Embed Size (px)
Citation preview

Intel Pentium MIntel Pentium M

OutlineOutline
HistoryHistory P6 Pipeline in detailP6 Pipeline in detail New featuresNew features
Improved Branch Improved Branch PredictionPrediction
Micro-ops fusionMicro-ops fusion Speed Step Speed Step
technologytechnology Thermal Throttle 2Thermal Throttle 2
Power and Power and PerformancePerformance

Quick Review of x86Quick Review of x86 8080 - 8-bit8080 - 8-bit 8086/8088 - 16-bit (8088 had 8-bit external data bus)8086/8088 - 16-bit (8088 had 8-bit external data bus)
- segmented memory model - segmented memory model 286286
- introduction of protected mode, which included: - introduction of protected mode, which included: segment limit checking, privilege levels, read- and exe-only segment segment limit checking, privilege levels, read- and exe-only segment optionsoptions
386 - 32-bit386 - 32-bit - segmented and flat memory model - segmented and flat memory model - paging - paging
486 - first pipeline486 - first pipeline - expanded the 386's ID and EX units into five-stage pipeline - expanded the 386's ID and EX units into five-stage pipeline - first to include on-chip cache - first to include on-chip cache - integrated x87 FPU (before it was a coprocessor) - integrated x87 FPU (before it was a coprocessor)
Pentium (586) - first superscalarPentium (586) - first superscalar - included two pipelines, u and v - included two pipelines, u and v - virtual-8086 mode - virtual-8086 mode - MMX soon after - MMX soon after
Pentium Pro (686 or P6) - three-way superscalar Pentium Pro (686 or P6) - three-way superscalar - dynamic execution - out-of-order execution, branch prediction, - dynamic execution - out-of-order execution, branch prediction, speculative executionspeculative execution - very successful micro-architecture - very successful micro-architecture
Pentium 2 and 3 - both P6Pentium 2 and 3 - both P6 Pentium 4 - new NetBurst architecturePentium 4 - new NetBurst architecture Pentium M - enhanced P6Pentium M - enhanced P6

Pentium Pro RootsPentium Pro Roots NexGen 586 (1994)NexGen 586 (1994)
Decomposes IA32 instructions into Decomposes IA32 instructions into simplersimplerRISC-like operations (R-ops or micro-ops)RISC-like operations (R-ops or micro-ops) Decoupled ApproachDecoupled Approach
NexGen bought by AMDNexGen bought by AMD AMD K5 (1995) – also used micro-opsAMD K5 (1995) – also used micro-ops
Intel Pentium ProIntel Pentium Pro Intel’s first use of decoupled architectureIntel’s first use of decoupled architecture

Pentium-M OverviewPentium-M Overview
Introduced March 12, 2003Introduced March 12, 2003 Initially called BaniasInitially called Banias Created by Israeli teamCreated by Israeli team Missed deadline by less than 5 daysMissed deadline by less than 5 days Marketed with Intel’s Centrino Marketed with Intel’s Centrino
InitiativeInitiative Based on P6 microarchitechtureBased on P6 microarchitechture

P6 Pipeline in a NutshellP6 Pipeline in a Nutshell
Divided into three clusters (front, middle, Divided into three clusters (front, middle, back)back) In-order Front-EndIn-order Front-End Out-of-order Execution CoreOut-of-order Execution Core RetirementRetirement
Each cluster is independentEach cluster is independent I.e. if a mispredicted branch is detected in the I.e. if a mispredicted branch is detected in the
front-end, the front-end will flush and retch front-end, the front-end will flush and retch from the corrected branch target, all while the from the corrected branch target, all while the execution core continues working on previous execution core continues working on previous instructionsinstructions
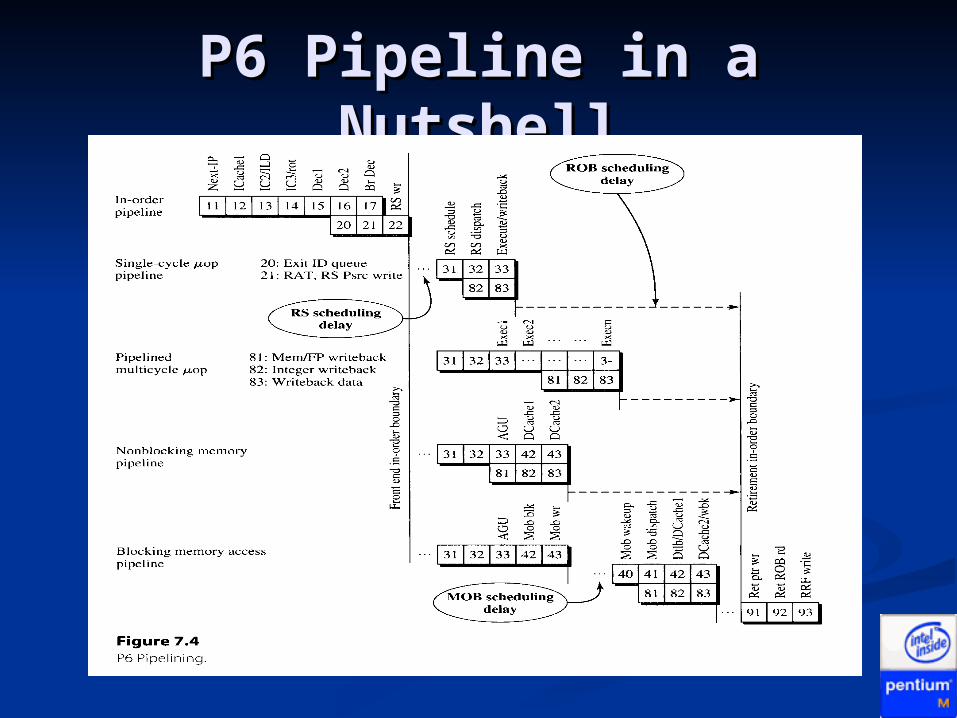
P6 Pipeline in a NutshellP6 Pipeline in a Nutshell


P6 Front-EndP6 Front-End Major units: IFU, ID, RAT, Allocator, BTB, BACMajor units: IFU, ID, RAT, Allocator, BTB, BAC Fetching (IFU)Fetching (IFU)
Includes I-cache, I-streaming cache, ITLB, ILDIncludes I-cache, I-streaming cache, ITLB, ILD No pre-decodingNo pre-decoding Boundary markings by instruction-length decoder Boundary markings by instruction-length decoder
(ILD)(ILD) Branch PredictionBranch Prediction
Predicted (speculative) instructions are markedPredicted (speculative) instructions are marked Decoding (ID)Decoding (ID)
Conversion of instructions (macro-ops) into micro-Conversion of instructions (macro-ops) into micro-opsops
Allocation of Buffer Entries: RS, ROB, MOBAllocation of Buffer Entries: RS, ROB, MOB

P6 Execution CoreP6 Execution Core Reservation Station (RS)Reservation Station (RS)
Waiting micro-ops ready to goWaiting micro-ops ready to go SchedulerScheduler
Out-of-order Execution of micro-opsOut-of-order Execution of micro-ops Independent execution units (EU)Independent execution units (EU) Must be careful about out-of-order memory Must be careful about out-of-order memory
accessaccess Memory ordering buffer (MOB) interfaces to the Memory ordering buffer (MOB) interfaces to the
memory subsystemmemory subsystem
Requirements for executionRequirements for execution Available operands, EU, and write-back busAvailable operands, EU, and write-back bus Optimal performanceOptimal performance

P6 RetirementP6 Retirement
In-order updating of architected In-order updating of architected machine statemachine state Re-order buffer (ROB)Re-order buffer (ROB)
Micro-op retirement – “all or none”Micro-op retirement – “all or none” Architecturally illegal to retire only partArchitecturally illegal to retire only part
of an IA-32 instruction of an IA-32 instruction In-ordering handling of exceptionsIn-ordering handling of exceptions
Legal to handle mid-execution, but illegalLegal to handle mid-execution, but illegalto handle mid-retirementto handle mid-retirement

PM Changes to P6PM Changes to P6
Most changes made in P6 front-endMost changes made in P6 front-end Added and expanded on P4 branch Added and expanded on P4 branch
predictorpredictor Micro-ops fusionMicro-ops fusion Addition of dedicated stack engine Addition of dedicated stack engine Pipeline lengthPipeline length
Longer than P3, shorter than P4Longer than P3, shorter than P4 Accommodates extra features aboveAccommodates extra features above

PM Changes to P6, cont.PM Changes to P6, cont. Intel has not released the exact length of the pipeline.Intel has not released the exact length of the pipeline. Known to be somewhere between the P4 (20 stage)Known to be somewhere between the P4 (20 stage)
and the P3 (10 stage). Rumored to be 12 stages.and the P3 (10 stage). Rumored to be 12 stages. Trades off slightly lower clock frequencies (than P4) Trades off slightly lower clock frequencies (than P4)
for better performance per clock, less branch for better performance per clock, less branch prediction penalties, …prediction penalties, …

Blue Man Group Blue Man Group Commercial BreakCommercial Break

BaniasBanias 11stst version version 77 million transistors, 77 million transistors,
23 million more than 23 million more than P4P4
1 MB on die Level 2 1 MB on die Level 2 cachecache
400 MHz FSB (quad 400 MHz FSB (quad pumped 100 MHZ)pumped 100 MHZ)
130 nm process130 nm process Frequencies between Frequencies between
1.3 – 1.7 GHz1.3 – 1.7 GHz Thermal Design Point Thermal Design Point
of 24.5 wattsof 24.5 watts http://www.intel.com/pressroom/archive/photos/centrino.htm

DothanDothan
Launched May 10, Launched May 10, 20042004
140 million 140 million transistorstransistors
2 MB Level 2 cache2 MB Level 2 cache 400 or 533 MHz FSB400 or 533 MHz FSB Frequencies between Frequencies between
1.0 to 2.26 GHz1.0 to 2.26 GHz Thermal Design Point Thermal Design Point
of 21(400 MHz FSB) of 21(400 MHz FSB) to 27 wattsto 27 watts
http://www.intel.com/pressroom/archive/photos/centrino.htm

Dothan cont.Dothan cont. 90 nm process technology on 300 mm 90 nm process technology on 300 mm
wafer.wafer. Provide twice the capacity of the 200 mm Provide twice the capacity of the 200 mm
while the process dimensions double the while the process dimensions double the transistor density transistor density
Gate dimensions are 50nm or approx half Gate dimensions are 50nm or approx half the diameter if the influenza virusthe diameter if the influenza virus
P and n gate voltages are reduced by P and n gate voltages are reduced by enhancing the carrier mobility of the Si enhancing the carrier mobility of the Si lattice by 10-20%lattice by 10-20%
Draws less than 1 W average powerDraws less than 1 W average power

BusBus Utilizes a split transaction deferred reply Utilizes a split transaction deferred reply
protocolprotocol 64-bit width64-bit width Delivers up to 3.2 Gbps (Banis) or 4.2 Delivers up to 3.2 Gbps (Banis) or 4.2
Gbps (Dothan) in and out of the Gbps (Dothan) in and out of the processorprocessor
Utilizes source synchronous transfer of Utilizes source synchronous transfer of addresses and dataaddresses and data Data transferred 4 times per bus clockData transferred 4 times per bus clock Addresses can be delivered times per bus Addresses can be delivered times per bus
clockclock

Bus update in DothanBus update in Dothan
http://www.intel.com/technology/itj/2005/volume09issue01/art05_perf_powerhttp://www.intel.com/technology/itj/2005/volume09issue01/art05_perf_power

L1 CacheL1 Cache 64KB total 64KB total
32 K instruction32 K instruction 32 K data (4 times P4M)32 K data (4 times P4M)
Write-back vs. write-through on P4Write-back vs. write-through on P4 In write-through cache, data is written to In write-through cache, data is written to
both L1 and main memory simultaneouslyboth L1 and main memory simultaneously In write-back cache, data can be loaded In write-back cache, data can be loaded
without writing to main memory, without writing to main memory, increasing speed by reducing the number increasing speed by reducing the number of slow memory writesof slow memory writes

L2 cacheL2 cache
1 – 2 MB 1 – 2 MB 8-way set associative8-way set associative Each set is divided into 4 separate power Each set is divided into 4 separate power
quadrants.quadrants. Each individual power quadrant can be set to a Each individual power quadrant can be set to a
sleep mode, shutting off power to those sleep mode, shutting off power to those quadrantsquadrants
Allows for only 1/32 of cache to be powered at Allows for only 1/32 of cache to be powered at any timeany time
Increased latency vs. improved power Increased latency vs. improved power consumptionconsumption

PrefetchPrefetch
Prefetch logic fetches data to the Prefetch logic fetches data to the level 2 cache before L1 cache level 2 cache before L1 cache requests occurrequests occur
Reduces compulsory misses due to Reduces compulsory misses due to an increase of valid data in cachean increase of valid data in cache
Reduces bus cycle penaltiesReduces bus cycle penalties

ScheduleSchedule P6 Pipeline in detailP6 Pipeline in detail
Front-EndFront-End Execution CoreExecution Core Back-EndBack-End
Power IssuesPower Issues Intel SpeedStepIntel SpeedStep
Testing the Testing the FeaturesFeatures x86 system registersx86 system registers Performance TestingPerformance Testing

IA-32 Memory ManagementIA-32 Memory Management Classic segmented model (cannot be disabled in protected Classic segmented model (cannot be disabled in protected
mode)mode) Separation of code, data, and stack into "segments“Separation of code, data, and stack into "segments“
Optional pagingOptional paging Segments divided into pages (typically 4KB)Segments divided into pages (typically 4KB) Additional protection to segment-protectionAdditional protection to segment-protection
I.e. provides read-write protection on a page-by-page basisI.e. provides read-write protection on a page-by-page basis
Stage 11 (stage 1) - Selection of address for next I-Stage 11 (stage 1) - Selection of address for next I-cache accesscache access Speculation – address chosen from competing sources (i.e. BTB, Speculation – address chosen from competing sources (i.e. BTB,
BAC, loop detector, etc.)BAC, loop detector, etc.) Calculation of linear address from logical (segment selector + Calculation of linear address from logical (segment selector +
offset)offset) Segment selector – index into a table of segment descriptors, which Segment selector – index into a table of segment descriptors, which
include base address, size, type, and access right of the segmentinclude base address, size, type, and access right of the segment Remember: only six segment selectors, so only six usable at a timeRemember: only six segment selectors, so only six usable at a time
32-bit code nowadays uses flat model, so OS can make do with only a 32-bit code nowadays uses flat model, so OS can make do with only a few (typically four) segmentsfew (typically four) segments
IFU chooses address with highest priority and sends it to stage IFU chooses address with highest priority and sends it to stage twotwo
P6 Front-end: Instruction P6 Front-end: Instruction FetchingFetching

P6 Front-end: Instruction P6 Front-end: Instruction FetchingFetching
Stage 12-13 - Accessing of cachesStage 12-13 - Accessing of caches Accesses instruction caches with address calculated in Accesses instruction caches with address calculated in
stage onestage one Includes standard cache, victim cache, and streaming bufferIncludes standard cache, victim cache, and streaming buffer
With paging, consults ITLB to determine physical page With paging, consults ITLB to determine physical page number (tag bits)number (tag bits)
Without paging, linear address from stage one becomes Without paging, linear address from stage one becomes physical addressphysical address
Obtains branch prediction from branch target buffer Obtains branch prediction from branch target buffer (BTB) (BTB)
BTB takes two cycles to complete one accessBTB takes two cycles to complete one access Instruction boundary (ILD) and BTB markingsInstruction boundary (ILD) and BTB markings
Stage 14 - Completion of instruction cache accessStage 14 - Completion of instruction cache access Instructions and their marks are sent to instruction Instructions and their marks are sent to instruction
buffer or steered to IDbuffer or steered to ID

P6 Front-end: Instruction P6 Front-end: Instruction FetchingFetching

P6 Front-end: Instruction P6 Front-end: Instruction DecodingDecoding
Stage 15-16 - Decoding of IA32 Instructions Stage 15-16 - Decoding of IA32 Instructions Alignment of instruction bytesAlignment of instruction bytes Identification of the ends of up to three instructionsIdentification of the ends of up to three instructions Conversion of instructions into micro-opsConversion of instructions into micro-ops
Stage 17 - Branch DecodingStage 17 - Branch Decoding If the ID notices a branch that went unpredicted by the BTB (i.e. if the If the ID notices a branch that went unpredicted by the BTB (i.e. if the
BTB had never seen the branch before), flushes the in-order pipe, and BTB had never seen the branch before), flushes the in-order pipe, and re-fetches from the branch target re-fetches from the branch target
Branch target calculated by BACBranch target calculated by BAC Early catch saves speculative instructions from being sent through the Early catch saves speculative instructions from being sent through the
pipelinepipeline Stage 21 - Register Allocation and RenamingStage 21 - Register Allocation and Renaming
Synonymous with stage 17 (a reminder of independent working units)Synonymous with stage 17 (a reminder of independent working units) Allocator used to allocate required entries in ROB, RS, LB, and SBAllocator used to allocate required entries in ROB, RS, LB, and SB Register Alias Table (RAT) consultedRegister Alias Table (RAT) consulted
Maps logical sources/destinations to physical entries in the ROB (or Maps logical sources/destinations to physical entries in the ROB (or sometimes RRF)sometimes RRF)
Stage 22 – Completion of Front-EndStage 22 – Completion of Front-End Marked micro-ops are forwarded to RS and ROB, where theyMarked micro-ops are forwarded to RS and ROB, where they
await execution and retirement, respectively.await execution and retirement, respectively.

P6 Front-end: Instruction P6 Front-end: Instruction DecodingDecoding

Register Alias Table Register Alias Table IntroductionIntroduction
Provides register renaming of integer and Provides register renaming of integer and floating-point registers and flags floating-point registers and flags
Maps logical (architected) entries to physical Maps logical (architected) entries to physical entries usually in the re-order buffer (ROB) entries usually in the re-order buffer (ROB)
Physical entries are actually allocated by the Physical entries are actually allocated by the AllocatorAllocator
The physical entry pointers become a part of the The physical entry pointers become a part of the micro-op’s overall state as it travels through the micro-op’s overall state as it travels through the pipeline pipeline

RAT DetailsRAT Details
P6 is 3-way super-scalar, so the RAT must P6 is 3-way super-scalar, so the RAT must be able to rename up to six logical be able to rename up to six logical sources per cyclesources per cycle
Any data dependences must be handledAny data dependences must be handled Ex:Ex: op1) ADD EAX, EBX, ECX (dest. = EAX)op1) ADD EAX, EBX, ECX (dest. = EAX)
op2) ADD EAX, EAX, EDXop2) ADD EAX, EAX, EDX
op3) ADD EDX, EAX, EDXop3) ADD EDX, EAX, EDX Instead of making op2 wait for op1 to retire, Instead of making op2 wait for op1 to retire,
the RAT provides data forwardingthe RAT provides data forwarding Same case for op3, but RAT must make sure that it Same case for op3, but RAT must make sure that it
gets the result from op2 and not op1gets the result from op2 and not op1

RAT Implementation RAT Implementation DifficultiesDifficulties
Speculative RenamingSpeculative Renaming Since speculative micro-ops flow by, the RAT must be able to Since speculative micro-ops flow by, the RAT must be able to
undo its mappings in the case of a branch mispredictionundo its mappings in the case of a branch misprediction Partial-width register reads and writesPartial-width register reads and writes
Consider a partial-width write followed by a larger-width readConsider a partial-width write followed by a larger-width read Data required by the read is an assimilation of multiple previous Data required by the read is an assimilation of multiple previous
writes to the register – to make sure, RAT must stall the pipelinewrites to the register – to make sure, RAT must stall the pipeline Retirement OverridesRetirement Overrides
Common interaction between RAT and ROBCommon interaction between RAT and ROB When a micro-op retires, its ROB entry is removed and its When a micro-op retires, its ROB entry is removed and its
result may be latched into an architected destination registerresult may be latched into an architected destination register If any active micro-ops source the retired op’s destination, If any active micro-ops source the retired op’s destination,
they must not reference the outdated ROB entrythey must not reference the outdated ROB entry Mismatch stallsMismatch stalls
Associated with flag renamingAssociated with flag renaming

The AllocatorThe Allocator Works in conjunction with RAT to allocate required entriesWorks in conjunction with RAT to allocate required entries In each cycle, assumes three ROB, RS, and LB and two SB In each cycle, assumes three ROB, RS, and LB and two SB
entriesentries Once micro-ops arrive, it determines how many entries are Once micro-ops arrive, it determines how many entries are
really neededreally needed ROB Allocation ROB Allocation
If three entries aren’t available the allocator will stallIf three entries aren’t available the allocator will stall RS AllocationRS Allocation
A bitmap is used to determine which entries are freeA bitmap is used to determine which entries are free If the RS is full, pipeline is stalledIf the RS is full, pipeline is stalled
RS must make sure valid entries are not overwrittenRS must make sure valid entries are not overwritten
MOB AllocationMOB Allocation Allocation of LB and SB entries also done by allocatorAllocation of LB and SB entries also done by allocator

PM Changes to P6 Front-PM Changes to P6 Front-EndEnd
Micro-op fusionMicro-op fusion Dedicated Stack EngineDedicated Stack Engine Enhanced branch predictionEnhanced branch prediction Additional stagesAdditional stages
Intel’s secretIntel’s secret Most likely required for extra Most likely required for extra
functionality abovefunctionality above

Micro-ops FusionMicro-ops Fusion Fusion of multiple micro-ops into one micro-opFusion of multiple micro-ops into one micro-op
Less contention for buffer entriesLess contention for buffer entries Similarity to SIMD data packingSimilarity to SIMD data packing Two examples of fusion from Intel Two examples of fusion from Intel
documentation:documentation: IA32 load-and-operate and store instructionsIA32 load-and-operate and store instructions Not known for certain whether these are the only Not known for certain whether these are the only
cases of fusioncases of fusion Possibly inspired by MacroOps used in K7 Possibly inspired by MacroOps used in K7
(Athlon)(Athlon)

Dedicated Stack EngineDedicated Stack Engine
Traditional out-of-order implementations Traditional out-of-order implementations update the Stack Pointer Register (ESP) by update the Stack Pointer Register (ESP) by sending a µop to update the ESP register with sending a µop to update the ESP register with every stack related instructionevery stack related instruction
Pentium M implementationPentium M implementation A delta register (ESPA delta register (ESPDD) is maintained in the front ) is maintained in the front
endend A historic ESP (ESPA historic ESP (ESPOO) is then kept in the out-of-) is then kept in the out-of-
order execution coreorder execution core Dedicated logic was added to update the ESP by Dedicated logic was added to update the ESP by
adding the ESPadding the ESPOO with the ESP with the ESPDD

ImprovementsImprovements The ESPThe ESPOO value kept in the out-of-order machine value kept in the out-of-order machine
is not changed during a sequence of stack is not changed during a sequence of stack operations, this allows for more parallelism operations, this allows for more parallelism opportunities to be realizedopportunities to be realized
Since ESPSince ESPDD updates are now done by a dedicated updates are now done by a dedicated adder, the execution unit is now free to work on adder, the execution unit is now free to work on other µops and the ALU’s are freed to work on other µops and the ALU’s are freed to work on more complex operationsmore complex operations
Decreased power consumption since large Decreased power consumption since large adders are not used for small operations and the adders are not used for small operations and the eliminated µops do not toggle through the eliminated µops do not toggle through the machine machine
Approximately 5% of the µops have been Approximately 5% of the µops have been eliminatedeliminated

ComplicationsComplications
Since the new adder lives in the front Since the new adder lives in the front end all of its calculations are end all of its calculations are speculative. This necessitates the speculative. This necessitates the addition of recovery table for all values addition of recovery table for all values of ESPof ESPOO and ESP and ESPDD
If the architectural value of ESP is If the architectural value of ESP is needed inside of the out-of-order needed inside of the out-of-order machine the decode logic then needs to machine the decode logic then needs to insert a µop that will carry out the ESP insert a µop that will carry out the ESP calculationcalculation

Branch PredictionBranch Prediction
Longer pipelines mean higher Longer pipelines mean higher penalties for mispredicted branchespenalties for mispredicted branches
Improvements result in added Improvements result in added performance and hence less energy performance and hence less energy spent per instruction retiredspent per instruction retired

Branch Prediction in Branch Prediction in Pentium MPentium M
Enhanced version of Pentium 4 Enhanced version of Pentium 4 predictorpredictor
Two branch predictors added that Two branch predictors added that run in tandem with P4 predictor: run in tandem with P4 predictor: Loop detectorLoop detector Indirect branch detectorIndirect branch detector
20% lower misprediction rate than 20% lower misprediction rate than PIII resulting in up to 7% gain in real PIII resulting in up to 7% gain in real performanceperformance
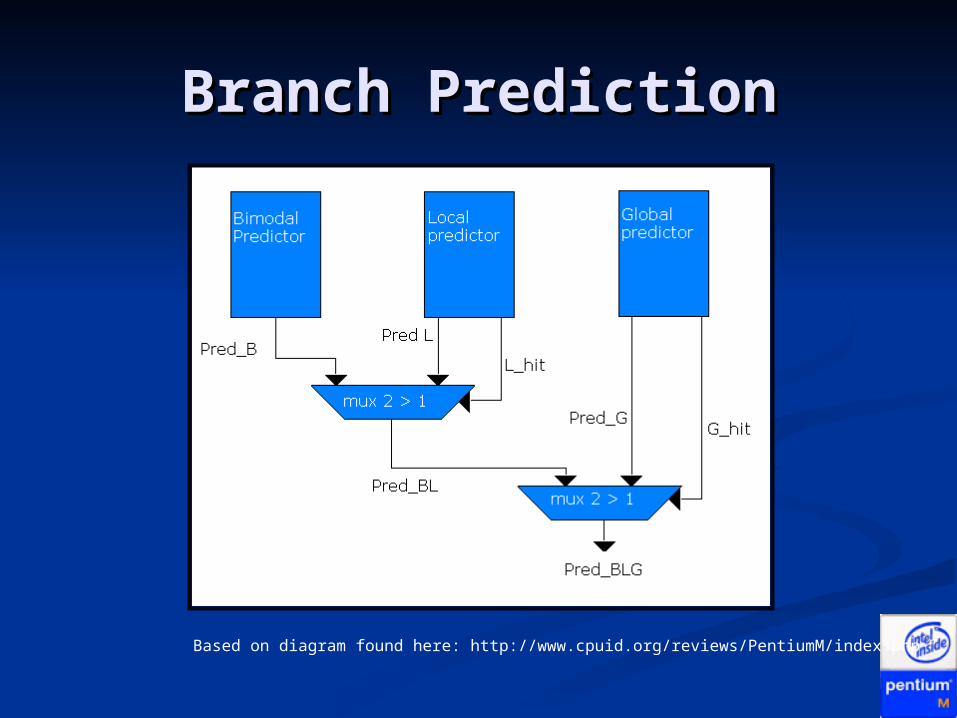
Branch PredictionBranch Prediction
Based on diagram found here: http://www.cpuid.org/reviews/PentiumM/index.php

Loop DetectorLoop Detector A predictor that A predictor that
always branches in a always branches in a loop will always loop will always incorrectly branch on incorrectly branch on the last iterationthe last iteration
Detector analyzes Detector analyzes branches for loop branches for loop behaviorbehavior
Benefits a wide Benefits a wide variety of program variety of program typestypes
http://www.intel.com/technology/itj/2003/volume07issue02/art03_pentiumm/p05_branch.htm

Indirect Branch Indirect Branch PredictorPredictor
Picks targets Picks targets based on global based on global flow control flow control historyhistory
Benefits programs Benefits programs compiled to compiled to branch to branch to calculated calculated addressesaddresses
http://www.intel.com/technology/itj/2003/volume07issue02/art03_pentiumm/p05_branch.htm

Reservation StationReservation Station Used as a store for µops to wait for their operands Used as a store for µops to wait for their operands
and execution units to become availableand execution units to become available Consists of 20 entriesConsists of 20 entries Control portion of the entry can be written to from Control portion of the entry can be written to from
one of three portsone of three ports Data portion can be written to from one of 6 Data portion can be written to from one of 6
available portsavailable ports 3 for ROB3 for ROB 3 for EU write backs3 for EU write backs
Scheduler then uses this to schedule up to 5 µops at Scheduler then uses this to schedule up to 5 µops at a timea time
During pipeline stage 31 entries that are ready for During pipeline stage 31 entries that are ready for dispatch are then sent to stage 32 dispatch are then sent to stage 32

CancellationCancellation
Reservation Station assumes that all Reservation Station assumes that all cache accesses will be hitscache accesses will be hits
In the case of a cache miss micro-In the case of a cache miss micro-ops that are dependant on the write-ops that are dependant on the write-back data need to be cancelled and back data need to be cancelled and rescheduled at a later timerescheduled at a later time
Can also occur due to a future Can also occur due to a future resource conflictresource conflict

RetirementRetirement Takes 2 clock cycles to completeTakes 2 clock cycles to complete Utilizes reorder buffer (ROB) to control retirement Utilizes reorder buffer (ROB) to control retirement
or completion of or completion of μμopsops ROB is a multi-ported register file with separate ROB is a multi-ported register file with separate
ports for ports for Allocation time writes of µop fields needed at retirementAllocation time writes of µop fields needed at retirement Execution Unit write-backsExecution Unit write-backs ROB reads of sources for the Reservation StationROB reads of sources for the Reservation Station Retirement logic reads of speculative result dataRetirement logic reads of speculative result data
Consists of 40 entries with each entry 157 bits Consists of 40 entries with each entry 157 bits widewide
The ROB participates inThe ROB participates in Speculative executionSpeculative execution Register renamingRegister renaming Out-of-order executionOut-of-order execution

Speculative ExecutionSpeculative Execution
Buffers results of the execution unit before Buffers results of the execution unit before commitcommit
Allows maximum rate for fetch and execute by Allows maximum rate for fetch and execute by assuming that branch prediction is perfect and assuming that branch prediction is perfect and no exceptions have occurred no exceptions have occurred
If a misprediction occurs:If a misprediction occurs: Speculative results stored in the ROB are immediately Speculative results stored in the ROB are immediately
discardeddiscarded Microengine will restart by examining the committed Microengine will restart by examining the committed
state in the ROBstate in the ROB

Register RenamingRegister Renaming
Entries in the ROB that will hold the Entries in the ROB that will hold the results of speculative µops are allocated results of speculative µops are allocated during stage 21 of the pipelineduring stage 21 of the pipeline
In stage 22 the sources for the µops are In stage 22 the sources for the µops are delivered based upon the allocation in delivered based upon the allocation in stage 21.stage 21.
Data is written to the ROB by the Data is written to the ROB by the Execution Unit into the renamed register Execution Unit into the renamed register during stage 83during stage 83

Out-of-order ExecutionOut-of-order Execution Allows µops to complete and write back their Allows µops to complete and write back their
results without concern for other µops executing results without concern for other µops executing simultaneouslysimultaneously
The ROB reorders the completed µops into the The ROB reorders the completed µops into the original sequence and updates the architectural original sequence and updates the architectural statestate
Entries in ROB are treated as FIFO during Entries in ROB are treated as FIFO during retirementretirement µops are originally allocated in sequential order so the µops are originally allocated in sequential order so the
retirement will also follow the original program orderretirement will also follow the original program order Happens during pipeline stage 92 and 93Happens during pipeline stage 92 and 93

Exception HandlingException Handling Events are sent to the ROB by the EU during stage 83Events are sent to the ROB by the EU during stage 83 Results sent to the ROB from the Execution Unit are Results sent to the ROB from the Execution Unit are
speculative results, therefore any exceptions encountered speculative results, therefore any exceptions encountered may not be realmay not be real
If the ROB determines that branch prediction was incorrect it If the ROB determines that branch prediction was incorrect it inserts a clear signal at the point just before the retirement inserts a clear signal at the point just before the retirement of this operation and then flushes all the speculative of this operation and then flushes all the speculative operations from the machineoperations from the machine
If speculation is correct, the ROB will invoke the correct If speculation is correct, the ROB will invoke the correct microcode exception handlermicrocode exception handler
All event records are saved to allow the handler to repair the All event records are saved to allow the handler to repair the result or invoke the correct macro handlerresult or invoke the correct macro handler
Pointers for the macro and micro instructions are also Pointers for the macro and micro instructions are also needed to allow the program to resume after completion by needed to allow the program to resume after completion by the event handlerthe event handler
If the ROB retires an operation that faults, both the in-order If the ROB retires an operation that faults, both the in-order and out-of-order sections are cleared. This happens during and out-of-order sections are cleared. This happens during pipeline stages 93 and 94pipeline stages 93 and 94

Memory SubsystemMemory Subsystem Memory Ordering Buffer (MOB)Memory Ordering Buffer (MOB)
Execution is out-of-order, but memory accesses Execution is out-of-order, but memory accesses cannot just be done in any ordercannot just be done in any order
Contains mainly the LB and the SBContains mainly the LB and the SB Speculative loads and storesSpeculative loads and stores
Not all loads can be speculativeNot all loads can be speculative I.e. a memory-mapped I/O ld could have unrecoverable side I.e. a memory-mapped I/O ld could have unrecoverable side
effectseffects Stores are never speculative (can’t get back Stores are never speculative (can’t get back
overwritten bits)overwritten bits) But to improve performance, stores are queued in the store But to improve performance, stores are queued in the store
buffer (SB) to allow pending loads to proceed buffer (SB) to allow pending loads to proceed Similar to a write-back cacheSimilar to a write-back cache

ScheduleSchedule P6 Pipeline in detailP6 Pipeline in detail
Front-EndFront-End Execution CoreExecution Core Back-EndBack-End
Power IssuesPower Issues Intel SpeedStepIntel SpeedStep
Testing the Testing the FeaturesFeatures x86 system registersx86 system registers Performance TestingPerformance Testing

Power IssuesPower Issues Power use = Power use = αα * C * V * C * V22 * F * F
αα = activity factor = activity factor C = C = effective capacitance V = voltageV = voltage F = operating frequencyF = operating frequency
Power use can be reduced Power use can be reduced linearly by lowering frequency linearly by lowering frequency and capacitance and and capacitance and quadratically by scaling voltagequadratically by scaling voltage

Mobile UseMobile Use
Mobile is bursty – full power is only Mobile is bursty – full power is only necessary for brief periodsnecessary for brief periods
Intel developed SpeedStep Intel developed SpeedStep technology to take advantage of this technology to take advantage of this fact and reduce power consumption fact and reduce power consumption during periods of inactivityduring periods of inactivity
http://www.intel.com/technology/itj/2003/volume07issue02/art05_power/p05_thermal.htm

SpeedStep I and IISpeedStep I and II
SpeedStep I and II used in previous SpeedStep I and II used in previous generationsgenerations Only two states: Only two states:
High performance (High frequency mode)High performance (High frequency mode) Lower power use (Low frequency mode)Lower power use (Low frequency mode)
ProblemsProblems Slow transition timesSlow transition times Limited opportunity for optimizationLimited opportunity for optimization

Pentium M GoalsPentium M Goals
Optimize for performance when plugged inOptimize for performance when plugged in Optimize for long battery-life when unpluggedOptimize for long battery-life when unplugged
Model Frequency (max / min) Vcore (max / min)
Pentium M 1,6GHz 1,6GHz / 600MHz 1,484v / 0,956v
Pentium M 1,5GHz 1,5GHz / 600MHz 1,484v / 0,956v
Pentium M 1,4GHz 1,4GHz / 600MHz 1,484v / 0,956v
Pentium M 1,3GHz 1,3GHz / 600MHz 1,388v / 0,956v
Pentium M 1,1GHzLow Voltage
1,1GHz / 600MHz 1,180v / 0,956v
Pentium M 900MHzUltra Low Voltage
1,6GHz / 600MHz 1,004v / 0,844v

SpeedStep IIISpeedStep III
Optimized to fix Optimized to fix limitations of previous limitations of previous generationsgenerations
Three innovations: Three innovations: Voltage-Frequency
switching separation Clock partitioning and
recovery Event blocking
FreqFreq..
VoltVolt..
1.6GH1.6GHzz
1.484 1.484 VV
1.4GH1.4GHzz
1.42V1.42V
1.2GH1.2GHzz
1.276V1.276V
1GHz1GHz 1.164V1.164V
800M800MHzHz
1.036V1.036V
600M600MHzHz
0.956 0.956 VV
The 6 states of the Pentium M 1,6GHz

Voltage-Frequency switching separation
Voltage scaling is Voltage scaling is stepped up and down stepped up and down incrementallyincrementally
This prevents clock This prevents clock noise and allows the noise and allows the processor to remain processor to remain responsive during responsive during transitiontransition
Once voltage target is Once voltage target is reached, frequency is reached, frequency is throttledthrottled
http://www.intel.com/technology/itj/2003/volume07issue02/art03_pentiumm/p10_speedstep.htm

Clock partitioning and recovery
During transition, During transition, only the core clock only the core clock and phase-locked-and phase-locked-loop are stoppedloop are stopped
This keeps logic This keeps logic active even while active even while the clock is stoppedthe clock is stopped
http://www.intel.com/technology/itj/2003/volume07issue02/art03_pentiumm/p10_speedstep.htm

Event blocking
To prevent loss of events To prevent loss of events during frequency and during frequency and voltage scaling when the voltage scaling when the core clock is stopped, core clock is stopped, interrupts, pin events, and interrupts, pin events, and snoop requests are snoop requests are sampled and savedsampled and saved
These events are These events are retransmitted once the retransmitted once the core clock becomes core clock becomes availableavailable
http://www.intel.com/technology/itj/2003/volume07issue02/art03_pentiumm/p10_speedstep.htm

LeakageLeakage
Transistors in off state still draw Transistors in off state still draw currentcurrent
As transistors shrink and clock As transistors shrink and clock speed increases, transistors leak speed increases, transistors leak more current causing higher more current causing higher temperatures and more power usetemperatures and more power use

Strained SiliconStrained Silicon
http://www.research.ibm.com/resources/press/strainedsilicon/

Benefits of Strained Benefits of Strained SiliconSilicon
Electrons flow up to 70% faster due to Electrons flow up to 70% faster due to reduced resistancereduced resistance
This leads to chips which are up to 35% This leads to chips which are up to 35% faster, without decrease in chip sizefaster, without decrease in chip size
Intel’s "uni-axial" strained silicon Intel’s "uni-axial" strained silicon process reduces leakage by at least five process reduces leakage by at least five times without reducing performance – times without reducing performance – the 65nm process will realize another the 65nm process will realize another reduction of at least four timesreduction of at least four times

High-K Transistor Gate High-K Transistor Gate Dielectric (coming soon)Dielectric (coming soon)
The dielectric used since the 1960s, The dielectric used since the 1960s, silicon dioxide, is so thin now that silicon dioxide, is so thin now that leakage is a significant problemleakage is a significant problem
A high-k (high dielectric constant) A high-k (high dielectric constant) material has been developed by Intel material has been developed by Intel to replace silicon dioxideto replace silicon dioxide
This high-k material reduces leakage This high-k material reduces leakage by a factor of 100 below silicon by a factor of 100 below silicon dioxidedioxide

More Advances to ExpectMore Advances to Expect
Continued lowering of capacitance Continued lowering of capacitance has helped reduce power has helped reduce power consumptionconsumption
Tri-gate transistors decreases Tri-gate transistors decreases leakage by increasing the amount of leakage by increasing the amount of surface area for electrons to flow surface area for electrons to flow throughthrough

ScheduleSchedule P6 Pipeline in detailP6 Pipeline in detail
Front-EndFront-End Execution CoreExecution Core Back-EndBack-End
Power IssuesPower Issues Intel SpeedStepIntel SpeedStep
Testing the Testing the FeaturesFeatures x86 system registersx86 system registers Performance TestingPerformance Testing

x86 System Registersx86 System Registers
EFLAGSEFLAGS Various system flagsVarious system flags
CPUIDCPUID Exposes type and available features of Exposes type and available features of
processorprocessor Model Specific Registers (MSRs)Model Specific Registers (MSRs)
rdmsr and wrmsrrdmsr and wrmsr ExamplesExamples
Enabling/Disabling SpeedStepEnabling/Disabling SpeedStep Determining and changing voltage/frequency pointsDetermining and changing voltage/frequency points MoreMore
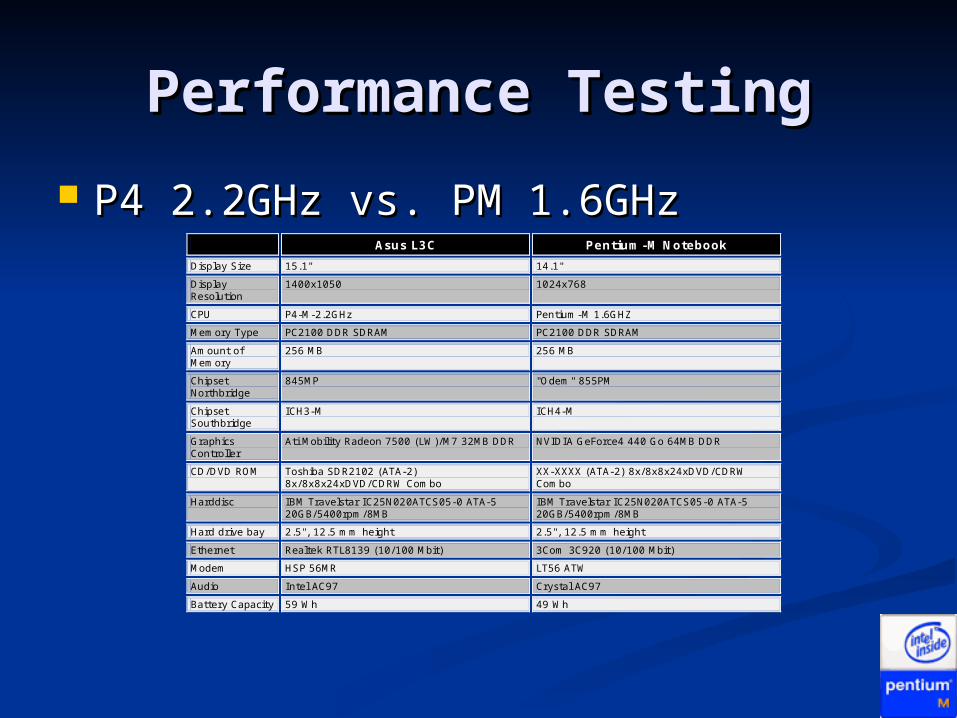
Performance TestingPerformance Testing
P4 2.2GHz vs. PM 1.6GHzP4 2.2GHz vs. PM 1.6GHz Asus L3C Pentium-M Notebook
Display Size 15.1" 14.1"
Display Resolution
1400x1050 1024x768
CPU P4-M-2.2GHz Pentium-M 1.6GHZ
Memory Type PC2100 DDR SDRAM PC2100 DDR SDRAM
Amount of Memory
256 MB 256 MB
Chipset Northbridge
845MP "Odem" 855PM
Chipset Southbridge
ICH3-M ICH4-M
Graphics Controller
Ati Mobility Radeon 7500 (LW)/M7 32MB DDR NVIDIA GeForce4 440 Go 64MB DDR
CD/DVD ROM Toshiba SDR2102 (ATA-2) 8x/8x8x24xDVD/CDRW Combo
XX-XXXX (ATA-2) 8x/8x8x24xDVD/CDRW Combo
Harddisc IBM Travelstar IC25N020ATCS05-0 ATA-5 20GB/5400rpm/8MB
IBM Travelstar IC25N020ATCS05-0 ATA-5 20GB/5400rpm/8MB
Hard drive bay 2.5", 12.5 mm height 2.5", 12.5 mm height
Ethernet Realtek RTL8139 (10/100 Mbit) 3Com 3C920 (10/100 Mbit)
Modem HSP 56MR LT56 ATW
Audio Intel AC97 Crystal AC97
Battery Capacity 59 Wh 49 Wh

BenchmarkBenchmark
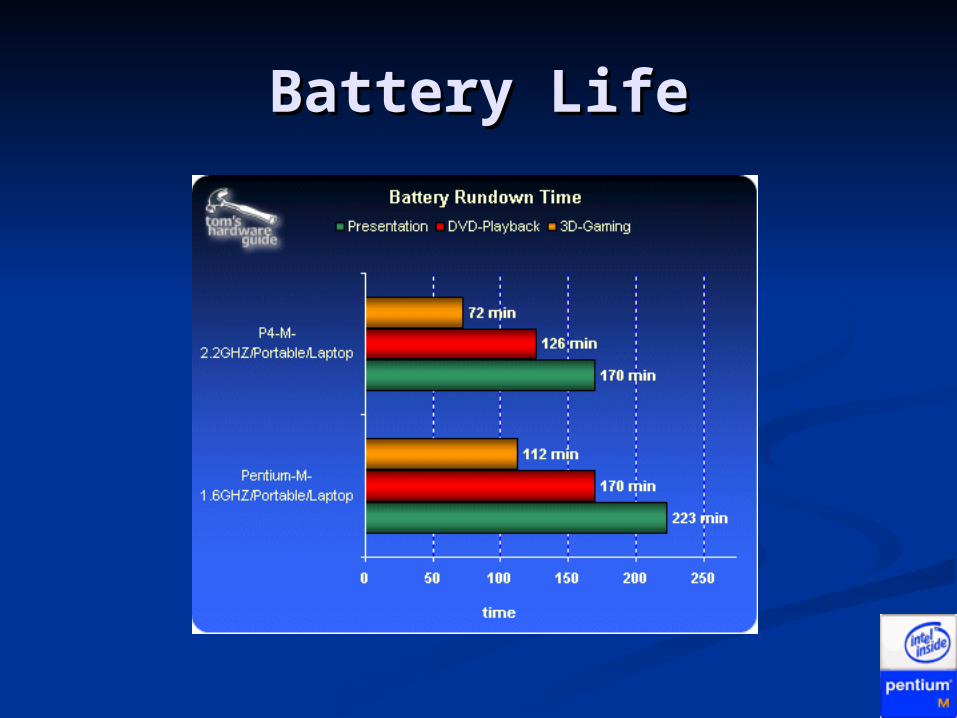
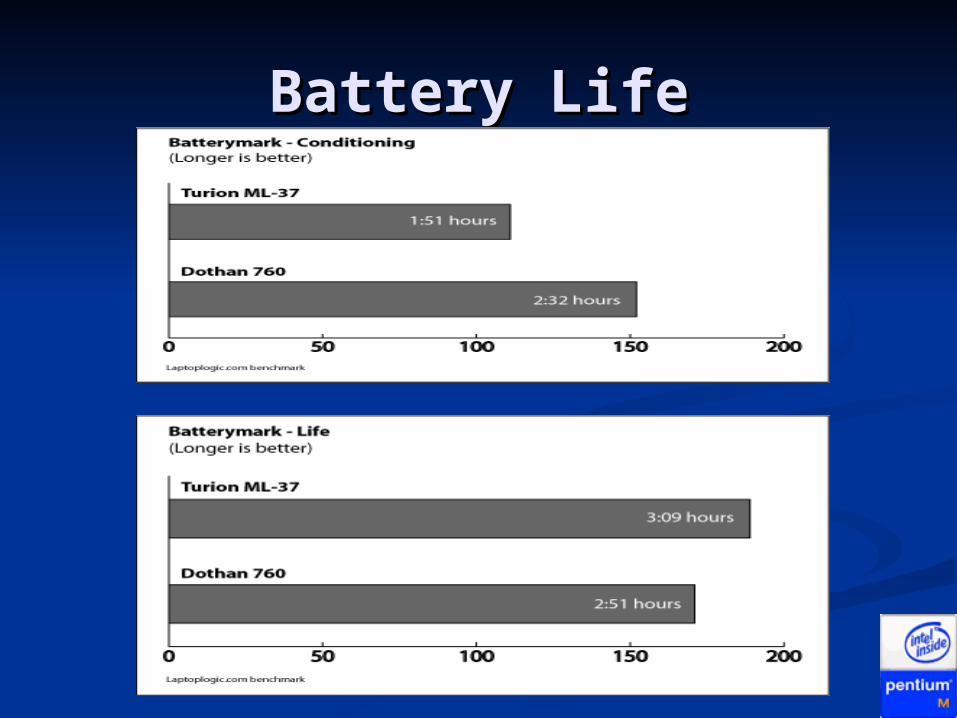
Battery LifeBattery Life

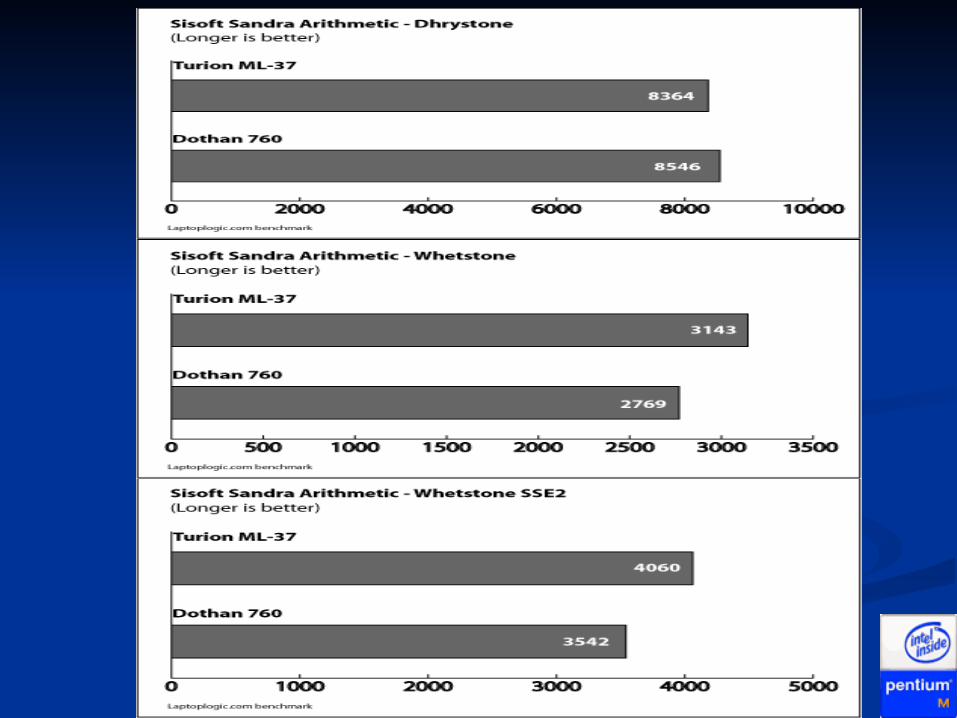
Pentium M vs AMD Pentium M vs AMD TurionTurionSpecifications Ferrari 4005 TravelMate 8104
Processor AMD Turion 64 Mobile ML-37 (2.0 GHz, 1MB L2 Cache)
Intel Pentium M Processor 760 (2.0 GHz, 2MB L2 Cache)
FSB/ HTT 1600MHz 533 MHz
Chipset ATI Radeon Xpress 200M Intel 915 PM Express
Wireless LAN
Broadcom 802.11b/g with SpeedBooster
Bluetooth Wireless I rDA
Intel PRO/Wireless 2915ABG (802.11a/b/g)
Bluetooth Wireless I rDA
LCD 15.4” WSXGA+ TFT LCD (1680x1050)
15.4” WSXGA+ TFT LCD (1680x1050)
Hard Drive 100GB Seagate Momentus
5400RPM 8MB Cache (ST9100823A)
100GB Seagate Momentus 5400RPM 8MB Cache
(ST9100823A)
Memory
1GB DDR400 SDRAM (2 x 512MB) on
Single-Channel Mode 2.5-3-3-7
1GB DDR2-533 SDRAM (2 x 512MB) on
Dual-Channel Mode 4-4-4-12
Graphics
ATI Mobility Radeon X700 128MB PCI-E (358 core/345 mem)
Driver version 6.14.10.6546
ATI Mobility Radeon X700 128MB PCI-E (358 core/345 mem)
Driver version 6.14.10.6546
Graphics Interface S-Video/TV-out/DVI-D S-Video/TV-out/DVI-D
Optical Drive Slot-Load DVD-RW Super-Multi Double Layer
Tray-Load DVD-RW Super-Multi Double Layer
Audio Realtek AC' 97 Realtek High Definition
Audio Interface Microphone, two stereo speakers, headphone/line-out with SPDIF
support
Microphone, two stereo speakers, headphone/line-out with SPDIF
support
Weight 6.3 lbs. with 8-cell battery 6.3 lbs. with 8-cell battery
Size (W x D x H) 14.3” x 10.5” x 1.2”-1.4” 14.3” x 10.5” x 1.2”-1.4”
Operating System Windows XP Professional w/SP2 Windows XP Professional w/SP2
Battery 4,800 mAh 4,800 mAh

GamingGaming
Battery LifeBattery Life

Future ProcessorsFuture Processors YonahYonah
Dual-core processor Dual-core processor Manufactured on a 65 nm processManufactured on a 65 nm process Starting at 2.16GHz with a 667 MHz FSB (166MHz quad-Starting at 2.16GHz with a 667 MHz FSB (166MHz quad-
pumped)pumped) Shared 2MB L2 cacheShared 2MB L2 cache Increased floating point performance with SSE3 Increased floating point performance with SSE3
instructionsinstructions
MeromMerom Based on EM64T ISABased on EM64T ISA Consume ~0.5 W of power, half of what the Dothan Consume ~0.5 W of power, half of what the Dothan
consumesconsumes Possibility of laptops with 10 hours of battery lifePossibility of laptops with 10 hours of battery life





























