Embed Size (px)
Citation preview

Introduction to translational and clinical bioinformatics
Connecting complex molecular information to clinically relevant decisions
using molecular profiles
Constantin F. Aliferis M.D., Ph.D., FACMI
Director, NYU Center for Health Informatics and Bioinformatics
Informatics Director, NYU Clinical and Translational Science Institute
Director, Molecular Signatures Laboratory,
Associate Professor, Department of Pathology,
Adjunct Associate Professor in Biostatistics and Biomedical Informatics, Vanderbilt University
1
Alexander Statnikov Ph.D.
Director, Computational Causal Discovery laboratory
Assistant Professor, NYU Center for Health Informatics and Bioinformatics, General Internal Medicine

Goals• Understand spectrum of Bioinformatics and Medical informatics activities
• Understand basic concepts of clinical/translational Bioinformatics
• Understand basic concepts of molecular profiling
• Introduction to high-throughput assays enabling molecular profiling
• Introduction to computational data analytics/bioinformatics enabling molecular profiling
• Understand analytic challenges and pitfalls/interpretation issues
• Discuss case study of profiles used to diagnose/treat patients
• Perform hands-on development of a molecular profile, finding novel biomarkers and testing profile/markers accuracy
Discussion supported by general literature and heavily grounded on:
- NYUMC informatics experts/research projects/grants/papers/entities/software systems
- Commercially availiable modalities & assays
2

Overview
• Session #1: Basic Concepts
• Session #2: High-throughput assay technologies
• Session #3: Computational data analytics
• Session #4: Case study / practical applications
• Session #5: Hands-on computer lab exercise
3

Session #1: Basic Concepts
• Understand spectrum of Bioinformatics and Medical informatics activities - NYUMC informatics
• Understand basic concepts of clinical/translational Bioinformatics
• Understand basic concepts of molecular profiling
• ALSO:
- emails/names/interests
- adjustments to plan
4
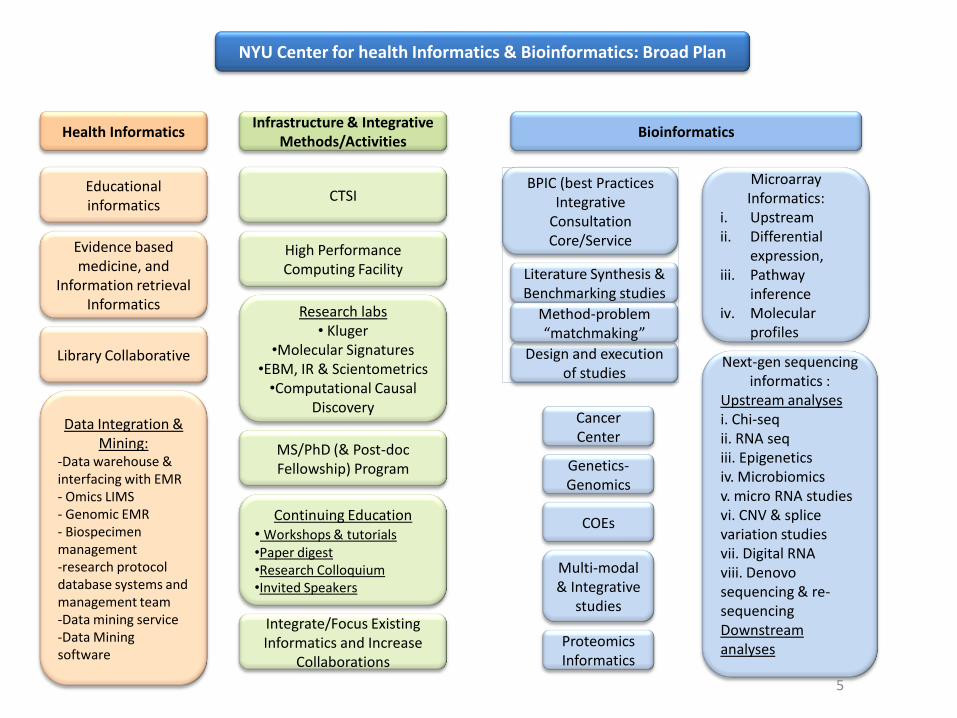
NYU Center for health Informatics & Bioinformatics: Broad Plan
Health Informatics Bioinformatics
BPIC (best Practices Integrative
Consultation Core/Service
Literature Synthesis & Benchmarking studies
Design and execution of studies
Method-problem “matchmaking”
Microarray Informatics:
i. Upstreamii. Differential
expression, iii. Pathway
inferenceiv. Molecular
profiles
Next-gen sequencing informatics :
Upstream analysesi. Chi-seqii. RNA seqiii. Epigeneticsiv. Microbiomicsv. micro RNA studiesvi. CNV & splice variation studiesvii. Digital RNAviii. Denovosequencing & re-sequencingDownstream analyses
Educational informatics
Evidence based medicine, and
Information retrieval Informatics
Library Collaborative
Data Integration & Mining:
-Data warehouse & interfacing with EMR- Omics LIMS- Genomic EMR- Biospecimenmanagement-research protocol database systems and management team-Data mining service-Data Mining software
Infrastructure & Integrative Methods/Activities
High Performance Computing Facility
MS/PhD (& Post-doc Fellowship) Program
Continuing Education• Workshops & tutorials•Paper digest•Research Colloquium•Invited Speakers
Research labs• Kluger
•Molecular Signatures•EBM, IR & Scientometrics
•Computational Causal Discovery
CTSI
Integrate/Focus Existing Informatics and Increase
Collaborations
5
ProteomicsInformatics
CancerCenter
Genetics-Genomics
COEs
Multi-modal & Integrative
studies

Current Capabilities: Areas
Health Informatics
Educational informatics
Evidence based medicine, and
Information retrieval Informatics
Library Collaborative
Infrastructure & Integrative Methods/Activities
High Performance Computing Facility
MS/PhD (& Post-doc Fellowship) Program
Continuing Education• Workshops & tutorials•Paper digest•Research Colloquium•Invited Speakers
Research labs• Kluger•Molecular Signatures•EBM, IR & Scientometrics•Computational Causal Discovery
CTSI
Integrate/Focus Existing Informatics and Increase
Collaborations
6
Data Integration & Mining:
-Data warehouse & interfacing with EMR- Omics LIMS- Genomic EMR- Biospecimenmanagement-research protocol database systems and management team-Data mining service-Data Mining software
Bioinformatics
BPIC (best Practices Integrative
Consultation Core/Service
Literature Synthesis & Benchmarking studies
Design and execution of studies
Method-problem “matchmaking”
Microarray Informatics:
i. Upstreamii. Differential
expression, iii. Pathway
inferenceiv. Molecular
profiles
Next-gen sequencing informatics :
Upstream analysesi. Chi-seqii. RNA seqiii. Epigeneticsiv. Microbiomicsv. micro RNA studiesvi. CNV & splice variation studiesvii. Digital RNAviii. Denovosequencing & re-sequencingDownstream analysesProteomics
Informatics
CancerCenter
Genetics-Genomics
COEs
Multi-modal & Integrative
studies
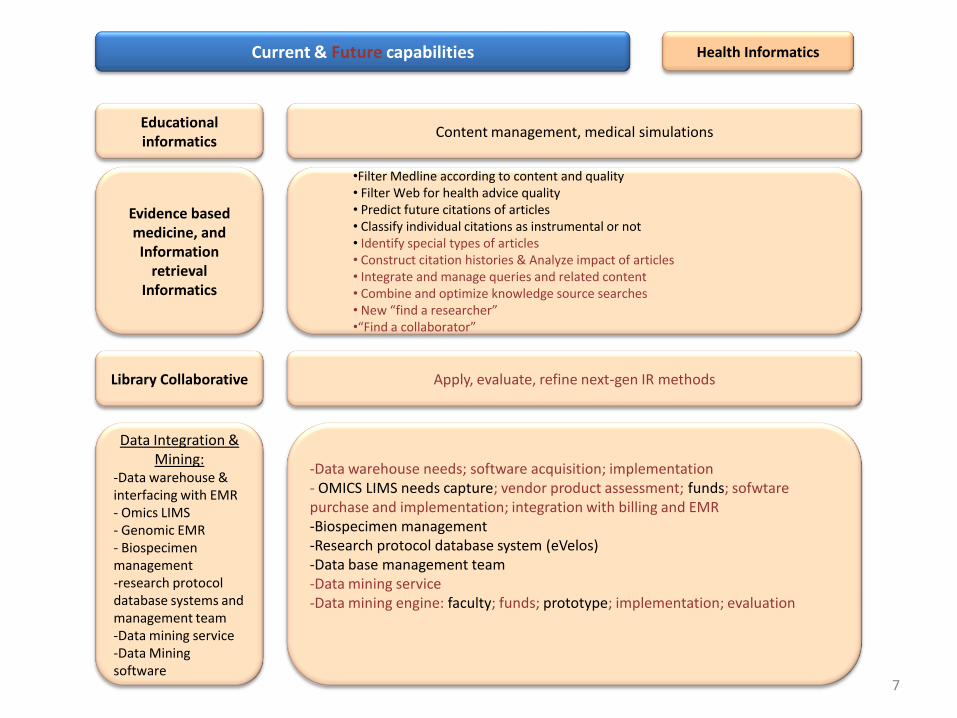
Current & Future capabilities Health Informatics
Educational informatics
Evidence based medicine, and Information
retrieval Informatics
Library Collaborative
Content management, medical simulations
•Filter Medline according to content and quality• Filter Web for health advice quality• Predict future citations of articles• Classify individual citations as instrumental or not• Identify special types of articles• Construct citation histories & Analyze impact of articles• Integrate and manage queries and related content• Combine and optimize knowledge source searches• New “find a researcher”•“Find a collaborator”
Apply, evaluate, refine next-gen IR methods
-Data warehouse needs; software acquisition; implementation- OMICS LIMS needs capture; vendor product assessment; funds; sofwtarepurchase and implementation; integration with billing and EMR-Biospecimen management-Research protocol database system (eVelos)-Data base management team-Data mining service-Data mining engine: faculty; funds; prototype; implementation; evaluation
7
Data Integration & Mining:
-Data warehouse & interfacing with EMR- Omics LIMS- Genomic EMR- Biospecimenmanagement-research protocol database systems and management team-Data mining service-Data Mining software

Current & Future capabilitiesInfrastructure & Integrative
Methods/Activities
High Performance Computing Facility
MS/PhD (& Post-doc Fellowship) Program
Continuing Education• Workshops & tutorials•Paper digest•Research Colloquium•Invited Speakers
Research labs• Kluger
•Molecular Signatures•EBM, IR & Scientometrics
•Computational Causal Discovery
CTSI
Integrate/Focus Existing Informatics and Increase
Collaborations
(supported by rest of objectives)
Sequencing server; hectar1; hectar2;
Funds; needs; grants; personnel post; specs; room/networking/access; Personnel hires; hw install; licenses; BP; launch
• Kluger TF /Regulation studies; high-throughput outcome prediction, specialized clustering methods
• Molecular Signatures development of molecular signatures for diagnosis outcome prediction and personalized medicine, discovery of diagnostic/imaging biomarkers and putative drug targets , deployment of signatures, automated software, new methods
•EBM, IR & Scientometrics development and evaluation of next-gen IR and scientometric models and studies
• Computational Causal Discovery discovery of pathways; studies of causal validity of bioinformatics discovery methods, multiplicity studies, automated software, active learning/experiment number minimization
Formal Training in Biomedical Informatics at pre and post-doctoral levels
Continuing Education• Workshops & tutorials• Paper digest• Research Colloquium• Invited Speakers
Faculty and Staff career development; Informatics Affiliates; Working Collaborations with Courant, Polytechnic, NYC Informatics and other non-NYUMC
entities8
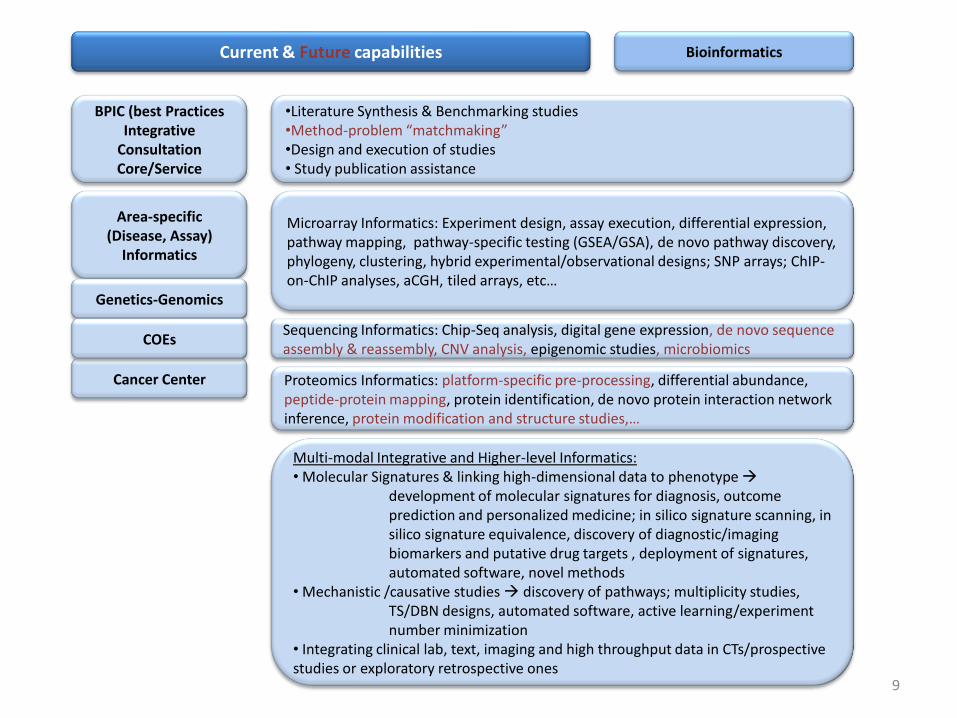
Current & Future capabilities Bioinformatics
BPIC (best Practices Integrative
Consultation Core/Service
•Literature Synthesis & Benchmarking studies•Method-problem “matchmaking”•Design and execution of studies• Study publication assistance
Microarray Informatics: Experiment design, assay execution, differential expression, pathway mapping, pathway-specific testing (GSEA/GSA), de novo pathway discovery, phylogeny, clustering, hybrid experimental/observational designs; SNP arrays; ChIP-on-ChIP analyses, aCGH, tiled arrays, etc…
Sequencing Informatics: Chip-Seq analysis, digital gene expression, de novo sequence assembly & reassembly, CNV analysis, epigenomic studies, microbiomics
Proteomics Informatics: platform-specific pre-processing, differential abundance, peptide-protein mapping, protein identification, de novo protein interaction network inference, protein modification and structure studies,…
Cancer Center
Area-specific (Disease, Assay)
Informatics
Genetics-Genomics
COEs
9
Multi-modal Integrative and Higher-level Informatics:• Molecular Signatures & linking high-dimensional data to phenotype
development of molecular signatures for diagnosis, outcome prediction and personalized medicine; in silico signature scanning, in silico signature equivalence, discovery of diagnostic/imaging biomarkers and putative drug targets , deployment of signatures, automated software, novel methods
• Mechanistic /causative studies discovery of pathways; multiplicity studies, TS/DBN designs, automated software, active learning/experiment number minimization
• Integrating clinical lab, text, imaging and high throughput data in CTs/prospective studies or exploratory retrospective ones

Summary Contacts (Until Centralized Consultation Service is Launched)
• Management of Clinical and protocol data James Robinson• Educational Informatics Mark Triola• Next-Gen Information Retrieval Lawrence Fu, Constantin Aliferis, TBD• Informatics for Data Mining Alexander Statnikov, Constantin Aliferis• Data Integration & Warehousing John Chelico, Ross Smith, Constantin Aliferis• High Performance Computing Constantin Aliferis, Ross Smith• Best Practices in Bioinformatics Constantin Aliferis, Alexander Statnikov• Sequencing Informatics Upstream:
Stuart Brown, Alexander Alekseyenko, Yuval Kluger, Jinhua Wang, TBD, TBD
Downstream:Alexander Alekseyenko, Yuval Kluger, Jinhua Wang, Alexander Statnikov, Constantin Aliferis
• Microarray Informatics Jiri Zafadil, Yuval Kluger, Jinhua Wang, Constantin Aliferis, Alexander Statnikov
• Cancer Informatics Yuval Kluger, Jinhua Wang, Stuart Brown, Jiri Zafadil, Constantin Aliferis
• Proteomics Informatics Stuart Brown, Jinhua Wang, Constantin Aliferis,Alexander Statnikov, TBD
• General Tools Stuart Brown• Specialized applications
(Genetics, Regulation, Pathways…) Stuart Brown, Yuval Kluger, Alexander Statnikov, Constantin Aliferis
• Molecular Signatures development, biomarker discovery, Multi-modal and Integrative studies Constantin Aliferis, Alexander Statnikov,
Yuval Kluger
10

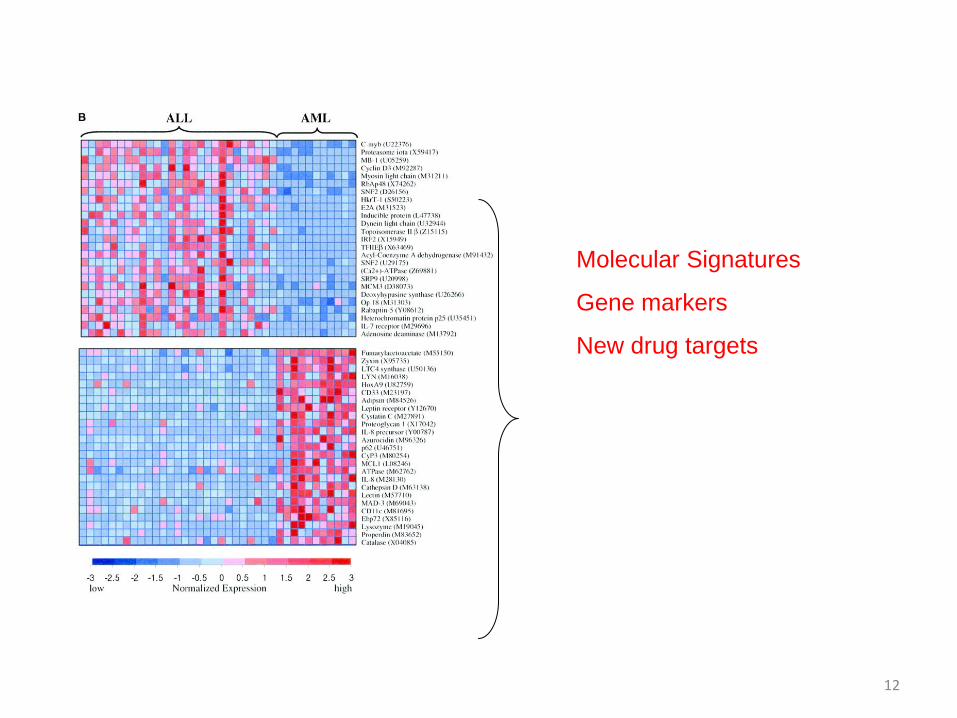
Molecular Signatures
Definition =
computational or mathematical models that link high-dimensional molecular information to phenotype of interest
11
12
Molecular Signatures
Gene markers
New drug targets

Molecular Signatures: Main Uses
1. Direct benefits: Models of disease phenotype/clinical outcome & estimation of the model performance
• Diagnosis• Prognosis, long-term disease management• Personalized treatment (drug selection, titration) (“predictive” models)
2. Ancillary benefits 1: Biomarkers for diagnosis, or outcome prediction• Make the above tasks resource efficient, and easy to use in clinical practice• Helps next-generation molecular imaging• Leads for potential new drug candidates
3. Ancillary benefits 2: Discovery of structure & mechanisms(regulatory/interaction networks, pathways, sub-types)
• Leads for potential new drug candidates
13

Molecular Signatures
The FDA calls them “in vitro diagnostic multivariate index assays”
1. “Class II Special Controls Guidance Document: Gene Expression Profiling Test System for Breast Cancer Prognosis”:
- addresses device classification2. “The Critical Path to New Medical Products”:- identifies pharmacogenomics as crucial to advancing medical product development and
personalized medicine. 3. “Draft Guidance on Pharmacogenetic Tests and Genetic Tests for Heritable Markers” & “Guidance for Industry: Pharmacogenomic Data Submissions”- identifies 3 main goals (dose, ADEs, responders),- define IVDMIA,- encourages “fault-free” sharing of pharmacogenomic data,- separates “probable” from “valid” biomarkers,- focuses on genomics (and not other omics),
14

• Increased Clinical Trial sample efficiency, and decreased costs or both, using placebo responder signatures ;
• In silico signature-based candidate drug screening;
• Drug “resurrection”
• Establishing existence of biological signal in very small sample situations where univariate signals are too weak;
• Assess importance of markers and of mechanisms involving those
• Choosing the right animal model
• …?
15
Less Conventional Uses of Molecular Signatures

OvaSure
Agendia Clarient Prediction Sciences
Veridex
LabCorp
University Genomics Genomic Health
BioTheranostics Applied Genomics Power3
Correlogic Systems
Recent molecular mignatures available for patient care
16
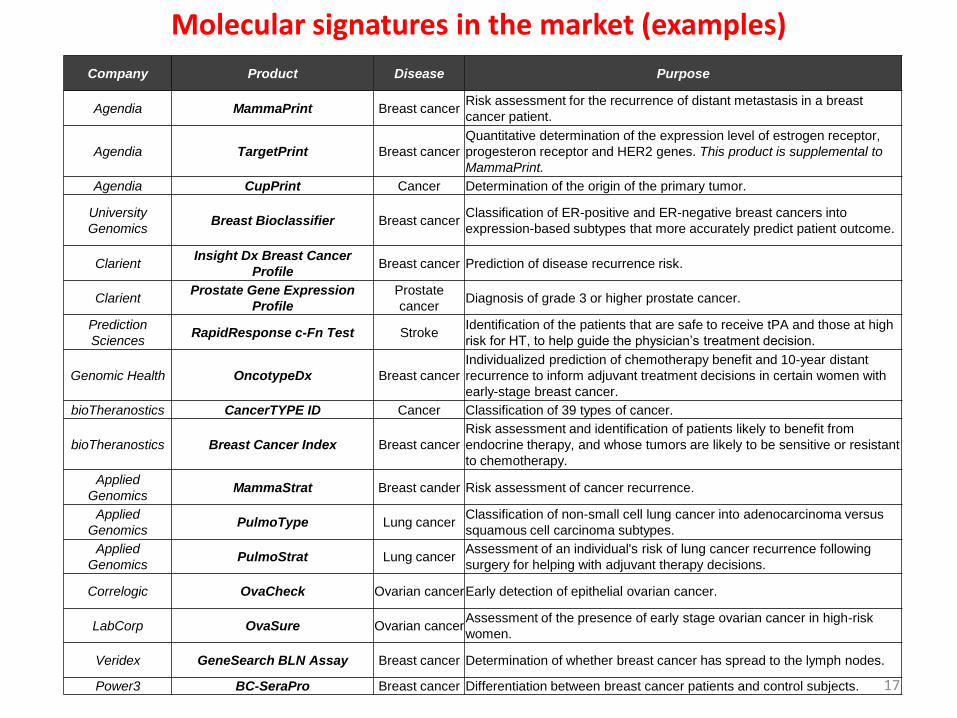
Company Product Disease Purpose
Agendia MammaPrint Breast cancerRisk assessment for the recurrence of distant metastasis in a breast
cancer patient.
Agendia TargetPrint Breast cancer
Quantitative determination of the expression level of estrogen receptor,
progesteron receptor and HER2 genes. This product is supplemental to
MammaPrint.
Agendia CupPrint Cancer Determination of the origin of the primary tumor.
University
GenomicsBreast Bioclassifier Breast cancer
Classification of ER-positive and ER-negative breast cancers into
expression-based subtypes that more accurately predict patient outcome.
ClarientInsight Dx Breast Cancer
ProfileBreast cancer Prediction of disease recurrence risk.
ClarientProstate Gene Expression
Profile
Prostate
cancerDiagnosis of grade 3 or higher prostate cancer.
Prediction
SciencesRapidResponse c-Fn Test Stroke
Identification of the patients that are safe to receive tPA and those at high
risk for HT, to help guide the physician’s treatment decision.
Genomic Health OncotypeDx Breast cancer
Individualized prediction of chemotherapy benefit and 10-year distant
recurrence to inform adjuvant treatment decisions in certain women with
early-stage breast cancer.
bioTheranostics CancerTYPE ID Cancer Classification of 39 types of cancer.
bioTheranostics Breast Cancer Index Breast cancer
Risk assessment and identification of patients likely to benefit from
endocrine therapy, and whose tumors are likely to be sensitive or resistant
to chemotherapy.
Applied
GenomicsMammaStrat Breast cander Risk assessment of cancer recurrence.
Applied
GenomicsPulmoType Lung cancer
Classification of non-small cell lung cancer into adenocarcinoma versus
squamous cell carcinoma subtypes.
Applied
GenomicsPulmoStrat Lung cancer
Assessment of an individual's risk of lung cancer recurrence following
surgery for helping with adjuvant therapy decisions.
Correlogic OvaCheck Ovarian cancerEarly detection of epithelial ovarian cancer.
LabCorp OvaSure Ovarian cancerAssessment of the presence of early stage ovarian cancer in high-risk
women.
Veridex GeneSearch BLN Assay Breast cancer Determination of whether breast cancer has spread to the lymph nodes.
Power3 BC-SeraPro Breast cancer Differentiation between breast cancer patients and control subjects.
Molecular signatures in the market (examples)
17

MammaPrint
• Developed by Agendia (www.agendia.com)
• 70-gene signature to stratify women with breast cancer that hasn’t spread into “low risk” and “high risk” for recurrence of the disease
• Independently validated in >1,000 patients
• So far performed 12,000 tests
• Cost of the test is $3,200
• In February, 2007 the FDA cleared the MammaPrint test for marketing in the U.S. for node negative women under 61 years of age with tumors of less than 5 cm.
• TIME Magazine’s 2007 “medical invention of the year”.
18

CupPrint
• Developed by Agendia (www.agendia.com)
• ~500-gene (~1900 probes) signature to identify primary site of 49 different types of carcinomas as well as other types of cancer such as sarcoma and melanoma.
• Several independent validation studies
19

ColoPrint
• In development & validation by Agendia (www.agendia.com)
• Multi-gene expression signature to determine the risk for recurrence in colorectal cancer patients
• Planning to seek FDA approval
References:• http://cancergenetics.wordpress.com/category/coloprint/
• http://www.bioarraynews.com/issues/7_34/features/141935-1.html
• http://life-science-ventures.com/downloads/PressreleaseColoPrintfinalJuly10th2007.pdf
20

Oncotype DX
Development synopsis
Main reference: Paik S, Shak S, Tang G, et al. A multigene assay to predict recurrence of tamoxifen-treated, node-negative breast cancer. N Engl J Med. 2004; 351(27):2817-26.
• Developed by Genomic Health (www.genomichealth.com )
• 21-gene signature to predict whether a woman with localized, ER+ breast cancer is at risk of relapse
• Independently validated in >1,000 patients
• So far performed 55,000 tests
• Cost of the test is $3,650
• Reimbursement. Information about reimbursement for molecular signatures from Aetna: http://www.aetna.com/cpb/medical/data/300_399/0352.html
• Oncotype DX did not undergo FDA review. Here is an article that mentions FDA review of Oncotype DX (slightly outdated): http://www.sciencemag.org/cgi/content/full/303/5665/1754
• The following paper shows the health benefits and cost-effectiveness benefits of using Oncotype DX: http://www3.interscience.wiley.com/cgi-bin/abstract/114124513/ABSTRACT
21
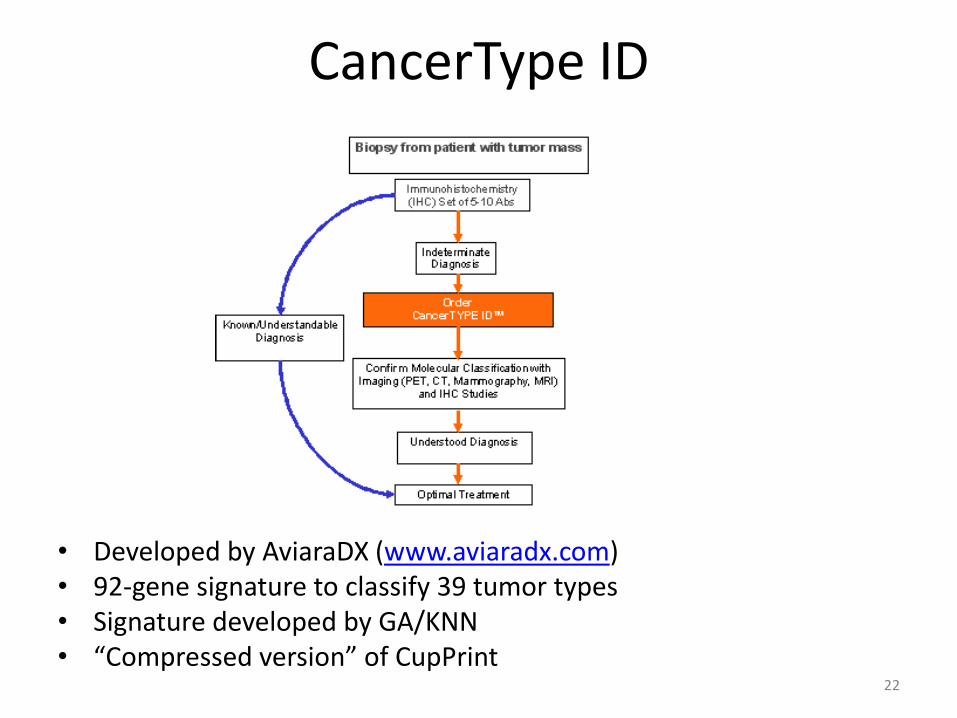
CancerType ID
• Developed by AviaraDX (www.aviaradx.com)• 92-gene signature to classify 39 tumor types• Signature developed by GA/KNN• “Compressed version” of CupPrint
22

Breast Cancer Index
• Developed by AviaraDX (www.aviaradx.com)
• Uses 7 genes (combines 5-gene MGI signature and 2-gene H/I signature)
• Stratifies breast cancer patients into groups with low or high risk of cancer recurrence and good or poor response to endocrine therapy.
• Validated in thousands of patients (treated & untreated)
23

GeneSearch Breast Lymph Node (BLN) Assay
• Developed by Veridex (www.veridex.com), a Johnson & Johnson company
• Test to detect if breast cancer has spread to the lymph nodes
• The GeneSearch BLN uses real-time reverse transcriptase-polymerase chain reaction (RT-PCR) to detect ammoglobin (MG) and cytokeratin 19 (CK 19) in lymph nodes.
• FDA approved
• Featured in TIME’s 2007 Top 10 Medical Breakthroughs list
24
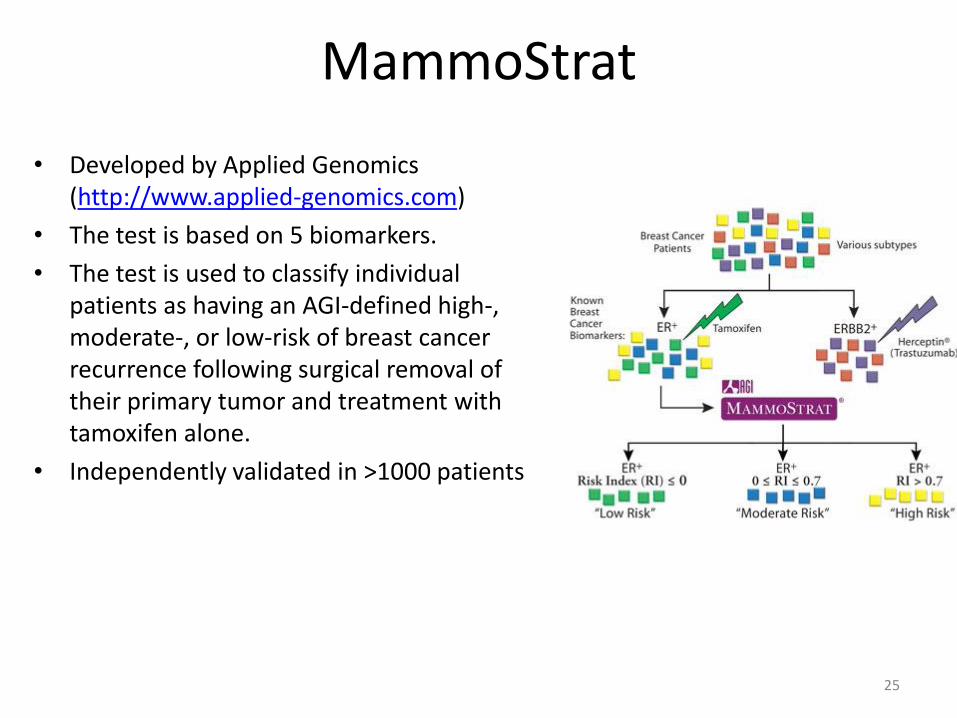
MammoStrat
• Developed by Applied Genomics (http://www.applied-genomics.com)
• The test is based on 5 biomarkers.
• The test is used to classify individual patients as having an AGI-defined high-, moderate-, or low-risk of breast cancer recurrence following surgical removal of their primary tumor and treatment with tamoxifen alone.
• Independently validated in >1000 patients
25

NuroPro
• Developed by Power3 (http://www.power3medical.com/)
• Early detection of neurodegenerative diseases: Alzheimer’s disease, ALS (Lou Gehrig’s disease), and Parkinson’s disease.
• Validation study in progress.
• Based on 59 proteins.
26

BC-SeraPro
• Developed by Power3 (http://www.power3medical.com/)
• Test for diagnosis of breast cancer (breast cancer case vs. control).
• Validation study in progress.
• Based on 22 proteins.
• Uses linear discriminant analysis; outputs a probability score.
27
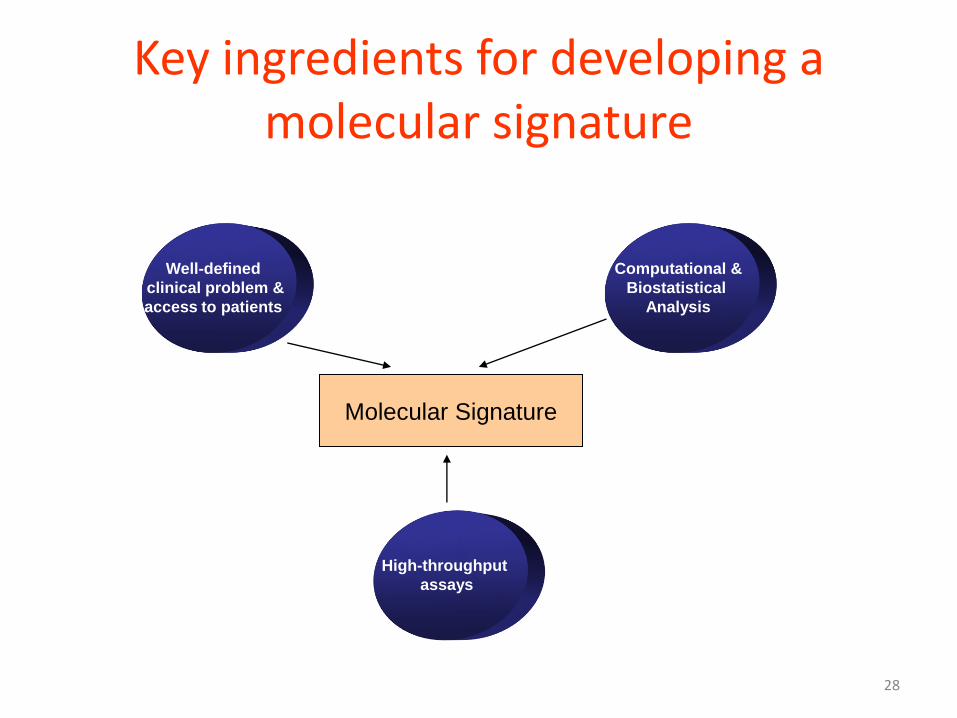
Key ingredients for developing a molecular signature
Well-defined
clinical problem &
access to patients
High-throughput
assays
Computational &
Biostatistical
Analysis
Molecular Signature
28

Challenges in Computational Analysis of omics data for development of molecular signatures
• Relatively easy to develop a predictive model + even easier to believe that a model is good when it is not false sense of security
• Several problems exist: some theoretical and some practical
• Omics data has many special characteristics and is tricky to analyze!
29

OvaCheck
• Developed by Correlogic (www.correlogic.com)
• Blood test for the early detection of epithelial ovarian cancer
• Failed to obtain FDA approval
• Looks for subtle changes in patterns among the tens of thousands of proteins, protein fragments and metabolites in the blood
• Signature developed by genetic algorithm
• Significant artifacts in data collection & analysis questioned validity of the signature:
- Results are not reproducible
- Data collected differently for different groups of patients
http://www.nature.com/nature/journal/v429/n6991/full/429496a.html
30

Data Set 1 (Top), Data Set 2 (Bottom)
Cancer
Normal
Other
Clock Tick
4000 8000 12000
Cancer
Normal
Other
A
B
C
D
E
F
Figure from
Baggerly et al
(Bioinformatics, 2004)
Problem with OvaCheck
31
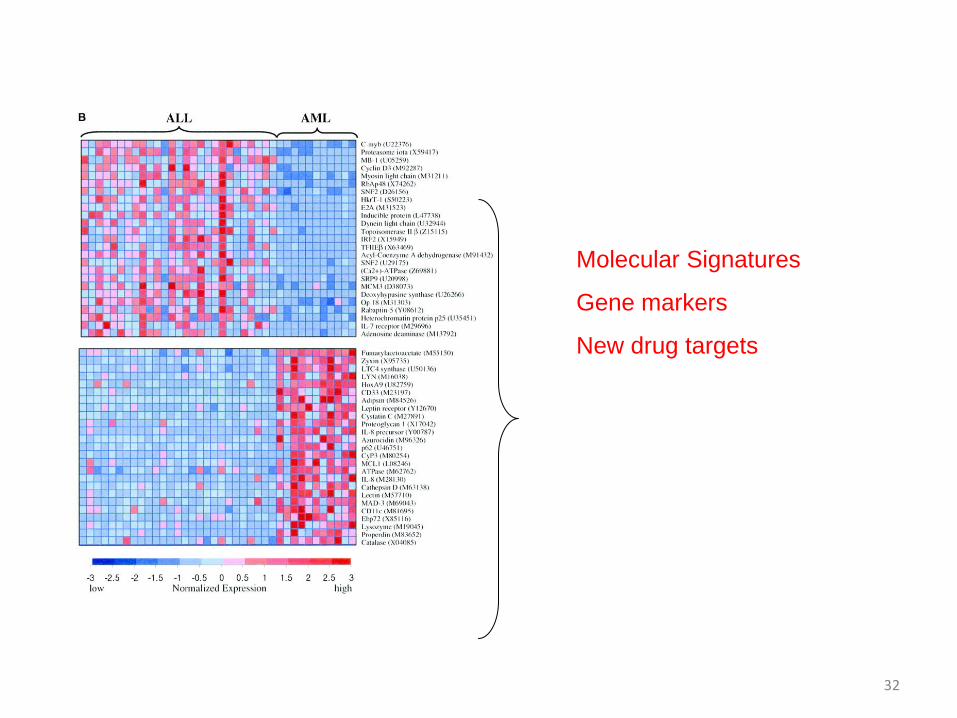
32
Molecular Signatures
Gene markers
New drug targets

33
Brief History of main “omics” technology: gene expression microarrays
• 1988: Edwin Southern files UK patent applications for in situ synthesized, oligo-nucleotide microarrays
• 1991: Stephen Fodor and colleagues publish photolithographic array fabrication method
• 1992: Undeterred by NIH naysayers, Patrick Brown develops spotted arrays
• 1993: Affymax begets Affymetrix
• 1995: Mark Schena publishes first use of microarrays for gene expression analysis• Edwin Southern founds Oxford Gene Technologies
• 1996: First human gene expression microarray study published• Affymetrix releases its first catalog GeneChip microarray, for HIV, in April
• 1997: Stanford researchers publish the first whole-genome microarray study, of yeast

34
Brief History of main “omics” technology: gene expression microarrays
(The scientist 2005)
• 1998: Brown's lab develops CLUSTER, a statistical tool for microarray data analysis; red and green "thermal plots" start popping up everywhere
• 1999: Todd Golub and colleagues use microarrays to classify cancers, sparking widespread interest in clinical applications
• 2000: Affymetrix spins off Perlegen, to sequence multiple human genomes and identify genetic variation using arrays
• 2001: The Microarray Gene Expression Data Society develops MIAME standard for the collection and reporting of microarray data
• 2003: Joseph DeRisi uses a microarray to identify the SARS virus• Affymetrix, Applied Biosystems, and Agilent Technologies individually array human
genome on a single chip
• 2004: Roche releases Amplichip CYP450, the first FDA-approved microarray for diagnostic purposes

35
An early kind of analysis: learning disease sub-types by clustering
patient profiles
Rb
p53

36
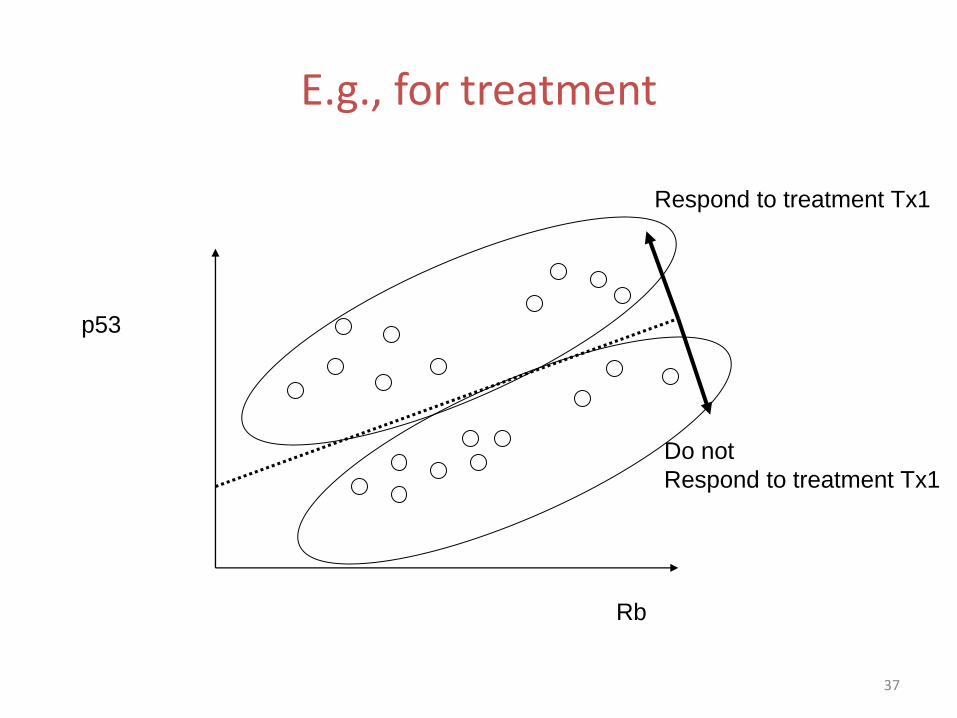
Clustering: seeking ‘natural’ groupings & hoping that they will be useful…
Rb
p53
37
E.g., for treatment
Rb
p53
Respond to treatment Tx1
Do not
Respond to treatment Tx1
38
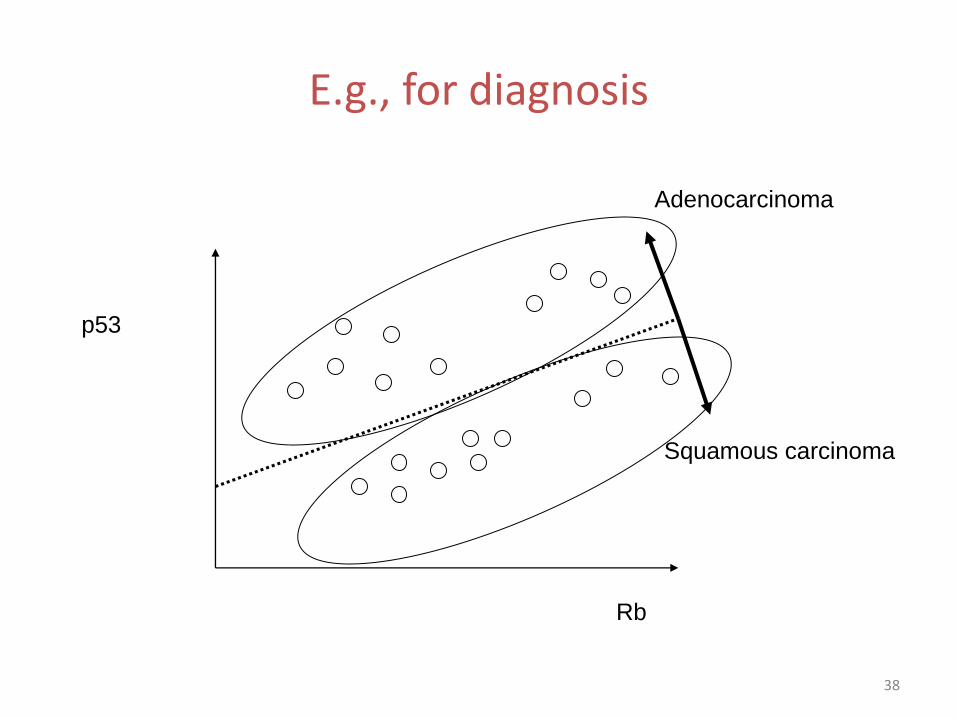
E.g., for diagnosis
Rb
p53
Adenocarcinoma
Squamous carcinoma

39
Another use of clustering
• Cluster genes (instead of patients):
– Genes that cluster together may belong to the same pathways
– Genes that cluster apart may be unrelated
40
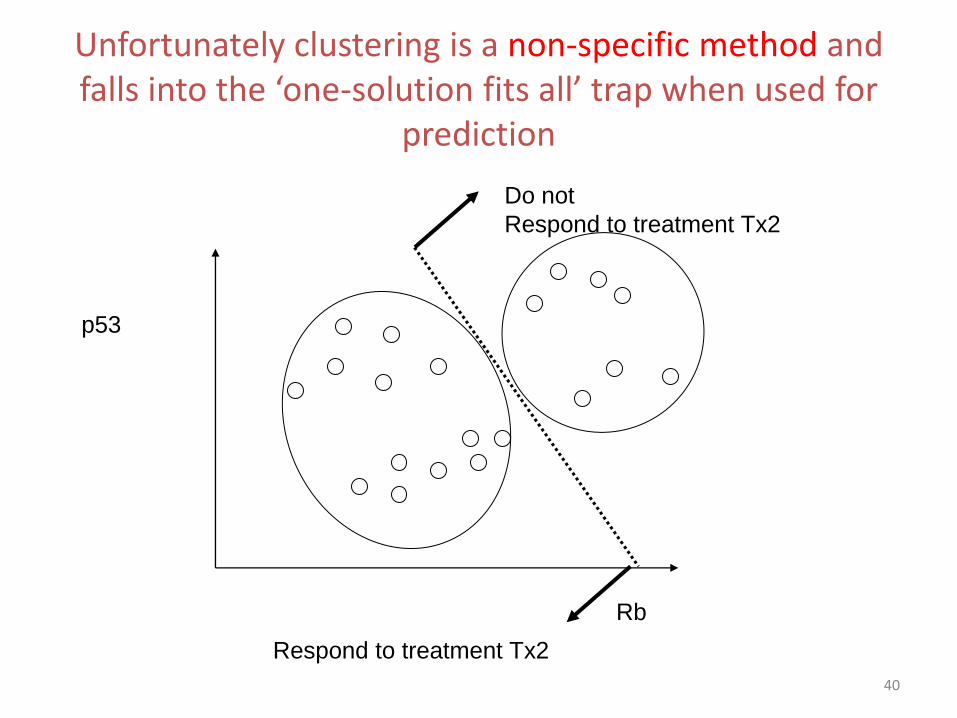
Unfortunately clustering is a non-specific method and falls into the ‘one-solution fits all’ trap when used for
prediction
Rb
p53
Respond to treatment Tx2
Do not
Respond to treatment Tx2

41
Clustering is also non-specific when used to discover pathway membership, regulatory control, or other
causation-oriented relationships
G1
Ph
G2
G3
It is entirely possible in
this simple illustrative
counter-example for
G3 (a causally
unrelated gene to the
phenotype) to be more
strongly associated
and thus cluster with
the phenotype (or its
surrogate genes) more
strongly than the true
oncogenic genes G1,
G2

42
Two improved classes of methods
• Supervised learning predictive signatures and markers
• Regulatory network reverse engineeringpathways

43
Supervised learning : use the known phenotypes
(a.k.a “labels) in training data to build signatures or find markers highly specific for that phenotype
TRAIN
INSTANCES
APPLICATION
INSTANCES
A
B C
D E
A1, B1, C1, D1, E1
A2, B2, C2, D2, E2
An, Bn, Cn, Dn, En
INDUCTIVE
ALGORITHM Classifier
OR
Regression Model
CLASSIFICATION
PERFORMANCE

44
TRAIN
INSTANCES
A
B C
D E
A1, B1, C1, D1, E1
A2, B2, C2, D2, E2
An, Bn, Cn, Dn, En
PERFORMANCE
A
B C
D
E
INDUCTIVE
ALGORITHM
Regulatory network reverse engineering

45
Supervised learning: a geometrical interpretation
+
+
+
+
++
+
+ +
+
p53
Rb
??
P1
P4
P2
P3
P5
Cancer patients
Normals
New case,
classified
as normalNew case,
classified
as cancer
SVM classifier
+
+
+
+
++
+
+ +
+
p53
Rb
??
P1
P4
P2
P3
P5
Cancer patients
Normals
New case,
classified
as normalNew case,
classified
as cancer
SVM classifier

46
• 10,000-50,000 (regular gene expression microarrays, aCGH, and early SNP arrays)
• >500,000 (tiled microarrays, new SNP arrays)
• 10,000-300,000 (regular MS proteomics)
• >10, 000, 000 (LC-MS proteomics)
This is the ‘curse of dimensionality problem’
In 2-D looks good but what happens in:

47
• Some methods do not run at all (classical regression)
• Some methods give bad results (KNN, Decision trees)
• Very slow analysis
• Very expensive/cumbersome clinical application
• Tends to “overfit”
High-dimensionality (especially with small samples) causes:

48
• Over-fitting ( a model to your data)= building a model that is good in original data but fails to generalize well to fresh data
• Under-fitting ( a model to your data)= building a model that is poor in both original data and fresh data
Two (very real and very unpleasant) problems: Over-fitting & Under-fitting

49
Intuitive explanation of overfitting & underfitting
• Play the game: find rule to predict who are the instructors in any given class (use today’s class to find a general rule)
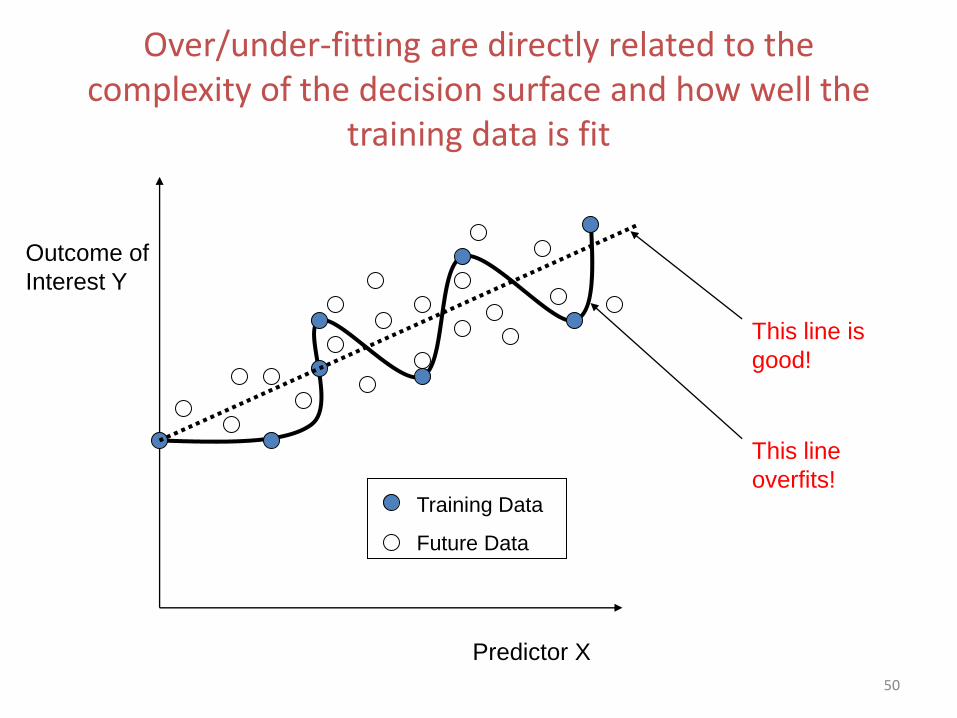
50
Over/under-fitting are directly related to the complexity of the decision surface and how well the
training data is fit
Predictor X
Outcome of
Interest Y
Training Data
Future Data
This line is
good!
This line
overfits!
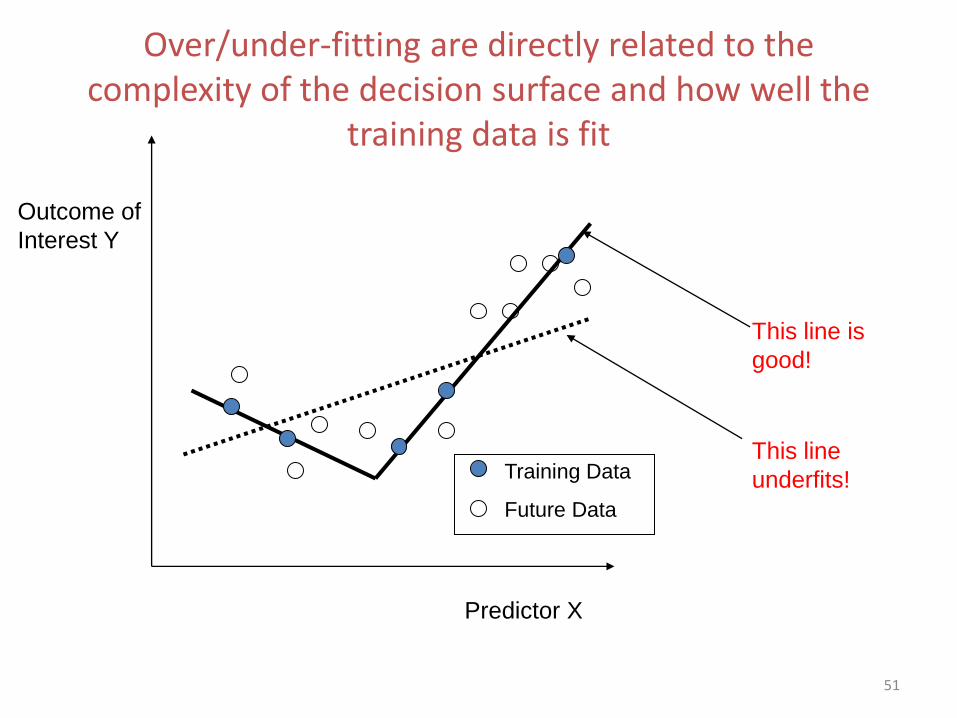
51
Over/under-fitting are directly related to the complexity of the decision surface and how well the
training data is fit
Predictor X
Outcome of
Interest Y
Training Data
Future Data
This line is
good!
This line
underfits!

52
Very Important Concept:
• Successful data analysis methods balance training data fit with complexity. – Too complex signature (to fit training data well) overfitting (i.e., signature does not generalize)
– Too simplistic signature (to avoid overfitting) underfitting (will generalize but the fit to both the training and future data will be low and predictive performance small).
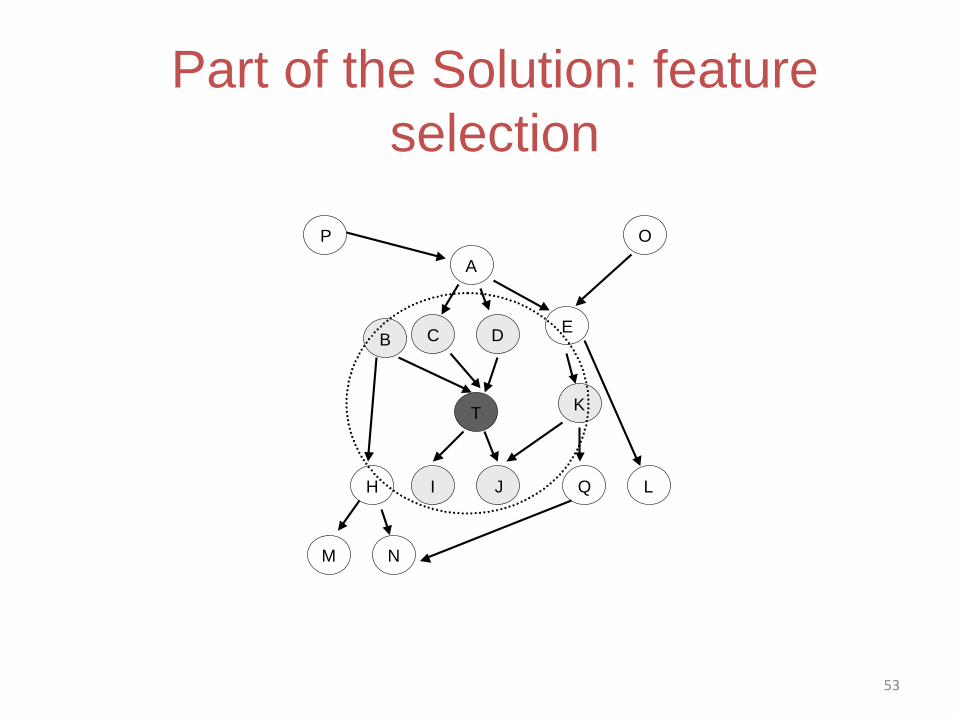
53
B
A
C DE
T
H I J
K
Q L
M N
P O
Part of the Solution: feature
selection

54
How well supervised learning works in practice?

55
Datasets• Bhattacharjee2 - Lung cancer vs normals [GE/DX]
• Bhattacharjee2_I - Lung cancer vs normals on common genes between Bhattacharjee2 and Beer [GE/DX]
• Bhattacharjee3 - Adenocarcinoma vs Squamous [GE/DX]
• Bhattacharjee3_I - Adenocarcinoma vs Squamous on common genes between Bhattacharjee3 and Su [GE/DX]
• Savage - Mediastinal large B-cell lymphoma vs diffuse large B-cell lymphoma [GE/DX]
• Rosenwald4 - 3-year lymphoma survival [GE/CO]
• Rosenwald5 - 5-year lymphoma survival [GE/CO]
• Rosenwald6 - 7-year lymphoma survival [GE/CO]
• Adam - Prostate cancer vs benign prostate hyperplasia and normals [MS/DX]
• Yeoh - Classification between 6 types of leukemia [GE/DX-MC]
• Conrads - Ovarian cancer vs normals [MS/DX]
• Beer_I - Lung cancer vs normals (common genes with Bhattacharjee2) [GE/DX]
• Su_I - Adenocarcinoma vs squamous (common genes with Bhattacharjee3) [GE/DX
• Banez - Prostate cancer vs normals [MS/DX]

56
Methods: Gene and Peak Selection Algorithms• ALL - No feature selection
• LARS - LARS
• HITON_PC -
• HITON_PC_W - HITON_PC+ wrapping phase
• HITON_MB -
• HITON_MB_W - HITON_MB + wrapping phase
• GA_KNN - GA/KNN
• RFE - RFE with validation of feature subset with optimized polynomial kernel
• RFE_Guyon - RFE with validation of feature subset with linear kernel (as in Guyon)
• RFE_POLY - RFE (with polynomial kernel) with validation of feature subset with polynomial optimized kernel
• RFE_POLY_Guyon - RFE (with polynomial kernel) with validation of feature subset with linear kernel (as in Guyon)
• SIMCA - SIMCA (Soft Independent Modeling of Class Analogy): PCA based method
• SIMCA_SVM - SIMCA (Soft Independent Modeling of Class Analogy): PCA based method with validation of feature subset by SVM
• WFCCM_CCR - Weighted Flexible Compound Covariate Method (WFCCM) applied as in Clinical Cancer Research paper by Yamagata (analysis of microarray data)
• WFCCM_Lancet - Weighted Flexible Compound Covariate Method (WFCCM) applied as in Lancet paper by Yanagisawa (analysis of mass-spectrometry data)
• UAF_KW - Univariate with Kruskal-Walis statistic
• UAF_BW - Univariate with ratio of genes between groups to within group sum of squares
• UAF_S2N - Univariate with signal-to-noise statistic
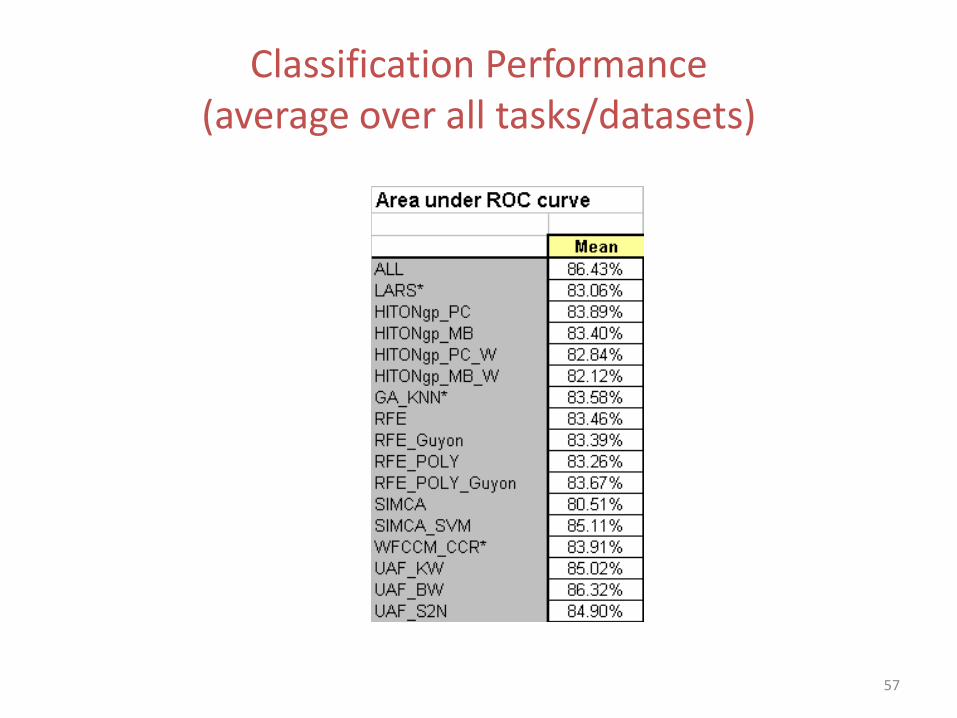
57
Classification Performance (average over all tasks/datasets)

58
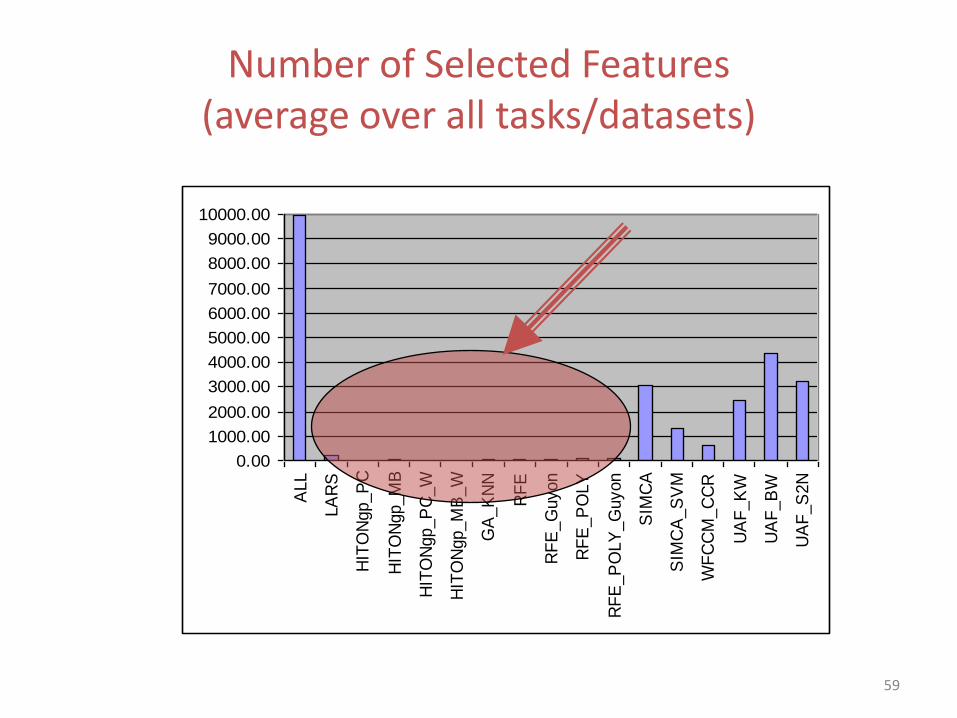
How well gene selection works in practice?
59
Number of Selected Features (average over all tasks/datasets)
0.00
1000.00
2000.00
3000.00
4000.00
5000.00
6000.00
7000.00
8000.00
9000.00
10000.00
ALL
LA
RS
HIT
ON
gp_P
C
HIT
ON
gp_M
B
HIT
ON
gp_P
C_W
HIT
ON
gp_M
B_W
GA
_K
NN
RF
E
RF
E_G
uyon
RF
E_P
OLY
RF
E_P
OLY
_G
uyon
SIM
CA
SIM
CA
_S
VM
WF
CC
M_C
CR
UA
F_K
W
UA
F_B
W
UA
F_S
2N

60
Number of Selected Features (zoom on most powerful methods)
0.00
20.00
40.00
60.00
80.00
100.00
LARS
HIT
ONgp_
PC
HIT
ONgp_
MB
HIT
ONgp_
PC_W
HIT
ONgp_
MB_W
GA_K
NN
RFE
RFE
_Guyo
n
RFE
_POLY
RFE
_POLY
_Guyo
n
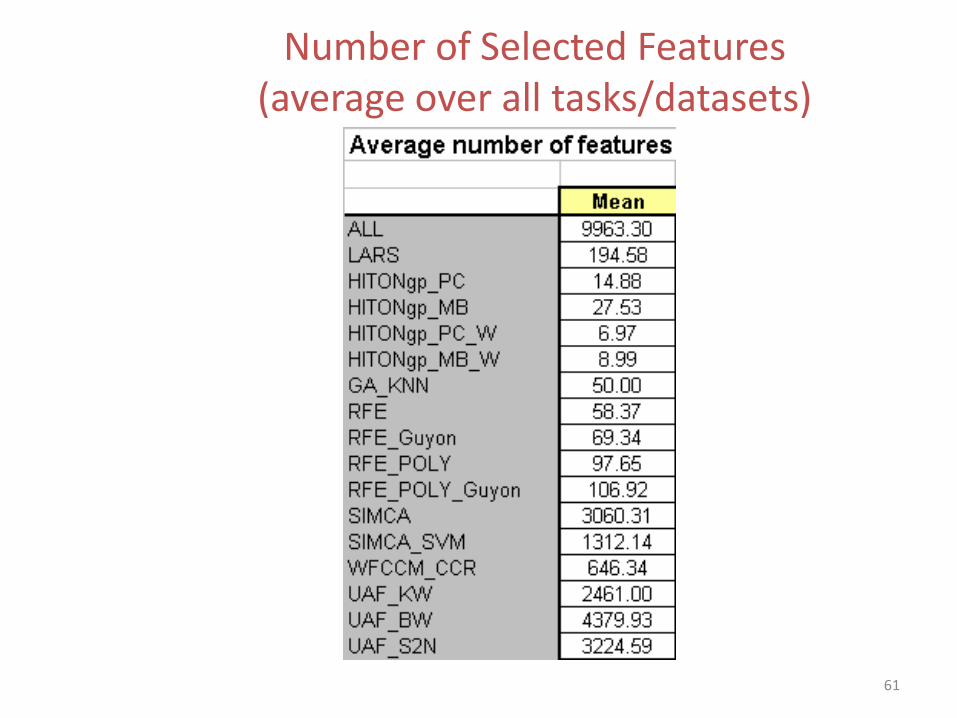
61
Number of Selected Features (average over all tasks/datasets)

62
• Special classifiers (with inherent complexity control) combined with feature selection & careful parameterization protocols overcome over-fitting & estimate future performance accurately.
• Caveats: analysis is typically complex and error prone. Need: (a) an experienced analyst on the team, or (b) a validated software system designed for non-experts.
Conclusions so far

Software
• Causal Explorer
• Gems
• Fast-aims
63

Causal Explorer
64
• Matlab library of computational causal
discovery and variable selection algorithms
• Introductory-level library to our causal algorithms
(~3% of our algorithms)
• Discover the direct causal or probabilistic relations around a response variable of interest (e.g., disease is directly caused by and directly causes a set of variables/observed quantities).
• Discover the set of all direct causal or probabilistic relations among the variables.
• Discover the Markov blanket of a response variable of interest, i.e., the minimal subset of variables that contains all necessary information to optimally predict the response variable.
• Code emphasizes efficiency, scalability, and quality of discovery
• Requires relatively deep understanding of underlying theory and how the algorithms operate

Statistics of Registered Users
65
• 739 registered users in >50 countries.
• 402 (54%) users are affiliated with educational, governmental, and non-profit organizations
• 337 (46%) users are either from private or commercial sectors.
• Major commercial organizations that have registered users of Causal Explorer include:
– IBM
– Intel
– SAS Institute
– Texas Instruments
– Siemens
– GlaxoSmithKline
– Merck
– Microsoft

Statistics of Registered Users
66
Major U.S. institutions that have registered users of Causal Explorer:
•Boston University•Brandies University•Carnegie Mellon University•Case Western Reserve University•Central Washington University•College of William and Mary•Cornell University•Duke University•Harvard University•Illinois Institute of Technology•Indiana University-Purdue University Indianapolis•Johns Hopkins University•Louisiana State University•M. D. Anderson Cancer Center•Massachusetts Institute of Technology
•Medical College of Wisconsin•Michigan State University•Naval Postgraduate School•New York University•Northeastern University•Northwestern University•Oregon State University•Pennsylvania State University•Princeton University•Rutgers University•Stanford University•State University of New York•Tufts University•University of Arkansas
•University of California Berkley•University of California Los Angeles•University of California San Diego•University of California Santa Cruz•University of Cincinnati•University of Colorado Denver•University of Delaware•University of Houston-Clear Lake•University of Idaho•University of Illinois at Chicago•University of Illinois at Urbana-Champaign•University of Kansas•University of Maryland Baltimore County•University of Massachusetts Amherst•University of Michigan
•University of New Mexico•University of Pennsylvania•University of Pittsburgh•University of Rochester•University of Tennessee Chattanooga•University of Texas at Austin•University of Utah•University of Virginia•University of Washington•University of Wisconsin-Madison•University of Wisconsin-Milwaukee•Vanderbilt University•Virginia Tech•Yale University

Other systems for supervised analysis of microarray data
Name Version Developer
Automatic model selection for
classifier and gene selection
methods
ArrayMiner ClassMarker 5.2 Optimal Design, Belgium No
Avadis Prophetic 3.3 Strand Genomics, USA No
BRB ArrayTools 3.2 Beta National Cancer Institute, USA No
caGEDA (accessed 10/2004)University of Pittsburgh and University of
Pittsburgh Medical Center, USANo
Cleaver1.0
(accessed 10/2004)Stanford University, USA No
GeneCluster2 2.1.7Broad Institute, Massachusetts Institute of
Technology, USANo
GeneLinker Platinum 4.5 Predictive Patterns Software, Canada No
GeneMaths XT 1.02 Applied Maths, Belgium No
GenePattern 1.2.1Broad Institute, Massachusetts Institute of
Technology, USANo
Genesis 1.5.0 Graz University of Technology, Austria No
GeneSpring 7 Silicon Genetics, USA No
GEPAS1.1
(accessed 10/2004)
National Center for Cancer Research (CNIO),
Spain
Limited
(for number of genes)
MultiExperiment Viewer 3.0.3 The Institute for Genomic Research, USA No
PAM 1.21a Stanford University, USALimited
(for a single parameter of the classifier)
Partek Predict 6.0 Partek, USA
Limited
(does not allow optimization of the choice
of gene selection algorithms)
Weka Explorer 3.4.3 University of Waikato, New Zeland No
There exist many good software packages for
supervised analysis of microarray data, but…
• Neither system provides a protocol for data analysis that
precludes overfitting.
• A typical software either offers an overabundance of
algorithms or algorithms with unknown performance.
• The software packages address needs only of
experienced analysts.
67
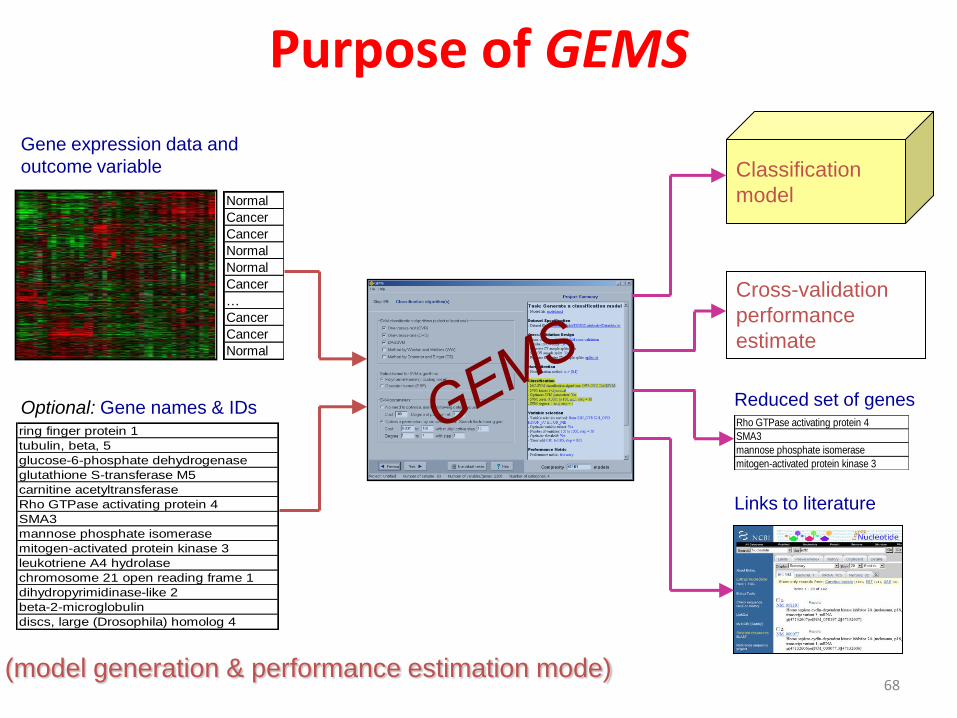
Purpose of GEMS
Normal
Cancer
Cancer
Normal
Normal
Cancer
…
Cancer
Cancer
Normal
Gene expression data and
outcome variable
ring finger protein 1
tubulin, beta, 5
glucose-6-phosphate dehydrogenase
glutathione S-transferase M5
carnitine acetyltransferase
Rho GTPase activating protein 4
SMA3
mannose phosphate isomerase
mitogen-activated protein kinase 3
leukotriene A4 hydrolase
chromosome 21 open reading frame 1
dihydropyrimidinase-like 2
beta-2-microglobulin
discs, large (Drosophila) homolog 4
Optional: Gene names & IDs
Cross-validation
performance
estimate
Classification
model
Rho GTPase activating protein 4
SMA3
mannose phosphate isomerase
mitogen-activated protein kinase 3
Reduced set of genes
Links to literature
(model generation & performance estimation mode)68

Purpose of GEMS
Gene expression data and
unknown outcome variable
Classification
model
(model application mode)
?
?
?
?
?
?
…
?
?
?
Performance
estimate
Normal
Cancer
Cancer
Normal
Normal
Cancer
…
Cancer
Cancer
Normal
Model predictions
69

70
Methods Implemented in GEMS
Cross-Validation
Designs
N-Fold CV
LOOCVOne-Versus-Rest
One-Versus-One
DAGSVM
Method by WW
Classifiers
Method by CSM
C-S
VM
Accuracy
RCI
Performance
Metrics
AUC ROC
S2N One-Versus-Rest
S2N One-Versus-One
Non-param. ANOVA
BW ratio
Gene Selection
Methods
HITON_MB
HITON_PC
[a, b]
(x – MEAN(x)) / STD(x)
x / STD(x)
x / MEAN(x)
Normalization
Techniques
x / MEDIAN(x)
x / NORM(x)
x – MEAN(x)
x – MEDIAN(x)
ABS(x)
x + ABS(x)
AUC ROC
HITON_MB
HITON_PC
(x – MEAN(x)) / STD(x)
x / STD(x)
x / MEAN(x)
x / MEDIAN(x)
x / NORM(x)
x – MEAN(x)
x – MEDIAN(x)
ABS(x)
x + ABS(x)

71
Software Architecture of GEMS
Wizard-Like User Interface
GEMS 2.0
Generate a classification
model
Estimate classification
performance
Apply existing model
to a new set of patients
Generate a classification model
and estimate its performance
Normalization
S2N One-Versus-Rest
S2N One-Versus-One
Non-param. ANOVA
BW ratio
Gene Selection
One-Versus-Rest
One-Versus-One
DAGSVM
Method by WW
Classification byMC-SVM
Method by CS
Cross-Validation Loopfor Performance Est.
N-Fold CV
LOOCV
Report Generator X
Cross-Validation Loopfor Model Selection
N-Fold CV
LOOCV
I
II
III
Accuracy
RCI
AUC ROC
PerformanceComputation
I
II
HITON_PC
HITON_MB
Computational Engine

72
GEMS 2.0: Wizard-Like Interface
Task selection Dataset specification Cross-validation design Normalization
ClassificationGene selectionPerformance metricLogging
Report generation Analysis execution

73
GEMS 2.0: Wizard-Like Interface
Input microarray
gene expression dataset
File with
gene names
File with gene
accession numbers
Output model

Statistics of registered users
• 800 users in >50 countries
• 350 academic & non-profit users
• 450 private & commercial users
• 205 scientific citations of major paper that introduced GEMS
• Major commercial organizations that have registered users of Causal Explorer include:
– Eli Lilly − Novartis
– IBM − GE
– Genedata − Nuvera Biosciences
– GenomicTree − Cogenetics
– Pronota
74
75
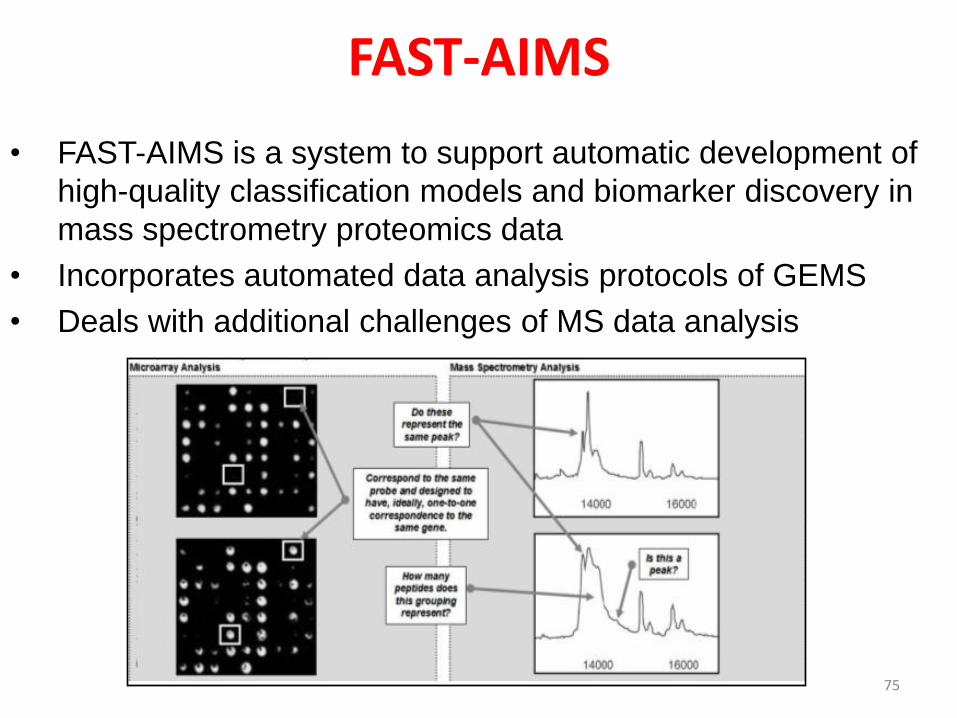
FAST-AIMS
• FAST-AIMS is a system to support automatic development of
high-quality classification models and biomarker discovery in
mass spectrometry proteomics data
• Incorporates automated data analysis protocols of GEMS
• Deals with additional challenges of MS data analysis

System Workflow
76

Evaluation in multiple user study
77

Projects 1
Project Goal & Data types/ design Stage Funding Other
involved
entities
Development of
placebo
responder
signatures for
Irritable Bowel
Syndrome
Re-analyze banked samples
from clinical trials to create
signature of placebo
responders; selected
proteomic markers and
clinical data from humans
In
progress
NIH Harvard,
NYU
Lung cancer
signatures and
AKT1 pathway in
lung cancer
Find signatures and
markers for lung cancer;
focus on local pathway
around AKT1; human
biopsy and cell line array
gene expression data
In
progress
NIH NYU,
Vanderbilt
78

Projects 2
Molecular signature and
biomarkers for
atherosclerosis progression
and regression
Find signatures, causative,
markers, predictive markers and
imaging markers; in aortic
transplantation and reversa
mouse models; microarray and
shotgun proteomic data
Transplantation
model signature
and markers
complete; reversa
model in
development
Industry,
NIH
(requested)
NYU, Merck
Predicting death from
community acquired
pneumonia
Find models that predict dire
outcomes in patients with CAP;
clinical and lab/imaging data
Completed NSF University of
Pittsburgh,
Carnegie
Melon
University
Signature for treatment
response in colorectal
cancer
Develop signature for treatment
response in colorectal cancer
patients; clinical and gene
expression data
In development NIH NYU
Prostate cancer risk and
treatment signatures
Develop signature for disease
risk and optimal management
of prostate cancer patients;
clinical and GWAS data
In development Donor funds,
DoD
(requested)
NYU
Pathways, markers and
signatures for pneumonia
development in HIV+
subjects
Discover pathways/markers and
develop signature for
pneumonia risk; clinical and
next-gen sequencing
microbiomic data
In development NIH
(requested)
NYU
79

Predicting physician
judgment in diagnosis of
melanomas& guideline
compliance
Predict physicians’ diagnoses and
compare to best practice guidelines for
compliance; clinical data and automated
imaging data
Completed EU University of
Trento,
Vanderbilt
Predicting risk for sepsis in
neonatal intensive unit
Discover optimal treatment strategies;
clinical and array gene expression data
In
development
NIH
(requested)
Vanderbilt,
NYU
Proteomic based diagnosis
of stroke and stroke-like
syndromes
Develop signatures for disease diagnosis;
selected proteomic data
Completed Industry
Outcome prediction models
for ARDS
Find signatures and markers for ARDS
detection and progression; human clinical
data from 3 big clinical trials
Completed NIH Vanderbilt
Molecular signatures for
treatment response in
keloids
Discover pathways/markers and develop
signature for treatment response; clinical
and microarray data
In
development
NIH NYU
80
Projects 3

Publications - new methods development 1Novel local causal network/pathway and biomarker discovery algorithms software and protocols
81
• “Algorithms for Large Scale Markov Blanket Discovery". I. Tsamardinos, C.F. Aliferis, A. Statnikov. In Proceedings of the 16th International
Florida Artificial Intelligence Research Society (FLAIRS) Conference, St. Augustine, Florida, USA; AAAI Press, pages 376-380, May 12-14,
2003.
• "Time and Sample Efficient Discovery of Markov Blankets and Direct Causal Relations". I. Tsamardinos, C.F. Aliferis, A. Statnikov. In
Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA; ACM Press,
pages 673-678, August 24-27, 2003.
• "HITON, A Novel Markov Blanket Algorithm for Optimal Variable Selection”. C. F. Aliferis, I. Tsamardinos, A. Statnikov. In Proceedings
of the 2003 American Medical Informatics Association (AMIA) Annual Symposium, pages 21-25, 2003.
• “Identifying Markov Blankets with Decision Tree Induction.” L. Frey, D. Fisher, I. Tsamardinos, C.F. Aliferis, A. Statnikov. In Proceedings
of the Third IEEE International Conference on Data Mining (ICDM), Melbourne, Florida, USA, IEEE Computer Society Press; pages 59-66,
November 19-22, 2003.
• "Gene Expression Model Selector (GEMS): a system for decision support and discovery from array gene expression data". A. Statnikov, I.
Tsamardinos, Y. Dosbayev, C.F. Aliferis. Int J Med Inform., Aug;74(7-8):491-503, 2005.
• “Factors Influencing the Statistical Power of Complex Data Analysis Protocols for Molecular Signature Development from Microarray
Data”. Aliferis CF, Statnikov A, Tsamardinos I, Schildcrout JS, Shepherd BE, Harrell FE. PLoS ONE 2009, 4: e4922.
• "Formative Evaluation of a Prototype System for Automated Analysis of Mass Spectrometry Data". N. Fananapazir, M. Li, D. Spentzos,
C.F. Aliferis. Proc AMIA Symposium, 2005.
• “Local Causal and Markov Blanket Induction for Causal Discovery and Feature Selection for Classification. Part I: Algorithms and
Empirical Evaluation” Constantin F. Aliferis, Alexander Statnikov, Ioannis Tsamardinos, Subramani Mani, and Xenofon D. Koutsoukos (to
appear in Journal of Machine Learning Research).
• “Local Causal and Markov Blanket Induction for Causal Discovery and Feature Selection for Classification. Part II: Analysis and
Extensions” Constantin F. Aliferis, Alexander Statnikov, Ioannis Tsamardinos, Subramani Mani, and Xenofon D. Koutsoukos (to appear in
Journal of Machine Learning Research).
• “Design and Analysis of the Causation and Prediction Challenge” I. Guyon, C.F. Aliferis, G.F. Cooper, A. Elisseeff, JP. Pellet, P. Spirtes, A.
Statnikov (to appear in Journal of Machine Learning Research).
• “GEMS: A System for Cancer Diagnosis and Biomarker Discovery from Microarray Gene Expression Data”. Statnikov A, Tsamardinos I,
Aliferis CF. AMIA Annual Symposium, 2005.
• “Using the GEMS System for Cancer Diagnosis and Biomarker Discovery from Microarray Gene Expression Data”. Statnikov A,
Tsamardinos I, Aliferis CF. Twelfth National Conference on Artificial Intelligence (AAAI), 2005.
• “Using GEMS for Cancer Diagnosis and Biomarker Discovery from Microarray Gene Expression Data”. Statnikov A, Tsamardinos I,
Aliferis CF. Thirteenth Annual International Conference on Intelligent Systems for Molecular Biology (ISMB), 2005.

Publications -new methods development 2Network reverse engineering/global causal discovery
82
• “A Novel Algorithm for Scalable and Accurate Bayesian Network Learning”.
L.E. Brown, I. Tsamardinos, C.F. Aliferis. In Proceedings of the 11th World Congress
on Medical Informatics (MEDINFO), San Francisco, California, USA; September 7-
11, 2004.
• “A Comparison of Novel and State-of-the-Art Polynomial Bayesian Network
Learning Algorithms” Laura E. Brown, Ioannis Tsamardinos, C. F. Aliferis. Proc
AAAI Conference, 2005.
• “The Max-Min Hill Climbing Bayesian Network Structure Learning Algorithm”.
I. Tsamardinos, L.E. Brown, C.F. Aliferis. Machine Learning, 65:31-78, 2006.
• “A Causal Modeling Framework for Generating Clinical Practice Guidelines
from Data”. S. Mani and C. Aliferis. ”AI in medicine Europe (AIME) Conference,
Amsterdam, July 2007.
• “Learning Causal and Predictive Clinical Practice Guidelines from Data”. S.
Mani, C. F. Aliferis, S. Krishnaswami, T. Kotchen. In International Medical
Informatics Congress, MEDINFO, 2007.
• “Local Causal and Markov Blanket Induction for Causal Discovery and Feature
Selection for Classification. Part I: Algorithms and Empirical Evaluation”
Constantin F. Aliferis, Alexander Statnikov, Ioannis Tsamardinos, Subramani Mani,
and Xenofon D. Koutsoukos (to appear in Journal of Machine Learning Research).

Publications - new methods development 3Theoretical properties of discovery methods
83
• "Towards Principled Feature Selection: Relevance, Filters, and Wrappers". I. Tsamardinos and C.F. Aliferis. In
Proceedings of the Ninth International Workshop on Artificial Intelligence and Statistics, Key West, Florida, USA,
January 3-6, 2003.
• "Why Classification Models Using Array Gene Expression Data Perform So Well: A Preliminary Investigation Of
Explanatory Factors". C.F. Aliferis, I. Tsamardinos, P. Massion, A. Statnikov, D. Hardin. In Proceedings of the 2003
International Conference on Mathematics and Engineering Techniques in Medicine and Biological Sciences
(METMBS), Las Vegas, Nevada, USA; CSREA Press, June 23-26, 2003.
• "A Theoretical Characterization of Linear SVM-Based Feature Selection". D. Hardin, I. Tsamardinos, C.F. Aliferis.
In Twenty-First International Conference on Machine Learning (ICML), 2004.
• “Are Random Forests Better than Support Vector Machines for Microarray-Based Cancer Classification?” A.
Statnikov, C.F. Aliferis. Proc AMIA Fall Symposium 2007.
• “Using SVM Weight-Based Methods to Identify Causally Relevant and Non-Causally Relevant Variables”.
Statnikov A., Hardin D., Aliferis CF. Workshop on: Feature Selection and Causality, NIPS, 2006.
• “Challenges in the Analysis of Mass-Throughput Data: A Technical Commentary from the Statistical Machine
Learning Perspective”. Aliferis CF, Statnikov A, Tsamardinos I. Cancer Informatics, 2: 133–162, 2006.
• “ Local Causal and Markov Blanket Induction for Causal Discovery and Feature Selection for Classification. Part
II: Analysis and Extensions” Constantin F. Aliferis, Alexander Statnikov, Ioannis Tsamardinos, Subramani Mani, and
Xenofon D. Koutsoukos (to appear in Journal of Machine Learning Research).
• “The Problem of Statistical Gene Instability in Microarray Studies: External Reproducibility and Biological
Importance of Unstable Genes and their Molecular Signatures” C.F. Aliferis, A. Statnikov, S. Pratap, E. Kokkotou.
(In preparation).
• “Application and Comparative Evaluation of Causal and Non-Causal Feature Selection Algorithms for
Biomarker Discovery in High-Throughput Biomedical Datasets”. Aliferis CF, Statnikov A., Tsamardinos I, Kokkotou
E, Massion PP. Workshop on Feature Selection and Causality, NIPS 2006.
• “Pathway induction and high-fidelity simulation for molecular signature and biomarker discovery in lung cancer
using microarray gene expression data”. Aliferis CF, Statnikov A, Massion P. In Proc 2006 American Physiological
Society Conference: Physiological Genomics and Proteomics of Lung Disease. November 2-5, 2006.

Publications - new methods development 4Other methodological studies with relevance for predictive modeling
84
• “Temporal Representation Design Principles: An Assessment in the Domain of Liver
Transplantation”. C.F. Aliferis, and G. F. Cooper. Proc AMIA Symp., 170-4, 1998.
• “Machine Learning Models For Lung Cancer Classification Using Array Comparative
Genomic Hybridization”. C. F. Aliferis, D. Hardin, P.Massion. Proc AMIA Symp., 7-11,
2002.
• "Machine Learning Models For Classification Of Lung Cancer and Selection of
Genomic Markers Using Array Gene Expression Data". C.F. Aliferis, I. Tsamardinos, P.
Massion, A. Statnikov, N. Fananapazir, D. Hardin. In Proceedings of the 16th International
Florida Artificial Intelligence Research Society (FLAIRS) Conference, St. Augustine,
Florida, USA; AAAI Press, pages 67-71, May 12-14, 2003.
• "Text Categorization Models for Retrieval of High Quality Articles in Internal
Medicine." Y. Aphinyanaphongs, C.F. Aliferis. In Proceedings of the 2003 American
Medical Informatics Association (AMIA) Annual Symposium, Washington, DC, USA; pages
31-35, 2003.
• “Text Categorization Models for Retrieval of High Quality Articles in Internal
Medicine”. Y. Aphinyanaphongs, I. Tsamardinos, A. Statnikov, D. Hardin, C.F. Aliferis. J
Am Med Inform Assoc., Mar-Apr;12(2):207-16, 2005.
• “A Semantic Model for Organizing Molecular Medicine "Omics" Modalities and
Evidence” Firas Wehbe, Pierre Massion, Cindy Gadd, Daniel Masys and C.F. Aliferis. (to
appear in Cancer Informatics).

Benchmarking Studies 1Evaluation of classifier algorithms
• Statnikov A, Aliferis CF, Tsamardinos I, Hardin D, Levy S: A comprehensive evaluation of multicategory
classification methods for microarray gene expression cancer diagnosis. Bioinformatics 2005, 21: 631-643.
• Statnikov A, Aliferis CF, Tsamardinos I: Methods for multi-category cancer diagnosis from gene expression
data: a comprehensive evaluation to inform decision support system development. Medinfo 2004 2004, 11:
813-817.
• Statnikov A, Wang L, Aliferis CF: A comprehensive comparison of random forests and support vector
machines for microarray-based cancer classification. BMC Bioinformatics 2008, 9: 319.
Evaluation of biomarker/variable selection algorithms
• Aliferis CF, Tsamardinos I, Statnikov A: HITON: a novel Markov blanket algorithm for optimal variable
selection. AMIA 2003 Annual Symposium Proceedings 2003, 21-25.
• Aliferis CF, Statnikov A, Massion PP: Pathway induction and high-fidelity simulation for molecular signature
and biomarker discovery in lung cancer using microarray gene expression data. Proceedings of the 2006
American Physiological Society Conference "Physiological Genomics and Proteomics of Lung Disease" 2006.
• Aliferis CF, Statnikov A, Tsamardinos I, Kokkotou E, Massion PP: Application and comparative evaluation of
causal and non-causal feature selection algorithms for biomarker discovery in high-throughput biomedical
datasets. Proceedings of the NIPS 2006 Workshop on Causality and Feature Selection 2006.
• Aliferis CF, Statnikov A, Tsamardinos I, Mani S, Koutsoukos XD: Local Causal and Markov Blanket Induction
for Causal Discovery and Feature Selection for Classification. Part II: Analysis and Extensions. Journal of
Machine Learning Research 2009.
• Aliferis CF, Statnikov A, Tsamardinos I, Mani S, Koutsoukos XD: Local Causal and Markov Blanket Induction
for Causal Discovery and Feature Selection for Classification. Part I: Algorithms and Empirical Evaluation.
Journal of Machine Learning Research 2009.
85

Benchmarking Studies 2
Comparison of algorithms for extraction of all maximally predictive and non-redundant
molecular signatures
• Statnikov A: Algorithms for Discovery of Multiple Markov Boundaries: Application
to the Molecular Signature Multiplicity Problem. Ph D Thesis, Department of
Biomedical Informatics, Vanderbilt University 2008.
Comparison of protocols to detect predictive signal of prognostic molecular signatures
• Aliferis CF, Statnikov A, Tsamardinos I, Schildcrout JS, Shepherd BE, Harrell FE:
Factors Influencing the Statistical Power of Complex Data Analysis Protocols for
Molecular Signature Development from Microarray Data. PLoS ONE 2009, 4:
e4922.
86

Patents
87
1. Aliferis CF, Tsamardinos I. Method, system, and apparatus for casual discovery and variable selection for classification. U.S. patent (US 7,117,185 B1).
2. Aliferis CF. Local Causal and Markov Blanket Induction Methods for Causal Discovery and Feature Selection from Data. U.S. provisional patent application (61149758).
3. Statnikov A, Aliferis CF. Methods for Discovery of Markov Boundaries from Datasets with Hidden Variables. U.S. provisional patent application (61145652).
4. Statnikov A, Aliferis CF. A Method for Determining All Markov Boundaries and Its Application for Discovering Multiple Optimally Predictive and Non-Redundant Molecular Signatures. U.S. provisional patent application.
5. Statnikov A, Aliferis CF, Tsamardinos I, Fananapazir N. Method and System for Automated Supervised Data Analysis. U.S. patent application (20070122347).

Grants 1
88
• NIH/NLM 2, R56 LM007948-04A1, Aliferis, PI, Causal Discovery Algorithms for Translational Research with High
-Throughput Data, 07/15/2008 – 07/14/2009 , $333,863.00
• NSF, NSF 0725746 , Guyon, PI, Causal Discovery Workbench and Challenge Program , 09/01/2007- 08/30/2009
• NIH/NCRR, 1 U54 RR024386-01A2, Cronstein, PI, Institutional Clinical and Translational Science Award ,
07/01/2009 – 06/30/2014, $32,411,416.00
• NIH/NCCAM, 1 R01 AT004662-01A1, Kokkotou, PI, Omics and Variable Responses to Placebo and Acupuncture
in Irritable Bowel Syndrome , 07/01/2009 – 06/30/2014 , $376,663.00
• NIH/NHLBI, 1 R01 HL089800-01A1, Schuening, PI , Genomics and Genetics of Acute Graft-Versus Host Disease,
07/01/2009 – 06/30/2014, $2,489,743.00
• NSF, Guyon, PI, Resource Allocation Strategies in Causal Modeling
• DOD, PC093319P1, Aliferis, PI, Enhanced prediction of prostate cancer risk and progression and causative gene
identification Award Mechanism: Synergistic Idea Development Award, 07/01/2010 – 06/30/2013, $750.000.00
• NIH, 1 S10 RR029683-01, Smith, PI, High Performance Computing Equipment to Support Biomedical Research at
NYU, 12/02/2009 – 11/30/20010, $650,433.00
• NIH, 1R01OD006352-01, Fisher, PI, Key Factors for the Regression and Imaging of Atherosclerosis, 09/01/2009 -
08/31/2014
• NIH, RO1 AR0566672, Cronstein, PI, The Pharmacology of Dermal Fibrosis, 09/01/09 - 08/30/2011, $295,242.00
• NIH, Blumenberg, PI, Skinomics , 09/01/2009-08/31/2011, 582,596.00
• NIH, 1U01HL098959-01, Weiden, PI, Bacterial, Fungal and Viral Microbiome in the Lung, 9/30/2009 – 9/29/2014
• NIH, RFA-OD-09-005, Aliferis, PI, Recovery Act Limited Competition: Supporting New Faculty Recruitment to
Enhance Research Resources through Biomedical Research Core Centers (P30), 09/30/2009 – 06/20/2010
• NIH, Jiyoung, PI, Integrative Analysis of Genome-wide Gene Expression for Prostate Cancer Prognosis
• NIH, Cllelland, PI, First Episode Psychiatric Illness: A Clinical, BioData and Biomaterials Resource

Grants 2• NIH/NHLBI 1 U01 HL081332-01 (Ware), “Biomarker Profiles in the Diagnosis/Prognosis of ARDS”, 08/12/2005 – 06/30/2009
Total Award: $6,059,257.
• NIH, NCI 1 U24 CA126479-01 (Liebler), “Clinical Proteomic Technology Assessment for Cancer”, 09/28/2006 – 08/31/2011,
Total Award: $7,388,990.
• NSF 0725746 (Guyon), “Causal Discovery Workbench and Challenge Program”, 08/15/2007 – 07/31/2009, Total Award:
$107,721.
• NIH, NLM 2 T15 LM007450-06 (Gadd) “Vanderbilt Biomedical Informatics Training Program”, 07/01/2007 – 06/30/2012, Total
Award: $3,969,225.
• NIH/NLM, 1 R01 LM007948-01 “Principled methods for very-large-scale causal discovery.” 07/01/2003 – 06/30/2006. Total
Award: $631,180.
• NIH/NLM BISTI Planning Grant, 1 P20 LM007613-01 (Stead) “Pilot Project Computational Models of Lung Cancer:
Connecting Classification, Gene Selection, and Molecular Sub-typing”, 09/01/2002 – 08/30/2004, Total Award: $226,500.
• NIH/NLM 1 T15 LM07450-01 (Miller), “Biomedical Informatics Training Grant.” 07/01/2002 – 06/30/2007, Total Award:
$3,966,644.
• BMS training contract, Fall-Spring 2002, Total Award: $150,000.
• “Vanderbilt Academic Venture Capital Fund support for the Discovery Systems Laboratory”, 07/01/2003 – 06/30/2006, Total
Award: $846,3471.
• “Vanderbilt University Discovery Grant to study Complex Modeling of Clinical Trial Data with Gene Expression Covariates &
Development of Optimal Re-analysis Policies” 07/01/2001 – 06/30/2002, Total Award: $50,000.
• “Causal Discovery Challenge” from PASCAL (Pattern Analysis, Statistical Modeling and Computational Learning). PASCAL is
the European Commission's IST-funded Network of Excellence for Multimodal Interfaces, 03/01/2006 – 11/30/2007, Total
Award: 18,000 Euros.
• NIH/NCI 1 P50 CA095103-01 (Coffey) “SPORE in GI Cancer” 09/24/2002 – 04/30/2007, Total Award: $11,851,282.
• NIH/NHLBI 1 U01 HL65962-01A1 (Roden) “Pharmacogenics of Arrhythmia Therapy”, 04/01/2001 – 03/31/2005, Total Award:
$11,189,918.
• NIH/NCI 1 P50 CA98131-01 (Arteaga) “SPORE in Breast Cancer” 08/01/2003 – 05/31/2008, Total Award: $12,804,130.
89

Main points, session #1• Molecular signatures are an important tool for research both
basic and translational; they are finding their way to clinical practice
• Data analytics of molecular signatures are very important
• We introduced the importance of bioinformatics for the analysis of high dimensional data and the creation of molecular signatures
90

For session #2• Review slides in today’s presentation and bring written
questions (if any) to discuss in subsequent sessions
• Read materials regarding assay technologies (to be distributed electronically). Note:– Basic principle underlying each technology
– Advantages over older technologies
– Limitations & technical difficulties
– How it may support your research interests now or in the future
91





























