Embed Size (px)
Citation preview

2© 2014 JT IT Consulting, LLC
Agenda
•What is Big Data? …and how does it effect our business?
•What is Hadoop? …and how does it work?
•What is Windows Azure HDInsight? …and how does it fit into the Microsoft BI Ecosystem?
•What tools are used to work with Hadoop & HDInsight?
•How do I get started using HDInsight?

3© 2014 JT IT Consulting, LLC
What is Big Data?
• Explosion in social media, mobile apps, digital sensors, RFID, GPS, and more have caused exponential data growth.
Volume (Size)
• Traditionally BI has sourced structured data, but now insight must be extracted from unstructured data like large text blobs, digital media, sensor data, etc.
Variety (Structure)
• Sources like Social Networking and Sensor signals create data at a tremendous rate; making it a challenge to capture, store, and analyze that data in a timely or economical manner.
Velocity (Speed)
Datasets that, due to their size and complexity, are difficult to store, query, and manage using existing data management tools or data processing applications.
4© 2014 JT IT Consulting, LLC
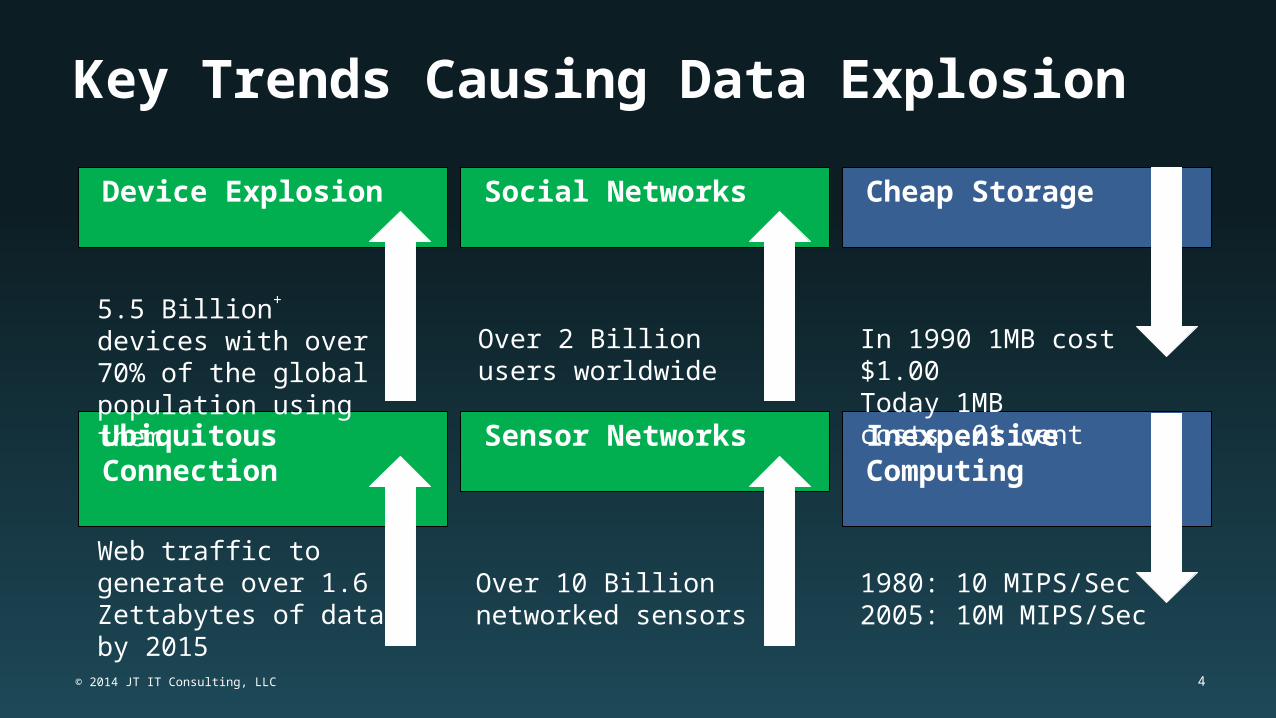
Key Trends Causing Data Explosion
Device Explosion
Ubiquitous Connection
Social Networks
Sensor Networks
Cheap Storage
InexpensiveComputing
5.5 Billion+ devices with over 70% of the global population using them.
Web traffic to generate over 1.6 Zettabytes of data by 2015
Over 2 Billion users worldwide
Over 10 Billion networked sensors
In 1990 1MB cost $1.00Today 1MB costs .01 cent
1980: 10 MIPS/Sec2005: 10M MIPS/Sec

5© 2014 JT IT Consulting, LLC
$Big Data is Creating Big Opportunities!
Big Data technologies are a top priority for most institutions: both corporate
and government
Currently, 49% of CEO’s and
CIO’s claim they are undertaking
Big Data projects
Software estimated to
experience 34% YOY compound
growth rate: 4.6B by 2015
Services estimate to
experience 39% YOY compound
growth rate: 6.5B by 2015
6© 2014 JT IT Consulting, LLC
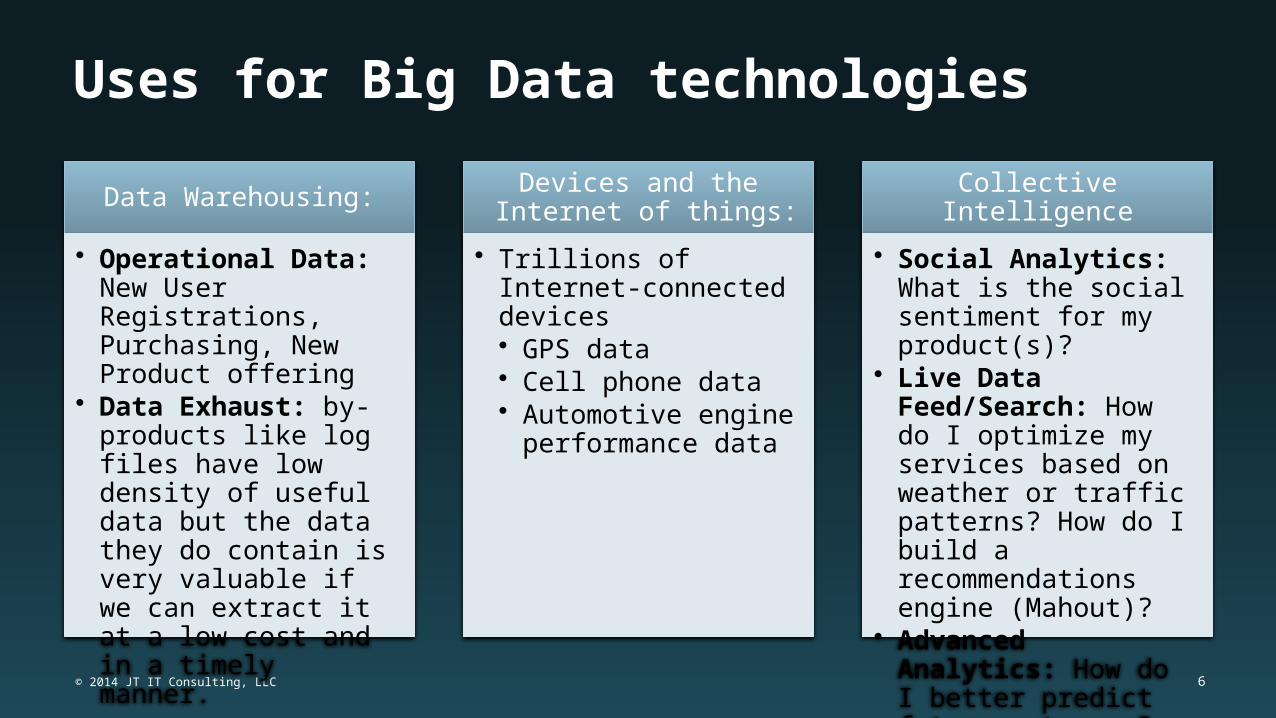
Uses for Big Data technologies
Data Warehousing:
• Operational Data: New User Registrations, Purchasing, New Product offering
• Data Exhaust: by-products like log files have low density of useful data but the data they do contain is very valuable if we can extract it at a low cost and in a timely manner.
Devices and the Internet of things:
• Trillions of Internet-connected devices• GPS data• Cell phone data• Automotive engine
performance data
Collective Intelligence
• Social Analytics: What is the social sentiment for my product(s)?
• Live Data Feed/Search: How do I optimize my services based on weather or traffic patterns? How do I build a recommendations engine (Mahout)?
• Advanced Analytics: How do I better predict future outcomes?
7© 2014 JT IT Consulting, LLC
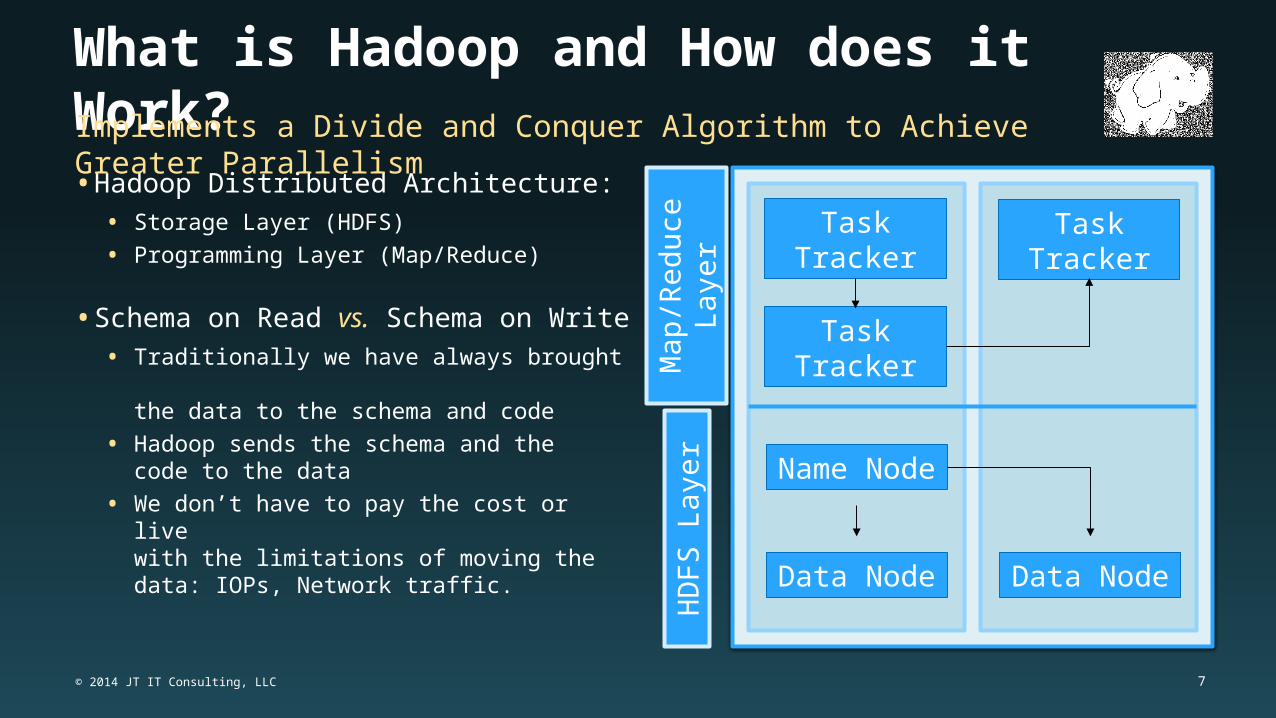
What is Hadoop and How does it Work?• Hadoop Distributed Architecture:
• Storage Layer (HDFS)
• Programming Layer (Map/Reduce)
• Schema on Read vs. Schema on Write• Traditionally we have always brought
the data to the schema and code
• Hadoop sends the schema and thecode to the data
• We don’t have to pay the cost or livewith the limitations of moving the data: IOPs, Network traffic.
Task Tracker
Task Tracker
Task Tracker
Name Node
Data NodeData Node
Map/R
educe
La
yer
HD
FS L
ayer
Implements a Divide and Conquer Algorithm to Achieve Greater Parallelism

8© 2014 JT IT Consulting, LLC
HDFS (Hadoop Distributed Files System)•Fault Tolerant:
• Data is distributed across each Data Node in the cluster (like RAID 5).
• 3 copies of the data is stored in case of storage failures.
• Data faults can be quickly detected and repaired due to data redundancy.
•High Throughput• Favors batch over interactive operations to support streaming large
datasets.
• Data files are written once and then closed; never to be updated.
• Supports data locality. HDFS facilitates moving the application code (query) to the data rather than moving the data to the application (schema on read).
9© 2014 JT IT Consulting, LLC
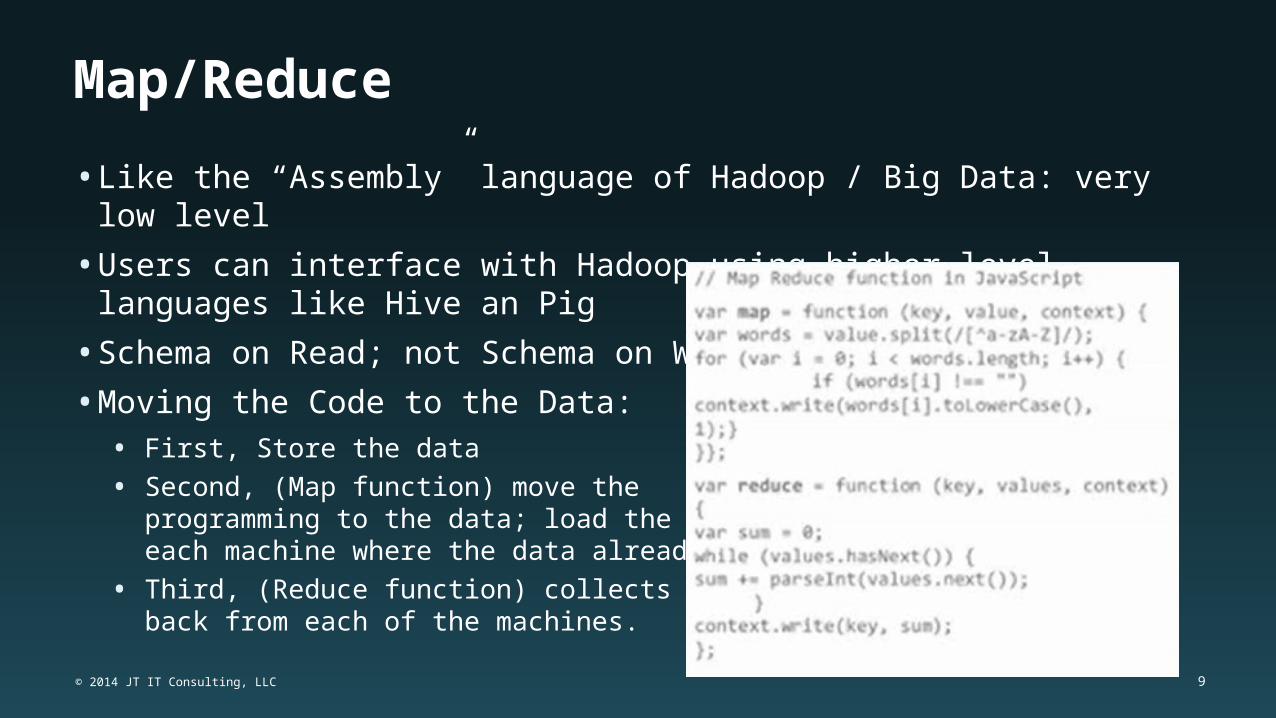
Map/Reduce
• Like the “Assembly” language of Hadoop / Big Data: very low level
• Users can interface with Hadoop using higher-level languages like Hive an Pig
• Schema on Read; not Schema on Write
• Moving the Code to the Data:• First, Store the data
• Second, (Map function) move the programming to the data; load the code on each machine where the data already resides.
• Third, (Reduce function) collects statisticsback from each of the machines.
10© 2014 JT IT Consulting, LLC
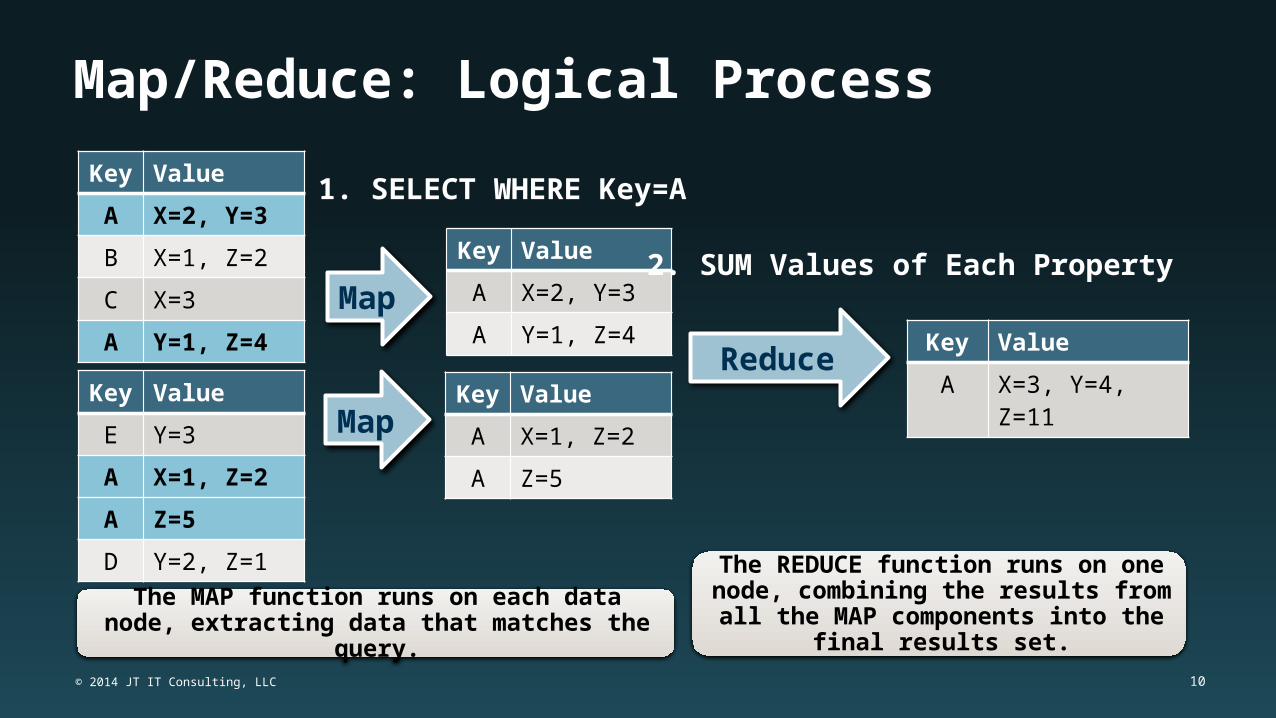
Map/Reduce: Logical Process
Key Value
A X=2, Y=3
B X=1, Z=2
C X=3
A Y=1, Z=4
Key Value
E Y=3
A X=1, Z=2
A Z=5
D Y=2, Z=1
Key Value
A X=2, Y=3
A Y=1, Z=4
Key Value
A X=1, Z=2
A Z=5
Key Value
A X=3, Y=4, Z=11
Map
Reduce
Map
1. SELECT WHERE Key=A
2. SUM Values of Each Property
The MAP function runs on each data node, extracting data that matches the query.
The REDUCE function runs on one node, combining the results from all the MAP components into the final results set.
11© 2014 JT IT Consulting, LLC
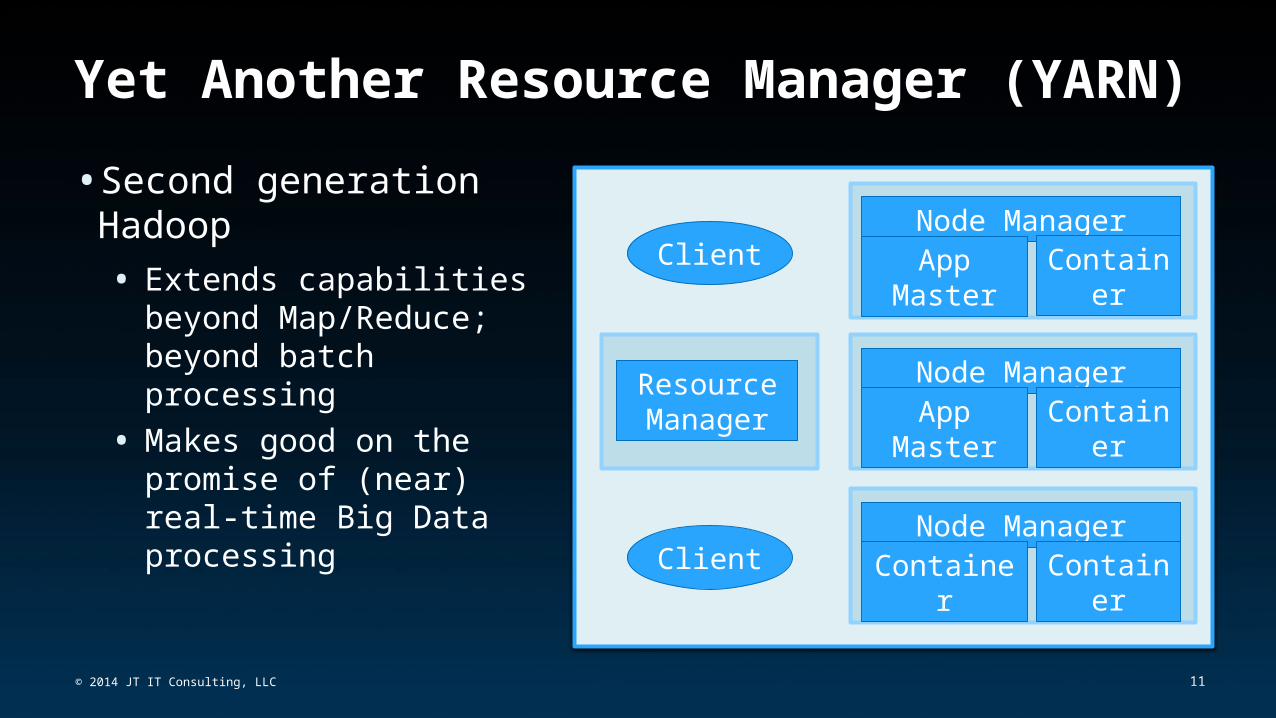
Yet Another Resource Manager (YARN)•Second generation
Hadoop• Extends capabilities
beyond Map/Reduce; beyond batch processing
• Makes good on the promise of (near) real-time Big Data processing
Node Manager
Resource Manager
App Master
Container
Node ManagerApp
MasterContaine
r
Node Manager
ContainerContaine
r
Client
Client
12© 2014 JT IT Consulting, LLC
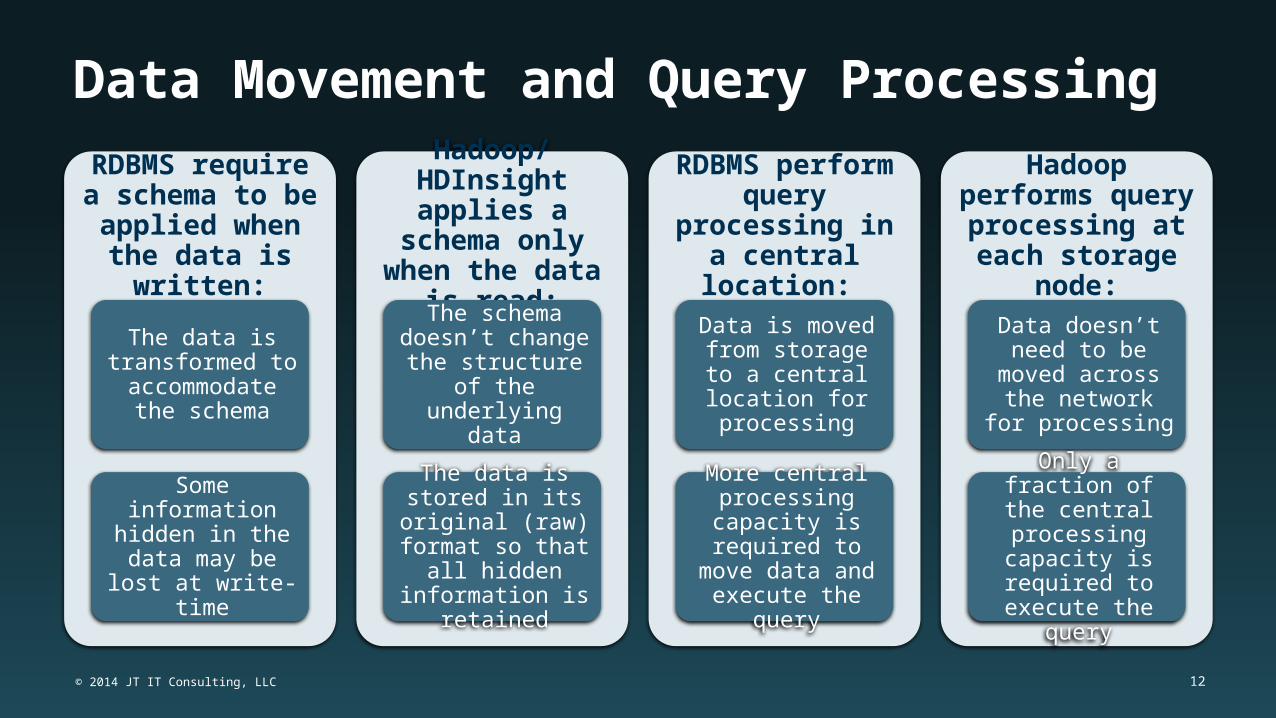
Data Movement and Query Processing RDBMS require a
schema to be applied when the data is written:
The data is transformed to
accommodate the schema
Some information hidden in the data
may be lost at write-time
Hadoop/HDInsight applies a schema
only when the data is read:
The schema doesn’t change the
structure of the underlying data
The data is stored in its original (raw) format so that all
hidden information is retained
RDBMS perform query processing
in a central location:
Data is moved from storage to a central
location for processing
More central processing capacity is required to move data and execute
the query
Hadoop performs query processing at each storage
node:
Data doesn’t need to be moved across
the network for processing
Only a fraction of the central
processing capacity is required to
execute the query
13© 2014 JT IT Consulting, LLC
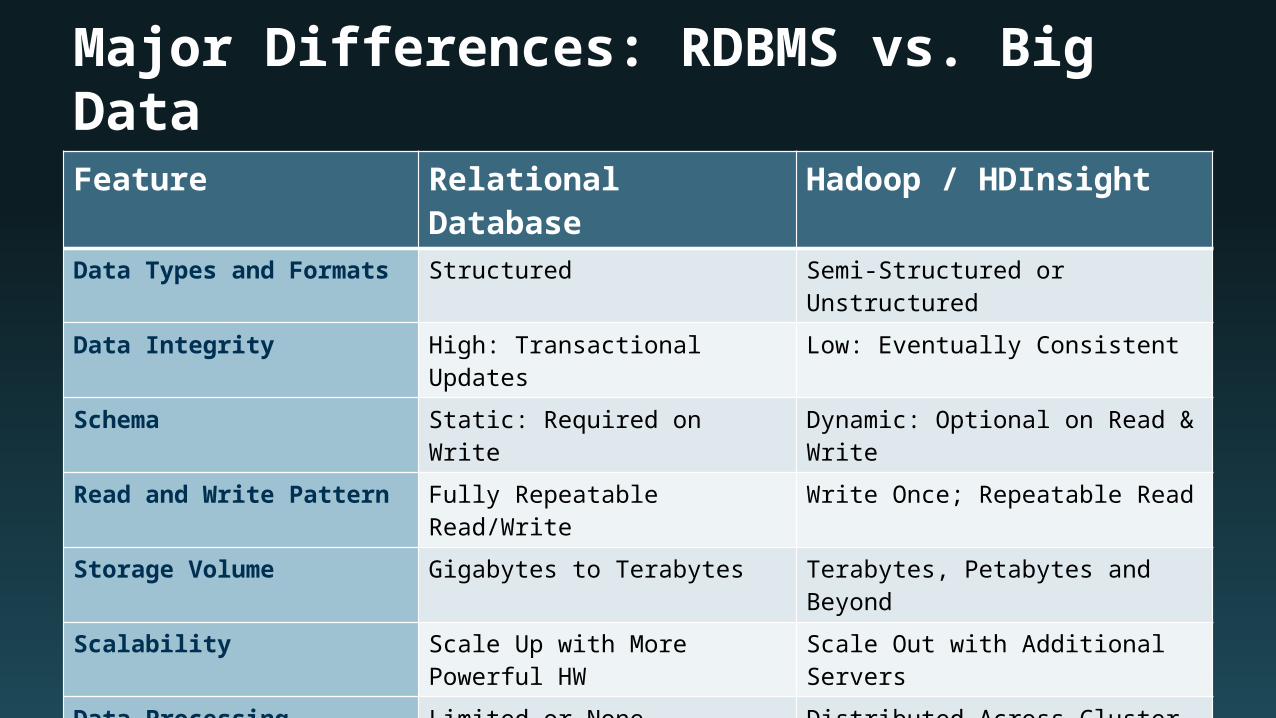
Major Differences: RDBMS vs. Big DataFeature Relational Database Hadoop / HDInsight
Data Types and Formats Structured Semi-Structured or Unstructured
Data Integrity High: Transactional Updates Low: Eventually Consistent
Schema Static: Required on Write Dynamic: Optional on Read & Write
Read and Write Pattern Fully Repeatable Read/Write Write Once; Repeatable Read
Storage Volume Gigabytes to Terabytes Terabytes, Petabytes and Beyond
Scalability Scale Up with More Powerful HW Scale Out with Additional Servers
Data Processing Distribution Limited or None Distributed Across Cluster
Economics Expensive Hardware & Software Commodity Hardware & Open Source Software

14© 2014 JT IT Consulting, LLC
Solution Architecture: Big Data or RDBMS?
• Perhaps you already have the data that contains the information you need, but you can’t analyze it with your existing tools. Or is there a source of data you think will be useful, but you don’t yet know how to collect it, store it, and analyze it?
Where will the source data come from?
• Is it highly structured, in which case you may be able to load it into your existing database or data warehouse and process it there? Or is it semi-structured or unstructured, in which case a Big Data solution that is optimized for textual discovery, categorization, and predictive analysis will be more suitable?
What is the format of the data?
• Is there a huge volume? Does it arrive as a stream or in batches? Is it of high quality or will you need to perform some type of data cleansing and validation of the content?
What are the delivery and quality characteristics
of the data?
• If so, do you know where this data will come from, how much it will cost if you have to purchase it, and how reliable this data is?
Do you want to combine the results with data from
other sources?
• Will you need to load the data into an existing database or data warehouse, or will you just analyze it and visualize the results separately?
Do you want to integrate with an existing
BI system?

15© 2014 JT IT Consulting, LLC
What is Windows Azure HDInsight?
• Windows Azure: Microsoft’s online storage and compute services
• HDInsight: Microsoft’s implementation of Apache Hadoop (Hortonworks Data Platform) as an online service
Makes Apache Hadoop readily available to the Windows community
• Enables Windows Azure subscribers to quickly and easily provision an HDInsight cluster across Windows Azure’s pool of storage and compute resources.
• Also enables them to quickly de-provision those clusters when they’re not needed.
• Allows subscribers to continuously store their data for later use.
Exposes Apache Hadoop services to the Microsoft programming ecosystem
• SQL Server: Analysis Services• PowerShell and the Cross-platform
Command-line tools• Visual Studio: CLR (C#, F#, etc.)• JavaScript• ODBC / JDBC / REST API• Excel Self-Service BI (SSBI): PowerQuery,
PowerPivot, PowerView and PowerMap
16© 2014 JT IT Consulting, LLC
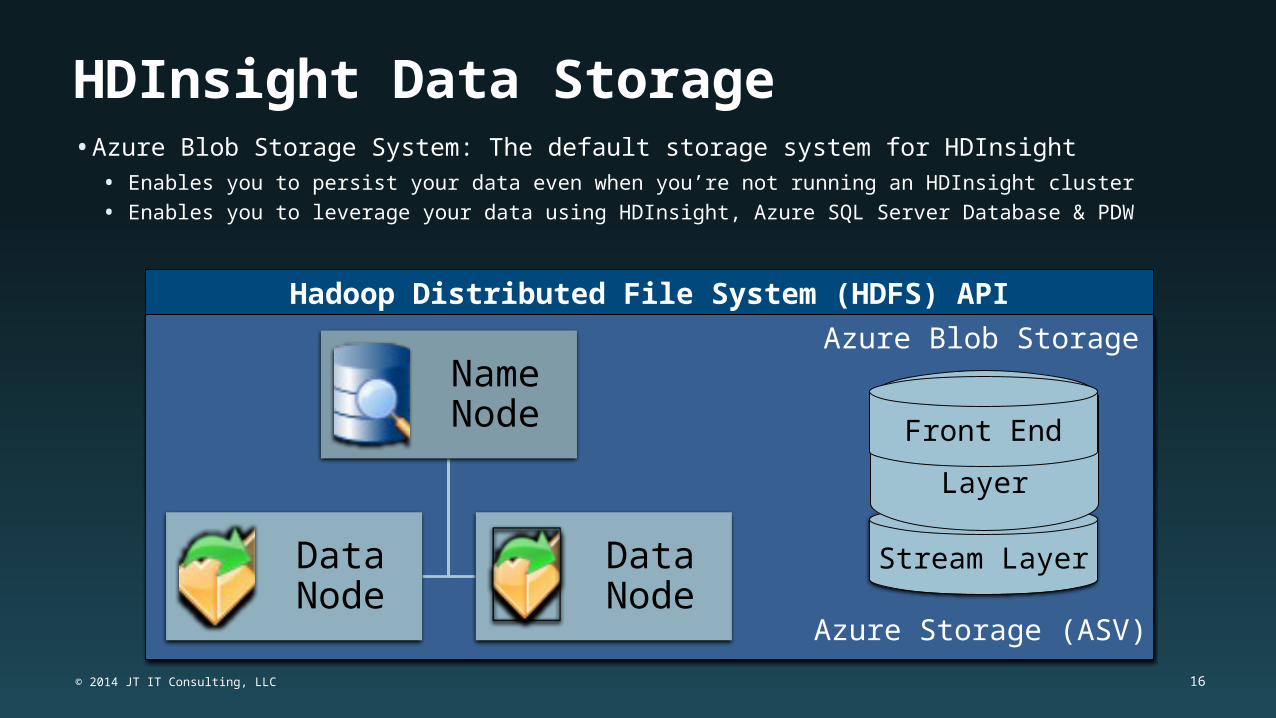
HDInsight Data Storage• Azure Blob Storage System: The default storage system for HDInsight
• Enables you to persist your data even when you’re not running an HDInsight cluster
• Enables you to leverage your data using HDInsight, Azure SQL Server Database & PDW
Name Node
Data Node
Data Node
Stream Layer
Partition Layer
Front End
Azure Storage (ASV)
Azure Blob Storage
Hadoop Distributed File System (HDFS) API

17© 2014 JT IT Consulting, LLC
Azure Storage Vault (ASV)
• The default file system for the HDInsight Service
• Provides scalable, persistent, sharable, highly-available storage
• Fast data access for compute nodes residing in the same data center
• Addressable via:• asv[s].<container>@<account>.blob, core.windows.net/path
• Requires storage key in core-site.xml:<property>
<name>fs.azure.account.key.accountname</name>
<value>keyvaluestring</value>
</property>
18© 2014 JT IT Consulting, LLC
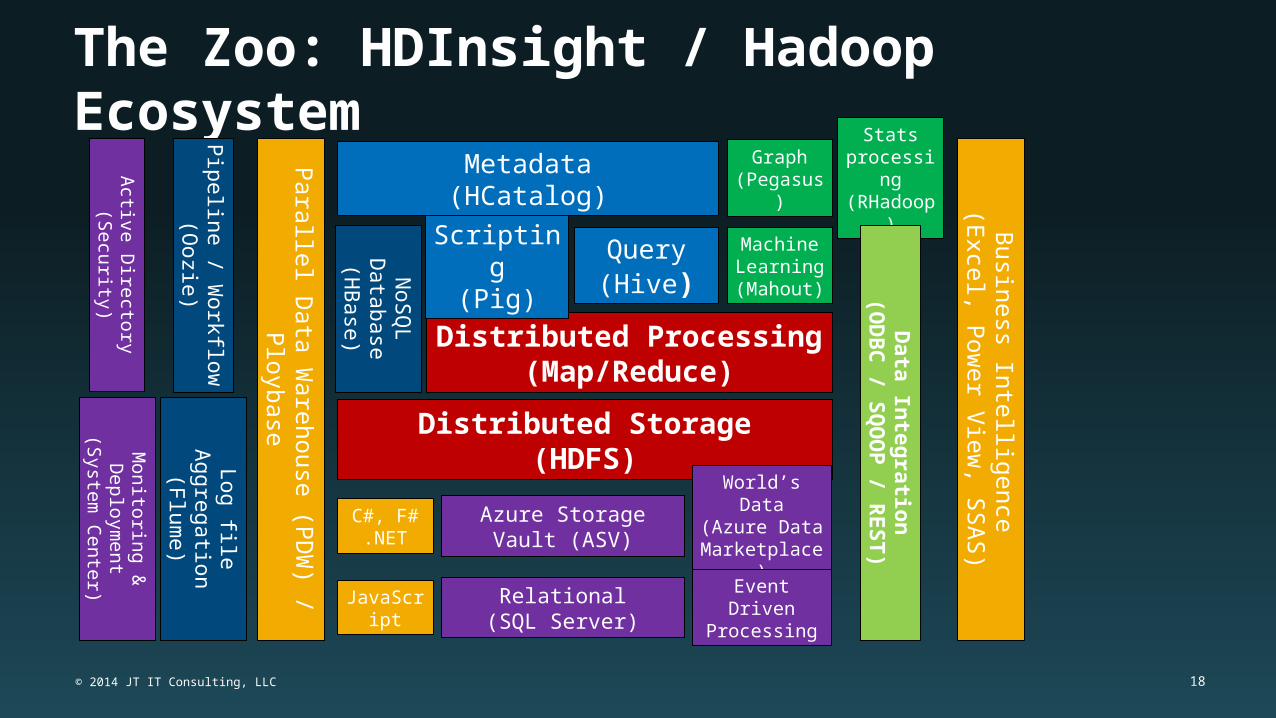
The Zoo: HDInsight / Hadoop Ecosystem
Distributed Processing(Map/Reduce)
Distributed Storage(HDFS)
Scripting(Pig)
Query(Hive)
Metadata(HCatalog)A
ctive D
irecto
ry(S
ecu
rity)
Mon
itorin
g &
D
eplo
ym
ent
(Syste
m C
ente
r)
World’s Data(Azure Data Marketplace)
Azure StorageVault (ASV)
NoSQ
L D
ata
base
(HB
ase
)
Pipelin
e / W
orkfl
ow
(Oozie
)Lo
g fi
le A
ggre
gatio
n(Flu
me)
C#, F#.NET
JavaScript
Stats processin
g(RHadoop
)
Graph(Pegasus)
Machine Learning(Mahout)
Data
Inte
gra
tion
(OD
BC
/ SQ
OO
P / R
ES
T)
Busin
ess In
tellig
ence
(E
xcel, Po
wer V
iew
, SS
AS
)
Relational(SQL Server)
Event Driven Processing
Para
llel D
ata
Ware
house
(PD
W) /
Plo
ybase
19© 2014 JT IT Consulting, LLC
Programming HDInsight
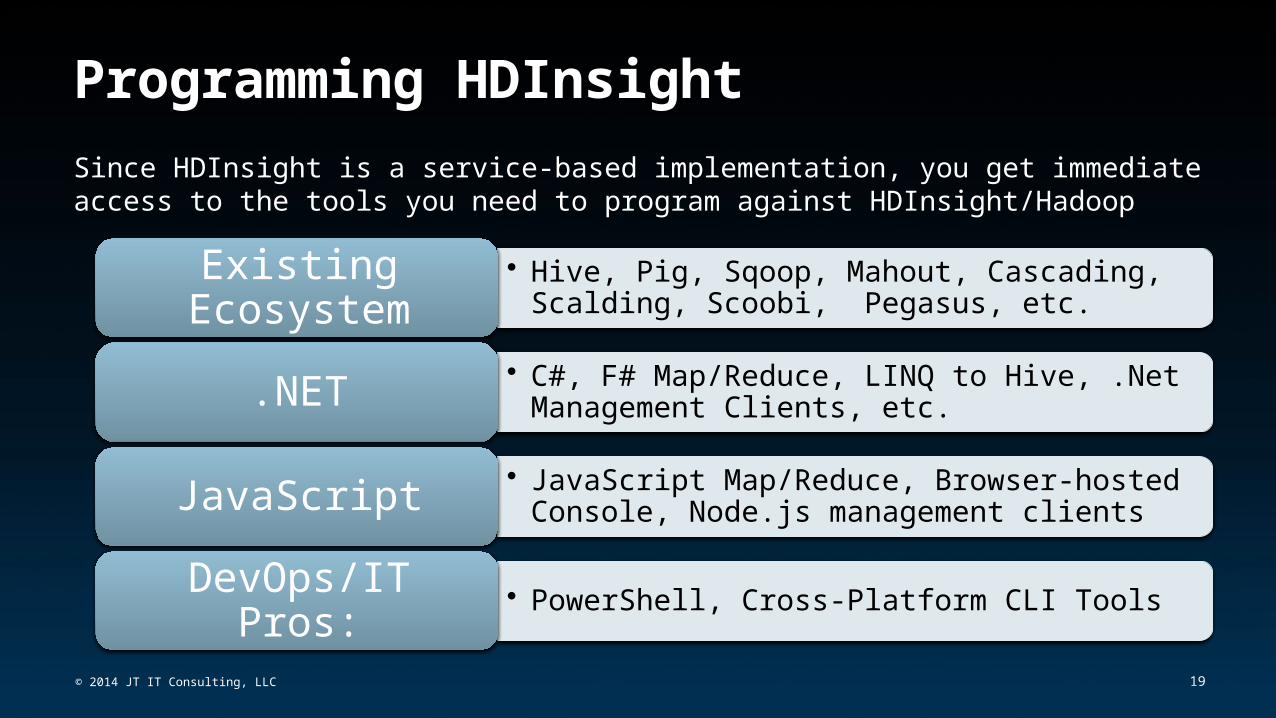
Since HDInsight is a service-based implementation, you get immediate access to the tools you need to program against HDInsight/Hadoop
• Hive, Pig, Sqoop, Mahout, Cascading, Scalding, Scoobi, Pegasus, etc.Existing Ecosystem
• C#, F# Map/Reduce, LINQ to Hive, .Net Management Clients, etc..NET
• JavaScript Map/Reduce, Browser-hosted Console, Node.js management clientsJavaScript
• PowerShell, Cross-Platform CLI ToolsDevOps/IT Pros:
20© 2014 JT IT Consulting, LLC
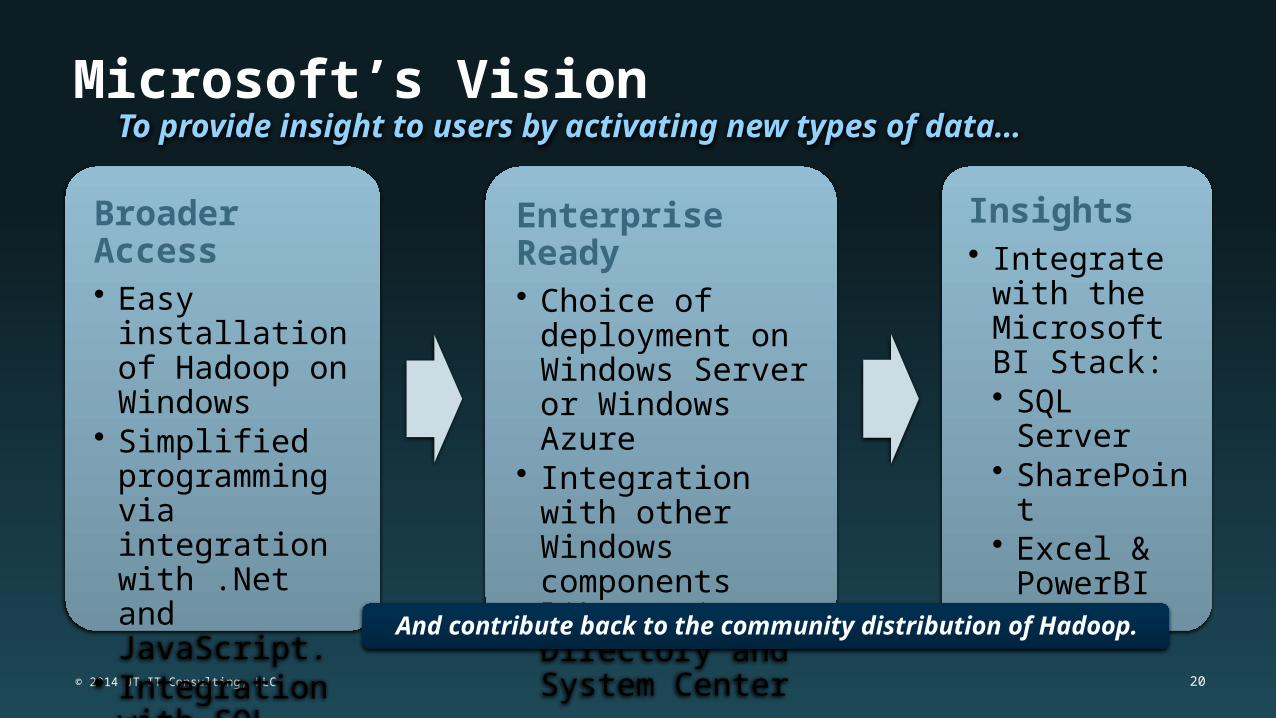
Microsoft’s Vision
Broader Access• Easy installation
of Hadoop on Windows
• Simplified programming via integration with .Net and JavaScript.
• Integration with SQL Server Data Warehouses
Enterprise Ready• Choice of
deployment on Windows Server or Windows Azure
• Integration with other Windows components like Active Directory and System Center
Insights• Integrate with
the Microsoft BI Stack:• SQL Server• SharePoint• Excel &
PowerBI
To provide insight to users by activating new types of data…
And contribute back to the community distribution of Hadoop.

21© 2014 JT IT Consulting, LLC
How do I get started with HDInsight?
1. Create an Windows Azure account (subscription)
2. Create an Azure Storage account
3. Create an Azure Blob Storage node
4. Provision an HDInsight Service cluster
5. Install Windows Azure PowerShell
6. Install Windows Azure HDInsight PowerShell
7. Setup Environment
22© 2014 JT IT Consulting, LLC
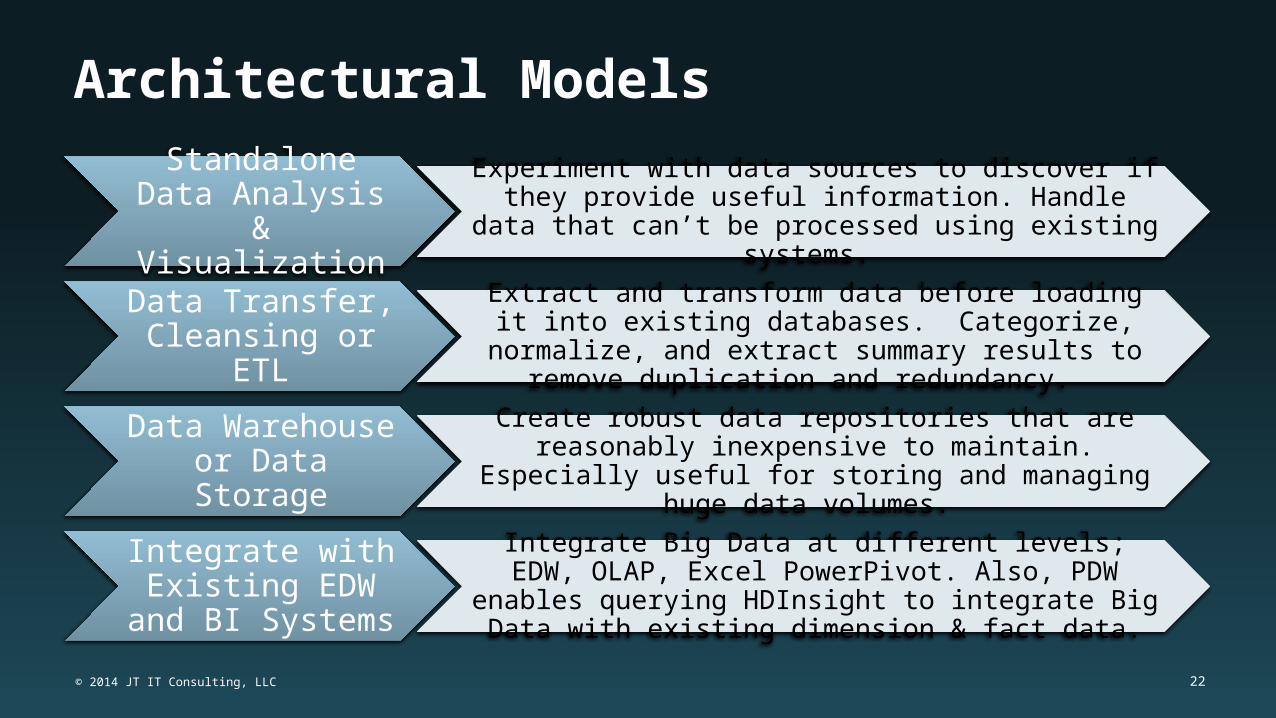
Architectural Models
Standalone Data Analysis &
Visualization
Experiment with data sources to discover if they provide useful information. Handle data that can’t be processed
using existing systems.
Data Transfer, Cleansing or ETL
Extract and transform data before loading it into existing databases. Categorize, normalize, and extract summary
results to remove duplication and redundancy.
Data Warehouse or Data Storage
Create robust data repositories that are reasonably inexpensive to maintain. Especially useful for storing and
managing huge data volumes.
Integrate with Existing EDW and
BI Systems
Integrate Big Data at different levels; EDW, OLAP, Excel PowerPivot. Also, PDW enables querying HDInsight to integrate Big Data with existing dimension & fact data.

24© 2014 JT IT Consulting, LLC
Resources
• http://www.windowsazure.com
• http://hadoopsdk.codeplex.com
• http://nugget.org/packages?q=hadoop
• PolyBase – David DeWitt http://www.Microsoft.com/en-us/sqlserver/solutions-technologies/data-warehousing/polybase.aspx
• PDW Website: http://Microsoft.com/en-us/sqlserver-solutions-technologies/data-warehousing/pdw.aspx
• http://blogs.technet.com/b/dataplatforminsider/archive/2013/04/25/insight-through-integration-sql-server-2012-parallel-data-warehouse-polybase-demo.aspx
25© 2014 JT IT Consulting, LLC
Tools
•http://azurestorageexplorer.codeplex.com

26© 2014 JT IT Consulting, LLC
Place title here
• HDInsight clusters can be provisioned when needed and then de-provisioned without loosing the data or metadata they have processed.
• Azure Storage Vault allow you to maintain that state; paying only for the storage and not the cluster(s).
• Since stream data often arrives in massive bursts, HDInsight can provide a buffer between that data generation and existing data warehouse/BI infrastructures.






























