Embed Size (px)
Citation preview

Introduction toHigh Performance Computing:
Parallel, Distributed, Grid Computing and More

Outline
• Motivation
• What is High Performance Computing?
• Parallel Computing
• Distributed Computing, Grid Computing, and More
• Future Trends in HPC
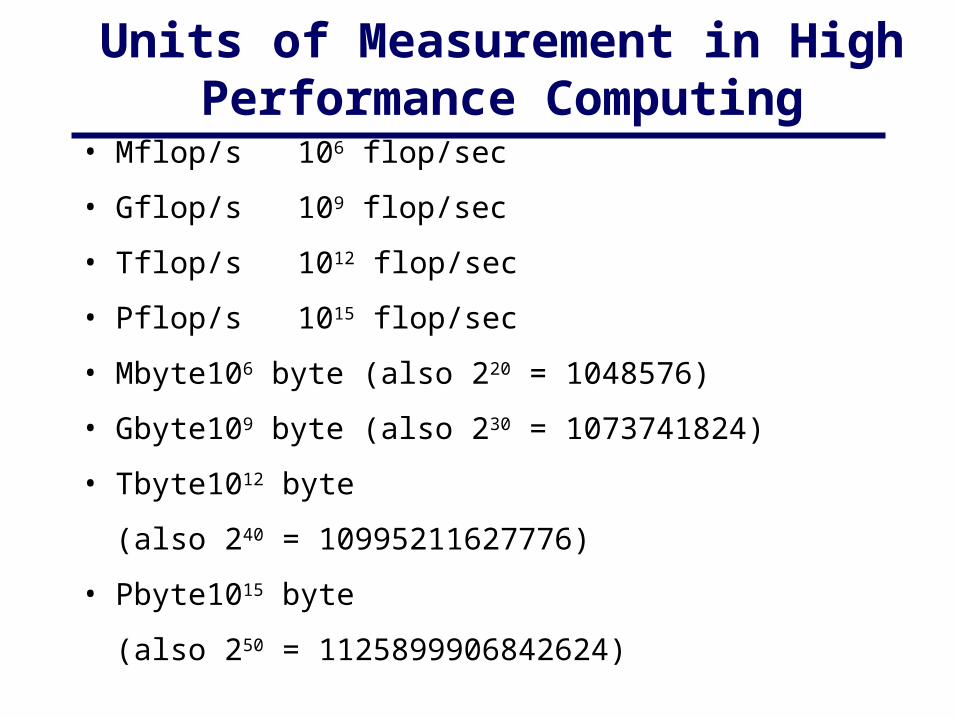
Units of Measurement in High Performance Computing
• Mflop/s 106 flop/sec
• Gflop/s 109 flop/sec
• Tflop/s 1012 flop/sec
• Pflop/s 1015 flop/sec
• Mbyte 106 byte (also 220 = 1048576)
• Gbyte 109 byte (also 230 = 1073741824)
• Tbyte 1012 byte
(also 240 = 10995211627776)
• Pbyte 1015 byte
(also 250 = 1125899906842624)

Why need powerful computers • Traditional scientific and engineering paradigm:
– Do theory or paper design.
– Perform experiments or build system.
• Limitations:– Too expensive -- build a throw-away passenger jet.– Too slow -- wait for climate or galactic evolution.– Too dangerous -- weapons, drug design, climate
experimentation.
• Computational science paradigm:– Use high performance computer systems to model the
phenomenon in detail, using known physical laws and efficient numerical methods.

Weather Forecasting
• Atmosphere modeled by dividing it into 3-dimensional cells.
• Calculations of each cell repeated many times to model passage of time.

Global Weather Forecasting Example
• Suppose whole global atmosphere divided into cells of size 1 mile 1 mile 1 mile to a height of 10 miles (10 cells high) - about 5 108 cells.
• Suppose each calculation requires 200 floating point operations. In one time step, 1011 floating point operations necessary.
• To forecast the weather over 7 days using 1-minute intervals, a computer operating at 1Gflops (109 floating point operations/s) takes 106 seconds or over 10 days.
• To perform calculation in 5 minutes requires computer operating at 3.4 Tflops (3.4 1012 floating point operations/sec).

Modeling Motion of Astronomical Bodies
• Each body attracted to each other body by gravitational forces. Movement of each body predicted by calculating total force on each body.
• With N bodies, N - 1 forces to calculate for each body, or approx.
N2 calculations. (N log2 N for an efficient approx. algorithm.)
• After determining new positions of bodies, calculations repeated.

• A galaxy might have, say, 1011 stars.
• Even if each calculation done in 1 ms (extremely optimistic figure), it takes 109 years for one iteration using N2 algorithm and almost a year for one iteration using an efficient N log2 N approximate algorithm.
Astrophysical N-body simulation by Scott Linssen (undergraduate UNC-Charlotte student).

Grand Challenge Problems
One that cannot be solved in a reasonable amount of time with today’s computers. Obviously, an execution time of 10 years is always unreasonable.
Examples
• Modeling large DNA structures
• Global weather forecasting
• Modeling motion of astronomical bodies.

More Grand Challenge Problems
• Crash simulation
• Earthquake and structural modeling
• Medical studies -- i.e. genome data analysis
• Web service and web search engines
• Financial and economic modeling
• Transaction processing
• Drug design -- i.e. protein folding
• Nuclear weapons -- test by simulations
How I used to make breakfast……….
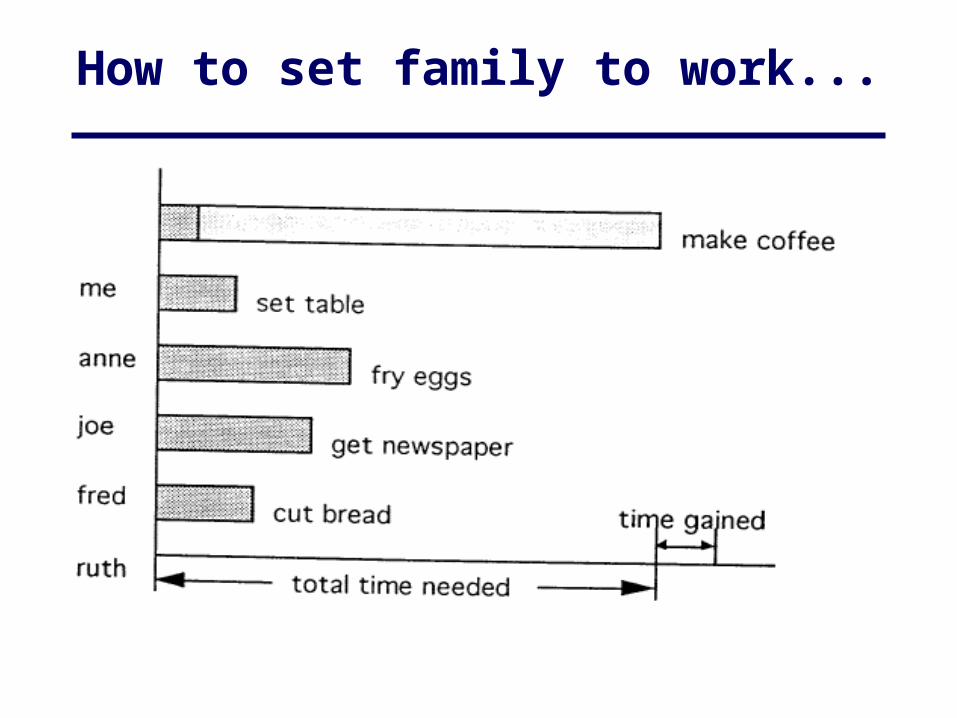
How to set family to work...
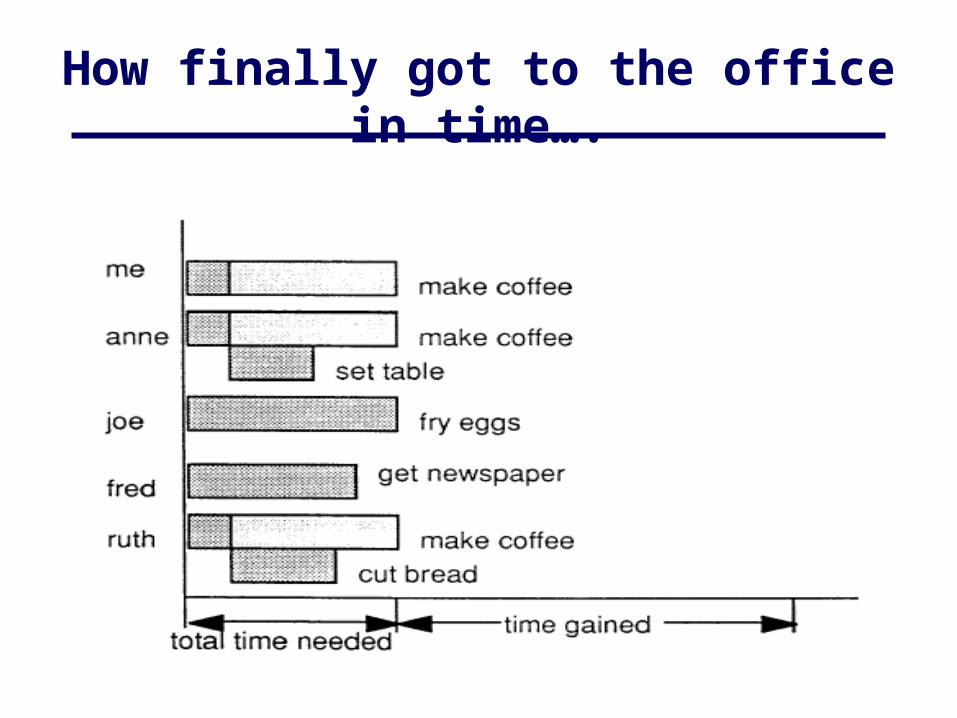
How finally got to the office in time….

Outline
• Motivation
• What is High Performance Computing?
• Parallel Computing
• Distributed Computing, Grid Computing, and More
• Future Trends in HPC

My Definitions
• HPC: any computational technique that solves a large problem faster than possible using single, commodity systems– Custom-designed, high-performance processors
(e.g. Cray, NEC)– Parallel computing– Distributed computing– Grid computing

My Definitions
• Parallel computing: single systems with many processors working on the same problem
• Distributed computing: many systems loosely coupled by a scheduler to work on related problems
• Grid computing: many systems tightly coupled by software and networks to work together on single problems or on related problems

Importance of HPC
• HPC has had tremendous impact on all areas of computational science and engineering in academia, government, and industry.
• Many problems have been solved with HPC techniques that were impossible to solve with individual workstations or personal computers.

The Economic Impact of High Performance Computing
• Airlines:– Large airlines recently implemented system-wide logistic optimization systems
on parallel computer systems.– Savings: approx. $100 million per airline per year.
• Automotive design:– Major automotive companies use large systems for CAD-CAM, crash testing,
structural integrity and aerodynamic simulation. One company has 500+ CPU parallel system.
– Savings: approx. $1 billion per company per year.
• Semiconductor industry:– Large semiconductor firms have recently acquired very large parallel computer
systems (500+ CPUs) for device electronics simulation and logic validation (ie prevent Pentium divide fiasco).
– Savings: approx. $1 billion per company per year.
• Securities industry:
– Savings: approx. $15 billion per year for U.S. home mortgages.

Outline
• Preface
• What is High Performance Computing?
• Parallel Computing
• Distributed Computing, Grid Computing, and More
• Future Trends in HPC

Parallel Computing
• Using more than one computer, or a computer with more than one processor, to solve a problem.
Motives• Usually faster computation - very simple idea - that n computers
operating simultaneously can achieve the result n times faster - it will not be n times faster for various reasons.
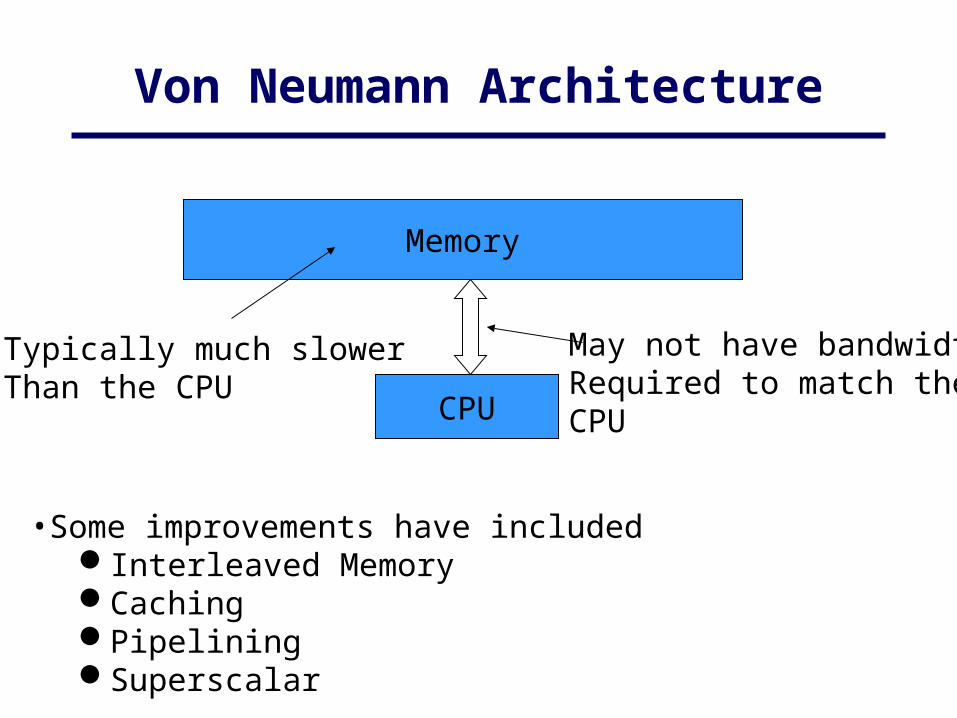
Von Neumann Architecture
CPU
Memory
Typically much slowerThan the CPU
May not have bandwidthRequired to match theCPU
•Some improvements have included
Interleaved MemoryCachingPipeliningSuperscalar
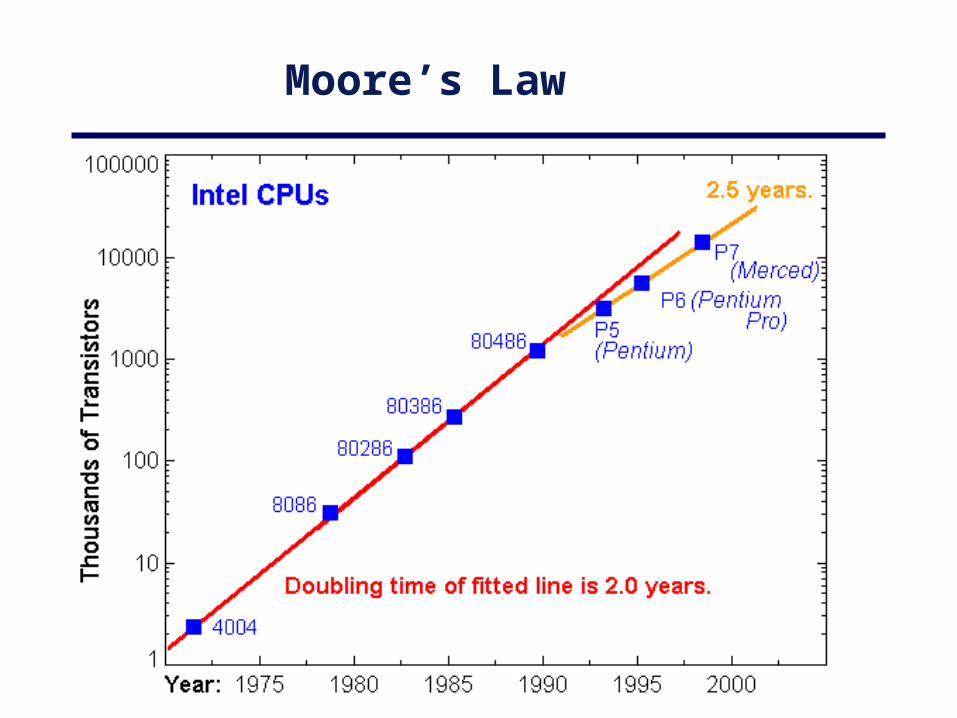
Moore’s Law
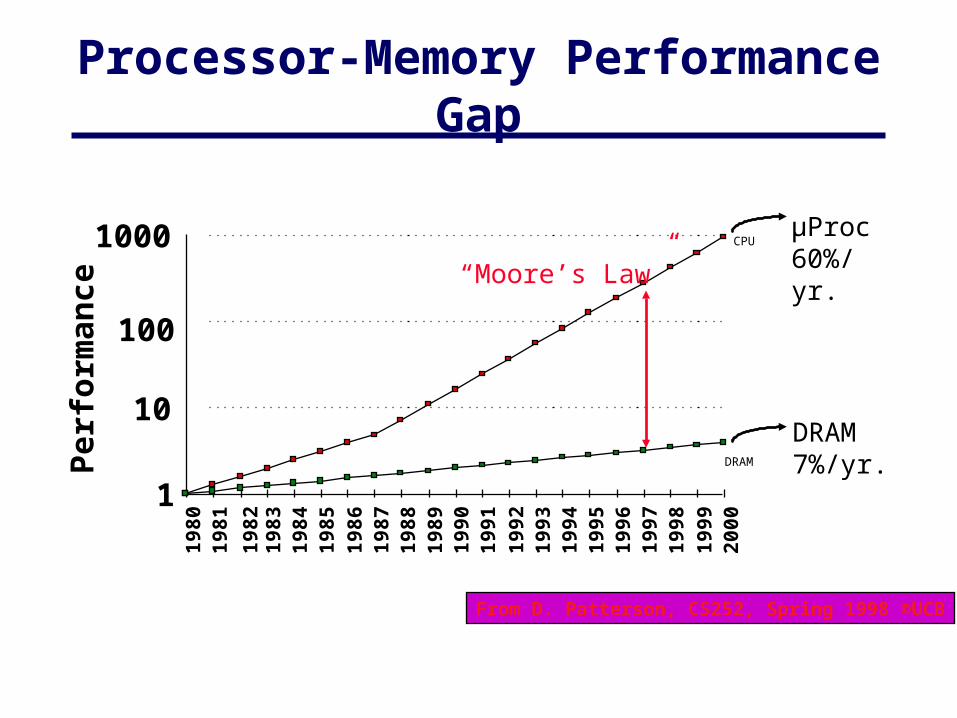
Processor-Memory Performance Gap
µProc60%/yr.
DRAM7%/yr.
1
10
100
1000
19
80
19
81
19
83
19
84
19
85
19
86
19
87
19
88
19
89
19
90
19
91
19
92
19
93
19
94
19
95
19
96
19
97
19
98
19
99
20
00
DRAM
CPU19
82
Per
form
ance
“ Moore’s Law”
From D. Patterson, CS252, Spring 1998 ©UCB

Parallel vs. Serial Computers
• Two big advantages of parallel computers:1. total performance
2. total memory
• Parallel computers enable us to solve problems that:– benefit from, or require, fast solution– require large amounts of memory– example that requires both: weather forecasting

Background
• Parallel computers - computers with more than one processor - and their programming - parallel
programming - has been around for more than 40 years.

Gill writes in 1958:
“... There is therefore nothing new in the idea of parallel programming, but its application to computers. The author cannot believe that there will be any insuperable difficulty in extending it to computers. It is not to be expected that the necessary programming techniques will be worked out overnight. Much experimenting remains to be done. After all, the techniques that are commonly used in programming today were only won at the cost of considerable toil several years ago. In fact the advent of parallel programming may do something to revive the pioneering spirit in programming which seems at the present to be degenerating into a rather dull and routine occupation ...”
Gill, S. (1958), “Parallel Programming,” The Computer Journal, vol. 1, April, pp. 2-10.
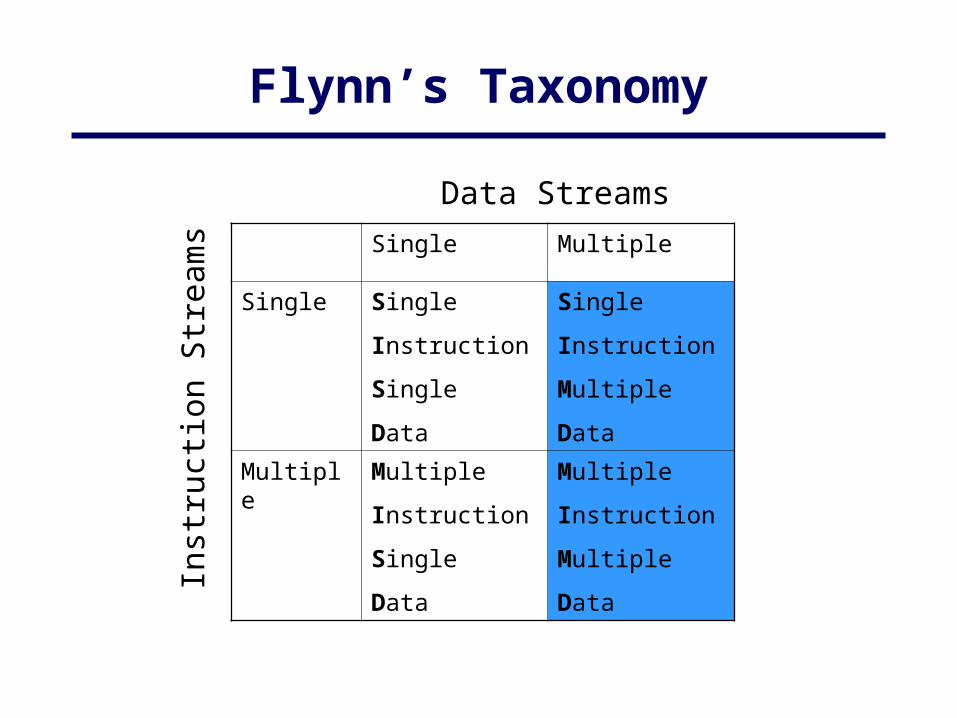
Flynn’s Taxonomy
Single Multiple
Single Single
Instruction
Single
Data
Single
Instruction
Multiple
Data
Multiple Multiple
Instruction
Single
Data
Multiple
Instruction
Multiple
Data
Data StreamsIn
stru
ctio
n S
trea
ms

Flynn’s Classifications
Flynn (1966) created a classification for computers based upon instruction streams and data streams:
– Single instruction stream-single data stream (SISD) computer
Single processor computer - single stream of instructions generated from program. Instructions operate upon a single stream of data items.

Single Instruction Stream-Multiple Data Stream (SIMD) Computer
• A specially designed computer - a single instruction stream from a single program, but multiple data streams exist. Instructions from program broadcast to more than one processor. Each processor executes same instruction in synchronism, but using different data.
• Developed because a number of important applications that mostly operate upon arrays of data.

Multiple Instruction Stream-Multiple Data Stream (MIMD) Computer
General-purpose multiprocessor system - each processor has a separate program and one instruction stream is generated from each program for each processor. Each instruction operates upon different data.
Both the shared memory and the message-passing multiprocessors so far described are in the MIMD classification.

Single Program Multiple Data (SPMD) Structure
Single source program written and each processor executes its personal copy of this program, although independently and not in synchronism.
Source program can be constructed so that parts of the program are executed by certain computers and not others depending upon the identity of the computer.
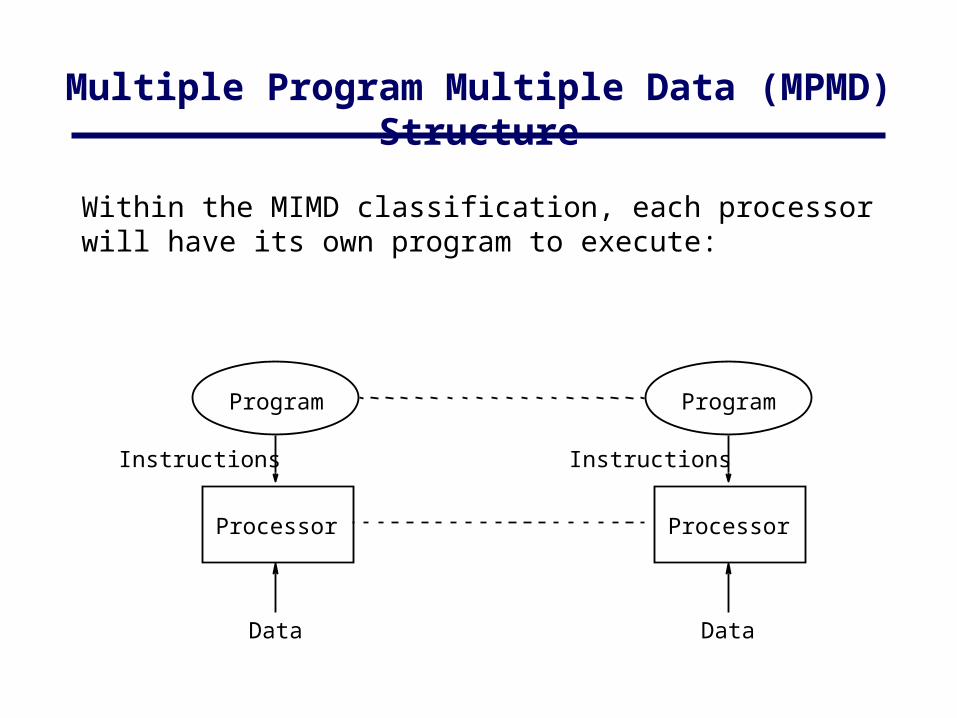
Multiple Program Multiple Data (MPMD) Structure
Within the MIMD classification, each processor will have its own program to execute:
Program
Processor
Data
Program
Processor
Data
InstructionsInstructions
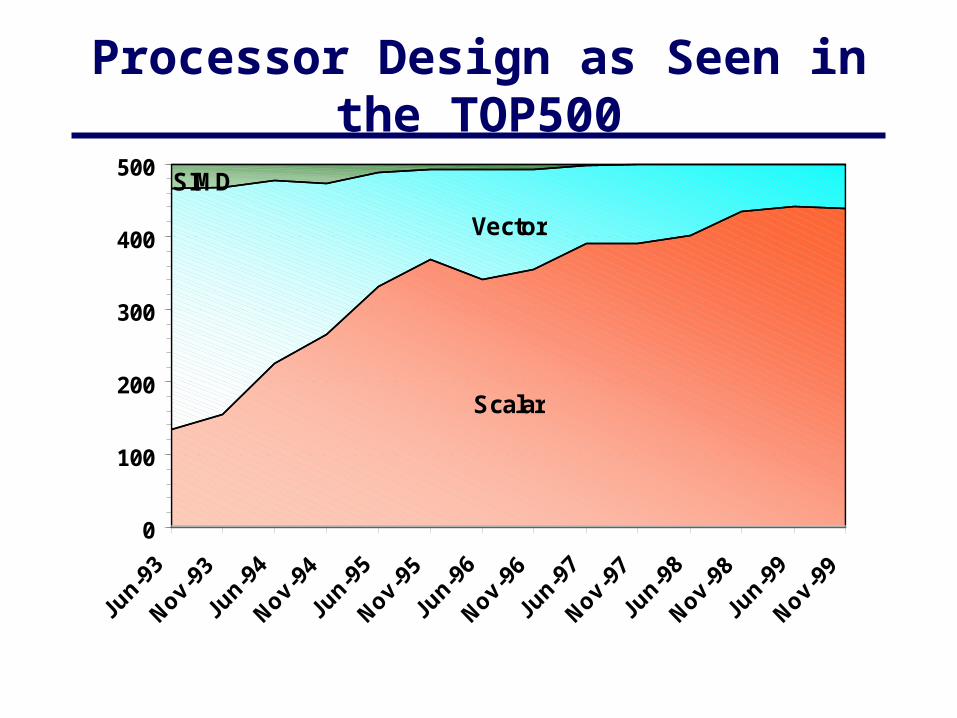
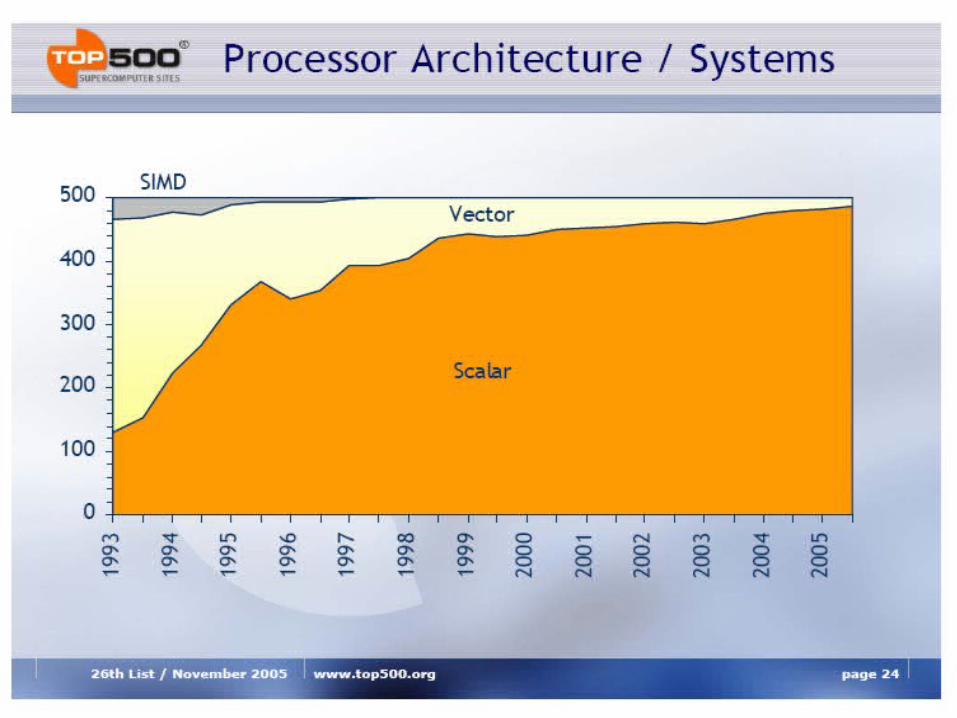
Processor Design as Seen in the TOP500
Scalar
Vector
SIMD
0
100
200
300
400
500
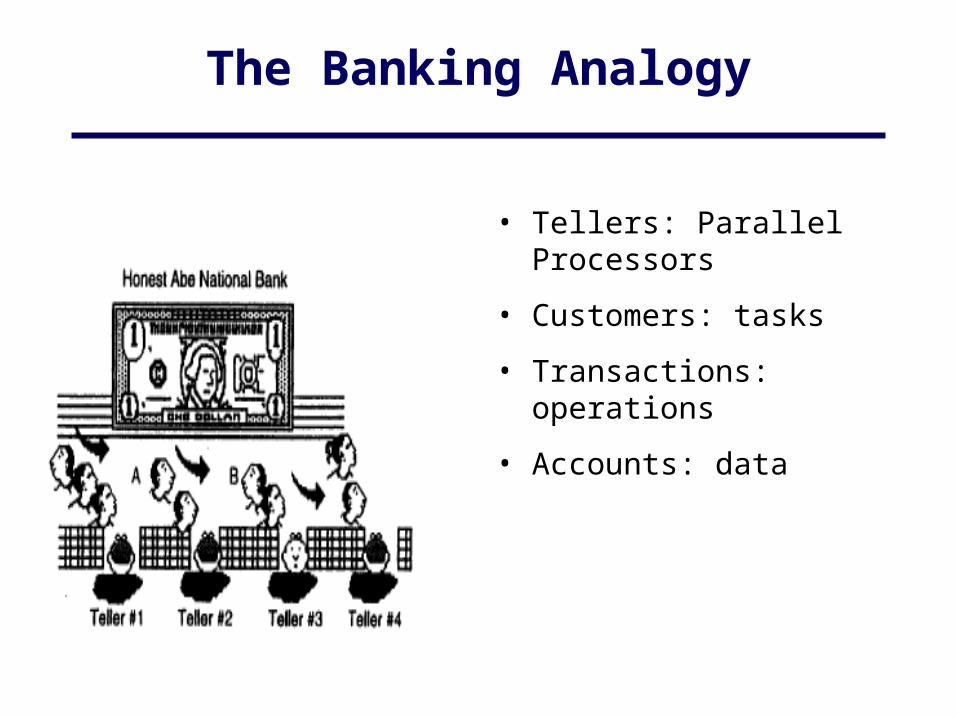
The Banking Analogy
• Tellers: Parallel Processors
• Customers: tasks
• Transactions: operations
• Accounts: data
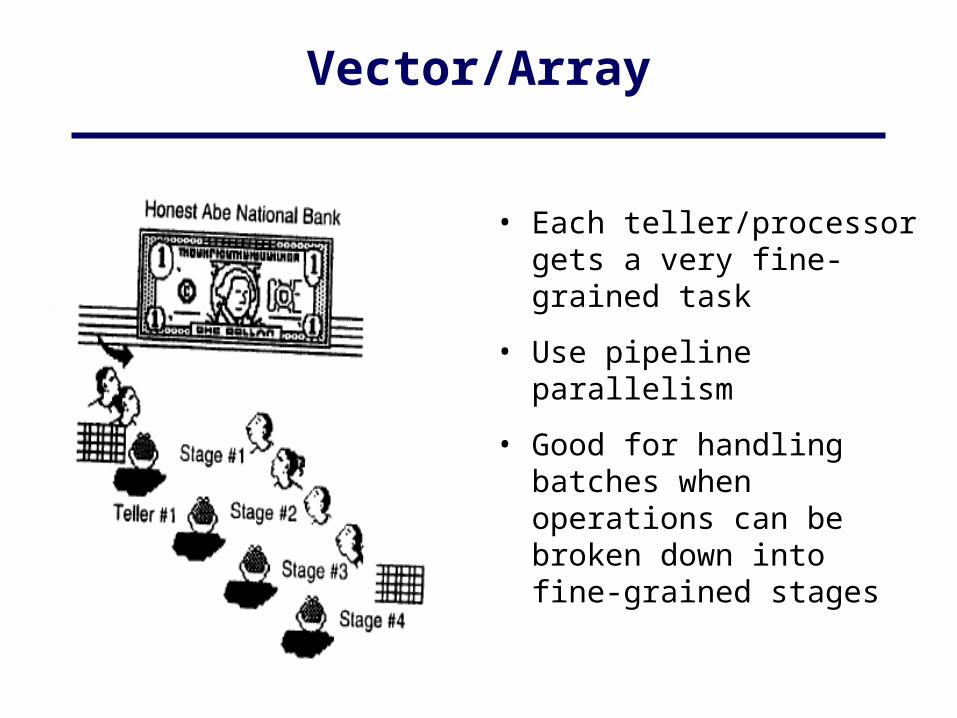
Vector/Array
• Each teller/processor gets a very fine-grained task
• Use pipeline parallelism
• Good for handling batches when operations can be broken down into fine-grained stages
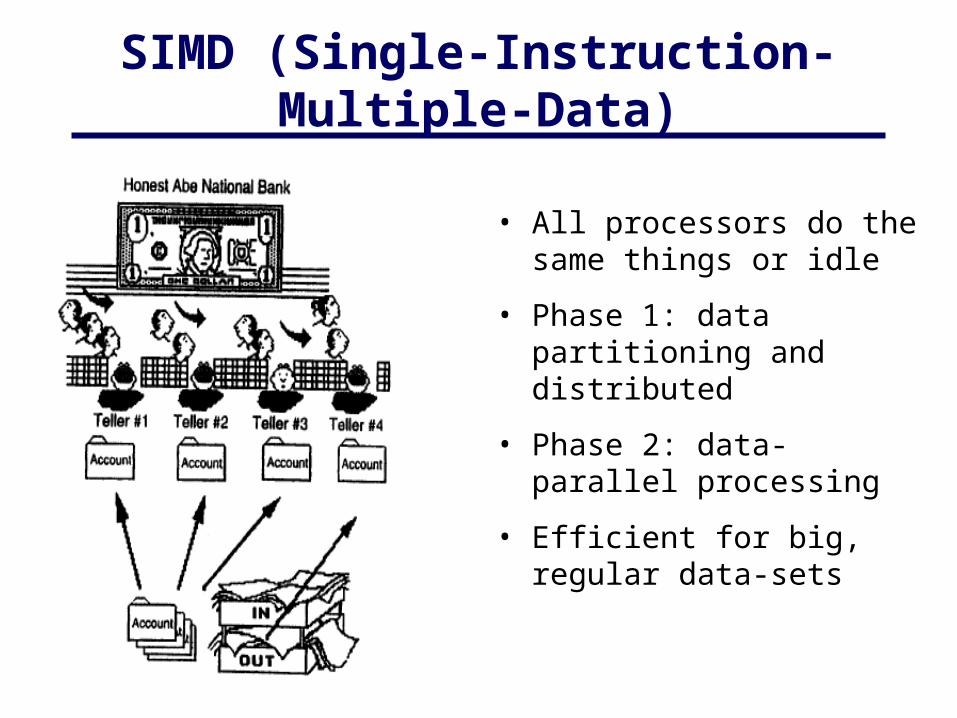
SIMD (Single-Instruction-Multiple-Data)
• All processors do the same things or idle
• Phase 1: data partitioning and distributed
• Phase 2: data-parallel processing
• Efficient for big, regular data-sets
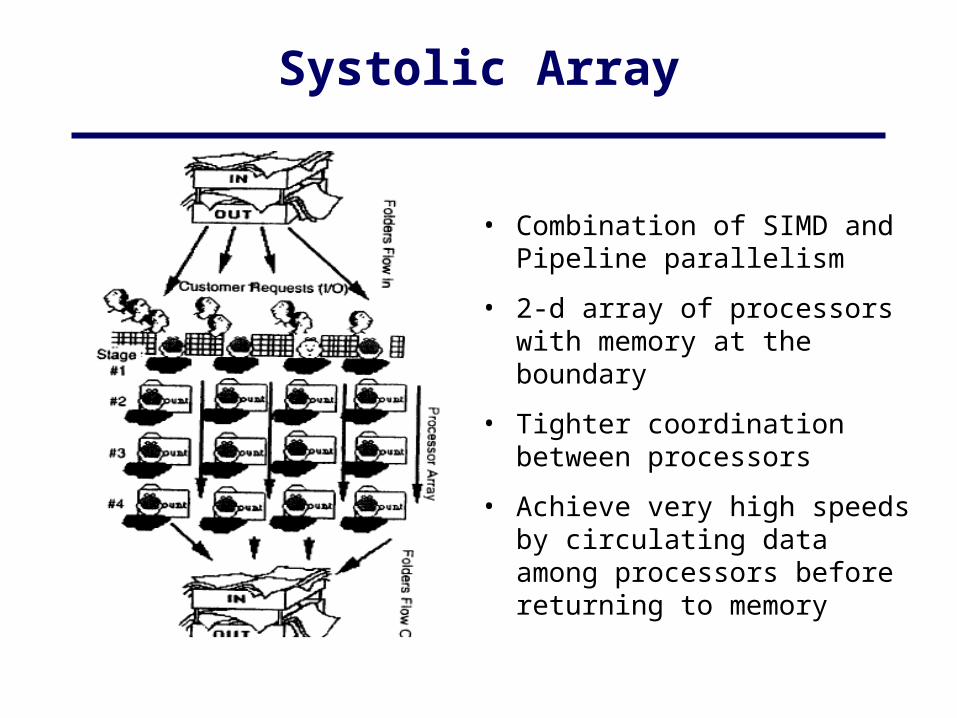
Systolic Array
• Combination of SIMD and Pipeline parallelism
• 2-d array of processors with memory at the boundary
• Tighter coordination between processors
• Achieve very high speeds by circulating data among processors before returning to memory
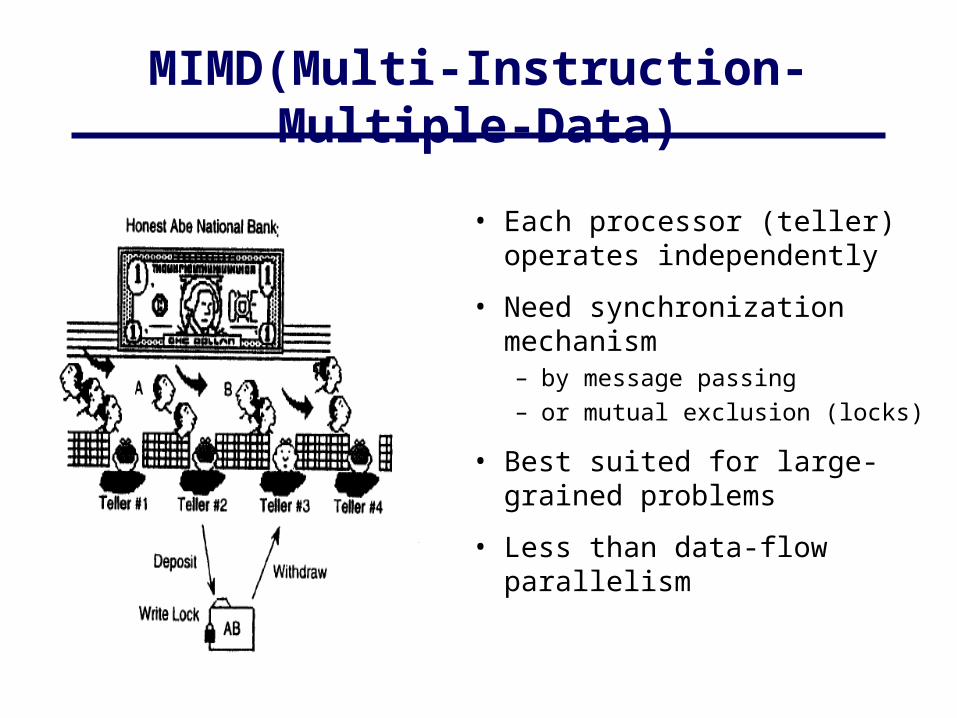
MIMD(Multi-Instruction-Multiple-Data)
• Each processor (teller) operates independently
• Need synchronization mechanism– by message passing– or mutual exclusion (locks)
• Best suited for large-grained problems
• Less than data-flow parallelism

Multiple Instruction Stream-Multiple Data Stream (MIMD) Computer
General-purpose multiprocessor system - each processor has a separate program and one instruction stream is generated from each program for each processor. Each instruction operates upon different data.
Both the shared memory and the message-passing multiprocessors so far described are in the MIMD classification.
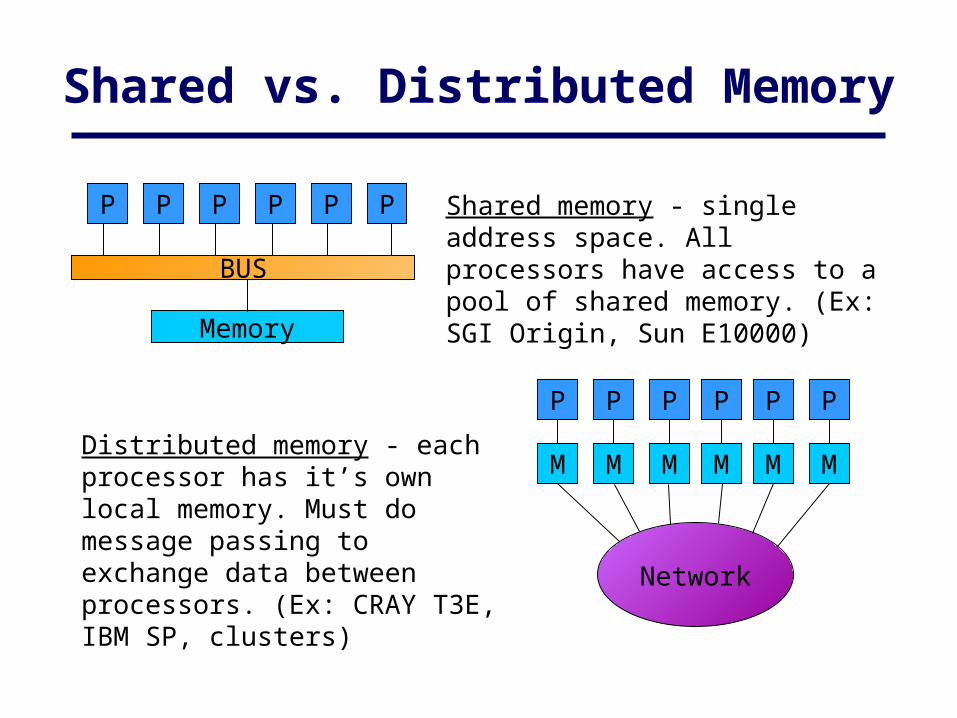
P P P P P P
BUS
Memory
M
P
M
P
M
P
M
P
M
P
M
P
Network
Shared memory - single address space. All processors have access to a pool of shared memory. (Ex: SGI Origin, Sun E10000)
Distributed memory - each processor has it’s own local memory. Must do message passing to exchange data between processors. (Ex: CRAY T3E, IBM SP, clusters)
Shared vs. Distributed Memory
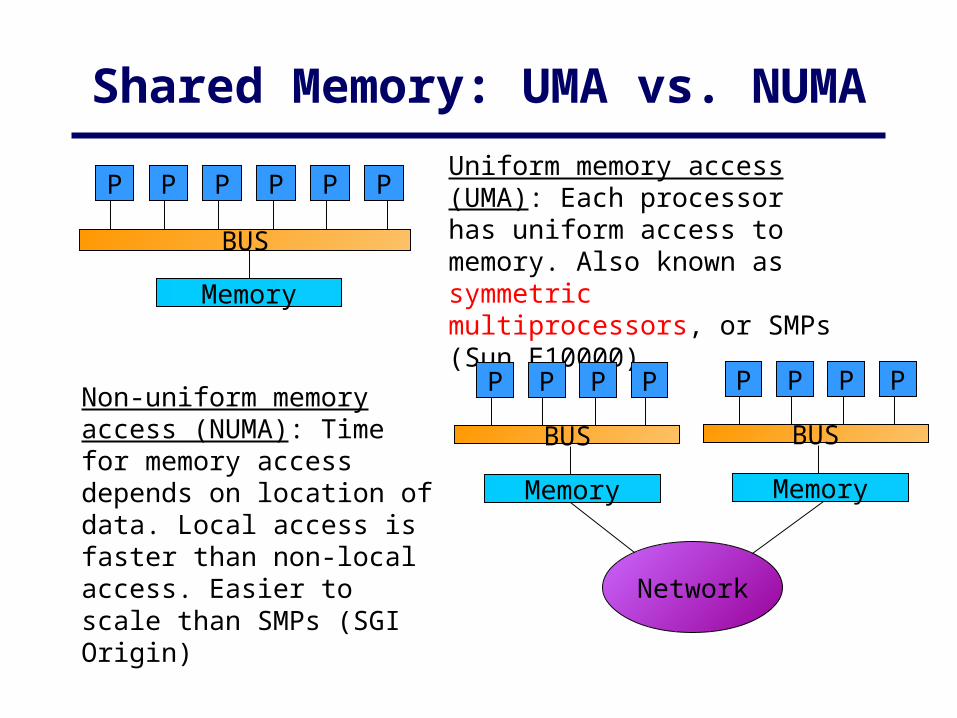
P P P P P P
BUS
Memory
Uniform memory access (UMA): Each processor has uniform access to memory. Also known as symmetric multiprocessors, or SMPs (Sun E10000)
P P P P
BUS
Memory
P P P P
BUS
Memory
Network
Non-uniform memory access (NUMA): Time for memory access depends on location of data. Local access is faster than non-local access. Easier to scale than SMPs (SGI Origin)
Shared Memory: UMA vs. NUMA
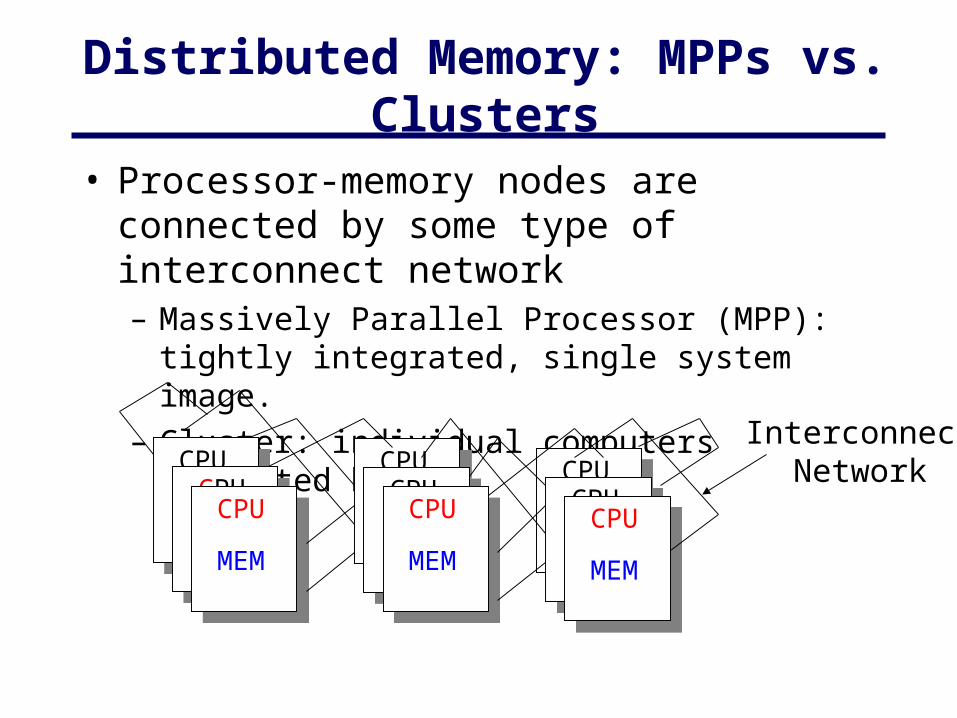
Distributed Memory: MPPs vs. Clusters
• Processor-memory nodes are connected by some type of interconnect network– Massively Parallel Processor (MPP): tightly
integrated, single system image.– Cluster: individual computers connected by s/w
CPU
MEM
CPU
MEM CPU
MEM
CPU
MEM
CPU
MEM
CPU
MEM CPU
MEM
CPU
MEM CPU
MEM
CPU
MEM
CPU
MEM
CPU
MEM
CPU
MEM
CPU
MEM CPU
MEM
CPU
MEM CPU
MEM
CPU
MEM
InterconnectNetwork

Massively Parallel Processors
• Each processor has it’s own memory:– memory is not shared globally– adds another layer to memory hierarchy (remote
memory)
• Processor/memory nodes are connected by interconnect network– many possible topologies– processors must pass data via messages– communication overhead must be minimized

Communications Networks
• Custom– Many vendors have custom interconnects that
provide high performance for their MPP system– CRAY T3E interconnect is the fastest for MPPs:
lowest latency, highest bandwidth
• Commodity– Used in some MPPs and all clusters– Myrinet, Gigabit Ethernet, Fast Ethernet, etc.

Types of Interconnects
• Fully connected– not feasible
• Array and torus– Intel Paragon (2D array), CRAY T3E (3D torus)
• Crossbar– IBM SP (8 nodes)
• Hypercube– SGI Origin 2000 (hypercube), Meiko CS-2 (fat tree)
• Combinations of some of the above– IBM SP (crossbar & fully connected for 80 nodes)– IBM SP (fat tree for > 80 nodes)

Interconnection Networks
• Limited and exhaustive interconnections
• 2- and 3-dimensional meshes
• Hypercube (not now common)
• Using Switches:– Crossbar– Trees– Multistage interconnection networks
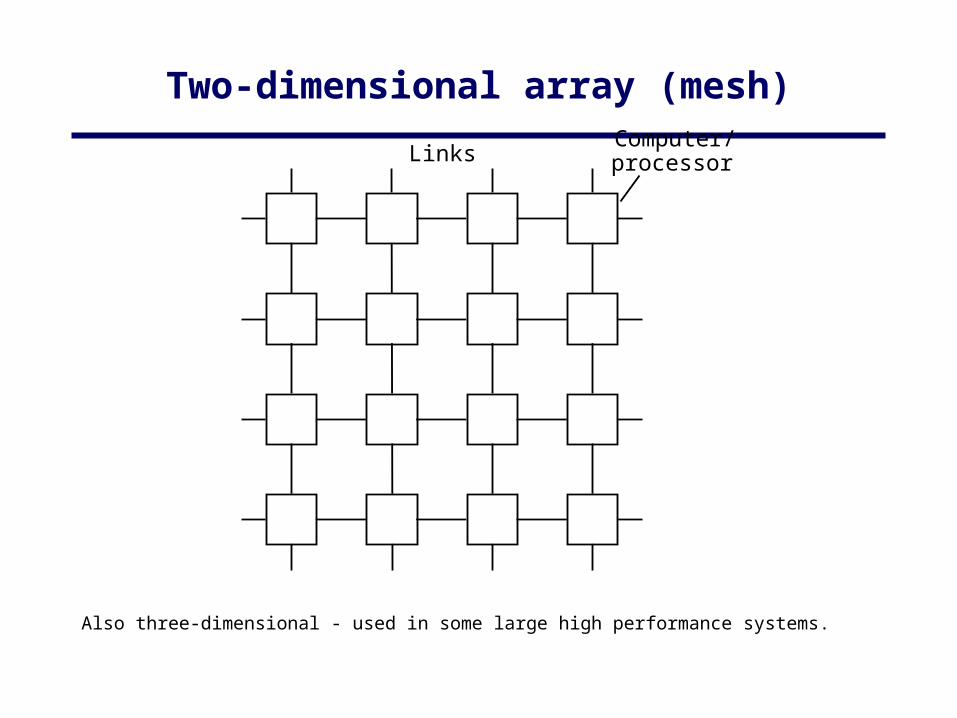
Two-dimensional array (mesh)
Also three-dimensional - used in some large high performance systems.
LinksComputer/processor
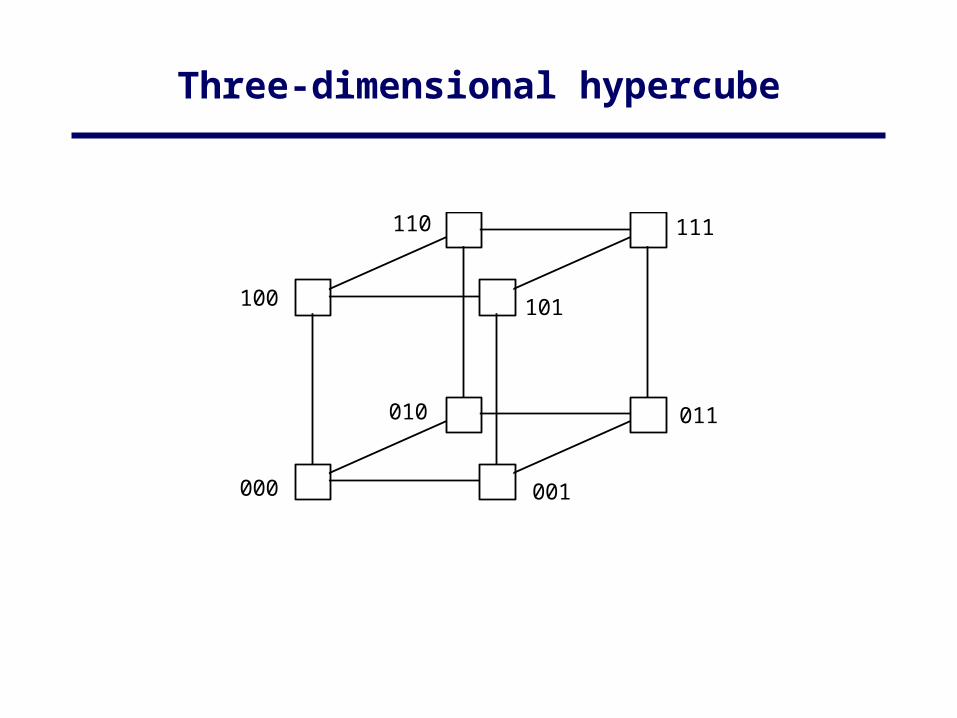
Three-dimensional hypercube
000 001
010 011
100
110
101
111
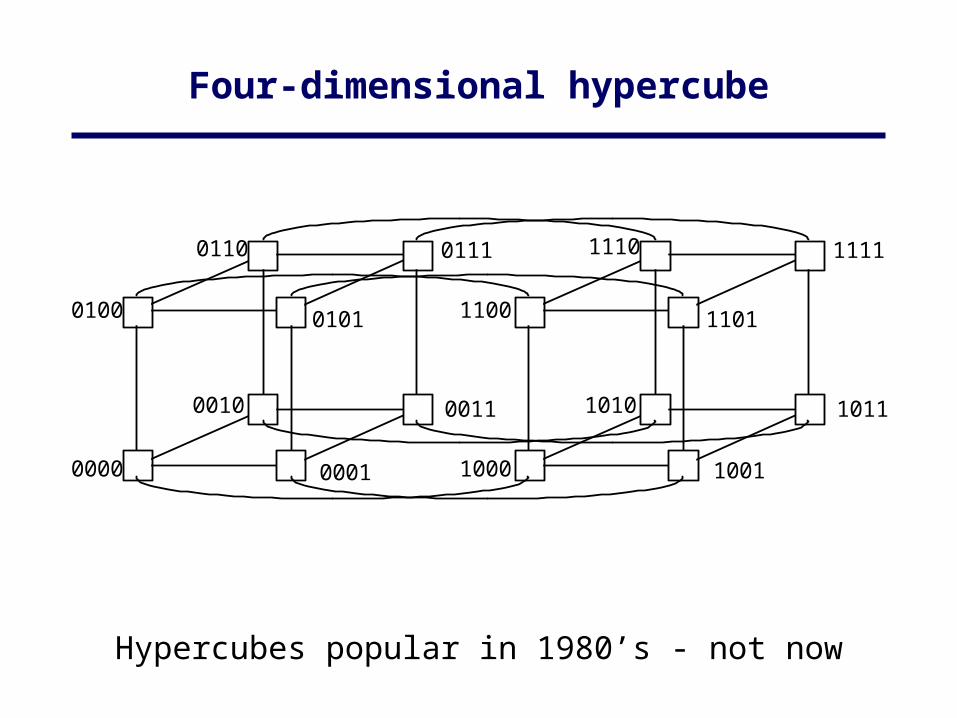
Four-dimensional hypercube
Hypercubes popular in 1980’s - not now
0000 0001
0010 0011
0100
0110
0101
0111
1000 1001
1010 1011
1100
1110
1101
1111
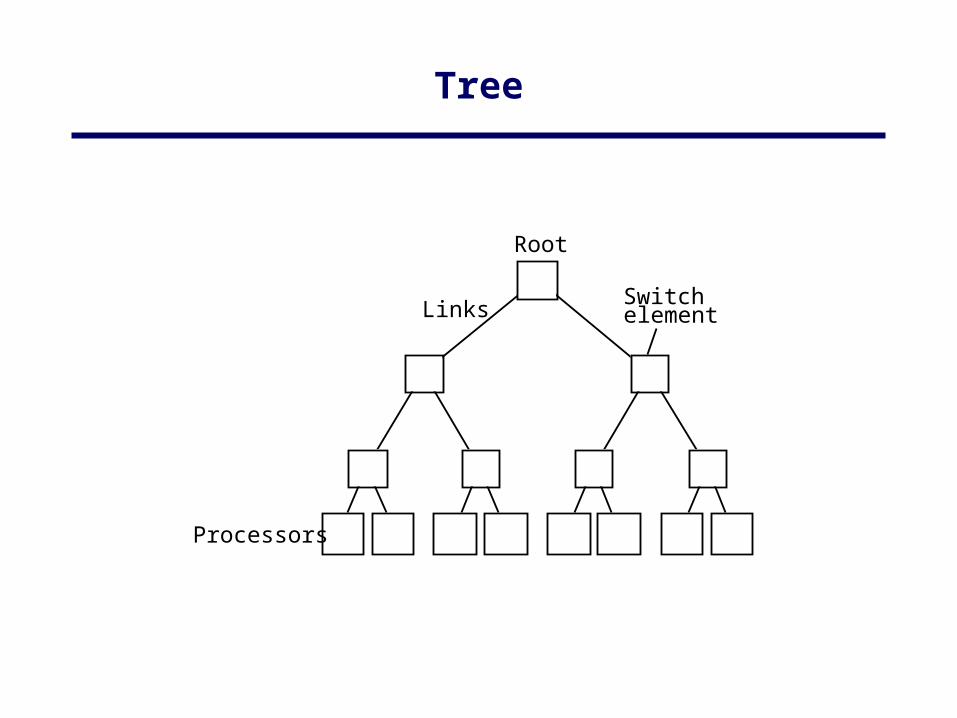
Tree
Switchelement
Root
Links
Processors
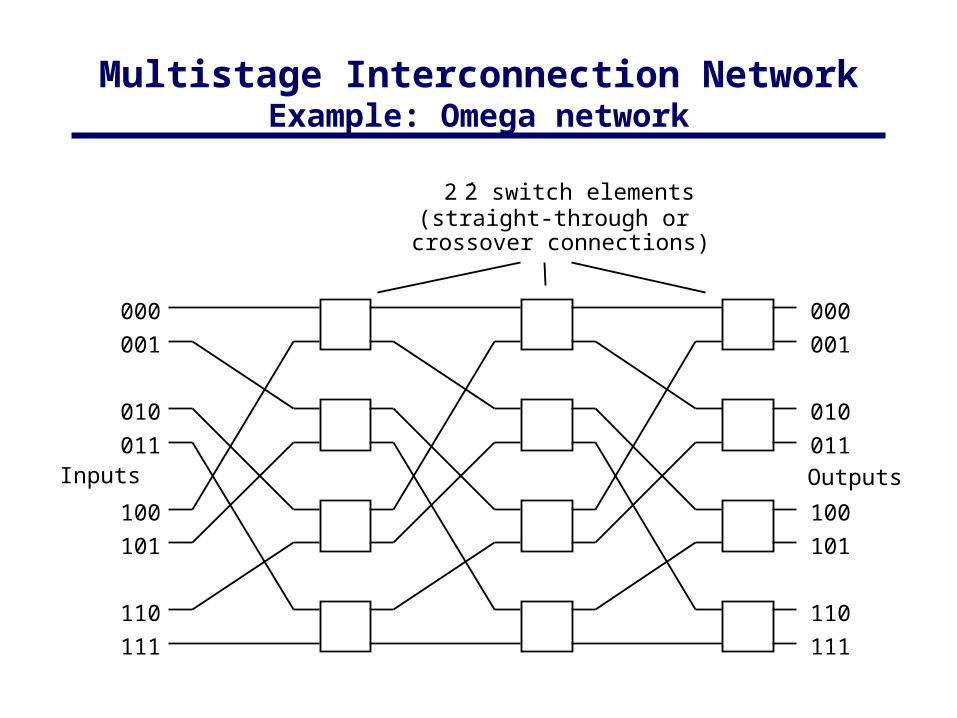
Multistage Interconnection NetworkExample: Omega network
000
001
010
011
100
101
110
111
000
001
010
011
100
101
110
111
Inputs Outputs
2 ´ 2 switch elements(straight-through or
crossover connections)

Clusters
• Similar to MPPs– Commodity processors and memory
• Processor performance must be maximized
– Memory hierarchy includes remote memory– No shared memory--message passing
• Communication overhead must be minimized
• Different from MPPs– All commodity, including interconnect and OS– Multiple independent systems: more robust– Separate I/O systems

Outline
• Preface
• What is High Performance Computing?
• Parallel Computing
• Distributed Computing, Grid Computing, and More
• Future Trends in HPC

Distributed vs. Parallel Computing
• Different– Distributed computing executes independent (but
possibly related) applications on different systems; jobs do not communicate with each other
– Parallel computing executes a single application across processors, distributing the work and/or data but allowing communication between processes
• Non-exclusive: can distribute parallel applications to parallel computing systems

SETI@home: Global Distributed Computing
• Running on 500,000 PCs, ~1000 CPU Years per Day– 485,821 CPU Years so far
• Sophisticated Data & Signal Processing Analysis
• Distributes Datasets from Arecibo Radio Telescope

Grid Computing
• Enable communities (“virtual organizations”) to share geographically distributed resources as they pursue common goals—in the absence of central control, omniscience, trust relationships.
• Resources (HPC systems, visualization systems & displays, storage systems, sensors, instruments, people) are integrated via ‘middleware’ to facilitate use of all resources.

Why Grids?
• Resources have different functions, but multiple classes resources are necessary for most interesting problems.
• Power of any single resource is small compared to aggregations of resources
• Network connectivity is increasing rapidly in bandwidth and availability
• Large problems require teamwork and computation
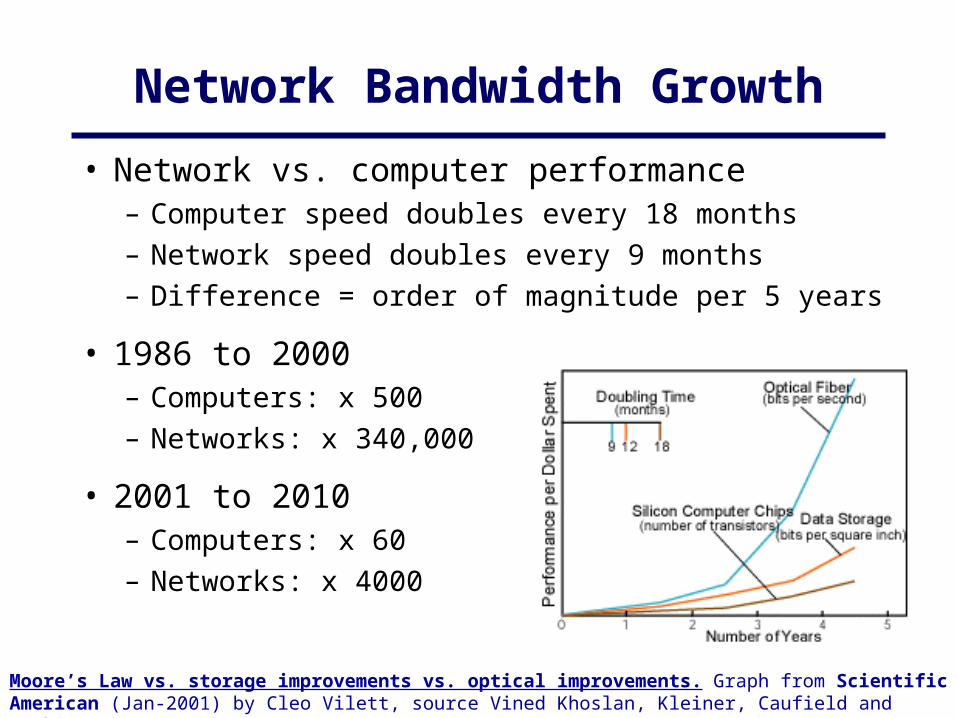
Network Bandwidth Growth
• Network vs. computer performance– Computer speed doubles every 18 months– Network speed doubles every 9 months– Difference = order of magnitude per 5 years
• 1986 to 2000– Computers: x 500– Networks: x 340,000
• 2001 to 2010– Computers: x 60– Networks: x 4000
Moore’s Law vs. storage improvements vs. optical improvements. Graph from Scientific American (Jan-2001) by Cleo Vilett, source Vined Khoslan, Kleiner, Caufield and Perkins.

Grid Possibilities
• A biochemist exploits 10,000 computers to screen 100,000 compounds in an hour
• 1,000 physicists worldwide pool resources for petaflop analyses of petabytes of data
• Civil engineers collaborate to design, execute, & analyze shake table experiments
• Climate scientists visualize, annotate, & analyze terabyte simulation datasets
• An emergency response team couples real time data, weather model, population data
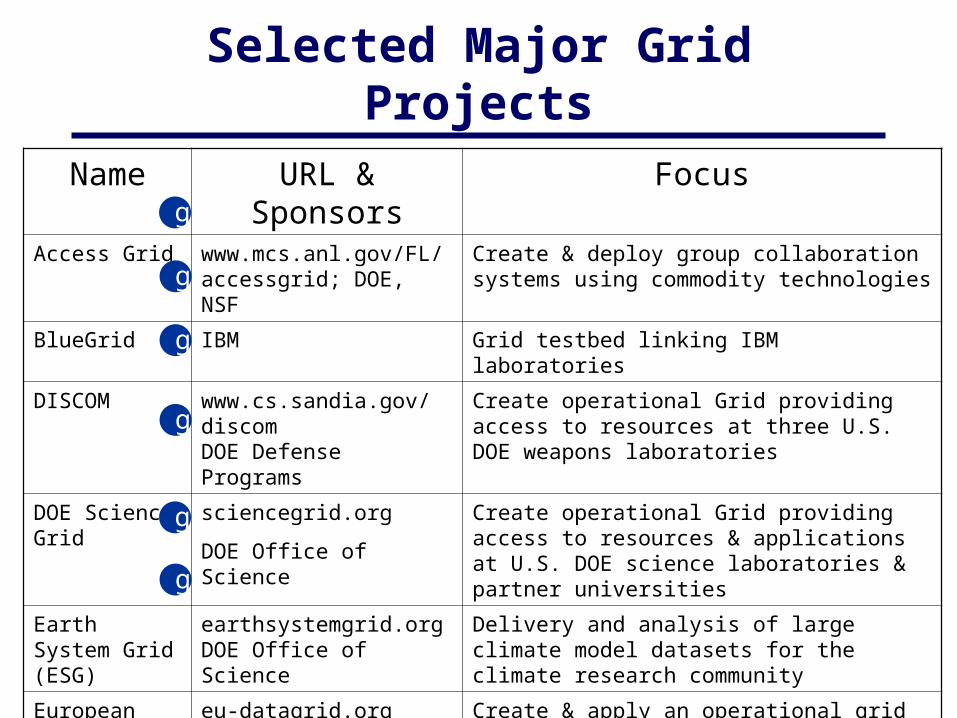
Selected Major Grid Projects
Name URL & Sponsors FocusAccess Grid www.mcs.anl.gov/FL/
accessgrid; DOE, NSFCreate & deploy group collaboration systems using commodity technologies
BlueGrid IBM Grid testbed linking IBM laboratories
DISCOM www.cs.sandia.gov/discomDOE Defense Programs
Create operational Grid providing access to resources at three U.S. DOE weapons laboratories
DOE Science Grid
sciencegrid.org
DOE Office of Science
Create operational Grid providing access to resources & applications at U.S. DOE science laboratories & partner universities
Earth System Grid (ESG)
earthsystemgrid.orgDOE Office of Science
Delivery and analysis of large climate model datasets for the climate research community
European Union (EU) DataGrid
eu-datagrid.org
European Union
Create & apply an operational grid for applications in high energy physics, environmental science, bioinformatics
g
g
g
g
g
g
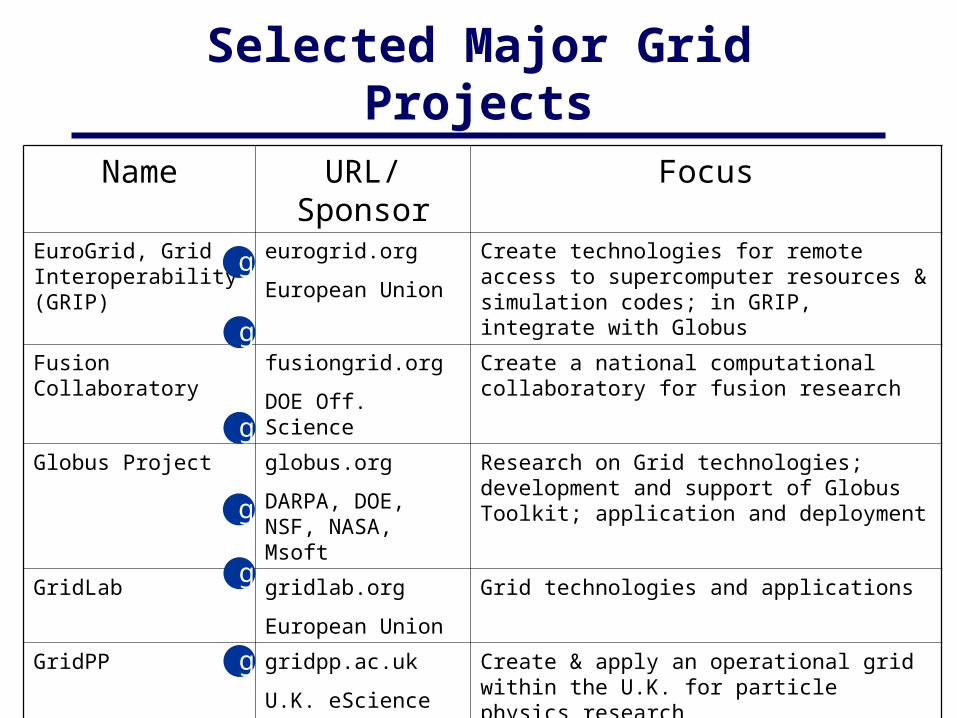
Selected Major Grid Projects
Name URL/Sponsor FocusEuroGrid, Grid Interoperability (GRIP)
eurogrid.org
European Union
Create technologies for remote access to supercomputer resources & simulation codes; in GRIP, integrate with Globus
Fusion Collaboratory fusiongrid.org
DOE Off. Science
Create a national computational collaboratory for fusion research
Globus Project globus.org
DARPA, DOE, NSF, NASA, Msoft
Research on Grid technologies; development and support of Globus Toolkit; application and deployment
GridLab gridlab.org
European Union
Grid technologies and applications
GridPP gridpp.ac.uk
U.K. eScience
Create & apply an operational grid within the U.K. for particle physics research
Grid Research Integration Dev. & Support Center
grids-center.org
NSF
Integration, deployment, support of the NSF Middleware Infrastructure for research & education
g
g
g
g
g
g
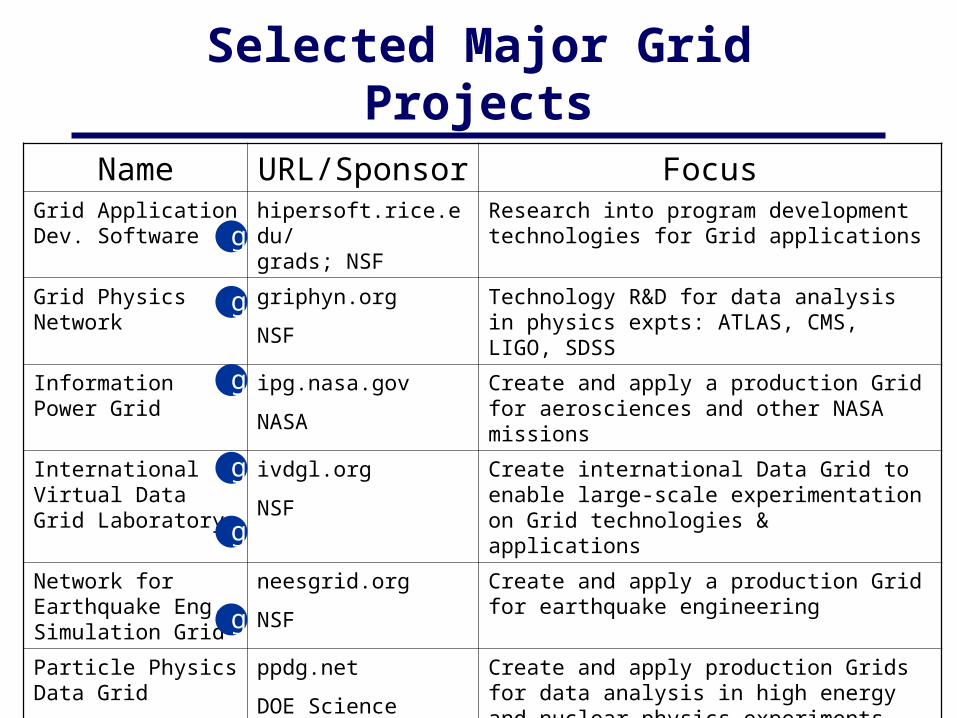
Selected Major Grid Projects
Name URL/Sponsor FocusGrid Application Dev. Software
hipersoft.rice.edu/grads; NSF
Research into program development technologies for Grid applications
Grid Physics Network griphyn.org
NSF
Technology R&D for data analysis in physics expts: ATLAS, CMS, LIGO, SDSS
Information Power Grid
ipg.nasa.gov
NASA
Create and apply a production Grid for aerosciences and other NASA missions
International Virtual Data Grid Laboratory
ivdgl.org
NSF
Create international Data Grid to enable large-scale experimentation on Grid technologies & applications
Network for Earthquake Eng. Simulation Grid
neesgrid.org
NSF
Create and apply a production Grid for earthquake engineering
Particle Physics Data Grid
ppdg.net
DOE Science
Create and apply production Grids for data analysis in high energy and nuclear physics experiments
g
g
g
g
g
g

Selected Major Grid Projects
Name URL/Sponsor FocusTeraGrid teragrid.org
NSF
U.S. science infrastructure linking four major resource sites at 40 Gb/s
UK Grid Support Center
grid-support.ac.uk
U.K. eScience
Support center for Grid projects within the U.K.
Unicore BMBFT Technologies for remote access to supercomputers
g
g
New
There are also many technology R&D projects: e.g., Globus, Condor, NetSolve, Ninf, NWS, etc.

Example Application Projects
• Earth Systems Grid: environment (US DOE)
• EU DataGrid: physics, environment, etc. (EU)
• EuroGrid: various (EU)
• Fusion Collaboratory (US DOE)
• GridLab: astrophysics, etc. (EU)
• Grid Physics Network (US NSF)
• MetaNEOS: numerical optimization (US NSF)
• NEESgrid: civil engineering (US NSF)
• Particle Physics Data Grid (US DOE)

Outline
• Preface
• What is High Performance Computing?
• Parallel Computing
• Distributed Computing, Grid Computing, and More
• Future Trends in HPC

TOP500 List
• Published twice a year with the 500 most powerful supercomputers in actual use
• Ranked according to LINPACK R_max
• Data available since 1993
• For details see http://www.top500.org/
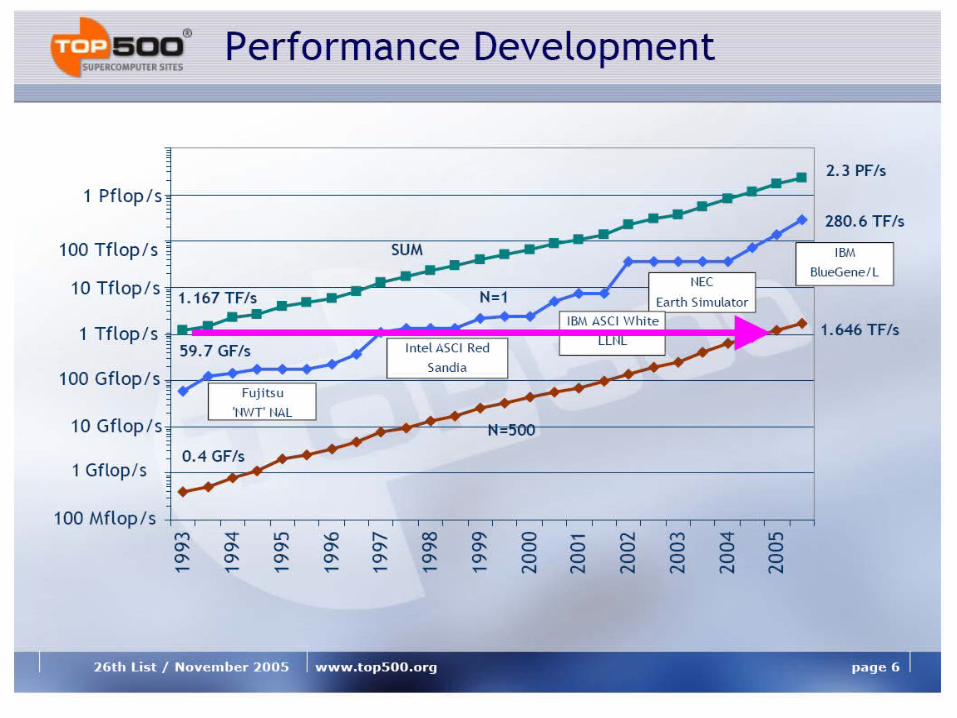
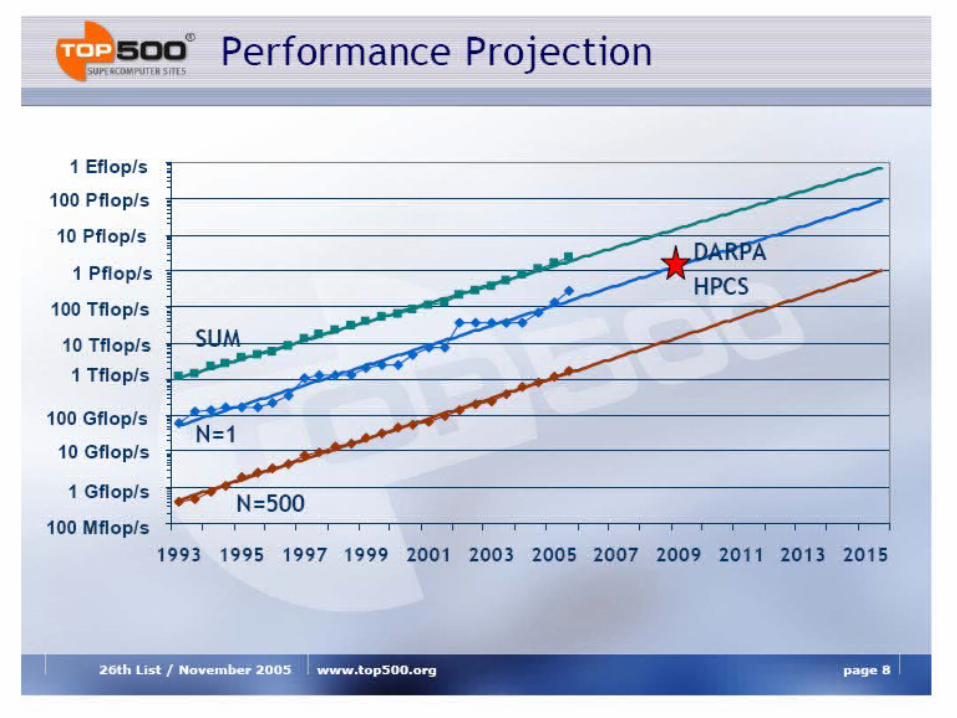
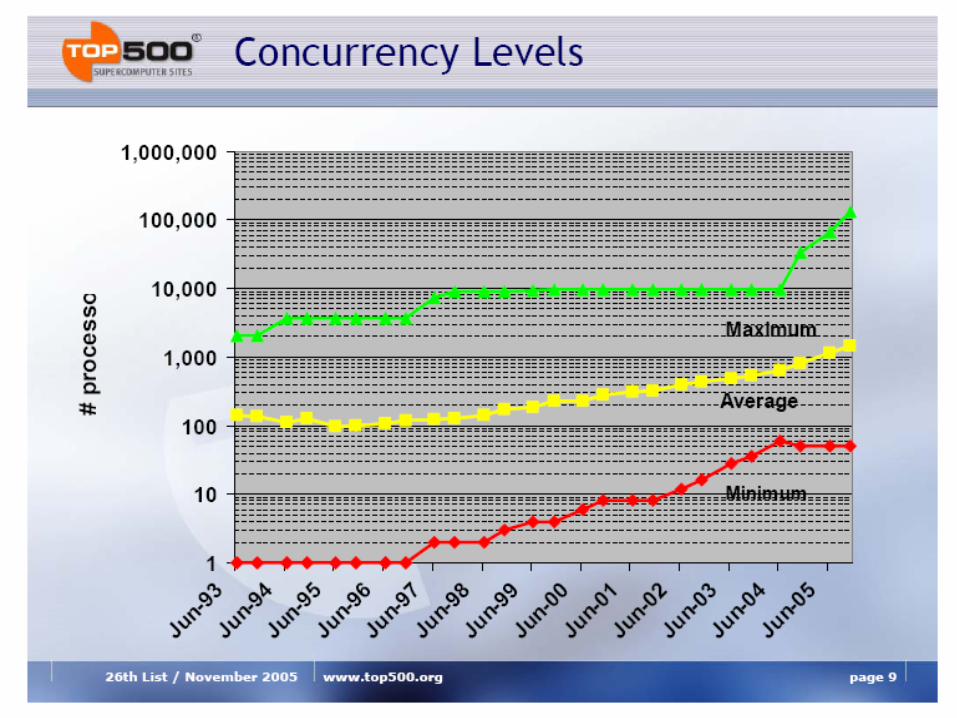
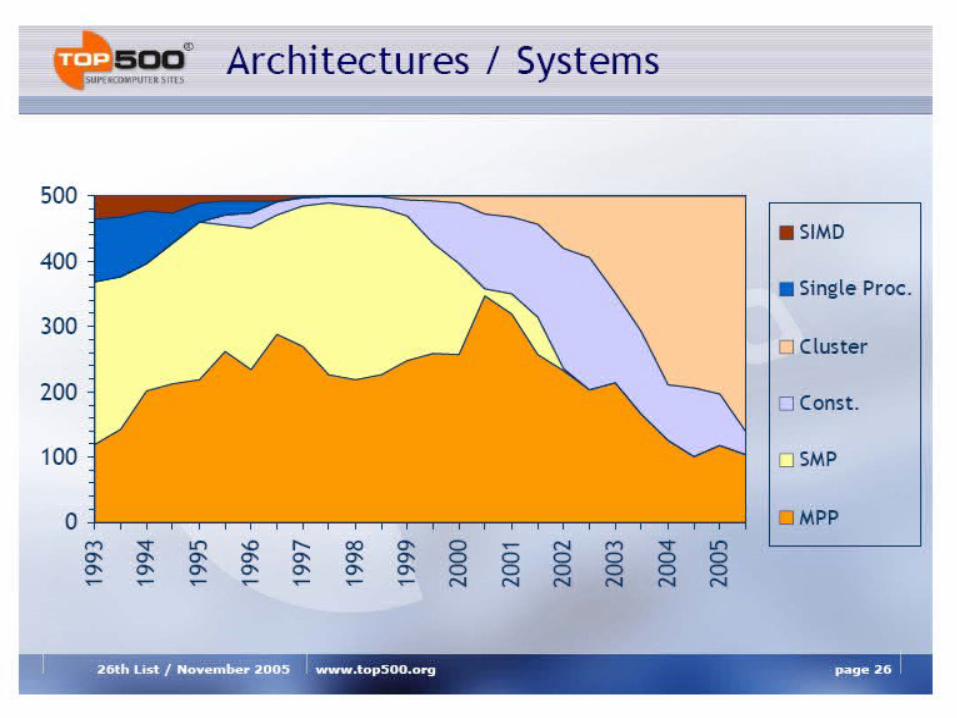
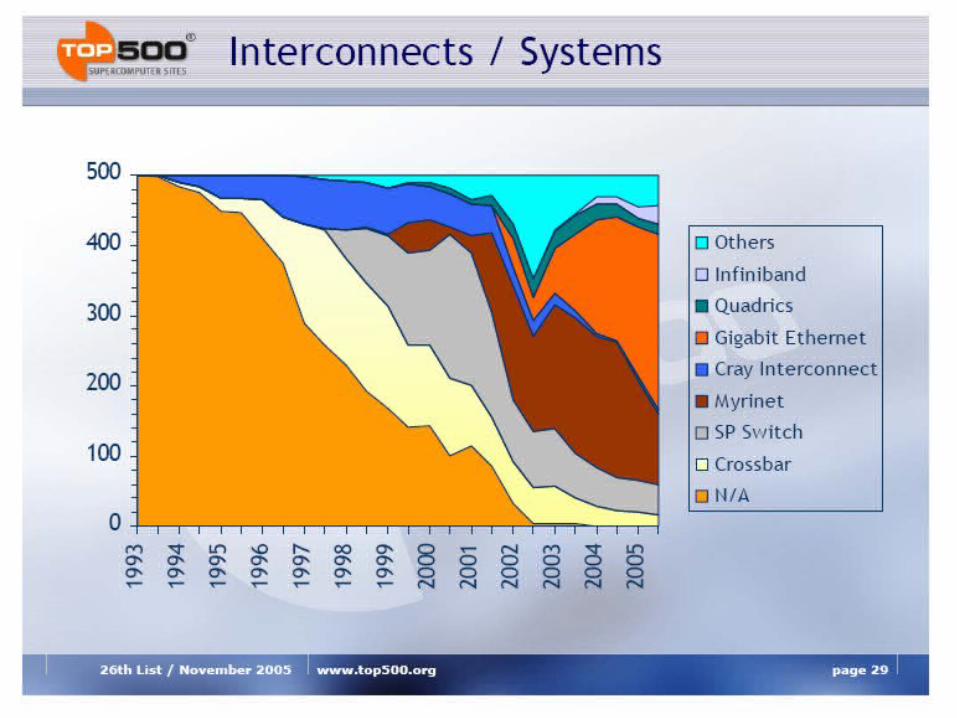
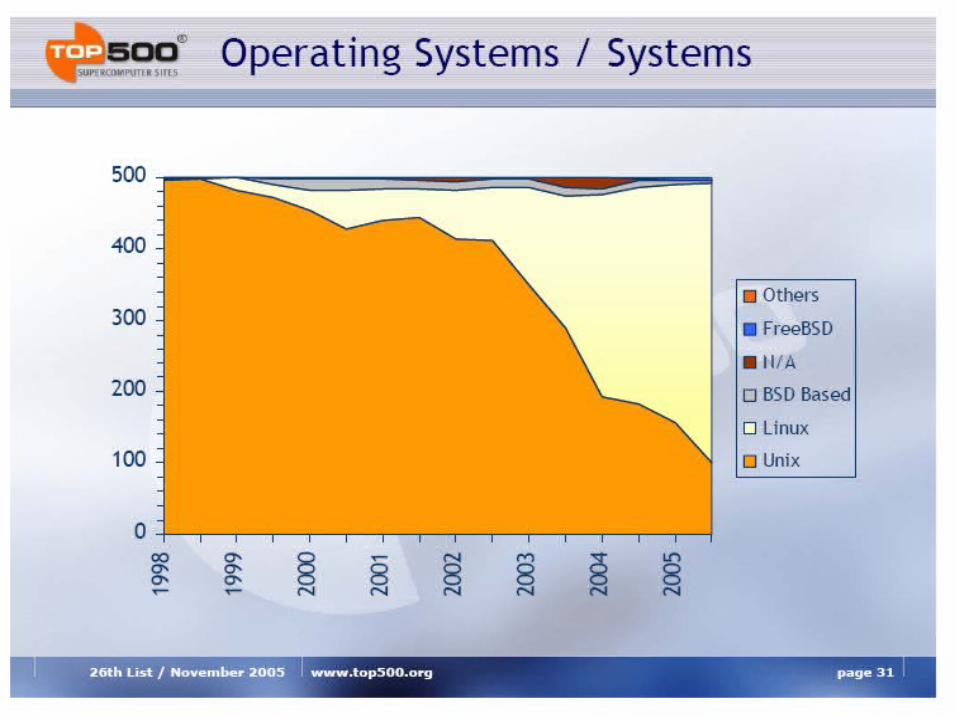
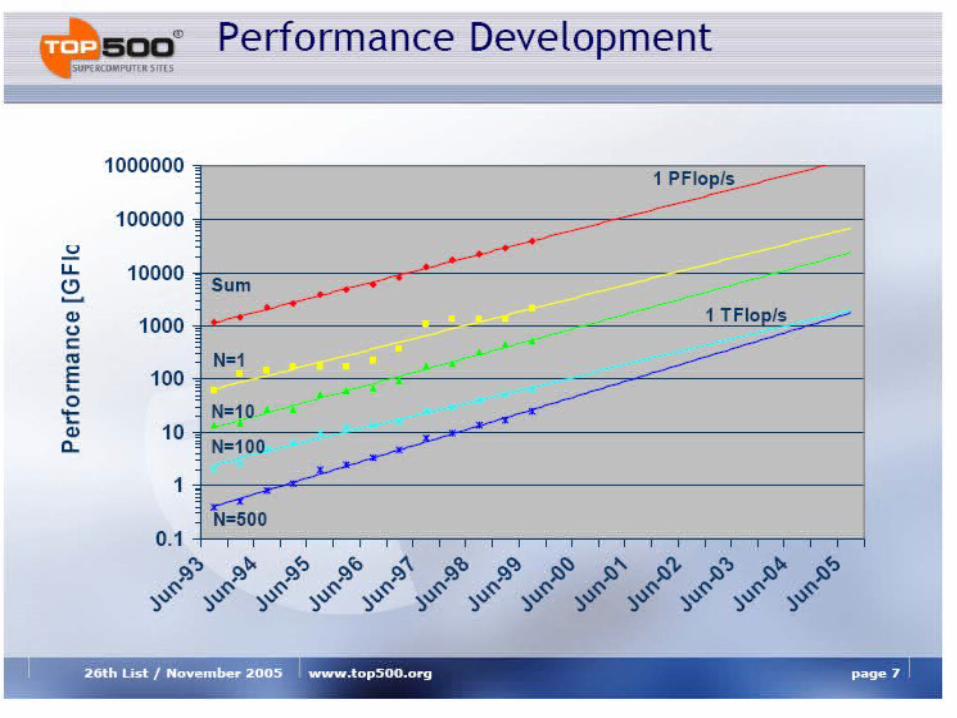

Analysis of TOP500 Extrapolation
• First 100~TFlop/s system by 2005
• About 1--2 years later than the ASCI path forward plans.
• No system smaller then 1~TFlop/s should be able to make the Top500
• First Petaflop system available around 2009
• Rapid changes in the technologies used in HPC systems, therefore a projection for the architecture or technology is difficult.

2000 - 2005: Technology Options
• Clusters– SMP nodes, with custom interconnet– PCs, with commodity interconnect– vector nodes (in Japan)
• Custom built supercomputers– Cray SV-2– IBM Blue Gene– HTMT
• Other technology to influence HPC– IRAM/PIM– Computational and Data Grids

Continued Linux Growth in HPC
• Linux popularity growing due to price and availability of source code
• Major players now supporting Linux, esp. IBM
• Head start on Intel Itanium

Grid Computing
• Parallelism will continue to grow in the form of– SMPs– clusters– Cluster of SMPs (and maybe DSMs)
• Grids provide the next level– connects multiple computers into virtual systems– Already here:
• IBM, other vendors supporting Globus• SC2001 dominated by Grid technologies• Many major government awards (>$100M in past year)

Emergence of Grids
• But Grids enable much more than apps running on multiple computers (which can be achieved with MPI alone)– virtual operating system: provides global
workspace/address space via a single login– automatically manages files, data, accounts, and
security issues– connects other resources (archival data facilities,
instruments, devices) and people (collaborative environments)

Grids Are Inevitable
• Inevitable (at least in HPC):– leverages computational power of all available
systems– manages resources as a single system--easier for
users– provides most flexible resource selection and
management, load sharing– researchers’ desire to solve bigger problems will
always outpace performance increases of single systems; just as multiple processors are needed, ‘multiple multiprocessors’ will be deemed so

Programming Tools
• However, programming tools will continue to lag behind hardware and OS capabilities:– Researchers will continue to drive the need for the
most powerful tools to create the most efficient applications on the largest systems
– Such technologies will look more like MPI than the Web… maybe worse due to multi-tiered clusters of SMPs (MPI + OpenMP; Active messages + threads?).
– Academia will continue to play a large role in HPC software development.

Grid-Enabled Software
• Commercial applications on single parallel systems and Grids will require that:– underlying architectures must be invisible: no
parallel computing expertise required– usage must be simple– development must not be to difficult
• Developments in ease-of-use will benefit scientists as users (not as developers)
• Web-based interfaces: transparent supercomputing (MPIRE, Meta-MEME, etc.).

Grid-Enabled Collaborative andVisual Supercomputing
• Commercial world demands:– multimedia applications– real-time data processing– online transaction processing– rapid prototyping and simulation in engineering,
chemistry and biology– interactive, remote collaboration– 3D graphics, animation and virtual reality
visualization

Grid-enabled Collaborative, Visual Supercomputing
• Academic world will leverage resulting Grids linking computing and visualization systems via high-speed networks:– collaborative post-processing of data already here– simulations will be visualized in 3D, virtual worlds
in real-time– such simulations can then be ‘steered’– multiple scientists can participate in these visual
simulations– the ‘time to insight’ (SGI slogan) will be reduced

Web-based Grid Computing
• Web currently used mostly for content delivery
• Web servers on HPC systems can execute applications
• Web servers on Grids can launch applications, move/store/retrieve data, display visualizations, etc.
• NPACI HotPage already enables single sign-on to NPACI Grid Resources

Summary of Expectations
• HPC systems will grow in performance but probably change little in design (5-10 years):– HPC systems will be larger versions of smaller
commercial systems, mostly large SMPs and clusters of inexpensive nodes
– Some processors will exploit vectors, as well as more/larger caches.
– Best HPC systems will have been designed ‘top-down’ instead of ‘bottom-up’, but all will have been designed to make the ‘bottom’ profitable.
– Multithreading is the only likely, near-term major architectural change.

Summary of Expectations
• Using HPC systems will change much more:– Grid computing will become widespread in HPC
and in commercial computing– Visual supercomputing and collaborative
simulation will be commonplace.– WWW interfaces to HPC resources will make
transparent supercomputing commonplace.
• But programming the most powerful resources most effectively will remain difficult.

















![GrADSolve - a Grid-based RPC system for Parallel Computing ...€¦ · NetSolve [9] is a Grid computing system developed at University of Tennessee. It is a Remote Procedure Call](https://img.pdfslide.us/doc/110x75/601910e1330bc560b964c905/gradsolve-a-grid-based-rpc-system-for-parallel-computing-netsolve-9-is-a.jpg)











