Embed Size (px)
Citation preview

Summary The Unity prototype tackles the schema integration
problem by constructing an integrated, global view in a bottom-up approach.
Constructing a global view in this manner requires describing data source semantics using a dictionary and a XML-based language.
The extraction process, which is semi-automatic in nature, is separated from the integration process.
Thus, the integration process is automatic, and there is no requirement for a global human integrator.
Systematic naming using a dictionary allows global queries to be graphically constructed without specifying joins between global relations.
The global view produced demonstrates properties similar to a dynamically constructed Universal Relation.

Benefits and Contributions The architecture automatically integrates relational
schemas into a global view for querying.
Unique contributions: Synthesizing a global view from the bottom-up instead of
top-down improves integration scalability. Organizing the global view as a hierarchy of concepts
instead of relations or predicates simplifies querying as the user does not have to specify specific relations or join conditions. This is called Querying by Context (QBC).
Query processing is achieved by dynamically discovering extraction rules based on the naming of fields and tables. The discovered rules are similar to the extraction rules of global-
as-view (GAV) systems.
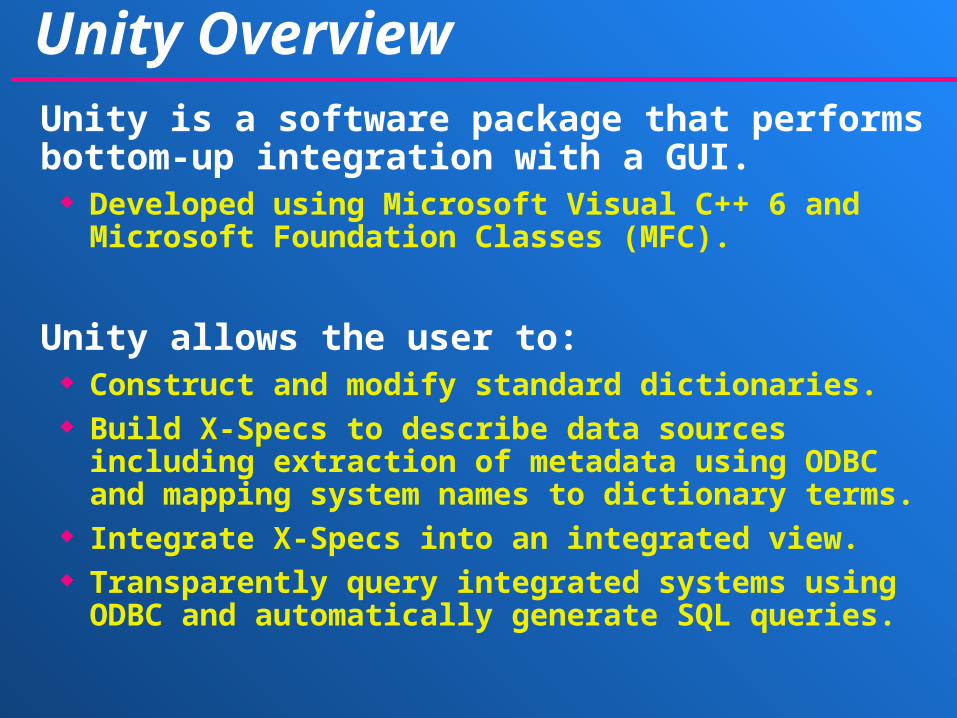
Unity Overview Unity is a software package that performs bottom-
up integration with a GUI. Developed using Microsoft Visual C++ 6 and Microsoft
Foundation Classes (MFC).
Unity allows the user to: Construct and modify standard dictionaries. Build X-Specs to describe data sources including
extraction of metadata using ODBC and mapping system names to dictionary terms.
Integrate X-Specs into an integrated view. Transparently query integrated systems using ODBC and
automatically generate SQL queries.

Architecture Components The architecture consists of four components:
A standard dictionary (SD) to capture data semantics SD terms are used to build semantic names describing semantics
of schema elements.
X-Specs for storing data source descriptions Relational database info. stored and transmitted using XML. Stores semantic names to describe schema elements.
Integration Algorithm Identical concepts in different databases are identified by similar
semantic names. Produces an integrated view of all database concepts.
Query Processor Allows the user to formulate queries on the view. Translates from semantic names in integrated view to SQL
queries and integrates and formats results. Involves determining correct field and table mappings and discovery of join conditions and join paths.

Querying by Context (QBC) Querying by context (QBC) is a methodology for
querying relational databases by semantics. Querying is performed by selecting semantic names that
represent query concepts from the integrated view. The integrated, context view contains all concepts
present in the databases referenced by semantic names.
Query by Context performs dynamic closure relating concepts for the user as they browse the integrated view.
This allows a limited form of recursive queries and eliminates the need for the user to specify joins.
The query processor maps the user’s selections and criteria to an actual SQL query.

References Publications:
Unity - A Database Integration Tool, R. Lawrence and K. Barker, TRLabs Emerging Technology Bulletin, Jan. 2000.
Multidatabase Querying by Context, R. Lawrence and K. Barker, DataSem2000, pages 127-136, Oct. 2000.
Integrating Relational Database Schemas using a Standardized Dictionary, SAC’2001 - ACM Symposium on Applied Computing, pages 225-230, March 2001.
Querying Relational Databases without Explicit Joins DASWIS 2001- International Workshop on Data Semantics in Web Information Systems (with ER'2001), Nov. 2001.
Further Information: http://www.cs.uiowa.edu/~rlawrenc/

IntegrationIntegration
ExampleExample
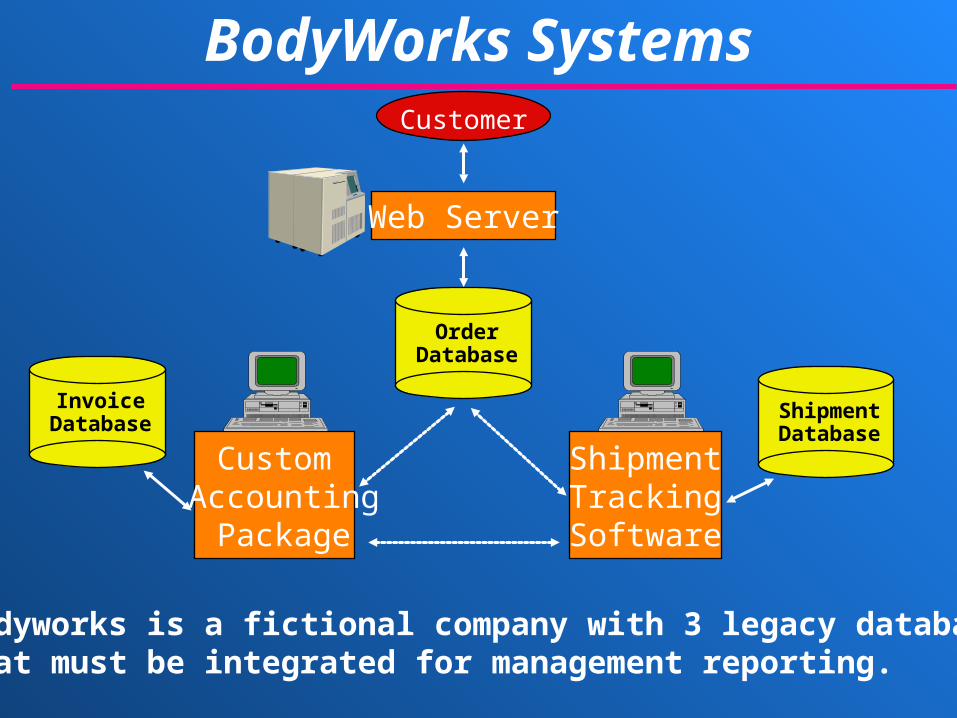
BodyWorks Systems
Web Server
Custom Accounting
Package
ShipmentTrackingSoftware
Customer
OrderDatabase
InvoiceDatabase
ShipmentDatabase
Bodyworks is a fictional company with 3 legacy databasesthat must be integrated for management reporting.
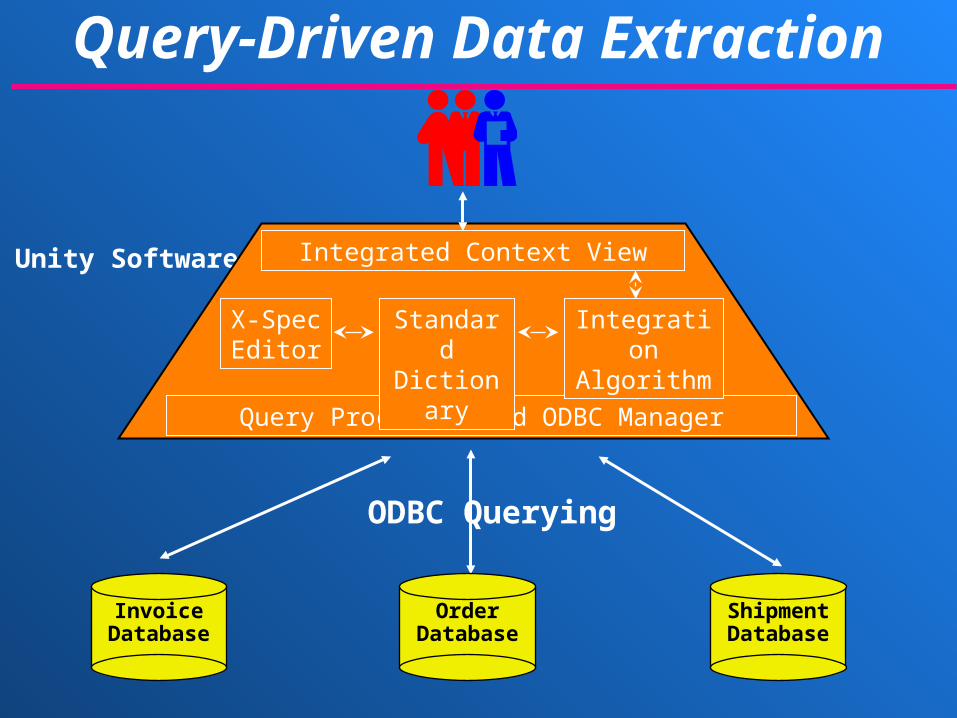
Query-Driven Data Extraction
InvoiceDatabase
OrderDatabase
ShipmentDatabase
Unity Software
ODBC Querying
Integrated Context View
Query Processor and ODBC Manager
X-Spec Editor
Standard Dictionary
Integration Algorithm

Integration is performed with 3 separate processes: Capture process: independently extract database schema
information into a XML document called a X-Spec. This process is a semi-automatic description using a dictionary.
Integration process: combines X-Specs into a structurally-neutral hierarchy of database concepts called an integrated context view. This process performs automatic name matching, but
imprecision may occur.
Query process: allows the user to formulate queries on the integrated view that are mapped by the query processor to structural queries (SQL) , executed using ODBC, and the results are combined using global keys. Users do not have to specify joins when querying the global view.
Integration Processes

The UnityThe Unity
PrototypePrototype
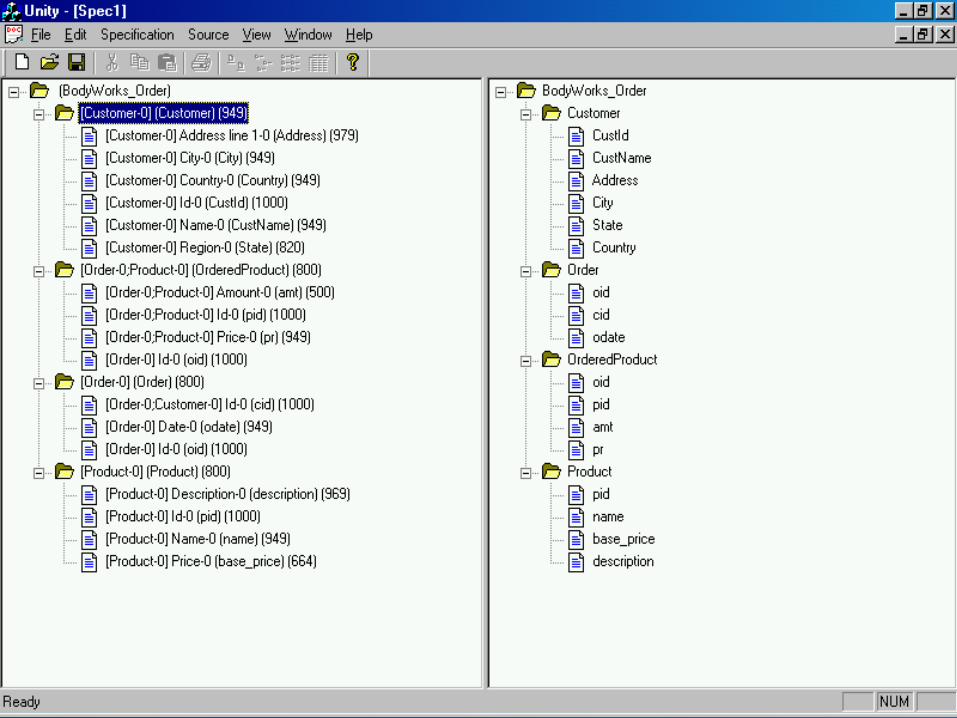
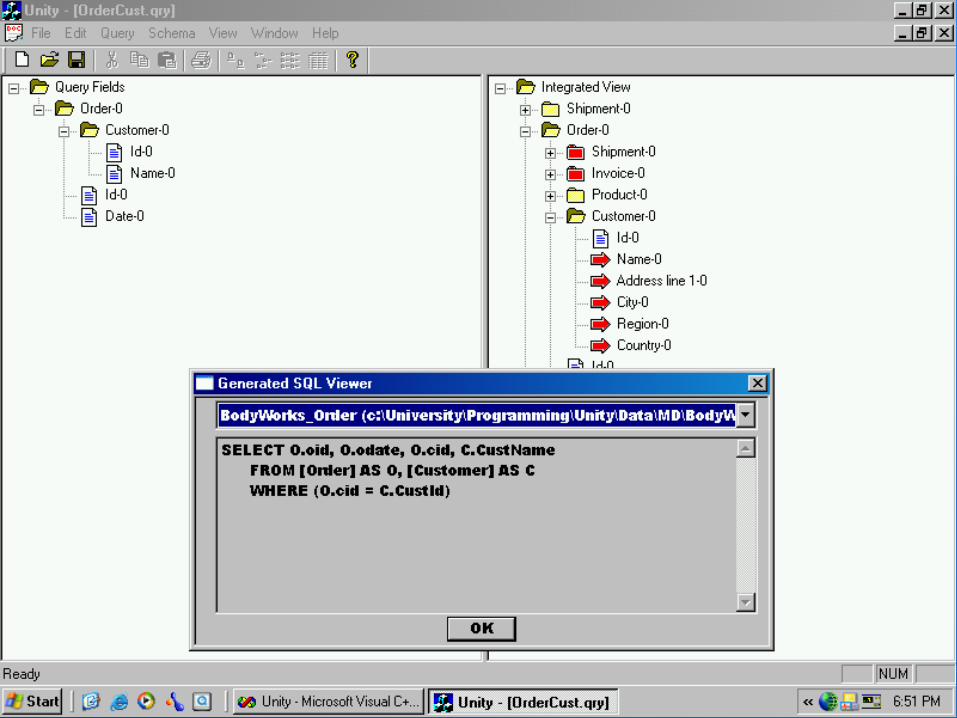
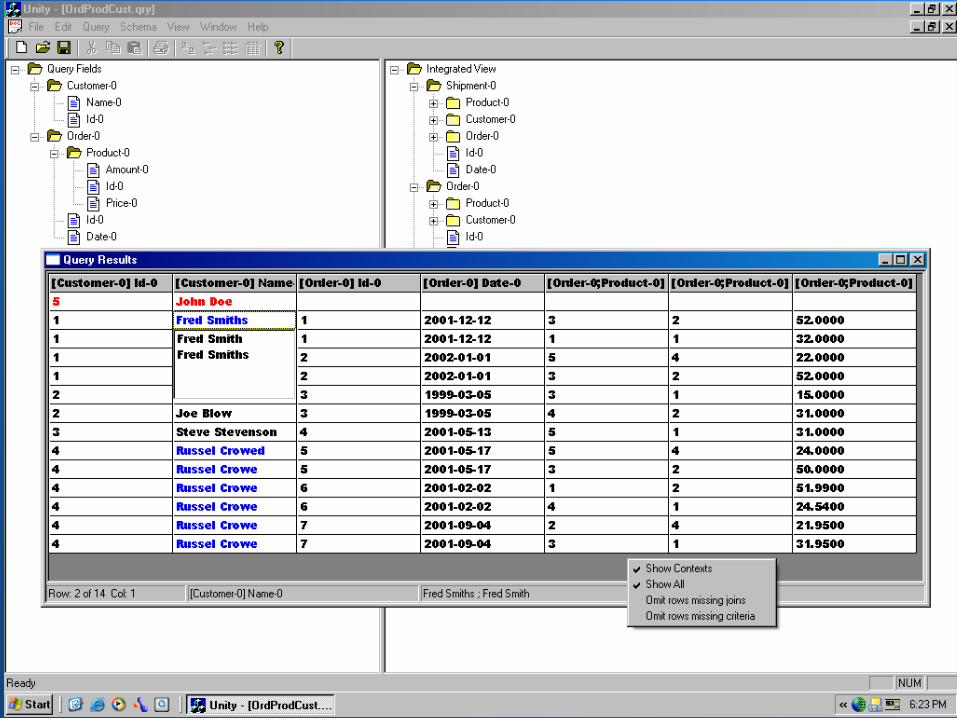

What is the open problem? The GAV and LAV approaches are both viable
methods for solving data integration.
However, the open problem is that neither approach performs schema integration - the construction of the global view itself.
GAV - GV constructed (schema integration performed) by global designer when specifying extraction rules.
LAV - GV is pre-defined using some previous integration process (most likely manual in nature).
Both methods rely on the concept of a global user to create the global schema.

How Unity is Different Our integration architecture called Unity is different
because it approaches the integration problem from a different perspective:
Thus, the integration problem is tackled from a different set of starting assumptions:
Do not assume pre-existing or manually created GV. However, assume we have a dictionary and a language
for describing schema and data element semantics. Attempt to automatically build a GV from source
descriptions of each data source.
How can we automate, or semi-automate, the construction of the global view by extracting information from the local data sources?

The Unity Approach Given a set of data sources and a dictionary and a
language to describe data semantics: 1) Semi-automatically extract and represent data source
semantics in the language using the dictionary. 2) Automatically match concepts across data sources by
using the dictionary to determine related concepts. This process effectively builds the global level relations or
objects initially assumed or created in other approaches. However, since there is no manual intervention, the precision of
global view construction is affected by inconsistencies in the descriptions of the data sources and matching concepts.
3) Automatically generate queries specified by the user using dictionary terms (not structures) and map the user's query to appropriate data elements in the local sources.

What is wrong with SQL? There is nothing wrong with SQL. However, SQL is
not a simple query language for many reasons: Querying by structure does not hide complexities
introduced due to database normalization. Structures (fields and tables) may be assigned poor
names that do not adequately describe their semantics. Notion of a “join” is confusing for beginner users
especially when multiple joins are present. SQL forces structural access which does not provide
logical query transparency and restricts logical schema evolution.
Querying multiple databases (without a global view) using SQL-variants is complex because naming and structural conflicts must be resolved during query formulation.































![Rad-Tolerant design of all-digital DLL Tuvia Liran [tuvia@ramon-chips.com ] Ran Ginosar [ran@ramon-chips.com ] Dov Alon [dov@ramon-chips.com ] Ramon-Chips](https://img.pdfslide.us/doc/110x75/56649f2e5503460f94c47f47/rad-tolerant-design-of-all-digital-dll-tuvia-liran-tuviaramon-chipscom-.jpg)