Embed Size (px)
Citation preview

Math Finan EconDOI 10.1007/s11579-012-0078-1
Informational inefficiency in financial markets
Dorje C. Brody · Bernhard K. Meister ·Matthew F. Parry
Received: 18 October 2011 / Accepted: 13 May 2012© Springer-Verlag 2012
Abstract The existence of an informational inefficiency in the equity market is identi-fied by analysing information publicly available on the internet. A large volume of blogdata is used for this purpose. Informational inefficiency is established by converting com-pany-specific blog sentiment data into a trading strategy and analysing its performance. Aninformation-based model that approximately replicates the strategy is developed to estimatethe degree of information disparity. The result shows that an efficient internet search enginecan considerably enhance market efficiency, as measured in terms of the information flowrate.
Keywords Information-based asset pricing · Statistical arbitrage ·Internet-data extraction · Information pricing
JEL Classification G14 · G15 · G17 · C11 · C53
1 Introduction
Since the dawn of history, information has always been generated locally; it then spreadsglobally by various means, often being lost and sometimes being rediscovered. Nothing hasfundamentally changed with the advent of the internet. Here again, information is generated
D. C. Brody (B)Mathematical Sciences, Brunel University, Uxbridge UB8 3PH,UKe-mail: [email protected]
B. K. MeisterDepartment of Physics, Renmin University of China, Beijing 100872, Chinae-mail: [email protected]
M. F. ParryDepartment of Mathematics and Statistics, University of Otago, Dunedin 9054, New Zealande-mail: [email protected]
123

Math Finan Econ
locally on individual web sites and then, due to the potency of content and presentation, aswell as the vagaries of place and timing, disappears into some data repository, or is pickedup and amplified, creating avalanche effects. Nowadays, information is often posted initiallyon blogs and micro-blogs, or discussed on bulletin boards, and only subsequently, with somedelay, reaches the traditional media as represented by newspapers and television. This dis-semination from a small to a wider circle of viewers is also of interest in the financial marketcontext, because as knowledge spreads, it starts influencing investment decisions. We dem-onstrate in this paper that by capturing these trends at an early stage of information diffusionin a systematic and quantitative manner it is possible to construct a superior trading strategy,thus establishing the existence of market inefficiencies.
A closely related issue to information extraction in financial markets is the valuation ofinformation. Suppose one is in possession of a piece of information, deemed valuable, thatone wishes to monetise. How does one price information, when information is viewed as atradable asset? For instance, consider the information that the price of a given stock will moveup the following day with 75 % likelihood. Leaving aside issues to do with insider tradingfor the moment, if one was to ‘sell’ this piece of information, how should one set a fair price?Evidently, in this example the price depends on a number of market factors, such as marketimpact. It also depends crucially on whether this information provision is a one-off event orwhether such information will be supplied on a regular basis. All these issues make it verydifficult to arrive at the notion of a ‘fair price’ of information. It is nevertheless possible toassociate a rate of return with the use of information, and this in turn can be used to valueinformation by means of, for example, utility indifference arguments.
In the efficient market theory ‘all’ the publicly available information is incorporated inthe price by the marginal investor. This bold statement, which comes in various forms, hasoften been criticised in the literature (e.g., [19]). Often there is an abundance of valuableinformation that is widely accessible to the whole market but from which not everyone hasthe resources or analytic capability to extract useful signals. Indeed, not even the so-called‘marginal’ investor appears to exploit this additional data. The important point to appreciatehere is that the distribution of information is never homogeneous because the ability to extractsomething useful is necessarily inhomogeneous across different market agents.
To establish a relation between information and investment return, we must first identifywhat is meant by ‘information’ in a quantitative manner. In financial markets informationconsists of two parts: signal and noise. By ‘signal’ we mean components of information thatare dependent on the actual return of, say, an investment; whereas by ‘noise’ we mean com-ponents of information that are statistically independent of the return of that investment. Bothcomponents have direct impact on price dynamics, but it is ultimately the signal componentthat determines the realised value of the return. Thus, given this noisy information, marketparticipants try their best to estimate the signal; this estimate (in a suitably defined sensediscussed below) in turn determines the random dynamics of the associated price process.
In many cases signal and noise are superimposed in an additive fashion. In other words,there are essentially two unknowns, ‘signal’ and ‘noise’, and one known, ‘signal plus noise’.The rate at which the signal is revealed to the market then determines the signal-to-noise ratio.The kind of information inhomogeneity discussed above therefore arises primarily from thefact that different agents have different signal-to-noise ratios. With further refinements, how-ever, one finds that the signal-to-noise ratio is itself rarely known in financial markets, i.e. it iswhat one might call a known unknown. Yet, it is the signal-to-noise ratio that directly affectsthe performance of an investment as well as the magnitude of the volatility. Of course, in anyrealistic strategy there are parameter choices that will also affect performance. Nevertheless,we can obtain a rough estimate for the relative ratios of signal-to-noise ratios of different
123

Math Finan Econ
agents from their performances. Here we illustrate how this can be achieved within a simplemodeling framework. We examine the ratio of two signal-to-noise ratios; one for the marketas a whole, and one for an internet-search based strategy.
The motivation behind our choice for using an internet-search based strategy, to be com-pared with the market, should be evident: most information circulates via the internet. Unliketraditional investment firms, large internet search engines, by their very nature and in spite ofbeing ‘outsiders’ to financial markets, are well positioned to extract signals from large datasets. From the viewpoint of internet search engines, the kind of analysis discussed here alsohas a profound implication. One of the key difficulties in the business of information pro-vision (e.g., search results, recommendations, and ratings) is in the quantitative assessmentof the validity and quality of the search engines or other recommendation tools. However,we now recognise that financial market dynamics provide a suitable testing ground, and onewith rapid feedback, for assessing the quality of internet recommendation tools. For exam-ple, a “celebrity popularity engine” offered by internet companies, useful to advertisers, canbe applied to individual companies; the quality of the engine, which otherwise would havebeen difficult to assess, can now be tested instantly against the future movements of thecorresponding stock prices.
We have therefore taken a large number of blog articles from the internet, applied stan-dard natural language processing (NLP) to convert numerous texts into numerical sentimentindices for individual listed companies, and then developed a trading strategy that convertsthe sentiment indices into portfolio positions. There are by now standard procedures fortext mining of this kind (see, e.g., [17]); here we have used an engine provided by a largeinternet search engine. The results of our analysis show the existence of a remarkable inef-ficiency in a highly liquid equity market. We also construct a theoretical model, within theinformation-based asset pricing framework of Brody–Hughston–Macrina (BHM), for thecharacterisation of the strategy. The model has the advantage that the ratio of the signal-to-noise ratios between the informed trader and the general market can be estimated fromthe investment performance. The issue of evaluating information is also discussed briefly.
This paper is organised as follows. In Sect. 2 we give a brief review of the BHM infor-mation-based pricing framework. This is followed in Sect. 3 by the consideration of an ele-mentary model to characterise a market consisting of two inequivalent filtrations; a smallerone for the general market and a larger one for the informed trader. In Sect. 4 we show theresult of the practical implementation of the strategy, based on real internet data. The issueof pricing information is then discussed in Sect. 5. We conclude in Sect. 6 with a generaldiscussion.
2 Information and asset price
To understand the interplay between information and asset price, we must first step back fromthe conventional approach in quantitative finance, and begin by identifying the main sourcesfor price movements at a phenomenological level. After a little reflection it should not bedifficult to identify two important factors, namely, risk preference and available information.To understand these two factors we list two possible scenarios: (i) I would have bought thenew Toyota car, had I not lost my job; (ii) I would have bought the new Toyota car, had I notread the news of the recall. In case (i) the assessment of the worthiness of the product has notchanged, but the purchase decision has nevertheless been affected by the changes in one’sappetite toward risk; whereas in case (ii) the assessment of the worthiness of the product haschanged due to the arrival of new information.
123

Math Finan Econ
It is often argued that the price dynamics is generated by supply and demand; this is indeedso, but it has to be noted that a large part of supply and demand in financial markets is inducedby the arrival of information (for example, an announcement of a substantial profit leadingto high demand for company shares). We thus take the view that the traditional ‘supply anddemand’ argument is in fact mostly the symptom and not the cause, at least in the case ofhighly liquid financial instruments.
As regards changes in risk preference, at the individual level this can be relatively volatile,but averaged over the market the volatility will be reduced. On the other hand, the flow ofinformation is significantly more dynamic and volatile. It is common for a dynamical systemto depend on fast moving and slowly moving variables; in the case of a financial market,information is the fast moving and risk preference is the slowly moving variable. For ourstrategy, the changes in overall risk preference will have little impact, because we shall onlytest market neutral strategies that have no exposure to the overall risk preference of the mar-ket. Therefore, our first simplifying assumption is to regard market risk preference as fixed,and focus attention on the structure of information. Phrased in more technical terms, we willassume that the pricing measure is given once and for all, and we shall construct the marketfiltration from the outset, which will be used to derive the price process. This is in line withthe BHM approach introduced in [12–14], which will now be reviewed briefly.
Consider an elementary asset that pays a single dividend X at time T (e.g., a credit-riskydiscount bond). We assume that there is an established pricing measure Q, under which therandom cash flow X has the a priori density p(x). In this case, market participants are con-cerned about the realised value of X . In particular, the risk-adjusted view of the market todayabout the cash flow is represented by the a priori density p(x). By tomorrow, however, themarket will obtain additional noisy information, based on which the market will update itsview, represented in the form of an a posteriori density for X .
As remarked above, this information consists of two components; signal and noise.Although the rate at which the signal is revealed to the market is generally unknown, andfurthermore it will change in time, let us assume for simplicity that it is known to the market,and that it is given by a constant σ . We also assume for the moment that the market is effi-cient in the sense that all available information is used in the determination of the price today.Hence there is no residual noise today. Likewise, the noise will vanish at time T when thevalue of X is revealed. To keep the matter simple, we model the noise term by the simplestGaussian process that vanishes at time 0 and time T —the Brownian bridge process {βtT }over the time interval [0, T ]. Therefore, our choice for the information is
ξt = σ Xt + βtT . (1)
The market filtration {Ft } is thus generated by the knowledge {ξs}0≤s≤t of the informationprocess.
The way to interpret the information process (1) is as follows. One can think of {ξt } asrepresenting an aggregate of information processes of the form
ξ it = σi Xt + β i
tT , (i = 1, 2, . . .), (2)
where the noise terms {β itT } may be correlated, emerging from a range of information sources.
Then the joint filtration associated with the family of information processes can be decom-posed (see [10] for detail) into one information process (1) and residual pure-noise processesthat will not affect market dynamics and thus can be ignored.
If we write PtT for the discount function, and assume that it is deterministic, then the priceat time t of the asset is determined by St = PtT E[X |Ft ]. A short calculation then shows thatthe price process is given by
123

Math Finan Econ
St = PtT
∫ ∞0 xp(x)e
TT −t
(σ xξt − 1
2 σ 2x2t)
dx∫ ∞
0 p(x)eT
T −t
(σ xξt − 1
2 σ 2x2t)
dx
. (3)
We see therefore that in the BHM approach it is possible to derive the price process in amanner that ‘replicates’ how price processes are generated in the first place via flow of infor-mation. In spite of the various simplifying assumptions, the resulting price process (3) isvery rich and possesses many desirable features. Perhaps the most notable, from a practicalpoint of view, is the fact that the pricing and the hedging of elementary contingent claims aremade easy on account of a particular measure-change technique that removes the complicateddenominator term in {St } (see [12] for details), in spite of the richness of the price dynamics(e.g., the asset volatility is highly stochastic).
3 Modelling the informed trader
Within the BHM framework it is straightforward to model information disparity seen in var-ious financial markets. Indeed, it has been shown in [9] that if there is an informed traderin a market who has access not only to the market information (1) but also to an additionalinformation source ξ ′
t = σ ′ Xt + β ′tT , then the informed trader can exploit the information
to generate statistical arbitrage.It is worth remarking in this context that there is a substantial literature on the study of filtra-
tion enlargements or alternative stochastic calculus for the modelling of insider trading (see,e.g., [3,18,20,6]). There are also other approaches to model market inhomogeneity by use ofan alternative probability measure or of the notion of diverse beliefs (see, e.g., [4,5,15]). Ourapproach here is related to, but different from some of the traditional approaches adopted inthe literature in that we explicitly model the market filtration, along with the impending cashflows associated with a given asset. In particular, price processes are not modelled directly;rather, they are derived by use of the pricing formulae.
For the purpose of the present analysis we shall modify the setup considered in [9] so asto replicate approximately the trading strategy that we have developed by use of data takenfrom the internet, and calibrate some of the model parameters. In this manner we are ableto provide a rough estimate for the performance of internet-based recommendation or ratingengines from investment performances.
Our modelling setup can be summarised as follows. We let X be a binary random variabletaking the values {0, 1}, where 1 represents price moving up by a unit over the period [0, T ]and 0 represents price moving down by a unit over the same period. At time 0 both the marketand the informed trader share the same information about the value of X , represented by thea priori probabilities (p, 1 − p). The informed trader, however, begins to gather informationfrom the internet, using text and data mining; whereas the general market gathers informationthrough more widely accessible sources such as newspaper articles and financial reports. Welet ξt of (1) represent the market information process, and ξ ′
t = σ ′ Xt + β ′tT represent the
extra information gathered from the internet, where the two noises {βtT } and {β ′tT } may be
dependent, with correlation ρ. It is shown in [9] that in the case of multiple informationsources the knowledge of the informed trader can be represented in the form of a singleeffective information process
ξ̂t = σ̂ Xt + β̂tT , (4)
123

Math Finan Econ
where σ̂ 2 = (σ 2 − 2ρσσ ′ + σ ′2)/(1 − ρ2), and
β̂tT = σ − ρσ ′
σ̂ (1 − ρ2)βtT + σ ′ − ρσ
σ̂ (1 − ρ2)β ′
tT . (5)
Therefore, the effective signal-to-noise ratio for the informed trader is given by σ̂ , whichcan be compared against the market signal-to-noise ratio σ . (Since we are assuming that theinformation-revelation rates are constant in time, we shall, by abuse of terminology, referthese rates as signal-to-noise ratios.)
At time T/2 both the market and the informed trader have accumulated noisy information,based on which they evaluate the a posteriori probabilities, pM and pI , respectively, thatX = 1. The trading strategy is as follows. If the a posteriori probability is larger than thethreshold value K+ then take a long position by the amount X̂t ; if the a posteriori probabilityis smaller than the threshold value K− then take a short position by the amount X̂t , whereX̂t = Et [X ] is the expectation of X using the market filtration. The values of K± used by thegeneral market participants and the informed trader are assumed to be the same so that thereis only one strategy used; the only difference lies in the information being used. Of course, ina practical implementation of such a strategy, parameters like T , K± will be optimised overa ’training’ period and thus different agents will most likely be using different parameters.However, the purpose here is to establish the existence of a statistical arbitrage, and for thismatter we consider the simple setup where all market participants employ the same fixedstrategy.
The position taken at time T/2 is then held till time T , at which point the profit or lossis made because the value of X is now revealed. Also at time T the next observation for thevalue of the random variable representing whether the asset price moves up or down overthe interval [T, 2T ] begins, and the same strategy is repeated over and over. Our model thusmakes an implicit simplifying assumption that the magnitude of the stock volatility over therange [nT, (n + 1)T ] is independent of the value of n.
Both the market and the informed trader employ the same strategy, but the informed traderon average makes better estimates for the realised value of X , thus statistically obtaininga higher rate of return than the market. The risk-neutral valuation of the market positioncan be made straightforwardly, because the resulting cash flow can be represented by therandom variable (X − X̂t )(1{X̂t > K+} − 1{X̂t < K−}). By a change of measure techniqueintroduced in [12] one can show that the value of the strategy is given by a formula analogousto the Black–Scholes option pricing formula. The valuation of the position of the informedtrader is less obvious, although one can show (see [9]) that the expected P&L difference ispositive, leading to a statistical arbitrage opportunity.
It is worth discussing the concept of statistical arbitrage here in a more general context.Suppose that there is a risky asset whose current price is S0. Assume a single-period setupso that the future value of the asset is given by the random variable ST . Consider an investorwho at time zero borrows θ S0 from a bank and purchases θ amount of the risky asset. Thevalue of the initial wealth therefore is V0 = θ S0 − θ S0 = 0. At time T the value of theportfolio becomes VT = θ ST − θ S̄0, where S̄0 is the forwarded price of S0. The risk neutralexpectation of VT is clearly given by
E[VT ] = Cov(θ, ST ), (6)
since E[ST ] = S̄0. If the market is informationally efficient, then θ cannot be correlated withST , since all noisy information about the future asset price ST is ‘consumed’ in the valuationS0 today of the asset. Putting the matter differently, the strategy θ has to be adapted to theinformation available today. Therefore, in an informationally-efficient market we have the
123

Math Finan Econ
no arbitrage condition E[VT ] = 0. However, the valuation of the strategy of the informedtrader gives E[VT ] �= 0 since θ in this case is not independent of ST . In particular, if θ ispositively correlated with ST , such as in the example above, then we have E[VT ] > 0, thuson average outperforming the market.
4 Implementation and calibration
In [8] we have implemented the strategy using publicly available information sources. Spe-cifically, we have gathered the totality of Japanese blog articles since 2006 and used them asour sole information source. In 2009, nearly 20 million Japanese blog articles appeared on theinternet, making a daily average of around 50,000 articles. Each blog article is weighted byits relevance (e.g., page views). Those with insufficient weight are regarded as ‘pure noise’and have been discarded from the analysis, thus leaving on average some 7,000 articles perday for the analysis.
Natural language processing (NLP) technology of Yahoo! Japan Corporation and YahooJapan Research Institute has been applied to analyse company specific comments of thelisted companies. The NLP classifies whether the comments relating to a given companyare positive, neutral, or negative; this classification is then used to establish sentiment indexfor each company. The numerical value thus obtained reflects the number of comments aswell as the relevance of each comment. Based on the sentiment index thus obtained, a tradingstrategy, analogous to the one described above, is developed. That is, if the sentiment is abovea threshold K+ then one takes a long position for a period T ; and similarly, if the sentimentis below K− then a short position is taken for a period T . The idea behind the strategy canbe illustrated as follows. If many people write complimentary remarks about a new productreleased by a given company, for instance, then it is likely that sales of the product will goup, leading to an increase in its share price.
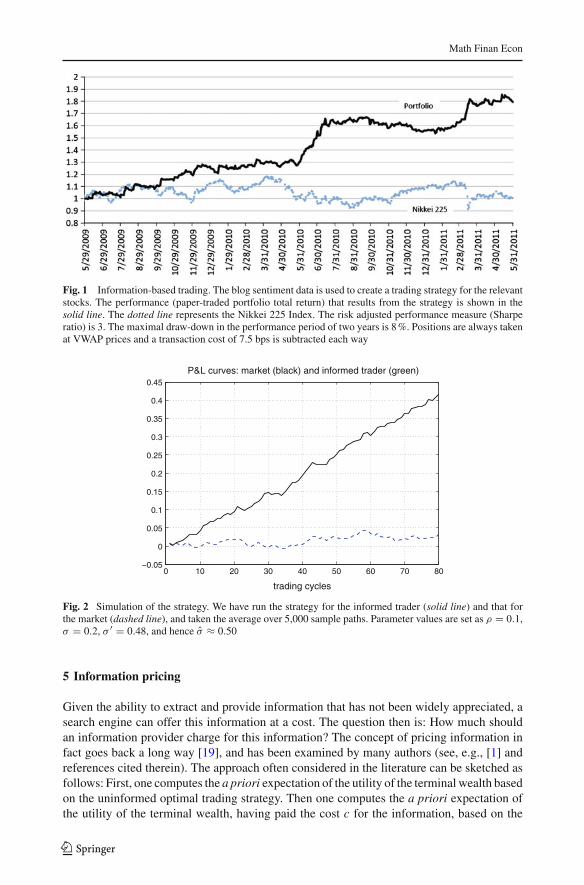
The strategy has been optimised using the data from 2008 to early 2009 the choice ofthe threshold values K± and the period T ), and applied for the seven month period fromJune 2009. Specifically, for the analysis presented here we have considered 10 companies forwhom the average numbers of blog comments are highest. In order to obtain a conservativeestimate for the ratio σ̂ /σ , and also to reduce exposure to the market risk preference, wehave adopted a long-short strategy against the Nikkei 225 Index. The result of the strategy,as well as the average stock prices of the active names and the Nikkei 225 Index, are shownin Fig. 1.
To obtain a rough estimate for the ratio σ̂ /σ we have simulated the strategy numerically,based on the assumption that the market value of the information flow rate is σ = 20 %.Because we do not yet have a suitable method of estimating the correlation ρ between thenoise in the blog sentiments and the noise for market investors, we can only give a range forour rough estimate. Fortunately, we find that the range for possible values of the ratio σ̂ /σ
across different values of ρ is relatively narrow:
2.4 �σ̂
σ� 2.6. (7)
These values are obtained by finding the values of σ̂ such that the performance of the modelagrees with the performance of the realised strategy, while fixing σ = 20 % and varying ρ.The results of the simulation associated with the choice ρ = 0.1 are shown in Fig. 2.
123
Math Finan Econ
Fig. 1 Information-based trading. The blog sentiment data is used to create a trading strategy for the relevantstocks. The performance (paper-traded portfolio total return) that results from the strategy is shown in thesolid line. The dotted line represents the Nikkei 225 Index. The risk adjusted performance measure (Sharperatio) is 3. The maximal draw-down in the performance period of two years is 8 %. Positions are always takenat VWAP prices and a transaction cost of 7.5 bps is subtracted each way
0 10 20 30 40 50 60 70 80−0.05
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
trading cycles
P&L curves: market (black) and informed trader (green)
Fig. 2 Simulation of the strategy. We have run the strategy for the informed trader (solid line) and that forthe market (dashed line), and taken the average over 5,000 sample paths. Parameter values are set as ρ = 0.1,σ = 0.2, σ ′ = 0.48, and hence σ̂ ≈ 0.50
5 Information pricing
Given the ability to extract and provide information that has not been widely appreciated, asearch engine can offer this information at a cost. The question then is: How much shouldan information provider charge for this information? The concept of pricing information infact goes back a long way [19], and has been examined by many authors (see, e.g., [1] andreferences cited therein). The approach often considered in the literature can be sketched asfollows: First, one computes the a priori expectation of the utility of the terminal wealth basedon the uninformed optimal trading strategy. Then one computes the a priori expectation ofthe utility of the terminal wealth, having paid the cost c for the information, based on the
123

Math Finan Econ
informed optimal trading strategy. The value of c that equates these two expectations thendetermines the utility-indifferent price of the information.
The issue of the a priori utility-indifference information pricing is that the cost c is oftenfixed irrespective of the quality of the information provided. In particular, in extreme circum-stances where the knowledge of ξ is sufficient to identify the exact value of the future assetreturn, it is possible to pay a small sum of money to purchase vital information and makeunlimited profit (in this case one is working with inequivalent probability measures, and assuch this scenario is excluded in the analysis of [1] however, it is not excluded in the pricingformula of [19]). To remedy this issue, an alternative approach to pricing information hasbeen proposed in [11]. The key idea there is to compare the a posteriori expectation of theinformed strategy against the a posteriori expectation of the uninformed strategy. That is, wethink of the notion of information provision as defined by the updating
p(x) → πξ (x) (8)
of the probability law concerning the uncertain future returns. Here p(x) denotes the a prioridensity, and πξ (x) the a posteriori density of the future return, given the value ξ of theinformation. Then the value of information, given a utility function U , can be determined bysolving the relation
E[U (W ∗p)] = Eπ [U (W ∗
π,c)] (9)
for c. Here, W ∗p denotes the random variable associated with the terminal wealth based on the
implementation of the a priori optimal strategy; whereas W ∗π,c denotes the random variable
associated with the terminal wealth based on the implementation of the a posteriori optimalstrategy, having paid c for the information. In this way, a quality-dependent fair price c(ξ)
of the information can be determined.It is worth remarking in this context the work of [4] using a different probability measure,
rather than filtration enlargement, as an alternative approach to assess the value of infor-mation. Our approach can perhaps be viewed as a kind of hybrid approach involving bothfiltration expansion and different probability measures, where the latter is derived from theformer on account of Bayesian updating of knowledge.
6 Discussion
We have extracted a trading signal from the abundant data accessible on the internet. Byapplying the results to the stock market, we were able to assess the performance of the infor-mation extraction and provision engine provided by internet search engines. The results haveidentified perhaps a surprising level of apparent inefficiency even in a highly liquid equitymarket, indicating the degree of information inhomogeneity.
It is of course well documented that asset prices in financial markets respond to theunravelling of information (e.g., [16,2]). Indeed, the realisation that information filtering andcommunication is the key for grasping social sciences such as economics has been recognisedsince [21]. Our analysis differs from previous work carried out in this area in that we explic-itly identify the existence of information disparity, rather than merely showing the impactof information on asset prices retrospectively, and derive a rough estimate for how muchmore the rate of information extraction could have been enhanced had the market been trulyefficient. In contrast with Google Finance, for instance, that provides a postmortem analysisof the relation between large price moves and revelations of news items, our informed traderis able to exploit internet-based information sources to anticipate price moves. In a similar
123

Math Finan Econ
line of analysis, Bollen et al. [7] reported that the sentiment analysis of Twitter texts can beused to predict future movements of stock indices.
The analysis reported in this paper is naturally of interest to statistical arbitrage funds,because the strategy is orthogonal to conventional strategies that rely on, for example, mar-ket microstructure. On the other hand, from the viewpoint of an internet search engine, onemight envisage a scenario whereby individual investors purchasing ‘signal’ from informa-tion providers and making their own investments. Such a model, however, is unlikely to besustainable, because if the signal is circulated broadly, it ceases to remain useful. As Wieneremphasises, concentration of useful information is intrinsically unstable due to the secondlaw [21]. The only way in which information can spontaneously be concentrated, at leastmomentarily, is via innovation. It is interesting therefore to reflect on the fact that in spite ofthe enhancement of technology in improving the method of information gathering and provi-sion, whose purpose a priori goes against the second law, ultimately such developments canonly result in enforcing the compliance with the second law. As a result, in the long run thesecond law will enhance the ‘efficiency’ of financial markets, but maybe also, paradoxically,the instability of financial markets, because in a noise-dominated market, the revelation ofthe true signal has a significant impact.
Acknowledgements The authors would like to thank Julian Brody, Robyn Friedman, Lane Hughston, YanTai Law, Andrea Macrina, and Kiyoshi Nitta for stimulating discussions.
References
1. Amendinger, J., Becherer, D., Schweizer, M.: A monetary value for initial information in portfolio opti-mization. Financ. Stoch. 7, 29–46 (2003)
2. Andersen, T., Bollerslev, T., Diebold, F.X., Vega, C.: Real-time price discovery in stock, bond and foreignexchange markets. J. Int. Econ. 73, 251–277 (2007)
3. Back, K.: Insider trading in continuous time. Rev. Financial Stud. 5, 387–409 (1992)4. Baudoin, F.: Modelling anticipations on financial markets. In: Carmona, R.A., Çinlar, E., Ekeland, I.,
Jouini, E., Scheinkman, J.A., Touzi, N. (eds.) Paris–Princeton lectures on mathematical finance 2002, pp.43–94. Springer, Berlin (2003)
5. Baudoin, F., Nguyen-Ngoc, L.: The financial value of a weak information on a financial market. Financ.Stoch. 8, 415–435 (2004)
6. Biagini, F., Øksendal, B.: A general stochastic calculus approach to insider trading. Appl. Math.Optim. 52, 167–181 (2005)
7. Bollen, J., Mao, H., Zeng, X.-J.: Twitter mood predicts the stock market. J. Comput. Sci. 2, 1–8 (2011)8. Brody, D.C., Brody, J., Meister, B., Parry, M.F.: Outsider trading. arXiv:1003.0764 (2010)9. Brody, D.C., Davis, M.H.A., Friedman, R.L., Hughston, L.P.: Informed traders. Proc. R. Soc. Lond.
A 465, 1103–1122 (2009)10. Brody, D.C., Law, Y.T.: Asset pricing with random information flow. arXiv:1009.3810 (2010)11. Brody, D.C., Law, Y.T.: Theory of information pricing. arXiv:1106.5706 (2011)12. Brody, D.C., Hughston, L.P., Macrina, A.: Beyond hazard rates: a new framework for credit-risk mod-
elling. In: Elliott, R., Fu, M., Jarrow, R., Yen, J.-Y. (eds.) Advances in mathematical finance: FestschriftVolume in Honour of Dilip Madan. Birkhäuser, Basel (2007)
13. Brody, D.C., Hughston, L.P., Macrina, A.: Information-based asset pricing. Int. J. Theor. Appl.Financ. 11, 107–142 (2008)
14. Brody, D.C., Hughston, L.P., Macrina, A.: Modelling information flows in financial markets. In: Di Nun-no, G., Øksendal, B. (eds.) Advanced mathematical methods for finance, pp. 133–153. Springer, Berlin(2011)
15. Brown, A.A., Rogers, L.C.G.: Diverse beliefs. arXiv:1001.1450 (2010)16. Engle, R.F., Ng, V.K.: Measuring and testing the impact of news on volatility. J. Financ. 48,
1749–1778 (1993)17. Feldman, R., Sanger, J.: The text mining handbook. Cambridge University Press, Cambridge (2007)
123

Math Finan Econ
18. Föllmer, H., Wu, C.-T., Yor, M.: Canonical decomposition of linear transformations of two independentBrownian motions motivated by models of insider trading. Stoch. Process. Appl. 84, 137–164 (1999)
19. Grossman, S.J., Stiglitz, J.E.: On the impossibility of informationally efficient markets. Am. Econ.Rev. 70, 393–408 (1980)
20. León, J.A., Navarro, R., Nualart, D.: An anticipating calculus approach to the utility maximization of aninsider. Math. Financ. 13, 171–185 (2003)
21. Wiener, N.: The human use of human beings, Revised edition. Eyre and Spottiswoode, London (1954)
123





























