Embed Size (px)
Citation preview

INTRODUCTION TO ARTIFICIAL INTELLIGENCE
Massimo Poesio
Unsupervised and Semi-Supervised Relation Extraction

NON-SUPERVISED METHODS FOR RELATION EXTRACTION
• Unsupervised relation extraction:– Hearst – Other work on extracting hyponymy relations– Extracting other relations: Almuhareb and Poesio, Cimiano and
Wenderoth• Semi-supervised methods
– KNOW-IT-ALL

HEARST 1992, 1998: USING PATTERNS TO EXTRACT ISA LINKS
• Intuition: certain constructions typically used to express certain types of semantic relations
• E.g., for ISA:– The seabass IS A fish– Swimming, running AND OTHER activities– Vehicles such as cars, trucks and bikes

TEXT PATTERNS FOR HYPONYMY EXTRACTION
HEARST 1998: NP {, NP}* {,} or other NPbruises …… broken bones, and other INJURIESHYPONYM (bruise, injury)
EVALUATION: 55.46% precision wrt WordNet

THE PRECISION / RECALL TRADEOFF
• X and other Y: high precision, low recall• X isa Y: low precision, high recall

HEARST’ REQUIREMENTS ON PATTERNS

OTHER WORK ON EXTRACTING HYPONYMY
• Caraballo ACL 1999• Widdows & Dorow 2002• Pantel & Ravichandran ACL 2004
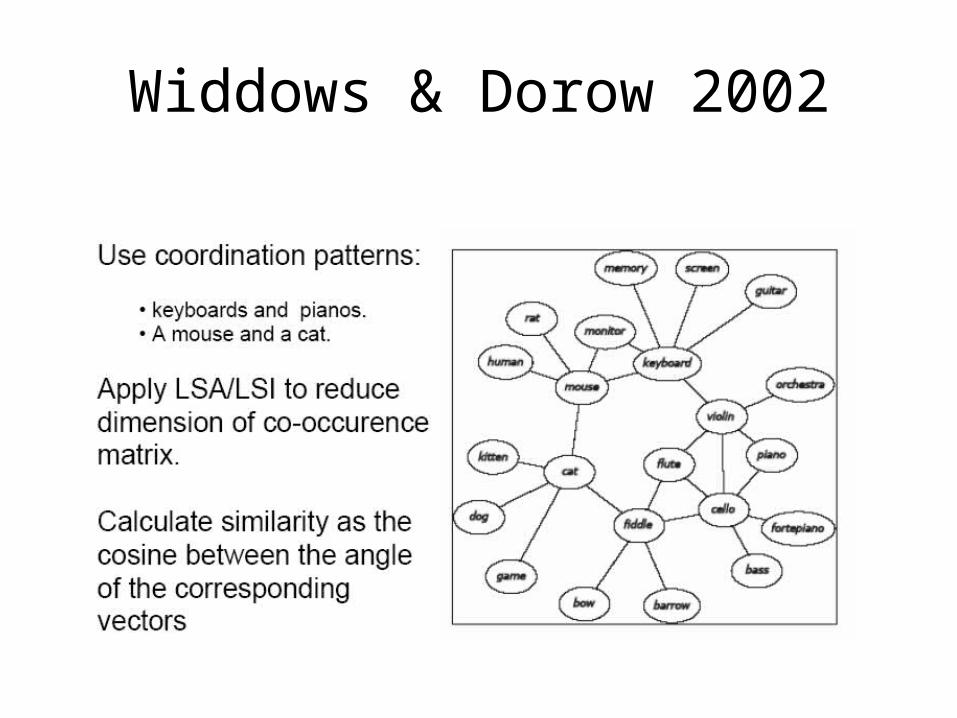
Widdows & Dorow 2002

Text patterns for (other) relation extraction
• Intuition: Hearst’s ideas can apply to other types of relations as well
• Some proposals:– Almuhareb & Poesio 2004 (attributes and values)– Cimiano et al 2005 (Pustejovsky qualia)

USING PATTERNS TO EXTRACT ATTRIBUTES AND VALUES
Woods (1975): “A is an attribute [feature] of C if we can say V is a/the A of C” ATTRIBUTE Pattern:
“the * of the C [is|was]” … the price of the car was …
To increase the precision of the patterns, we put some restrictions (is and was), to make sure that C stands for a concept..
VALUE pattern: “[a|an|the] * C [is|was]”
… an expensive car is … Both patterns are low precision, high recall: some filtering is needed
WEIGHTING in this work

EXTRACTING ATTRIBUTES AND VALUES, (2)
Web an increasingly popular `corpus’ (Grefenstette, 1999; Keller and Lapata, 2003) Its size outweighs other problems (lack of balance, etc.)
(Almuhareb and Poesio 2004): use the Google API to extract from the Web information about concepts using text patterns Our search requests to Google take the general form “s1 * s2”
(including the double quotes). We get frequencies of occurrence of a pattern; these
frequencies are then weighed using the t-test We also tried MI, 2 and log-likelihood (Dunning 1993)
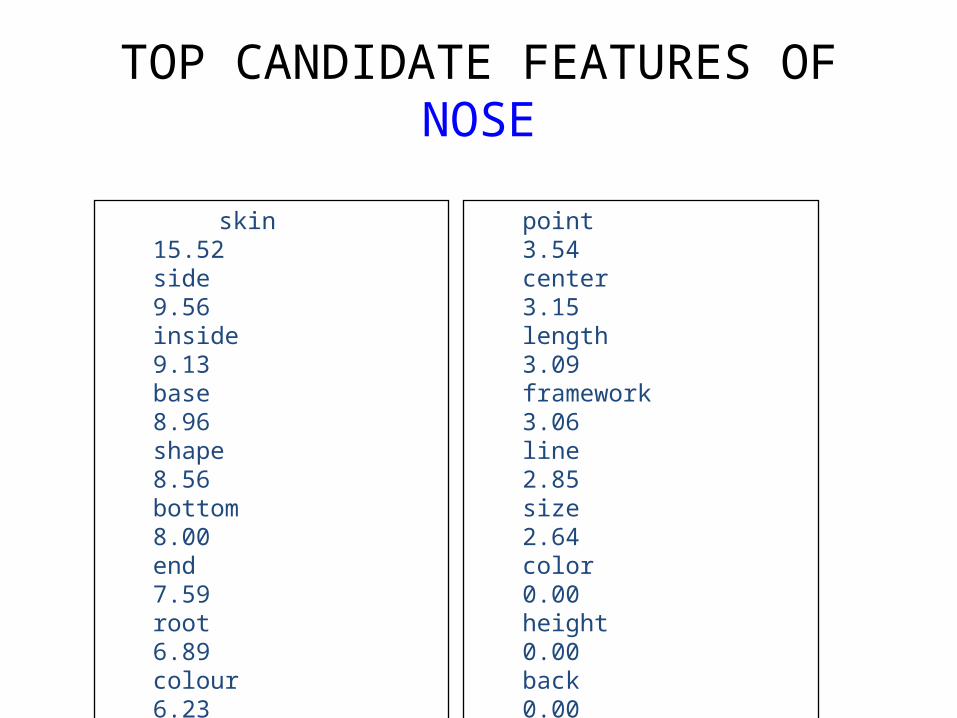
TOP CANDIDATE FEATURES OF NOSE
skin 15.52side 9.56inside 9.13base 8.96shape 8.56bottom 8.00end 7.59root 6.89colour 6.23 structure 5.25width 5.23function 4.86interior 4.81purpose 4.78appearance 4.34floor 4.00
point 3.54center 3.15length 3.09 framework 3.06line 2.85size 2.64color 0.00height 0.00back 0.00

Cimiano and Wenderoth 2005
• Extract from text the information about concepts specified by Pustejovsky’s Generative Lexicon theory
• Evaluation: human judgments

PUSTEJOVSKY’S GENERATIVE LEXICON
• Pustejovsky (1991, 1995): lexical entries have a QUALIA STRUCTURE consisting of four ‘roles’– FORMAL role: what type of object it is (shape, color,
….)– CONSTITUTIVE role: what it consists of (parts, stuff,
etc.)• E.g., for books, chapters, index, paper ….
– TELIC role: what is the purpose of the object (e.g., for books, READING)
– AGENTIVE role: how the object was created (e.g., for books, WRITING)

EXAMPLE: QS FOR “KNIFE”
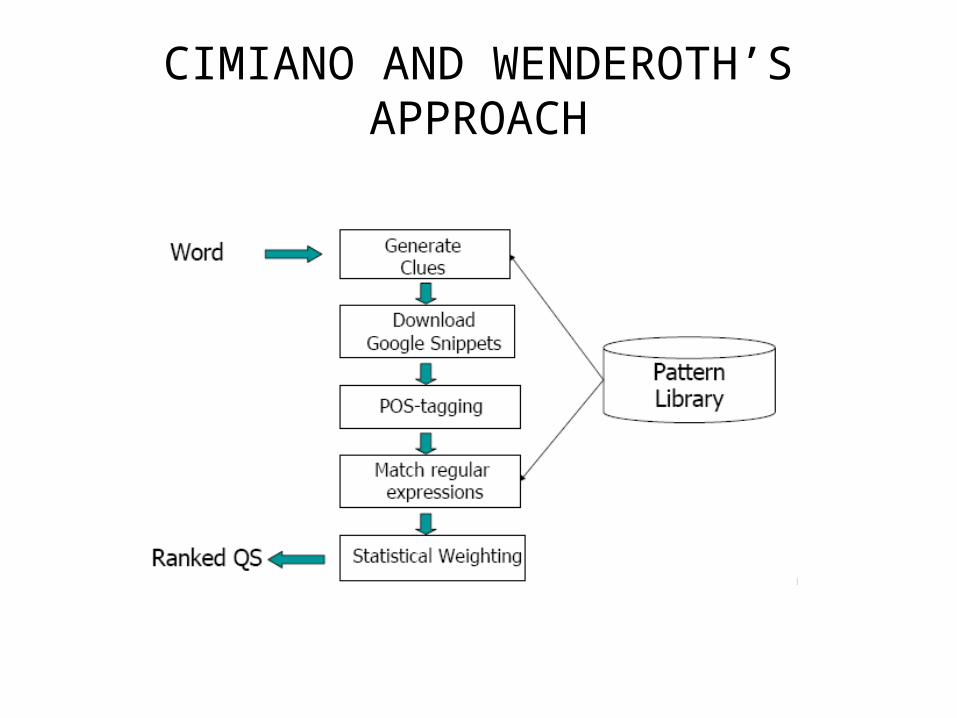
CIMIANO AND WENDEROTH’S APPROACH

PATTERNS FOR THE CONSTITUTIVE ROLE

GOOD EXAMPLES

PROBLEMS

PATTERNS FOR THE FORMAL ROLE

PATTERNS FOR THE AGENTIVE ROLE

PATTERNS FOR THE TELIC ROLE

Parsing for relation extraction
• Patterns are rigid– The purpose of AXES and KNIVES is to cut …– The Sphinx is a RECENTLY DISCOVERED animal …
• Using a parser may increase recall

Almuhareb & Poesio 2005
• Repeat experiments of Almuhareb and Poesio 2004, but using a parser to identify the attribute and value constructions
• Parser used: RASP (a dependency parser)
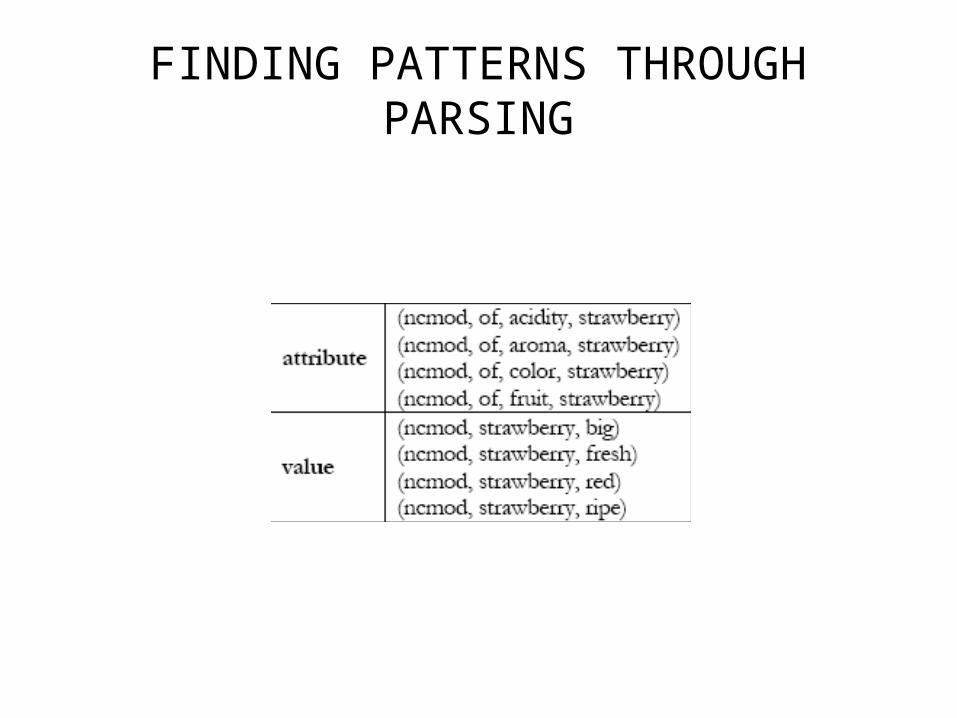
FINDING PATTERNS THROUGH PARSING

Attributes in lexical acquisition (Almuhareb and Poesio)
LOOKING ONLY FOR (POTENTIAL) ATTRIBUTES AND THEIR VALUES BETTER THAN USING ALL GRS

BUT: SOME CANDIDATE FEATURES OF DEER
the first / last of the deer the rest / majority of the deer the picture / image / photos of the deerthe cave / mountain / lake of the deer the meaning of the deer [in Western philosophy / … ]

Semi-supervised methods
• Hearst 1992: find new patterns by using initial examples as SEEDS
• This approach has been pursued in a number of ways– Espresso (Pantel and Pennacchiotti 2006)– OPEN INFORMATION EXTRACTION (Etzioni and
colleagues)

THE GENERIC SEMI-SUPERVISED ALGORITHM
1. Start with SEED INSTANCES Depending on algorithm, seed may be hand-generated or
automatically obtained2. For each seed instance, extract patterns from
corpusChoice of patterns depends on algorithm
3. Output the best patterns according to some metric4. (Possibly) iterate steps 2-3

THE ESPRESSO SEMI-SUPERVISED ALGORITHM
1. Start with SEED INSTANCES Hand-chosen
2. For each seed instance, extract patterns from corpus Generalization of whole sentence
3. Output the best patterns according to some metric A metric based on PMI
4. Do iterate steps 2-3

STRUDEL
• Extract from corpora candidate concept-property-CONNECTOR triples– LICE in a number of DOGS
• Rank concept-property pairs by the number of connectors– Intuition: ‘important’ properties are expressed in
a number of ways

STRUDEL: ranking

STRUDEL: methods

BOOK according to STRUDEL

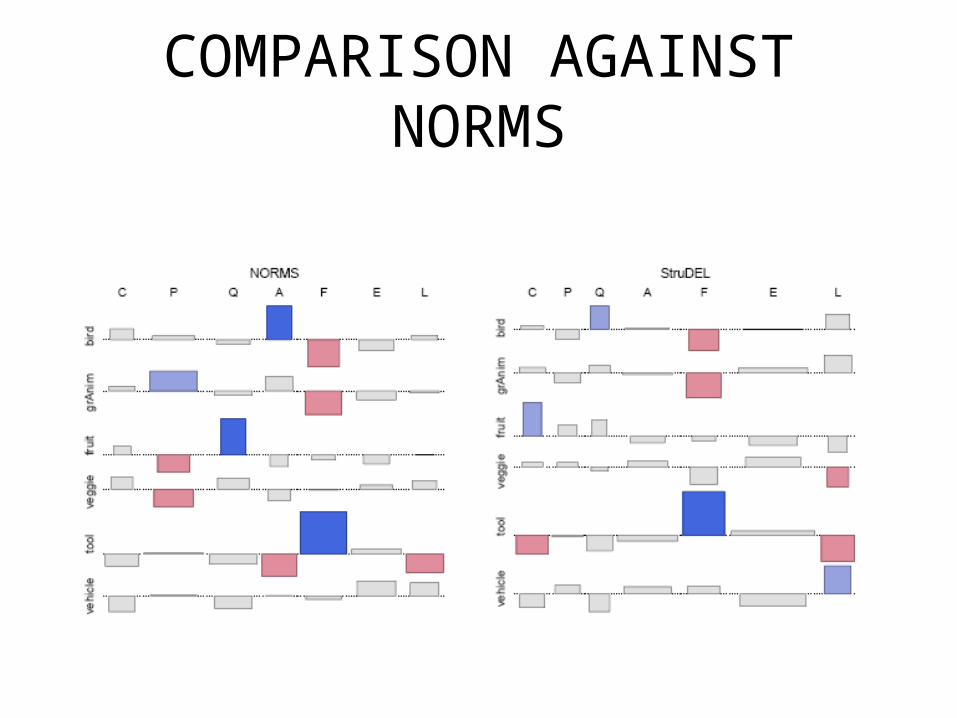
STRUDEL: evaluation
• By comparison with McRae et al’s NORMS databases
• Categorization (aka clustering)
COMPARISON AGAINST NORMS

Clustering

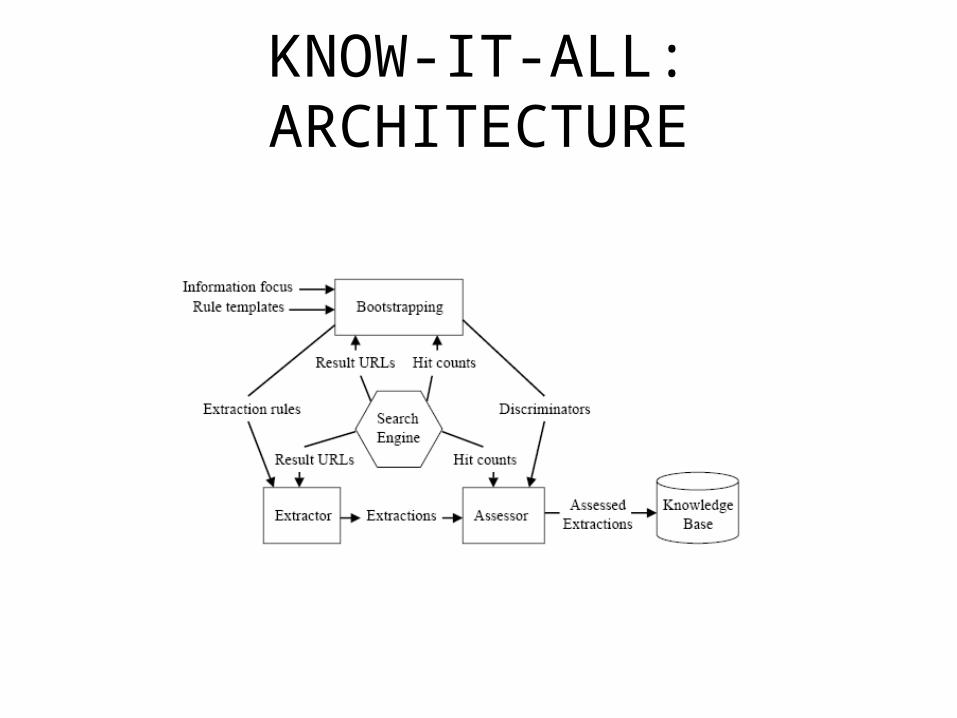
KNOW-IT-ALL
• A system for ontology population developed by Oren Etzioni and collaborators at the University of Washington
KNOW-IT-ALL: ARCHITECTURE

INPUT

BOOTSTRAPPING
• This first step takes the input domain predicates and the generic extraction patterns and produces domain-specific extraction patterns

EXTRACTION PATTERNS

EXTRACTOR
• Uses domain-specific extraction patterns + syntactic constraints– In “Garth Brooks is a country singer” , country
NOT extracted as an instance of the pattern “X is a NP”
• Produces EXTRACTIONS (= instances of the patterns that satisfy the syntactic constraints)

ASSESSOR
Estimates the likelihood of an extraction using POINTWISE MUTUAL INFORMATION between the extracted INSTANCE and DISCRIMINATOR phrases
E.g., INSTANCE: LiegeDISCRIMINATOR PHRASES: “is a city”

ESTIMATING THE LIKELIHOOD OF A FACT
P(f | ) and P(f | ) estimated using a set of positive and negative instances

TERMINATION CONDITION
• KNOW-IT-ALL could continue searching for instances – But for instance, COUNTRY has only around 300
instances• Stop: Signal-to-Noise ratio– Number of high probability facts / Number of low probability ones

OVERALL ALGORITHM
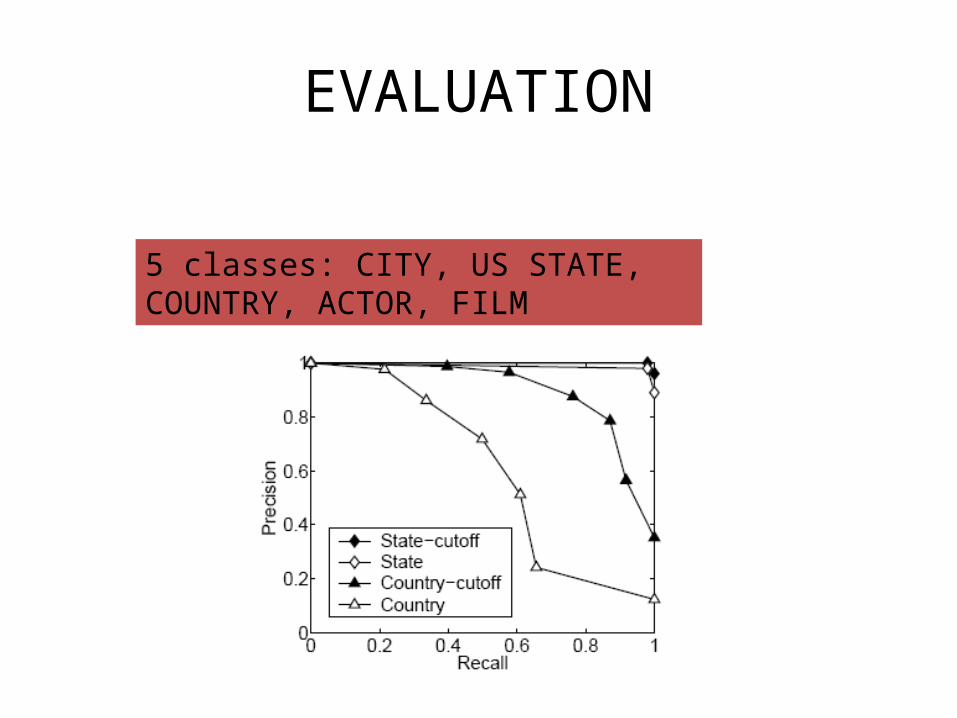
EVALUATION
5 classes: CITY, US STATE, COUNTRY, ACTOR, FILM

EXTENSION: LEARNING PATTERNS
• The specializations of generic patterns do not include many very useful domain-specific patterns
• E.g., – “<film> STARRING X” – “HEADQUARTERED IN <city>”

THE KNOW-IT-ALL SEMI-SUPERVISED STEP
1. Start with seed instances in this case, generated by domain-independent extractors
2. For each seed instance, query Web and extract patterns
in this case, pattern = window of size n centered on class word
3. Output the best patterns
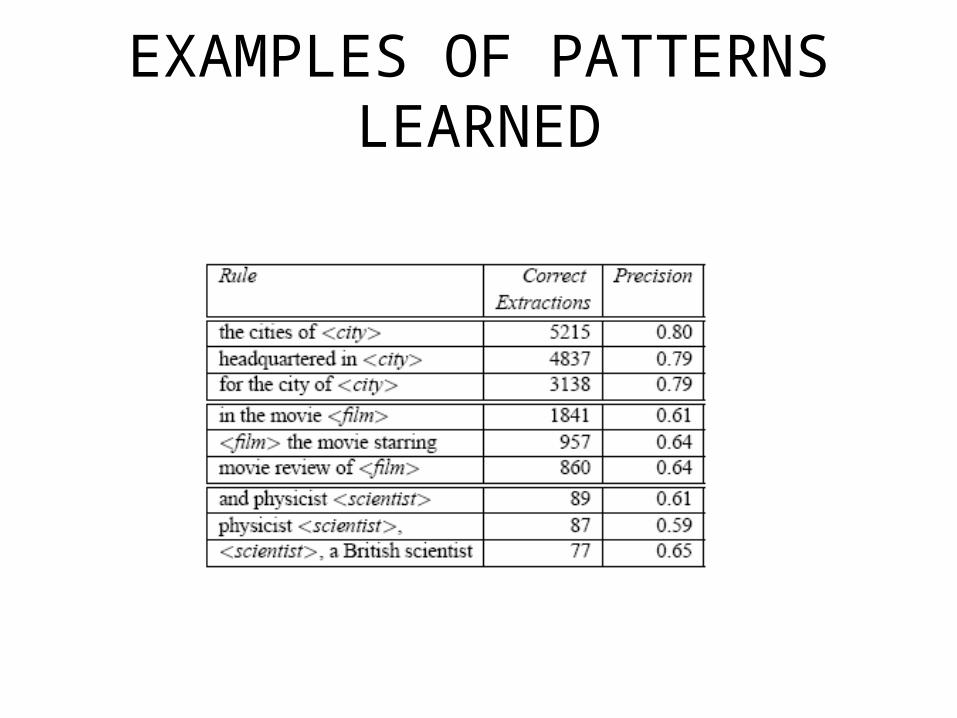
EXAMPLES OF PATTERNS LEARNED

EXTENSION: LIST EXTRACTION
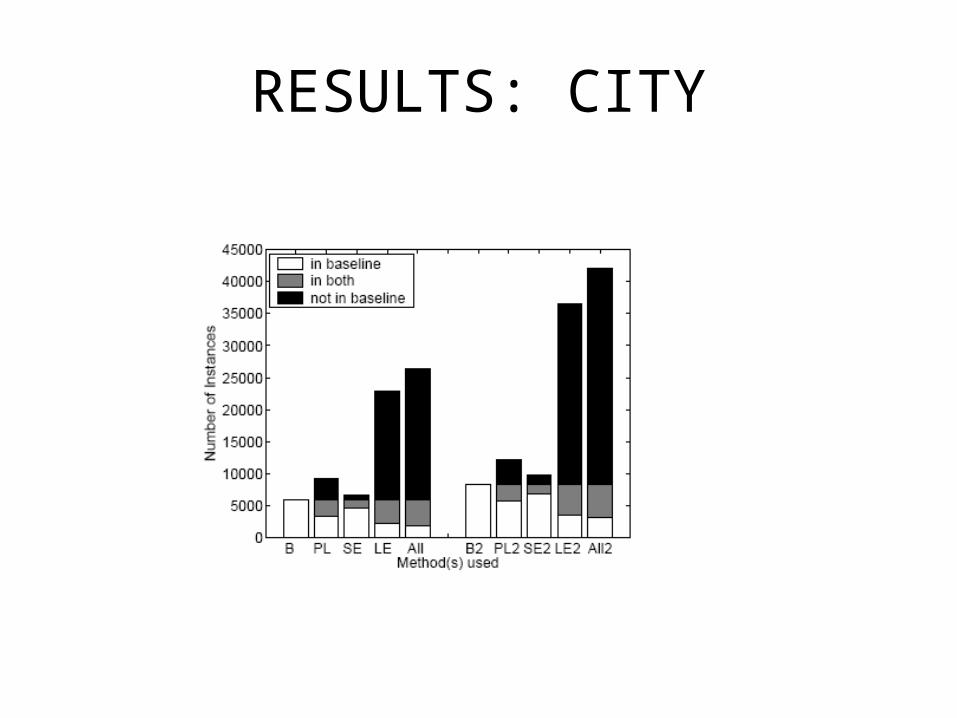
RESULTS: CITY
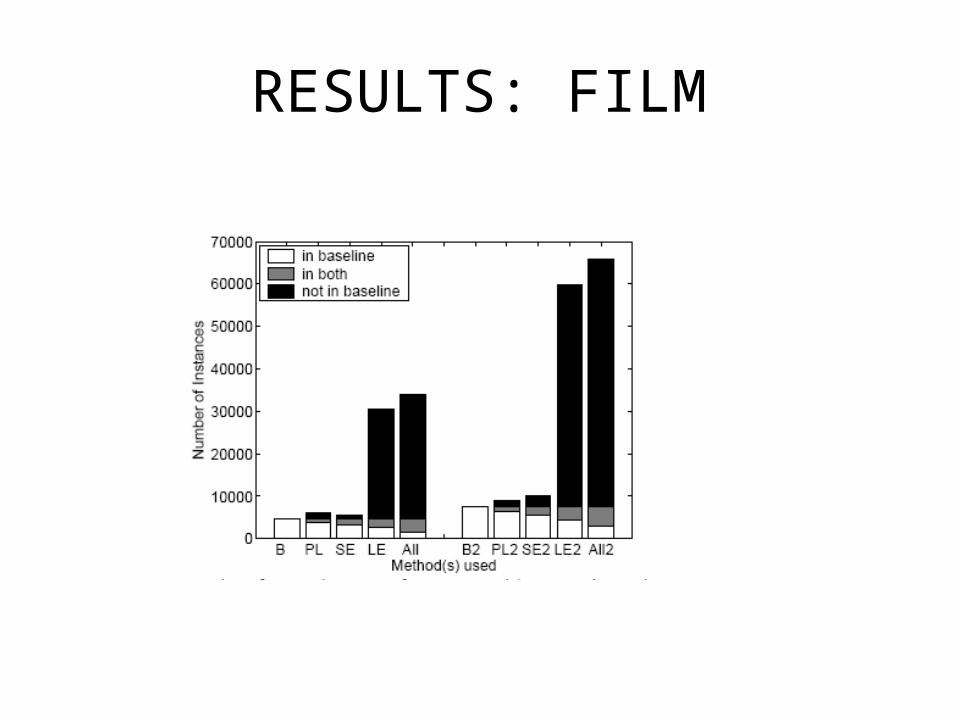
RESULTS: FILM

OVERALL JUDGMENT
• Very solid engineering work combining lots of ideas developed from others
• Main limitation: no attempt at discriminating between distinct instances with same name





























