Embed Size (px)
Citation preview

Inter-Processor Communication for
Heterogeneous Dual Core Systems
Chun-Ming Huang, Ph.D.National Chip Implementation Center (CIC)
2006/09/27

C. M. Huang / SLDC-IPC / 09.2006 2
Agenda IPC Overview IPC Schemes Nokia DSP Gateway TI DSP/BIOS Link IPC Hardware Architecture Conclusions

IPC Overview

C. M. Huang / SLDC-IPC / 09.2006 4
What is IPC? Inter-Process Communication Inter-Processor Communication
P1 P2
Single-Chip Multi-Chip
Single-Core
Multi-Core
C1 C2
C1 C2 C3 C4
C1
C1 C2
C1 C2
C1 C2 C3 C4
C1
C1 C2
P1
P2
P1
P2
P1
P2
P1
P2
P1
P2
P1
P2
P1
P2
P1
P2
P1
P2
C1 C2
C1 C2 C3 C4
C1
C1 C2
P1
P2
P1
P2
P1
P2
P3
How to provide inter-process communication How to provide inter-process communication services for multi-core systems?services for multi-core systems?

C. M. Huang / SLDC-IPC / 09.2006 5
Independent & Cooperating Process Processes executing concurrently in the multitasking
environment may be either independent processes or cooperating processes
A process is independent if it cannot affect or be affected by the other processes executing in the system; any process that does not share data with any other process is independent
A process is cooperating if it can affect or be affected by the other processes executing in the system; any process that shares data with other processes is a cooperating process
Silberschatz, et al., Operating System Principles, Seventh Edition

C. M. Huang / SLDC-IPC / 09.2006 6
Why Allow Process Cooperation? Information sharing Computation speedup Modularity Convenience
Cooperating processes requires an inter-process communication (IPC) mechanism that will allow them to exchange data and information
Silberschatz, et al., Operating System Principles, Seventh Edition

C. M. Huang / SLDC-IPC / 09.2006 7
IPC Example Unix pipe ls –l / | grep 2005 | wc 2 19 98 The grep utility searches text files for a pattern and prints all l
ines that contain that pattern. The wc utility displays a count of lines, words and characters
in a text file. Data exchange Synchronization

C. M. Huang / SLDC-IPC / 09.2006 8
Operating System Kernel Components Process scheduler
– determines when and for how long a process execute on a processor Memory manager
– determines when and how memory is allocated to processes and what to do when memory becomes full
I/O manager– services input and output requests from and to hardware devices
Inter-process communication (IPC) manager– allows processes to communicate with one other
File system manager– organizes named collections of data on storage devices and provides an
interface for accessing data on those devicesDeitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 9
Linux Kernel 2.6.17.11drwxr-xr-x arch
drwxr-xr-x block
drwxr-xr-x crypto
drwxr-xr-x drivers
drwxr-xr-x fs
drwxr-xr-x include
drwxr-xr-x init
drwxr-xr-x ipc
drwxr-xr-x kernel
drwxr-xr-x lib
drwxr-xr-x mm
drwxr-xr-x net
drwxr-xr-x scripts
drwxr-xr-x security
drwxr-xr-x sound
drwxr-xr-x usr
-rw-r--r-- Makefile
-rw-r--r-- compat.c
-rw-r--r-- compat_mq.c
-rw-r--r-- mqueue.c
-rw-r--r-- msg.c
-rw-r--r-- msgutil.c
-rw-r--r-- sem.c
-rw-r--r-- shm.c
-rw-r--r-- util.c
-rw-r--r-- util.h
http://www.kernel.org

C. M. Huang / SLDC-IPC / 09.2006 10
Machine-Independent SW in the FreeBSD KernelCategory Lines of Code Percentage of Kernel (%)Headers 38,158 4.8initialization 1,663 0.2kernel facilities 53,805 6.7generic interfaces 22,191 2.8interprocess communication 10,019 1.3
terminal handling 5,798 0.7virtual memory 24,714 3.1vnode memory 22,764 2.9local filesystem 28,067 3.5miscellaneous filesystems (19) 58,753 7.4network filesystem 22,436 2.8network communication 46,570 5.8Internet V4 protocols 41,220 5.2Internet V6 protocols 45,527 5.7IPsec 17,956 2.2netgraph 74,338 9.3cryptographic support 7,515 0.9GEOM layer 11,563 1.4CAM layer 41,805 5.2ATA layer 14,192 1.8ISA bus 10,984 1.4PCI bus 72,366 9.1pccard bus 6,916 0.9Linux compatibility 10,474 1.3Total Machine Independent 689,794 86.4
McKusic & Neville-Neil, The Design and Implementation of the FreeBSD Operating System

C. M. Huang / SLDC-IPC / 09.2006 11
Homogeneous vs. Heterogeneous
TI OMAP 5910
Sun

C. M. Huang / SLDC-IPC / 09.2006 12
Multiprocessor OS Organizations Can classify systems based on how processors share
operating system responsibilities Three types
– Master/slave– Separate kernels– Symmetrical organization
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 13
Master/Slave Master/Slave organization
– Master processor executes the operating system– Slaves execute only user processors– Hardware asymmetry– Low fault tolerance– Good for computationally intensive jobs– Example: nCUBE system
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 14
Separate Kernels Separate kernels organization
– Each processor executes its own operating system– Some globally shared operating system data– Loosely coupled– Catastrophic failure unlikely, but failure of one processor results in
termination of processes on that processor– Little contention over resources– Example: Tandem system
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 15
Symmetrical Organization Symmetrical organization
– Operating system manages a pool of identical processors– High amount of resource sharing– Need for mutual exclusion– Highest degree of fault tolerance of any organization– Some contention for resources– Example: BBN Butterfly
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 16
Memory Access Architectures Memory access
– Can classify multiprocessors based on how processors share memory
– Goal: Fast memory access from all processors to all memory• Contention in large systems makes this impractical
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 17
Uniform Memory Access Uniform memory access (UMA) multiprocessor
– All processors share all memory– Access to any memory page is nearly the same for all processors
and all memory modules (disregarding cache hits)– Typically uses shared bus or crossbar-switch matrix– Also called symmetric multiprocessing (SMP)– Small multiprocessors (typically two to eight processors)
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 18
Uniform Memory Access
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 19
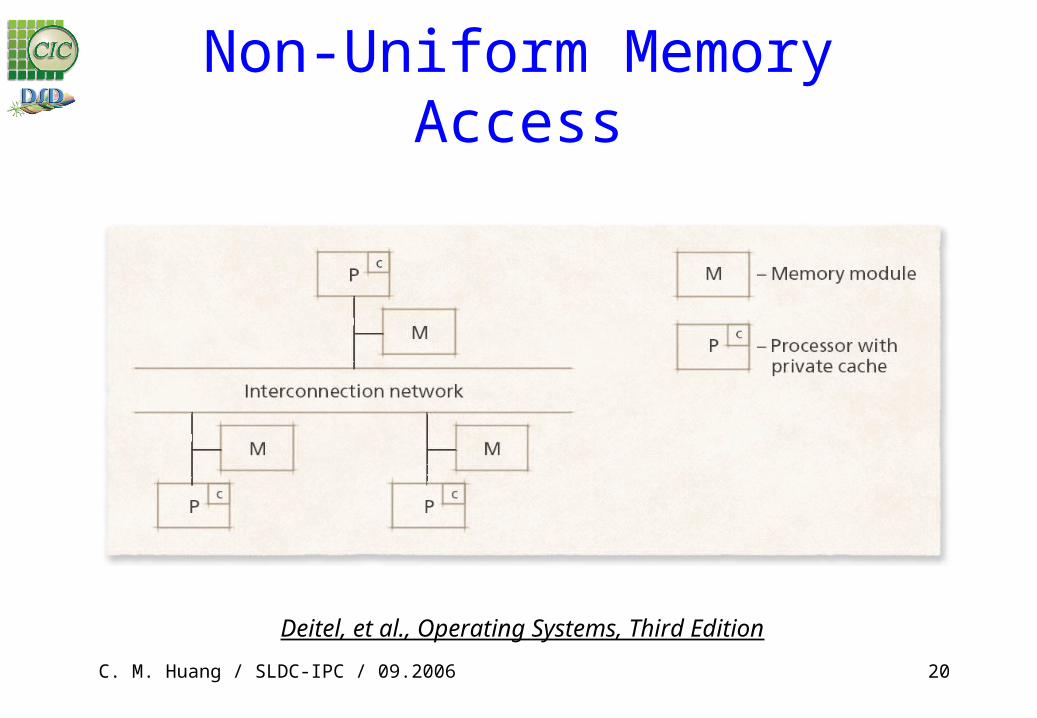
Non-Uniform Memory Access Non-uniform memory access (NUMA) multiprocessor
– Each node contains a few processors and a portion of system memory, which is local to that node
– Access to local memory faster than access to global memory (rest of memory)
– More scalable than UMA (fewer bus collisions)
Deitel, et al., Operating Systems, Third Edition
C. M. Huang / SLDC-IPC / 09.2006 20
Non-Uniform Memory Access
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 21
Cache-Only Memory Architecture Cache-only memory architecture (COMA) multiprocessor
– Physically interconnected as a NUMA is• Local memory vs. global memory
– Main memory is viewed as a cache and called an attraction memory (AM)
• Allows system to migrate data to node that most often accesses it at granularity of a memory line (more efficient than a memory page)
• Reduces the number of cache misses serviced remotely• Overhead
– Duplicated data items– Complex protocol to ensure all updates are received at all processors
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 22
Cache-Only Memory Architecture
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 23
No Remote Memory Access No-remote-memory-access (NORMA) multiprocessor
– Does not share physical memory– Some implement the illusion of shared physical memory—shared
virtual memory (SVM)– Loosely coupled– Communication through explicit messages– Distributed systems– Not networked system
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 24
No Remote Memory Access
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 25
Four Possible Cases
Symmetrical OSs Asymmetrical OSs
HomogeneousCores
CPU_A(OS_X)CPU_A(OS_X)
CPU_A(OS_X)CPU_A(OS_Y)
HeterogeneousCores
CPU_A(OS_X)CPU_B(OS_X)
CPU_A(OS_X)CPU_B(OS_Y)

IPC Schemes

C. M. Huang / SLDC-IPC / 09.2006 27
Communication via Files Communication via files is in fact the oldest way of
exchanging data between programs. Program A writes data to a file and Program B reads it. In a system in which only one program can be run at any given time, this does not present any problem.
In a multitasking system, however both programs could be run as processes at least quasi-parallel to each other. Race conditions then usually produce inconsistencies in the file data which result from one program reading a data area before the other has finished modifying it, or both processes modifying the same area of memory at the same time.

C. M. Huang / SLDC-IPC / 09.2006 28
Communication via Files Locking entire files
– lock file– fcntl( ) (POSIX), flock( ) (BSD 4.3)
Locking file areas (record locking)– Deadlock
1
2
...
Process 2Process 1
ReadWrite
WriteRead
C. M. Huang / SLDC-IPC / 09.2006 29
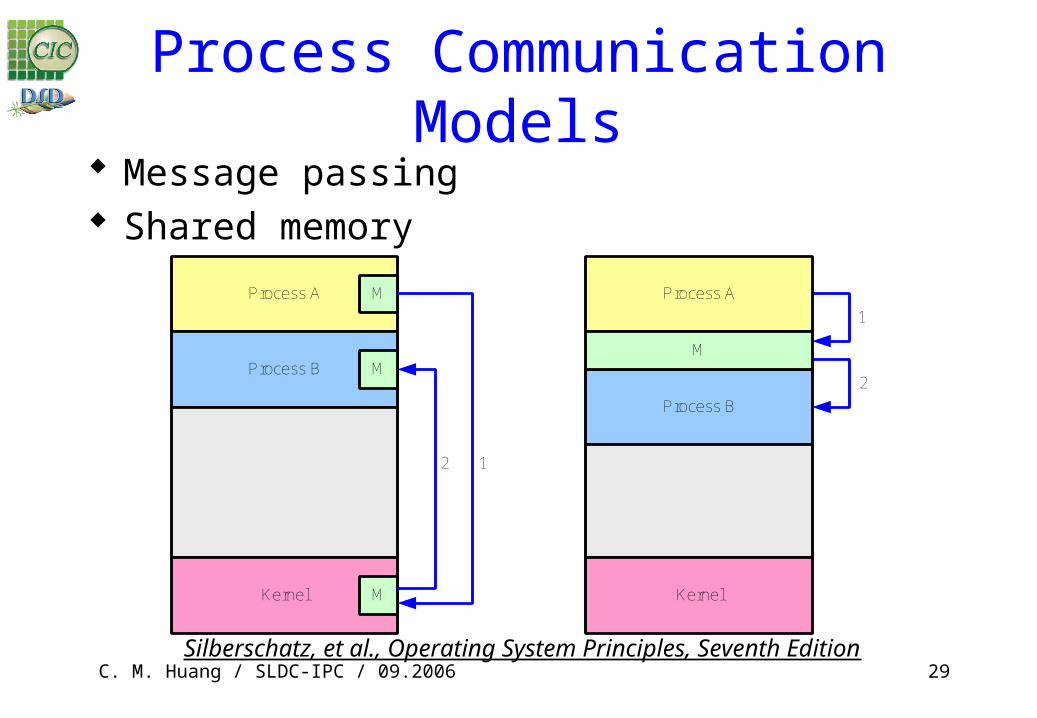
Process Communication Models Message passing Shared memory
Process A M
Process B M
Kernel M
2 1
Process A
Process B
M
Kernel
2
1
Silberschatz, et al., Operating System Principles, Seventh Edition

C. M. Huang / SLDC-IPC / 09.2006 30
IPC for Linux Linux IPC
– Many IPC mechanisms derived from traditional UNIX IPC • Allow processes to exchange information
– Some are better suited for particular applications• For example, those that communicate over a network or exchange short
messages with other local applications
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 31
IPC for Linux Signal Pipe Message queue Shared memory System V Semaphores Sockets

C. M. Huang / SLDC-IPC / 09.2006 32
Signals Signals
– One of the first interprocess communication mechanisms available in UNIX systems
– Kernel uses them to notify processes when certain events occur– Do not allow processes to specify more than a word of data to ex
change with other processes– Created by the kernel in response to interrupts and exceptions, a
re sent to a process or thread• as a result of executing an instruction (such as a segmentation fault)• from another process (such as when one process terminates another) • from an asynchronous event
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 33
POSIX Signals
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 34
Signals A process/thread can handle a signal by
1. Ignore the signal—processes can ignore all but the SIGSTOP and SIGKILL signals.
2. Catch the signal—when a process catches a signal, it invokes its signal handler to respond to the signal.
3. Execute the default action that the kernel defines for that signal Default actions
– Abort: terminate immediately– Memory dump: Copies execution context before exiting– Ignore– Stop (i.e., suspend)– Continue (i.e., resume)
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 35
Signals Signal blocking
– A process or thread can block a signal• Signal is not delivered until process/thread stops blocking it
– While a signal handler is running, signals of that type are blocked by default• Still possible to receive signals of a different type
– Common signals are not queued• Real-time signals provide signal queuing
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 36
Pipes Pipes
– Producer process writes data to the pipe, after which the consumer process reads data from the pipe in first-in-first-out order
– When pipe is created, an inode that points to pipe buffer (page of data) is created
– Access to pipes is controlled by file descriptors• Can be passed between related processes (e.g., parent and child)
– Named pipes (FIFOs) ↔• Can be accessed via the directory tree
– Limitation: Fixed-size buffer
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 37
Message Queues Message queues
– Allow processes to transmit information that is composed of a message type and a variable-length data area
• Stored in message queues, remain until a process is ready to receive them• Related processes can search for a message queue identifier in a global
array of message queue descriptors– Message queue descriptor contains
» Queue of pending messages » Queue of processes waiting for messages » Queue of processes waiting to send messages » Data describing the size and contents of the message queue
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 38
Shared Memory Shared memory [protection schemes]
– Advantages• Improves performance for processes that frequently access shared data• Processes can share as much data as they can address
– Standard interfaces• System V shared memory• POSIX shared memory
– Does not allow processes to change privileges for a segment of shared memory
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 39
System V Shared Memory System Calls
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 40
Shared Memory Shared memory implementation
– Treats region of shared memory as a file– Shared memory page frames are freed when file is deleted– Tmpfs (temporary file system) stores such files
• Tmpfs pages are swappable• Permissions can be set• File system does not require formatting
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 41
System V Semaphores System V semaphores
– Designed for user processes to access via the system call interface Semaphore arrays
– Protect a group of related resources– Before a process can access resources protected by a semaphore
array, the kernel requires that there be sufficient available resources to satisfy the process’s request
– Otherwise, kernel blocks requesting process until resources become available
Preventing deadlock– When a process exits, the kernel reverses all the semaphore
operations it performed to allocate its resourcesDeitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 42
Sockets Sockets
– Allows pairs of processes to exchange data by establishing direct bidirectional communication channels
– Primarily used for bidirectional communication between multiple processes on different systems, but can be used for processes on the same system
– Stored internally as files– File name used as socket’s address, accessed via the VFS
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 43
Sockets Stream sockets
– Implement the traditional client/server model– Data is transferred as a stream of bytes– Use TCP to communicate, so they are more appropriate for reliable co
mmunication Datagram sockets
– Faster, but less reliable communication– Data is transferred using datagram packets
Socketpairs– Pair of connected, unnamed sockets– Limited to use by processes that share file descriptors
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 44
sf01a:cmhuang[/] ipcs
IPC status from <running system> as of Thu Sep 21 14:35:30 CST 2006T ID KEY MODE OWNER GROUPMessage Queues:
Shared Memory:m 1 0x50000d1d --rw-r--r-- root rootm 2 0xabbaca01 --rw-rw-rw- pc62 TRm 3103 0 --rw-rw-rw- cmhuang DSDm 1404 0 --rw-rw-rw- root root
Semaphores:s 0 0x1 --ra-ra-ra- root roots 2031617 0 --ra-ra-ra- cmhuang DSDs 917506 0 --ra-ra-ra- cmhuang DSD

C. M. Huang / SLDC-IPC / 09.2006 45
IPC for WinXP Data oriented
– Pipes– Mailslots (message queues)– Shared memory
Procedure oriented / object oriented– Remote procedure calls– Microsoft COM objects– Clipboard– GUI drag-and-drop capability
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 46
Pipes Manipulated with file system calls
– Read– Write– Open
Pipe server– Process that creates pipe
Pipe clients– Processes that connect to pipe
Modes– Read: pipe server receives data from pipe clients– Write: pipe server sends data to pipe clients– Duplex: pipe server sends and receives data
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 47
Pipes Anonymous Pipes
– Unidirectional– Between local processes– Synchronous– Pipe handles, usually passed through inheritance
Named Pipes– Unidirectional or bidirectional– Between local or remote processes– Synchronous or asynchronous– Opened by name– Byte stream vs. message stream– Default mode vs. write-through mode
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 48
Mailslots Mailslot server: creates mailslot Mailslot clients: send messages to mailslot Communication
– Unidirectional– No acknowledgement of receipt– Local or remote communication– Implemented as files– Two modes
• Datagram: for small messages• Server Message Block (SMB): for large messages
Deitel, et al., Operating Systems, Third Edition
C. M. Huang / SLDC-IPC / 09.2006 49
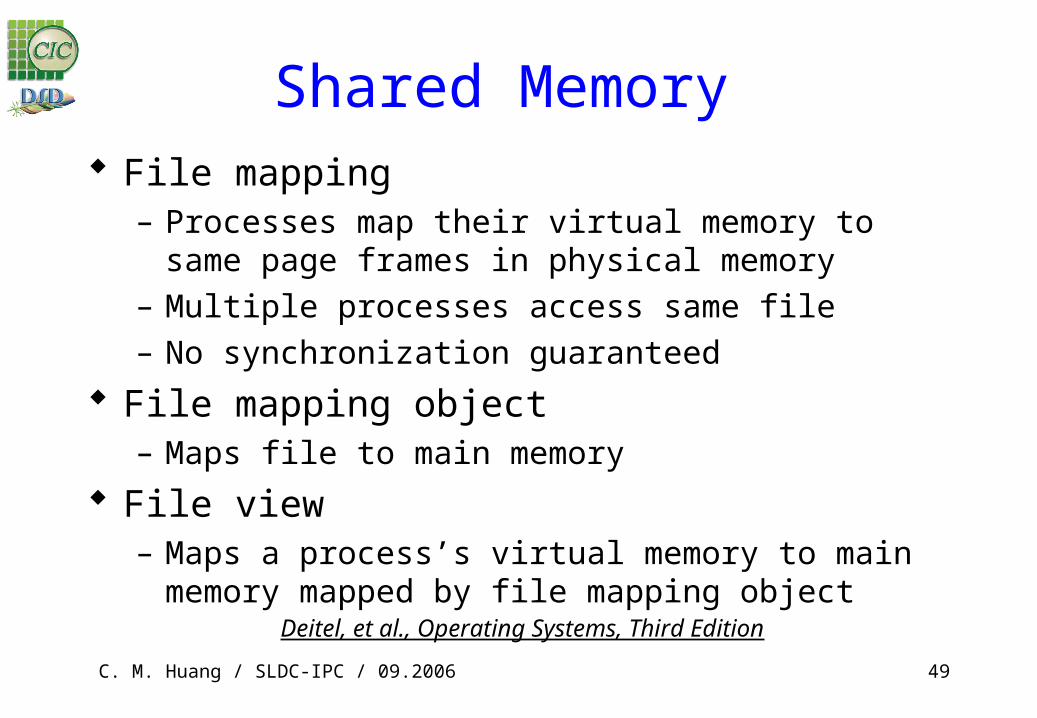
Shared Memory File mapping
– Processes map their virtual memory to same page frames in physical memory
– Multiple processes access same file– No synchronization guaranteed
File mapping object– Maps file to main memory
File view– Maps a process’s virtual memory to main memory mapped by file
mapping objectDeitel, et al., Operating Systems, Third Edition

Nokia DSP Gateway

C. M. Huang / SLDC-IPC / 09.2006 51
Nokia DSP Gateway Overview Supports TI OMAP1510, 1610, 5910, 5912, 2410, and 2412. GPP side
– Linux kernel 2.6.6– Linux device driver– Access DSP through normal system calls such as read() and write()
DSP side– TI DSP/BIOS– DSP kernel library (tokliBIOS) and API
http://dspgateway.sourceforge.net/pub/index.php

C. M. Huang / SLDC-IPC / 09.2006 52
Nokia DSP Gateway Overview Current version: 3.3.1 (2006-09-13) Open source software Current license state:
Release License
1.0 GPL
2.X GPL
3.XARM pack DSP pack
GPL BSD

C. M. Huang / SLDC-IPC / 09.2006 53
TI OMAP 1610

C. M. Huang / SLDC-IPC / 09.2006 54
Summary of changes from v2.6.5 to v2.6.6 ============================================
<[email protected].(none)> [ARM PATCH] 1777/1: Add TI OMAP support to ARM core files
Patch from Tony Lindgren
This patch updates the ARM Linux core files to add support for Texas Instruments OMAP-1510, 1610, and 730 processors.
OMAP is an embedded ARM processor with integrated DSP.
OMAP-1610 has hardware support for USB OTG, which might be of interest to Linux developers. OMAP-1610 could be easily be used as development platform to add USB OTG support to Linux.
This patch is an updated version of an earlier patch 1767/1 with the dummy Kconfig added for OMAP as suggested by Russell King here:
http://www.arm.linux.org.uk/developer/patches/viewpatch.php?id=1767/1
This patch is brought to you by various linux-omap developers.
http://www.kernel.org/pub/linux/kernel/v2.6/ChangeLog-2.6.6

C. M. Huang / SLDC-IPC / 09.2006 55
TI DSP/BIOS Scalable real-time kernel Real-time scheduling and synchronization Host-to-target communication Real-time instrumentation Preemptive multi-threading Hardware abstraction Real-time analysis and configuration tools Application programs use DSP/BIOS by making calls to the API All DSP/BIOS modules provide C-callable interfaces

C. M. Huang / SLDC-IPC / 09.2006 56
DSP Gateway System Architecture

C. M. Huang / SLDC-IPC / 09.2006 57
Mailbox in OMAP1 Each set of mailbox registers consists of two 16-bit registers and a 1-bit
flag register. The interrupting processor can use one 16-bit register to pass a data
word to the interrupted processor and the other 16-bit register to pass a command word.

C. M. Huang / SLDC-IPC / 09.2006 58
Mailbox in OMAP2 6 sets of mailbox registers, and each message register can carry a 32-
bit data two mailbox queues are reserved, MAILBOX_0 for ARM to DSP
direction and MAILBOX_1 for DSP to ARM direction

C. M. Huang / SLDC-IPC / 09.2006 59
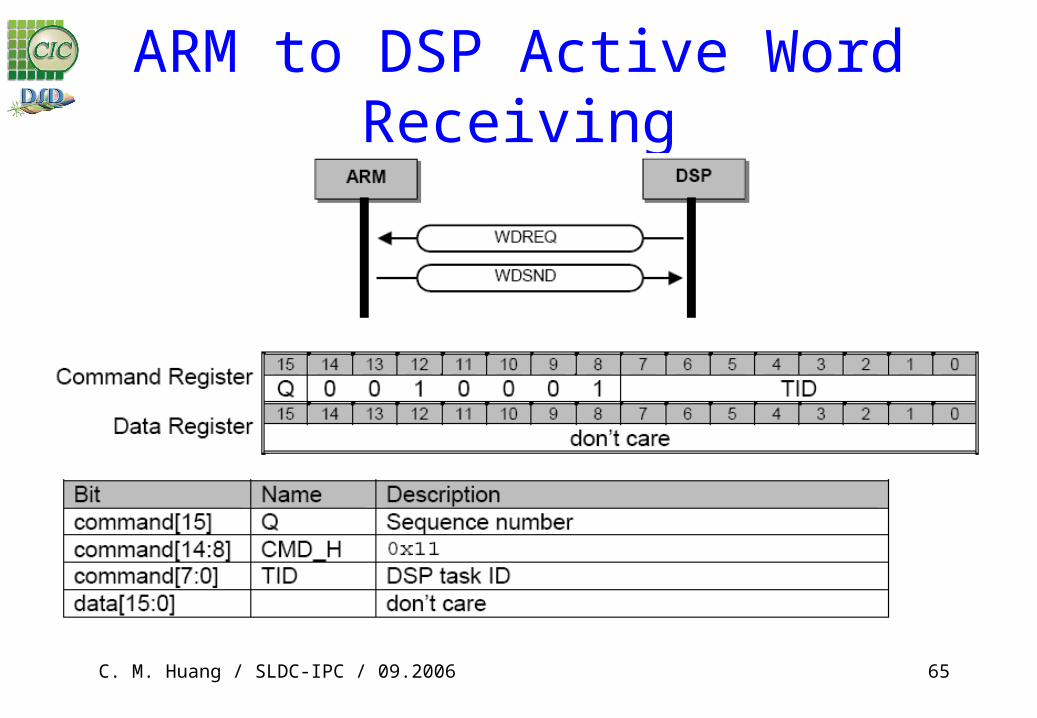
Mailbox Command and Data Register Command register bit definitions
Data register bit definitions

C. M. Huang / SLDC-IPC / 09.2006 60
Mailbox Command Definition

C. M. Huang / SLDC-IPC / 09.2006 61
Mailbox Command Sequence Configuration sequence
– System configuration– Task configuration– Task add/delete
Data transfer sequence– ARM to DSP transfer– DSP to ARM transfer– Task control– Read/write DSP register– Read/write DSP system parameters

C. M. Huang / SLDC-IPC / 09.2006 62
System Configuration Sequence

C. M. Huang / SLDC-IPC / 09.2006 63
DSPCFG Command

C. M. Huang / SLDC-IPC / 09.2006 64
ARM to DSP Passive Word Receiving
C. M. Huang / SLDC-IPC / 09.2006 65
ARM to DSP Active Word Receiving

C. M. Huang / SLDC-IPC / 09.2006 66
ARM to DSP Passive Block Receiving

C. M. Huang / SLDC-IPC / 09.2006 67
IPC Buffer It is unrealistic to transfer a large amount of data between tw
o processors with only mailbox registers. Therefore, IPBUF (Inter-Processor Buffer) is introduced for the large block data transfer.
There are three types of IPBUFs:– Global IPBUF– Private IPBUF– System IPBUF

C. M. Huang / SLDC-IPC / 09.2006 68
Global IPBUF The Global IPBUFs are defined for the block data transfer be
tween ARM and DSP. The Global IPBUF lines are identified with BID (Buffer ID), an
d all tasks can use them commonly. The maximum line size is 64k words (128k bytes).

C. M. Huang / SLDC-IPC / 09.2006 69
Global IPBUF

C. M. Huang / SLDC-IPC / 09.2006 70
DSP Gateway Linux Device Interfaces

C. M. Huang / SLDC-IPC / 09.2006 71
DSP Gateway Linux APIs

C. M. Huang / SLDC-IPC / 09.2006 72
Passive Receiving Task

C. M. Huang / SLDC-IPC / 09.2006 73
Active Receiving Task

TI DSP/BIOS Link

C. M. Huang / SLDC-IPC / 09.2006 75
TI DSP/BIOS Link For TI OMAP5910/5912, Davinci, and DM642 devices. DSP/BIOS Link is a no-charge, royalty-free product and is pr
ovided in C source code form. Current version: 1.30.06 (Nov. 22, 2005) Portable across different operating systems. OS (GPP) + DSP/BIOS (DSP)
http://focus.ti.com/dsp/docs/dspsupportatn.tsp?sectionId=3&tabId=477&familyId=44&toolTypeId=5

C. M. Huang / SLDC-IPC / 09.2006 76
DSP/BIOS Link Supported Platforms Davinci running Montavista Linux Pro 4.0 or PrKernel v4.1 on
ARM OMAP5912 running Montavista Linux Pro 3.1 on ARM DA300 running PrKernel v4.1 on ARM DM642 connected to a PC running Red Hat Linux 9.0 or Red
Hat Enterprise Linux 4.0

C. M. Huang / SLDC-IPC / 09.2006 77
Software Architecture of DSP/BIOS Link

C. M. Huang / SLDC-IPC / 09.2006 78
On the GPP Side The OS ADAPTATION LAYER encapsulates the generic OS services
that are required by the other components of DSP/BIOS LINK. This component exports a generic API that insulates the other components from the specifics of an OS. All other components use this API instead of direct OS calls. This makes DSP/BIOS LINK portable across different operating systems.
The LINK DRIVER encapsulates the low-level control operations on the physical link between the GPP and DSP. This module is responsible for controlling the execution of the DSP and data transfer using defined protocol across the GPP-DSP boundary.

C. M. Huang / SLDC-IPC / 09.2006 79
On the GPP Side The PROCESSOR MANAGER maintains book-keeping
information for all components. It also allows different boot-loaders to be plugged into the system. It builds exposes the control operations provided by the LINK DRIVER to the user through the API layer.
The DSP/BIOS LINK API is interface for all clients on the GPP side. This is a very thin component and usually doesn’t do any more processing than parameter validation. The API layer can be considered as ‘skin’ on the ‘muscle’ mass contained in the PROCESSOR MANAGER and LINK DRIVER.

C. M. Huang / SLDC-IPC / 09.2006 80
On the DSP Side The LINK DRIVER is one of the drivers in DSP/BIOS. This
driver specializes in communicating with the GPP over the physical link.
There is no specific DSP/BIOS LINK API on the DSP. The communication (data/message transfer) is done using the DSP/BIOS modules - SIO/GIO/MSGQ.

C. M. Huang / SLDC-IPC / 09.2006 81
DSP/BIOS Link Key Components PROC
– This component represents the DSP processor in the application space.
– This component provides services to:• Initialize the DSP & make it available for access from the GPP.• Load code on the DSP.• Start execution from the run address specified in the executable.• Read from or write to DSP memory.• Stop execution.• Additional platform-specific control actions.
– In the current version, only one processor is supported. However, the APIs are designed to support multiple DSPs and hence they accept a processorID argument to support this future enhancement.

C. M. Huang / SLDC-IPC / 09.2006 82
DSP/BIOS Link Key Components CHNL
– This component represents a logical data transfer channel in the application space.
– CHNL is responsible for the data transfer across the GPP and DSP. – CHNL is an acronym for ‘channel’.– A channel (when referred in context of DSP/BIOS LINK) is:
• A means of transferring data across GPP and DSP.• A logical entity mapped over a physical connectivity between the GPP and
DSP.• Uniquely identified by a number within the range of channels for a specific
physical link towards a DSP.• Unidirectional. The direction of a channel is decided at run time based on the
attributes passed to the corresponding API.

C. M. Huang / SLDC-IPC / 09.2006 83
DSP/BIOS Link Key Components MSGQ
– This component represents queue based messaging– This component is responsible for exchanging short messages of
variable length between the GPP and DSP clients. It is based on the MSGQ module in DSP/BIOS.
– The messages are sent and received through message queues.– A reader gets the message from the queue and a writer puts the
message on a queue. A message queue can have only one reader and many writers. A task may read from and write to multiple message queues.

C. M. Huang / SLDC-IPC / 09.2006 84
DSP/BIOS Link Key Components POOL
– This component provides APIs to open and close memory pools, which are used by the CHNL and MSGQ component for allocating the buffers used in data transfer and messaging respectively.
– This component is responsible for providing a uniform view of different memory pool implementations, which may be specific to the hardware architecture or OS on which DSP/BIOS LINK is ported. This component is based on the POOL interface in DSP/BIOS.

C. M. Huang / SLDC-IPC / 09.2006 85
Initialization Phase API PROC
– PROC_Setup()– PROC_Attach()– PROC_Load()
CHNL– CHNL_Create()– CHNL_AllocateBuffer()
MSGQ– MSGQ_TransportOpen()– MSGQ_Open()– MSGQ_SetErrorHandler()– MSGQ_Locate()
POOL– POOL_Open()

C. M. Huang / SLDC-IPC / 09.2006 86
Execution Phase API PROC
– PROC_Start()– PROC_Read()– PROC_Write()– PROC_Stop()
CHNL– CHNL_Issue()– CHNL_Reclaim()
MSGQ– MSGQ_Alloc()– MSGQ_Put()– MSGQ_Get()– MSGQ_GetSrcQueue()– MSGQ_Free()

C. M. Huang / SLDC-IPC / 09.2006 87
Finalization Phase API PROC
– PROC_Detach()– PROC_Destroy()
CHNL– CHNL_FreeBuffer()– CHNL_Delete()
MSGQ– MSGQ_Release()– MSGQ_TransportClose()– MSGQ_Close()
POOL– POOL_Close()

IPC Hardware Architecture

C. M. Huang / SLDC-IPC / 09.2006 89
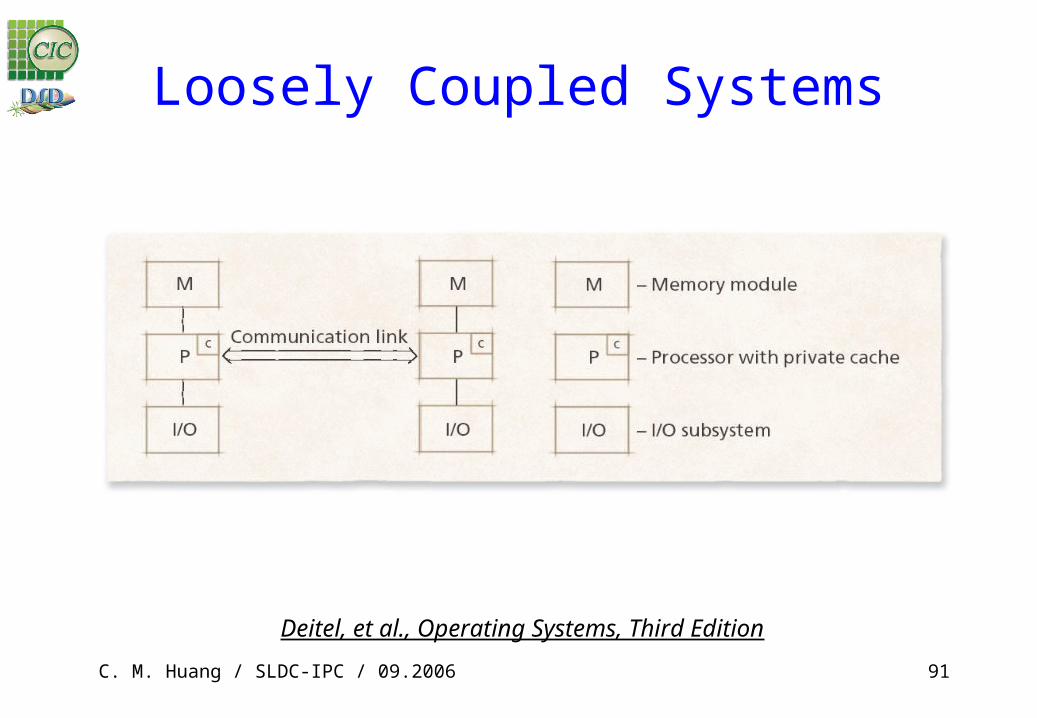
Tightly Coupled vs. Loosely Coupled Systems
Tightly coupled systems– Processors share most resources including memory– Communicate over shared buses using shared physical memory
Loosely coupled systems– Processors do not share most resources– Most communication through explicit messages or shared virtual
memory (although not shared physical memory) Comparison
– Loosely coupled systems: more flexible, fault tolerant, scalable– Tightly coupled systems: more efficient, less burden to operating
system programmers Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 90
Tightly Coupled Systems
Deitel, et al., Operating Systems, Third Edition
C. M. Huang / SLDC-IPC / 09.2006 91
Loosely Coupled Systems
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 92
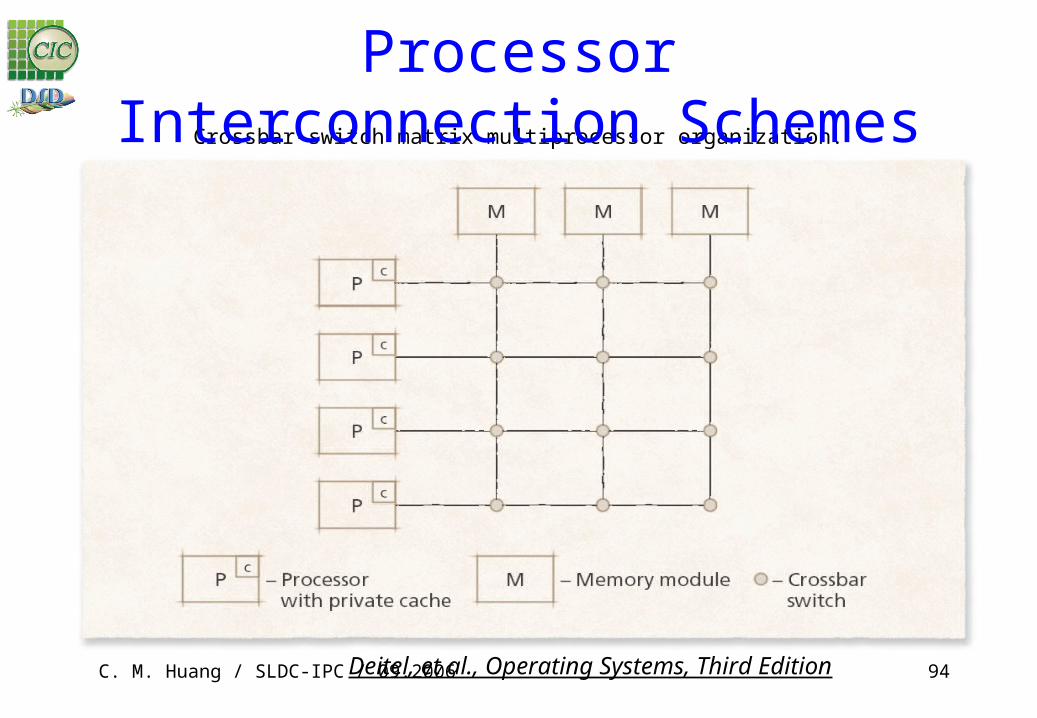
Processor Interconnection Schemes Interconnection scheme
– Describes how the system’s components, such as processors and memory modules, are connected
– Consists of nodes (components or switches) and links (connections)
– Parameters used to evaluate interconnection schemes• Node degree• Bisection width• Network diameter• Cost of the interconnection scheme
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 93
Shared bus multiprocessor organization.
Processor Interconnection Schemes
Deitel, et al., Operating Systems, Third Edition
C. M. Huang / SLDC-IPC / 09.2006 94
Crossbar-switch matrix multiprocessor organization.
Processor Interconnection Schemes
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 95
4-connected 2-D mesh network.
Processor Interconnection Schemes
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 96
3- and 4-dimensional hypercubes.
Processor Interconnection Schemes
Deitel, et al., Operating Systems, Third Edition

C. M. Huang / SLDC-IPC / 09.2006 97
Multistage baseline network.
Processor Interconnection Schemes
Deitel, et al., Operating Systems, Third Edition
C. M. Huang / SLDC-IPC / 09.2006 98
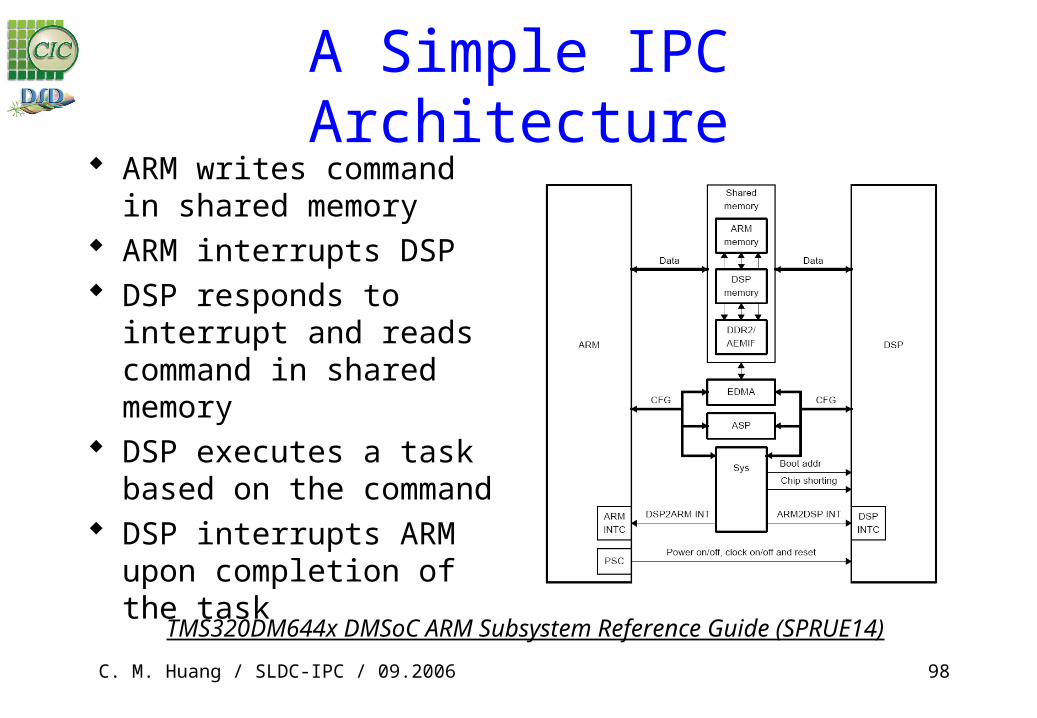
A Simple IPC Architecture ARM writes command in shared
memory ARM interrupts DSP DSP responds to interrupt and
reads command in shared memory
DSP executes a task based on the command
DSP interrupts ARM upon completion of the task
TMS320DM644x DMSoC ARM Subsystem Reference Guide (SPRUE14)

C. M. Huang / SLDC-IPC / 09.2006 99
TI OMAP5910

C. M. Huang / SLDC-IPC / 09.2006 100
OMAP5910 IPC Architecture Mailbox registers
– Each direction 32bit x 2– Interrupt occurrence
MPU interface (MPUI)– MPU accesses DSP memory
space directly Shared memory
– Arrangement with the Traffic Controller
– 3 type of memories– Best suitable to large amount of
data sharing

C. M. Huang / SLDC-IPC / 09.2006 101
Traffic Controller (TC) The IMIF allows access to the 192K bytes of on-chip SRAM. The EMIFS interface provides 16-bit-wide access to asynchronous or synchronous m
emories. The EMIFF Interface provides access to 16-bit-wide access to standard SDRAM me
mories. The TC provides the functions of
– arbitrating contending accesses to the same memory interface from different initiators (MPU, DSP, System DMA, Local Bus),
– synchronization of accesses due to the initiators and the memory interfaces running at different clock rates,
– and the buffering of data allowing burst access for more efficient multiplexing of transfers from multiple initiators to the memory interfaces.
The TC’s architecture allows simultaneous transfers between initiators and different memory interfaces without penalty. For instance, if the MPU is accessing the EMIFF at the same time, the DSP is accessing the IMIF, transfers may occur simultaneously since there is no contention for resources.

C. M. Huang / SLDC-IPC / 09.2006 102
ARM IPCM Module The IPCM provides up to 32 mailboxes with control logic and
interrupt generation to support inter-processor communication.
An AHB interface enables access from source and destination cores.
The IPCM:– sends interrupts to other cores– passes small amounts of data to other cores.
A source core can have multiple mailboxes and send messages in parallel (multitasking).
PrimeCell Inter-Processor Communications Module Technical Reference Manual

C. M. Huang / SLDC-IPC / 09.2006 103
IPCM Components 1-32 programmable mailboxes, each comprising:
– a single 1-32-bit Mailbox Source Register– a single 1-32-bit Mailbox Destination Register – a single 2-bit Mailbox Mode Register– a single 1-32-bit Mailbox Mask Register– a single 2-bit Mailbox Send Register– 0-7 32-bit data registers to store the message.
1-32 sets of read-only interrupt status registers, one for each interrupt, each comprising:– 1-32-bit Raw Interrupt Status Register (each bit corresponds to each mailbox)– 1-32-bit Masked Interrupt Status Register (each bit corresponds to each mailbox).
A 32-bit Configuration Status Register

C. M. Huang / SLDC-IPC / 09.2006 104
IPCM Functional Block
PrimeCell Inter-Processor Communications Module Technical Reference Manual
C. M. Huang / SLDC-IPC / 09.2006 105
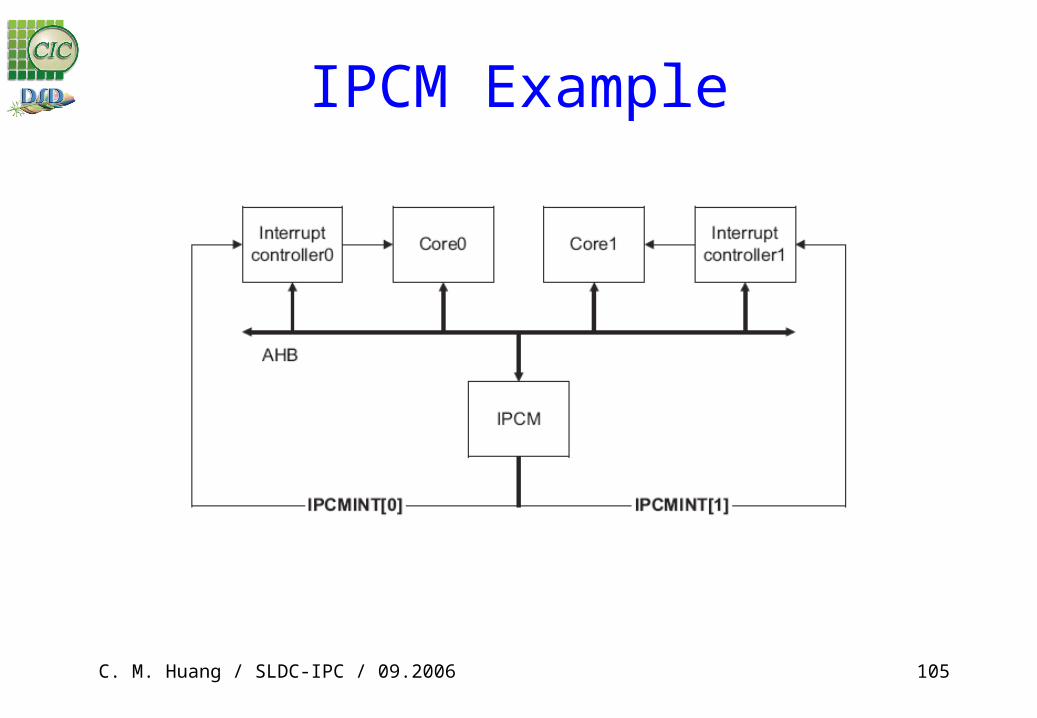
IPCM Example

C. M. Huang / SLDC-IPC / 09.2006 106
IPCM Example Core0 has a message to send to Core1. Core0 claims the mailbox by
setting bit 0 in the Mailbox Source Register. Core0 then sets bit 1 in the Mailbox Destination Register, enables the interrupts and programs the message into the Mailbox Data Registers. Finally, Core0 sends the message by writing 01 to the Mailbox Send Register. This asserts the interrupt to Core1.
When Core1 is interrupted, it reads the Masked Interrupt Status Register for IPCMINT[1] to determine which mailbox contains the message. Core1 reads the message in that mailbox, then clears the interrupt and asserts the acknowledge interrupt by writing 10 to the Mailbox Send Register.
Core0 is interrupted with the acknowledge message, completing the operation. Core0 then decides whether to retain the mailbox to send another message or release the mailbox, freeing it up for other cores in the system to use it.

Conclusions

C. M. Huang / SLDC-IPC / 09.2006 108
Conclusions IPC schemes for supporting many cores Performance and power consumption analysis for different
IPC schemes IPC API schemes

Thanks for Your Attention!