Embed Size (px)
Citation preview

http://hpc.sagepub.com
Computing Applications International Journal of High Performance
DOI: 10.1177/1094342006064504 2006; 20; 233 International Journal of High Performance Computing Applications
J. Nieplocha, V. Tipparaju, M. Krishnan and D. K. Panda High Performance Remote Memory Access Communication: The Armci Approach
http://hpc.sagepub.com/cgi/content/abstract/20/2/233 The online version of this article can be found at:
Published by:
http://www.sagepublications.com
can be found at:International Journal of High Performance Computing Applications Additional services and information for
http://hpc.sagepub.com/cgi/alerts Email Alerts:
http://hpc.sagepub.com/subscriptions Subscriptions:
http://www.sagepub.com/journalsReprints.navReprints:
http://www.sagepub.co.uk/journalsPermissions.navPermissions:
http://hpc.sagepub.com/cgi/content/refs/20/2/233 Citations
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

233ARMCI: REMOTE MEMORY COPY
HIGH PERFORMANCE REMOTE MEMORY ACCESS COMMUNICATION: THE ARMCI APPROACH
J. Nieplocha1
V. Tipparaju1
M. Krishnan1
D.K. Panda2
Abstract
This paper describes the Aggregate Remote Memory CopyInterface (ARMCI), a portable high performance remotememory access communication interface, developed orig-inally under the U.S. Department of Energy (DOE) AdvancedComputational Testing and Simulation Toolkit project andcurrently used and advanced as a part of the run-timelayer of the DOE project, Programming Models for Scala-ble Parallel Computing. The paper discusses the model,addresses challenges of portable implementations, anddemonstrates that ARMCI delivers high performance on avariety of platforms. Special emphasis is placed on thelatency hiding mechanisms and ability to optimize noncon-tiguous data transfers.
Key words: Remote Memory Access, one-sided commu-nication, programming models, ARMCI, high performancenetworks
1 Introduction
Remote memory access (RMA) operations facilitate anintermediate programming model between message pass-ing and shared memory. This model combines some advan-tages of shared memory, such as direct access to shared/global data, and the message-passing model, namely thecontrol over locality and data distribution. Certain typesof shared memory applications can be implemented usingthis approach. In some other cases, remote memory oper-ations can be used as a high-performance alternative tomessage passing. On many modern platforms, RMA isdirectly supported by hardware and is the lowest-leveland often most efficient communication paradigm availa-ble (Nieplocha et al. 2002a).
A portable RMA interface is needed both for develop-ing applications and for creating a communication layerfor libraries and compiler run-time systems, especially forthe reemerging global address space languages. ARMCIwas developed to serve the latter purpose (Nieplocha andCarpenter 1999; Nieplocha and Ju 2000; Nieplocha et al.2002a; Nieplocha et al. 2003) by complementing MPI-2(message passing interface), which targets application devel-opers and imposes certain rules and restrictions on dataaccess (e.g. window serialization, access epochs) or progressrules that are absent in vendor-specific interfaces such asthe Cray SHMEM (Bariuso and Knies 1994), IBM LAPI(Shah et al. 1998), and Quadrics Elan (Petrini et al. 2003).These rules and restrictions were introduced to increaseportability (for use in heterogeneous environments), increaseconsistency of application programming interface (API)and compatibility with MPI-1, improve language interop-erability, and reduce opportunities for writing erroneousapplication code (e.g. locks for remote memory in passivecommunication model or access epochs to memoryexposed through the MPI windows). ARMCI, on the otherhand, leaves the library/compiler developer in charge ofmanaging protection and consistency of data accessed byRMA communication and does not support heterogene-ous environments or provide Fortran bindings. Therefore,ARMCI, as a more streamlined system, is able to focus ondelivering performance in addition to providing a wide-spread portability for homogeneous hardware platforms.
Many of the existing native RMA systems offer onlylimited or no interfaces for noncontiguous data transfers,the capability often needed in scientific applications. Thewell-known Cray SHMEM library (Bariuso and Knies1994), available on all the Cray and SGI platforms aswell as on clusters of PCs (Parkin et al. 1997; Parzyszek,
The International Journal of High Performance Computing Applications,Volume 20, No. 2, Summer 2006, pp. 233–253DOI: 10.1177/1094342006064504© 2006 SAGE Publications
1COMPUTATIONAL SCIENCES AND MATHEMATICS DEPARTMENT, PACIFIC NORTHWEST NATIONAL LABORATORY, RICHLAND, WA 99352. ([email protected])2OHIO STATE UNIVERSITY
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

234 COMPUTING APPLICATIONS
Nieplocha, and Kendall 2000), supports only put/get oper-ations for contiguous data and scatter/gather operationsfor the basic data types. The Virtual Interface Architecture(VIA) (Compaq Computer Corp., Intel Corp., and Micro-soft Corp. 1997) and more recent industry Infiniband inter-face specification go further in terms of supporting suchtransfers. However, its scatter/gather type of operationscan transfer data between a noncontiguous location inmemory and a contiguous buffer. For example, in scien-tific codes, where data in a section of one array is trans-ferred to a section of another array, the Infiniband remotedirect memory access (RDMA) interfaces would requireadditional memory copy to an intermediate buffer andtherefore are not optimal1. Extensive support for handlingnoncontiguous data transfers is an important characteris-tic of ARMCI. It offers explicit noncontiguous communi-cation interfaces with strided and generalized I/O vectorAPIs and then uses a variety of techniques (e.g. active mes-sages, threads, nonblocking communication, pipelining)to optimize their performance.
Because ARMCI was developed to support develop-ment of libraries and compiler run-time systems, for prac-tical reasons it was designed also to be compatible withmessage-passing libraries, primarily MPI but also parallelvirtual machine (PVM). Such compatibility is necessaryfor applications that frequently use hybrid programmingmodels or rely on standard parallel libraries, such asScaLAPACK (Blackford et al. 1997). In addition, the col-lective operations used by most parallel applications areprovided by MPI. ARMCI was developed originally as apart the U.S. Department of Energy (DOE) advanced com-putational software collection (DOE2000 ACTS Toolkit)project. Currently, it is used as a part of the run-time sys-tem developed by the Center for Programming Models forScalable Parallel Computing project (pmodels), sponsoredby DOE. For example, ARMCI is used to implement Glo-bal Arrays (GA) (Nieplocha, Harrison, and Littlefield 1994,1996; Nieplocha et al. 2002b), the portable Co-Array Fortran
(CAF) compiler (Numrich and Reid 1998 ), and the portableSHMEM library (Parzyszek, Nieplocha, and Kendall 2000)(see Figure 1). In the past, it has been used also in theAdlib PCRC run-time system (Nieplocha and Carpenter1999) for a high-performance Fortran (HPF) compiler. Inaddition, ARMCI has been adopted by the Cray Corpora-tion and offered on their latest Cray XD1 supercomputer.
This paper is organized as follows. Section 2 discussesthe RMA model and compares the approach of ARMCI toother RMA interfaces. Section 3 describes the capabilitiesof ARMCI. Section 4 focuses on capabilities ARMCI offersfor latency hiding. Section 5 describes the architecture,protocols, and techniques used in the ARMCI implemen-tation to deliver high performance across a variety of plat-forms. Section 6 provides experimental results. Finally,conclusions are presented in Section 7.
2 RMA Communication and the ARMCI Approach
The traditional RMA communication facilitates data trans-fers between a buffer of a local processor and anotherlocation in the remote processor memory. However, coop-eration with the remote processor is not required to com-plete the data transfer. The RMA model is closely alignedwith RDMA capabilities of modern networks (Infiniband,Myrinet, VIA, Elan), which provide hardware support toread from or write to remote memory locations. With theexception of Elan, which offers virtual memory RDMA,the networks listed above require the source and destina-tion buffers to be registered with the network adapter inadvance of the communication. Registration allows thenetwork adapter driver to establish virtual memory trans-lations and lock the buffers in physical memory. RDMA isa simple communication model that enables network adapt-ers on two ends of the network to complete data transferasynchronously and avoid remote-host processing. Thissimplicity makes RDMA, in most cases, the highest-per-formance data-transfer mechanism available. If commu-nication buffers are registered, RMA operations such asput or get map directly to the RDMA write or put operationssupported by the hardware. Because the RMA model doesnot require a remote processor to match message tags ordeal with early message arrivals, as required in messagepassing, RMA can achieve higher performance on thesenetworks as well.
MPI-2 offers one version of RMA with two specificvariations—active and passive target one-sided commu-nication. For wide portability (including heterogeneousplatforms) and other reasons discussed by the MPI Forum,the MPI-2 RMA model is rather different from the RMAflavors found in vendor-specific interfaces, such as LAPIon the IBM SP, RDMA on the Hitachi SR-8000, MPlib onthe Fujitsu VPP-5000, or SHMEM on the Cray systems (see
Fig. 1 ARMCI can coexist with MPI as an implementa-tion layer for multiple programming models and appli-cations. Collective operations are provided by MPI.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

235ARMCI: REMOTE MEMORY COPY
Figure 2). Differences between these models can be sig-nificant in terms of progress rules and semantics, and theyalso can affect performance. MPI-2 offers a model closelyaligned with traditional message passing (MPI-1) andincludes high-level concepts such as windows, epochs,and distinct progress rules for passive and active targetcommunication. A recent paper (Bonachea and Duell 2003)asserts that the MPI-2 model is not optimal for imple-menting global address space languages due to excessivesynchronization and its complex progress rules.
2.1 Communication Progress
ARMCI distinguishes itself from MPI-2 by relying onsimpler progress rules, which are motivated by hardwaresupport for the RMA operations on the current architec-tures. The progress rules in ARMCI follow those in theCray SHMEM. Unlike many other portable RMA inter-faces, such as the one-sided “active” communication modelin the MPI-2, or put/get operations in Generic Active Mes-sages (Culler et al. 1994), GASNet (Bonachea 2002), orData Movement and Control Substrate (DMCS; Barker et al.2002), ARMCI guarantees that its one-sided operationsare fully unilateral (i.e. complete regardless of the actionstaken by the remote process). In particular, polling theapplication by remote process (implicit when making alibrary call, or explicit by calling provided polling inter-face) is not required for communication progress. In thisrespect, ARMCI is similar to the MPI “passive target” andthe vendor-specific RMA interfaces2. In designing ARMCI,we assumed that relying on explicit or implicit polling wouldreduce responsiveness (Bhoedjang, Ruhl, and Bal 1998;Perkovic and Keleher 1999) and lead to an intolerableincrease in latencies when the remote process is in thepurely computational phase of execution and thus unableto assist in completion of data transfers. Although compilerscan insert polling calls into the user code, many real appli-cations relying on third-party and mixed-language soft-
ware or making calls to standard system libraries calls (e.g.LAPACK) limit feasibility of that approach in practice.
2.2 Overlapping Communication with Computations
Despite the progress in networking technologies, the gapbetween processor speed and network latency has beenincreasing. As a result of this trend, the ability to overlapcommunication with computation through the use of non-blocking communication is becoming critical. Given thesimplicity of its communication model (with source anddestination for data transfer explicitly known, no send/receive tag and buffer matching, and no early messagearrival processing), RMA offers opportunities for design-ing implementations that provide a high degree of overlapbetween communication and computations. In addition toreducing or eliminating data movement on the remote side,a communication library should return control to the userprogram as soon as possible, giving the application anopportunity to work on computations while the communi-cation is being completed by the underlying network hard-ware. ARMCI offers nonblocking versions of the RMAoperations and strives to maximize the potential for over-lapping communication with computation on individualplatforms.
2.3 Noncontiguous Data Transfers
Another important design goal for ARMCI is to optimizeperformance of noncontiguous data transfers. Noncontig-uous data transfers in scientific computing are quite com-mon—for example, they correspond to communicationinvolving sections of multidimensional dense arrays orsparse matrix operations. In the absence of the noncontig-uous interfaces, such applications 1) use multiple contigu-ous calls (preferably nonblocking) or 2) pack noncontiguousdata to a contiguous buffer, transfer the data, and thenunpack. Neither of these alternatives provides optimal per-formance. For the first approach, in most cases, the per-formance loss is due to the communication subsystemhandling each contiguous portion of the data as a separatemessage. This causes the communication startup costs tobe incurred multiple times rather than once. The secondapproach, although it can provide acceptable performancein the send/receive model, is hardly appropriate for RMAcommunication because explicit cooperation with theremote process would be required to either pack (for put)or unpack (for get) the data on the remote side.
On modern systems, there are many ways a communi-cation library could optimize the performance if a noncon-tiguous communication interface is used. For example, itcould 1) minimize the number of underlying networkpackets by packing distinct blocks of data into as few
Fig. 2 Comparison of communication calls in the CraySHMEM, MPI-2 “active target,” and MPI-2 “passive tar-get” communication. The solid lines illustrate data trans-fer. Dotted lines illustrate matching calls (active target)or potential synchronization (passive target).
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

236 COMPUTING APPLICATIONS
packets as possible, 2) minimize the number of interruptsin the interrupt-driven message-delivery systems, and 3)take advantage of any available shared memory optimi-zations (prefetching/poststoring) on the shared memorysystems. In principle, remote copy operations should mapdirectly—without intermediate copying of the data—tothe native high-performance memory copy operations(including bulk data transfer facilities) on shared memoryhardware.
2.4 Memory Model
For performance reasons, ARMCI operations requireremote data to be allocated using the provided memoryallocation functions. This requirement allows ARMCI touse the type of memory that allows fastest access (e.g.shared memory on SMP clusters). In addition, the libraryprovides a memory allocator for local memory. The localmemory allocator is optional and could be used by appli-cations for allocating “good” memory that makes commu-nication from it faster.
One of the issues central to performance and scalabilityis memory consistency. Although the sequential consist-ency model (Scheurich and Dubois 1987) is straightforwardto use, weaker consistency models (Dubois, Scheurich, andBriggs 1986) can offer higher performance on modernarchitectures and have been implemented on actual hard-ware. The ARMCI approach is to use a weaker than sequen-tial consistency model that is still relatively straightforwardfor an application programmer. It is similar to the locationconsistency model of Gao and Sarkar (2000).
ARMCI distinguishes two types of completion of thestore operations (i.e. put, scatter) targeting global sharedmemory—local and remote. The blocking store operationreturns after the operation is completed locally; i.e. the userbuffer containing the source of the data can be reused.The operation completes remotely after either a memoryfence operation or a global barrier synchronization is called.The fence operation is required in the critical sections ofthe user code if the globally visible data is modified.
The blocking operations (put/scatter) are ordered onlyif they target the same destination. Operations that do notgo to the same destination can complete in arbitrary order.The nonblocking load/store operations complete in arbitraryorder. The programmer uses wait/test operations to ordercompletion of these operations, if desired. Ordering canbe removed from blocking operations by simply replacingthe original blocking operation by a nonblocking opera-tion followed immediately by the wait operation.
2.5 Implementation Flexibility
Some networks and native communication interfaces onthese networks do not have direct support for all the RMA
operations offered by the portable interfaces discussedabove. Other networks have a rich functionality set butintroduce substantial performance compromises. For exam-ple, IBM LAPI (Shah et al. 1998), an active message libraryfor the IBM SPs, does support contiguous and noncontigu-ous RMA but is not copy-free and requires implicit use ofthe host processor (CPU) on both sides of data transfer.As the memory copies degrade performance and hostCPU resources are taken away from the application, thisapproach usually has an adverse affect on the overallapplication performance and scalability. To maximizeapplication performance, it is important to avoid datamovement and protocol processing on the remote side asmuch as possible. RMA models that require explicit syn-chronization might incur overhead on the part of theapplication running on the remote side. For example, theMPI-2 one-sided operations involve synchronizationbetween the source and the destination for every one-sided operation via a fence, a lock, or a dedicated Post-Wait coordination in the active target mode (Gropp et al.1998; Traff, Ritzdorf, and Hempel 2000), at least in prin-ciple.
The ARMCI specification does not describe or assumeany particular implementation model, e.g. threads. Theimplementation should exploit the most efficient mech-anisms available on a given platform and might includeactive messages, native put/get, shared memory, and/orthreads.
3 Overview of Capabilities
ARMCI offers extensive functionality in the area of RMAcommunication: 1) data transfer operations, 2) atomic oper-ations, 3) locks, and 4) memory management and synchro-nization operations. In scientific computing, applicationsoften require transfers of noncontiguous data that corre-spond to fragments of multidimensional arrays, sparsematrices, or other more complex data structures. Withremote memory communication APIs that support onlycontiguous data transfers, it is necessary to transfer non-contiguous data using multiple communication opera-tions. This often leads to inefficient network utilizationand involves increased overhead. ARMCI, however, offersexplicit noncontiguous data interfaces—strided and gen-eralized I/O vectors that allow descriptions of the datalayout so that they could, in principle, be transferred in asingle message (described below). Of course, the effec-tiveness of actual transfers depends on the ability ofunderlying networks to deal with noncontiguous data(e.g. scatter/gather operations). However, even when scat-ter/gather operations are not supported by the network,the ARMCI strided and vector operations take advan-tage of the information—for example, at the level of datapacking/unpacking (in the client/server implementation
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

237ARMCI: REMOTE MEMORY COPY
described in Section 5)—so that the overall number of mes-sages and network packets is reduced.
ARMCI relies on a message-passing library (e.g. MPI)for interaction with the resource manager, process creation,and management of the execution environment. Specialeffort is needed at the implementation stage to ensure thatthe programmer can use message-passing calls along withARMCI calls. This interoperability is essential due to thewidespread popularity of MPI.
3.1 Data Transfer Operations
A get operation transfers data from the remote processmemory (source) to the calling process local memory (des-tination). A put operation transfers data from the local mem-ory of the calling process (source) to the memory of aremote process (destination). Register-memory operations(value_put/value_get) transfer a value stored in a registerof local process to remote process memory (destination) byavoiding the overhead of passing through the buffer man-agement layer (local memory subsystem).
The nonblocking API is derived from the blockinginterface by adding a handle argument that identifies aninstance of the nonblocking request. All the nonblockingtransfer functions are prototyped to work as transfers withboth an “explicit” and an “implicit” handle, which storeimportant information about the initiated data transfer.The descriptor is implemented as an abstract data type.This is motivated by a simpler implementation so that adata transfer descriptor can be stored in the applicationspace. If a NULL value is passed to the argument repre-senting a handle (thus representing an implicit handle),the function does an implicit handle nonblocking transfer.The handle can be used to represent multiple operationsof the same type (i.e. all puts or all gets). Using the so calledaggregate handle, multiple requests can be internally com-bined and processed as a single message (actually by call-ing ARMCI_PutV/GetV/AccV). Nonblocking operationsallow users to initiate an RMA call and then return controlto the user program. The data transfer is completed locallyby calling a wait operation. Waiting on a nonblocking putoperation ensures that data is injected into the networkand the user buffer can be reused. In case of blocking andnonblocking store operations, before accessing the modi-fied data safely from other nodes, the programmer has toissue a fence operation (ARMCI_Fence). ARMCI_Fencecompletes data transfers on the remote side. Unlike theblocking operation, the nonblocking operations are notordered.
3.2 Noncontiguous Data Transfers
In most scientific applications, data transfer among proc-esses represents the data, which is part of global data struc-
tures. If the global data structure is a multidimensionalarray (which is common), then the data to be transferredis not contiguous (i.e. single block), but is made up ofmultiple blocks of contiguous data (i.e. noncontiguous).In ARMCI, noncontiguous data transfer can be done inthree ways: 1) contiguous data transfer for each and everyblock, 2) noncontiguous data copied into a contiguousbuffer and sent in a single data transfer, or 3) the opti-mized noncontiguous data formats in ARMCI for highperformance. ARMCI offers two formats to describe non-contiguous layouts of data in memory—generalized I/Ovector and strided.
3.2.1 Generalized I/O vector (GIOV) format Gen-eralized I/O vector is the most general format intendedfor multiple sets of equally sized data segments movedbetween arbitrary local and remote memory locations. Itextends the format used in the UNIX readv/writev opera-tions. It uses two arrays of pointers, one for source andone for destination addresses (see Figures 3 and 4). Thelength of each array is equal to the number of segments.Some operations that would map well to this formatinclude scatter and gather. The format also would allowtransferring a triangular section of a two-dimensional arrayin one operation. For example, in the generalized I/O vec-tor format, a put operation that copies data to the processmemory (proc) has the following interface:
int ARMCI_PutV(armci_giov_t dscr_arr[], int arr_len, int proc)
Fig. 3 Source and destination pointer arrays. Non-con-tiguous data transfer using generalized vector format.
Fig. 4 ARMCI Vector and Strided data structures.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from
238 COMPUTING APPLICATIONS
The first argument is an array of size arr_len. Eacharray element specifies a set of equally sized segments ofdata copied from the local memory to the memory at theremote process proc.
3.2.2 Strided format Strided format is an optimiza-tion of the generalized I/O vector format. It is intended tominimize storage required to describe sections of densemultidimensional arrays. Instead of including addresses forall the segments, it specifies only an address of the firstsegment in the set for source and destination (Figures 4and 5). The addresses of the other segments can be com-puted using the stride information. With the strided for-mat, a put operation that copies data to the destination(proc) has the following interface:
int ARMCI_PutS(src_ptr, src_stride_arr, dst_ptr, dst_stride_arr, count, stride_levels, proc)
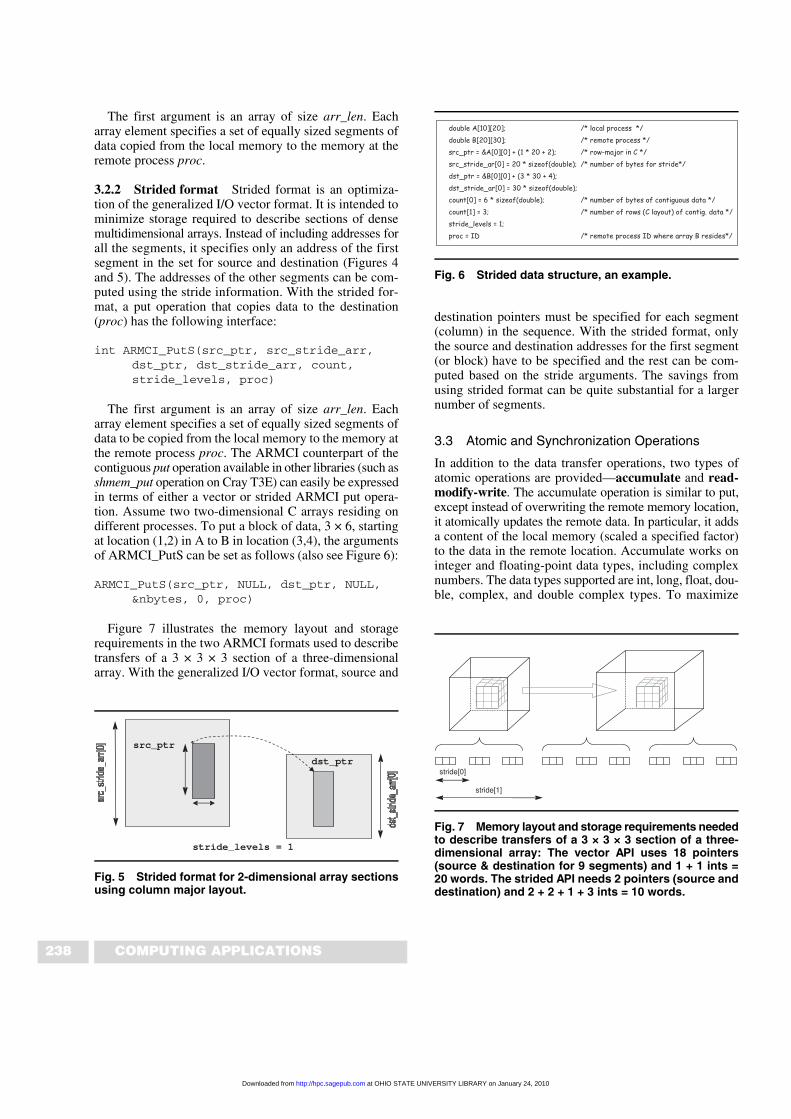
The first argument is an array of size arr_len. Eacharray element specifies a set of equally sized segments ofdata to be copied from the local memory to the memory atthe remote process proc. The ARMCI counterpart of thecontiguous put operation available in other libraries (such asshmem_put operation on Cray T3E) can easily be expressedin terms of either a vector or strided ARMCI put opera-tion. Assume two two-dimensional C arrays residing ondifferent processes. To put a block of data, 3 × 6, startingat location (1,2) in A to B in location (3,4), the argumentsof ARMCI_PutS can be set as follows (also see Figure 6):
ARMCI_PutS(src_ptr, NULL, dst_ptr, NULL, &nbytes, 0, proc)
Figure 7 illustrates the memory layout and storagerequirements in the two ARMCI formats used to describetransfers of a 3 × 3 × 3 section of a three-dimensionalarray. With the generalized I/O vector format, source and
destination pointers must be specified for each segment(column) in the sequence. With the strided format, onlythe source and destination addresses for the first segment(or block) have to be specified and the rest can be com-puted based on the stride arguments. The savings fromusing strided format can be quite substantial for a largernumber of segments.
3.3 Atomic and Synchronization Operations
In addition to the data transfer operations, two types ofatomic operations are provided—accumulate and read-modify-write. The accumulate operation is similar to put,except instead of overwriting the remote memory location,it atomically updates the remote data. In particular, it addsa content of the local memory (scaled a specified factor)to the data in the remote location. Accumulate works oninteger and floating-point data types, including complexnumbers. The data types supported are int, long, float, dou-ble, complex, and double complex types. To maximize
Fig. 5 Strided format for 2-dimensional array sectionsusing column major layout.
Fig. 6 Strided data structure, an example.
Fig. 7 Memory layout and storage requirements neededto describe transfers of a 3 × 3 × 3 section of a three-dimensional array: The vector API uses 18 pointers(source & destination for 9 segments) and 1 + 1 ints =20 words. The strided API needs 2 pointers (source anddestination) and 2 + 2 + 1 + 3 ints = 10 words.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

239ARMCI: REMOTE MEMORY COPY
opportunities for efficient implementation, it is not specifiedwhich process will perform the required computations.
Another type of atomic operation available is read-modify-write. Two types of operators for that operation aresupported—fetch-and-add and swap. The fetch-and-addcombines the specified integer (int or long) value with thecorresponding integer value at the remote memory loca-tion and returns the original value found at that location.This operation can be used to implement shared countersand other synchronization mechanisms. The data typessupport int and long. The swap operation swaps the con-tent of remote memory location with the specified localinteger value. The operation is supported also for int andlong data types.
ARMCI supports distributed mutex operations for syn-chronization required in critical sections of the user code.The user can create a set of mutexes associated with a spec-ified process and use locking operations (ARMCI_Lock/ARMCI_Unlock) on individual mutexes in that set.
3.4 Memory Allocation
For performance reasons, ARMCI operations require theremote data to be allocated using the provided memoryallocation function, ARMCI_Malloc. This requirementallows ARMCI to use the type of memory that allowsfastest access (e.g. shared memory on SMP clusters). Inaddition, the library provides a local memory allocator,ARMCI_Malloc_local. Although it is not required to usethat interface for allocating communication buffers, onsome platforms (e.g. Myrinet or Infiniband clusters)substantial performance benefits could be achieved bydoing so. This is because the library can allocate “besttype of memory” for the inter-processor communica-tion. ARMCI_Malloc is a collective memory allocator,whereas ARMCI_Malloc_local works like the standardMalloc call. Another important difference between thesecalls is that only memory allocated with ARMCI_Mallocis accessible from other processors. Memory allocatedby ARMCI_Malloc_local is private to the given proc-essor.
3.5 Exposing System and Locality Information
When optimizing performance, it is sometimes useful toexploit the task-mapping to the system hardware. For exam-ple, on clusters of SMP nodes, a programmer can chooseto use shared memory directly instead of RMA within eachSMP node. This is quite feasible because ARMCI_Mallocallocates shared memory. On shared memory systems,RMA operations such as put/get are implemented asmemory copies. These copies in some circumstances canbe avoided by accessing shared data directly. For exam-ple, this technique was used in (Krishnan and Nieplocha
2004) to optimize performance of the parallel matrix mul-tiplication.
ARMCI provides system configuration informationthrough a set of interfaces that recursively define commu-nication domains. For example, on a cluster with SMPnodes, there are two communication domains—sharedmemory within the SMP node and network domainbetween the nodes. For such a system, the programmercan determine logical assignment and proximity of taskswithin each SMP node and take advantage of shared mem-ory communication, thus avoiding the memory copy. Ascalable shared memory system, such as SGI Altix, is rep-resented by a single shared memory domain. Similarly,on the Cray X1, the memory allocated by ARMCI can beused directly through the load/store operations, thusavoiding the overhead of the function calls and increasingthe opportunities for code vectorization. However, becauseremote shared memory on the X1 is not cacheable, copyingremote data to a local buffer (e.g. using ARMCI_Get) mightimprove performance for some applications (Krishnan andNieplocha 2004).
The information on the system and task locality infor-mation are determined by ARMCI at the startup timebased on the hostname and other information and isexploited internally to choose the underlying communi-cation protocol ((Nieplocha, Ju, and Straatsma 2000). Forexample, on clusters with SMP nodes, ARMCI does notuse network communication protocols when transferringdata between tasks residing on the same node.
3.6 Other Interfaces
In addition to the RMA interfaces, and primarily for inter-nal use, ARMCI includes a small set of collective message-passing operations, including broadcast, reduce, allreduce,and barrier. In most cases, these operations are imple-mented as wrappers to collectives in the message-passinglibrary with which ARMCI is running. However, whenimplemented independently using shared memory andRMA operations, on some platforms they can deliverperformance competitive to MPI (Tipparaju, Nieplocha,and Panda 2003).
4 Latency Hiding Mechanisms
The gap between processor and network communicationperformance (especially with respect to latency) has beengrowing despite the impressive progress in high-perform-ance interconnect technology achieved during the lastdecade. For example, in 1990 on the NCUBE/2 massivelyparallel system employing a 2 Mflop/s processor, themessage-passing latency ranged from 65–130 µs, depend-ing on the interface flavor. Today, the 1.5-GHz Itanium-2processor is rated at 6 Gflop/s and is employed in Linux
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

240 COMPUTING APPLICATIONS
clusters connected with networks (e.g. Myrinet) that sup-port ~10 µs latency at the MPI layer. This growing gap isnot specific to the commodity clusters. For example, theCray X1 processor is rated at 12.8 Gflop/s (MSP mode),while the MPI latency is roughly the same as on the Pen-tium-4 based Linux clusters with Myrinet. Therefore, thegrowing gap between CPU and communication latency isa fundamental problem that requires attention in the designof all layers of communication protocol stacks as well asscalable parallel algorithms.
We can address the above issue only by combiningquality implementation of the communication interfaceswith algorithms capable of exploiting available mecha-nisms for latency tolerance. Latency tolerance (or latencyhiding) can be accomplished through different techniques,including overlapping communication with computation(Strumpen and Casavant 1994) by the use of nonblockingcommunication (Culler et al. 1993; Baden and Fink 1998).Another technique is coalescing small put/get messages(i.e. aggregation) (Pham and Albrecht 1999) into largerones to eliminate startup cost (Bell et al. 2003) for asmany messages as possible and to improve network utili-zation.
4.1 Nonblocking Communication
Nonblocking operations initiate a communication calland then return control to the application. The user whowishes to exploit nonblocking communication as a tech-nique for latency hiding by overlapping communicationwith computation implicitly assumes that progress incommunication can be made in a purely computationalphase of the program execution when no communicationcalls are made. Unfortunately, that assumption is oftennot satisfied in practice—the availability of nonblockingAPI does not guarantee that overlapping communicationwith computation is always possible (White and Bova1999). Because the RMA model is simpler than MPI (e.g.it does not involve message-tag-matching or early arrivalof messages), in principle more opportunities for overlap-ping communication with computation are available.However, we found that these opportunities are not auto-matically exploited by deriving implementations of non-blocking APIs from their blocking counterparts. Forexample, the communication protocols used to optimizeblocking transfers of data from nonregistered memory bypipelined copy and network communication through a setof registered memory buffers (Nieplocha et al. 2002a) canachieve very good performance by tuning the messagefragmentation in the pipeline (Wang et al. 1998). How-ever, pipelining is not effective for nonblocking commu-nication as memory copy requires the active host CPUinvolvement and therefore reduces the potential for effec-tive overlapping communication with computation. To
increase the overlap, we expanded the use of direct (zero-copy) protocols on networks that require memory regis-tration, such as Myrinet.
In ARMCI, a return from a nonblocking operation callindicates a mere initiation of the data transfer process, andthe operation can be completed locally by making a call tothe wait routine. Waiting on a nonblocking put or anaccumulate operation ensures that data was injected intothe network and the user buffer can now be reused. Com-pleting a get operation ensures that data has arrived into theuser memory and is ready for use. A wait operation ensuresonly local completion. The library imposes a limit on thenumber of outstanding requests allowed (if necessary, itcan transparently complete an old request and free up theresources for a new request). For performance reasons (Kimand Veidenbaum 1997), ARMCI supports only a weak con-sistency for operations targeting remote memory. Unliketheir blocking counterparts, the nonblocking operations arenot ordered with respect to the destination. Performanceis one reason; the other is that by ensuring ordering, weincur additional and possibly unnecessary overhead onapplications that do not require ordered operations. Whennecessary, ordering can be done by calling a fence opera-tion, which is provided to the user to confirm remotecompletion, if needed.
4.2 Implicit and Explicit Aggregation
Aggregation of requests is another mechanism for improv-ing latency tolerance. Multiple nonblocking data transfer(put/get) requests can be aggregated into a single data trans-fer operation to improve the data transfer rate. Especiallyif there are multiple data transfer requests of small messagesizes, aggregating those requests into a single large requestreduces the latency, thus improving performance. Thistechnique is unique in its ability to sustain high band-width use and enables high throughput. Each of theserequests can be of a different size and independent of datatype. The aggregate data transfer operation is also inde-pendent of the type of put/get operation; that is, it can bea combination of regular, strided, or vector put/get opera-tions. Two types of aggregation are available: 1) explicitaggregation, where the multiple requests are combined bythe user through the use of the strided or generalized I/Ovector data descriptor, and 2) implicit aggregation, wherethe combining of individual requests is performed byARMCI.
Users can rely on a single aggregate handle to representmultiple requests. Any number of operations to/from thesame processor can use the same aggregate handle. A waiton such a handle completes all the aggregated requests.For multiple small sends, aggregating is usually muchfaster and gives better performance. Figure 8 illustrates theaggregate data transfer. It shows that the descriptors of
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

241ARMCI: REMOTE MEMORY COPY
multiple put requests are stored in an aggregate bufferand, once the wait call is issued, the data transfer is com-pleted.
5 High-Performance Implementation
The ARMCI model does not describe or assume any par-ticular implementation model (for example, threads). Oneof the primary design goals was to allow wide portabilityof the library. Another goal was to allow an implementa-tion that exploits the most efficient mechanisms availableon a given platform, which might involve active messages(von Eicken et al. 1992), native contiguous/noncontigu-ous put/get, shared memory, and/or threads. For example,depending on whatever solution delivers the best per-formance, ARMCI accumulate (atomic reduction) mightor might not have been implemented using the “ownercomputes” rule. In particular, this rule is used on IBM SPswhere accumulate is executed inside the Active Messagehandler on the processor that owns the remote data, whereason the Cray T3E the requesting processor performs thecalculations (by locking memory, copying data, accumu-lating, putting updated data back, and unlocking) withoutinterrupting the data-owner. On many clusters of work-stations, the ARMCI data server thread/process on theremote side acts as a representative of the destinationprocess. It receives the data and accumulates it into desti-nation process memory (see Section 5.1).
On shared memory systems, ARMCI_Malloc providesshared memory to the user. This approach greatly simpli-fies implementation and improves performance by allow-ing the library to use simply an optimized memory copyrather than other more costly mechanisms for movingdata between separate address spaces. This is acceptablein the libraries and compiler run-time systems we consid-ered because they are responsible for the memory alloca-
tion and can easily use ARMCI_Malloc rather than thelocal memory allocation. In addition, ARMCI provides amemory allocator for local memory (ARMCI_Malloc_local) and processor subgroups (ARMCI_Malloc_group)(Krishnan et al. 2004). ARMCI_Malloc is a collectivememory allocator, whereas ARMCI_Malloc_local workslike the standard Malloc call.
On distributed-memory platforms, ARMCI uses a combi-nation of the data server approach (described in Section 5.1)and the native remote memory copy (e.g. SHMEM onCray T3E and LAPI on IBM SP GM for Myrinet basedclusters, VAPI for Mellanox Infiniband HCA-based clus-ters). Our previous work (Nieplocha and Carpenter 1999;Nieplocha and Ju 2000; Nieplocha, Ju, and Straatsma2000; Nieplocha et al. 2002a, 2003; Tipparaju, Nieplocha,and Panda 2003; Tipparaju et al. 2004) discusses manysuch protocols and their implementations on differentplatforms. The ARMCI ports on shared memory systemsare based on the shared memory operations (Unicos sharedmemory on the Cray J90 and Cray X1, System V on otherUnix systems, and memory mapped files on Windows NT)and optimized remote memory copies for noncontiguousdata transfers. Mutual exclusion is implemented usingvendor-specific locks (on SGI, HP, Sun, Linux/Intel, Cray-J90), System V semaphores (remaining Unix systems), orthread mutexes (Windows NT).
5.1 Thin-Wrapper vs Data Server
The preferred way of implementation is if the functional-ity required by an ARMCI call is directly provided to it bythe native communication layer. In that case, the call isimplemented as a thin wrapper to the correspondingnative communication call (Figure 9). On some platforms,
Fig. 8 Implicit aggregate data transfer.
Fig. 9 Addressing portability in ARMCI implementa-tions.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

242 COMPUTING APPLICATIONS
native communication protocols are limited in their abil-ity to provide all the functionality ARMCI delivers to itsusers.
On platforms with limited/no support for one-sidedoperations, an extra “data server” process (Unix) or threadis forked on each cluster node to service communicationrequests from its clients, i.e. user MPI tasks (see Figure 10).To prevent server thread/process in the absence of one-sided communication requests from consuming resourcesneeded by the user processes, special care is needed toreduce CPU use by using blocking wait as a default ratherthan active polling of the network interfaces. ARMCIdoes not rely on a polling operation but gives the user anoption to enable polling versus blocking on the data serveras a compile-time choice. In addition, if ARMCI detectsextra processing resources, it enables polling because itdoes impact the overall application performance, thanksto the sufficient CPU resources.
5.2 Multiple Communication Protocols
ARMCI has to work around several system and network-specific constraints in its design of efficient communica-tion protocols on several platforms. To deliver good per-formance despite the constraints, ARMCI implements andswitches between many communication protocols basedon a few system/network-specific parameters. One of thebiggest platform-specific constraints is the requirementby network protocols such as GM and Infiniband to havethe memory they send-from/receive-to to be registered.Unfortunately, for many systems on which these networkcards are used, the cost of registration/deregistration isvery high and the amount of memory that can be regis-tered/locked is limited. This constraint has a profoundimpact on the implementation strategies of user-level RMA
on this network. ARMCI uses three techniques to addressthe requirement for registered memory: 1) copying datavia preallocated registered memory buffers (we refer tothis as the host-based/buffered technique); 2) providingon-demand dynamic memory registration and deregistra-tion (or lazy deregistration) as a part of the data transfer;and 3) providing the user with a memory-allocation inter-face that allocates registered memory underneath.
5.2.1 Host-based/buffered baseline and pipelined pro-tocols The host-based/buffered protocols involve move-ment of data from/to pre-allocated buffers. On systemswhere the network can move data only from registeredmemory, these buffers are registered on allocation. Fornoncontiguous operations, the noncontiguous chunks ofdata are packed into these pre-allocated buffers and sentto a buffer on the remote side, where they are unpackedand copied into the destination by the data server thread.The ARMCI Put data-transfer operation illustrates howthe basic (referred to as baseline) and pipelined host-based/buffered protocols are designed.
ARMCI Put comprises three phases (see Figure 11). 1)A data copy is sent from the source data to the messagesend buffer (a pre-pinned, pre-allocated buffer, allocatedwhen ARMCI is initialized), which we represent as theCOPYS phase. This copy is done in chunks of the sizes ofthe message send buffer. 2) In the actual data-transmis-sion phase, the gm_send_with_callback function is usedto transmit data in the message send buffer to the destina-tion. In this phase, the data from the message send bufferat the source node is DMAed to a receive buffer at thedestination node. This phase is represented as the XMITand RECV phase, where XMIT stands for an operationperformed at the sender NIC to DMA the data and RECVrepresents an operation performed at the receiver toreceive the data into a receive buffer. 3) The data is cop-ied to the destination memory location from the receivebuffer at the destination side, which is represented as theCOPYR phase.
We have designed and implemented a pipelined ver-sion of the ARMCI put operation, essentially pipeliningboth the receiver and the sender side. In the pipeline, weoverlap the XMIT and the COPYS phase as well as theRECV and the COPYR phase. The pipelined implemen-tation has multiple send and receive buffers. Hence, theCOPYS phase here is overlapped with the XMIT and theCOPYR phase overlapped with RECV. Instead of copy-ing one chunk of data, transmitting it, and then waitingfor an acknowledgement, we maintain a set of send buff-ers. Our analysis after timing the COPYS and the XMITphase shows that the ratio of time taken in the XMITphase to the time taken in the COPYS phase is between 1and 3 for most message sizes. This implies that two buff-ers would be enough in most cases to efficiently fill the
Fig. 10 Client-server architecture of ARMCI.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

243ARMCI: REMOTE MEMORY COPY
pipeline and optimize the pipelined algorithm perform-ance.
ARMCI Get is implemented along similar lines. Figure 12shows the implementation of the host-based/buffered Getprotocol in ARMCI on platforms where contiguous DMAPut is supported but DMA Get is not. The client that needsto do the Get sends a request (Step 1) to the remote node.The data server thread/process on the remote node receivesthe request (Step 2). Here, the data server on the remoteside can take two paths, depending on if it can directlyDMA from the user data on its side (see Option A in Fig-ure 12) or not (Option B in Figure 12). For cases when theGet request is for non-contiguous data, even if the userdata is indirectly DMAable, it might not always be possi-ble to DMA it. For cases when the data on the remote sidecan directly be DMAed without being copied, the dataserver DMAs from the user buffer (Step 3, Option B in
Figure 12). For cases when the data cannot be directlyDMAed from the user buffer, the data server copies thedata into an internal DMAable buffer (Step 3, Option A inFigure 12) and then DMAs it from the internal buffer tothe internal buffer on the client. The client, on receipt ofthe data into its internal buffer, moves it into the destination.This protocol requires a copy on both sides. By breakingthe message into chunks and moving data from one chunkwhile the previous chunk is being copied, a significantpercentage of the copy cost is hidden. By overlapping thedata copy with data transmission, and breaking up themessage in such a way that the first chunk is smaller thanthe rest, this copy-based protocol hides some of the costassociated with copying the data by overlapping it withthe reception of the next chunk (Nieplocha et al. 2003).On systems where the copy bandwidth is higher than net-work bandwidth, the copy of the current chunk may be
Fig. 11 Timeline of a host-based/buffered pipelined Put protocol.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

244 COMPUTING APPLICATIONS
completed while the next chunk is arriving. However, thisscheme is useful when data cannot be registered or if theuser data is in small noncontiguous chunks. An analysisof performance to be expected with this method is done in(Nieplocha et al. 2003).
5.2.2 On-demand dynamic memory registration pro-tocols Many communication protocols such as GM, VIA,InfiniBand, and Hitachi-RDMA can send/receive from onlyregistered memory because of the way network cards work.The cost of registration is platform/OS-specific and isusually high. Because the registered memory cannot beswapped out by the operating system, there is also a limiton how much memory can be registered at a given time(hence, registering the entire memory in the system is not anoption on machines with virtual memory). For messagesizes where registration is cheaper than copying the data,ARMCI switches to a protocol that registers/unregistersthe user memory dynamically. This on-demand registrationis particularly useful when the data size to be transmitted islarge and contiguous. ARMCI sends a message to theremote-side data server to register the destination mem-ory, meanwhile attempting to register the local memory.After an acknowledgement from the remote side that theregistration was successful, the data transfer is completedas a direct/zero-copy data transfer (Nieplocha et al. 2002a).
5.2.3 Zero-copy/host-assisted zero-copy protocolsBy providing interfaces to allocate registered memoryand using on-demand dynamic memory registration,
ARMCI attempts to use zero-copy protocols whereverpossible and beneficial. Another extension to the zero-copy protocols is useful on networks that do not supportRDMA Read or have limited-performance or low-perform-ance RDMA Read (e.g. SCI). The client doing the getoperation sends a request to the helper thread on the remotenode. The helper thread, upon receiving a get request, ini-tiates a RDMA put and then resumes polling/blocking.As a result, request processing overhead on the remotehost is very little. We verified the effectiveness of thisapproach on the Myrinet GM 1.6 (Myricom 1999). TheARMCI Get latency dropped from 27 µs to 24 µs by usingthe host-assisted approach. Get bandwidth improved from198 MB for copy based protocol to 244 MBps for host-assisted zero-copy contiguous get, thereby showing thatthis approach is not just high-performance but also adap-tive to the platforms that do not have support for RDMAread.
This host-assisted zero-copy approach is a little moreinvolved for noncontiguous data transfers. This approachfor noncontiguous data transfers can be implementedonly on networks that provide some limited noncontigu-ous data transfer functionality (e.g. VIA, IBA VAPI non-contiguous send/recv). Because a noncontiguous datatransfer would involve transfer of multiple segments ofdata, our strategy is to use the scatter/gather message-passing feature where available (e.g. IBA) to achieve thezero-copy transfer (Tipparaju et al. 2004). For a host-assisted zero-copy get (Figure 13), the source node postsa scatter-receive descriptor to receive the vector/strided
Fig. 12 Host-based/buffered pipelined Get protocol.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

245ARMCI: REMOTE MEMORY COPY
data and then sends a request to the remote host with theremote stride/vector information. The helper thread onthe remote host receives the request and then posts a cor-responding VAPI gather-send by converting the stride/vector information in the request message into a VAPIgather-send descriptor.
6 Experimental Evaluation
In this section, we present experimental results demon-strating the performance of ARMCI in the context of twoclasses of microbenchmarks. One class illustrates theperformance of ARMCI operations by comparing themto the native communication protocols and MPI and meas-uring certain characteristics, such as the potential foroverlapping communication with computations or theeffectiveness of aggregation. The second class shows theperformance of ARMCI implementation of two applica-tion kernels: NAS Multi-Grid (MG) and sparse matrixvector multiplication. The purpose in this case is to dem-onstrate the performance improvement ARMCI can deliverto applications. The four platforms on which these bench-marks were run are as follows:
• a dual processor 1-GHz Itanium2 cluster with Mel-lanox A1 “Cougar” cards at Pacific Northwest NationalLaboratory (PNNL), hereafter referred to as the Infini-band cluster;
• a dual processor 1.5-GHz Itanium2 processor clusterwith Quadrics Elan4 cards, the supercomputer at PNNL,hereafter referred to as the Elan4 cluster;
• a dual processor 2.4-GHz Pentium-4 Linux cluster withMyrinet-2000 (M3F-PCI64C-2 cards) at the State Uni-
versity of New York at Buffalo, hereafter referred to asthe Myrinet cluster;
• a Cray X1 massively parallel vector supercomputer atOak Ridge National Laboratory.
ARMCI Put/Get latency on these platforms is shown inTable 1.
6.1 ARMCI Microbenchmarks
The first benchmark is designed to demonstrate theperformance of ARMCI Put and Get operations. It alsodemonstrates the effectiveness of the low-overheadimplementation of these operations over the native com-munication protocols.
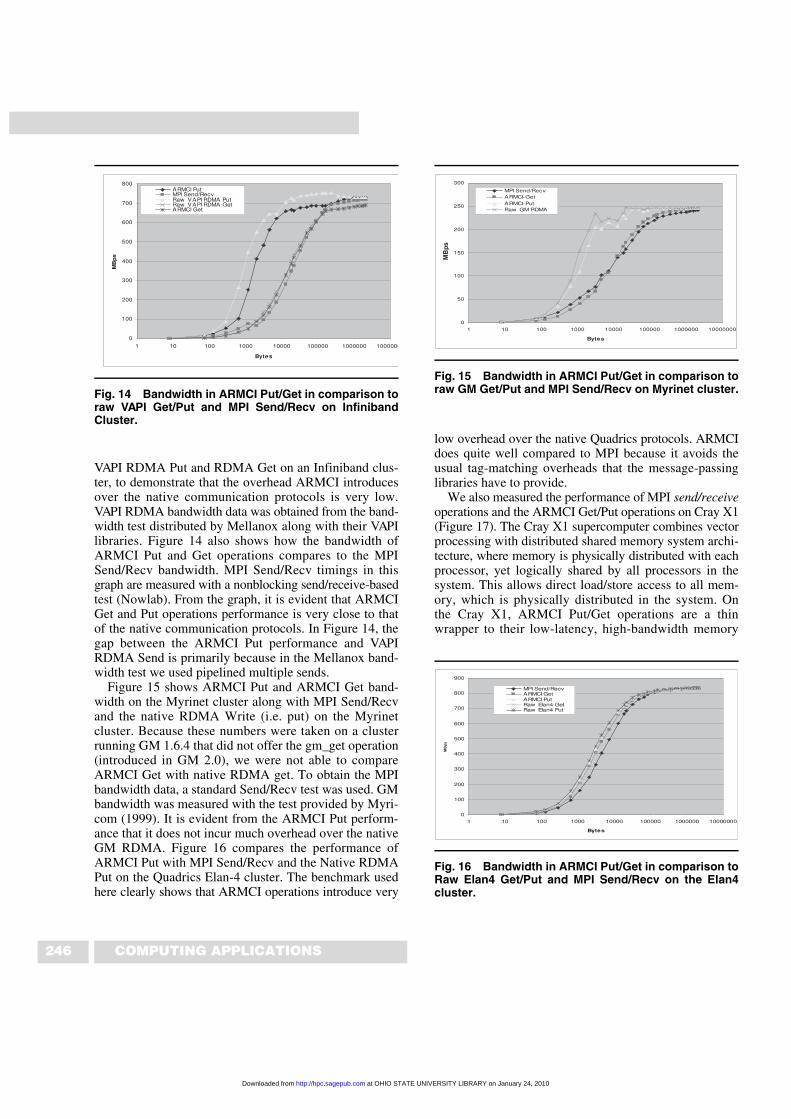
Figure 14 shows ARMCI Put and ARMCI Get band-width on the Infiniband cluster. ARMCI’s port over Infini-band has been written on top of Mellanox VAPI, which isbased on Infiniband Verbs (InfiniBand Trade Associa-tion 2000). Hence Figure 14 also shows the bandwidth of
Fig. 13 Host assisted Get protocol for noncontiguous data.
Table 1ARMCI Put/Get latency on various platforms
Network Protocol Latency
Put (microseconds)
Latency Get
(microseconds)
Myrinet Cluster 12.8 17.8
Cray X1 2.0 2.1
Elan4 cluster 2.45 4.56
Infiniband Cluster 7.4 16.0
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from
246 COMPUTING APPLICATIONS
VAPI RDMA Put and RDMA Get on an Infiniband clus-ter, to demonstrate that the overhead ARMCI introducesover the native communication protocols is very low.VAPI RDMA bandwidth data was obtained from the band-width test distributed by Mellanox along with their VAPIlibraries. Figure 14 also shows how the bandwidth ofARMCI Put and Get operations compares to the MPISend/Recv bandwidth. MPI Send/Recv timings in thisgraph are measured with a nonblocking send/receive-basedtest (Nowlab). From the graph, it is evident that ARMCIGet and Put operations performance is very close to thatof the native communication protocols. In Figure 14, thegap between the ARMCI Put performance and VAPIRDMA Send is primarily because in the Mellanox band-width test we used pipelined multiple sends.
Figure 15 shows ARMCI Put and ARMCI Get band-width on the Myrinet cluster along with MPI Send/Recvand the native RDMA Write (i.e. put) on the Myrinetcluster. Because these numbers were taken on a clusterrunning GM 1.6.4 that did not offer the gm_get operation(introduced in GM 2.0), we were not able to compareARMCI Get with native RDMA get. To obtain the MPIbandwidth data, a standard Send/Recv test was used. GMbandwidth was measured with the test provided by Myri-com (1999). It is evident from the ARMCI Put perform-ance that it does not incur much overhead over the nativeGM RDMA. Figure 16 compares the performance ofARMCI Put with MPI Send/Recv and the Native RDMAPut on the Quadrics Elan-4 cluster. The benchmark usedhere clearly shows that ARMCI operations introduce very
low overhead over the native Quadrics protocols. ARMCIdoes quite well compared to MPI because it avoids theusual tag-matching overheads that the message-passinglibraries have to provide.
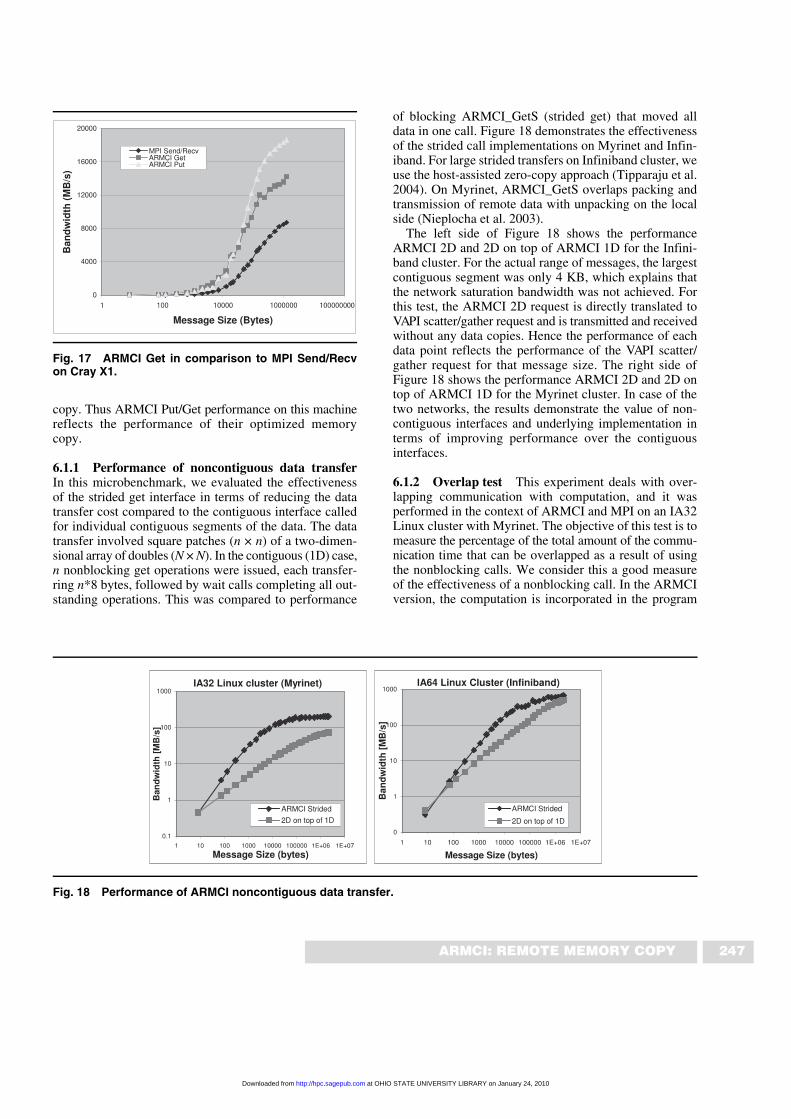
We also measured the performance of MPI send/receiveoperations and the ARMCI Get/Put operations on Cray X1(Figure 17). The Cray X1 supercomputer combines vectorprocessing with distributed shared memory system archi-tecture, where memory is physically distributed with eachprocessor, yet logically shared by all processors in thesystem. This allows direct load/store access to all mem-ory, which is physically distributed in the system. Onthe Cray X1, ARMCI Put/Get operations are a thinwrapper to their low-latency, high-bandwidth memory
Fig. 14 Bandwidth in ARMCI Put/Get in comparison toraw VAPI Get/Put and MPI Send/Recv on InfinibandCluster.
Fig. 15 Bandwidth in ARMCI Put/Get in comparison toraw GM Get/Put and MPI Send/Recv on Myrinet cluster.
Fig. 16 Bandwidth in ARMCI Put/Get in comparison toRaw Elan4 Get/Put and MPI Send/Recv on the Elan4cluster.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from
247ARMCI: REMOTE MEMORY COPY
copy. Thus ARMCI Put/Get performance on this machinereflects the performance of their optimized memorycopy.
6.1.1 Performance of noncontiguous data transferIn this microbenchmark, we evaluated the effectivenessof the strided get interface in terms of reducing the datatransfer cost compared to the contiguous interface calledfor individual contiguous segments of the data. The datatransfer involved square patches (n × n) of a two-dimen-sional array of doubles (N × N). In the contiguous (1D) case,n nonblocking get operations were issued, each transfer-ring n*8 bytes, followed by wait calls completing all out-standing operations. This was compared to performance
of blocking ARMCI_GetS (strided get) that moved alldata in one call. Figure 18 demonstrates the effectivenessof the strided call implementations on Myrinet and Infin-iband. For large strided transfers on Infiniband cluster, weuse the host-assisted zero-copy approach (Tipparaju et al.2004). On Myrinet, ARMCI_GetS overlaps packing andtransmission of remote data with unpacking on the localside (Nieplocha et al. 2003).
The left side of Figure 18 shows the performanceARMCI 2D and 2D on top of ARMCI 1D for the Infini-band cluster. For the actual range of messages, the largestcontiguous segment was only 4 KB, which explains thatthe network saturation bandwidth was not achieved. Forthis test, the ARMCI 2D request is directly translated toVAPI scatter/gather request and is transmitted and receivedwithout any data copies. Hence the performance of eachdata point reflects the performance of the VAPI scatter/gather request for that message size. The right side ofFigure 18 shows the performance ARMCI 2D and 2D ontop of ARMCI 1D for the Myrinet cluster. In case of thetwo networks, the results demonstrate the value of non-contiguous interfaces and underlying implementation interms of improving performance over the contiguousinterfaces.
6.1.2 Overlap test This experiment deals with over-lapping communication with computation, and it wasperformed in the context of ARMCI and MPI on an IA32Linux cluster with Myrinet. The objective of this test is tomeasure the percentage of the total amount of the commu-nication time that can be overlapped as a result of usingthe nonblocking calls. We consider this a good measureof the effectiveness of a nonblocking call. In the ARMCIversion, the computation is incorporated in the program
Fig. 17 ARMCI Get in comparison to MPI Send/Recvon Cray X1.
Fig. 18 Performance of ARMCI noncontiguous data transfer.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

248 COMPUTING APPLICATIONS
in the form of a delay. An increasing amount of computa-tion is gradually inserted between the initiating nonblockingget call and the wait completion call. As we keep increas-ing the computation, at some point the sum of the non-blocking call issue overhead and computation wouldexceed the idle CPU time, and hence the total benchmarkrunning time would increase. This point gives us themaximum possible overlap. We performed this experi-ment on two nodes with one node issuing the nonblock-ing get for data located on the other, and then waiting forthe transfer to be completed in the ARMCI_Wait call.The timings were averaged over 1000 iterations. Wehave measured the performance of this microbenchmarkfor ARMCI direct and buffered protocols. For the directprotocols, no copy is required on local or remote side andhence the remote side overhead just involves initiation ofdata transfer. For the buffered protocols, when remotememory is registered and contiguous, processing on theremote side does not involve any copies. However, if theremote memory is not registered, a cost of copying datainto a registered buffer is incurred on the remote side(Tipparaju et al. 2004). We also implemented an MPIversion of the above benchmark because our motivationwas to compare the percentage of the total data transfertime available to the application to do computation bothin ARMCI and in the MPI nonblocking send/receiveoperations. In MPI, if the node needs a portion of datafrom another node, it sends a request and waits on a non-blocking receive for the response. We measured the com-putation overlap for both the ARMCI and the MPIversions of the benchmark, and the results are plotted inFigure 19.
We observe that on Myrinet, ARMCI offers a higherlevel of overlap than MPI. The buffered protocol is able
to achieve about 90% overlap. For large messages, thispercentage drops because of time involved in copying tothe destination buffer. In the direct protocol, we are ableto overlap almost the entire time (greater than 99%)except the time involved in issuing the nonblocking get.The difference between two protocols also represents theoverhead the buffered protocol imposes on the remoteside. The MPI version does reasonably well up to mes-sage size 16 kb. At 16 kb and beyond, the MPI imple-mentation switches to rendezvous protocol. This has aserious impact on the computation overlap because thehandshake involved in the protocol occurs in MPI_Wait.Hence, the only part that can be overlapped is until thereceipt of “request to send” and not until the actual datatransfer is completed. There have been several studiestrying to analyze and benchmark the MPI overlap. Theexperimental results illustrating limited opportunities foroverlapping communication and computation are con-sistent with findings reported for multiple MPI imple-mentations in Liu et al. (2003), White and Bova (1999)and Lawry et al. (2002). White and Bova (1999) describesome experiments to analyze and test the overlap forbasic asynchronous MPI calls for MPI implementationon different platforms. Another related paper (Lawry etal. 2002) provides a portable benchmark suite for assess-ing overlap. One of the methods relies on polling toadvance progress, and the authors use another metric,availability, for their assessment. Our benchmark doesnot introduce additional MPI library calls for makingprogress, looks for plain overlap performance gains, andis probably more representative of how real applicationsuse nonblocking communication.
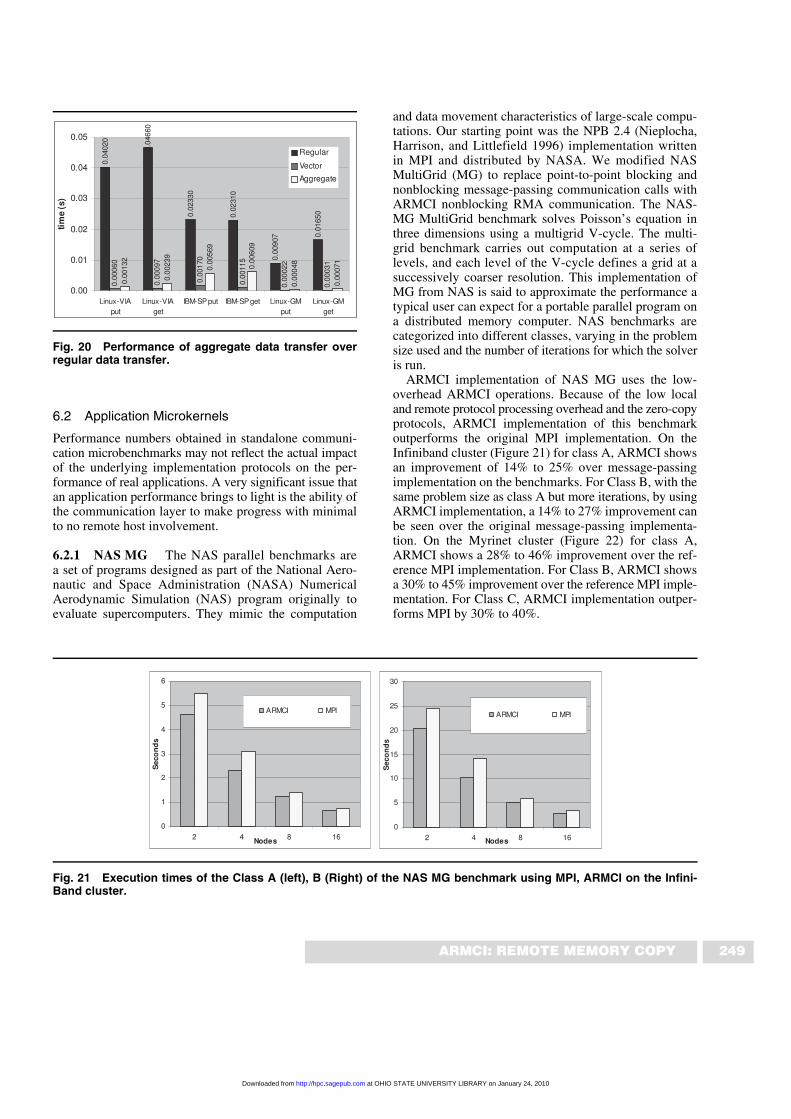
6.1.3 Aggregation test A simple benchmark test waswritten to compare the performance of regular, vector,and implicit aggregate put/get operations. In the test,1000 values of type double located in nonadjacent mem-ory locations were transferred using 1000 calls to regularnonblocking put and get calls, with and without enablingaggregation. Also, 1000 doubles were stored in a vectordescriptor and transferred in a single vector operation tomeasure the overhead of the aggregation over the singlevector call. The experiments were performed on the 500-MHz Pentium-III Linux cluster with Giganet cLAN(VIA) at PNNL, a Power-3 IBM-SP at NERSC, and aPentium-4 Linux cluster with Myrinet at SUNY Buffalo.Figure 20 shows that aggregation is helpful in reducingthe data transfer time over the regular put/get operationin all cases. This is primarily because aggregation avoidsthe cost involved in sending multiple small requests andhence avoids protocol processing and calls initiationcosts. The graph also indicates that aggregating multipledata transfer requests performs almost as well as a singlevector operation.
Fig. 19 Percentage computation overlap for increas-ing message sizes for MPI and ARMCI direct (zero-copy) and buffered-pipelined (Section 5.2.1) proto-cols.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from
249ARMCI: REMOTE MEMORY COPY
6.2 Application Microkernels
Performance numbers obtained in standalone communi-cation microbenchmarks may not reflect the actual impactof the underlying implementation protocols on the per-formance of real applications. A very significant issue thatan application performance brings to light is the ability ofthe communication layer to make progress with minimalto no remote host involvement.
6.2.1 NAS MG The NAS parallel benchmarks area set of programs designed as part of the National Aero-nautic and Space Administration (NASA) NumericalAerodynamic Simulation (NAS) program originally toevaluate supercomputers. They mimic the computation
and data movement characteristics of large-scale compu-tations. Our starting point was the NPB 2.4 (Nieplocha,Harrison, and Littlefield 1996) implementation writtenin MPI and distributed by NASA. We modified NASMultiGrid (MG) to replace point-to-point blocking andnonblocking message-passing communication calls withARMCI nonblocking RMA communication. The NAS-MG MultiGrid benchmark solves Poisson’s equation inthree dimensions using a multigrid V-cycle. The multi-grid benchmark carries out computation at a series oflevels, and each level of the V-cycle defines a grid at asuccessively coarser resolution. This implementation ofMG from NAS is said to approximate the performance atypical user can expect for a portable parallel program ona distributed memory computer. NAS benchmarks arecategorized into different classes, varying in the problemsize used and the number of iterations for which the solveris run.
ARMCI implementation of NAS MG uses the low-overhead ARMCI operations. Because of the low localand remote protocol processing overhead and the zero-copyprotocols, ARMCI implementation of this benchmarkoutperforms the original MPI implementation. On theInfiniband cluster (Figure 21) for class A, ARMCI showsan improvement of 14% to 25% over message-passingimplementation on the benchmarks. For Class B, with thesame problem size as class A but more iterations, by usingARMCI implementation, a 14% to 27% improvement canbe seen over the original message-passing implementa-tion. On the Myrinet cluster (Figure 22) for class A,ARMCI shows a 28% to 46% improvement over the ref-erence MPI implementation. For Class B, ARMCI showsa 30% to 45% improvement over the reference MPI imple-mentation. For Class C, ARMCI implementation outper-forms MPI by 30% to 40%.
Fig. 20 Performance of aggregate data transfer overregular data transfer.
Fig. 21 Execution times of the Class A (left), B (Right) of the NAS MG benchmark using MPI, ARMCI on the Infini-Band cluster.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from
250 COMPUTING APPLICATIONS
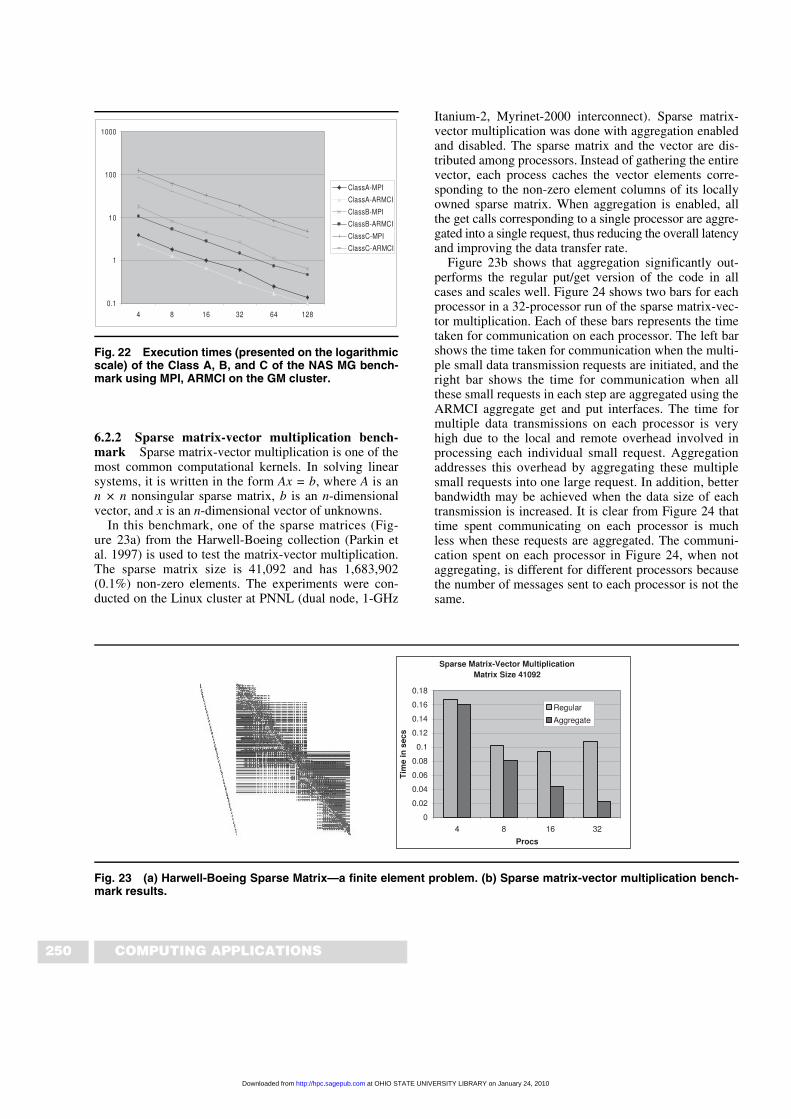
6.2.2 Sparse matrix-vector multiplication bench-mark Sparse matrix-vector multiplication is one of themost common computational kernels. In solving linearsystems, it is written in the form Ax = b, where A is ann × n nonsingular sparse matrix, b is an n-dimensionalvector, and x is an n-dimensional vector of unknowns.
In this benchmark, one of the sparse matrices (Fig-ure 23a) from the Harwell-Boeing collection (Parkin etal. 1997) is used to test the matrix-vector multiplication.The sparse matrix size is 41,092 and has 1,683,902(0.1%) non-zero elements. The experiments were con-ducted on the Linux cluster at PNNL (dual node, 1-GHz
Itanium-2, Myrinet-2000 interconnect). Sparse matrix-vector multiplication was done with aggregation enabledand disabled. The sparse matrix and the vector are dis-tributed among processors. Instead of gathering the entirevector, each process caches the vector elements corre-sponding to the non-zero element columns of its locallyowned sparse matrix. When aggregation is enabled, allthe get calls corresponding to a single processor are aggre-gated into a single request, thus reducing the overall latencyand improving the data transfer rate.
Figure 23b shows that aggregation significantly out-performs the regular put/get version of the code in allcases and scales well. Figure 24 shows two bars for eachprocessor in a 32-processor run of the sparse matrix-vec-tor multiplication. Each of these bars represents the timetaken for communication on each processor. The left barshows the time taken for communication when the multi-ple small data transmission requests are initiated, and theright bar shows the time for communication when allthese small requests in each step are aggregated using theARMCI aggregate get and put interfaces. The time formultiple data transmissions on each processor is veryhigh due to the local and remote overhead involved inprocessing each individual small request. Aggregationaddresses this overhead by aggregating these multiplesmall requests into one large request. In addition, betterbandwidth may be achieved when the data size of eachtransmission is increased. It is clear from Figure 24 thattime spent communicating on each processor is muchless when these requests are aggregated. The communi-cation spent on each processor in Figure 24, when notaggregating, is different for different processors becausethe number of messages sent to each processor is not thesame.
Fig. 22 Execution times (presented on the logarithmicscale) of the Class A, B, and C of the NAS MG bench-mark using MPI, ARMCI on the GM cluster.
Fig. 23 (a) Harwell-Boeing Sparse Matrix—a finite element problem. (b) Sparse matrix-vector multiplication bench-mark results.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

251ARMCI: REMOTE MEMORY COPY
7 Conclusions
This paper described ARMCI, a high-performance portablecommunication library that specializes in remote memoryaccess communication. The paper described the approachand differences between ARMCI and other systems thatprovide RMA communication. The distinguishing featuresof ARMCI are simple progress rules, availability of opti-mized interfaces for noncontiguous data transfers, wide-spread portability, and high performance delivered througha combination of different protocols and methods selectedon individual platforms. The targeted use for ARMCI isdevelopment of libraries and run-time systems rather thanend-user applications. In this context, ARMCI was shown todeliver performance that closely matched that of the nativelow-level communication protocols while providing a port-able interface. In addition to being used for optimizing theperformance of application kernels, the ARMCI libraryhas been found useful for developing and supporting Glo-bal Arrays, portable SHMEM, and portable Co-ArrayFortran compilers. For the last five years, it has been usedsuccesfully (directly and indirectly) in large and complexapplications running on a variety of modern platforms.
Acknowledgments
This work was performed under the auspices of the U.S.Department of Energy (DOE) at Pacific Northwest NationalLaboratory (PNNL). It was supported by the DOE 2000
ACTS project of the Center for Programming Models forScalable Parallel Computing, both sponsored by the Math-ematical, Information, and Computational Science Divi-sion of the DOE Office of Computational and TechnologyResearch and the William R. Wiley Environmental Molec-ular Sciences Laboratory. PNNL is operated by Battellefor DOE under Contract DE-AC05-76RL01830.
Authors Biographies
Dr. Jarek Nieplocha is a Laboratory Fellow and thetechnical group leader of the Applied Computer ScienceGroup in Computational Sciences and Mathematics Divi-sion of the Fundamental Science Division at PacificNorthwest National Laboratory (PNNL). He is also theChief Scientist for High Performance Computing in Com-putational Sciences and Mathematics Division. His areaof research has been in techniques for optimizing collec-tive and one-sided communication operations on modernnetworks, runtime systems, parallel I/O, and scalable pro-gramming models. He received four best paper awards atleading conferences in high performance computing:IPDPS’03, Supercomputing’98, IEEE High PerformanceDistributed Computing HPDC-5, and IEEE Cluster’03conference, and an R&D-100 award. He authored and coau-thored over 70 peer reviewed papers. Dr. Nieplocha par-ticipated in MPI Forum in defining the MP-2 standard. Heis also a member of editorial board of International Jour-nal of Computational Science and Engineering.
Fig. 24 Time spent on communication on each processor in the sparse matrix vector multiplication in a 32-proces-sor case.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

252 COMPUTING APPLICATIONS
Manojkumar Krishnan is a senior research scientistin the Applied Computer Science Group, ComputationalSciences and Mathematics Division of Pacific NorthwestNational Laboratory. Krishnan’s research interests includehigh-performance computing, parallel algorithms, run-time systems, HPC programming models, and interproc-essor communications. Krishnan is working with theHigh Performance Computing group at Pacific NorthwestNational Laboratory towards the research and developmentof the Global Arrays toolkit, ARMCI, and Common Com-ponent Architecture. Krishnan authored and co-authoredmore than 20 peer-reviewed conference and journalpapers.
Vinod Tipparaju is one of the key developers ofARMCI and Global Arrays in the Applied Computer Sci-ence team at the Pacific Northwest National Laboratory.Vinod has played a key role in porting, maintaining andoptimizing ARMCI on to many new networks and plat-forms. His recent research includes an extensive study onutilizing network concurrency and RMA in collectivecommunication operations and fault tolerant run-timesystems. Vinod Tipparaju received his Bachelors of Tech-nology in Computer Science from Nagarjuna Universityand his Masters in Computer Science from the Ohio StateUniversity. Vinod has authored several papers in the HPCarea.
Dhabaleswar K. (DK) Panda is a Professor of Compu-ter Science at the Ohio State University. His researchinterests include parallel computer architecture, high per-formance networking, and network-based computing. Hehas published over 160 papers in these areas. His researchgroup is currently collaborating with National Laborato-ries and leading companies on designing various commu-nication and I/O subsystems of next generation HPCsystems and datacenters with modern interconnects. TheMVAPICH (MPI over VAPI for InfiniBand) package devel-oped by his research group (http://nowlab.cis.ohio-state.edu/projects/mpi-iba/) is being used by more than 180organizations world-wide to extract the potential of Infin-iBand-based clusters for HPC applications. Dr. Panda is arecipient of the NSF CAREER Award, OSU LumleyResearch Award (1997 and 2001), and an Ameritech Fac-ulty Fellow Award. He is a senior member of IEEE Com-puter Society and a member of ACM.
Note1 Tipparaju et al. (2004) describe a so-called host-assisted
approach that supports noncontiguous data transfer with zero-copy characteristics on Infiniband.
2 LAPI on the IBM SP can be configured so that polling might berequired for progress.
References
Baden, S. B. and Fink, S. J. 1998. Communication overlap inmulti-tier parallel algorithms. Proceedings of Supercom-puting, Orlando, FL, November.
Bariuso, R. and Knies, A. 1994. SHMEM’s User’s Guide, CrayResearch, Inc., SN-2516, rev. 2.2.
Barker, K., Chrisochoides, N., Dobbelaere, J., Nave, D., andPingali, K. 2002. Data movement and control substrate forparallel adaptive applications. Concurrency Practice andExperience 14:77–101.
Bell, C., Bonachea, D., Cote, Y., Duell, J., Hargrove, P., Hus-bands, P., Iancu, C., Welcome, M., and Yelick, K. 2003.An evaluation of current high-performance networks.Proceedings of 17th IPDPS.
Bhoedjang, R. A. F., Ruhl, T., and Bal, H. E. 1998. EfficientMulticast on Myrinet Using Link-Level Flow Control.Proceedings of the 27th International Conference on Par-allel Processing (ICPP’98), pp 381–390, August.
Blackford, L. S. et al. 1997. ScaLAPACK Users’ Guide. Societyfor Industrial and Applied Mathematics.
Bonachea, D. 2002. GASNet Specification. Spec v1.1. U.C.Berkeley Tech Report. UCB/CSD-02-1207.
Bonachea, D. and Duell, J. 2003. Problems with using MPI 1.1and 2.0 as compilation targets for parallel language imple-mentations. 2nd Workshop on Hardware/Software Sup-port for High Performance Scientific and EngineeringComputing, SHPSEC-PACT.
Compaq Computer Corp., Intel Corp., and Microsoft Corp.1997. Virtual interface architecture specification, Decem-ber 1997.
Culler, D., Keeton, K., Liu, L., T. Mainwaring, A., Martin, R.,Rodrigues, S., Wright, K., and Yoshikawa, C. 1994. TheGeneric Active Message Interface Specification. Techni-cal Report, UC Berkeley.
Culler, E., Dusseau, A., Goldstein, S., Krishna-murthy, A.,Lumetta, S., Eicken, T., and Yelick, K. 1993. Parallel pro-gramming in Split C. Proceedings of Supercomputing.
Dubois, M., Scheurich, C., and Briggs, F. 1986. Memory accessbuffering in multiprocessors. Proceedings of the 13thAnnual International Symposium on Computer Architec-ture, pp 434–442, June.
Gao, G. R. and Sarkar, V. 2000. Location Consistency-A NewMemory Model and Cache Consistency Protocol. IEEETrans. Computers 49(8):798–813.
Gropp, W., Huss-Lederman, S., Lumsdaine, A., Lusk, E., Nitz-berg, B., Saphir, W., and Snir, M. 1998. MPI – The Com-plete Reference, volume 2, The MPI Extensions, MITPress.
InfiniBand Trade Association. 2000. InfiniBand ArchitectureSpecification, Release 1.0, October 24 2000. http://www.infinibandta.org/home
Kim, S. and Veidenbaum, A. V. 1997 The effect of limitednetwork bandwidth and its utilization by latency hidingtechniques in large-scale shared memory systems. Pro-ceedings of PACT’97.
Krishnan M. and Nieplocha, J. 2004. A Matrix MultiplicationAlgorithm Suitable for Clusters and Scalable SharedMemory Systems. In proceedings of the International Par-
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from

253ARMCI: REMOTE MEMORY COPY
allel and Distributed Computing Symposium IPDPS’04,Santa Fe, NM.
Krishnan, M., Tipparaju, V., Palmer, B., and Nieplocha, J. 2004.Processor-Group Aware Runtime Support for Shared- andGlobal-Address Space Models. 3rd Workshop on Compileand Runtime Techniques for Parallel Computing, Interna-tional Conference on Parallel Processing.
Lawry, B., Wilson, R., Maccabe, A. B., and Brightwell, R.2002. COMB: A Portable Benchmark Suite for AssessingMPI Overlap. Proceedings of IEEE Cluster’02.
Liu, J., Chandrasekaran, B., Jiang, J. W. W., Kini, S., Yu, W.,Buntinas, D., Wyckoff, P., and Panda. D. K. 2003. Per-formance Comparison of MPI Implementations overInfiniBand, Myrinet and Quadrics. Proc. of Supercomput-ing.
Myricom. 1999. The GM Message Passing System, 10/16/1999.Nieplocha, J. and Carpenter, B. 1999. ARMCI: A Portable
Remote Memory Copy Library for Distributed Array Librar-ies and Compiler Run-time Systems. Proc. RTSPP of IPPS/SDP’99.
Nieplocha, J. and Ju, J. 2000. ARMCI: A Portable AggregateRemote Memory Copy Interface, Version 1.1, October 30.http://www.emsl.pnl.gov:2080/docs/parsoft/armci/armci1-1.pdf.
Nieplocha, J., Harrison, R.J., and Littlefield, R.J. 1994. GlobalArrays: A Portable Shared Memory Programming Modelfor Distributed Memory Computers. Proc. Supercomput-ing’94, IEEE CS Press, pp. 340–349.
Nieplocha, J., Harrison, R .J., and Littlefield, R.J. 1996. GlobalArrays: A Nonuniform Memory Access ProgrammingModel for High-Performance computers The Journal ofSupercomputing 10:197–220.
Nieplocha, J., Harrison, R., Krishnan, M., Palmer, B., and Tip-paraju, V. 2002b. Combining shared and distributed mem-ory models: Evolution and recent advancements of theGlobal Array Toolkit. Proceedings of POHLL’2002 work-shop of ICS-2002, NYC.
Nieplocha, J., Ju, J., and Straatsma, T.P. 2000. A multiprotocolcommunication support for the global address space pro-gramming model on the IBM SP. In Proceedings of Euro-Par 2000 Parallel Processing, (eds A. Bode et al.),Springer Verlag LNCS 1900.
Nieplocha, J., Tipparaju, V., Ju, J., and Apra, E. 2003. One-sided communication on Myrinet. Cluster Computing6:115–124.
Nieplocha, J., Tipparaju, V., Saify, A., and Panda, D. 2002a.Protocols and Strategies for Optimizing Remote MemoryOperations on Clusters. Proc. Communication Architec-ture for Clusters Workshop of IPDPS.
Nowlab OSU MVAPICH team. MPI Bandwidth benchmark.http://nowlab.cse.ohio-state.edu/projects/mpi-iba/per-formance/osu_bw.c
Numrich, R. W. and Reid, J. K. 1998. Co-Array Fortran for par-allel programming. ACM Fortran Forum 2:1–31.
Parkin, S. et al. 1997. High Performance Virtual Machines(HPVM): Clusters with Supercomputing APIs and Per-
formance. Eighth SIAM Conference on Parallel Process-ing for Scientific Computing (PP97), March.
Parzyszek, K., Nieplocha, J., and Kendall, R.A. 2000. A gener-alized portable SHMEM library for high performancecomputing. Proc. Parallel and Distributed Computing andSystems PDCS.
Perkovic, D. and Keleher, P. J. 1999. Responsiveness withoutInterrupts. Proceedings of the 13th International Confer-ence on Supercomputing, June.
Petrini, F., Coll, S., Frachtenberg, E., and Hoisie A. 2003. Per-formance Evaluation of the Quadrics Interconnection Net-work. Journal of Cluster Computing 6(2):125–142.
Pham, D. and Albrecht, C. 1999. Optimizing Message Aggre-gation for Parallel Simulation on High Performance Clus-ters. Proceedings of 7th Intern. Symposium on Modeling,Analysis and Simulation of Computer and Telecommuni-cation Systems.
pmodels. Center for Programming Models for Scalable ParallelComputing. www.pmodels.org
Scheurich C. and Dubois, M. 1987. Correct memory operationof cache-based multiprocessors. Proceedings of the 14thAnnual International Symposium on Computer Architec-ture, pp 234–243, June.
Shah, G., Nieplocha, J., Mirza, J,. Kim, C., Harrison, R.,Govindaraju, R. K., Gildea, K., DiNicola, P., and Bender,C. 1998. Performance and experience with LAPI: a newhigh-performance communication library for the IBM RS/6000 SP. Proceedings of the International Parallel Process-ing Symposium, IPPS’98, pp 260–266,
Strumpen, V. and Casavant, T. L. 1994. Exploiting communi-cation latency hiding for parallel network computing:model and analysis. Proc. PDS’94.
Tipparaju, V., Nieplocha, J., and Panda, D. 2003. Fast Collec-tive Operations Using Shared and Remote MemoryAccess Protocols on Clusters. Proceedings IPDPS’03.
Tipparaju, V., Santhmaraman, G., Nieplocha, J., and Panda,D.K. 2004. Host-assisted zero-copy remote memoryaccess communication on Infiniband. In proceedings of theInternational Parallel and Distributed Computing Sympo-sium, IPDPS’04, Santa Fe, NM.
Traff, J. L., Ritzdorf, H., and Hempel, R. 2000. The implemen-tation of MPI2 one-sided communication for the NECSX-5. Proceedings of Supercomputing.
von Eicken, T., Culler, D.E., Goldstein, S.C., and Schauser,K.E. 1992. Active Messages: a Mechanism for IntegratedCommunication and Computation. Proceedings of 19thInt. Symp on Computer Architecture.
Wang, R. Y., Krishnamurthy, A., Martin, R. P., Anderson, T. E.,and Culler, D. E. 1998. Modeling and Optimizing Com-munication Pipelines. ACM SIGMETRICS Conference onMeasurement and Modeling of Computer Systems.
White, J. B. and Bova, S. W. 1999. Where’s the overlap? Over-lapping communication and computation in several popu-lar MPI implementations. Proceedings of the Third MPIDevelopers’ and Users’ Conference, March.
at OHIO STATE UNIVERSITY LIBRARY on January 24, 2010 http://hpc.sagepub.comDownloaded from







![Automated Tracing and Visualization of Software Security ...web.cse.ohio-state.edu/~machiraju.1/teaching/CSE... · the Threat Modeling Tool [8] to manually create a high-level architecture](https://img.pdfslide.us/doc/110x75/5f4fbc7757712b67c20c8a5d/automated-tracing-and-visualization-of-software-security-webcseohio-stateedumachiraju1teachingcse.jpg)





















