Embed Size (px)
Citation preview

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Introduction to Job Submission
and Scheduling
Minnesota Supercomputing Institute
University of Minnesota
10-19-2021
Ham C Lam, Ph.D.
Scientific Computing Solution group
email: [email protected]

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
High Performance Computing (HPC) at MSI
What can I do with HPC?
❏ Solving large problems with little time
❏ Run simulation and analysis of large volume of data that would not be possible with standard computers
❏ Be creative!

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Connecting to MSI
Overview of job submission and scheduling
HPC resource allocation methods
Slurm job examples
Troubleshooting
Content
Job submission and scheduling

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
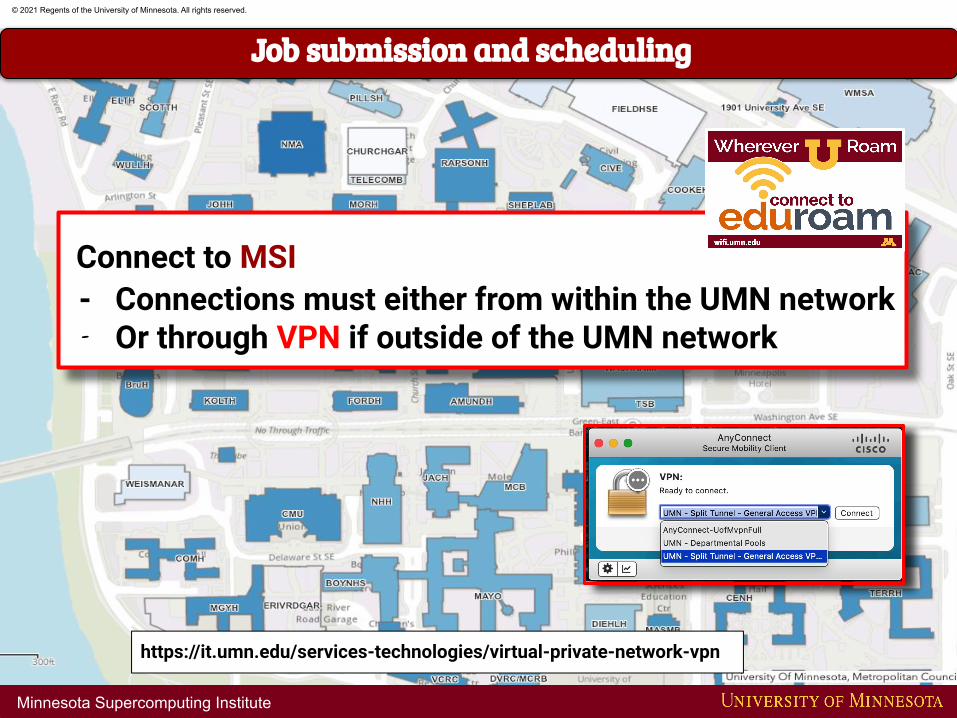
Connect to MSI
Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
Connect to MSI - Connections must either from within the UMN network- Or through VPN if outside of the UMN network
https://it.umn.edu/services-technologies/virtual-private-network-vpn

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Connecting to MSI
https://www.msi.umn.edu/content/connecting-hpc-resources

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Connecting to MSI
Linux and Mac users can ‘ssh’ directly to mesabi or mangi using a terminal application.
ssh -Y <username>@mesabi.msi.umn.edussh -Y <username>@mangi.msi.umn.edu
mesabi headnode
mangi headnode
Secure Shell (SSH)

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Connecting to MSI
Window users can use “PuTTY”
https://www.msi.umn.edu/support/faq/how-do-i-configure-putty-connect-msi-unix-systems
Secure Shell (SSH)

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Connecting to MSI
Graphical connections with “NX” using a web browser
https://nx.msi.umn.edu
For more information https://www.msi.umn.edu/support/faq/how-do-i-get-started-nx

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Connecting to MSI
https://notebook.msi.umn.edu
Graphical connections with “NICE” using a web browser
For more information https://www.msi.umn.edu/support/faq/how-do-i-get-started-jupyter-notebooks

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
Overview of job submission and scheduling

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
❏ What is job scheduling?It is the process of arranging, controlling and optimizing work and workloads in a shared HPC environment.
❏ Why do we need job scheduling?● MSI serves over 1000 groups and 5000 users with
limited HPC resources so we all must share the computing hardware.
● Automated allocation of limited resources● Tracking and monitoring jobs

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
❏ Who manages the scheduling?Slurm! A resource manager and a job scheduler designed to allocate compute resources to HPC users and much more.
❏ What does slurm do?Allocate compute resources for job requests from usersKeeps track of compute resources on the clusterAssigns priorities to jobsLaunches jobs on assigned compute nodes

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
How to think about a job?
In eneral, a suc es l job need 3 thing to wor correctly● Har r e r e● So w (li s , mo s, et )● The ob r t a g t e r re s a
to h y e Sl s ed !
On t e other hand, a failed job can also ue to ● Har r (e.g. no ug m or al te )● So w (Bug , ve n an , et )● The s p (Maj y o h e)

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
How to think about a job?
Hardware (general considerations)● CPU● CO● Memor● Storage s a e (home, local /tmp, or lobal scratch)● Walltime limit on ar are (Hour ? Minutes?)
*Cores is a hardware term that describes the number of independent central processing units in a single computing component (die or chip)

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Hardware
- A group of computers form the high performance computing system called a cluster.
- Each computer in a cluster is called a node.- Each node can talk to each other through a
high speed network.- Each node has multiple processors with
multiple cores and large memory.
0 1 2 3
4 5 6 7
0 1 2 3
4 5 6 7Node CPU socket CORE ID
Physical ID = {0, 1}
High Performance Computing (HPC)

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Software
How to think about a job?
Software ● Module sy tem (e.g. mo ule loa gcc)● My home dire tor (s e ific o are)● Virtual environment (conda activate m _env)● Container (doc er, singularity)

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Software
Description Command Example
See all available modules module avail module avail
Load a module module load module load matlab/2021a
Unload a module module unload module unload matlab/2021a
Unload all modules module purge module purge
See what a module does module show module show matlab/2021a
List currently loaded modules module list module list
MSI has hundreds of software modules. Software modules are used to alter environmental variables, in order to make software available.
Some module commands:

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Allocation of HPC resources for batch processing
a. Running batch jobs ( )i. -Create a job
ii. -Slurm partitionsb. Interact with SLURM
i. -Submit jobsii. -Check job status
c. Job priority
Job submission and scheduling
Allocation of HPC resources for interactive use
srun salloc
sbatch

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Request resource allocation
slurm commands
sbatch
srun
salloc
If invoked at a login headnode, it will create a new allocation and execute the command following srun.If invoked within a batch script, it will run the given command in parallel using the current allocation requested by the job script.
It works like srun but always results in a new allocation when it is invoked. This new allocation can be used to run commands or programs.
Request resource allocation through a job script or at the command lines. If invoked at command lines with options, these options take precedence over the #SBATCH options in the job script.

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Create a batch job To run a batch job, you need to first create a job script and use the command to submit the job to the slurm scheduler
Script interpreter (Bash)#!/bin/bash ← 1st line of your script
SLURM DIRECTIVES1. Start with “#SBATCH”2. Parsed by Slurm but ignored by Bash3. Can be separated by spaces4. Comments between and after directives
are allowed5. Must be before actual commands
Programs or commandsCommands you want execute on a compute node
SBATCH command2
A batch script1Job script
Find a partition!3 ** The small partition is our default partition
sbatch
Hardware Software

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Slurm job partitions
● A logical set(s) of compute nodes grouped together depending on their hardware characteristics or function.
● A slurm job partition can been seen as an automated waiting list for use of a particular set of computational hardware.
● Different job partitions have different resources and limitations.
● Make sure to choose a job partition which has resources and limitations suitable to your jobs
For the complete list of all partitions: https://www.msi.umn.edu/partitions

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
A job script essentialsThe #SBATCH directives (put inside your job script)
--nodes=N
--ntasks=N
--mem=NG
--mem-per-cpu=NG
--tmp=NG
--time=hrs:min:sec
-p=<Name>
--exclusive?
--exclusive
--ntasks=N
--time=hrs:min:sec
Request N tasks to be allocated (Unless otherwise specified, one task maps to one CPU core).
Set a limit on the total walltime of the job allocation
-p=<partition name> Request a specific partition for the resource allocation
The job allocation can not share nodes with other running jobs

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
A job script essentials
Other recommended #SBATCH directives (good for troubleshooting too!)
--error=<file_name>
--output=<file_name>
--account=<group account>
Write job script’s standard output to the specified file
Charge resources used by the job to specified account
--job-name=<string> Specify a name for the job allocation
Write job script's standard error to the specified file
--mem=NG Specify the memory required per node
--mem-per-cpu=NG Minimum memory required per allocated CPU
--tmp=NG Request N gb of the local scratch space storage
--nodes=N Request N nodes to be allocated

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
A job script essentials
--mail-user=<address> Send email to address (multiple comma separated addresses OK)
--mail-type=<event> Specify which events for which you want to be notified
Email notification
Event Description
BEGIN Job begins
END Job ends
FAIL Job fails
ALL BEGIN + END + FAIL
TIME_LIMIT_50 Elapsed time reaches 50% of allocated time
TIME_LIMIT_80 Elapsed time reaches 80% of allocated time
TIME_LIMIT_90 Elapsed time reaches 90% of allocated time
Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
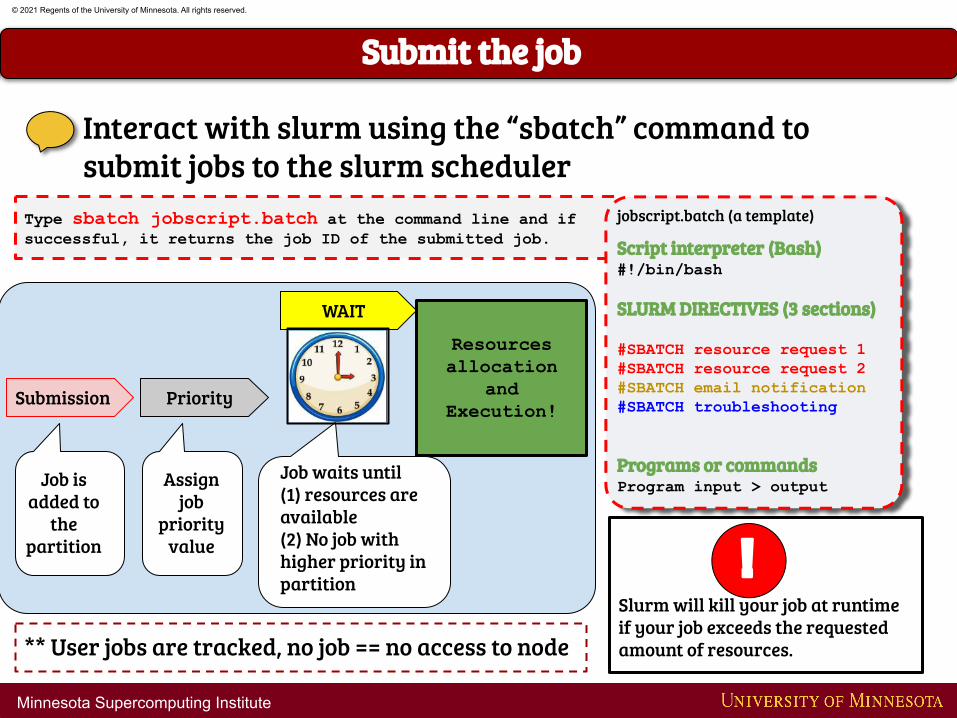
Type sbatch jobscript.batch at the command line and if successful, it returns the job ID of the submitted job.
Submit the job
Script interpreter (Bash)#!/bin/bash
SLURM DIRECTIVES (3 sections)
#SBATCH resource request 1#SBATCH resource request 2#SBATCH email notification #SBATCH troubleshooting
Programs or commandsProgram input > output
jobscript.batch (a template)
Interact with slurm using the “sbatch” command to submit jobs to the slurm scheduler
** User jobs are tracked, no job == no access to node
Job is added to
the partition
Submission Priority
WAIT
Resources allocation
and Execution!
Assign job
priority value
Job waits until (1) resources are available (2) No job with higher priority in partition
Slurm will kill your job at runtime if your job exceeds the requested amount of resources.
!

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Check job status
Example
squeue -u <username>
View jobs in the Slurm scheduling queue for user <username>
(ST) JOB STATE CODES
PD PENDING Job is awaiting resource allocation
NODELIST (REASON)
CG COMPLETING Job is in the process of completing
CA CANCELLED Job was explicitly cancelled by the user/admin
R RUNNING Job currently has an allocation
Priority One or more higher priority jobs exist for this partition
Resources The job is waiting for resources to become available
ReqNodeNotAvail Some node specifically required by the job is not currently available.

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job priority
My job’s priority
AGE The longer the job waits in queue, its age factor gradually increases.
FAIRSHARE Prioritizes jobs belonging to underserviced users/accounts. 1) is adjusted based on the recent usage of group members, 2) is proportional to the compute resources used by the group, and 3) impact on priority decay over time.
JOB SIZE Jobs requesting more CPUs are favored (large jobs).
More information: https://www.msi.umn.edu/content/hpc

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
A few interactive job examples

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Interactive job
srun
More information: https://www.msi.umn.edu/content/interactive-queue-use-srun
● General form:srun <resource options> user-provided-command <args> e.g. srun -t 100 -N1 -n1 -c4 -p small ./my_program args
lamx0031@ln0003 [12:19:08] srun -N 1 -n 1 -c 4 -p small ./omp_hwsrun: Setting account: supportsrun: job 7000821 queued and waiting for resourcessrun: job 7000821 has been allocated resourcesHello World from thread = 0Number of threads = 4Hello World from thread = 2Hello World from thread = 3Hello World from thread = 1lamx0031@ln0003 [12:19:30]
● The most common use of srun is to launch an interactive session on one or more compute nodes with the “--pty” option.e.g. srun -t 100 -N1 -n1 -c4 -t 100 -p interactive --pty bash
● User-provided command can be “/bin/bash” (to launch an interactive shell) or a script with arguments.
If necessary, srun will first create a resource allocation in which to run the parallel job.
1 node, 1 task, 4 cores job

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
hamlam~~> [15:03:58 ~] ssh -Y [email protected] login: Mon Sep 13 08:19:04 2021 from ra-full-mfa-10-20-39-63.vpn.umn.edu------------------------------------------------------------------------------- University of Minnesota Supercomputing Institute Mesabi HP Haswell Linux Cluster-------------------------------------------------------------------------------For assistance please contact us at https://www.msi.umn.edu/support/[email protected], or (612)626-0802.-------------------------------------------------------------------------------Home directories are snapshot protected. If you accidentally delete a file inyour home directory, type "cd .snapshot" then "ls -lt" to list the snapshotsavailable in order from most recent to oldest.
January 6, 2021: Slurm is now the scheduler for all nodes.------------------------------------------------------------------------------- lamx0031@ln0005 [15:04:14 ~] srun -N 1 -n 1 -c 1 --tmp=50g --mem=16gb -t 720 -p interactive --pty bashsrun: Setting account: support lamx0031@cn2001 [15:04:24 ~]
Interactive job
Interactive job (srun)
Partition(s) to consider: interactive, interactive-gpu, and others (small, k40, v100 etc)
lamx0031@ln0005 [15:07:55 ~] srun -N 1 -n 1 -c 1 --mem=16gb --x11 -t 720 -p small --pty bash srun: Setting account: supportsrun: job 6452464 queued and waiting for resourcessrun: job 6452464 has been allocated resources lamx0031@cn0339 [15:08:33 ~]
-N node, -n task, -c core
Recommended for debugging and testing/benchmarking.
More information: https://www.msi.umn.edu/content/interactive-queue-use-srun

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Interactive jobUse ‘srun’ to request 1 node, 1 task, and 1 CPU core for interactive work
srun
More information: https://www.msi.umn.edu/content/interactive-queue-use-srun

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Interactive GPU job lamx0031@ln0006 [13:08:27 ~] srun -N 1 -n 1 -c 1 --mem=8gb --gres=gpu:v100:1 -t 120 -p v100 --pty bashsrun: Setting account: support lamx0031@cn2103 [13:08:34 ~] nvidia-smiWed Sep 15 13:08:47 2021+-----------------------------------------------------------------------------+| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. || | | MIG M. ||===============================+======================+======================|| 0 Tesla V100-PCIE... Off | 00000000:39:00.0 Off | 0 || N/A 37C P0 35W / 250W | 0MiB / 32510MiB | 2% Default || | | N/A |+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+| Processes: || GPU GI CI PID Type Process name GPU Memory || ID ID Usage ||=============================================================================|| No running processes found |+-----------------------------------------------------------------------------+ lamx0031@cn2103 [13:08:47 ~]
Interactive job
Recommended for debugging and testing/benchmarking.
Partition(s) to consider: k40, interactive-gpu, and v100

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Interactive job
Use ‘salloc’ to request 1 GPU for interactive work
salloc
Why are we not seeing a GPU made available?

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Interactive job
Use ‘salloc’ to request 1 GPU
salloc
Need both the “--gres=gpu:<x>:<n>” and the partition -p
options
To release allocationUse scancel <job id>

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
Slurm batch job examples

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
#!/bin/bash#SBATCH --job-name=serial_job # create a short name for your job#SBATCH --nodes=1 # node count#SBATCH --ntasks=1 # total number of tasks across all nodes#SBATCH --cpus-per-task=1 # cpu-cores per task (>1 if multi-threaded tasks)#SBATCH --mem-per-cpu=4G # memory per cpu-core (what is the default?)#SBATCH --time=00:01:00 # total run time limit (HH:MM:SS)#SBATCH --mail-type=begin # send email when job begins#SBATCH --mail-type=end # send email when job ends#SBATCH [email protected]#SBATCH -e slurm-%j.err#SBATCH -o slurm-%j.out
python myscript.py
Serial job --nodes=1 # specify one node--ntasks=1 # claim one task (by default 1 per CPU-core)
Partition(s) to consider: small, amdsmall
Batch job examples

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
# The --cpus-per-task=4 tells slurm to run a single task using 4 cores
#!/bin/bash#SBATCH --job-name=multithreaded # create a short name for your job#SBATCH --nodes=1 # node count#SBATCH --ntasks=1 # total number of tasks across all nodes#SBATCH --cpus-per-task=4 # cpu-cores per task (>1 if multi-threaded tasks)#SBATCH --mem-per-cpu=4G # memory per cpu-core (4G is default)#SBATCH --time=00:10:00 # maximum time needed (HH:MM:SS)#SBATCH --mail-type=begin # send email when job begins#SBATCH --mail-type=end # send email when job ends#SBATCH --mail-user=<userID>@umn.edu
module load matlabmatlab < script.m > output
Multithreaded job
Partition(s) to consider: small, amdsmall
Batch job examples

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Advanced batch job examples
Advanced slurm batch job examples

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
#!/bin/bash#SBATCH --nodes=1#SBATCH --ntasks-per-node=1#SBATCH --time=00:10:00#SBATCH --job-name=job_array_test#SBATCH --array=1-5 # 5 jobs
python arraytest.py file-${SLURM_ARRAY_TASK_ID}.txt > output_${SLURM_ARRAY_TASK_ID}
Slurm job arraySlurm job array is a collection of jobs that differ from each other by only a single index parameter. Creating a job array provides an easy way to group related jobs together.
Batch job examples
What if my input files do not have a numerical index? Use ‘awk’ls -l mydir > fileslistmyfile=$(cat fileslist | awk -v afile=${SLURM_ARRAY_TASK_ID} '{if (NR==afile) print $9}')Program $myfile
Shorter submission times than submitting jobs individually.
All jobs in a job array must have the same resource requirements
https://www.msi.umn.edu/support/faq/how-do-i-use-job-array

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
#!/bin/bash#SBATCH --nodes=1#SBATCH --ntasks-per-node=1#SBATCH --time=00:10:00#SBATCH --job-name=job_array_test#SBATCH --array=1-5 # 5 jobs
python arraytest.py file-${SLURM_ARRAY_TASK_ID}.txt > output_${SLURM_ARRAY_TASK_ID}
Slurm job array
Partition(s) to consider: small, amdsmall, amdlarge, etc
Slurm job array is a collection of jobs that differ from each other by only a single index parameter. Creating a job array provides an easy way to group related jobs together.
Job examples
Shorter submission times than submitting jobs individually.
All jobs in a job array must have the same resource requirements

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
#!/bin/bash#SBATCH --nodes=1#SBATCH --ntasks=10#SBATCH --mem-per-cpu=1G#SBATCH --time=01:00:00#SBATCH --partition small#SBATCH [email protected]#SBATCH --mail-type=BEGIN,END#SBATCH -e slurm-%j.err#SBATCH -o slurm-%j.out
cd $SLURM_SUBMIT_DIRmodule load parallelparallel -v --delay .3 -j $SLURM_NTASKS myscript
Parallel job
You can “ssh cn0609”
Job examples

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Preemption?
Some running jobs (preemptees) can be interrupted by other running jobs (preemptors). A job may either be a preemptor (default), or a preemptee (optional), but not both in the preempt and preempt-gpu partitions.
What happen to my job when it is preempted?Cancel or Requeue options: When re-queue, your job must be able to pick up where it left off or can deal with interruption effectively when it restarts.
Main reason to run a preempt jobs?Same priority value as non-preempt jobs but with a smaller fairshare impact!
Preemptable job
Job examples

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
#!/bin/bash#SBATCH --nodes=1#SBATCH --ntasks=10#SBATCH --mem-per-cpu=1G#SBATCH --time=01:00:00#SBATCH [email protected]#SBATCH --mail-type=BEGIN,END#SBATCH -e slurm-%j.err#SBATCH -o slurm-%j.out#SBATCH --partition preempt#SBATCH --requeue
module load parallel
# use --resume to deal with interruptionparallel -v --delay .3 -j $SLURM_NTASKS --joblog logs/testjob.log --resume myscript
Preemptable job
Partition(s) to consider: preempt and preempt-gpuThese partitions allow the use of idle interactive resources. Jobs submitted to the preempt queue may be killed at any time to make room for an interactive job.
Job examples

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
#!/bin/bash#SBATCH --nodes=1#SBATCH --ntasks=24#SBATCH --mem-per-cpu=1G#SBATCH --time=01:00:00#SBATCH --partition k40 # Send the job to the k40 partition#SBATCH --gres=gpu:k40:2 # Request 2 K40 GPUs, a full node#SBATCH [email protected]#SBATCH --mail-type=BEGIN,END#SBATCH -e slurm-%j.err#SBATCH -o slurm-%j.out
conda activate torch-env-src #activate conda environment
module load gccmodule load cuda/11.2python run_torch.py
GPU jobs
Partition(s) to consider: k40, preempt-gpu, v100
Job examples

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
#!/bin/bash#SBATCH --nodes=1#SBATCH --ntasks=10#SBATCH --mem-per-cpu=1G#SBATCH --time=01:00:00#SBATCH --partition=ram2t#SBATCH [email protected]#SBATCH --mail-type=BEGIN,END#SBATCH -e slurm-%j.err#SBATCH -o slurm-%j.out
module load singularity
##run a program inside the container
singularity exec -e container.sif program
Users application specific jobs
Container batch job (singularity or docker)
Use the “-B” bind option if you need to bring in data or files outside your home directory since singularity by default only mounts your home directory into the container.

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
#!/bin/bash#SBATCH --job-name=test#SBATCH --nodes=2#SBATCH --ntasks=48#SBATCH --partition k40#SBATCH --gres=gpu:k40:2 #SBATCH --mem=120G#SBATCH --ntasks-per-node=24#SBATCH --cpus-per-task=1#SBATCH --time=00:10:00 #SBATCH --mail-type=begin #SBATCH --mail-type=end #SBATCH [email protected]
#SBATCH -e training-%j.err#SBATCH -o training-%j.out
cd ${SLURM_SUBMIT_DIR}sh neuralnetwork.sh
Custom environment batch job (anaconda, virtualenv, etc)
Users application specific jobs
#!/bin/bashset -xnode=$(hostname)
# make sure module loadssource /panfs/roc/msisoft/modules/3.2.6/init/bashmodule load cuda/11.2module load gcc/8.2.0
# activate the conda env here. /panfs/roc/msisoft/anaconda/anaconda3-2018.12/etc/profile.d/conda.shconda activate tensorflow_gpu_2.0
cd /home/support/lamx0031/My_Tutorial/Tensorflow/Multi_nodes/Codeecho "$node run_neuralnetwork.sh argv: $@"
python neuralnetwork.py $@ #use 2 GPUsif [[ $? != 0 ]]; then echo "python neuralnetwork.py failed"else echo "Finish running neuralnetwork.py using slave node: $node"fi
conda deactivate
neuralnetwork.sh
Prefer to “GPU jobs” example slide for how to activate conda environment directly in the job script

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
#!/bin/bash#SBATCH --nodes=1#SBATCH --ntasks=10#SBATCH --mem-per-cpu=1G#SBATCH --time=10:00:00#SBATCH --partition=<private queue>#SBATCH --mail-user=<address>#SBATCH --mail-type=BEGIN,END#SBATCH -e slurm-%j.err#SBATCH -o slurm-%j.out
python mnist.py
Dedicated nodes jobs
Partition(s) to consider: private queue
Job examples

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
Common Job Failures
1. Memory Limit
2. Time limit
3. Software modules
4. Disk quota
5. Conda environment

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
sbatch messages: incorrect resource configuration
lamx0031@ln0006 [14:02:05 ~] sbatch myscriptsbatch: error: Setting account: supportsbatch: error: Memory specification can not be satisfiedsbatch: error: Batch job submission failed: Requested node configuration is not available
For example, if you requested more memory than what a compute node actually has.*Check our Slurm partitions specification webpage for proper configuration settings
Troubleshooting

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Submitting jobs: a dry-run
lamx0031@ln0006 [12:57:54 ~] sbatch --test-only myscript.shsbatch: Setting account: supportsbatch: Job 1433090 to start at 2021-03-10T18:42:53 using 4 processors on nodes cn0166 in partition smalllamx0031@ln0006 [12:57:54 ~]
A good way to validate the slurm script and return an estimate of when a job would be scheduled to run
Troubleshooting

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Cancel jobs
lamx0031@cn2001 [13:14:45 ~] sbatch myscript.shsbatch: Setting account: supportSubmitted batch job 1385990 lamx0031@cn2001 [13:14:59 ~] scancel 1385990
scancel -u lamx0031 --state=running # cancel all my running jobs scancel -u lamx0031 --state=pending # cancel all my pending jobs
Troubleshooting

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Hold and release jobs
lamx0031@cn1001 [15:52:26 ~] sbatch myscript.shsbatch: Setting account: supportSubmitted batch job 1437891lamx0031@cn1001 [15:52:37 ~] squeue -u lamx0031 JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 1437891 small myscript lamx0031 PD 0:00 8 (None) lamx0031@cn1001 [15:52:54 ~] scontrol hold 1437891 lamx0031@cn1001 [15:53:03 ~] squeue -u lamx0031 JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 1437891 small myscript lamx0031 PD 0:00 8 (JobHeldUser) lamx0031@cn1001 [15:53:06 ~] scontrol release 1437891 lamx0031@cn1001 [15:56:01 ~] squeue -u lamx0031 JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 1437891 small myscript lamx0031 PD 0:00 8 (None)
Troubleshooting

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
The University of Minnesota is an equal opportunity educator and employer. This presentation is available in alternative formats upon request. Direct requests to Minnesota Supercomputing Institute, 599 Walter library, 117 Pleasant St. SE, Minneapolis, Minnesota, 55455, 612-624-0528.
Good to know
● Job limits: each group is limited to 10,000 CPU cores, 8 V100 GPUs, and 40TB of memory.
● Scratch space for jobs: /scratch.local and /scratch.global
● Do not run compute intensive workload on the head nodes, submit it to slurm!
● Errors will fail your job (even a tiny typo in a command), try to build your job script interactively before running them remotely!

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
The University of Minnesota is an equal opportunity educator and employer. This presentation is available in alternative formats upon request. Direct requests to Minnesota Supercomputing Institute, 599 Walter library, 117 Pleasant St. SE, Minneapolis, Minnesota, 55455, 612-624-0528.
Need more help?
Check our SLURM webpagehttps://www.msi.umn.edu/slurm
Submit a ticket to the helpdeskEmail: [email protected]://www.msi.umn.edu/content/helpdesk
SLURM cheatsheethttps://slurm.schedmd.com/pdfs/summary.pdf

Minnesota Supercomputing Institute
© 2021 Regents of the University of Minnesota. All rights reserved.
Job submission and scheduling
Hands-on demonstration




























