Embed Size (px)
Citation preview

Introduction to Applied Linguistics:
Machine Translation

Machine translation is the process of translating a sentence from the source language to the target language by a computer. This procedure is based on statistics extracted from existing human translations and/or rules about the langauges.

Intelligence gathering
Political and trading interests
EU: 24 official languages

Machine Translation seen as a cryptographical problem:
“When I look at an article in Russian, I say ‘This is really written in English, but it has
been coded in some strange symbols. I will now proceed to decode.’” …
“Even if it would translate only scientific material (where the semantic difficulties are very notably less), and even if it did produce an inelegant (but intelligible) result, it would seem to me worth while” (excerpts from a letter written be Warren Weaver to Norbert Wienern, 1947)

Weaver report: 1949
First Machine Translation conference: 1952, MIT, Bar-Hillel » “Mechanical translation with a pre-editor, and writing for MT”
» “Word-by-word translation”
» “General mechanical translation and universal grammar”
» etc.
Georgetown-IBM experiment: 1954 (6 rules, 250-word vocabulary) E.g. “Mi pyeryedayem mislyi posryedstvom ryechyi.” →
→ “We transmit thoughts by means of speech.”
Great hopes: 1956-1966

ALPAC report (1966):
» ALPAC = Automatic Language Processing Advisory Committee
» reported on poor-quality MT (vs. much better, inexpensive manual labor) despite significant government investment
» resulted in a reduction of research and development efforts, reduced funding

I. Common natural language processing challanges
a) Lexical ambiguity
homonymy: bank1 vs. bank2
polysemy: bulb (electric ~ / the stem of a plant) (antagonism: humans concentrate on one reading at a time)
b) Structural ambiguity:
I hate flying planes.
I saw the girl with the telescope.

c) Ellipsis - Who wants to live forever?
- Mary and John [want to live forever].
d) Scope problems, e.g. ˃ It was not raining yesterday.
( a) it was not raining, b) it was raining but not yesterday)
˃ I wasn’t listening all the time. ( a) For the whole time I wasn’t listening. b) I was listening occasionally.)
˃ You may not smoke here. (aux. negation, wide scope)
˃ My sister may not like the color. (main verb negation, narrow)
e) Compounding ˃ It is very “productive”, you cannot list them all.
˃ May be difficult to detect (e.g. A+N compounds: full moon)
˃ Compounds within compounds [[[water meter] cover] [adjustment screw]]
˃ Recursion student film society committee video scandal inquiry

II. Translation-specific challenges
a) Lexical challenges: a) A concept may not be lexicalized in the TL (e.g. Eskimo
has several words for snow)
b) The right TL equivalent for the SL word depends on context (due to factors such as ambiguity, style, etc.)
c) idioms, phrases, collocations: may vary across langauges
b) Grammatical dissimilarities a) articles (e.g. no articles in Russian)
b) tense and aspect (e.g. no present perfect in Hungarian)
c) case markers (inflectional vs. agglutinative/fusional),
d) number (e.g. the presence of dual in English),
e) gender (gender neutral pronouns in Hungarian), etc.
c) Cultural challenges

Goal: automatic translation from SL (source language) to TL
Translated units: sentences
Methods
» Direct methods ˃ idea: replace TL words for SL words
˃ statistical direct methods (e.g. Google Translate, Webfordítás) : replace the most probable TL word sequences for SL sequences
» Rule-based systems (rely on grammatical rules) ˃ a SL-dependent or SL-independent analysis phase + TL- dependent or
independent generation (independent in the case of interlingua representation)
˃ transfer or interlingua-based

More detail on interlingual-representation:
» the internal representation is language-independent
» an example: “like”: [CAUSE(X, [BE (Y, [PLEASED])])]
» this method facilitates n-way translations (EN→HU, EN→GER, HU→RUS, etc.) via a common representation
» step 1: parse SL sentence until you have full interlingual representation; step 2: generate sentences in TLs

No knowledge of grammatical rules
Uses a statistical model that determines the most likely translation of a string of words/morphemes
Based on a large amount of known human translation

A sizeable amount of parallel corpora is needed:
Corpus: a collection of texts
Parallel corpus: contains the same texts in SL and TL
The more the better:
~30 million words could be OK 100 million+ : better

The Rosette stone
» inscribed in 196 BC
» found in 1799 in Egypt
» now on display in the British Museum
The same text (a decree) in three languages/orthographies:
» Hieroglyphic Egyptian
» Demotic Egyptian (casual variety)
» Ancient Greek ← best understood

Alignment of source and target language units:
» sentences
» words or morphemes
Alignment can be already present in the parallel corpus (‚aligned corpora’, alignment is usually done at the sentence level) or can be carried out automatically (less precise).
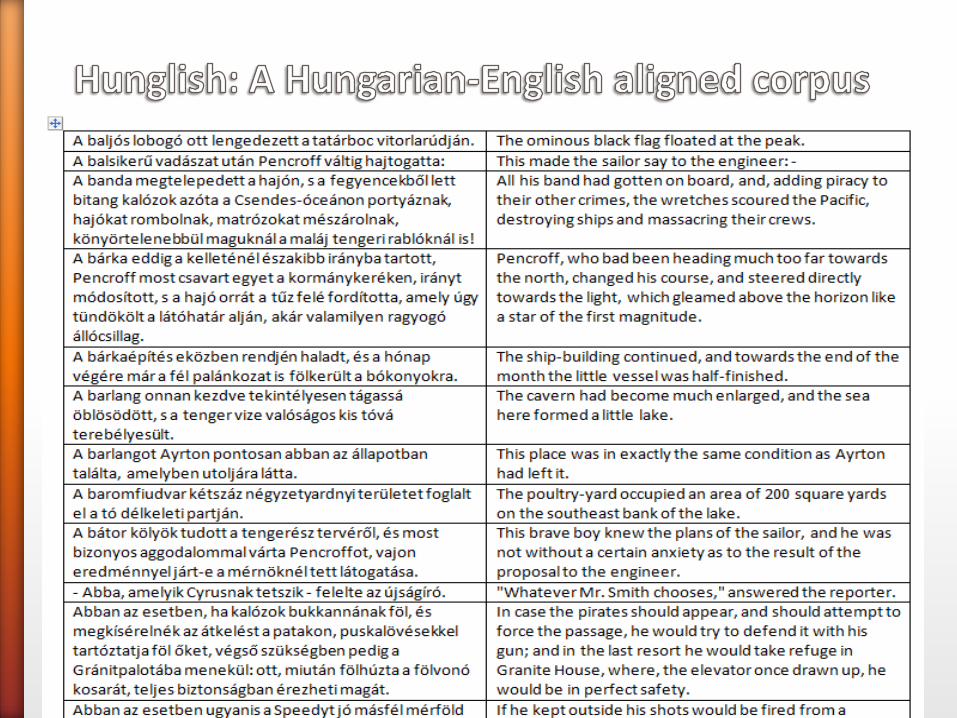

Alignment to sentences (if corpus is not aligned):
1 SL sentence translates to 1 TL sentence in 90% of cases. But 1:0, 0:1, 1:N, N:1 mappings are also possible.
A simple check: check the sequence of short/long sentences in SL and also in TL (count the words). If the sequences are similar, then 1:1 mappings are likely.
You can also use a small translation vocabulary to check the mapping.

Within the sentences:
finding and pairing translation segments in SL and TL (mapping options: 1:1, 1:N, N:1, 1:0, 0:1 …)

We can compute the likelihood of a word’s occurrence on its own / in bigrams / in trigrams, etc. in that particular context.
We are looking for the most probable translation, which maximizes the likelihood of all segments’ appearing in their desired positions.

Steps:
1. We parse the SL sentence, the resulting representation will describe the grammatical relations within the sentence.
2. We transfer the SL representation into a TL representation using rules OR we make a guess based on statistics -> we get a TL representation
3. We generate the TL sentence from the TL grammatical representation
Problem cases:
» no parse for the SL sentence
» too many alternative parses
» It is not enough to translate the structure, we must also find the right equivalents of SL words.

» Human evaluation
» Automatic evaluation
» Evaluation levels:
˃ corpus
˃ document
˃ sentence

» Adequacy: is the meaning of the SL sentence conveyed by the TL translation?
» Fluency: is the sentence grammatical in the TL?
These are rated on a scale (e.g. 1 to 5)
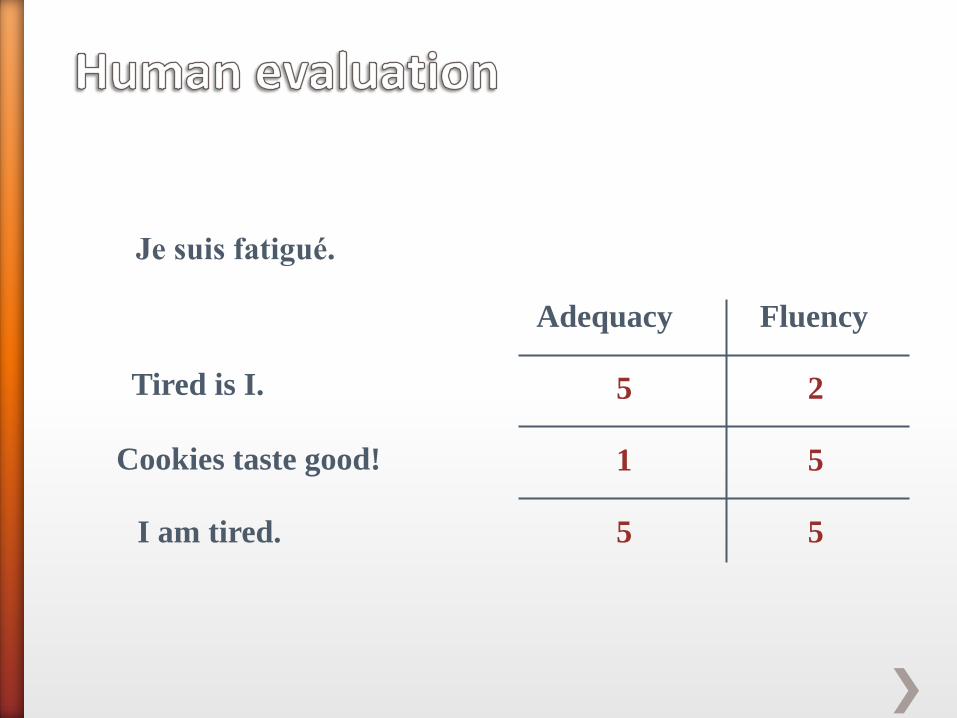
Je suis fatigué.
Tired is I.
Cookies taste good!
I am tired.
Adequacy Fluency
5
1
5
2
5
5

Evaluation metric: method for assigning a numerical score to a translation
Automatic evaluation metrics often rely on a comparison with previously completed human translations. Common methods: » Word Error Rate (WER) » Position-Independent Word Error Rate (PER) » BLEU There is no good automatic metric at the sentence level. There is no automatic metric that returns a meaningful measure of absolute quality (instead, they are useful for comparing MT systems).

WER: „edit” distance (# of steps) to reference translation
Possible edit operations to reach reference translation:
» insertion
» deletion
» substitution
» Captures fluency well
» Captures adequacy less well
» Too rigid in matching
Output = „he saw a man and a woman“
Reference = „he saw a woman and a man“
WER gives no credit for „woman“ or „man“

PER: measures lack of overlap in bag of words
Captures adequacy at single word (unigram) level
Does not capture fluency
Too flexible in matching
Output 1 = „he saw a man“
Output 2 = „a man saw he“
Reference = „he saw a man“
Output 1 and Output 2 get same PER score!

Goal: to combine WER and PER ˃ Tradeoff between strict matching of WER and flexible
matching of PER
BLEU compares the 1,2,3,4-gram overlap with one or more reference translations.
˃ BLEU penalizes generating long strings because they would unfairly overlap more
˃ References are usually 1…4 translations (done by humans!)
» BLEU correlates well with average of fluency and adequacy at corpus level ˃ but not at sentence level

Today’s material in the exam:
Use the following paper for the test:
Dorr, Jordan and Benoit (1998) A Survey of Current Paradigms in Machine Translation. Sections 2 and 4 (pp. 2-4 and pp. 12-18). The URL of the article is on the syllabus.





























