Embed Size (px)
Citation preview

Introduction to PerlIntroduction to Perl
Giorgos GeorgakilasGiorgos Georgakilas•Graduated from C.E.I.D.Graduated from C.E.I.D.•M.Sc. degree in ITMBM.Sc. degree in ITMB•Ph.D. student in DIANA-LabPh.D. student in DIANA-Lab [email protected]
Perl>

Regular ExpressionsRegular Expressions
• Simple matchSimple matchmy $string = “sequence1: atcgtagcgtacaggcatgctagctagtcgatc”;my $string = “sequence1: atcgtagcgtacaggcatgctagctagtcgatc”;if ($string =~ if ($string =~ mm/atcg/){ #use !~ for checking if it does not match/atcg/){ #use !~ for checking if it does not match
print "match\n";print "match\n";}}
• Loop for multiple matchingLoop for multiple matchingmy $string = “sequence1: atcgtagcgtacaggcatgctagctagtcgatc”;my $string = “sequence1: atcgtagcgtacaggcatgctagctagtcgatc”;my @motifs = qw(att cgg tgg aaa);my @motifs = qw(att cgg tgg aaa);for my $trimer (@motifs) {for my $trimer (@motifs) {
if ($string =~ m/if ($string =~ m/$trimer$trimer/) {/) {print "$trimer is found\n";print "$trimer is found\n";
}}}}
Matching Matching literalsliterals

Regular ExpressionsRegular Expressions
• In most cases we don’t know exactly what to look forIn most cases we don’t know exactly what to look for
WildcardsWildcards
SymbolSymbol MeaningMeaning. Any character except newline, including spaces
\d Any digit
\D Any non digit
\w Any alphanumeric or underscore
\W Any non-alphanumeric or underscore
\s Any whitespace
[atgc] Any character inside the square brackets
[^atgc] Any character NOT inside the square brackets
• A simple example of wildcard useA simple example of wildcard usemy $seq = "atacgatmcagct";my $seq = "atacgatmcagct";if ($seq =~ /if ($seq =~ /[^atcg][^atcg]/) {/) {
print "\$seq contains non atcg characters\n";print "\$seq contains non atcg characters\n";}}

Regular ExpressionsRegular Expressions
• Special characters that reflect quantity in string matchingSpecial characters that reflect quantity in string matching
Quantifiers Quantifiers & Anchors& Anchors
SymbolSymbol MatchesMatches ExampleExample? 0 or 1 times** tc?t matches tct and tt
+ 1 or more times tc+t matches tccccct
* 0, 1 or more times tc*t matches tct, tcct, tt
{3} exactly 3 times tc{3} matches tccct only
{3,} 3 or more times tc{3,}t matches tccct, tcccct, etc
{,3} up to 3 times tc{,3}t matches tct, tcct, tccct only
{2,3} between 2 and 3 times tc{2,3}t matches tcct, tccct only
• A simple example of anchors and quantifiersA simple example of anchors and quantifiersmy $string = “sequence1: atcgtagcgtacaggcatgctagctagtcgatc”;my $string = “sequence1: atcgtagcgtacaggcatgctagctagtcgatc”;if ($string =~ /if ($string =~ /^̂\w\w++:\s[atcg]:\s[atcg]+$+$/){/){
print "sequence OK\n";print "sequence OK\n";}}

Regular ExpressionsRegular Expressions
• Special characters that modify the regex interpretationSpecial characters that modify the regex interpretation
Pattern Pattern ModifiersModifiers
ModifierModifier MeaningMeaningi Makes match case-insensitive
x Ignores literal space & permits comments
s Allows . to match a newline
m Lets ^ and $ match to a \n within a multiline string
g Allows multiple matches
e Allows code execution in regex
• An example of An example of ii modifier modifier"aTGCGAGct" =~ /atgc/"aTGCGAGct" =~ /atgc/ii; #will match; #will match

Regular ExpressionsRegular ExpressionsPattern Pattern
ModifiersModifiers
• An example of An example of xx modifier modifier$string =~ /sequence(\d+)$string =~ /sequence(\d+) # match the id# match the id
:\s*:\s* # colon and variable whitespace# colon and variable whitespace (\w+)(\w+) # the sequence# the sequence //xx;;• An example of An example of ss modifier modifier
my $string = "actg\ntcag";my $string = "actg\ntcag";$string =~ /ac.+ag/$string =~ /ac.+ag/ss;;
• An example of An example of mm modifier modifiermy $string = "actg\ntcat";my $string = "actg\ntcat";$string =~ /g$/; #doesn't match$string =~ /g$/; #doesn't match$string =~ /g$/$string =~ /g$/mm; #matches; #matches
• An example of An example of gg modifier modifiermy $a = 'atgctagtctagcgatgcatgtgttgtgcgtatgtga';my $a = 'atgctagtctagcgatgcatgtgttgtgcgtatgtga';my my @matches =@matches = $a =~/t\wg/ $a =~/t\wg/gg;;
• An example of An example of ee modifier modifiermy $pattern = “atgc”;my $pattern = “atgc”;$string =~ /reverse($pattern)/$string =~ /reverse($pattern)/ee;;

Regular ExpressionsRegular ExpressionsCapturing Capturing
texttext
• BackreferencesBackreferences$string=~$string=~//(\d+)(\d+)\s\s(\w+)(\w+)\s\s(\d{2,3})(\d{2,3})\s\s(\w*)(\w*)//;;$1$1, , $2$2, , $3$3, , $4$4, , $+$+, , $&$&
• Match indicesMatch indices@- match start indices; @- match start indices; $-[0]$-[0], , $-[1]$-[1] … (index of first matching character) … (index of first matching character)@+ match end indices; @+ match end indices; $+[0]$+[0], , $+[0]$+[0] … (index of last matching character +1) … (index of last matching character +1)
• Leftovers (:-O)Leftovers (:-O)$’ holds the part of the string after the regex match$’ holds the part of the string after the regex match$` holds the part of the string before the regex match$` holds the part of the string before the regex match
• Attention!Attention!Do not overuse them or the performance will slow downDo not overuse them or the performance will slow downRead-only that persist until the next regex matchRead-only that persist until the next regex match

Regular ExpressionsRegular ExpressionsSubstitutions / sSubstitutions / s
• ss/PATTERN/PATTERN//REPLACEMENT/REPLACEMENT/my $dna = “atgctagtctagcgatgcatgtgttgtgcgtatgtga”;my $dna = “atgctagtctagcgatgcatgtgttgtgcgtatgtga”;
• replace 1st 'a' with 't'replace 1st 'a' with 't'$dna =~ $dna =~ ss/a/a//t/;t/;print “$dna\n”;print “$dna\n”;
• replace all 'a's with 't's - a global substitutionreplace all 'a's with 't's - a global substitution$dna =~ $dna =~ ss/a/a//t/g;t/g;
• replace with e modifierreplace with e modifiermy $reversed;my $reversed;($reversed = $dna) =~ ($reversed = $dna) =~ ss/(\w+)/(\w+)//reverse($1)/eg;reverse($1)/eg;print "\$dna is $dna, \$reversed is $reversed\n";print "\$dna is $dna, \$reversed is $reversed\n";
my $reversed = $dna =~ my $reversed = $dna =~ ss/(\w+)/(\w+)//reverse($1)/eg;reverse($1)/eg;print "\$dna is $dna, \$reversed is $reversed\n";print "\$dna is $dna, \$reversed is $reversed\n";
$dna remains intact and the substitution happens in $reverse
The substitution happens in $dna and $reversed gets the status

Regular ExpressionsRegular ExpressionsSubstitutions / trSubstitutions / tr
• trtr/CHARACTERS/CHARACTERS//REPLACEMENTS/REPLACEMENTS/my $dna = “atgctagtctagcgatgcatgtgttgtgcgtatgtga”;my $dna = “atgctagtctagcgatgcatgtgttgtgcgtatgtga”;
• replace all ‘a’s with ‘t’replace all ‘a’s with ‘t’$dna =~ $dna =~ trtr/a/a//t/;t/;
• replace all ‘a’s and ‘g’s with ‘t’sreplace all ‘a’s and ‘g’s with ‘t’s$dna =~ $dna =~ trtr/ag/ag//t/;t/;
• mind the number of replacement charactersmind the number of replacement characters$dna =~ $dna =~ trtr/a/a//tg/; #’a’s will be replaced by ‘t’tg/; #’a’s will be replaced by ‘t’
• no need to use the g modifier!no need to use the g modifier!

Handling FilesHandling FilesI/OI/O
• open(FILEHANDLE,MODE,FILENAME) error check;open(FILEHANDLE,MODE,FILENAME) error check;open(FILE,”>”,”/home/username/file_to_write.txt”) or die “$!\n”;open(FILE,”>”,”/home/username/file_to_write.txt”) or die “$!\n”;““>” create/overwrite content>” create/overwrite content““<“ read from (default operand if mode is not selected)<“ read from (default operand if mode is not selected)““>>” create/add content>>” create/add content
• reading from filereading from filemy $first_line=<FILE>;my $first_line=<FILE>;my $second_line=<FILE>;my $second_line=<FILE>;
my @all_lines=<FILE>;my @all_lines=<FILE>;
while(my $line=<FILE>){while(my $line=<FILE>){chomp $line; #chop!!chomp $line; #chop!!……
} }

Handling FilesHandling FilesI/OI/O
• parsing the linesparsing the lines while(my $line=<FILE>){while(my $line=<FILE>){
chomp $line; #chop!!chomp $line; #chop!!
my @tempLine=split(/\t/,$line);my @tempLine=split(/\t/,$line); #with split (#with split (!!!!))my $temp=~/\w+\t\d+/;my $temp=~/\w+\t\d+/; #with plain regex#with plain regex
}}
• writing to a filewriting to a fileopen(OUTFILE,”>out_file_name.txt”) or die “$!\n”;open(OUTFILE,”>out_file_name.txt”) or die “$!\n”;print OUTFILE “This will be printed in the file\n”;print OUTFILE “This will be printed in the file\n”;
• appending to a fileappending to a fileopen(OUTFILE,”>>new_or_existing_file_name.txt”) or die “$!\n”;open(OUTFILE,”>>new_or_existing_file_name.txt”) or die “$!\n”;print OUTFILE “This will be printed in the end of the existing file\n”;print OUTFILE “This will be printed in the end of the existing file\n”;
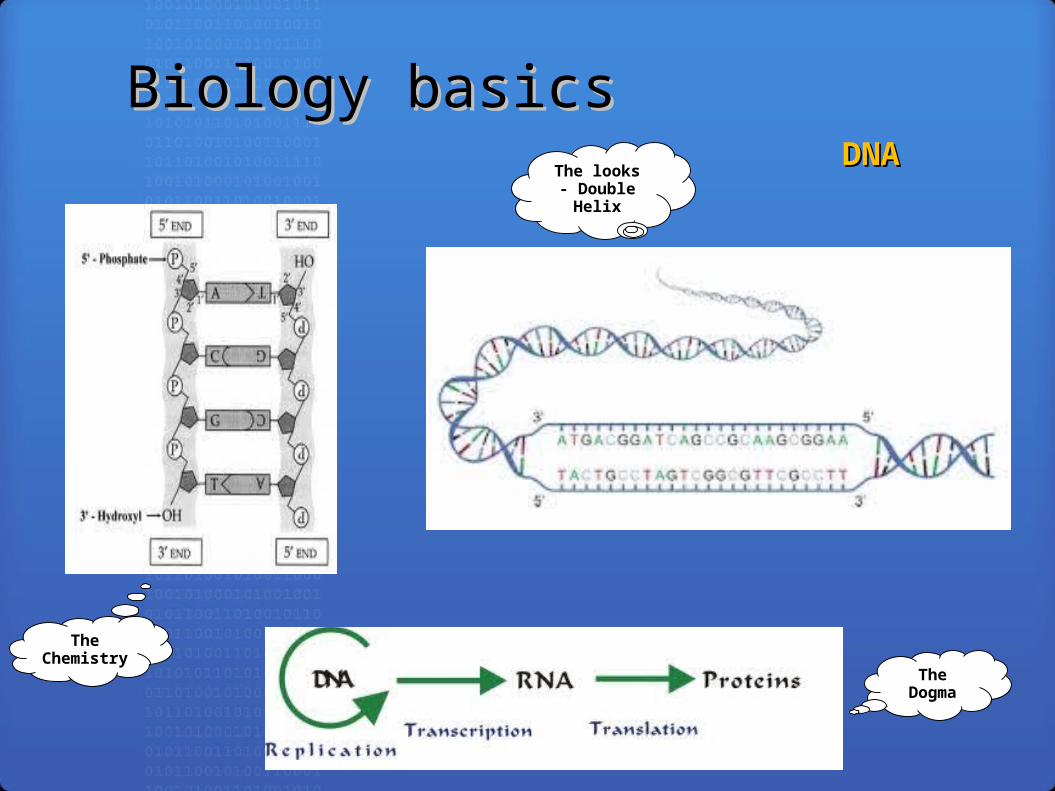
Biology basicsBiology basicsDNADNA
The Dogma
The Chemistry
The looks - Double Helix

• Scientists conjectured that proteins came from DNA; but how did DNA Scientists conjectured that proteins came from DNA; but how did DNA code for proteins?code for proteins?
• If one nucleotide codes for one amino acid, then there’d be 4If one nucleotide codes for one amino acid, then there’d be 411 amino amino acidsacids
• However, there are 20 amino acids, so at least 3 bases codes for one However, there are 20 amino acids, so at least 3 bases codes for one amino acid, since 4amino acid, since 422 = 16 and 4 = 16 and 433 = 64 = 64
• This triplet of bases is called a “codon”This triplet of bases is called a “codon”
64 different codons and only 20 amino acids means that the coding 64 different codons and only 20 amino acids means that the coding is degenerate: more than one codon sequence code for the same is degenerate: more than one codon sequence code for the same amino acidamino acid
Uncovering the codeUncovering the codeDNA => ProteinsDNA => Proteins

• In going from DNA to proteins, there is an In going from DNA to proteins, there is an intermediate step where mRNA is made from intermediate step where mRNA is made from DNA, which then makes proteinDNA, which then makes protein
• Why the intermediate step?Why the intermediate step?
DNA is kept in the nucleus, while protein DNA is kept in the nucleus, while protein sythesis happens in the cytoplasm, with the sythesis happens in the cytoplasm, with the help of ribosomeshelp of ribosomes
Central Dogma RevisitedCentral Dogma Revisited
Genetic CodeGenetic Code

Reading FramesReading Frames
• Since nucleotide sequences are “read” three bases at a time, there are three Since nucleotide sequences are “read” three bases at a time, there are three possible “frames” in which a given nucleotide sequence can be “read” (in the possible “frames” in which a given nucleotide sequence can be “read” (in the forward direction)forward direction)
• Taking the complement of the sequence and reading in the reverse direction gives Taking the complement of the sequence and reading in the reverse direction gives three more reading framesthree more reading frames
Open Reading FramesOpen Reading Frames
• Concept: Region of DNA or RNA sequence that could be translated into a peptide Concept: Region of DNA or RNA sequence that could be translated into a peptide sequence (open refers to sequence (open refers to absenceabsence of stop codons) of stop codons)
• Prerequisite: A specific genetic codePrerequisite: A specific genetic code
• Definition:Definition:
(start codon)(start codon) (amino acid coding codon)(amino acid coding codon)nn (stop codon) (stop codon)
• Note: Not all ORFs are actually usedNote: Not all ORFs are actually used
Revisiting the CodeRevisiting the Code(Open?) Reading Frames(Open?) Reading Frames

ExerciseExerciseRegexps!!Regexps!!
Objective 1Objective 1
•Open the file named exercise_1_random_sequence.dat with Perl.Open the file named exercise_1_random_sequence.dat with Perl.•Find its reverse complement!Find its reverse complement!
Objective 2Objective 2
•Open the file (yersinia_genome.fasta) with the complete Yersinia Open the file (yersinia_genome.fasta) with the complete Yersinia genome and find the possible start and end positions of its genes! genome and find the possible start and end positions of its genes! Tips:Tips:•The beginning of each gene is mapped by the following pattern. There is The beginning of each gene is mapped by the following pattern. There is an 8 letter consensus known as the Shine-Dalgarno sequence an 8 letter consensus known as the Shine-Dalgarno sequence (TAAGGAGG) followed by 4-10 bases downstream before the initiation (TAAGGAGG) followed by 4-10 bases downstream before the initiation codon (ATG). However there are variants of the Shine-Dalgarno codon (ATG). However there are variants of the Shine-Dalgarno sequence with the most common of which being [TA][AC]AGGA[GA][GA].sequence with the most common of which being [TA][AC]AGGA[GA][GA].•The end of the gene is specified by the stop codon TAA, TAG and TGA. The end of the gene is specified by the stop codon TAA, TAG and TGA. It must be taken care the stop codon is found after the correct Open It must be taken care the stop codon is found after the correct Open Reading Frame (ORF).Reading Frame (ORF).•Don’t forget to check the reverse complement!Don’t forget to check the reverse complement!

Web Sources for PerlWeb Sources for Perl
www.perl.com www.perldoc.com www.perl.org www.perlmonks.org





























