Embed Size (px)
Citation preview

Introduction to Language ModelsEvaluation in information retrieval
Lecture 4

Last lecture: term weighting
tf.idf term weighting
wdwdw df
Ntfidftf log. ,,
tfw,d = # of occurrences of word w in doc d term frequency
N = number of documents in the collection
dfw = # of docs in the collection that contain w document frequency

Last lecture: vector representation
Vector representation- Binary vector- Frequency vector- tf.idf vector
Each component corresponds to a word– Sparse vectors (lots of 0 elements)

Last lecture: document similarity
k and s are the vector representations of two documents
ii
ii
ii
i
sk
sk
sk
sksksim
22
.),(

Fried chicken example (p.770)
Query (‘fried chicken’)– q = (1,1)
Document j (‘fired chicken recipe’)– j = (3,8)
Document k (‘poached chicken recipe’)– k = (0,6)

q = (1,1); j = (3,8); k = (0,6)
8198.0180
11
)819)(11(
8131),(
jqsim
7071.072
6
)360)(11(
6101),(
kqsim
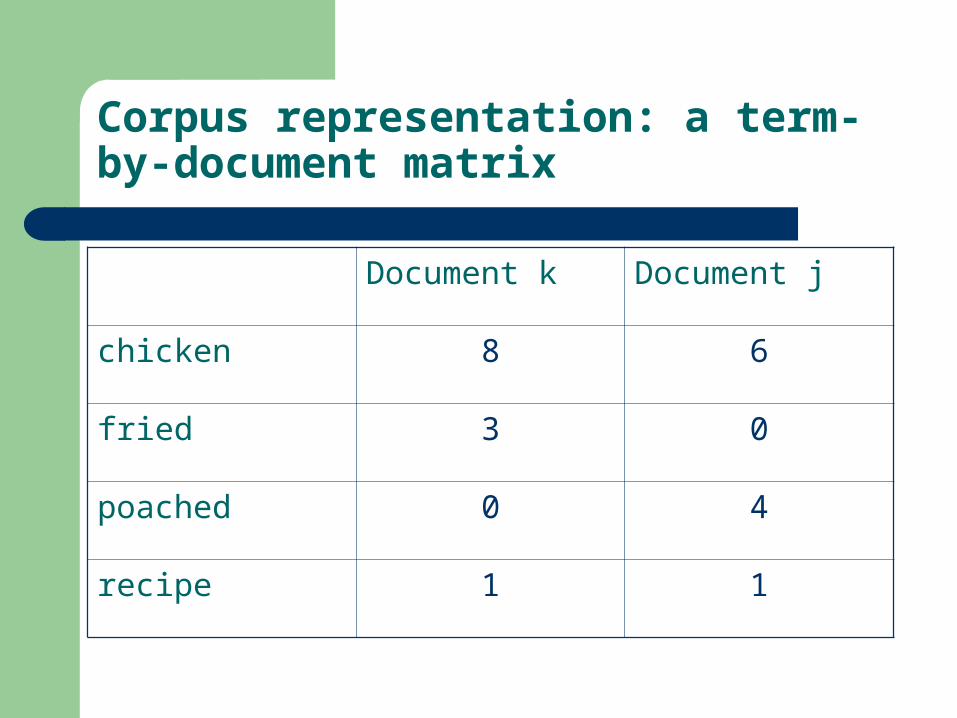
Corpus representation: a term-by-document matrix
Document k Document j
chicken 8 6
fried 3 0
poached 0 4
recipe 1 1

Document length influence
If term t appears say 50 times in a 100 word paper and 80 times in a 5000 word document, where is the word more descriptive?– Maximum tf normalization: divide tf by the maximum
tf observed in the document
When computing document similarity– What happens when one document subsumes the
other?

Language models: introduction

Next Word Prediction
From a NY Times story...– Stocks ...– Stocks plunged this ….– Stocks plunged this morning, despite a cut in interest
rates– Stocks plunged this morning, despite a cut in interest
rates by the Federal Reserve, as Wall ...– Stocks plunged this morning, despite a cut in interest
rates by the Federal Reserve, as Wall Street began

Next Word Prediction
From a NY Times story...– Stocks ...– Stocks plunged this ….– Stocks plunged this morning, despite a cut in interest
rates– Stocks plunged this morning, despite a cut in interest
rates by the Federal Reserve, as Wall ...– Stocks plunged this morning, despite a cut in interest
rates by the Federal Reserve, as Wall Street began

Claim
A useful part of the knowledge needed to allow Word Prediction can be captured using simple statistical techniques
In particular, we'll rely on the notion of the probability of a sequence (of letters, words,…)

Applications
Why do we want to predict a word, given some preceding words?– Rank the likelihood of sequences containing
various alternative hypotheses, e.g. for ASR
Theatre owners say popcorn/unicorn sales have doubled...
– Spelling correction– IR: how likely is a document to generate a query

N-Gram Models of Language
Use the previous N-1 words in a sequence to predict the next word
Language Model (LM)– unigrams, bigrams, trigrams,…
How do we train these models?– Very large corpora

Simple N-Grams
Assume a language has T word types in its lexicon, how likely is word x to follow word y?– Simplest model of word probability: 1/T– Alternative 1: estimate likelihood of x occurring in new text
based on its general frequency of occurrence estimated from a corpus (unigram probability)
popcorn is more likely to occur than unicorn
– Alternative 2: condition the likelihood of x occurring in the context of previous words (bigrams, trigrams,…)
mythical unicorn is more likely than mythical popcorn
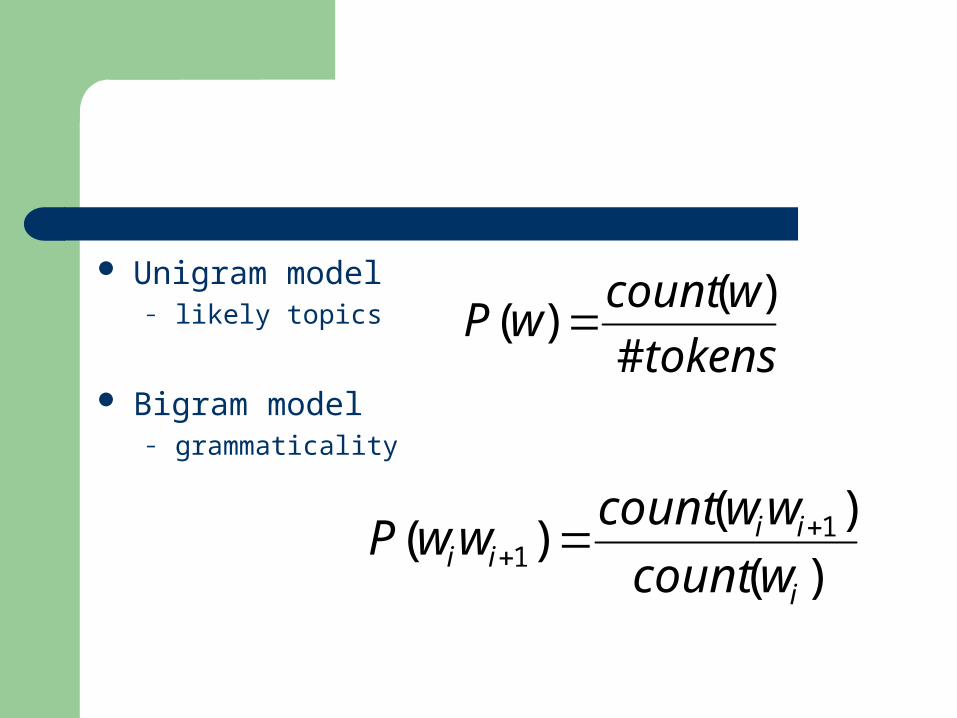
Unigram model– likely topics
Bigram model– grammaticality
tokens
wcountwP
#
)()(
)(
)()( 1
1i
iiii wcount
wwcountwwP

Computing the Probability of a Word Sequence
Compute the product of component conditional probabilities?– P(the mythical unicorn) = P(the) P(mythical|the) *
P(unicorn|the mythical)
The longer the sequence, the less likely we are to find it in a training corpus
P(Most biologists and folklore specialists believe that in fact the mythical unicorn horns derived from the narwhal)
Solution: approximate using n-grams

Bigram Model
Approximate by – P(unicorn|the mythical) by P(unicorn|mythical)
Markov assumption: the probability of a word depends only on the probability of a limited history
Generalization: the probability of a word depends only on the probability of the n previous words– trigrams, 4-grams, …– the higher n is, the more data needed to train– backoff models…
)11|( nn wwP )|( 1nn wwP

A Simple Example: bigram model
– P(I want to each Chinese food) = P(I | <start>) P(want | I) P(to | want) P(eat | to) P(Chinese | eat) P(food | Chinese) P(<end>|food)

Generating WSJ

Google N-Gram Release
serve as the incoming 92 serve as the incubator 99 serve as the independent 794 serve as the index 223 serve as the indication 72 serve as the indicator 120 serve as the indicators 45 serve as the indispensable 111 serve as the indispensible 40 serve as the individual 234

Evaluation in information retrieval
How do we know one system is better than another?
How can we tell if a new feature improves performance?
Metrics developed for IR are used in other fields as well

Gold standard/ground truth
Given a user information need, documents in a collection are classified as either relevant or nonrelevant
Relevant = pertinent to the user information need

Information needs are not equivalent to queries
Information on whether drinking red wine is more effective at reducing your risk of heart attack than white wine
Pros and cons of low fat diets for weight control
Health effects from drinking green tea

Needed for evaluation
Test document collection Reasonable number of information needs
– At least 50
Relevance judgments – Practically impossible to get these for every
document in the collection– Usually only for the top ranked results returned
form systems


Accuracy
Problematic measure for IR evaluation
– (tp+tn)/(tp+tn+fp+fn)
99.9% of the documents will be nonrelevant– Trivially achieved high performance

Precision

Recall

Precision/Recall trade off
Which is more important depends on the user needs
– Typical web users High precision in the first page of results
– Paralegals and intelligence analysts Need high recall Willing to tolerate some irrelevant documents as a price
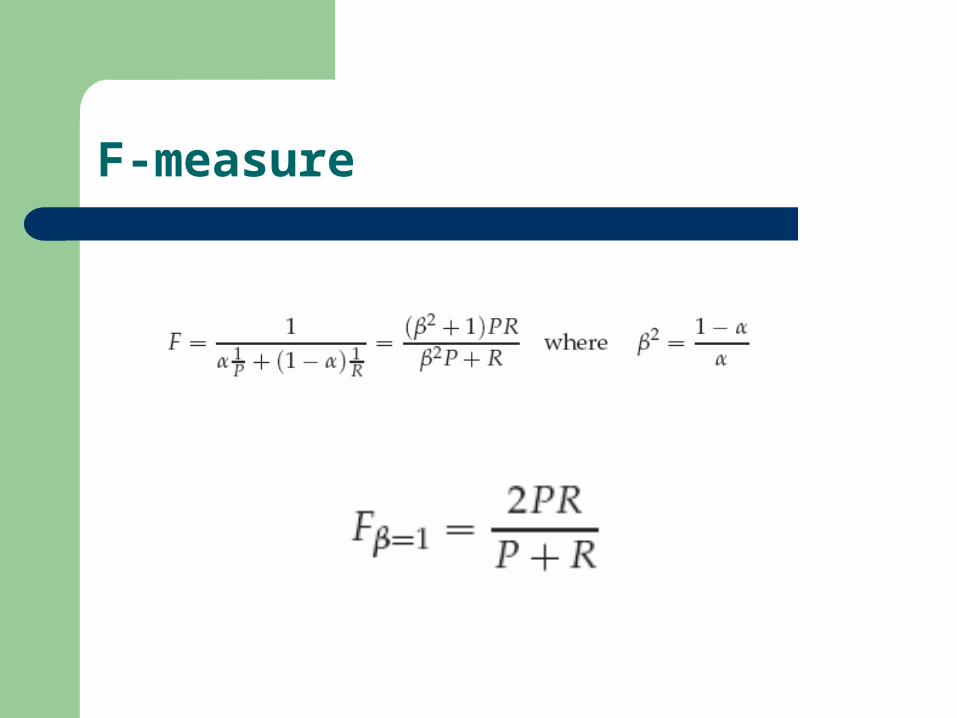
F-measure





























