Embed Size (px)
Citation preview

Intel® oneAPI Math Kernel Library (oneMKL) Introduction
March 2021
Gennady Fedorov, Technical Consulting Engineer, Intel Architecture, Graphics & Software (IAGS)
Intel OneMKL Introduction2
Notices & Disclaimers
Intel technologies may require enabled hardware, software or service activation. Learn more at intel.com or from the OEM or retailer.
Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Optimization Notice: Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice Revision #20110804. https://software.intel.com/en-us/articles/optimization-notice
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.
Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. See backup for configuration details. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See configuration disclosure for details. No product or component can be absolutely secure.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
NOTE this slide is added as part of the template after Title Slide options. Recommend keeping it there.

Intel OneMKL Introduction3
Agenda
▪ oneMKL Content
▪ oneMKL, What’s New
▪ oneMKL OpenMP Offload Interfaces
▪ DEMO
▪ Linking with oneMKL
▪ oneMKL Known Issues/Limitations
▪ Q&A

Intel OneMKL Introduction4
Agenda
▪ oneMKL Content
▪ oneMKL, What’s New
▪ oneMKL OpenMP Offload Interfaces
▪ DEMO – BLAS, OpenMP Offloading
▪ Linking with oneMKL
▪ oneMKL Known Issues/Limitations
▪ Q&A
Intel OneMKL Introduction5
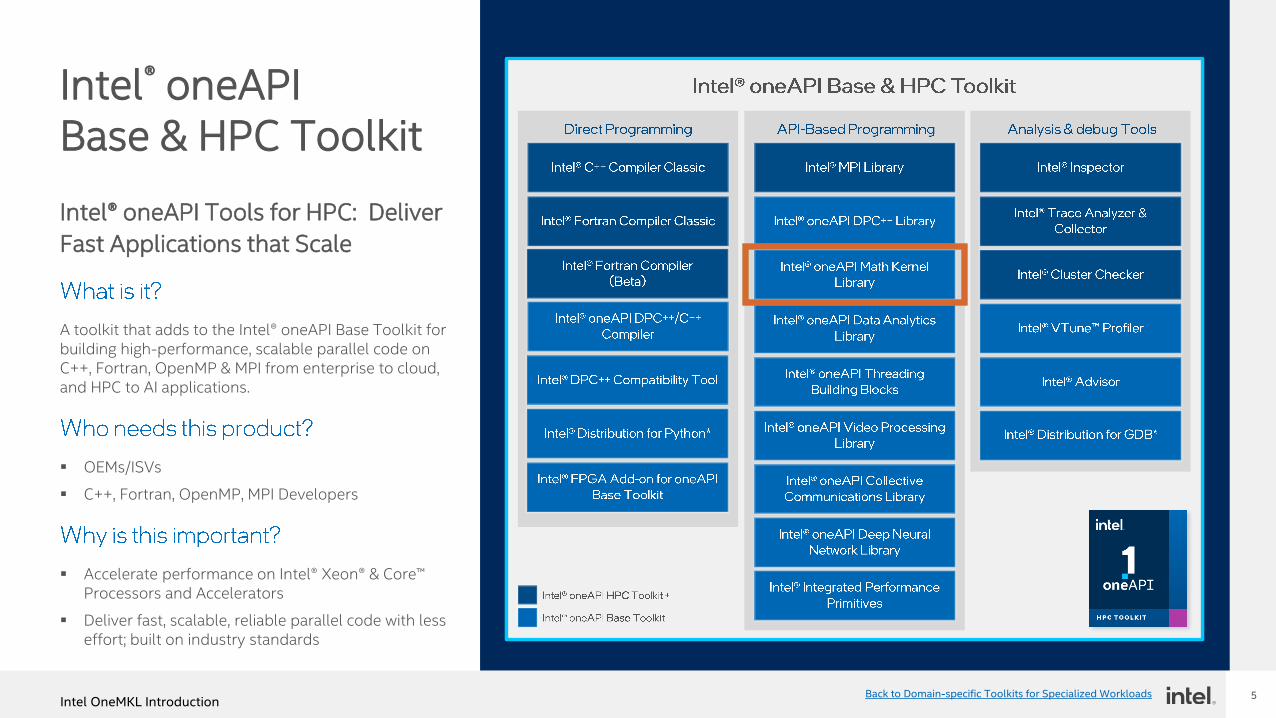
Intel® oneAPI Base & HPC Toolkit
Intel® oneAPI Tools for HPC: Deliver
Fast Applications that Scale
A toolkit that adds to the Intel® oneAPI Base Toolkit for building high-performance, scalable parallel code on C++, Fortran, OpenMP & MPI from enterprise to cloud, and HPC to AI applications.
▪ OEMs/ISVs
▪ C++, Fortran, OpenMP, MPI Developers
▪ Accelerate performance on Intel® Xeon® & Core™ Processors and Accelerators
▪ Deliver fast, scalable, reliable parallel code with less effort; built on industry standards
Back to Domain-specific Toolkits for Specialized Workloads
Intel OneMKL Introduction6
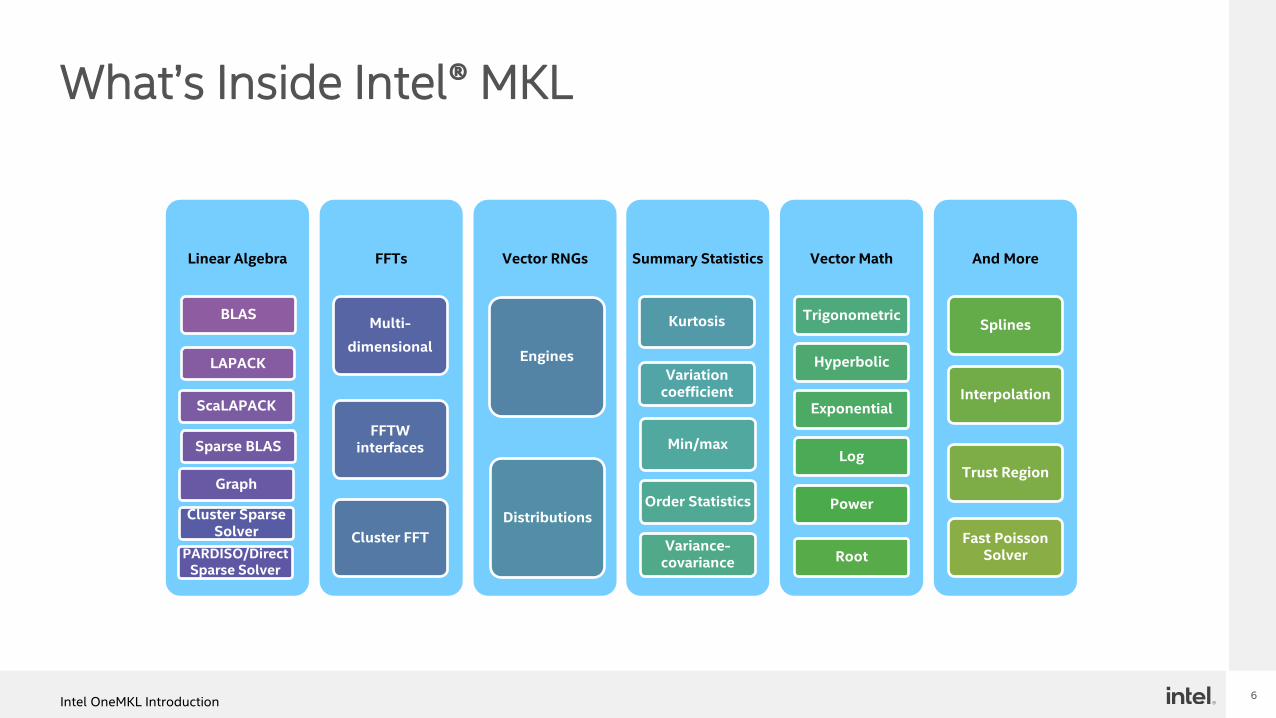
What’s Inside Intel® MKL
Linear Algebra
BLAS
LAPACK
ScaLAPACK
Sparse BLAS
Graph
PARDISO/Direct Sparse Solver
Cluster Sparse Solver
FFTs
Multi-
dimensional
FFTW interfaces
Cluster FFT
Vector RNGs
Engines
Distributions
Summary Statistics
Kurtosis
Variation coefficient
Min/max
Order Statistics
Variance-covariance
Vector Math
Trigonometric
Hyperbolic
Exponential
Log
Power
Root
And More
Splines
Interpolation
Trust Region
Fast Poisson Solver

Intel OneMKL Introduction7
Agenda
▪ oneMKL Content
▪ oneMKL, What’s New
▪ oneMKL OpenMP Offload Interfaces
▪ DEMO – BLAS, OpenMP Offloading
▪ Linking with oneMKL
▪ oneMKL Known Issues/Limitations
▪ Q&A
Intel OneMKL Introduction8
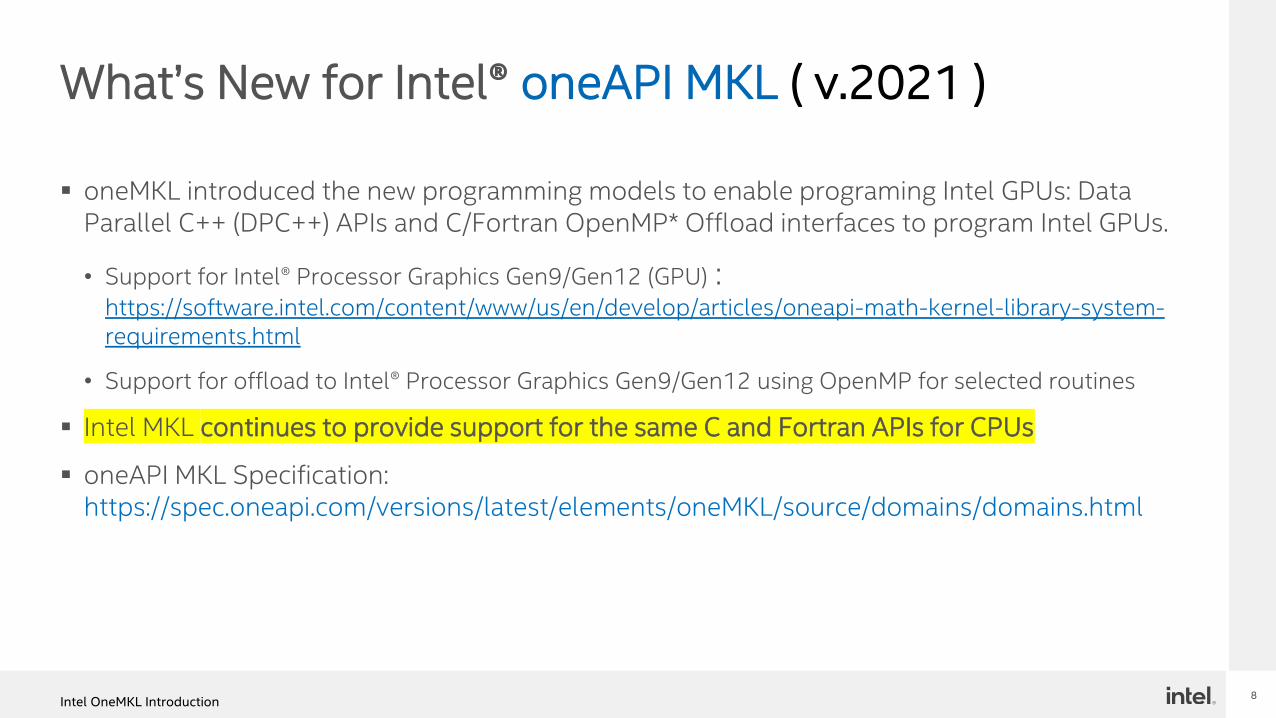
What’s New for Intel® oneAPI MKL ( v.2021 )
▪ oneMKL introduced the new programming models to enable programing Intel GPUs: Data Parallel C++ (DPC++) APIs and C/Fortran OpenMP* Offload interfaces to program Intel GPUs.
• Support for Intel® Processor Graphics Gen9/Gen12 (GPU) : https://software.intel.com/content/www/us/en/develop/articles/oneapi-math-kernel-library-system-requirements.html
• Support for offload to Intel® Processor Graphics Gen9/Gen12 using OpenMP for selected routines
▪ Intel MKL continues to provide support for the same C and Fortran APIs for CPUs
▪ oneAPI MKL Specification: https://spec.oneapi.com/versions/latest/elements/oneMKL/source/domains/domains.html
Intel OneMKL Introduction9
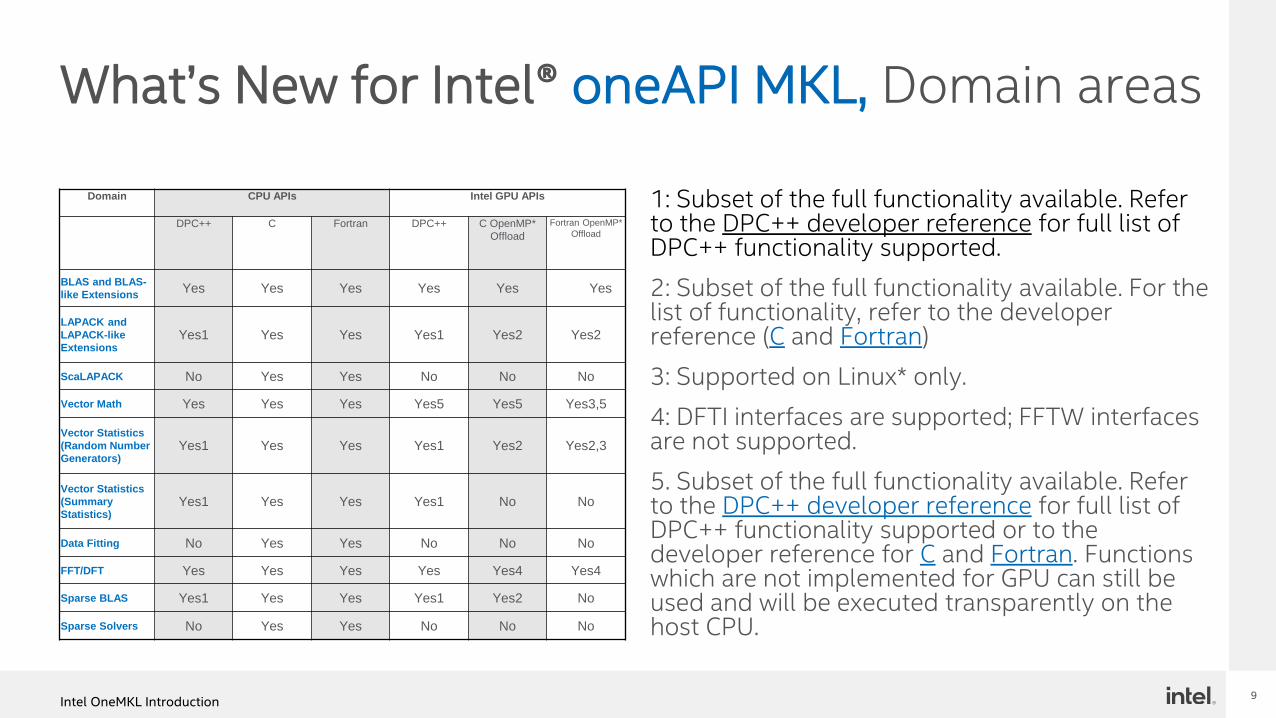
What’s New for Intel® oneAPI MKL, Domain areas
1: Subset of the full functionality available. Refer to the DPC++ developer reference for full list of DPC++ functionality supported.
2: Subset of the full functionality available. For the list of functionality, refer to the developer reference (C and Fortran)
3: Supported on Linux* only.
4: DFTI interfaces are supported; FFTW interfaces are not supported.
5. Subset of the full functionality available. Refer to the DPC++ developer reference for full list of DPC++ functionality supported or to the developer reference for C and Fortran. Functions which are not implemented for GPU can still be used and will be executed transparently on the host CPU.
Domain CPU APIs Intel GPU APIs
DPC++ C Fortran DPC++ C OpenMP*
Offload
Fortran OpenMP*
Offload
BLAS and BLAS-
like ExtensionsYes Yes Yes Yes Yes Yes
LAPACK and
LAPACK-like
ExtensionsYes1 Yes Yes Yes1 Yes2 Yes2
ScaLAPACK No Yes Yes No No No
Vector Math Yes Yes Yes Yes5 Yes5 Yes3,5
Vector Statistics
(Random Number
Generators)Yes1 Yes Yes Yes1 Yes2 Yes2,3
Vector Statistics
(Summary
Statistics)Yes1 Yes Yes Yes1 No No
Data Fitting No Yes Yes No No No
FFT/DFT Yes Yes Yes Yes Yes4 Yes4
Sparse BLAS Yes1 Yes Yes Yes1 Yes2 No
Sparse Solvers No Yes Yes No No No
Intel OneMKL Introduction10
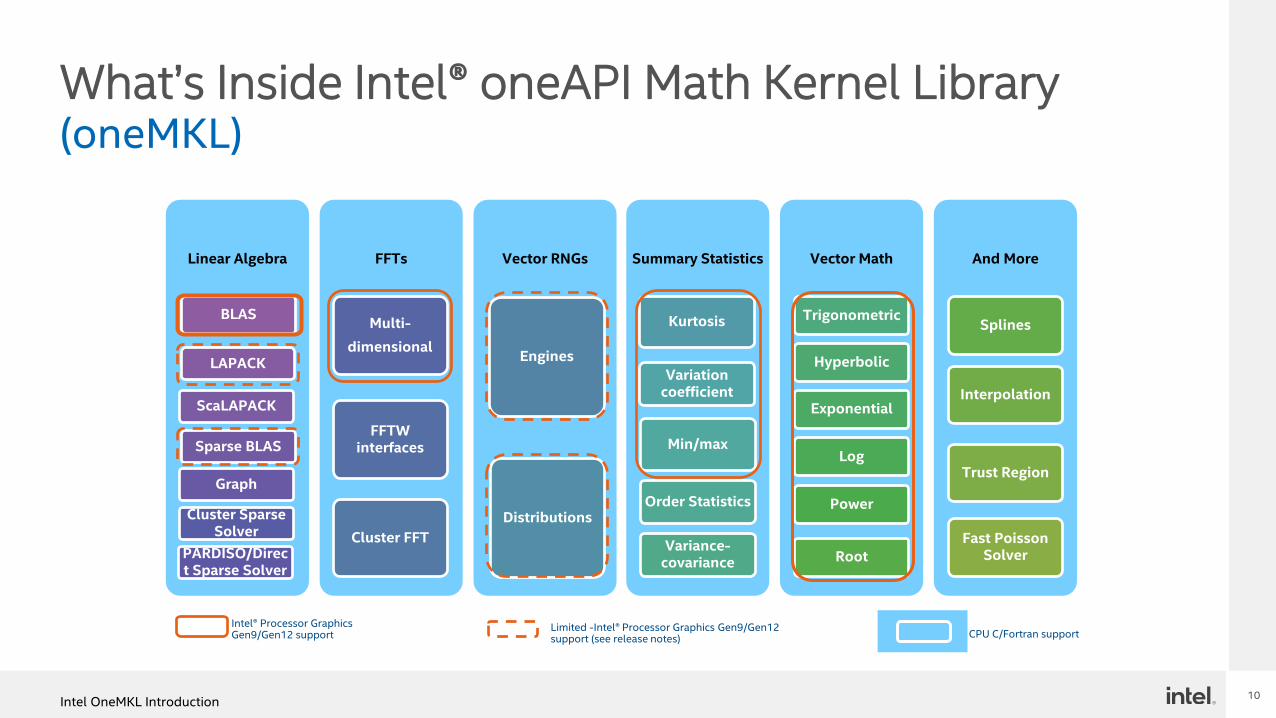
What’s Inside Intel® oneAPI Math Kernel Library(oneMKL)
Linear Algebra
BLAS
LAPACK
ScaLAPACK
Sparse BLAS
Graph
PARDISO/Direct Sparse Solver
Cluster Sparse Solver
FFTs
Multi-
dimensional
FFTW interfaces
Cluster FFT
Vector RNGs
Engines
Distributions
Summary Statistics
Kurtosis
Variation coefficient
Min/max
Order Statistics
Variance-covariance
Vector Math
Trigonometric
Hyperbolic
Exponential
Log
Power
Root
And More
Splines
Interpolation
Trust Region
Fast Poisson Solver
Intel® Processor Graphics Gen9/Gen12 support
Limited -Intel® Processor Graphics Gen9/Gen12 support (see release notes) CPU C/Fortran support

Intel OneMKL Introduction11
Agenda
▪ oneMKL Content
▪ oneMKL, What’s New
▪ oneMKL OpenMP Offload Interfaces
▪ DEMO – BLAS, OpenMP Offloading
▪ Linking with oneMKL
▪ oneMKL Known Issues/Limitations
▪ Q&A
Intel OneMKL Introduction12
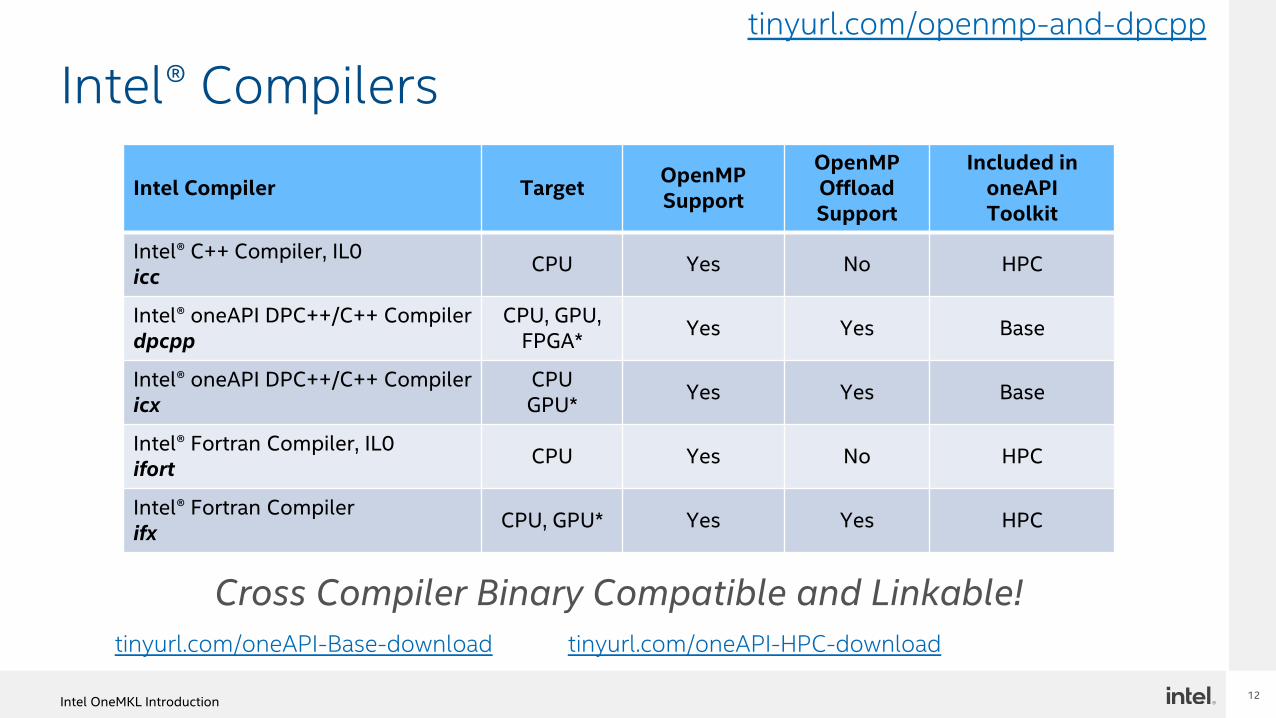
Intel® Compilers
Intel Compiler TargetOpenMPSupport
OpenMP OffloadSupport
Included in oneAPIToolkit
Intel® C++ Compiler, IL0 icc
CPU Yes No HPC
Intel® oneAPI DPC++/C++ Compiler dpcpp
CPU, GPU, FPGA*
Yes Yes Base
Intel® oneAPI DPC++/C++ Compiler icx
CPUGPU*
Yes Yes Base
Intel® Fortran Compiler, IL0 ifort
CPU Yes No HPC
Intel® Fortran Compiler ifx
CPU, GPU* Yes Yes HPC
Cross Compiler Binary Compatible and Linkable!
tinyurl.com/oneAPI-Base-download tinyurl.com/oneAPI-HPC-download
tinyurl.com/openmp-and-dpcpp

Intel OneMKL Introduction13
▪ Drivers
• icx (C/C++), ifx (Fortran)
▪ OPTIONS
-fiopenmp
• Selects Intel Optimized OMP
• -fopenmp for Clang* O.S. OMP
• -qopenmp NO!! rejected, only in ICC/IFORT
-fopenmp-targets=spir64
• Needed for OMP Offload
• Generates SPIRV code fat binary for offload kernels
OpenMP with Intel® Compilers
tinyurl.com/intel-openmp-offloadGet Started with OpenMP* Offload Feature to GPU:

Intel OneMKL Introduction14
Offload: OpenMP* 4.0 for Devices - Constructs
▪ Target construct transfer control and data from the host to the device
▪ Syntax (C/C++) #pragma omp target [clause[[,] clause],…] structured-block
▪ Syntax (Fortran) !$omp target [clause[[,] clause],…] structured-block !$omp end target
▪ Clauses device(scalar-integer-expression) map([{alloc | to | from | tofrom}:] list) if(scalar-expr)

Intel OneMKL Introduction15
Offload: Key OpenMP Directives (C)
#pragma omp target data
Map host-side variables to device variables inside this block.
#pragma omp target enter data#pragma omp target exit data
Map/unmap host-side variables to device variables: the two halves of #pragma omp target data.
#pragma omp target variant dispatch
Offload oneMKL calls inside this block to the GPU.
#pragma omp target
Offload execution of block to the GPU.

Intel OneMKL Introduction16
int main() {long m = 10, n = 6, k = 8, lda = 12, ldb = 8, ldc = 10;long sizea = lda * k, sizeb = ldb * n, sizec = ldc * n;double alpha = 1.0, beta = 0.0;
// Allocate matricesdouble *A = (double *) mkl_malloc(sizeof(double) * sizea, 64);double *B = (double *) mkl_malloc(sizeof(double) * sizeb, 64);double *C = (double *) mkl_malloc(sizeof(double) * sizec, 64);
// Initialize matrices […]…
// Compute C = A * B on CPUcblas_dgemm(CblasColMajor, CblasNoTrans, CblasNoTrans, m, n, k,
alpha, A, lda, B, ldb, beta, C, ldc);
…}
𝐶 ← 𝛼𝐴𝐵 + 𝛽𝐶
GEMM with oneMKL C API
Intel OneMKL Introduction17
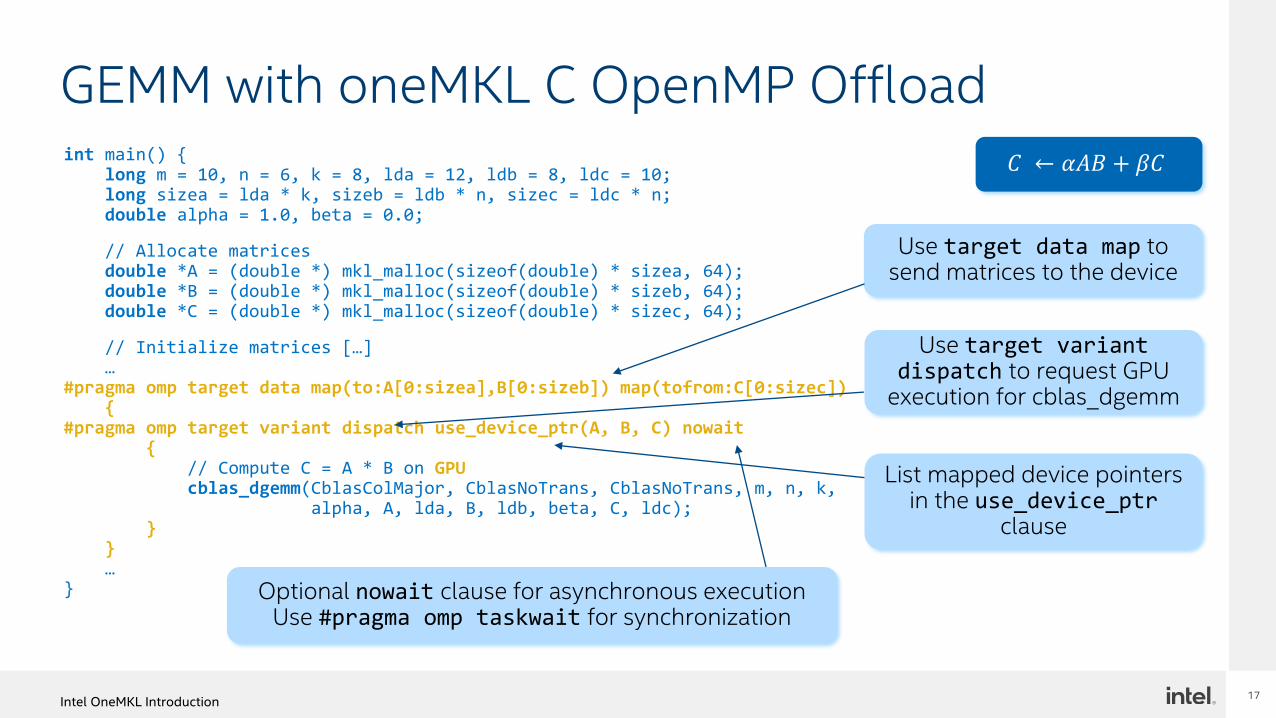
int main() {long m = 10, n = 6, k = 8, lda = 12, ldb = 8, ldc = 10;long sizea = lda * k, sizeb = ldb * n, sizec = ldc * n;double alpha = 1.0, beta = 0.0;
// Allocate matricesdouble *A = (double *) mkl_malloc(sizeof(double) * sizea, 64);double *B = (double *) mkl_malloc(sizeof(double) * sizeb, 64);double *C = (double *) mkl_malloc(sizeof(double) * sizec, 64);
// Initialize matrices […]…
#pragma omp target data map(to:A[0:sizea],B[0:sizeb]) map(tofrom:C[0:sizec]){
#pragma omp target variant dispatch use_device_ptr(A, B, C) nowait{
// Compute C = A * B on GPUcblas_dgemm(CblasColMajor, CblasNoTrans, CblasNoTrans, m, n, k,
alpha, A, lda, B, ldb, beta, C, ldc);}
}…
}
Use target data map to send matrices to the device
Use target variant dispatch to request GPU
execution for cblas_dgemm
List mapped device pointers in the use_device_ptr
clause
Optional nowait clause for asynchronous executionUse #pragma omp taskwait for synchronization
𝐶 ← 𝛼𝐴𝐵 + 𝛽𝐶
GEMM with oneMKL C OpenMP Offload

Intel OneMKL Introduction18
… // module files
program main
integer :: m = 10, n = 6, k = 8, lda = 12, ldb = 8, ldc = 10integer :: sizea = lda * k, sizeb = ldb * n, sizec = ldc * ndouble :: alpha = 1.0, beta = 0.0double, allocatable :: A(:), B(:), C(:)
// Allocate matrices…allocate(A(sizea))…
// Initialize matrices……
! Compute C = A * Bcall dgemm(‘N’, ‘N’, m, n, k, alpha, A, lda, B, ldb, beta, C, ldc)
…end program
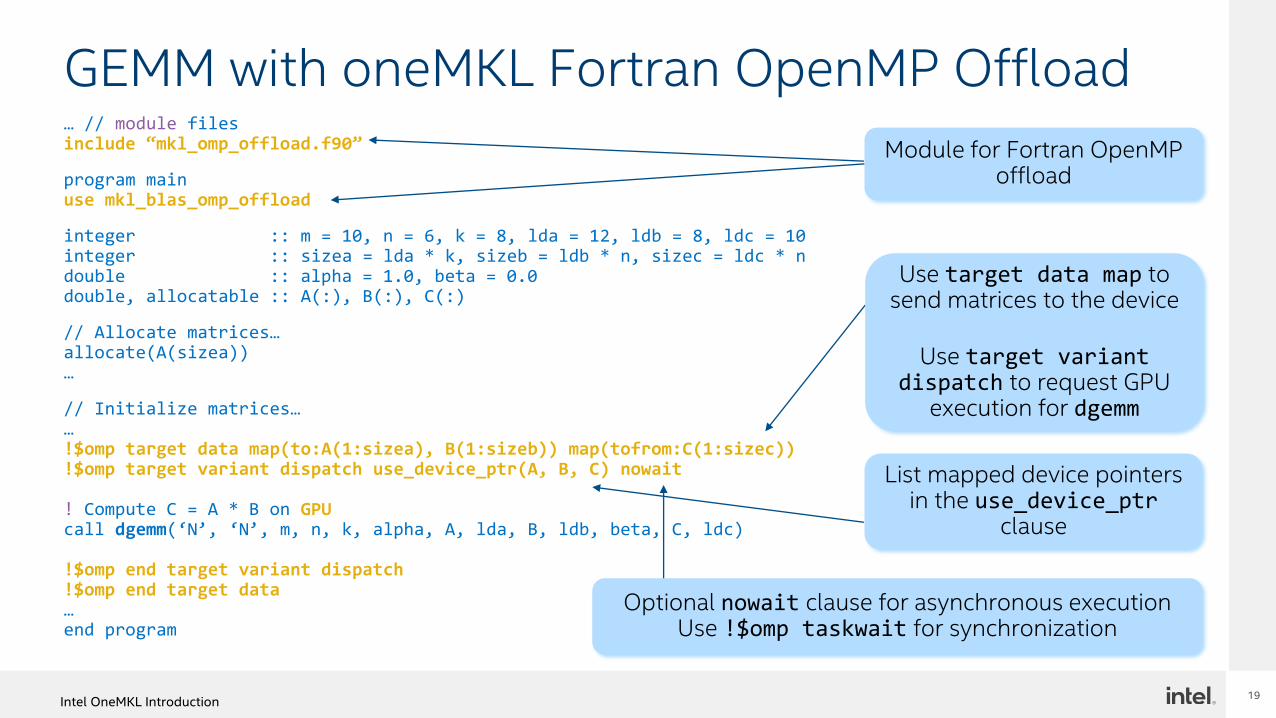
GEMM with oneMKL Fortran OpenMP Offload
Intel OneMKL Introduction19
… // module filesinclude “mkl_omp_offload.f90”
program mainuse mkl_blas_omp_offload
integer :: m = 10, n = 6, k = 8, lda = 12, ldb = 8, ldc = 10integer :: sizea = lda * k, sizeb = ldb * n, sizec = ldc * ndouble :: alpha = 1.0, beta = 0.0double, allocatable :: A(:), B(:), C(:)
// Allocate matrices…allocate(A(sizea))…
// Initialize matrices……!$omp target data map(to:A(1:sizea), B(1:sizeb)) map(tofrom:C(1:sizec))!$omp target variant dispatch use_device_ptr(A, B, C) nowait
! Compute C = A * B on GPUcall dgemm(‘N’, ‘N’, m, n, k, alpha, A, lda, B, ldb, beta, C, ldc)
!$omp end target variant dispatch!$omp end target data…end program
GEMM with oneMKL Fortran OpenMP Offload
Use target data map to send matrices to the device
Use target variant dispatch to request GPU
execution for dgemm
List mapped device pointers in the use_device_ptr
clause
Optional nowait clause for asynchronous executionUse !$omp taskwait for synchronization
Module for Fortran OpenMP offload

Intel OneMKL Introduction20
Agenda
▪ oneMKL Content
▪ oneMKL, What’s New
▪ oneMKL OpenMP Offload Interfaces
▪ DEMO – BLAS, OpenMP Offloading
▪ Linking with oneMKL
▪ oneMKL Known Issues/Limitations
▪ Q&A

Intel OneMKL Introduction21
Demo, BLAS
▪ Review sgemm_offload.cpp, makefile
▪ Build and Run:
• ./a.out 4
• ./a.out 400
• ./a.out 4000
▪ export MKL_VERBOSE=1
• ./a.out 4

Intel OneMKL Introduction22
Demo, BLAS, cont.
▪ Enabling the OpenMP profiling
▪ #LIBOMPTARGET_PROFILE=T - Enables OpenMP profiling, also prints the chosen device
▪ #LIBOMPTARGET_PLUGIN=OpenCL - Target OpenCL backend instead of Level0
▪ #LIBOMPTARGET_DEBUG=1 - Forces OpenMP to dump debug info
• export LIBOMPTARGET_DEBUG=1
• ./a.out 100 > 1.log 2>&1
• Less 1.log | grep 400
▪ https://openmp.llvm.org/docs/design/Runtimes.html

Intel OneMKL Introduction23
Agenda
▪ oneMKL Content
▪ oneMKL, What’s New
▪ oneMKL OpenMP Offload Interfaces
▪ DEMO – BLAS, OpenMP Offloading
▪ Linking with oneMKL
▪ oneMKL Known Issues/Limitations
▪ Q&A
Intel OneMKL Introduction24
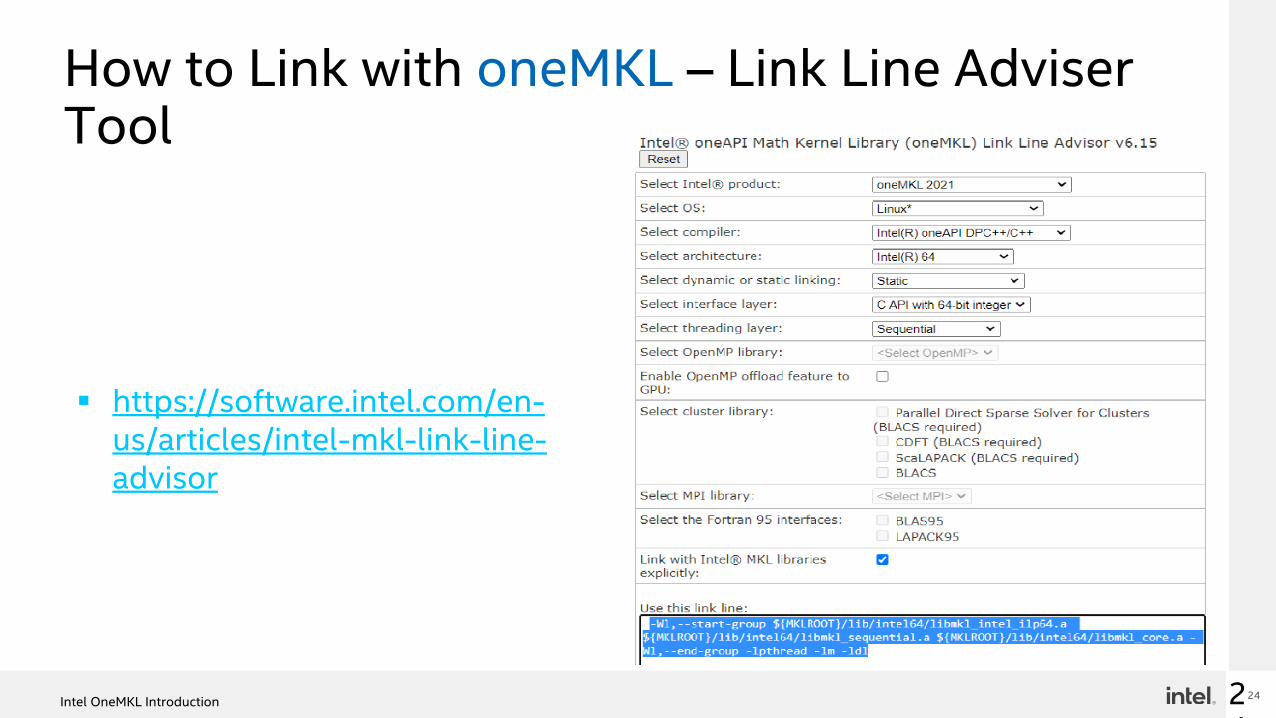
How to Link with oneMKL – Link Line Adviser Tool
24
▪ https://software.intel.com/en-us/articles/intel-mkl-link-line-advisor

Intel OneMKL Introduction25
25
Building & Linking with oneMKL – OpenMP Offload
▪ Headers
#include “omp.h”
#include “mkl_omp_offload.h”
▪ Build flags (new flags highlighted)
icx -c -DMKL_ILP64 -m64 -fiopenmp -fopenmp-targets=spir64 –mllvm -vpo-paropt-use-raw-dev-ptr
-I${MKLROOT}/include source.c -o source.o
▪ Link flags (example: dynamic link; sequential threading)
icx source.o -fiopenmp -fopenmp-targets=spir64 -mllvm -vpo-paropt-use-raw-dev-ptr
-L${MKLROOT}/lib/intel64 -lmkl_intel_ilp64 -lmkl_sequential -lmkl_core -lOpenCL -lpthread -ldl
-lm -o source.out

Intel OneMKL Introduction26
26
How to Link with oneMKL in Linux*
▪ DPC++ interfaces with static linking on Linux
dpcpp -fsycl-device-code-split=per_kernel -DMKL_ILP64 <typical user includes and linking flags and other libs> ${MKLROOT}/lib/intel64/libmkl_sycl.a -Wl,--start-group ${MKLROOT}/lib/intel64/libmkl_intel_ilp64.a ${MKLROOT}/lib/intel64/libmkl_<sequential|tbb_thread>.a ${MKLROOT}/lib/intel64/libmkl_core.a -Wl,--end-group -lsycl -lOpenCL -lpthread -ldl –lm
▪ DPC++ interfaces with dynamic linking on Linux
dpcpp -DMKL_ILP64 <typical user includes and linking flags and other libs> -L${MKLROOT}/lib/intel64 -lmkl_sycl -lmkl_intel_ilp64 -lmkl_<sequential|tbb_thread> -lmkl_core -lsycl -lOpenCL -lpthread -ldl -lm

Intel OneMKL Introduction27
Agenda
▪ oneMKL Content
▪ oneMKL, What’s New
▪ oneMKL OpenMP Offload Interfaces
▪ DEMO – BLAS, OpenMP Offloading
▪ Linking with oneMKL
▪ oneMKL Known Issues/Limitations
▪ Q&A

Intel OneMKL Introduction28
Intel® oneAPI MKL, Known Issues/Limitations
▪ Dynamic linking on Windows* is supported only for the BLAS and LAPACK domains.*
▪ DFT on Intel GPU and Intel® oneAPI Level Zero backend may result in incorrect results for large batch sizes. To run DFT on Intel GPU, set the environment variable SYCL_BE=PI_OPENCL.
▪ Static linking on Windows* can take significant time (up to 10 minutes).
▪ OpenMP* offload is only supported for static libraries on Windows*.
▪ MKL 2021 backward compatibility has been broken due to the oneTBBchangings **
* https://software.intel.com/content/www/us/en/develop/articles/oneapi-math-kernel-library-release-notes.html
** (https://software.intel.com/content/www/us/en/develop/articles/tbb-revamp.html)

Intel OneMKL Introduction29
Intel® oneAPI Math Kernel Library Resources
Intel® Math Kernel Library (Intel® MKL) site
Intel® oneAPI Math Kernel Library
Intel® DevCloud for oneAPI Projects
software.intel.com/intel-mkl
software.intel.com/oneAPI/mkl
https://software.intel.com/en-us/devcloud/oneapi
Online Service Center (Paid support) https://supporttickets.intel.com/servicecenter?lang=en-US
Intel® MKL Forumhttps://community.intel.com/t5/Intel-oneAPI-Math-Kernel-Library/bd-p/oneapi-math-kernel-library
Intel® MKL Benchmarkshttps://software.intel.com/content/www/us/en/develop/tools/math-kernel-library/benchmarks.html
Intel® MKL Link Line Advisor https://software.intel.com/content/www/us/en/develop/articles/intel-mkl-link-line-advisor.html

Intel OneMKL Introduction30
Q & A

31





























