Embed Size (px)
DESCRIPTION
Formal aspects of security; Security analysis methodologies; Security verification; Security protocols; Security architectures and formalisms; Security and design vulnerability; Security and privacy protection; Performance and security; Secure group communication/multicast; Software design security; Middleware security; Security for nomadic code; Intrusion detection systems; Static analysis for software security; Security modelingIdentity management; Security law enforcement; PKI; PKI Key management; Incident response planning; Intrusion detection and event correlation; Firewalls; Trust management; Software security assuranceSecure protocols; Applied cryptography; Smart cards; Biometrics; Digital rights management; Electronic surveillance; Database securityInternet security; Security in wireless; Sensor/cellular network security; Ad hoc network security; Security in peer-to-peer networks; Security in wireless multimedia systems; Security in different networks (mesh, personal, local, metropolitan, GSM, Bluetooth, WiMax, IEEE 802.x, etc.); Security of emergency servicesInformation hiding; Anonymity; Authentication; Data Integrity; Security data mining; Data confidentiality and integrity; Information flow protection; Trustworthy networks: authentication, privacy and security models; Secure service discovery; Secure location-based service; Information survivabilityThreat taxonomies and modeling; Security threats; Threats propagation; Anti-malware technologies; Engineering anti-malware; Anti-virus, anti-spyware, anti-phishing; Malware propagation models; Profiling security information; Vulnerability analysis and countermeasures; Denial of service attacks; Measurements and metrics; Testing samples and techniques; Quarantine/reuse decisions; Anti-malware tool performance; Anti-malware tool suites; Open-source anti-malware; Host-based anti-malware; On-line anti-malware scanningMessaging, viruses, spyware; Advanced misuse detection techniques /machine learning, natural language processing, challenge-response, etc./; Message filtering, blocking, authentication; Digital signatures; Generalized spamming /over email, Internet telephony, instant messaging, mobile phone, phishing, etc. /; Spam compression and recognition; Learning misuse patterns; Payment schemes; Economics of generalized spam; Tracking abuse tactics and patterns; Protecting legitimate use patterns; Methods for testing protection robustness; Costs and benefits of messaging use and misuse; Standards for messaging and misuse reporting; Legal aspects /identity theft, privacy, freedom of speech, etc./Fundamentals for SHS; Privacy and protection for SHS; Identify and location management in SHS; Authentication and authorization in SHS; Access control and security policies in SHS; Trust and reputation management; Security context-based interfaces for SHS; SHS for accessibility and elderly/disabled people; Real-time challenges for SHS in eHealth environments; Architectures and systems for SHS; Network technologies and protocols for SHS; Ubiquitous/pervasive platform and middleware for SHS; Services and applications for SHS; SHS on campuses and hotels; SHS for mission critical laboratories; Content protection and digital rights management for SHS; Intelligent devices, sensor network/RFID for SHS; Intrusion detection and computer forensics for SHS; SHS and Homeland security; Personal data privacy and protection in SHS; Emerging standards and technologies for SHS; Commercial and industrial for SHS; Case studies, prototypes and experienceFundamentals on highly dynamic environments; Privacy and predefined access control dilemma; Privacy police, provisions and obligations; Dependability in dynamic environments; Protection of digital documents in dynamic environments; On-line activities in high dynamic systems; Law enforcement in high dynamic systems; Personalization; Privacy and transparency; Distributed usage control; Privacy complianceFoundations of
Citation preview

International Journal of Computer Science Issues
Volume 2, August 2009ISSN (Online): 1694-0784ISSN (Printed): 1694-0814
© IJCSI PUBLICATIONwww.IJCSI.org
Security Systems and Technologies
International Journal of Computer Science Issues
Volume 2, August 2009ISSN (Online): 1694-0784ISSN (Printed): 1694-0814
© IJCSI PUBLICATIONwww.IJCSI.org
Security Systems and Technologies

© IJCSI PUBLICATION 2009
www.IJCSI.org

EDITORIAL T h e r e a r e s e v e r a l j o u r n a l s a v a i l a b l e i n t h e a r e a s o f C o mp u t e r S c i e n c e
hav ing d i f f e r en t po l i c i e s . I JCSI i s among t he f ew o f t hose who be l i eve
g i v i n g f r e e a c ce s s t o s c i e n t i f i c r e s u l t s w i l l h e l p i n a d v a n c i n g c o mp u t e r
s c i e n ce r e s e a rc h an d h e l p t h e f e l l o w s c i e n t i s t .
I J C S I p a y p a r t i c u l a r c a r e i n e n s u r i ng w i d e d i s s e mi n a t i o n o f i t s a u t h o r s ’
w o r k s . A p a r t f r o m b e i n g i n d e x e d i n o the r da t abase s (Goog le Scho l a r ,
DOAJ , C i t eSee rX , e t c…) , I JCSI ma kes a r t i c l e s ava i l ab l e t o be
d o w n l o a d e d f o r f r e e t o i n c r e a s e t h e c h a n c e o f t h e l a t t e r t o b e c i t e d .
F u r t h e r mo r e , u n l i k e mos t j o u r n a l s , I J C S I s e n d a p r i n t e d c o p y o f i t s i s s u e
t o t h e c o n c e r n e d a u t h o r s f r e e o f c h a r g e i r r e s p e c t i v e o f g e o g r a p h i c
l o c a t i o n .
I J C S I E d i t o r i a l B oa r d i s p l ea s e d t o p r e s e n t I JC S I V o l u me T w o ( I J C S I V o l .
2 , 2 0 0 9 ) . T h i s e d i t i o n i s a r e s u l t o f a s p e c i a l c a l l f o r p a p e r s on Secu r i t y
S y s t e ms a n d T e c h n o l o g i e s . T h e p a p e r a c c e p t a n c e r a t e f o r t h i s i s s u e i s
3 3 . 3 % ; s e t a f t e r a l l s u b mi t t e d p a p e r s have been r ece ived w i t h i mp o r t a n t
c o m m e n t s a n d r e c o m m e n d a t i o n s f r o m o u r r e v i e w e r s .
We s ince r e ly hope you wou ld f i nd impor t a n t i d e a s , c o n c e p t s , t e c h n i q u e s ,
o r r e s u l t s i n t h i s spe c i a l i s sue .
As f i na l words , PUBLISH, GET CIT ED and MAKE AN IMPAC T. I J C S I E d i t o r i a l B oa r d A u g u s t 2 0 0 9 w w w . i j c s i . o r g

IJCSI EDITORIAL BOARD Dr Tristan Vanrullen Chief Editor LPL, Laboratoire Parole et Langage - CNRS - Aix en Provence, France LABRI, Laboratoire Bordelais de Recherche en Informatique - INRIA - Bordeaux, France LEEE, Laboratoire d'Esthétique et Expérimentations de l'Espace - Université d'auvergne, France Dr Mokhtar Beldjehem Professor Sainte-Anne University Halifax, NS, Canada Dr Pascal Chatonnay Assistant Professor Maître de Conférences Université de Franche-Comté (University of French-County) Laboratoire d'informatique de l'université de Franche-Comté (Computer Sience Laboratory of University of French-County) Prof N. Jaisankar School of Computing Sciences, VIT University Vellore, Tamilnadu, India

IJCSI REVIEWERS COMMITTEE • M r . M a r k u s S c h a t t e n , U n i v e r s i t y o f Z a g r e b , F a c u l t y o f O r g a n i z a t i o n a n d I n f o r ma t i c s , C r o a t i a • Mr . Fo r r e s t Sheng Bao , Texas Tech Un ive r s i t y , USA • M r . V a s s i l i s P a p a t a x i a r h i s , D e p a r t me n t o f I n f o r ma t i c s a n d T e l e c o m m u n i c a t i o n s , N a t i o n a l a n d K a p o d i s t r i a n U n i v e r s i t y o f A t h e n s , P a n e p i s t i mi o p o l i s , I l i s s i a , G R - 1 5 7 8 4 , A t h e n s , G r e e c e , G r e e c e • D r M o d e s t o s S t a v r a k i s , U n i v a r s i t y o f t h e A e g e a n , G r e e c e • P r o f D r . M o h a m e d A b d e l a l l I b r ah im , Facu l t y o f Eng inee r i ng - A l e x a n d r i a U n i v e r i s t y , E g yp t • D r Fad i KHALI L , LAAS - - CNRS Labo ra to ry , F r ance • D r D i mi t a r T r a j a n o v , F a c u l t y o f E l ec t r i c a l Eng inee r i ng and In fo r ma t ion t e c h n o l o g i e s , s s . Cy r i l a n d M e t h o d i u s Un ives i t y - Skop j e , Macedon i a • D r J i n p i n g Y u a n , C o l l e g e o f I n f o r ma t i o n S y s t e m a n d M a n a g e m e n t , N a t i o n a l U n i v . o f D e f e n s e T e c h . , C h i n a • D r A l e x i o s L a z a n a s , M i n i s t r y o f E d u c a t i o n , G r e e c e • D r S t a v r o u l a M o u g i a k a k o u , U n i v e r s i t y o f B e r n , A R T O R G C e n t e r f o r B i o me d i c a l E n g i n e e r i n g R e s e a r c h , S w i t z e r l a n d • D r DE RUNZ, C ReSTIC-SIC , IUT de Re ims , Un ive r s i t y o f Re ims , F r a n c e • M r . P r a mo d k u m a r P . G u p t a , D e p t o f B i o i n f o r ma t i c s , D r D Y P a t i l U n i v e r s i t y , I n d i a • D r A l i r e z a F e r e i d u n i a n , S c h o o l o f E C E , U n i v e r s i t y o f T e h r a n , I r a n • Mr . F r ed V iezens , O t to -Von-Gue r i c k e - U n i v e r s i t y M a g d e b u r g , G e r ma n y • Mr . J . Ca l eb Goodwin , Un ive r s i t y o f T e x a s a t H o u s t o n : H e a l t h S c i e n c e Cen t e r , USA • D r . R i c h a r d G . B u s h , L a w r e n c e Te c h n o l o g i c a l U n i v e r s i t y , U n i t e d S t a t e s • D r . O l a O s u n k o y a , I n f o r ma t io n S e c u r i t y A r c h i t e c t , U S A • Mr . Ko t sokos t a s N .An ton i o s , T E I P i r a e u s , H e l l a s • P r o f S t e v e n T o t o s y d e Z ep e t n e k , U o f H a l l e -Wi t t e n b e r g & P u rd u e U & N a t i o n a l S u n Y a t - s e n U , G e r ma n y , U S A , T a i w a n • M r . M A r i f S i d d i q u i , N a j r a n U n i v e r s i t y , S a ud i A r a b i a • M s . I l k n u r I c k e , T h e G r a d u a t e C e n t e r , C i t y Un ive r s i t y o f New York , USA • P r o f M i r o s l a v B a c a , A s s oc i a t e d P r o f e s s o r / Fa c u l t y o f O r g a n i z a t i o n a n d I n fo r ma t i c s / U n i v e r s i t y o f Z ag r e b , C r oa t i a • D r . E l v i a R u i z B e l t r á n , In s t i t u t o Te c n o l ó g i co d e A g u a s c a l i e n t e s , M e x i c o • Mr . Mous t a f a Banbouk , Eng inee r du Te l ecom, UAE • M r . K e v i n P . M o n a g h a n , W a y n e S t a t e U n i v e r s i t y , D e t r o i t , Mi ch i g a n , USA • Ms . Mo i r a S t ephens , Un ive r s i t y o f Sydney , Aus t r a l i a

• Ms . Maryam Fe i l y , Na t i ona l Advanced IPv6 Cen t r e o f Exce l l ence ( N A V 6 ) , U n i v e r s i t i S a i n s M a lays i a (USM) , Ma lays i a • D r . C o n s t a n t i n e Y I A L O U R I S , I n f o r ma t i c s L a b o r a t o r y A g r i c u l t u r a l Un ive r s i t y o f A thens , Greece • D r . She r i f Ed r i s Ahme d , A in Sha ms U n i v e r s i t y , F a c . o f a g r i c u l t u r e , D e p t . o f G e n e t i c s , E g y p t • M r . B a r r i n g t o n S t e w a r t , C e n t e r f o r R e g i o n a l & T o u r i s m R e s e a r c h , D e n ma r k • M r s . A n g e l e s Abe l l a , U . d e M o n t r e a l , C a n a d a • D r . Pa t r i z i o Ar r i go , CNR ISMAC, i t a l y • M r . A n i r b a n M uk h o p a d h y a y , B . P . P o d d a r I n s t i t u t e o f M a n a g e m e n t & Techno logy , I nd i a • Mr . D inesh Ku mar , DAV Ins t i t u t e o f E n g i n e e r i n g & T e c h n o l o g y , I n d i a • M r . J o r g e L . H e r n a n d e z - A r d i e t a , INDR A SISTEMAS / Un ive r s i t y Ca r lo s I I I o f Madr id , Spa in • M r . A l i R e z a S ha h r e s t a n i , U n i v e r s i t y o f Ma laya (UM) , Na t i ona l Advanced IPv6 Cen t r e o f Exce l l ence (NAv6) , Ma lays i a • M r . B l a g o j R i s t e v s k i , F a c u l t y o f Admi n i s t r a t i on and In fo rma t ion S y s t e ms M a n a g e m e n t - B i t o l a , R e p u b l i c o f M a c e d o n i a • Mr . Maur i c io Eg id io Can t ão , De p a r t me n t o f C o mp u t e r S c i e n c e / U n i v e r s i t y o f S ã o P a u l o , B r a z i l • M r . T h a d d e u s M . C a r v a j a l , T r i n i t y U n i v e r s i t y o f A s i a - S t L u k e ' s C o l l e g e o f N u r s i n g , P h i l i p p in e s • M r . J u l e s R u i s , F r a c t a l C o n s u l t a n c y , T h e n e t h e r l a n d s • M r . M o h a m m a d I f t e k h a r H u s a in , Un ive r s i t y a t Bu f f a lo , USA • D r . D e e p a k L a xmi N a r a s imha , VIT Un ive r s i t y , INDIA • D r . Pao l a D i Ma io , DMEM Unive r s i t y o f S t r a thc lyde , UK • D r . B h a n u P r a t a p S i n g h , I n s t i t u t e o f I n s t r u me n t a t i o n E n g i n e e r i n g , K u r u k s h e t r a U n i v e r s i t y K u r u k s h e t r a , I n d i a • M r . S a n a U l l a h , I n h a U n i v e r s i t y , S o u t h K o r e a • Mr . Co rne l i s P i e t e r P i e t e r s , Condas t , The Ne the r l ands • D r . A m o g h K a v i ma n d a n , T h e M a t h Wor k s I n c . , U S A • D r . Zh inan Zhou , Sa ms ung Te l ecommun ica t i ons Ame r i ca , USA • M r . A l b e r t o d e S a n t o s S i e r r a , U n i v e r s i d a d P o l i t éc n i c a d e M ad r i d , S p a i n • D r . M d . A t i q u r R a h ma n A h a d , D e p a r t me n t o f A p p l i e d P h y s i c s , E l e c t r o n i c s & C o m m u n i c a t i o n E n g i n e e r in g ( A P E C E ) , U n i v e r s i t y o f D h a k a , Bang l adesh • D r . C h a r a l a mp o s B r a t s a s , L a b o f M ed ica l I n fo r ma t i c s , Med ica l Facu l t y , A r i s t o t l e U n i v e r s i t y , T h e s s a l o n i k i , Gr e e c e • M s . A l e x i a D i n i K o u n o u d e s , C y p r u s Un ive r s i t y o f Techno logy , Cyp rus • M r . A n t h o n y G e s a s e , U n i v e r s i t y o f D a r e s s a l a a m C o m p u t i n g C e n t r e , T a n z a n i a • D r . J o r g e A . R u i z - V a n o y e , U n i v e r s i d a d J u á r e z A u t ó n o ma d e T a b a s c o , M e x i c o

• D r . A l e j a n d r o Fue n t e s P e n n a , U n i v e r s i d a d Po p u l a r Au t ó n o ma d e l E s t a d o d e P u e b l a , M é x i c o • D r . O c o t l á n D í a z - P a r r a , U n i v e r s idad Juá r ez Au tónoma de Tabasco , M é x i c o • M r s . N a n t i a I a ko v i d o u , A r i s t o t l e U n i v e r s i t y o f T h e s s a l o n i k i , G r e e c e • Mr . V inay Chopra , DAV Ins t i t u t e o f E n g i n e e r i n g & T e c h n o l o g y , J a l andha r • M s . C a r me n L a s t r e s , U n i v e r s i d a d P o l i t éc n i c a d e M ad r i d - C en t r e fo r S ma r t E n v i r o n me n t s , S p a i n • D r . San j a Laza rova -Molna r , Un i t ed Arab Emi ra t e s Un ive r s i t y , UAE • M r . S r i k r i s h n a Nu d u r u ma t i , I ma g i n g & P r i n t i n g G r o u p R & D H u b , H e w l e t t - P a c k a r d , I n d i a • D r . O l i v i e r N o c e n t , C R e S T I C / S I C , U n i v e r s i t y o f R e i ms , F r a n c e • Mr . Bu rak C izmec i , I s i k Un ive r s i t y , Tu rkey • D r . C a r l o s J a i m e B a r r i o s H e r n a n d e z , L IG (Labo ra to ry Of In fo rma t i c s o f Grenob l e ) , F r ance • M r . M d . R a b i u l I s l a m, R a j s h a h i u n i v e r s i t y o f E n g i n e e r i n g & T e c h n o l o g y ( R U E T ) , B a n g l a d e s h • D r . LAKHOUA Mohame d Na jeh , ISSA T - L a b o r a t o r y o f A n a l y s i s a n d Con t ro l o f Sys t e ms , Tun i s i a • D r . A l e s s a n d r o L a v a c c h i , D e p a r t m e n t o f C h e mi s t r y - U n i v e r s i t y o f F i r e n z e , I t a l y • Mr . Mungwe , Un ive r s i t y o f O ldenbu rg , Ge rmany • M r . S o m n a t h T a g o r e , D r D Y P a t i l U n i v e r s i t y , I n d i a • M r . N e h i n b e J o s h u a , U n i v e r s i t y o f Es sex , Co l ches t e r , Es sex , UK • Ms . Xueq in Wa n g , ATCS, USA • D r . Bo r i s l av D Di mi t rov , Depa r t m e n t o f G e n e r a l P r a c t i c e , R o y a l Co l l ege o f Su rgeons i n I r e l and , Dub l in , I r e l and • D r . Fond jo Fo tou F rank l i n , Langs ton Un ive r s i t y , USA • M r . H a y t h a m M o h t a s s e b , D e p a r t m e n t o f Compu t ing - Un ive r s i t y o f L i n c o l n , U n i t e d K i n g d o m • D r . V i s h a l G o y a l , D e p a r t me n t o f C o mp u t e r S c i e n c e , P u n j a b i U n i v e r s i t y , P a t i a l a , I n d i a • M r . T h o ma s J . C l a n c y , A C M , U n i t e d S t a t e s • D r . Ahme d Nab ih Zak i Rashed , Dr . i n E l e c t r o n i c E n g i n e e r i n g , F a c u l t y o f E l e c t r o n i c E n g i n e e r i n g , me n o u f 3 2 9 5 1 , E l e c t r o n i c s a n d E l e c t r i c a l Commun ica t i on Eng inee r ing Depa r tme n t , Menouf i a un ive r s i t y , EGYPT, EGYPT • D r . R u s h e d K a n a w a t i , L I P N , F r a n c e • Mr . Ko te shwar Rao , K G REDDY COLLE GE OF ENGG.& TECH, C HILKUR, RR DIST . ,AP , INDIA • M r . M . N a g e s h K u ma r , D e p a r t me n t o f E l e c t r o n i c s a n d C o m mu n i c a t i o n , J . S . S . r e s e a r c h f o u n d a t i o n , M y s o r e Un i v e r s i t y , M y s o r e - 6 , I n d i a • D r . B a b u A M a n j a s e t t y , Re s e a rch & Indus t ry Incuba t i on Cen t e r , D a y a n a n d a S a g a r In s t i t u t i o ns , , I n d i a

• M r . S a q i b S a e e d , U n i v e r s i t y o f S i e g e n , G e r ma n y • D r . I b r a h i m N o h a , G r e n o b l e I n f o r m a t i c s L a b o r a t o r y , F r a n c e • Mr . Muhammad Yas i r Qad r i , Un ive r s i t y o f Es sex , UK

TABLE OF CONTENTS 1. Towards a General Definition of Biometric Systems Markus Schatten, Miroslav Baca and Mirko Cubrilo, Faculty of Organization and Informatics, University of Zagreb, Pavlinska 2, 42000 Varaždin, Croatia 2. Philosophical Survey of Passwords M Atif Qureshi, Arjumand Younus and Arslan Ahmed Khan, UNHP Research Karachi, Sind, Pakistan 3 . Global Heuristic Search on Encrypted Data (GHSED) Maisa Halloush, Department of Computer Science, Al-Balqa Applied University, Amman, Jordan Mai Sharif, Barwa Technologies, Doha, Qatar 4. Comprehensive Security Framework for Global Threads Analysis Jacques Saraydaryan, Exaprotect R&D, Villeurbanne, 69100, France Fatiha Benali and Stéphane Ubeda, INSA Lyon, Villeurbanne, 69100, France 5. Self-Partial and Dynamic Reconfiguration Implementation for AES using FPGA Zine El Abidine Alaoui Ismaili and Ahmed Moussa, Innovative Technologies Laboratory, National School of Applied Sciences, Tangier, PBox 1818, Morocco 6. Web Single Sign-On Authentication using SAML Kelly D. Lewis, Information Security, Brown-Forman Corporation, Louisville, KY 40210, USA James E. Lewis, Engineering Fundamentals, Speed School of Engineering, University of Louisville, Louisville, KY 40292, USA 7. An Efficient Secure Multimodal Biometric Fusion Using Palmprint and Face Image Nageshkumar.M, Mahesh.PK and M.N. Shanmukha Swamy, Department of Electronics and Communication, J.S.S. research foundation, Mysore University, Mysore-6 8. DPRAODV: A Dynamic Learning System Against Blackhole Attack In AODV Based MANET Payal N. Raj, Computer Engineering Department, SVMIT, Bharuch, Gujarat, India Prashant B. Swadas, Computer Engineering Department, B.V.M., Anand, Gujarat, India

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
1
Towards a General Definition of Biometric Systems
Markus SCHATTEN1 , Miroslav BAČA1 and Mirko ČUBRILO1
1 Faculty of Organization and Informatics, University of Zagreb Pavlinska 2, 42000 Varaždin, Croatia
{markus.schatten, miroslav.baca, mirko.cubrilo}@foi.hr
Abstract A foundation for closing the gap between biometrics in the narrower and the broader perspective is presented trough a conceptualization of biometric systems in both perspectives. A clear distinction between verification, identification and classification systems is made as well as shown that there are additional classes of biometric systems. In the end a Unified Modeling Language model is developed showing the connections between the two perspectives. Key words: biometrics, biometric system, set mappings, conceptualization, classification.
1. Introduction
The term biometrics comming from ancient greek words (bios) for life and (metron) for measure
is often used in different contexts to denote different meanings. At the same time there are very similar and often synonimic terms in use like biometry, biological statistics, biostatistics, behaviometrics etc. The main aim of this paper is to show the connection between these various views of biometrics as well as to continue our research on the essence of biometric systems. In [2] we showed how to apply a system theory approach to the general biometric identification system developed by [8] in order to extend it to be aplicable to unimodal as well as multimodal biometric identification, verification and classification systems in the narrower (security) perspective of biometrics. The developed system model is partialy presented on figure 1.
Fig. 1 Pseudo system diagram of the developed model.
In [3] we argued that there is a need for an open
biometrics ontology that was afterwards partially build in [1] and [7]. During the development of this ontology crucial concepts like biometric system, model, method, sample, characteristic, feature, extracted structure as well as others were defined. We also developed a full taxonomy of biometric methods in the narrower perspective in [6] that contributed to a unique framework for communication. All this previous research showed that there is confusion when talking about different types or classes of biometric systems. Most contemporary literature only makes distinction between verification and identification systems but some of our research showed that there are more different classes like simple classification systems that seem to be a generalization of verification as well as identification systems [7]. As we shall show in our following reasoning by taking the input and output sets of the different processes in biometric systems that define biometric methods into consideration, as well as mappings between them a concise conceptualization emerges that seems to applicable to any biometric system.
2. Basic Definitions in Biometrics
In order to reason about biometrics we need to introduce some basic definitions of concepts used in this paper. These definitions were crutial to the development of a selected biometrics segments ontology as well as an taxonomy of biometric methods. First of all, we can approach biometrics in a broader and in a narrower perspective as indicated before. In the broader perspective biometrics is the statistical research on biological phenomenae; it is the use of mathematics and statistics in understanding living beeings [4]. In the narrower perspective we can define biometrics as the research of possibilities to recognize persons on behalf

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
2
of their physical and/or behavioral (psychological) characteristics. We shall approach biometrics in the broader perspective in this paper. A biometric characteristic is a biological phenomenon's physical or behavioral characteristic that can be used in order to recognize the phenomenon. In the narrower perspective of biometrics physical characteristics are genetically implied (possibly environmental influenced) characteristics (like a person's face, iris, retina, finger, vascular structure etc.). Behavioral or psychological characteristics are characteristics that one acquires or learns during her life (like a handwritten signature, a person's gait, her typing dynamics or voice characteristics). These definitions are allmost easily translated into the broader perspective of biometrics. Depending on the number of characteristics used for recognition biometric systems can be unimodal (when only one biometric characteristic is used) or multimodal (if more than one characteristic is used). A biometric structure is a special feature of some biometric characteristic that can be used for recognition (for example a biometric structure for the human biometric characteristic finger is the structure of papillary lines and minutiea, for the human biometric charactersitic gait it is the structure of body movements during a humans walk etc.). The word method comes from the old greek (methodos) that literarly means “way or path of transit” and implies an orderly logical arrangement (usually in steps) to achieve an attended goal [9; pp. 29]. Thus a biometric method is a series of steps or activities conducted to process biometric samples of some biometric characteristic usually to find the biometric characteristic's holder (in the narrower perspective) or a special feature of the biometric sample (in the broader perspective). A model is a (not neccesarily exact) image of some system. It's main purpose is to facilitate the aquiring of information about the original system [5; pp. 249]. A biometric model is thus a sample of a biometric system that facilitates the aquiring of information about the system itself as well as information about biometric characteristics. In [2] and [7] we showed that biometric models consist of biometric methods for preprocessing and feature extraction, quality control as well as recognition. A sample is a measured quantity or set of quantities of
some phenomenae in time and/or space. Thus a biometric sample represents a measured quantity or set of quantities of a biological phenomenae [7]. A biometric template or extracted structure is a quantity or set of quantities aquired by a conscious application of a biometric feature extraction or preprocessing method on a biometric sample. These templates are usually stored in a biometric database and used for reference during recognition, training or enrollment of a biometric system.
3. Conceptualizing Input and Output Mappings
Having the basic concepts defined we can formalize the domain using the following seven sets: (1) as the set of all biometric samples, (2) as the set of all preprocessed samples, (3) as the set of all biometric templates or extracted structures, (4) as a subset of
representing all extracted structures that are suitable for recognition after quality control, (5) as the set of all biological phenomenas (in the broader perspective) or all persons (in the narrower one) represented by biometric structures on behalf of which recognition is made possible, (6) as a subset of of all biological phenomenas that are enrolled, and (7) as the set of all recognition classes. Using these sets we can formalize the classes of biometric methods shown on figure 1. The sampling process, the preprocessing, the feature extraction process, the quality control process as well as the recognition process are described using the mappings shown in the following set of equations respectively:
Figure 2 shows the mapping of the sampling process. One can observe that every value from has its argument in . Arguments from can have 0 or

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
3
more values in . This can be explained easily because there is a high probability that not every biological phenomenon will be sampled by one biometric system, but every biometric sample is a sample of a real biological phenomenas.\footnote.1 There is also a considerable probability that a group of biological phenomenas will yield the same sample which is depending on the quality of the sampling technology.
Fig. 2 Mapping of the sampling process.
In multimodal systems one sample can be made on behalf of more than one feature, what would yield a different figure than the one above. But, since every sample is made on behalf of exactly features (where
is the number of characteristics used in the multimodal system) we can consider the tuple
(where are partial features that are being sampled) to be only one feature. The mapping would thus have arguments and the figure wouldn't change, or likewise the set would consist of tuples.
Fig. 3 Mapping of the preprocessing process.
Figure 3 shows the mapping of the preprocessing process which happens to be a function (since every 1 Presuming that there are no fake biometric samples in
element from the domain is associated with some element in the co-domain ). The function is surjective but not necessarily injective since some samples can yield the same preprocessed sample even if they are distinct. Figure 4 shows the mapping of the feature extraction process which also happens to be a function (since every element from the domain is associated with some element in the co-domain ). The function is likewise surjective and likewise not necessarily injective since some preprocessed samples can yield the same extracted structure even if they are distinct.
Fig. 4 Mapping of the feature extraction process.
There is another possibility in multimodal systems, when samples aren't multimodal, but structures are extracted from multiple samples. As in the case of the sampling process mentioned before we can consider the
elements in to be tuples of samples (where is the is the number of characteristics used in the multimodal system) that are used to extract a single structure.
Fig. 5 Mapping of the quality control process.
The mapping of the quality control process is shown on figure 5. Every value from has its argument in but the opposite does not necessarily hold true since some extracted structures do not pass the quality test and

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
4
are abandoned. Thus, every argument from has 0 or 1 values in and the values are unique. Likewise figure 6 shows the mapping of the recognition process that is similar to the previous one. Again, every value from has its argument in but the opposite is not necessarily true since some structures that passed the quality test cannot be recognized and classified into one of the classes for recognition in . We could define a
set where is the class for all unrecognized structures but we left this part out due to concept consistency and simplicity. Thus, every argument in has 0 or 1 image in whereby the images are not necessarily unique.
Fig. 6 Mapping of the recognition process.
Special cases of the recognition process mapping include the case when and the case when is a mapping of two variables. In the former case we have the mapping that represents an actively functioning biometric identification system. In
the letter case we have the mapping
(whereby elements of are tuples where and ) that represent an actively
functioning biometric verification system.
4. Conceptualizing Mapping Cardinalities of the Recognition Process
If we consider the mapping of the recognition process and presume that the biometric system is active (thereby eliminating passive periods) we can observe the following situations: • If one tuple of one person information and one
extracted structure are mapped to exactly one class
and then the system is a biometric verification system in normal (active) functioning. We denote this mapping with .
• If one extracted structure is being mapped to one of classes where is the cardinality of set then
the system is a biometric classification system in normal (active) functioning. We denote this mapping
with . • If one extracted structure is being mapped to one of
classes where is the cardinality of set and then the system is a biometric
identification system in normal active functioning. We denote this mapping with
. • If tuples of person information and extracted
structures (where is the cardinality of set ) are being mapped individually into exactly one class and when then the system is a biometric verification system during training. We denote this
mapping with . • If extracted structures are being mapped
individually into one of classes then the system is a biometric classification system during training. We denote this mapping with
. • If extracted structures are being mapped
individually into one of classes and then the system is a biometric identification system during training. We denote this mapping with
. • If groups of tuples consisting of person
information and extracted structure are being mapped into exactly one of classes (whereby
, and is the number of extracted structures per person)2 the system is a biometric verification system during enrollment. We denote this mapping with
. • If groups of extracted structures are being
mapped into one of classes (whereby
, and is the number of 2 Usually a standard number of samples is used for enrollment but can be variable due to lack of such standard or due to eliminated samples during other processes of the biometric system.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
5
extracted structures per class) the system is a biometric classification system during enrollment. We denote this mapping with
. • If groups of extracted structures are being
mapped into one of classes (whereby
, and is the number of extracted structures per person) the system is a biometric identification system during enrollment. We denote this mapping with
. From this reasoning we can conclude that biometric verification and identification systems are only special cases of biometric classification systems when the number of classes into which extracted structures are mapped into are equivalent to the set of biological phenomenas (or persons in the narrower sense) that are enrolled. Further we can observe three distinct situations in biometric systems recognition process cardinalities defined in equation where is the number of extracted structures (or tuples in the case of verification systems) on the input to the recognition process, and the number of classes (outputs) into which the inputs are being mapped.
1. In the case when and the biometric system is in normal (everyday) use.
2. In the case when and the biometric system is in the training phase.
3. In the case when and
the biometric system is in the enrollment phase (whereby is an positive integer possibly inside an interval,
).
5. Conceptualizing Relations Between the Defined Sets
Figure 7 shows the UML (Unified Modeling Language) class diagram of the defined concepts that gives us even deeper insight of the domain being conceptualized. Every class applies for some of the previously defined sets. The class Phenomenon applies to the set of all biological phenomenas. As the diagram shows there is a special subset defined by the class Person. Every Person instance is an instance of Phenomenon. There are also
two other special subsets of denoted by the set of all enrolled phenomenas or persons in the narrower sense of biometrics. Thus every instance of Enrolled phenomenon is an instance of Phenomenon, every instance of Enrolled person is an instance of Person, as well as every Enrolled person is an instance of Enrolled phenomenon.
Fig. 7 UML Class Diagram of the Defined Concepts.
As shown in the diagram any Phenomena can consist of zero or more biometric Structure instances, while a biometric Structure is part of exactly one biological Phenomena. Following the process flow from figure 1 we can observe that every Sample instance is made on behalf of one or more Structure instances3 and thus the set is represented with the class Sample. The case that a sample is made on behalf of more biometric structures applies only to multimodal systems where multiple biometric structures are sampled into exactly one sample. Every instance of Preprocessed sample instance is derived from exactly one Sample instance where the class Preprocessed sample corresponds to the set . Further on every Extracted structure instance is extracted from one or more Preprocessed sample instances. The class Extracted structure represents the two sets concerning biometric templates or extracted structures and depending on the value of an instance's status attribute. If the value is untested or failed the instance belongs into set (since the instance hasn't been tested for quality or it hasn't pass the quality test). In the opposite case when the value is 3 Presuming again that there are only real biometric samples in

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
6
passed the instance belongs into the set since it has been tested for quality and passed the test. The enumeration holding the values of the status attribute has been left out form the diagram for the sake of simplicity. The case when an extracted structure is extracted from more biometric samples applies only to multimodal biometric systems that extract features on behalf of more biometric samples, whilst the case when on extracted structure is extracted from only one sample applies to unimodal biometric systems. Every Extracted structure can be classified into zero or more instances of Class whilst every Class instance applies to zero or more instances of Extracted structure. The Class class represents the set as it is obvious from our previous reasoning. There is correspondence between the Class class and the Enrolled phenomenon class depending on the purpose of the system as argued before. From this reasoning we can conclude that the classes Structure, Sample, Preprocessed sample, Extracted structure and Class apply to both biometrics in the narrower and the broader perspective. If the connected classes are Phenomenon and Enrolled phenomenon we are talking about the broader perspective of biometrics. In the other case when the connected classes are Person and Enrolled person the narrower perspective comes into play. Since Person is a special case of Phenomenon and Enrolled person is a special case of Enrolled phenomenon the narrower perspective of biometrics is only a special case of the broader one.
6. Conceptualizing Relations Between the Defined Sets
In this paper we showed a simple conceptualization of biometric systems. If one considers a general biometric system consisting of a series of processes she can observe the input and output sets of any given process. By mapping these sets in a sequence of events one can observe their features. The recognition process is of special interest since the special cases of the possible mappings define the three types of biometric systems (classification, verification, identification) as well as the three possible processing conditions (everyday use, training, enrollment). As we showed, biometric verification and identification systems are only special cases of biometric classification systems where the number of classes into which samples
are classified into is equivalent to the number of enrolled biological phenomenas (in the broader sense of biometrics) or the number of enrolled persons (in the narrower perspective). We argued that biometrics in the narrower and in the broader perspective have a lot in common especially when talking about data and data manipulation techniques. Biometrics in the narrower perspective is and remains a special case of biometrics in the broader perspective. Thus this conceptualization presents a clear framework for communication on any biometric system topic. The only thing that seems to be the difference is the semantic context in which the same methods are used. So we ask our self, why making a difference? The developed UML model merges the two perspectives by stating that biometrics in information sciences and information system security specialization of biometrics in mathematics, statistics and biology. The narrower perspective heavily depends on theories from the broader one, but insights from information system's security biometrics are of course usefull in the biology, mathematics and statistics perspective especially when talking about system planning and implementation. If we add this conceptualization to our previously developed open ontology of chosen parts of biometrics, as well as to the developed systematization and taxonomy of biometric methods, characteristics, features, models and systems we get an even clearer framework for communicating about biometrics that puts our research into a broader perspective. Future research shall yield an open ontology of biometrics in the broader perspective.
Acknowledgments
Results presented in this paper came from the scientific project “Methodology of biometrics characteristics evaluation” (No. 016-0161199-1721) supported by Ministry of Science Education and Sports Republic of Croatia. References [1] M. Bača, M. Schatten, and B. Golenja, “Modeling
Biometrics Systems in UML”. in IIS2007 International Conference on Intelligent and Information Systems Proceedings. 2007, Vol. 18, pp. 23–27.
[2] M. Bača, M. Schatten, and K. Rabuzin, “A Framework for

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
7
Systematization and Categorization of Biometrics Methods”. in IIS2006 International Conference on Intelligent and Information Systems Proceedings. 2006, Vol. 17, pp. 271–278.
[3] M. Bača, M. Schatten, and K. Rabuzin, “Towards an Open Biometrics Ontology”, Journal of Information and Organizational Sciences, Vol. 31, No. 1, 2007, pp. 1–11.
[4] R. H. Jr. Giles, “Lasting Forests Glossary”. Available at http://fwie.fw.vt.edu/rhgiles/appendices/glossb.htm, Accessed: 28th February 2005.
[5] D. Radošević, Osnove teorije sustava, Zagreb: Nakladni zavod Matice hrvatske, 2001.
[6] M. Schatten, M. Bača, and K. Rabuzin, “A Taxonomy of Biometric Methods”, in ITI2008 International Conference on Information Technology Interfaces Proceedings, Cavtat/Dubrovnik: SRCE University Computing Centre 2008; 389–393.
[7] M. Schatten, “Zasnivanje otvorene ontologije odabranih segmenata biometrijske znanosti” M.S. Thesis, Faculty of Organization and Informatics, University of Zagreb, Varaždin, Croatia, 2008.
[8] J. L. Wayman, “Generalized Biometric Identification System Model”, in National Biometric Test Center Collected Works 1997. - 2000. San Jose: San Jose State University. 2000, pp. 25–31.
[9] M. Žugaj, K. Dumičić and V. Dušak, Temelji znanstvenoistraživačkog rada. Metodologija i metodika, Varaždin: TIVA & Faculty of Organization and Informatics, 2006.
M. Schatten received his bachelors degree in Information systems (2005), and his masters degree in Information Sciences (2008) both on the faculty of Organization and Informatics, University of Zagreb where he is currently a teaching and research assistent. He is a member of the Central European Conference on Intelligent and Information Systems organizing comitee. He is a researcher in the Biometrics center in Varaždin, Croatia. M. Bača received his bachelor degree form Faculty of Electrical Engineering in Osijek (1992), second bachelors degree form High Police School in Zagreb (1996), MSc degree form Faculty of Organization and Informatics, Varaždin (1999), PhD degree from Faculty of Organization and Informatics, Varaždin (2003). He was an Assistant professor, University of Zagreb, Faculty of Organization and Informatics (2004-2007), and is currently an Associated professor, University of Zagreb, Faculty of Organization and Informatics. He is a member of various professional societies and head of the Central European Conference on Intelligent and Information Systems organizing comitee. He is also the head of the Biometrics center in Varaždin, Croatia. He lead 2 scientific projects granted by the Ministry of Science, Education and Sports of Croatia. M. Čubrilo received his bachelors (1979) and masters (1984) degree from the Faculty of Natural Sciences and Mathematics, University of Zagreb. He received his PhD degree from the Faculty of Electrotechnics, University of Zagreb (1992). He is currently a full professor at the Faculty of Organization and Informatics, University of Zagreb. He was main editor of the Journal of Information and Organization Sciences. He was leader of 2 scientific projects granted by the Ministry of Science, Education and Sports of Croatia.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
8
Philosophical Survey of Passwords
M Atif Qureshi1, Arjumand Younus2 and Arslan Ahmed Khan3
1 UNHP Research
Karachi, Sind, Pakistan [email protected]
2 UNHP Research
Karachi, Sind, Pakistan [email protected]
3 UNHP Research Karachi, Sind, Pakistan
Abstract Over the years security experts in the field of Information Technology have had a tough time in making passwords secure. This paper studies and takes a careful look at this issue from the angle of philosophy and cognitive science. We have studied the process of passwords to rank its strengths and weaknesses in order to establish a quality metric for passwords. Finally we related the process to human senses which enables us to propose a constitutional scheme for the process of password. The basic proposition is to exploit relationship between human senses and password to ensure improvement in authentication while keeping it an enjoyable activity. Key words: Context of password, password semantics, password cognition, constitution of password, knowledge-based authentication 1. Introduction No doubt information is a valuable asset in this digital age. Due to the critical nature of information, be it personal information on someone’s personal computer or information systems of large organizations, security is a major concern. There are three aspects of computer security: authentication, authorization and encryption. The first and most important of these layers is authentication and it is at this layer that passwords play a significant role. Most common authentication mechanisms include use of an alphanumeric based word that only the user to be authenticated knows and is commonly referred to as passwords [1]. The SANS Institute indicates that weak or nonexistent passwords are among the top 10 most critical computer vulnerabilities in homes and businesses [2]. Philosophical analysis of passwords can lead to the refinement of the authentication process. This approach has rarely been adopted in the exploration and design of computer security. Passwords too are entities having an
existence of their own and this lead us to study them under a philosophical context. Passwords: this word is essentially composed of two words i.e. pass and word so you pass if you have the right word. Even before the advent of computers watchwords existed in the form of secret codes, agents of certain command for their respective authorization or administration used watchword e.g. for identifying other agents [3] and the underlying concept is essentially the same today. Next we move on to word: in this context word is not necessarily something making dictionary-based sense (we do keep passwords that make no meaning e.g. passwords like adegj or a2b5et). Hence Passwords are keys that control access. They let you in and keep others out. They provide information control (passwords on documents); access control (passwords to web pages) and authentication (proving that you are who you say you are) [4]. In this paper we take a deep look into both the theory and philosophy of passwords; in short we will be addressing a fundamental question: can password semantics enable them to mimic Nature’s way of keeping secrets and providing security.
1.1 Why philosophical perspective of passwords
Ontology is a philosophical term used to describe a particular theory about the nature of being or the kinds of things that have existence [5]. In the context of passwords it implies a careful and thorough dive into the existence and nature of passwords and their relationship to users and computers. A password has a relationship with the user’s mind and therefore it should be linked with specific user’s mindset by creating a sensible bridge between the two. In short password must be backed by a certain philosophy

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 11
IJCSIIJCSI
which establishes a link between concerned rational entities i.e. user and system of recognition.
1.2 Outline
The organization of this paper is as follows: in section 2 we take a careful look into the problems of the existing password schemes and analyze the existing solutions. In section 3 we propose some suggestions in light of our philosophical approach at the same time evaluating and presenting a critique of the existing mechanisms. Finally section 4 concludes the discussion.
2. The Password Problem
When it comes to the area of computer security there is a heavy reliance on passwords. But the main drawback of passwords is what is termed as the “password problem” [6] for text-based passwords. We will refer to this problem as the “classical password problem.” This problem basically arises from either two of the following facts:
1) Human memory is limited and therefore users cannot remember secure passwords as a result of which they tend to pick passwords that are too short or easy to remember [7]. Hence passwords should be easy to remember.
2) Passwords should be secure, i.e., they should look random and should be hard to guess; they should be changed frequently, and should be different on different accounts of the same user. They should not be written down or stored in plain text. But unfortunately users do not tend to follow these practices [8].
Tradeoffs have to be made between convenience and security due to the shortcomings of text-based passwords. Now we explore some techniques that have been adopted to minimize the tradeoffs and increase computer security.
2.1 Attempts to Address the Problem
Current authentication techniques fall into three main areas: token-based authentication, biometric-based authentication and knowledge-based authentication. Token-based authentication techniques [9] use a mark or a symbol for identification which is only known to the authenticating mechanism and it is under the possession of the user just like a coin which has no meaning other than that known to the mechanism. An example is that of key cards and smart cards. Many token-based authentication systems also use knowledge-based techniques to enhance
security. For example ATM cards are generally used together with a PIN number [1]. Biometrics systems are being heavily used [10], biometric authentication refers to technologies that measure and analyze human physical and behavioral characteristics for authentication purposes. Examples of physical characteristics include fingerprints, eye retinas and irises, facial patterns and hand measurements, while examples of mostly behavioral characteristics include signature, gait and typing patterns. Voice is considered a mix of both physical and behavioral characteristics. However, it can be argued that all biometric traits share physical and behavioral aspects. Knowledge-based techniques are most common and will mainly be the focus of our discussion and under which both text-based and picture-based passwords are subcategorized. 2.1 An Extension of Knowledge-Based Passwords A new phenomenon that computer security researchers have recently explored under the domain of knowledge-based passwords is that of graphical passwords i.e. passwords that are based on pictures. They have motivated their studies on some psychological studies revealing that humans remember pictures better than text [11]. Picture-based passwords are subdivided into recognition-based and recall-based approaches. Using recognition-based techniques, a user is presented with a set of images and the user passes the authentication by recognizing and identifying the images he or she selected during the registration stage. Using recall-based techniques, a user is asked to reproduce something that he or she created or selected earlier during the registration stage.
3. Passwords from a Philosophical Viewpoint
As previously mentioned we focus on an ontological study of passwords and that too under the light of philosophy. However ontology has its definition in Computer Science (more specifically in Artificial Intelligence [5]). In fact at the start of this century emerged a whole new field namely cognitive science [12] which brought scholars of philosophy and computer science close to each other and under this field computer scientists are closely studying working of the human mind to make computational tasks efficient. It is this approach that we also propose and that’s one main reason why we say that passwords should be studied from a philosophical perspective. Passwords have never managed a distinct line whether it is a single unit of work or a process. If the password follows

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
12
IJCSIIJCSI
a cognitive paradigm then password recognition is a complete process just like the human mind follows a certain process in recognizing and authenticating known people; similarly computers should take passwords as a process in the light of philosophy. In fact we believe that much of the drawbacks in previous approaches are due to treating password as a unit of work and not carefully viewing the details of the entire process in close context with the human mind. The password recognition process is a detailed DFD (data flow diagram) rather than a context DFD. Once we are clear that password recognition is a process we must now look at ways that can make this process friendly for the humans at the same time ensuring security to the maximum level. A common point that is raised when addressing the classical password problem defined in the previous section is that human factors are the weakest link in a computer security system [13]. But here we raise an important question: is human really the weak link here or is it the weakness of evaluation procedure for password that under utilizes the intelligence and senses of human that make him look as a naive link in whole process of text-based passwords environment. In fact human intelligence and senses if properly utilized can result in best-possible security mechanism.
3.1 Some Problems in Earlier Attempts
In section 2.1 we explored some attempts to solve the classical password problem. However each of the techniques that have been proposed has some drawbacks which can be summarized as follows:
• The token-based passwords though secure but require a token (permit pass) which could be misplaced, stolen, forgotten or duplicated and the biggest drawback is that the technique can only be applied in limited domains not within the reach of common user.
• The biometric passwords are efficient in that they
are near to a human’s science and do not require remembrance rather they are closely linked with humans but they are expensive solutions and cannot be used in every scenario.
• Knowledge based passwords require
remembrance and are sometimes breakable or guessable.
3.2 Proposed Directions to Prevent Possible Attacks
Following directions can be adopted in order to improve the security of passwords at the same time making it an enjoyable/sensible activity to ensure user satisfaction:
1. Appropriate utilization of human senses in the passwords.
2. Increase in the domain set of password by introducing a greater deal of variety.
3. Empowering user to make selection from domain set of variety to ensure his mental and physical satisfaction.
4. Introducing facility of randomization into the password.
5. Ensure the establishment of a link between system and specific human mind from domain set.
A discussion on possible attacks and tips for prevention (in light of philosophy and cognitive science) follows:
• Brute force search: is basically a global attack on passwords to search for all possible combinations of alpha numerals (in case of text-based passwords) and graphical images (in case of graphical passwords). In short brute force launches attack of words that can be text-based, activity and mixed courses of action. The brute force attack can be prevented with ease by application of point 2, 4 and 5 mentioned above and as a result the brute-force attack becomes computationally impossible. This philosophy should be kept in mind and the engine should be such that point 3 also follows as a logical consequence.
• Dictionary Attacks: are regional attacks that run
through a possible series of dictionary words, activities and mixed courses of action until one works. Even some graphical passwords are vulnerable to these types of attacks. However these can be prevented in an effective manner by application of techniques mentioned in point 4 and 5. This will allow maximum sense exploitation so dictionary attacks would fail most often.
• Shoulder surfing: is when an attacker directly
watches a user during login, or when a security camera films a user, or when an electromagnetic pulse scanner monitors the keyboard or the mouse, or when Trojan login screens capture

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 11
IJCSIIJCSI
passwords etc [6]. This attack can easily be prevented with the simple approach proposed in point 4 in the pass-word the pass should be the same but we should not take the word as static thereby making it pass-sense.
• Guessing: is a very common problem associated
with text-based passwords or even graphical passwords. Guess work is possible when the domain is limited and choices are few; in other words there is a lesser utilization of senses. So this threat can easily be prevented by practicing points 1, 3 and 4.
• Spy ware: is type of malware that collects user’s
information about their computational behavior and personal information. This attack can easily fail in the light of above mentioned points 4 and 5 which imply that the password is making sense to both human and computer but not spyware.
All these suggestions were for the knowledge-based passwords but this philosophy can also be applied on other two categories as mentioned in section 3.1. Biometrics and token-based authentication mechanisms cannot be deployed everywhere because of the amount of investment and ease of use. But these authentication mechanisms can be treated as choice for domain set as mentioned in point 2 and leaving the choice to user as discussed in point 3.
3.3 Redefinition of the Password Problem
In the classical scenario the domain of the problem was simply limited to text-based passwords but the three solutions proposed: token-based passwords, biometric passwords and knowledge-based passwords (under which come both text-based and graphical passwords) widen the scope of the problem. Furthermore the directions that we have proposed in section 3.2 can lead to other issues in the password arena. The treatment of password recognition as a process and exploitation of human senses in the process seems to be an appealing idea but it naturally leads to a redefinition of the password problem. Hence first of all we must redefine the password problem in order to extend its domain and increase the size of the universe of discourse. We can redefine the problem as follows:
1. Introducing variety into the domain set of password is a task that must be given due consideration and any attempt to implement the philosophical concepts explored in this paper must address the question: How and in what ways can variety be introduced into the passwords so
that N^K formulation sustains more with N than with K where N is single input or action and K is length of input.
2. We have stated that password recognition is a process in itself but the details and phases of that process have to be identified. To accommodate philosophical ideas one must carefully model the process of evaluation (i.e. input and validation).
3. By exploiting senses to ensure variety does not mean to exhaust user both physically and mentally but means to enhance level of comfort and freedom to choose from variety that lead in securing system sensibly.
4. Randomization in password should follow the common sense rather than heavy mental exercise in a way that senses tell computer system “Yes, I am the right person. Please let me pass!”
5. In security critical zones, heavy investment is made to ensure protection at the level of authentication but lacks to decide level of quality achieved. The discussion in section 3.2 will give transparency for proper budgeting, level of comfort and level of security achieved in authentication mechanism.
In short a sensible link between the human mind and the computer system for verification is a complex problem and is a great challenge for researchers in the field of computer security
4. Conclusions
This paper has thrown light onto the philosophy of passwords and their study in connection with the human mind. Although the points that were mentioned in this paper have been noted by different researchers at different times but there’s no single place where the entire “password philosophy” has been defined. Thus we have laid out the constitutional terms for any study of intelligent and smart passwords. The two main points that we have identified in this “Constitution of Passwords” are as follows:
1. Password is not just a unit of work; rather it is a complete process.
2. Password should incorporate common sense of humans.
3. There must be quality assurance at the level of authentication mechanism.
This philosophy can play vital role for immediate practitioners if they keep tradeoff of in their mind before producing a secure solution and as well as for researchers

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
12
IJCSIIJCSI
to dive into challenging problems that have been left open for them. References [1] X. Suo, Y. Zhu, G. S. Owen, "Graphical Passwords: A
Survey," 21st Annual Computer Security Applications Conference (ACSAC'05), 2005, pp. 463-472.
[2] R. L. Wakefield, "Network Security and Password Policies", CPA Online Journal, 2004. http://www.nysscpa.org/cpajournal/2004/704/perspectives/p6.htm
[3] From The Histories of Polybius published in Book VI Vol. III of the Loeb Classical Library edition Public Domain translation: The Roman Military System, Book Cited in http://penelope.uchicago.edu/Thayer/E/Roman/Texts/Polybius/6*.html
[4]The Hacker Highschool Project, ISECOM 2004. http://www.hackerhighschool.org/lessons/HHS_en11_Passwords.pdf
[5] S. Russell and P. Norvig, Artificial Intelligence – A Modern Approach 2nd Edition, Pearson Education Series in Artificial Intelligence
[6] S. Wiedenbeck, J. Waters, J.C. Birget, A. Brodskiy, N. Memon, “Authentication using graphical passwords: Basic results”, Human-Computer Interaction International (HCII 2005), Las Vegas, July 25-27, 2005.
[7] A. Adams and M. A. Sasse, "Users are not the enemy: why users compromise computer security mechanisms and how to take remedial measures," Communications of the ACM, vol. 42, pp. 41-46, 1999.
[8] M. Kotadia, “Microsoft: Write down your passwords” in ZDNet Australia, May 23, 2005.
[9] R. Molva, G. Tsudik, "Authentication Method with Impersonal Token Cards," IEEE Symposium on Security and Privacy, 1993, p. 56.
[10]A. Jain, L. Hong and S. Pankanti, "Biometric Identification," Communications of the ACM, vol. 33, pp. 167-176, 2000.
[11] R. N. Shepard, "Recognition memory for words, sentences, and pictures," Journal of Verbal Learning and Verbal Behavior, vol. 6, pp. 156-163, 1967.
[12] Cognitive Science Definition by Berkeley http://ls.berkeley.edu/ugis/cogsci/major/about.php [13] A. S. Patrick, A. C. Long, and S. Flinn, "HCI and Security
Systems," presented at CHI, Extended Abstracts (Workshops). Ft. Lauderdale, Florida, USA, 2003.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
13
Global Heuristic Search on Encrypted Data (GHSED)
Maisa Halloush, Mai Sharif
1 Department of Computer Science, Al-Balqa Applied University, Amman, Jordan
2 Barwa Technologies, Doha, Qatar
Abstract
Important document are being kept encrypted in remote servers. In order to retrieve these encrypted data, efficient search methods needed to enable the retrieval of the document without knowing the content of the documents In this paper a technique called a global heuristic search on encrypted data (GHSED) technique will be described for search in an encrypted files using public key encryption stored on an untrusted server and retrieve the files that satisfy a certain search pattern without revealing any information about the original files. GHSED technique would satisfy the following: (1) Provably secure, the untrusted server cannot learn anything about the plaintext given only the cipher text. (2) Provide controlled searching, so that the untrusted server cannot search for a word without the user's authorization. (3) Support hidden queries, so that the user may ask the untrusted server to search for a secret word without revealing the word to the server. (4) Support query isolation, so the untrusted server learns nothing more than the search result about the plaintext.
Key words: Heuristic Table, Controlled Search, Query Isolation, hidden queries, false positive, hash chaining
1. Introduction With more and more files stored on not necessarily trusted external server, concerns about this file falling into the wrong hand grow (i.e. server administrator can read my file). Thus users often store their data encrypted to ensure confidentiality of data on remote servers, for more space, cost & convenience. But what happen if the client wants to retrieve particular files (the files that satisfy certain search pattern or keyword)? A method is needed to search in the files for a particular keyword (search pattern) and only retrieve the files that contain that keyword. For example, consider a server that stores various files encrypted for "Alice" by others. A server wants to test whether the files contain the keyword "urgent" so that it could forward the file accordingly. "Alice", on the other hand does not wish to
give the server the ability to decrypt all her files or even know anything about the search keyword. A technique called a global heuristic search on encrypted data (GHSED) that enables server to search for a specific pattern on encrypted files without revealing any information to the untrusted server or any loss of data confidentiality will be defined and constructed, and its security would be proved. It also would be proved to have a minimal collision rate and stable construction time and it would also be proven to be applied to databases records, emails or audit logs. (GHSED) technique is an enhancement over the (HSED) technique (Heuristic Search on Encrypted Data) technique [1], where they present "a new technique capable of handling large data keyword search in an encrypted document using public key encryption stored in untrusted server without revealing the content of the search and the document. The prototype provides a local search, minimizing communication overhead and computations on both the server and the client."[1]. (HSED) technique enables the server to efficiently search for a keyword without communication overhead since the message is encrypted and heuristic table construction is done on the client side. It also implies no additional computation overhead on the email server because no decryption is performed on the server since their model uses the public key cryptographic system. So unlike other techniques that use symmetric key cryptography, (HSED) technique reduces computation and communication overhead on the sever, in addition requires no additional computation except for simply calculating a hash function that serves as the address of an entry in the heuristic table."[1] However, one of the disadvantages in (HSED) technique was that it deals with each document alone. When the sever search for a document that has a specific keyword it search all the document's heuristic table, this would be

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
14
easy if the server has a small number of documents, but what if it has a large number of document? This would be too hard and needs a lot of time. Therefore, (GHSED) technique handles this problem by making a GHT (Global Heuristic Table) together with the HT (Heuristic Table) used in (HSED) technique. Another disadvantage was that they drop the possibility of repeated word in a document; this would also be solved in (GHSED) technique, since this is a very common situation and has to be solved.
2. Global HEURISTIC SEARCH ON ENCRYPTED DATA (GHSED) As shown in the previous section; (HSED) technique use heuristic table to make the search secure. Although the time needed to scan the heuristic table is encountered very little, it takes O(M*e) to search in all documents in the server, cause it must go through one heuristic table per each document. In this paper the same idea of (HSED) technique will be used; that is using public key cryptography, and search all keywords in document, but with one heuristic table for all documents in the server. This heuristic table will be named as Global Heuristic Table (GHT), and it will contain information about each word exists in documents stored in the server. Suppose "Alice" wants to store her encrypted documents in a form that could be searchable. To do this a Global Heuristic Table (GHT) will be used to contain every keyword in the documents stored in the server; each keyword will point to all documents in which the keyword located in. The pointers will be illusory pointers; that is the keyword will point to a binary array which contains every document number that the keyword exists in. It is clear that every document will be given a number before stored in the server. When "Alice" wants to retrieve all documents which contain a specific keyword, she will send a trapdoor to the server. The server will use this trapdoor to search the Global Heuristic Table (GHT) and find the keyword, then retrieve the documents number which contain the keyword, and send the documents to "Alice". In the next subsections we will illustrate how (GHSED) technique works, we will show the roll of every party involved in the search; that is the document generator, the searcher, and the server. 2.1 The Document Generator Side
When "Alice" wants to store an encrypted document in the server she will construct heuristic table HT which will be used by the server to embed it in the GHT. Then "Alice" will encrypt the document by "Alice’s" public key Apub. The document and the HT will be sent to the server. These steps are illustrated figure 2.1.
Fig 2.1: Steps of Constructing the Files.
The heuristic table HT will be constructed as follows: For each keyword in the document a record in the heuristic table HT will be added as shown in Table 2.1
Table 2.1: Heuristic Table Header.
Where: Indexi = H(Wi) Calculated hash function used as
index to both HT and GHT entries.
KI(Wi) = ∑=
n
j 1( chlj(Wi)* chwj( Wi )) The sum of each
position of the ith character of the word multiplied by the character weight.
EWi Keyword Wi Encrypted using Apub
Sum(EWi) = ∑=
n
j 1dj The sum of digits of the encrypted
keyword EWi.
Ver-key(Wi) = KI(Wi) || Sum(EWi)

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
15
2.2 The Server Side Two operations will be done in the server side: the first one is storing the encrypted documents is a way to be searchable. The second one is to return documents which contain specific keyword when needed. After building the HT which is related to the encrypted document, it will be sent to the server to be stored in it. The server will give a number to the document which will be used to define it. Then the server will embed the HT into GHT. The document with its HT will be stored in the server, as shown in figure 2.2.
Fig 2.2: Steps done on the server side to store the documents.
GHT is a binary array contains information about each keyword exists in one or more documents stored in the server. If two words have the same index, the changing will be used. Each keyword in the GHT has a pointer to a binary array, which contains all documents numbers in which the keyword exists. Using the binary array will facilitate the operation done on the array. Each entry in HT should be added to the GHT, such that, the index of both the HT and the GHT is the same. If no index exists in the GHT same as in HT then a new entry will be added in the GHT. This entry will contain both KI and Ver-Key and a pointer to a binary array which contains the document number. If the index in HT exists in the GHT, then the entries of the table will be checked to see if we have the same word in the GHT by comparing both KI and Ver-key. If it is a new keyword then a new chain entry will be created and a pointer to a binary array which contains the document number. But if it is an existing keyword then just an entry containing the document number will be added in the binary array which contains the documents number. 2.3 Return Documents Which Contain a Specific Keyword
When "Alice" wants to retrieve the files that contain a specific keyword, she sends a trapdoor T (Tew, TKI) to the server - Tew: Keyword encrypted with "Alice’s" public key
- TKI = ∑=
n
j 1( chlj(Wi)* chwj( Wi ))
This trapdoor is used by the server to calculate an index in the global heuristic table GHT, that may the word locate The position of the ith character of Wi in the language multiplied by its position in the word. Note that "Alice" then signs this trapdoor using her Private Key. Digital signature is used to allow the server identify that the trapdoor is sent by the recipient. Enc (Trapdoor(Tew, TKI), Apriv) This will lead to an entry in the global heuristic table, the server can then retrieve the first and second column's entries from the heuristic table which is < KI > < Ver- key > and calculate:
Sum(Tew ) = ∑=
n
j 1 dj The sum of digits of the first
part of the trapdoor Tw Ver- key’(Tew) = KI || Sum(Tew) The calculated Ver- key’(Tew) will be compared to Ver- key(W), which is the second table entry indexed by H(Tew). If there is a match then the word exists in one of the files stored in the server, if not the index entry will be checked to see if there is a collided entries, if yes then the chain will be checked until a match will be found, if no match is found then the word does not exist. If the word found in the GHT then the server will check the documents serial numbers that contains the specified word and send documents to "Alice". These steps are shown in figure 2.3.
Fig 2.3.: Steps done on the server side for searching for the documents.
3. Results (GHSED) technique algorithm mainly has two parts: embedding the heuristic table into the Global heuristic
IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
16
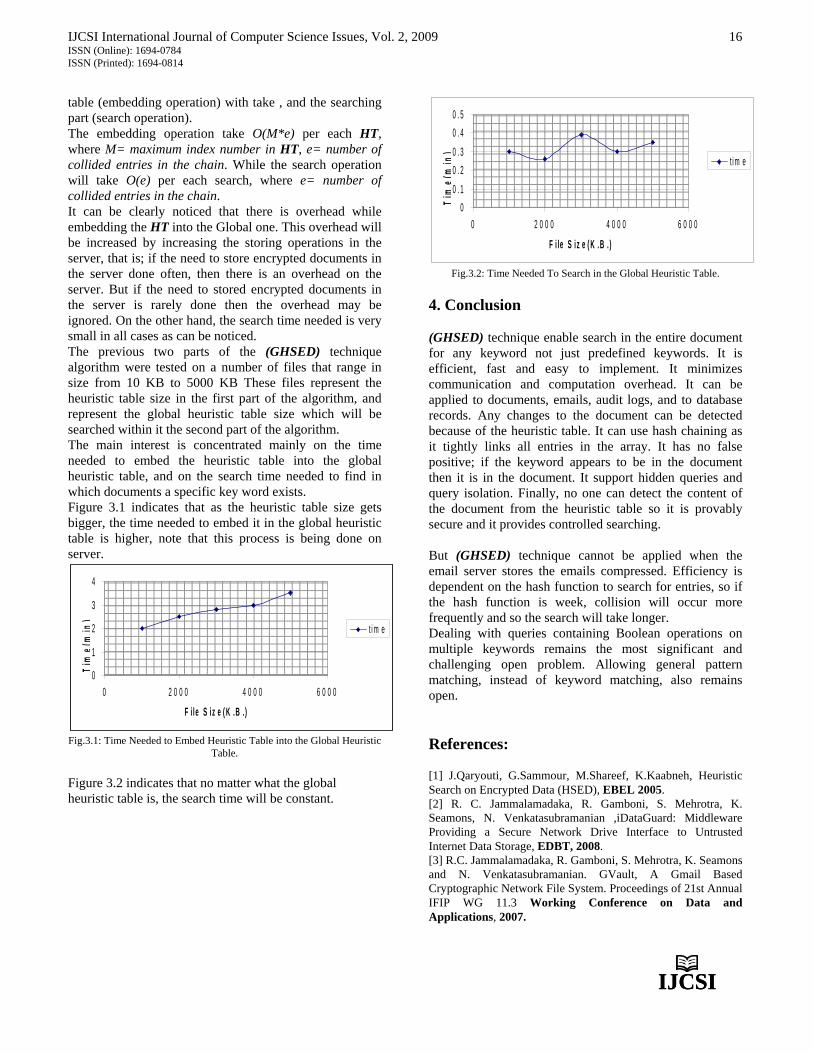
table (embedding operation) with take , and the searching part (search operation). The embedding operation take O(M*e) per each HT, where M= maximum index number in HT, e= number of collided entries in the chain. While the search operation will take O(e) per each search, where e= number of collided entries in the chain. It can be clearly noticed that there is overhead while embedding the HT into the Global one. This overhead will be increased by increasing the storing operations in the server, that is; if the need to store encrypted documents in the server done often, then there is an overhead on the server. But if the need to stored encrypted documents in the server is rarely done then the overhead may be ignored. On the other hand, the search time needed is very small in all cases as can be noticed. The previous two parts of the (GHSED) technique algorithm were tested on a number of files that range in size from 10 KB to 5000 KB These files represent the heuristic table size in the first part of the algorithm, and represent the global heuristic table size which will be searched within it the second part of the algorithm. The main interest is concentrated mainly on the time needed to embed the heuristic table into the global heuristic table, and on the search time needed to find in which documents a specific key word exists. Figure 3.1 indicates that as the heuristic table size gets bigger, the time needed to embed it in the global heuristic table is higher, note that this process is being done on server.
0
1
2
3
4
0 2 0 0 0 4 0 0 0 6 0 0 0
F i le S iz e ( K .B . )
Tim
e(m
in)
t i m e
Fig.3.1: Time Needed to Embed Heuristic Table into the Global Heuristic
Table.
Figure 3.2 indicates that no matter what the global heuristic table is, the search time will be constant.
00 .10 .20 .30 .40 .5
0 2 0 0 0 4 0 0 0 6 0 0 0
F i le S iz e ( K .B . )
Tim
e(m
in)
t i m e
Fig.3.2: Time Needed To Search in the Global Heuristic Table.
4. Conclusion (GHSED) technique enable search in the entire document for any keyword not just predefined keywords. It is efficient, fast and easy to implement. It minimizes communication and computation overhead. It can be applied to documents, emails, audit logs, and to database records. Any changes to the document can be detected because of the heuristic table. It can use hash chaining as it tightly links all entries in the array. It has no false positive; if the keyword appears to be in the document then it is in the document. It support hidden queries and query isolation. Finally, no one can detect the content of the document from the heuristic table so it is provably secure and it provides controlled searching. But (GHSED) technique cannot be applied when the email server stores the emails compressed. Efficiency is dependent on the hash function to search for entries, so if the hash function is week, collision will occur more frequently and so the search will take longer. Dealing with queries containing Boolean operations on multiple keywords remains the most significant and challenging open problem. Allowing general pattern matching, instead of keyword matching, also remains open. References: [1] J.Qaryouti, G.Sammour, M.Shareef, K.Kaabneh, Heuristic Search on Encrypted Data (HSED), EBEL 2005. [2] R. C. Jammalamadaka, R. Gamboni, S. Mehrotra, K. Seamons, N. Venkatasubramanian ,iDataGuard: Middleware Providing a Secure Network Drive Interface to Untrusted Internet Data Storage, EDBT, 2008. [3] R.C. Jammalamadaka, R. Gamboni, S. Mehrotra, K. Seamons and N. Venkatasubramanian. GVault, A Gmail Based Cryptographic Network File System. Proceedings of 21st Annual IFIP WG 11.3 Working Conference on Data and Applications, 2007.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
17
[4] Bijit Hore, Sharad Mehrotra, Hakan Hacigumus. Handbook of Database Security: Applications and Trends. pages 163-190, 2007. [5] Hakan Hacigumus, Bijit Hore, Bala Iyer, Sharad Mehrotra. Secure Data Management in Decentralized Systems. pages 383 – 425, 2007. [6] Richard Brinkman, Jeroen Doumen, and Willem Jonker. Secure Data Management, pages 18-27 2004. [7] E. Goh. Secure Indexes, In the Cryptology ePrint Archive, Report 2003/216, 2004. http://eprint.iacr.org/2003/216/. [8] Richard Brinkman, Ling Feng, Jeroen Doumen, Pieter H. Hartel, and Willem Jonker. Efficient Tree Search in Encrypted Data. WOSIS pages 126-135 2004. [9] Y. Chang and M. Mitzenmacher, Privacy Preserving Keyword searches on Remote Encrypted Data, Cryptology ePrint Archive, Report 2004/051, 2004. [10] K.Bennett, C. Grothoff, T. Horozov and I. Patrascu. Efficient sharing of encrypted data. In proceedings of ACISP 2002. [11] B. Chor, O. Goldreich, E. Kushilevitz and M. Sudan, Private Information Retrieval, Journal of ACM, Vol. 45, No. 6, 1998. [12] S. Jarecki, P. Lincoln and V. Shmatikov. Negotiated privacy. In the International Symposium on Software Security, 2002. [13] W. Ogata, and K. Kurosawa. Oblivious Keyword Search, Special issue on coding and cryptography, Journal of Complexity, Vol.20, 2004. [14] Richard Brinkman, Berry Schoenmakers, Jeroen Doumen, and Willem Jonker. Experiments with Queries over Encrypted Date Usinf Seacrete Sharing. Information Systems Security Journal, 13(3):14–21, July. 2004. http://eprints.eemcs.utwente.nl/7410/01/fulltext.pdf. [15] B. Waters, D. Balfanz, G. Durfee and D. Smetters. Building an Encrypted and Searchable Audit Log. Proceedings of the Network and Distributed System Security Symposium, NDSS 2004, ISBN 1-891562-18-5, 2004. [16] Searching in encrypted data, Jeroen Doumen, http://www.exp-math.uniessen.de/zahlentheorie/gkkrypto/kolloquien/abstract_20040722_1.pdf, WOSIS 2004.
[17] D.Song, D.Wanger, and A.Perrig. Practical techniques for searches on encrypted data. In IEEE Symposium on Security and Privacy, 2000. [18] Efficient Tree Search in Encrypted Data , R. Brinkman, L. Feng, J. Doumen, P.H. Hartel and W. Jonker, (2004), http://www.ub.utwente.nl/webdocs/http://www.ub.utwente.nl/webdocs/ctit/1/000000f3.pdf. [19] Boneh, G. Di Crescenzo, R. Ostrovsky, and G. Persian. Public key encryption with keyword search. In proceedings of Eurocrypt 2004, LNCS 3027, 2004. [20] A Survey of Public-Key Cryptosystems, Neal Koblitz, Alfred J. Menezes,http://www.math.uwaterloo.ca/~ajmeneze/publications/publickey.pdf, 2004. [21] P. Golle, , B.Waters; J. Staddon, Secure conjunctive keyword search over encrypted data. In proceedings of the Second International Conference on Applied Cryptography and Network Security (ACNS-2004); June 8-11 2004. [22] Hash functions: Theory, attacks, and applications, Ilya Mironov research.microsoft.com/users/mironov/papers/hash_survey.pdf, 2005. [23] Collisions for Hash Functions, MD4, MD5, HAVAL-128 and RIPEMD, Xiaoyun Wang , Dengguo Feng , Xuejia Lai , Hongbo Yu, http://eprint.iacr.org/2004/199.pdf, 2004. [24] William Stallings, Cryptography and Network Security: Principles and Practice, 3/E, Publisher: Prentice Hall, Copyright: 2000. Maisa Halloush Received the B.Sc. and M.Sc. scientific degrees in computer science 2002 and 2007, respectively. Her master thesis was about information security. She is continuing doing research in the same topic. Working currently as IT instructor in Al Quds College. She is also involved in writing books related to E-Business, Software Engineering, and Operating System. Mai Sharif Received the B.Sc. and M.Sc. scientific degrees in computer science 1997 and 2005, respectively. She has more than 10 years experience in business analysis and software development. She has two published papers. Currently her areas of interest include information security, ripple effect in software modules, e-learning.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
18
Comprehensive Security Framework for Global Threads Analysis
Jacques SARAYDARYAN, Fatiha BENALI and Stéphane UBEDA
1 Exaprotect R&D Villeurbanne, 69100, France
2 INSA Lyon Villeurbanne, 69100, France [email protected]
3 INSA Lyon Villeurbanne, 69100, France
Abstract Cyber criminality activities are changing and becoming more and more professional. With the growth of financial flows through the Internet and the Information System (IS), new kinds of thread arise involving complex scenarios spread within multiple IS components. The IS information modeling and Behavioral Analysis are becoming new solutions to normalize the IS information and counter these new threads. This paper presents a framework which details the principal and necessary steps for monitoring an IS. We present the architecture of the framework, i.e. an ontology of activities carried out within an IS to model security information and User Behavioral analysis. The results of the performed experiments on real data show that the modeling is effective to reduce the amount of events by 91%. The User Behavioral Analysis on uniform modeled data is also effective, detecting more than 80% of legitimate actions of attack scenarios.
Key words: Security Information, Heterogeneity, Intrusion Detection, Behavioral Analysis, Ontology.
1. Introduction
Today, information technology and networking resources are dispersed across an organization. Threats are similarly distributed across many organization resources. Therefore, the Security of information systems (IS) is becoming an important part of business processes. Companies must deal with open systems on the one hand and ensure a high protection on the other hand. As a common task, an administrator starts with the identification of threats related to business assets, and applies a security product on each asset to protect an IS. Then, administrators tend to combine and multiply security products and protection techniques such as firewalls, antivirus, Virtual Private
Network (VPN), Intrusion Detection System (IDS) and security audits. But are the actions carried out an IS only associated with attackers? Although the real figures are difficult to know, most experts agree that the greatest threat for security comes not only from outside, but also from inside the company. Now, administrators are facing new requirements consisting in tracing the legitimate users. Do we need to trace other users of IS even if they are legitimate? Monitoring attackers and legitimate users aims at detecting and identifying a malicious use of the IS, stopping attacks in progress and isolating the attacks that may occur, minimizing risks and preventing future attacks to take counter measures. To trace legitimate users, some administrators perform audit on applications, operating systems and administrators products. Events triggered by these mechanisms are thus relevant for actions to be performed by legitimate users on these particular resources. Monitoring organization resources produces a great amount of security-relevant information. Devices such as firewalls, VPN, IDS, operating systems and switches may generate tens of thousands of events per second. Security administrators are facing the task of analyzing an increasing number of alerts and events. The approaches implemented in security products are different, security products analysis may not be exact, they may produce false positives (normal events considered as attacks) and false negatives (Malicious events considered as normal). Alerts and events can be of different natures and level of granularity; in the form of logs, Syslog, SNMP traps, security alerts and other reporting mechanisms. This

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
19
information is extremely valuable and the operations that must be carried out on security require a constant analysis of these data to guarantee knowledge on threats in real time. An appropriate treatment for these issues is not trivial and needs a large range of knowledge. Until recently, the combined security status of an organization could not be decided. To compensate for this failure, attention must be given to integrate local security disparate observations into a single view of the composite security state of an organization. To address this problem, both vendors and researchers have proposed various approaches. Vendors’ approaches are referred to as Security Information Management (SIM) or Security Event Management (SEM). They address a company’s need to manage alerts, logs and events, and any other security elementary information coming from company resources such as networking devices of all sorts, diverse security products (such as firewalls, IDS and antivirus), operating systems, applications and databases. The purpose is to create a good position for observation from which an enterprise can manage threats, exposure, risk, and vulnerabilities. The industry’ approaches focus on information technology events in addition to security event. They can trace IS user, although the user is an attacker or a legitimate user. The intrusion detection research community has developed a number of different approaches to make security products interact. They focus on the correlation aspect in the analysis step of data, they do not provide insights into what properties of the data being analyzed. The question asked in this article is to know what is missing in today’s distributed intrusion detection. However, it is not clear how the different parts that compose Vendor product should be. Vendor’s approaches do not give information on how data are modeled and analyzed. Moreover, vendors claim that they can detect attacks, but how can they do if the information is heterogeneous? How can they rebuild IS misuse scenarios? All the same, research works lack of details on the different components, which make the correlation process effective. They were developed in particular environments. They rarely address the nature of the data to be analyzed, they do not give global vision of the security state of an IS because some steps are missing to build the IS scenarios of use. Both approaches do not indicate how they should be implemented and evaluated. Therefore, a coherent architecture and explanation of a framework, which manages company’s security effectively is needed. The framework must collect and normalize data across a company structure, then cleverly analyze data in order to give administrators a global view of the security status
within the company. It can send alerts to administrators so that actions can be taken or it can automate responses that risks can be addressed and remediated quickly, by taking actions such as shutting down an account of a legitimate user who misuses the IS or ports on firewalls. The distributed architecture concept, DIDS (Distributive Intrusion Detection System), first appeared in 1989 (Haystack Lab). This first analysis of distributed information did not present a particular architecture but collected the information of several audit files on IS hosts. The recent global IS monitoring brings new challenges in the collection and analysis of distributed data. Recent distributed architectures are mostly based on Agents. These types of architectures are mainly used in research projects and commercial solutions (Arcsight, Netforensic, Intellitactics, LogLogic). An agent is an autonomy application with predefined goals [31]. These goals are various: monitor an environment, deploy counter-measures, pre-analyze information, etc. The autonomy and goal of an agent would depend on a used architecture. Two types of architecture can be highlighted, distributive centralized architecture and distributive collaborative architecture. Zheng Zhang et al. [1] provided a hierarchical centralized architecture for network attacks detection. The authors recommend a three-layer architecture which collects and analyzes information from IS components and from other layers. This architecture provides multiple levels of analysis for the network attacks detection; a local attack detection provided by the first layer and a global attack detection provided by upper layers. A similar architecture was provided by [39] for the network activity graph construction revealing local and global casual structures of the network activity. K. Boudaoud [4] provides a hierarchical collaborative architecture. Two main layers are used. The first one is composed of agents which analyze local components to discover intrusion based on their analysis of their own knowledge but also with the knowledge of other agents. The upper layer collects information from the first layer and tries to detect global attacks. In order to detect intrusions, each agent holds attacks signatures (simple pattern for the first layer, attack graph for the second layer). Helmer et al. [13] provide a different point of view by using mobile agents. A light weight agent has the ability to “travel" on different data sources. Each mobile agent uses a specific schema of analysis (Login Failed, System Call, TCP connection) and can communicate with other agents to refine their analyses. Despite many discussions, scalability, analysis availability and collaborative architecture are difficult to apply, in today’s, infrastructure but also time and effort consuming.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
20
Thus, despite known drawbacks, distributive centralized architectures will be used in our approach for the analysis of distributive knowledge in the IS. All IS and User behaviors’ actions are distributed inside IS components. In order to collect and analyze these knowledge, we propose an architecture composed of distributed agents allowing distributive data operations. Distributive agent aims at collecting data by making pre-operations and forwarding this information to an Analysis Server. The Analysis Server holds necessary information to correlate and detect abnormal IS behaviors. This architecture is a hierarchical central architecture. Distributive agents share two main functionalities: • a collector function aiming at collecting information on
monitored components, • an homogenization function aiming at standardizing and
filtering collected information. As shown in figure 1, three types of agents are used. The constructor-based agent aims at collecting information from a specific IS components (Window Host, Juniper firewall). The multi-collector based agent aims at collecting information from several IS components redirecting their flow of log (syslog). Then, the multi-service based agent aims at collecting several different information (system log, Web server application log) from a single IS component. This paper presents a comprehensive framework to manage information security intelligently so that processes implemented in analysis module are effective. We focus our study on the information modeling function, the information volume reductions and the Abnormal Users Behavior detection. A large amount of data triggered in a business context is then analyzed by the framework. The results show that the effectiveness of the analysis process
is highly dependent on the data modeling, and that unknown attack scenarios could be efficiently detected without hard pre-descriptive information. Our decision module also allows reducing false positive. The reminder of this paper is structured as follows. In the next section, related work on security event modeling and behavioral analysis is covered. In the third section, the proposed modeling for event security in the context of IS global vision is presented. Section 4 details the anomaly detection module. The validation of the homogenization function and the anomaly detection module is performed on real data and presented in Section 5. Finally, the conclusions and perspectives of our work are mentioned in the last section.
2. Related Work
As mentioned in the introduction, security monitoring of an IS is strongly related to the information generated in products’ log file and to the analysis carried out on this information. In this section, we address both event modeling and Behavioral Analysis state of the art.
2.1 Event Modeling
All the research works performed on information security modeling direct our attention on describing attacks. There is a lack of describing information security in the context of a global vision of the IS security introduced in the previous section. As events are generated in our framework by different products, events can be represented in different formats with a different vocabulary. Information modeling aims to represent each product event into a common format. The common format requires a common specification of the semantics and the
Fig. 1 Global Anomaly Intrusion Detection Architecture

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
21
syntax of the events. There is a high number of alerts classification proposed for use in intrusion detection research. Four approaches were used to describe attacks: list of terms, taxonomies, ontologies and attacks language. The easiest classification proposes a list of single terms [7, 18], covering various aspects of attacks. The number of terms differs from an author to another one. Other authors have created categories regrouping many terms under a common definition. Cheswick and Bellovin classify attacks into seven categories [5]. Stallings classification [38] is based on the action. The model focuses on transiting data and defines four categories of attacks: interruption, interception, modification and fabrication. Cohen [6] groups attacks into categories that describe the result of an attack. Other authors developed categories based on empirical data. Each author uses an events corpus generated in a specific environment. Neumann and Parker [25] works were based on a corpus of 3000 incidents collected for 20 years; they created nine classes according to attacking techniques. Terms tend to not be mutually exclusive; this type of classification can not provide a classification scheme that avoids ambiguity. To avoid these drawbacks, a lot of taxonomies were developed to describe attacks. Neumann [24] extended the classification in [25] by adding the exploited vulnerabilities and the impact of the attack. Lindqvist and Jonson [21] presented a classification based on the Neumann classification [25]. They proposed intrusion results and intrusion techniques as dimension for classification. John Howard [16] presented a taxonomy of computer and network attacks. The taxonomy consists in five dimensions: attackers, tools, access, results and objectives. The author worked on the incidents of the Computer Emergency Response Team (CERT), the taxonomy is a process-driven. Howard extends his work by refining some of the dimensions [15]. Representing attacks by taxonomies is an improvement compared with the list of terms: individual attacks are described with an enriched semantics, but taxonomies fail to meet mutual exclusion requirements, some of the categories may overlap. However, the ambiguity problem still exists with the refined taxonomy. Undercoffer and al [3] describe attacks by an ontology. Authors have proposed a new way of sharing the knowledge about intrusions in distributed IDS environment. Initially, they developed a taxonomy defined by the target, means, consequences of an attack and the attacker. The taxonomy was extended to an ontology, by defining the various classes, their attributes and their relations based on an examination of 4000 alerts. The authors have built correlation decisions based on the
knowledge that exists in the modeling. The developed ontology represents the data model for the triggered information by IDSs. Attack languages are proposed by several authors to detect intrusions. These languages are used to describe the presence of attacks in a suitable format. These languages are classified in six distinct categories presented in [12]: Exploit languages, event languages, detection languages, correlation languages, reporting languages and response languages. The Correlation languages are currently the interest of several researchers in the intrusion detection community. They specify relations between attacks to identify numerous attacks against the system. These languages have different characteristics but are suitable for intrusion detection, in particular environments. Language models are based on the models that are used for describing alerts or events semantic. They do not model the semantics of events but they implicitly use taxonomies of attacks in their modeling. All the researches quoted above only give a partial vision of the monitored system, they were focused on the conceptualization of attacks or incidents, which is due to the consideration of a single type of monitoring product which is the IDS. It is important to mention the efforts done to realize a data model for information security. The first attempts were undertaken by the American agency - Defense Advanced Research Projects Agency (DARPA), which has created the Common Intrusion Detection Framework (CIDF) [32]. The objective of the CIDF is to develop protocols and applications so that intrusion detection research projects can share information. Work on CIDF was stopped in 1999 and this format was not implemented by any product. Some ideas introduced in the CIDF have encouraged the creation of a work group called Intrusion Detection Working Group (IDWG) at Internet Engineering Task Force (IETF). IETF have proposed the Intrusion Detection Message Exchange Format (IDMEF) [8] as a way to set a standard representation for intrusion alerts. IDMEF became a standard format with the RFC 476521. The effort of the IDMEF is centered on alert syntax representation. In the implementations of IDSs, each IDS chooses the name of the attack, different IDSs can give different names to the same attack. As a result, similar information can be tagged differently and handled as two different alerts. Modeling information security is a necessary and important task. Information security is the input data for all the analysis processes, e.g. the correlation process. All
1 http://www.rfc-editor.org/rfc/rfc4765.txt

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
22
the analysis processes require automatic processing of information. Considering the number of alerts or events generated in a monitored system, the process, which manages this information, must be able to think on these data. We need an information security modeling based on abstraction of deployed products and mechanisms, which helps the classification process, avoids ambiguity to classify an event, and reflects the reality. Authors in [16,21] agree that the proposed classification for intrusion detection must have the following characteristics: accepted, unambiguous, understandable, determinist, mutually exclusive, exhaustive. To ensure the presence of all these characteristics, it is necessary to use an ontology to describe the semantics of security information.
2.2 Behavioral Analysis
Even if Host Intrusion Detection System (HIDS) and Network Intrusion Detection System (NIDS) tools are known to be efficient for local vision by detecting or blocking unusual and forbidden activities, they can not detect new attack scenarios involving several network components. Focusing on this issue, industrial and research communities show a great interest in the Global Information System Monitoring. Recent literatures in the intrusion detection field [30] aim at discovering and modeling global attack scenarios and Information System dependencies (IS components relationships). In fact, recent approaches deal with the Global Information System Monitoring like [22] who describes a hierarchical attack scenario representation. The authors provide an evaluation of the most credible attacker’s step inside a multistage attack scenario. [28] computes also attack scenario graphs through the association of vulnerabilities on IS components and determines a "distance" between correlated events and these attack graphs. In the same way, [26] used a semi-explicit correlation method to automatically build attack scenarios. With a pre-processing stage, the authors model pre-conditions and post conditions for each event. The association of pre and post conditions of each event leads to the construction of graphs representing attack scenarios. Other approaches automatically discover an attack scenario with model checking methods, which involves a full IS component interaction and configuration description [36]. However, classical intrusion detection schemes are composed of two types of detection: Signature based and Anomaly based detections. The anomaly detection is not developed regarding to Global IS Monitoring. Few approaches intend to model system normal behavior. Authors in [11] model IS components’ interactions in
order to discover causes of IS disaster (Forensic Analysis). The main purpose of this approach is to build casual relationships between IS components to discover the origin of an observed effect. The lack of anomaly detection System can be explained by the fact that working on the Global vision introduces three main limitations. First of all, the volume of computed data can reach thousands of events per second. Secondly, collected information is heterogeneous due to the fact that each IS component holds its own events description. Finally, the complexity of attacks scenarios and IS dependencies increases very quickly with the volume of data.
3. Event Modeling
As we previously stated, managing information security has to deal with the several differences existing in the monitoring products. To achieve this goal, it is necessary to transform raw messages in a uniform representation. Indeed, all the events and alerts must be based on the same semantics description, and be transformed in the same data model. To have a uniform representation of semantics, we focus on concepts handled by the products, we use them to describe the semantics messages. In this way, we are able to offset products types, functions, and products languages aside. The Abstraction concept was already evoked in intrusions detection field by Ning and Al [27]. Authors consider that the abstraction is important for two primary reasons. First, the systems to be protected as well as IDSs are heterogeneous. In particular, a distributed system is often composed of various types of heterogeneous components. Abstraction becomes thus a necessary means to hide the difference between these component systems, and to allow the detection of intrusions in the distributed systems. Secondly, abstraction is often used to remove all the non relevant details, so that IDS can avoid an useless complexity and concentrate on the essential information. The description of the information generated by a deployed solution is strongly related to the action perceived by the system, this action can be observed at any time of its life cycle: its launching, its interruption or its end. An event can inform that: an action has just started, it is in progress, it failed or it is finished. To simplify, we retained information semantics modeling via the concept of observed action. We obtain thus a modeling that fits to any type of observation, and meets the abstraction criteria. 3.1 Action Theory In order to model the observed action, we refer to the works that have already been done in the Action Theory of the philosophy field. According to the traditional model of the action explained by the authors in [9,19], an action is an Intention directed to an Object and uses a Movement. It

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
23
is generally conceded that intentions have a motivation role for the action. Authors underline that this role is not limited in starting the action but in supporting it until its completion. Our actions utilize movements, explanation of the action remains incomplete if we do not take into account the movements. Movement is the means to achieve the action. The object is the target towards which the action is directed to. In summary, the human actions are in conformity with a certain logic. To say that an agent carries out an action A, it is to say that the agent had an Intention I, by making a Movement M to produce an effect on a Target T of Action A. Action’s basic model is so composed by the following concepts: intention, movement and target.
3.2 Event Semantics
We observe the action performed in the monitored system and see that this action is dissociating from the human mind. We add another concept, i.e. the Effect, to the basic model (Intention, Movement and Target) of the Action Theory. We can say that this modeling is a general modeling, it can be adapted to any context of the monitoring such as in IS intruders monitoring, or in the monitoring of bank physical intruders. All we have to do, is to instantiate the meta-model with the intrusion detection context’s vocabulary. We have outlined an adaptation of this meta-model to our context of the IS monitoring from threats. The concepts are redefined as follows: • Intention: the objective for which the user carries out
his action, • Movement: the means used to carry out the objective of
the user, • Target: the resource in the IS to which the action is
directed to, • Gain: the effect produced by the action on the system,
i.e. if the user makes a success of his attempt to carry out an action or not.
Security information is an Intention directed towards a Target which uses a Movement to reach the target, and produces a Gain. Figure 2 illustrates the ontology concepts, the semantic relation between the concepts, and the general semantics of a security event. In order to identify the intentions of a user’s IS, we have studied the attacker strategy [17,26]. In fact, once the attacker is in the IS, he can undergo both attacker’s and legitimate user’s action. Analyzing attacker strategy provides an opportunity to reconstruct the various steps of an attack scenario or an IS utilization scenario, and perform pro-active actions to stop IS misuse. According to the attacker strategy, we have identified four intentions:
• Recon: intention of collecting information on a target, • Authentication: intention to access to the IS via an
authentication system, • Authorization: intention to access to a resource of an
IS, • System: intention of modifying the availability of an IS
resources. Intentions are carried out through movements. We have
categorized the movement into seven natures of movements:
• Activity: all the movements related to activities which do not change the configuration of the IS,
• Config: all the movements which change configuration, • Attack: all the movements related to attacks, • Malware: all the movements related to malwares.
Malware are malicious software programs designed specifically to damage or disrupt a system,
• Suspicious: all the movements related to the suspicious activities detected by the products. In some cases, a product generates an event to inform that there was a suspicious activity on a resource, this information is reported by our modeling as it is.
• Vulnerability: all the movements related to vulnerabilities.
• Information: the probes can produce messages which do not reflect the presence of the action, they reflect a state observed on the IS.
Under each one of these main modes, we have identified the natures of movements. A movement is defined by a mode of movements (such as Activity, Config, Information, Attack, Suspicious, Vulnerability or Malware) and a nature of movement (such as Login, Read, Execute, etc.), the mode and the nature of the action defines the movement. As the model must be adapted to the context of the global vision of IS’s security monitoring, it is clear that we have defined movements of presumed normal actions or a movement of presumed dangerous actions. An intention is able to have several movements, for example, an access to the IS performed by the opening of a user’s session or by an account’s configuration or by a bruteforce attack. Each IS resource can be a target of an IS user activity. Targets are defined according to intentions.
Fig. 2 Security message semantics

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
24
• In the case of the Recon intention, an activity of information collection is carried out on a host. The target represents the host on whom the activity was detected.
• In the case of the Authentication intention, an activity of access to an IS is always carried out under the control of an authentication service. The target is represented by a pair (target1, target2), target1 and target2 refer respectively to the system that performs the authentication process and the object or an attribute of the object that authenticates on the authentication service.
• In the case of the Authorization intention, an access to an IS resource is always carried out under the control of a service, this service allows the access to a resource based on access criteria. The target is represented by a pair (target1, target2). Target1 and Target2 refer respectively to the resource which filters the accesses (which manages the rights of the users or groups) and the resource on which rights were used to reach it.
• In the case of the System intention, an activity depends on the availability of the system. The target is represented by a pair (target1, target2). Target1 and Target2 refer respectively to a resource and a property of the resource, for example (Host, CPU).
These constraints on the targets enable us to fix the level of details to be respected in the modeling. We have defined the Gain in the IS according to the Movement mode.
• In the case of the Activity and Config movement mode, Gain takes the values: Success, Failed, Denied or Error.
• In the case of the Malware, Vulnerability, Suspicious and Attack movement mode, Gain takes the value Detected.
• In the case of the Information movement mode, the event focuses on information about the system state. Gain is related to information on control and takes the values: Valid, Invalid or Notify, or related to information on thresholds and takes the values Expired, Exceeded, Low or Normal.
The result is an ontology described by four concepts: Intention, Movement, Target, Gain, tree semantics relations: Produce, Directed to, Use between the concepts, a vocabulary adapted to the context of the IS monitoring against security violation, and rules explaining how to avoid the ambiguity. For example, for an administrator action who succeeded in opening a session on a firewall, the ontology describes this action by the 4-uplets: Authentication (refers to the intention of the user), Activity Login (refers to the movement carried out by the user), Firewall Admin (refers to the target of the action carried out) and Success (refers to the result of the action). The category of the message to which this action belongs is:
Authentication_Activity.Login_Firewall.Admin_Successes. We have identified 4 Intentions, 7 modes of Movement, 52 natures of Movement, 70 Targets and 13 Gains.
3.3 Event Data Model
It seems reasonable that the data model for information security can be based on standards. We have mentioned in 2.1 that the format IDMEF becomes a standard. We use this data model like a data model for event generated in a products interoperability context. This format is composed of two subclasses Alert and Heartbeat. When the analyzer of an IDS detects an event for which he has been configured, it sends a message to inform their manager. Alert class is composed of nine classes: Analyzer, CreateTime, DetectTime, analyserTime, Source, Target, Classification, Assessment, and AdditionalData. The IDMEF format Classification class is considered as a way to describe the alert semantics. The ontology developed in this framework describes all the categories of activities that can be undertaken in an IS. We define the Classification of the IDMEF data model class by a category of the ontology that reflects the semantics of the triggered raw event. Figure 3 illustrates the format IDMEF with modification of the class Classification. Finally, with the proposed ontology and the adapted IDMEF data model to information security in the context of global IS view, information is homogeneous. Indeed, all processes that can be implemented in the analysis server can be undertaken including the behavioral analysis.
4. Behavioral Analysis
Anomaly Detection System differs from signature based Intrusion Detection System by modeling normal reference instead of detecting well known patterns. Two periods are distinguished in Anomaly Detection: a first period, called training period, which builds and calibrates the normal reference. The detection of deviant events is performed during a second period called exploitation. We propose an Anomaly Detection System composed of four main blocks as shown in figure 4. The Event Collection and Modeling block aims at collecting normalized information from the different agents. The Event Selection block would filter only relevant information (see section 4.3). The Anomaly Detection block would model user’s behaviors through an activity graph and a Bayesian Network (see section 4.1.1) during a training period and would detect anomaly (see section 4.2) in the exploitation period. Then all behavioral anomalies are evaluated by the Anomaly Evaluation block

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
25
which identifies normal reference update from dangerous behavioral anomalies (see section 4.4). Each block will be explained in the following sections.
4.1 Model Method Selection
Modeling user behavior is a well-known topic in NIDS or HIDS regarding local component monitoring. The proliferation of security and management equipment units over the IS brings a class of anomaly detection. Following user behaviors over the IS implies new goals that anomaly detection needs to cover. First of all we need to identify the owner of each event occurring on the IS. Then our model should be able to hold attributes identifying this owner. The fact that all users travel inside the IS implies that the user activity model should models sequences of events representing each user’s actions on all IS components. Moreover, user behavior can be assimilated to a dynamic system. Modeling user activities should enhance periodical phenomena and isolate sporadic ones. Then, user behaviors hold major information of the usage of the system and can highlight the users’ behaviors compliance
with the security policy. This property should offer the ability to make the model fit the IS policies or plan future system evolutions to a security analyst. To achieve that, user activities modeling should be Human readable.
Several modeling methods are used for normal reference modeling in Anomaly Detection (e.g. classification, Neural Network, States Automaton, etc). Nevertheless three of them deal with the new goals: Hidden Markov Model, stochastic Petri Network and Bayesian Network. In Hidden Markov Model and stochastic Petri Network methods each node of sequences identifies one unique system or event state. Modeling the events of each user on each IS components would lead to the construction of a huge events graph. All these techniques can model probabilistic sequences of events but only Bayesian Network provides a human understandable model. Bayesian Networks (BN) are well adapted for user’s activities modeling regarding the Global Monitoring goals and provide a suitable model support. BN is a probabilistic graphical model that represents a set of variables and their conditional probabilities. BNs are built around an oriented acyclic graph which represents the structure of the network. This graph describes casual relationships between the variables. By instantiating a variable, each conditional probability is computed using mechanism of inference and the BN gives us the probabilities of all variables regarding this setting. By associating each node to a variable and each state of a node to a specific value, BN graph contracts knowledge in human readable graph. Furthermore, BNs are useful for learning probabilities in pre-computed data set and are well appropriate for the deviance detection. BN inference allows injecting variable values in BN graph and determining all conditional probabilities related to the injected proof. To achieve a user activity Bayesian Network model, we need to create a Bayesian Network structure. This structure would refer to a graph of events where each node represents an event and each arc a causal relationship between two events. Some approaches used learning methods (k2 algorithm [11]) to reveal a Bayesian structure in a dataset. In the context of a global events monitoring, lots of parameters are involved and without some priori knowledge, self learning methods would extract inconsistent relationships between events. Following our previous work [34] on user behaviors analysis, we specify three event’s attributes involved in the identification of casual relationships: user login, IP address Source and Destination. Here, we enhance the fact that legitimate users performed two types of actions: local actions and remote actions. First, we focus our attention on event’s attributes identifying local user action. The couple of attributes ‘Source IP address’ and ‘user name’ is usually used to identify users. These two attributes allow tracking user activities in a same location (e.g. work station, application server). To monitor remote user
Fig. 3 The IDMEF data model with the class Classification represented by the category of the ontology that describes the

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
26
actions only, ‘Destination IP address’ and ‘source IP address’ attributes can be used. Then, to monitor a physical user location move, only the ‘user login name’ can be used to follow them. These three attributes, i.e. user login, IP address Source and destination, are combined to determine correlation rules between two collected events as defined in our work [33]. Two events are connected together if: • the events share the same source IP address and/or User
name, • the target IP address of the first event is equal to the
source IP address of the second, The event correlation process would be realized during a training period. The resulting correlated events build an oriented graph, called users activity graph, where each node represents an event and each arc a causal relationship according to the correlation definition. Nevertheless, user’s activity graph is too large and concentrated to be
efficient for a Bayesian structure. We propose a merging function that gathers events according to their normalization. Based on the edge contraction definition [10], we compute a new graph, called merged graph, where each node represents a cluster of events sharing the same meaning (same semantics) and holding a list of events attributes which identifies the owner of each event in this cluster. The resulting graph would show casual relationships between each user’s events classes as described in section 5.1. This merged graph is used as the basis of our Bayesian structure. Classical Bayesian Networks are built on acyclic oriented graph which is not the case here because of user activities periodical sequences of events. Although some methods exist to allow Bayesian Network working on cyclic graph [23], most Bayesian libraries do not support cycles. To be
compliant with this technical constraint, we follow the recommendation defined in our work [33] by creating a "loop node" expressing recurrent events points in a sequence. After the Bayesian Network structure creation, the training data set is used to compute conditional probabilities inside the Bayesian Network. We use the simple and fast counting-learning algorithm [37] to compute conditional probabilities considering each event as an experience. The time duration between collected events can also be modeled by adding information in the Bayesian Network. The relation between clusters of events can be characterized by a temporal node holding the time duration probabilities between events. This extension is defined in detail in [35].
4.2 Anomaly Detection
The anomaly detection is performed during the exploitation period. This period intends to highlight abnormal behaviors between received data set and the trained user’s activities model. First of all, we compute a small user activities graph as defined in section 4.1.1 for a certain period of time represented by a temporal sliding windows on incoming events. This graph reflects all the users activities interactions for the sliding windows time period. This detection graph is then compared with our normal user model (BN) which makes two types of deviances emerged: graph structure deviance detection and probabilistic deviance detection. To check the structure compliance between both graphs, we first control the
Fig. 4 Global Anomaly Intrusion Detection Architecture

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
27
correctness of each graph’s features, and then we check if the detected event’s classes belong to our reference, if the relationships between event’s classes are valid and if the detected event’s attributes are valid. Finally, each step of each sequence of events inside the detection graph is injected in the Bayesian Network. For each step, our model evaluates the probability to receive a specific event knowing it precedence events, if this probability is below a threshold the events is considered as deviant. When a deviance is detected, an alert is sent to the security analyst.
4.3 Event Selection
To prevent from a graph overloading, i.e. an expensive memory and CPU consumption, we simplify our model to provide only the relevant information about User Behaviors [34]. Indeed, with a huge volume of distinct events coming from the monitoring IS, the complexity of user activities increases greatly. On large IS, lots of interactions can appear between user actions. In the worst case, the resulting graph can be a heavy graph. So, to specify the relevance of collected events, we studied the interactions between legitimate user’s behaviors and attacker’s strategy [34]. We define a new way to reduce the model’s complexity of user or system activities representation. We introduce the notion of necessary transit actions for an attacker to achieve these objectives: these actions are called Checkpoints. Checkpoints are based on different classes of attacker scenarios; User to Root, Remote to Local, Denial of Service, Monitoring/Probe and System Access/Alter Data. We enrich this attacks classification with classes of malicious actions (Denial of Service, Virus, Trojan, Overflow, etc). For each scenario, we provide a list of Checkpoints which determine all the necessary legitimate activities needed by an attacker to reach such effects. For instance, to achieve a User to Root effect an attacker chooses between six different variants of scenarios (Gain, Injection, Overflow, Bypass, Trojan, Virus). A checkpoint related to an Injection 1 is, for example, a command launch. We analyzed all the checkpoints of all the possible actions leading to one of these five effects. We propose a selection of thirteen checkpoints representing different types of events involved in at least one of the five effects. These checkpoints reflect the basis of the information to detect attacker’s activities. We also provide a description of the context to determine if all
1 An injection consists in launching an operation through a started session or service.
checkpoints need to be monitored regarding to the nature and the location of a component. We extract the core information needed to detect misuses or attack scenarios. Thus, we do not focus our work on all the data involved in misuse or variant of attack scenarios but only on one piece of data reflecting the actions shared by the user’s and attacker’s behavior. We also study a couple of sequences of actions selection following an identical consideration. Both checkpoints and sequences selections provide a significant model complexity reduction. Indeed, we manage a reduction of 24% of nodes and 60% of links. This selection slightly reduces the detection rate of unusual system use and reduces false positive of 10%.
4.4 Anomaly Evaluation
The lack of classical anomaly detection system is mainly due to a high false positive rate and poor information description about deviant events. The majority of these false positive comes from the evolution of the normal system behavior. Without a dynamic learning process, anomaly models become outdated and produce false alerts. The update mechanism has been enhanced by some previous works [14,29] which point out two main difficulties. The first difficulty is the choice of the interval time between two update procedures [14]. On one hand, if the interval time is too large, some Information System evolutions may not be caught by the behavior detection engine. On the other hand, if it is too small, the system learns rapidly but loses gradual behavior changes. We do not focus our work especially on this issue but we assume that, by modeling users’ activities behaviors, a day model updating is a good compromise between a global User behavior evolution and the time consumption led by such updates. The second difficulty is the selection of appropriate events to update the reference in terms of event natures. Differentiating normal behavior evolution from suspicious deviation is impossible without additional information and context definition. To take efficient decisions, we need to characterize each event through specific criteria. These criteria should identify the objective of the end user behind the deviating events. We focus our work on this second issue and follow the approach in [40] that analyzes end users security behavior. Our evaluation process evaluates a deviating event through a three dimensions evaluation of each deviating events: the intention behind the event, the technical

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
28
expertise needed to achieve the event and the criticality of the targeted components by the event, each dimension characterizes a property of the deviating event. All received events are associated with one of the three types of movements introduced in section 5.1: the intention of the configuration which defines beneficial moves trying to improve the system, intention of activity which represents usual activity on the IS or neutral activity and then the intention of attack which refers to all the malicious activities in the system. The degree of deviation of an event would inform us how far an event from the normal use of the system is. We assume that the more an event is far from normal behavior, the more this deviating event holds malicious intention. Finally, other past events linked by casual relationship with the deviating one lead also the malicious intention. The expertise dimension defines the technical expertise needed by a user to realize an event. This expertise is computed on the type of actions realized by the event (action of configuration or action of activity), the type of a targeted component (a Router needs more technical expertise than a Work Station) and the owner of the event (classical user or administrator). Finally, the event’s impact on IS will depend on the targeted component. Thus, we evaluate a deviating event also by the criticality of the targeted component. This criticality is evaluated by combining vulnerabilities held by the targeted component, the location of the targeted component (e.g. LAN, Public DeMilitary Zone, etc) and its business importance (e.g. critical authentication servers are more important than workstations regarding the business of the company). According to all dimensions definitions, each deviating point will be located in this three dimension graph. The three dimension representation increases the analyst visibility of deviating events. Nevertheless, some automatic actions could considerably help analyst to decide if a deviant event is related to a normal system evolution or to intrusive activity. We propose to build a semi-automatic decision module to define which deviating events fit normal system evolutions and which ones reflect attackers’ activities. Our semi-automatic decision module is a supervised machine learning method. We used a training data set composed of deviating events located in our three-dimension graph. Each point of the training data set is identified as a normal system evolution or attackers’ activities by security analysts. To learn this expertise knowledge, we use a Support Vector Machine (SVM) to define frontiers between identified normal points and attack points. The SVM technique is a well known classification algorithm [20] which tries to find a separator between communities in upper dimensions. SVM also
maximizes the generalization process (ability to not fall in an over-training). After the construction of frontiers, each deviating events belonging to one community will be qualified as a normal evolution or attackers’ activity and will receive a degree of belonging to each community. After that, two thresholds will be computed. They define three areas; normal evolution of system area, suspicious events area and attack or intrusive activities area. Each deviating events belonging to normal evolution area will update our normal Bayesian model. Each deviating events belonging to the intrusive activities area or suspicious area will create an alarm and send it to an analyst.
5. Experimentation
In this section, we aim to make into practice the two proposed modules, event modeling and User Behavioral Analysis, while using a large corpus of real data. Event modeling experience will normalize raw events in the ontology’s categories that describe her semantics. User behavioral analysis experimentation will use normalized events generated by events modeling module to detect abnormal behaviors.
5.1 Event Modeling
To study the effectiveness of the modeling proposed in Section 5.1, we focused our analysis on the exhaustiveness of the ontology (each event is covered by a category) and on the reduction of event number to be presented to the security analyst. We performed an experiment on a corpus of 20182 messages collected from 123 different products.
The main characteristic of this corpus is that the events are collected from heterogeneous products, where the products manipulate different concepts (such as attacks detection, virus detection, flaws filtering, etc.). The sources used are security equipment logs, audit system logs, audit application logs and network component logs. Figure 5 illustrates the various probes types used and, into brackets, the number of probes per type is specified. The classification process was performed manually by the experts. The expert reads the message and assigns it to the category which describes its semantics. The expert must extract the intention from the action which generated the message, the movement used to achieve the intention, the
Fig 5: Type of used product

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
29
target toward which the intention was directed and the gain related to this intention. We have obtained, with the manual classification of raw events, categories of various sizes. The distribution of the messages on the categories is represented on figure 6. Some categories are large, the largest one contains 6627 events which presents a rate of 32,83% of the corpus. This is due to the monitoring of the same activity by many products or to the presence of these signatures in many
products. The representation of the events under the same semantics reinforces the process of managing the security in a cooperative context and facilitates the task of the analyst (more detail in [2]). In addition, we had a singleton categories, 732 raw events forming their own category, which represent a rate of 42,21% of all categories and which represent only 3,63% of the corpus. Event modeling has reduced the number of events by 91,40% (from 20182 to 1734). The presence of singleton categories can be explained by the following points: only one product among the deployed products produces this type of event. A signature, which is recognized by a product and not recognized by an another, errors made by experts generated the creation of new categories, they do not have to exist theoretically, and the presence of targets monitored rarely increases the number of singleton categories, because the movement exists several times, but only once for these rare targets. We observe that the category of the movement Suspicious introduced into our ontology is quite necessary to preserve the semantics of a raw event which reflects a suspicion. These types of events will be processed with the User Behavioral Analysis. Ontology does not make it possible to analyze event, its goal is to preserve raw events semantics. The proportions of the various categories depend on the deployed products and the activities to be
supervised by these products. The conclusion that we can draw from this study is that a good line of defense must supervise all the activities aimed in an IS, and that the cooperative detection should not be focused on the number of the deployed products but on the activities to be supervised in the IS. This result can bring into question the choice of the defense line for the IS.
5.2 Behavioral Analysis
Actual Intrusion Detection System operating on a Global Information System Monitoring lacks of large test dataset aiming at checking their efficiency and their scalability. In this section, we provide our results on our Anomaly Intrusion Detection System using a real normalized data set. We deployed our architecture on a real network and collected events coming from hundreds of IS components. DataSet Analysis: Our dataset analysis comes from a large company composed of hundreds of users using multiple services. The dataset has been divided into two datasets: one training data set composed of events collected for 23 days and the other one (test data set) composed of events collected for 2 days after the training period. The training dataset aims at train-ing our engine and creating a user normal behavioral model. The test ‘dataset’ has been enriched of attack scenarios in or-der to test our detection engine. First of all, the test data set is used to test the false alarms rate (false positive rate) of our engine. Then attack scenarios will be used to determine our detection rate, and more over the false negative rate (not detected attacks rate) of our engine. The major parts of the collected events are web server information and authentication information. We can notice that during the monitored period, some types of events are periodic (like Authentication_Activity .Login.
Fig. 6 Events Distribution on the Ontology's Categories
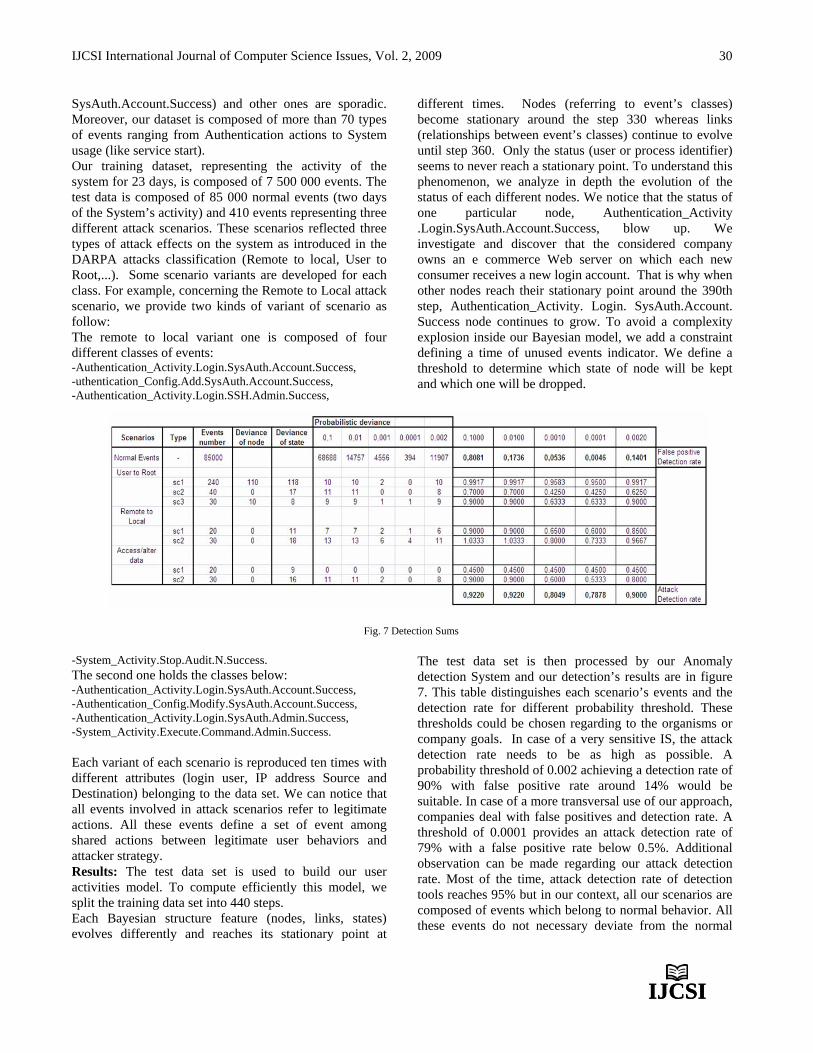
IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
30
SysAuth.Account.Success) and other ones are sporadic. Moreover, our dataset is composed of more than 70 types of events ranging from Authentication actions to System usage (like service start). Our training dataset, representing the activity of the system for 23 days, is composed of 7 500 000 events. The test data is composed of 85 000 normal events (two days of the System’s activity) and 410 events representing three different attack scenarios. These scenarios reflected three types of attack effects on the system as introduced in the DARPA attacks classification (Remote to local, User to Root,...). Some scenario variants are developed for each class. For example, concerning the Remote to Local attack scenario, we provide two kinds of variant of scenario as follow: The remote to local variant one is composed of four different classes of events: -Authentication_Activity.Login.SysAuth.Account.Success, -uthentication_Config.Add.SysAuth.Account.Success, -Authentication_Activity.Login.SSH.Admin.Success,
-System_Activity.Stop.Audit.N.Success. The second one holds the classes below: -Authentication_Activity.Login.SysAuth.Account.Success, -Authentication_Config.Modify.SysAuth.Account.Success, -Authentication_Activity.Login.SysAuth.Admin.Success, -System_Activity.Execute.Command.Admin.Success. Each variant of each scenario is reproduced ten times with different attributes (login user, IP address Source and Destination) belonging to the data set. We can notice that all events involved in attack scenarios refer to legitimate actions. All these events define a set of event among shared actions between legitimate user behaviors and attacker strategy. Results: The test data set is used to build our user activities model. To compute efficiently this model, we split the training data set into 440 steps. Each Bayesian structure feature (nodes, links, states) evolves differently and reaches its stationary point at
different times. Nodes (referring to event’s classes) become stationary around the step 330 whereas links (relationships between event’s classes) continue to evolve until step 360. Only the status (user or process identifier) seems to never reach a stationary point. To understand this phenomenon, we analyze in depth the evolution of the status of each different nodes. We notice that the status of one particular node, Authentication_Activity .Login.SysAuth.Account.Success, blow up. We investigate and discover that the considered company owns an e commerce Web server on which each new consumer receives a new login account. That is why when other nodes reach their stationary point around the 390th step, Authentication_Activity. Login. SysAuth.Account. Success node continues to grow. To avoid a complexity explosion inside our Bayesian model, we add a constraint defining a time of unused events indicator. We define a threshold to determine which state of node will be kept and which one will be dropped.
The test data set is then processed by our Anomaly detection System and our detection’s results are in figure 7. This table distinguishes each scenario’s events and the detection rate for different probability threshold. These thresholds could be chosen regarding to the organisms or company goals. In case of a very sensitive IS, the attack detection rate needs to be as high as possible. A probability threshold of 0.002 achieving a detection rate of 90% with false positive rate around 14% would be suitable. In case of a more transversal use of our approach, companies deal with false positives and detection rate. A threshold of 0.0001 provides an attack detection rate of 79% with a false positive rate below 0.5%. Additional observation can be made regarding our attack detection rate. Most of the time, attack detection rate of detection tools reaches 95% but in our context, all our scenarios are composed of events which belong to normal behavior. All these events do not necessary deviate from the normal
Fig. 7 Detection Sums

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
31
behavior that is why our detection rate is slightly below classical detection rate. We can estimate that little less than 10% of the test attack’s events belong to normal behavior (legitimate event and attributes). Despite this constraint, we still reach detection rate from 80% to 90%.
6. Conclusion and Perspectives
Our main goal throughout this paper was to describe a framework that addresses companies: managing the company’s security information to protect the IS from threats. We proposed an architecture which provides a global view of what occurs in the IS. It is composed of different agent types collecting and modeling information coming from various security products (such as firewalls, IDS and antivirus), Operating Systems, applications, databases and other elementary information relevant for the security analysis. An Analysis Server gathers all information sent by agents and provides a behavioral Analysis of the user activities. A new modeling for describing security information semantics is defined to address the heterogeneity problem. The modeling is an ontology that describes all activities that can be undertaken in an IS. By using real data triggered from products deployed to protect the assets of an organization, we shown that the modeling reduced the amount of events and allowed automatic treatments of security information by the analysis algorithms. The model is extensible, we can increase the vocabulary according to the need such as adding a new movement to be supervised in the IS. The model can be applied to other contexts of monitoring such as the monitoring of physical intruders in a museum; all we have to do is to define the adequate vocabulary of the new context. We demonstrated that unknown attack scenarios could be efficiently detected without hard pre description information through our User Behavioral Analysis. By using only relevant information, User’s behaviors are modeled through a Bayesian network. The Bayesian Network modeling allows a great detection effectiveness by injecting incoming events inside the model and computing all conditional probabilities associated. Our Anomaly evaluation module allows updating dynamically a User’s model, reducing false positive and enriching Behavioral Anomalies. The experimentation on real data set highlights our high detection rate on legitimate action involved in Attack scenarios. As data are modeled in the same way, User Behavioral Analysis results show that the effectiveness of the analysis processes is highly dependent on the data modeling.
The proposed framework can be useful to other processes. Indeed, the ontology is necessary to carry out counter-measures process, the results of User Behavioral Analysis allowing the administrator to detect legitimate users that deviate from its behavior, a reaction process can then be set up to answer malicious behaviors. References [1] Z. Zhang, J. Li, C. Manikopoulos, J. Jorgenson, and J. Ucles.
Hide: A hierarchical network intrusion detection system using statistical preprocessing and neural network classification. In the 2001 IEEE Workshop on Information Assurance and Security, 2001.
[2] F. Benali, V. Legrand, and S. Ubéda. An ontology for the management of heterogeneous alerts of information system. In The 2007 International Conference on Security and Management (SAM’07), Las Vegas, USA, June 2007.
[3] J. L. Undercoffer, A. Joshi, and J. Pinkston. Modeling computer attacks an ontology for intrusion detections. The Sixth International Symposium on Recent Advances in Intrusion Detection. September 2003.
[4] K. Boudaoud. Un système multi-agents pour la détection d’intrusions. In JDIR’2000, Paris, France, 2000.
[5] W. R. Cheswick and S. M. Bellovin. Firewalls and Internet Security Repelling the Wily Hacker. Addison-Wesley,
1994. [6] F. B. Cohen. Protection and security on the information
superhighway. John Wiley & Sons, Inc., New York, NY, USA, 1995.
[7] F. B. Cohen. Information system attacks: A preliminary classification scheme. Computers and Security, 16, No. 1:29-46, 1997.
[8] D. Curry and H. Debar. Intrusion detection message exchange format. http://www.rfc-editor.org/rfc/rfc4765.txt.
[9] Davidson. Actions, reasons, and causes. Journal of Philosophy, pages 685-700 (Reprinted in Davidson 1980, pp. 3-19.), 1963.
[10] T. Wolle and H. L. Bodlaender. A note on edge contraction. Technical report, institute of information and computing sciences, Utrecht university, 2004.
[11] T. Duval, B. Jouga, and L. Roger. Xmeta a bayesian approach for computer forensics. In Annual Computer Security Applications Conference (ACSAC), 2004.
[12] S. T. Eckmann, G. Vigna, and R. A. Kemmerer. STATL: an attack language for state-based intrusion detection. In Journal of Computer Security, 10:71-103, 2002.
[13] G. Helmer, J. S. K. Wong, V. G. Honavar, L. Miller, and Y. Wang. Lightweight agents for intrusion detection. Journal
of Systems and Software, 67:109-122, 2003. [14] M. Hossain and S. M. Bridges. A framework for an adaptive
intrusion detection system with data mining. In 13th Annual Canadian Information Technology Security Symposium, 2001.
[15] J. Howard and T. Longstaff. A common language for computer security incidents. Sand98-8667, Sandia International Laboratories, 1998.
[16] J. D. Howard. An Analysis of Security Incidents on the Internet PhD thesis, Carnegie Mellon University, Pittsburgh,

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
32
Pennsylvania 15213 USA, April 1997. [17] M.-Y. Huang, R. J. Jasper, and T. M. Wicks. A large scale
distributed intrusion detection framework based on attack strategy analysis. Computer Networks (Amsterdam, Netherlands: 1999, 31(23-24):2465-2475, 1999.
[18] D. Icove, K. Seger, and W. VonStorch. Computer Crime: A Crimefighter’s Handbook. Inc., Sebastopol, CA, 1995.
[19] I. D. J., P. J. R., and T. S. Executions, motivations, and accomplishments. Philosophical Review, 102(4), Oct 1993.
[20] A. Keleme, Y. Liang, and S. Franklin. A comparative study of different machine learning approaches for decision making. In Recent Advances in Simulation, Computational Methods and Soft Computing, 2002.
[21] U. Lindqvist and E. Jonsson. How to systematically classify computer security intrusions. In proceeding of the IEEE Symposium on Security and Privacy, pages 154-163, 1997.
[22] S. Mathew, C. Shah, and S. Upadhyaya. An alert fusion framework for situation awareness of coordinated multistage attacks. In Proceedings of the Third IEEE International Workshop on Information Assurance, 2005.
[23] T. P. Minka. Expectation propagation for approximate bayesian inference. In the 17th Conference in Uncertainty in Artificial Intelligence, 2001.
[24] P. G. Neumann. Computer-Related Risks. Addison-Wesley, October 1994.
[25] P. G. Neumann and D. B. Parker. A summary of computer misuse techniques. In Proceedings of the 12th National Computer Security Conference, pages 396-407, Baltimore, Maryland, October 1989.
[26] A. J. Stewart. Distributed metastasis: A computer network penetration methodology. Phrack Magazine, 55(9), 1999.
[27] P. Ning, S. Jajodia, and X. S. Wang. Abstraction-based intrusion detection in distributed environments. ACM Transaction Information and System Security, 4(4):407-452, 2001.
[28] S. Noel, E. Robertson, and S. Jajodia. Correlating intrusion events and building attack scenarios through attack graph distances. In Proceedings of the 20th Annual Computer Security Applications Conference, 2004.
[29] R. Puttini, Z. Marrakchi, and L. Me. Bayesian classification model for real-time intrusion detection. In 22nd International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering, 2002.
[30] X. Qin and W. Lee. Attack plan recognition and prediction using causal networks. In Proceedings of the 20th Annual Computer Security Applications Conference, 2004.
[31] R. A. Wasniowski. Multi-sensor agent-based intrusion detection system. In the 2nd annual conference on Information security curriculum development, 2005.
[32] S.-C. S, Tung.B, and Schnackenberg.D. The common intrusion detection framework (CIDF). In The Information Survivability Workshop, Orlando, FL, October 1998. CERT Coordination Center, Software Engineering Institute.
[33] J. Saraydaryan, V. Legrand, and S. Ubeda. Behavioral anomaly detection using bayesian modelization based on a global vision of the system. In NOTERE’07, 2007.
[34] J. Saraydaryan, V. Legrand, and S. Ubeda. Behavioral intrusion detection indicators. In 23rd International Information Security Conference (SEC 2008), 2008.
[35] J. Saraydaryan, V. Legrand, and S. Ubeda. Modeling of information system correlated events time dependencies. In NOTERE’ 08, 2008.
[36] O. Sheyner. Scenario Graphs and Attack Graphs. PhD thesis, Carnegie Mellon University, 2004.
[37] D. J. Spiegelhalter and S. L. Lauritzen. Sequential updating of conditional probabilities on directed graphical structures. Networks ISSN 0028-3045, 20:579-605, 1990.
[38] W. Stallings. Network and Internetwork Security: Principles and Practice. Prentice-Hall, Inc, Upper Saddle River, NJ, USA, 1995.
[39] S. Staniford-Chen, S. Cheung, R. Crawford, M. Dilger, J. Frank, J. Hoagland, K. Levitt, C. Wee, R. Yip, and D. Zerkle. Grids - a graph-based intrusion detection system for large networks. In Proceedings of the 19th National Information Systems Security Conference, 1996.
[40] J. M. Stanton, K. R. Stam, P. Mastrangelo, and J. Jolton. Analysis of end user security behaviors. Computers & Security, Volume 24: Pages 124-133, 2005.
Jacques Saraydaryan holds a Master’s Degree in Telecoms and Networks from National Institute of Applied Sciences (INSA), Lyon –France in 2005, and a Ph.D. in computer sciences from INSA, Lyon France in 2009. He is a Research Engineer at the Exaprotect company, France. His research focus is on IS Security especially on Anomaly intrusion detection system. His research work has been published in international conferences such as Secrureware’08, Securware’07. He has one patent with Exaprotect Company.
Fatiha Benali holds a Master’s Degree in Fundamental Computer Sciences at Ecole Normale Supérieure (ENS), Lyon -France, and a Ph.D. in computer sciences from INSA, Lyon-France in 2009. She is a Lecturer in the Department of Telecommunications Services & Usages and a researcher in the Center for Innovations in Telecommunication and Services integration (CITI Lab) at INSA, Lyon- France. Her research focus on IS security notably on information security modeling. Her research work has been published in international conferences such as Security and Management (SAM’07), Securware’08. She has 2 papers awarded and one patent with Exaprotect Company. Stéphane Ubéda holds a PhD in computer sciences at ENS Lyon - France in 1993. He became an associated professor in the Jean-Monnet University-France in 1995, obtain an Habilitation to conduct research in 1997 and became in 2000 full professor at the INSA of Lyon. He is a full professor at INSA of Lyon in the Telecommunications department. He is the director of the CITI Lab, he is also the head of the French National Institute for Research in Computer Science and Control (INRIA) Project named AMAZONES for AMbient Architectures: Service-Oriented, Networked, Efficient, Secure.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
33
IJCSIIJCSI
Self-Partial and Dynamic Reconfiguration Implementation for AES using FPGA
Zine El Abidine ALAOUI ISMAILI and Ahmed MOUSSA
Innovative Technologies Laboratory, National School of Applied Sciences,
Tangier, PBox 1818, Morocco [email protected]
Abstract This paper addresses efficient hardware/software implementation approaches for the AES (Advanced Encryption Standard) algorithm and describes the design and performance testing algorithm for embedded system. Also, with the spread of reconfigurable hardware such as FPGAs (Field Programmable Gate Array) embedded cryptographic hardware became cost-effective. Nevertheless, it is worthy to note that nowadays, even hardwired cryptographic algorithms are not so safe. From another side, the self-reconfiguring platform is reported that enables an FPGA to dynamically reconfigure itself under the control of an embedded microprocessor. Hardware acceleration significantly increases the performance of embedded systems built on programmable logic. Allowing a FPGA-based MicroBlaze processor to self-select the coprocessors uses can help reduce area requirements and increase a system's versatility. The architecture proposed in this paper is an optimal hardware implementation algorithm and takes dynamic partially reconfigurable of FPGA. This implementation is good solution to preserve confidentiality and accessibility to the information in the numeric communication. Key words: Cryptography; Embedded systems; Reconfigurable computing; Self-reconfiguration
1. Introduction
Today, ultra deep submicronic technologies offer high scale density of integration for communication systems. This growth in integration has been accompanied with dramatically increase of complexity and transaction speed of this systems. As a consequence, security becomes a challenge and a critical issue especially for real time applications where materiel and software resources are very precious and necessary to provide a minimum of service quality. Indeed, today speed and computing power impose the recourse to sophisticated and more complicated
cryptography algorithms for high level security. Full software implementation is very heavy and slows down considerably speed of the information exchange. From another side, full hardware implementation is very expensive in terms of area, power and can also deteriorate speed of information transitions. This can be done dynamically at run-time and without user interaction, while the static part of the chip is not interrupted. The idea we put into practice is a coarse-grained partially dynamically reconfigurable implementation of a cryptosystem. Our prototype implementation consists of a FPGA which is partially reconfigured at run-time to provide countermeasures against physical attacks. The static part is only configured upon system reset. Some advantages of dynamic reconfiguration for cryptosystems have been explored before [1, 2, 3]. In such systems, the main goal of dynamic reconfigurability is to use the available hardware resources in an optimal way. This is the first work that considers using a coarse-grained partially dynamically reconfigurable architecture in cryptosystems to prevent physical attacks by introducing temporal and/or spatial jitter [4, 5]. This paper presents an optimal implementation of the AES (Advanced Encryption Standard) cryptography algorithm by the use of a dynamic partially reconfigurable FPGA [6]. The reconfigurable aspect adapts the allowed basic bloc size to both the loop number and the size of the provided information, and makes all the AES blocs reconfigurable. The paper is organized as follows: section 2 describes the AES algorithm. Reconfigurable FPGA and self reconfigurable methodology is presented in section 3, 4 and 5. The proposed methodology of algorithm implementation is given in section 6. Finally, results are presented and illustrated in section 7.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
34
IJCSIIJCSI
2. AES Encryption Algorithm
The National Institute of Standards and Technology (NIST) has initiated a process to develop a Federal Information Processing Standard (FIPS) for the AES, specifying an Advanced Encryption Algorithm to replace the Data Encryption Standard (DES) which expired in 1998 [6,7]. NIST has solicited candidate algorithms for inclusion in AES, resulting in fifteen official candidate algorithms of which five have been selected as finalists. Unlike DES, which was designed specifically for hardware implementations, one of the design criteria for AES candidate algorithms is that they can be efficiently implemented in both hardware and software. Thus, NIST has announced that both hardware and software performance measurements will be included in their efficiency testing. However, prior to the third AES conference in April 2000, virtually all performance comparisons have been restricted to software implementations on various platforms [5]. In October 2000, NIST chose Rijndael as the Advanced Encryption Algorithm. The AES use the Rijndael encryption algorithm with cryptography keys of 128, 192, 256 bits. As in most of the symmetrical encryption algorithms, the AES algorithm manipulates the 128 bits of the input data, disposed in a 4 by 4 bytes matrix, with byte substitution, bit permutation and arithmetic operations in finite fields, more specifically, addition and multiplications in the Galois Field 28 (GF(28 )). Each set of operations is designated by round. The round computation is repeated 10, 12 or 14 times depending on the size of the key (128, 192, 256 bits respectively). The coding process includes the manipulation of a 128-bit data block through a series of logical and arithmetic operations. In the computation of both the encryption and decryption, a well defined order exists for the several operations that have to be performed over the data block. The following describes in detail the operation performed by the AES encryption in each round. The State variable contains the 128-bit data block to be encrypted. In the Encryption part, first the data block to be encrypted is split into an array of bytes called as state matrix. This algorithm is based on round function, and different combinations of the algorithm are structured by repeating the round function different times. Each round function contains uniform and parallel four steps: SubBytes, ShiftRows, MixColumn and AddRoundKey transformation and each step has its own particular functionality. This is represented by this flow diagram. Here the round key is derived from the initial key and repeatedly applied to transform the block of plain text into cipher text blocks. The block and the key lengths can be independently
specified to any multiple of 32 bits, with a minimum of 128 and a maximum of 256 bits. The repeated application of a round transformation state depends on the block length and the key length. For various block length and key length variable’s value are given in table1. The number of rounds of AES algorithm to be performed during the execution of the algorithm is dependent on the key size. The number of rounds, Key length and Block Size in the AES standard is summarized in Table 1 [8].
Table 1: Margin specifications Key-Block-Round Combinations for AES
Key length (Nk round)
Key length (Bits)
Number of Round (Nr)
AES-128 4 128 10 AES-192 6 192 12 AES-256 8 256 14
As mentioned before the coding process consists on the manipulation of the 128-bit data block through a series of logical and arithmetic operations, repeated a fixed number of times. This number of rounds is directly dependent on the size of the cipher key. In the computation of both the encryption and decryption, a well defined order exists for the several operations that have to be performed over the data block. The encryption/decryption process runs as follows in figure 1.
Fig.1: AES algorithm
(a) Encryption Structure (b) Decryption Structure
The next subsections describe in detail the operation performed by each of the functions used above, for the particular case of the encryption.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
35
IJCSIIJCSI
2.1 The SubBytes Transformation
The SubBytes transformation is a non-linear byte substitution that acts on every byte of the state in isolation to produce a new byte value using an S-box substitution table. The action of this transformation is illustrated in Figure 2 for a block size of 4. This substitution, which is invertible, is constructed by composing two transformations: - First the multiplicative inverse in the finite field
described earlier, with the {00} element mapped to itself. - Second the affine transformation over GF(28) defined by:
(1) for 0 ≤ i < 8 where bi is the ith bit of the byte, and ci is the ith bit of a byte c with the value {63} or {01100011}. Here and elsewhere, a prime on a variable b’ indicates that its value is to be updated with the value on the right.
Fig. 2. SubBytes acts on every byte in the state
In matrix form the affine transformation element of this S-box can be expressed as:
2.2 The ShiftRows Transformation
The ShiftRows transformation operates individually on each of the last three rows of the state by cyclically shifting the bytes in the row such that:
(2) This has the effect of moving bytes to lower positions in the row except that the lowest bytes wrap around into the top of the row (note that a prime on a variable indicates an updated value). The action of this transformation is illustrated in Figure 3.
Fig. 3: Proposed beam former ShiftRows() cyclically shifts the last three rows in the State.
2.3 The MixColumns Transformation
The MixColumns transformation acts independently on every column of the state and treats each column as a four-term polynomial. The columns are considered as polynomials over GF(28) and multiplied modulo x4+1 with a fixed polynomial a(x), given by
a(x) = {03}x3+ {01}x2+ {01}x + {02} (3) This equation can be written as a matrix multiplication. Let:
S’(x) =a(x)X S(x): (4) In matrix form the transformation used given in where all the values are finite field elements as discussed in Section 2.
(5)
The action of this transformation is illustrated in Figure 3.
Fig. 4: MixColumns() operates on the State column-by-column.
2.4 The AddRoundKey Transformation
In the AddRoundKey transformation Nb words from the key schedule, described later, are each added (XOR) into the columns of the state so that:

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
36
IJCSIIJCSI
(6) Where the key schedule words [7] will be described later and round is the round number in the range 1≤ round ≤Nr. The round number starts at 1 because there is an initial key addition prior to the round function. The action of this transformation is illustrated in Figure 5.
Fig.5: AddRoundKey() XORs each column of the State with a word from
the key schedule.
3. Reconfigurable Hardware Technology
Field Programmable Gate Array (FPGA) is an integrated circuit that can be bought off the shelf and reconfigured by designers themselves. With each reconfiguration, which takes only a fraction of a second, an integrated circuit can perform a completely different function. FPGA consists of thousands of universal building blocks, known as Configurable Logic Blocks (CLBs), connected using programmable interconnects. Reconfiguration is able to change a function of each CLB and connections among them, leading to a functionally new digital circuit. In recent years, FPGAs have been used for reconfigurable computing, when the main goal is to obtain high performance at a reasonable coast at the hardware implemented algorithms. The main advantage of FPGAs is their reconfigurability, i.e. they can be used for different purposes at different stages of computation and they can be. Besides Cryptography, application of FPGAs can be found in the domains of evolvable and biologically-inspired hardware, network processor, real-time system, rapid ASIC prototyping, digital signal processing interactive multimedia, machine vision, computer graphics, robotics, embedded applications, and so forth. In general, FPGAs tend to be an excellent choice when dealing with algorithms that can benefit from the high parallelism offered by the FPGA fine grained architecture. Significant technical advances have led to architecture to combine FPGAs logic blocks and interconnect matrices, with one or more microprocessors and memory blocks integrated on a single chip [9, 10]. This hybrid technology is called Configurable System on Chip (CSoC). Example for the CSoC technology are the Xilinx Virtex Pro II, the virtex 4, and virtex 5 FPGAs families, with include one or
more hard-core Power PC processor embedded along with the FPGA’s logic fabric. Alternatively, soft processor cores that are implemented using part of the FPGAs logic fabric are also available. This approach is more flexible and less costly than the CSoC technology [11]. Many soft processors core are now available in commercial products. Some of the most notorious examples are: Xilinx 32-bits MicroBlaze and PicoBlaze, and the Altera Nios and 32-bits Nios II processors. These soft processor cores are configurable in the since that the designer can introduce new custom instructions or data paths. Furthermore, unlike the hard-core processors included in the Configurable System-on-Chip (CSoC) technology, designers can add as many soft processor cores as they may need. (Some designs could include 64 such processors or even more).
4. Dynamic Partial Reconfiguration
The incredible growth of FPGA capabilities in recent years and the new features included on them has opened many new investigation fields. One of the more interesting ones concerns partial reconfiguration and its possibilities [12,9]. This feature allows the device to be partially reconfigured while the rest of the device continues its normal operation. Partial reconfiguration is the ability to reconfigure preselected areas of an FPGA anytime after its initial configuration while the design is operational. By taking advantage of partial reconfiguration, hardware can be shared between various applications and upgraded remotely without rebooting and thus resource utilization can be increased [12].
Fig. 6: Reconfigurable FPGA structure
FPGA devices are partially reconfigured by loading only a subset of configuration frames into the FPGA internal configuration memory. The Xilinx Virtex-II Pro FPGAs allow partial reconfiguration in two forms: static and dynamic. Static (or shutdown) partial reconfiguration takes place when the rest of the device is inactive and in shutdown mode. The non-reconfigurable area of the FPGA is held in reset and the FPGA enters the start-up sequence after partial reconfiguration is completed. In contrast, in dynamic (or active) partial reconfiguration new data can

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
37
IJCSIIJCSI
be loaded to dynamically reconfigure a particular area of FPGA while the rest of it is still operational. User design is not suspended and no reset and start-up sequence is necessary.
Fig. 7: Static and dynamic part for system reconfigurable
5. Self Partial Dynamic Reconfiguration
The Dynamic Partial Self-Reconfiguration (DPSR) concept is the ability to change the configuration of part of an FPGA device by itself while other processes continue in the rest of the device. A self-reconfiguring platform is reported that enables an FPGA to dynamically reconfigure itself under the control of an embedded microprocessor [10]. A partially reconfigurable design consists of a set of full designs and partial modules. The full and partial bitstreams are generated for different configurations of a design. The idea of implementing a self-reconfiguring platform for Xilinx Virtex family was first reported in [10]. The platform enabled an FPGA to dynamically reconfigure itself under the control of an embedded microprocessor. The hardware component of Self Reconfiguring Platform (SRP) is composed of the internal configuration access port (ICAP), control logic, a small configuration cache, and an embedded processor. The embedded processor can be Xilinx Microblaze, which is a 32-bit RISC soft processor core [13]. The hard-core Power PC on the virtex II Pro can also be used as the embedded processor. The embedded processor provides intelligent control of device reconfiguration run-time. The provided hardware architecture established the framework for the implementation of the self-reconfiguring platforms. Internal configuration access port application program interface (ICAP API) and Xilinx partial reconfiguration toolkit (XPART) provide methods for reading and modifying select FPGA resources and support for re-locatable partial bitstreams. Taking advantage of FPGA capacity presented above, we try to develop a flexible architecture of the AES implementation. The complexity of this arises from the algorithm architecture associated to the loop number and information size [13,4, 5, 14, 15, 3, 16]. The main idea of this work is to adapt the basic bloc size to the loop number and the size of the available
information. The global architecture of the proposed system using dynamically reconfigurable FPGA is illustrated below (Cf. Fig. 8)
Fig. 8: Global architecture for self-reconfigurable system
6. A Self-Reconfigurable Implementation of AES
Our principal contribution in this article, is to conceive an optimal system allowing the implementation of the AES by using the self-reconfigurable dynamic method.
6.1 Methodology implementation To increase the performance of the implemented circuit, especially cost, power and inaccessibility, all of the AES blocs may be reconfigurable [17]. So, the used parameters for reconfiguration are implanted inside the manager module of reconfiguring, and it is possible to quickly cross from a safe configuration to another by updating a hard system protection. The control and management module of reconfiguration allows choosing a correct memory program (PR) and generating a reconfiguration signal (Cf. Fig. 9). The real dynamic reconfiguration procedure of the AES is preceded by two controllers: the first one, achieved by Microblaze processor, computes the reconfiguration parameters using the available signal and the key size. This is the current state of the system. The second one computes the best parameters under input constraints, and writes these parameters in the configuration register for managing the reconfiguration process.
Fig.9: Global architecture for implementation the AES
AES Core Reconfigurable
Manager Controller
MicroBlaze -
Initialisation
ICAP attacks
Key
Det
ectio
n

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
38
IJCSIIJCSI
In Figure 10, we present the modular design and reconfiguration cryptosystem.
Fig. 10: Modular Design and Reconfiguration cryptosystem.
6.2 Configuration controller finite state machine
As described previously, the configuration controller is developed with a finite state machine. With the knowledge of the memory mapping, the configuration management finite state machine is relatively simple. The configuration controller is used only for normal FPGA configuration when power is switched on. Figure 11 shows the four-global-states used by the configuration controller. The first state of this four-states FSM (Finite State Machine) is an start state. To change state the configuration controller waits for detection the length key signal. This signal is the begin-signal of the normal configuration process.
Fig. 11: Finite state machine configuration controller
7 Implementation Result
To test the proposed method, in first time, we have implemented the AES algorithm with on the Spartan II (XC2S200E) and Virtex II (XC2V500) of Xilinx. The results are summarized in the Table 2.
Table 2: comparison of the different implementations of the AES
FPGA
Resource
Resource Used/Total Resource
(XC2S200E)
Resource Used/Total Resource
(XC2V500)
Slices 196/2353 192/072
Slice Flip-Flops
92/4704 78/6144
4-input LUTs 352/4704 342/6144 AE
S-12
8
BRAMs 6/14 6/32
Slices 265/2353 241/3072
Slice Flip-Flops
102/4704 76/6144
4-input LUTs 467/4707 341/6144 AE
S-19
2
BRAMs 6/14 6/32
Slices 252/2353 207/3072
Slice Flip-Flops
99/4704 81/6144
4-input LUTs 469/4704 381/6144 AE
S-25
6
BRAMs 6/14 6/32
The performance implementation of AES cryptographic is presented in the table 3.
Table 3: Performance implementation for AES
Parameter Device XC2S200E)
Device (XC2V500)
Minimum Period (ns) 35.520 13.674
Maximum Frequency 28.742 78.59
Clock Cycle Used 250 250
Thtoughput (Mbps) 16.362 40.57
AE
S-12
8
TPS (kbps/slice) 83 232 Minimum Period (ns) 41.387 13.863
Maximum Frequency 25.825 71.78
Clock Cycle Used 300 300
Thtoughput (Mbps) 11.361 31.72
AE
S-19
2
TPS (kbps/slice) 41 135
A E
Minimum 37.648 15.043
MicroBlaze
System
Rec
onfig
urab
le
Are
a A
ES1
28
MicroBlaze System
Rec
onfig
urab
le
Are
a A
ES1
92
Reconfiguration
MicroBlaze
System
Rec
onfig
urab
le
Are
a A
ES2
56
Reconfiguration
Start
Crypto AES 128
Crypto AES 192
Crypto AES 256
Change of length
Key length (128 bits)
Key length (192 bits)
Key length (256 bits)
Change of length
Change of length
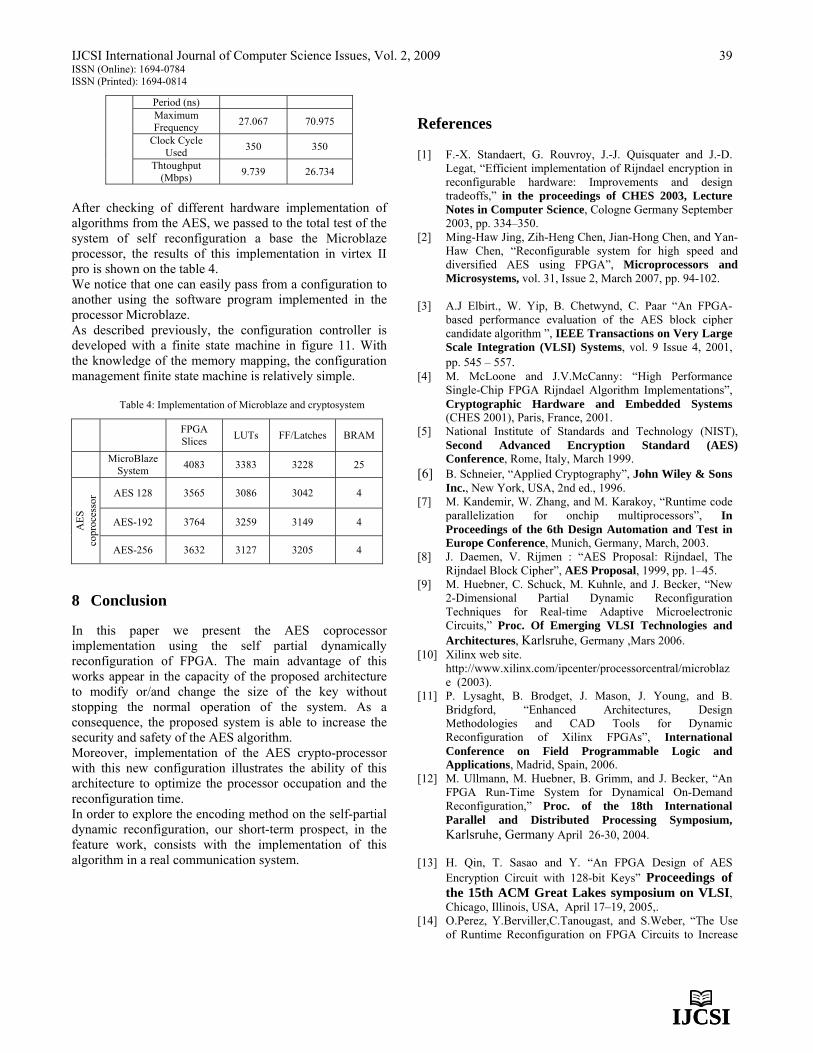
IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
39
IJCSIIJCSI
Period (ns) Maximum Frequency 27.067 70.975
Clock Cycle Used 350 350
Thtoughput (Mbps) 9.739 26.734
After checking of different hardware implementation of algorithms from the AES, we passed to the total test of the system of self reconfiguration a base the Microblaze processor, the results of this implementation in virtex II pro is shown on the table 4. We notice that one can easily pass from a configuration to another using the software program implemented in the processor Microblaze. As described previously, the configuration controller is developed with a finite state machine in figure 11. With the knowledge of the memory mapping, the configuration management finite state machine is relatively simple.
Table 4: Implementation of Microblaze and cryptosystem
FPGA Slices LUTs FF/Latches BRAM
MicroBlaze System 4083 3383 3228 25
AES 128 3565 3086 3042 4
AES-192 3764 3259 3149 4 AES
co
proc
esso
r
AES-256 3632 3127 3205 4
8 Conclusion
In this paper we present the AES coprocessor implementation using the self partial dynamically reconfiguration of FPGA. The main advantage of this works appear in the capacity of the proposed architecture to modify or/and change the size of the key without stopping the normal operation of the system. As a consequence, the proposed system is able to increase the security and safety of the AES algorithm. Moreover, implementation of the AES crypto-processor with this new configuration illustrates the ability of this architecture to optimize the processor occupation and the reconfiguration time. In order to explore the encoding method on the self-partial dynamic reconfiguration, our short-term prospect, in the feature work, consists with the implementation of this algorithm in a real communication system.
References [1] F.-X. Standaert, G. Rouvroy, J.-J. Quisquater and J.-D.
Legat, “Efficient implementation of Rijndael encryption in reconfigurable hardware: Improvements and design tradeoffs,” in the proceedings of CHES 2003, Lecture Notes in Computer Science, Cologne Germany September 2003, pp. 334–350.
[2] Ming-Haw Jing, Zih-Heng Chen, Jian-Hong Chen, and Yan-Haw Chen, “Reconfigurable system for high speed and diversified AES using FPGA”, Microprocessors and Microsystems, vol. 31, Issue 2, March 2007, pp. 94-102.
[3] A.J Elbirt., W. Yip, B. Chetwynd, C. Paar “An FPGA-
based performance evaluation of the AES block cipher candidate algorithm ”, IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 9 Issue 4, 2001, pp. 545 – 557.
[4] M. McLoone and J.V.McCanny: “High Performance Single-Chip FPGA Rijndael Algorithm Implementations”, Cryptographic Hardware and Embedded Systems (CHES 2001), Paris, France, 2001.
[5] National Institute of Standards and Technology (NIST), Second Advanced Encryption Standard (AES) Conference, Rome, Italy, March 1999.
[6] B. Schneier, “Applied Cryptography”, John Wiley & Sons Inc., New York, USA, 2nd ed., 1996.
[7] M. Kandemir, W. Zhang, and M. Karakoy, “Runtime code parallelization for onchip multiprocessors”, In Proceedings of the 6th Design Automation and Test in Europe Conference, Munich, Germany, March, 2003.
[8] J. Daemen, V. Rijmen : “AES Proposal: Rijndael, The Rijndael Block Cipher”, AES Proposal, 1999, pp. 1–45.
[9] M. Huebner, C. Schuck, M. Kuhnle, and J. Becker, “New 2-Dimensional Partial Dynamic Reconfiguration Techniques for Real-time Adaptive Microelectronic Circuits,” Proc. Of Emerging VLSI Technologies and Architectures, Karlsruhe, Germany ,Mars 2006.
[10] Xilinx web site. http://www.xilinx.com/ipcenter/processorcentral/microblaze (2003).
[11] P. Lysaght, B. Brodget, J. Mason, J. Young, and B. Bridgford, “Enhanced Architectures, Design Methodologies and CAD Tools for Dynamic Reconfiguration of Xilinx FPGAs”, International Conference on Field Programmable Logic and Applications, Madrid, Spain, 2006.
[12] M. Ullmann, M. Huebner, B. Grimm, and J. Becker, “An FPGA Run-Time System for Dynamical On-Demand Reconfiguration,” Proc. of the 18th International Parallel and Distributed Processing Symposium, Karlsruhe, Germany April 26-30, 2004.
[13] H. Qin, T. Sasao and Y. “An FPGA Design of AES
Encryption Circuit with 128-bit Keys” Proceedings of the 15th ACM Great Lakes symposium on VLSI, Chicago, Illinois, USA, April 17–19, 2005,.
[14] O.Perez, Y.Berviller,C.Tanougast, and S.Weber, “The Use of Runtime Reconfiguration on FPGA Circuits to Increase

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
40
IJCSIIJCSI
the Performance of the AES Algorithm Implementation”, Journal of Universal Computer Science, vol. 13, no. 3, 2007, pp.349-362.
[15] N. Saqib, F.Rodriguez-Henriquez, and A. Diaz-Pérez, “Two approaches for a single-Chip FPGA Implementation of an Encyptor/Decryptor AES Core” International C-Conference on Field-Programmable Logic and Applications , Lisbon , Portugal, September 2003 .
[16] M Mogollon: “Cryptography and Security Services: Mechanisms and Applications” Cybertech Publishing, 2007.
[17] Z.A, Alaoui, A. Moussa, A. Elmourabit and K. Amechnoue “Flexible Hardware Architecture for AES Cryptography Algorithm” IEEE Conference on Multimedia Computing and Systems, ouarzazate, morocco, April 2009.
Z. alaoui-Ismaili, received the DEA in electronics in 1997 and the Ph.D. degree in Electronics and industrial Computer Engineering in 2002, both from University IbnTofail de Kenitra, Morocco. He is currently researcher teacher at the Telecoms & Electronics department of National School of Applied Sciences tangier, Morocco, since June 2003. His main research interests are FPGA based reconfigurable computing applications, with a special focus on dynamic partial reconfiguration and embedded systems. Dr. Alaoui_Ismaili authored or coauthored more than 10 papers journal and conference. He is president of Association Moroccan Society of microelectronics. A. Moussa, was born in 1970 in Oujda, Morocco. He received the Licence in Electronics from the University of Oujda, Morocco, in 1994, and the PhD in Automatic Control and Information Theory from the University of Kenitra, Morocco, in 2001. He worked two years as a post-graduate researcher at the University of Sciences and Technology of Lille, France. At 2003 he joined Sanofi-Aventis research laboratory in Montpellier, France where he supervised Microarray analysis activities .He is now a professor at the National School of Applied Sciences in Tangier-Morocco and his current research interests are in the application of the Markov theory and multidimensional data analysis to image processing, and embedded systems.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
41
Web Single Sign-On Authentication using SAML
Kelly D. LEWIS, James E. LEWIS, Ph.D.
Information Security, Brown-Forman Corporation Louisville, KY 40210, USA [email protected]
Engineering Fundamentals, Speed School of Engineering, University of Louisville
Louisville, KY 40292, USA [email protected]
Abstract Companies have increasingly turned to application service providers (ASPs) or Software as a Service (SaaS) vendors to offer specialized web-based services that will cut costs and provide specific and focused applications to users. The complexity of designing, installing, configuring, deploying, and supporting the system with internal resources can be eliminated with this type of methodology, providing great benefit to organizations. However, these models can present an authentication problem for corporations with a large number of external service providers. This paper describes the implementation of Security Assertion Markup Language (SAML) and its capabilities to provide secure single sign-on (SSO) solutions for externally hosted applications. Keywords: Security, SAML, Single Sign-On, Web, Authentication
1. Introduction
Organizations for the most part have recently started using a central authentication source for internal applications and web-based portals. This single source of authentication, when configured properly, provides strong security in the sense that users no longer keep passwords for different systems on sticky notes on monitors or under their keyboards. In addition, management and auditing of users becomes simplified with this central store.
As more web services are being hosted by external service providers, the sticky note problem has reoccurred for these outside applications. Users are now forced to remember passwords for HR benefits, travel agencies, expense processing, etc. - or programmers must develop custom SSO code for each site. Management of users becomes a complex problem for the help desk and custom built code for each external service provider can become difficult to administer and maintain.
In addition, there are problems for the external service provider as well. Every user in an organization will need to be set up for the service provider’s application, causing a duplicate set of data. Instead, if the organization can control this user data, it would save the service provider time by not needing to set up and terminate user access on a daily basis. Furthermore, one central source would allow the data to be more accurate and up-to-date.
Given this set of problems for organizations and their service providers, it is apparent that a solution is needed that provides a standard for authentication information to be exchanged over the Internet. Security Assertion Markup Language (SAML) provides a secure, XML-based solution for exchanging user security information between an identity provider (our organization) and a service provider (ASPs or SaaSs). The SAML standard defines rules and syntax for the data exchange, yet is flexible and can allow for custom data to be transmitted to the external service provider.
2. Background
The consortium for defining SAML standards and security is OASIS (Organization for the Advancement of Structured Information Standards). They are a non-profit international organization that promotes the development and adoption of open standards for security and web services. OASIS was founded in 1993 under SGML (Standard Generalized Markup Language) Open until its name change in 1998. Headquarters for OASIS are located in North America, but there is active member participation internationally in 100 countries on five continents [1].

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
42
SAML 1.0 became an OASIS standard toward the end of 2002, with its early formations beginning in 2001. The goal behind SAML 1.0 was to form a XML framework to allow for the authentication and authorization from a single sign-on perspective. At the time of this milestone, other companies and consortiums started extending SAML 1.0. While these extensions were being formed, the SAML 1.1 specification was ratified as an OASIS standard in the fall of 2003.
The next major revision of SAML is 2.0, and it became an official OASIS Standard in 2005. SAML 2.0 involves major changes to the SAML specifications. This is the first revision of the standard that is not backwards compatible, and it provides significant additional functionality [2]. SAML 2.0 now supports W3C XML encryption to satisfy privacy requirements [3]. Another advantage that SAML 2.0 includes is the support for service provider initiated web single sign-on exchanges. This allows for the service provider to query the identity provider for authentication. Additionally, SAML 2.0 adds “Single Logout” functionality. The remainder of this text will be discussing implementation of a SAML 2.0 environment.
There are three roles involved in a SAML transaction – an asserting party, a relying party, and a subject. The asserting party (identity provider) is the system in authority that provides the user information. The relying party (service provider) is the system that trusts the asserting party’s information, and uses the data to provide an application to the user. The user and their identity that is involved in the transaction are known as the subject.
The components that make up the SAML standard are assertions, protocols, bindings and profiles. Each layer of the standard can be customized, allowing specific business cases to be addressed per company. Since each company’s scenarios could be unique, the implementation of these business cases should be able to be personalized per service and per identity providers.
The transaction from the asserting party to the relying party is called a SAML assertion. The relying party assumes that all data contained in the assertion from the asserting party is valid. The structure of the SAML assertion is defined by the XML schema and contains header information, the subject and statements about the
subject in the form of attributes and conditions. The assertion can also contain authorization statements defining what the user is permitted to do inside the web application.
The SAML standard defines request and response protocols used to communicate the assertions between the service provider (relying party) and the identity provider (asserting party). Some example protocols are [4]:
• Authentication Request Protocol – defines how the service provider can request an assertion that contains authentication or attribute statements
• Single Logout Protocol – defines the mechanism to allow for logout of all service providers
• Artifact Resolution Protocol – defines how the initial artifact value and then the request/response values are passed between the identity provider and the service provider.
• Name Identifier Management Protocol – defines how to add, change or delete the value of the name identifier for the service provider
SAML bindings map the SAML protocols onto standard lower level network communication protocols used to transport the SAML assertions between the identity provider and service provider. Some example bindings used are [4]:
• HTTP Redirect Binding – uses HTTP redirect messages
• HTTP POST Binding – defines how assertions can be transported using base64-encoded content
• HTTP Artifact Binding – defines how an artifact is transported to the receiver using HTTP
• SOAP HTTP Binding – uses SOAP 1.1 messages and SOAP over HTTP
The highest SAML component level is profiles, or the business use cases between the service provider and the identity provider that dictate how the assertion, protocol and bindings will work together to provide SSO. Some example profiles are [4]:

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
43
• Web Browser SSO Profile – uses the Authentication Request Protocol, and any of the following bindings: HTTP Redirect, HTTP POST and HTTP Artifact
• Single Logout Profile – uses the Single Logout Protocol, which can log the user out of all service providers using a single logout function
• Artifact Resolution Profile – uses the Artifact Resolution Protocol over a SOAP HTTP binding
• Name Identifier Management Profile – uses the name Identifier management Protocol and can be used with HTTP Redirect, HTTP POST, HTTP Artifact or SOAP
Two profiles will be briefly discussed in more detail, the artifact resolution profile and web browser SSO profile. The artifact resolution profile can be used if the business case requires highly sensitive data to pass between the identity provider and service provider, or if the two partners want to utilize an existing secure connection between the two companies.
This profile allows for a small value, called an artifact to be passed between the browser and the service provider by one of the HTTP bindings. After the service provider receives the artifact, it transmits the artifact and the request/response messages out of band from the browser back to the identity provider. Most likely the messages are transmitted over a SSL VPN connection between the two companies. This provides security for the message, plus eliminates the need for the assertions to be signed or encrypted which could potentially reduce overhead. When the identify provider receives the artifact, it looks up the value in its database and processes the request. After all out of band messages are transmitted between the identity provider and service provider, the service provider presents the information directly to the browser.
The web browser SSO profile may be initiated by the identify provider or the service provider. If initiated by the identity provider, the assertion is either signed, encrypted, or both. In the web browser SSO profile, all of the assertion information is sent at once to the service provider using any of the HTTP bindings and protocols. The service provider decrypts if necessary and checks for message integrity against the signature. Next, it parses the SAML XML statements and gathers any attributes that were passed, and then performs SSO using the
Assertion Consumer Service. The diagram in Figure 1 shows the identity provider initiated SAML assertion.
Figure 1: Identity Provider Initiated SAML Assertion Flowchart
If the user accesses the external webpage without passing through the internal federated identity manager first, the service provider will need to issue the SAML request back to the identity provider on behalf of the user. This process of SSO is called service provider initiated. In this case, the user arrives at a webpage specific for the company, but without a SAML assertion. The service provider redirects the user back to the identity provider’s federation webpage with a SAML request, and optionally with a RelayState query string variable that can be used to determine what SAML entity to utilize when sending the assertion back to the service provider.
After receiving the request from the service provider, the identity provider processes the SAML request as if it came internally. This use case is important since it allows users to be able to bookmark external sites directly, but still provides SAML SSO capabilities with browser redirects. Figure 2 demonstrates this service provider initiated use case.
The most popular business use case for SAML federation is the web browser SSO profile, used in conjunction with the HTTP POST binding and authentication request protocol. The implementation and framework section will discuss this specific use case and the security needed to protect data integrity.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
44
Figure 2: Service Provider Initiated SAML Assertion Flowchart
3. Implementation/Framework
There are numerous identity and federation manager products on the market that support federation via SAML versions 1.1 and 2.0, as well as several open source products. OpenSAML, an open source toolkit, is available to support developers working with SAML. Shibboleth is an example of an open source project that uses the OpenSAML toolkit. Sun Microsystems has a product called OpenSSO that is an open source version of their commercial product, OpenSSO Enterprise. Computer Associates provides an access manager called SiteMinder and RSA has a product called Federated Identity Manager to name a few. Regardless of which product is selected, as long as it conforms to the standards of SAML, all products can be used interchangeably with no compatibility issues.
The process of setting up federation involves configuring a local entity, a partner entity, and an association between the two that forms the federation. The local entity must be manually configured inside the federation software; however, for SAML 2.0 the process of setting up the partner entity has been made easier with the introduction of metadata. Since the SAML standard is flexible and can allow a number of custom configurations, certain agreements and configuration information must be initially set up between two partners. Exchanging metadata containing this specific
information determines the specifications that will be used in a particular business case.
Once the metadata file has been received from the partner entity, this XML file can be uploaded into the federation software without any additional configuration needed for the partner entity. This process saves time and reduces the possibility for error. The file contains elements and attributes, and includes an EntityDescriptor and EntityID that specifies to which entity the configuration refers.
There are many optional elements and attributes for metadata files; some that may apply are Binding, WantAuthRequestsSigned, WantAssertionsSigned, SingleLogoutService, etc. To review the entire list of elements available for the metadata file, see the OASIS metadata standard [5].
When manually configuring a local entity, first determine the parameters to be passed in the assertion that will be the unique username for each user. Normally this value is an email address or employee number, since they are guaranteed to be exclusive for each individual. In some federation products, values from a data source can be automatically utilized with the SAML assertion. These values can be extracted from different data sources such as LDAP, or another source that could be tied into a HR system. While setting up the local entity there are other considerations, such as how the parameters will be passed (in attributes or nameID), a certificate keystore for the association, and type of signing policies required.
The following sample metadata shown in Figure 3 is an example that would be sent from the local entity (identity provider in this case) to the partner entity (service provider) to load into the federation software. The descriptor shows titled as “IDPSSODescriptor”, which demonstrates this is metadata from an identity provider.
Some elements are mandatory, such as entityID, yet others are optional, such as ID and OrganizationName. The elements to note are the Single Sign-On Service binding, location, protocol support section, and key descriptor and key info areas. In this example, the binding must be performed by an HTTP-POST, and the supported protocol is SAML 2.0.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
45
<md:EntityDescriptor ID="MyCompany" entityID="mycompany:saml2.0" xmlns:ds="http://www.w3.org/2000/09/xmldsig#" xmlns:md="urn:oasis:names:tc:SAML:2.0:metadata" xmlns:query="urn:oasis:names:tc:SAML:metadata:ext:query" xmlns:saml="urn:oasis:names:tc:SAML:2.0:assertion" xmlns:xenc="http://www.w3.org/2001/04/xmlenc#"> <md:IDPSSODescriptor WantAuthnRequestsSigned="false" protocolSupportEnumeration= "urn:oasis:names:tc:SAML:2.0:protocol"> <md:KeyDescriptor use="encryption"> <ds:KeyInfo xmlns:ds="http://www.w3.org/2000/09/xmldsig#"> <ds:X509Data> <ds:X509Certificate> CERTIFICATE </ds:X509Certificate> </ds:X509Data> </ds:KeyInfo> <md:EncryptionMethod Algorithm="http://www.w3.org/2001/04/xmlenc#aes128-cbc"> </md:EncryptionMethod> </md:KeyDescriptor> <md:KeyDescriptor use="signing"> <ds:KeyInfo xmlns:ds="http://www.w3.org/2000/09/xmldsig#"> <ds:X509Data> <ds:X509Certificate> CERTIFICATE </ds:X509Certificate> </ds:X509Data> </ds:KeyInfo> </md:KeyDescriptor> <md:SingleSignOnService Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-POST" Location="http://mycompany.com/sso/SSO"> </md:SingleSignOnService> </md:IDPSSODescriptor> <md:Organization> <md:OrganizationName xml:lang="en-us"> My Company Org </md:OrganizationName> <md:OrganizationDisplayName xml:lang="en-us"> My Company </md:OrganizationDisplayName> <md:OrganizationURL xml:lang="en-s"> http://www.mycompany.com </md:OrganizationURL> </md:Organization> </md:EntityDescriptor>
Figure 3: Sample Identity Provider Metadata XML
Figure 4 demonstrates an example metadata XML file that would be sent from a service provider to an identity provider for loading into the federation software. Note that the descriptor is “SPSSODescriptor”, indicating service provider single sign-on descriptor.
In this case, “WantAuthnRequestsSigned” is equal to true, as opposed to the previous example in Figure 3.
Also, there are two KeyDescriptors, one for signing and one for encrypting. This indicates the service provider requires both for the assertion. There are two methods of binding listed for the assertion consumer service: the HTTP Post and the HTTP Artifact. These two metadata samples show how custom each company can be with unique SAML requirements.
<EntityDescriptor entityID="mypartner:saml2.0" xmlns="urn:oasis:names:tc:SAML:2.0:metadata"> <SPSSODescriptor AuthnRequestsSigned="true" WantAssertionsSigned="true" protocolSupportEnumeration= "urn:oasis:names:tc:SAML:2.0:protocol"> <KeyDescriptor use="signing"> <ds:KeyInfo xmlns:ds="http://www.w3.org/2000/09/xmldsig#"> <ds:X509Data> <ds:X509Certificate>CERTIFICATE</ds:X509Certificate> </ds:X509Data> </ds:KeyInfo> </KeyDescriptor> <KeyDescriptor use="encryption"> <ds:KeyInfo xmlns:ds="http://www.w3.org/2000/09/xmldsig#"> <ds:X509Data> <ds:X509Certificate>CERTIFICATE</ds:X509Certificate> </ds:X509Data> </ds:KeyInfo> <EncryptionMethod Algorithm="http://www.w3.org/2001/04/xmlenc#aes128-cbc"> <xenc:KeySize xmlns:xenc="http://www.w3.org/2001/04/xmlenc#">128 </xenc:KeySize> </EncryptionMethod> </KeyDescriptor> <NameIDFormat> urn:oasis:names:tc:SAML:2.0:nameid-format:transient </NameIDFormat> <AssertionConsumerService index="0" isDefault="true" Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-POST" Location="https://mypartner.com/federation/metaAlias/sp"/> <AssertionConsumerService index="1" Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-Artifact" Location="https://mypartner.com/federation/metaAlias/sp"/> </SPSSODescriptor> </EntityDescriptor>
Figure 4: Sample Service Provider Metadata XML
After the metadata is exchanged and all entities are set up, the assertion can be tested and verified using browser tools and decoders. For this example, the service provider implementation of the HTTP POST method will be described briefly.
The identity provider must first determine what URL the federation software requires, and what attributes need to

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
46
be passed with the POST data, such as entityID or RelayState. The browser HTTP-POST action contains hidden SAMLResponse and RelayState fields enclosed in a HTML form. After the browser POST is received by the service provider, the Assertion Consumer Service validates the signature and processes the assertion, gathering attributes and other conditions that could optionally be required. The service provider also obtains the optional RelayState variable in the HTML form, determines the application URL, and redirects the browser to it providing single sign-on to the web application [4].
To validate the sent attributes in the assertion with this HTTP POST example, a browser add-on program can be used to watch exactly what is sent between the browser and the partner. A few browser add-ons are “HttpFox” [6] which can be used with Mozilla Firefox, and “HttpWatch” [7] which can be used with Mozilla Firefox or Internet Explorer. After capturing HTTP data, the browser POST action can be verified to ensure the proper attributes are passed to the partner. The POST action shows the hidden SAMLResponse and RelayState fields in the HTML form, and can be used to validate the data sent to the service provider.
The SAMLResponse field is URL encoded, and must be decoded before reading the assertion. Depending on the requirements, the assertion must be signed, or signed and encrypted. For testing purposes, first only sign the assertion so it can be URL decoded into a non-encrypted readable version. Figure 5 shows an example of a URL decoded SAMLResponse and has been shortened for readability, designated by capital words.
<samlp:Response xmlns:saml="urn:oasis:names:tc:SAML:2.0:assertion" xmlns:samlp="urn:oasis:names:tc:SAML:2.0:protocol" Consent="urn:oasis:names:tc:SAML:2.0:consent:unspecified" Destination="https://mypartner.com/metaAlias/sp" ID="ad58514ea9365e51c382218fea" IssueInstant="2009-04-22T12:33:36Z" Version="2.0"> <saml:Issuer>http://login.mycompany.com/mypartner</saml:Issuer> <ds:Signature xmlns:ds="http://www.w3.org/2000/09/xmldsig#"> SIGNATURE VALUE, ALGORITHM, ETC. </ds:Signature> <samlp:Status> <samlp:StatusCode Value="urn:oasis:names:tc:SAML:2.0:status:Success"> </samlp:StatusCode> </samlp:Status> <saml:Assertion ID="1234" IssueInstant="2009-04-22T12:33:36Z" Version="2.0"> <saml:Issuer>http://login.mycompany.com/mypartner</saml:Issuer>
<ds:Signature xmlns:ds="http://www.w3.org/2000/09/xmldsig#"> SIGNATURE VALUE, ALGORITHM, ETC. </ds:Signature> <saml:Subject> <saml:NameID>NAMEID FORMAT, INFO, ETC</saml:NameID> <saml:SubjectConfirmation Method="urn:oasis:names:tc:SAML:2.0:cm:bearer"> <saml:SubjectConfirmationData NotOnOrAfter="2009-04-22T12:43:36Z" Recipient="https://mypartner.com/metaAlias/sp"> </saml:SubjectConfirmationData> </saml:SubjectConfirmation> </saml:Subject> <saml:Conditions NotBefore="2009-04-22T12:28:36Z" NotOnOrAfter="2009-04-22T12:33:36Z"> <saml:AudienceRestriction> <saml:Audience>mypartner.com:saml2.0</saml:Audience> </saml:AudienceRestriction> </saml:Conditions> <saml:AuthnStatement AuthnInstant="2009-04-22T12:33:20Z" SessionIndex="ccda16bc322adf4f74d556bd"> <saml:SubjectLocality Address="192.168.0.189" DNSName="myserver.mycompany.com"> </saml:SubjectLocality> </saml:AuthnStatement> <saml:AttributeStatement xmlns:xs=SCHEMA INFO> <saml:Attribute FriendlyName="clientId" Name="clientId" NameFormat="urn:oasis:names:tc:SAML:2.0: attrname-format:basic"> <saml:AttributeValue>1234</saml:AttributeValue> </saml:Attribute> <saml:Attribute FriendlyName="uid" Name="uid" NameFormat="urn:oasis:names:tc:SAML:2.0: attrname-format:basic"> <saml:AttributeValue>[email protected] </saml:AttributeValue> </saml:Attribute> </saml:AttributeStatement> </saml:Assertion> </samlp:Response>
Figure 5: Sample SAML Assertion
For testing purposes with this sample assertion, the attributes toward the end of the XML should be verified. In this example, two attributes are being passed: clientID and uid. The clientID is a unique value that has been assigned by the service provider indicating which company is sending the assertion. The uid in this case is the email address of the user requesting the web resource. After receiving and validating these values, the service provider application performs SSO for the user. Once these values have been tested and accepted as accurate, the SAML assertion can be encrypted if required, and the service provider application can be fully tested.
There are important security aspects to be considered, given that the relying party fully trusts the data in the

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
IJCSIIJCSI
47
SAML assertion. The integrity of the message must be preserved from man-in-the-middle attacks and other spoofs. In dealing with this scenario, A SAML assertion can be unsigned, signed, or signed and encrypted depending on the type of data and the sensitivity required per application. The SAML standard allows for message integrity by supporting X509 digital signatures in the request/response transmissions. SAML also supports and recommends HTTP over SSL 3.0 and TLS 1.0 for situations where data confidentiality is required [8].
As analyzed by Hansen, Skriver, and Nielson there are some major issues in the SAML 1.1 browser/artifact profile using TLS security [9]. In SAML 2.0, this profile was improved to repair a majority of these security issues; however there is one existing problem in the specification examined by Groß and Pfitzmann [10]. Groß and Pfitzmann devised a solution to this exploit by creating a new profile that produces two artifacts, with the token being valid only when it consists of both values, thus eliminating successful replay of a single token. Additional work has also been performed on recently proposed attack scenarios. Gajek, Liao, and Schwenk recommend two new stronger bindings for SAML artifacts to the TLS security layer [11].
An additional scenario that could compromise data integrity is a replay attack that intercepts the valid assertion and saves the data for impersonation at a later time. Both the identity provider and the service provider should utilize the SAML attributes NotBefore and NotOnOrAfter shown in Figure 5. These values should contain a time frame that is as short as possible, usually around 5 minutes. In addition, the identity provider can insert locality information into the assertion, which the service provider can verify is valid against the IP address of the requesting user. For additional security considerations, see the OASIS security and privacy considerations standard [8].
4. Conclusions/Best Practices
In conclusion, the benefits of SAML are abundant. Organizations can easily, yet securely share identity information and security is improved by eliminating the possibility of shared accounts. User experience is enhanced by eliminating additional usernames and
passwords, which also allows for fewer helpdesk calls and administrative costs.
Companies should have documentation available to exchange when setting up SAML associations, since each SAML use case can be customized per individual business need. Service providers can use different security protocols, such as signed only, versus signed and encrypted. In addition, some service providers may only use the nameID section of the assertion, while others might use custom attributes only. This upfront documentation can save troubleshooting time during the implementation and testing phases of the project.
Furthermore, during testing phases it is helpful to use a sample test site for the service provider and also to test with SAML assertions signed only. The sample test site allows for the ability to isolate a test of only the SAML connection between the two partners, before testing of the application occurs. Testing with signed only assertions allows for the ability to URL decode the HTML hidden input field, and validate the data being passed to the service provider. This ensures the correct data in the assertion is sent and can be tested prior to the service provider site being fully prepared for testing.
Additionally, using SAML metadata is very helpful since it eliminates typos and errors when setting up the partner entity. These metadata files can help the identity provider understand exactly what the service provider needs in the SAML assertion. Both the identity provider and service provider should utilize metadata files, not only to speed up manual work when entering data into the federation software, but to also reduce human error.
The OASIS Security Services Technical Committee continues to improve upon the current SAML 2.0 standard by developing new profiles to possibly be used in later releases. For example, one area OASIS has already improved upon was a supplement to the metadata specifications that added new elements and descriptor types. Both identity providers and service providers should be aware of any changes to SAML standards that are ratified by OASIS. Staying current and not deviating from the standards helps to ensure compatibility, resulting in less customized configurations between organizations.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
IJCSIIJCSI
48
References [1] OASIS Frequently Asked Questions “http://www.oasis-
open.org/who/faqs.php”, 2009. [2] P. Madsen. SAML 2: The Building Blocks of Federated
Identity “http://www.xml.com/pub/a/2005/01/12/saml2.html”, 2005.
[3] Differences Between SAML V2.0 and SAML V1.1. “https://spaces.internet2.edu/display/SHIB/SAMLDiffs”, Feb. 2007.
[4] N. Ragouzis et al. Security Assertion Markup Language (SAML) V2.0 Technical Overview. “http://www.oasis-open.org/committees/download.php/22553/sstc-saml-tech-overview.pdf”, Feb. 2007.
[5] S. Cantor et al. Metadata for the OASIS Security Assertion Markup Language (SAML) V2.0. “http://docs.oasis-open.org/security/saml/v2.0/saml-metadata-2.0-os.pdf”, March 2005.
[6] M. Theimer. HttpFox 0.8.4. “https://addons.mozilla.org/en-US/firefox/addon/6647”, 2009.
[7] HttpWatch. “http://www.httpwatch.com/”, 2009. [8] F. Hirsch et al. Security and Privacy Considerations for the
OASIS Security Assertion Markup Language (SAML) V2.0. “http://docs.oasis-open.org/security/saml/v2.0/saml-sec-consider-2.0-os.pdf”, March 2005.
[9] S. M. Hansen, J. Skriver, and H. R. Nielson. “Using static analysis to validate the SAML single sign-on protocol”, in Proceedings of the 2005 workshop on Issues in the theory of security (WITS ’05), 2005, pages 27–40.
[10] T. Großand, and B. Pfitzmann, “Saml Artifact Information Flow Revisited”. Research Report RZ 3643 (99653), IBM Research, “http://www.zurich.ibm.com/security/publications/2006/GrPf06.SAML-Artifacts.rz3643.pdf”, 2006.
[11] S. Gajek, L. Liao, and J. Schwenk. “Stronger TLS bindings for SAML assertions and SAML artifacts”, in Proceedings of the 2008 ACM Workshop on Secure Web Services (SWS ’08), 2008, pages 11-20.
Kelly D. Lewis graduated with a B.S. of Computer Engineering
and Computer Science at the University of Louisville in 2001. She received her M. Eng. at the University of Louisville in the same discipline in 2005, publishing a thesis titled “Student Performance Evaluation Package using a Web Interface and a Database”. She started her Information Technology career in 1999 with the United States Army Research Institute. She has been employed for Brown-Forman Corporation the last 8 years, and has worked a Systems Administrator, Network Engineer, and presently holds a Security Analyst position in Information Security. Her focus is on network security, automation, and single sign-on technologies.
James E. Lewis graduated with a B.A. in Computer Science from Hanover College in 1994, and earned a M.S. in Computer Science from the University of Louisville in 1996, with a thesis focusing on expert systems and networking. He received a Ph.D. in Computer Science and Engineering from the University of Louisville in 2003, publishing a dissertation with an emphasis in distributed genetic algorithms. He started teaching in 1995,
and is currently an Assistant Professor in the Department of Engineering Fundamentals at the University of Louisville’s Speed School of Engineering, where he received this appointment in 2004. He has fourteen publications on various topics including distributed algorithms, intelligent system design, and engineering education that were published in national and international conference proceedings. He has also been invited to present on critical thinking in engineering education at two conferences. He has been awarded two research grants for his critical thinking and case study initiatives. He is a member of the ACM and ASEE organizations. His research interests include parallel and distributed computer systems, cryptography, security design, engineering education, and technology used in the classroom.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
49
IJCSIIJCSI
An Efficient Secure Multimodal Biometric Fusion Using Palmprint and Face Image
Nageshkumar.M, Mahesh.PK and M.N. Shanmukha Swamy
1 Department of Electronics and Communication, J.S.S. research foundation, Mysore University, Mysore-6
2 Department of Electronics and Communication, J.S.S. research foundation, Mysore University, Mysore-6
3 Department of Electronics and Communication, J.S.S. research foundation, Mysore University, Mysore-6
Abstract Biometrics based personal identification is regarded as an effective method for automatically recognizing, with a high confidence a person’s identity. A multimodal biometric systems consolidate the evidence presented by multiple biometric sources and typically better recognition performance compare to system based on a single biometric modality. This paper proposes an authentication method for a multimodal biometric system identification using two traits i.e. face and palmprint. The proposed system is designed for application where the training data contains a face and palmprint. Integrating the palmprint and face features increases robustness of the person authentication. The final decision is made by fusion at matching score level architecture in which features vectors are created independently for query measures and are then compared to the enrolment template, which are stored during database preparation. Multimodal biometric system is developed through fusion of face and palmprint recognition. Keywords: Biometrics, multimodal, face, palmprint, fusion module, matching module, decision module. 1 INTRODUCTION A multimodal biometric authentication, which identifies an individual person using physiological and/or behavioral characteristics, such as face, fingerprints, hand geometry, iris, retina, vein and speech is one of the most attractive and effective methods. These methods are more reliable and capable than knowledge-based (e.g. Password) or token-based (e.g. Key) techniques. Since biometric features are hardly stolen or forgotten.
However, a single biometric feature sometimes fails to be exact enough for verifying the identity of a
person. By combining multiple modalities enhanced performance reliability could be achieved. Due to its promising applications as well as the theoretical challenges, multimodal biometric has drawn more and more attention in recent years [1]. Face and palmprint multimodal biometrics are advantageous due to the use of non-invasive and low-cost image acquisition. In this method we can easily acquire face and palmprint images using two touchless sensors simultaneously. Existing studies in this approach [2, 3] employ holistic features for face representation and results are shown with small data set that was reported.
Multimodal system also provides anti-spooling measures by making it difficult for an intruder to spool multiple biometric traits simultaneously. However, an integration scheme is required to fuse the information presented by the individual modalities. This paper presents a novel fusion strategy for personal identification using face and palmprint biometrics [8] at the features level fusion Scheme. The proposed paper shows that integration of face and palmprint biometrics can achieve higher performance that may not be possible using a single biometric indicator alone. This paper presents a new method called canonical form based on PCA, which gives better performance and better accuracy for both traits (face & palmprint). The rest of this paper is organized as fallows. Section 2 presents the system structure, which is used to increase the performance of individual biometric trait; multiple

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
50
IJCSIIJCSI
1
1 n
iI i
N =
Ψ = ∑
I I iφ = −Ψ
1
1 NT T
i ii
C A AN
φ φ=
= =∑
1 1
n nT
ij i ji j
Q C I C a c c= −
= =∑∑
[ ]1 2, ........... NA φ φ φ=
classifiers are combined using matching scores. Section 3 presents feature extraction using canonical form based on PCA. Section 4, the individual traits are fused at matching score level using sum of score techniques. Finally, the experimental results are given in section 5. Conclusions are given in the last section.
2 SYSTEM STRUCTURE
The multimodal biometrics system is developed using two traits (face & palmprint) as shown in the figure1. For both, face & palmprint recognition the paper proposes a new approach called canonical form based on PCA method for feature extraction. The matching score for each trait is calculated by using Euclidean distance. The modules based on individual traits returns an integer value after matching the templates and query feature vectors. The final score is generated by using the sum of score technique at fusion level, which is then passed to the decision module. The final decision is made by comparing the final score with a threshold value at the decision module.
Figure1. Block diagram of face and palmprint multimodal biometric system
3 FEATURE EXTRACTION USING CANONICAL FORM BASED ON PCA APPROACH
The “Eigenface” or “Eigenpalm” method proposed by Turk and Pentland [5] [6] is based on Karhunen-Loeve Expression and is motivated by the earlier work of Sirovitch and Kirby [7][8] for efficiently representing picture of images. The Eigen method presented by Turk and Pentland finds the principal components (Karhunen-Loeve Expression) of the image distribution or the eigenvectors of the covariance matrix of the set of images. These eigenvectors can be thought as set of features, which together characterized between images. Let a image I (x, y) be a two dimensional array of intensity values or a vector of dimension n. Let the training set of images be I1, I2, I3,…….In. The average image of the set is defined by (1) Each image differed from the average by the vector. This set of very large vectors is subjected to principal component analysis which seeks a set of K orthonormal vectors Vk, K=1,…...., K and their associated eigenvalues λk which best describe the distribution of data. The vectors Vk and scalars λk are the eigenvectors and eigenvalues of the covariance matrix: (2) Where the matrix finding the eigenvectors of matrix Cnxn is computationally intensive. However, the eigenvectors of C can determine by first finding the eigenvectors of much smaller matrix of size NxN and taking a linear combination of the resulting vectors [6]. The canonical method proposed in this paper is based on Eigen values and Eigen vectors. These Eigen valves can be thought a set of features which together characterized between images. Let Q be a quadratic form given by (3)

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
51
IJCSIIJCSI
1 2[ ( ), ( )......... ( )]nX a x a x a x=
2
1( , ) ( ( ) ( ))
n
i j r i r jr
d x x a X a X=
= −∑
P̂
1ˆ ˆP I P D− =1ˆ ˆI P D P−=
( )12FINAL Face PalmMS MS MSα β= ∗ + ∗
( ) ( ) ( )1 1ˆ ˆ ˆ ˆT T TQ C I C C PDP C C P D P C− −= = =
Therefore “n” set of eigen vectors corresponding “n” eigen values. Let be the normalized modal matrix of I, the diagonal matrix is given by Where (4) Then (5) The above equation is known as a canonical form or sum of squares form or principal axes form. The following steps are considered for the feature extraction:
(1) Select the text image for the input (2) Pre-process the image (only for palm image) (3) Determine the eigen values and eigen vectors of
the image (4) Use the canonical for the feature extraction.
3.1 EUCLIDEAN DISTANCE: Let an arbitrary instance X be described by the feature vector Where ar(x) denotes the value of the rth attribute of instance x. Then the distance between two instances xi and xj is defined to be
( , )i jd x x ;
(6) 4 FUSION The different biometric system can be integrated to improve the performance of the verification system. The following steps are performed for fusion: (1) Given the query image as input, features are extracted
by a individual recognition. (2) The weights α and β are calculated. (3) Finally the sum of score technique is applied for
combining the matching score of two traits i.e. face and palmprint. Thus the final score MNFINAL is given by
(7) Where α and β are the weights assigned to both the traits. The final matching score (MSFINAL) is compared against a certain threshold value to recognize the person as genuine or an impostor. 5 EXPERIMENTAL RESULTS We evaluate the proposed multimodal system on a data set including 720 pairs of images from 120 subjects. The training database contains a face & palmprint images for each individual for each subject.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
52
IJCSIIJCSI
Fig.2. Canonical form based Palm images. (a) Original image (b) Grey image (c) Resized image (d) Normalized modal image (e) Diagonalization image
Fig.3. Canonical form based Face images. (a) Original image (b) Grey image (c) Resized image (d) Normalized modal image (e) Diagonalization image The multimodal system has been designed at multi-classifier & multimodal level. At multi-classifier level, multiple algorithms are combined better results. At first experimental the individual systems were developed and tested for FAR, FRR & accuracy. Table1 shows FAR, FRR & Accuracy of the systems.
Table1: The Accuracy, FAR, FRR of face & palmprint
In the last experiment both the traits are combined at matching score level using sum of score technique. The results are found to be very encouraging and promoting for the research in this field. The overall accuracy of the system is more than 97%, FAR & FRR of 2.4% & 0.8% respectively. 6 CONCLUSION Biometric systems are widely used to overcome the traditional methods of authentication. But the unimodal biometric system fails in case of biometric data for particular trait. Thus the individual score of two traits (face & palmprint) are combined at classifier level and trait level to develop a multimodal biometric system. The performance table shows that multimodal system performs better as compared to unimodal biometrics with accuracy of more than 98%.
REFERENCES [1] Ross.A.A, Nandakumar.K, Jain.A.K. Handbook of Multibiometrics.
Springer-Verlag, 2006. [2] Kumar.A, Zhang.D Integrating palmprint with face for user
authentication. InProc.Multi Modal User Authentication Workshop, pages 107–112, 2003.
[3] Feng.G, Dong.K, Hu.D, Zhang.D When Faces Are Combined with Palmprints: A Novel Biometric Fusion Strategy. In Proceedings of ICBA, pages 701–707, 2004.
[4] G. Feng, K. Dong, D. Hu & D. Zhang, when Faces are combined with Palmprints: A Noval Biometric Fusion Strategy, ICBA, pp.701-707, 2004.
[5] M. Turk and A. Pentland, “Face Recognition using Eigenfaces”, in Proceeding of International Conference on Pattern Recognition, pp. 591-1991.
[6] M. Turk and A. Pentland, “Face Recognition using Eigenfaces”, Journals of Cognitive Neuroscience, March 1991.
[7] L. Sirovitch and M. Kirby, “Low-dimensional Procedure for the Characterization of Human Faces”, Journals of the Optical Society of America, vol.4, pp. 519-524, March 1987.
[8] Kirby.M, Sirovitch.L. “Application of the Karhunen-Loeve Procedure for the Characterization of Human Faces”, IEEE Transaction on Pattern Analysis and Machine Intelligence, vol. 12, pp. 103-108, January 1990.
[9] Daugman.J.G, “High Confidence Visual Recognition of Persons by a Test of Statistical Independence”, IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 15, no. 11, pp. 1148-1161, Nov. 1993.
Nageshkumar M., graduated in Electronics and

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
53
IJCSIIJCSI
Communication from Mysore University in 2003, received the M-Tech degree in Computer Science & Engineering from V.T.U., Belguam, presently pursing Ph.D under Mysore University. He was lecturer in J.V.I.T. Mahesh. P.K., graduated in Electronics and Communication from Bangalore University in 2000, received the M-Tech degree in VLSI design & Embedded Systems from VTU Belguam, presently pursing Ph.D under Mysore University. He was lecturer in J.S.S.A.T.E., Nodia and later Asst. Professor in J.V.I.T.
Dr. M.N.Shanmukha Swamy, graduated in Electronics and Communication from Mysore University in 1978, received the M-Tech degree in Industrial Electronics from Mysore University and then received PhD from Indian Institute of Science, Bangalore. Presently he is working as a Professor in S.J.C.E., Mysore. So for he has more than 10 research papers published, journals, articles, books and conference paper publications.

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
54
IJCSIIJCSI
DPRAODV: A DYANAMIC LEARNING SYSTEM AGAINST BLACKHOLE ATTACK IN AODV BASED MANET
Payal N. Raj, Prashant B. Swadas 1 Computer Engineering Department, SVMIT
Bharuch, Gujarat, India [email protected]
2 Computer Engineering Department, B.V.M.
Anand, Gujarat, India [email protected]
Abstract Security is an essential requirement in mobile ad hoc networks to provide protected communication between mobile nodes. Due to unique characteristics of MANETS, it creates a number of consequential challenges to its security design. To overcome the challenges, there is a need to build a multifence security solution that achieves both broad protection and desirable network performance. MANETs are vulnerable to various attacks, blackhole, is one of the possible attacks. Black hole is a type of routing attack where a malicious node advertise itself as having the shortest path to all nodes in the environment by sending fake route reply. By doing this, the malicious node can deprive the traffic from the source node. It can be used as a denial-of-service attack where it can drop the packets later. In this paper, we proposed a DPRAODV (Detection, Prevention and Reactive AODV) to prevent security threats of blackhole by notifying other nodes in the network of the incident. The simulation results in ns2 (ver-2.33) demonstrate that our protocol not only prevents blackhole attack but consequently improves the overall performance of (normal) AODV in presence of black hole attack. Keywords: MANETs, AODV, Routing protocol, blackhole attack.
1. Introduction
Mobile ad hoc network (MANET) is one of the recent active fields and has received spectacular consideration because of their self-configuration and self-maintenance. Early research assumed a friendly and cooperative environment of wireless network. As a result they focused on problems such as wireless channel access and multihop routing. But security has become a primary concern to provide protected communication between mobile nodes in a hostile environment. Although mobile ad hoc networks have several advantages over wired networks, on
the other side they pose a number of non-trivial challenges to the security design as they are more vulnerable than wired networks [1]. These challenges include open network architecture, shared wireless medium, demanding resource constraints, and, highly dynamic network topology. In this paper, we have considered a fundamental security problem in MANET to protect its basic functionality to deliver data bits from one node to another. Nodes help each other in conveying information to and fro and thereby creating a virtual set of connections between each other. Routing protocols play an imperative role in the creation and maintenance of these connections. In contrast to wired networks, each node in an ad-hoc networks acts like a router and forwards packets to other peer nodes. The wireless channel is accessible to both legitimate network users and malicious attackers. As a result, there is a blurry boundary separating the inside network from the outside world.
Many different types of routing protocols have been developed for ad hoc networks and have been classified into two main categories by Royer and Toh (1999) as Proactive (periodic) protocols and Reactive (on-demand) protocols. In a proactive routing protocol, nodes periodically exchange routing information with other nodes in an attempt to have each node always know a current route to all destinations [2]. In a reactive protocol, on the other hand, nodes exchange routing information only when needed, with a node attempting to discover a route to some destination only when it has a packet to send to that destination [3]. In addition, some ad hoc network routing protocols are hybrids of periodic and on-demand mechanisms.
Wireless ad hoc networks are vulnerable to various attacks. These include passive eavesdropping, active interfering, impersonation, and denial-of-service. A single solution cannot resolve all the different types of attacks in ad hoc networks. In this paper, we have designed a novel method to detect blackhole attack: DPRAODV, which isolates that malicious node from the network. We have complemented the reactive system on every node on the

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
55
IJCSIIJCSI
network. This agent stores the Destination sequence number of incoming route reply packets (RREPs) in the routing table and calculates the threshold value to evaluate the dynamic training data in every time interval as in [4]. Our solution makes the participating nodes realize that, one of their neighbors is malicious; the node thereafter is not allowed to participate in packet forwarding operation.
In Section 2 of this paper, we summarize the basic operation of AODV (Ad hoc On-Demand distance Vector Routing) protocol on which we base our work. In Section 3, we discuss related work. In Section 4, we describe the effect of blackhole attack in AODV. Section 5 presents the design of our protocol; DPRAODV that protects against blackhole attack. Section 6 discusses the performance evaluation based on simulation experiments. Finally, Section 7 presents conclusion and future work
2. Theoretical background of AODV
AODV is a reactive routing protocol; that do not lie on active paths neither maintain any routing information nor participate in any periodic routing table exchanges. Further, the nodes do not have to discover and maintain a route to another node until the two needs to communicate, unless former node is offering its services as an intermediate forwarding station to maintain connectivity between other nodes [3]. AODV has borrowed the concept of destination sequence number from DSDV [5], to maintain the most recent routing information between nodes.
Whenever a source node needs to communicate with another node for which it has no routing information, Route Discovery process is initiated by broadcasting a Route Request (RREQ) packet to its neighbors. Each neighboring node either responds the RREQ by sending a Route Reply (RREP) back to the source node or rebroadcasts the RREQ to its own neighbors after increasing the hop_count field. If a node cannot respond by RREP, it keeps track of the routing information in order to implement the reverse path setup or forward path setup [6]. The destination sequence number specifies the freshness of a route to the destination before it can be accepted by the source node. Eventually, a RREQ will arrive to node that possesses a fresh route to the destination. If the intermediate node has a route entry for the desired destination, it determines whether the route is fresh by comparing the destination sequence number in its route table entry with the destination sequence number in the RREQ received. The intermediate node can use its recorded route to respond to the RREQ by a RREP packet, only if, the RREQ’s sequence number for the destination is greater than the recorded by the intermediate node. Instead, the intermediate node rebroadcasts the RREQ
packet. If a node receives more than one RREPs, it updates its routing information and propagates the RREP only if RREP contains either a greater destination sequence number than the previous RREP, or same destination sequence number with a smaller hop count. It restrains all other RREPs it receives. The source node starts the data transmission as soon as it receives the first RREP, and then later updates its routing information of better route to the destination node. Each route table entry contains the following information:
• Destination node • Next hop • number of hops • Destination sequence number • Active neighbors for the route • Expiration timer for the route table entry
The route discovery process is reinitiated to establish
a new route to the destination node, if the source node moves in an active session. As the link is broken and node receives a notification, and Route Error (RERR) control packet is being sent to all the nodes that uses this broken link for further communication. And then, the source node restarts the discovery process.
As the routing protocols typically assume that all nodes are cooperative in the coordination process, malicious attackers can easily disrupt network operations by violating protocol specification. This paper discusses about blackhole attack and provides routing security in AODV by purging the threat of blackhole attacks
3. Related works in securing AODV
There are basically two approaches to secure MANET: (1) Securing Ad hoc Routing and (2) Intrusion Detection [7].
3.1 Secure Routing
The Secure Efficient Ad hoc Distance vector routing protocol (SEAD) [8] employs the use of hash chains to authenticate hop counts and sequence numbers in DSDV. Another secure routing protocol, Ariadne[9] assumes the existence of a shared secret key between two nodes based on DSR (reactive) routing protocol. The Authenticated Routing for Ad hoc networks (ARAN) is a standalone protocol that uses cryptographic public-key certificates in order to achieve the security goals [10]. Security-Aware Ad hoc Routing (SAR) uses security attributes such as trust values and relationships [11].
The computation overhead involved in the above mentioned protocols is awful and often suffer from scalability problems. As a preventive measure, the packets

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
56
IJCSIIJCSI
are carefully signed, but an attacker can simply drop the packet passing through it, therefore, secure routing cannot resist such internal attacks. So our solution provides a reactive scheme that triggers an action to protect the network from future attacks launched by this malicious node.
3.2 Intrusion Detection System
Zhang and Lee [12] present an intrusion detection technique for wireless ad hoc networks that uses cooperative statistical anomaly detection techniques. The use of anomaly based detection techniques results in too many number of false positives. Stamouli proposes architecture for Real-Time Intrusion Detection for Ad hoc Networks (RIDAN) [7]. The detection process relies on a state-based misuse detection system. Therefore, each node requires extra processing power and sensing capabilities.
In [13], the method requires the intermediate node to send Route Confirmation Request (CREQ) to next hop towards the destination. This operation can increase the routing overhead resulting in performance degradation. In [14], source node verifies the authenticity of node that initiates RREP by finding more than one route to the destination, so that it can recognize the safe route to destination. This method can cause the routing delay, since a node has to wait for RREP packet to arrive from more than two nodes. In [4], the feature used is dest_seq_no, which reflects the trend of updating the threshold and hence reflecting the adaptively change in network environment.
Therefore, a method that can prevent the attack without increasing routing overhead and delay is required. All the above mentioned approaches except [4], use static value for threshold. To resolve the problem, threshold value should be reflecting current network environment by updating its value. And also, our solution ensures that a node once detected as malicious cannot participate in forwarding and sending of a data packet in the network.
4. Description of Blackhole attack
MANETs are vulnerable to various attacks. General attack types are the threats against Physical, MAC, and network layer which are the most important layers that function for the routing mechanism of the ad hoc network. Attacks in the network layer have generally two purposes: not forwarding the packets or adding and changing some parameters of routing messages; such as sequence number and hop count. A basic attack that an adversary can execute is to stop forwarding the data packets. As a result, when the adversary is selected as a route, it denies the communication to take place. In blackhole attack, the malicious node waits for the neighbors to initiate a RREQ packet. As the node receives the RREQ packet, it will
immediately send a false RREP packet with a modified higher sequence number. So, that the source node assumes that node is having the fresh route towards the destination. The source node ignores the RREP packet received from other nodes and begins to send the data packets over malicious node. A malicious node takes all the routes towards itself. It does not allow forwarding any packet anywhere. This attack is called a blackhole as it swallows all objects; data packets [15].
Fig. 1 Blackhole attacks in MANETs
In figure 1, source node S wants to send data packets to a destination node D in the network. Node M is a malicious node which acts as a blackhole. The attacker replies with false reply RREP having higher modified sequence number. So, data communication initiates from S towards M instead of D.
5. DPRAODV: Solution against blackhole attack
In normal AODV, the node that receives the RREP packet first checks the value of sequence number in its routing table. The RREP packet is accepted if it has RREP_seq_no higher than the one in routing table. Our solution does an addition check to find whether the RREP_seq_no is higher than the threshold value. The threshold value is dynamically updated as in [4] in every time interval. As the value of RREP_seq_no is found to be higher than the threshold value, the node is suspected to be malicious and it adds the node to the black list. As the node detected an anomaly, it sends a new control packet, ALARM to its neighbors. The ALARM packet has the black list node as a parameter so that, the neighboring nodes know that RREP packet from the node is to be discarded. Further, if any node receives the RREP packet, it looks over the list, if the reply is from the blacklisted node; no processing is done for the same. It simply ignores the node and does not receive reply from that node again. So, in this way, the malicious node is isolated from the network by the ALARM packet. The continuous replies from the malicious node are blocked, which results in less Routing overhead. Moreover, unlike AODV, if the node is found to be malicious, the routing table for that node is not updated, nor the packet is forwarded to another node.
RREQ RREP Data
D
S
MA
B
C

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
57
IJCSIIJCSI
The threshold value is dynamically updated using the data collected in the time interval. If the initial training data were used, then the system could not adapt the changing environment. The threshold value is the average of the difference of dest_seq_no in each time slot between the sequence number in the routing table and the RREP packet. The time interval to update the threshold value is as soon as a newer node receives a RREP packet. As a new node receives a RREP for the first time, it gets the updated value of the threshold. So our design not only detects the blackhole attack, but tries to prevent it further, by updating threshold which reflects the real changing environment. Other nodes are also updated about the malicious act by an ALARM packet, and they react to it by isolating the malicious node from network.
6. Evaluation of DPRAODV
6.1 Simulation Environment
For simulation, we have used ns2 (v-2.33) network simulator [16]. Mobility scenarios are generated by using a Random waypoint model by varying 10 to 70 nodes moving in a terrain area of 800m x 800m. Each node independently repeats this behavior and mobility is varied by making each node stationary for a period of pause time. The simulation parameters are summarized in Table 1.
Table 1: Simulation Parameters Parameter Value Simulator Ns-2(ver.2.33) Simulation time 1000 s Number of nodes 70 Routing Protocol AODV Traffic Model CBR Pause time 2 (s) Maximum mobility 60 m/s No. of sources 5 Terrain area 800m x 800m Transmission Range 250m No. of malicious node 1
A new Routing Agent is added in ns-2 to include the
blackhole attack. In order to implement blackhole attack, the malicious node generates a random number between 15 and 200, adds the number to the sequence number in RREQ and then generates the sequence number in RREP. In our simulation, the communication is started between source node to the destination node in presence of the malicious node. The node number of source node, destination node and malicious node are 2, 7 and 0 respectively.
6.2 Simulation Evaluation Methodology
The simulation is done to analyze the performance of the network’s various parameters. The metrics used to evaluate the performance are given below:
• Packet Delivery Ratio: The ratio of the data delivered to the destination to the data sent out by the source.
• Average End-to-end delay: The difference in the time it takes for a sent packet to reach the destination. It includes all the delays, in the source and each intermediate host, caused by the routing discovery, queuing at the interface queue etc.
• Normalized routing overhead: This is the ratio of routing-related transmissions (RREQ, RREP, RERR etc) to data transmissions in a simulation. A transmission is one node either sending or forwarding a packet. Either way, the routing load per unit data successfully delivered to the destination.
6.2 Simulation Analysis and Results
Various network contexts are considered to measure the performance of a protocol. These contexts are created by varying the following parameters in the simulation.
• Network size: variation in the number of mobile nodes.
• Traffic load: variation in the number of sources • Mobility: variation in the maximum speed
Fig. 2 Impact of Mobility on the performance
(a)
(b)

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009 ISSN (Online): 1694-0784 ISSN (Printed): 1694-0814
58
IJCSIIJCSI
Figure 2a and 2b conclude the simulation based on the
effect of mobility on the DPRAODV compared to normal AODV. The PDR stays within acceptable limits almost 4-5% lower than it should normally be with minimum overhead.
Fig. 3 Impact of Network Size on the performance
All the above three contexts are simulated and tested to see the effect of network size on Packet Delivery Ratio( PDR), Average End-to end delay and Normalized Routing Overhead.
From figure 3a and b, we analyze that, under blackhole attack, the PDR of DPRAODV is improved by 80-85%
than AODV under attack with Average-End-to-end delay almost same as normal AODV.
In Figure 3c, it is observed that there is slight increase
in Normalized Routing Overhead, which is quite negligible. In AODV under attack, the delay will be less and routing overhead will be quite high compared to normal AODV, so our comparison is between normal AODV and DPRAODV.
Fig. 4 Impact of Traffic Load on the performance
From the figure 4, it is clear that as the traffic load increases, the PDR of DPRAODV increases by approximately 60% than AODV under attack. As our solution generates ALARM packet, there is slight increase in Normalized Routing Overhead with almost same Delay as normal AODV.
(a)
(b)
(c)
(a)
(b)
(c)

IJCSI International Journal of Computer Science Issues, Vol. 2, 2009
59
IJCSIIJCSI
7. Conclusions
In DPRAODV, we have used a very simple and effective way of providing security in AODV against blackhole attack. As from the graphs illustrated in results we can easily infer that the performance of the normal AODV drops under the presence of blackhole attack. Our prevention scheme detects the malicious nodes and isolates it from the active data forwarding and routing and reacts by sending ALARM packet to its neighbors. Our solution: DPRAODV increases PDR with minimum increase in Average-End-to-end Delay and normalized Routing Overhead.
Acknowledgments
This work is sponsored by the Institute of Science and Technology for Advanced Studies and Research (ISTAR), Vallabh Vidyanagar, Gujarat, India. References [1] Hao Yang, Haiyun Luo. Fan Ye, Songwu Lu, and Lixia
Zhang. “Security in mobile ad hoc networks: Challenges and solutions”. IEEE Wireless Communications , February 2004
[2] Shree Murthy and J. J. Garcia-Luna-Aceves. “An Efficient Routing Protocol for Wireless Networks”. Mobile Networks and Applications, 1(2):183–197, 1996.
[3] Charles E. Perkins and Elizabeth M. Royer. “Ad-Hoc On- Demand Distance Vector Routing”. In Proceedings of the Second IEEE Workshop on Mobile Computing Systems and Applications (WMCSA’99), pages 90–100, February 1999.
[4] Satoshi Kurosawa, Hidehisa Nakayama, Nei Kat, Abbas Jamalipour, and Yoshiaki Nemoto, “Detecting Blackhole Attack on AODV-based Mobile Ad Hoc Networks by Dynamic Learning Method”, International Journal of Network Security, Vol.5, No.3, P.P 338-346, Nov. 2007
[5] C. Perkins and P. Bhagwat. “Routing over multihop wireless network for mobile computers”. SIGCOMM ’94 : Computer Communications Review:234-244, Oct. 1994.
[6] C. E. Perkins, S.R. Das, and E. Royer, “Ad-hoc on Demand Distance Vector (AODV)”. March 2000, http://www.ietf.org/internal-drafts/draft-ietf-manet-aodv-05.txt
[7] Ioanna Stamouli, “Real-time Intrusion Detection for Ad hoc Networks” Master’s thesis, University of Dublin, Septermber 2003.
[8] Y.-C. Hu, D.B. Johnson, and A. Perrig, “SEAD: Secure Efficient Distance Vector Routing for Mobile Wireless Ad hoc Networks,” Proc. 4th IEEE Workshop on Mobile Computing Systems and Applications, Callicoon, NY, June 2002, pp. 3-13.
[9] Y.-C. Hu, A. Perrig, and D.B. Johnson, “Ariadne: A Secure On-Demand Routing Protocol for Ad hoc Networks,” Proc. 8th ACM Int’l. Conf. Mobile Computing and Networking (Mobicom’02), Atlanta, Georgia, September 2002, pp. 12-23.
[10] Kimaya Sanzgiti, Bridget Dahill, Brian Neil Levine, Clay shields, Elizabeth M, Belding-Royer, “A secure Routing Protocol for Ad hoc networks In Proceedings of the 10th
IEEE International Conference on Network Protocols (ICNP’ 02), 2002
[11] S. Yi, P. Naldurg, and R. Kravets, “Security-Aware Ad hoc Routing for Wireless Networks,” Proc. 2nd ACM Symp. Mobile Ad hoc Networking and Computing (Mobihoc’01), Long Beach, CA, October 2001, pp. 299-302.
[12] Y. Zhang and W. Lee, "Intrusion detection in wireless ad – hoc networks," 6th annual international Mobile computing and networking Conference Proceedings, 2000.
[13] S. Lee, B. Han, and M. Shin, “Robust routing in wireless ad hoc networks,” in ICPP Workshops, pp. 73, 2002.
[14] M. A. Shurman, S. M. Yoo, and S. Park, “Black hole attack in wireless ad hoc networks,” in ACM 42nd Southeast Conference (ACMSE’04), pp. 96-97, Apr. 2004.
[15] Dokurer, Semih.”Simulation of Black hole attack in wireless Ad-hoc networks”. Master's thesis, AtılımUniversity, September 2006
[16] Kevin Fall and Kannan Varadhan (Eds.), "The ns Manual", 2006, available from http://www-mash.cs.berkeley.edu/ns/

IJCSI CALL FOR PAPERS JANUARY 2010 ISSUE
The topics suggested by this issue can be discussed in term of concepts, surveys, state of the art, research, standards, implementations, running experiments, applications, and industrial case studies. Authors are invited to submit complete unpublished papers, which are not under review in any other conference or journal in the following, but not limited to, topic areas. See authors guide for manuscript preparation and submission guidelines. Accepted papers will be published online and authors will be provided with printed copies and indexed by Google Scholar, CiteSeerX, Directory for Open Access Journal (DOAJ), Bielefeld Academic Search Engine (BASE), SCIRUS and more. Deadline: 15th December 2009 Notification: 15th January 2010 Online Publication: 31st January 2010 • Evolutionary computation • Industrial systems • Evolutionary computation • Autonomic and autonomous systems • Bio-technologies • Knowledge data systems • Mobile and distance education • Intelligent techniques, logics, and
systems • Knowledge processing • Information technologies • Internet and web technologies • Digital information processing • Cognitive science and knowledge
agent-based systems • Mobility and multimedia systems • Systems performance • Networking and telecommunications
• Software development and deployment
• Knowledge virtualization • Systems and networks on the chip • Context-aware systems • Networking technologies • Security in network, systems, and
applications • Knowledge for global defense • Information Systems [IS] • IPv6 Today - Technology and
deployment • Modeling • Optimization • Complexity • Natural Language Processing • Speech Synthesis • Data Mining
All submitted papers will be judged based on their quality by the technical committee and reviewers. Papers that describe research and experimentation are encouraged. All paper submissions will be handled electronically and detailed instructions on submission procedure are available on IJCSI website (http://www.ijcsi.org). For other information, please contact IJCSI Managing Editor, ([email protected]) Website: http://www.ijcsi.org

© IJCSI PUBLICATION 2009
www.IJCSI.org

IJCSIIJCSI
© IJCSI PUBLICATIONwww.IJCSI.org
The International Journal of Computer Science Issues (IJCSI) is a refereed journal for scientific papers dealing with any area of computer science research. The purpose of establishing the scientific journal is the assistance in development of science, fast operative publication and storage of materials and results of scientific researches and representation of the scientific conception of the society.
It also provides a venue for researchers, students and professionals to submit on-going research and developments in these areas. Authors are encouraged to contribute to the journal by submitting articles that illustrate new research results, projects, surveying works and industrial experiences that describe significant advances in field of computer science.
Indexing of IJCSI:
1. Google Scholar2. Directory for Open Access Journals (DOAJ)3. Bielefeld Academic Search Engine (BASE)4. CiteSeerX5. SCIRUS
Frequency of Publication: Monthly
IJCSIIJCSI
© IJCSI PUBLICATIONwww.IJCSI.org
The International Journal of Computer Science Issues (IJCSI) is a refereed journal for scientific papers dealing with any area of computer science research. The purpose of establishing the scientific journal is the assistance in development of science, fast operative publication and storage of materials and results of scientific researches and representation of the scientific conception of the society.
It also provides a venue for researchers, students and professionals to submit on-going research and developments in these areas. Authors are encouraged to contribute to the journal by submitting articles that illustrate new research results, projects, surveying works and industrial experiences that describe significant advances in field of computer science.
Indexing of IJCSI:
1. Google Scholar2. Directory for Open Access Journals (DOAJ)3. Bielefeld Academic Search Engine (BASE)4. CiteSeerX5. SCIRUS
Frequency of Publication: Monthly






![From Human-Computer Interaction to Human …human computer interaction could be found in [12]. IJCSI International Journal of Computer Science Issues, Vol. 11, Issue 1, No 1, January](https://img.pdfslide.us/doc/110x75/5fdd4bb798ada3257652436b/from-human-computer-interaction-to-human-human-computer-interaction-could-be-found.jpg)






















