. We havealso conducted a broader performance evaluationusing eight other numerical benchmarks.
We demonstrated that we can deliver Java perfor-mance in the range of 55–90 percent of the best
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 49

FORTRAN performance for a variety of benchmarks.This step is very important in making Java the pre-ferred environment for developing large-scale nu-merically intensive applications. However, there ismore than just performance to our approach. TheArray package and associated libraries create a Javaenvironment with many of the features that expe-rienced FORTRAN programmers have grown accus-tomed to. This combination of delivering featuresand performance for numerical computing in thecontext of the Java language is the core of our ap-proach to making Java the environment of choicefor new numerical computing.
Regarding future work, we want to exploit more ofthe benefits generated by the Array package. Oneof our goals is automatic parallelization of user codedeveloped with the Array package. We can leveragemany techniques developed for parallelizingFORTRAN and C, but good alias disambiguation isessential. We are currently implementing alias dis-ambiguation techniques in our compiler, taking ad-vantage of the semantics of the Array package.Another area we are exploiting is data layout opti-mization. By hiding the actual layout of data fromthe user (elements can only be accessed through getand set accessor methods), the Array package facil-itates optimizations of this layout. In particular, weare pursuing the use of recursive block formats,6
which can be very beneficial in systems with deepmemory hierarchies. By taking advantage of theseand other optimizations, we can envision a futurenot too distant in which Java numerical codes willactually outperform their FORTRAN counterparts.
Acknowledgments
The authors wish to thank Ven Seshadri of IBM Can-ada for helping and supporting our experiments withHPCJ.
Appendix A: The data mining computation
The specific data mining problem considered hereinvolves recommending new products to customersbased on previous spending behavior. As input, wehave available both detailed purchase data for thecustomer set, as well as a product taxonomy that gen-erates assignments of each product to spending cat-egories. In the specific application discussed here,we utilize approximately two thousand such catego-ries. Recommendations are drawn from a subset ofeligible products. For each customer, a personalizedrecommendation list is generated by sorting this list
of eligible products according to a customer-specificscore computed for each product. In some commer-cial situations, there may be an incentive to prefer-entially recommend some products over others be-cause of overstocks, supplier incentives, or increasedprofit margins. This information can be introducedinto the recommendation strategy via product-de-pendent scaling factors, with magnitudes reflectingthe relative priority of recommendation. We nowgive a more precise description of the scoringalgorithm.
Let there be m products eligible for recommenda-tion, p customers, and n spending categories. Eachproduct i has associated with it an affinity vector Ai ,where Aik is the affinity of product i with spendingcategory k. These affinities can be interpreted as theperceived appeal of this product to customers withparticipation in this spending category. They are de-termined by precomputing associations37 at the levelof spending categories. The collection of affinity vec-tors from all products forms the m 3 n affinity ma-trix A. This matrix is sparse and organized so thatproducts with the same nonzero patterns in their af-finity vectors are adjacent. The matrix is shown inFigure 21. Because of this organization, matrix A canbe represented by a set of g groups of products. Eachgroup i is defined by f i and l i , the indices of the firstand last products in the group, respectively. All prod-ucts with the same nonzero pattern belong to thesame group. This nonzero pattern for the productsin group i is represented by an index vector I i , whereI ik is the position of the kth nonzero entry for thatgroup. Let len(I i) be the length of index vector I i .Also, let g i 5 l i 2 f i 1 1 be the number of productsin group i. Then the affinity matrix Gi for group iis the g i 3 len(I i) dense matrix with only the non-zero entries of rows fi to li of A. This representationof A is shown in Figure 21.
Each customer j has an associated spending vectorSj , where Sjk is the normalized spending of customerj in category k. The collection of spending vectorsof all customers forms the p 3 n spending matrixS. This matrix is also sparse, but customers are notorganized in any particular order. (The affinity ma-trix is relatively static and can be built once, whereasthe spending matrix may change between two exe-cutions of the scoring algorithm.) We also define ap 3 n normalizing matrix N, which has the samenonzero pattern as S, but with a one wherever S hasa nonzero:
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200050

Njk 5 H1 if Sjk Þ 00 if Sjk 5 0 (3)
The structure of matrices S and N are shown in Fig-ure 22. The nonzero pattern of row j of matrix S isrepresented by an index vector J j , where J jk is theposition of the kth nonzero entry for that row (cus-tomer). The actual spending values are representedby a dense vector s j , of the same length as J j , whichhas only the nonzero entries for row j of S. This rep-resentation of S is shown in Figure 22. Matrix N doesnot have to be represented explicitly.
Let r i be the priority scaling factor for product i asdiscussed earlier in this appendix. The score F ij ofcustomer j against product i is computed as:
Fij 5 ri
Ok51n AikSjkOk51n AikNjk
(4)
Note that ¥k51n AikS jk is the dot-product of row i of
A by column j of S T . Similarly, ¥k51n AikNjk is the
dot-product of row i of A by column j of N T . LetLp(r1 , r2 , . . . , rm) denote an m 3 p matrix L with
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 51

L ij 5 r i , 1 # i # m, 1 # j # p. Then, Equation4 can be rewritten as a matrix operation:
F 5 Lp~r1, r2, . . . , rm! p ~ A 3 S T! 4 ~ A 3 N T!(5)
where 3 denotes matrix multiplication, 4 denotestwo-dimensional array (or element-by-element) di-vision, and p denotes two-dimensional array (ele-ment-by-element) multiplication.
Using the representations of A and S discussed pre-viously, the scores for a customer j against all prod-ucts in a product group i can be computed in thefollowing way. First, two vectors « and h of size nare initialized to zero:
«@1 ; n# 5 0(6)
h@1 ; n# 5 0
Then, the compressed vector s j is expanded by as-signing its values to the elements of « indexed by J j .(This is a scatter operation.) Similarly, an expandedrepresentation of the jth row of N is stored into h:
«@ Jj# 5 sj (7)
h@ Jj# 5 1
Now, the scores of customer j against products f i tol i can be computed by:
F@ fi ; li, j# 5 L1~rfi, rfi11, . . . , rli! p ~Gi 3 «@Ii#!
4 ~Gi 3 h@Ii#! (8)
where 3 now denotes matrix-vector multiplication,and 4 and p denote one-dimensional array (element-by-element) division and multiplication, respectively.Note that we have two gather operations, in «[I i]and h[I i]. If we group several customers together,
forming a block from customer j1 to customer j2, theoperations in Equation 8 become dense matrix mul-tiplications, array division, and array multiplication:
F@ fi ; li, j1 ; j2# 5 Lj22j111~rfi, rfi11, . . . , rli!
p ~Gi 3 «@Ii, j1 ; j2#! 4 ~Gi 3 h@Ii, j1 ; j2#! (9)
Matrix multiplication can be implemented more ef-ficiently than matrix-vector multiplication. This isparticularly true on cache-based RISC (reduced in-struction set computing) microprocessors, since ma-trix multiplication can be organized through block-ing to better exploit the memory hierarchy.
In our experiments, the affinity matrix A is stored asa set of 93 dense blocks, each block representing adistinct group. The S matrix is stored in compressedrows. Finally, the F matrix, because of its relativelylarge number of nonzeros, is stored in expandedform. We used the problem parameters shown inTable 1.
Appendix B: The MICROSTRIP computation
In a shielded microstrip structure (see Figure 23A),n parallel microstrips run inside a homogeneous in-sulator. A conducting shield, at a reference poten-tial V shield 5 0, completely encloses the structure.Each microstrip k is at a voltage Vk with respect tothe shield. We want to compute the value of the po-tential field F( x, y) in each point of the structure.The potential field F( x, y) is described by a partialdifferential equation.
The first step in computing a numerical solution forthe field F( x, y) is to discretize the problem domainthrough a rectangular grid of evenly spaced points.Figure 23B illustrates this discretization. The gridhas shape (w 1 1) 3 (h 1 1), and s is the grid step,or space between consecutive grid points. Points inthe structure can be identified by their coordinatesin the grid. We use the notation F i, j to denote thevalue of the potential field in point (i, j) of the grid.Using the discretization, and applying several sim-plifications to the physics of the problem, we arriveat the following equation for the potential field:
Fi11, j 1 Fi21, j 1 Fi, j11 1 Fi, j21 2 4Fi, j 5 0 (10)
for all points (i, j) of the insulator. This, in fact, cor-responds to a system of equations in the unknownF i, j for all i and j. One approach to solving such a
Table 1 Problem parameters for our data miningapplication
Matrix Size(Rows 3Columns)
Numberof
Nonzeros
Fractionof
Nonzeros
A 10 350 3 2103 397559 1.83%S 4 800 3 2103 231194 2.29%F 10 350 3 4800 20759569 41.79%
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200052

system is through an iterative method called Jacobirelaxation. We start with some arbitrary initial ap-proximation of the potential field, F i, j
0 , for all points(i, j). (The values on the microstrips and the shieldare fixed by the problem boundary conditions.) Then,for each point (i, j), we compute a better approx-imation of the solution through the expression
F i, j1 5
14 ~F i11, j
0 1 F i21, j0 1 F i, j11
0 1 F i, j210 ! (11)
In the next iteration of the method we compute aneven better approximation:
F i, j2 5
14 ~F i11, j
1 1 F i21, j1 1 F i, j11
1 1 F i, j211 ! (12)
We continue this process until we converge to somesatisfactory solution. (A typical condition is that wewant the difference between F k and F k11 to be verysmall.) From a programming point of view, we repre-sent the field by two arrays, a and b, of size (w 1 1) 3(h 1 1). We can then write the relaxation step as
for i 5 1, 2, . . . , w 2 1for j 5 1, 2, . . . , h 2 1
b(i, j) 5 14 (a(i 1 1, j) 1 a(i 2 1, j)
1 a(i, j 1 1) 1 a(i, j 2 1)) (13)end
end
where a is used to represent the current value of thepotential field F and b its next value. We are inter-ested in the case where F is a complex-valued func-
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 53

tion. We can measure progress in our iterative solverby computing the error between the previous andcurrent approximation for F as follows:
error 5 0for i 5 0, 1, . . . , w
for j 5 0, 1, . . . , herror 5 error 1 abs(b(i, j) 2 a(i, j)) (14)
endenderror 5 error/((w 1 1) 3 (h 1 1))
The entire iterative solver is a combination of re-laxation steps and error computation, as shown inFigure 24. For clarity, we omit the code that han-dles the boundary conditions at the microstrips. Al-though important, that code represents only a smallfraction of the computation. The interested readercan obtain more detailed information from Refer-ence 21. For the particular problem computed in the
MICROSTRIP benchmark, the grid size is 1000 3 1000and there are four microstrips, each of cross section100 3 10 grid steps, running through the insulator.
*Trademark or registered trademark of International BusinessMachines Corporation.
**Trademark or registered trademark of Sun Microsystems, Inc.
Cited references
1. “Java Grande Forum Report: Making Java Work for High-End Computing,” Java Grande Forum Panel, SC98, Orlando,FL (November 1998), http://www.javagrande.org/reports.htm.
2. V. Seshadri, “IBM High-Performance Compiler for Java,”AIXpert Magazine (September 1997), http://www.developer.ibm.com/library/aixpert.
3. S. P. Midkiff, J. E. Moreira, and M. Snir, “Optimizing ArrayReference Checking in Java Programs,” IBM Systems Jour-nal 37, No. 3, 409–453 (1998).
4. V. Sarkar, “Automatic Selection of High-Order Transforma-tions in the IBM XL FORTRAN Compilers,” IBM Journalof Research and Development 41, No. 3, 233–264 (May 1997).
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200054

5. S. Muchnick, Advanced Compiler Design and Implementation,Morgan Kaufman Publishers, San Francisco, CA (1997).
6. F. G. Gustavson, “Recursion Leads to Automatic VariableBlocking for Dense Linear-Algebra Algorithms,” IBM Jour-nal of Research and Development 41, No. 6, 737–755 (Novem-ber 1997).
7. M. Kandemir, A. Choudhary, J. Ramanujam, and P. Ban-erjee, “A Matrix-Based Approach to the Global Locality Op-timization Problem,” Proceedings of the International Confer-ence on Parallel Architectures and Compilation Techniques(PACT’98), Paris (October 1998), pp. 306–313.
8. M. Kandemir, A. Choudhary, J. Ramanujam, N. Shenoy, andP. Banerjee, “Enhancing Spatial Locality via Data Layout Op-timizations,” Proceedings of Euro-Par’98, Southampton, UK,Lecture Notes in Computer Science, Springer-Verlag, Inc.,1470, 422–434 (September 1998).
9. G. Rivera and C.-W. Tseng, “Data Transformations for Elim-inating Conflict Misses,” Proceedings of the ACM SIGPLAN’98Conference on Programming Language Design and Implemen-tation, Montreal (June 1998), pp. 38–49.
10. P. Wu, S. P. Midkiff, J. E. Moreira, and M. Gupta, “EfficientSupport for Complex Numbers in Java,” Proceedings of theACM 1999 Java Grande Conference (1999), pp. 109–118.
11. J. C. Adams, W. S. Brainerd, J. T. Martin, B. T. Smith, andJ. L. Wagener, Fortran 90 Handbook: Complete ANSI/ISO Ref-erence, McGraw-Hill Book Co., Inc., New York (1992).
12. R. Parsons and D. Quinlan, “Run Time Recognition of TaskParallelism within the P11 Parallel Array Class Library,”Proceedings of the Scalable Parallel Libraries Conference (Oc-tober 1993), pp. 77–86.
13. Parallel Programming Using C11, G. V. Wilson and P. Lu,Editors, MIT Press, Cambridge, MA (1996).
14. U. Banerjee, Dependence Analysis, in the book series LoopTransformations for Restructuring Compilers, Kluwer Ac-ademic Publishers, Boston, MA (1996).
15. J. J. Dongarra, I. S. Duff, D. C. Sorensen, and H. A. van derVorst,SolvingLinearSystemsonVectorandSharedMemoryCom-puters, Society for Industrial and Applied Mathematics, Phil-adelphia, PA (1991).
16. P. V. Artigas, M. Gupta, S. P. Midkiff, and J. E. Moreira,“High-Performance Numerical Computing in Java: Languageand Compiler Issues,” Ferrante et al., Editors, 12th Interna-tional Workshop on Languages and Compilers for Parallel Com-puting, Springer-Verlag, Inc., New York (August 1999).
17. J. E. Moreira, S. P. Midkiff, and M. Gupta, “From Flop toMegaflops: Java for Technical Computing,” Proceedings ofthe 11th International Workshop on Languages and Compilersfor Parallel Computing, LCPC’98 (1998), pp. 1–17.
18. E. Simoudis, “Reality Check for Data Mining,” IEEE Expert:Intelligent Systems and Their Applications 11, No. 5, 26–33 (Oc-tober 1996).
19. E. Anderson, Z. Bai, C. Bischof, J. Demmel, J. Dongarra,J. DuCroz, A. Greenbaum, S. Hammarling, A. McKenney,S. Ostrouchov, and D. Sorensen, LAPACK User’s Guide, So-ciety for Industrial and Applied Mathematics, Philadelphia,PA (1995).
20. IBM Engineering and Scientific Subroutine Library for AIX—Guide and Reference, IBM Corporation (December 1997).
21. J. E. Moreira and S. P. Midkiff, “Fortran 90 in CSE: A CaseStudy,” IEEE Computational Science and Engineering 5, No.2, 39–49 (April–June 1998).
22. G. H. Golub and C. F. van Loan, Matrix Computations, JohnsHopkins Series in Mathematical Sciences, The Johns Hop-kins University Press, Baltimore, MD (1989).
23. W. H. Press, S. A. Teukolsky, W. T. Vetterling, and B. P. Flan-
nery, Numerical Recipes in Fortran: The Art of Scientific Com-puting, Cambridge University Press, UK (1992).
24. B. Blount and S. Chatterjee, “An Evaluation of Java for Nu-merical Computing,” Proceedings of ISCOPE’98, Lecture Notesin Computer Science, Springer-Verlag, Inc. 1505, 35–46 (1998).
25. R. F. Boisvert, J. J. Dongarra, R. Pozo, K. A. Remington,and G. W. Stewart, “Developing Numerical Libraries in Java,”ACM 1998 Workshop on Java for High-Performance NetworkComputing, ACM SIGPLAN (1998), http://www.cs.ucsb.edu/conferences/java98.
26. M. Schwab and J. Schroeder, “Algebraic Java Classes for Nu-merical Optimization,” ACM 1998 Workshop on Java for High-Performance Network Computing, ACM SIGPLAN (1998),http://www.cs.ucsb.edu/conferences/java98.
27. A. J. C. Bik and D. B. Gannon, “A Note on Native Level 1BLAS in Java,” Concurrency, Practical Experience (UK) 9, No.11, 1091–1099 (November 1997), presented at Workshop onJava for Computational Science and Engineering—Simulationand Modeling II (June 21, 1997).
28. H. Casanova, J. Dongarra, and D. M. Doolin, “Java Accessto Numerical Libraries,” Concurrency, Practical Experience(UK) 9, No. 11, 1279–1291 (November 1997), presented atWorkshop on Java for Computational Science and Engineer-ing—Simulation and Modeling II, Las Vegas, NV (June 21,1997).
29. V. Getov, S. Flynn-Hummel, and S. Mintchev, “High-Per-formance Parallel Programming in Java: Exploiting NativeLibraries,” ACM 1998 Workshop in Java for High-PerformanceNetwork Computing, ACM SIGPLAN (1998), http://www.cs.ucsb.edu/conferences/java98.
30. M. Cierniak and W. Li, “Just-in-Time Optimization for High-Performance Java Programs,” Concurrency, Practical Expe-rience (UK) 9, No. 11, 1063–1073 (November 1997), presentedat Workshop for Java Computational Science and Engineering—Simulation and Modeling II, Las Vegas, NV (June 21, 1997).
31. P. Wu and D. Padua, “Beyond Arrays—A Container-Cen-tric Approach for Parallelization of Real-World Symbolic Ap-plications,” Proceedings of the 11th International Workshop onLanguages and Compilers for Parallel Computing, LCPC’98(1998), pp. 197–212.
32. W.-M. Ching and D. Ju, “Execution of Automatically Par-allelized APL Programs on RP3,” IBM Journal of Researchand Development 35, Nos. 5/6, 767–777 (1991).
33. R. G. Willhoft, “Parallel Expression in the APL2 Language,”IBM Systems Journal 30, No. 4, 498–512 (1991).
34. F. Bodin, P. Beckmann, D. Gannon, S. Narayana, and S. X.Yang, “Distributed pC11: Basic Ideas for an Object Par-allel Language,” Scientific Programming 2, No. 3, 7–22 (1993).
35. IBM Parallel Engineering and Scientific Subroutine Library forAIX—Guide and Reference, IBM Corporation (December1997).
36. J. V. W. Reynders, J. C. Cummings, M. Tholburn, P. J. Hinker,S. R. Atlas, S. Banerjee, M. Srikant, W. F. Humphrey, S. R.Karmesin, and K. Keahey, “POOMA: A Framework for Sci-entific Simulation on Parallel Architectures,” Proceedings ofFirst International Workshop on High Level Programming Mod-els and Supportive Environments, Honolulu, HI (April 16,1996), pp. 41–49. Technical report is available at http://www.acl.lanl.gov/PoomaFramework/papers/papers.html.
37. R. Agrawal, T. Imielinski, and A. Swami, “Mining Associ-ation Rules Between Sets of Items in Large Databases,” Pro-ceedings of the 1993 ACM SIGMOD International Conferenceon Management of Data, Washington (May 1993), pp. 207–216.
IBM SYSTEMS JOURNAL, VOL 39, NO 1, 2000 MOREIRA ET AL. 55

Accepted for publication September 1, 1999.
Jose E. Moreira IBM Research Division, Thomas J. Watson Re-search Center, P.O. Box 218, Yorktown Heights, New York 10598(electronic mail: [email protected]). Dr. Moreira received B.S.degrees in physics and electrical engineering in 1987 and an M.S.degree in electrical engineering in 1990, all from the Universityof Sao Paulo, Brazil. He received his Ph.D. degree in electricalengineering from the University of Illinois at Urbana-Champaignin 1995. Dr. Moreira is a research staff member in the ScalableParallel Systems Department at the Watson Research Center.Since joining IBM at the Research Center in 1995, he has workedon various topics related to the design and execution of parallelapplications. His current research activities include performanceevaluation and optimization of Java programs and schedulingmechanisms for the ASCI Blue-Pacific project.
Samuel P. Midkiff IBM Research Division, Thomas J. Watson Re-search Center, P.O. Box 218, Yorktown Heights, New York 10598(electronic mail: [email protected]). Dr. Midkiff received a B.S.degree in computer science in 1983 from the University of Ken-tucky, and M.S. and Ph.D. degrees in computer science from theUniversity of Illinois at Urbana-Champaign in 1986 and 1992,respectively. Dr. Midkiff is a research staff member in the Scal-able Parallel Systems Department at the Watson Research Cen-ter, and an adjunct assistant professor at the University of Illi-nois, Urbana-Champaign. Since joining the Research Center in1992, Dr. Midkiff has worked on the design and development ofthe IBM XL HPF compiler and projects related to the compi-lation of numerical programs. His current research areas are op-timizing computationally intensive Java programs, static compi-lation of Java for shared memory multiprocessors, and the analysisof explicitly parallel programs.
Manish Gupta IBM Research Division, Thomas J. Watson Re-search Center, P.O. Box 218, Yorktown Heights, New York 10598(electronic mail: [email protected]). Dr. Gupta is a researchstaff member and manager, High Performance ProgrammingEnvironments, at the Watson Research Center. He received aB.Tech. degree in computer science from the Indian Institute ofTechnology, Delhi, in 1987, an M.S. from Ohio State Universityin 1988, and a Ph.D. in computer science from the University ofIllinois in 1992. He has worked on the development of the IBMHPF compiler for the SPTM machines, parallelizing FORTRAN90 and C compilers on shared memory machines, and more re-cently, on optimizing Java compilers. His research interests in-clude high-performance compilers, programming environments,and parallel architectures.
Pedro V. Artigas IBM Research Division, Thomas J. Watson Re-search Center, P.O. Box 218, Yorktown Heights, New York 10598(electronic mail: [email protected]). Mr. Artigas received a B.S.degree in electrical engineering in 1996 from the University ofSao Paulo, Brazil. He is currently working on his master’s degreethesis and will soon obtain an M.S. degree from the same uni-versity (expected at the beginning of year 2000). Mr. Artigas iscurrently a cooperative fellowship student at the Watson ResearchCenter. His research activities include performance evaluationand optimization of Java programs and the development of a pro-totype high-performance static Java compiler. His research in-terests include high-performance compilers and computer archi-tectures, parallel architectures, processor micro-architectures, andoperating systems.
Marc Snir IBM Research Division, Thomas J. Watson ResearchCenter, P.O. Box 218, Yorktown Heights, New York 10598 (elec-tronic mail: [email protected]). Dr. Snir is a senior manager atthe Watson Research Center, where he leads research on scal-able parallel systems. He and his group developed many of thetechnologies that led to the IBM SP product, and they continueto work on future SP generations. Dr. Snir received a Ph.D. inmathematics from the Hebrew University of Jerusalem in 1979.He worked at New York University on the NYU Ultracomputerproject from 1980 to 1982, and worked at the Hebrew Universityof Jerusalem from 1982 to 1986, when he joined the Watson Re-search Center. He has published close to 100 journal and con-ference papers on computational complexity, parallel algorithms,parallel architectures, and parallel programming. He has recentlycoauthored the High Performance FORTRAN and the MessagePassing Interface standards. He is on the editorial board of Trans-actions on Computer Systems and Parallel Processing Letters. Heis a member of the IBM Academy of Technology, an ACM Fel-low, and an IEEE Fellow.
Richard D. Lawrence IBM Research Division, Thomas J. WatsonResearch Center, P.O. Box 218, Yorktown Heights, New York 10598(electronic mail: [email protected]). Dr. Lawrence is a researchstaff member and manager, Deep Computing Applications, at theWatson Research Center. He received the B.S. degree from Stan-ford University in chemical engineering, and the Ph.D. degreefrom the University of Illinois in nuclear engineering. Prior tojoining IBM Research in 1990, he held research positions in theApplied Physics Division at Argonne National Laboratory andat Schlumberger-Doll Research. His current work is in the de-velopment of high-performance data mining applications in theareas of financial analysis and personal recommender systems.He has received IBM Outstanding Innovation Awards for his workin scalable data mining and scalable parallel processing.
Reprint Order No. G321-5715.
MOREIRA ET AL. IBM SYSTEMS JOURNAL, VOL 39, NO 1, 200056





























